
Abstract
GFRP rebar is a desirable alternative to steel rebar especially in harsh environments with advantages of light weight, high strength, stable chemical properties, and corrosion resistance. However, there is a lack of understanding on the durability of GFRP rebar which significantly limits its engineering applications. Unfortunately, it is almost impossible to develop any simple theoretical model to predict the residual strength of GFRP rebar after environmental exposure. To effectively address this research gap, this paper investigates machine learning models to predict the residual tensile strength of GFRP rebar due to environmental degradation. Firstly, a database was built from the literature containing a total of 350 tensile testing results of GFRP rebar after experimental exposure. Six key influencing parameters were considered, including fiber content, bar diameter, resin type, exposure temperature, pH, and aging time. Secondly, machine learning models were trained and tested using the database, and the selected models included Decision Tree, Random Forest, Support Vector Machine (SVM), Multilayer Perceptron (MLP), and Long and Short-Term Memory (LSTM) models. The LSTM model demonstrated the best performance in strength prediction, achieving an R2 of 0.96 on the training set and 0.91 on the testing set. Thirdly, the influencing parameters were ranked using SHAP and Random Forest in terms of their impact on the residual tensile strength of GFRP rebar, and it was found that temperature has the most significant effect followed by fiber content, exposure time, pH and bar diameter, while resin type showed the least importance. Notably, SHAP analysis also showed that the coupling of different parameters also had impact on the residual strength, and the combined effect of fiber content with other parameters was the most prominent. This paper demonstrates the feasibility of machine learning models in the durability study of GFRP composite materials.
Introduction
Fiber reinforced composites (FRP) are widely used in aerospace, automotive and civil engineering due to their desirable properties like light weight, high strength and corrosion resistance (Rubino et al., 2020; Subbaya and Nithin, 2017; Yang et al., 2019). FRP rebars are compelling alternatives to traditional steel rebars due to their corrosion resistance in harsh environments which is desirable for improving the service life of infrastructure (Rubino et al., 2020). Notably, Glass Fiber Reinforced Polymer (GFRP) rebars have emerged as the predominant choice due to their low production cost, well-established manufacturing technology, and chemical stability (Nkurunziza et al., 2005; D'Antino et al., 2018).
GFRP rebars may degrade in tensile strength under harsh service environments. For example, it was found (Al-Salloum et al., 2013; Wu et al., 2022) that the GFRP tensile strength may decrease under temperature and alkalinity exposures. It was reported (Amaro et al., 2013; Rocha et al., 2017) that the resin matrix of GFRP rebars is more vulnerable to environmental effects than the glass fibers. Resin undergoes plasticization due to moisture absorption leading to swelling, molecular change, and microcracks, which negatively affects the mechanical properties of the rebars.
The strength reduction of GFRP rebars is complex and affected by many factors. In real applications, the bars are exposed to different environmental conditions which may be coupled. This coupling effect cannot be captured by traditional accelerated durability testing in the lab. It is extremely challenging to predict strength reduction of GFRP rebars using traditional lab testing and theoretical modelling. On the other hand, machine learning emerges as a powerful tool for regression and classification problems in civil engineering (Baghaei and Hadigheh, 2021; Feng et al., 2020; Yin and Liew, 2021). For example, Baghaei and Hadigheh (2021) used various machine learning models such as decision tree, support vector machine (SVM), and artificial neural network (ANN) to predict the bond strength between FRP and concrete in wet environment, and they found that ANN has the best performance. Yin and Liew (2021) evaluated the interfacial shear strength and maximum pull-out force of FRP composites using five machine learning models. They found that the effect of each factor on these interfacial properties was nonlinear, and the interfacial shear strength was affected by the fiber diameter the most (Yin and Liew, 2021). Feng et al. (2020) used an integrated algorithm to predict the compressive strength of concrete. It was found that the AdaBoost integrated algorithm was the most efficient and accurate, and it was also able to capture the changes in compressive strength due to different curing time.
Recurrent class neural network (RNN) has been developed for time series problems (Medsker and Jain, 1999; Sherstinsky, 2020). Compared with traditional neural networks, RNN has a simple memory function, which can store the temporal information in the data and transfer it inside the network. However, traditional RNN model suffers from gradient vanishing and explosion, which severely limits its effectiveness for long sequence problems. To overcome this issue, Hochreiter and Schmidhuber (1997) proposed the Long Short-Term Memory Neural Networks (LSTM), which incorporates a gating mechanism to effectively capture and regulate information over long sequences, thereby mitigating gradient-related issues.
LSTM model has been successfully used to predict the strength of materials. Zhang et al. (2019) investigated the fused deposition molding (FDM) printing process, and used LSTM model to predict the tensile strength of the manufactured parts considering the other material properties and printing parameters. The results confirmed that LSTM was effective in modelling the sequential layer-by-layer FDM process, and found that the extrusion temperature, printing speed and layer height had a greater impact on the tensile strength prediction. Chen et al. (2022) predicted the compressive strength of high-strength concrete with machine learning models and investigated the effect of parameters including cement ratio, aggregate, and water reducer on the compressive strength. LSTM was found to have higher accuracy and reliability than other machine learning models.
This paper aims to predict the residual tensile strength of GFRP rebars after exposure to complex environmental conditions using machine learning models. A database was established using experimental results in the literature. Machine learning models like Decision Tree, Random Forest, Support Vector Machine (SVM), Multilayer Perceptron (MLP), and Long and Short-Term Memory (LSTM) models were trained and tested using the database. The effectiveness and accuracy of these machine learning models were compared. The key parameters affecting the tensile strength of GFRP rebars were evaluated and ranked using SHAP and Random Forest methods. The correlation of influencing parameters and its impact on tensile strength of GFRP rebar was investigated using SHAP based on LSTM model. It was found that LSTM showed the best performance to predict the residual tensile strength of GFRP rebar. According to the SHAP values based on LSTM model, the most important parameters affecting the tensile strength were exposure temperature and fiber content, followed by exposure time, pH and bar diameter, while resin type showed the least importance. The correlation between influencing parameters also had impact on the tensile strength, and it was found that the combined effect of fiber content with other parameters was the most prominent. This paper demonstrates the important role and significant potential of machine learning as a powerful tool for durability study of GFRP rebars.
Database
Database description

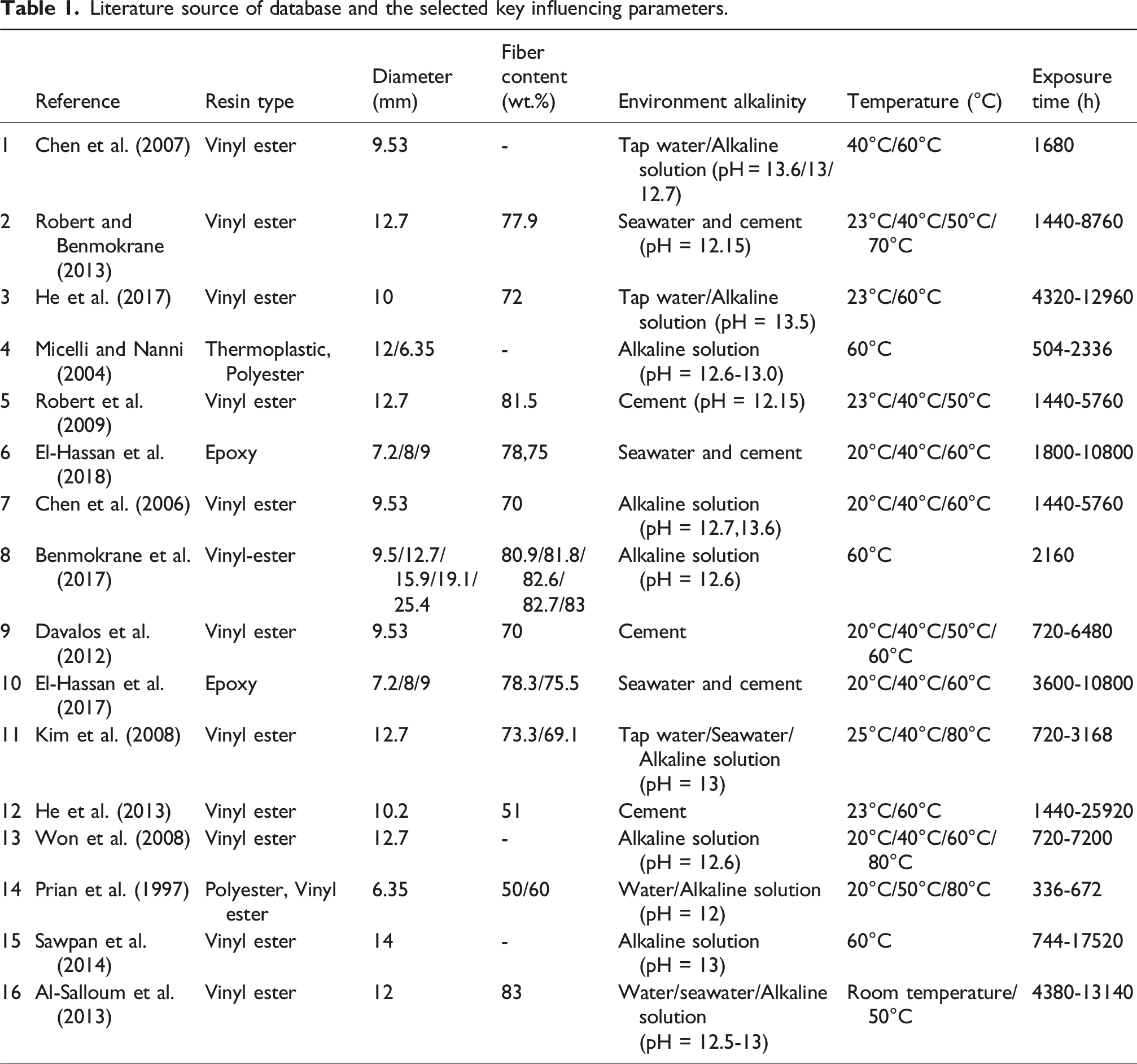
Literature source of database and the selected key influencing parameters.
For the six key parameters in Table 1, the published papers may not report all of them. Research find missing data can lead to biased analysis, inaccurate predictions, and overall performance degradation in machine learning models. When the proportion of missing data is high, it can distort relationships between variables, leading to misinformed conclusions (Ayilara et al., 2019; Emmanuel et al., 2021). Furthermore, missing data mechanisms can be categorized into Missing Completely at Random (MCAR), Missing at Random (MAR), and Not Missing at Random (NMAR). The collected GFRP rebar tensile strength data follows the MAR mechanism, meaning that the probability of missing data depends on the observable variables but is independent of the missing data itself. In the study of GFRP reinforcement, factors such as resin type, fiber content, and environmental temperature are objective and do not change due to the recording process. Therefore, for MAR data, applying appropriate imputation methods can effectively improve data quality, thereby enhancing the predictive performance of machine learning models (Ayilara et al., 2019; Emmanuel et al., 2021). Plaia and Bondi (2006) applied a simple imputation method to reconstruct monitored meteorological data and studied the impact of imputation methods on data quality. The results showed that a simple imputation method incorporating multiple types of information effectively restored the missing data.
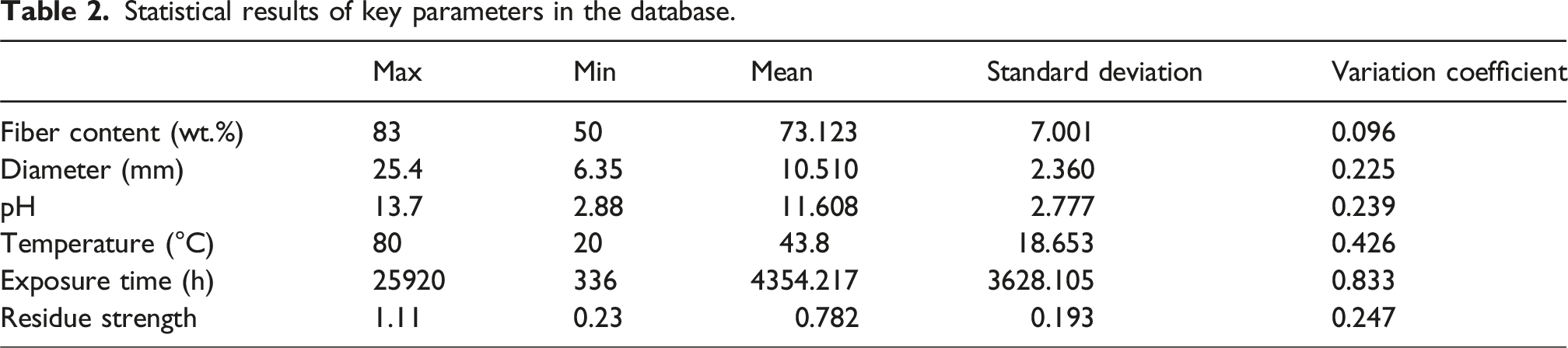
Statistical results of key parameters in the database.
Data regularization
Due to the varying units of different influencing parameters, their absolute values have significant disparity. For instance, the maximum exposure time is 25,920 hours, whereas the pH has a minimum value of just 2.33. Such a large-scale difference can affect the accuracy of the machine learning model and slow down its convergence. Therefore, it is essential to regularize the data.
Common regularization methods include Min-Max Scaling and Z-score Standardization. The Min-Max Scaling method scales data within a specified range, typically [0,1], based on the difference between the maximum (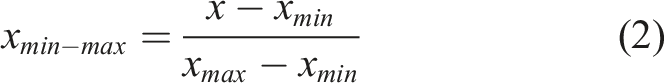

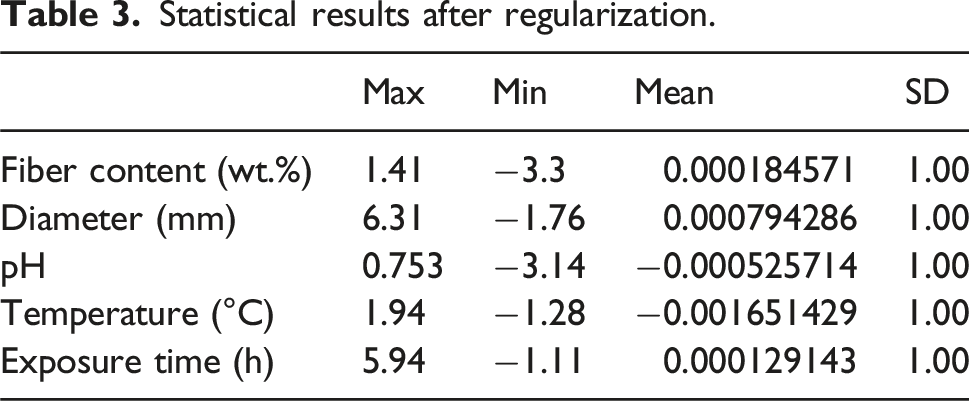
Statistical results after regularization.
Machine learning modelling
Machine learning models generally handle problems in two main categories: classification and regression. Predicting the residual tensile strength of GFRP rebars falls into the regression category. Decision Tree and Random Forest, as representative tree-based models, provide strong interpretability and are effective in handling structured tabular data. Support Vector Machine (SVM), a kernel-based algorithm, performs well in small-sample and high-dimensional scenarios with nonlinear relationships. The Multilayer Perceptron (MLP), a type of feedforward neural network, offers robust nonlinear modeling capabilities with relatively simple architecture. Long Short-Term Memory (LSTM), as an advanced recurrent neural network, is particularly suited for modeling temporal dependencies in sequential data.
Based on these complementary strengths, Decision Tree, Random Forest, SVM, MLP, and LSTM were selected as the machine learning models for predicting the residual tensile strength of GFRP rebars.
Decision tree, Random Forest, and support vector machine (SVM) models
This paper employs Decision Tree, Random Forest, and Support Vector Machine (SVM) models because they are the most used representative machine learning models. Decision Tree (Myles et al., 2004) is a tree-structured machine learning model that builds a tree through a series of decision nodes, each representing a feature (influencing parameters in this paper) to divide the dataset into different subsets. At each node, the model makes a decision based on the feature’s condition to choose the next node until reaching a leaf node, which contains the final category label or regression value. The performance of a decision tree is determined by hyperparameters related to the tree. A common decision tree model is the CART (Classification and Regression Trees) algorithm, which constructs a complex decision tree first and then prunes it according to the data outcome to achieve optimal results.
Random Forest (Breiman, 2001) is an ensemble model composed of many decision trees, as shown in Figure 1. For any given tree n, it generates independent, identically distributed random vector Structure of the Random Forest model.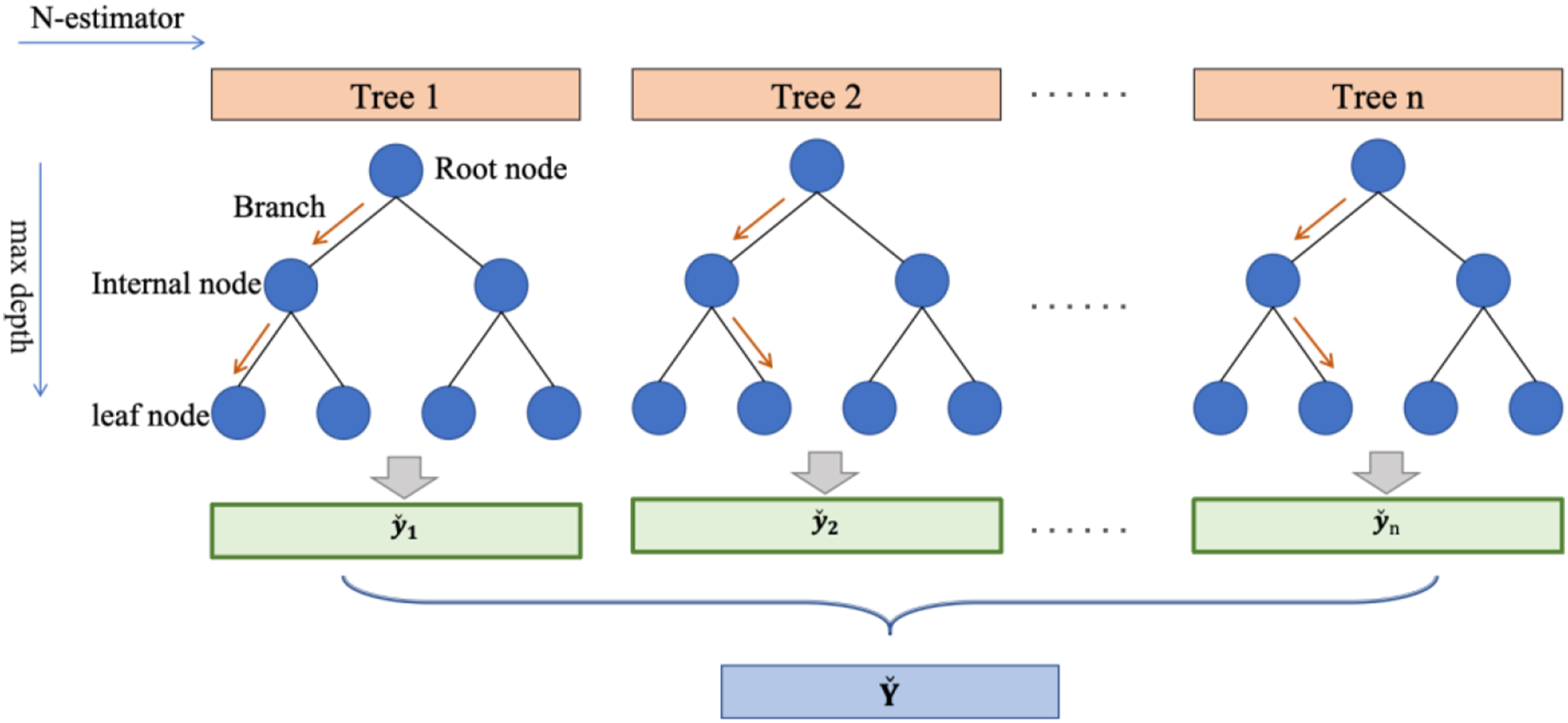
Random Forest follows the CART algorithm of Decision Tree for feature selection and division but differs in two main aspects. Firstly, in feature selection, while Decision Tree chooses the best feature from all available features at each split, Random Forest selects the best feature from a subset of randomly chosen features. Secondly, in terms of training data, Random Forest uses the bagging method, where multiple subsets of the original training data are obtained through sampling with replacement, and multiple decision trees are independently trained. The final prediction is the average of each tree’s results, unlike Decision Trees which often uses the entire dataset. Compared to Decision Tree model, Random Forest reduces the risk of overfitting and enhances generalizability.
Moreover, Random Forest measures the importance of each feature using the entropy reduction method. Each tree in the Random Forest uses features to split data, calculating the entropy used by the feature at each split point. The more the entropy decreases at a node, the more important that feature is considered. Therefore, it can rank the input features in terms of their importance for the output, which is significant for guiding experimental design in this study.
Support Vector Machine (SVM) (Noble, 2006) is a powerful supervised learning model that aims to find the decision boundary, or ‘hyperplane’, that maximally separates different categories. SVM introduces kernel functions that map the original data to a higher-dimensional space, transforming nonlinear problems in low dimensions into linear problems in high dimensions, making originally inseparable features in the raw data separable in higher dimensions, as shown in Figure 2. Structure of the SVM model.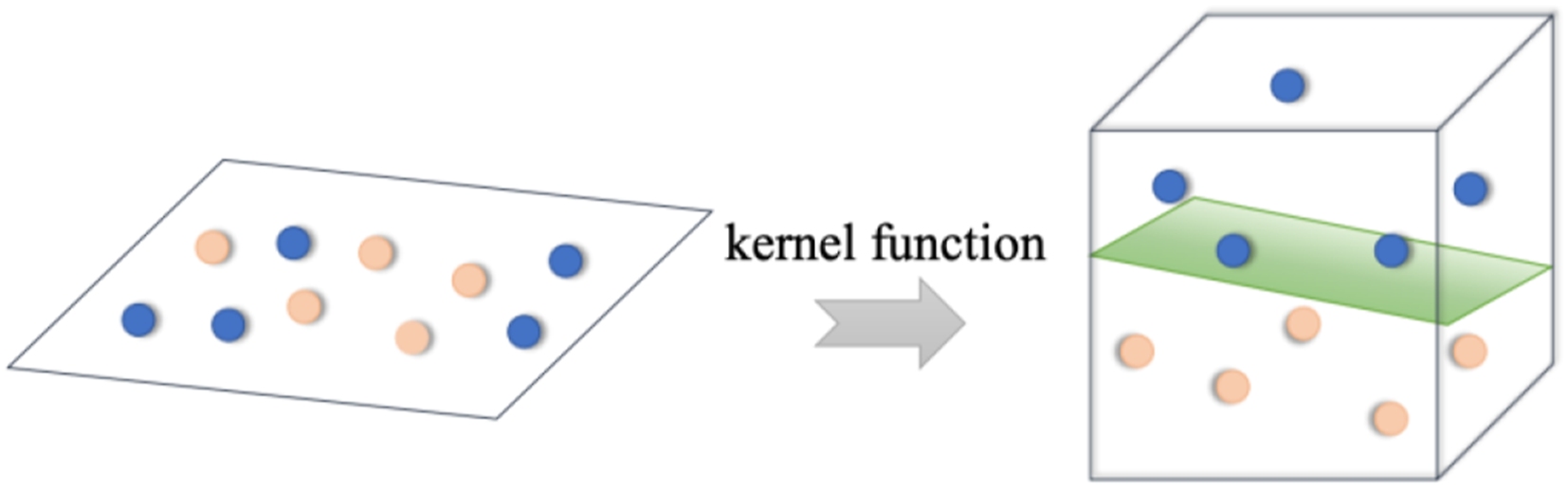
Common kernel functions include linear kernel (linear), polynomial kernel (polynomial), radial basis function kernel also known as Gaussian kernel (RBF) and sigmoid kernel. Linear kernel is the most basic type of kernel, which is mostly used in linearly separable data with low computational complexity and fast computational speed. 
The polynomial kernel adds parameters to the linear kernel to fit more complex data structures, as equation (5).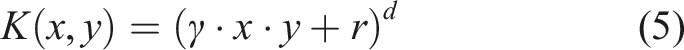
Here,
The RBF kernel is mostly used for nonlinear data. 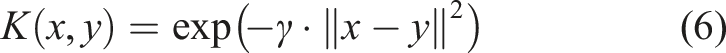
The Sigmoid kernel is similar to an activation function and is able to map the input data between −1 and 1. However, it does not satisfy the requirement of positive definiteness of the kernel function, which requires that all of the kernel eigenvalues are non-negative, and this can lead to failure in finding the global optimal solution, thus affecting the performance and stability of the model.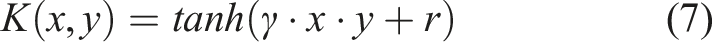
SVM model achieves good generalization with suitable kernel functions and proper penalties.
Deep learning models
Building upon machine learning and with enhanced computing capabilities, deep learning models have evolved to address more complex problems. They have deepened in structure and complexity, forming “end-to-end” fully automated models that do not require manual intervention and can effectively extract features beneficial for solving problems from existing data.
Multilayer Perceptron (MLP) model (Pal and Mitra, 1992), developed from Artificial Neural Networks (ANN), is a feedforward neural network. The model consists of an input layer, hidden layers, and an output layer, with each layer containing multiple neurons interconnected. In this study, MLP model for GFRP rebar’s tensile strength prediction includes nine neurons in the input layer and one neuron in the output layer, as shown in Figure 3. Nine neurons in the input layer include the five influencing parameters in Table 3 plus four resin type that is epoxy, vinyl ester, polyester, thermoplastics. The process of information passing from the input layer to the hidden and output layers is called forward propagation, while the process of calculating parameter gradients through the loss function and transmitting them back from the output to the hidden layers is known as backpropagation. The MLP model adjusts itself through iterations of forward and backpropagation to achieve optimal performance. Structure of the MLP model.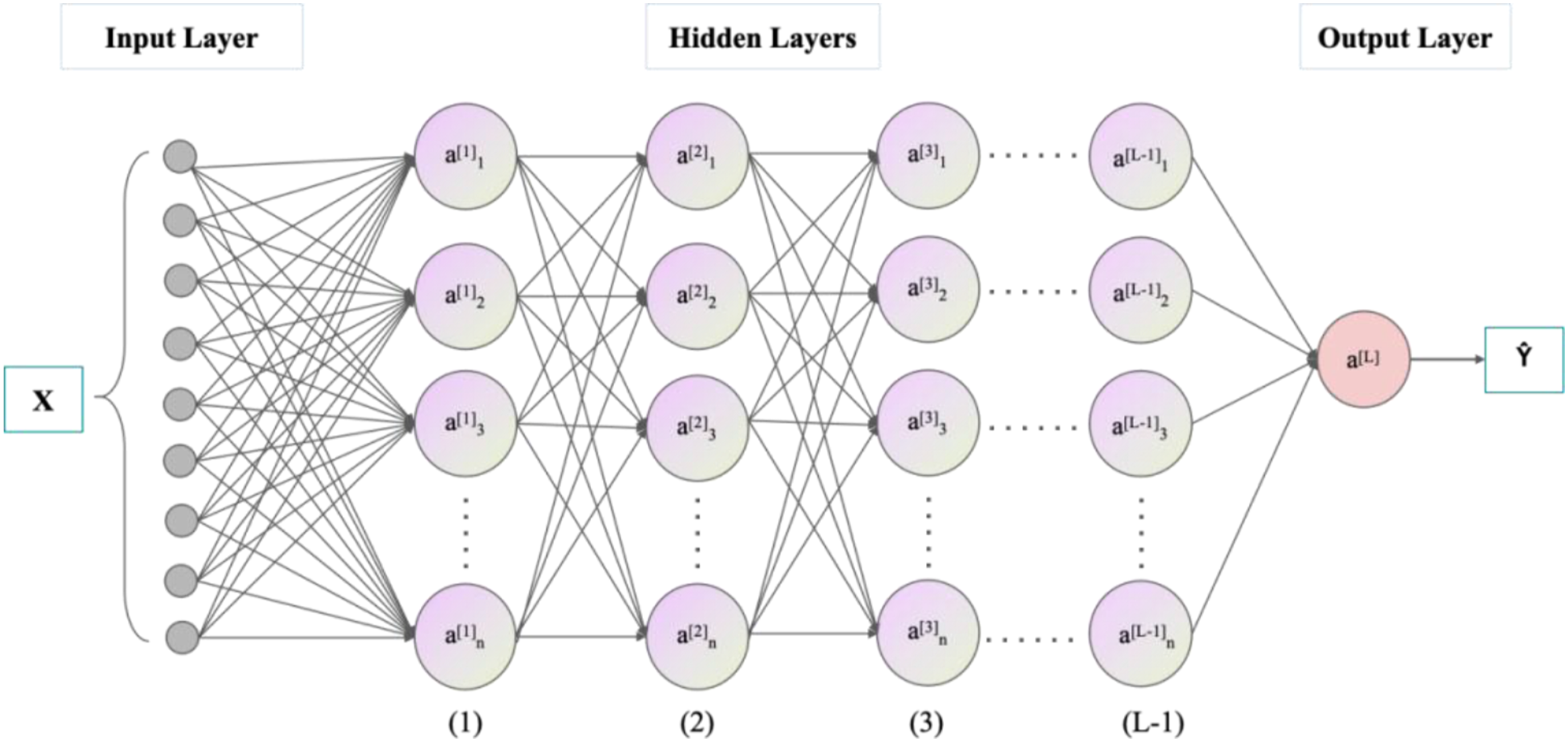
During the model’s forward propagation, non-linear activation functions are introduced to enhance the model’s ability to learn complex non-linear relationships. Common activation functions include ReLU, Sigmoid, and Tanh. Their formulas and curves are shown in Figure 4. ReLU function could not consider negative parameters values, and Sigmoid function only output positive values. Both of them are not suitable for the database in this paper, which has both negative and positive values of all parameters. Therefore, the Tanh activation function is selected. Activation functions.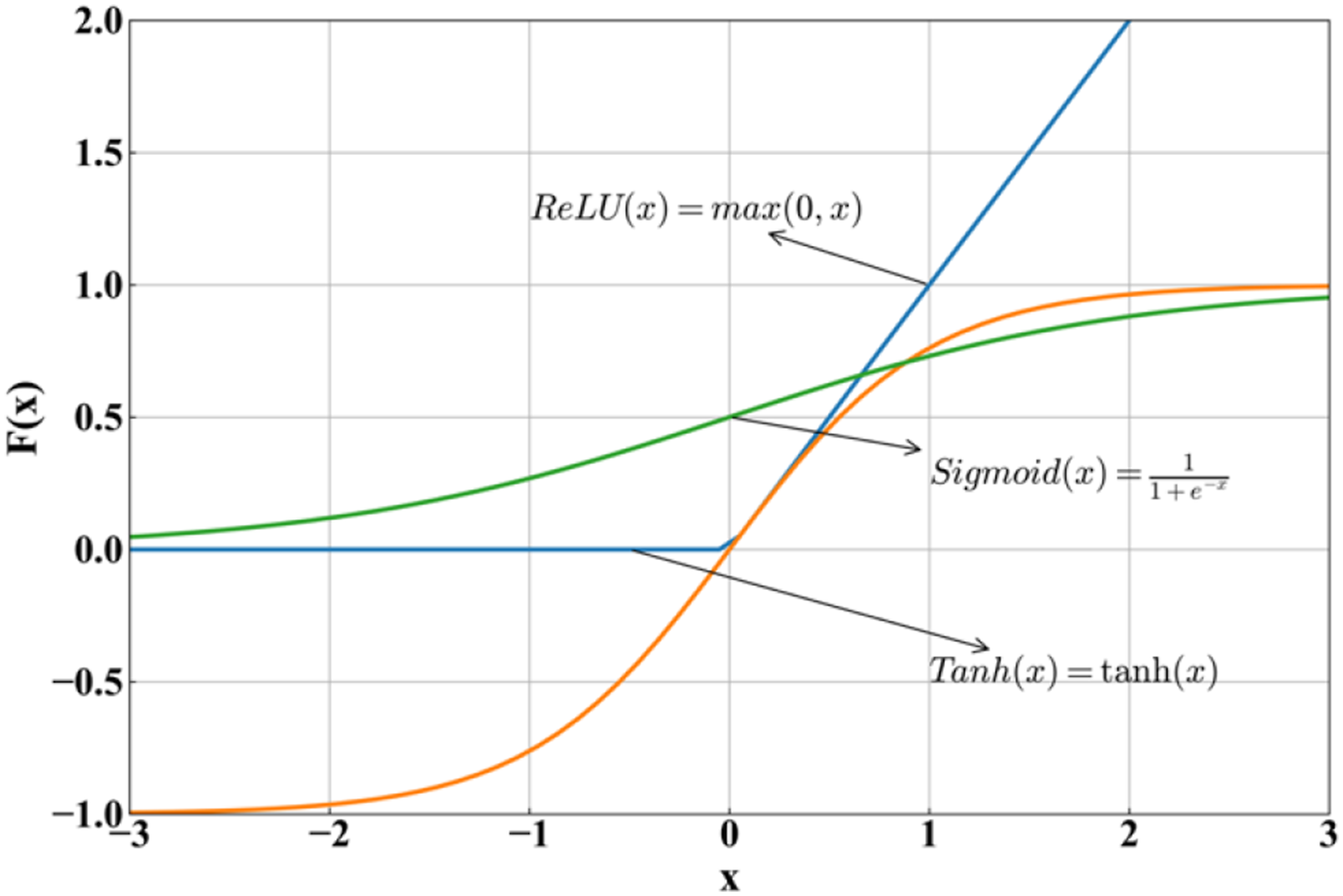
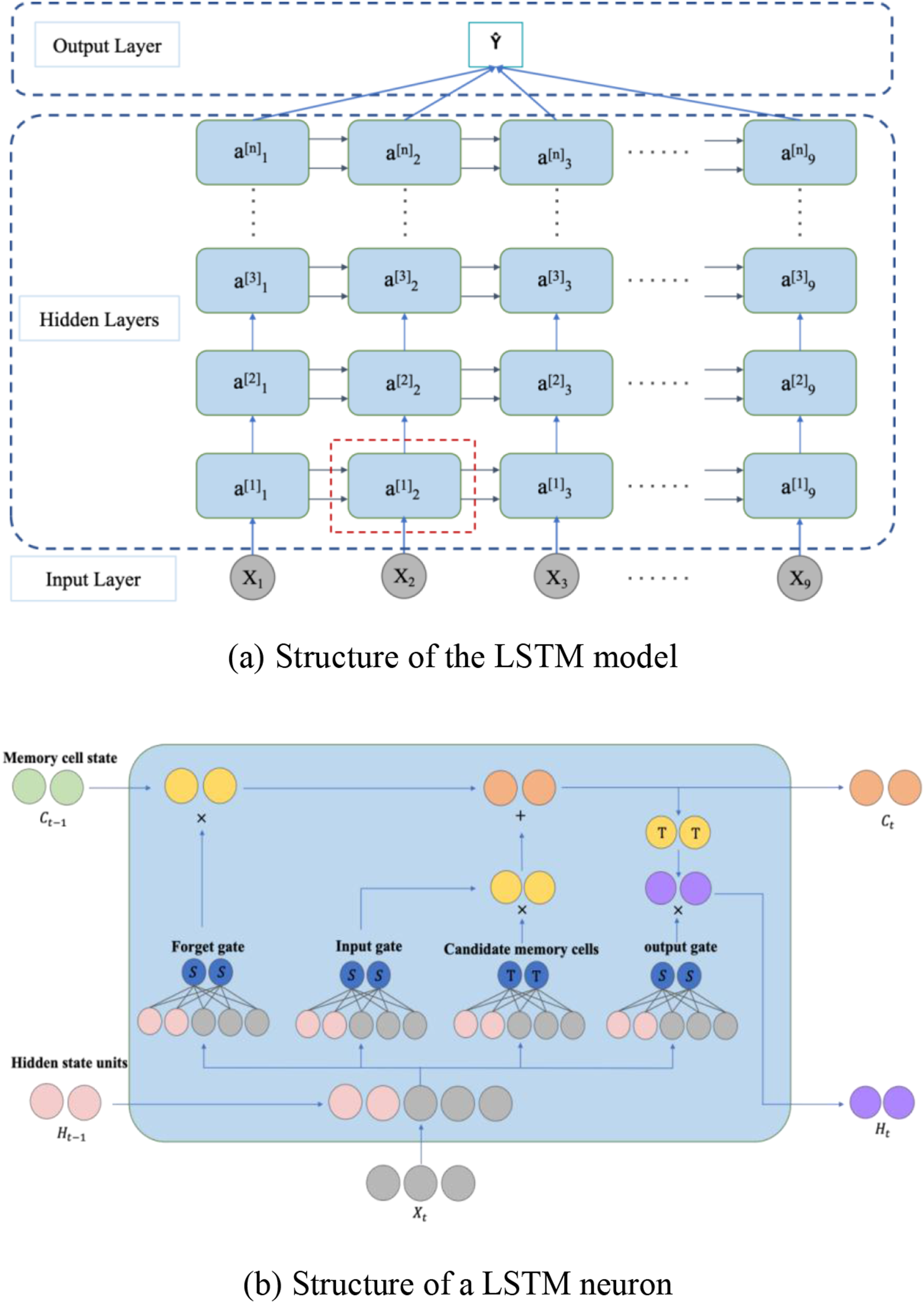
Long Short-Term Memory (LSTM) model (Hochreiter and Schmidhuber, 1997) is a type of neural network capable of remembering information for both short and long durations. It has achieved significant success in problems like time series prediction. LSTM is a variant of the Recurrent Neural Network (RNN). Unlike traditional neural networks, RNN introduces memory functions in their hidden layers, allowing them to retain information from previous time steps. However, RNN can suffer from vanishing or exploding gradients when processing long input sequences due to the recurrent multiplication of weight matrices. LSTM addresses these issues by introducing Gated Recurrent Unit (GRU) and memory cells on top of RNN, thereby controlling the retention and transmission of information (Sherstinsky, 2020).
LSTM has a standard chain-like structure as shown in Figure 5(a). Each repeating unit (or neuron) in Figure 5(b) consists of four network layers, including three gates (input, forget, and output gates) and a memory cell. The input to the gates at each time step includes the current input and the hidden state computed from the previous time step with the output determined by a fully connected layer using a Sigmoid activation function, which ensures gate values ranging between [0,1]. The computational process is as follows: (1) Gate calculations: the input LSTM model. (a) Structure of the LSTM model, (b) Structure of a LSTM neuron.
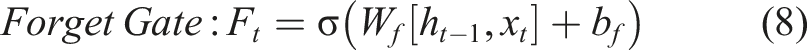
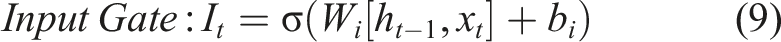
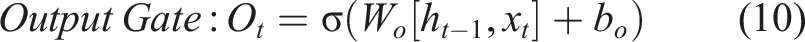
Here, (2) Calculating the candidate memory cell: using the Tanh activation function, the information that needs to be updated into the memory cells is calculated. (3) Updating the memory cell: (4) Calculating the hidden state: after obtaining the memory cell
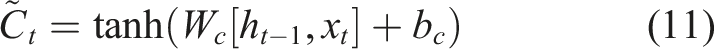
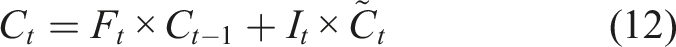
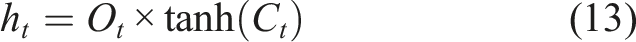
Modelling results
Selection of hyperparameters
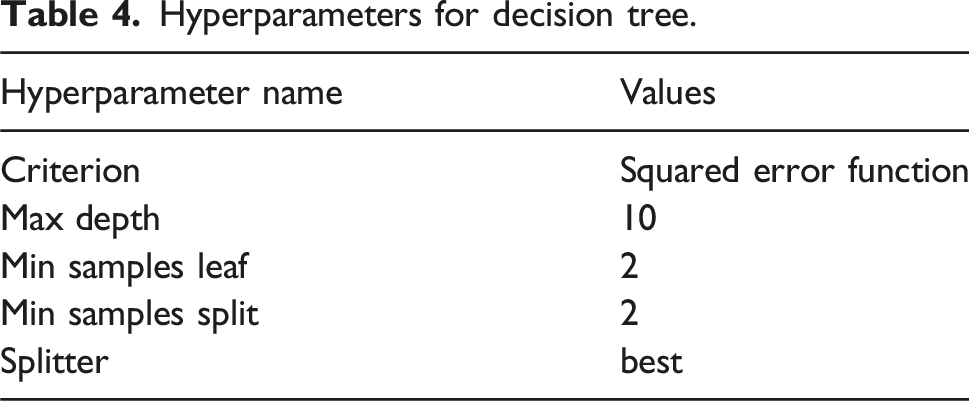
The paper uses Decision Tree, Random Forest and SVM that comes with the sklearn module in Python. Pytorch is used for coding the MLP and LSTM models. The key hyperparameters in Decision Tree are maximum tree depth, minimum number of samples required to split internal nodes, minimum number of data required per leaf. The hyperparameters are coordinated to achieve the best prediction. For SVM, the important hyperparameters are kernel function type, kernel parameters, and regularization parameters.
To obtain the optimal parameter values, grid search with cross-validation method is used in these machine learning models. Grid search is an exhaustive search method that finds the optimal hyperparameters by traversing the possible combinations of hyperparameters. Cross-validation (CV) is a method for evaluating the performance of a model by dividing the dataset into multiple, non-overlapping training and testing sets for determining the performance of the hyperparameters. The combination of hyperparameters is determined by grid search, and then the performance of the set of parameters on the model is determined by cross-validation, so that the combination of hyperparameters with the best prediction is selected.
The above procedure to determine hyperparameters cannot be used for deep learning models due to the complex model structure, massive neuron data, and high computational cost. It can only be determined by manually adjusting the hyperparameters. The batch size, learning rate, activation function, number of hidden layers, neuron size, and dropout rate are all common hyperparameters for MLP and LSTM models. In addition to the above hyperparameters, the time step hyperparameter in LSTM plays an important role in the model’s processing and understanding of time series data. The time step hyperparameter is integral to the model’s ability to discern dependencies within the dataset, embodying the memory function of the architecture. A protracted time step suggests an enhanced capacity for the model to retain information, thereby enabling it to apprehend more extensive long-term data dependencies. Furthermore, the time step governs the frequency with which data points are incorporated into each input sequence, thereby directly influencing the quantum of data engaged during each iteration of training. This has a consequential impact on both the model’s performance and its training efficiency. By propagating forward and backward at each time step, the model can effectively learn the information in the middle of the sequence and thus perfectly predict the data trend.
Hyperparameters for decision tree.
Hyperparameters for random forest.

Hyperparameters for SVM.

Hyperparameters for MLP.

Hyperparameters for LSTM.

Prediction performance of different models
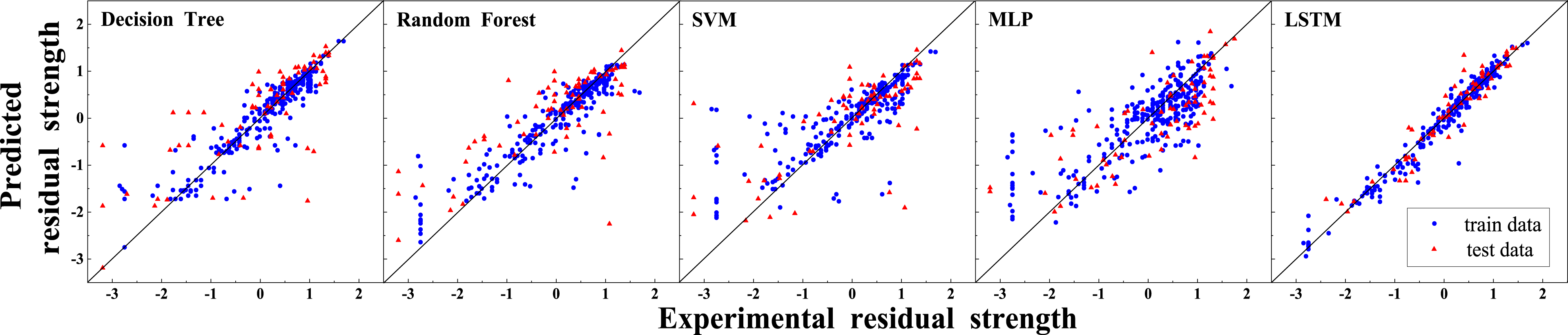
Figure 6 shows the predicted results of each model. In general, most models are more accurate for positive values and less accurate for negative values. In order to further evaluate the performance of each model, the coefficient of determination (R2), the mean square error (MSE), the mean absolute error (MAE), and the root mean square error (RMSE) were chosen as accuracy indicators. The closer R2 is to 1, and the smaller MSE, MAE, RMSE is, the more accurate the model is. The accuracy indicators can be calculated using the following equations. Prediction results of different models.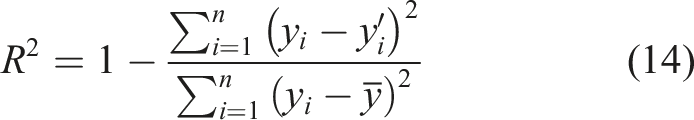
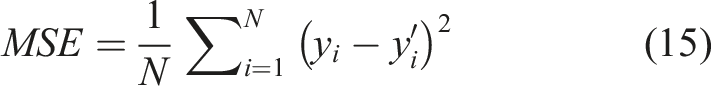
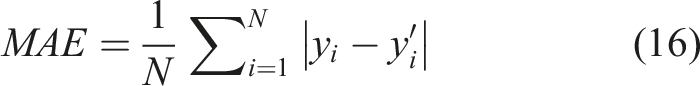
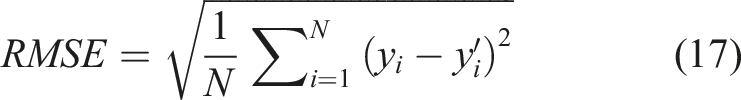
Accuracy indicators of different models.
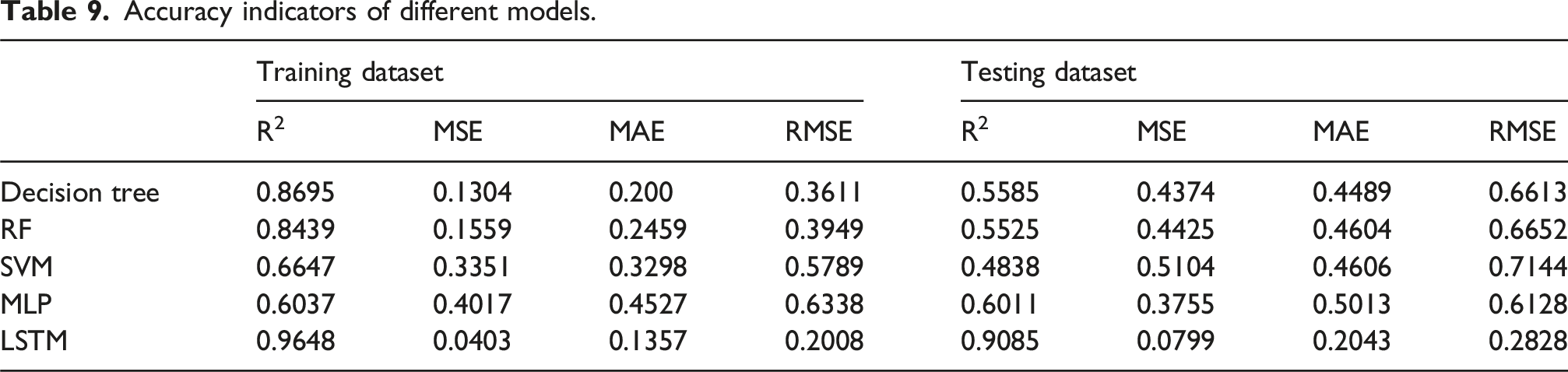
Overfitting is common in machine learning and is not necessarily detrimental. The primary goal of any model is to achieve the lowest possible error on the testing dataset, ensuring strong predictive performance. In general, as model complexity increases, training error decreases. However, for the testing dataset, an optimal level of model complexity exists—beyond this point, additional complexity may reduce generalizability. The complexity of a model is often controlled by hyperparameters, as listed in Tables 4–8 for the selected models. These hyperparameters are fine-tuned using cross-validation to identify their optimal values, thereby minimizing overfitting and improving model performance.
Performance of Random Forest when changing Max depth values.

Performance of Random Forest when changing Min samples leaf values.

Performance of Random Forest when changing Min samples split values.

Importance analysis of influencing parameters on the residue tensile strength of GFRP rebar
Definition of SHAP value
Understanding the importance of each influencing parameter on the residue tensile strength of GFRP rebar is crucial as it can guide experimental research and design, saving the cost of trial and error. In this context, Lundberg and Lee (2017), based on the principles of game theory, proposed the SHAP (Shapley additive explanation) method, compatible with machine learning models. SHAP method provides a way to explain the impact of each feature (influencing parameters in this paper) on the model’s predictions (residual tensile strength), enhancing the interpretability of balck-box models like LSTM. The SHAP value for each feature quantifies its contribution to the prediction of residual tensile strength.
The core of the SHAP method is to calculate a corresponding SHAP value for each feature variable. It uses an additive feature attribution approach to explain each SHAP value. The model’s prediction is then interpreted as the sum of the attribution values of each input feature. The specific formula is: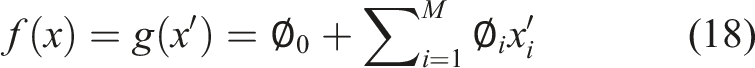
Here, x is the model’s original input, and x' is the simplified vector of input feature.
To better understand the SHAP interpretability, Figure 7 illustrates the calculation process of the SHAP values for a sample x = {x
1
,x
2
,x
3
,x
4
} consisting of four features, where the prediction model result f(x) is computed. The process begins with the expected value of the model’s prediction E(f(x)) as the initial constant Example of calculating SHAP values.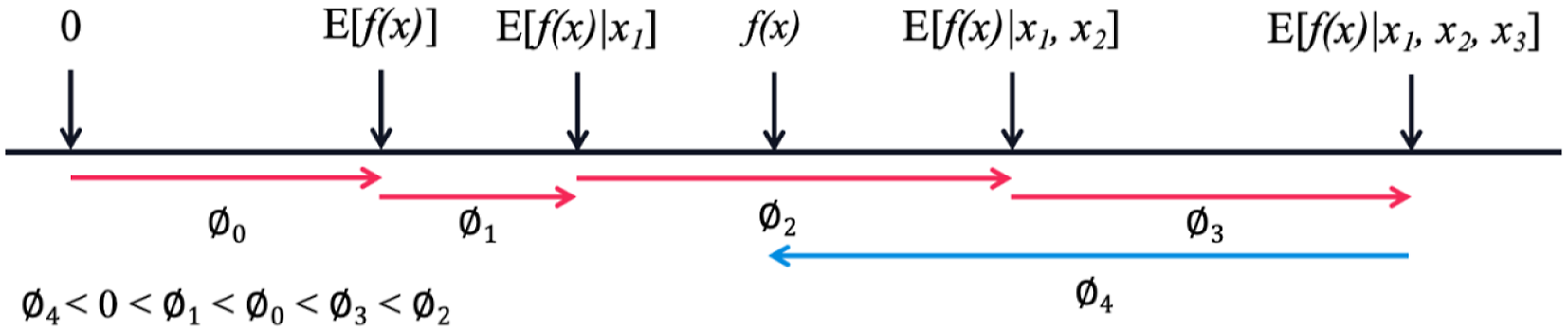
Finally, in addition to considering the features themselves, the SHAP method takes into account all possible combinations of feature variables. Therefore, for feature 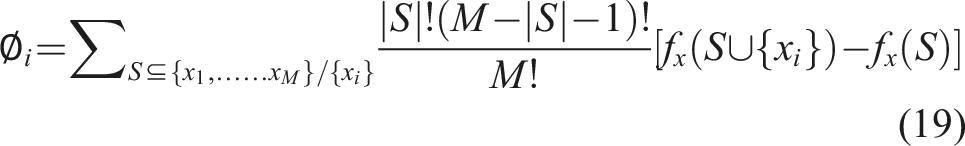
Here, S is a subset of the sample feature variables, representing the set of all input features excluding
It should be noted that, SHAP is only applicable when the influencing parameters are not highly linearly correlated. Otherwise, SHAP value cannot be used to evaluate the importance of influencing parameters. The linear correlation between influencing parameters is evaluated using Pearson Correlation Coefficient (PCC) as given in the following equation. The closer the absolute PCC value to 1, the stronger the linear correlation between two influencing parameters. A positive value indicates a positive correlation, where a negative value indicates a negative correlation.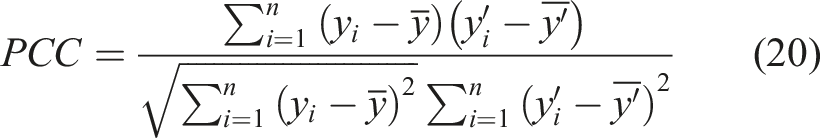
PCC results are presented in Figure 8. Apart from the correlation between resin type (RT) and fiber content (FC), PCC values between other parameters are below 0.4, indicating no apparent linear correlation among these variables, ensuring the applicability of SHAP method. PCC results. Please note that the closer the PCC value is to 1, the stronger correlation is between two parameters. The color of the cell is a measure of PCC value as per the color scale.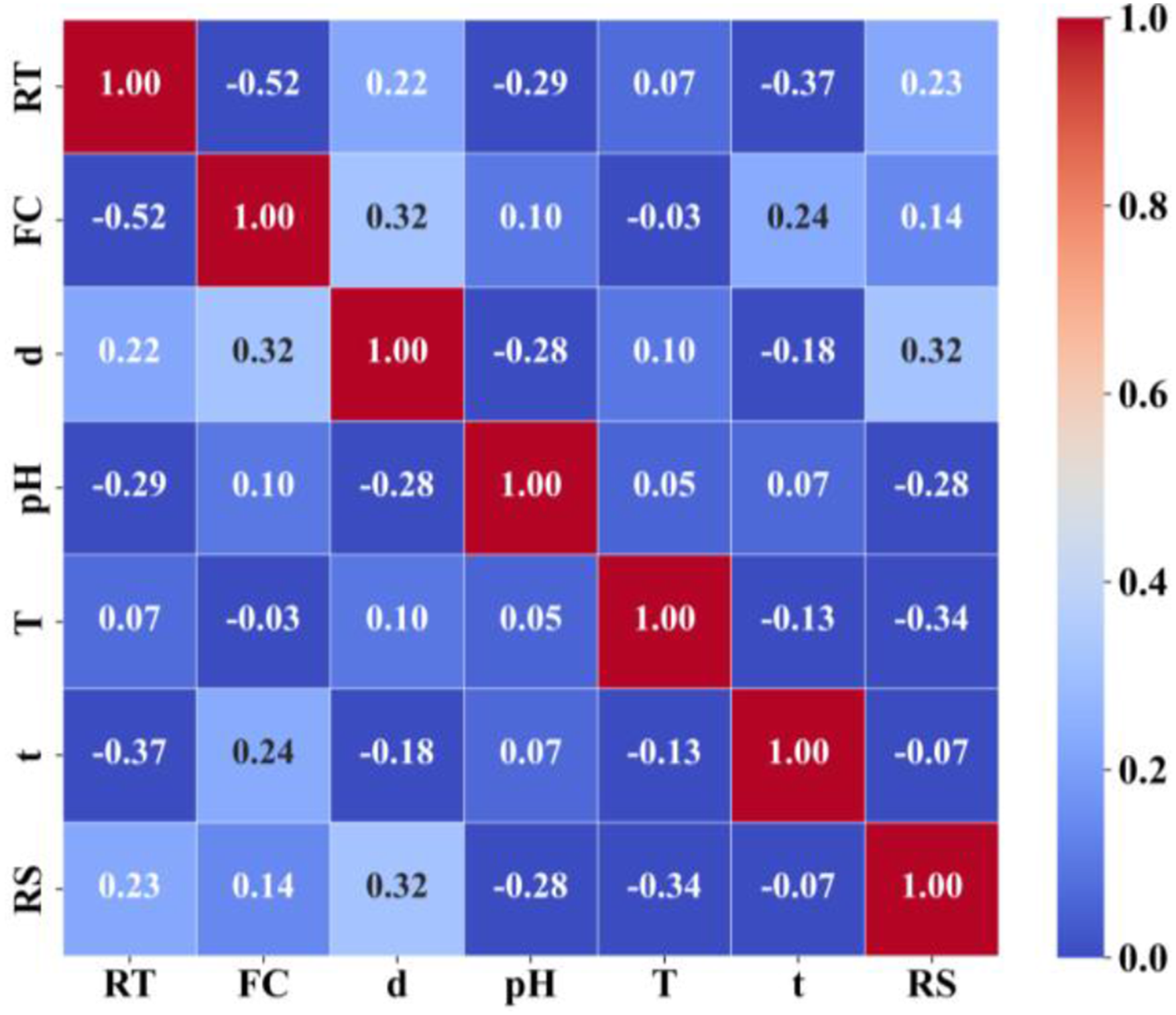
PCC values can be used to assess the correlation between various influencing parameters and residual tensile strength. Exposure temperature, bar diameter, pH value, and resin type show a stronger correlation with residual tensile strength, while exposure time and fiber content have a weaker correlation. Additionally, exposure temperature and pH exhibit a negative correlation with the residual tensile strength, meaning that as temperature increases and the environment becomes more alkaline, the residual tensile strength decreases. In contrast, the bar diameter shows a positive correlation, indicating that larger diameters correspond to higher residual tensile strength, which is consistent with the underlying principles of tensile strength calculation.
The overall Pearson Correlation Coefficients among the influencing factors indicate weak inter-variable correlations, with the exception of a relatively high correlation between resin type and fiber content, showing a PCC value of −0.52. This is reasonable because resin type normally matches with particular fiber content in bar manufacturing practices.
Importance analysis using SHAP and Random Forest
Feature selection and importance ranking methods are widely used in data processing. In engineering materials, feature importance ranking helps to identify key influencing factors, optimize material properties, and guide design and construction. Common feature selection methods include SHAP-based feature selection and model-based feature importance analysis. Both methods have been proven to effectively and accurately identify key features (Kim and Kim, 2022; Liu et al., 2022; Wang et al., 2024). The SHAP interpretability method, as a post-model approach, provides post-model explanation and analysis, independent of the prediction model type. By considering all possible combinations of feature variables, SHAP calculates the SHAP value for each feature based on the additivity principle, enabling feature importance ranking and analysis of feature interactions. In contrast, model-based feature analysis methods, such as Random Forest, analyze features during the model training process, evaluating feature importance based on the accuracy of data splits. This method focuses on the individual effect of each feature on model prediction but ignores the relationships between features. Compared to SHAP’s post-hoc analysis, model-based methods like Random Forest require fewer computational resources but are limited in scope, particularly when dealing with large feature sets or complex relationships. Research indicates that when the number of features is small (M < 15), both methods yield similar performance in terms of the area under the Precision-Recall curve (AUPRC), demonstrating their consistent effectiveness (Wang et al., 2024). However, when the number of features is large (M > 150), SHAP is more effective for identifying key features (Liu et al., 2022). In the study of GFRP rebar tensile strength, given that the feature count (M = 9) is small, both methods were used to analyze the influence of features on the residual tensile strength of GFRP rebars.
Figure 9 shows the feature density scatter plot for MLP and LSTM models based on SHAP values. The influencing parameters are arranged on both sides of the figure in the order of their importance level on the residual strength of the GFRP rebar. For each influencing parameter, the spread width of the SHAP value indicates the level of importance, that is the wider the more important. If the red points correspond to positive SHAP values, it means the parameter has positive impact on the residual strength, and vice versa. Importance ranking of influencing parameters by SHAP. Please note the spread width of the SHAP value indicates the level of importance, that is the wider the more important. The red points correspond to positive SHAP values, it means the parameter has positive impact on the residual strength, and vice versa.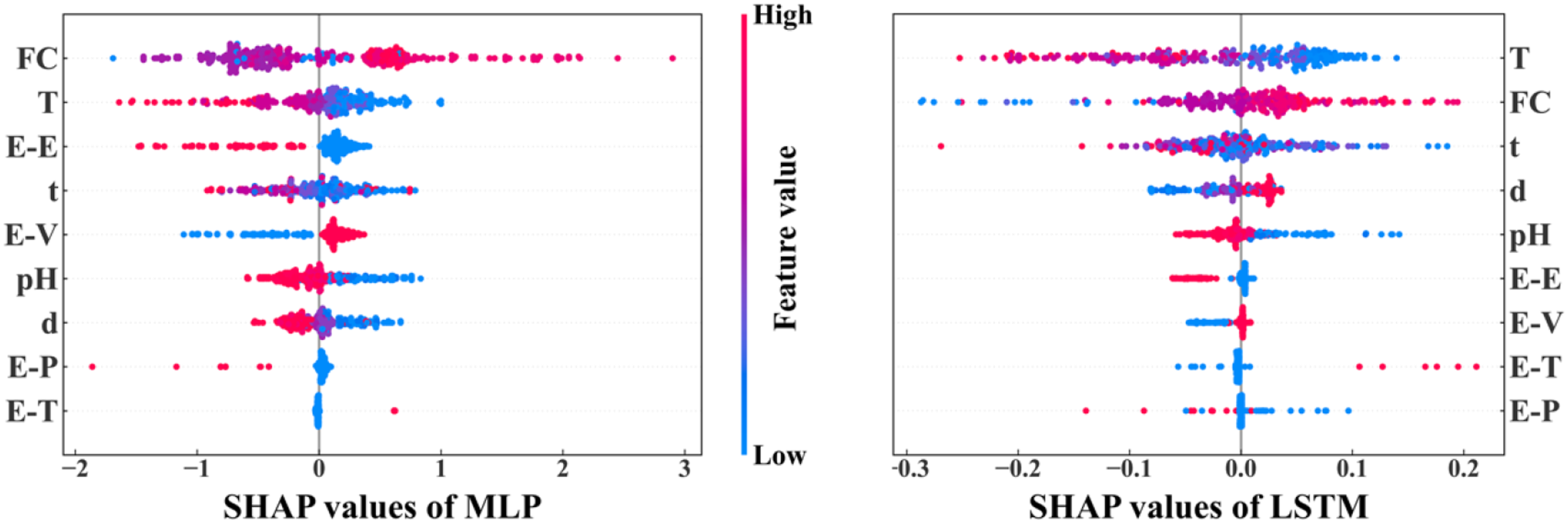
According to the results of both MLP and LSTM models, the most important parameters affecting the tensile strength of GFRP rebar are exposure temperature and fiber content. The least important parameter is the resin type. Both models show that epoxy and vinyl ester have more impact than polyester and thermoplastic. In particular, temperature has a negative impact, with residual tensile strength decreases as temperature rises. Similarly, exposure time and pH also have negative impact. Fiber content mainly shows a positive impact. These results are consistent with the experimental observations in the literature which confirms the accuracy of SHAP assessment.
The importance of influencing parameters is ranked using Random Forest as in Figure 10. It shows that environmental parameters (exposure temperature, pH) are generally more important than the material property parameters (bar diameter, fiber content, resin type). Similar to the SHAP results, temperature has the most significant impact on the tensile strength of GFRP rebar, followed by pH, bar diameter, fiber content, with resin type the least important. The exposure temperature has the most significant impact as confirmed by both SHAP and Random Forest which is consistent with experimental observations. For example, Feng et al. (2022) found that increased temperature lead to a significant decrease in bar tensile strength, and Al-Salloum et al. (2013) confirmed this phenomenon, discovering that GFRP rebars exposed to high temperature conditions for 18 months had an average tensile strength loss of 24.05%, while rebars in normal temperature had almost no strength loss. Importance ranking of influencing parameters by Random Forest.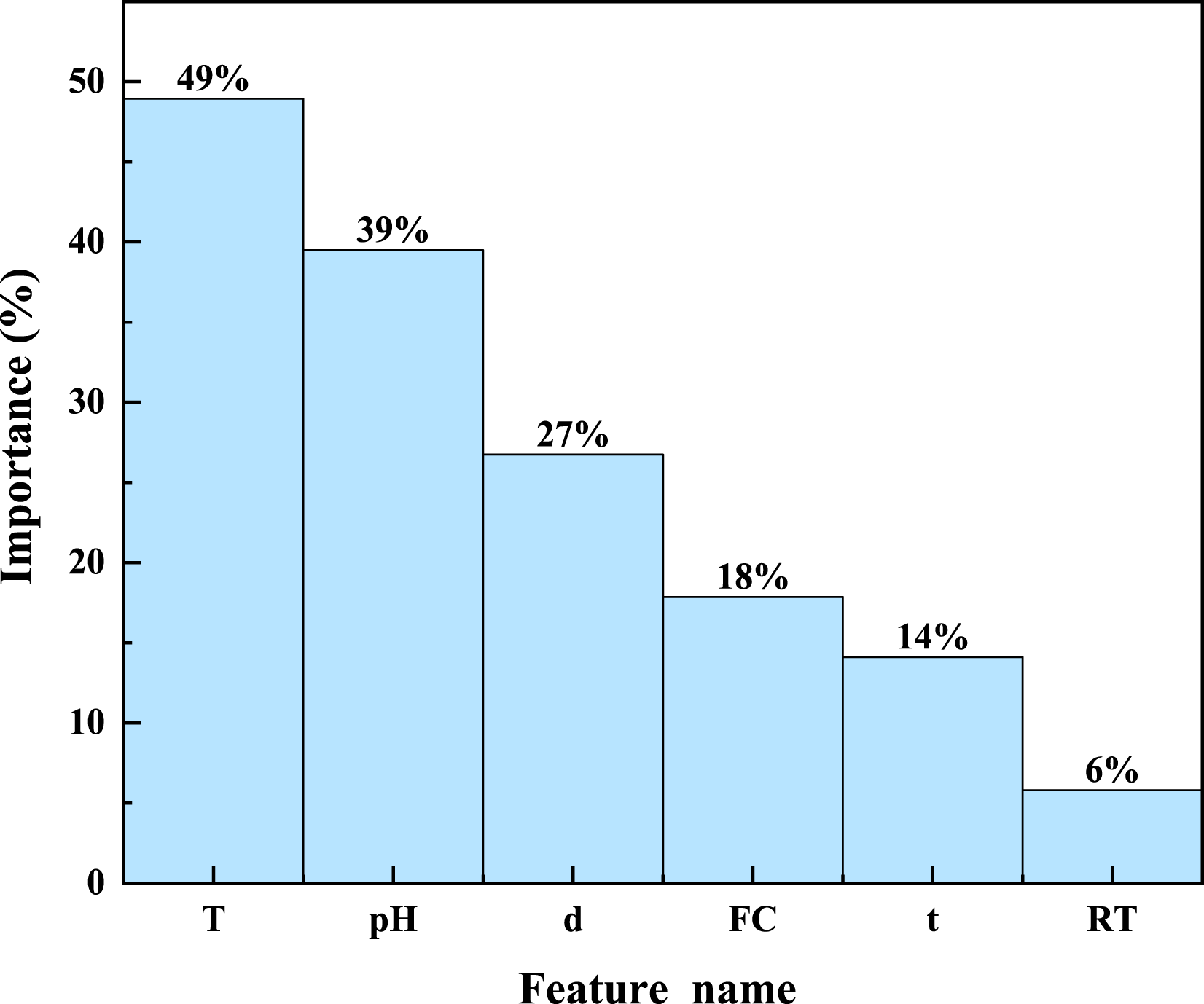
Random Forest and SHAP have different mechanism which yield different importance rankings of influencing parameters. For example, Random Forest ranks pH value as the second most important parameter, but SHAP ranks pH value lower than fiber content. This indicates that pH has more noticeable impact if the other parameters do not present (Random Forest individual importance). If pH works with other parameters, its importance decreases (SHAP correlation effect). For example, it was observed that (Almusallam et al., 2013) GFRP rebars in alkaline solution with chloride ions under high temperature even showed 11% higher residual tensile strength than the bars immersed in tap water. It suggests that the coupling of pH and chloride ions reduces the impact of pH on the residual strength of GFRP rebar. This was explained (Almusallam et al., 2013; Feng et al., 2022) that a thin salt layer formed on the GFRP rebar surface, hindering water penetration leading to less strength reduction than in tap water.
In summary, temperature has the most impact on the tensile strength of GFRP rebar, both when acting alone (Random Forest) and in combination with other factors (SHAP). pH has a more noticeable impact when acting alone (Random Forest) compared to when combined with other factors (SHAP). Regarding the resin type, epoxy has a clear impact on tensile strength, while the other resin types have a smaller impact.
Correlation analysis
To further evaluate the correlation of different influencing parameters and its impact on the tensile strength of GFRP rebar, a correlation analysis is conducted based on 264 randomly selected data points (75% of database) using SHAP based on LSTM model, as shown in Figure 11. The diagonal line indicates the impact of respective parameter on the tensile strength, while off-diagonal elements represent the effect of correlation between two parameters, that is the wider the spread on the horizontal axis, the more impact the correlation generates. Figure 10 reveals that the combined effect of exposure temperature and fiber content with other parameters is the most prominent, followed by time and pH. The combined effect of resin type with other parameters is not significant. Impact of correlation between two parameters on the tensile strength of GFRP rebar using SHAP value based on LSTM model.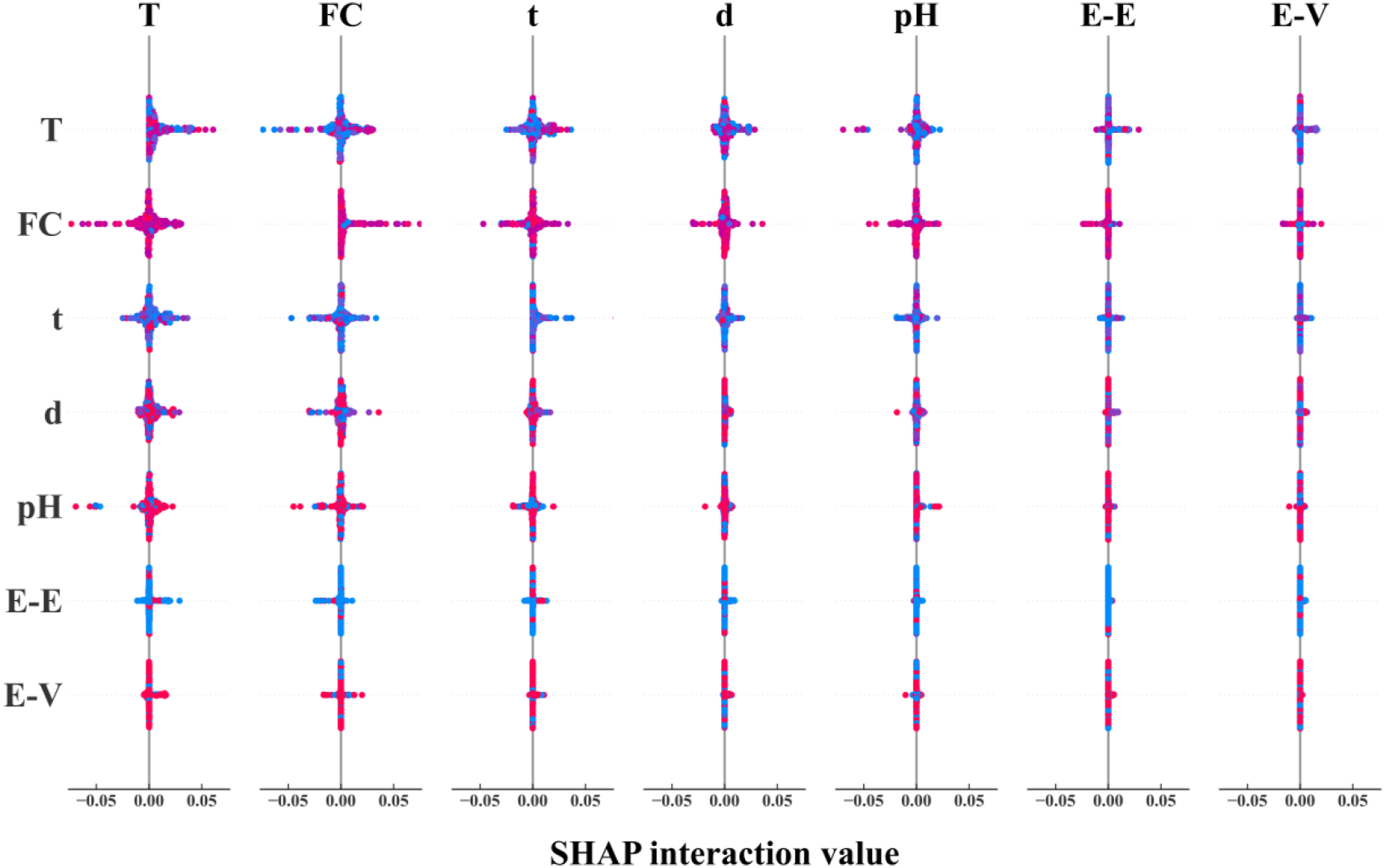
Figure 12 shows the impact of individual parameters on the tensile strength within the study range and the other parameters with the most significant correlation. Where, the horizontal and vertical coordinates represent the studied parameter with its corresponding SHAP value, and the variation of SHAP value represents the trend of the parameter’s influence on the residual tensile strength, for example, in the fiber content plot, with the growth of the fiber fraction, the range of the color is gradually extended from the lower left corner (the position of SHAP values = −0.2), to the upper right corner (the position of SHAP values = 0.1), indicating that the residual tensile strength of GFRP rebar rises with increasing mass fraction. Similarly, with the increase of bar diameter, the residual tensile strength of GFRP rebar increase. In contrast, as the temperature rises and time lengthens, the residual tensile strength decreases. The residual tensile strength tends to decrease with pH value, that is when the environment is highly alkaline (pH > 12), the residual tensile strength significantly decreases, reaching its lowest at a pH of 13.7. Shap correlation analysis.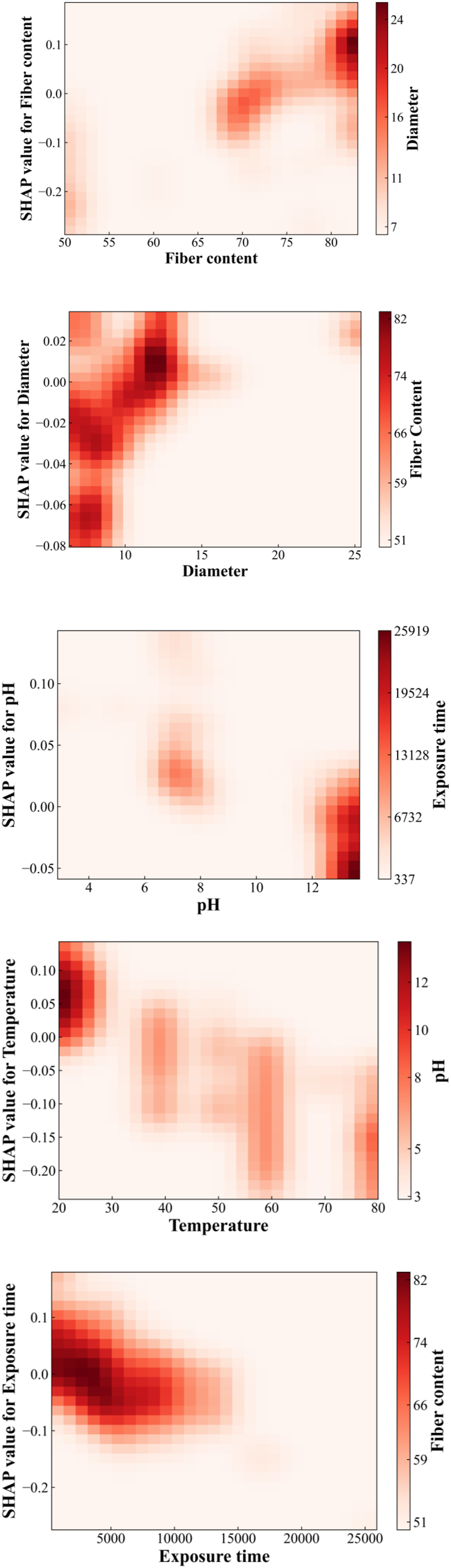
The right side of Figure 12 shows the parameters most correlated with the considered parameter, the depth of color represents the magnitude of correlated parameter, with darker colors indicating larger values. For example, in the fiber content plot, the deepest part of the color corresponds (d > 12 mm) to within the 80% fiber mass fraction region, and the bar diameter continues to increase as the fiber mass fraction increases, indicating higher fiber content correlates to larger bar diameter, aligning with actual engineering practices. Meanwhile, in the 75-80% fiber content range, some combinations of high fiber content with small diameter occur, predominantly with epoxy resin, suggesting that epoxy requires a lower fiber content compared to other resins. The coupling of temperature with pH occurs across the full range, and the most significant effect on the reduction of residual tensile strength of GFRP rebar is observed at low temperatures (20°C) in highly alkaline environments (pH > 12), which corresponds to the hindrance of water molecule diffusion by salt-ion films at high temperatures, as mentioned in Feng et al. (2022) and Almusallam et al. (2013) and proves that the pH effect is mainly independent. However, the pH parameter still accelerates the loss with other parameters, for example, high alkalinity can have a serious effect on the strength reduction under a long period of time.
Overall, the interdependence among the parameters is intricate. Through correlation analysis of the parameters in Figure 10, it is discovered that the mass fraction of fiber content (as a material property), and temperature (as an environmental parameter), exhibit the most significant coupling effect with other parameters. Conversely, the coupling effect between fiber type and other parameters is minimal. In the correlation analysis of continuous variables in Figure 11, it is observed that the bar diameter demonstrates the strongest positive correlation with the fiber weight fraction. Moreover, when the exposure time is short, the residual tensile strength of GFRP rebar is higher under high temperature than ambient temperature, under equivalent high alkalinity condition. Nonetheless, if the exposure time is longer than 13,000 hours, high temperature and alkaline environment introduces more tensile strength reduction of GFRP rebars.
Please note that, to ensure the reliability and robustness of the analysis of influencing parameters on the residual tensile strength of GFRP rebars, three validation approaches were employed in this section. First, domain knowledge from existing literature was used to assess the plausibility of the importance rankings, providing expert-based justification. Second, both SHAP value analysis and Random Forest-based model interpretation were applied to enable cross-validation between two different methodological perspectives in Section 5.2. The consistency/differences observed between these two approaches enhances confidence in the findings. Third, the identified key parameters were further supported by experimental evidence reported in the literature, demonstrating alignment between data-driven insights and observed physical behavior. Together, these complementary validation strategies provide a solid foundation for the interpretation of results and underscore the relevance of the identified influencing factors. Future experimental studies are encouraged to further corroborate and refine these findings.
Conclusion
This paper presents a study to predict residual tensile strength of GFRP rebar due to environmental degradation using machine learning models, including Decision Trees, Random Forest, Support Vector Machine (SVM), Multilayer Perceptron (MLP), and Long and Short-Term Memory (LSTM). A dataset containing 350 data points on GFRP rebar tensile tests were collected from published literature, including six influencing parameters that is fiber content, bar diameter, resin type, temperature, pH, and exposure time. The importance of these parameters was also analyzed and ranked using Random Forest and SHAP in terms of their impact on the tensile strength. Based on the results in the paper, the following conclusions can be drawn: (1) The LSTM model achieved the best performance in predicting the residual tensile strength of GFRP rebar under environmental degradation, with R2 values of 0.96 on the training dataset and 0.91 on the testing dataset. This was followed by the Decision Tree, Random Forest, MLP, and SVM models. However, the Decision Tree, Random Forest, and SVM models exhibited overfitting, showing better performance on the training dataset than on the testing dataset. In particular, the Decision Tree and Random Forest models had R2 values above 0.8 on the training set, which dropped to approximately 0.55 on the testing set. (2) SHAP analysis indicates that temperature and fiber content are the top two most important parameters affecting GFRP rebar tensile strength, with temperature has negative and fiber content has positive effects. Additionally, fiber content is most likely coupled with other parameters and this coupling also affects the tensile strength. These results are consistent with experimental observations. (3) Random Forest and SHAP analysis show that temperature has the most impact on the tensile strength of GFRP rebar, both when acting alone (Random Forest) and in combination with other parameters (SHAP). pH has a more noticeable impact when acting alone (Random Forest) compared to when combined with other parameters (SHAP). (4) It is recommended that LSTM model be used for the prediction of the tensile strength of GFRP rebars due to environmental degradation. Additionally, fiber content is a very important parameter for GFRP rebar durability and it should be considered and reported in any future durability investigations.
Limited by the experimental conditions, data collection time, and available resources, this study is based on only 350 open-source tensile test data for GFRP rebars, and lacks long-term data on the variation in tensile strength of GFRP rebars in engineering applications. Additionally, due to engineering cost and demand, the fiber content, bar diameter and matrix type of GFRP rebars are generally fixed. This limits the ability to explore the coupling relationships between different feature combinations and their impact on the long-term mechanical properties. Nevertheless, the proposed predictive model and feature analysis methods still provide theoretical support for improving the tensile mechanical performance of GFRP rebars. Further research should focus on collecting more diverse long-term mechanical performance data of GFRP rebars in engineering applications to further refine related models and theories.
Supplemental Material
Supplemental Material - Machine learning-based prediction of tensile strength of glass fiber-reinforced polymer rebar under environmental conditions
Supplemental Material for Machine learning-based prediction of tensile strength of glass fiber-reinforced polymer rebar under environmental conditions by Yuqing Cheng, Xiangdong Geng, Chao Wu in Advances in Structural Engineering.
Footnotes
Acknowledgement
The authors also would like to thank the support by the Composites for Energy Infrastructure Group at Imperial College London. The corresponding author acknowledges the support by UKRI through the Future Leaders Fellowship program (MR/X034054/1), and thanks the consistent support and inspiration by Jingheng (Hadan) Wu.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: UK Research and Innovation; MR/X034054/1
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The raw/processed data required to reproduce these findings cannot be shared at this time as the data also forms part of an ongoing study.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.