
Abstract
Orthotropic steel decks (OSD) are widely used in the bridge industry, but they are susceptible to fatigue cracking due to various factors such as weld defects, overload traffic, and complicated welded joint configurations. Traditional crack detection methods rely mainly on visual inspection, which is time-consuming and prone to errors. Recently, many crack detection methods based on machine vision have been introduced. However, accurately and effectively detecting fatigue cracks of OSD remains challenging due to the indistinct nature of these cracks compared to the background and their susceptibility to various types of noise. To address these problems, this research proposes an improved Mask Region-based Convolutional Neural Network (Mask R-CNN). The proposed model enhances the feature extraction ability of the original Mask R-CNN by introducing a Convolutional Block Attention Module (CBAM) and Path Augmentation Feature Pyramid Network (PAFPN) into the backbone network. Additionally, a morphological closing operation is performed on the extracted fatigue cracks to address the problem of disjoint cracks. On the basis of crack mask closure, the pixel-wise quantization of cracks was achieved using relevant OpenCV functions. Evaluation on a crack dataset of OSD shows that the proposed model outperforms other methods with precision, recall, average precision (AP), and F1 score of 83.98%, 84.44%, 77.9%, and 84.21%, respectively. In conclusion, the experiment validates that the proposed model can effectively detect, segment, and quantify fatigue cracks of OSD.
Keywords
The highlights of this work are summarized as follows (1) A deep learning framework based on improved Mask R-CNN to simultaneously detect and segment the fatigue cracks of OSD was introduced. (2) The CBAM was adopted in the backbone network of Mask R-CNN to strengthen the feature information extraction of the region of interest for the crack part. The path augmentation feature pyramid network (PAFPN) module was used to promote the information propagation of the backbone network of the Mask R-CNN model. (3) In this research, the morphological closure operation and the proposed crack detection of OSD algorithm are combined to improve the integrity of crack segmentation, facilitating subsequent quality assessment of inspection. (4) Based on the crack mask closure, relevant OpenCV functions are used to extract the crack skeleton and quantify the length and width of the crack in a pixel-wise sense.
Introduction
Orthotropic steel decks (OSD), by virtue of high rigidity, lightweight, applicability for modular construction, low maintenance and life cycle costs, etc., have been wildly used in new bridges and also in rehabilitation of the existing bridges. However, these decks have been plagued by fatigue cracking problems, mainly as a result of weld defects, overload traffic and complicated welded joints configurations (Connor et al., 2012). The initiation and propagation of fatigue cracks will reduce the reliability and integrity of the bridge, and ultimately will shorten its service life. A timely manner to identify these fatigue cracks and administer effective rehabilitation measures can curtail the maintenance needs and extend the service life of OSD. In present engineering practice, visual inspection is the primary measure of fatigue crack inspection, which hold out high requirements to inspectors’ professional competence and experiences (Campbell et al., 2020), as well as accessibility and safety concerns. In addition, time and manpower involved in visual inspection are considerable, too.
Compared with visual inspection, non-destructive testing (NDT) employing advanced sensing technology can realize local damage detection of bridges and greatly reduce the error and subjectivity of inspection. Common nondestructive testing technologies include radiography, ultrasound, dye-penetrant and magnetic-particle testing, and acoustic emission (Megid et al., 2019). These NDT methods can be used for quantitative detection of fatigue cracks, but they require physical emission or contact detection at close range. Moreover, they are very expensive and difficult to be widely applied to the detection of the whole bridge. As an alternative, automatic visual inspection system has recently been proposed to the local damage detection of bridges for the sake of costs reduction, efficiency and safety improvements. The main point of this system was to apply computer vision-based methods to identify damages in photos of components obtained by unmanned aerial vehicle (UAV) or other shooting equipment (He et al., 2022; Wang et al., 2020; Zhong et al., 2018).
There are many researches combining computer vision (CV) and image processing technology to detect cracks in pavement and concrete bridges (Cheng et al., 2003; Liu et al., 2016; Nagarajaiah and Yang, 2017; Oliveir and Correia, 2013; Peng et al., 2015; Yang, 2016). Traditional image processing methods mainly include threshold segmentation, edge detection and region growth, etc. It mainly processes digital images directly based on the pixel value, and generates the output of defects. However, the output results of these methods are very dependent on manual parameter setting, and have some disadvantages such as poor portability and limited extracted feature information.
With the introduction of deep learning, more abundant feature information from original images can be acquired, which can adapt to different specific situations and has good robustness and reliability, providing a new idea for crack image recognition (Hsieh and Tsai, 2020; LeCun et al., 2015; Xu et al., 2022). Specifically, the convolutional neural networks (CNNs) are good at processing image data and are generally designed to implement object detection, semantic segmentation and instance segmentation. Recently, there have been many attempts to use CNN-based algorithms to identify superficial defects in the area of civil engineering, and they have proven to be very effective (Cha et al., 2017; Dorafshan et al., 2018; Han et al., 2022; Yan et al., 2021). The object detection accuracy and/or speed are further improved with the advent of enhanced models such as Faster R-CNN (Ren et al., 2017), YOLO (Redmon et al., 2016) and SSD (Wei et al., 2015). Cha et al., (2018) modified and trained the Faster R-CNN model to detect five surface damages (concrete cracks, medium- and high-level steel corrosions, bolt corrosion and steel layer), with a mean AP 87.8% of the five types of damages. Zhang et al. (2022) improved YOLO algorithm and PSPNet (Zhao et al., 2017) algorithm to realize automatic detection and segmentation of bridge surface cracks. Ni Y et al. (2023) implemented the detection of cracks using the YOLOv5s algorithm, and combined the Ostu method and the median algorithm to calculate the length and width of concrete cracks. The method can meet meet the accuracy requirements, but the crack detection and quantification are not well integrated together, in which it is also necessary to extract the crack mask using Ostu method before the subsequent crack quantification can be completed. Wang et al. (2021) used the SSD algorithm to extract the advanced features of tunnel crack images, free from the impact of noise such as shadows, water spots and scratches. Despite the above achievements, the method of object detection is not able to output detailed crack morphology information.
As for semantic segmentation, its robustness of pixel-level segmentation, which is able to extract detailed crack morphology information, is increased with the proposal of FCN (Shelhamer et al., 2017), U-Net (Ronneberger et al., 2015), SegNet (Badrinarayanan et al., 2017) and other models. Dung and Anh (2019) used FCN to conduct semantic segment of concrete cracks, with an average accuracy of about 90%. Liu et al. (2019) selected the U-net model to detect concrete cracks. The trained U-net can recognize the crack position from the input original image under various conditions, such as illumination, messy background and width of cracks, etc. This article discusses the challenges of detecting fatigue cracks in steel box girders and proposes a modified U-net with a novel Self-Attention-Self-Adaption (SASA) neuron for deep-learning-based image segmentation, which allows for "plug and play" of arbitrary conventional neural networks and achieves high recognition results. Zhao et al. (2022) introduced a modified U-Net model equipped with a novel Self-Attention-Self-Adaption (SASA) neuron for crack segmentation specifically tailored for steel bridges. When combined with the CRED (Crack Random Elastic Deformation) algorithm, this research demonstrated a remarkable 29.8% enhancement in terms of Intersection over Union (IoU) compared to the standard U-Net model. In a recent study by Xu et al. (2023a), a lightweight semantic segmentation method was proposed for complex structural cracks. This approach replaced the ResNet101 backbone network in the DeepLabv3+ model with the lightweight MobileNetV2, resulting in a substantial reduction in network parameters and enabling real-time crack identification. Furthermore, Xu et al. (2023a), (2023b) introduced a task-aware meta-learning approach for universal structural damage segmentation, achieving improved segmentation accuracy compared to conventional methods with fewer training images and demonstrating enhanced generalization to new structural damage categories.
Most of the research objects of the above models are concerned about concrete cracks and road cracks (Bang et al., 2019; Cui et al., 2021; Li et al., 2021; Ye et al., 2023; Yang et al., 2018), while limited researches had been conducted on the identification of fatigue cracks for steel bridges. Xu et al. (2017) proposed a framework for identifying and extracting cracks from images of steel box girders on bridges using a restricted Boltzmann machine algorithm and consumer-grade camera images. Building upon this, Xu et al. (2018) introduced an improved depth fusion convolutional neural network (FCNN) for recognizing cracks in field images of steel box girders featuring complex interference, although it faced challenges in distinguishing between cracks and other structural defects like corrosion. A pixel-level fatigue crack segmentation framework based on codec network was developed by Dong et al. (2021) for complex background images of steel structures. Because the image background was removed in their methods, it may be difficult to determine the location of the crack in actual situations.
The instance segmentation is able to achieve the purpose of both target detection and semantic segmentation. For example, it can classify and locate the cracks in the photos, and perform pixel level segmentation for each crack. In recent years, the instance segmentation algorithm (Du et al., 2020; Lee and Park, 2020; Zhang et al., 2020) has had an outstanding performance in the field of computer vision, and has promoted the research in crack detection and segmentation. Kim and Cho, (2019) used Mask and Region-Based Convolutional Neural Network (Mask R-CNN) model to detect concrete cracks and measured the width of the crack in combination with image processing method. Xue et al., (2021) employed Mask R-CNN as a baseline to improve its performance from both the properties of shield tunnel leakage datasets and the detection errors of the original model in the testing set. Zhao et al., (2021) used the integrated method of coupling PANET model and A* algorithm to complete the segmentation and quantification of tunnel lining cracks. This method can reduce inaccuracies associated with crack discontinuities and image skeletonization.
In conclusion, the instance segmentation algorithm can better reflect the classification, number, location and geometry information of cracks, eliminating the limitations of object detection and semantic segmentation in crack detection. Among them, Mask R-CNN is a unified instance segmentation framework proposed by He et al., (2017), through which the cracks can be simultaneously classified, detected and segmented. This capability is particularly advantageous in scenarios where achieving accurate and fine-grained object boundaries is of paramount importance. Compared with other methods, Mask R-CNN algorithm has a very good performance on the COCO (Lin et al., 2014) instance division data set. Therefore, this research proposes an improved method based on Mask R-CNN for fatigue crack detection and segmentation of orthotropic steel decks.
The research object of this research is the fatigue crack of OSD. Compared with concrete and pavement cracks, it has the following characteristics: (1) the fatigue cracks mostly appear at the nearby of welded joints; (2) the width and length of fatigue cracks are smaller; (3) the fatigue cracks are easily affected by noises such as corrosions, resulting in poor contrast between cracks and background, which increases the difficulty of feature extraction. In view of the above characteristics, higher requirements are demanded for Mask R-CNN algorithm: (1) it needs to pay more attention to the characteristic information of specific parts; (2) it needs to extract more rich image feature information, especially the effective use of low-layer feature high-resolution information. For these causes, this research has improved the Mask R-CNN algorithm to suit the needs of fatigue crack detection of OSD.
First, CBAM (Woo et al., 2018) module, which is able to focus local information of feature images, is introduced in the backbone network of Mask R-CNN to targeting crack-prone areas. It makes the computing resources more incline to focus on the target region, so as to strengthen the feature information extraction of crack region.
Secondly, it was found that the edge information of the crack will be lost when using the original Mask R-CNN to identify the fatigue cracks of OSD. This indicates that the feature extraction method in the original Mask R-CNN can be further improved. It is worth noting that low-level features help identify the edges and contours of the object. However, in the main network of Mask R-CNN, there is a long path from low-level features to top-level features, which leads to the loss of the available positioning information of the bottom-level features. This problem will affect the subsequent fatigue crack detection and segmentation tasks. Therefore, in order to obtain enhanced features with rich low-level information, a path augmentation feature pyramid network (PAFPN) (Liu et al., 2018) constructed based on original Mask R-CNN to fuse multi-scale feature maps is introduced to make full use of the information of all size feature maps.
In addition, morphological closing operation is integrated into a trained model to solve the "disjoint problem" of cracks, so that the segmentation morphology of cracks is more complete and accurate, and the effect of crack morphological segmentation is improved.
On the basis of crack mask closure, quantifying the length and width of bridge cracks is necessary to provide useful information for evaluating, maintaining, and managing bridges. Currently, most crack quantification methods extract crack masks from original images (Yang et al., 2018; Kim and Cho, 2019; Kalfarisi et al., 2020) and extract crack skeletons using skeleton algorithms or refinement algorithms. Then, they calculate the number of pixel points for crack length and width based on the skeletons. Yang et al., (2018) compared four crack skeleton extraction methods and found that the medial axis method is optimal in terms of accuracy and efficiency for crack quantification. Therefore, this research uses the relevant OpenCV functions to implement the crack quantification method based on the medial skeleton.
In particular, the contributions of proposed approach are summarized as follows: (1) A deep learning framework based on Mask R-CNN to simultaneously detect and segment the fatigue cracks of OSD was introduced. (2) The CBAM module was adopted in the backbone network of Mask R-CNN to strengthen the feature information extraction of the region of interest for the crack part, suppress less useful information and improve the accuracy of crack detection. (3) A path augmentation feature pyramid network (PAFPN) module is employed to facilitate the information propagation of the Mask R-CNN backbone network. This module is shared by object detection and mask prediction, which improves the performance of crack detection and segmentation.
The rest of the article are organized as follows. The framework of the Mask R-CNN algorithm and the improved version was firstly introduced. The source of data and the establishment of the data set were then expounded. The following section evluates and discusses the test results of the different models. The final section concludes this research.
Methodology
Methodology overview
In this study, in order to accurately detect the fatigue crack of OSD in bridge industry, the feature extraction network of the original Mask R-CNN algorithm is improved to enhance the extraction of crack features by introducing CBAM module and PAFPN module, and the morphological closing operation is introduced to improve the segmentation effect of cracks. Finally, the pixel-wise quantification of crack length and width is achieved based on the crack mask closure. Figure 1 represents the proposed procedure for fatigue crack detection of OSD, mainly in three parts: (1) data preparation; (2) model optimization, training and evaluation; (3) analyzing and comparing the fatigue crack detection results of OSD under various algorithms. The proposed procedure for fatigue crack detection of OSD based on improved Mask R-CNN.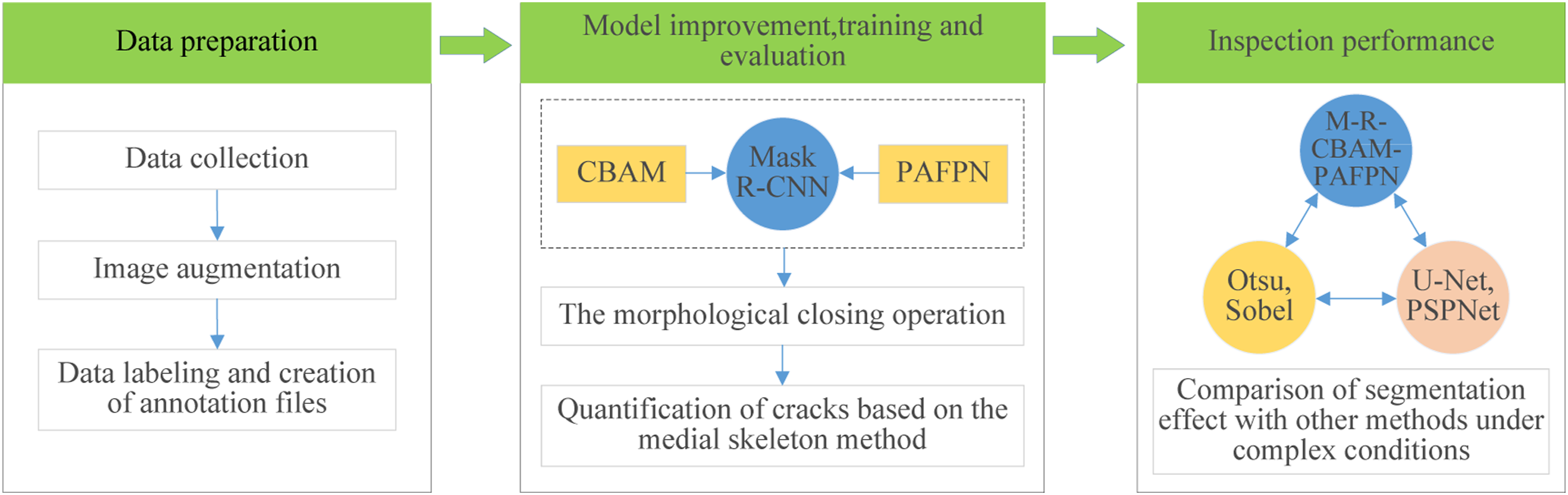
Overview of mask R-CNN
Mask R-CNN is a very flexible framework that is improved from Faster R-CNN to achieve accurate object detection and instance segmentation by adding a segmentation mask generating branch. The network structure of Mask R-CNN is shown in Figure 2, which mainly includes feature extraction layer, region proposal network (RPN), ROIAlign and Network Heads. Overall architecture of the Mask R-CNN.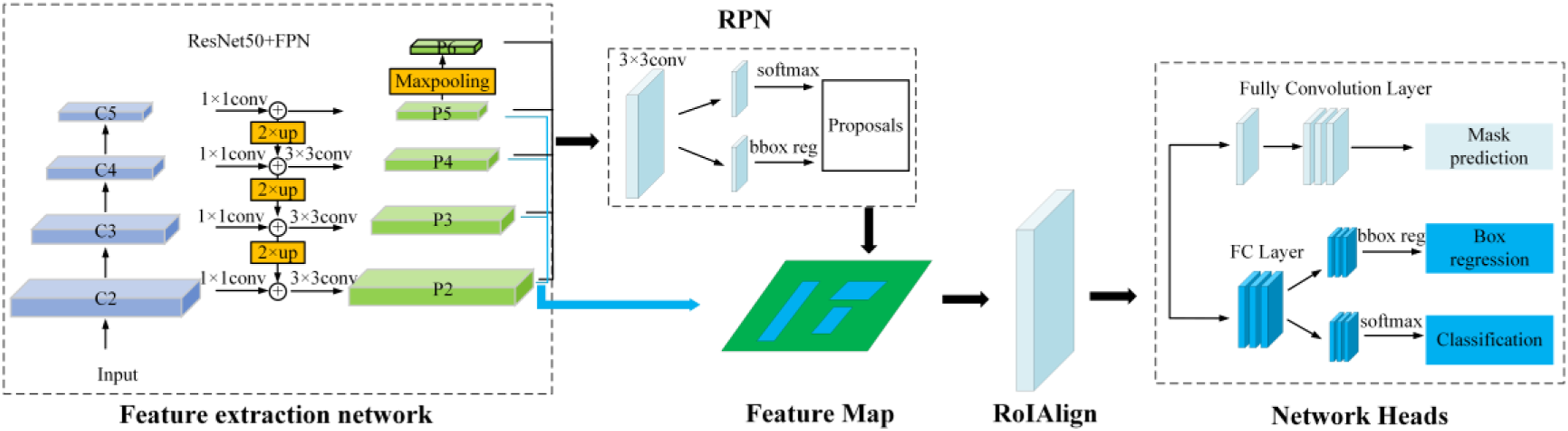
Feature extraction network
Deep residual network (ResNet), proposed by He et al., (2016), can effectively alleviate the problem of disappearance and training degradation of deep network, thereby improving the convergence performance of the network. In order to balance the accuracy and efficiency, Resnet50 is adopted in this research. As shown in Figure 2, ResNet50 network extracts features from the input image and generates feature maps at each stage of {C2, C3, C4, C5} from bottom to top. Low-level feature maps like C2 contain more texture information, while high-level feature maps like C5 contain more semantic information. Then, the feature maps obtained through ResNet50 are used as the input of the FPN (feature pyramid network) (Lin et al., 2017) to extract the multi-scale features, by combining the high resolution of low-level features and high semantic information of high-level features.
Region proposal network (RPN) and RoIAlign
Taken the feature maps obtained from feature extraction network as input, region proposal network (RPN) is used to generate high-quality region of interest (RoI). The actual coordinates of the pixels on the feature maps can be obtained by the mapping relationship between the pixels on the feature maps and the pixels in the original picture. By randomly combining the different area scales and aspect ratio, several anchor boxes can be generated for each corresponding pixel on the feature maps. The RPN classifies the anchor boxes of foreground and background target, and then performs bounding box regression on the anchors containing foreground objects to make them closer to the real target box, and finally outputs RoIs. Non maximal suppression (NMS) is adopted to further screen the ROIs to reduce the number of anchor boxes without targets and to retain effective target anchor boxes.
The generated RoIs and the corresponding feature maps are then taken as the input of RoIAlign. RoIAlign is a feature mapping operation, which adjusts the size of the anchor box to a fixed size, solves the area mismatch problem caused by two quantifications in the ROI pooling operation, and thus improves the accuracy of pixel-level segmentation.
Crack instance segmentation and loss function
As shown in Figure 2, after RoIAlign operation, there are the fully connected layer and fully convolutional layers. The full connection layer is employed for classification and regression of the bounding box, and the fully convolutional layers is used for crack instance segmentation.
The loss function denotes the differences between the prediction and the ground truth, which is essential for network training. In this research, the loss function of the Mask R-CNN model is mainly divided into three parts: classification loss L
cls
, boundary box regression loss L
box
and mask loss L
mask
:
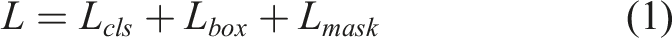
Model optimization approaches
The optimization of the model is presented in Figure 3. The red dashed box in the figure represents the optimized parts. The improvement measures are made of three parts: (1) adding CBAM module to Resnet network; (2) replacing the FPN module in the original Mask R-CNN with PAFPN module; (3) the disjoint problem of cracks is solved by the morphological closing operation of the detected cracks. Specific optimization details will be described in the following sections. Overall framework after model optimization.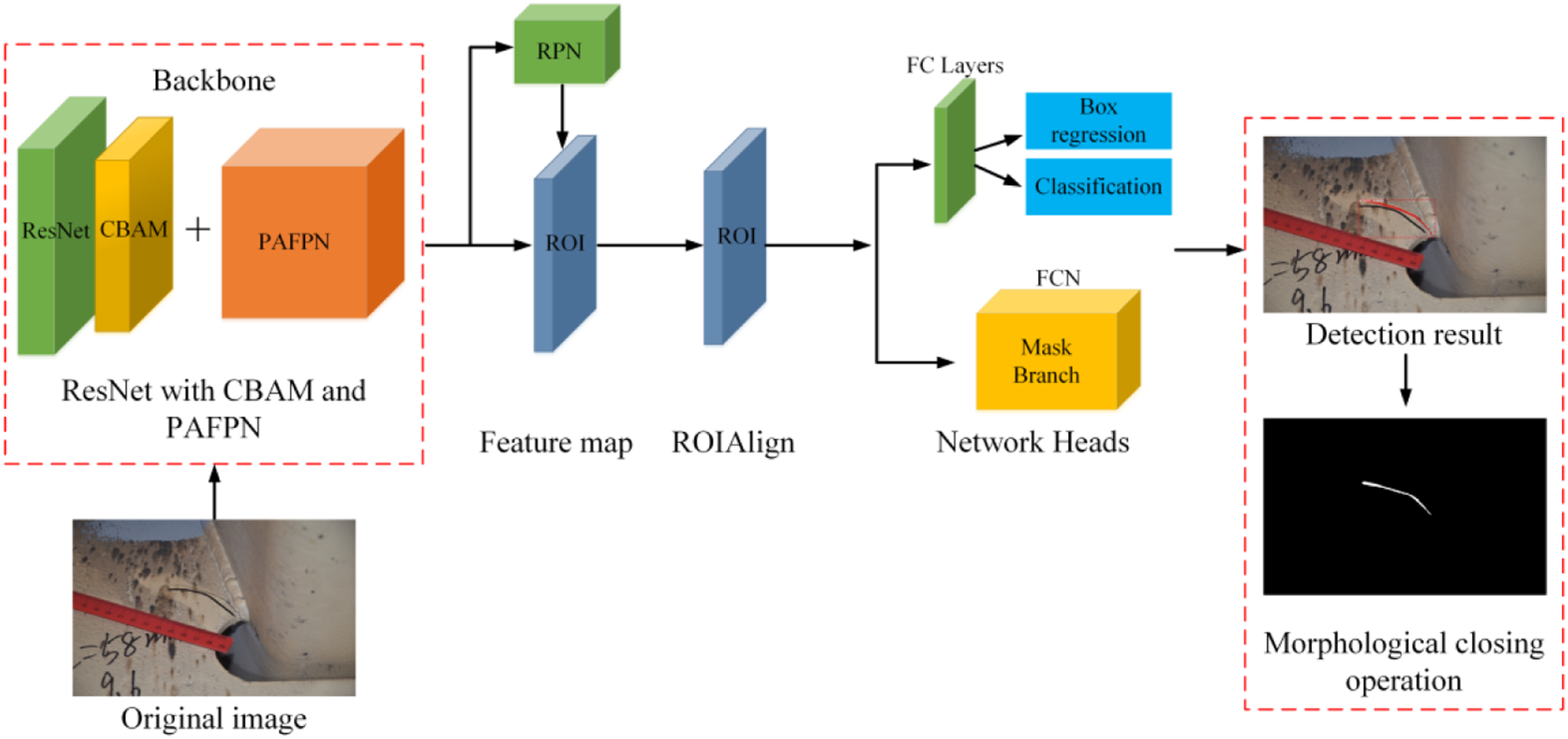
CBAM-Based feature extraction network
CBAM (Woo et al., 2018) is a lightweight and general module, which can be seamlessly integrated into any CNN architecture with negligible additional overhead, and can carry out end-to-end training with basic network. In this research, the mixed domain attention CBAM module is introduced to make the neural network pay more attention to the target area, suppress irrelevant information and improve the overall accuracy of target detection.
As seen in Figure 4, CBAM module consists of channel attention module and spatial attention module, which can respectively learn ‘what’ and ‘where’ to pay attention. Firstly, a channel attention map M
C
(F) is obtained through the channel attention module, given an input of intermediate feature map F. It is then multiplied with F to obtain the channel-refined feature F'. By the same process, taken F' as the input, the final refined output F'' can be obtained by multiplying the spatial attention map M
S
(F'), the output of the spatial attention module, by F. This whole process can be summarized as follows: Convolutional block attention module.


The feature extraction network of Mask R-CNN is composed of ResNet and FPN. In this research, CBAM attention module is added to ResNet50 network. Figure 5 shows exactly where the CBAM module is integrated into the ResBlock. The fusion of CBAM and ResBlock in ResNet.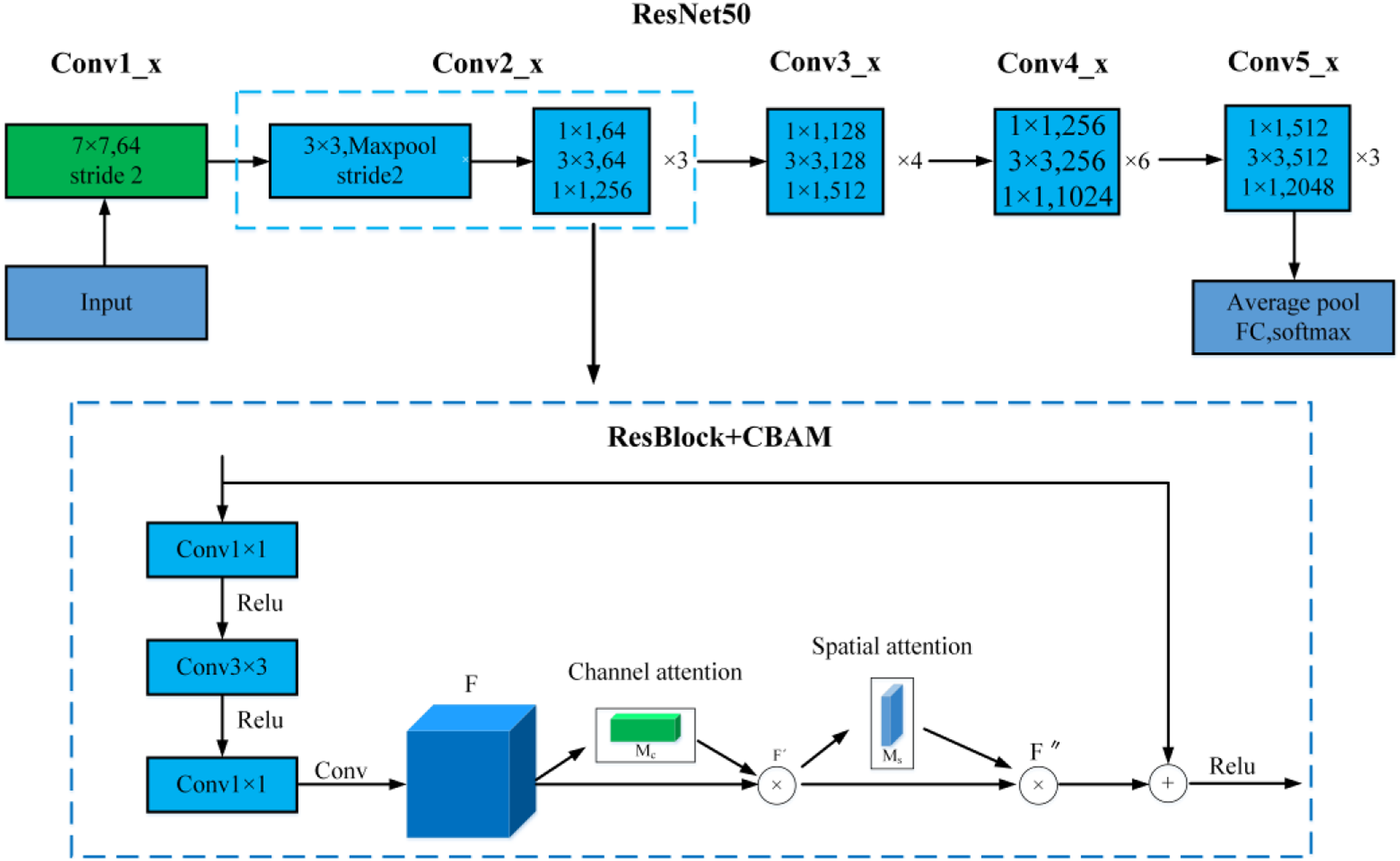
Path augmentation feature pyramid network
In CNN detectors, high-level features are strongly related to entire objects, while low-level features are more related to local information of the objects. This suggests that there is a need for better ways to take full advantage of both high-level and low-level features. However, in the original Mask R-CNN, the feature pyramid network (FPN) adopts a single top-down propagation method, which makes very limited use of low-level feature information. This is because there are 100+ layers of long paths from low layers to the topmost one, leading to the loss of localization information due to pooling and deconvolution in the feature extraction process. In order to solve this problem, a path augmentation feature pyramid network (PAFPN) (Liu et al., 2018) was adopted in this research. By adding a bottom-up path enhancement module and a feature fusion operation module, the bottom-up "short" path, which passes through less than 10 layers, can better retain the low-level feature information. Figure 6 details the proposed PAFPN module, where the red dotted line represents the original long path from the lower level to the topmost level, while the dotted blue line represents the new "short" path. Architecture of the PAFPN module.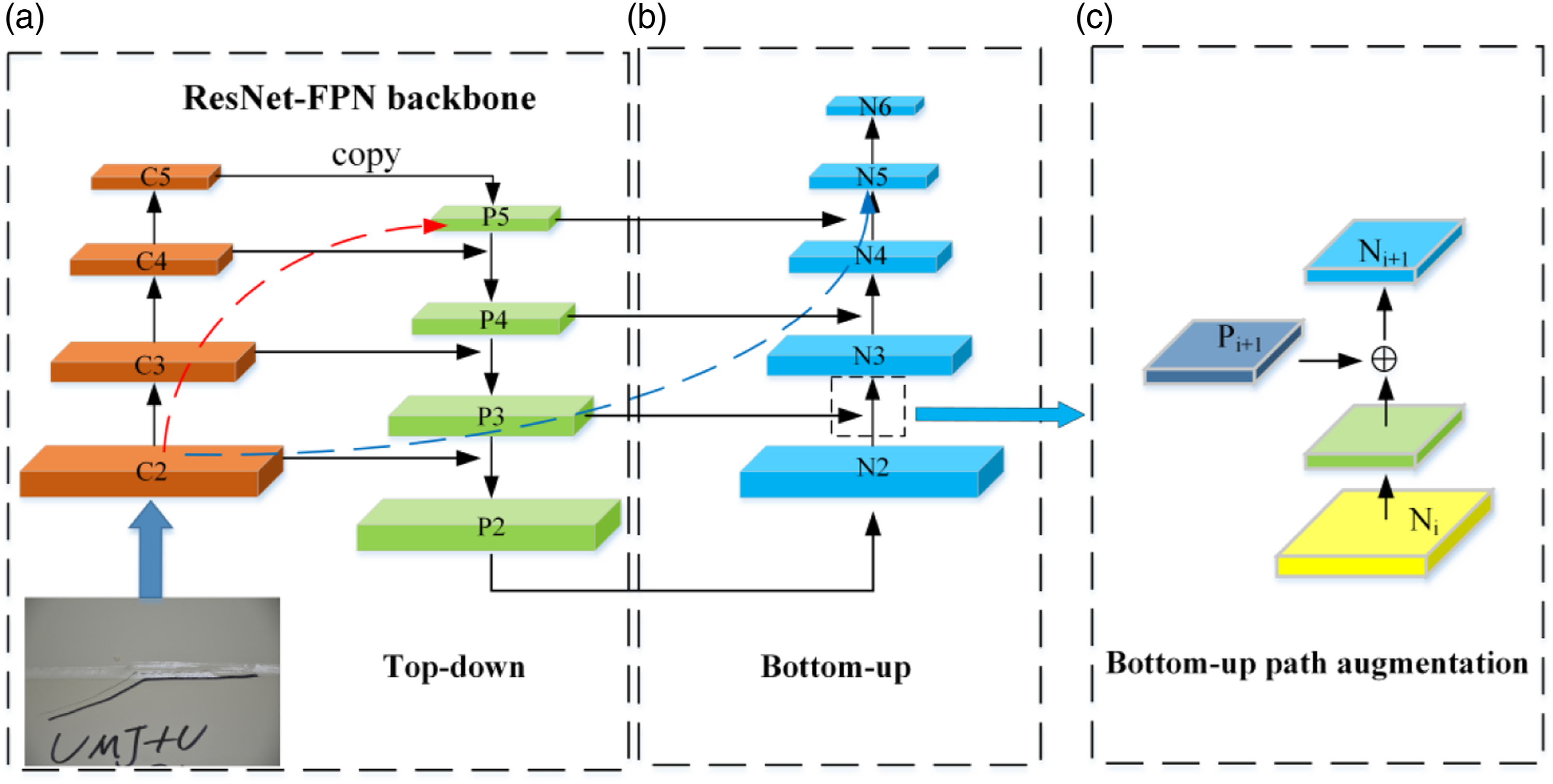
The {N2, N3, N4, N5} is the corresponding feature maps generated by {P2, P3, P4, P5}, where N2 is copied directly from P2 without any processing. The merging operations for feature fusion are illustrated in Figure 6(c). The Ni feature map is up-sampled twice to be the same size as Pi+1, and then these two are added to output a new feature map Ni+1.
The morphological closing operation
The morphological closing operation is defined as an operation that dilates and then erodes a binary image using structuring elements (Raid et al., 2014), which can be cross, rectangle or ellipse structure. The morphological closing operation can eliminate small voids, smooth the contours of objects, connect narrow discontinuity points and gullies, and fill broken wheel lines. A typical operation is presented in Figure 7. In Figure 7(b), the results depict the outcome of the crack detection and segmentation through the utilization of the Mask R-CNN algorithm. Subsequently, in Figure 7(c), the original image has been omitted, leaving solely the crack mask, which is subsequently subjected to binarization. Finally, Figure 7(d) displays the results of implementing morphological closure operations to close the identified cracks, which is to establish a foundation for the subsequent quantification of the cracks. The procession of the morphological closing operation.
Medial skeleton method
As bridge surface images often contain multiple cracks, it is necessary to use the connected component labeling algorithm to "separate" different cracks and assign each crack a different label before calculating their parameters. This allows the extraction of the skeleton from different cracks. In this research, the skimage.morphology.medial_axis (image, mask=None, return_distance=True) function is used to extract the skeleton. By setting return_distance=True, the distance between all points on the medial axis and the background distance values can be obtained to calculate the crack width. Then, the cv2.countNonZero() function is used to count the number of pixel points for both crack length and width, respectively, achieving the quantification of crack length and width in a pixel-wise sense. The specific computation flow is illustrated in Figure 8. Flow chart of crack quantification.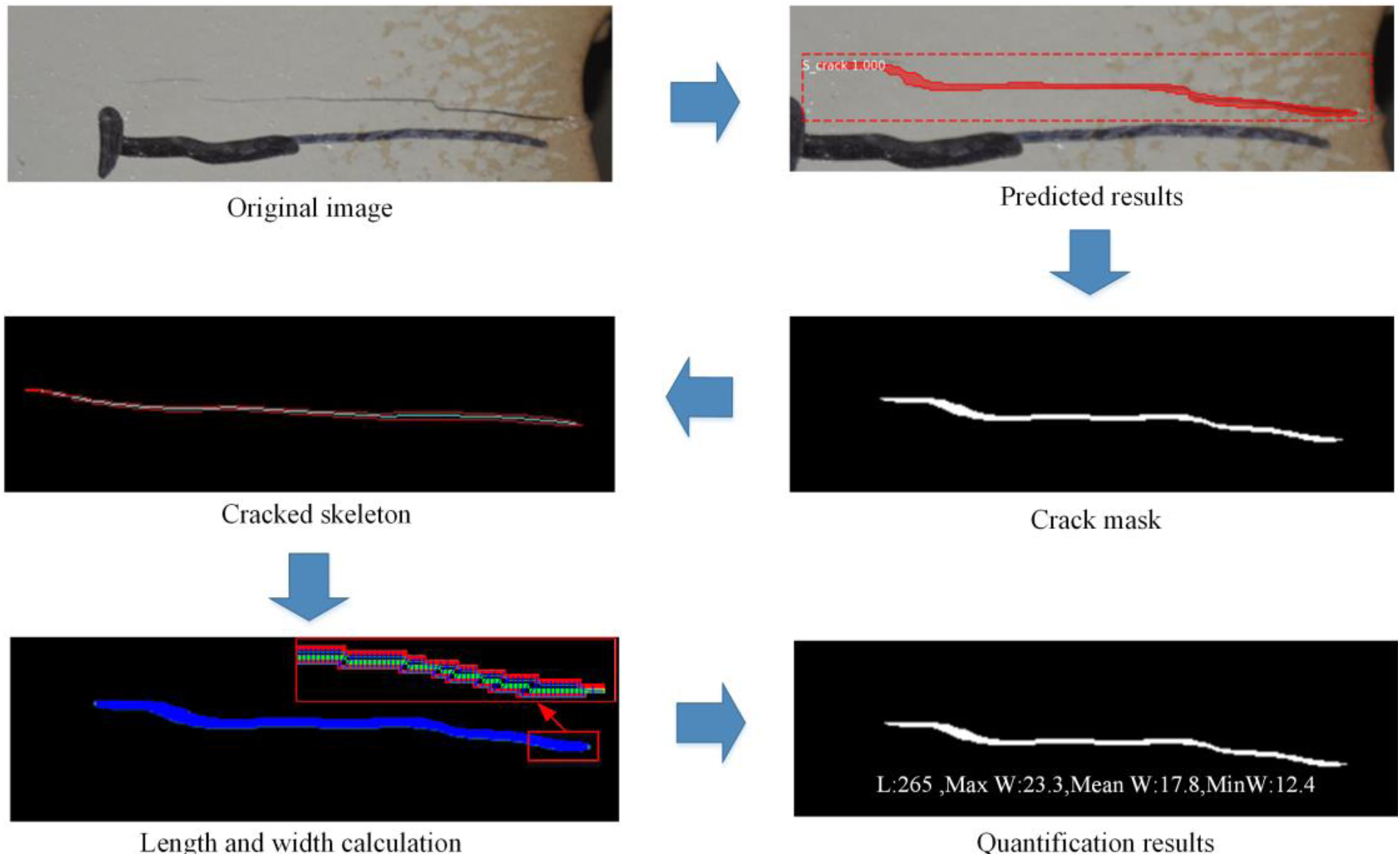
After using the relevant Opencv function to combine the crack binary image with the medial skeleton method to measure the crack length and width in a pixel-wise sense, the actual length and width of the crack can be quantified by combining relevant parameters of the UAV-mounted HD camera and the distance between the UAV and the bridge surface at the time of UAV photography. For instance, the object distance U, which is the distance between the UAV equipped with a rangefinder and the target, can be used. The following equation can be derived from the corresponding principle of lens imaging when the HD camera captures the crack image:
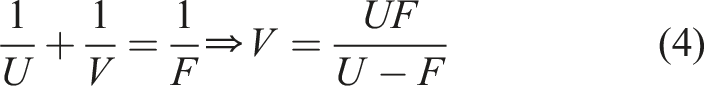
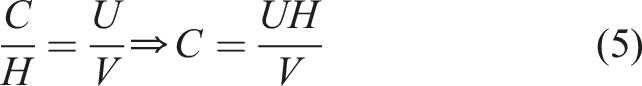
By substituting equation (4) into equation (5), the following equation (6) can be obtained:

Regarding the imaging size H, there are:

Based on the above equations (6) and (7), equation (8) can be introduced:
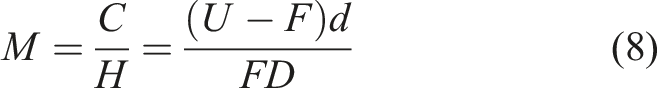
Datasets of fatigue cracks of orthotropic steel decks
Dataset Preparation
In this research, a total of 300 fatigue crack images of OSD are originated from three parts, as shown in Figure 9. The first part comes from the authors, with a total of 50 photos. The second part consists of 200 images, including 120 photos with 4928×3264 pixels and 80 photos with 5152×3864 pixels, were provided by the organizing Committee of the 1st International Project Competition for Structural Health Monitoring (IPC-SHM, 2020; Bao et al., 2020). The third part comes from APESS2018_Steel_Girder_Crack_ID_dataset (Tang and Hu, 2018), 50 images with a size of 4928×3264 pixels. It can be seen from Figure 8 that these images not only contain cracks but also a variety of noises such as scratches, markers, shadows, welding lines and corrosions. Dataset: (a) from authors; (b) from IPC-SHM; (c) from APESS2018_Steel_Girder_Crack_ID_dataset.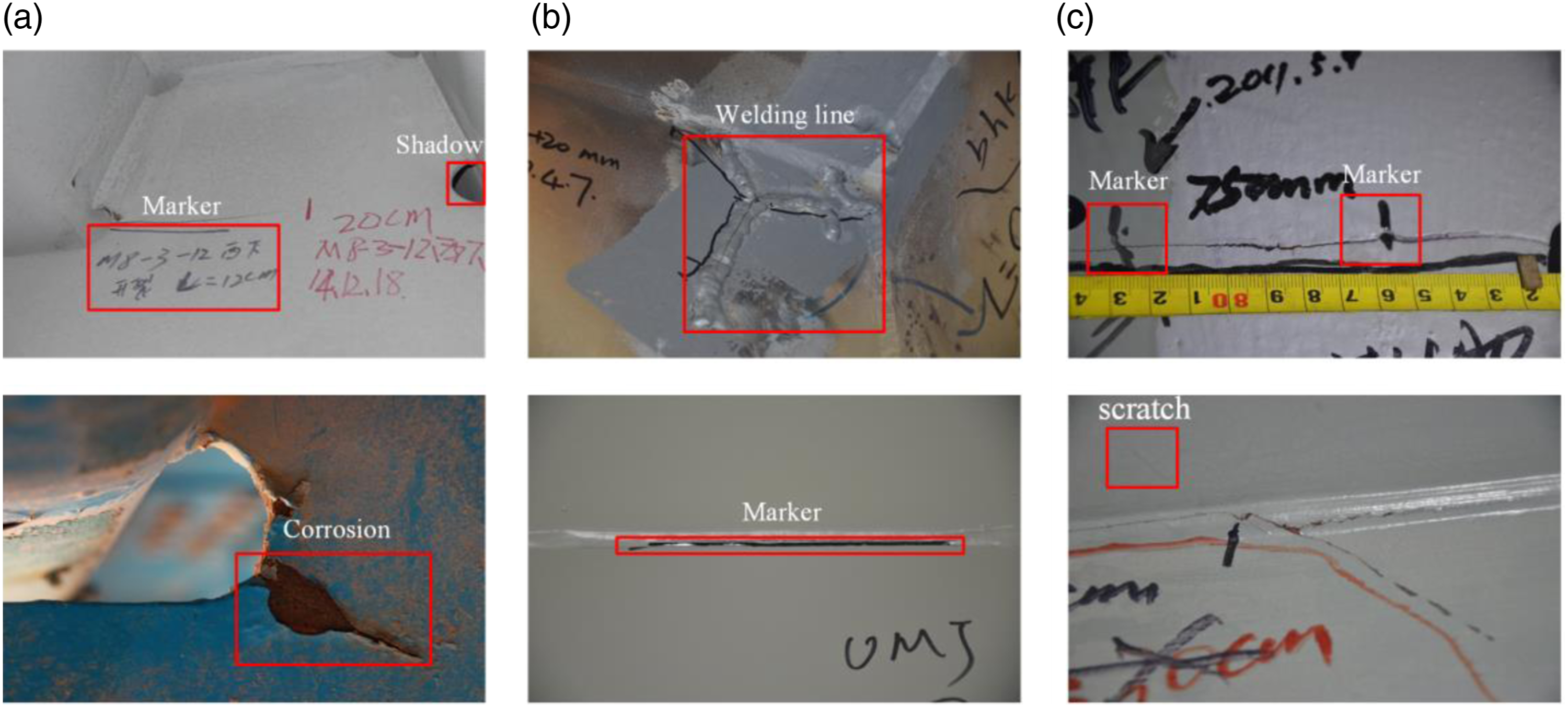
Due to the large pixel size of the original photos, considering the limitation of network structure and hardware, as well as the influence of different size images on training speed and feature extraction, these 300 raw images were scaling down to 1024×640 pixels.
Dataset preprocessing
Since a sufficiently large dataset is essential for deep learning algorithms with millions of parameters, data augmentation is commonly adopted to enlarge the dataset size and avoid overfitting during the training process. In this research, the original data was enhanced by the image processing method, mainly including noise adding, brightness adjusting, random points adding, mirroring and random flipping. A combination of at least two image processing methods were used for each image enhancement. Each image was enhanced three times to get 1200 images. Among them, 1000 crack images were reserved for algorithm calibration and 200 crack images for testing. The calibration data were further spilled into training set (800 images) and validation set (200 images) at a ratio of 8:2. In the current study, 1200 images were annotated using Labelme labeling software. Cracks in the image were annotated along the boundary using the polygon region shapes. After annotating these images, many JSON files will be generated, including the file name, class alias, polygon coordinates and other annotation information.
Experiments on fatigue cracks of orthotropic steel decks
Mask R-CNN modeltraining and validation
Hardware environment and software version.

Considering the limit of computer hardware capacity, the batch size of the training dataset was set as one and the weight decay and momentum set as 0.0001 and 0.9, respectively. In this research, stage-wise training strategy was adopted to help the model converge earlier and avoid the gradient explosion in the early training stage. In the first stage of training, only the head part of the whole network (specifically described in the Network Heads section of Figure 2) was trained for 60 epochs at an initial learning rate of 0.001. Then, in the second stage of training, the learning rate was reduced by 10 times and all layers of the backbone network were activated to continue training for 60 epochs. Throughout the training process, the network was trained for a total of 120 epochs.
Description and labeling of the four methods.
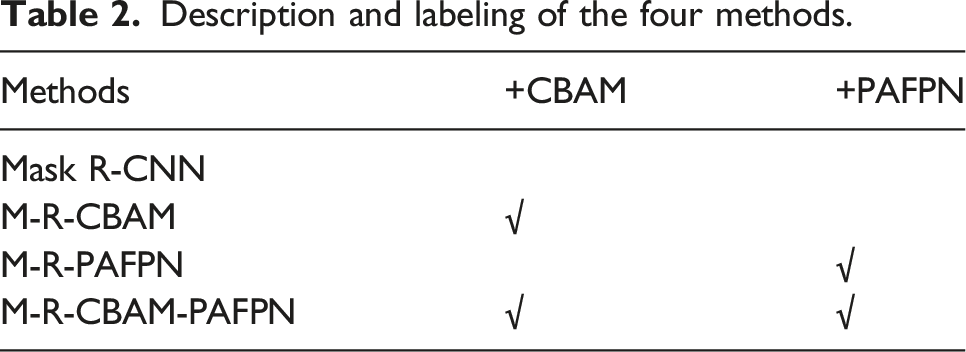
To verify the effectiveness of the improved Mask R-CNN algorithm, these four algorithms were trained on the same dataset, and then their performances are compared. The improved three Mask R-CNN algorithms used the same training parameters and training strategy as the original Mask R-CNN. The loss curves of the original Mask R-CNN and the improved algorithms are shown in Figure 10. The loss curves of four algorithms.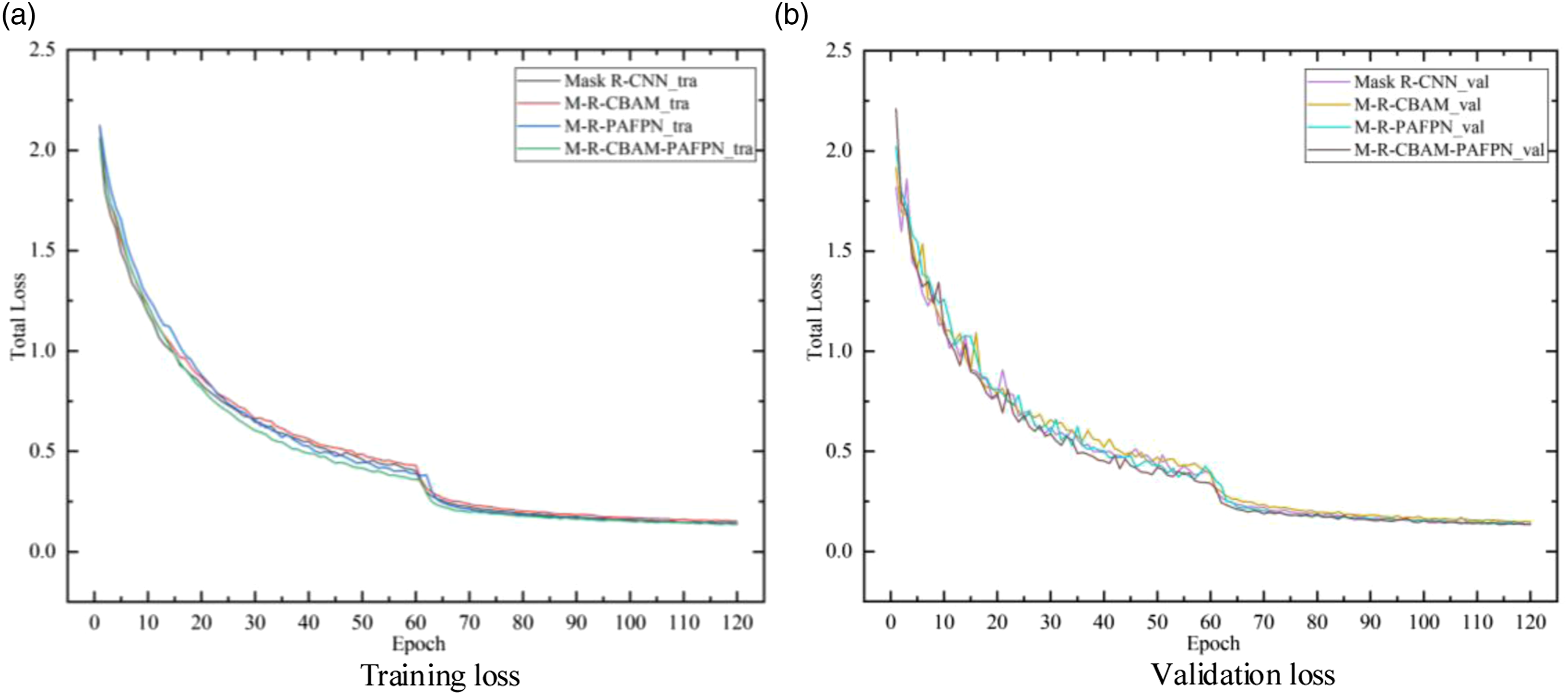
It can be seen from Figure 10 that the loss curves of four algorithms share the same trend. During the first stage of training (the first 60 epochs), the training loss shows a quick declining trend, which can be attributed to the high learning rate. After 60 epochs, as all layers of the backbone network were activated and the learning rate decreased, the declination of loss function starts to slow down. After 120 epochs, the losses of four models show convergence. Therefore, the weight parameters of the trained four models obtained at 120 epochs were used to conducted experiments on the testing dataset.
Evaluation Indicators
In this research, the precision, recall, AP and F1 score were selected as evaluation indicators to evaluate the performance of models, so as to find the optimal parameter configuration and improvement scheme. AP value is the area under the P-R curve, in which the recall is taken as X-axis and the precision as Y-axis. It characterizes the comprehensive performance of the binary classifier in precision and recall to a certain extent. The F1 score is the harmonic score of precision and recall, which can more scientifically evaluate the performance of a classifier. TP denotes true positive (an actual crack pixel is correctly predicted), FP denotes false positive (an actual uncrack pixel is falsely predicted as cracked), and FN denotes false negative (an actual crack pixel is predicted as uncracked). These four indicators can be calculated by equations (9)–(12).

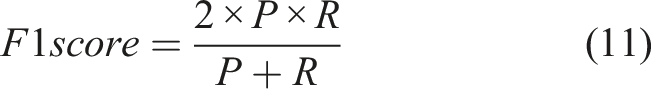
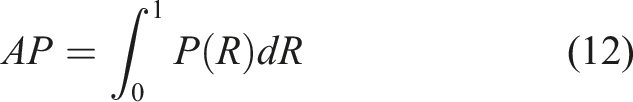
Experimental results and comparative analysis
Compare the performance of four models.
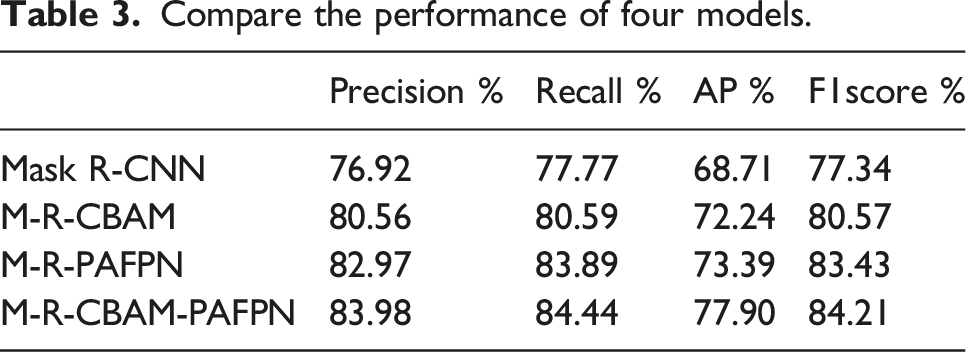
In general, it can be seen from Table 3 that three improved models have better results in the detection of fatigue cracks on OSD than the original Mask R-CNN model. For two models only adding one module, M-R-CBAM and M-R-PAFPN have a detection accuracy respectively 3.53% and 4.68% higher than that of the original algorithm in terms of the AP, 3.23% and 6.09% higher in terms of F1. This can be attributed to the introduce of CBAM module and PAFPN module. As for the model M-R-CBAM-PAFPN adding both modules, it has a better detection accuracy than either of the model with single module addition. The AP of M-R-CBAM-PAFPN is respectively 5.66% and 4.51% higher than those of the M-R-CBAM and M-R-PAFPN, 3.64% and 0.78% higher in terms of F1. This shows that introducing both CBAM module and PAFPN module has better detection accuracy than introducing either of them alone. Actually, compared with other three models, M-R-CBAM-PAFPN achieved optimal results in terms of all four evaluation indicators, demonstrating the superior accuracy of this method in crack segmentation.
In order to further compare the segmentation effect of these four models on the fatigue crack of OSD, some representative segmentation results are presented in Figure 11. Examples of the crack detection results using four models. The green box pointed by the green arrow represents the enlarged version of the crack area, and the position of the small red triangle represents the difference in the detection effect.
It can be seen from Figure 11 that M-R-CBAM-PAFPN has better performance than original Mask R-CNN in terms of fatigue crack detection accuracy and segmentation integrity of OSD. Take the first two rows as example, the original Mask R-CNN has disjoint problem of crack segmentation, while M-R-CBAM is better in keeping integrality of crack segmentation. This proves the effectiveness of introducing CBAM's module to enhance the information extraction of crack region. In the third and fifth rows, the crack segmentation effect of the original Mask R-CNN and M-R-CBAM are poor, and only a part of the crack was segmented. In contrast, M-R-PAFPN overcomes this problem, which not only detects the integral crack, but also the crack segmentation results are closer to the ground truth. This illustrates that the feature extraction network with PAFPN module can obtain richer low-level feature information and realize more accurate detection of crack targets. In the fourth row, the original Mask R-CNN has wrong check, while the improved Mask R-CNN accurately completes the detection and segmentation of cracks. These images show the fatigue cracks of OSD at different positions. From the effects of detection, M-R-CBAM-PAFPN has the advantages of both CBAM module and PAFPN module.
Comparison of segmentation effect with other methods under complex conditions
As noted above, the images in the dataset not only contain cracks but also many disturbances such as scratches, markers, welding lines and corrosions, which is in line with practical inspection situations. To further demonstrate the superiority of M-R-CBAM-PAFPN in dealing with crack segmentation in complex environments, the Sobel operator edge detection, Otsu method, U-Net and PSPNet were implemented to compare with the detection results of M-R-CBAM-PAFPN on the same dataset, as seen in Figure 12. Crack detection results of different methods under complex conditions. The white solid lines represent the missed and wrong check caused by noises, and the green solid frame represents the amplification of the crack area.
The detection results show that the Sobel operator and Otsu method both performed poorly. The main reason is that the images have complicated backgrounds, in which some distractors, such as markers, welding lines, the edges of shadows and measurement ruler, have similar characteristics to crack regions in terms of shape and grey value. Therefore, many disturbances were mistakenly identified as crack, which make it impossible to identify the shape and location of actual cracks. As for the U-Net model, it detected a clear outline of crack segmentation, while in the meantime some scratches, welding lines and corrosions were wrongly identified as cracks. And a relatively fuzzy crack area may lead to missed detection of cracks for this model. The fifth column of images shows that in complex environments, the PSPNet model was almost unaffected by noise in crack identification, but its outline of crack segmentation is very rough by a closer look. In contrast, M-R-CBAM-PAFPN has better performance in dealing with all kinds of noises, and its crack segmentation contour is accurate and clear, which is closer to the actual situation of cracks.
Examples of the morphological closing operations in disjoint crack region
Through the detection results of four models on the test set, it can be seen that the introduction of CBAM module and PAFPN module helped alleviate the problem of disjoint cracks to a certain extent. In order to further solve this problem, the morphological closing operation, a procedure depicted in Figure 3 and further described in Figure 7, was added to output the cracks in the image as a polygon. Firstly, it generates a binary image by assigning one to the inside of the polygons and 0 to the outside of the polygons. Subsequently, during the morphological closure operation, a 50×50 elliptical structural element was meticulously selected through iterative experimentation. This specific structural element proved highly effective in closing gaps within the cracks present in images of the dimensions utilized in this study. The representative results after morphological closing operation are shown in Figure 13. Crack disjoint problem: (a) original image, (b) actual prediction, (c) generation of binary image and (d) the morphological closing operation, with a 50×50 ellipse structuring element. The green box represents a larger version of the area where the crack does not intersect, and the red box represents the situation of the disjoint area after morphological closing operation.
By observing the first three rows, it was found that the segmented morphology of the crack is closer to the real crack morphology after the morphological closing operation in the disjoint crack region. However, from the fourth row, it can be seen that the method cannot connect disjoint cracks that are far apart from each other, which indicated that this method has certain limitations. In the future, crack kernels (Lee et al., 2019) and guided image filtering (He et al., 2013) can be used to further solve the problem of crack disjoint. The above research has proven that the combination of M-R-CBAM-PAFPN model and morphological closing operation method can make the segmentation morphology of fatigue cracks of OSD more accurate and complete.
Crack quantification
Since the parameters of the UAV-mounted camera and the distance between the UAV and the bridge surface at the time of imaging were unknown, it was not possible to calculate the actual length and width of the cracks. As a result, this study focused on achieving crack length and width quantification in the pixel-wise sense. Figure 14 presents some test examples of the crack length and width quantification method proposed in this study. Example of crack quantification method in this research.
The process of crack quantification in this study is demonstrated in Figure 14. Firstly, the crack image is input as shown in the first column. Then, the mask of the crack is extracted using the M-R-CBAM-PAFPN model's test script and saved as a binary image, as shown in the second column. Next, the mask breakpoint is handled using the morphological closing operation, resulting in a closed mask image as shown in the third column. Finally, the medial skeleton-based length and width measurements are applied to achieve crack quantification in the pixel-wise sense, as shown in the fourth column.
Conclusions
In this research, by introducing CBAM module and PAFPN module, an improved model was proposed on the basis of the Mask R-CNN algorithm to detect and segment fatigue cracks of orthotropic steel decks. A total of 300 fatigue crack images of OSD, which come from in-service steel bridges, were established as the dataset to verify the proposed model. Based on the analysis results of the study, the following conclusions can be drawn: (1) The study proves that the proposed model has a better performance in detecting fatigue cracks of OSD than the original Mask-R-CNN algorithm. The introduction of CBAM or PAFPN module alone are able to improve the performance of models, with a detection accuracy respectively 3.53% and 4.68% higher than that of the original algorithm in terms of the AP, 3.23% and 6.09% higher in terms of F1. As for the model M-R-CBAM-PAFPN adding both modules, it has a better detection accuracy than either of the model with single module addition. Its AP is respectively 5.66% and 4.51% higher than those of the M-R-CBAM and M-R-PAFPN, 3.64% and 0.78% higher for F1. This shows that introducing both CBAM module and PAFPN module has better detection accuracy than introducing either of them alone. (2) This work also validates the performance of the proposed algorithm in challenging background with a variety of noises such as scratches, markers, shadows, welding lines and corrosions. The proposed M-R-CBAM-PAFPN was compared with the Sobel operator edge detection, Otsu method, U-Net and PSPNet on the same dataset. The detection results show that the M-R-CBAM-PAFPN has better performance in dealing with all kinds of noises, and its crack segmentation contour is accurate and clear, which is closer to the actual situation of cracks. (3) In order to further improve the performance of proposed algorithm, an additional procedure of the morphological closing operation was added to output the cracks of the images. By observing the detection results, it was found that the combination of M-R-CBAM-PAFPN model and morphological closing operation method can effectively improve the accuracy and integrity of crack segmentation. This study proposes a specific process for achieving crack quantification using the medial skeleton method after the crack mask closure. However, it should be noted that due to the lack of camera calibration, only crack quantification in the pixel-wise sense is possible at this stage. Further studies on crack quantification can be conducted in conjunction with specific experiments to achieve more accurate measurements in physical units. (4) The proposed method has effectively detected and segmented the fatigue cracks of OSD, but the segmentation accuracy requires further improvement. Also, the particular crack type of OSD has not classified, which can facilitate the automatic generation of inspection reports. In the future, fatigue crack images of OSD under different light levels can be collected at specific locations to enhance the data, so as to realize the judgment of crack categories and improve the segmentation of crack morphology, so that the mask of the crack area is more accurate.
Footnotes
Acknowledgments
The authors would like to thank the organizations of the International Project Competition for SHM (![]() ) ANCRiSST, Harbin Institute of Technology (China), and University of Illinois at Urbana-Champaign (USA) for providing the crack data of steel bridges. Thanks to the contributors of the APESS2018 dataset.
) ANCRiSST, Harbin Institute of Technology (China), and University of Illinois at Urbana-Champaign (USA) for providing the crack data of steel bridges. Thanks to the contributors of the APESS2018 dataset.
Author contributions
Yang Zhao: Conceptualization, Methodology, Experiments, Funding acquisition, Validation, Writing - original draft & editing; Pengyu Wang: Investigation, Data curation, Methodology, Experiments, Writing - original draft & editing; Shunyao Cai: Conceptualization, Methodology, Supervision, Validation, Funding acquisition, Writing - original draft & review; Huahuai Sun: Methodology, Supervision, Writing - review & editing; Zhihao Wang: Methodology, Supervision, Writing - review & editing.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Natural Science Foundation of China (Grant No.51908089) and Key R & D and Promotion Special Project of Henan Province (Tackling key science and Technology) (Grant No.202102310251).
Data Availability Statement
The raw data required to reproduce these findings are partly provided by the organizers of the 1st International Project Competition for Structural Health Monitoring (IPC-SHM, 2020), partly originated from the APESS2018 Steel Girder Crack ID dataset (Tang and Hu, 2018) and partly from the authors which is available upon reasoned request.