
Abstract
Aims:
This longitudinal case study examines phonemic category development in a Mandarin-Japanese 2L1 bilingual at 11;2 and 11;10.
Methodology:
The recordings for this study were collected when the participant was 11;2 and 11;10 years old, respectively. Each recording session comprised recordings in both Mandarin and Japanese, with a 4-day interval between the recordings for each language. Therefore, there were two recordings for each language condition.
Data Analysis:
For Mandarin and Japanese vowels, the focus was on F1 and F2. For stops, voice onset time (VOT) and onset F0 were analyzed. In addition, two Univariate General Linear Models examined whether VOT was a cue for stop differentiation in Mandarin, and two Multivariate General Linear Models assessed whether both VOT and onset F0 were cues for stop differentiation in Japanese. The results of this study were also compared with those from a previous study examining adult Japanese monolinguals and Mandarin-Japanese 2L1 adult bilinguals.
Findings and Conclusions:
The participant separated the vowels in the two languages more distinctly and adjusted the use of VOT and F0 as cues for Japanese stop differentiation from the first session to the second. This indicates a marked development in understanding the phonemic differences between Mandarin and Japanese, both in terms of vowels and stops. Compared to Mandarin-Japanese 2L1 adult bilinguals and adult Japanese monolinguals, the participant gradually aligns with Mandarin-Japanese 2L1 adult bilinguals’ phonemic patterns while diverging from adult Japanese monolinguals.
Originality:
This longitudinal study focuses on a teenage 2L1 bilingual, whereas most previous studies have concentrated on either young 2L1 bilingual children or adult 2L1 bilinguals. In addition, this study compares the teenage 2L1 bilingual with both adult monolinguals and adult 2L1 bilinguals, whereas most previous studies compare 2L1 bilingual children with either age-matched monolingual children or monolingual adults.
Significance:
This study reveals that significant phonemic adjustments and strategic refinements occur during the teenage years, suggesting that this period is possibly crucial for achieving efficient bilingual language management, although this may indicate some movement from monolingual patterns toward 2L1 adult bilingual patterns.
Introduction
Longitudinal studies of vowel and consonant category development in a child provide valuable insights by documenting the acoustic variations of vowels and consonants in an individual over time. Most of these studies focus on either young bilinguals or monolinguals (Oh et al., 2011; Simon, 2010; Yang et al., 2015), leaving teenage bilinguals understudied. To illustrate, Yang et al. (2015) document the English vowel category development in a monolingual Mandarin boy who is 3 years and 7 months old (3;7). The young sequential bilingual quickly restructures and separates his two language systems. A new L2 vowel system is established by drastically reorganizing the existing vowel space to maximize the contrast between the two vowel systems. The limited L2 vowel space then gradually expands as the learner identifies phonological contrasts in L2 and moves toward achieving the acoustic targets of native monolingual speakers. Ultimately, the two vowel systems become distinct (see also Aoyama et al., 2004; Oh et al., 2011).
However, whether the conclusion from the above studies can be applied to teenage bilinguals with two first languages (hereafter 2L1 bilinguals) is still an open question. In a 2L1 bilingual, the two language systems exist together, developing concurrently rather than sequentially. This simultaneous acquisition might lead to different patterns of phonemic category development compared to those observed in sequential bilinguals since the interaction between the two languages could result in phonological processes and structures different from those in sequential bilinguals. However, while there are many studies on young 2L1 bilinguals, young 2L1 bilinguals may behave differently from their teenage counterparts due to various factors such as cognitive development and linguistic exposure.
To address the research gap just noted, this longitudinal case study aims to explore the phonemic category development in a teenage Mandarin-Japanese 2L1 bilingual at the age of 11;2 and 11;10. This study examines the acoustic characteristics of vowels and stops, as well as the cues for stop differentiation, in Mandarin and Japanese across two time points for the participant. There are numerous studies on acoustic cues in stop differentiation by monolinguals. However, very few studies have examined acoustic cues in stop differentiation by teenage 2L1 bilinguals at different time points. It remains unclear whether they use the same cues as monolinguals or adult 2L1 bilinguals, or whether they switch from one cue to another over time.
This paper is composed of six sections. Section “Previous studies” discusses the vowels and stops in Mandarin and Japanese and reviews results concerning phonemic category development in previous studies. Section “The experiment” gives the details of the experiment and the participant for the present study. Section “Data analysis” presents the acoustic analysis and statistical analysis results. Section “Discussion” discusses the indications of the results from this study. Section “Conclusion” concludes the whole paper.
Previous studies
This section first briefly discusses vowels and consonants in Mandarin and Japanese, respectively, and then reviews results concerning phonemic category development in monolingual and 2L1 bilingual children in previous studies.
Vowels in Mandarin and Japanese
Vowels in Mandarin
Linguists have argued for decades about the number of vowels in the Mandarin phonemic inventory (Cheng, 1973; Duanmu, 2000; Hashimoto, 1970; Hockett, 1947; Pulleyblank, 1984). Hockett (1947) is perhaps the first to suggest a five-vowel system of [i, u, y, e, a]. Hashimoto (1970) treats high vowels [i, u, y] as underlying glides /j, w, ɥ/, and proposes a two-vowel system of [ə, a] (see also Wang, 1993). Pulleyblank (1984) is arguably the most extreme, proposing a system with only underlying glides, eliminating vowels entirely. Cheng (1973) claims that six underlying vowels exist in Mandarin ([i], [u], [e], [o], [ɑ], [ɤ]), which have 12 surface representations. Duanmu (2000) and Lin (2007) both present a five-vowel system: [i], [u], [y], [ə], [a]. Among these vowels, the vowels [ə] and [a] undergo backness harmony with the coda and have several variations (see also Duanmu, 1999; Mou, 2006; S. Xu, 1980). Generally speaking, [i], [u], [y], and [a] are not questioned, while there is strong uncertainty about [ə] (Duanmu 2000; Wiese, 1997; Wu, 2021). This is because the vowel [ə] has a large number of variations in different phonemic environments. For example, [ə] fronts to [e] before high vowels. Therefore, this study excludes [ə] from consideration and focuses exclusively on [i], [u], [y], and [a]. Mandarin vowels in diphthongs are also excluded because vowel nuclei in diphthongs are different from their respective monophthongs, except for [o] in [ow] (Shih, 1995). In addition, to exclude the potential influence of the coda, this paper focuses on [i], [u], [y], and [a] in open syllables only. For example, [i] in [mi] (迷 “lost”) is included in this study, while [i] in [in] (音 “sound”) is excluded. One note needs to be made here: vowels in open syllables in Mandarin are basically long (Duanmu, 1999, 2000; Zhou, 1999).
Vowels in Japanese
Five vowel phonemes ([i], [u], [e], [o], [a]) are in the modern Tokyo Japanese phonemic inventory (Hirata, 2004; Kubozono, 2015; Vance, 1987). Among these, [i] and [u] are high vowels, [e] and [o] are mid vowels, and [a] is a low vowel. Vowels exhibit a short-long phonemic length contrast, for example, [biru] (ビル “beer”) vs. [biiru] (ビール “building”). The exact ratio of a long vowel to a short one is subject to accent and speech rate, but most research reports that the ratio falls somewhere between 1.2 and 1.8 in spontaneous speech (Hirata, 2004; Kozasa, 2004; Minagawa et al., 2003) and 2.4 and 3.2 in isolated word reading (Han, 1962; Tsukada, 2011). This study takes all five vowels in Japanese into consideration. To have a parallel comparison with Mandarin, this study also exclusively focuses on vowels in open syllables in Japanese. To exemplify, [e] in [ne.ko] (ネコ “cat”) is included, while [e] in [nen.do] (ねんど “clay”) is excluded.
Consonants in Mandarin and Japanese
Duanmu (2000) lists 20 underlying consonants in Mandarin. Shibatani (1990) gives 14 consonantal phonemes in Modern Japanese. If variants and allophones are taken into consideration, the number of consonants in Mandarin and Japanese would be even larger. It is impossible to compare all these consonants in one paper. Stops may be a good choice for this paper since stops in Mandarin and Japanese have both similarities and differences (whose details will be given in the following two subsections). In addition, most previous studies on consonant development in monolinguals focus on stops, especially voice onset time (henceforth VOT). This gives the present study a benchmark for comparison. Thus, this paper exclusively focuses on the stops in Mandarin and Japanese.
VOT, first proposed by Lisker and Abramson (1964), is the length of time between the release of a stop and the onset of vocal fold vibration (Davenport & Hannahs, 2020; Lisker & Abramson, 1964; Rogers, 2000). According to Lisker and Abramson (1964), stops in world languages can be classified into three categories: voicing lead, short lag, and long lag. Since Lisker and Abramson (1964), a large body of research has furthered this line of research (see, e.g., Keating, 1984; Keating et al., 1983; Laver, 1994; Lee, 2018). Although disagreements exist (Caramazza & Yeni-Komshian, 1974; Cho & Ladefoged, 1999; Raphael et al., 1995; Takada, 2011), it is generally agreed that the voicing contrast in most languages typically involves two of the three categories proposed by Lisker and Abramson (1964). Therefore, VOT has become a standard measure for distinguishing between voicing and voicelessness in stops, with zero set at the moment of consonant release (Hullebus et al., 2018; Kong et al., 2012; Mielke & Nielsen, 2018; Raphael, 2021). VOT is considered negative when voicing starts before the stop is released, termed voicing lead. Conversely, VOT is considered positive when voicing starts after the release of the stop. Voiceless stops always exhibit a positive VOT, while the VOT for voiced stops varies across languages, being either positive, negative, or both. For instance, Hungarian and Spanish feature voiced stops with voicing lead and voiceless stops with short lag. In contrast, German and English have voiced stops with both voicing-lead and short-lag VOTs, and voiceless stops with long-lag VOT.
In addition to VOT, another phonetic feature that could differentiate stops is the fundamental frequency following stops (onset F0; hereafter F0). Although Lisker and Abramson (1964) suggest that VOT is a unified measure to precisely categorize stops, recent studies claim that a combination of VOT and F0 is necessary to distinguish the stops in some languages (Bijankhan & Nourbakhsh, 2009; Dmitrieva et al., 2015; Lo, 2022; Son, 2017). The common pattern across languages is that VOT and F0 exhibit correlation in the production of voicing, with F0 generally higher after voiceless stops than after voiced stops (Hombert, 1976; House & Fairbanks, 1953; Lehiste & Peterson, 1961; Ohde, 1984; Whalen, 1990).
Mandarin stops
In Mandarin, all stops are voiceless and differentiated by aspiration: voiceless unaspirated stops /p, t, k/ and voiceless aspirated stops /ph, th, kh/ (Luo, 2018; Shimizu, 1996, 1999). At the beginning of words, the unaspirated stops /p, t, k/ have slight aspiration, similar to their counterparts in Japanese (Shimizu, 1996). VOT is the primary cue distinguishing Mandarin stops: unaspirated stops have shorter VOTs than aspirated ones (Chao et al., 2006; Lisker, 1975, 1978; Peng et al., 2009; Raphael, 2005).
Although F0 serves as a secondary cue in distinguishing stops in languages such as Korean and Japanese, it may not play the same role in Mandarin because F0 is used to cue lexical tones (Francis et al., 2006; Gandour, 1974; Hombert, 1977). Most studies indicate that F0 after unaspirated stops is generally lower than that after aspirated stops in Mandarin (Guo & Kwon, 2022; Iwata & Hirose, 1976; Lai et al., 2009; Luo, 2018; Shimizu, 1996), while some studies have reported the opposite [Xu & Xu, 2003; see similar findings from Thai (Gandour, 1974) and from the Wu and Gan Chinese dialects (Shi, 1998)].
Japanese stops
Japanese features voiceless stops /p, t, k/, along with voiced stops /b, d, g/ (Itoh et al., 1980; Kubozono, 2015; Shibatani, 1990). These six stops only occur in word-initial and word-medial positions (Okada, 1999; Vance, 1987). In word-initial positions, the voiceless stops are slightly aspirated (Riney et al., 2007; Shimizu, 1996). For voiced stops, Itoh et al. (1980) observe that their VOTs are negative, supported by other studies (Kobayashi, 1981; Shimizu, 1993, 1996, 1999). However, recent studies demonstrate that voiced stops tend to be devoiced in word-initial positions, particularly among speakers born after the 1930s (Kong et al., 2012; Takada, 2004, 2011). Consequently, Japanese voiced stops exhibit two variants: a voiceless unaspirated variant with short-lag VOT and a voiced variant with voicing-lead VOT. When voiced stops become voiceless unaspirated, their VOTs overlap with those of voiceless stops in Japanese (Gao & Arai, 2019; Takada, 2004, 2011; Takada et al., 2015). In Tokyo Japanese, fewer than 25% of voiced stops have voicing-lead VOTs (Kong et al., 2012; Takada, 2004, 2011). F0 is considered a secondary cue in distinguishing the stops in Japanese (Homma, 1980; Shimizu, 1993, 1996, 1999; Takada, 2011; Takada et al., 2015). Despite some debate over the exact F0 contours in various accent contexts, it is generally agreed that the F0 is high after voiceless stops and low after voiced stops (Gao et al., 2019; Kawasaki, 1983; Mizuguchi & Tateishi, 2018). In Japanese, onset F0 is influenced by voicing contrasts at the phonological level, not VOT (Gao & Arai, 2019; Ishihara, 1998; Kawasaki, 1983; Shi, 1998; Shimizu, 1993; Takada, 2011).
Phonemic category development in monolingual and 2L1 bilingual children
It is claimed that although the phonemic category for stop consonants is not completely developed until the age of 10 (Lee & Iverson, 2012; Mack, 1989; Whitworth, 2000), 2L1 bilingual children can distinctly produce the vowels of both languages in a way similar to monolingual children by the age of 4 (Gildersleeve-Neumann et al., 2008, 2009; Gildersleeve-Neumann & Wright, 2010; Lee, 2018; Lee & Iverson, 2012). To exemplify, Goldstein and Washington (2001) examine 4-year-old Spanish-English 2L1 bilingual children and report that the bilinguals’ production accuracy of English stops (97%) and Spanish stops (93%) was comparable to that of monolingual English-speaking (96.8%) and Spanish-speaking children (90%), respectively. However, Goldstein and Washington (2001) also emphasize that the speech production in both languages by the 2L1 bilingual children is different from that by monolinguals (see also Fabiano-Smith & Goldstein, 2010).
In fact, according to some scholars, phonemic categories keep developing and becoming more precise until adolescence even among monolinguals (Hazan & Barrett, 2000; Nittrouer, 2005; Zlatin & Koenigsknecht, 1976). For example, Hazan and Barrett (2000) report that 12-year-old monolingual children who are native speakers of British English are still unable to categorize phonemic contrasts of /g/-/k/, /d/-/t/, /s/-/z/, and /s/-/ʃ/ in an adult-like manner. Given that even monolinguals continue to refine their phonemic categories until adolescence, there is a strong possibility that 2L1 bilinguals experience similar developmental trajectories. However, there is very limited research on 2L1 teenage bilinguals. Whitworth (2000), as one of the few related studies, analyzes VOT and intrinsic vowel length in German and English by two German-English 2L1 bilingual children, aged 9;11 and 12;5. Whitworth (2000) concludes that the two bilingual children can produce corresponding patterns in each language. However, their production is not identical to corresponding adult monolinguals.
There are even fewer longitudinal investigations on 2L1 teenage bilinguals. In addition, previous studies usually focus on vowel durations or VOT durations of stops in the two languages by 2L1 bilinguals. Another interesting but nevertheless understudied perspective is cue weighting: (1) whether teenage 2L1 bilinguals use the same cues to distinguish the stops in their two languages as their respective monolinguals and (2) whether teenage 2L1 bilinguals shift from using one cue to another.
The experiment
Considering the research gap noted in section “Previous studies,” this study conducts a longitudinal investigation of a Mandarin-Japanese 2L1 bilingual teenager. He was born in China, moved to Japan at the age of 2;0, began Mandarin acquisition after birth, and started Japanese acquisition at the age of 2;0. He entered a Japanese nursery 2 weeks after coming to Japan and stayed there 5 days a week. Both of his parents are native speakers of Mandarin and talk to him in Mandarin at home. The participant acquires Japanese through natural exposure at a local Japanese nursery and primary school, where all instructions are conducted by native Japanese-speaking teachers. Mandarin is the language he uses at home and during annual visits to China, while Japanese is the language he uses at school and with his friends. Children exposed to both languages before 3 years old are considered to be undergoing bilingual first language acquisition (Davies, 2004; De Houwer, 1990; Genesee & Nicoladis, 2007; McLaughlin, 1978). Therefore, this teenager is a Mandarin-Japanese 2L1 bilingual.
The recordings for this study were collected when the participant was 11;2 and 11;10 years old, respectively. Each recording session comprised recordings in both Mandarin and Japanese, with a 4-day interval between the recordings for each language. Therefore, there are two recordings for each language condition. The Mandarin recordings were the participant reading the Mandarin passages in his Mandarin textbook, which is for him to study Mandarin at home. The Japanese recordings were the participant reading the Japanese passages in his Japanese textbook, which he used at his primary school. Text reading was chosen based on the following three reasons: (1) the participant is familiar with the texts in these textbooks, allowing him to read them comfortably and fluently; (2) since the texts in the textbooks are generally formal, this ensures that all recordings in both language conditions are in the same speech style; and (3) both this study and a previous study by the present author, involving Mandarin-Japanese 2L1 adult bilinguals, include text reading; this makes it possible to use the previous study as a benchmark for comparison. All recordings were collected using the Voice Memo application on the author’s iPhone in a quiet room at the participant’s home, and later converted to WAV format for acoustic analysis.
Data analysis
The author segmented and labeled the recordings on speech waveforms and wideband and narrowband spectrograms generated on Praat.
Vowels in Mandarin and Japanese
Only vowels in open syllables were acoustically analyzed to ensure that all vowels were taken from the same phonetic environments as much as possible. For Mandarin, the focus was on [i], [u], [y], and [a], while for Japanese the focus was on [i], [u], [e], [o], and [a]. The guidelines laid out in Ladefoged and Johnson (2010), Ciocca and Whitehill (2013), and Knight and Setter (2021) were generally followed. The segmental boundaries were identified generally by taking spectral transitions into consideration. A vowel was typically identified as the segment of a speech signal between the onset and offset points of vocalic activity. After the segmentation, the duration of each vowel was calculated.
The first two formants (F1 and F2) are usually sufficient to represent vowels (Lehiste & Peterson, 1961; Peeters, 1987; Repp, 1989), so the F1 and F2 of each vowel were also measured on Praat. The formant ceiling was set to 8,000 Hz since this study involved a teenager. F1 is inversely related to vowel height, while F2 indicates the degree of backness of a vowel. The F1 and F2 data from each recording of each language condition were respectively Bark-scaled to ensure that the data were more comparable. This allows a more accurate comparison of vowel qualities across the different ages of the participant. A vowel trajectory can be illustrated with the inverse of F1 as the vertical axis and F2 as the horizontal axis. Figure 1 presents the Bark-scaled F2 values of each vowel in Mandarin and Japanese across each recording session on the x-axis, and the inversed Bark-scaled F1 values on the y-axis. The hollowed markers stand for the data obtained when the participant was 11;2, and the solid markers for the data obtained when he was 11;10. The triangular markers stand for the Mandarin data, and the circular markers stand for the Japanese data.
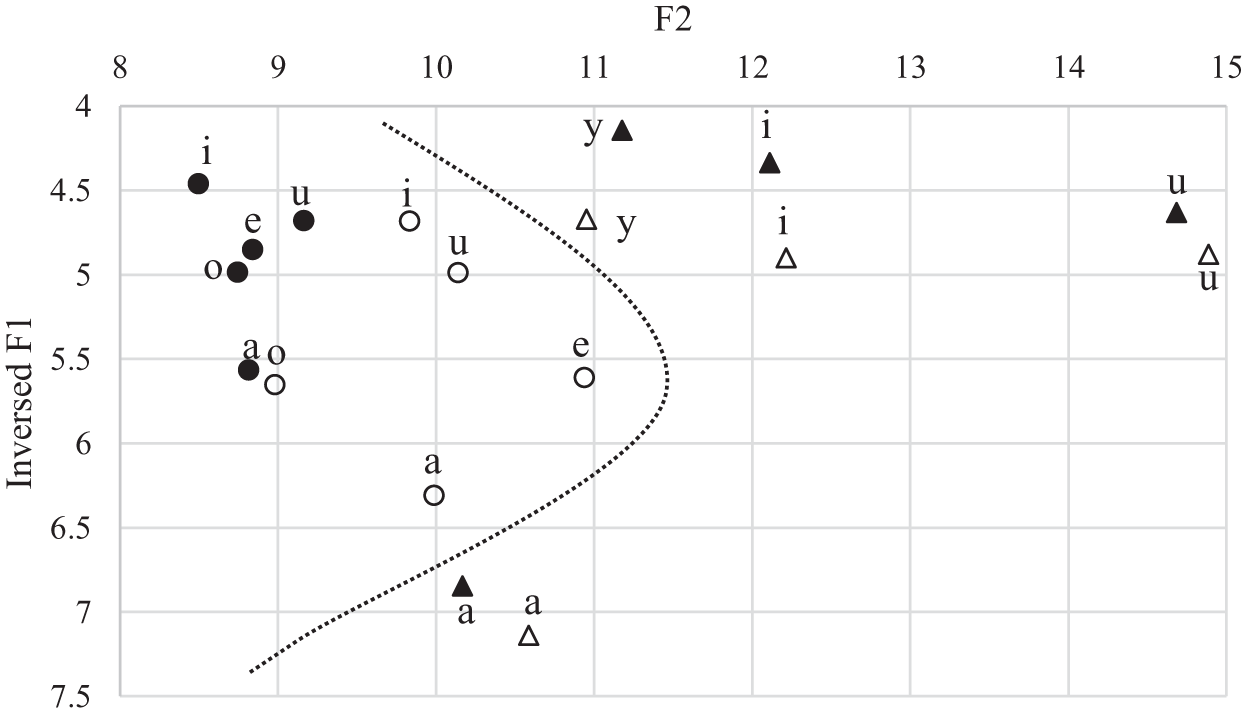
The vowel trajectory.
Figure 1 graphically illustrates that, overall, Mandarin vowels are more back and higher compared to Japanese vowels. In Figure 1, both the Mandarin and Japanese vowels have shifted higher along the y-axis from the first session to the second, suggesting that both Mandarin and Japanese vowels have been raised from the first session to the second. In addition, the Mandarin vowels have moved marginally along the x-axis, while the Japanese vowels have moved further front along the x-axis.
Figure 1 shows that Mandarin data from the two sessions cluster together, as do Japanese data. A separation curve can be drawn between the Mandarin and Japanese clusters. This indicates that the vowel systems of Mandarin and Japanese are separate and can be differentiated based on their acoustic characteristics. The Mandarin and Japanese vowels have drifted further apart from the first session to the second. This suggests that the boy was becoming more proficient and consistent in distinguishing between the vowel systems of Mandarin and Japanese as he progressed through the sessions, indicating notable progress in his phonemic category development. The exact F1 and F2 values are given in Table 1.
Bark-scaled F1 and F2 values and duration in milliseconds per vowel per language per session.
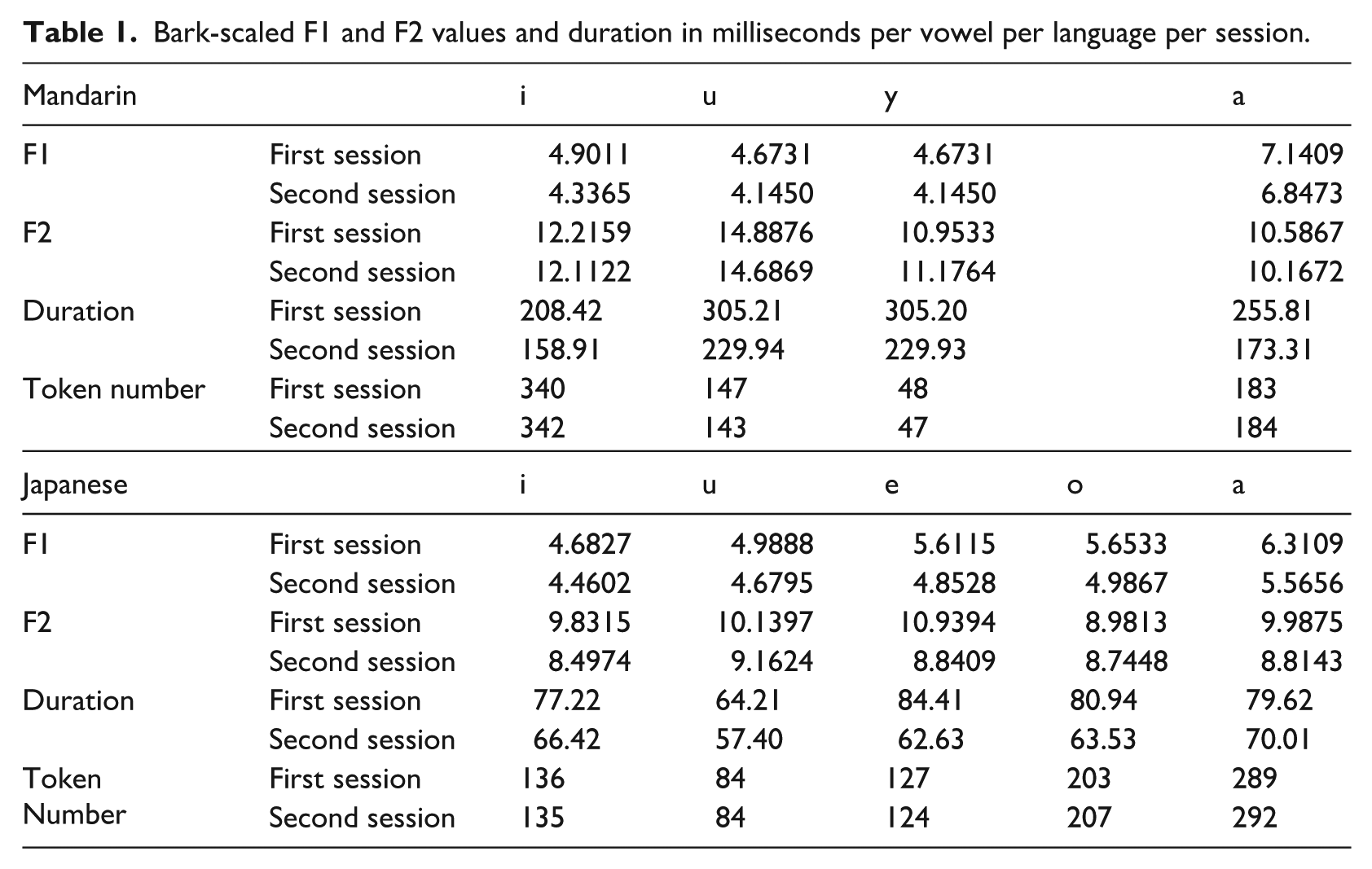
In Table 1, the vowels [i] and [u], the common phonemic vowels between Mandarin and Japanese are more similar in terms of F1 than F2: (1) [i] and [u] do not have a substantial difference in terms of F1 between the two language conditions in either the first or second session, suggesting that [i] and [u] have similar height in the two languages; but (2) both [i] and [u] display higher F2 values in Mandarin than in Japanese in both sessions, indicating that [i] and [u] are more back in Mandarin than in Japanese. However, the common vowel [a] is different both in terms of F1 and F2 between Mandarin and Japanese, especially in the second recording session, suggesting that the participant showed increasing ability to separate and produce the vowel [a] distinctly in Mandarin and Japanese. The participant continued to develop separate phonemic categories for [i], [u], and [a] in each language rather than merging them into a single undifferentiated category.
Compared to the results in the first session, the results from both languages in the second session were generally smaller in value both in terms of F1 and F2. The only exception was [y] in Mandarin which had a slightly higher value of F2 in the second session. This suggests that overall, the vowels in both languages have become higher and more front.
In Mandarin, [i], [u], and [y] did not have a large difference in terms of F1 between the two sessions, which indicated that they were of roughly the same height. In terms of F2, [y] and [i] were more front than [u]. These are in line with the depiction concerning vowels in Mandarin noted in section “Vowels in Mandarin.” Turning to vowels in Japanese, [i] and [u] were high vowels, [e] and [o] were mid vowels, and [a] was a low vowel, according to their F1 values in Table 1. This aligns with the characteristics of Japanese vowels reviewed in section “Vowels in Japanese.”
In terms of duration, all vowels in both Mandarin and Japanese were shorter in the second session compared to the first session. This may indicate enhanced fluency in both languages in the second session. The durations of [i], [u], and [a] in Mandarin were longer than those in Japanese. The results here echo the note in section “Vowels in Mandarin” that vowels in open syllables in Mandarin are long.
Stops in Mandarin and Japanese
The author segmented and annotated the recordings, measuring both VOT and F0 using Praat. The focus was exclusively on the stops at the word-initial position for both Mandarin and Japanese recordings to have a parallel comparison. VOT was determined from speech waveforms and wideband spectrograms generated in Praat. For voiceless stops, VOT was marked as the interval between the stop release and the start of glottal vibration (Lavoie, 2001; Riney et al., 2007). Oral closure was indicated by a lack of acoustic energy in the formant frequency band on a spectrogram, while oral release was shown by a rapid onset of energy in this range. For voiced stops, VOTs were marked as negative if voicing occurred before the release. If there was no voice bar, the interval between the stop release and the onset of the voiced vowel was measured as a positive VOT. In the Japanese recordings, words starting with [t] or [d] followed by the vowel [i] or [u] were excluded from this study because these stops transformed into affricates or the fricative /z/ before high vowels, producing sounds like [tɕi], [tsu], [dʑi], and [zu] (Vance, 1987, 2008). In addition, the vowels [i] and [u] in the syllables [ki] and [ku] in Japanese frequently became devoiced, making the VOT and onset F0 for [k] unmeasurable. Therefore, such data points were omitted.
F0, measured in Hertz (Hz), was determined at the onset of the vowel following the stop using narrowband spectrograms generated in Praat with a 0.025-second window length. The onset corresponded to the start of periodicity, indicated by a zero crossing after the release burst. Some tokens did not show a pitch track at the onset of vowels and were therefore excluded.
VOT durations and Bark-scaled F0 values
Table 2 gives Bark-scaled F0 values to make data from different sessions comparable. Overall, the durations of positive VOT in both Mandarin and Japanese does not have much variation from the first session to the second. The following five tendencies can be observed in Table 2: (1) the VOTs of the unaspirated stops in Mandarin are much shorter than those of the aspirated stops; (2) the VOTs of the voiceless triplets in Japanese are somewhere between the VOTs of the unaspirated and aspirated stops in Mandarin; (3) the positive VOTs of the voiced stops in Japanese are close to those of the voiceless stops in Japanese; (4) the F0s after the unaspirated stops in Mandarin are generally lower than those after the aspirated stops; and (5) the F0s after the voiceless stops in Japanese tend to be higher than those after the voiced ones. These tendencies are in line with the general tendency of VOT and F0 in Mandarin and Japanese languages reported in Shimizu (1996, 1999). This indicates the participant’s proficiency in navigating the phonological systems of both languages.
VOT duration in milliseconds and Bark-scaled F0 value per stop per language per session.
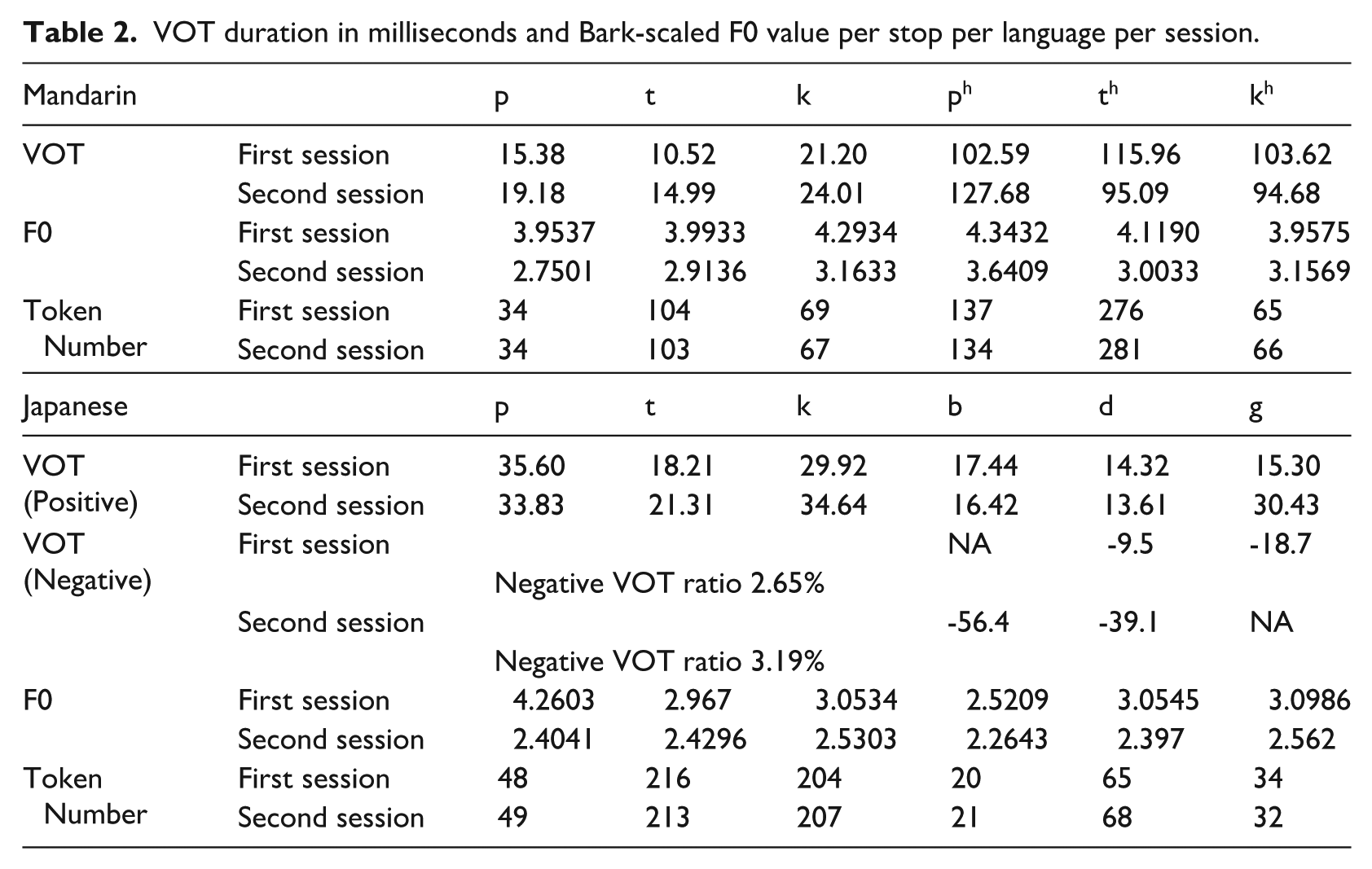
Negative VOT ratio in Table 2 represents the percentage of prevoiced VOTs among all voiced stops in Japanese. NA means that related data do not exist. Although both sessions gave very low negative VOT ratios, the second session appeared to show a tendency to increase. The present author has also conducted a study on Mandarin-Japanese 2L1 adult bilinguals and adult Japanese monolinguals (Liu & Moon, n.d.), in which the participants were asked to read a Japanese text. In Liu and Moon (n.d.), the negative VOT ratio was 1.92% for adult Japanese monolinguals and 10.26% for Mandarin-Japanese 2L1 adult bilinguals. Therefore, the observed increase in the negative VOT ratio in the teenage 2L1 bilingual participant’s speech production for this study may suggest a further departure from the adult Japanese monolingual pattern but a developing alignment with the Mandarin-Japanese 2L1 adult bilingual pattern.
In addition, the difference in Bark-scaled F0 values between Mandarin and Japanese has narrowed from the first session to the second, suggesting that the participant is becoming more efficient by finding a unified pitch production approach that works for both languages. This may be a sign of his developing proficiency and adaptability. As the participants in Liu and Moon (n.d.) are adults and the participant for this study is a teenager, it is difficult to make a direct comparison in F0 between the two studies. The general tendency is that the difference in terms of F0 between the voiceless and voiced stops for both adult Japanese monolinguals and Mandarin-Japanese 2L1 adult bilinguals is quite small in Liu and Moon (n.d.). The teenage participant here also shows such a tendency. This appears to indicate that the participant for this study is gradually shifting more toward adult Japanese monolinguals and Mandarin-Japanese 2L1 adult bilinguals in this small respect.
VOT and F0 as cues in stop differentiation
This section will turn its attention to VOT and F0 as cues in stop differentiation in Mandarin and Japanese.
VOT as a cue in Mandarin stop differentiation
Initially, two Multivariate General Linear Models (henceforth MGL Models) were carried out using the SPSS Statistics for Windows Version 27.0 (IBM 2020; hereafter SPSS) to examine whether the participant uses both VOT and F0 to distinguish the stops in Mandarin in the two sessions from the perspectives of aspiration (unaspirated, aspirated) and stop type (velar, alveolar, labial). The alpha value was set at 0.05.
Both MGL models suggested that only VOT was a cue in Mandarin stop differentiation (the first MGL Model: p < .001 for VOT, p = .812 for F0; the second MGL Model: p < .001 for VOT, p = .091 for F0). Therefore, two Univariate General Linear Models (henceforth UGL Models) were carried out to examine the correlation between VOT and aspiration (unaspirated, aspirated) and stop type (velar, alveolar, labial) in Mandarin. Their results are reported in Table 3.
The UGL models for the correlation of VOT with Mandarin stop differentiation.
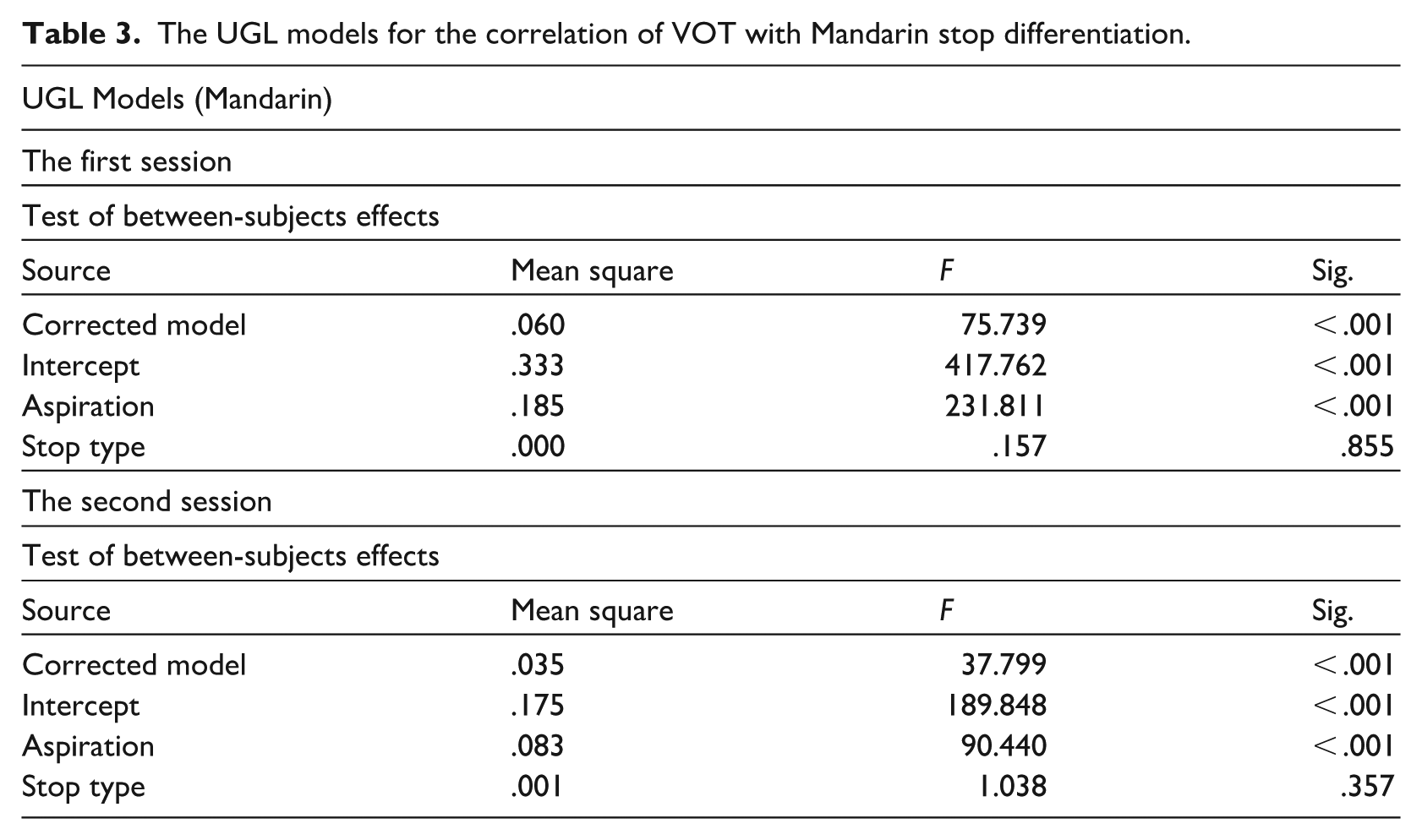
In Table 3, two separate UGL Models were carried out on the Mandarin data from the first and second sessions, respectively. Their results suggest that VOT in Mandarin distinguished aspirated stops from unaspirated ones in both sessions (p < .001, p < .001). The correlation between VOT and Mandarin stops has not changed from the first session to the second. However, VOT did not distinguish stop type in Mandarin in either session (p = .855, .357). The results concerning Mandarin are in line with the review in section “Mandarin stops” that VOT is the main cue in stop differentiation in Mandarin. More specifically, VOT differentiates aspirated stops from unaspirated ones in this participant.
VOT and F0 as cues in Japanese stop differentiation
Two MGL Models were carried out using the SPSS to examine whether the participant used both VOT and F0 to distinguish the stops in Japanese from the perspectives of voicedness (voiceless, voiced) and stop type (velar, alveolar, labial). The alpha value was still set at 0.05.
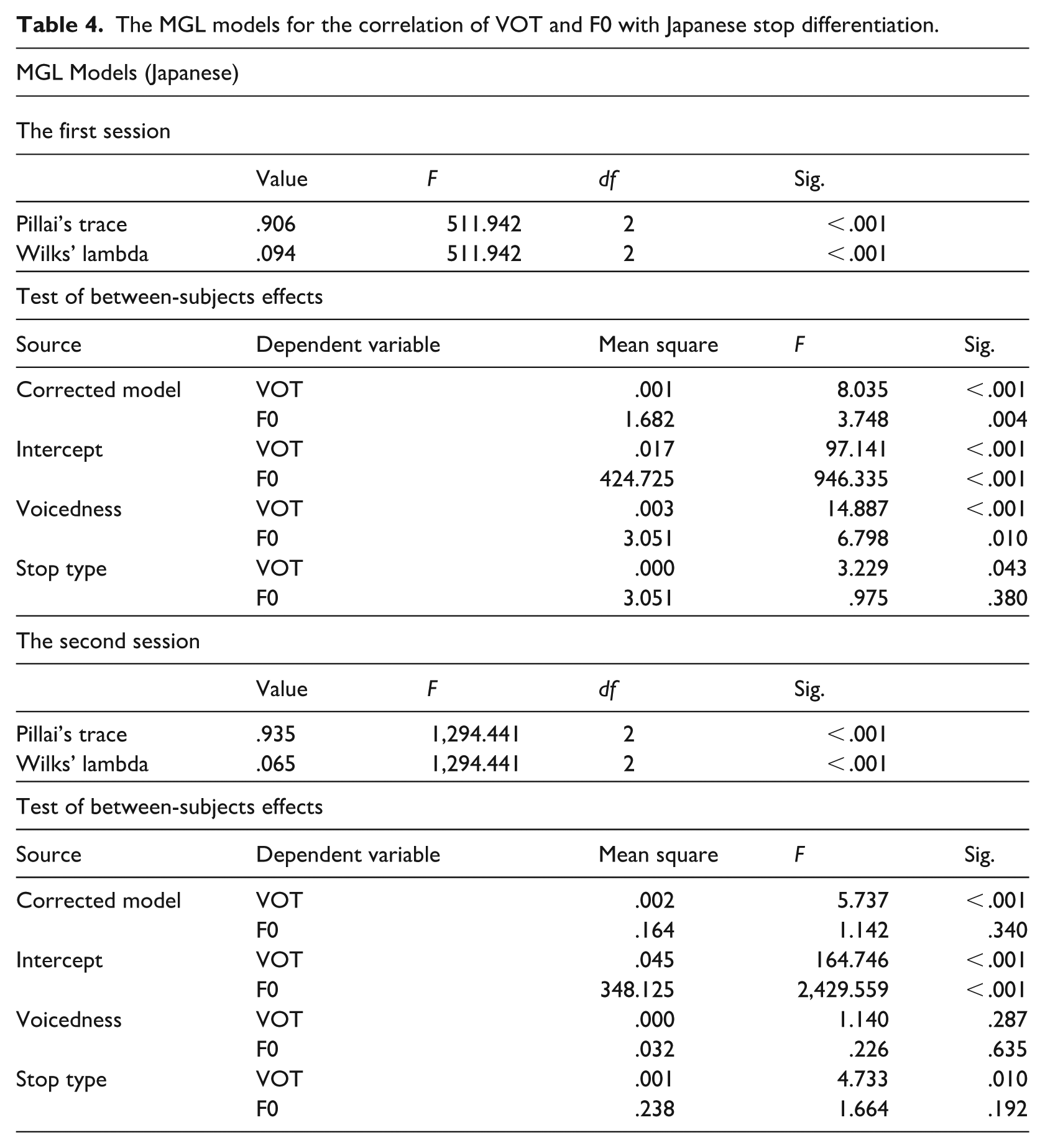
In Table 4, two MGL Models were carried out on the Japanese data from the two recording sessions. The first MGL Model for the first recording session in Table 4 indicates that both VOT and F0 were cues in Japanese stop differentiation (p < .001, p = .004). However, VOT and F0 had different roles in this session: (1) VOT distinguished voiceless stops from voiced ones and velars from alveolars and labials (p < .001, p = .043); but (2) F0 only differentiated voiceless stops from voiced ones (p = .010); F0 did not distinguish velars from alveolars and labials (p = .380). The second MGL Model for the second session in Table 4 suggests that only VOT was a cue in Japanese stop differentiation (p < .001), while F0 was not (p = .340). VOT did not differentiate voiceless stops from voiced ones (p = .287), but it distinguished velars from alveolars and labials (p = .010). Strictly speaking, both VOT and F0 have changed their roles in Japanese stop differentiation in this longitudinal study: (1) VOT distinguished both voicedness and stop type in the first session, while it only distinguished stop type in the second session and (2) F0 was a cue in Japanese stop differentiation in the first session, while it was not a cue anymore in the second session.
The MGL models for the correlation of VOT and F0 with Japanese stop differentiation.
Discussion
Combining the results in Table 1 through Table 4 together, the participant seems to have become more efficient in distinguishing the two languages both in terms of vowels and stops from the first session to the second: (1) in terms of vowels, the participant separates the vowels in the two languages further from the first session to the second and (2) in terms of stops, the participant has undergone changes in the use of VOT and F0 as cues in Japanese stop differentiation. The participant appears to understand the differences between Mandarin and Japanese and tries to adjust his strategies to distinguish the two languages more efficiently. What is surprising is that the 8-month period between 11;2 and 11;10 could present such a development.
Yang et al. (2015) observe the drastic reorganizing of the vowel space of the first language for the vowel space of the second language to maximize the contrast between the two vowel systems by the 3;7 sequential bilingual as he restructured and separated his two language systems. Ultimately, the two vowel systems became distinct (Yang et al., 2015). The present study demonstrates that even at the age of 11;10, the separation of the two vowel systems is still going on in the 2L1 bilingual teenager, at least in terms of the vowels that this study has focused on.
The present study also compares the present participant with adult Japanese monolinguals and Mandarin-Japanese 2L1 adult bilinguals in Liu and Moon (n.d.). Liu and Moon (n.d.) report that adult Japanese monolinguals use VOT to distinguish both voicedness and stop type (p < .001, p < .001), and F0 to differentiate voicedness, but not stop type (p < .001, p = .107). In the first recording session for this study, the Mandarin-Japanese 2L1 bilingual teenager used both VOT and F0 as cues in Japanese stop differentiation similarly to the adult Japanese monolinguals in Liu and Moon (n.d.). In contrast, Mandarin-Japanese 2L1 adult bilinguals in Liu and Moon (n.d.) only used VOT as a cue to distinguish both voicedness and stop type (p = .049, p < .001). In the second session, the participant only used VOT as a cue in Japanese stop differentiation. From the first to the second session, the participant has shifted away from the adult Japanese monolinguals but has become more aligned with the Mandarin-Japanese 2L1 adult bilinguals in Liu and Moon (n.d.), although he is not yet completely identical to these bilinguals. It appears that 2L1 bilingual children may initially align each language closely with monolingual norms, but later develop adjustments in each language to help distinguish the two first languages efficiently, and finally align with 2L1 adult bilingual norms. Liu and Moon (n.d.) compare Korean-Japanese and Mandarin-Japanese 2L1 adult bilinguals both with each other and with Japanese monolinguals and conclude that both Korean-Japanese and Mandarin-Japanese have adopted approaches that can efficiently distinguish their two first languages. It seems that the teenage 2L1 bilingual here has employed a similar approach. The details are given below.
First, the changing role of F0 in Japanese may be attributed to the fact that Mandarin and Japanese have a large difference in terms of stops: (1) Mandarin only has voiceless stops, while Japanese has both voiceless and voiced stops and (2) the two sets of voiceless stops in Mandarin have different VOT values from the set of voiceless stops in Japanese. It appears relatively easy to distinguish the stops in these two languages, rendering the use of too many cues unnecessary. Thus, the participant did not use F0 to differentiate the Japanese stops in the second session.
Second, the present participant produced more prevoiced tokens of voiced stops in Japanese from the first to the second session (2.65% vs. 3.19%). Since voicing contrast is absent in Mandarin, relying more on the voicing contrast can make the distinction between Japanese and Mandarin, and the distinction between Japanese voiceless and voiced stops easier. This approach is similar to that adopted by the Mandarin-Japanese 2L1 adult bilinguals in Liu and Moon (n.d.), although they have a higher prevoicing rate of 10.26%. However, as the adult Japanese monolinguals in Liu and Moon (n.d.) are reported to have a 1.92% prevoicing rate, both the present participant, especially in the second session, and the Mandarin-Japanese 2L1 adult bilinguals in Liu and Moon (n.d.) have much larger prevoicing rates than the Japanese monolinguals.
According to the Speech Learning Model and the revised Speech Learning Model (hereafter the SLM framework; Flege, 1987, 1995, 2003; Flege & Bohn, 2021), category formation is gradual and often incomplete in second language speakers, so even new sounds absent in the first language may not result in fully established contrasts in second language production. Viewed against the SLM framework, this study highlights a key difference between 2L1 bilinguals and second language speakers: while second language learners often struggle to establish new contrasts that are absent in their first language, 2L1 bilinguals can maintain or strengthen such contrasts, perhaps because both languages develop concurrently, allowing distinct phonetic categories to form. Based on the results from both Korean-Japanese and Mandarin-Japanese 2L1 bilinguals, Liu and Moon (n.d.) summarize that the two phonetic systems of 2L1 adult bilinguals are both separate and adaptive, exhibiting language-specific differentiation shaped by the need to preserve contrastiveness across languages. The teenage Mandarin-Japanese 2L1 bilingual participant in this study has also shown such a tendency. However, as he is still in the process of aligning more with Mandarin-Japanese 2L1 adult bilinguals from the first session to the second, it suggests that 2L1 bilingual children are still undergoing phonemic category development over 11 years old.
Goldstein and Washington (2001) report that although 4-year-old Spanish-English 2L1 bilingual children have similar accuracy rates of Spanish and English stops as respective monolingual children, their speech production in both languages is different from that by monolinguals. Similarly, in this study, the 2L1 bilingual teenager does not fully align with adult Japanese monolinguals—and notably, even beyond the age of 11, continues to drift away from them over time.
In comparison with the results in studies on phonemic category development in the monolingual children reviewed in section “Phonemic category development in monolingual and 2L1 bilingual children,” the teenage 2L1 bilingual participant here appears to demonstrate that phonemic category formation is not complete at the age of 11;10, contrary to the claim that stop consonants are completely developed at 10 and vowels even earlier (Lee & Iverson, 2012; Mack, 1989; Whitworth, 2000). The result here is not surprising, considering that the 9;11 and 12;5 bilingual children in Whitworth (2000) were not the same as corresponding adult monolinguals either, and the 12-year-old monolingual children in Hazan and Barrett (2000) could not categorize phonemic contrasts of English voiceless-voiced stop pairs in the same way as adults.
Taken together, the present study suggests that 2L1 bilingual teenagers are still optimizing the efficiency of managing two languages. This demonstrates how bilingual children adaptively refine their phonemic categories to navigate their dual-language environments more effectively. The period examined in this study, between 11;2 and 11;10, may represent a developmental phase in 2L1 bilingual language acquisition. In addition, since this study has shown that the teenage 2L1 bilingual adopts approaches similar to those of 2L1 adult bilinguals and appears to be gradually approaching the 2L1 adult bilingual pattern, it is plausible to assume that the participant may eventually reach a similar state as these 2L1 adult bilinguals. However, the timing of this potential convergence must be left to future research.
Conclusion
According to some earlier findings, phonemic categories continue to develop until adolescence in monolingual individuals. However, much less attention has been given to the phonemic category development in teenage 2L1 bilinguals. This paper addresses this gap by examining both vowel and consonantal developments in a Mandarin-Japanese 2L1 bilingual between 11;2 and 11;10.
This study finds that the participant undergoes significant phonemic category development during this 8-month period. Notably, the participant shows a tendency toward the phonemic patterns observed in Mandarin-Japanese 2L1 adult bilinguals, although he has not yet fully reached that stage. In addition, there is a tendency away from adult Japanese monolinguals. Therefore, this study concludes that the teenage years may be a crucial period for phonemic category development in 2L1 bilinguals: it is possible that during this time, they understand more about the two languages, make adjustments, and gradually align with the phonemic patterns of adult 2L1 bilinguals. It can be argued that the conclusion is drawn from two small respects. It is worthwhile exploring other respects, that is, the respects where the two languages of a 2L1 bilingual have more similarities, to further examine the conclusion from this paper. This awaits future research.
Footnotes
Acknowledgements
For help in getting this article to its final form, my special gratitude goes to Professor Jacques Durand for his advice on acoustic analysis, to Professor Eiji Yamada for advice and discussion, to Professor Robert Long for editing this paper, and to the anonymous reviewers and the editors of the present journal for detailed and helpful feedback. All remaining errors are my own responsibility.
Ethical considerations
Ethical approval for this study was obtained from the Ethical Review Board of Fukuoka Institute of Technology. All procedures were conducted in accordance with the board’s guidelines and relevant ethical standards.
Consent to participate
Written informed consent was obtained from the participant prior to data collection. The participant was informed about the purpose of the study, the procedures involved, the right to withdraw at any time without penalty, and the confidentiality of the data.
Funding
The author disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study is funded by the 2025 Scholarship Fund for Young/Women Researchers from the Promotion and Mutual Aid Corporation for Private Schools of Japan.
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.