
Abstract
Objectives:
Object wh-questions are more difficult for monolingual children to comprehend than subject questions. Especially difficult are object-which questions that appear to be significantly more difficult than both (object/subject) who and subject-which questions. Our research examines the manifestation of this difficulty among bilingual preschool children (L1-English, L2-Hebrew) as compared with their Hebrew monolingual peers, exploring the two languages of the bilinguals.
Approach:
Using a character selection task, the empirical goal of the study is to analyze the differences between monolinguals and bilinguals and between the languages of the bilinguals. The theoretical goal is to explain the difficulty which cuts across the two populations, namely, the comprehension of object-which questions.
Data and Analysis:
A total of A total of 55 preschool children, aged 4.4–6.4, participated in the study: 20 monolinguals and 35 bilinguals. A mixed linear model analysis, a general linear model, multiple linear regression analyses, and chi-square tests were used to analyze the data.
Findings:
(1) Monolingual and bilingual children (in their L2) have similar trajectories: object-which questions present difficulties to all participants, and their comprehension systematically follows the comprehension of object-who questions; (2) similar trajectories are also found in the two languages of the bilingual children, with L1-English object-which questions lagging behind L2-Hebrew object-which questions.
Originality:
The comparison between the two populations, and especially between the two languages of the bilinguals, led us to take a closer look at the syntactic processing of which-questions. We explored the possibility that the set restriction computation is the source of children’s difficulty, overloading their working memory resources.
Significance:
Our research demonstrates that monolingual and bilingual (syntactic) development is essentially the same. However, when syntactic processes interact with additional factors, such as working memory resources and language-specific properties, as is the case in object-which questions in Hebrew versus English, the gap between the two populations might widen.
Introduction
Children find object wh-questions more difficult to comprehend than subject questions. Especially difficult are object-which questions that appear to be significantly more difficult than both (object/subject) who-questions, and subject-which questions.
The present study documents the comprehension of who- and which-questions by monolingual (ML) Hebrew-speaking preschool children and their bilingual ([BL] L1-English, L2-Hebrew) peers. The comparison between MLs and BLs is expected to identify developmental aspects which are common to both populations and those differentiating them. Variations observed will be discussed assuming the Set Restriction hypothesis as the source of children’s difficulty, elaborating on the strategy employed by children as well as on its consequences for the comprehension of wh-questions. Testing BLs in both languages enables specifying the unique contribution of the linguistic properties of each language to the acquisition of the same structure and exploring potential cross-linguistic influence. Using within-subject design further enables controlling differences in the general cognitive development or other experimental effects. This is especially beneficial for explicating different degrees of difficulty, if found, in the two languages.
Comprehension and structure of wh-questions
Wh-questions may differ as to the position of the wh-phrase (subject questions vs. object-questions), and as to the type of the wh-phrase (who/what vs. which-NP).
Subject questions versus object questions
A common cross-linguistic finding is that subject questions (1a, b) are easier to comprehend than object questions (1c, d)). This has been reported in a variety of studies with typically developing children, using mainly offline measures such as sentence-picture matching tasks (Benţea & Durrleman, 2014; Contemori et al., 2018—using an online visual world paradigm; Friedmann et al., 2009; Friedmann & Novogrodsky, 2011; Goodluck, 2005, 2010), children with hearing-impairment or children with specific language impairment (SLI; Friedmann & Novogrodsky, 2011; Friedmann & Szterman, 2011), healthy adults (Crain & Fodor, 1985; Frazier & Clifton, 1983), and aphasic patients (Avrutin, 2000; Garraffa & Grillo, 2008; Grillo, 2008; Hickok & Avrutin, 1995, 1996): (1) a. Who scratches the dog? S-who b. Which cat scratches the dog? S-which c. Who does the dog scratch? O-who d. Which cat does the dog scratch? O-which (specific)
The asymmetry between these two types of questions has received various accounts. Roughly speaking, the difficulty with object questions is attributed to either a longer dependency between the wh-phrase and its original position—preverbal in subject question, postverbal in object questions (e.g., Avrutin, 2000), or to the intervention effect induced by the subject occurring between the object wh-phrase and its original postverbal position (e.g., Friedmann et al., 2009).
Who-questions versus which-questions
Following the terminology introduced in Pesetsky (1987), wh-phrases like which cat are D(iscourse)-linked, prompting an answer chosen from a set of referents already existing in the discourse, whereas wh-phrases like who/what are not. The contrast between the two types of wh-questions has been studied both from the grammatical (semantic, syntactic) perspective (superiority effects, island phenomena, e.g., Cinque, 1990; Pesetsky, 1987; Szabolcsi & Zwarts, 1993), and from the processing one (e.g., comprehension, reading times). Research on the comprehension of the two types of questions suggests that which-questions are harder to comprehend than who-questions (Kaan et al., 2000; Shapiro, 2000). Roughly speaking, the difficulty is attributed to the referential nature and the presence of lexical material in a D-linked wh-phrase, requiring more initial processing (e.g., Goodall, 2015 and references cited therein).
A further subdivision of which-phrases alludes to specific which-phrases (e.g., which cat in [1d]), as opposed to generic which-phrases (e.g., which animal in [2]) (Donkers et al., 2013 for adults; Goodluck, 2005 for children). Based on these studies, only specific object-which questions cause difficulties in comprehension; the generic which-questions pattern together with who-questions. Donkers et al. (2013) show a significant interaction of question type (who/which) and structural order (subject/object question), with the generic which-questions patterning together with who-questions rather than with specific which-questions: (2) Which animal does the dog scratch? O-which (generic)
To summarize, subject questions (1a, b) are comprehended well from quite early on, regardless of the type of the wh-element (who/which). Comprehension of object questions ([1c, d], (2)) is achieved later, with the comprehension of specific object-which questions (1d) being the latest.
In principle, Hebrew wh-questions have the same derivation as their English counterparts, involving movement of the wh-phrase to Spec-CP (a sentence-initial position) (3), (4) (the trace notation, t, marks the original position of the wh-phrase) (Chomsky, 1981): (3) a. mi t soret et ha-kelev? who scratches ACC the-dog “Who scratches the dog?” b. eize xatul t soret et ha-kelev? which cat scratches ACC the-dog “Which cat scratches the dog?” (4) a. et mi ha-kelev soret t? ACC who the-dog scratches “Who b. et eize xatul ha-kelev soret t? ACC which cat the-dog scratches “Which cat
Despite the structural similarity, there are three noteworthy differences between Hebrew and English:
The presence of the auxiliary do in English, but not in Hebrew (see the glosses in [4]), raises the question of whether this functional element may have any effect on the comprehension of object questions in English, and if so, in what way.
The occurrence of the accusative marker et in Hebrew, but not in English, might be significant for the comprehension of object questions (4), having an ameliorating effect.
The overt subject–verb agreement in Hebrew, namely, when the subject DP and the object DP have different gender or number features (e.g., (5a)–(5c)) could facilitate comprehension of object questions, similarly to its effect on the comprehension of Hebrew object relative clauses (Günzberg-Kerbel et al., 2008), raising the question of whether this is indeed the case in Hebrew for both MLs and BLs:
(5) a. et eize xatul ha-kelev soret t? ACC which cat (Masc) the-dog (Masc) scratches-Masc “Which cat does the dog scratch?” b. et eize xatul ha-zebra soret
ACC which cat (Masc) the-zebra (Fem) scratches-Fem “Which cat does the zebra scratch?” c. et eize xatul ha-klav
ACC which cat (Masc.sg.) the-dogs (Masc-pl) scratch-Masc-pl “Which cat do the dogs scratch?”
Studies on the acquisition of Hebrew have already shown that the occurrence of et does not improve the comprehension of topicalized sentences or object relative clauses which include this element (Botwinik-Rotem, 2008; Friedmann & Novogrodsky, 2004; Levy & Friedmann, 2008). Therefore, we will only address the influence of the English auxiliary do and the (gender) agreement in Hebrew.
The present study
The present study explores between-subject (ML vs. BL) and within-subject (English vs. Hebrew) differences in the comprehension of wh-questions. The goals of the study are empirical and theoretical. The empirical goal is to analyze the differences between MLs and BLs and between the languages of the BLs, to sharpen our understanding of BL language development. Based on our empirical findings, the theoretical goal is to explain the difficulty which cuts across the two populations, namely, the comprehension of object-which questions.
To address the empirical goal, the following questions will be addressed:
1. Are there between-subject differences (MLs vs. BLs) in the comprehension of wh-questions? Do the two populations differ quantitatively, manifesting the same developmental trajectories, or qualitatively, with BLs exhibiting non-native patterns of acquisition?
2. For the BLs, are there within-subject differences (between the two languages of the BLs) in the comprehension of wh-questions? If there are differences, are they quantitative or qualitative? How are the differences affected by variables such as chronological age, and age of onset of bilingualism (AOB)?
3. How do language-specific properties (e.g., Hebrew agreement; English do) affect between-subject and within-subject differences?
It is predicted that MLs will outperform BLs (in their L2) showing a similar developmental trajectory, with object-which questions being more difficult for both populations. The within-subject analysis is expected to show better performance in one of the two languages, with sensitivity to chronological age or AOB. Language-specific properties, such as Hebrew agreement or English do might impact children’s performance.
To address the theoretical goal, the discussion will revolve around the following questions:
4. What is the source of the difficulty underlying the comprehension of object-which questions?
5. What are the consequences of this source of difficulty? Namely, (1) how does it affect children, and (2) what is the result of this effect on the syntactic processing of the relevant structures?
Assuming that the source of the difficulty is the set restriction computation (the Set Restriction hypothesis, to be elaborated ahead), we will offer a theoretical account that takes into consideration the syntactic processing of wh-questions in the BL context, where two languages are parsed by the same processor.
Method
Participants
A total of 55 preschool children, aged 4.4–6.4, participated in the study: 20 ML (mean age = 62.95 months) and 35 BLs (mean age = 66.42 months), with no significant age difference (p = .115). The BL children had AOB not later than 4.3 (range 0–51) and length of exposure (LoE) to Hebrew of at least a year and a half (range 18–74). All participants came from English-speaking homes and attended Hebrew-speaking preschools in two English–Hebrew speaking communities in Israel with a dense English-speaking population. Participants’ linguistic ability was evaluated via the Goralnik Screening Test (Goralnik, 1995) for Hebrew, and the Clinical Evaluation of Language Fundamentals Preschool-2 (CELF Preschool-2; Wiig et al., 2004) for English. Based on the results of these language assessment tests, all BL children were functional BLs, with an adequate representation of BLs with varying proficiency levels: balanced, L1-dominant, and L2-dominant. The dominance was determined according to scores within or below the ML norm on both tests. Parental consent was obtained for all study participants, and the study was approved by the Bar-Ilan University institutional review board for studies directly involving human participants, as well as the Israeli Ministry of Education.
Task, procedure, and analysis
Comprehension of wh-questions was tested via a character selection task, based on pictures of the type shown in Figure 1 (pictures from Cohen, 2008). The task included a total of 40 questions, divided equally between position and type: 20 subject and 20 object questions, including who- and which-questions for each position. Half of the items included characters of the same gender, while the other half included characters of different genders, to test for the effect of the gender cue (in Hebrew). The habitual aspect was used in all English questions, and the present tense in the Hebrew questions, as seen in (1), is repeated here:
a mi soret et ha-kelev? Who scratches the dog? who scratches ACC the-dog b. eize xatul soret et ha-kelev? Which cat scratches the dog? which cat scratches ACC the-dog
a. et mi ha-kelev soret? Who does the dog scratch? ACC who the-dog scratches b. et eize xatul ha-kelev soret? Which cat does the dog scratch? ACC which cat the-dog scratches
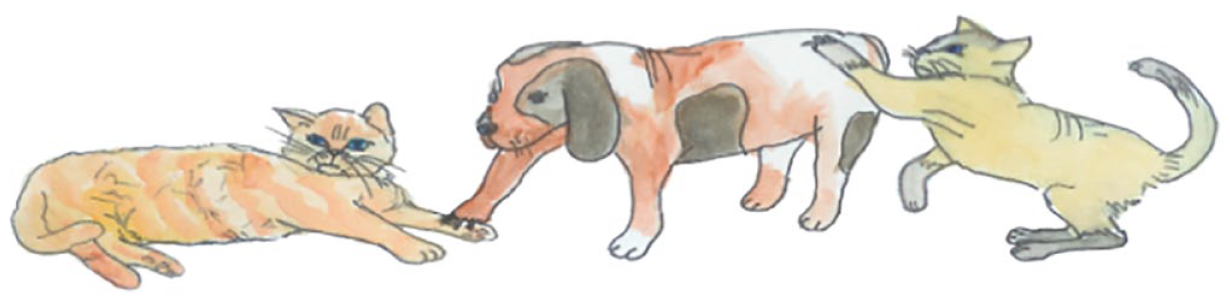
An example of a picture with three characters that was presented to the participants.
Children were tested in each language in a separate session, 2 weeks apart, by a native speaker of that language. The same items were used for the English and Hebrew study, and the order of the languages was balanced. The experimenter explained to the child that she would present pictures and ask questions, after which the child should point to an answer. The pictures were presented manually, and the experimenter read the questions from an answer sheet.
Children’s responses were scored as correct or incorrect (1 or 0), and a score was calculated in percentages for each of the four types in each language separately. A mixed linear model analysis (MLMA) with linguistic status (ML/BL) as the between-subject factor and position (subject/object) and type (who/which) as repeated measures was used for the comparison between MLs and BLs, exploring potential main effects for position (subject/object) and type (who/which) as well as interactions. Among the BLs, a general linear model (GLM) with repeated measures was conducted to compare the two languages, exploring the potential main effects for language (Hebrew/English) and type (who/which), and interaction between the two. These tests were also performed for the analysis of errors, both between and within the participants. Effect of position was not included since accuracy levels in subject questions were high. Multiple linear regression analyses were used to establish the relationship between levels of accuracy in the comprehension task and participant variables such as linguistic status, chronological age, and AOB. LoE was excluded from the analysis since it highly correlated with AOB (r = −.876). Chi-square tests were used to check the distribution of children below, at, and above chance levels. As there were three possible responses in each picture, the target character, the theta-role reversal character, and the wrong character, there was a 33% chance of selecting the appropriate figure, and a 66% chance of failing to do so. Upon testing for binominal probability twice, once for success and once for failure, we show that with 10 items (the total of items for each position and question type), 7 or more out of 10 is above chance (p = .018), whereas 3 or fewer out of 10 is below chance (p = .02). A score of 4–6 is thus considered chance level, namely, guessing. Finally, chi-square tests of association were conducted to compare the frequency of errors with and without the gender cue in Hebrew. Specifically, there were four conditions manipulating question type and cue (2 × 2/square design), with five items in each condition. The total number of items in each condition depended on the number of participants. Hence, it was 100 for MLs and 175 for BLs (MLs: 5 × 20; BLs: 5 × 35).
Results
Descriptive statistics for the overall levels of accuracy of both populations, on all four conditions of wh-questions, are presented in Table 1.
Accuracy in the four types of wh-questions in Hebrew and English (percentage of correct responses out of all responses).

An MLMA conducted for Hebrew with linguistic status (ML/BL) as the between-subject factor and position (subject/object) and type (who/which) as repeated measures yielded a significant main effect for linguistic status, F(1) = 7.06, p = .009; position, F(1) = 109.307, p < .001; and question type, F(1) = 14.018, p < .001. The conditions that led to higher accuracy levels included MLs, subject questions, and who-questions, respectively. Interaction was observed between linguistic status and position, F(1) = 11.033, p = .001, such that the decrease in accuracy for object questions relative to subject questions was more pronounced in BLs versus MLs. Interaction was also observed between position and question type, F(1) = 7.350, p = .008, such that the decrease in accuracy for which questions relative to who questions was more pronounced in object versus subject questions. That is, the results show that the two populations manifest the same developmental trajectories, showing a quantitative difference: which questions are, in general, harder for children than who questions within both MLs and BLs, with object questions being more difficult for BL children.
A GLM with repeated measures was conducted for the BLs only comparing the two languages, revealing a significant main effect for language (Hebrew/English), F(1, 34) = 19.83, p < .001, as well as for type (who/which), F(1, 34) = 82.92, p < .001, and an interaction between language and type, F(1, 34) = 11.22, p < .01, such that the decrease in accuracy for object-which questions relative to object-who questions was more pronounced in English than in Hebrew. A paired t-test traced this effect to a significant difference between English and Hebrew for object-which questions, t(34) = 5.35, p < .001, with lower scores in English, while there was no such difference in who questions.
Predictors of performance on object-which questions
Four multiple linear regression models were used to test for the best predictors of the performance on object-which questions: two on Hebrew only among all participants, and two for the BLs only. In the first model, chronological age, linguistic status (MLs/BLs), and accuracy on object-who questions were introduced. The motivation to include linguistic status in the model was to examine possible differences beyond being an ML/BL. The trigger to include object-who questions as a predictor was to examine whether the difficulty derives from the object position in principle or rather an internal difference within object questions, namely, question type. Only accuracy on object-who questions was a significant predictor (β = .61, p < .001). In other words, comprehension of object-which questions is predicted by comprehension of object-who questions, both among MLs and BLs, regardless of their chronological age. The second model focused on the predictors of object-which questions among BL children only. Chronological age, AOB, and accuracy on object-who questions were introduced as predictors. Here again, only object-who questions yielded a statistically significant result (β = .71, p < .001). In sum, none of the participant variables (chronological age, AOB, number of languages) predicted comprehension of object-which questions.
The third and fourth multiple linear regression models, analyzing both languages together, were performed to examine which variables predict best the BLs’ performance on object-which questions. In the third model, chronological age, AOB, and accuracy on object-who questions were introduced. Only object-who was found significant (β = .59, p < .001). In other words, BLs’ comprehension of object-which questions was predicted by comprehension of object-who questions, regardless of their chronological age and AOB. The fourth model focused on English only (similar to the focus of the second model on Hebrew). Once again, while chronological age and AOB did not play a role, comprehension of English object-who questions predicted comprehension of English object-which questions (β = .56, p < .01). In sum, none of the participant variables (chronological age, AOB, language) predicted comprehension of object-which questions, for both languages together and for each language separately. 1
Chance-level analyses
Linguistic status (between-subjects)
Analyses of chance level for the individual participants further support the linguistic status effect. Table 2 reports the number of children who performed below chance, at chance, and above chance on Hebrew object-who and object-which questions.
Performance level of all participants in Hebrew object questions (number and percentage).

According to Table 2, the chance distribution differed between the two populations. A chi-square test showed a significant effect of participants’ linguistic status (ML or BL) on chance-level distribution, χ2(1) = 4.48, p < .05, only for object-who questions. For object-which, it was borderline (p = .05). While most MLs performed above chance on object-who questions (85%), many BLs (43%) were still at chance, showing a guessing pattern. As for object-which questions, a third of both MLs and BLs were still guessing, but while most MLs (60%) were above chance, BLs were evenly distributed across the levels with 34% of the children scoring above chance and 32% below chance. The analyses of each population reinforce the quantitative difference between them, with no qualitative difference, suggesting that both populations go through the same developmental trajectory, with the BLs lagging slightly behind.
Language (within-subject comparisons)
Table 3 reports the number of BL children who performed below chance, at chance, and above chance on English and Hebrew object-who and object-which questions.
Performance level of bilinguals in English and Hebrew object questions (number and percentage).
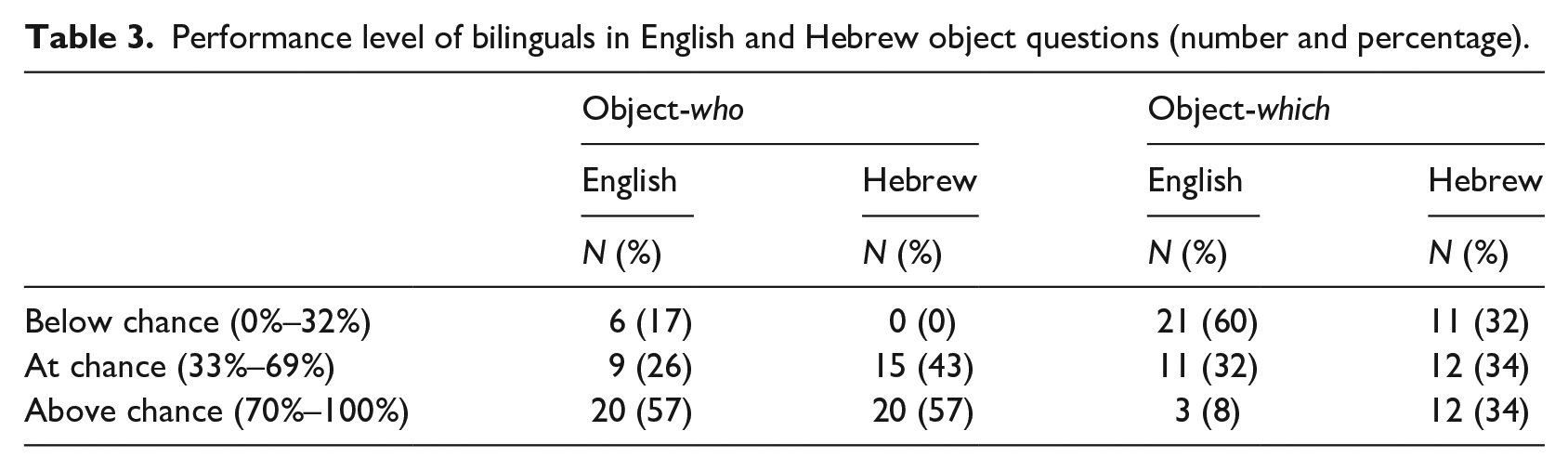
Chi-square tests showed a significant difference between English and Hebrew, manifested in the different pattern of distribution of the responses only in English, for both object-who, χ2(2) = 9.31, p < .01, and object-which questions, χ2(2) = 13.97, p < .01.
In object-who questions, in both languages, more than half of the participants were above chance, and the superiority of Hebrew was manifested by the lack of any participants performing below chance. In object-which question the picture was totally different: almost all the participants were below or at chance level in English, while in Hebrew they were evenly distributed across the levels.
Error analysis of object questions
To further substantiate our claim that the difference between the two populations is merely quantitative, an error analysis was conducted. Errors were divided into two main types: a reversal error (pointing to the right figure but with Agent rather than Theme theta-role), and other error (mostly, pointing to the wrong character, e.g., a dog instead of one of the cats). The results are presented in Table 4.
Types of errors in object questions in Hebrew by monolinguals and bilinguals (percentages out of all responses).

and b mark significant comparisons.
A GLM with linguistic status (ML/BL) showed a significant difference between MLs and BLs in reversal errors on object-which questions, 19.5% versus 33.14%; F(1, 53) = 5.74, p < .05, and “other” errors on object-who questions, 3.5% versus 10.62%; F(1, 53) = 6.48, p < .05, such that BLs had more errors than MLs.
Use of agreement cue in Hebrew
Table 5 presents the frequencies (and percentages) of errors of both ML and BL participants to explore their potential use of the agreement cue or the lack thereof when presented with the questions. Each cell presents the frequency of comprehension errors for each position and type of question as a function of the agreement cue. The lower the raw number of errors in the + cue condition, the more likely that the cue was helpful.
Frequency (and percentage) of errors as a function of the agreement cue in Hebrew questions.

Note. Total number of items per condition—monolinguals 100; bilinguals 175.
Table 5 shows that in subject questions, the number of errors was not high, and the agreement cue makes little difference. Chi-square tests of association showed a significant difference only among MLs for subject-which, χ2(1) = 7.78, p < .01. In object questions, however, the agreement cue reduced the number of errors for MLs in both question types but for BLs only in object-who questions. Chi-square tests of association showed significant differences for object-who and object-which among MLs, χ2(1) = 14.62, p < .001; χ2(1) = 12.72, p < .001, and for object-who among BLs, χ2(1) = 17.25, p < .001. However, no effect was found for agreement cue in object-which questions among BLs (p = .74).
Within-subject comparisons: error analysis of object questions by language
Focusing on BLs, Table 6 presents the types of errors in object questions in Hebrew and English.
Types of errors in object questions for the bilingual group (percentage out of all responses).
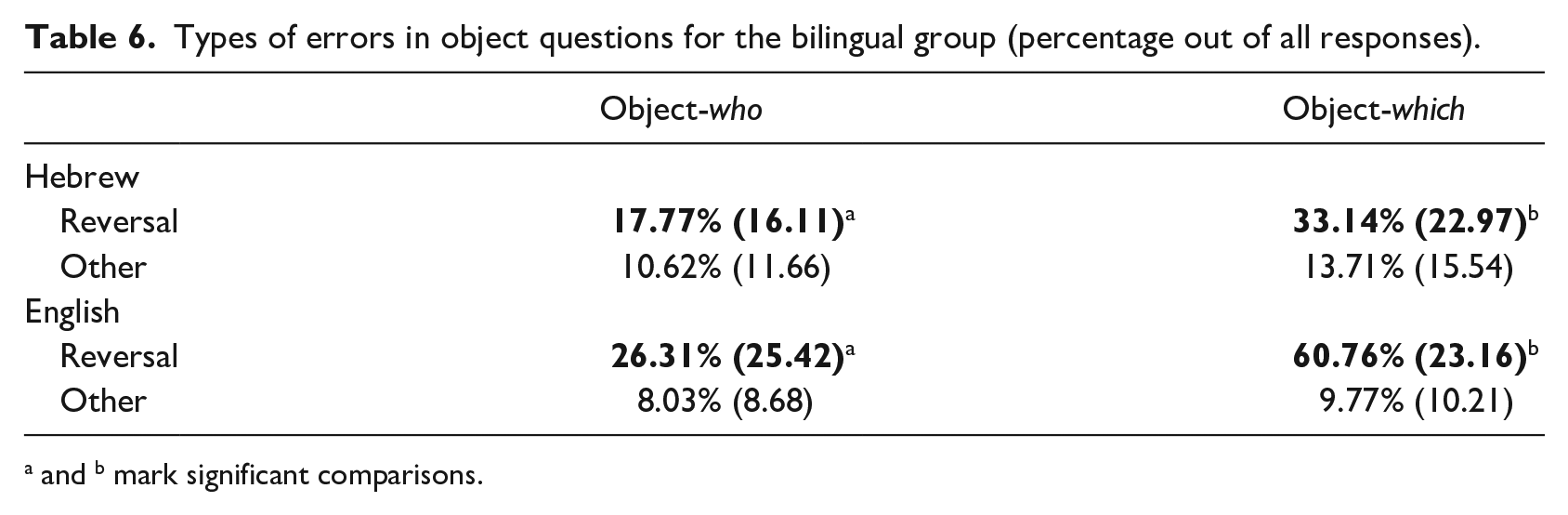
and b mark significant comparisons.
A GLM with repeated measures revealed a significant main effect for language (Hebrew/English), F(1, 34) = 19.83, p < .001), as well as for type of error (reversal/other), F(3, 102) = 65.11, p < .001, and an interaction between language and type of error, F(3, 102) = 17.59, p < .001. That is, reversal errors were significantly more frequent in English object-which questions (60.76%) compared with Hebrew (33.14%). Paired t-tests showed that there were significantly more reversal errors in English than in Hebrew, in both object-who, t(34) = −2.24, p < .05, and object-which questions, t(34) = −6.13, p < .001.
In sum, the error analysis further confirms that English lags behind Hebrew mostly in comprehension of object-which questions.
Discussion
Our results enabled addressing most of the empirical questions raised at the onset of this study. As predicted, MLs outperform BLs (in the L2) showing a similar developmental trajectory, with object-which questions being more difficult for both populations. Moreover, the comprehension of object-who questions was the best predictor of the comprehension of object-which questions, showing that to comprehend object-which (D-linked) questions, it is necessary but not sufficient to comprehend object-who questions. That is, object-which questions also require choosing an answer from a set of referents. Although there are some differences between the two populations, these differences are quantitative, rather than qualitative, and the developmental trajectories of both populations are essentially the same.
The within-subject analysis of the BL speakers presented better performance in Hebrew than in English, reflecting the observed difficulty with object-which questions in English, with no sensitivity to chronological age or AOB. The differences between the two languages of the BLs are quantitative rather than qualitative—in both languages, comprehension of who-questions precedes which-questions. The observed performance on object questions suggests that the children in the study have the syntactic knowledge necessary to comprehend object-who questions, but are still in the process of developing the capacity to handle the unique aspects of the interpretation of object-which questions, a difficulty which is enhanced in their L1, English.
Language-specific properties were found to impact children’s performance: (1) English object-which questions were found harder to comprehend than their Hebrew counterparts. We will argue that this is so, due to the ambiguous nature of the English auxiliary do (section “Answering the theoretical questions”); (2) the agreement cue in Hebrew facilitated ML children’s comprehension of both types of object questions, while it was effective only in object-who questions for the BL children, with no facilitating effect in object-which questions.
In what follows, we briefly discuss the pattern of effectiveness of the agreement cue manifested by the two populations.
The agreement cue in sentence comprehension
In principle, syntactic processing is an automatic procedure, not dependent on morphological cues in any crucial way, as witnessed by languages which have poor or almost no morphological marking in the relevant (verbal) domain (e.g., English, Chinese). However, that does not mean that in languages with cues, speakers (while comprehending) do not automatically rely on them. In most processing theories, using existing morphological cues is part of automatic processing (e.g., constraint-based theories as in MacDonald et al., 1994; cue-based retrieval, Lewis & Vasishth, 2005).
It is reasonable to assume that using these cues may add to the cognitive load during syntactic processing, probably affecting the working memory resources. If this line of reasoning is on the right track, the inability to use the agreement cue may suggest that the structure which can benefit from this cue is already highly taxing (or not fully acquired yet), precluding any additional cognitive load.
The fact that MLs can use the agreement cue in both types of object questions can be taken to indicate that both types of questions are not taxing for this population in any respect. Similarly, BLs can use the cue in object-who questions, suggesting that for them, too, this structure presents no special demands, and moreover, that they are aware of this cue and know how to use it. Thus, the fact that the effect of the cue is not observed in their comprehension of object-which questions suggests that its use in this structure introduces a cognitive load superseding the already existing cognitive demands this structure (still) imposes on the BLs. Specifically, when syntactic processes interact with additional factors such as working memory resources, as seems to be the case in which-questions, the gap between the two populations might widen, possibly because in the BL mind the same resources are allocated to the processing of two languages.
Next, based on our results, we turn to the theoretical questions raised at the onset of our study.
Answering the theoretical questions
Clearly, object-which questions present difficulty in both languages and for both populations. This is in line with previous findings (e.g., Friedmann et al., 2009; Goodluck, 2005). The surprising finding of our study is the difference attested between the two languages of the same participants, namely, the very poor comprehension of the English object-which questions, which differ from their Hebrew counterparts in requiring the auxiliary verb do.
The question arises as to the source of the attested difficulty underlying the comprehension of object-which questions in both languages and of the negative effect of the auxiliary do in English.
The limitation of existing hypotheses
According to some of the existing proposals, the difficulty of object-which questions might be attributed to (1) the need to establish the link to the previous discourse coupled with movement from object position (The Discourse (D)-linking Hypothesis, Avrutin, 2000; Pesetsky, 1987, 2000; Shapiro, 2000); (2) an intervention effect due to movement from object position causing processing overload (The Intervener Hypothesis, Friedmann et al., 2009); or (3) a tasking semantic computation involved in which-questions (The Set Restriction Hypothesis, Donkers et al., 2013; Goodluck, 2010).
Abstracting away from the details of these hypotheses, none of them can account for the significantly lower performance on English object-which questions as compared with their Hebrew counterparts. This is so, because Hebrew and English wh-questions are virtually identical (in the relevant respects), utilizing overt fronting of the wh-phrase. The difference between the languages is the occurrence of the auxiliary do in English, as opposed to the absence of such an element in Hebrew. An auxiliary verb is a functional syntactic element. As such, it has no bearing on pragmatic or semantic procedures, and it does not affect the processing load presumably induced by the intervention effect. It can, however, affect the parsing of a sentence, especially since do is ambiguous: it is not only functional but can also occur as a lexical verb (e.g. The cat did it.).
It is noteworthy that the occurrence of the auxiliary do cannot be the source for the poor comprehension of English object-which questions, as witnessed by the much better comprehension of object-who questions. Therefore, in line with the aforementioned hypotheses, we assume that the source of the attested difficulty is the nature of the wh-phrase (which-DP). Arguably, this difficulty is enhanced in conjunction with the occurrence of do.
In the following subsections we will show that assuming the Set Restriction hypothesis as the source of children’s difficulty naturally leads to the children’s strategy for managing this difficulty. This, in turn, will be argued to have a substantial effect only on the syntactic processing (comprehension) of object-which questions, leaving the syntactic processing of subject-which questions, as well as object-who questions, unaffected.
The structure of the argument to be developed in the following subsections is schematized below.
Our working hypothesis:
The set restriction computation (relevant only for which-questions) is difficult for children, causing them to misanalyze the interrogative which-DP as a lexical DP[-wh] (section “Set restriction as the source of difficulty”).
The consequences of children’s strategy during processing of which-questions:
- in English/Hebrew subject questions the misanalyzed which-DP immediately precedes the verb and therefore it is analyzed correctly as the subject (section “Good comprehension of subject-which questions in both languages”)
- in Hebrew object questions (“which cat the dog bites?”), there are two DPs preceding the verb. Each of them can be analyzed as the subject/object. As a result, a random reversal of thematic roles is expected (section “Theta-role reversal in Hebrew object-which questions”).
- in English object questions (Which cat
With this in mind, we start with our hypothesis.
Set restriction as the source of difficulty
Under the Set Restriction hypothesis, the computation involved in set restriction is what underlies the difficulty in processing specific which-questions. Roughly speaking, comprehension of a specific which-phrase (e.g., which cat, rather than which animal or just who) requires a construction of a predefined set of entities and choosing a specific entity from this set. Reasonably, such a computation burdens the working memory. The burden can be rather minor, resulting in a processing challenge detectable only during highly sensitive testing, as is the case for adults (Cowles, 2003). It can, however, be substantial, probably exceeding preschool children’s processing resources.
Importantly, when children fail to execute a certain computation, they tend to resort to some strategy enabling them to bypass the difficulty (Grodzinsky & Reinhart, 1993; Reinhart, 1999). We propose that due to the difficulty to execute the semantic computation involved in set restriction, children ignore the which element, reanalyzing an interrogative which-DP[+wh] as a non-interrogative, namely, representing it as lexical DP[-wh]. Despite the absence of the overt wh-element on the DP, arguably the sentence remains interrogative, with the relevant interpretative feature [+Q] associated with the appropriate functional head (e.g., C). Although this strategy is applied both in subject- and in object-which questions, it has an adverse effect only in the comprehension of object-which questions, given the syntactic processing model outlined below. Note that object-who questions, unlike object-which questions, are not expected to present special difficulties, because the set restriction computation does not apply to who/what phrases, as they do not denote restricted sets. Consequently, the interrogative phrase, who, is represented as such.
The syntactic processing model
We assume that syntactic processing is done according to predicates (Pritchett, 1992; Siloni, 2014). This means that the incoming words entering the processor are kept in a memory buffer (a “store,” henceforth) before being integrated into the structure. The structure of the sentence is built upon the arrival of the verb. Processing is fully automatic, with no look-ahead, and it is guided by the following, informally stated, principle: The processor attempts to satisfy the predicate-argument relations as soon as possible; at any given moment of the processing the processor attempts to link the θ-roles of the verb to the arguments, and to incorporate all the arguments in the store into the structure (Pritchett, 1992). Since the processor is part of the computational system (CS), it is sensitive to syntactic entities such as wh-phrases versus lexical DPs, Case, agreement, and so on. In most cases, there is only one way to satisfy the processing principle at any processing step. However, in some sentences at some point of processing, there actually exist two processing options which are equal in terms of predicate–argument relations, and therefore are taken randomly by the processor (Pritchett, 1992).
In the following subsections, we examine the processing stages of (1) subject-which questions, whose derivation and processing are identical in Hebrew and English; (2) Hebrew object-which questions; and (3) English object-which questions. This will enable us to account for the contrast in the comprehension of subject-which questions versus object-which questions in general (namely, in both languages), for the radically poor comprehension of English object-which questions as compared with their Hebrew counterparts (Table 1), as well as for the error patterns (Table 6).
Good comprehension of subject-which questions in both languages
As there is no difference between the languages in subject-which questions, we analyze them together: (6) eize xatul soret et ha-kelev? which cat scratches ACC the-dog “Which cat scratches the dog?”
In processing (6), the reanalyzed which-cat (represented as a lexical, non-interrogative DP, schematized with a very pale which) enters the processor and is put in the store, awaiting the predicate. As the verb scratches enters the processor, the structure is built with this DP in subject position, as there is no other way to incorporate it in the structure. Once the second DP (the dog) is encountered, it is incorporated in the object position of the verb, and the correct parsing is complete:
[DP which cat]
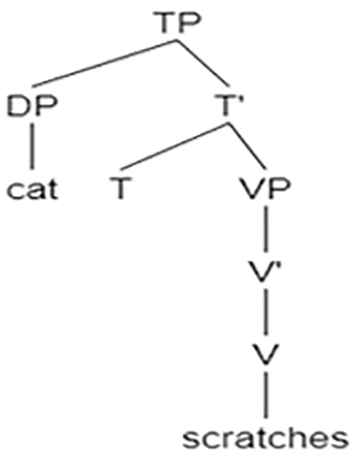
[V scratches] θ1, θ2 →
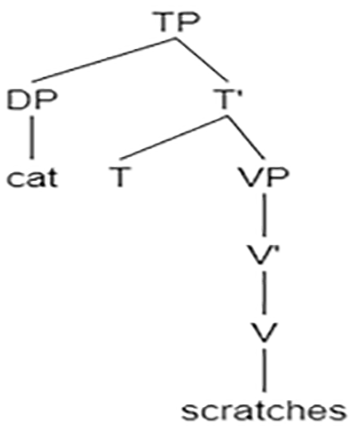
[DP the dog]→
Note that the Set Restriction hypothesis, in itself, erroneously predicts this type of questions to be problematic because they include a which-DP, triggering the complex set restriction computation. But this is only half of the story. Based on the processing stages presented above, the complexity of the set restriction computation indeed invokes children’s strategy to ignore the which element. However, the strategy employed by children in subject-which questions does not compromise children’s comprehension of the structure, because it does not affect the (correct) assignment of the thematic roles. The fact that this result is attested in both languages of our BL participants is fully expected as the structure of subject questions in both languages is identical.
We next consider the processing of object-which questions, whose comprehension differed markedly from the comprehension of subject-which questions.
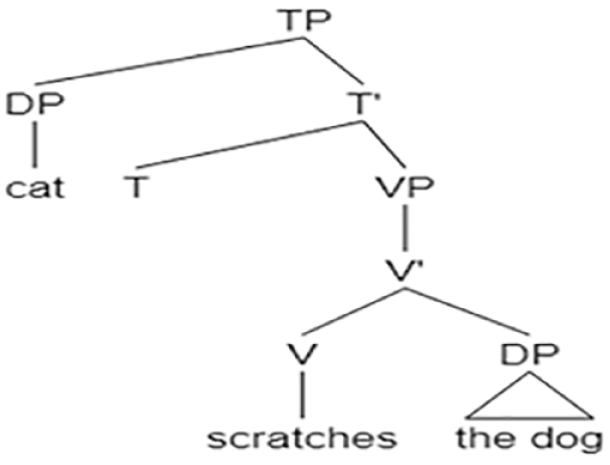
Theta-role reversal in Hebrew object-which questions
The comprehension of this type of questions (7) was significantly worse than the comprehension of both, object-who and subject-which questions (Table 1). The main error these questions induced was the reversal error (Table 6). Since object questions are not identical in Hebrew and in English (the latter includes the auxiliary do, which does not exist in Hebrew), we discuss the processing of this structure in the two languages separately, starting with the Hebrew version: (7) et eize xatul ha-kelev soret? Hebrew ACC which cat the-dog scratches “Which cat does the dog scratch?”
The main difference between the parsing of subject- and object-which questions is the number of DPs in the store upon the arrival of the verb. In the processing of object-which questions (7), as opposed to the processing of subject-which questions (6), there are two DPs waiting in the store before the verb arrives (the reanalyzed which-DP, “the cat” and the subject DP, “the dog”). As the main verb enters the processor, any of them can be assigned θ1 (Agent) or θ2 (Theme) randomly, resulting sometimes in a reversal error (if “the cat” is assigned the Agent): 2
[DP eize-xatul] (the cat)
[DP ha-kelev] (the dog)
[V soret] θ1, θ2 (scratches) → two possible structures:
theta-reversal correct reading
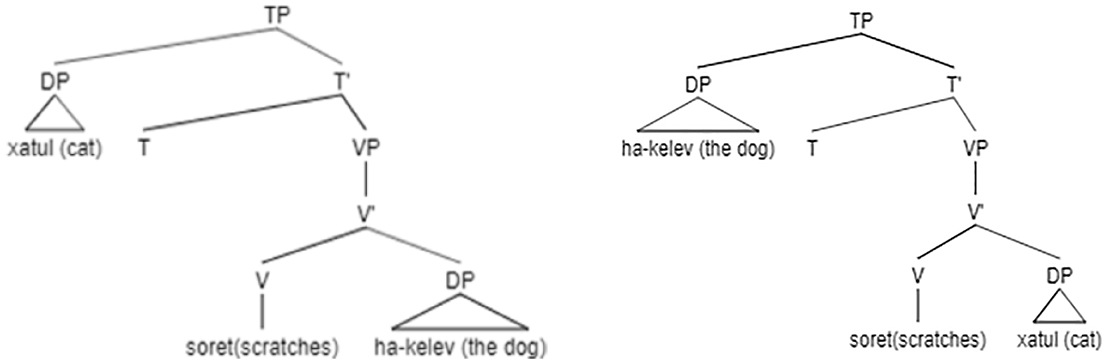
Since the two processing options do not exist in the comprehension of subject-which questions, but only in object-which questions, children’s performance on object-which questions is significantly worse than their performance on subject-which questions.
Even more theta-role reversal in English object-which questions
We suggest that the large proportion of theta-role reversal in English object-which questions is due to the ambiguous classification of the verb do. As aforementioned, the English do can be either a functional, auxiliary verb, not assigning any thematic roles, occurring in (wh-) questions (8), or it can be a lexical, theta-assigning verb, following a lexical, non-interrogative DP (9): (8) Which cat does the dog scratch? (9) Cats do amazing things.
If do is processed as functional, the processing of (8) is very similar to the processing of the Hebrew object-which question (7). Specifically, there are two DPs in the store, which-cat, the dog, as well as the auxiliary do. The structure is formed only upon the arrival of the lexical, theta-assigning verb, scratches. Like in Hebrew, this situation may lead to theta-reversal errors, because the assignment of the thematic roles to the two DPs is random.
Importantly, however, in English object questions: the (object) DP, (which-cat[-wh]), is in the store upon the arrival of do. Since this DP is not marked as interrogative, nothing forces the processor to treat do as functional, on the contrary. The absence of the overt interrogative specification on this DP creates a context similar to (9) rather than to (8), where do functions as a lexical, theta-assigning, verb.
If do is processed as lexical, the course of processing takes the following form: upon the arrival of do, there is just one DP, which-cat, in the store. It is immediately assigned the Agent, and the incoming, “subject” DP (the dog), is assigned a Theme. This results in a reversal of thematic roles error:
[DP which-cat]
[V does] θ1, θ2
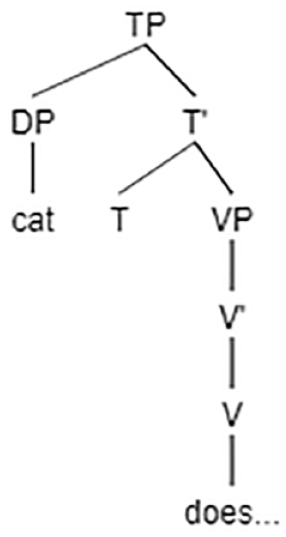
[DP the dog]
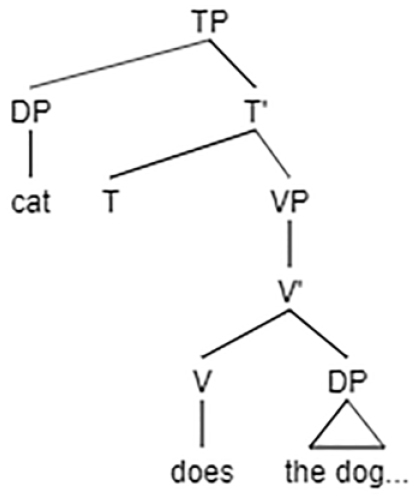
It is noteworthy that upon the arrival of the actual main verb, a global reanalysis is required to correct the misanalysis of do. Based on findings from a variety of languages, such a reanalysis is not performed by children until around 11:0 (e.g., Arosio et al., 2009—for Italian; Botwinik-Rotem, 2008—for Hebrew; Choi & Trueswell, 2010—for Korean).
Thus, in the processing of English object-which questions, the comprehension is extremely poor, because either: (1) the thematic roles are assigned randomly by the main verb (like in Hebrew), resulting in some amount of theta-role reversal; or (2) there is a reversed theta-role assignment by the “lexical” do. The existence of (2) in English, but not in Hebrew, leads to additional theta-role reversal in English.
Importantly, none of the above is expected to take place in English object-who questions. In this type of questions there are two distinct DPs: an interrogative one (who) and a lexical one (the dog). Since the DP which is in the store upon the arrival of do is an interrogative one (who), do is analyzed invariably as a functional, auxiliary verb. The structure is formed upon the arrival of the lexical verb (scratches), whose Agent role is assigned correctly to the lexical DP the dog (which is by then also in the store), while the Theme is assigned to (the trace of) the interrogative DP, who.
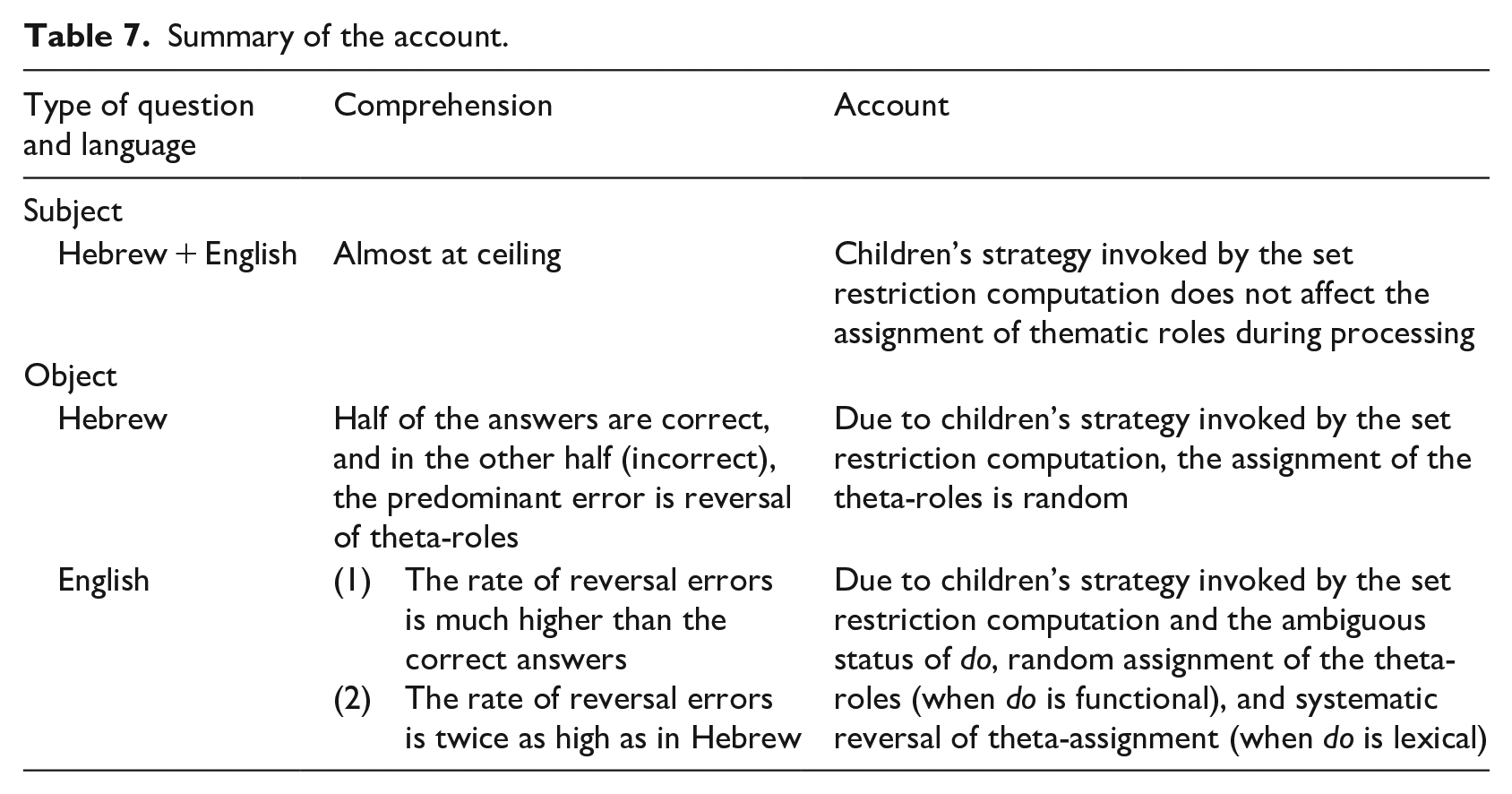
For the sake of clarity, Table 7 summarizes our account of comprehension of which-questions in the two languages of the BLs.
Summary of the account.
Conclusion
In this paper, we have examined the comprehension of wh-questions by BL preschool children (L1-English, L2-Hebrew) as compared with their Hebrew ML peers, as well as the comprehension of the two languages of the BLs. Our main focus was the comprehension of object-questions, as both populations performed almost at ceiling on subject-questions.
The between-population comparison showed that BLs lag behind MLs, especially in the comprehension of object-which questions. Nevertheless, there seemed to be no qualitative differences between the two populations; comprehension of subject questions preceded comprehension of object questions, and comprehension of object-who questions preceded and predicted comprehension of object-which questions. The same developmental trajectory of the two populations was indicated by the percentage of MLs and BLs performing at chance, below chance, and above chance levels, the type of errors, and the ability to use the agreement cue. The within-population comparison showed that BLs presented better performance in Hebrew than in English due to exacerbated difficulties with object-which questions.
The comparison between the two populations, and especially between the two languages of the BLs, led us to take a closer look at the syntactic processing of which-questions. We explored the possibility that the set restriction computation is the source of children’s difficulty, overloading their working memory resources. As a result, children may ignore the which element altogether, treating the interrogative which-DP as a non-interrogative lexical DP. This hypothesis enabled us to account for the familiar facts, namely, the clear distinction between the comprehension of object-who and subject-which questions on one hand, and the comprehension of object-which questions on the other hand. Object-who questions are comprehended well because they do not involve the set restriction computation and the consequent children’s strategy. Subject-which questions are also comprehended well, despite the set restriction computation and the accompanying children’s strategy, because the processing stages of this structure, namely the allocation of the theta-roles is fully and correctly determined. In contrast, in the processing of object-which questions, the thematic roles of the verb can be linked randomly to the two lexical DPs waiting in the store, giving rise to a certain amount of reversal errors. We have attributed the extremely high proportion of reversal errors in English to the ambiguity of the verb do (either as functional or lexical); the lexical classification of do triggers reversed theta-role assignment, adding to the proportion of theta-role reversal in English.
It is noteworthy that the Set Restriction hypothesis, in itself, is not equipped to deal with the full range of our findings as it just states the source of the difficulty without elaborating on the consequences of this difficulty for children. We have shown that the account of the difference between Hebrew and English object-which questions is made possible only due to the close examination of the children’s strategy regarding which-DP and the consequent detailed processing stages of this structure.
In sum, our research demonstrates that ML and BL (syntactic) development is essentially the same. However, when syntactic processes interact with additional factors, such as working memory resources and language-specific properties, as is the case in object-which questions in Hebrew versus English, the gap between the two populations might widen.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.