
Abstract
Aims and Objectives:
In this paper, a novel approach to the distinction between borrowing and code-switching is proposed, called the Simple View of borrowing and code-switching. Under this view, listedness is seen as the key condition for classifying words or multiword units (MWUs) as borrowings. For MWUs, listedness is operationalized with mutual information (MI) scores: the higher the MI score of a given set of words, the higher the likelihood it is listed in the lexicon. Under the Simple View, the distinction between borrowing and code-switching is seen as a specific instantiation of the distinction between what belongs in the lexicon (fixed, arbitrary patterns) and what is computed online (productive rules), and should therefore be considered as part of the grammar.
Methodology:
Assumptions from the Simple View were tested on a corpus of switches of single words and MWUs from a Turkish-German code-switching corpus (87,000 words), which was transcribed in CHAT format.
Data and analysis:
The frequency of switches in either direction, and their morphosyntactic integration patterns were analysed with CLAN. The formulaicity of the MWUs was analysed with MI scores through Sketchengine.
Findings:
The MI scores of the donor language MWUs were found to be above 3, which is the cut-off point for formulaicity in Corpus Linguistics. Thus, the MWUs were found to be borrowings. In addition, MWUs were found to be more likely to be borrowed than single words.
Originality:
Insights about formulaic language from Corpus Linguistics and Second Language Acquisition were used to inform analyses of language contact phenomena, and new ways to test the model are proposed.
Significance:
The Simple View offers a unified approach to borrowing of lexical items and function words and opens a new avenue for research using neuroscientific methods to test whether items are listed in speakers’ mental lexicons.
Keywords
Introduction
In this paper, I will argue that the two-way distinction between borrowing and code-switching does not offer a good account for the variety of other-language material that can travel between languages. While single-word items from a donor language are often considered to be borrowings and longer other-language stretches are seen as code-switches (Deuchar, 2020; Poplack, 2018), the length of a unit is unlikely to be the defining criterion which allows us to separate borrowing from code-switching. That length is not helpful to decide this matter is clear from the corpus linguistic literature on Formulaic language (FL) is generally defined as multiword language phenomena which holistically represent a single meaning or function, and are likely mentally stored and used as unanalyzed wholes, as are single words.
Formulaic language can take many different forms, and may include
The occurrences of MWUs in bilingual speech compel us to revisit the definitions of borrowing and code-switching. The alternative account offered here is called the
I also argue that the discussion about the variability in language contact phenomena should be informed by insights from corpus-linguistic approaches to formulaic language, and propose the
Distinguishing borrowing and code-switching
One of the most fiercely debated issues in the field of language contact is how to distinguish borrowed material that has become part of the lexical stock of a contact language, and code-switching between two languages. Borrowing is illustrated in (1), where we find the English verb job, which has been borrowed into German, and is listed in the Duden Online, 2 with the meaning ‘to carry out temporary work with the aim to earn a living’. The German suffix -en has been added to indicate third person plural, and an extra letter (b) has been added to conform to German spelling rules. In (2), by contrast, longer stretches of two languages (in this case Alsatian German and French) alternate, which is commonly seen as typical for code-switching. In all examples, Dutch, German, and Welsh are given in italics, French and Spanish are underlined, English is given in capital letters, Arabic in capital letters and italics, and Turkish in regular type font.
(1) Das Modell des Studienkontos bietet allerdings den zahlreichen Teilzeitstudenten, die viel nebenher jobben, bessere Chancen. The model of the study account offers better opportunities to the many part-time students who job alongside their studies. (Der Spiegel, 21/2000, p. 67) in Seidel (2010, p. 55) (2) Ah ja, noh het er getankt, Ah yes, now he has filled up, but he should so make his full the evening ‘Oh yes, so he filled up, but he should really fill up in the evening’. (Gardner-Chloros, 1991)
In a recent volume on lexical borrowing, 3 Poplack (2018) defines borrowing as ‘the process of transferring or incorporating lexical items originating from one language into discourse of another’ (Poplack, 2018, p. 6). In the same volume, Poplack proposes that LOLIs are borrowings, whereas ‘multiword stretches’ from another language are code-switches. Furthermore, borrowings tend to be frequent and wide-spread in a community (Poplack suggest that they should be used by at least ten speakers) and morpho-syntactically integrated into the recipient language. Thus, jobben in (1) would qualify as a borrowing not only because it is a LOLI but also because it has been integrated into German grammar in that a German suffix marking the third person plural has been attached to the root.
The distinction between borrowing and code-switching is, first of all, important for researchers attempting to formulate constraints on code-switching (i.e., rules for where in a sentence code-switching is (im)possible or (un)likely), because theories need to be tested against an unambiguous corpus of code-switches. Second, for psycholinguistic and neuroscientific studies of code-switching, the distinction is important too, because reaction times or event-related potential (ERP) signals will differ for other language items that have been integrated into the lexicon of a receiving language, such as those in (1), and for code-switches, such as those in (2). However, distinguishing between both phenomena is difficult, both conceptually and empirically. An overview of the criteria that have been used to distinguish borrowing and code-switching can be found in Table 1.
Overview of criteria that have been used to distinguish borrowing and code-switching.

The various criteria do not have equal importance, and there are problems with many of these. First of all, bilingual corpora are often very small by comparison with monolingual corpora, which makes it difficult to assess how frequent or wide-spread a word is. In addition, as one reviewer observes, the frequency of a particular item may differ across different bilingual communities, which makes generalizations very difficult. Second, the contact languages may have converged (at the syntactic/morphological and/or phonological levels), which makes it very difficult to assess whether a word has been integrated or not. Third, there are exceptions to all criteria listed here: in Brussels Dutch, for example, many French adverbs are not syntactically integrated (in that they do not trigger Verb Second) despite being listed in dictionaries as a borrowing from French (see below and Treffers-Daller, 1994, for discussion). Conversely, it is possible for a pre-posed Turkish adverbial clause to trigger Verb Second, as in (3), where the adverbial clause buraya gelirken ‘when I came here’ is clearly a code-switch, but it occupies the position in front of the inflected verb hab’ ‘have’ (in bold). Thus, the Turkish adverbial clause triggers Verb Second.
4
(3) Ben bura-ya gel-ir-ken I here-DAT come-AOR-ger have I myself PTCP-be-happy-PTCP ‘When I came here, I was happy.’ (TuGeBic03)
However, there is variability at this point too, because for some speakers a preposed adverbial clause does not trigger Verb Second, as can be seen in (4), where the inflected verb wußte ‘knew’ follows the subject pronoun ich ‘I’.
(4) Weißt du was ey, ben Almanya’dan gel-ir-ken ich Know you what, ey, I Germany-ABL come-AOR-ger I knew not how . . . ‘You know what, ey, when I came to Germany I did not know how . . .’ (TuGeBic10)
Thus, switched pre-posed adverbial clauses can be integrated into German grammar, but this is not necessarily true for all clauses of this type (see also Demske & Wiese, 2016 for further details on variability in the application of Verb Second in varieties of German). For further in-depth discussion of various criteria for borrowing and code-switching, and issues related to these, the reader is referred to Deuchar (2020) and Deuchar and Stammers (2016).
A completely different model emerges from Muysken’s (2000, 2013, 2014) work. According to Muysken (2014), we need to distinguish between surface manifestations and underlying processes in language contact. The question then is whether borrowing and code-switching represent truly different underlying processes. In his view, this is not the case because both borrowing and code-switching make use of the same two different basic strategies,
5
namely (5) ‘the people stopped paying’. (Bentahila & Davies, 1983)
On the other hand, it can involve alternation, as in (2), where a large chunk in German and a large chunk in French appear in succession. So, under this view, the underlying processes behind the borrowing/code-switching dichotomy, are insertion and alternation.
How insertion and alternation map onto borrowing of LOLIs versus code-switching of full determiner phrases (DPs), which are unambiguous code-switches in Poplack’s framework, can be seen in Table 2.
Mapping of borrowing and code-switching onto insertion and alternation.
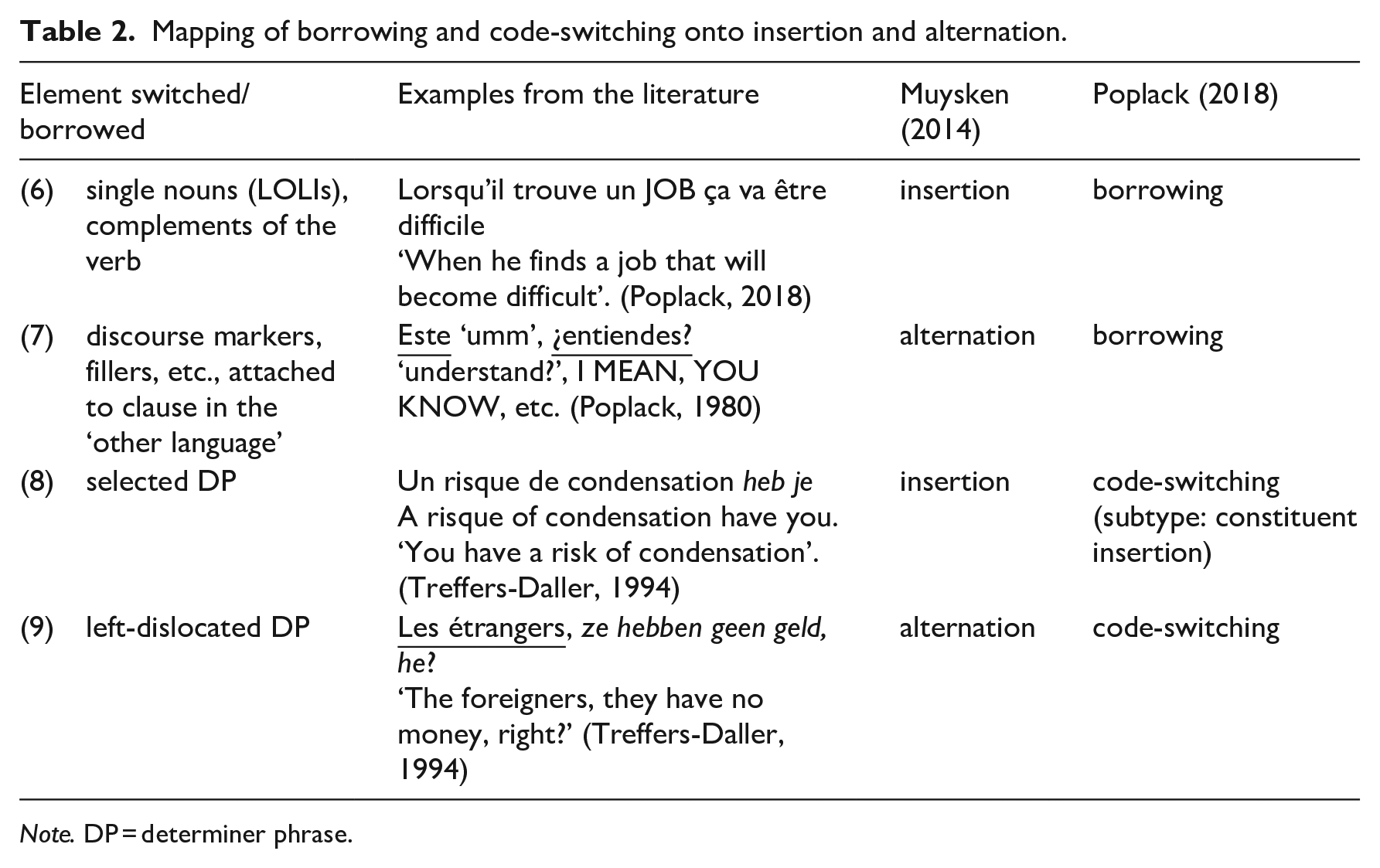
Note. DP = determiner phrase.
While job in (6) is clearly an insertion, as it is part of an NP that is selected by the verb in the clause, it is possible, or even likely that some LOLIs enter the language via a process of alternation rather than insertion, if they are adjuncts rather than selected elements. This could be the case for the tags and fillers in (7) or for adverbs such as first in (10), which are not selected by the verb. It seems unlikely that the same process underlies both the appearance of job and the tags.
(10) ‘The English use their language first, why shouldn’t we?’ (Poplack et al., 1988)
Note that un risqué de condensation ‘a condensation risk’ in (8) is considered as an insertion because the DP occupies the first position in the clause and triggers Verb Second. Thus, its position is clearly different from that of French adverbs, such as pertang from French pourtant ‘however’ in Brussels Dutch, which do not trigger Verb Second.
In summary, borrowing groups together phenomena that are clearly distinct (nouns and tags), and code-switching is a cover term for adjoined NPs and selected NPs, which are also syntactically very different from each other. The different processes underlying these phenomena are captured by Muysken’s typology but not by the distinction between borrowing and code-switching.
Reconsidering the classical division
There are several additional reasons to reconsider the classical distinction between borrowing and code-switching. First of all, Muysken’s (2014) division between insertion and alternation is firmly rooted in syntactic theory, and reflects the distinction between selected elements (insertion) and adjuncts (alternation), the relevance of which is attested independently in monolingual grammars. Thus, an extra bilingualism-only mechanism is not created to account for bilingual speech. Second, length (one word vs multiword stretches) is not such an attractive criterion as length is not a fundamental principle of syntactic organization. Admittedly, length plays some role in the success of borrowings, as shown by Calude et al. (2020), who show that shorter donor language items were more successful in being adopted by bilingual speakers than longer ‘native’ translation equivalents. However, this is not absolute length, but relative length and relates to the difference in length (measured in syllables) of two possible alternative ways of talking about the same thing, which are in competition in a particular speech community. This is different from assuming that length in words is a fundamental organizational principle behind the distinction between borrowing and code-switching.
Third, the principle of recursion applies to words (in that simple words can become complex through compounding) as well as phrases (in that complex phrases can be built inside other phrases). Thus, words can become very long if the process of compounding is applied recursively, and the same is true for phrases. It would indeed be rather arbitrary to say that only compounds consisting of two words still count as borrowings (e.g., car industry), whereas compounds consisting of three words (e.g., car industry manager) would be a code-switch. It seems to me that length does not play a key role here, and borrowed compounds could equally well consist of three or more words that have been combined. Thus wide angle lenses when used in a Welsh utterance, as in (11), which is classified as a code-switch in Deuchar (2020), would not be a code-switch under the Simple View, because it is a compound noun that functions as a unit and is inserted as a whole into Welsh.
6
(11) pan dach chi ‘n defnyddio WIDE-ANGLE LENSES when be.2PL.PRES PRON.2PLLL PRT use.NONFIN wide-angle lenses ‘When you use wide-angle lenses . . .’
A fourth reason for reconsidering the typology is that alongside the many prototypical cases of borrowing, such as those in (1), there are also many cases that are more peripheral, in that some but not all of the criteria listed in Table 1 apply. Borrowed compounds are examples of such less prototypical cases, because they include French loan constructions such as attorney general or notary public, which retain French word order (N + A) (Bauer & Renouf, 2001). The fact that there are exceptions to typologies, as well as exceptions to rules, is well known and is inherent in any typology, because typologies are models, and models are necessarily a simplification of the complexities found in real life (see Simon & Wiese, 2011, for an in-depth discussion).
Most of the discussion about the distinction between both language contact phenomena has focused on the status of LOLIs and on whether or not these can be ‘bona fide’ code-switches. The problem with LOLIs is that they do not appear frequently enough in datasets to be classified as unambiguous borrowings. For Poplack LOLIs are
The Simple View of borrowing and code-switching
A simpler way of looking at the distinction between borrowing and code-switching might be to say that the defining characteristic of borrowing is that it involves the addition of vocabulary to the recipient language lexical stock, or the substitution of items already in the stock (Albó, 1970; cited in Van Hout & Muysken, 1994), while code-switching does not entail such additions or substitutions. In borrowing, the donor language grammar is not actively involved, but in code-switching it is. In addition, the recipient language grammar can be actively involved in borrowing, in that borrowings can be morpho-syntactically, phonologically, or semantically integrated, but this not a necessary condition for words to become borrowed into a language, as can be seen from the many bare forms that occur in mixed speech (see Budzhak-Jones & Poplack, 1997; Muysken, 2000; Owens, 2005). For approaches which see morpho-syntactic integration as a defining feature of borrowing, such bare forms are problematic. While there are solutions to this, in that patterns and rates of integration (or lack thereof) can be compared with monolingual benchmarks (Poplack, 2018), bare forms are not a problem if listedness rather than integration is considered the defining feature of borrowing. Lack of integration can also be observed at the level of phonology, as some words retain the phonological characteristics of the donor language, such as the discourse marker donc ‘so’ in Brussels French, which is pronounced with a nasal vowel [dɔ̃k] which is not part of the Brussels Dutch vowel inventory (Treffers-Daller, 1994; see also Holden, 1976, for detailed analyses of the phonological adaptation of loanwords).
Put differently, the dilemma of distinguishing between lexical borrowing and code-switching can be seen as a specific instantiation of the problems involved in delimiting what belongs in the lexicon (fixed, arbitrary patterns) and what is computed online (productive rules), and should therefore be considered as part of the grammar. If this approach is taken,
(I) The listedness criterion:
The key criterion for a word to be considered as a borrowing is listedness in the mental lexicon of the speakers of the recipient language.
Here the assumption is made that speakers know whether or not a particular word or MWU is listed in their lexicon, and can identify these items as such. This issue is taken up again in the “Discussion and conclusion” section.
Frequency is obviously related to listedness, as LOLIs that appear more frequently are more likely to become listed, but there are many LOLIs that are infrequent, such as clafoutis, which is ‘a type of dessert consisting of fruit, typically cherries, baked in a sweet, custard-like batter’, and which is listed in the online Oxford English Dictionary (OED). It is a French borrowing, but it is not a frequent word in English according to the OED. 7 It is no doubt also possible for LOLIs to become less frequent in the course of development, when they are replaced by other terms, although the trajectory over time of LOLIs has not been investigated in great detail (but see Chesley & Baayen, 2010; Poplack & Dion, 2012). Thus, frequency is not a necessary condition for LOLIs to be classified as borrowings.
An advantage of the choice of listedness over integration or frequency as the key defining feature for borrowing is that this criterion also applies to
The existence of MWUs, such as compounds, collocations, lexical phrases (see Wood, 2020 for an overview), can throw further light on the distinction between grammar and lexis, and on the role of listedness in distinguishing between borrowing and code-switching. Research into lexical processing and corpus linguistics has shown that the lexicon is likely to contain a wide range of MWUs, which are retrieved as such, as unanalysed units, during language processing. Delimiting what is productive and rule-bound and what is stored as an unanalysed unit is a key issue therefore not only for the discussion about the distinction between borrowing and code-switching, but also in, for example, the literature on regular and irregular plural formation (Pinker, 2015; Simon & Wiese, 2011). Therefore, we turn our attention to MWUs now.
MWUs in bilingual data: the formulaicity criterion
According to Poplack (2018) compounds may also qualify as borrowings if they function as a single word, as is the case for English barbershop in Canadian French. While canonical cases such as barbershop may be easily identifiable as compounds, because they are written together, that is not always the case, because different parts of compounds are sometimes separated, as the difference between doorstep and front door illustrates, and some are written with hyphens (open-handed). Compounds can also consist of a combination of more than two words, as in door number plates. Indeed, in their discussion of around 3,000 new compound formations extracted from a 360 million word corpus from articles in the Independent, Bauer and Renouf (2001) demonstrate there is a wide range of phenomena that can broadly be described as compounds, but which includes items such as lady-in-waiting, mother-in-law (Bauer & Renouf, 2001, p. 103).
That there are many MWUs in language has been known at least since the seminal publication of Pawley and Syder (1983). Importantly, they note ‘there is a cline between fully lexicalized formations on the one hand and nonce forms on the other’ (Pawley & Syder, 1983, p. 192). Their use of the term ‘nonce forms’ is particularly revealing because it underlines that the issue of determining whether something is ‘established’ or ‘nonce’ is not specific to bilingual data, but a wider issue in lexicology. Corpus linguistic analyses have since shown that MWUs (also called
In the field of language contact, Backus (2003) was the first to observe that switches often consist of (12) Politiek gesprek-ler-i ophoud-en yap-ın la political conversation-PL-ACC stop-INF do-IMP man ‘Stop the politics conversations, man’ (Backus, 1992, 2003, p. 98)
Particularly relevant for the current purposes is that Backus shows that Dutch compounds are more likely to appear as an insertion in Turkish discourse than single nouns. The reason for this is that compounds such as Dutch arbeidsbureau ‘job centre’ (and other fixed expressions) are semantically more specific than single words such as arbeid ‘work’ or bureau ‘office’. Put differently, arbeidsbureau is the conventional expression for the institution unemployed people in the Netherlands can visit to find work, and it is likely more convenient to retrieve this compound from the lexicon during speech production than to try and find a Turkish equivalent for it.
Thus, in the field of language contact it is by now well known that donor language items often consist of more than one word. The question then arises how MWUs are treated in code-switching/borrowing. Deciding whether or not these are borrowings or code-switches is difficult, just as it is for LOLIs, because of the wide range of phenomena that might enter the recipient language as MWUs. Moreover, the wide range of criteria do not always point in the same direction (Deuchar & Stammers, 2016). However, it seems that if a donor language item which appears in a stretch of speech in the recipient language display a degree of
An attractive option might therefore be to add formulaicity to the borrowing criteria for in Table 1, because for MWUs listedness can be operationalized as formulaicity. A formulation of this criterion is given in (II): (II) the formulaicity criterion
A MWU from a donor language that occurs in a stretch of speech from a recipient language is likely to be a borrowing if its MI score is high. If its MI score is low, it is a code-switch.
To illustrate how this works, I have computed the MI scores for collocations of the word Lehrer ‘teacher’ in the German deTenTen2012 corpus under Sketchengine, having set the left context to -1 and the right context to 0, because I only want to see collocations with words that immediately precede Lehrer. The results are given in Table 3.
Collocations of Lehrer ‘teacher’ with words immediately preceding it and their MI scores as computed under Sketchengine.

Note. MI: mutual information.
Table 3 shows that combinations of function words such as die ‘the’ and dieser ‘this’ with Lehrer obtain very low MI scores, while content words (e.g., adjectives) that collocate with Lehrer obtain much higher scores. 11 This happens because articles and demonstratives can occur with any noun. They are not really collocates of the noun, contrary to the content words listed in Table 3. On the basis of these results, we could conclude that if we find verbeambetete(r) Lehrer ‘teacher with civil servant status’ in a Turkish utterance, it is a borrowing because it has a high MI score, but if we find dieser Lehrer ‘this teacher’ in a Turkish context it is a code-switch. Of course, determining the exact cut-off point is difficult. If the criterion of MI scores larger than 3 is used (which is a widely used cut-off point in vocabulary studies), this would mean that unser Lehrer ‘our teacher’ is a borrowing but der Lehrer ‘the teacher’ a code-switch, which is not likely to be correct. What constitutes an appropriate cut-off point for identifying borrowing in a particular language pair is an empirical question that cannot be answered here. The answer to this question will depend on the speech community under investigation, as there are likely to be differences between speech communities at this point.
The formulaicity criterion is, in fact, a slight reformulation of Backus’ (2003) ‘unit hypothesis’, given in (III).
(III) The ‘unit’ hypothesis:
Every multimorphemic EL insertion is a unit, inserted into a ML clausal frame.
However the formulaicity criterion differs from the unit hypothesis in two ways. First, the formulaicity criterion makes explicit reference to the concept of formulaicity, and second, it does not assume that all units are necessarily formulaic. As it is well known, free phrases are also units, although phrases are not formulaic but built from scratch on the basis of productive grammar rules. In other words, MWUs and free phrases are both units, in the sense intended in the unit hypothesis, but they are different kinds of units, even if the differences are scalar rather than absolute.
As Poplack (2018) also suggests that compounds might qualify as borrowings, this is an obvious group of items on which to test the formulaicity criterion. If formulaicity is indeed an important characteristic of borrowing, one wonders whether MWUs might, in fact, be more successful than single words in entering a recipient language. There is some evidence for this: Compounds were indeed more likely to appear as insertions than single nouns in Backus (2003).
To test the formulaicity criterion, we would need to look beyond nominal compounds, however, because not all languages make productive use of this type of compounds (Sadock, 1998). In French, for example, N + N compounding is not productive: Instead of N + N compounds,
It is not currently known which of the other constructions which fall under the broad label of MWUs would also qualify as borrowings in bilingual data, but the default assumption should be that this is the case for all types of MWUs listed in Wood (2020). However, compounding is a highly productive process in some languages (see also the “The current project” section), and therefore, language users may well create novel compounds which are not listed in the mental dictionaries of either language. To do so, the speaker would need to use the grammar rules for creating compounds in the respective languages. A clear indication that bilinguals can be very creative with compounds is the existence of
(13) BEACH + häus-er ‘beach hous-es’ (Clyne, 2003)
To create novel mixed compounds, the speaker or writer would need to combine grammar rules of both languages, which would be typical of code-switching but not borrowing. Over time, however, such mixed compounds may become part of the lexical stock of a recipient language, and thus be listed as is the case for mixed compounds in Brussels Dutch (Treffers-Daller, 2005). The formulaicity of such mixed compounds can then be measured in the same way as for monolingual compounds.
Compounding in Turkish and German
The focus is here on nominal compounds, as this type is productive in both Turkish (Kornfilt, 1997) and German (Donalies, 2007) and the properties of nominal compounding have been described in great detail for both languages. I will begin by defining compounds and summarizing compounding rules for Turkish and German.
Defining compounding
For the purposes of the current paper, the definition of compounds provided by Granger and Paquot (2008, p. 40) will be used.
12
Compounds are morphologically made up of two elements which have independent status outside these word combinations. They can be written separately, with a hyphen or as one orthographic word. They resemble single words in that they carry meaning as a whole and are characterized by high degrees of inflexibility, viz. set order and non-interruptibility of their parts. Examples: black hole, goldfish, blow-dry.
Although many criteria are used to distinguish between free forms and compounds (see Trips & Kornfilt, 2015 for a review), finding criteria that cover all cases and are universally applicable remains very difficult. According to some observers (e.g., Gross, 1996; ten Hacken, 2021), the differences between compounds and phrases are relative rather than absolute. Ten Hacken (2021, p. 19) puts this very nicely: (. . .) for individual speakers (linguists), there are prototypical instances and a gradual transition to non-instances without a clear, natural borderline.
There is a great variety of structures which can be described as compounds. As it is not possible to cover all of these in this paper and verbal compounds have been treated extensively in the literature on bilingualism (e.g., Muysken, 2000, in this paper the main focus is on nominal compounds, and in particular on N + N compounds, such as door knob.
Nominal compounds in Turkish
In Turkish, the head of the compound is the right-hand-side element. That can be seen by comparing (14), where kitap ‘book’ is the head, and the compound represents a kind of book, not a kind of school, while in (14), where kitap is the non-head, and the meaning of the compound is a kind of fair rather than a kind of book. In N + N compounds, such as those in (14) and (15), there often is a compound marker on the head of the construction, which resembles the possessive marker. The specific form of the suffix is determined by the rules for vowel harmony (see Kornfilt, 1997, pp. 498–500).
(14) okul kitab-ı School book-CmpM ‘textbook’ (Kornfilt, 1997, p. 474) (15) kitap fuar-ı book fair-CmpM ‘book fair’
There are also other options for N + N compounds, because in some cases the compound marker can be left out, as in (16).
(16) çoban salata shepherd salad ‘shepherd’s salad’ (Göksel & Kerslake, 2011, p 34)
Nominal compounds in German
Like in Turkish, nominal compounds 13 are right-headed, as can be seen in (17), where Haus ‘house’ is the head, and Holz ‘wood’ the non-head, and the construction refers to a type of house, rather than a type of wood. In (18), by contrast, Holz constitutes the right-hand-side element, and the expression refers to a type of wood. In German compounds are normally written together, which is not common in Turkish.
(17) Holz + haus (Donalies, 2007) wooden house ‘wooden house’ (18) Brenn + holz fire wood ‘fire wood’
In many cases there is an
(19) Tag + es + licht day + ITF + light ‘daylight’ (Wegener, 2003, p. 426) (20) Kind + er + krankheit child + ITF + illness ‘childhood illness’ (Wegener, 2003, p. 426)
The current project
In this paper I set out to test a number of key assumptions of the Simple View of Borrowing and Code-switching against a corpus of Turkish-German code-switching collected in the 1990s, and recently made available to the research community (Treffers-Daller & Çetinoğlu, 2022).
The research questions for the current project were as follows:
How frequent are LOLIs by comparison with donor language compounds in both directions?
To what extent can donor language compounds be shown to be formulaic using MI scores?
To what extent are LOLIs and compounds integrated into the recipient language?
Are there any mixed compounds?
Which underlying processes (insertion or alternation) are used most frequently for LOLIs and compounds in the data?
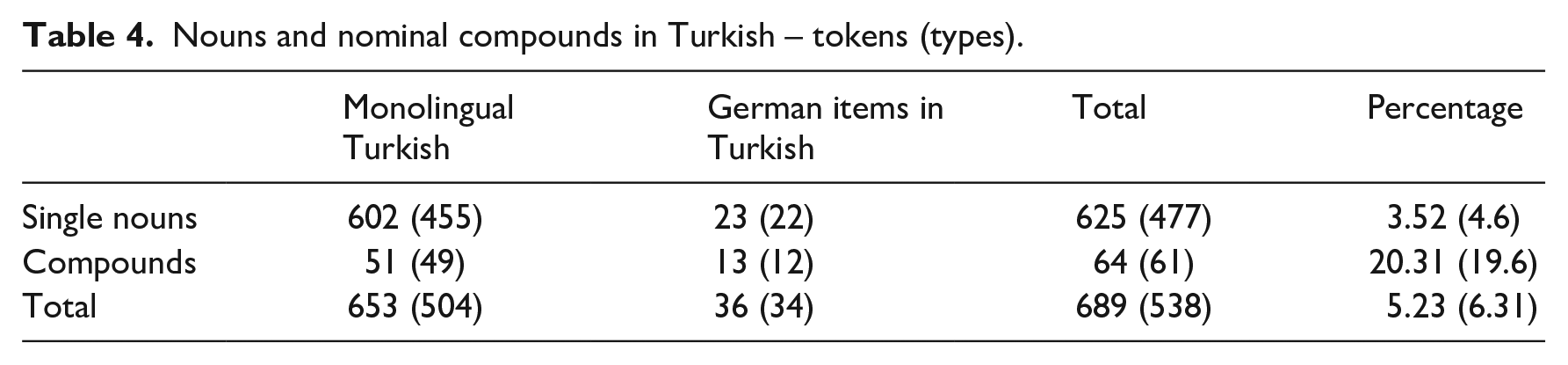
A Turkish-German bilingual corpus (TuGeBic) was used to test the assumptions of the Simple View. The corpus contains transcripts of conversations of twelve males and 24 females between the ages of 18 and 50, who were recorded in the 1990s in either Turkey or Germany. Participants were Turkish-German bilinguals, the majority of whom were students, and others were personal friends and family members of the Turkish-German research assistant who collected and transcribed the data (see Treffers-Daller & Cetinoğlu, 2022, for further details). 14 The corpus consists of 87,681 tokens, roughly equally divided between Turkish (43,785 tokens) and German (43,210) and 686 tokens, which consist of morphemes from both languages. There are 10,141 monolingual utterances in the dataset and 4,510 bilingual utterances. 15 The occurrence of LOLIs and donor language compounds in utterances where there was only one switch/borrowing (namely the LOLI or the donor language compound) were coded in the first 10 transcripts of this corpus (N = 20,566 tokens). There were also 88 utterances where more than one unit was mixed, but these have not been included in the current analyses, as determining the matrix language becomes very problematic in such cases. These deserve a more detailed treatment at a later stage. Nouns and compounds in monolingual stretches were also coded, to facilitate a comparison of the frequency of LOLIs and donor language compounds against each other and against monolingual items in the corpus. 16 In total 625 single nouns and 64 compounds were coded manually in Turkish utterances, and 483 single nouns and 83 compounds were coded in German utterances (see Tables 4 and 5 for details).
Nouns and nominal compounds in Turkish – tokens (types).
Nouns and nominal compounds in German – tokens (types).

Results
In this section the results of the analyses for each research question will be presented.
The relative frequency of LOLIs and donor language compounds
Table 4 gives an overview of the absolute and the relative frequency of nouns and compounds in monolingual utterances, as well as of LOLIs and donor language compounds in recipient language utterances. It shows that single German single nouns are far less likely to be selected for inclusion in a Turkish sentence (3.52%) than German compounds (20.3%), and this difference is statistically significant (χ2 = 1434.09, df = 3, p < .001). Interestingly, Backus (2003) also reports that Dutch compounds have a 20% chance of being selected for insertion in Turkish discourse, so our findings confirm those observations for German-Turkish code-switching. Table 5 provides the same information for German utterances. The likelihood of Turkish compounds appearing in German is lower (8.9%) but still higher than that for nouns (5.59%). Again this difference is statistically significant (χ2 = 928.56, df = 3, p < .001).
The formulaicity of donor language compounds
As there are no dictionaries of German borrowings in Turkish or Turkish borrowings in German, this criterion cannot be used to evaluate the listedness of donor language compounds. Instead, MI scores were computed for donor language compounds. For those Turkish donor language compounds in the TuGeBiC corpus that were attested in the Turkish TrTenTen2012 corpus, the MI scores computed with Sketchengine were higher than 3, which is a cut-off point widely used in vocabulary studies (see Table 6). For German, MI scores cannot be computed in the standard way with Sketchengine because German compounds are written together, and MI scores can only be computed under this software for words that are written apart. The MI scores for the German compounds were therefore computed by hand 17 (see Table 7). All MI scores found were above 3. We can therefore assume that the compounds found in each language are indeed formulaic.
Turkish compounds in German: translation equivalents, standardized frequency in the Turkish web 2012 corpus (trTenTen12), and MI scores.
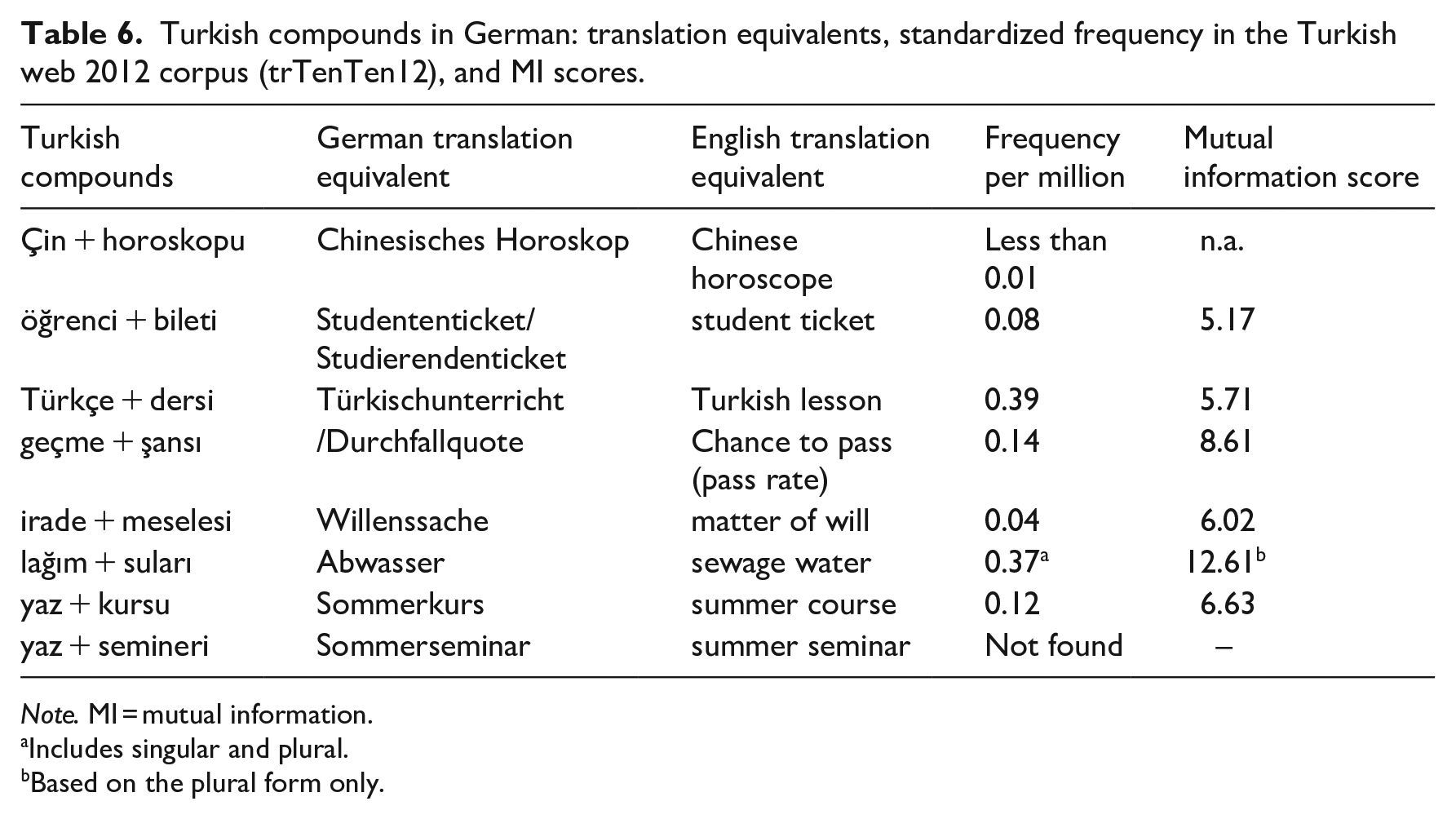
Note. MI = mutual information.
Includes singular and plural.
Based on the plural form only.
German compounds in Turkish: translation equivalents, standardized frequency in the German web 2018 corpus (deTenTen18), and MI scores.
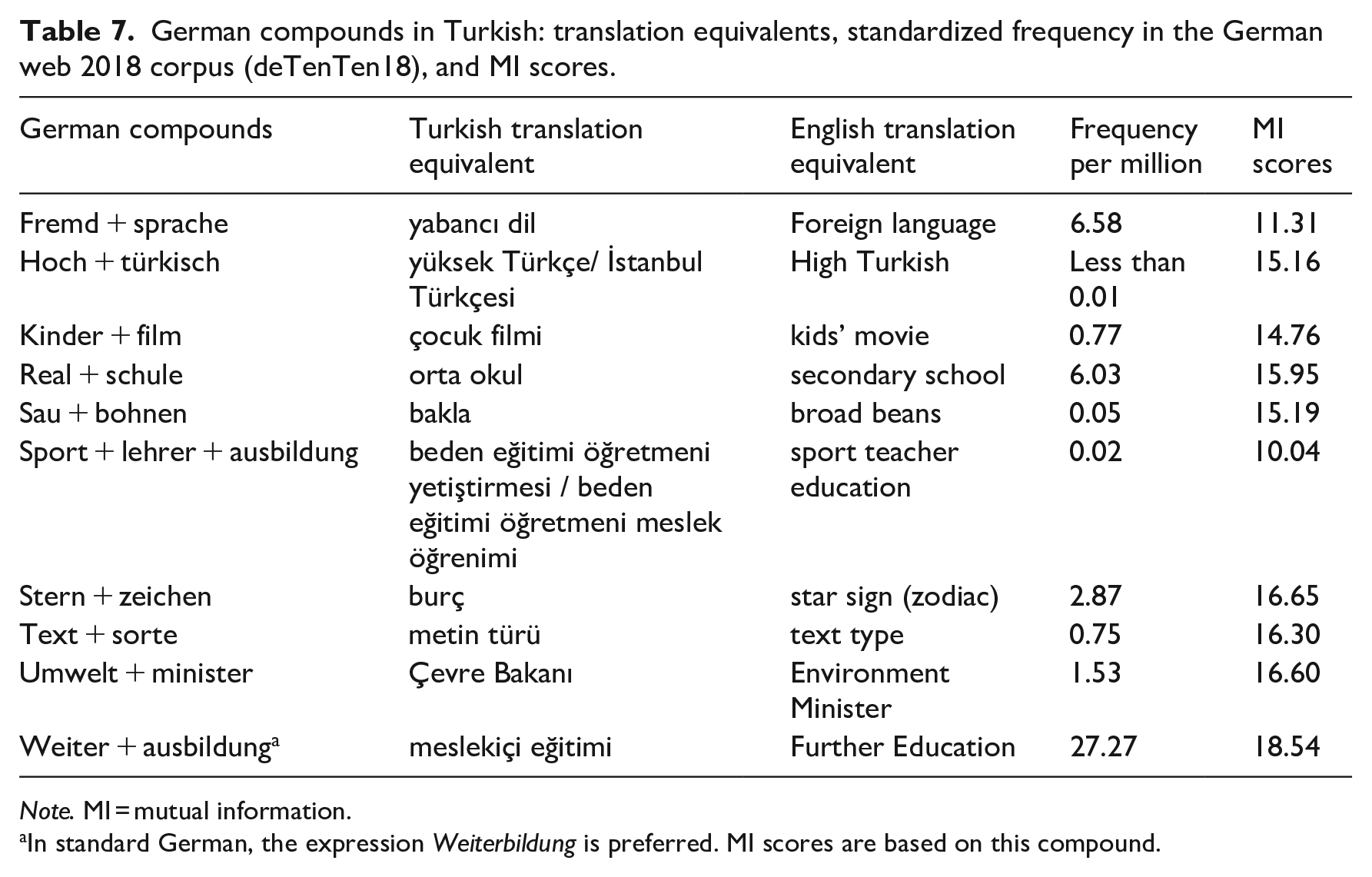
Note. MI = mutual information.
In standard German, the expression Weiterbildung is preferred. MI scores are based on this compound.
The integration of the donor language compounds into Turkish and German
First of all, we note that the compounds in monolingual and bilingual utterances are all right-headed, as might be expected, given the fact that this is the canonical word order for compounds in both languages. Determining to what extent word order in mixed compounds is German or Turkish is therefore not possible. Second, Turkish N + N compounds that are found in German utterances receive a Turkish compound marker as in (21), as is regularly the case when this expression is used in Turkish utterances.
(21) Die ganzen lağım + su-lar-ı! the whole sewage water-PL-CmpM ‘All the sewage water!’ (TuGeBic10)
While lağım suları ‘sewage water’ is clearly integrated into the German DP, in that it is accompanied by a German determiner and an inflected adjective, in most cases, Turkish compounds are not integrated into German DPs, because there is no article in constructions where this would be expected. In other words, the compounds in (22) and (23) are examples of bare nouns. In (21), the preposition would need to be followed by the determiner dem, which is marked for dative case or instead the form im (which is a merger of the preposition in and the determiner dem) would need to be used.
(22) Wir wurden jetzt geprüft in Türkçe + ders + i We were now tested in Turkish lesson + CmpM ‘We were then tested in (a) Turkish lesson’. (TuGeBic10) (23) Das ist irade mesele + si That is will matter + CmpM ‘That is (a) matter of will’. (TuGeBic10)
It is possible that determiners are left out because choosing determiners automatically implies allocating a gender to the noun too. This could be problematic for some speakers, as there is no nominal gender in Turkish, and it may not be clear to the speaker which gender would be appropriate. It seems that using a bare noun strategy is the preferred option for inserting Turkish compounds into German. A second strategy in the data is to use the plural form of the compound as for lağım + su-lar-ı instead of lağım + su-yu in (20), which could be seen as an avoidance strategy on the part of the speaker, as the plural is the same for masculine, feminine, and neuter nouns. A third option is to use the dislocation strategy, as in (24), because an article is not required there either. The use of Dings ‘thingie’ in (24) could signal the speaker has word finding difficulties on this occasion too.
(24) Ich hab’ Dings mal gelesen, Çin + horoskop-u I have thingie once read, Chinese horoscope-CmpM ‘I read (a) Chinese horoscope once’. (TuGeBic10)
The absence of German articles before some LOLIs can be a sign of lack of mastery with some speakers of the first generation, who learned German as adults as in (25), which stems from a Turkish-German returnee who lived in Germany for about 14 years and learned German as an adult. However, most of the speakers in the TuGeBic corpus were born in Germany and had attended German schools.
(25) Gibt es hier kapıcı? Is there here concierge ‘Is there (a) concierge here?’ (TuGeBic08)
Conversely, German compounds are clearly integrated into Turkish, in that they are combined, for example, with regular Turkish possessive suffixes, as in (26), where the Turkish first person singular possessive marker -m ‘my’ is attached to Fremdsprache ‘foreign language’. It automatically erases the compound marker, as would be expected according to the Turkish grammar rules (see Kornfilt, 1997 for details).
(26) Çünkü benim asıl Fremd + sprache-m Türkisch-dir. Because my main foreign language-1sg Turkish + COP ‘Because my main foreign language is Turkish’. (TuGeBic07)
Integration of LOLIs into Turkish can also be seen in the addition of Turkish plurals, and case marking to German nouns, as in (27), where German Kassette is marked with the German plural suffix -en as well as the Turkish plural in -ler, and receives an accusative case marker.
(27) Kassett-en-ler-i sen al-acak-sın. Cassette-PL-PL-ACC you buy-FUT-2sg ‘You buy the cassettes’. (TuGeBic07)
Turkish LOLIs can be integrated into German, but adding an -s plural to a Turkish noun, as in (28) is much rarer than adding a Turkish plural form (-ler/-lar) to a German noun. Note that dönem ‘semester’ is well integrated into a German DP in that it has the appropriate case and gender markers on the preposition and the adjective.
(28) Und dann habe ich auch im zweiten dönem keine zayıf-s. And then have I also in.the-DAT second semester no low marks-PL ‘And then I do not have low marks in the second semester either’. (TuGeBic03)
That donor language compounds can consist of more than two parts, as can be seen in (31), where we find a German compound with a complex non-head in a Turkish utterance, as in (29).
(29) Yani Sport + lehrer + Ausbildung mu? so sports teacher education ‘So, sports teacher education?’ (TuGeBic07)
While the compound in (29) does not contain an interfix, there are German compounds in the Turkish data that do contain an interfix, and there is a mixed compound with an interfix too (34). This variability is to be expected because interfixes are not obligatory for all German compounds, and there are no cases where an interfix is missing in compounds that require one. Among the German compounds in monolingual German utterances from the TuGeBic corpus there are several (30 and 31) with such interfixes.
(30) Stand + es + amt registry + ITF + office ‘registry office’ (31) Mark + en + hose brand + ITF + trousers ‘brand trousers’
There are hardly any errors with compounding. Two erroneous structures were found, one of which involved the selection of an incorrect derivational suffix (-ier instead of -iv for deriving an adjective from a verb), as in (32), and the other was an error with a mixed compound (see section Mixed compounds). However, to what extent this indicates the speakers’ ability to build compounds was compromised cannot be determined on the basis of these examples.
(32) Ja, das ist mein Adoptier + sohn Yes that is my adopted son ‘Yes, that is my adopted son’. (TuGeBic 10)
Mixed compounds
There are eight mixed compounds in the data (see Table 8), and for most of these, the head is Turkish, which may reflect the fact that Turkish is the matrix language of many clauses. One of the exceptions is (33), where the compound consists of a Turkish non-head kayın ‘in-law’ and a German head Sohn ‘son’, which are combined in a mixed compound. Although many kinship terms for in-laws are formed with kayın, ‘son-in-law’ is not one of them. The standard Turkish for son-in-law is damat, which the speaker does not use. Instead, the speaker produces the German translation equivalent Schwiegersohn as the next token.
(33) Almanya’da ben-im kayın + sohn, Schwieger + sohn Germany-LOC I-1sg.POSS in-law + son, in-law + son. ‘My son-in-law is in Germany’. (TuGeBic01)
Mixed compounds.

The speaker cannot find the word for teacher diploma, but is helped by the interlocutor.
For all but one of these mixed compounds, the non-head consists of one lexical item only. The exception is (34), where the non-head is also a compound.
(34) Nee, işte so Einkauf + s + bummel + yer-ler-e No, here, such shopping + ITF + spree + place-PL-DAT ‘No, here, to such shopping spree places’. (TuGeBic10)
Underlying processes
As for the underlying processes through which donor language compounds are introduced into recipient language clauses, the overwhelming majority are
Discussion and conclusion
In this paper, I have argued that the key criterion which makes a fundamental distinction between borrowing and code-switching is listedness, and that the advantage of the Simple View over other views of borrowing is that it is applicable not only to lexical borrowing, but also to borrowing of function words. To measure listedness one could investigate whether borrowings are listed in a dictionary of the recipient language (if available), but more important is whether an item is listed in the mental lexicon of speakers of the recipient language. For MWUs, listedness can be operationalized as MI scores, which ‘indicate how likely a given set of words are to occur together in a set sequence by comparison to chance’ (Wood, 2020, p. 38). Here MI scores are chosen to operationalize listedness because an expression with a high MI score is likely to be listed as such in the lexicon. The other borrowing criteria that are often mentioned in the literature apply variably: Borrowings can but do not need to consist of just one word, they can but do not need to be morpho-syntactically integrated, and finally, they can be frequent in a dataset but often they are not.
This view of borrowing and code-switching was subsequently tested against a Turkish-German corpus, the TuGeBic corpus (Treffers-Daller & Çetinoğlu, 2022). The findings largely confirmed the assumptions of the model: It was found, first of all, that compounds had a much higher chance of being selected as a borrowing than single words, in both directions, which confirmed findings of Backus (2003), but would be unexpected if the defining characteristic of borrowing was that borrowings consist of a single word. Second, evidence for the formulaicity of the Turkish compounds was found through the computation of MI scores. Third, morpho-syntactic criteria turned out not to be very useful to establish whether words were borrowings, because (a) compounds are right-headed in both languages and (b) Turkish inflection was regularly applied to German nouns, but this process was much less productive in the opposite direction. Indeed, Turkish compounds were often inserted into German as bare forms, without articles that would indicate gender and case. In this context it may be relevant to note that omission of articles is quite common in some varieties of German, in particular Kiezdeutsch, a new urban dialect that was developed by young people with or without a migration background (Wiese, 2011). This means that it may not be appropriate to assume that the standard norms for the use of articles apply to the current data set, which makes studying how borrowings/code-switches are integrated syntactically very difficult. Third, the frequency criteria could hardly be used because most of the donor language items were very infrequent.
A limitation of the study is that the corpus was small by comparison with other bilingual corpora. It is not impossible that some forms are more frequent if more data are being analysed, but it is unlikely that this would change the overall picture dramatically, because as Poplack et al. (1988, p. 57) report, ‘borrowed words tend not to be recurrent’. This is, in fact, common in all corpora: As Kornai (2007) notes, about 40%–60% of all word types in large corpora appear only once. Thus, borrowings are not different from indigenous words with respect to their frequency distribution.
In future research, it will need to be established what constitutes an appropriate cut-off point for MI scores in studies of borrowing. As some combinations of function words and content words (e.g., the teacher) obtain MI scores above 3, it is possible that the cut-off point of 3 for MI scores is not the appropriate level for identifying borrowing. It is also possible that different cut-off points apply to different speech communities, reflecting community-specific norms.
Further information about community norms could be obtained from experimental approaches. As Deuchar (2020) points out, we need more information about community norms for code-switching, but the same is true for borrowing. Experiments could take the form of a frequency judgement task (Hofweber et al., 2019) for which bilinguals are asked how frequently they encounter a particular mixed utterance with donor language single words or MWUs in their environment. One would expect utterances with LOLIs or donor language MWUs that have been added to a speaker’s recipient language mental lexicon to be encountered as frequently as monolingual utterances. Crucially, in such a task, participants are NOT asked to give a grammaticality judgement or say whether they use such sentences themselves. Instead, they are asked to provide a judgement which reflects personal perceptions of community norms. The effects of size, morpho-syntactic integration, and frequency on these judgements could then be measured precisely.
Mixed compounds would be of particular interest here because such compounds are novel creations. Thus, these will not be listed in the donor language dictionary. Such mixed compounds should therefore trigger a response that is different from those given to unmixed donor language compounds, unless these mixed compounds have become listed in the recipient language already. Further evidence would come from neuroscientific approaches, as one would expect borrowings of listed items and switches of non-listed items to trigger different ERP signals (see Moreno et al., 2002; Zeller et al., 2016, for neuroscientific approaches to code-switching).
Because the distinction between borrowing and code-switching is essentially a specific instantiation in bilingualism of the basic distinction between words and rules, studying how single words and MWUs from one language are used in another language can also contribute to theory building on the distribution of labour between vocabulary and grammar. This can, however, only be done if the focus shifts from a language contact-internal discussion about the distinction between borrowing and code-switching, towards a discussion of how language contact patterns can contribute to a better understanding of the wider issue of what is rule-bound productive language behaviour and what is stored and retrieved as an unanalysed whole. This would have the added benefit of research from the field of language contact having a greater chance of being perceived by researchers in neighbouring disciplines (e.g., Corpus Linguistics and Second Language Acquisition).
Footnotes
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author received no financial support for the research, authorship, and/or publication of this article.