
Abstract
Aims and objectives/purpose/research questions:
This study revisits the finding that code-switched language comprehension takes longer than non-switched language.
Design/methodology/approach:
Using an auditory moving window task, bilinguals operating in single (English) or dual (Spanish–English) language communities listened to sentences presented auditorily. Sentences in Experiments 1a to b were in Spanish and critical targets were either a code-switch or a borrowing, where an English target was pronounced in Spanish. Experiments 2a to b compared code-switched versus non-switched targets within Spanish sentences. Sentences for Experiment 3 were in English with critical targets in Spanish. Context (low/high constraint) and word frequency (low/high) were manipulated.
Data and analysis:
Data were analyzed using linear mixed effect models (N = 358), with phonetics (code-switch vs. borrower), context (high- vs. low-constraint), word frequency (high vs. low), and bilingual group (code-switcher vs. English-dominant) as fixed factors, and items and subjects as random factors.
Findings/conclusions:
Findings from the three experiments suggested that code-switched language results in a processing cost. The bilingual’s linguistic system demands more memory and time to successfully integrate the code-switched information into the sentence. Word frequency and context, as predicted by the featural restriction model, affected the processing of the code-switched targets.
Originality:
This study is one of the first attempts to investigate bilingual processing employing the auditory moving window technique and the first one to find an interactive effect of context and the type of bilingual and mixed language processing.
Significance/implications:
The results suggest that there are differences in language switch costs moderated by word frequency, phonetics, and linguistic environment (monolingual vs. bilingual) among bilinguals. The results also suggest that the auditory moving window technique is sensitive to the classic bilingual factors such as code-switching, and other robust psycholinguistic factors such as context and word frequency.
Introduction
This study is motivated by the observation that bilingual speakers mix or code-switch their languages simultaneously and effortlessly when communicating. In code-switching, a word or a phrase in one language is substituted for a word or a phrase in a second language (L2) (Heredia & Altarriba, 2001; Li, 1996). Code-switching is so prevalent in parts of the southwest of the United States that it is often referred to as Spanglish to denote the active and dynamic interaction of Spanish and English during the communicative process, as illustrated in sentences (1a to b) below (Dewaele et al., 2020): (1a) I would like a hamburger without (1b) Quiero una hamburguesa sin
Sentence (1a) is an English non-switched or monolingual sentence. Sentence (1b) is an inter-sentential code-switched sentence with an English target (pickles) replacing the Spanish word pepinillo. How might bilinguals comprehend sentence 1b?
Bilingual sentence processing and retrieval of code-switched words
One important aspect of sentences 1a to b is that, from the standpoint of an information processing approach (cf. Bates et al., 2001), consistency of the various linguistic cues (e.g., syntax + context + language congruency) would result in a fast and efficient processing of sentence (1a). Sentence (1b), however, would represent a case in which linguistic cue consistency might affect the processing of the code-switched target. The code-switched word would not benefit from the preceding linguistic cues of Spanish. This cue inconsistency might result in a processing cost in which the bilingual’s linguistic system demands additional memory allocation and time to successfully integrate the code-switched word into the sentence.
Experimental evidence showing that bilinguals control their languages when switching from one language to another in language production is more than abundant (Costa & Santesteban, 2004; Meuter & Allport, 1999). As argued by Green (2018), representations in the non-selected language are suppressed for the duration until they become activated to allow for code-switching. Switching costs that bilinguals experience are typically accounted for by the on-guard monitoring and inhibition attempts when being in one language mode and their attempts to remain in that particular language mode (Grosjean, 2008). One prediction is that bilinguals might experience slower processing during code-switching. However, this hypothesis remains to be confirmed, as very little research has been done on spoken language comprehension.
Code-switching in different interactional contexts
What are the effects of the community “interactional context” of language use and its influence on code-switching and cognitive control? Verreyt et al. (2016) compared the performance of unbalanced bilinguals, balanced non-switching, and balanced switching bilinguals on two executive control tasks. Verreyt et al.’s (2016) results showed that only balanced switching bilinguals outperformed the other two groups, indicating that language-switching experience, rather than high L2 proficiency determine bilingual advantages. However, Hartano and Yang’s (2016) investigation into the role of bilinguals’ interactional context and task-switching performance failed to find differences between single and dual switchers. In fact, the hypothesized interactional context and predicted switch cost differences did not transpire, underscoring the role of the factor interactional context of conversational exchanges in task-switching (cf. Bialystok, 2017).
The current study
One purpose of this study was to revisit the finding that code-switched words take longer to comprehend than monolingual sentences of the type described in (1a to b), respectively. In one of the few studies involving spoken language, Soares and Grosjean (1984) used a phoneme lexical decision task to investigate code- and non-switched sentences. While attending to sentences presented binaurally, bilinguals listened for a prespecified phoneme (/p/ for pickles) to decide if the target containing the phoneme was a word/nonword. Bilinguals were faster to make lexical decisions for non-switched than for code-switched targets. Soares and Grosjean’s suggested that word retrieval during the processing of code-switched, as opposed to non-switched language, required an extra amount of time. However, some researchers (Cieślicka & Heredia, 2016; Kheder & Kaan, 2016; Li, 1996) reject such a notion on the grounds of methodological issues. For example, Cieślicka & Heredia (2016) had bilinguals named visually presented targets that were related or unrelated (peace/mouth) to a critical prime (WAR) embedded in English or Spanish spoken sentence preceded by unbiased (It is difficult to admit a WAR . . . ) or biased context (Soldiers are trained for WAR . . . ) toward the critical prime. When the spoken sentences were in English, participants were faster to name English than Spanish targets, thus replicating the base language effect (Grosjean, 2008) that non-switched sentences are faster than code-switched sentences. This finding was generalized to both unbiased and biased contextual conditions. However, when sentences were in Spanish the opposite was true. Bilinguals whose first language (L1) was Spanish and second language (L2) was English were actually faster in naming English visual targets than Spanish targets. Cieślicka & Heredia (2016) interpreted these findings as counter to the base language effect that suggests that the language being spoken has a strong effect on which language will be favored during lexical access.
A second purpose of this study was to assess the usefulness of the auditory moving window (AMW) technique (e.g., Ferreira, Anes, & Horine, 1996; Ferreira, Henderson, et al., 1996) in addressing bilingual language processing. It is a self-paced and non-invasive language comprehension task. AMW provides a precise index of a processing load across a sentence. Participants in this task are presented with a sentence, as in (1c), that has been digitized into a sound wave and partitioned into small segments (depicted by “∧”). Participants press a computer button and listen to successive sound segments, composed of one or two words, until the entire sentence is heard: (1c) Dame ∧ una hamburguesa ∧ sin ∧ PICKLES ∧ please∧
Times between button presses, or inter-response times (IRTs), are recorded for the critical target(s). The IRT for the target pickles, for example, would represent the amount of time taken by the bilingual to fully process the code-switched item. Analysis is typically performed on IRTs or on difference times (DTs). DTs are the difference between the IRT and the duration of the segment during the digitizing of the target. DTs represent an objective and direct measurement of the processing load. This task allows for the possibility of studying those bilinguals who report difficulties in their L1 reading and writing abilities, simply because most of their formal education has been in their L2 (Heredia & Altarriba, 2001).
Another purpose of this study was to re-examine the effects of phonetics (Li, 1996), context (e.g., Altarriba et al., 1996; Li, 1996; Li & Yip, 1998), and word frequency (Altarriba et al., 1996). “True” code-switches and “borrowings” for the phonetics variables are operationalized in terms of pronunciation. In sentence (1c), for example, if the critical target is pronounced in its English form (|’pIk[ə]ls|), it is considered a true code-switch; if pronounced as a Spanish word (|pikos|), it is a borrowing. The phonetic properties of code-switched word have been found to interact with the recognition speed of bilinguals (e.g., Li, 1996). More precisely, the processing costs in a bilingual sentence would depend on the word phonetics. Questions of interest are whether the code-switched word is pronounced in the guest or in the base language (i.e., a borrowing) and how its pronunciation affects its comprehension.
Evidence concerning context is limited. When context has been systematically studied in the spoken language domain, it has failed to interact with such variables as phonetics, phonotactics (Li, 1996), and language condition (Li & Yip, 1998). At the reading level, Altarriba et al.’s (1996) study stands out as one of the few studies showing a significant interaction between context and word frequency. Altarriba et al. used eye movements to measure eye fixations during the comprehension of code-switched and non-switched English sentences (see Table 1). Spanish-English bilinguals read high- (prior context biasing meaning of critical target) or low-constraint sentences (prior context not biasing meaning of critical target). Critical targets (Spanish vs. English) were of low- or high-word frequency. Results showed that for code-switched sentences (2a, 2c), fixation durations for low-frequency targets were significantly shorter for high-constraint than for low-constraint sentence conditions. That is, the processing of code-switched targets was facilitated under the high-constraint contextual condition. This result is consistent with previous findings suggesting that low frequency words benefit from the context effect (e.g., Becker, 1979). However, processing of the high-frequency targets was affected by sentence constraint in the opposite direction. Target words in the high-constraint condition exhibited longer fixation durations than those in the low-constraint one. High-constraint sentences increased fixation times for the Spanish targets. Results were interpreted in terms of a featural restriction model (e.g., Schwanenflugel & LaCount, 1988). Accordingly, sentence constraint restricts the number of featural descriptions that are generated as participants read a sentence and determine whether a possible candidate specifically matches the features generated by the preceding context. Increasing the sentence constraint decreases the number of possible candidates that can be generated, which may contain the expected featural descriptions. Fewer candidates will be able to match the description set up by the prior context. The lower the contextual constraint, the greater the number of candidates generated that may share some of the featural descriptions.
Sample sentences used in Experiments 1 to 3 (adapted from Altarriba et al., 1996, p. 478).

Note. Experiments 1–2 involved Spanish translation of these sentences.
Thus, as sentences (2a and 2b) are being read, the word deposit activates and triggers money because this concept is the best match and it is highly descriptive and associated with things related to banks and the act of saving money. If presented with the English target (non-switched target, as in 2b), facilitation would have occurred. However, dinero in 2a would be a mismatch because it is in another language and time is needed to decide whether the Spanish target is semantically identical to the expected English target. Therefore, a comparison between sentences 2a and 2b predicts a significant shorter fixation time for the non-switched sentence (2b). A significant three-way interaction between language (code- vs. non-switched targets) × sentence constraint (high vs. low) × frequency (high vs. low) might have picked up on this predicted finding. However, no significant interaction between language and sentence constraint is reported by Altarriba et al. (1996). This issue is re-examined in this study. Unlike previous studies, we utilize the AMW that, in our view, is high on ecological validity and sets minimal additional cognitive demands on the participants.
Experiments 1a to b re-examine a potential interaction of phonetics (i.e., code-switching vs. borrowings) with word frequency and sentence constraint. Sentences were in Spanish, and critical code-switches and borrowings were in English (the guest language). We ask the following questions: What are the effects of word phonetics and word frequency? Is the frequency effect more likely to benefit code-switches than borrowings? What are the effects of sentence constraint and phonetics? Is sentence constraint more likely to benefit code-switches than borrowings? In addition, we wanted to compare language processing differences between bilinguals operating in a monolingual environment, where English is the dominant language (Experiment 1a), versus bilinguals functioning in a bilingual community where Spanish and English are used simultaneously (Experiment 1b). Finally, if the AMW is similar to the eye-tracking paradigm, Altarriba et al.’s (1996) reported interaction between word frequency and sentence constraint should be replicated.
Experiments 2a to b were similar to Experiment 1, except that a non-switched condition (a Spanish target) replaced the borrowing condition. This manipulation was included in an effort to further inspect the effects of frequency and sentence constraint under code- and non-switching language conditions. For Experiment 3, sentences were in English and targets were either in Spanish (code-switched) or in English (non-switched). This experiment was an attempt to replicate Altarriba et al. (1996) results, but with an auditory moving paradigm. Of special interest is the expected statistical interaction between word frequency and sentence constraint.
General method
The experiments reported here used a standard procedure as described in this section. Where an experiment departs from this procedure, exact changes are specified with the description of the experiment.
Experiment 1a
Participants
Fifty-seven bilinguals from the University of California, San Diego (UCSD; Mage = 20.6, SD = 2.1) subject pool participated in the experiment. Two participants reported Spanish as their L2, and the rest reported English as L2, and the language of communication at UCSD. Bilinguals’ reading and writing proficiencies in English were evaluated significantly higher than Spanish. Speaking and comprehension abilities were rated as comparable between Spanish and English. For the Spanish–English bilinguals, the L2 was the language of formal education, and the language used more frequently on a typical day.
Materials and design
Thirty-two high-frequency and 32 low-frequency English words were taken from Altarriba et al. (1996). Mean frequency for high frequency was 161 and 7 for low-frequency words. Word length was comparable (5.8 vs. 5.9 letters) for both word types. English word frequencies were taken from Kŭcera and Francis (1967). Spanish targets were direct translations of English targets. Mean frequency for the Spanish high frequency was 75, and 5.0 for low frequency words. Word length for both word types was comparable (6.0 vs. 6.1 letters). Spanish word frequencies were obtained from Juilland and Chang-Rodríguez (1964).
Sentences for Experiment 1 were Spanish translations of Altarriba et al.’s (1996) English sentences (see Table 1). Care was taken to ensure that the Spanish translations were as close as possible to the original English sentences. Low- and high-constraint sentences were generated for every target. Contextual manipulation (low- vs. high-constraint) was based on Altarriba et al.’s (1996) norming using a cloze test procedure. Cloze probability for high- and low-frequency targets in the high-constraint sentence condition was .7. Cloze probability for low-constraint sentences and high frequency words was .07, and .03 for the low-frequency words (p > .05). There was a reported significant difference on completion rates between high- and low-constraint sentences. Sentences were constructed in such a way that the critical target appeared near the middle of the sentence. A total of 64 pairs of sentences were constructed.
Spanish sentences were recorded by a female Spanish–English bilingual. Sentences were read directly into a Sony TCD-8 Digital Audio Tape-corder. Recordings were entered into an Apple computer using Macromedia SoundEdit 16 Version 2. A sampling rate of 44.1 Khz with a 16-bit format was used for digitizing. For every sentence condition, an English target was recorded as either a code-switch or a borrowing. Code-switches were pronounced in Standard English and borrowings were adapted to Spanish pronunciation. Sixty-four additional filler sentences were constructed following the same procedure as the experimental sentences. Half of the fillers contained a code-switch and the other half contained a borrowing. Borrowings and code-switches were placed at random throughout the sentence. Five sentences were used as practice trials.
All sentences were converted into sound wave files. Using waveforms and auditory feedback, markers (e.g., “∧”) were placed at the location defining the boundaries of the desired segment (see Sentence 3a). Segments consisted of one or two words, but the critical target was always presented as one segment. A beep sound of 200 ms was placed at the end of the waveform to signal the end of the sentence: (3a) He wanted∧to deposit∧all∧of his∧DINERO∧at the∧credit union
For each critical target, four combinations were possible; a high- or low-constraint sentence paired with a high-frequency code-switched or borrowing target, and a high- or low-constraint sentence paired with a low-frequency code-switched or borrowing target. Each target was assigned to one of the four lists using a Latin square design. This procedure assured that experimental targets were counterbalanced across the four lists, such that a given sentence with a critical target and contextual sentence appeared in only one condition on each list so as to eliminate any potential repetition-bias effects. Each list contained 128 sentences. Thirty-two of these sentences were code-switched targets. For the high-frequency targets, eight were embedded in a high- and another eight were embedded in a low-constraint sentence. Low-frequency targets followed the same procedure. The 32 targets in the borrowing condition followed the same pattern as the code-switched targets. Sixty-four fillers were included for each list. For each list, sentences were combined in a pseudo-random order, with the constraint that no more than three experimental targets occurred consecutively. Additional five sentences served as practice trials. To ensure that participants were paying attention, 14 true–false questions that asked participants details about a preceding sentence were included throughout each experimental list.
Procedure
Upon arrival to the laboratory, participants gave written informed consent. Subsequently, participants read instructions in Spanish on a computer screen. Participants were told that sentences would be presented in segments and to listen to the entire sentence, and to press a designated button on a computer device to advance from one segment to the next. They were asked to press the button as quickly as possible but not to sacrifice understanding, because their comprehension would be tested with True/False questions throughout the session.
Sentence segments were presented over headphones (Optimus Pro-50MX). To advance from one segment to the next, participant pressed and released a computer button. IRT was measured from the button-press to start the critical segment until the button was pressed again to continue to the next segment. The experiment was controlled by PsyScope (Cohen et al., 1993) and participants’ IRTs were controlled by the PsyScope Button Box (Cohen et al., 1993) connected to a Star Max 3000 Motorola Macintosh compatible computer. Stimuli were played at a medium volume setting through a set of Apple speakers.
Results and discussion
Jamovi V. 1.1.9 and restricted maximum likelihood GAMLj-general analyses for linear models V. 2.0 were used to perform linear mixed effects (LME) analyses, with phonetics (code-switch vs. borrower), context (high- vs. low-constraint sentence), and word frequency (high vs. low) as fixed factors, and items and subjects as random factors. For all reported experiments, fixed factors were deviation contrast-coded, and IRTs above 250 ms and z-scores below 3.5 were included in the analyses.
For all analyses, random intercepts for subject and item, and by-subject and -item random slopes are included and reported as appropriate (Barr et al., 2013). Following Aguinis et al. (2013) recommendations, an initial null model with random intercepts for subjects was carried out to justify the inclusion of subjects into the analysis. Interclass correlations ranging from .05 to .20 justify the inclusion of the random effect into the LME analysis (Aguinis et al., 2013). The inclusion of random intercepts and slopes into the models was done in a step-wise fashion using likelihood ratio test to determine model fit improvement. Unless specified, all analyses included subject and item as random intercept.
Excluded outliers constituted 1.1% of the data. Following Ferreira, Henderson et al.’s (1996), data were first analyzed by IRT and then by DT. LME analyses of the IRT data failed to produce any reliable effects.
DT analyses produced a significant main effect of phonetics, F(1,250) = 4.21, p = .041. This effect revealed that bilinguals processed code-switched targets 36 ms faster (M = 536 ms, SE = 21.1) than borrowings (M = 572 ms, SE = 21.1). No other effects were significant, p > .1.
To better understand differences between code-switches and borrowings, Experiment 1b involved bilingual speakers operating in a bilingual environment known for code-switching. This experiment allowed us to compare bilinguals that are functionally monolingual speakers of English (Experiment 1a) and code-switchers (Experiment 1b).
Experiment 1b
Participants
Seventy-three bilinguals from the Texas A&M International University (TAMIU) subject pool participated in the experiment. All participants reported using Spanish and English with friends and family. This is a unique linguistic characteristic in South Texas where bilinguals continuously mix their two languages during the communicative process. However, English (L2) was reported as the language of formal instruction and communication at the university and local school system. In regard to reading, writing, speaking, and comprehension proficiencies, English was rated significantly higher than Spanish.
Materials and procedure
Materials and procedures were identical to those of Experiment 1a.
Results and discussion
Exclusion of outliers constituted 1.2% of the IRT data. As in Experiment 1b, the analyses of IRT failed to produce any statistically significant main or interactive effects.
For the DT data, the LME analyses with subject and item as random effects revealed a main effect of word frequency, F(1,244) = 3.93, p = .048. Low-frequency words (M = 437 ms, SE = 21.0) were processed 30 ms faster than high frequency words (M = 466 ms, SE = 21.0). Although Ferreira, Henderson, et al. (1996) using the AMW have successfully replicated the word frequency effect, where high-frequency words are recognized more quickly than low-frequency words, the word frequency reversal might be due to the nature of the experimental stimuli averaged across low- versus highly constrained context and phonetic conditions, which might have disrupted the comprehension of highly predicted or activated but incongruent high-frequency targets. In this case, low-frequency words would be less activated and not as affected by the preceding linguistic conditions (Altarriba et al., 1996). Thus, the present result suggests that the AMW is indeed sensitive to bilingual linguistic manipulations and to word frequency effects.
To assess differences between bilinguals in Experiment 1a, whose L2 was most dominant, and bilinguals in Experiment 1b, who lived in a community in which both languages are used simultaneously, data from both groups were analyzed as a four-factor mixed design with group (English dominant vs. code-switchers), the additional level, as a between subjects fixed factor.
The main effect for group was statistically reliable, F(1,116.3) = 9.60, p = .002. This main effect shows that code-switchers (M = 945 ms, SE = 19.2) were 79 ms faster in processing targets than English-dominant bilinguals (M = 1,024 ms, SE = 20.0). These differences between groups show that two bilingual types represent different bilingual populations. No other effects reached statistical significance.
DT analyses with random intercept by subject and item revealed a main effect of group, F(1,116) = 14.5, p < .001. Code-switchers (M = 454 ms, SE = 19.1) were 98 ms faster in processing critical targets than participants with English as their dominant language (M = 552 ms, SE = 20.0). And a two-way interaction of group by language, F(1,7,157) = 12.2, p < .001. This interaction is summarized in Figure 1.
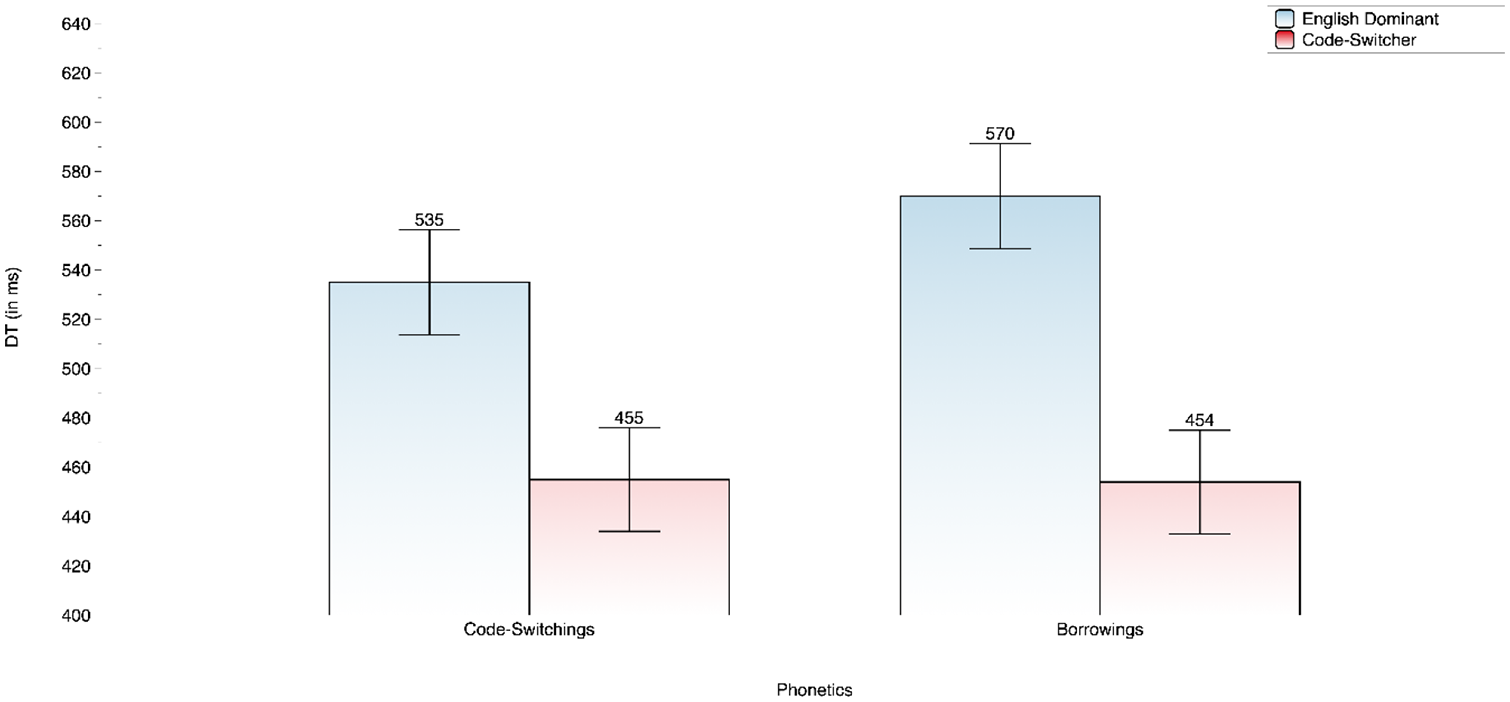
Two-way interaction of phonetics × group as a function of DT.
Follow-up simple effects revealed that code-switchers were faster to process code-switches and borrowings than English dominant bilinguals; code-switchers were equally fast in comprehending code-switches and borrowings. In contrast, English-dominant bilinguals were faster recognizing code-switches than borrowings. This language advantage of code-switchers could be due to their highly developed language-switching skill and cognitive flexibility (cf. Bialystok, 2017).
Experiment 2a addressed the manner in which bilingual speakers might comprehend code-switched versus non-switched (or monolingual) sentences. What are the effects of context and word frequency in the comprehension of code-switched versus monolingual language processing?
Experiment 2a
Participants listened to Spanish sentences with embedded English code-switched and Spanish non-switched targets. As in Experiment 1a, bilinguals were Spanish–English bilinguals operating in a linguistic environment in which English was the dominant language of communication.
Participants
Thirty-five bilinguals from the UCSD subject pool participated in the experiment. All participants reported English as the language of communication at UCSD and with friends. Although Spanish was the L1, all participants rated English higher in reading, writing, speaking, and comprehension.
Materials and procedure
Materials and procedures were identical to those of Experiment 1, with the exception that Spanish targets (recorded by the same bilingual as in Experiment 1) were embedded in the Spanish sentences to create the Spanish non-switched (or monolingual) condition.
Results and discussion
Excluded outliers constituted 1.2% of the IRT data. LME analyses by subject and item as random intercept and language as by-subject and by-item random slope produced a main effect of language, F(1,64.7) = 7.0, p = .01. Bilinguals were 64 ms faster in processing non-switched (M = 953 ms, SE = 23.8) than code-switched targets (M = 1,017 ms, SE = 27.0). No other effects reached statistical significance.
Further analysis by DTs failed to show any other statistically significant effects for main and interactive effects. The new finding from this experiment shows that the AMW is sensitive to the base language effect (Soares & Grosjean, 1984).
Experiment 2b
Experiment 2b attempted to replicate the base language effect observed in Experiment 2a with a bilingual population known for its code-switching from a bilingual community in which both Spanish and English are used interchangeably.
Participants
Seventy-three bilinguals from the TAMIU subject pool participated in the experiment. Even though bilinguals reported using both languages interchangeably, their reading, writing, speaking, and comprehension were rated higher for English than Spanish.
Materials and procedure
Materials and procedures were the same as those in Experiment 2a.
Results and discussion
Data screening for outliers eliminated 0.4% of the data. IRT analyses failed to produce any statistically reliable effects. Data from Experiments 2a to b were combined to compare between the two types of bilingual participants.
LME analyses produced a main effect of language (1, 260) = 6.55, p = .011. Bilinguals processed a non-switched target 47 ms faster (M = 964 ms, SE = 21.3) than a code-switched one (M = 1011 ms, SE = 21.3). Language interacted with group, F(1,6,456) = 8.04, p = .005. Figure 2 summarizes the two-way interaction.
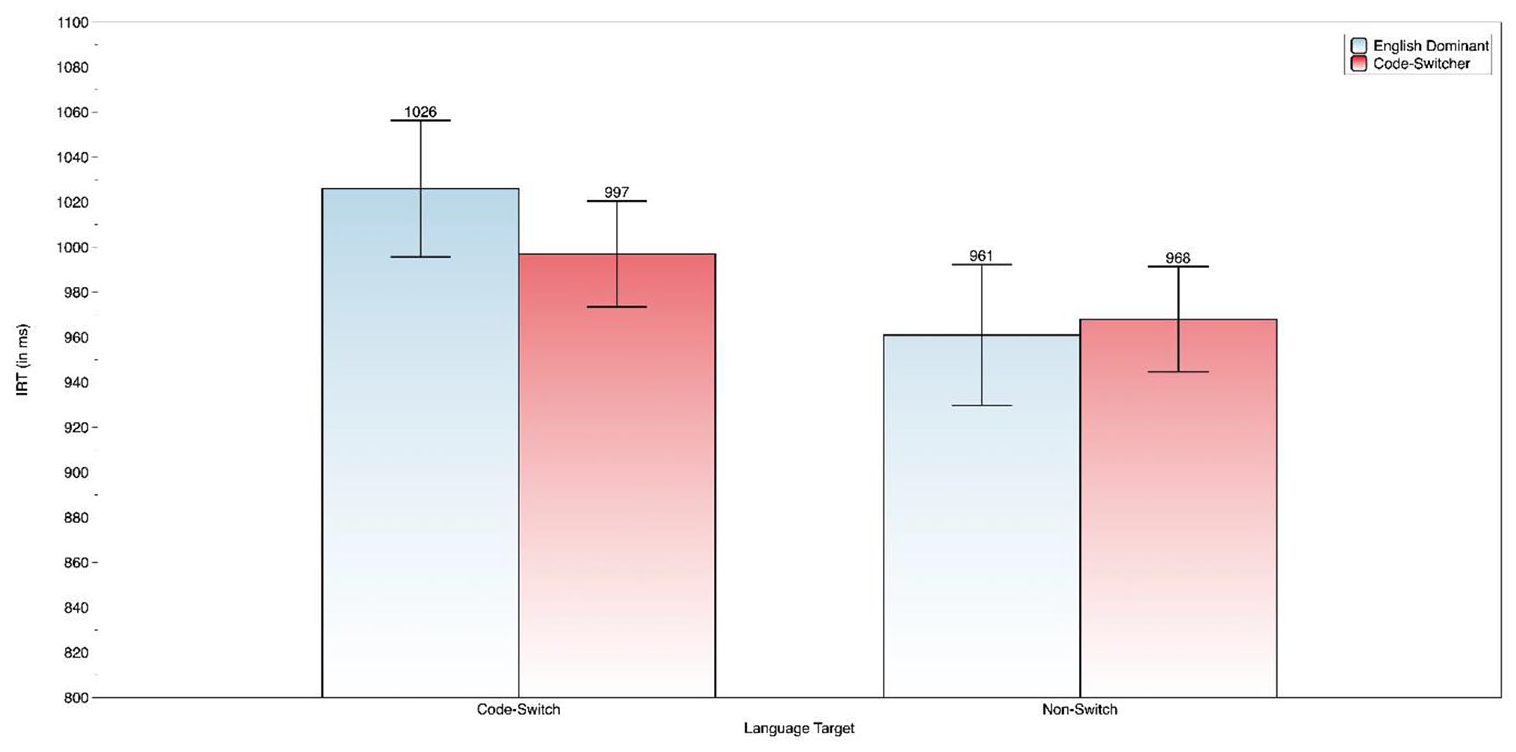
Two-way interaction of language × group as a function of IRT.
Follow-up multiple comparisons showed that bilinguals in the English dominant environment were 58 ms faster in responding to non-switched than code-switched targets. No other simple effects reached significance. The two-way interaction qualifies the main effect of language revealing that the English-dominant bilinguals were more sensitive to the language base effect. As in Experiment 1, code-switchers were equally fast in both language conditions.
The three-way interaction of group by language and context was significant, F(1, 6,455) = 5.16, p = .023. This interaction shows that bilinguals in the English dominant condition responded faster to non-switched targets in the low-constraint than high-constraint context condition.
DT analyses produced a two-way interaction of language by group, F(1,6,456) = 8.03, p = .005. The only meaningful finding was that bilinguals from the English-dominant environment were faster responding to non-switched targets. There was a three-way interaction of group by language and by context, F(1,6,456) = 5.20, p = .023. As in the IRT results, the interaction revealed a general tendency for bilinguals in the English environment to respond faster to non-switched targets in the low-constraint context condition.
Overall, the combined results of Experiments 2a to b are suggestive of a possible interaction of language (i.e., code-switched vs. non-switched) and context, as reported by Altarriba et al. (1996). However, one potential issue with Experiments 2a to b is that the sentences were in Spanish, and, typically, bilinguals report higher language proficiencies in English. Experiment 3 was a direct replication of Altarriba et al. (1996). Sentences were in English and the critical targets were in Spanish (code-switch) and English (monolingual).
Experiment 3
Participants
One-hundred and twenty-one bilinguals from the TAMIU subject pool participated in the study. Three participants were excluded due to not following directions. As in Experiment 2, participants were code-switchers and lived in a bilingual community.
Materials and procedure
Materials from Altarriba et al. (1996) were recorded by a Spanish–English bilingual, following the procedures identical to those in Experiments 1–2.
Results and discussion
Excluded outliers constituted 1.4% of the data. LME analyses with subject and item as random intercept and language as a by-subject random slope revealed a main effect of language, F(1,253.1) = 44.1, p < .001. In this case, non-switched items (M = 866 ms, SE = 15.2) were 83 ms faster than code-switched targets (M = 949 ms, SE = 15.2). There was a marginal main effect of word frequency, F(1, 245.0) = 3.52, p = .062. Bilinguals were more likely to respond faster to low frequency (M = 897 ms, SE = 153.3) than high-frequency targets (M = 918 ms, SE = 15.3).
The two-way interaction between context and frequency was reliable, F(1,246.9) = 3.95, p = .050. The general pattern of results emerging for this interaction suggests that low-frequency targets were responded to faster (than high-word frequency) under low-constraint contextual conditions. Indeed, the overall results replicate the base language effect reported in Experiment 2 and the exhibited patterns of the two-way interaction of word frequency by constrained context provides additional support to Altarriba et al.’s (1996) feature restriction model.
LME analysis by DT with subject and item as random intercept and language as by-subject random slope revealed a main effect of language, F(1,252) = 23.9, p < .001. No other effects reached statistical significance. This language effect as a function of DT produced an interesting reversal, in which code-switched targets (M = 445 ms, SE = 15.9) were processed 61 ms faster than non-switched targets (M = 506 ms, SE = 15.3). This was an unexpected reversal that may be explained by difference between IRTs and targets durations which were longer for Spanish than English.
To further assess possible differences between the comprehension of code-switched information, data from Experiment 2b (Spanish sentences) and Experiment 3 (English sentences) were combined. Sentences were treated as a between subject variable. LME with subject and item as random intercept, and by-item and by-subject random slope, with group, language sentence, and contextual constraint as fixed effects.
For the IRT analyses, the main effect of language sentence type was statistically reliable, F(1,220) = 5.74, p < .05. English sentences were responded to faster (M = 916 ms, SE = 17.1) than Spanish (M = 980 ms, SE = 20.3). The language main effect was also significant, F(1,457) = 5.87, p < .05. English targets were processed faster (M = 933 ms, SE = 14.3) than Spanish targets (M = 964 ms, SE = 15.0). The main effect of contextual constraint was marginally significant, F(1,407) = 3.37, p = .07. This marginal effect of contextual constraint suggests that participants were faster to respond to targets under low-constraint contextual conditions. Most important, sentence type interacted with language, F(1,457) = 21.2, p < .001. Figure 3 summarizes the interaction of sentence type and language.
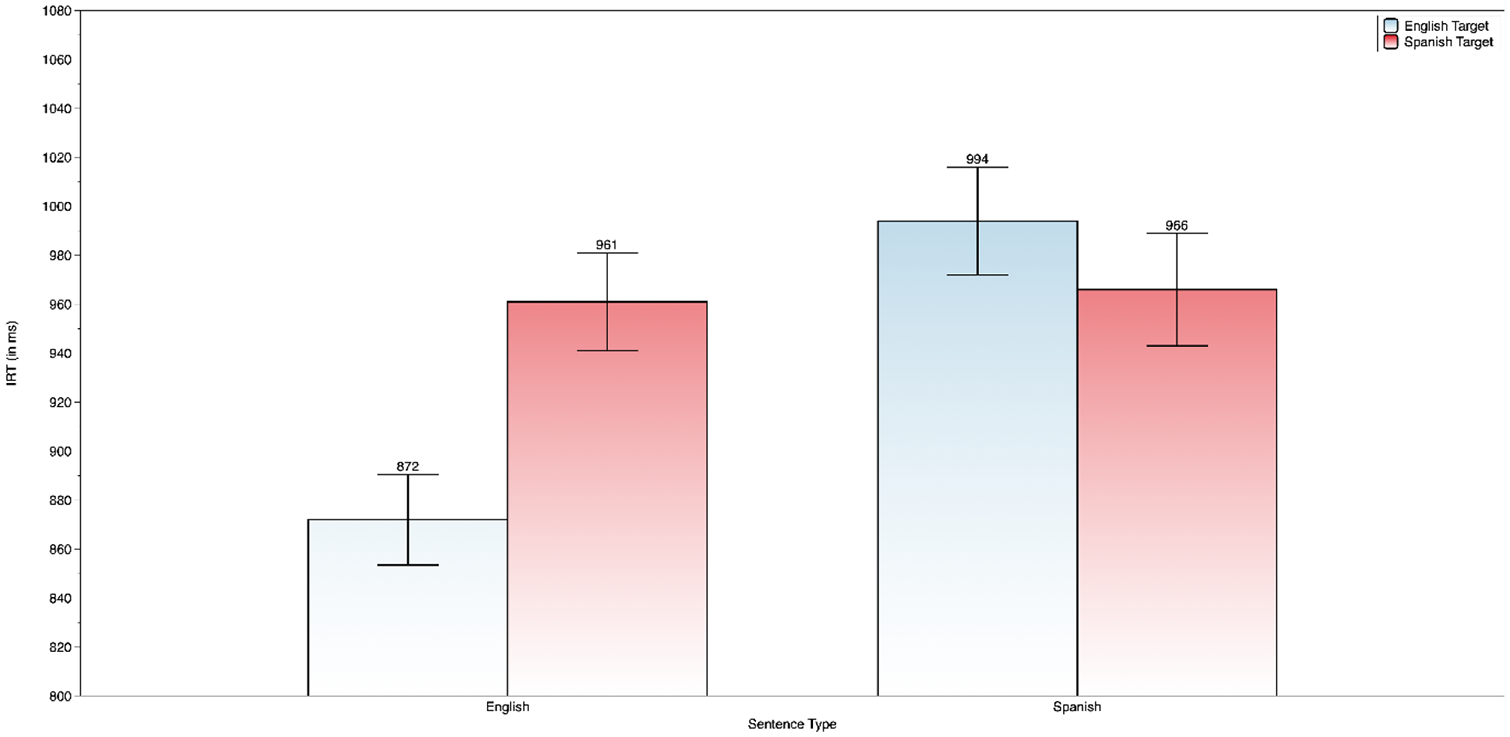
Two-way interaction of sentence type × language as a function of IRT.
Follow-up simple effects revealed that bilinguals took about the same amount of time processing Spanish targets, regardless of whether the sentence was in Spanish (non-switch) or English (code-switched). Spanish (code-switched) targets in the English sentence condition were processed about 89 ms slower than English (non-switched) targets, providing further support for the base language effect, but only for English sentences. For Spanish sentences English (code-switched) targets took about 122 ms longer then when the sentence was in Spanish.
DT analyses produced a significant two-way interaction of language by sentence type, F(1, 492) = 13.5, p < .001. The two-way interaction is summarized in Figure 4.
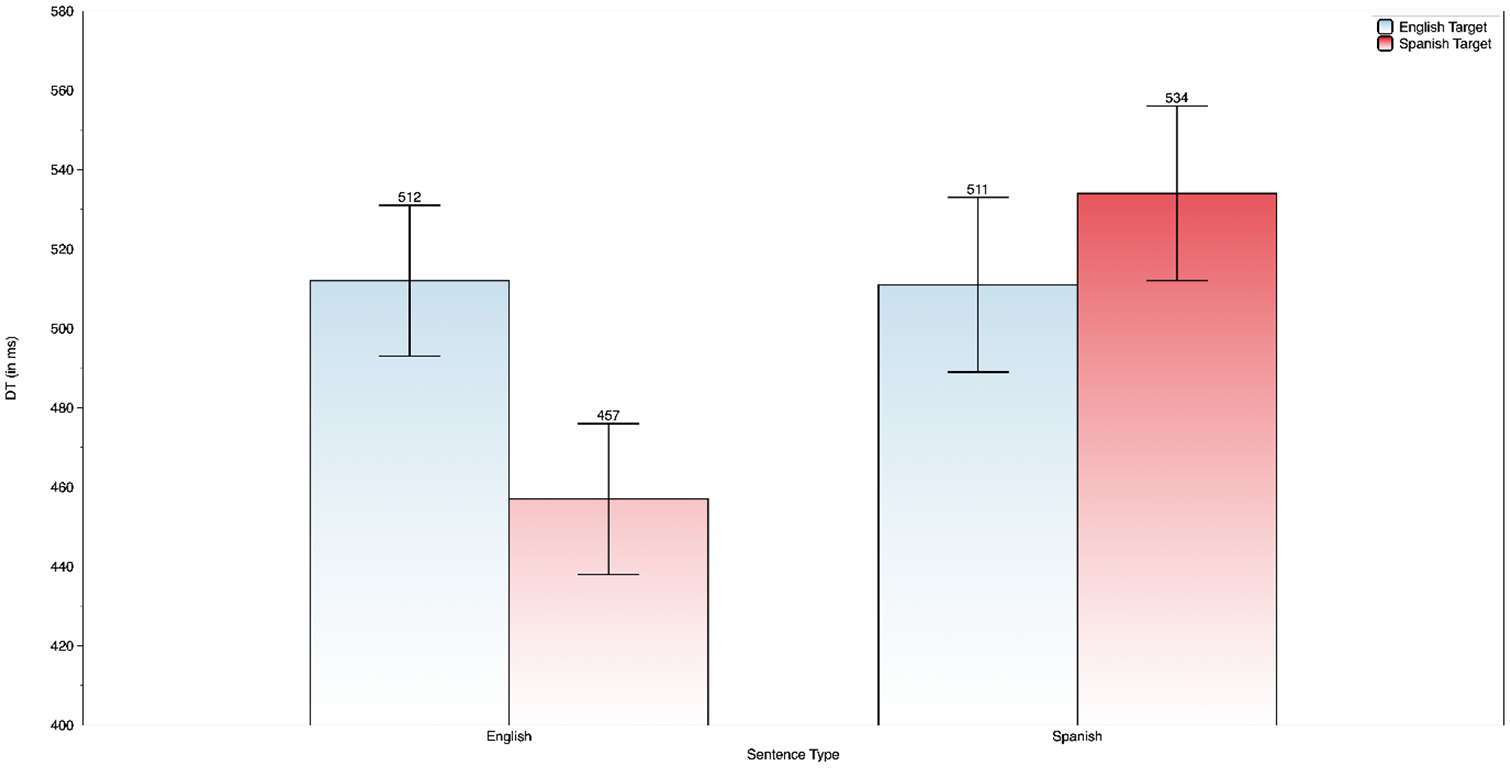
Two-way interaction of sentence type × language as a function of DT.
Follow-up simple effects revealed that Spanish (code-switched) targets were processed faster in the English sentence condition than when the sentence was in Spanish (the non-switched condition). However, for the Spanish sentences, bilinguals took the same amount of time processing code-switched and non-switched targets alike.
General discussion
Three experiments explored the comprehension of code-switched language using the AMW our results suggest that the AMW is sensitive to classic bilingual factors such as phonetics (code-switching vs. borrowing; Experiment 1), code-switching (Li, 1996; Experiments 2 and 3), and other robust language effects, such as word frequency and context effects (see, for example, Altarriba et al., 1996; Ferreira, Henderson, et al., 1996).
The overall results suggest that there are differences in language switch costs mediated by word frequency, phonetics, and linguistic environment among bilingual participants with different usage of Spanish and English. In Experiments 1a to b, bilinguals living in an environment where English was the dominant language processed code-switched targets faster than borrowings as they listened to Spanish sentences. Code-switchers, or participants from a bilingual community using both Spanish and English interchangeably, were equally fast to process code-switches and borrowings. In relation to word frequency effects, unlike the studies reported by Ferreira, Henderson, et al. (1996) utilizing the AMW, and Altarriba et al. (1996), results from experiment 1 revealed that low-frequency words were responded to faster than high frequency ones. This reversal could be due to nature of the experimental manipulations of this study (i.e., phonetics, context). The results of Experiments 1a to b replicate and extend Li’s (1996) findings where code-switches were faster than borrowings. Our results replicate this finding, but only for bilinguals operating in an environment where the L2 (i.e., English) is the functional language. It appears that code-switches and borrowings provide the same amount of information to those bilinguals that utilize both languages interchangeably. Thus, the AMW appears to be sensitive to the “bilingual phonetic effect” reported by Li (1996) using a gating and a cue shadowing task (see also Grosjean, 1988).
Experiments 2a to b combined looked at the traditional code-switched versus non-switched (monolingual) sentences to determine processing differences. Bilinguals from the same population as those in Experiments 1a to b listened to Spanish sentences with a code-switched (English) or non-switched (Spanish) target. First, the base language effect (Grosjean, 1988; Li, 1996) was replicated. However, this effect was more pronounced for bilinguals in the English dominant environment. Although bilingual code-switchers were generally faster to process code-switched targets than English dominant bilinguals, the base effect for this group was not as pronounced. Second, the bilingual group (code-switchers vs. English dominant), language (code- vs. non-switched target), and context (low- vs. high-constraint) interacted both by the IRT and DT analyses. These results are suggestive and partially replicate Altarriba et al.’s (1996) findings showing the effects of constrained context in the comprehension of code-switched targets. As in Altarriba et al.’s and, as predicted by the feature restriction model, preceding biasing context had an effect on the processing of code-switched targets. Code-switched targets that mismatched the anticipations generated by the highly restricted candidates activated by the language sentence and contextual information took longer to process. To the best of our knowledge, this is the first finding showing this interactive effect of context and the type of bilingual and mixed language. Li (1996), for example, argues for an interactive effect of context with other factors such as phonetics, phonotactics, and mixed language. However, Li’s findings reveal main effects of context only.
When code-switchers (Experiment 3) listened to English sentences and code-switched (Spanish) versus non-switched (English) targets, code-switched targets took longer to process, thus replicating the robust bilingual base language effect. In terms of word frequency, as in Experiment 2, bilinguals were faster at comprehending low-frequency targets embedded in low-constraint context, but they showed processing costs as they listened to high-frequency targets under high-constraint contextual conditions. Again, these results provide further support for the feature restriction model and Altarriba et al.’s (1996).
In general, there was a tendency for bilinguals to process Spanish targets equally fast, regardless of the sentence condition. However, bilinguals experienced increased processing costs comprehending code-switched (English) targets as they listened to Spanish sentences (i.e., the base language). We can conclude that bilinguals have less processing cost when they comprehend mixed language input, compared to the condition when the language of the sentence is English. Similarly, these results corroborate previous findings by Cieślicka and Heredia (2016) showing that the ease with which bilinguals access words in their languages depends on language usage or dominance.
Finally, to explain the differences in findings among bilingual participants living in environments with different dominant languages, we could safely conclude that the daily use of a language plays an important role when exploring language switch costs in bilinguals (Green, 2011). Finally, to the best of our knowledge, this study is one of the first attempts to investigate bilingual processing with the use of the AMW methodology. Further research using this ecologically valid experimental tool should be conducted to shed more light on the relationship between bilingual language processing and interactional contexts.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Ethics statement
All participants gave written informed consent in accordance with the Declaration of Helsinki, and the American Psychological Association’s Ethical Principles of Psychologists and Code of Conduct. The protocol was approved by the Institutional Review Boards of the University of California-San Diego, and Texas A&M International University.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by National Science Foundation Grant SBR-95204E9 to Roberto R. Heredia. The writing of this article was also supported by the TAMIU Advancing Research and Curriculum Initiative (TAMIU ARC) awarded by the US Department of Education Developing Hispanic-Serving Institutions Program (Award # P031S190304).