
Abstract
Objectives:
The study reports adult L2 Italian learners’ and native speakers’ (NS) choices between null and overt subject pronouns in a written illustrated story. The aim of the study is to ascertain whether learners have different perceptions of the aboutness topic compared with NS.
Methodology:
A total of 338 adult L2 Italian learners having different L1s filled in the blanks of a written story by choosing between the null pronoun and the third-person pronoun lui “he.”
Data and analysis:
The outcome variable was learners’ and NS’ choices between null and overt pronominal subject. Independent variables were: “anaphora” (“null” or “pronominal”) and “position” (“intrasentential,” when the antecedent and the gap were in the same sentence, and “intersentential,” when the antecedent and the gap were in two separate sentences).
Findings:
When the antecedent and the gap occurred in adjacent scenes of the story separated by punctuation, L2 learners—unlike NS—tended to reactivate the overt subject pronoun. Learners’ proficiency, L1, length of instruction, and knowledge of verb morphology significantly modulated the results.
Originality:
Punctuation in written texts strongly affects the likelihood that L2 learners use anaphoric means to reactivate the topic. L2 learners’ perception of aboutness in discourse is less robust and more affected by topic shifts and interruptions.
Implications:
Null subjects in texts should be dealt with upfront in second language instruction. Syllabi should deal with the difference between the use of overt and null pronouns in discourse.
Overview and motivation
The study reports adult second language (L2) Italian learners’ and native speakers’ (NS) choices between null and overt preverbal subject pronouns in a written illustrated story. Both NS’ and learners’ preference for null pronouns may depend on their moment-to-moment appraisal of pragmatic aboutness, that is, whether they clearly identify the aboutness topic (AT) and perceive it as continuous or discontinuous in the ongoing discourse. Learners may have different perceptions of aboutness compared with NS. Learners’ perception of aboutness in a written text is essential for living in a bilingual environment. In real life, L2 learners are exposed much more frequently to texts than to isolated sentences. For example, in all official L2 Italian proficiency tests, learners are asked to comprehend written texts of various lengths and complexity. However, classroom practice and course syllabi seldom provide examples of the difference between the use of overt and null pronouns in discourse (Matteini, 2012). The aim of our study is twofold: to describe an L2 Italian learner’s perception of aboutness and also to suggest that this important feature of prodrop languages should be dealt with upfront in second language instruction (“Conclusion” section).
Background
Reactivation of pronominal anaphora in L2 discourse
Research on L2 Italian null pronouns in discourse has mostly relied on the analysis of spontaneous oral production and re-telling data. Studies on referential and topic movement in Italian L2 learners’ interlanguages—mainly developed within a European project on the Topic component in learners’ varieties (Chini, 2010; Dimroth & Starren, 2003; Hendriks, 2003)—compared different sets of ± prodrop language pairs with respect to the anaphoric means used to establish, maintain, and shift sentence and discourse topics in spoken narratives. Their results suggested that L2 learners tend to be overexplicit in their referential choices in contexts of topic continuity. Learners showed a preference for heavy anaphoric expressions (e.g., nouns and stressed pronouns) where lighter means (e.g., null pronouns) would have been the preferable option in both their L1 and the target language. Studies on the topic component in learners’ varieties also suggested that in contexts of topic continuity, while early learners were inclined to overextend either the null or the overt anaphoric option, intermediate learners tended to extensively overuse only redundant overt syntactic anaphors (e.g., for Italian, see Chini, 2010). As a result, intermediate learners generally produced syntactically redundant and, consequently, poorly cohesive narratives. This could also be regarded as a tendency to plan and process the narrative at a lower textual level, which results, on one side, in the production of a sequence of unconnected sentences, and, on the other side, in a search for the topical antecedent that hardly overcomes the sentence boundaries. The non-prescriptive nature of the use of heavy versus light syntactic anaphors within a text may partially explain the late acquisition of target-like topical anaphoric means and the late (if ever) acquisition of target-like principles of information organization (e.g., perspective-taking) in the text (Carroll & von Stutterheim, 2003; for the distinction between early and late or “very late” acquired phenomena, see Tsimpli, 2014). Finally, the learners’ L1 alone—whether it is a prodrop language or not—did not seem to be a relevant variable, although the extent of redundancy varies slightly depending on the language pair (Hendriks, 2003).
Pronominal anaphora and aboutness
Reactivation of pronominal anaphora in an L2 multisentence text depends on an L2 learner’s perception of aboutness, which is generally defined as the relation between the referent and a meaningful portion of a text (e.g., Frascarelli, 2007). Both the length and the structure of such “meaningful portion of text” may determine learners’ need to reactivate the AT. As to the length, traditional definitions of topic have often distinguished between discourse topic (DT) and sentence topic (ST). DT is what a particular discourse unit is about, whereas ST is what a sentence is about (Dooley, 2007; Givón, 1983; Lambrecht, 1994). ST indicates a pragmatic relation with the referent that is confined in the sentence, while DT indicates a pragmatic relation among larger units (Halliday & Hasan, 1976; van Dijk, 1977). Yet, in establishing the AT, the difference between ST and DT does not concern only the width of the text that they cover, but also its structure. This is the amount of—either converging or contrasting—information that the listener/reader must handle. For example, Reinhart (1981, p. 53) defines “aboutness” as the effect of a given assertion on the context set and as the effect of the organization of the information in this set from the reader/listener. The context set of a given discourse is the set of propositions the speaker/reader accepts to be true at a given point in the text. The AT is therefore coded by the listener/reader through the incremental weighing of all topics—either ST or DT—as they are encountered and processed, one at a time. AT is eventually established after any topic candidate for AT status has first been checked, and then demoted or promoted (maintained or changed) in the ongoing discourse.
Topic continuity and accessibility co-determine the perception of aboutness
Within a single sentence, being mentioned just once suffices for being upgraded to the AT rank (if all other semantic, thematic, and pragmatic conditions are satisfied). Instead, at the text/discourse level, the first mention of a topic is not enough to determine its AT status, that is, whether or not it will be outranked by another AT candidate in the ongoing discourse. More specifically, while in isolated sentences, ST shifts depend on what is explicitly mentioned, an established AT does not need to be mentioned explicitly to remain alive at a discourse level and in a reader’s working memory. An important dimension to evaluate whether a topic is a good candidate for being eventually established as the AT in a text is continuity. As Givón (1992) observes, “the topic is only ‘talked about’ or ‘important’ if it remains ‘talked about’ or ‘important’ across a number of successive clauses” (p. 8). According to Givón (1983, pp. 7–15), there are three general aspects that guarantee topic continuity: (a) thematic continuity (being about the same theme), (b) action continuity (temporal sequentiality and adjacency), and (c) topic/participant continuity, 1 which is the primary focus of the current paper (or research). Two major variables affect AT continuity in a text. The first one is topic adjacency. As a matter of fact, AT can survive across textual gaps and be discontinuous. A textual gap is an empty referential space, that is, the distance between the last explicit mention of the referent and the place where the reader feels the need to reactivate it. AT continuity is achieved more easily when there are no gaps, when the number of gaps is low, or when they are small (either of limited extension or close to one another). Givón’s (1983) notion of continuity in discourse (applied to both spoken and written discourse) establishes the criterion of “length of absence from register” (“look-back” or referential distance). This criterion specifies that the shorter the gap, the easier the AT identification so that a topic in the preceding clause is by definition easier to identify. The gap between the previous occurrence in the discourse of an AT and its current occurrence in a clause is expressed in terms of the number of clauses to the left. The minimal value (or complete adjacency) is one clause to the left (maximally continuous), the highest value is 20 clauses to the left. Another variable that modulates AT continuity is topic accessibility. According to the Accessibility Theory (Ariel, 1990, 1996, 1999, 2004), all referring expressions—anaphora and null pronouns included—should be accounted for in terms of discourse functions rather than in terms of discourse profiles. While the latter reflect speaker’s choice and patterns of use referring expressions are associated with in discourse (e.g., pronouns refer to main characters while full NPs refer to subsidiary characters), discourse functions are more abstract and concerns how referring expressions code a specific degree of mental accessibility (Ariel, 2004, p. 93). Mental accessibility defines how easily an item can be retrieved from memory storage during discourse. When a speaker chooses an expression to refer to a previously mentioned entity, she “chooses her referring expression according to how she assesses the accessibility of the specific entity for her addressee at the current stage of discourse” (Ariel, 1999, p. 204). The choice among different anaphoric means depends on the speaker’s assumptions about the degree of accessibility of an entity in the listener’s memory storage and different referring expressions mark different degrees of accessibility. For example, definite descriptions (such full nouns) “require the intended referents to be entertained at a relatively low level of accessibility” (Ariel, 2004, p. 94). According to the Givón’s scalar concept of topic accessibility and continuity, indefinite null pronouns code for the least accessible and continuous topics, while zero anaphoras code for the most accessible and continuous ones. Between these two, there are a series of coding devices ranging from cleft/focus constructions and contrastive topicalizations (toward the less accessible extreme of the continuum), to definite null pronouns and stressed and unstressed pronouns or grammatical agreement (toward the more accessible end of the continuum). Another factor affecting accessibility is the degree of cohesion between the clauses in which the antecedent and its anaphora occur. The Conjoinability Hypothesis (C. N. Li & Thompson, 1979) predicts that the degree of cohesion between the two clauses contributes toward the establishment of the degree of accessibility. Lower cohesion between clauses decreases the accessibility of the antecedent and promotes the use of overt pronominals in contexts of [-Topic Shift]. Nevertheless, there is no categorical correlation between referring expressions and degree of accessibility. This might explain optionality in the use of null versus overt pronominal subjects in the context of [- Topic Shift] in NS. Other factors that hinder accessibility are text segmentation (i.e., paragraphing) (Giora & Lee, 1996), rhetorical purposes (Fox, 1993) and a shift in topic time and/or place (e.g., for Italian, Berretta, 1986).
AT continuity as a function of semantics and punctuation
Semantics and punctuation may play a role in the readers’ assessment of AT continuity within a text too. Givón (1983, p. 351) distinguishes between “minor juncture” and “major juncture.” Minor junctures do not break thematic continuity, as it is the case of commas followed by and, then, because, when, so or no conjunction at all. In contrast, major junctures tend to be marked by periods or breaks, which may also be followed by an introductory phrase (e.g., anyway), often contrastive. As a consequence, the latter junctures tend to break action and theme continuity more severely. Overt pronouns are often used at major rather than at minor junctures because in the former contexts, topic activation decreases as referent retrieval requires the processing of information available beyond one clause. To sum up, the assessment of AT continuity across sentences in a text is a multidimensional process, where semantics interacts with discourse-related features and with the segmentation of the story into different scenes.
Study rationale
We investigated whether and how the macro-analysis level (discourse) affected the micro-analysis level (sentence) in L2 competence. Our claim is that participants in our experiment would choose between lighter or heavier anaphoric means depending on their perception of AT continuity (or lack thereof). Namely, they would evaluate every topic in the proper context set, which is the place where the reader/listener classifies the information received or exchanged. To track this process, we interfered with AT continuity in a written text by manipulating the story plot and punctuation. The subdivision of the story in scenes and punctuation may alter participants’ perception of one crucial aspect of AT continuity, namely, its accessibility. If L2 Italian learners turn out to be significantly more sensitive than Italian NS to the consequences of artificial text segmentation, it may be because—at a specific point of the text that they are reading—they have lost the information that keeps connected denotata and prepositions. This could happen either because of text length or because of the way the text is organized and divided into scenes. In the latter case, L2 learners will resort to heavier expressions (the overt pronoun) to recover the information that got lost.
Research questions and predictions
Our study addressed three research questions:
Do learners and NS refer to the antecedent (the AT) by using overt or null preverbal subject pronouns?
Do developmental and individual-level factors (proficiency, L1 instruction, length of immersion and instruction, knowledge of L2 verb morphology) affect participants’ choices between null and overt pronouns?
Do semantics, the presence of disambiguating pictures, and the presence of contrastive focus affect participants’ choices between overt or null pronouns?
Our prediction is that participants will use null pronouns when they perceive the discourse AT as continuous and when identification gaps are smaller and easier for the reader to cross. In contrast, participants will choose overt pronouns when tracking aboutness is problematic. Developmental and individual-level factors may affect learners’ decisions too. We expect more proficient learners to pattern more closely to NS than to beginners. We also expect that learners’ knowledge of verb morphology, length of instruction, and length of immersion will positively correlate with the choice of null pronouns.
Material and methods
Participants
Two groups of speakers participated in this study: L2 learners of Italian (non-native [NN]) and NS of Italian. The initial learner group consisted of 358 L2 Italian undergraduate students (age: 19–25 years, M = 22.3) recruited from a group of universities in Northern and Central Italy (University Milan, Pavia, Verona, Perugia, Genoa). These participants were Erasmus students, international exchange students, and Marco Polo Turandot students. 2 Twenty learners were subsequently excluded because they failed to comprehend the story in the test (as they performed below the “comprehension threshold,” see the “Procedure” section). Therefore, the final learner group included 338 participants. Learners were assigned to four categories according to the values of the null subject parameter (NSP) as established in the current generative literature (e.g., Roberts & Holmberg, 2010), with two important differences (which we will explain below): (a) consistent prodrop languages—such as Italian, Greek, Turkish, and Arabic—are those that feature null subjects in all persons and tenses; (b) partial prodrop languages license null subjects only in some persons of the verb, for example, Finnish and Brazilian Portuguese third subject pronouns cannot be null, whereas third impersonal pronouns can be null; (c) discourse (radical) pro-drop languages—such as Chinese, Japanese, and Korean—allow non-expression of both pronominal subjects and objects and lack verb morphology; (iv) non-prodrop languages are languages—such as English, German, French, and Icelandic—in which pronominal subjects are expressed by pronouns in subject position that are normally if not obligatorily present (Dryer, 2013, see Duguine, 2017 for discussion).
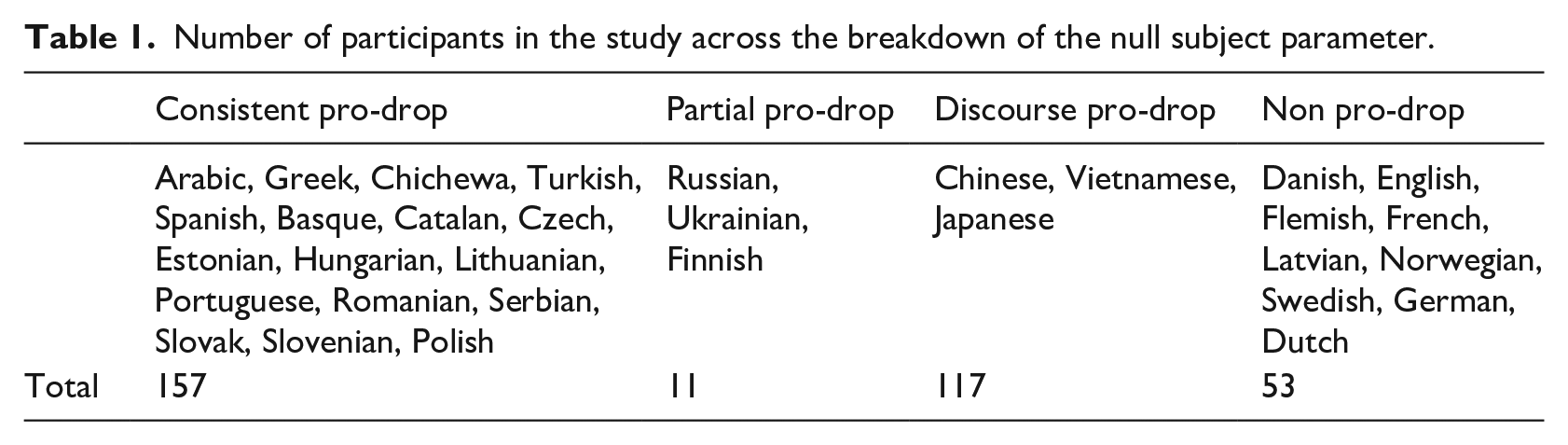
Unlike Roberts and Holmberg (2010), in the current study, we classified German and Dutch as non-prodrop languages. The reason for this classification, also endorsed by authors like Barbosa (2019) and Biberauer (2018), is that our research is concerned with anaphoric, i.e., necessarily referential, pronominals, and not with expletive ones: the presence of an expletive-drop feature was therefore not factorized. Biberauer (2018) in particular discusses the idea that the opposition between null and expletive subjects in German and Dutch needs to be understood as the surface reflex of a completely different formal property to that assumed for consistent prodrop languages. In other words, the presence of expletives would be the result of quite different underlying factors than those explaining the presence/absence of overt versus null pronouns. The second difference with Roberts and Holmberg (2010) concerns the fact that, in the current study, Turkish, Basque, Hungarian, and Chichewa (as representative of Bantu) are classified as consistent prodrop languages rather than discourse prodrop languages. An ongoing debate concerns whether only agreement-less languages of the East Asian type (e.g., Chinese) should be classified as discourse/radical prodrop languages (see the counter-example of Basque, Duguine, 2014). As pointed out by an anonymous reviewer, with respect to argument-drop possibilities, the four languages mentioned above behave more like discourse prodrop languages (e.g., Chinese, Vietnamese, Japanese) than consistent prodrop languages: for example, objects are droppable under quite different circumstances to those of languages that have only subject agreement. To check whether different grouping criteria might have affected the results, two separate statistics were run: in one, we considered the 13 participants speaking Turkish, Basque, Hungarian, and Chichewa as belonging to the “consistent prodrop” group, and in the other, we considered the same participants as belonging to the “discourse prodrop group.” The results of the comparison between these models are briefly discussed in the “Mixed effects model statistics” section. In Table 1, the learners’ L1s split according to NSP values is shown. In Table 2, the number of speakers for each L1 is reported
Number of participants in the study across the breakdown of the null subject parameter.
Number of participants in the study for each L1.
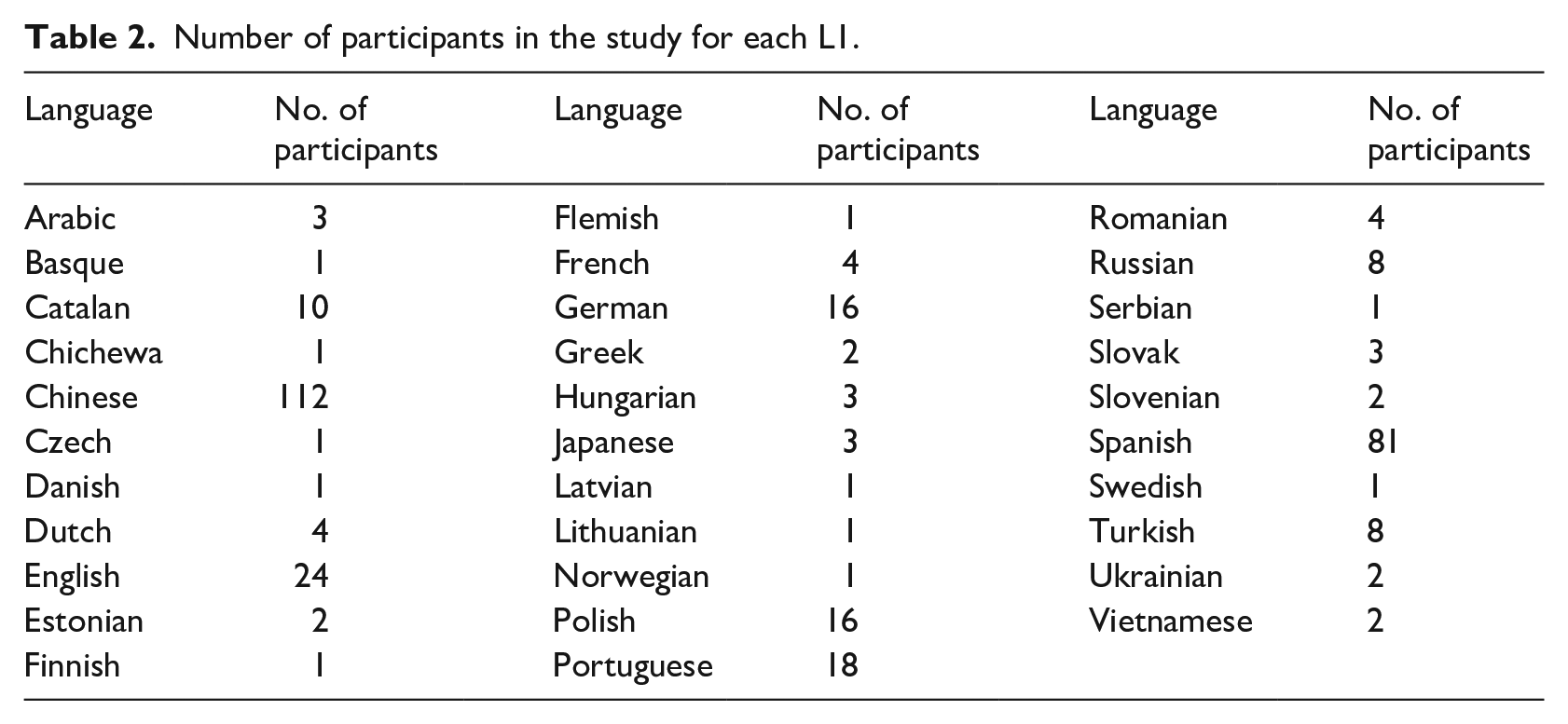
As it often happens in the case of convenience samples collected for the purpose of psychological research in learning environments, such as schools and universities (Wild et al., 2022), our sample was unbalanced too, at least with respect to participants’ L1, as well as their L2 proficiency. In fact, most participants—57% of the total number—were NS of either Chinese (from the Marco Polo Turandot Program) or Spanish (Erasmus students), and the participants’ proficiency level was skewed toward initial and low-intermediate stages of acquisition (78.7% of the total), with only 13 participants (3.8 %) who fell in the “advanced” group, as shown in Table 3.
Number of participants, average length of immersion (no. of months), and instruction (no. of months) across proficiency levels.
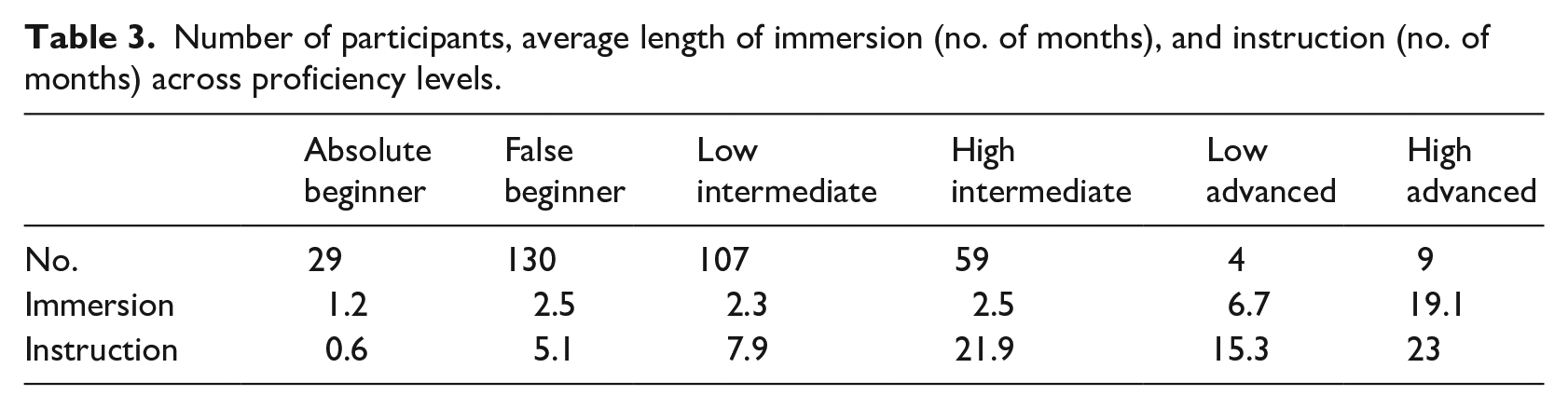
Participants’ proficiency level was tested via the administration of the CILS (Certificato di Italiano Lingua Straniera “Certificate of Italian as a foreign language”), which is an official L2 Italian proficiency test created by the University for Foreigners of Siena 3 in accordance with the guidelines of the Common European Framework of Reference for languages. This has become a standard proficiency assessment method in experimental second language acquisition (SLA) studies over the last 20 years (Rastelli, 2018). The test was administered to all participants at the beginning of the experiment. We adopted a unique scale test rather than different tests for each L2 proficiency level. Unique scale (or “curve” methodology) is widely adopted in experimental studies, especially in those that regress proficiency onto online measures (e.g., reaction times). Unique scale tests have the advantage of making standard deviations (SDs) directly comparable. Through SD comparison, it is possible to see whether experimental groups are homogeneous. This is not possible by using centering and standardization of scores that come from different tests (e.g., z-scores). As a centered measure of proficiency, we used the B1 level test, which is composed of four sections: listening comprehension, reading comprehension, metalinguistic knowledge, and written composition. Following an established practice in Italian universities, students who scored between 90 and 100 (M = 89.5, SD = 6) were considered advanced (C1–C2); students whose scores fell in the range between 60 and 89 (M = 71.5, SD = 9.6) were grouped in the intermediate (B1–B2) levels; students who scored below 60 (M = 40.5, SD = 8.6) were labeled as beginner (A2).
It is, however, possible that the six-level model of L2 proficiency—which follows the breakdown proposed in the CILS—was too fine-grained for the purposes of the current study, especially because of the paucity of advanced participants (only 3.8% of the total) compared with the large number of beginners and intermediate learners. Perhaps a simpler model based on three levels (“beginner,” “intermediate,” and “advanced”) would have better captured the distribution of our sample. Moreover, many SLA experimental studies (e.g., especially those utilizing Event-Related Potentials ERP and eye-tracking) that factorize proficiency as an independent variable tend to cut down the number of variable levels to increase the statistical significance and power of regression models (see Rastelli, 2018 for a review). Table 4 reports participants’ distribution across the values of NSP if a three-level rather than a six-level model of proficiency is chosen.
Number of participants across combined proficiency levels (“beginner,” “intermediate,” and “advanced”)—and percentages over the total number—across the values of the NSP.
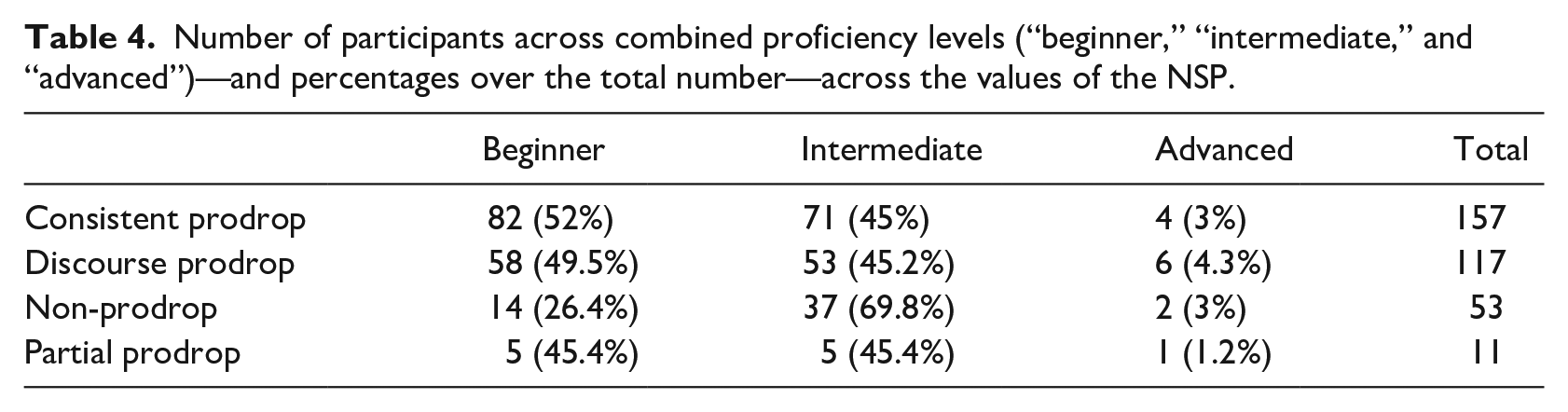
By looking at Table 4, we can notice that while the sample is still biased toward beginner and intermediate proficiency levels, participants with consistent prodrop, discourse prodrop, and partial prodrop L1s are homogeneously distributed across proficiency (the only relevant exception being the high number of intermediate participants among speakers of non-prodrop languages). In conclusion, while the three-layer breakdown still shows that advanced learners are under-represented in our sample, but it highlights that such skewness does not significantly impact participants’ distribution across NSP categories.
Finally, although speakers of non-prodrop language were not the most proficient learners, they reported the highest scores in terms of length of immersion and instruction, as shown in Table 5.
Mean length of instruction and immersion across the breakdown of the prodrop parameter.

Information about immersion—operationalized as participants’ length of stay in Italy (in months)—was collected through a written questionnaire before the experiment. In the cases of simultaneous bilingual (and quasi-bilingual) speakers, for example, Spanish-Catalan and Russian-Ukrainian, participants were categorized as NS of the language spoken at home and/or with close relatives and friends.
Learners’ knowledge of L2 verb morphology was assessed through a test taken from the CILS exam (level B1) and included 25 gaps to be filled with the conjugated form (for Tense, Mood, Person and Number) of the infinitive provided in brackets. The following tenses were targeted: Presente Indicativo (Simple Present, nine occurrences), Passato Prossimo (Present Perfect/Past Perfective; eight occurrences), Imperfetto (Past Imperfective; seven occurrences), and Futuro semplice (Simple Future; one occurrence). The test was timed and participants had 10 minutes to complete it.
The control group of Italian NS consisted of 90 participants (age range: 17–24 years). All participants provided written informed consent and were naïve to the aim of the study. Participation was voluntary.
The Pragmatic Cloze Test
Our stimuli consisted of a short pragmatic cloze test (PCT) (N = 129 words) made of 11 sentences, 4 among which four were monoclausal, five biclausal, and two triclausal. In the test, each clause corresponded to a scene of the story. Scenes were presented either in complex sentences consisting of two or three conjoined clauses separated by a coordinative or adversative conjunction, or in simple monoclausal sentences, separated by a full stop (Figure 1).

The Pragmatic Cloze Test (PCT) with relative English translation.
A cloze test is a comprehension task where participants are asked not only to understand the text, but also to choose between two or more competing options, some of them plausible and at least one implausible (distractor). To avoid ambiguity with the events of the story, in our PCT the written text was preceded, on the same sheet, by a six-scene picture story illustrating the story. This choice is meant to reduce the number of potentially uncontrolled variables, in two ways: First, since the task was untimed and participants were free to re-read the sentences, learners’ choice between null and overt pronouns could not be attributed to memory limitations or to processing constraints (e.g., non-adjacency of subject–verb agreement). Second, since the drawings of the illustrated story eliminated any ambiguity concerning the referent, L2 learners’ decisions were not biased by difficulties in comprehending the text. The text included paratactic constructions only (coordinative, temporal, and adversative). The PCT included 15 gaps, 12 of which were places of potential antecedent reactivation (PAR) of the AT, while 3 were distractors to be filled with articles, an adverb, or a preposition (i.e., where the choice of the pronoun was inacceptable). PAR (i.e., cloze blanks or gaps) always corresponded to a preverbal grammatical subject, which could be either the overt singular masculine Italian pronoun lui “he” or the null pronoun / _ /. With respect to spoken spontaneous narrations, the PCT has the advantage to deter participants from resorting to explicit antecedent reactivation because they find it difficult to retrieve the reference from previous discourse. In contrast, in the PCT, everything participants need to choose among is available, for three reasons. First, the AT (Giulio) is the main character of the story and is highly accessible because it coincides with the grammatical subject of the sentence. Second, AT continuity is ensured: the last mention of the AT never goes beyond two clauses to the left of any gap. Third, processing difficulties are reduced to the minimum since subject–verb agreement is at the third person singular throughout. Finally, there is no competition among null pronouns for anaphora bridging. In fact, sentences are paratactic (coordinate, adversative or temporal) and either share the same antecedent across or within sentences like in (1), or the gap (underlined) is contrasted with a topic-subject like in (2): (1) pro vede che è tardi e pro saluta Marta “(he)i realizes that it’s late and (he)i says goodbye to Marta” (2) l’amica va a casa a piedi, “his friend goes back home on foot, while
Procedure
Learners and NS were asked to fill in the blanks of the PCT and to carefully consider the pictures in case of uncertainty. The task was not timed. Participants were told that the story was about a boy called Giulio. This information was meant to let them identify the AT from the very beginning of the test. Average PCT completion time was ~12 minutes. Since the PCT is a comprehension task, we defined a “comprehension threshold of tolerance” to ensure that participants’ choices between null and overt pronominal subjects did not depend on their difficulties to understand a text in the target language. For this reason, we included three implausible distractors (out of 15 items) that we used to measure text comprehension. There were 20 learners who scored less than 14 points on the PCT, that is, they chose more than one distractor, and, for this reason, were excluded from the analysis.
Variable levels
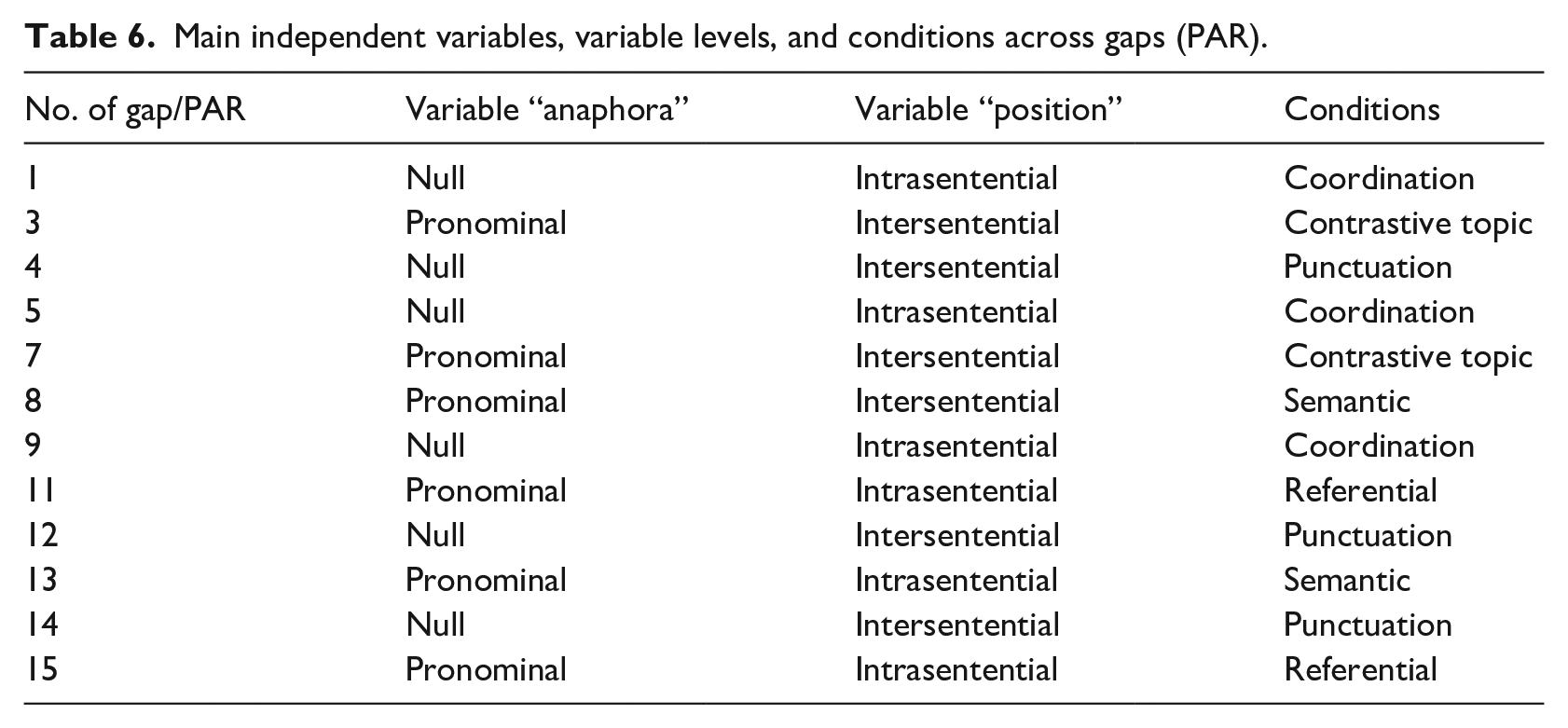
The outcome variable in our study was learners’ and NS’ choices between null and overt pronominal subject (“completion”). There were two independent main variables in our study: “anaphora” and “position.” The variable anaphora had two levels, “null” and “pronominal,” depending on whether the expected completion was the null pronoun or the overt masculine subject pronoun lui “he.” Whether completions with null or overt pronouns were “expected” or “unexpected” was established through a pilot study based on the judgments by a panel of Italian NS, 2 weeks prior to the experiment. 5 This pilot study was exclusively aimed at preparing the material and was not used to establish as a benchmark for learners and NS comparison. The two levels of the variable “anaphora” were evenly distributed across gaps (=PAR): 6 gaps required null anaphora, while 6 required pronominal anaphora completions. Regarding the experimental conditions, in gaps 1, 5, and 9 of the PCT, null anaphora was the preferred option (based on NS’ judgments) because the gaps were located in coordinate sentences (“coordinate” condition), where the subject of the coordinate sentence coincided with the subject of the main sentence (-Topic Shift). Also in gaps 4, 12, and 14, the gap and the antecedent shared the same grammatical subject, but this time they were separated by punctuation (“punctuation” condition). In these cases, the overt pronoun was the preferred choice in the target language because punctuation creates ST discontinuity (+ Topic Shift) in adjacent clauses. Namely, the overt pronoun indexed the ST of the clause as being different from the ST of the immediately previous clause. Pronominal anaphoras were made necessary by three different conditions: (a) the presence of a contrastive topic (“contrastive” condition, gaps 3 and 7); (b) verb semantic properties (“semantic” condition, gaps 8 and 13), where the verb selected a human agent as ST, different from the immediately preceding [- human] ST; and (c) referential ambiguity (“referential” condition, gaps 11 and 15). In this latter case, the selection of the appropriate human referent and, consequently, the choice of the adequate anaphoric linkage, is disambiguated by the contextual information provided by the pictures.
Regarding the second main variable, that is, “position,” all 12 gaps in the PCT were interspersed within and across sentences. The use of punctuation (i.e., full stops) split the experimental variable in two levels: “intrasentential” (the condition when the antecedent AT and the gap were in the same sentence) and “intersentential” (the condition when the antecedent AT and the gap were in two separate sentences). Full stops were meant to create artificial breaks in the stream of events described by the story. They were arbitrary, in that they could have been replaced by commas, coordination, asyndeton, with no effect on the story.
Variables, levels, and the relative conditions in the study were nested as follows. The levels “intrasentential” and “intersentential” of the variable “position” were evenly distributed across conditions in the null anaphora level. This means that all sentences in the “coordinate” condition were intrasentential while all sentences in the “punctuation” condition were intersentential. On the contrary, the levels of the variable “position” cut across the conditions of pronominal anaphora: two contrastive gaps (3,7) and one semantic gap (8) were intersentential, while two referential gaps (11, 15) and one semantic gap (13) were intrasentential. Nesting and uneven cross-interaction among variables, levels and conditions were chosen for the sake of keeping the naturalness of the text and to conceal the rationale of the experiment to participants as much as possible. Such interactions were all kept into account in the statistical analysis. Table 6 visualizes the main independent variables of the study, along with their levels and conditions.
Main independent variables, variable levels, and conditions across gaps (PAR).
Results
Descriptive statistics
Table 7 reports the mean and SD of NS’ and learners’ choices between the six null and six pronominal expected completions.
Mean (M) and standard deviation (SD) of native (NS) and non-native (NN) participants’ choices between null and pronominal anaphora.

One can notice two facts: (a) NS’ and learners’ completions differed especially in the null anaphora condition (the first row of the table), that is, when the null pronoun was expected and (b) in the pronominal anaphora condition, NS scored almost 1 point lower (4.66 vs 5.52) than they did in the null anaphora condition. Table 8 reports participants’ choices across the variable “position” (when the gap and its antecedent are separated by punctuation and when they occur in the same sentence).
Mean scores (M) and standard deviation (SD) out of the three expected null and three expected pronominal completions by native (NS) and non-native (NN) participants in intersentential and intrasentential conditions.
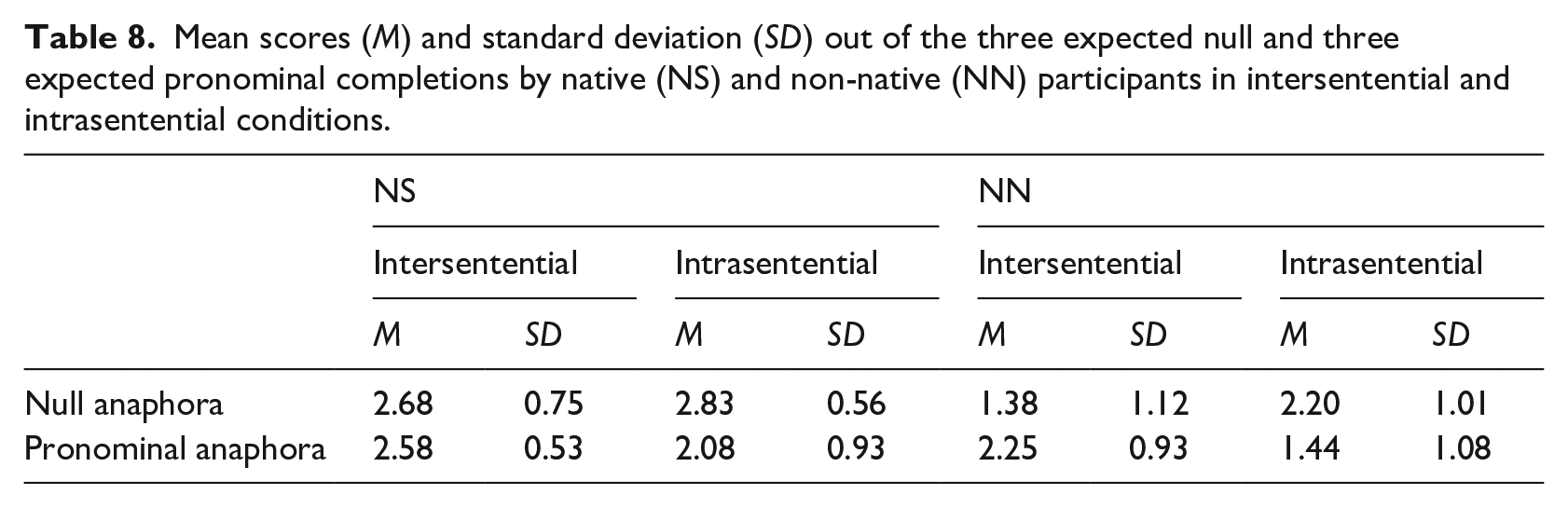
One may observe three facts: (a) the difference between NS and NN participants—that we noticed to be greater in the null anaphora condition—which became maximal (>1.30 points) when the antecedent and the gap were separated by punctuation (in the “intersentential” condition); (b) in contrast, in the pronominal anaphora condition, the difference between NN and NS participants increased when the gap and the antecedent occur in the same sentence (in the “intrasentential” condition); and (c) NS and NN participants patterned more similarly when choosing the overt pronoun across sentences (intersentential condition). All these contrasts are visualized in Figure 2.
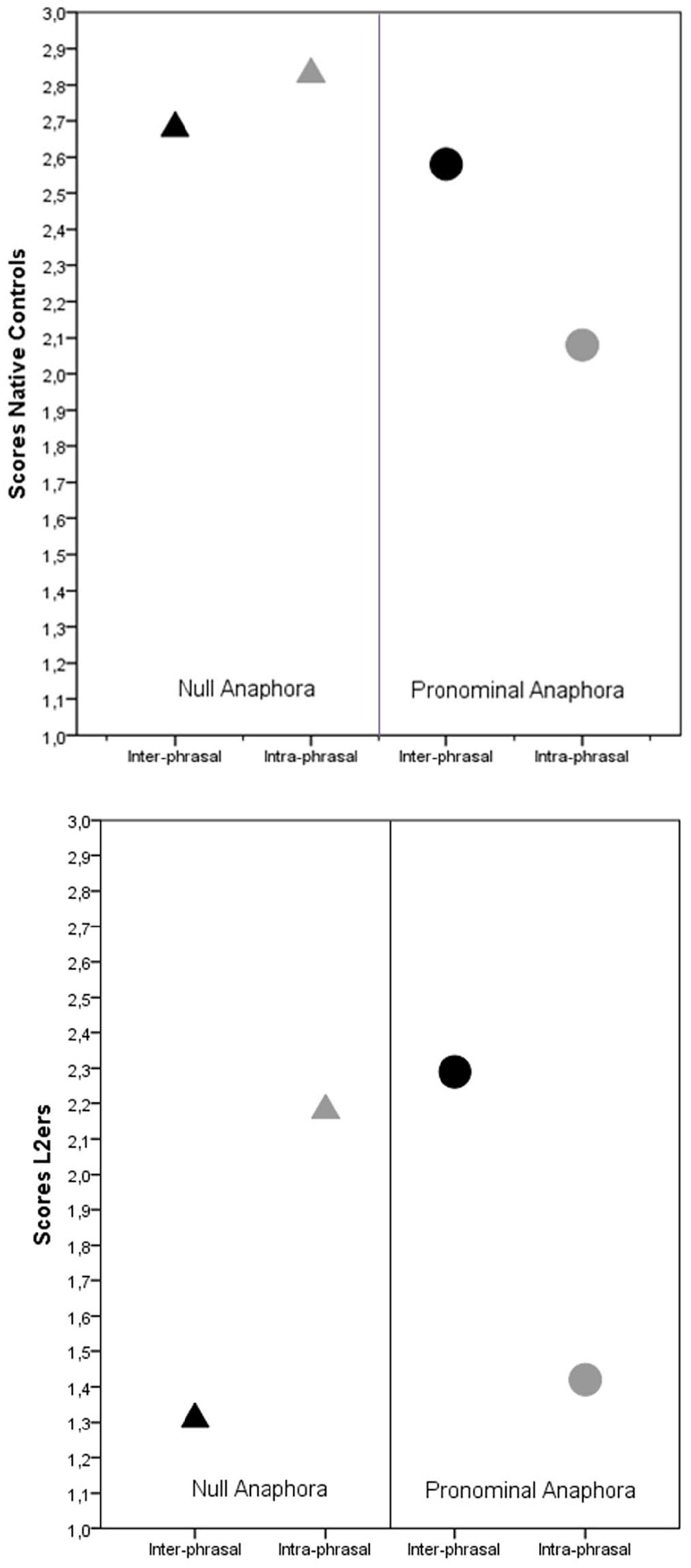
Mean scores differences between null and pronominal anaphora by position (inter- and intrasentential) by NS (above) and NN (below) participants.
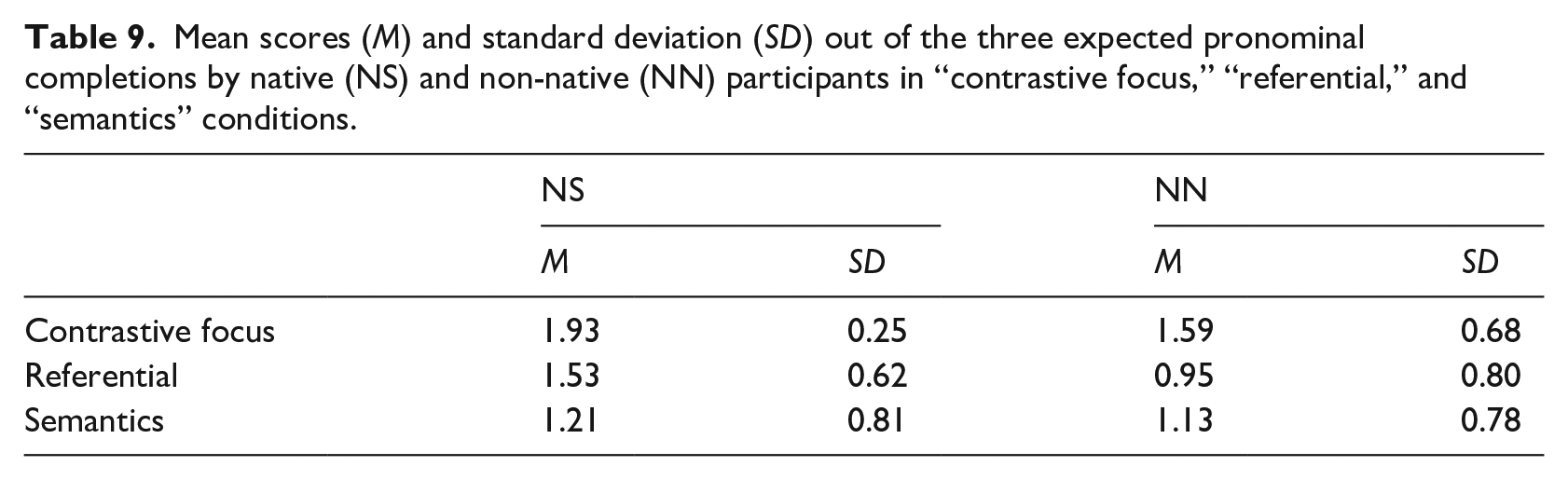
When choosing the overt pronoun in the intrasentential condition, NN relied less than NS on the pictures to disambiguate the referent. As to the semantics of the antecedent, one can notice that both NN and NS participants were unlikely to utilize overt pronouns when the main verb selected a human agent as ST, different from the immediately preceding [- human] ST (as in gap 8: L’autobus arriva, lui sale “The bus arrives, _ / he / gets on”). In such cases, as the results of the pilot study had suggested (Note 5), the choice of the overt pronoun was expected given the fact that AT has to survive the challenge of competing antecedent (l’autobus, “the bus”) which shares with Giulio the same number (singular) and gender (masculine). In contrast, NN and NS were similarly sensitive to the presence of a contrastive focus when choosing the overt pronoun across sentences. This latter observation is confirmed by Table 9, where the factors that favored or hindered NS and NN choices of pronominal anaphora are compared.
Mean scores (M) and standard deviation (SD) out of the three expected pronominal completions by native (NS) and non-native (NN) participants in “contrastive focus,” “referential,” and “semantics” conditions.
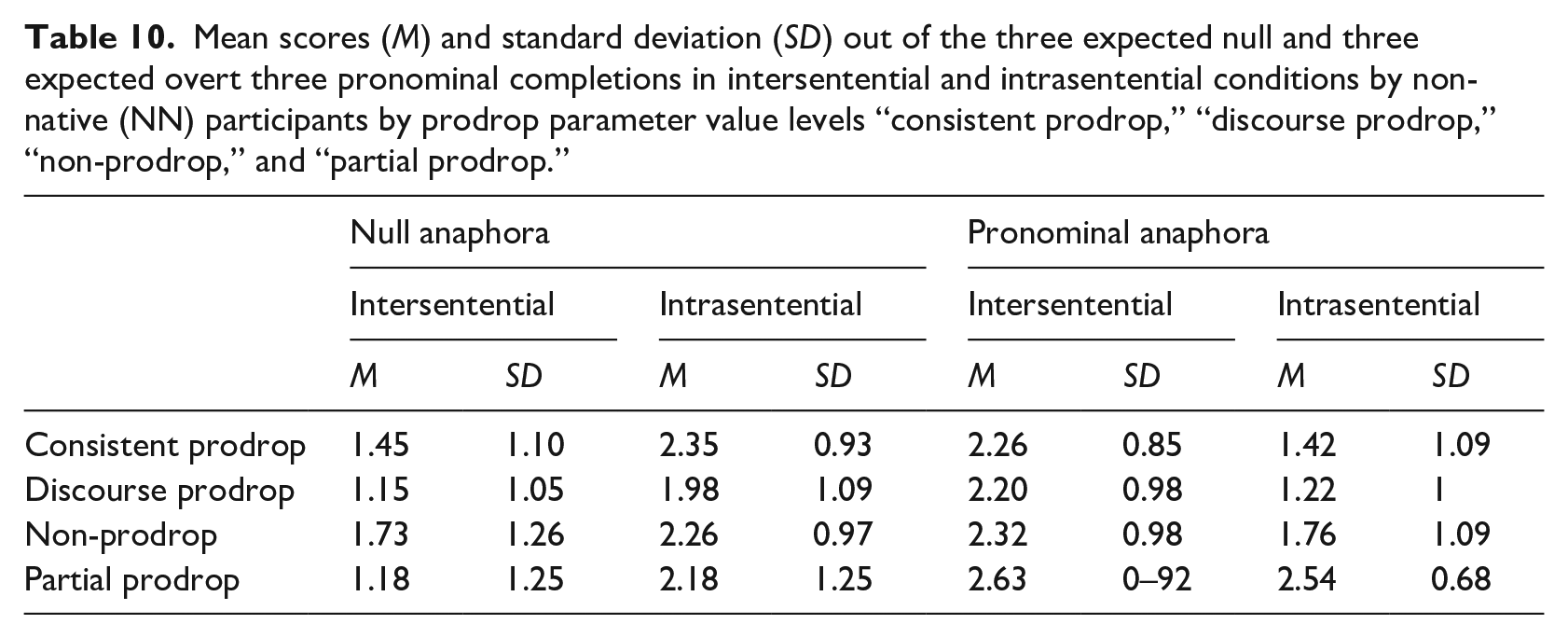
The impact of NN participants’ first languages on the choice between null and overt pronoun across intersentential and intrasentential conditions is reported in Table 10 and visually represented Figures 3 and 4, where the mean scores and the SDs were sorted out—respectively—according to the eight most represented L1s in the sample and according to the four values of the prodrop parameter of those languages.
Mean scores (M) and standard deviation (SD) out of the three expected null and three expected overt three pronominal completions in intersentential and intrasentential conditions by non-native (NN) participants by prodrop parameter value levels “consistent prodrop,” “discourse prodrop,” “non-prodrop,” and “partial prodrop.”
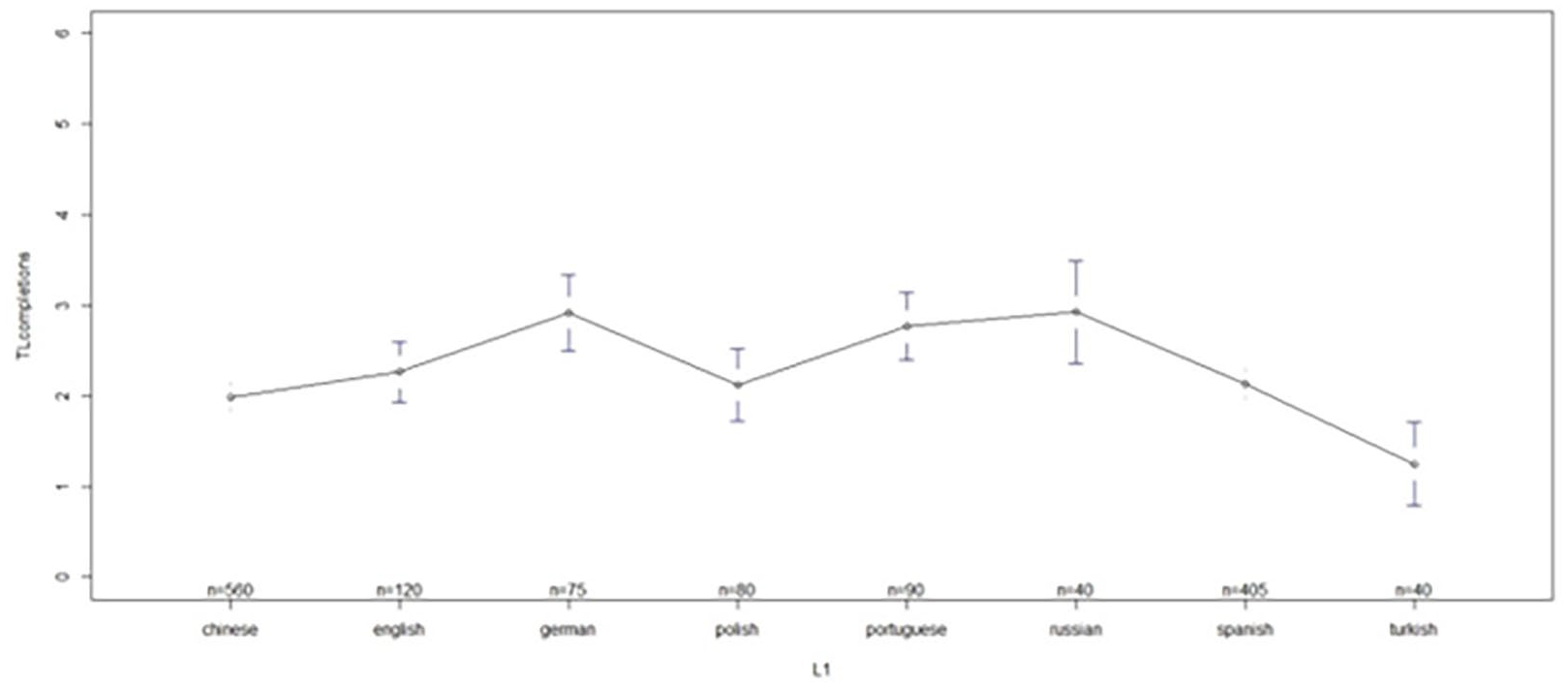
Mean scores across the most represented NN participants’ L1s (with no. of observations and confidence intervals).
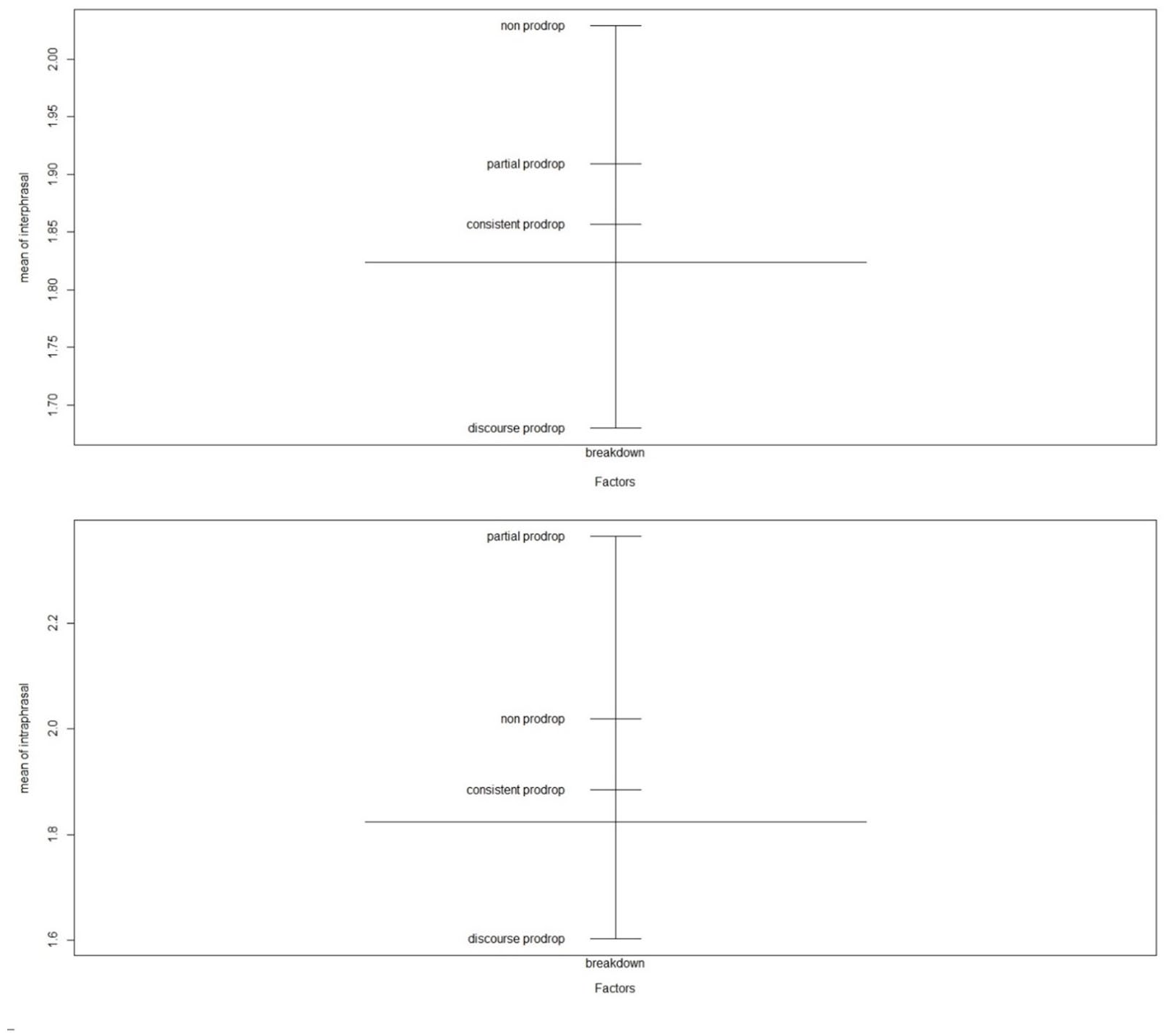
Mean scores in intersentential (above) and intrasentential (below) conditions across the breakdown of the prodrop parameters.
There is no easy explanation for the observed patterns. Figure 3 suggests that especially L1 Turkish (n = 8) and L1 Chinese (n = 112) speakers performed below average, L1 German (n = 16) and L1 Russian (n = 8) performed above average, while L1 English (n = 24), L1 Polish (n = 16) and L1 Spanish (n = 81) speakers were the closest to the mean. A look at Figure 4 confirms that speakers of consistent prodrop languages (e.g., Spanish, Portuguese) and speakers of discourse prodrop languages (e.g., Chinese) behaved very differently in both the null anaphora and in the pronominal anaphora condition. Quite unexpectedly, speakers of non-prodrop languages (e.g., French, n = 4, and English, n = 24) scored higher than speakers of prodrop languages (e.g., Spanish, n = 81), only in the null anaphora condition. As previously mentioned, while speakers of non-prodrop language were not the most proficient learners, according to the results of the CILS test (Table 5), they were the most immersed and the most instructed ones. Whether instruction and immersion could have played a bigger role more than proficiency in enabling learners to drop unnecessary pronouns is discussed in the “Conclusion” section. Finally, speakers of partial prodrop languages (e.g., Russian) patterned differently depending on the variable “position”: they were well above average in the pronominal anaphora condition, and below average in the null condition.
A possible objection is that such results can be due to the unbalanced samples of participants. Indeed, speakers of partial prodrop languages (n = 11) and non-prodrop languages (n = 53) were fewer than speakers of consistent prodrop languages (n = 157) and discourse prodrop languages (n = 117). However, SDs were similar across groups (with the only exception of the partial prodrop group), indicating that the presence of outliers (particularly affecting smaller groups) was not the only decisive factor for the differences between groups, which can be ascribed to individual differences. The impact of NN participants’ knowledge of Italian on the choice between null and overt pronoun in intersentential and intrasentential conditions is displayed in Figure 5, where proficiency levels (according to the CEFR, “Participants” section) are plotted on the x axis.
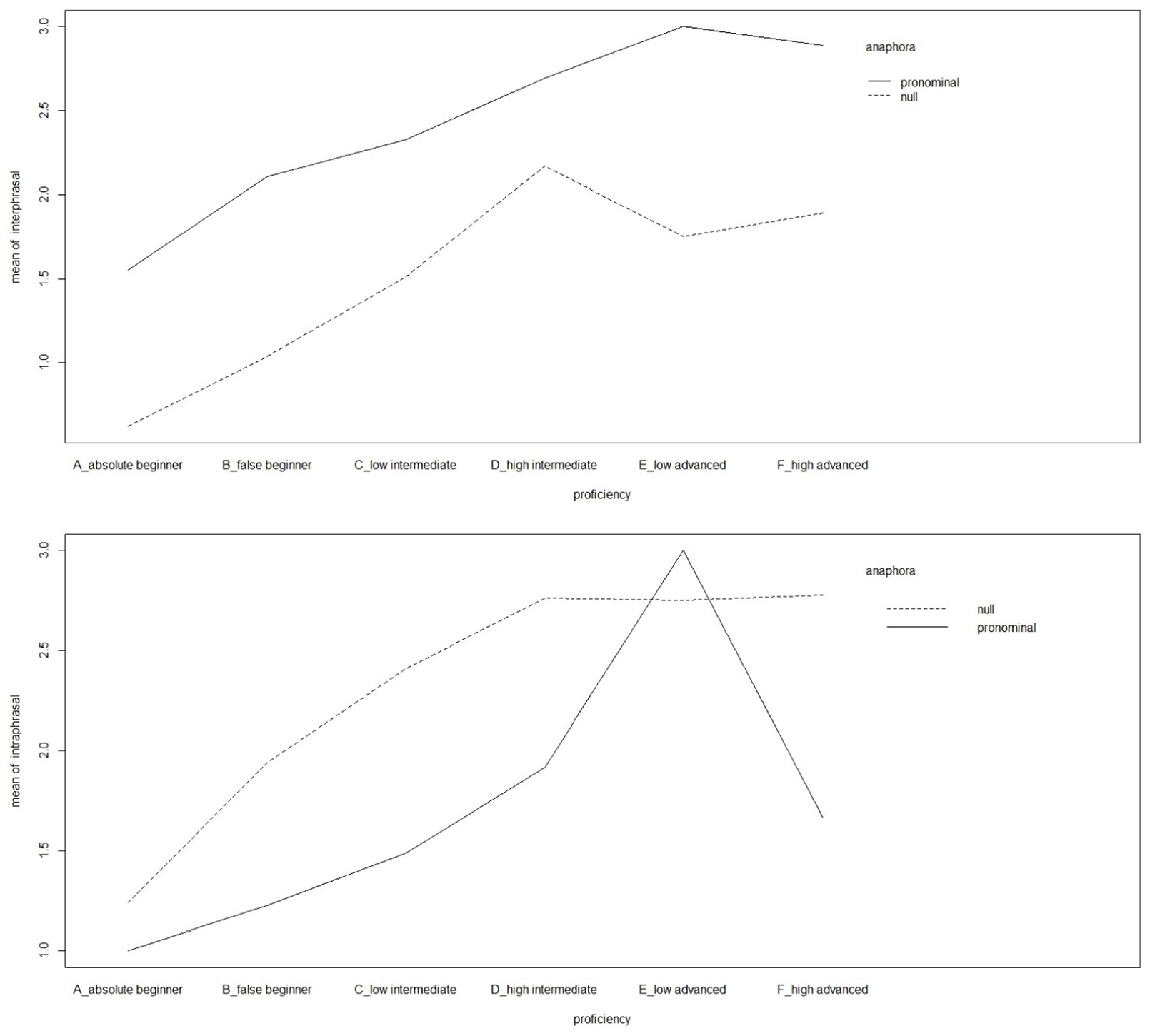
Mean scores in intersentential (above) and intrasentential (below) conditions by NN participants’ proficiency levels (complete six-level model).
The figure suggests that means scores in both conditions were a direct function of increasing L2 proficiency. Yet, advanced-high participants performing like intermediate-high ones in the intrasentential condition represent a notable exception to the general trend. However, if we utilize the simplified three-level model of proficiency in place of the six-level one (suggested by the official CILS exams taken by NN participants, cf. “Participants” section, Table 4), the relationship between proficiency and the choice of null versus pronominal completion in both intra- and intersentential conditions becomes straightforwardly collinear, as both the upper and lower panel of Figure 6 clearly suggest.
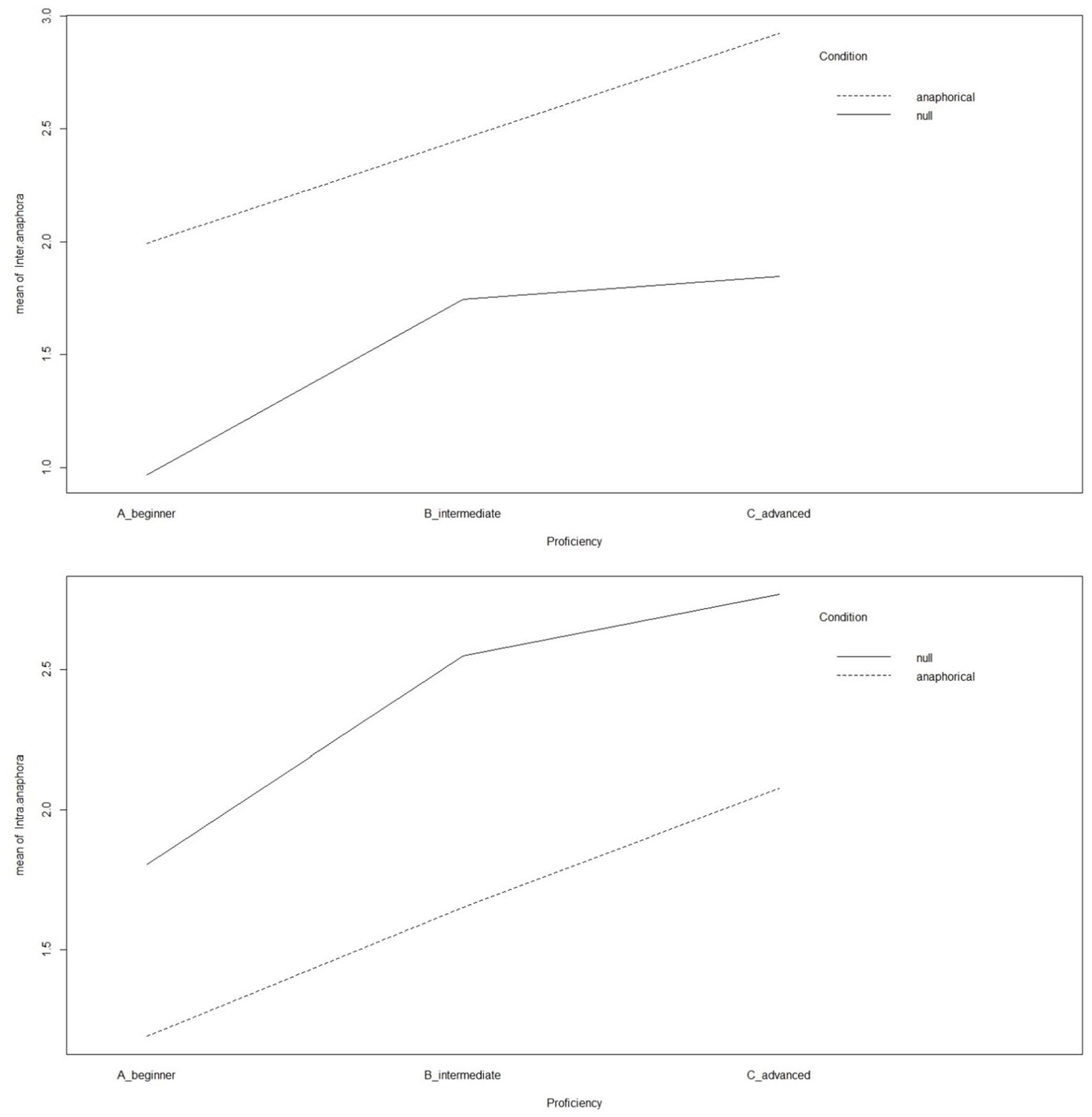
Mean scores in intersentential (above) and intrasentential (below) conditions by NN participants’ proficiency levels (simplified model).
If we restrict the comparison only to NS and the most advanced NN participants, we see that the average difference between such groups was 0.90 points in the null condition and only 0.34 points in the pronominal condition. However, such differences exclusively concerned the intersentential condition (when the gap and the antecedent were separated by punctuation). In all other conditions, the most advanced L2 learners and the Italian NS patterned alike. There is of course the risk that the small numbers of participants (4 advanced-low learners and 13 advanced-high) may have played a bigger role than it did in larger groups of participants. If we turn to the three-layer model of L2 proficiency—in which advanced-high and advanced-low speakers are merged—we obtain a slightly larger group of participants (n = 13). Yet, also in this case, the difference with NS does not change (0.84 points in the null condition and 0.34 in the anaphora condition, with no significant differences in the intrasentential condition). Finally, as to bivariate statistics, no correlation was found between mean NN participants’ scores and length of immersion in Italy (Pearson’s correlation = 0.04) and between mean scores and length of language instruction (Pearson’s correlation = 0.12). Only a weak positive correlation was found between mean scores and NN participants’ scores in the morphology test (Pearson’s correlation = 0.25).
Mixed-effects model statistics
Since the design of this experiment contained within-subject (all level variables being within-subject) and between-group variables (NN vs NS), and since the observations in the dataset were not independent (with multiple responses for each subject and many variable levels being nested), we used a linear mixed-effects (LME) model (Baayen, 2008, pp. 241–295; Winter, 2020, pp. 232–273) to run the analysis. Besides respecting the independence assumption, this method ensures that both individual variation among participants in each group (by-subject variation) and variation among different items (by-item variation) are handled properly. To avoid type I error, we used a random slope model, where subjects and items are allowed to have differing intercepts and different slopes for the fixed effects of interest (Barr et al., 2013). We used maximum likelihood (ML) estimation and the likelihood ratio test to compare the likelihood of the models and to attain p-values, which were obtained by testing the full model with the effect(s) in question against the model without the effect(s) in question (or their interactions). We used R version 3.5.2 (R Core Team, 2012) and lmer() function from the lme4 package (Bates et al., 2015) to perform LME analysis of the relationship between participants’ completions, kind of anaphora, position of gap and antecedent and all other descriptive and developmental variables. Prior visual inspection of residual plots did not reveal any clear deviations from homoscedasticity or normality in the data.
To answer RQ1—asking whether NN and NS participants would refer to the antecedent by using the overt or null preverbal subject pronoun—we built a full predictor model with GROUP (levels: “NN” and “NS”), ANAPHORA (levels: “null” vs “pronominal”), and POSITION (levels: “intersentential” and “intrasentential”) as fixed variables and intercepts for subjects and items, as well as by-subject and by-item random slopes as random variables. The model showed that the variable GROUP (the difference between NS’ and NN’ responses) and POSITION (the gap and the antecedent being or not separated by punctuation) significantly impacted participants’ choices (χ2 = 81.366, df 1, p = <2.2e−16***; χ2 = 112.457, df 1, p = <2.2e−16***) both in the intersentential (χ2 = 82.676, df 1, p = <2.2e−16***) and in the intrasentential conditions (χ2 = 49.168, df 1, p = 2.35e−12***). The variable ANAPHORA did not bring a significant improvement to the model individually (χ2 = 0.6114, df 1, p = .434257), while its interaction with GROUP did (χ2 = 14.8083, df 1, p = .000119). Indeed, while NS participants’ responses were significantly different in both the null and pronominal anaphora conditions (χ2 = 21.514, df 1, p = 3.513e−06***), NN participants’ responses were not (χ2 = 1.0454, df 1, p = .3066). Within the NS group, choices between null and pronominal anaphora differed more when the gap and the antecedent were in the same sentence (Intrasentential χ2 = 38.101, df 1, p = 6.718e−10***) than when they were separated by punctuation (Intersentential χ2 = 1.0581, df 1, p = .3036).
To answer RQ2—asking whether developmental and individual-level factors would affect NN participants’ choices—we built a full predictor model with PROFICIENCY, BREAKDOWN (of the prodrop parameter), length of INSTRUCTION, length of IMMERSION, MORPHOLOGY SCORE, and L1 as fixed variables and intercepts for subjects and items, as well as by-subject and by-item random slopes as random variables. PROFICIENCY, BREAKDOWN, MORPHOLOGY SCORE, L1, and INSTRUCTION all contributed significantly to the full predictor model (PROFICIENCY χ2 = 99.256, df 5, p <2.2e−16***; BREAKDOWN χ2 = 11.162, df 3, p = .01088*; MORPHOLOGY χ2 = 37.243, df 1, p = 1.043e−09***; L1 χ2 = 91.967, df 31, p = 5.905e−08***; INSTRUCTION χ2 = 22.99, df 1, p = 1.628e−06). In contrast, IMMERSION did not contribute to the model (χ2 = 0.0092, df 1, p = .92361). Proficiency, breakdown, instruction, morphology score, L1, and instruction affected the model in both the intersentential and intrasentential anaphora conditions, without significant differences between the production of target-like null and overt pronouns (all p ⩾ .3). When we restricted the analysis to the most proficient learners—in both the six- and three-layer proficiency models outlined in the “Participants” section—we found that the variable GROUP was not predictive in isolation (χ2 = 0.0374, df 1, p = .8466), while its interaction with ANAPHORA and POSITION was. Namely, the difference between NS and advanced NN participants was significant with null pronouns in the intersentential condition (χ2 = 17.9596, df 1, p = .0001259***), but not in the intrasentential one (χ2 = 0.0442, df 1, p = .8334). Finally, the interaction between proficiency, immersion and the breakdown of the prodrop parameter contributed significantly to the predictive power of the model (PROFICIENCY × BREAKDOWN χ2 = 23.884, df 6, p = .0005485; IMMERSION × BREAKDOWN χ2 = 28.9275, df 6, p = 6.279e−05). To see whether the decision of including the 13 participants who were NS of Turkish, Basque, Hungarian and Chichewa in the “consistent prodrop” group affected the results, as already mentioned, two separate predictor models were built, one considering those participants as belonging to the “consistent prodrop” group, another considering the same participants as belonging to the “discourse prodrop group.” The models differed only with respect to the fixed variable BREAKDOWN (of the prodrop parameter). The likelihood ratio test showed no differences between the models in either (intersentential/intrasentential) condition, nor in the production of target-like null and overt pronouns (all χ2 ⩽ 0.07, all p ⩾ .2)
To answer RQ3—asking whether language-related and contextual factors would affect participants’ choices—we built a full predictor model with GROUP (NN vs NS), SEMANTICS (animate vs inanimate antecedent), REFERENT (the presence of a disambiguating picture) and (contrastive) FOCUS as fixed variables and intercepts for subjects and items, as well as by-subject and by-item random slopes as random variables. The factors GROUP and FOCUS contributed significantly to the model. With respect to GROUP, NN and NS responses were significantly different across all conditions (χ2 = 8.796, df 1, p = 4.246e−11***), except for SEMANTICS, where values were similar (p = .09). As for FOCUS, when the sentence featured contrastive focus, responses were significantly higher in both groups compared with the other variables (χ2 = 4.563, df 3, p = .0002522***).
Summary of findings and shortcoming
The difference between NS and NN participants’ scores was maximal when the null pronoun and its antecedent occurred in adjacent scenes of the story each expressed by a monoclausal sentence, separated from the preceding and following sentence by punctuation. The difference was minimal in the “contrastive focus” condition, when the required overt pronoun and its antecedent were in the same sentence. Learners’ proficiency and L1 were strong predictors of NN scores, in both the null and the overt pronominal anaphora condition. Even advanced learners, who, in overt pronoun usage, performed in a very native-like fashion, showed substantial differences with the NS in null pronoun use, especially when it was separated from its antecedent by punctuation. Speakers of non-prodrop and partial prodrop languages performed better than speakers of consistent prodrop and discourse prodrop languages in the null pronoun condition. Length of instruction and knowledge of verb morphology (as well as their interactions with the breakdown of the prodrop parameter) impacted learners’ scores across all conditions, whereas length of immersion did not. When an overt pronoun was required because of the presence of a contrastive focus, NN participants’ responses were more target-like. Semantics and the presence of disambiguating pictures had little or no impact on participants’ scores. Possibly the most important shortcoming of the current study is the composition of the NN sample. It would have been valuable to have had more advanced L2 learners, especially to establish more precisely how similarly NS and the most advanced NN use null and overt pronouns. The fact that—in our convenience sample—advanced learners were under-represented and outnumbered by beginning learners limits the generalizability of the findings.
Discussion
Non-optional 6 and optional pronouns in discourse
There is a certain amount of variance in our data, among both NN and NS participants. This might indicate that the choice between null and overt pronouns in discourse is more optional than in isolated sentences. Givón (1983) pointed out that the pro-drop parameter in discourse is never mandatory: “In fact the reactivation of a highly available referent by means of an explicit syntactic means is dispreferred, not agrammatical: it doesn’t produce agrammatical sentences, but results just in redundancy” (p. 12). Our data suggest that—with respect to optionality—a sharp distinction between null and overt pronouns should be made. Indeed, optionality in our data did not concern intersentential null pronouns, a domain in which NS and NN participants’ choices were systematically different. Regardless of their L1, even the most advanced NN learners tended to avoid the null pronoun every time the antecedent was in a different scene of the story, no matter the linear distance. NN learners, unlike Italian NS, lost contact with the AT of the story every time the scene of the story changed and the antecedent was in a different—albeit adjacent—sentence. Optionality in our data concerned the cases where the overt pronoun was required to disambiguate between competing antecedents (animate vs inanimate) within the same sentence. Lowest scores by NN participants in such condition might indicate optionality because, in the same condition, NS participants too, on average, scored almost one point lower (4.66 vs 5.52) than they did when the null pronoun was required. Perhaps both NS and NN participants did not deem it mandatory to reactivate the overt pronoun when the AT antecedent was in the same sentence, made exception for cases of contrastive focus.
In seemingly stark contrast to the data concerning our NS participants’ choices of null pronouns, Frascarelli (2007, 2018); explains why and in what circumstances a certain degree of optionality must be expected, even from Italian NS, in the interpretation of null subjects within the same sentence, roughly corresponding to our intra-phrasal condition. The Topic Criterion proposed by Frascarelli (2007, 2018) states that the C-domain sentences contain a position in which the [+ aboutness] feature is encoded and matched by the null subject. Provided that it is continuous, the [+ aboutness] Topic can be null. This implies that every sentence contains a position where the speaker must check the [+ aboutness] feature of any DP candidate for that role (Frascarelli, 2018, p. 212). Once the AT is identified and established in discourse, such [+ aboutness] feature is maintained continuously—and silently—across sentences through AT chains, at least until a new A-Topic is encountered. The presence and effectiveness of AT chains would explain the general principle: “avoid [a] strong pronoun, whenever it agrees with the current A-Topic” (Frascarelli, 2018, p. 219). Frascarelli (2018) presents some evidence (paper and pencil acceptability judgments data, with permitted responses “OK,” “NO,” or “??,” intended as “not fully”) showing—for example—that when the null subject pro sits in the complement of a so-called “bridge verb” (verbs of saying or opinion) like in sentence (3), NS can refer it to either an overt DP (i.e., Leo) or a silent one: (3) Leo ha detto che pro ha comprato una casa Leo have.3SG say.PST.PTCP that have.3SG buy.PST.PTCP a house “Leo said that he | pro bought a house”
Based on these data, Frascarelli (2018) concludes that the interpretation of pro in Italian always requires the previous identification of the AT heading the AT chain as a necessary condition. In the absence of a context clearly indicating the element where aboutness is successfully checked by speakers, the sentence is likely considered ambiguous not only by L2 learners—as our data confirm too—but also by many Italian NS. We must recall, however, that in the PCT—unlike in the sentences utilized by Frascarelli (2018)—establishing the AT was never an issue for participants. Indeed, in our PCT, (a) the AT (Giulio) was always accessible to the highest degree as it was the grammatical subject of the sentence, (b) AT continuity was always ensured by the fact that the last mention of the AT never went beyond two clauses to the left of any gap, and (c) there were no competing silent pronouns for anaphora bridging because sentences were always paratactic (coordinate, adversative, or temporal) and, therefore, shared the same antecedent across or within sentences. Given how the experimental conditions in the current study were set and controlled for in regression models, we can safely exclude that—in our data at least—there was optionality in the choice of null subjects in both intrasentential and—to a slightly lesser extent—intersentential conditions by the NS participants. Lack of optionality is exactly what set NN and NS participants apart in our study.
Participants’ L1
Learners’ first languages significantly impacted the scores, but its impact is not easily interpretable. We observed three puzzling facts. The first one concerns speakers of non-prodrop languages (e.g., English, German, French) dropping the unnecessary pronoun more often than speakers of prodrop languages (e.g., Spanish, Portuguese). Such evidence apparently flies on the face of L1-transfer accounts of the prodrop parameter, such as classical studies demonstrating the acceptance of referential null subjects in English tensed clauses by L1-Spanish speakers (e.g., White, 1985). There is no unique explanation for our findings though. Probably proficiency, length of instruction, and length of immersion all played a role because speakers of non-prodrop languages were by far more immersed (6 months on average) and had received more hours of formal instruction than all other learners (see Table 5). As the statistical analysis showed, the interaction between the amount of instruction, length of immersion, and the values of the breakdown parameter significantly impacted the results.
The second puzzling piece of finding—although less unexpected—concerns the difference among speakers of consistent prodrop languages. For example, L1-Portuguese learners’ scores were significantly more target-like that those of the L1-Spanish learners, which in turn were more target-like than the L1-Turkish learners’ scores. 7 Inconsistencies between speakers of consistent (canonical) prodrop languages are widely reported in the literature about null pronoun acquisition (Sorace et al., 2009; Sorace & Serratrice, 2009). Within-group differences cannot explain the discrepancies observed among speakers of the consistent prodrop group either, because proficiency levels, length of immersion, and amount of instruction were even and comparable.
The last puzzling fact concerns L1-Chinese (a radical prodrop language) learners, who performed way below average, especially in the null pronoun condition. The case of Chinese learners may appear special, but the assumption that speakers of a radical prodrop (“topic prominent”) language should find it easy to drop unnecessary overt pronouns in an L2is incautious for at least two reasons. First, the structure of Chinese might not have exerted any influence on the acquisition of Italian. Unlike in Italian, the conditions under which STs can be dropped in Chinese may vary greatly depending on the circumstances and speakers. For example, the pronoun subject wo “I” in a declarative sentence such as (4) is optional. It is neither necessarily emphatic nor does it necessarily suggest the presence of a contrastive focus (Cherici, 2021): (4) Zuótiān wo zài wàimiàn chī-le fàn yesterday I in out eat-PFV rice “Yesterday I ate out and had some rice”
Unlike in Italian, a rule governing prodrop in Chinese is that adjacent identical co-referring subjects are avoided. This conforms to the studies claiming the degrees of tolerance for unnecessary overt pronouns differ a lot between Chinese and Italian. For example, unlike Italian, Chinese arguments can be overtly realized even in unmarked utterances, and there are not as strict syntactico-pragmatic constraints regulating their distribution, although expletives must be null (Cherici, 2021). Moreover, the different use and distribution of null/overt subjects between Italian and Chinese is mirrored by their frequency: for Chinese, X. Li and Bayley (2018) report that among the 6,691 subject pronoun occurrences coded, overt subjects amounted to 47%, whereas for Italian, Lorusso et al. (2005) report that overt subjects were present only in the 26% of the adult NSs’ utterances analyzed. Interestingly, Frascarelli and Casentini (2019, p. 26) maintain that Chinese shows a lower degree of tolerance also for the use and acceptability of silent topics at the beginning of AT chains. In other terms, although aboutness can be started and established by a silent topic, the ideal antecedent for an NS in radical Chinese is an overt, local AT. This could at least partially explain why L1 Chinese participants performed way below average especially in the intersentential condition, when the antecedent and the null pronoun were separated by a full stop.
Another reason for Chinese speakers’ resistance to dropping unnecessary pronouns may be the impact of pedagogical intervention, more specifically, in the way Italian is taught to these students in China (and also in Italy).
Classroom instruction
Instruction had a significant impact on the production of both null and overt target-like pronouns. More instructed learners produced more target-like completions. L1 Chinese learners in our sample were among the lowest proficient and least immersed learners, and had received a lesser amount instruction on average. However, it is also the kind of instruction—rather than its length alone—that might have impacted our data. During Italian language classes in China, unnecessary Italian subject pronouns are very often read aloud by the teacher and pupils altogether as a mean to highlight the variance in verb endings. This practice is extremely common when Chinese students are taught Romance languages, both in China and in Europe, because it is believed to help them memorize verb conjugation (Rastelli, 2021). This practice is common not only in Italy, but also in Europe, even in the contexts where more communicative approaches to foreign language teaching are preferred (see Cherici, 2021, pp. 14–15 and bibliography quoted there). If Chinese students are used to memorize the verb and pronoun altogether, it is likely that they develop the expectation that any Italian verb must be preceded by an overt pronoun, regardless of the context. The reluctance of Chinese participants to drop the unnecessary pronoun in our test may be a side effect of the peculiar language instruction that language learners receive in China.
Acceptance of null pronouns and the story plot
Segmentation of the story in scenes (one clause = one scene) and punctuation separating adjacent scenes significantly affected the perception of aboutness by L2 learners (regardless of L1 and proficiency). When there was a change of scene and when adjacent scenes were separated by only a full stop, it was unlikely for a null pronoun to bridge the anaphora and its (close) antecedent. Put it differently, in our L2 learners’ perception, only overtly expressed ATs managed to survive through the story plot. Null pronouns did not. Recall that in our stimuli, other potential sources of difficulties—both processing-related and structural (such as subordination and subject–verb agreement, see O’Grady, 2011)—were removed. Nevertheless, also advanced learners did not tolerate null pronouns when their antecedent was immediately adjacent, although in another sentence. This cannot be explained solely by invoking the existence of memory-based constraints on AT accessibility, or “how long giveness lasts” in a speaker’s mind (Ariel, 1990, p. 11). Perhaps more psychological and representational levels than just discourse-related and processing-related factors should be included in the analysis. For example, the structure of the narrative itself and the cognitive correlates of how narrative events unfold in time should be taken into account. Future research will perhaps help reveal whether L2 learners’ difficulties in anaphora bridging have something to do with how NS’ and learners’ brain/mind traces the structure of the story and how a story plot develops.
Conclusion
As remarked in the “Overview and motivation” section, the teaching of the constraints that regulate the use of overt pronouns in Italian, both in texts and discourse, is one of the greatest shortcomings in L2 classroom pedagogy. L2 Italian textbooks—with perhaps a unique exception 8 —lack any indications of when it is advisable to drop unnecessary pronouns and when pronouns should be dropped to avoid ambiguity. L2 learners’ inability to drop unnecessary pronouns in certain circumstances not only characterizes non-nativelikeness and foreigner talk, but it can also represent the source of serious misunderstandings in comprehension and everyday interactions with NS. As research on L2 syntax-discourse interface has showed, the choice between null and overt subject pronouns results from complex interactions between syntactic and extra-syntactic constraints, which may be hierarchized differently depending on the differences and similarities between the L1 and the L2. For the reasons explained in the “Pronominal anaphora and aboutness” section, the choice between null and overt pronouns should be easier within than across sentences, for example, in a text. Within a sentence, null subjects are preferred in the topic-continuity condition, while overt subject pronouns seem preferred when the ST shifts. In both these cases, however, the constraints at the syntax-discourse interface act “not necessarily in a categorical fashion” (Tsimpli, 2014, p. 289), and exceptions can be easily found. In contrast, as the results of our study possibly contributed to demonstrate, null subjects in texts are admitted by L2 learners only within the same sentence and in coordinate sentences, while overt subject pronouns are used within a sentence in cases of contrastive focus. The divide between NN and NS participants mainly concerns null pronouns, which seem to be prohibited in the learners’ competence whenever there is an interruption in the story, be it due to the use of a full stop or to an abrupt change of scene. In our study, these constraints seem to follow precise rules. In general, the results suggest that L2 learners may have a different perception of aboutness (when and how the AT must be reactivated) compared with NS. This is hardly something that L2 pedagogy can affect, probably because in a NN competence, the notion of AT is more frail, sensitive to working memory limitations and processing resources. At this point, one may legitimately wonder whether instruction can possibly make a difference and help learners see when pronouns should be dropped in complex texts. Considering the results of our study, one can see that especially speakers of non-prodrop languages (e.g., French and English) scored higher than speakers of prodrop languages (e.g., Spanish) only in the null anaphora conditions. Such participants were not the most proficient (based on their CILS performance), but they were by far the most immersed and the most instructed in our participant pool. This might perhaps indicate that instruction and immersion in the country where the language is spoken do play a crucial role. L2 learners may benefit from exposure to manipulated input and/or explicit intervention that could go beyond sentence-focused instruction. As a matter of fact, it is only when dealing with longer, more complex contexts—where multiple AT candidates may intervene and compete—and not when reading isolate sentences, that L2 learners’ capacity to track aboutness can be better trained.
Footnotes
Acknowledgements
I wish to thank Arianna Zuanazzi for collecting the data and Michela Biazzi for the theoretical background. All flaws are mine.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.