
Abstract
Aims and objectives:
The study investigated narrative microstructure skills of Arabic-speaking immigrant children in Canada (N = 75; age range 7–12 years) with specific focus on diglossia and the lexical distance between Spoken Arabic (SpA) and Standard Arabic (StA). The study also tested the relationship between microstructure and macrostructure and probed into the relative importance of general versus diglossia-specific features of microstructure in predicting macrostructure.
Design/methodology/approach:
Participants were asked to tell a story from a picture using an Arabic version of the Test of Narrative Language (Gillam & Pearson, 2004). Instructions to participants were given in StA.
Data and analysis:
General measures of microstructure were coded: number of tokens, number of types, type/token ratio, and mean length of utterance (MLU). In addition to these general measures, we coded the average frequency of five diglossia-specific word types: (a) identical words, which keep the same phonological form in StA and SpA; (b) SpA cognates, namely, cognate words that keep different yet related forms in StA and SpA, used in their SpA form; (c) StA cognates, cognate words used in their StA forms; (d) unique SpA words; and (e) unique StA words. Regression analysis was used to predict macrostructure from general and diglossia-specific features of microstructure.
Findings/conclusions:
Results showed that the bulk of the lexicon of the narratives produced by immigrant children consisted of words and word forms that are within SpA: identical words, SpA cognates, and unique SpA words; StA word forms appeared less frequently, and English code-switched words were very rare. Results also showed that the microstructure features of narrative length in tokens and type/token ratio significantly predicted macrostructure beyond the children’s age and Arabic language proficiency. However, when diglossia-specific lexical features were added as predictors, the frequency of StA words predicted unique variance in macrostructure beyond age, Arabic language proficiency, and narrative length. Findings advance our understanding of narrative skills in Arabic diglossia among new immigrants and the role of lexical distance in narrative production in this context.
Originality:
The study is innovative in investigating the manifestation of diglossia in narrative microstructure features and the role of diglossia-specific features in predicting macrostructure, as well as in testing this question among immigrant children.
Significance/implications:
The study demonstrates the multifaceted lexicon of diglossic Arabic speakers as reflected in the microstructure of their narratives and the prevalence of SpA word forms in their lexicons. The study also demonstrates a significant relationship between microstructure and macrostructure, and the important role of StA lexical features of microstructure in predicting macrostructure. The results of the study have theoretical implications for the importance of lexical distance in understanding narrative production in children at both the microstructure and macrostructure levels. The study also has practical implications for assessment and intervention with Arabic-speaking children in diglossic Arabic.
Introduction
Narrative production is a fundamental aspect of spoken language ability and an effective tool for testing the ability to construct and communicate ideas using complex linguistic, cognitive, and social skills (Duinmeijer et al., 2012; Sartwell, 2006; Tsimpli et al., 2016). Narrative production is a discourse genre organized around a setting, characters, actions, and outcomes (Rumpf et al., 2012) through which the narrator conveys character perspective to explain motivations and actions (Heilmann et al., 2010; Stein & Glenn, 1979). The literature distinguishes two levels of discourse in narratives: microstructure and macrostructure (e.g., Petersen et al., 2008). Macrostructure refers to the overall story structure, whereas microstructure refers to the language deployed in storytelling.
Children’s acquisition of narrative discourse has been investigated in diverse populations and languages including Arabic (Hipfner- et al., 2015; Fichman et al., 2017; Sah & Torng, 2019), and this research has outlined some general patterns in the acquisition of narrative skills across languages (Lucero, 2015). Yet, few studies have focused on narrative skills in Arabic diglossia (however, see Leikin et al., 2014; Ravid et al., 2014), a context characterized by the co-existence of two linguistically distant language varieties: a spoken variety used for everyday speech and in which narrative skills probably first develop, and a standard variety which is acquired later and in which narratives that are read from print are expected to be delivered. Few studies have also addressed narrative skills among immigrant populations in general (e.g., Gamez et al., 2016) or among Arabic-speaking immigrants. The current research examines narrative skills in Arabic among immigrant school-age children in Canada. Specifically, we investigate the microstructure of narratives and the manifestation of diglossia in the composition of the lexicons of children as reflected in the microstructure. We also examine the relationship between narrative microstructure and macrostructure. Although the concept of diglossia may not be straightforwardly maintained in the context of Arab immigrants (Albirini & Benmamoun, in press), the study directly tested this question and investigated the linguistic manifestation of diglossia in the lexicon used by children in narrative production. Because the children in our sample were born in their Arab country of origin and had received some instruction, though often interrupted, in Arabic in these countries, our analysis of microstructure focused on the lexical distance between SpA and StA as it is reflected in storytelling, and we probed whether lexical distance features into the relationship between microstructure and macrostructure.
Narrative skills: macrostructure and microstructure
Narrative macrostructure is often captured by what is referred to as Story Grammar (SG) (Stein & Glenn, 1979). SG offers a universal organizational model for analyzing the macrostructure of narratives in terms of setting, characters, and episodic structure. An episode is defined as a part, scene, or event of a story that is complete in and of itself (Soodla & Kikas, 2010; Stein & Glenn, 1979; Trabasso et al., 1989; Westby, 2005). Within the SG model, narratives begin with a setting that provides background information about characters and sets place and time. The setting is followed by one or more episodes that are connected temporally or causally, referred to as a goal–attempt–outcome (GAO) schema (Westby, 2005). The goal (G) reflects the character’s motivation to solve a problem triggered by an initiating event (IE), whereas the attempt refers to the effort to satisfy the goal and the outcome (O) refers to the degree of success in achieving the goal. The IE evokes an internal response (IR) in the protagonist (emotion, desire, belief) that prompts the protagonist to attempt to achieve a goal. The story ending relates to a final remark such as “The end,” whereas the meta-ending refers to the narrator’s reflections on the story.
SG analysis has been used to assess children’s communicative competence (Botting, 2002; Paradis et al., 2011). In typically developing children, the number of SG elements included in oral narratives was found to grow with age (Applebee, 1978). For example, children aged 4–4.6 years included a central theme and three SG components (IE, attempt, and outcome), whereas children aged between 5 and 7 years included at least five story grammar elements, adding a setting and an ending (Applebee, 1978). By about the age of 10 years, children were found to be able to make explicit reference to characters’ IRs (Bishop & Donlan, 2005).
Unlike macrostructure, which captures the global structure of a story, narrative microstructure captures the language deployed in the telling of the story. It reflects the narrator’s mastery of basic language structures and a range of lexical, morphological, syntactic, and semantic features. Microstructural indices include measures of general productivity (e.g., number of utterances, number of words), syntactic complexity (e.g., mean length of utterance), morphology and morpho-syntax (e.g., verbal tense/aspect, inflectional morphology), lexical knowledge (e.g., lexical aspect and manner of motion/cause verbs), lexico-grammatical features (e.g., locative particles, prepositional phrases, connectives), and linguistic content (e.g., lexical diversity using type/token ratios [TTRs], ratio of different content to function words) (Heilmann et al., 2016; Rezzonico et al., 2016).
Whereas some features of microstructure may be language-specific, marked developmental patterns in microstructural quality are evident across languages (Berman, 2009; Stein & Glenn, 1979). The language of storytelling starts to develop at a young age, and development is prolonged continuing well past the age of 10 years (Blankenstijn & Scheper, 2003). Lexical diversity is evident at age 4 (Elbers & Van Loon-Vervoorn, 2000), as is the use of complex propositions (Justice et al., 2006; Kaderavek & Sulzby, 2000; Reilly et al., 2004). Nonetheless, children gradually produce longer narratives using more varied content words (Justice et al., 2006) and more complex syntactic structures with age (Berman & Nir-Sagiv, 2007 ). Given its long developmental trajectory and the multiplicity of linguistic knowledge and skills it incorporates, microstructure has served as a tool for assessing language development in children.
According to one view, macrostructure and microstructure capture different aspects of productive narrative skill and are independent of each other. This view is based mainly on evidence from bilingual children showing interrelatedness of macrostructure skills across the two languages but different patterns of microstructure in each of the two languages (Gagarina et al., 2016). In contrast with this position, other researchers argue that that microstructure and macrostructure are inter-related. For instance, cognitive-driven schema theory (Berman, 1988, 1999; Karmiloff-Smith, 1979) and form–function approaches to language and narrative acquisition (Berman & Slobin, 1994) argue that the development of narrative production relies on the integration of micro and macro processes. As such, narrative production involves the integration of top-down cognitive processes to organize and connect story events (i.e., macrostructure) with bottom-up linguistic processes to select appropriate lexical and morphosyntactic forms in the course of storytelling (i.e., microstructure). Hence, top-down representations are activated in the process of selecting linguistic forms to connect ideas together (Hickmann, 2002, 2004).
Form–function approaches to narrative acquisition (Berman & Slobin, 1994; Hickmann, 2002; Karmiloff-Smith, 1979) focus on the interaction of cognition and language, explicating the role of cognitive maturity and linguistic skills in the development of narrative forms (the selection of appropriate lexical and morphosyntactic forms) and functions (the intent and content of the narrative, for example, to chain events in chronological sequence, to motivate). Berman and Slobin (1994) tested how microstructural forms support narrative macrostructure and drive narrative skill development. Narrative skill development was measured in terms of increased productivity and complexity, as well as change in form–function relations. It was found that, with age, old forms assume new functions, and at the same time, new forms are recruited to meet old functions (Slobin, 1973). For example, in the narratives of 3- and 4-year-olds, “and” is used as utterance initial and its function is to announce that the narrator has more to say in the same conversational turn. In the narratives of 5- and 6-year-olds, its position is also clause initial; however, the function is to chain events in chronological sequence. In the narratives of 9- and 10-year-olds, “and” functions to chunk within a given discourse topic and the intention conveyed is “the events or states are related” (Berman, 2009).
Recent studies have focused on the relationship between various indices of microstructure and changes in macrostructure (e.g., Heilmann et al., 2010; Mäkinen et al., 2014). Overall, these studies demonstrate that an increase in macrostructural competence involves changes in the way microstructural features are deployed for emerging discourse functions, and that changing relations between microstructure and macrostructure are informative indices of narrative development. Understanding the relationship between microstructure and macrostructure has theoretical implications, but it is also practically important since narrative production is a well-known predictor of children’s language, literacy, and academic achievement, both in L1 (Pinto et al., 2016; Suggate et al., 2018) and in L2 learners (Saiegh-Haddad & Spolsky, 2014; Uchikoshi et al., 2016).
A small number of studies have examined the relations between narrative microstructure and macrostructure (Terry et al., 2013). Heilmann et al. (2010) tested this question using hierarchical regression analysis. They investigated the relations between lexical indicators of microstructure (number of tokens and number of types) and grammatical features (mean length of C-units and subordination index, a measure of clausal density), on the one hand, and overall story structure, on the other, among English-speaking children aged 5–7 years. This study showed that lexical and grammatical features significantly predicted narrative macrostructure, with lexical features proving stronger predictors than grammatical features.
Given the intimate relationship between general oral language skills and narrative ability, research has addressed the effect of differences in language exposure on narrative skills development. This question was mostly tested in bilinguals. Bitetti and Hammer (2016) investigated the impact of home language experiences and exposure (based on maternal report of frequency of literacy activities, activities with caregivers, and number of children’s books in the home) on the English narrative microstructure and macrostructure of Spanish–English bilingual children from preschool through first grade. Findings indicated that home language experiences and exposure were positively related to narrative quality (Gagarina et al., 2012).
The question of the influence of differences in language exposure on language and narrative skill is paramount in language minority contexts, such as immigrant contexts, and in heritage language contexts in which speakers immigrate at a young age to a foreign country or are born in a foreign country to language minority parents. Immigrant children might vary in the degree of exposure to their native language depending on age of arrival to the foreign country, and this has consequences for language proficiency (Hoff, 2006; Paradis et al., 2021; Soto- et al., 2021) and well-being (Paradis et al., 2020). Heritage language speakers’ exposure to their native language comes mainly from parents and siblings at home, and so their first language often does not reach native-like attainment in adulthood (Benmamoun et al., 2013). Albirini (2014) used a narrative task to measure the language proficiencies of Egyptian and Palestinian heritage speakers of Arabic in the United States and the contribution of linguistic, social, and demographic factors to proficiency in heritage language Arabic. The results showed that language use, language input, family role, community support, and parents’ language were all correlated positively with language proficiency indices of grammatical accuracy and syntactic complexity as manifested on the narrative task. Yet, language use was the only significant predictor. In the same context, Paradis et al. (2020) tested the role of language environment factors on school-aged Arabic-L1 English-L2 Syrian refugee children in Canada. The results indicated that environmental factors, such as language use, exposure, and richness (engagement in language-rich activities), accounted for more variance in the L2 than the L1, but maternal and paternal education factors accounted for variance in both languages.
Given the diglossic nature of Arabic in which language exposure is distributed between the two varieties used in different settings (Ferguson, 1959) and functions (Albirini, 2016), language proficiency, at least for children raised in a native diglossic context, involves acquiring knowledge about the structures and functions of the two varieties (Albirini & Benmamoun, in press) and proficiency in using the two varieties according to the acceptable sociolinguistic norms of diglossia: Spoken Arabic (SpA) for everyday speech and Standard Arabic (StA) for formal speech and for reading and writing (Albirini, 2016; Saiegh-Haddad & Spolsky, 2014). This task has been shown to challenge children growing up in a native diglossia and to show a long developmental trajectory, at least when literacy-related metalinguistic and reading skills are tested (Saiegh-Haddad, 2018). Evidence also shows that the language proficiencies of native speakers of Arabic are higher in the spoken variety than in StA, at least when oral language skills are targeted (Albirini, 2019). Moreover, Arab homes were found to be poor in high-quality informal literacy experiences and in exposure to StA, and this was correlated with measures of emergent literacy in children (Aram et al., 2013; Saiegh-Haddad & Spolsky, 2014).
Given the unique sociolinguistic context of diglossia and the rich linguistic reservoir it offers to children, it is informative to study microstructure narrative skills in diglossia and the relationship between microstructure and macrostructure. This investigation would shed light on the relationship between linguistic skills and higher order discourse organizational skills in a context where lexical skills are distributed between different varieties. Moreover, it is informative to investigate the manifestation of diglossia in the composition of the lexicon deployed in the narratives produced by children and the extent of reliance on lexical features from the two varieties. Specifically, it is informative to probe whether and which diglossia-specific lexical features are deployed at the level of microstructure, and whether they predict quality of the narratives at the macrostructure level.
Arabic: diglossia and lexical distance
Arabic is a root-based Semitic language in which lexical items are formed by simultaneously interdigitating at least two bound morphemes: a root and a word-pattern. Roots provide the core semantic meaning of all the words within the same root-related family, whereas patterns consist of vocalic skeletons (together with a closed set of fixed consonants) with designated slots for the root consonants (Saiegh-Haddad & Henkin-Roitfarb, 2014). All verbs and many nouns and adjectives are composed of roots and patterns, and the meaning, syntactic, and phonological properties of words change for each root–pattern combination. For example, the root KTB, (ب ت ك) is associated with the concept “to write. An example of derivations based on this root are the words /ka:tib/ (بتاك) “writer”; /maktu:b/ (بوتكم) “written.” Psycholinguistically, the mental lexicon of Arabic speakers appears to also be organized along the morphological units of roots and word patterns, both in adults (Boudelaa, 2014; Boudelaa & Marslen-Wilson, 2010) and in children (Asli-Badarneh & Leikin, 2019; Shalhoub-Awwad & Leikin, 2016), and this has been shown to be compatible with early morphological processing in reading and spelling acquisition (Saiegh-Haddad, 2013; Saiegh-Haddad & Taha, 2017; Taha & Saiegh-Haddad, 2017). In turn, morphological processing has been proposed by the MAWRID (Model of Arabic Word Reading In Development) model (Saiegh-Haddad, 2018) to be a core building block of word reading development in Arabic.
One of the most prominent sociolinguistic features of Arabic is diglossia, which is a long-lasting and a rather stable co-existence of two varieties of the same language within the same speech community for use in different settings (Ferguson, 1959) and for different communicative functions (Albirini, 2016). According to Ferguson (1959), diglossia consists of a stable coexistence of two related forms of a language, High and Low variety, that are used in different social contexts. StA is to a great extent uniform across the Arabic-speaking world and is used mainly for conventional reading and writing in Arabic as well as for formal speech (Holes, 2004). It is considered the “prestigious” High form of the language and is therefore used for formal functions such as praying and education. In contrast, different local dialects of SpA are used for everyday verbal communication and informal transactions (e.g., Holes, 2004; Saiegh-Haddad, 2003, 2012; Versteegh, 2001; for a more nuanced discussion of diglossia in Arabic today, see Albirini, 2016). In contrast with Ferguson dichotomy between spoken and standard varieties of Arabic, which he himself later revisited, the diglossic context of Arabic may be better viewed as a continuum or levels and that speakers make gradual transitions between the various varieties (Albirini, 2016). In this context, Badawi (1973) distinguishes between five intermediate levels for use of Arabic in Egypt, whereas Bassiouney (2009) proposes theoretically an infinite number of levels.
Dialects of SpA are all structurally related to StA (Maamouri, 1998). At the same time, when compared linguistically, they all differ from StA in phonological, morphological, morphosyntactic, and lexical structure (Saiegh-Haddad & Spolsky, 2014). This linguistic distance is probably the most prominent in phonological and lexical domains. Lexical knowledge in Arabic diglossia is distributed between the two varieties of the language. Saiegh-Haddad and Spolsky (2014) analyzed a corpus of 4,500 word types derived from a corpus of 17,500 word tokens of 5-year-old Palestinian Arabic (PA)–speaking children living in Israel. They classified words on the basis of the lexical and lexico-phonological distance between the forms of the words as they used in PA and their parallel form in StA. This analysis yielded three types of words in the spoken lexicons of preschool children: identical, cognate, and unique words. Identical words (which were found to make up 21.2% of the word types in the corpus tested) are lexically and phonologically identical in the two varieties (e.g., /žamal/ “camel,” or /daftar/ “notebook”). Cognate words (40.6%) keep different yet related phonological forms in the two varieties, namely, they share some phonological characteristics but differ, many times systematically, in other phonological characteristics. Cognates differ in terms of the degree of phonological distance in SpA and StA forms, that is, in terms of the number of phonological alterations between the two forms (involving phoneme deletion, addition, and substitution). An example of an StA–SpA cognate pair distinguished by one vocalic alteration is StA /ʃams/–SpA /ʃamis/ “sun.” The cognate pair StA /miqlama/–SpA /miɁlami/ “pencil case” is distinguished by two phonological parameters: a consonant and a vowel, whereas the cognate pair StA /ța:Ɂira/–SpA /țayya:ra/ “airplane” is distinguished by more than three vocalic alterations (Saiegh-Haddad & Haj, 2018; Saiegh-Haddad, in press). The third lexical category observed in the lexicons of preschool children is unique SpA words (38.2%) which have a lexical (and phonological) form in SpA that is completely different from their form in StA often because the SpA word is a loan word that has been fully integrated within SpA (e.g., StA /juzda:n/–SpA /ħaqi:ba/ “bag” or StA /ħiza:m/–SpA /kʃa:t/ “belt”). Unique SpA words often have parallel yet completely distinct forms in StA, referred to as unique StA words. The corpus that Saiegh Haddad and Spolsky (2014) analyzed did not report any unique StA words actively produced by children during natural free play in the kindergarten center. Yet, some were recorded during parroting StA songs by children. The data also revealed a very rare use of Hebrew code-switched words (2%).
The linguistic distance between StA and SpA was found to influence children’s acquisition of basic linguistic and metalinguistic skills in the standard variety (Saiegh-Haddad, 2003, 2004, 2007; Saiegh-Haddad et al., 2011). At the lexical level, Saiegh-Haddad and Haj (2018) showed that the lexical and lexico-phonological distance between SpA and StA had a significant impact on lexical-phonological representational quality in the lexicon of children. As such, children had difficulty judging whether the pronunciation of a target StA word was accurate when the word had a form in StA that was different from its form in SpA. This was the case even when the distance consisted in just a single consonantal phoneme, and the StA word was within the child’s receptive vocabulary. Across all ages, identical words were easier to judge than cognate words, and both were easier than unique words. The authors also found that the quality of phonological representation of cognate words was commensurate with the degree of phonological distance (measured by the number of phonological distance parameters) between the StA and SpA forms of the cognate word.
These results have implications for lexical processes in narrative production in Arabic. To produce a narrative in Arabic, words have to be retrieved from a complex integrated lexicon that stores both SpA and StA words (Nevat et al., 2014), some of which are partially related cognates and others are unique lexical forms in SpA and StA. Given this complex lexicon, selection and retrieval of lexical items likely involve competition between the less familiar, inaccurate, and unstable StA representations of words with their more dominant and more accurately represented SpA forms. Such diglossia-specific features of microstructure might affect top-down processing for generation of macrostructure as predicted by form–function approaches (Berman & Slobin, 1994), according to which attention allocated to language processing at the local level detracts from the overall structural quality of the narrative given limited cognitive resources (Berman, 1988, 2008; Berman & Slobin, 1994; Karmiloff-Smith, 1979). That said, the diglossic context and related lexical competition and selection have been shown to incur a cognitive advantage in children (Eviatar & Ibrahim, 2001). This advantage might help children handle lexical processes during narrative production.
Narrative skills in Arabic diglossia were only slightly investigated. Ravid et al. (2014) tested narrative development among 97 monolingual Arabic Palestinian children in the north of Israel across seven age groups (nursery school through adulthood). Using a retelling task, the study showed the predicted increase in story length with age. More interestingly, the study revealed that while no explicit instructions were given with resect to language choice during retelling, children used both StA and SpA structures. Moreover, use of StA structures was evident even in the young preschoolers (despite lack of direct instruction in StA at this grade level), and it was found to increase with grade level especially in lexical and morphosyntactic structure.
Leikin et al. (2014) examined the influence of diglossia on story comprehension and production among 30 Arab preschool children by asking them to retell two different stories: one in StA (after it had been told in StA) and one in SpA (after it had been told in SpA). Comprehension questions in StA and SpA followed each of the StA and SpA narrations, respectively. The results showed that narrative comprehension of the StA stories was lower than comprehension of the SpA stories. This finding suggested that the linguistic gap between SpA and StA together with the limited exposure to StA impacted StA narrative comprehension (Abu-Rabia, 2000; Feitelson et al., 1993). With respect to narrative production, the study showed that when retelling a story in StA, children produced shorter texts and shorter clauses and made many more morphosyntactic errors than when they retold a story in SpA.
The studies reviewed above show that narrative skills in Arabic might be directly impacted by the diglossic reality. Narrative comprehension skills are better in SpA than in StA and productivity indices in StA are lower in StA than in SpA, although they increase gradually with age. Language exposure and input are crucial factors in language development and relatedly narrative skills, especially in bilingual contexts (Carroll, 2017; De Houwer, 2018; Hoff, 2006) and diglossia (Saiegh-Haddad, in press; Saiegh-Haddad & Armon-Lotem, in press). Language exposure is also critical for language and narrative skill development in immigrant contexts where exposure is limited, and in similar contexts like heritage language contexts (Albirini, 2014; Armon-Lotem et al., 2011; Benmamoun et al., 2013; Meir & Polinsky, 2019; Paradis et al., 2021).
This study tests microstructure narrative skills in Arabic-speaking immigrants in Canada with specific focus on how diglossia is manifested in the lexicon deployed by children in the narratives. It also tests the relationship between microstructure and macrostructure skills, as well as the role of diglossia-specific lexical distance features in this relationship, given the possible effect of lexical distance on lexical competition and retrieval, and on the amount of cognitive efforts left for macro-level organizational skills. Although the concept of diglossia may not be straightforwardly maintained in the context of Arab immigrants (Albirini & Benmamoun, in press), the children in our sample were born in their Arab country of origin and had received some instruction, though often interrupted, in Arabic in these countries. Therefore, our analysis of microstructure focused on the lexical distance between SpA and StA as it is reflected in storytelling, and we probed whether lexical distance features into the relationship between microstructure and macrostructure.
Arabic-speaking immigrants in Canada
Children growing up in Arab immigrant families in Canada often speak their native language at home, but, like other immigrants in Canada, they receive schooling in the language of the majority. Immigrant children may also receive some instruction in speaking, writing, and reading in Arabic through school Arabic language programs. Participation in these programs is voluntary.
Immigrant and heritage language speakers often present with variable and heterogeneous linguistic outcomes (Montrul, 2018) as a function of chronological age (Montrul, 2012), onset of exposure to the second language, and individual variation in linguistic experience (Ahn et al., 2017). Research has shown that one of the most important factors predicting language acquisition of the heritage language is amount of exposure (Armon-Lotem et al., 2011). Most immigrant and heritage language speakers develop unbalanced skills because their input is typically divided between two languages. Moreover, they often have rudimentary linguistic and literacy skills in their heritage language compared to the dominant majority language (Meir & Polinsky, 2019). This led to increased theoretical linguistic interest in this population (Benmamoun et al., 2013). In the context of Arabic heritage language speakers, Albirini (2018) examined the effect of age of onset of exposure to English as a second language and amount of L1 input on achievement in agreement morphology, plural morphology, and relative clauses. The study indicated that age of exposure to English and amount of Arabic input at home correlated positively with the children’s achievements in all tasks, but age of exposure to L2 was the only significant predictor of the accuracy scores. In the same context, both Paradis et al. (2021) and Soto-Corominas et al. (2021) demonstrated that first-generation Arabic heritage language children in Canada show strong heritage-L1 maintenance, and that factors such as age and input have differential effects on heritage language performance.
Like other immigrants and heritage language speakers, Arabic-speaking immigrants are naturally less exposed to Arabic than their majority language counterparts. Therefore, they show gaps in lexical knowledge and other linguistic gaps when compared with monolinguals as reflected in word naming (Albirini, 2015), word selection, use of numbers, prepositions and possessives (Albirini & Benmamoun, 2014), morphological skills (Benmamoun et al., 2014), and some aspects of syntax, such as verb–subject–object (VSO) (Bos, 1997). In contrast, their phonological skills, namely, vowel production, appear to converge with Arab monolinguals (Saddah, 2011). These gaps in linguistic knowledge are attributed to lack of active use and exposure to Arabic, social factors (e.g., extent of relationships with the Arab community, religious affiliation), attitudes regarding the importance of Arabic, and language loss (Rouchdy, 2013). Given their limited linguistic proficiency and the dominance of the societal language, it is informative to study the nature of the microstructure of narratives, as well as the relationship between microstructure and macrostructure narrative skills. A question of particular interest is the role of the lexical distance in Arabic diglossia in narrative production and the extent to which diglossia-specific lexical features of microstructure might predict macrostructure narrative skills.
Against this backdrop, the study addresses the following questions: (1) What is the composition of the lexicon deployed by Arabic-speaking immigrants in narrative production; specifically, what is the extent of use of diglossia-specific lexical distance features in the oral narratives produced by children? (2) What is the relationship between narrative microstructure (number of tokens, number of types, TTR, MLU) and narrative macrostructure, beyond differences between immigrants in chronological age, age of arrival to Canada, Arabic receptive vocabulary, and oral exposure to Arabic at home? (3) Do diglossia-specific lexical distance features factor into the relationship between narrative microstructure and macrostructure skills in this population?
Method
Participants
The sample of the study consisted of 75 Arabic-English bilingual children (39 males, 36 females) aged 7–12 years (mean age = 9;8, SD = 19.58) recruited from 53 Arabic-speaking immigrant families residing in a large urban center in Canada. The children spoke varieties of Eastern/Mashriq dialects of Arabic, with the majority of them originating in Syria (N = 20), Egypt (N = 17), and Jordan (N = 14). The remaining children came from Lebanon (N = 9), Palestine (N = 8), and Iraq (N = 7). With regard to age of arrival, 15 children arrived in Canada between ages 1 and 4 years, 31 between ages 4 and 8 years, 11 between ages 8 and 13 years, and 18 children were born in Canada. This latter small subgroup of the sample may be referred to as heritage language speakers, namely, children born in Canada to Arabic-speaking first-generation parents. These 18 children out of the total sample of 75 children had all their parents reporting speaking Arabic at home.
In all, 44% of the children in our sample attended preschool in their Arab country of origin. Also, about 40% of them enrolled in Arabic-medium schools in their Arab country of origin for a period of 1–6 years before arriving in Canada. Arabic was reported by the parents of all the participants to be the primary language spoken at home; only 45.3% (n = 34) reported using English at home besides Arabic and mainly in interactions with their siblings.
All children attended English-medium public schools in Canada as well as Arabic language programs on the weekend (maximum of 4 hours per week). Excluded from this were four children who attended private Islamic schools in which the primary language of instruction was English, but who also took one Arabic language/Islamic studies class for 45 minutes per day, for 5 days per week. Almost half of the children in our sample (52%) attended preschool in Canada through participation in junior and senior kindergarten publicly funded early learning programs that implement government-mandated curricula targeting specific learning outcomes.
In total, 71% of the mothers and 79% of the fathers of participants held an undergraduate or a professional/graduate degree. None of the participating children had an identified developmental disorder or learning disability. Participants’ average socioeconomic status (SES) was 3.4.
Table 1 presents means and standard deviations (SDs) for the background information measures across the whole sample.
Descriptive statistics of background measures.
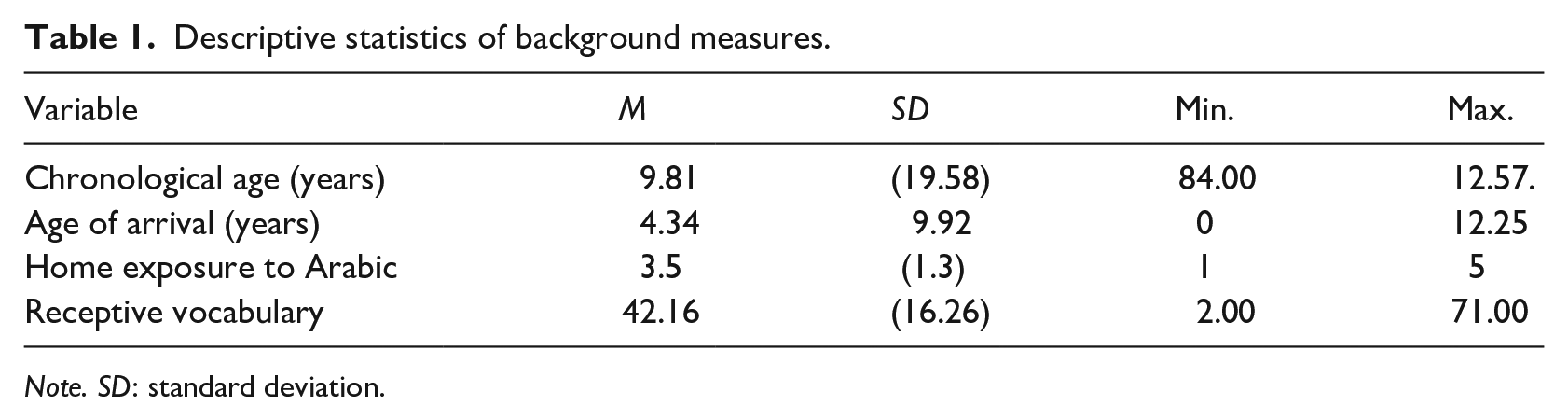
Note. SD: standard deviation.
Materials
Background information tasks
Language Questionnaire
All parents of the children participating in the study completed a demographic questionnaire (The Canadian Bilingual School-aged Children [Use and Exposure]) (MacLeod et al., in preparation) which related to the child’s language development, home language environment, and parental demographic information.
Exposure to Arabic Questionnaire
A questionnaire was used to measure the frequency of the child’s engagement in speaking, listening, reading, or writing activities in Arabic over a week. Engagement was assessed on a Likert-type scale of 1–5 (1 = never or almost never, 5 = very often). Speaking and listening activities in Arabic included watching TV shows and movies, music, singing, reading poetry, and storytelling. Reading and writing activities included reading books, messaging, doing homework, and reading the Quran.
Arabic receptive vocabulary test
Arabic receptive vocabulary was assessed using a standardized subtest of the Arabic Language Assessment Battery (ALAB; Assadi et al., 2015). This test consists of a total of 73 items of increasing difficulty. For each item, the examiner orally presented the target word and the child was asked to point to one of four pictures that best represented the word. The test was discontinued after the child failed in identifying eight consecutive words. Cronbach’s alpha of the performance of our sample on this test was .95.
Test of narrative language
An Arabic translation of a shortened version of the Test of Narrative Language (TNL) (Gillam & Pearson, 2004) was used to assess the children’s oral narrative production. The children were instructed in StA to look at a wordless picture and to tell a story about it. The experimenter encouraged the child to remain on task and did not interfere in story production in any way that could influence the content or the structure of the story. The child’s story was recorded for later transcription and scoring. Two versions of the task (Unicorn and Aliens) were used. Half of the children received the Aliens version; the other half received the Unicorn version. Children were free to generate their stories in whichever variety of Arabic they chose. Cronbach’s alpha for this task was .78.
Transcription and coding
Children were audio recorded as they generated their narrative. The narratives were subsequently transcribed broadly phonemically by trained native Arabic-speaking graduate and undergraduate students who are each a native speaker of one of the four dialects spoken by the participants (Syrian, Lebanese, Egyptian, and PA). The Syrian native speaker had near native speaking familiarity with Iraqi Arabic. Data were then coded for macrostructure and microstructure.
Macrostructure
SG elements
Each script was divided into episodes. The narratives were then coded in terms of the number of settings, IEs, goals, attempts, outcomes, IRs, endings, and meta-endings per each episode of the narrative (Stein & Glenn, 1979). A score of 1 was awarded for each element if it was mentioned and a zero score if it was not. The maximum number of SG elements was 16. The mean number of SG elements was calculated by dividing the total number of points awarded by 7, the number of elements (settings, goals, attempts, outcomes, IRs, endings, meta-endings).
Microstructure
General indices
The analysis of narrative microstructure employed two types of indices: general and diglossia-specific. First, general measures of narrative length and lexis were coded: total number of words or tokens (TW) including word repetitions, total number of different words or word types, TTR, MLU, and number of code-switched English word types and tokens.
Diglossia-specific lexical indices
Following Saiegh-Haddad and Spolsky (2014), five categories of words were coded based on the lexical distance between SpA and StA. These words included (a) identical words; (b) SpA cognates, namely, cognate words in their SpA form; (c) StA cognates, namely, cognate words in their StA form; (d) unique SpA words; and (e) unique StA words. Identical words are lexically and phonologically identical in StA and SpA (e.g., /na:m/“sleep,” /ʔakal/“ate”). Cognate words are paired lexical items that have overlapping phonological forms in SpA and StA (e.g., SpA /ʔim/“mother”–StA /ʔum/). Unique words share the same semantic representation (the same concept/meaning) but are lexically (and naturally also phonologically) different with a unique form in StA (unique StA words) and SpA (Unique SpA words), for example, unique StA /masak/–unique SpA /3arash/ “catch.” Inflected forms were counted as tokens of the same word type (e.g., /raʔat/ she saw, /raʔu/“they saw”). Table 2 presents means and standard deviations (SDs) for the narrative measures across the whole sample.
Descriptive statistics of narrative measures.
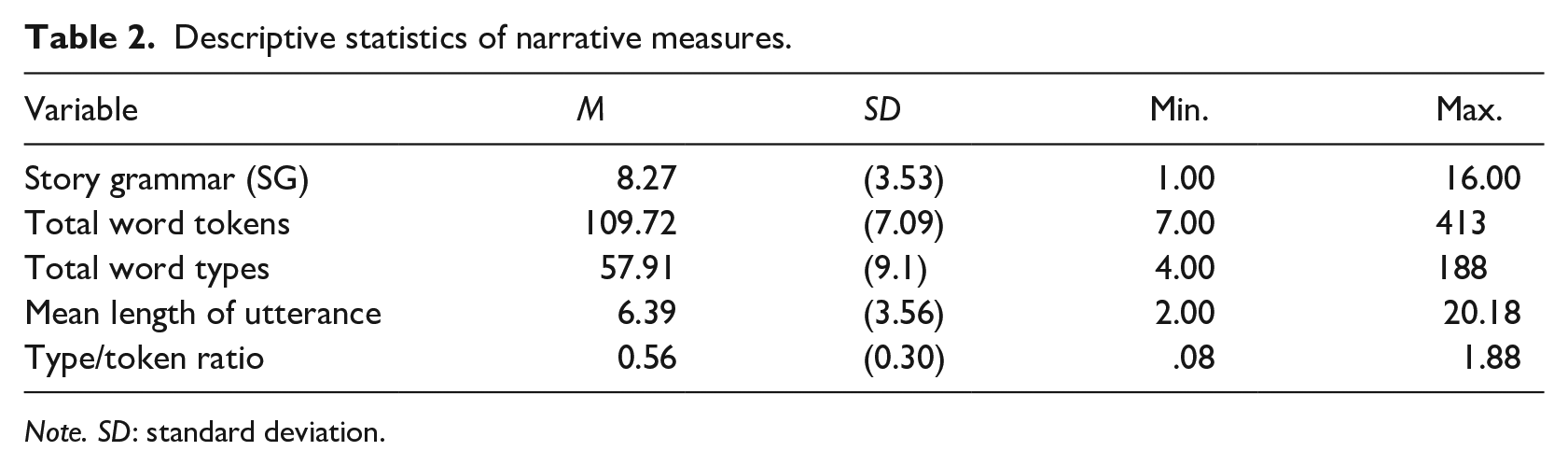
Note. SD: standard deviation.
Procedure
Data collection occurred in the child’s home during the fall of the school year. All children were administered the vocabulary task first, followed by the TNL narrative production task. All tasks were administered to children by trained graduate and undergraduate research assistants who were fluent in Arabic and native/near native speakers of the dialect of the participant. A graduate student in linguistics who is a native speaker of Arabic coded the narratives for macrostructure. The coding of the microstructure was conducted by five native speakers or near native speakers representing the five dialects of the children participating in the study as noted above.
Twenty percent of the transcripts were chosen randomly and coded by a second rater, a native speaker of Arabic, for interrater reliability. Interrater reliability was conducted using the following formula: [number of agreements/(number of agreements + disagreements)] ×100 (Sackett, 1978). The interrater reliabilities for macrostructure and for, identical, cognate (SpA and StA), unique SpA, and unique StA words were .91, .90.5, .92, and .93, respectively.
Results
The first research question addressed the diglossia-specific lexical features of microstructure, namely, the lexicon deployed by children in narrative production in light of the lexical distance in Arabic diglossia. To address this question, all the words used in the narratives were coded for diglossia-specific word types: identical words, SpA cognates, StA cognates, unique SpA words, and unique StA words. Table 3 provides summary statistics of the frequency and mean use of diglossic lexical categories in types and tokens per each lexical category. We also tested other general features of microstruture and macrostructure elements of the narratives produced by children. Table 4 provides means and SDs of the general measures of microstructure and macrostructure that were coded (total number of tokens/narrative length, total number of types, TTR, MLU, and SG).
Summary statistics of lexical categories targeted.
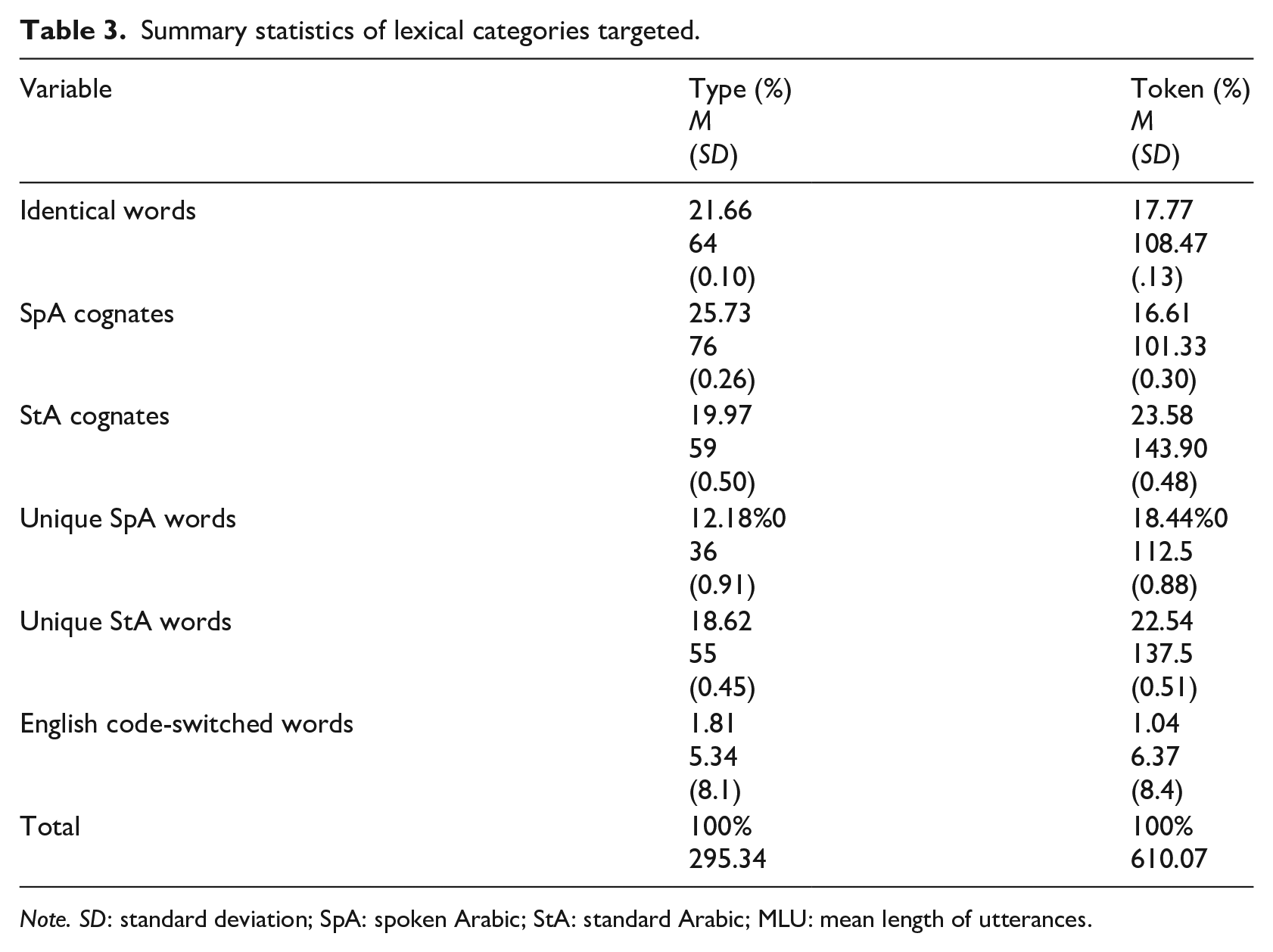
Note. SD: standard deviation; SpA: spoken Arabic; StA: standard Arabic; MLU: mean length of utterances.
Inter-correlations among all variables.

Note. TTR: type/token ratio; MLU: mean length of utterances; SG: story grammar elements.
p < .05. **p < .05. ***p < .001.
As Table 3 shows, the lexicon that was deployed in the narratives produced by children consisted mainly of SpA cognate words, making up 25.73% of the total number of word types used in the narratives. This was followed by identical words making up 21.55%, StA cognates making up 19.97%, unique StA words making up 18.62%, and finally unique SpA words making up 12.18%. Children produced significantly many more SpA cognates than StA cognates—t(74) = 5.1, p < .05. Yet, they used significantly many more unique StA words than unique SpA words—t(74)= 7.2, p < .01. English code-switched words made up 1.81% of the total number of word types used in the narratives.
Next, we tested the intercorrelations between the various indices of microstructure and macrostructure targeted in the study and the background variables summarized in Table 1. The results from this analysis are summarized in Table 4.
Table 4 shows that macrostructure (number of SG elements) was strongly associated with two background variables: chronological age (p < .001) and age of arrival to Canada (p < .01); macrostructure was also moderately correlated with Arabic exposure at home (p < .05) and Arabic receptive vocabulary (p < .05).
With respect to the correlation between macrostructure and the general microstructure measures, macrostructure was correlated with narrative length in total number of tokens (p < .01), with the general measure of TTR (p < .001), and with MLU (p < .001). Finally, with respect to the diglossia-specific lexical features, macrostructure was correlated with the frequency of use of StA cognates (p < .001) and with the use of unique StA words (p < .001).
To better understand the relationship between general measures of narrative microstructure and narrative macrostructure, we conducted a hierarchical linear regression analysis. Children’s chronological age, age of arrival to Canada, gender, Arabic exposure at home, and receptive vocabulary were entered in Step 1 This was followed by narrative length in total number of tokens, TTR, and MLU in Step 2.
Table 5 shows the final beta weights for all variables. In Step 1, chronological age and age of arrival to Canada predicted 36% unique variance in narrative macrostructure. Arabic exposure, gender, and vocabulary did not predict any additional unique variance. In the next step, narrative length and TTR explained an additional 4% unique variance. Altogether, chronological age, age of arrival to Canada, narrative length, and TTR all made significant contributions to the prediction of narrative macrostructure, accounting for 36% and 40% of the variance in Steps 1 and 2, respectively.
Hierarchical linear regression predicting narrative macrostructure (based on general TTR and classical measures).
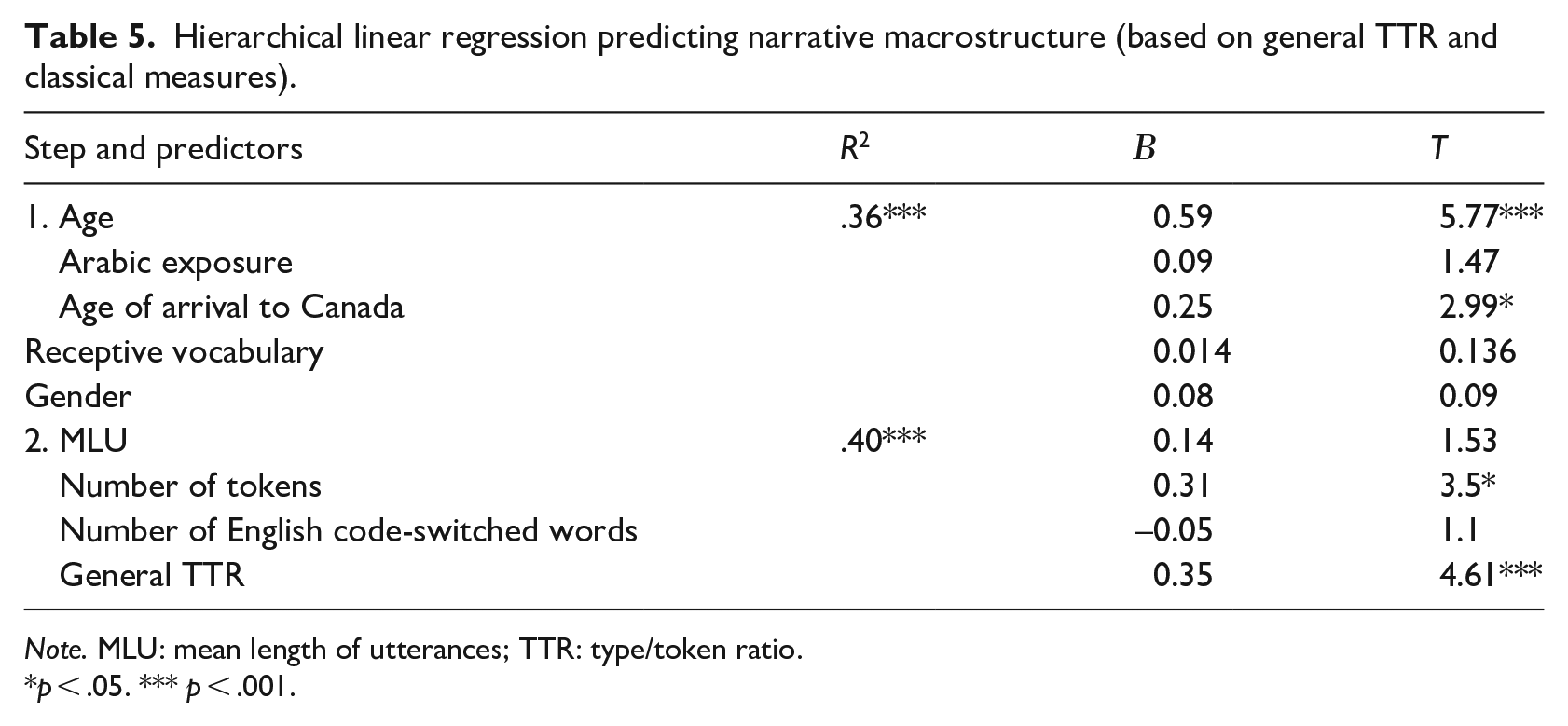
Note. MLU: mean length of utterances; TTR: type/token ratio.
p < .05. *** p < .001.
To examine the contribution of diglossia-specific lexical distance features to the prediction of narrative macrostructure, we conducted a similar hierarchical linear regression but entered the diglossia-specific lexical features (identical words, SpA cognates, StA cognates, unique SpA words, and unique StA words) in Step 3. We also added English code-switched words to the lexical indicators in this same step. Notably, the general measure of TTR used in the previous analysis was not entered in this analysis. Instead, the mean percentage of word types in each of the lexical categories listed above (diglossia-specific lexical features and English code-switched words) was used as predictor variables.
Table 6 shows the final beta weights for all variables. As in the previous analysis, chronological age and age of arrival to Canada predicted 35% unique variance in narrative macrostructure in Step 1. Arabic home exposure and Arabic vocabulary scores did not predict any additional unique variance. In Step 2, narrative length accounted for 45% variance and explained an additional 10% unique variance. In the third step, only StA cognates and unique StA words predicted significant unique variance accounting for a total of 65% and 20% unique variance, respectively. While StA cognates made the largest contribution to the prediction of narrative macrostructure (B = 0.49), unique StA words also made a unique contribution (B = 0.32). The rest of the diglossia-specific lexical features did not contribute any unique variance.
Hierarchical linear regression predicting narrative macrostructure by diglossia-specific lexical variables.
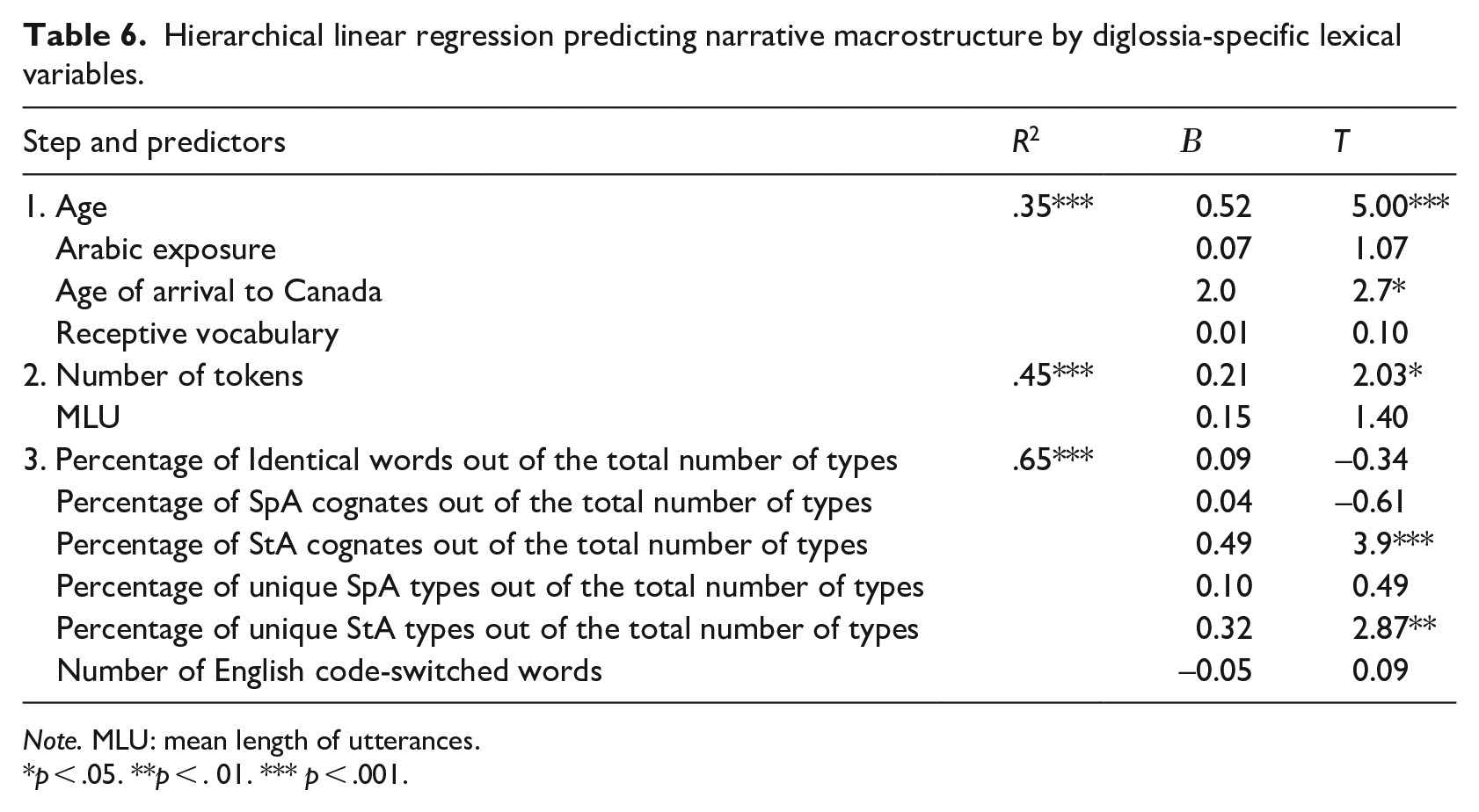
Note. MLU: mean length of utterances.
p < .05. **p < . 01. *** p < .001.
Discussion
The current study had two aims. The first aim was to explicate the manifestation of diglossia in the composition of the lexicon deployed by immigrant children in narrative production. Although the concept of diglossia may not be straightforwardly maintained in the context of Arab immigrants (Albirini & Benmamoun, in press), the children in our sample were born in their Arab country of origin and had received some instruction in Arabic in these countries. Therefore, we investigated the manifestation of diglossia in the narratives produced by children focusing the analysis of microstructure on the lexical distance between SpA and StA. The second aim of the study was to study the relationship between microstruture and macrostructure. Specifically, we aimed to probe whether diglossia-specific lexical features of the microstructure predicted macrostructure beyond general measures of microstructure.
Language proficiency in Arabic requires skill in using both SpA and StA, as well as in switching between them according to the sociolinguistic setting (Ferguson, 1959, 1991) and the communicative function (Albirini, 2016). In this study, children were free to tell their stories in whichever language variety they chose. However, instructions were given in StA to ensure uniform dialect-neutral instructions and to mimic a school-related academic activity and encourage students to take the task seriously. As expected from research in native diglossia, although instructions were given in StA, the children used both language varieties attesting to their diglossic background. They also used very few English code-switched words attesting to their Arabic-dominant linguistic background.
With respect to the first question of the study which pertained to the manifestation of diglossia in the composition of the lexicons of immigrant children as reflected in narrative production, the results showed that the lexicon that was deployed by children consisted mainly of words or word forms within their SpA, making up 59.46% of the total number of word types: identical words (21.55 %), SpA cognates (25.73%), and unique SpA words (12.18%). In contrast, StA words made up a smaller portion that amounted to 38.59%: StA cognates (19.97%) and unique StA words (18.62%). Cognates are words that are used both in SpA and in StA, but they have only partially overlapping phonological forms in each variety (as in consonant or vowel deletion, addition, or substitution). These different forms of the same word in SpA and StA were called in this study SpA cognates and StA cognates, respectively. The results showed that children produced many more SpA cognates than StA cognates. This finding is interesting and it reflects the salience, dominance, and retrievability of these SpA word forms as opposed to their parallel StA forms. This is a reasonable finding given that the SpA form of the cognate is the form that speakers use in everyday speech and for all mediocre communicative functions. Also, because the narratives were produced orally, the time constraints on checking, revising, and monitoring might have factored into this finding too favoring the SpA form of cognates which is easier to access and has greater representational quality. In contrast with the SpA form of cognates, the StA form is less accurately represented (Saiegh-Haddad & Haj, 2018), is more difficult to process in memory (Saiegh-Haddad & Ghawi-Dakwar, 2017), and is reasonably also less accessible in the course of narrative oral production. So, it seems that in the competition between the two forms of cognates for selection among immigrant children in an oral narrative production task for which instructions are given in StA, the SpA forms of cognates win the race.
In contrast with cognates, unique words have non-overlapping unique forms in SpA and StA. The results showed that, unlike cognates which were used more in their SpA form (SpA cognates) than in their StA form (StA cognates), children opted more for unique StA words than unique SpA words. Unique StA words, by definition, have parallel unique forms in SpA (unique SpA words) which are more familiar to children and higher in frequency in their input. Yet, unique SpA words, and unlike unique StA words, do not have a conventional spelling in the Arabic orthography, and in turn, no orthographic form that might be directly associated with them. Therefore, they may be more easily discarded or inhibited in a task that is StA-oriented, such as the one used in this study (Albirini, 2016). This might explain why unique SpA words were used much less in the current narrative production task than unique StA words. Given that unique SpA and unique StA words are equally functional for the purpose of narrating, as they are synonymous, the finding that unique StA words were relied upon more frequently than unique SpA words reinforces the idea that children were aiming at producing their narratives in StA rather than in SpA.
The finding that SpA cognates were used more often than StA cognates, whereas unique StA words were used more often than unique SpA words might also be attributed to the larger phonological distance between the two forms of the latter (unique words) than the former (cognates). As such, if the claim that children were aiming at producing a narrative in StA is correct, then children might have found it easier to access unique StA targets than StA cognates because of the larger linguistic distance between unique StA words and their corresponding unique SpA words than between the SpA and StA overlapping forms of a cognate word. This hypothesis is for future research to pursue.
The sample of this study consisted mostly of Arab immigrants whose parents reported that Arabic was the primary language of the home and half of whom had some schooling in an Arabic-speaking country of origin. Moreover, their narrative microstructure reflects the predominance of SpA word forms, a rather high reliance on the StA lexicon, and very rare code switching to English. This implies that the language behavior of our immigrant sample as reflected in narrative production mimics the patterns predicted for and observed among speakers in a native diglossia (Ravid et al., 2014). Nonetheless, direct comparison with Arabic speakers in a native diglossia is warranted. Another relevant comparison is non-immigrant language minority speakers, such as heritage language speakers (Benmamoun et al., 2013). Albirini and Benmamoun (forthcoming) argue that Arabic heritage language speakers represent a diglossia-less situation because they have less exposure to SpA and StA in the public sphere compared to monolingual speakers of Arabic in the Arab region who see diglossia in action in their lives. The sample of the study which consisted mainly of immigrant children does not seem to represent a diglossia-less context. Nonetheless, as said above, our sample consisted mainly of immigrant children, but it also included a small subgroup of heritage language speakers. Future research should experiment with heritage speakers and immigrant children separately to track down differences and similarities between them in language and narrative skill development.
The second question pertained to the microstructure skills of children and the relationship between narrative microstructure and macrostructure. To address this question, we examined SG elements as indicators of macrostructure. Microstructure was tested based on general measures including text length by total number of tokens, total number of types, TTR, and MLU. Regression analyses showed that the quality of narrative macrostructure was predicted by the chronological age of the children and by age of arrival to Canada. Chronological age and age of arrival to Canada reflect the time that these immigrant children spent in their Arab country of origin or the number of years they spent in an Arabic native speaking environment and in a native diglossia. Interestingly, these factors continue to predict a large amount of variance in the children’s skill in narrative macro structure. This finding accords with earlier research (Gagarina et al., 2012; Meir & Polinsky, 2019, Armon-Lotem et al., 2011). Unexpectedly, however, variations in our immigrant sample in receptive vocabulary and in home exposure to Arabic did not explain any additional variance. This does not align with earlier research (Heilmann et al., 2010), and it might be related to the large differences between the children in our sample in chronological age (7–12) and in age of arrival to Canada (from birth to 13 years), leaving little variance to be accounted for by vocabulary and home exposure (Heilmann et al., 2010).
With respect to the question of microstructure predictors of macrostructure, the results showed that, beyond differences between children in chronological age and age of arrival to Canada, narrative macrostructure was predicted by narrative length in word tokens and by TTR. In other words, the longer the narratives were and the more lexically diverse, the better the macrostructure. Narrative length is an index of language productivity, and our results align with earlier research in showing that this parameter is a predictor of macrostructure (Heilmann et al., 2010). In the same way, our results corroborate earlier finding in showing that lexical diversity and richness predict narrative macrostructure (e.g., Heilmann et al., 2010; Terry et al., 2013). Altogether, these findings demonstrate the inter-dependence between microstructure and macrostructure and that they support form–function views (Berman & Slobin, 1994), which argue that microstructural forms support narrative macrostructure and drive narrative skill development. This interrelatedness might be related to cognitive skills; narrative production relies on the integration of top-down cognitive processes to organize and connect story events (i.e., macrostructure) with bottom-up linguistic and lexical process (Karmiloff-Smith, 1979).
It is noteworthy that the average mean length of utterance, a measure of syntactic complexity, was not found to be a significant predictor of macrostructure beyond narrative length and lexical diversity, indicating a stronger role of lexical skills than grammatical skills in predicting macrostructure (Heilmann et al., 2010; Rakhlin et al., 2020). It is noteworthy that our current study used a measure of MLU as the average number of words per utterance. This measure might be less sensitive to differences in macrostructure skills in Arabic. Instead, mean length of utterance by morpheme may be a more sensitive measure (Parker & Brorson, 2005). Tallas and Dromi (in press) used MLU in morpheme to assess language acquisition among PA-speaking children (age 2–5 years). They found that the mean length of utterance in morphemes was more sensitive than MLU in words in capturing early language development in Arabic. This question is also for future research to pursue.
Given the observed manifestation of diglossia in the composition of the lexicon used by children, the next question that this study tested was whether the diglossia-specific lexical distance microstructural features predicted narrative macrostructure. To address this question, we used a similar regression to the one we used earlier, yet instead of a general measure of TTR, we entered the means of each of the diglossia-specific lexical features in Step 3, as well as the mean of code-switched English words. This analysis revealed that chronological age and age of arrival to Canada were again significant predictors, and together with text length they accounted for 45% of the variance. More importantly, when diglossia-specific lexical indicators were entered, narrative macrostructure was uniquely predicted by the mean percentage of use of StA cognates and unique StA words, with this model accounting for a total of 65% of the variance, namely, with the diglossia-specific lexical features adding 20% additional explained variance. This finding demonstrates that in addition to relevant background variables and general microstructure indicators, prediction of narrative macrostructure in Arabic diglossia benefits from diglossia-specific lexical indicators. These diglossia-specific indicators that are most predictive of macrostructure are related to lexical skills in StA and they comprise use of StA cognates and unique StA words. Why might this be the case?
We argue that the use of StA for the purpose of narration places considerable cognitive demands on children. The instructions for the narrative task at hand were given in StA and the task was administered at school. Hence, StA might have been primed and selected, or at least aspired for as the language that fulfills this academic function in diglossia. As children have limited processing capacity, facility at retrieval of StA cognates and unique StA words eases the cognitive burden on lexical selection and retrieval on the part of children and allows more attention to be directed to overall macrostructure. This implies that StA macrostructure narrative production in Arabic diglossia might require not only sufficient linguistic skills of familiarity with StA lexical forms but also heightened access to these lexical forms and cognitive flexibility in managing the competition and in switching between SpA and StA forms.
It is to be remembered that our data and conclusions are limited by the nature of our immigrant sample. Our Arabic-speaking immigrant sample might be similar to heritage language Arabic speakers in some respects as in their lower linguistic proficiency compared with monolinguals living in an Arabic-speaking region; some might even develop their Arabic linguistic skills in a “diglossia-less” context with no sufficient exposure to StA forms and functions (Albirini, 2015, Albirini & Benmamoun, forthcoming). However, the majority of participants in our sample arrived in Canada at a rather late age, and all of them reported living in households where the primary language was Arabic. Also, all of them reported attending Arabic language classes on the weekend and being involved in reading and oral activities in StA at home. Given all this, it is reasonable to argue that our Arabic-speaking immigrant sample have developed diglossic proficiency, and this appears to be reflected in the composition of the lexicon deployed in their narratives, albeit more reduced in scope. Indeed, a comparison of our results with reported measures of lexical productivity and diversity in Arabic-speaking monolingual children in a native Arabic diglossia (Ravid et al., 2014) reveals large differences between the two groups.
The results of this study have important theoretical implications. They demonstrate the complexity of the lexicon of diglossic speakers (Saiegh-Haddad & Haj, 2018) and the interplay between this complexity and narrative production in children. The study also highlights the centrality of linguistic distance in understanding linguistic processing in diglossic Arabic at all levels including in narrative production (Saiegh-Haddad, 2018). The results also support theories arguing for the mutual interdependence of micro- and macrostructure skills development in children (Berman & Slobin, 1994). Practically, the results point to the importance of considering diglossia-specific lexical distance features when using narrative production in assessment and intervention. They also point to the importance of helping children develop accurate representations of StA words and efficiency of retrieval of StA words because these skills set a limitation on the ability to organize an orally presented story at least when the narrative is produced in StA (Saiegh-Haddad & Everatt, 2017; Saiegh-Haddad & Armon-Lotem, forthcoming). Whether the same factors would hold for a story produced in a written form of StA is a question for future research to pursue.
Several limitations of the study should be acknowledged. The first is the small sample size within each age groups and the large range of chronological age and age of arrival to Canada. To address this variability, we tested vocabulary knowledge and collected parental reports of exposure to Arabic and entered these variables in the regression analysis in the first step. Future research should opt for a sample that is less heterogeneous.
The second limitation is the use of instructions in StA which has primed use of this variety and strongly affected the patterns of results we achieved. Further research should elicit comparable narratives in SpA and StA separately and compare indicators of microstructure and macrostructure, as well as the relationship between the two in the two elicitation conditions independently to test for similarities and differences in the way diglossia is manifested in narrative production in the two language varieties. Finally, this study did not test non-verbal IQ or any other cognitive skills such as memory and executive functioning. Testing of differences between participants in cognitive ability and in executive functions and particularly flexibility/switching is another limitation that future research should address.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The Auther recieved a fellowship from the Council of Higher Education Council.