
Abstract
Aim:
This paper examines whether second-generation Turkish heritage speakers in the Netherlands follow language-specific patterns of reference tracking in Turkish and Dutch, focusing on discourse status and pragmatic contexts as factors that may modulate the choice of referring expressions (REs), that is, the noun phrase (NP), overt pronoun and null pronoun.
Methodology:
Two short silent videos were used to elicit narratives from 20 heritage speakers of Turkish, both in Turkish and in Dutch. Monolingual baseline data were collected from 20 monolingually raised speakers of Turkish in Turkey and 20 monolingually raised speakers of Dutch in the Netherlands. We also collected language background data from bilinguals with an extensive survey.
Data and analysis:
Using generalised logistic mixed-effect regression, we analysed the influence of discourse status and pragmatic context on the choice of subject REs in Turkish and Dutch, comparing bilingual data to the monolingual baseline in each language.
Findings:
Heritage speakers used overt versus null pronouns in Turkish and stressed versus reduced pronouns in Dutch in pragmatically appropriate contexts. There was, however, a slight increase in the proportions of overt pronouns as opposed to NPs in Turkish and as opposed to null pronouns in Dutch. We suggest an explanation based on the degree of entrenchment of differential RE types in relation to discourse status as the possible source of the increase.
Originality:
This paper provides data from an understudied language pair in the domain of reference tracking in language contact situations. Unlike several studies of pronouns in language contact, we do not find differences across monolingual and bilingual speakers with regard to pragmatic constraints on overt pronouns in the minority pro-drop language.
Significance:
Our findings highlight the importance of taking language proficiency and use into account while studying bilingualism and combining formal approaches to language use with usage-based approaches for a more complete understanding of bilingual language production.
Keywords
Introduction
Throughout discourse, speakers track the novelty versus continuity of the entities they mention by choosing between richer versus reduced forms of referring expressions (REs; Ariel, 1990; Givón, 1983). For example, they may introduce a referent with a rich RE, e.g., ‘a young woman’, but maintain that same referent with a reduced form, for example, ‘she’ in the next clause. When referents are new in discourse, they are not highly accessible and therefore need to be expressed with richer REs such as noun phrases (NPs). When referents are maintained across consecutive clauses, however, referents have highly accessible representations and reduced forms, such as pronouns, and in some cases, null pronouns (i.e. argument drop) are informative enough for successful reference tracking (Ariel, 1990; Givón, 1983). This systematic relation between the discourse status of referents (i.e. whether a referent is (re)introduced or maintained) and the richness of the REs that are used for those referents has been found for several spoken as well as signed languages (Arnold, 1998; Frederiksen & Mayberry, 2018; Hickmann & Hendriks, 1999; Perniss & Özyürek, 2015). Languages, however, might show cross-linguistic differences with regard to the reduced RE form they favour. For example, they may differ in whether the null pronoun is the most common form to mark reference maintenance or not (i.e. pro-drop versus non-pro-drop) and whether the choice between the overt pronoun and the null pronoun is pragmatically motivated, as is often the case in pro-drop languages such as Spanish and Turkish. In Turkish, for example, referents are maintained mainly with a null pronoun as in (1b). 3 When referents are pragmatically marked for similarity, contrast or topic shift, contrastingly the overt pronoun is usually preferred over the null pronoun (Enç, 1986), as in (1d) where the subject referent is marked for contrast and is expressed with an overt pronoun, o ‘she/he’ instead of a null pronoun.
(1)
(a) Muratj dün sinema-ya git-ti.
Murat yesterday cinema-DAT go-PAST.3SG
‘
(b) ∅j film-i beğen-me-miş.
∅ movie-ACC like-NEG-PAST.EV.3SG
‘
(c) Aynı film-i Suzani da izle-miş.
Same movie-ACC Suzan too watch-PAST.EV.3SG
‘
(d) Ama
But she a.lot like-PAST.EV.3SG
‘But
This paper examines reference tracking strategies of bilingual speakers in a contact situation. Comparing bilingual data to a monolingual 1 baseline 2 in each language, it asks whether second-generation heritage speakers of Turkish in the Netherlands follow language-specific patterns of reference tracking in Turkish and in Dutch. Turkish is a pro-drop language in which the choice between overt and null pronouns is assumed to be modulated by pragmatic context (Enç, 1986; Turan, 1995), but not so much by the discourse status of referents. Contrastingly, Dutch is a non-pro-drop language where the choice between overt and null pronouns is not assumed to be pragmatically motivated (Carminati, 2002). However, Dutch differentiates between a stressed (zij/hij ‘she/he’) and a reduced variant (ze/ie ‘she/he’) of the third-person personal pronouns. The stressed variant has been suggested to be sensitive to pragmatic contexts, that is, the presence of contrast and/or topic shift (Kaiser, 2011; Kaiser & Trueswell, 2004), similar to what triggers the use of an overt versus a null pronoun in Turkish. This paper aims to investigate whether bilingual speakers of Turkish and Dutch use language-specific ways of reference tracking in relation to both the discourse status of referents and the pragmatic contexts in which REs are used.
Reference production by bilingual speakers of a pro-drop language in contact with a non-pro-drop language has been previously studied, mostly focusing on the relative distribution of overt and null pronouns in relation to pragmatic contexts. The predominant pattern that came out of those studies is that bilingual speakers might loosen the discourse-pragmatic constraints on overt pronouns in the pro-drop language. That is, they may use overt pronouns in pragmatically ‘redundant’ contexts, for example when a referent is not marked for similarity, contrast or topic shift (Flores-Ferrán, 2004; Gürel, 2004; Montrul, 2004; Silva-Corvalan, 1994). The ability to use null pronouns, on the other hand, was suggested to stay intact, with the exception of severe cases of attrition (Polinsky, 1995).
The majority of previous studies on pronouns have examined the contact between pro-drop Spanish and the non-pro-drop English in the USA (e.g. Flores-Ferrán, 2004; Montrul, 2004; Silva-Corvalan, 1994). In addition, in many studies, the heritage speakers did not have high attainment of the pro-drop language (Montrul, 2004; Polinsky, 1995; Silva-Corvalán, 1994). Here, we study the contact between Turkish and Dutch as an understudied language pair in the domain of reference tracking. Furthermore, there is usually high language attainment in the Turkish community in the Netherlands (Backus, 2013). The heritage speakers use both Turkish and Dutch regularly in diverse settings (Backus, 2013; Extra & Yağmur, 2010) and they have high proficiency in each language. There are not enough data available from such populations with high attainment in the pro-drop language and not much known is about whether those speakers still show loosening of the pragmatic constraints on overt pronouns in the pro-drop language.
Apart from providing data from an understudied language pair in the domain of reference tracking, we contribute to the literature in the following noteworthy ways. Firstly, we study both the minority and the majority language (Turkish and Dutch, respectively), comparing bilingual data to the monolingual baseline in each language to investigate whether bilingualism has consequences for both languages (Brown & Gullberg, 2011; Pavlenko, 2003). Most often, only the minority language is studied because it is usually weakly mastered by most speakers and it is not expected to influence the majority language. Secondly, we study not only overt and null pronouns but also richer forms of REs, that is, NPs, with the aim of understanding reference production in a more comprehensive way. NPs are often left out of the analysis in previous studies because their use as opposed to reduced forms of REs usually does not show cross-linguistic variation across pro-drop and non-pro-drop languages, unlike the use of overt versus null pronouns. However, as we take subject REs as our empirical domain of interest, we also study NPs as well as overt and null pronouns. Finally, in addition to pragmatic context that may modulate the use of overt versus null pronouns in pro-drop languages, we also take into account the discourse status of referents, that is, whether referents are re-introduced into discourse after some intervening clauses or maintained across consecutive clauses. Overall, the relative distribution of null and overt pronouns in pro-drop languages has been mainly studied with regard to only pragmatic contexts so far. However, especially for Turkish, we do not know much about whether and how the discourse status of referents also plays a role on the quantitative distribution of these two forms and whether the discourse status effect may also exhibit cross-linguistic influence.
Before we lay out the present study, we introduce how discourse status and pragmatic context may influence the choice of differential RE types, and we review previous studies of bilingual reference tracking.
Discourse status and reference tracking
Previous studies have shown that there is a systematic relation between the discourse status of a referent and how much information speakers provide while referring to that referent (Aksu-Koç & Nicolopoulou, 2015; Arnold, 1998; Azar & Özyürek, 2015; Contemori & Dussias, 2016; Givón, 1983; Gullberg, 2006; Hendriks, Koster & Hoeks, 2014; Hickmann & Hendriks, 1999; Perniss & Özyürek, 2015). Referents that are maintained across consecutive clauses are expressed with reduced forms, such as pronouns. These forms do not contain rich information because their referents have active and accessible representations in the memories of speakers and addressees (Ariel, 1990; Foraker & McElree, 2007). Referents that are new or re-introduced after some intervening clauses, on the other hand, are usually expressed with richer forms, such as NPs. That is because when a referent has a less accessible representation in memory, speakers and addressees need to more information to activate and initiate that referent, which results in the use of fuller forms of referring expressions (Fukumura, van Gompel, Harley, & Pickering, 2011).
Studies that have examined reference tracking in bilingualism in relation to discourse status have mainly focused on adult second language (L2) learners. A common finding from those studies is that overall, the L2 learners are sensitive to discourse status, but they are sometimes more explicit than the first language (L1) speakers, similar to the so-called ‘waffle phenomenon’ suggesting that L2 speakers may use paraphrases when they cannot find a specific RE, for example repeating NPs as longer expressions instead of using pronouns as reduced forms (Edmondson & House, 1991). For example, the L2 learners may use a NP in contexts in which the L1 speakers would use a pronoun (Gullberg, 2006; Yoshioka, 2008), especially in maintained referent contexts. Over-explicitness in the L2 has been observed for learners of both pro-drop (Sorace & Filiaci, 2006; Yoshioka, 2008) and non-pro-drop languages (Gullberg, 2006), and it seems to be modulated by language proficiency. Over-explicitness usually occurs in the discourse when the L2 learners reach intermediate proficiency (Frederiksen & Mayberry, 2018; Hendriks, 2003) and disappears with high proficiency (Polio, 1995).
Studies that have examined reference production by adult heritage speakers have mostly focused on the use of overt pronouns in relation to pragmatic contexts, but not so much in relation to the discourse status of referents. Given that the relation between REs and discourse status may vary between typologically different languages may vary (e.g. the overt pronoun being the default marker of reference maintenance in non-pro-drop languages but not in pro-drop languages), discourse status is an important factor to examine in connection to bilingual reference tracking. In this study, we do so.
Pragmatic context and reference tracking
Languages may show cross-linguistic variation with regard to whether pragmatic context influences the use of REs, in particular regarding the choice between overt and null pronouns. For example, the choice between overt and null subjects in pro-drop languages such as Spanish and Turkish is often regulated by the pragmatic context, for example, whether the subject is marked for similarity, contrast or topic shift (Enç, 1986; Silva-Corvalán, 1994; Tsimpli, Sorace, Heycock & Filliaci, 2004), although such choice is not assumed to be pragmatically motivated in non-pro-drop languages such as German and English (Carminati, 2002). On the other hand, the overt pronoun is the most frequently used RE in maintained referent contexts in non-pro-drop languages (Contemori & Dussias, 2016; Flecken, 2011; Gullberg, 2006; Hendriks et al., 2014), while the null pronoun is the preferred form in such contexts in pro-drop languages (Montrul, 2004; Torres Cacoullos & Travis, 2010). In non-pro-drop languages, however, null pronouns are restricted to certain structures, such as ellipses and finite coordinate clauses (Davidson, 1996).
Although the choice between the overt and the null pronoun in non-pro-drop languages is not assumed to be pragmatically motivated, some non-pro-drop languages, such as Dutch and Estonian, have stressed and reduced variations of personal pronouns, and the stressed variant has been suggested to be sensitive to contrast and/or topic switch (Kaiser, 2010, 2011; Kaiser & Trueswell, 2004). The distinction between stressed and reduced pronouns in non-pro-drop languages, however, has not received as much attention as the distinction between overt and null pronouns in pro-drop languages (Kaiser, 2010). In addition, we are not aware of studies that have investigated contact between a pro-drop language and a non-pro-drop language that has stressed and reduced pronouns, which is the case in this study.
Due to the abovementioned cross-linguistic differences between pro-drop and non-pro-drop languages, the production and the processing of overt and null pronouns by bilinguals have been studied intensely, mostly focusing on whether bilingual speakers learn and maintain the pragmatic constraints on the use of subject pronouns in the pro-drop language. It is usually found that bilingual speakers produce and accept overt subject pronouns in pragmatically ‘redundant’ contexts more often than monolinguals, for example when referents are not pragmatically marked for similarity, contrast or topic shift. Such patterns have been attested for regarding advanced L2 learning (Belletti, Bennati, & Sorace, 2007; Sorace & Filiaci, 2006), language attrition (e.g. Gürel, 2004; Polinsky, 1995; Silva-Corvalán, 1994; Tsimpli et al., 2004), bilingual language acquisition (Haznedar, 2010; Paradis & Navarro, 2003; Pinto, 2006; Serratrice, Sorace, & Paoli, 2004) and also heritage speakers (Keating, VanPatten, & Jegerski, 2011; Montrul, 2004; Montrul & Polinsky, 2011).
Previous findings on bilingual subject pronouns have been interpreted as showing that overt pronouns in a pro-drop language are vulnerable to cross-linguistic influence from a non-pro-drop language in which overt pronouns are frequently used and are not pragmatically marked (in comparison to null pronouns) (Gürel, 2004; Montrul, 2004; Müller & Hulk, 2001; Schmitt, 2000; Tsimpli et al., 2004). It has also been suggested that the cause of the vulnerability to cross-linguistic influence of overt pronouns in pro-drop languages is the syntax–pragmatics interface (e.g. Müller & Hulk, 2001). The most tested formulation of this proposal, the Interface Hypothesis (IH, Sorace & Filiaci, 2006), proposes that some linguistic structures, such as the production and processing of overt pronouns in pro-drop languages, require the integration and coordination of syntactic and pragmatic information in real time. Bilinguals might be less efficient at integrating information from different domains and updating the mental discourse model when needed, possibly due to less automatised syntactic processing strategies. Therefore, interface phenomena are harder to acquire and more vulnerable to cross-linguistic influence than structures that require only syntactic knowledge, for example the use of null pronouns. This vulnerability may lead to the overgeneralisation of the overt pronoun as a ‘default’ unmarked form to relieve processing overload (Chamorro, Sorace, & Sturt, 2016; Sorace, 2011; Sorace & Filiaci, 2006; Sorace & Serratrice, 2009).
Although bilingual speakers have been found to use overt pronouns in unmarked contexts in the pro-drop language more often than monolinguals, the majority of these findings come from studies with participants who had relatively low proficiency in the pro-drop language. Therefore, we do not know whether previous findings about pragmatically ‘redundant’ overt pronouns also hold for speakers with high proficiency in the pro-drop language. In one study, however, Montrul (2004) found for Spanish in the USA that speakers with an intermediate proficiency level in Spanish used 50% of their overt pronouns in pragmatically redundant contexts, whereas only 9% of overt pronouns were used in such contexts by speakers with an advanced proficiency level (p. 137). On the other hand, none of the pronouns were used in pragmatically redundant contexts in monolingual baseline data. It is then plausible that the level of proficiency in the pro-drop language may modulate the extent to which bilingual speakers use redundant overt pronouns. Such a proposal would be in line with a usage-based approach to language acquisition (Bybee, 2006; Tomasello, 2003).
The usage-based approach proposes that there is a link between the frequency of use of a pattern and how strong its representation is in the memory of an individual speaker, that is, its degree of entrenchment (Brooks & Tomasello, 1999; Bybee, 2006). Constructions that are frequently used have strong representations in memory, and thus they are strongly entrenched. Therefore, they will stay activated and accessible for the speakers (de Bot and Clyne, 1989; Green, 2003; Paradis, 2007) and can easily be retrieved for further use (Bybee, 2010; Croft, 2000; Ellis, 2016; Langacker, 1987; MacWhinney, 2012). Constructions that are weakly entrenched, on the other hand, will have less accessible representations in memory and this may make them more vulnerable to cross-linguistic influence (Backus, 2013). Speakers will have less automatised processing routines for those constructions, which will induce a higher cognitive cost during processing and production compared to constructions with high levels of entrenchment. Note that unlike the IH, the usage-based approach was not originally proposed to account for reference tracking strategies of bilingual speakers and has most profitably been developed to account for L1 acquisition. Findings from other studies on language contact suggest its usefulness, however. Language use (in terms of frequency, range and contexts), for example, has been found to be a predictor of grammatical accuracy (Albirini, 2014), including the ‘appropriate’ use of pronouns in language contact situations (Travis, Torres Cacoullos, & Kidd, 2017).
Studying heritage speakers with high proficiency in the pro-drop language and who use both Turkish and Dutch on a daily basis, we will lay out our predictions following the IH and a usage-based approach and will later evaluate how well either approach accounts for the data we present. Note, however, that this study was not set up to test either approach: it is rather a first extensive exploratory study of reference tracking in Dutch and Turkish by second-generation heritage speakers of Turkish in the Netherlands.
Present study
This study asks whether second-generation Turkish heritage speakers in the Netherlands follow the language-specific strategies of reference tracking in Turkish and in Dutch with regard to the discourse status of referents and their pragmatic contexts. It elicits narratives using two short silent videos, providing data that resemble everyday-like contexts while at the same time controlling for the broad topics to be narrated. The data consist of Turkish and Dutch narratives produced by the same set of heritage speakers as well as monolingually raised speakers of Turkish in Turkey and monolingually raised speakers of Dutch in the Netherlands. With this study, we aim to contribute to the existing literature on reference tracking by bilinguals in the following ways.
Firstly, we provide data from an understudied language pair in the domain of reference tracking in language-contact situations, which has been mostly studied for Spanish in the USA. Secondly, we study both the minority and the majority language, as bilingualism may have consequences for both (Brown & Gullberg, 2011; Pavlenko, 2003). Most often, only the heritage language is studied, which is usually the weaker language of the bilingual speakers. The population we study here is different in the sense that the Turkish community in the Netherlands exhibits high attainment of the heritage language. Some factors that contribute to the high attainment of Turkish are high percentages of marriages to spouses from Turkey, easy access to Turkish media and TV series and summer-long holidays in Turkey (see Backus, 2013, for a review). In addition, maintenance of Turkish is often considered important and a ‘core value’ for Turkish identity (Extra & Yağmur, 2010: 131), which is also likely to motivate high language maintenance within the Turkish community. We do not know much about reference tracking by such bilingual speakers who have high proficiency in the heritage language and use it on a regular basis. Thirdly, we study not only overt and null pronouns but also richer forms of REs, that is, NPs, with the aim of understanding reference production in more comprehensive ways. Previous studies have mostly focused on the use of overt pronouns in relation to null pronouns, as these two forms show prominent cross-linguistic differences with regard to reference tracking across pro-drop and non-pro-drop languages. However, as we take subject referent expression as our empirical domain of interest, we study all forms of expressions that refer to subject arguments.
Finally, we study both the overall proportional distribution of overt and null pronouns and the pragmatic contexts in which these two forms are used. Some previous studies only looked at the overall distribution and found higher proportions of overt pronouns in bilinguals compared to monolinguals (Albirini, Benmamoun & Saadah, 2011; Koban Koç, 2016). Some studies, on the other hand, looked at the pragmatic distribution of overt pronouns and found that bilinguals were more likely to use overt pronouns in pragmatically ‘redundant’ contexts where referents were not marked for pragmatic information, such as similarity, contrast or topic shift (Montrul, 2004; Tsimpli et al., 2004). Therefore, it seems that the overall proportional distribution of overt and null pronouns as well as the pragmatic contexts in which they are used are the aspects for which bilingual speakers may divert from the monolingual baseline. In this paper, we study reference tracking considering both the discourse status of referents and the pragmatic contexts in which REs are used.
Cross-linguistic differences between Turkish and Dutch
In Turkish, many clauses have null subjects and the subject referent is marked through person inflection on the verb. In contrast, in Dutch null subjects are restricted to certain structures, such as ellipses and finite coordinate clauses (Davidson, 1996). Furthermore, overt pronouns are pragmatically marked forms in Turkish and they mark information such as emphasis, contrast and topic switch (Enç, 1986; Erguvanlı-Taylan, 1986; Kerslake, 1987; Özsoy, 1987; Turan, 1995). In Dutch, like in other non-pro-drop languages, the use of overt pronouns as opposed to null pronouns is not assumed to be pragmatically motivated (Carminati, 2002). However, Dutch differentiates between a stressed (zij/hij ‘she/he’) and a reduced variant (ze/ie ‘she/he’) of the third-person personal pronouns. The stressed variant has been suggested to be sensitive to the presence of contrast and/or topic switch (Kaiser, 2011; Kaiser & Trueswell, 2004), similar to what triggers the use of an overt pronoun as opposed to a null pronoun in Turkish.
Turkish and Dutch also differ with regard to gender marking on personal pronouns. Third-person pronouns in Turkish (o ‘he/she’ for singular and onlar ‘they’ for plural) do not encode gender and they have the same phonological form as the distal demonstrative pronoun ‘that / those’. Dutch, on the other hand, marks gender on the third-person singular pronouns: hij/ie is the equivalent of ‘he’ and ze/zij is the equivalent of ‘she’ in English. The third-person plural pronoun ze ‘they’, on the other hand, does not mark gender. In Dutch, there is no form overlap between the personal and demonstrative pronouns, although the distal demonstrative die ‘that’ can be used for both animate and inanimate third-person singular and plural subject referents (Kaiser, 2011; Vogels, Maes, & Krahmer, 2014).
Reference tracking in Turkish in contact situations
Studies of reference tracking by speakers of Turkish who also speak a non-pro-drop language have mostly focused on children. Bilingual Turkish-speaking children in contact situations were found to be sensitive to the language-specific ways of reference tracking. They did not show any differences from the monolingual children in Turkey with regard to the overall frequency of overt and null pronouns (Aarssen 1996; Verhoeven, 1990) or the pragmatic contexts in which overt pronouns were used (Özcan, Keçik, Topbaş, & Konrat, 2000).
As for adult bilingual speakers, Doğruöz and Backus (2009) looked at subject pronouns in informal interviews with second-generation heritage speakers of Turkish in the Netherlands. They found no cross-linguistic influence with regard to the frequency of overt subject pronouns, although a few cases of the first-person pronoun were attested in contexts in which monolinguals would not use a pronoun. In a recent study, Koban Koç (2016) collected interview data from first- and second-generation Turkish heritage speakers in New York City and found that heritage speakers used significantly higher percentages of overt pronouns than the speakers in Turkey. Note, however, that this study does not consider the pronouns in relation to pragmatic contexts, which makes the interpretation of the findings difficult as a comparison of the sheer number of overt pronouns is not always informative. Thus, there is a need for thorough and systematic studies with regard to the proportional distributions of REs and the pragmatic and discourse contexts in which they are used in Turkish in language contact situations. This paper aims to fill this gap, offering data from each language of the bilinguals and also from monolingual baselines.
Predictions
We expect bilingual speakers to behave similarly to the monolingual baselines, and therefore to re-introduce referents mainly with NPs and to maintain them mainly with overt pronouns in Dutch and with null pronouns in Turkish. Based on previous studies of bilingual reference tracking in a pro-drop language (e.g. Montrul, 2004; Polinsky, 1995; Tsimpli et al., 2004), one could expect a higher proportion of overt pronouns in bilingual Turkish compared to the monolingual baseline. In line with the predictions of the IH (Sorace & Filiaci, 2006), we could also expect bilinguals to generalise overt pronouns to pragmatically unmarked contexts in Turkish and use ‘redundant’ overt pronouns in contexts that do not signal similarity, contrast or topic shift. Assuming the use of stressed personal pronouns as opposed to reduced variants in Dutch is also sensitive to the presence of contrast and/or topic shift (Kaiser, 2011; Kaiser & Trueswell, 2004), similar to what triggers the use of an overt pronoun as opposed to a null pronoun in Turkish, we can also expect bilinguals to use ‘redundant’ stressed pronouns in Dutch more often compared to the monolingual baseline.
If the presence and the extent of cross-linguistic influence on subject pronouns, however, are modulated by language use and proficiency, then we would not expect differences in bilingual use of pronouns compared to the monolingual baselines with regard to either the proportional distribution or the pragmatic contexts, considering that the bilingual speakers in this study are highly proficient in both Turkish and Dutch. Reference tracking is characterised by extremely high frequency as all speakers practice it many times a day. From a usage-based approach (Bybee, 2006; Tomasello, 2003), this would lead us to expect that overt pronouns are highly entrenched as pragmatically marked forms in Turkish in the memory of bilingual speakers. Considering that the level of entrenchment is a main determiner of how well constructions are maintained in bilingualism (Backus, 2013; Paradis, 2007; Travis et al., 2017), we would then expect overt pronouns as pragmatically marked forms in Turkish to be resistant to cross-linguistic influence from Dutch, where subjects are typically overtly expressed and have an unmarked status. In this case, bilingual speakers would maintain the pragmatic constraints on the choice of overt pronouns and would not be likely to use ‘redundant’ pronouns, at least not more often than monolingual speakers. Similarly, we would not expect bilinguals to produce ‘redundant’ stressed pronouns in Dutch more often than monolingual speakers.
Participants
20 heritage speakers of Turkish studying in Nijmegen, the Netherlands (14 females; Mage = 23.3, SD = 2.95), 20 monolingually raised speakers of Turkish studying in Istanbul, Turkey (17 females; Mage = 22.2, SD = 1.75), and 20 monolingually raised speakers of Dutch studying in Nijmegen, the Netherlands (14 females; Mage = 21.5, SD = 2.73), participated in the study for payment or course credit. Bilingual participants filled in a detailed survey about their language history and language use as well as the demographics of their care-givers.
All heritage speakers were second-generation immigrants who were born and raised in the Netherlands by first-generation parents, who themselves were born in Turkey and immigrated to the Netherlands form Turkey. The mean age of immigration to the Netherlands was 15.9 (SD = 5.12) for the mothers and 19.0 (SD = 7.24) for the fathers. When the participants in this study were born, the mothers on average had already lived in the Netherlands for 9.2 years (SD = 6.66) and fathers for 11.15 years (SD = 7.46). As previously mentioned, there is overall a high level of language attainment in the Turkish community in the Netherlands and there are not many speakers who cannot speak Turkish well (Backus, 2013; Extra & Yağmur, 2010), which is in line with previous sociolinguistic studies on Turkish immigrant groups in Western Europe, summarised by Backus (2013) and Yağmur (2016), which generally report high levels of language maintenance.
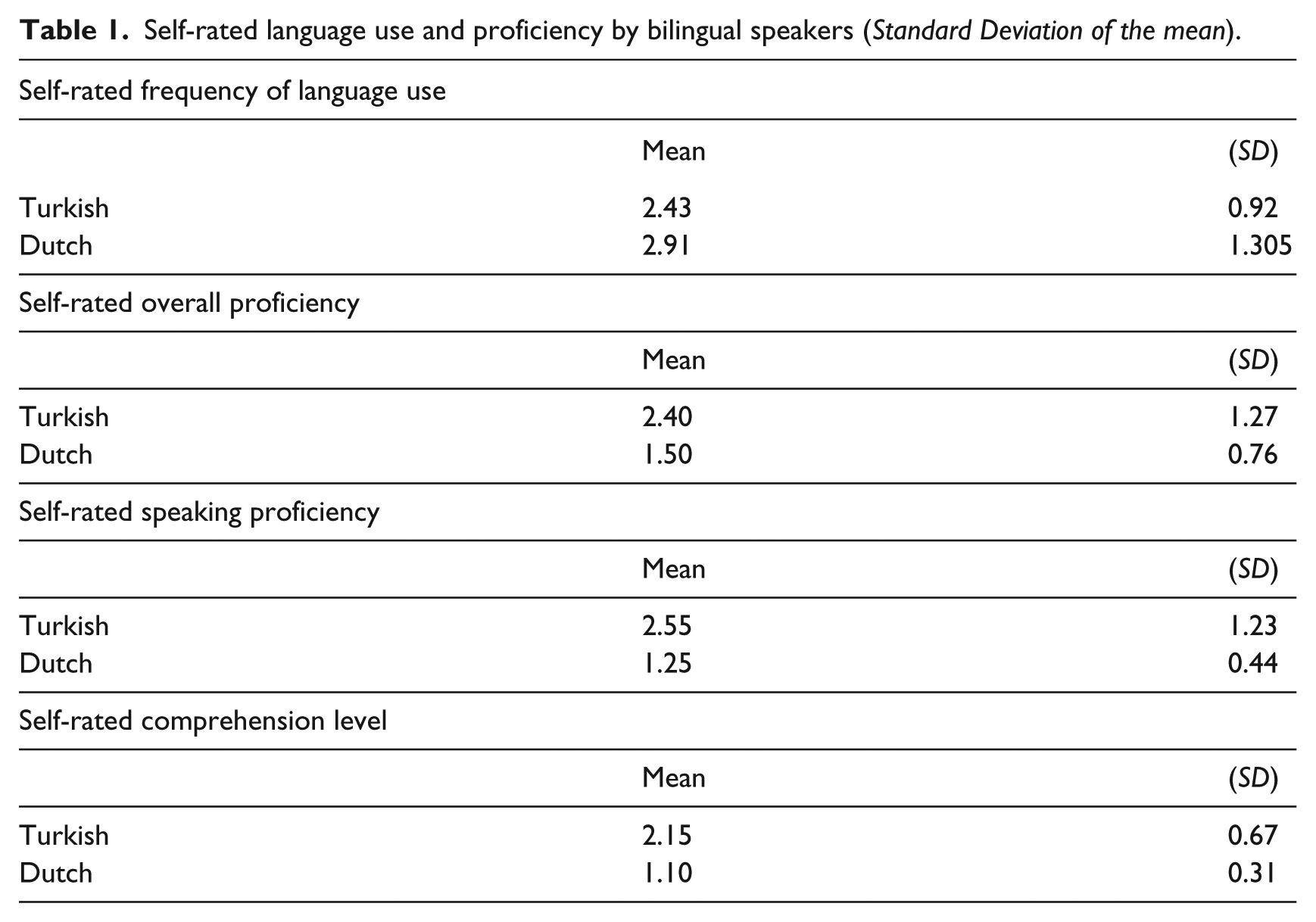
The bilingual speakers in this study acquired the heritage language Turkish as their L1 at home during early years and Dutch as their L2, to which they have had increasing exposure after they started to attend school at age four. They did not have schooling or formal language training in Turkish. Bilinguals reported that their parents had spoken to them more often in Turkish than in Dutch during the early years (between the ages of 0 and 5), while some parents started to mix Turkish and Dutch in their input in later years. On a five-point Likert scale, the bilingual speakers rated their current language use in various environments and with various interlocutors (1 = never; 2 = rarely; 3 = sometimes; 4 = most of the time; 5 = all the time) as well as their overall and speaking proficiency in both Turkish and Dutch (1 = native; 2 = native-like; 3 = advanced; 4 = intermediate 5 = beginner) and their comprehension level (1 = everything; 2 = almost everything; 3 = most parts; 4 = partially; 5 = quite little).
Bilinguals’ self-rated frequencies of language use for Turkish and Dutch did not differ significantly (ß = −0.484, SE = 0.330, t-value = −1.465, p = .143). 4 They rated their overall proficiency in Turkish as well as their speaking proficiency to be somewhere between native-like and advanced, although the rating scores were even higher for Dutch (ß = 0.900, SE = 0.15, t-value = 2.853, p = .004 and ß = 1.300, SE = 0.284, t-value = 4.582, p < .001, respectively). They also reported to overall comprehend almost everything in Turkish, although the rating scores were again higher for Dutch (ß = 1.050, SE = 0.161, t-value = 6.528, p < .001). Bilingual speakers also reported to mainly speak Dutch at school and Turkish at home with their parents, while mostly mixing the two languages among friends (11 participants out of 20 reported to have mainly friends of Turkish descent). All participants reported Dutch as the language they speak the best.
Table 1 summarises the mean scores for the frequency of language use and proficiency. Self-rated overall proficiency scores did not significantly correlate with the self-rated language use scores in either Turkish (rs = −.154, p = .516) or Dutch (rs = −.034, p = .888).
Self-rated language use and proficiency by bilingual speakers (Standard Deviation of the mean).
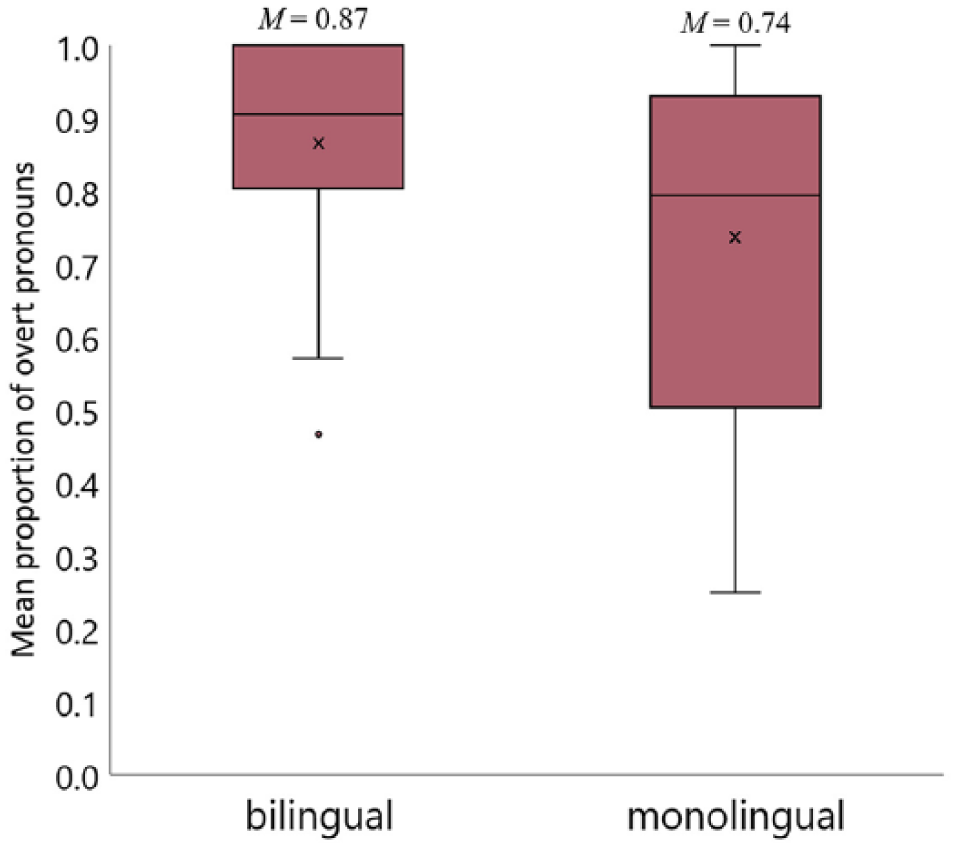
We used speech analysis software Praat (Boersma, 2001) to measure participants’ articulation rate across both languages (number of syllables/time) for a 10-second speech sample from the elicited narratives (cf. De Jong & Wempe, 2009 for the script). Bilingual speakers were not significantly faster or slower than their monolingual counterparts in Dutch t(38) = 0.934, p = .356, but they showed a trend of speaking slower than monolinguals in Turkish t(38) = 1.994, p = .053. Figure 1 5 represents the mean articulation rates for bilingual and monolingual speakers. The articulation rate did not significantly correlate with self-rated proficiency or the amount of self-reported language use either in Turkish (rs = −.124, p = .604 and rs = −.099, p = .677, respectively) or in Dutch (rs = −.185, p = .435 and rs = .184, p = 438, respectively).
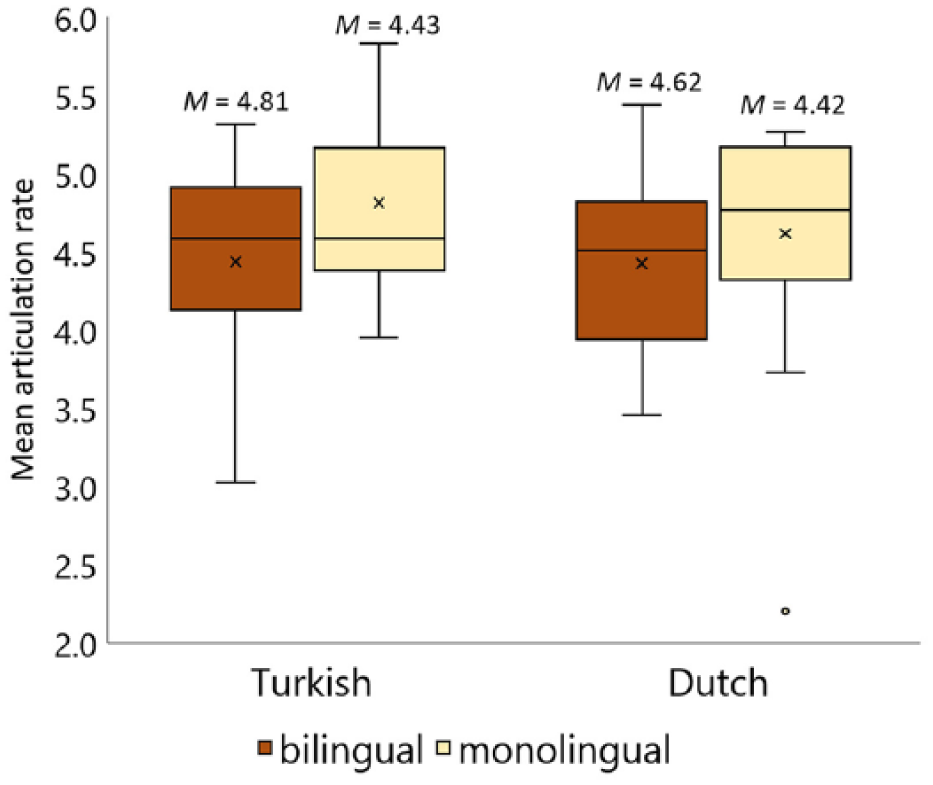
Main articulation rates in Turkish and Dutch, calculated as the number of syllables divided by speech time.
We chose to use an oral fluency measure as an indicator of overall language proficiency because telling a coherent narrative fluently requires proficiency in the lexical, syntactic and discourse-pragmatic domains as well as in utterance planning (Polinsky, 2008). ‘More proficient speakers seem to have less of a problem with lexical access and general construction of the clause. This in turn accounts for a faster speech rate’ (Polinsky, 2008: 60). Speech rate as a proficiency measure has been previously used in language contact research (Benmamoun et al., 2013; Polinsky, 2008, 2011; van Suchtelen, 2016). In addition, the script we used was previously used in a study of Turkish-German bilinguals, and there the articulation rate was shown to correlate with speakers’ C-test (a text completion test) scores (Daller, Yıldız, de Jong, Kan, & Basbaği, 2010).
Stimuli
We used two short silent videos (cf. Azar, Backus, & Özyürek, 2016, 2017) to elicit narratives. In one video, three women are engaged in cooking activities (kitchen video, Perniss & Özyürek, 2015) and in the other, two women and a man are engaged in office activities (office video). Figure 2 illustrates stills depicting different segments from each video. See the Appendices for a detailed list of the events that take place in each video.

Stills form the two video stimuli, kitchen video at the top and office video at the bottom.
Procedure
Participants watched the two stimulus videos one by one on a computer screen and narrated what they had seen to an addressee. The computer screen turned white after each video and stayed white during the narrations. The addressees were not confederates, there was a different addressee in each session and they did not see the videos before or during the narrations. They were instructed that they were going to answer two short written questions about each narrative and that they could ask clarification questions after the narration was done. Once the instructions were given, the experimenter left the room and came back after each narration with questions for the addressee. Bilingual speakers repeated the task once in Turkish with a Turkish monolingual addressee and once in Dutch with a Dutch monolingual addressee, with at least a two-week interval between the two data collection sessions. The order of the two videos and language was counterbalanced. All sessions were videotaped. Monolingual speakers performed the task once.
Data coding
Native speakers of each language transcribed the data. We first divided the narratives into clauses, units with a single subject argument and a single predicate (Berman & Slobin, 1994). We coded coordinated clauses as separate clauses (e.g. the woman who was helping the man stood up and she walked to the bookshelf was coded as two clauses). We did not code relative clauses that modified nouns (e.g. the woman who was helping the man) as separate clauses but treated them as the modifier of the noun (in this case who was helping the man was not coded as a separate clause). This was to make sure that the coding scheme was comparable across Turkish and Dutch (relative clauses are finite in Dutch but non-finite in Turkish). We coded only the clauses with animate subjects to control for animacy as a possible factor that might affect the choice of REs (Vogels et al., 2014) and omitted commentary about the characters (e.g. ‘I think she is the mother’) from the analyses to be able to compare our results to previous studies of reference tracking in extended discourse that followed a similar coding scheme (e.g. Debreslioska, Özyürek, Gullberg, & Perniss, 2013).
Next, we coded the resulting set of animate subject arguments for discourse status (cf. Hickmann & Hendriks, 1999). We coded subject referents as maintained if they referred to the same entity as the subject of the immediately preceding clause. Referents that were mentioned in the discourse previously but not in the immediately preceding clause, either as the subject or object argument, were coded as re-introduced. We did not analyse the cases of introduction (first mention of referents) as we were only interested in how speakers tracked references once they were introduced. Note that although we did not code and analyse the subject referents of commentary clauses, we took them into account while coding the continuity of subject arguments. We later coded re-introduced and maintained subject arguments for the type of the RE: NP (e.g. bare noun, determiner plus noun or nouns modified by an adjective or relative clause), overt pronoun (personal pronoun, demonstrative pronoun, indefinite and stressed and reduced personal pronoun for Dutch) or null pronoun. Example (2) from bilingual Turkish and Example (3) from bilingual Dutch show the discourse status and RE type coding categories extracted from our datasets.
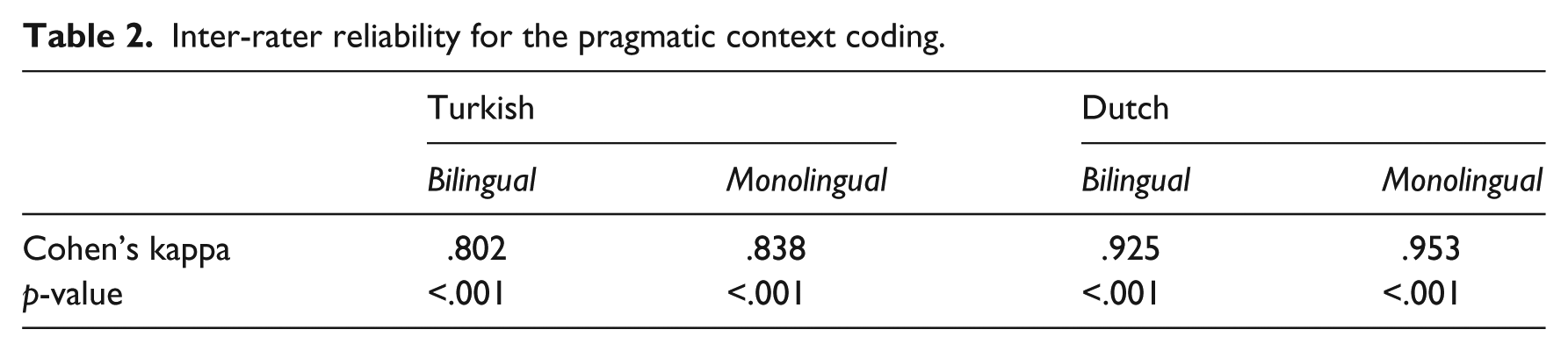
Finally, two speakers of Turkish and two speakers of Dutch coded overt and null subject pronouns for pragmatic context, that is, whether speakers organised clauses in a way that would signal similarity or contrast between different referents or between the propositions related to the referents, or topic switch. Example (2e) is an example of similarity marking such that the subject argument of (2e) walks towards the bookshelf and this is similar to the action that is expressed in Example (2b). The similarity between the actions of the two referents is marked with an overt subject pronoun, o ‘she’ in Example (2e). Example (3d), on the other hand, is an example of contrast such that the subject argument in Example (3d) manages to open the jar in contrast to the action of the subject argument in Example (3b). The contrast between the actions of the two referents is marked with a stressed personal pronoun, zij ‘she’ in Example (3d). There were only a few cases of topic shift in our dataset, and therefore we mainly refer to similarity and contrast when we talk about pragmatic marking in the remainder of this paper. The two coders reached 100% agreement for each language in a meeting where the initial discrepancies were discussed and resolved. Table 2 summarises the initial agreement values.
(2)
a. Sonradan gel-en kadın kalk-ıyo.
Later come-REL woman stand-PROG.3SG
‘
b. ∅ kitaplığ-a doğru gid-iyo.
∅ bookshelf-DAT towards go-PROG.3SG
‘
c. Büro-da otur-an oğlan kağıt-lar-ı toplu-yo.
Office-LOC sit-REL boy paper-PL-ACC collect- PROG.3SG
‘
d. Sonra ∅ kalk-ıyo.
Then ∅ stand-PROG.3SG
‘Then
e.
He too bookshelf-DAT towards go-PROG.3SG
‘
(3)
a. Het meisje met ’t roze T-shirt wil-t een potje openmak-en.
The girl with the pink T-shirt want-PRS.3SG a jar open-INF
‘
b. Maar die krijg-t ze niet los.
But that get- PRS.3SG she not loose
‘But
c. Degene die staa-t probeer-t ook.
The.one that stand- PRS.3SG try- PRS.3SG also
d. En
And she get- PRS.3SG the finally loose
‘And
Inter-rater reliability for the pragmatic context coding.
Analyses
We analysed Turkish and Dutch data separately, comparing bilingual data to a monolingual baseline in each language. This is because we are mainly interested in whether there are possible differences in heritage speakers’ reference tracking strategies from the monolingual baselines, which then would be informative about the possible effects of language contact on the production of subject REs.
We analyses the data using generalised logistic mixed-effect regression using the glmer function from the lme4 package (cf. Bates, Maechler, Bolker, & Walker, 2015) in the software R, version 3.4.3 (see Contemori & Dussias, 2016, for a similar analysis of reference tracking in L1 and L2 discourse). All analyses made use of variants of the generalised linear model with binomial error structure, because the dependent variables were binary. Analyses accounted for individual variance by including random intercepts for participants and random slopes for Pragmatic Context and/or the Discourse Status by participants (see Baayen, Davidson, & Bates, 2008, for more information on mixed-effects modelling in language research). Sometimes a maximal model with both random intercepts and slopes (cf. Barr, Levy, Scheepers, & Tilly, 2013) did not converge, or the model returned a perfect correlation (+/–1.00) between the random factors, which suggests the data might have been over-fitted. We explain below the procedure that we followed in those cases for each analysis. Although all analyses were run on the presence/absence of a category as the dependent variable, figures show mean proportions of a category across all participants for ease of illustration. The specifications and outputs of all models are provided in the Appendices.
Results
Reference tracking in Turkish narratives
There were in total 1713 subject REs in Turkish: 744 from bilingual speakers and 969 from monolingual speakers. Table 3 shows that the most frequently used RE types in Turkish are NPs and null pronouns; NPs are mainly used in re-introduced referent contexts and null pronouns in maintained referent contexts, in line with Turkish being a pro-drop language.
The distribution of referring expression types in Turkish bilingual and monolingual narratives. Raw number (percentage).
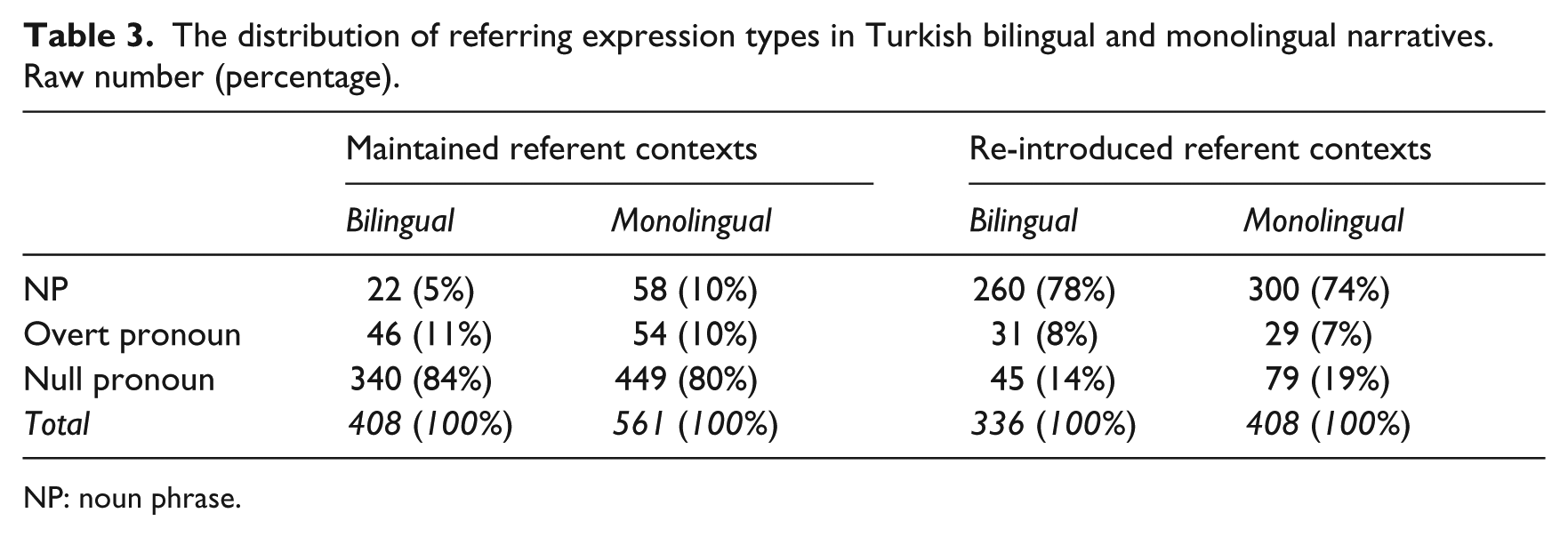
NP: noun phrase.
Overt versus null pronouns
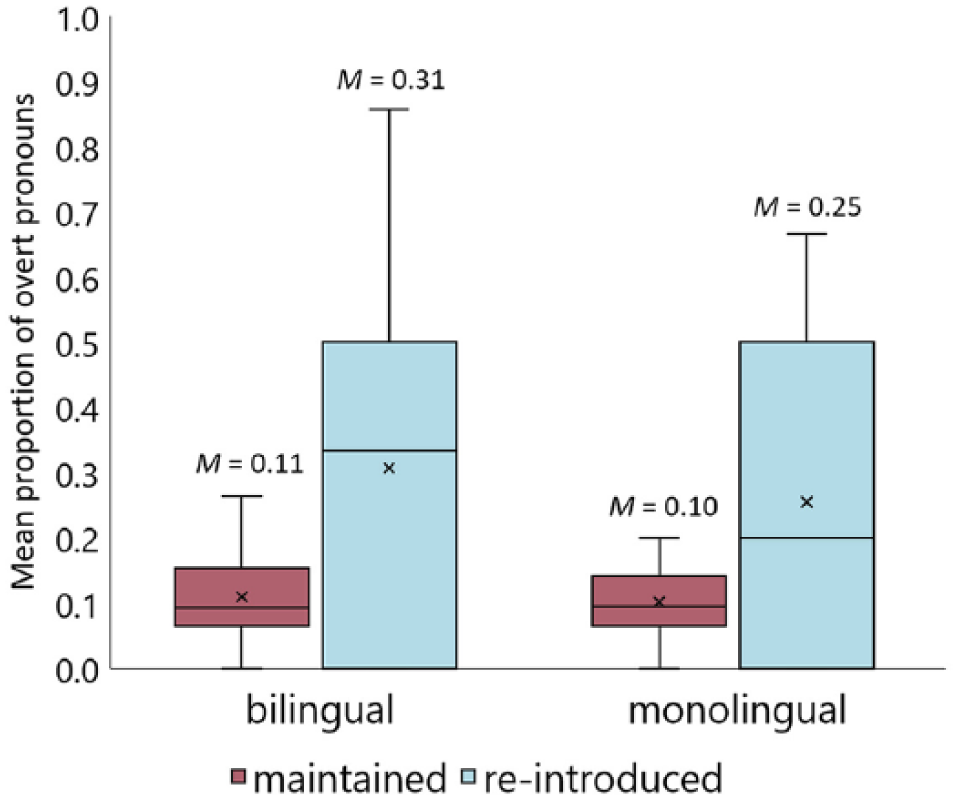
We first analysed the relative distribution of overt and null pronouns in Turkish narratives, excluding NPs from the analysis. The dependent variable was the presence/absence of an overt pronoun as opposed to a null pronoun and the fixed factors were Discourse Status (maintained, re-introduced), Language Status (bilingual, monolingual) and Pragmatic Context (marked, unmarked). The maximal model with both random intercepts for participants and random slopes (for discourse status and pragmatic context) by participants did not converge. We first take out the interaction for random slopes from the model, which did not converge, either. Next, we forced the random intercepts and random slopes not to be correlated, which did not converge. Then we removed the random intercepts from the model. This did not converge, either. Finally, we simplified the model by taking out the random slopes from the model and re-introduced random intercepts into the model. 6 The analysis with random intercepts only returned a significant main effect of Discourse Status (ß = 1.110, SE = 0.458, z-value = 2.428, p = .015) such that the relative frequency of overt pronouns as opposed to null pronouns was higher in re-introduced referent contexts than in maintained referent contexts. The analysis also returned a significant main effect of Pragmatic Context (ß = −2.673, SE = 0.355, z-value = −7.529, p < .00001) with overt pronouns being used more frequently in pragmatically marked contexts compared to pragmatically unmarked contexts, which is in line with the previous theoretical analyses of overt versus null pronouns in Turkish. On the other hand, we did not find a significant main effect of Language Status (ß = 0.199, SE = 0.337, z-value = 0.589, p = .556), suggesting bilingual speakers did not significantly vary from monolingual speakers in how they used overt and null pronouns with regard to discourse status or pragmatic context. We did not find any significant two-way or three-way interactions, either. Figure 3 represents the mean proportions of overt pronouns in maintained and re-introduced referent contexts in bilingual and monolingual Turkish and Table 4 summarises the distribution of overt and null pronouns in marked and unmarked contexts.
The mean proportions of overt pronouns out of all overt and null pronouns in maintained and re-introduced referent contexts in bilingual and monolingual Turkish.
The distribution of overt and null pronouns across marked and unmarked contexts in bilingual and monolingual Turkish narratives. Raw number (percentage).
Note that null pronouns were used relatively often in re-introduced referent contexts in Turkish. This occurred mainly when referents had been previously introduced as a group performing a joint activity a few clauses earlier (e.g. Iki kız masada sebze doğruyo ‘Two girls are slicing vegetables at the table’). When those referents were re-introduced further in the discourse, they were re-introduced with a null pronoun (e.g.∅ bi kavanoz açamaya çalışıyolar ‘(They) are trying to open a jar’) and the predicate was marked for third-person plural (-lAr), and therefore the subject referent was unambiguous.
Even though we found that overt pronouns were sensitive to pragmatic context, surprisingly they were not the ‘default’ form for pragmatically marked contexts, unlike what has been suggested in the previous literature. Especially in maintained referent contexts, the overt pronoun was used about as often as the null pronoun in both monolingual and bilingual narratives. It is possible that the association of overt pronouns with the marked status of a referent is less categorical in Turkish than it is in other pro-drop languages. We will come back to this in the Summary of findings and discussion section. Null pronouns, on the other hand, were the ‘default’ choice in pragmatically unmarked contexts.
Overt pronouns versus NPs
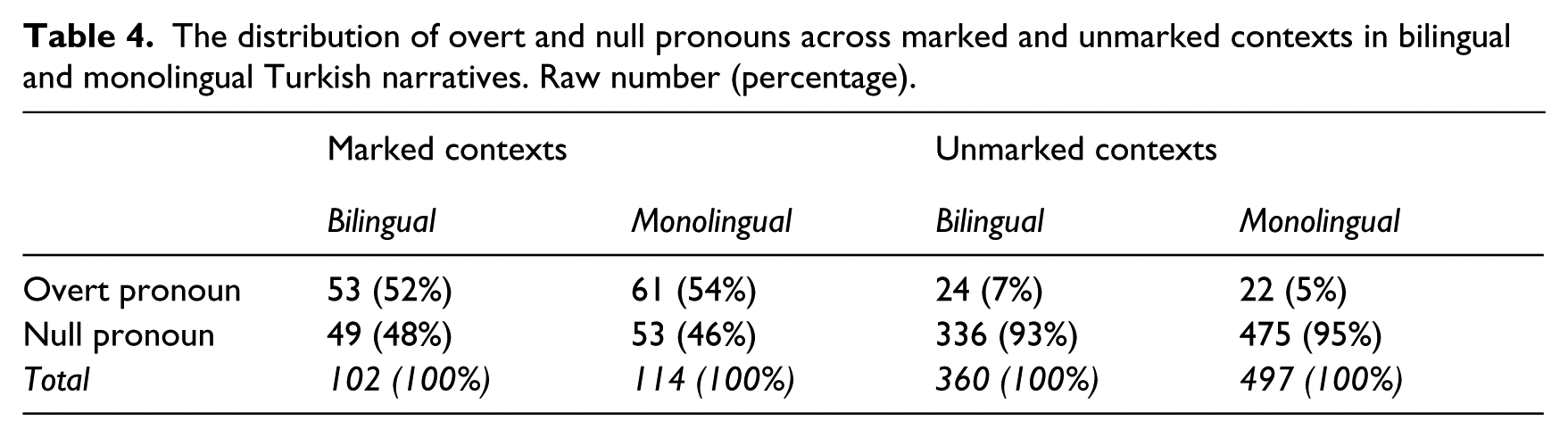
We next analysed the relative distribution of overt pronouns and NPs, excluding null pronouns from the analysis. The dependent variable was the presence/absence of an overt pronoun as opposed to a NP and the fixed factors were Discourse Status (maintained, re-introduced) and Language Status (bilingual, monolingual). The maximal model with random intercepts for participants and random slopes for discourse status by participants returned a significant main effect of Discourse Status (ß = −3.155, SE = 0.400, z-value = −7.880, p < .0001) and a significant main effect of Language Status (ß = −0.818, SE = 0.335, z-value = −2.441, p = .015), but no significant interaction of the two (ß = 0.689, SE = 0.500, z-value = 1.377, p = .168). The analysis showed that both monolingual and bilingual speakers were less likely to choose an overt pronoun as opposed to a NP in re-introduced referent contexts in comparison to maintained referent contexts. Overall, however, bilingual speakers used more overt pronouns and fewer NPs than monolingual speakers. Figure 4 represents the mean proportions of overt pronouns in maintained and re-introduced referent contexts in bilingual and monolingual Turkish.
The mean proportions of overt pronouns out of all overt pronouns and NPs in maintained and re-introduced referent contexts in bilingual and monolingual Turkish.
Reference tracking in Dutch narratives
There were in total 1449 subject REs in Dutch narratives: 748 from bilingual speakers and 701 form monolingual speakers. Table 5 shows that NPs and overt pronouns are the most frequently used RE types in Dutch; NPs are mainly used in re-introduced referent contexts and overt pronouns in maintained referent contexts, in line with Dutch being a non-pro-drop language.
The distribution of referring expression types in Dutch bilingual and monolingual narratives. Raw number (percentage).

NP: noun phrase.
Overt versus null pronouns
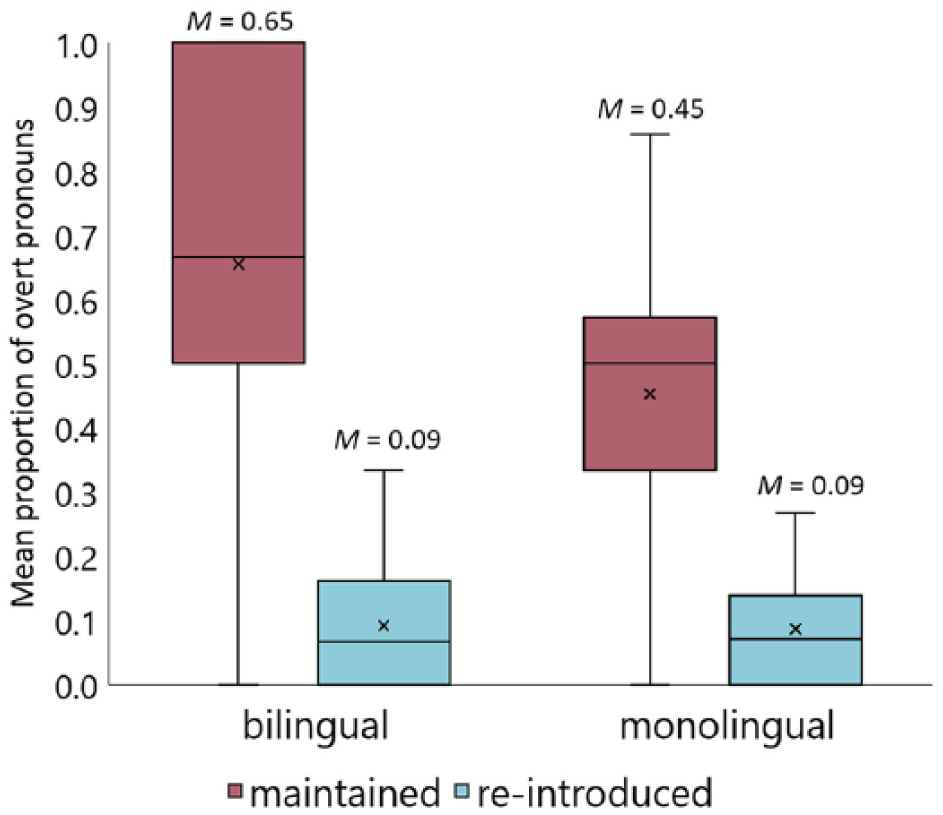
We first analysed the distribution of overt and null pronouns in Dutch narratives, excluding NPs from the analysis. Unlike in Turkish, pragmatic context is not considered to influence the distribution of overt versus null pronouns in non-pro-drop languages (Carminati, 2002), and therefore we did not include pragmatic context as a predictor in our analysis. Due to the low number of null pronouns in re-introduced referent contexts (N = 4), we analysed the presence of overt pronouns as opposed to null pronouns only in maintained referent contexts with Language Status (bilingual, monolingual) as the fixed factor. The model also included random intercepts for participants. The analysis returned a significant main effect of Language Status (ß = −1.084, SE = 0.465, z-value = −2.330, p =.020), with bilingual speakers using more overt pronouns than the monolinguals did. Figure 5 represents the mean proportions of overt pronouns in maintained referent contexts in bilingual and monolingual Dutch.
The mean proportions of overt pronouns out of all overt and null pronouns in maintained referent contexts in bilingual and monolingual Dutch.
Note that the proportions of overt and null pronouns add up to 100%, meaning monolingual speakers used more null pronouns (M = 0.27) than bilingual speakers (M = 0.13). Example (4) from monolingual Dutch and Example (5) from bilingual Dutch exemplify the difference across monolingual and bilingual Dutch in the use of pronouns.
(4)
a. Kom-t een meisje binnen.
Come-PRS.3SG a girl inside
‘
b. Ø pak-t een bureaustoel.
Ø pick- PRS.3SG an office.chair
‘
c. En Ø gaa-t naast die jongen zit-ten.
And Ø go- PRS.3SG next.to that boy sit-INF
‘And
(5)
a. Toen kwam-∅ er een meisje binnen.
Then PST/come-3SG there a girl inside. (cf. nonpast kom-t)
‘Then
b. En ze ging-∅ naast die jongen zit-ten.
And she PST/go-3SG next.to that boy sit-INF (cf. nonpast gaa-t)
‘And
c. En ze ging-∅ help-en met ’t orden-en.
And she PST/go-3SG help-INF with the sort-INF (cf. nonpast gaa-t)
‘And
Given that Dutch is a non-pro-drop language, it is perhaps surprising that the relative frequency of null pronouns in comparison to overt pronouns was relatively high in the monolingual Dutch data. We examined whether the differences in frequency of overt and null pronouns across monolingual and bilingual narratives might be modulated by differences in the use of certain linguistic structures, in particular subject–verb inversion and clause coordination.
Subject–verb inversion in Dutch (e.g. Vanavond ga ik sporten ‘Tonight go I sporting’; i.e. ‘tonight I’ll exercise’) requires an overt subject: dropping the subject would be ungrammatical. There were similar proportions of clauses with inversed subject–verb in monolingual Dutch (32%) and bilingual Dutch (39%). In addition, when we examined only clauses without inversion, bilinguals still used overt pronouns (79% overt and 21% null pronouns) more often than monolinguals (63% overt and 37% null pronouns). Bilinguals also did not seem to differ in how often they coordinated clauses with a coordinating word, a structure that, if used to different extents, could have modulated the frequency of null pronouns in Dutch. 51% of null pronouns in monolingual Dutch and 63% of null pronouns in bilingual Dutch were used in coordinated clauses with coordinating conjunctions, such as en ‘and’, of ‘or’ or dus ‘thus’. Hence, we can eliminate differential use of particular syntactic constructions as possible causes of the difference in frequency of overt and null pronouns across monolingual and bilingual Dutch. We will later discuss other explanations for the lower frequency of null pronouns in bilingual Dutch.
Stressed versus reduced pronouns
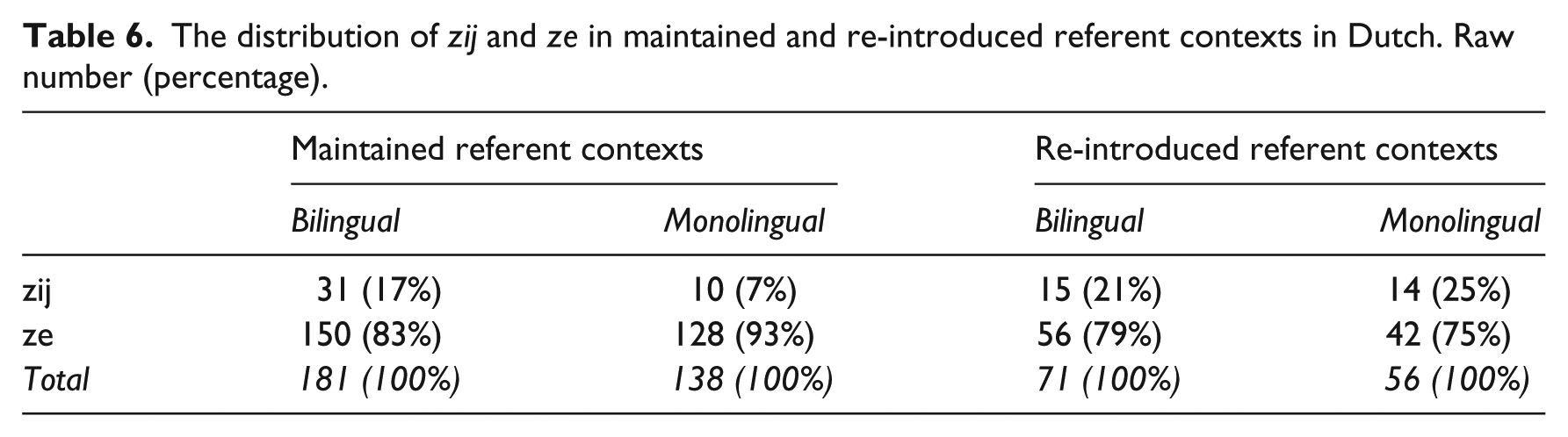
We next analysed the distribution of stressed and reduced personal pronouns in Dutch narratives. We focused only on feminine pronouns, stressed pronoun zij ‘she’ and reduced pronoun ze ‘she’, because the masculine reduced pronoun ie ‘he’ is a clitic and cannot occur in sentence-initial subject positions (Donaldson, 1996; Kaiser & Trueswell, 2004). There were in total 376 cases of ze (206 in the bilingual and 170 in the monolingual narratives) and 70 cases of zij (46 in the bilingual and 24 in the monolingual narratives). Table 6 summarises the distribution of the stressed and reduced variants of pronouns in relation to the discourse status and Table 7 in relation to the pragmatic contexts.
The distribution of zij and ze in maintained and re-introduced referent contexts in Dutch. Raw number (percentage).
The distribution of zij and ze in marked and unmarked contexts in Dutch. Raw number (percentage).
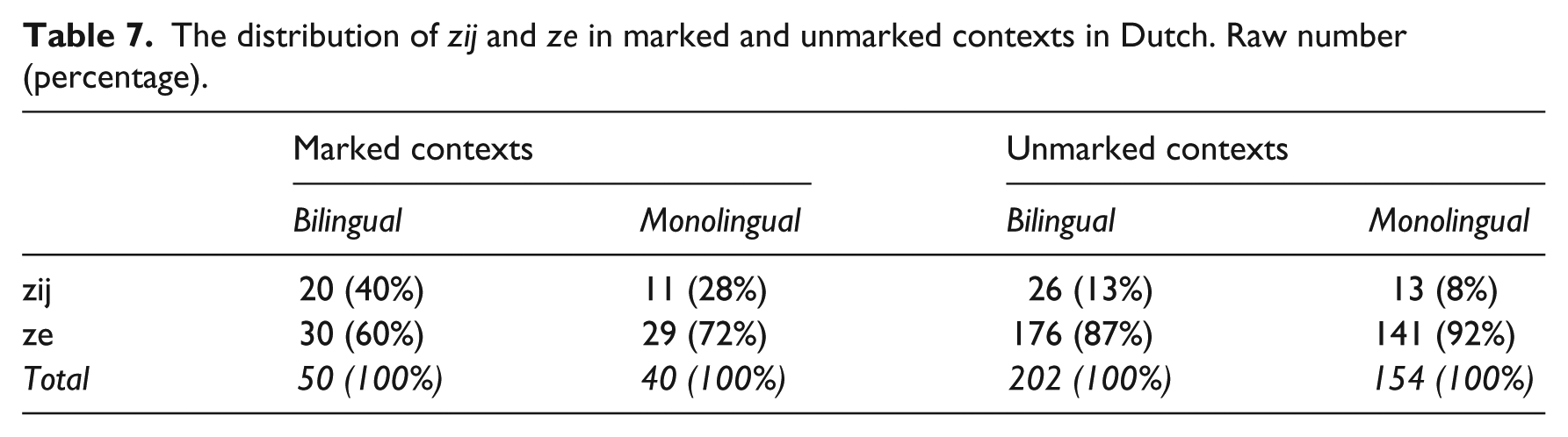
The maximal model with both random intercepts for participants and random slopes (for discourse status and pragmatic context) by participants did not converge. We first take out the interaction for random slopes from the model, which did not converge either. Next, we forced the random intercepts and random slopes not to be correlated, which did not converge. Then we removed the random intercepts from the model. This did not converge, either. Finally, we simplified the model by taking out the random slopes from the model and re-introduced random intercepts into the model. 7 The analysis with random intercepts only returned a significant main effect of Pragmatic Contexts (ß = −1.832, SE = 0.525, z-value = −3.487, p = .0005), such that zij as opposed to ze was more likely to be used in pragmatically marked contexts compared to pragmatically unmarked contexts. We did not find a significant main effect of Discourse Status (ß = 0.191, SE = 0.522, z-value = 0.366, p =.715) or Language Status (ß = −0.829, SE = 0.531, z-value = −1.561, p =.119). There were no significant two-way or three-way interactions, either.
Overt pronouns versus NPs
Finally, we analysed the influence of discourse status on the likelihood of using an overt pronoun as opposed to a NP in Dutch, excluding null pronouns from the data. The maximal model with both random intercepts for participants and random slopes for discourse status by participants did not converge. We first take out the interaction for random slopes from the model, which did not converge either. Next, we forced the random intercepts and random slopes not to be correlated, which this time returned a converging model. However, the levels of Discourse Status had a perfect correlation (1.00), which suggests the model is over-fitted. We therefore simplified the model by taking out the random slopes. 8 The analysis with random intercepts only returned a significant main effect of Discourse Status (ß = −3.929, SE = 0.292, z-value = −13.467, p < .00001), with overt pronouns being used less frequently in re-introduced referent contexts than in maintained referent contexts. We did not find a significant main effect of Language Status (ß = −0.352, SE = 0.381, z-value = −0.923, p =.356) or a significant interaction between Discourse Status and Language Status (ß = 0.044, SE = 0.395, z-value = 0.111, p = .911). Figure 6 represents the mean proportions of overt pronouns in maintained and re-introduced referent contexts in bilingual and monolingual Dutch.
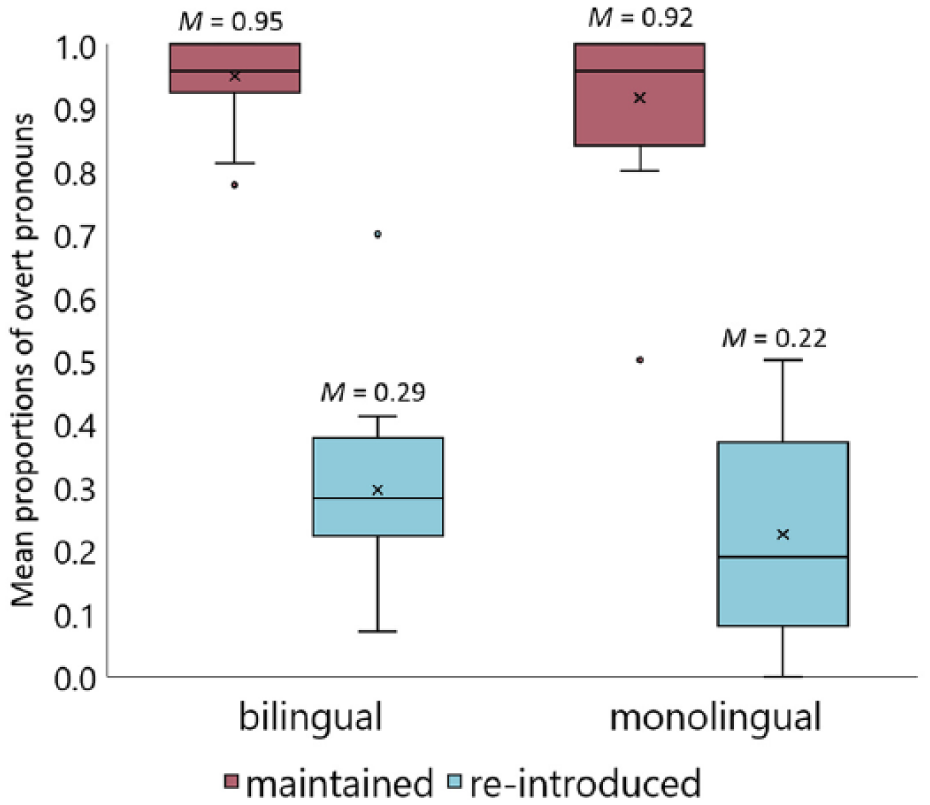
The mean proportions of overt pronouns out of all overt pronouns and NPs in maintained and re-introduced referent contexts in bilingual and monolingual Dutch.
Summary of findings and discussion
This paper has investigated reference tracking strategies of second-generation Turkish heritage speakers in the Netherlands who use both Turkish and Dutch on a daily basis and who have high proficiency in each language. We elicited narratives using two short videos and studied how bilingual speakers used different types of REs, that is, NPs and overt and null pronouns, for subject referents in those narratives, comparing the bilingual data to monolingual baselines in Turkish and Dutch. We examined the distribution of RE forms, taking into account both the discourse status of referents (i.e. re-introduced or maintained) and the pragmatic contexts in which they are used (i.e. whether they were marked for similarity or contrast). Overall, we did not find much difference between bilingual and monolingual speakers, especially with regard to pragmatic constraints. We found, however, some patterns that we did not expect. We will first summarise the findings for the influence of discourse status and then the pragmatic contexts on the use of REs. We will discuss our findings in relation to the IH (Sorace & Filiaci, 2006) and the usage-based account (Albirini, 2014; Bybee, 2010; Travis et al., 2017), the two theoretical approaches that we outlined in the Introduction and Predictions sections.
Discourse status and reference tracking
With regard to the influence of discourse status on the use of REs, we had predicted that bilingual speakers would behave similarly to the monolingual baseline and re-introduce referents mainly with NPs and maintain them mainly with overt pronouns in Dutch and null pronouns in Turkish. We did indeed find that bilingual speakers re-introduced referents with richer forms of REs and they also followed the language-specific strategies of reference maintenance in both Turkish and Dutch: they maintained referents mainly with null pronouns in Turkish and with overt pronouns in Dutch. At the same time, however, we found some patterns that we did not expect, especially in maintained referent contexts. We discuss the findings for Turkish first.
Turkish
We did not find an increase in the relative distribution of overt subject pronouns in relation to null subject pronouns in bilingual Turkish. Bilingual speakers did not significantly differ from the monolingual baseline with regard to the proportion of overt versus null subject pronouns. Recall that several previous studies had attested an increase in overt subject pronouns in a pro-drop language in contact with a non-pro-drop language (Albirini et al., 2011; Koban Koç, 2016; Montrul, 2004; Polinsky, 1995). However, we did find an increase in the use of overt pronouns in relation to NPs in the bilingual narratives. Bilingual speakers used relatively more overt pronouns and fewer NPs than their monolingual peers. Looking at the distribution of overt pronouns and NPs across the two discourse status contexts, the differences between bilingual and monolingual speakers seem to be driven by maintained referent contexts, as the proportions of overt pronouns and NPs in re-introduced referent contexts (M = 0.09 and 0.91, respectively) are the same across bilingual and monolingual narratives.
We argue that the differences we found can be explained by a usage-based account (cf. Bybee, 2010), more specifically the importance it attaches to the level of entrenchment of NPs and overt pronouns in relation to discourse status in Turkish and Dutch. Neither NPs nor overt pronouns are likely to be much more highly entrenched than the other as reference maintenance markers in Turkish, since monolingual speakers do not seem to have a strong preference for either form in maintained referent contexts (55% NPs opposed to 45% overt pronouns). When all RE forms in maintained referent contexts were considered, 80% were null pronouns in monolingual Turkish as opposed to only 10% NPs and 10% overt pronouns (Table 3). Therefore, for most speakers, both NPs and overt pronouns may be only weakly entrenched as maintenance markers for speakers of Turkish. In Dutch, on the other hand, speakers have a strong preference for overt pronouns over NPs as reference maintenance markers (8% NPs as opposed to 92% overt pronouns in monolingual narratives; Table 5), with null pronouns playing only a minor role. Due to their much higher frequency, overt pronouns as markers of maintained reference are likely to be highly entrenched for most speakers of Dutch. We suggest that this high degree of entrenchment in Dutch competes with the weakly entrenched representation of NPs as reference maintenance markers in Turkish. Bilingual speakers, then, might have transferred the dominant and entrenched pattern from Dutch to Turkish and replaced some of the NPs with overt pronouns in maintained referent contexts. Such transfer, however, did not replace null pronouns. For monolingual Turkish speakers, null pronouns have highly entrenched representations as reference maintenance markers, as opposed to overt pronouns (90% null pronouns as opposed to 10% overt pronouns). This probably makes null pronouns resistant to influence from Dutch and not likely to be replaced by overt pronouns.
Dutch
We found that bilingual speakers used comparatively more overt pronouns and fewer null pronouns in maintained referent contexts in Dutch than monolingual speakers. Following a usage-based reasoning, we argue that bilinguals mostly stick to the overt pronoun in those contexts because null pronouns, not very frequent in Dutch to begin with, may have weaker representations as reference maintenance markers in the bilinguals’ Dutch than in the monolinguals’ Dutch. Because null subjects are not particularly frequent in maintained referent contexts, they are unlikely to be strongly entrenched as markers of reference maintenance. Overt pronouns, on the other hand, are by far the most frequently used forms in those contexts. Therefore, bilinguals may have replaced some of the null pronouns with the dominant form of reference maintenance, that is, overt pronouns. To explain why bilingual speakers appear to have weaker representations of these null pronouns, it may be useful to consider their Dutch-speaking sociolinguistic environment.
The weaker entrenchment of null pronouns as reference maintenance markers in bilingual Dutch compared to monolingual Dutch might be related to the variety of Dutch spoken in the Turkish immigrant community. Given the presence of many first-generation immigrants in the community, our participants’ social networks will have always included many people whose Dutch is that of a learner, from beginners’ level to very advanced. L2 learners may make more use of explicit REs, such as overt pronouns, given that over-explicitness is often reported for L2 learners (Frederiksen & Mayberry, 2018; Gullberg, 2006; Hendriks, 2003). As a result, null pronouns might have been more infrequent in the input for our bilingual second-generation participants than for their monolingual Dutch peers. If null subjects were used rarely in the input, this would have triggered a stronger association of the overt pronoun with reference maintenance than it may have in monolingual speakers, conditioning bilingual speakers to use overt pronouns without much variation whenever a referent is maintained. Relative lack of exposure to certain forms may explain the differences between bilingual and monolingual speakers (Rinke & Flores, 2014) – in our case the relative lack of exposure to null subjects in Dutch. In the absence of a comprehensive picture of Dutch as used by the Turkish immigrant community, however, we cannot know whether low use of null pronouns is indeed typical of their speech. Nonetheless, we may interpret the fact that all bilinguals in this study had parents who were late L2 learners of Dutch and that over-explicitness has been frequently reported for L2 speech as support for this suggested explanation.
If we consider the findings for Turkish and Dutch together, bilingual speakers seem to use overt pronouns more often than the monolingual baselines in both languages, but only in relation to the forms used infrequently for reference maintenance, that is, NPs in Turkish and null pronouns in Dutch. We propose that the strongly entrenched forms compete with the weakly entrenched forms in each language and, therefore, some of the null pronouns in maintained referent contexts get replaced with overt pronouns in bilingual Dutch while some of NPs in the same contexts get replaced by overt pronouns in bilingual Turkish. We argue that when the relation between a certain RE form and a certain discourse status is weakly entrenched, bilinguals may replace it with the more strongly entrenched form.
Pragmatic contexts and reference tracking
With regard to the influence of pragmatic contexts on the use of REs, we had different predictions. In line with the predictions of the IH (Sorace & Filiaci, 2006), we expected bilinguals to generalise overt pronouns to pragmatically unmarked contexts in Turkish and thus use ‘redundant’ overt pronouns in contexts that do not signal similarity, contrast or topic shift. Assuming stressed personal pronouns in Dutch are also sensitive to pragmatic information, such as contrast and topic shift, we also expected bilinguals to use ‘redundant’ stressed pronouns in Dutch more often compared to monolingual speakers. On the other hand, if cross-linguistic influence in bilingualism is modulated by language use and proficiency, we would not have expected differences in the bilingual use of pronouns compared to the monolingual baselines in either Turkish or Dutch, in line with a usage-based approach (Bybee, 2006; Tomasello, 2003). Because bilingual speakers in this study use Turkish regularly and on a daily basis, they are expected to have highly entrenched representations of the overt pronoun as a pragmatically marked form. Similarly, we would not expect bilinguals to produce ‘redundant’ stressed pronouns in Dutch either, considering bilingual speakers use Dutch on a regular basis, as well.
For Turkish, we found that both bilingual and monolingual speakers were more likely to use overt pronouns, as opposed to null pronouns, in pragmatically marked contexts, in line with previous accounts of pronouns in Turkish (cf. Enç, 1986). Some previous studies had found that bilingual speakers of a pro-drop language that is in contact with a non-pro-drop language were more likely to accept or use pragmatically ‘redundant’ overt pronouns, that is, when referents were not marked for similarity, contrast or topic shift (Keating et al., 2011; Montrul, 2004). This was not the case for the bilingual population that we studied here, as there were no statistically significant differences in the frequency of overt pronouns in pragmatically unmarked context in Turkish across the bilingual (M = 0.07) and monolingual narratives (M = 0.05).
For Dutch, we found that both bilingual and monolingual speakers were more likely to use the stressed pronoun zij as opposed to the reduced pronoun ze in pragmatically marked contexts. Furthermore, there were no significant differences between bilingual and monolingual speakers in terms of the frequency of stressed zij in pragmatically unmarked contexts in Dutch (M = 0.13 and M = 0.08 for bilinguals and the monolinguals, respectively). Considering that we found no differences in the use of subject pronouns in relation to pragmatic contexts across bilingual and monolingual narratives, either in Turkish or in Dutch, our findings seem to be more in line with the predictions of the usage-based approach than those of the IH.
It is interesting that in the Turkish baseline, we found that not all overt pronouns were used in marked contexts (see Table 4), given that overt pronouns in pro-drop languages are strongly associated with pragmatic markedness. For example, in Montrul’s (2004) Spanish data almost 100% of overt pronouns occur in pragmatically marked contexts. It is possible that the association of overt pronouns with the pragmatically marked status of a referent is less categorical in Turkish than in Spanish. However, our data and analyses do not enable us to give a clear account of what might be behind this less categorical association. Future research should investigate other possible conditions that might govern the use of overt pronouns in Turkish, for example whether certain verb classes, tense categories or the presence of negation favour overt pronouns more than others, as has been suggested for Spanish (Harrington & Pérez-Leroux, 2016; Orozco, 2016; Travis et al., 2017).
We would like to note that constructions that show variation in the monolingual baseline have been previously suggested to be harder to acquire and to be more vulnerable to cross-linguistic influence due to the inconsistency in the input (De Prada Pérez & Pascual y Cabo, 2012; Rinke & Flores, 2014). It seems that the distribution of overt and null pronouns in pragmatically marked contexts in Turkish shows quite some variation in the monolingual baseline. It is remarkable that bilingual speakers who are second-generation immigrants have maintained the pragmatic constraints on overt pronouns despite this variation and the possibility that the syntax–pragmatics interface induces further uncertainty.
Overall, our findings for the relative distribution of overt and null pronouns are not in line with the findings from the majority of studies on bilingual subject pronouns, which found that bilingual speakers overuse overt pronouns (Albirini et al., 2011) or use them in pragmatically unmarked contexts (Flores-Ferrán, 2004; Montrul, 2004; Silva-Corvalán, 1994). We suggest that the difference in the findings is related to the high language attainment of Turkish heritage speakers in the Netherlands. We would like to suggest that even though interface structures might be more vulnerable to cross-linguistic influence due to the processing cost associated with them (a proposal that this paper did not set out to test), this cost might be reduced when bilingual speakers have high proficiency in their pro-drop language and use it regularly. In those cases, bilingual speakers would have strong entrenchment of routines associated with the integration of syntactic and pragmatic information, which would lead to fairly automatised processing of overt pronouns as pragmatically marked forms. This might explain why not all bilingual speakers show indeterminacy at the syntax–pragmatics interface, just like the highly advanced Spanish heritage speakers in Montrul’s study (2004). Those speakers used overt pronouns in pragmatically unmarked contexts to a much lesser degree (M = 0.09) than the speakers with intermediate proficiency (M = 0.50).
Conclusion
We studied reference tracking in an understudied language pair, that is, pro-drop Turkish in contact with non-pro-drop Dutch in the Netherlands. We found that bilingual reference tracking strategies were overall similar to the monolingual baseline in both Turkish and Dutch. For Turkish, we did not find differences in either the proportional distribution of overt versus null subject pronouns or the pragmatic contexts in which those forms were used. Bilinguals were not more likely than monolingual speakers to use overt pronouns in pragmatically unmarked contexts. Therefore, we provided evidence that bilingual speakers of a pro-drop language in contact with a non-pro-drop language do not always show indeterminacy with regard to the realisation of overt pronouns in their pro-drop language. For the particular population we studied, continuous use and exposure to the pro-drop language might have led bilingual speakers to maintain the pragmatic constraints on overt pronouns (Albirini, 2014). We therefore suggested that even if there is processing cost associated with interface phenomena (cf. Sorace & Filiaci, 2006), it might be reduced when speakers have high language proficiency in their pro-drop language and use the language frequently.
Although bilingual speakers seemed to exhibit monolingual-like patterns overall, we also found some subtle differences between bilingual and monolinguals, characterised by an increase in the use of overt pronouns for both languages, especially in maintained reference contexts. While maintaining referents, bilinguals used more overt pronouns and fewer NPs than monolingual speakers in Turkish and they used more overt pronouns and fewer null pronouns than monolingual speakers in Dutch. We offered an explanation based on the degree of entrenchment of different RE types in relation to maintained referent contexts as the possible source of differences in bilingual narratives. Note, however, that in the case of the data we present here, it is not possible to determine independently how deeply entrenched a structure is. The suggestions we present here would merit further research that combines corpus analysis with controlled experiments. Corpus analysis would provide the circumstantial evidence of frequency (widely assumed to be one of the major determinants of entrenchment), while experimental data (e.g. reaction times in lexical decision tasks) would provide evidence about ease of activation (widely assumed to reflect the degree of entrenchment).
Given some intriguing results and the suggestions we made to account for them, we want to stress that future research should include indices of language use and proficiency as a controlled variable in their design and study speaker groups with more variation in these two aspects for a better understanding of how they are related to differences in bilingual reference tracking strategies. Here we explored reference tracking strategies of adult Turkish heritage speakers in the Netherlands in a controlled setting for the first time. In doing so, we constructed a usage-based account for our findings and we feel this has at the very least something to add to the formal linguistic theories that have been suggested on the basis of earlier work. We would like to draw attention to the importance of interpreting formal approaches to language use in the light of psycholinguistic and usage-based approaches for a more complete understanding of the many factors that contribute to language change as ‘usage feeds into the creation of grammar just as much as grammar determines the shape of usage’ (Bybee, 2006, p. 730).
Footnotes
Appendices
Acknowledgements
We thank the Max Planck Institute for Psycholinguistics Nijmegen for technical support and Dr Ayşe Caner and Dr Nihan Ketrez for providing the location and participants for the Turkish monolingual data collection in Istanbul, Turkey. We also thank Dr Pamela Perniss for the same-gender stimulus video, Dr Ercenur Űnal for the reliability coding for pragmatic context in Turkish, Marlou Rasenberg for the reliability coding for pragmatic context in Dutch and Marie Marking for coding the presence/absence of subject–verb inversion in Dutch. We are also grateful to Dr. Susanne Brouwer for her help with the R script.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.