
Abstract
Aims and objectives/purpose/research questions:
This study aims to improve our understanding of common switching patterns by examining determiner–noun–adjective complexes in code-switching (CS) in three language pairs (Welsh–English, Spanish–English and Papiamento–Dutch). The languages differ in gender and noun–adjective word order in the noun phrase (NP): (a) Spanish, Welsh, and Dutch have gender; English and Papiamento do not; (b) Spanish, Welsh, and Papiamento prefer post-nominal adjectives; Dutch and English, prenominal ones. We test predictions on determiner language and adjective order derived from generativist accounts and the Matrix Language Frame (MLF) approach.
Design/methodology/approach:
We draw on three publicly available spoken corpora. For the purposes of these analyses, we re-coded all three datasets identically. From the three re-coded corpora we extracted all monolingual and mixed simplex NPs (DetN) and complex NPs with determiners (determiner–adjective–noun (DetAN/NA)). We then examined the surrounding clause for each to determine the matrix language based on the finite verb.
Data and analysis:
We analysed the data using a linear regression model in R statistical software to examine the distribution of languages across word class and word order in the corpora.
Findings/conclusions:
Overall, the generativist predictions are borne out regarding adjective positions but not determiners and the MLF accounts for more of the data. We explore extra-linguistic explanations for the patterns observed.
Originality:
The current study has provided new empirical data on nominal CS from language pairs not previously considered.
Significance/implications:
This study has revealed robust patterns across three corpora and taken a step towards disentangling two theoretical accounts. Overall, the findings highlight the importance of comparing multiple language pairs using similar coding.
Introduction
Studies of code-switching (CS) – or the use of multiple languages in one utterance – cover a range of languages and linguistic domains (e.g. Bullock & Toribio, 2009; Deuchar, 2012). However, many issues remain poorly understood. For instance, the question of what does and does not occur in CS remains difficult to assess given the poor accessibility of comparable data for meta-analysis. Theoretical accounts make different predictions about the location and the directionality of switches but the empirical evidence remains contradictory.
The current study aims to improve our understanding of common switching patterns by examining noun phrases (NPs; determiner–noun–adjective complexes) as a conflict domain in three language pairs. We examine three conversation corpora whose languages have different properties in the nominal domain, namely Welsh–English, Spanish–English, and Papiamento–Dutch. Importantly, the languages differ with regard to gender and noun–adjective word order. Spanish, Welsh and Dutch have gender whereas English and Papiamento (a creole spoken in the Dutch Antilles (Gordon, 2005; Kouwenberg & Murray, 1994)) do not. Spanish, Welsh and Papiamento prefer post-nominal adjectives, whereas Dutch and English prefer prenominal adjectives. These language pairs thus allow us to test predictions about NP-switching in cases where word order differs across languages and where there are asymmetries regarding gender marking.
To guide the analyses we consider predictions derived from two theoretical traditions, namely generativist accounts (Cantone & MacSwan, 2009; Liceras, Fuertes, Perales, Pérez-Tattam & Spradlin, 2008) and the Matrix Language Frame (MLF) approach (Myers-Scotton, 1993). We explore how they can account for the relationship between determiners and nouns, and the complex relationships in adjectivally modified NPs. To do so, we compare these constructions in three identically coded corpora.
Background
In early analyses of CS the notion of grammatical surface equivalence played an important role. Following Pfaff (1979), Poplack (1980; 1981) postulated two famous constraints. The free morpheme constraint states that switching is not possible between a bound morpheme and its host. The equivalence constraint further restricts CS to locations in the clause where surface structures of the languages match, prohibiting switching where the surface orders differ. Many studies ensued, often reporting counterexamples to the constraints (Azuma, 1993; Bentahila & Davies, 1983; Berk-Seligson, 1986; Cantone & Müller, 2008; Di Sciullo, Muysken & Singh 1986; Jake, Myers-Scotton & Gross 2002; Myers-Scotton, 1997; Myers-Scotton & Jake, 2000).
In the generativist approach, scholars claimed that the underlying grammar of the languages involved were what constrained CS rather than the surface constraints. For example, Woolford (1983) argued that in a CS utterance each grammar contributes part of the sentence (cf. Belazi, Rubin & Toribio, 1994; Di Sciullo et al., 1986). Similarly, MacSwan (1999) argued that the constraints accounting for monolingual grammars, described in the Minimalist Program (Chomsky, 1995), should also account for CS/bilingual grammars.
A psycholinguistically inspired approach, the MLF (Myers-Scotton, 1993), instead assumes an asymmetry between a matrix language providing the morphosyntactic frame (i.e. the functional elements), and an embedded language providing lexical elements.
CS in the nominal domain
Observations of switches within NPs abound in the literature. Timm (1975) and Lipski (1978) both reported frequent mixed NPs in Spanish–English bilingual production especially between determiners and nouns (DetN). Pfaff (1979), noting similar patterns, suggested that such switches occur since no structural conflicts arise between the two languages, a notion further developed by Poplack (1980) in the equivalence constraint.
Other observations suggested a switching asymmetry. Joshi (1985) noted that in Marathi–English combining Marathi determiners with English nouns was acceptable (kati chairs), but not the inverse (*the khurcya). He introduced the notion of a Matrix language and proposed the asymmetry constraint, stating that ‘switching a category of the matrix language to a category of the embedded grammar is permitted, but not vice-versa’ (Joshi, 1985, p. 192).
In the same vein, the MLF approach (Jake et al., 2002) proposed the bilingual NP hypothesis, stating that determiners in mixed nominal constructions should come from the matrix language of the clause, with nominal constructions in the embedded language being permitted but not preferred. Investigating Welsh–English bilinguals, Deuchar (2005, 2006) found that all mixed NPs consisted of a Welsh determiner (Det) and an English noun (N) in utterances where the matrix language was Welsh, thereby lending support to the hypothesis.
Liceras et al. (2008) while examining Spanish–English child and Spanish-dominant adult bilinguals, observed a preference for Spanish determiners with English nouns (e.g. la chair) over English determiners with Spanish nouns (e.g. the silla). They argued that the findings supported a generativist view where the language with the richest array of ‘uninterpretable phi features’ provides the surface realization of the functional category. Since Spanish determiners carry two uninterpretable features (gender and number), they will be dominant.
A few studies directly testing the MLF (determiners from the matrix language) against generativist predictions (determiners from the language with most phi features) in Spanish–English and Welsh–English bilinguals have found results to be either broadly consistent with both sets of predictions or inconclusive (Fairchild and van Hell, 2015; Herring, Deuchar, Parafita Couto, & Moro Quintanilla, 2010). Herring et al. (2010) found that the generativist account was successful in explaining all their Welsh–English data and most of the Spanish–English data. However, they also observed that the success of the generativist account was due to the fact that the language of the verb was almost always Welsh or Spanish, i.e. languages with grammatical gender. In the few clauses where the finite verb was in English, an English determiner was usually found contrary to generativist predictions. Fairchild and van Hell (2017) experimentally examined determiner–noun switches in Spanish–English bilinguals. Their results did not support the predictions of either model. However, they discuss two factors that may have affected their results: (a) they were focusing on externally-induced switches rather than spontaneous, natural switches; and (b) their participants were English-dominant.
More complex NPs have also been examined. Di Sciullo et al. (1986) found noun–adjective switches in Italian–English NPs despite different preferred adjective–noun word orders in these languages. Cantone and MacSwan (2009), investigating German–Italian NPs, concluded that the language of the adjective determined word order. Vanden Wyngaerd (2016) found support for this generalization in French–Dutch NPs. In contrast, Parafita Couto, Deuchar and Fusser (2015), when examining English–Welsh, found that the MLF prediction (where the matrix language determines adjective position) better accounted for the data.
In sum, despite the comparative wealth of observations and theoretical accounts offered to explain them, the evidence is still contradictory. To assess whether this is an artefact of different methods and coding schemes (cf. Pérez-Leroux, O’Rourke & Sunderman, 2014), we must compare similar data types from several language pairs coded identically.
The current study
The current study tests predictions derived from generativist accounts (Cantone & MacSwan, 2009; Liceras et al., 2008) and the MLF account (Myers-Scotton, 1993, 2002) concerning the mechanisms underpinning NP-internal switches. We extend previous work by focusing on both simplex and complex NPs, specifically the language of the determiner and noun–adjective word order.
For the language of the determiner, generativism predicts that the determiner is provided by the language with more grammaticized/phi features. The MLF account instead predicts that the determiner is provided by the matrix language and determined by finite verb morphology.
For noun–adjective word order, the prediction derived from Cantone and MacSwan (2009) is that the language of the adjective determines its position. The MLF predicts that adjectives occur in the position matching the matrix language.
We test these predictions on three language pairs: Welsh–English, Spanish–English, and Papiamento–Dutch. These languages differ in gender and noun–adjective word order: Spanish, Welsh and Dutch have gender, English and Papiamento do not; Spanish, Welsh and Papiamento prefer post-nominal adjectives, Dutch and English prefer prenominal ones.
Table 1 summarises the predictions from the two accounts regarding determiners and adjective–noun order.
Predictions.

Method
Corpora
We draw on three publicly available corpora (see Appendix 1).
Welsh–English
The Welsh–English corpus (Deuchar, Davies, Herring, Parafita Couto & Carter, 2014) consists of 40 hours of recordings, with 151 speakers from various educational backgrounds (81 female, age range 10–80 years) engaged in dyadic conversation on a free topic. Of the speakers, 63% (n = 95) assessed their own proficiency as equally high in both languages. Of the remaining 56 speakers, 66% (n = 37) reported being more proficient in Welsh. The recordings have been transcribed in CHAT format (see MacWhinney, 2000). An example of a nominal switch is found in (1) (English in bold):
(1) yr # dynes
DET woman crazy
‘…that crazy woman’ (Stammers 5:512)
Spanish–English
The Spanish–English corpus (Deuchar et al., 2014) – collected in Miami, Florida (FL) – consists of 30 hours of recordings with 85 speakers (52 female, age range 11–78 years). Of the speakers, 62% (n = 53) assessed their own proficiency to be equally high in both languages. Of the remaining 32 speakers, 69% (n = 22) reported being more proficient in English. The corpus was collected and transcribed in the same fashion as the Welsh–English corpus. An example of a nominal switch is found in (2) (English in bold):
(2) esto es un pequeño
DEM is a small pocket
‘This is a small pocket…’
[Herring 63, *KEV]
Papiamento–Dutch
The Papiamento–Dutch corpus consists of three hours of free conversation from six four-party conversations involving 25 early functional Papiamento–Dutch bilinguals (15 female, age range 18–61) born in Aruba (n = 10), Curaçao (n = 9) and Surinam (n = 1), but resident in the Netherlands at the time of recording (Gullberg, Indefrey, & Muysken, 2009). Their educational background ranged from vocational training to university education. All participants reported using both languages to the same extent daily in a range of situations and to habitually code-switch with other bilinguals. Nevertheless, 24 out of the 25 speakers reported that Papiamento was their ‘best language’.
The conversations are transcribed using standard Dutch and Aruban orthography with phonetic modifications, hesitations and overlapping speech marked. The transcripts are glossed and tagged for language and word class using the coding scheme from Muysken, Kook, and Vedder (1996). An example of a nominal switch is found in (3) (Papiamento in bold).
(3)
det.INDEF eleven mixed
‘
Data and coding
The current analyses are based on subsets of the Welsh–English (42 speakers) and Spanish–English corpora (19 speakers), and on the entire Papiamento–Dutch corpus (25 speakers). Table 2 specifies the details. The subsets match the bigger corpora with regard to speakers’ gender and age.
The three corpora.
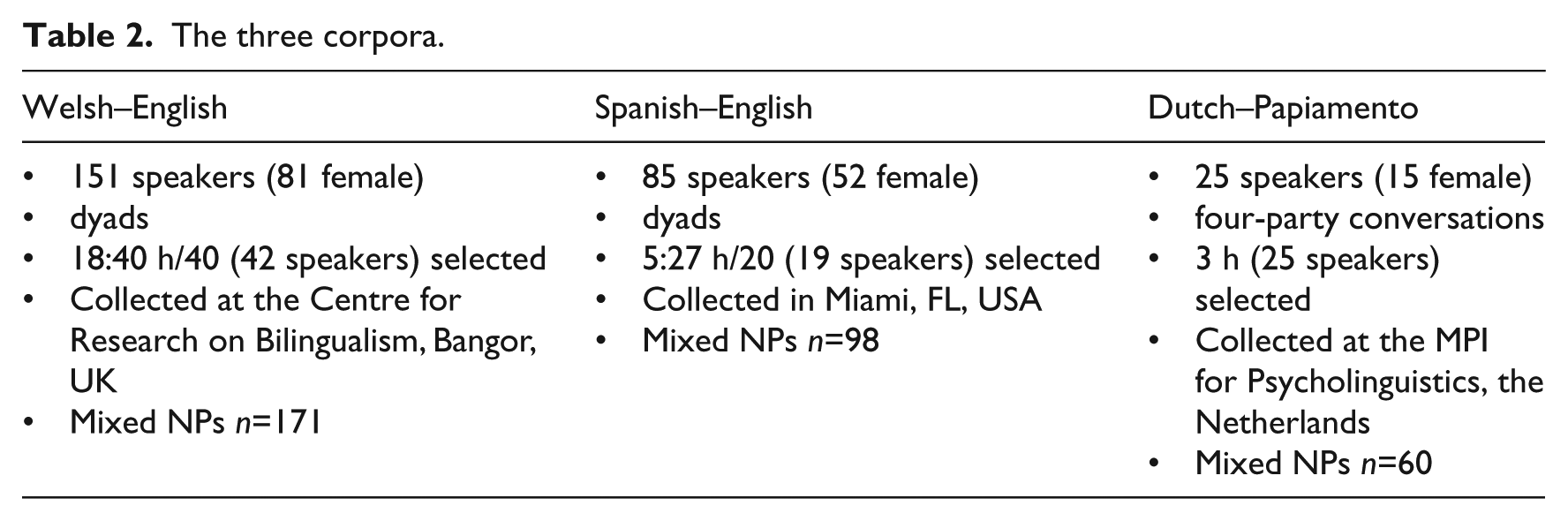
For the purposes of these analyses, we re-coded all three datasets identically. Each NP was coded for the grammatical category of the constituting parts (e.g. determiner–adjective–noun, determiner–noun, etc.). ‘Determiners’ included articles, demonstrative and possessive pronouns. ‘Adjectives’ (A) included adjectives and adjectivised nouns.
We also coded each NP-internal grammatical element for language. Each word was tagged for source language (Spanish, Welsh, English, Papiamento or Dutch). ‘Foreign’ words found in the lexicon of monolingual speakers and in dictionaries were tagged as a separate category (e.g. internet) unless the phonetic realization determined source language.
From the three re-coded corpora we extracted all monolingual and mixed simplex NPs (DetN) and complex NPs with determiners (determiner–adjective–noun; DetAN/NA) (see Appendix 2). We excluded all cases of mixed NPs that included words where language was ambiguous (WE n = 12; SE n = 6; PD n = 10).
We examined the surrounding clause to determine the matrix language based on the finite verb (following Herring et al., 2010). The matrix language was exclusively Welsh and Papiamento, respectively, in the Welsh–English and Papiamento–Dutch corpora. In the Spanish–English corpus, Spanish was the matrix language in 79% of the cases (79/100) and English in 10% (10/100). There were 11 cases where the matrix language could not be identified.
In the discussions below, we shall refer to A-languages (Welsh, Spanish and Papiamento) and B-languages (English and Dutch, in bold font).
Analyses
We analysed the data using a linear regression model using the lm command in R statistical software (version 0.98.953) to examine distribution of A- and B-languages across word class and word order in the corpora.
Results
Table 3 presents the distribution of monolingual and mixed NPs in the corpora. Monolingual NPs are presented for descriptive purposes but the analyses focus only on the mixed NPs (Welsh–English n = 171; Spanish–English n = 98; Papiamento–Dutch n = 60).
Distribution of monolingual and mixed NPs in the three corpora (W = Welsh; E = English; S = Spanish; P = Papiamento; D = Dutch). Simplex = DetN; Complex = DetNA/AN.

Table 3 also shows the distribution of mixed simplex NPs (DetN) versus mixed complex NPs (DetNA/AN). The patterns are remarkably similar. In all corpora the majority of the mixed NPs are of the simplex type (85% for Welsh–English, 94% for Spanish–English and 68% for Papiamento–Dutch, respectively).
Mixed simplex NPs
First, we investigated the distribution of languages across Dets and Ns in DetN switches. Specifically we examined the extent to which Dets came from A-languages (Welsh, Spanish and Papiamento) and Ns from B-languages (English and Dutch, in bold), as shown in examples (4)–(6). The data were aggregated by subject and language combination, and proportions of AB-switches were calculated for each row of the aggregated dataset. A linear regression model was fit to these proportions with corpus as fixed effect. Since the AB-distribution pattern manifested itself most strongly in the Welsh–English corpus, this corpus was coded as the baseline against which the other corpora were compared. The intercept of the linear model therefore represents the Welsh–English corpus. Figure 1 shows the distribution of DetN switches over languages in mixed simplex NPs.
(4) y
DetW thingE
‘the thing’
(5) el
DetS environmentE
‘the environment’
(6) e
DetP pedestrianD
‘the pedestrian’
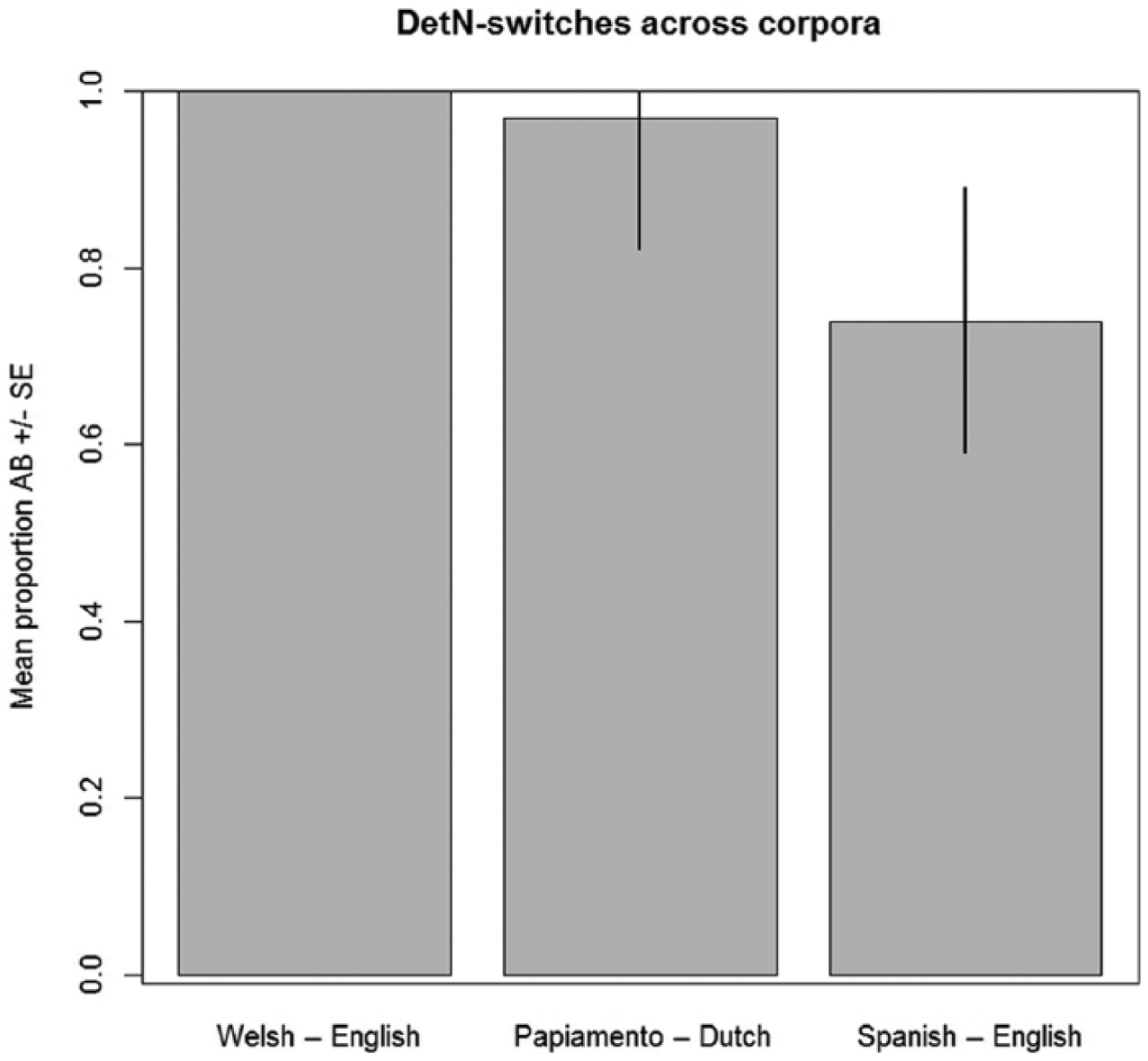
DetN switches across corpora.
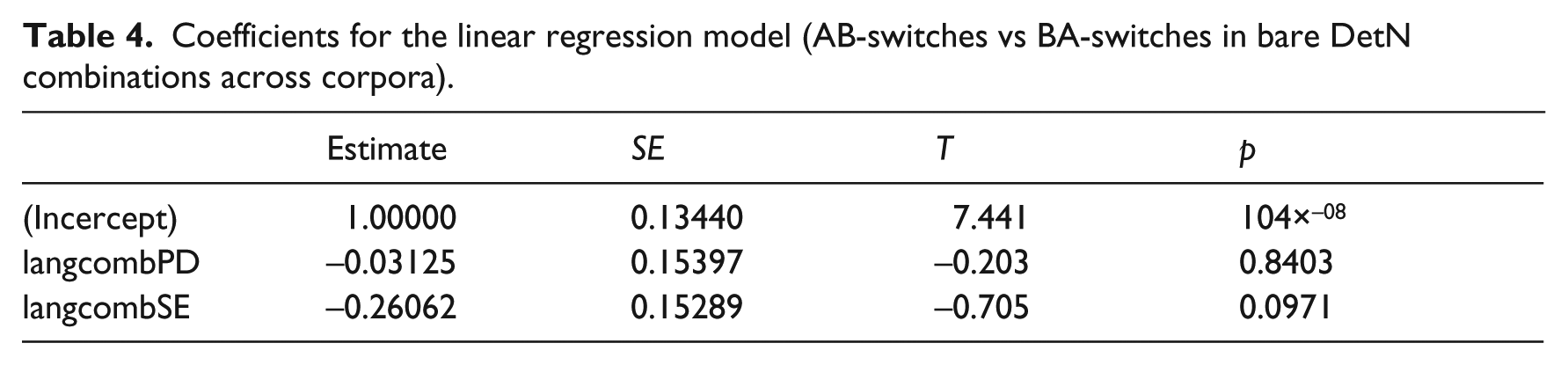
Figure 1 reveals that in all corpora the AB-switches are the most frequent (100% in Welsh–English; 97% in Papiamento–Dutch; 74% in Spanish–English). AB-switches in the Spanish–English corpus are numerically fewer than in the other corpora but the difference does not reach significance (see Table 4).
Coefficients for the linear regression model (AB-switches vs BA-switches in bare DetN combinations across corpora).
Overwhelmingly, Dets also occur in the same language as the matrix language of the clause (100% match in Welsh–English and Papiamento–Dutch with two exceptions in Spanish–English).
Mixed complex NPs
Next, we examined the distribution of Det, N and A in all mixed complex NPs across languages and word order.
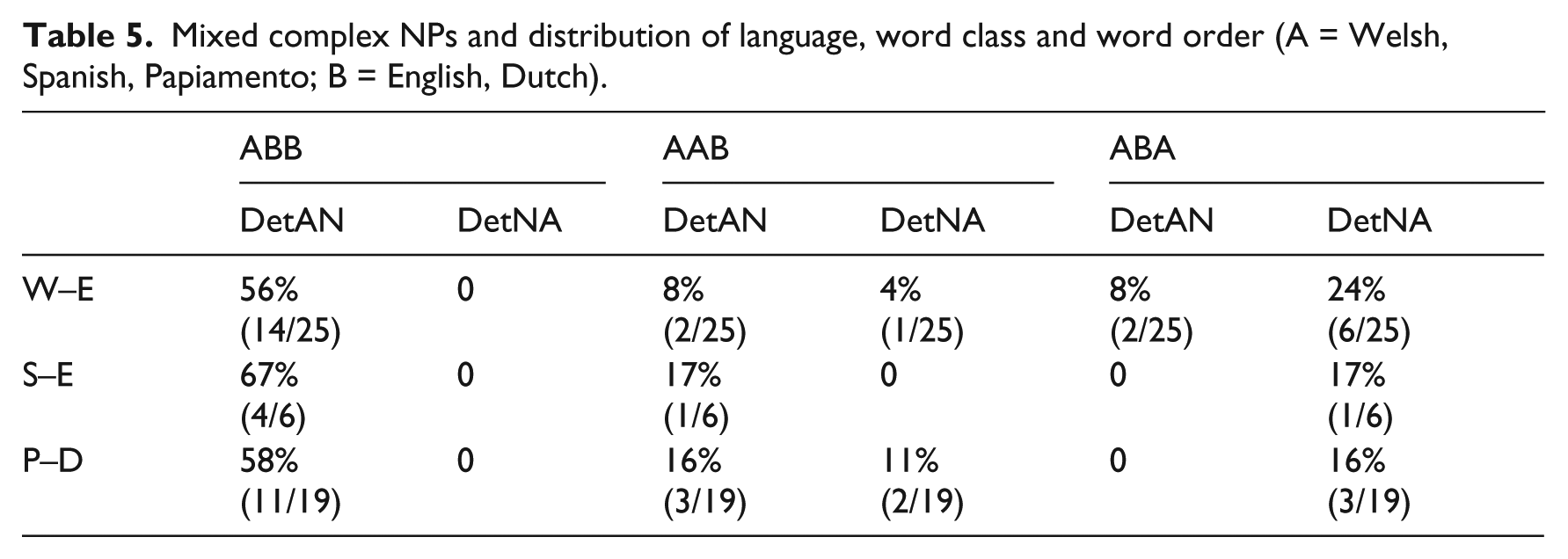
Table 5 reveals that the most frequent type of complex mixed NP in all corpora are DetAN with ABB language distributions, that is, combinations of Dets from A-languages (Welsh, Papiamento and Spanish) and AN-clusters from B-languages (English and Dutch) (examples (7)–(9)). The data points are too few for a statistical comparison to be made across the corpora but the pattern is quite clear. The frequency of other combinations is very low (range 0–6).
Mixed complex NPs and distribution of language, word class and word order (A = Welsh, Spanish, Papiamento; B = English, Dutch).
(7) y
DetW BelgianE loafE
‘the Belgian loaf’
(8) los
DetS dryE wallsE
‘ the dry walls’
(9) un
DetP difficultD choiceD
‘a difficult choice’
Discussion
The analyses of the mixed NPs in the three corpora reveal three key patterns;
Simplex switches between Det and N dominate in all language pairs;
In mixed NPs Dets overwhelmingly come from Welsh (+gender), Spanish (+gender) and Papiamento (-gender), respectively;
Preposed adjectives are the most common in all language pairs followed by Ns in the same language.
The determiner results provide evidence against generativist predictions (which were Dets in Welsh, Spanish and Dutch) since Papiamento provided Dets. Critically, Papiamento should not provide Dets according to the generativist prediction as it lacks gender/phi features. Instead, we can see the matrix languages (Welsh, Spanish, English and Papiamento) provided Dets (the results show an overwhelming match between Dets and matrix languages).
In contrast, the word order results support predictions from both approaches. Dets in Welsh, Spanish and Papiamento are followed by AN clusters in English and Dutch with As in the prenominal position as is typical of these languages. These results match the generativist predictions. Arguably, they also match MLF predictions but in a different form than posited in Table 1. In examples (6)–(9) As and Ns come from the same language, and critically not the matrix (A-) language of the clause but from the embedded (B-) languages. However, the MLF allows for these constructions referring to such AN clusters as ‘embedded language islands’ (Myers-Scotton, 1993). In such islands, the grammar of the embedded language prevails.
Generally, it is striking that switches predominantly occur between Dets and AN clusters – not between As and Ns. Moreover in the nine instances of switches between A and N found, the A position always matches the matrix language in accordance with MLF but not necessarily with generativist predictions. Counterexamples to generativist predictions were found in the Welsh–English (n = 1) and the Papiamento–Dutch corpus (n = 6) where English and Dutch As occurred postnominally.
Arguably then, the MLF predictions best fit the results overall whereas the generativist predictions are mainly supported for word order but not for gender instantiated on Dets. These findings highlight the importance of comparing multiple language pairs with similar coding. Two of the corpora did not allow any distinction to be made between the theoretical accounts; only the Papiamento–Dutch corpus did.
All three corpora display clear asymmetries in the switching patterns between A- and B-languages. A pertinent question is what determines the direction of those asymmetries. An extra-linguistic factor – language dominance – is often discussed as a possible candidate (Liceras, Fernández Fuertes, & Klassen, 2016) either at the community level (Carter, Deuchar, Davies, & Parafita Couto, 2011; Parafita Couto, Davies, Carter, & Deuchar, 2014) or at the individual level (Pérez-Leroux et al., 2014). The majority of the Welsh–English and Papiamento–Dutch bilinguals reported being more dominant in Welsh and Papiamento, respectively. In both cases, the CS patterns seem to fit with individual and community-wide dominance. In contrast, in the Spanish–English corpus, individual dominance varies more. This may explain why we find more cases of English Dets and Spanish N than expected (26%, cf. Figure 1). Yet, despite this variation, the CS patterns are similar to the other corpora. Self-reported dominance may therefore not be the best predictor for the patterns observed.
Another possibility is that switching directionality is affected by another extra-linguistic factor. Blokzijl, Deuchar & Parafita Couto (2017) has recently suggested that switches tend to be towards the language of power or the language with superior social status. The patterns observed in the three corpora with Dets from what could be described as the minority languages (Welsh in the UK; Spanish in Miami; Papiamento in the Netherlands) and lexical material from ‘majority’ languages (English in the UK and in Miami; Dutch in the Netherlands) are certainly consistent with this suggestion.
A related but slightly different construct is frequency of use. Psycholinguistically, frequency effects are known to affect ease of processing in comprehension and production (Ellis, 2002 for an overview). The more frequent a word combination is in the input, the more likely the words are to be named together again. Dets are among the most frequent items in a language, and if Dets are prevalent in one language in a bilingual’s input, this should reinforce the same language choice in production. Such an exposure-driven account is posited by Valdés, Kroff (2016) suggesting that bilingual speakers converge on conventional production patterns. The ‘islands’ in the mixed complex NPs – accounting for the prenominal adjective word order advantage – may at least in part be determined by speakers’ relative experience with the adjective–noun combinations in question. These issues should be studied experimentally, drawing inspiration from recent studies of multi-word units and collocations (e.g. Gyllstad & Wolter, 2016; Sprenger 2003). The challenge will be to find evidence for frequency patterns in bilingual corpora and even more so to determine with what input frequencies a bilingual individual operates (cf. Green, 2011).
Other issues to explore include priming, a cousin of the frequency effect, whereby what has just been processed is likely to be repeated (e.g. Bock, 1986). One speaker’s CS seems to facilitate another speaker’s similar switching (Fricke & Kootstra, 2016; Kootstra, van Hell & Dijkstra, 2010), which suggests that this is an important mechanism to consider.
To conclude, the current study has provided new empirical data on nominal CS from language pairs not previously considered. It has revealed robust patterns across three corpora and taken a step towards disentangling two theoretical accounts. Obviously, many issues remain to be explored. Clearly, further descriptive and experimental work is needed – as are accessible corpora – if we are to understand the complex phenomenon that is CS.
Footnotes
Appendix 1
URLs to the corpora:
Welsh–English
Retrieved from http://bangortalk.org.uk/speakers.php?c=siarad
Spanish–English
Retrieved from http://bangortalk.org.uk/speakers.php?c=miami
Papiamento–Dutch
Retrieved from http://www.mpi.nl/resources/data/browsable-corpora-at-mpi
Appendix 2: Mixed NPS
Acknowledgements
We gratefully acknowledge funding and support from the British Council Researcher Exchange Programme; from the Max Planck Institute for Psycholinguistics, Nijmegen; and from the Nederlandse Organisatie voor Wetenschappelijk Onderzoek (NWO; MPI 56-384, The Dynamics of Multilingual Processing, M. Gullberg, P. Indefrey, W. Klein). We also thank the following people for their help with data collection, transcription, coding, and other data treatment; in Bangor: F. Aveledo, D. Carter, P. Davies, M. Deuchar, K. Donnelly, M. Fusser, J. Herring, S. Lloyd-Williams, E. Robert, and J. Stammers; in Nijmegen: I. Brasileira, A. van Doorn, Z. Fransisco, F. Hellwig, N. Josephina, J. Lourens, B. du Pau, M. del Rosario, and M. Williams; in Lund: Henrik Garde, Josine Greidanus. Finally, we are grateful to P. Indefrey and P. Muysken for their input to the Papiamento-Dutch project.
Funding
This research received no specific grant from any funding agency in the public, commercial, or not-for-profit sectors.