
Abstract
This paper examines the research by Fiona Leverick and demonstrates the methodological flaws in much of the ‘rape myth’ and mock jury research. Other ideas about rape myths and the ‘justice gap’ are explored and seen to be questionable. Furthermore, through a detailed examination of the rape myth acceptance scales, which Leverick describes as being ‘scientifically validated’, we trace the ideological and political-ethical nature of these scales and show a clear one-sidedness in how researchers have used them. Most particularly, we find that there is one-sidedness when it comes to the question of victim empathy. One result of this is that mock jury research has indicated that victim empathetic participants are finding individuals guilty of rape, despite the lack of evidence, and almost nothing has been said about the potential miscarriages of justice being demonstrated in these cases. The argument is thus made that rather than there being overwhelming evidence of rape myth prejudices amongst the public, there appears to be a one-sidedness amongst most rape myth researchers that is encouraging a sentiment of victim empathy that could distort the principles of justice regarding defendants being innocent until proven guilty based on a need to prove guilt beyond reasonable doubt. 1
Introduction
In her paper on rape myths and jury decision making, Fiona Leverick argued that there was ‘overwhelming evidence that prejudicial and false beliefs held by jurors about rape affects their evaluation of the evidence and their decision making in rape cases’ (Leverick, 2020: 255) (my empahsis). Subsequently, in 2021, the chief legal officer in Scotland, Lord Advocate Dorothy Bain, made a case for juryless trials in rape cases and explained that ‘We should be properly informed by the work of Fiona Leverick’ (Taylor, 2021). Juryless trials have become a reality in Scotland, or at least a potential reality following the proposal made in the Scottish government's Victims, Witnesses, and Justice Reform Bill, published in April 2023. In the online factsheet explaining this proposal, Leverick's paper is highlighted as showing the ‘influence of rape myths’ (Scottish Government, 2023). Supporting the juryless trial project, chief executive of Rape Scotland Sandy Brindley explained that there was ‘overwhelming evidence’ that jury members are influenced by ‘rape myths’ (Green, 2023).
Despite the claim that there is 'overwhelming evidence' supporting the need to have juryless trials in rape cases, the reaction against the proposal has been significant. Back in 2021, president of the Scottish Criminal Bar Association Tony Lenehan warned against the potential elitism of lone judges overseeing rape trials, noting that serious criminal cases of this kind are ‘ill-suited to judgment by a single mind drawn from an entirely middle aged, affluent, university educated pool of people’. At this time, defence advocate Thomas Ross described the idea of juryless trials as an ‘authoritarian nightmare’ (Taylor, 2021). 2
By May 2023 the Scottish Bar Association that represents criminal defence solicitors announced that there would be a boycott of the pilot scheme for juryless trials, something that meant the proposed project would potentially not go ahead. Vice president Stuart Murray said that the pilot project was a ‘blatant attempt to increase conviction rates’, noting that failings in rape cases related more to the investigative stage and the difficulty of proving beyond reasonable doubt cases where there is often a lack of evidence such as CCTV footage and extensive witness testimony (BBC, 2023).
Academic papers and research projects assessing rape myths have been produced since the 1970s (Brownmiller, 1975). They have often been motivated by the relatively low conviction rate of rape cases. Much of this research promotes the idea that there are ‘rape myths’ that limit the possibility of guilty verdicts in rape cases. In the last decade, Fiona Leverick has become one of the leading academics exploring this idea, indeed her name is mentioned 19 times in Lady Dorrian's document, Improving the Management of Sexual Offence Cases, a document that led to the proposed Victims’ Bill (Scottish Courts, 2021). What Fiona Leverick did in 2020 was to pull together past research to demonstrate that the evidence of prejudicial and false beliefs held by juries was ‘overwhelming’. Partly as a result of her work, this understanding has been used as a basis to have juryless trials in rape cases.
Here we will examine Leverick's claims in detail to ascertain the extent to which there is or is not overwhelming evidence of rape myths in society.
Methodological problems of Fiona Leverick’s claim of ‘overwhelming evidence’
In May 2023 Fiona Leverick and co-authors James Chalmers and Vanessa Munro argued that the proposed Victims, Witnesses and Justice Reform (Scotland) Bill was ‘without doubt one of the most significant pieces of criminal justice legislation in the history of the Scottish Parliament’. They also argued that the weight of evidence of rape myths justified a pilot project where rape cases would be overseen by a judge and no jury. Here, they note one of the key concerns regarding rape trials in Scotland is that the ‘conviction rate in rape/attempted rape prosecutions was 51%, lower than for any other crime’. This is a concern that has been raised in many other countries and is often discussed in terms of a ‘justice gap’.
If we include cases that are reported to the police but never get to court, Leverick, Chalmers and Munro note, this brings the number of successful rape convictions down to 5.5 per cent. The potential need to get rid of juries, they note, relates to the difficulty of addressing ‘false beliefs’ and ‘juror prejudices’, and as such, they conclude, the ‘evidence to justify a pilot is there’ (Chalmers et al., 2023).
Leverick's paper, ‘What do we know about rape myths and juror decision making?’ (Leverick, 2020) is a meta-analysis of past research. Using tables that chart the outcomes of this research, Leverick demonstrates that in 57 pieces of research about rape myths, 95 per cent of them found a relationship between rape myths and the way that jurors make decisions about guilt and innocence (or not guilty). This would appear to justify her claim that there is overwhelming evidence of rape myths. However, the veracity of this research is questionable, something that Leverick notes herself.
For example, for research with a sample of people to be applicable to the population as a whole, one must use random and unbiased sampling methods. If your sample is not representative of the population in question (for example, of the Scottish population), then you cannot make valid statistical inferences or generalisation. In Table 1 of this rape myth paper that looks at 29 pieces of research we find that none of the samples is random. Twenty-four of the 29 papers used student participants, for example, and only two were UK-based.
Work with German, Spanish or American people and students may be comparable at some level, but there may also be differences within these countries. Indeed, in the Sokratis Dinos paper cited by Leverick, the point is made that: Rape myths in part reflect societal or cultural attitudes and as such researchers have found variations in the prevalence of rape myths between different countries. In general the prevalence of negative attitudes towards rape victims ranges from 18.3% (United Kingdom) to 29.5% (Canada) amongst western countries and 32.9 (Hong Kong) to 51.5% (Malaysia) in eastern countries. More recent studies have found similar cultural differences, which underline the importance of the sociocultural context in terms of the historical, political, religious and economic factors in shaping rape myths and attitudes towards rape (Dinos et al., 2015).
In Leverick's next table, Table 2, we find 28 pieces of research. Again, none of the samples were random, 19 of them were made up of student participants and only four were based in the UK.
Leverick notes herself that these mock jury studies ‘sometimes use a convenient sample of students’ (Leverick, 2020: 259), meaning that there is an inevitable difference ‘in terms of characteristics like age and education’ compared with the general population.
Another major problem, which we will look at below with reference to Cheryl Thomas’s work, is that the individuals involved in these jury projects are ‘mock’ jurors i.e., these are not real juries dealing with real cases, and all of the participants, unlike in real juries, are volunteers. With regard to the potentially problematic or unrealistic nature of mock jury trials, in another piece of research involving Fiona Leverick it is noted that ‘it is important to bear in mind the limitations of any research using mock juries’ (Ormston et al., 2019). This concern about mock jury research is commonly recognised, as McEwan points out, ‘laboratory experiments and mock trials appear to be the best alternative psychologists can adopt’, but ‘[i]t would be dangerous to make too much of their findings’ (McEwan, 2000: 111). Likewise, Kapardis (2010: 162) notes that: ‘Many psycho-legal researchers would agree…that authors of unrealistic jury simulations should qualify their findings and should refrain from putting them forward as the basis for policy changes’.
Furthermore, Leverick notes herself that many of the research projects use methods that are ‘less realistic’ than others. For example, rather than using in person jury settings or using videos of mock trials, participants are simply given ‘written vignettes (a short—usually single paragraph and no more than one page—summary of events)’, supplemented with other trial summaries (Leverick, 2020: 259). Looking at the 57 pieces of research in Tables 1 and 2, we find that 40 of them used written vignettes. Summarising some of these problems, Leverick notes that a lot of the studies ‘use short written vignettes (with no legal directions) or (what are now regarded as) outdates RMA scales’. Furthermore, in terms of the lack of reality involved in these mock jury research projects, ‘Some of the studies used measures of guilt far removed from the binary decision that jurors make in reality’ (2020: 266).
Significantly, unlike real juries who must deliberate before making their decision about guilt and innocence, Leverick notes, with her examples, ‘most mock jury studies do not include this element’. Indeed, of the 57 studies listed in these tables, only two involved any deliberation. Recognising many of the flawed research methods of these projects Leverick (2020: 266) notes that ‘not all of the studies suffered from methodological weaknesses. The best of the studies in terms of realism were the two experiments undertaken by Willmott.’
Dominic Willmott used local people in an English town, not just students, that were representative of the local population, although not of the country as a whole, with many more South Asian and Black Afro-Caribbean participants being represented in the sample (Willmott et al., 2018). His work attempted to be more representative by using a random sample from the electoral register. However, the random nature of this sample was undermined by the necessary voluntary nature of those who came forward to carry out the mock jury trial research and as such, this ‘first come, first served’ approach meant that even Willmott's work cannot be used to extrapolate to the population as a whole (Willmott, 2017: 120).
Willmott used a mock trial video based on real rape cases and included pre-trial instructions and post-trial directions (or more accurately, pre-evidence instruction and post-evidence direction), using professional actors who were recorded in a real courtroom, included jury deliberation in groups of 12 and used the preferred AMMSA (Acceptance of Modern Myths About Sexual Aggression) scale. As a result, Willmott's work is an excellent attempt at dealing with many of the pitfalls of much of the previous research but the difficulty of the juries not being actual juries remains. Willmott explains that ‘participants were asked to take their role as a juror seriously throughout the duration of the trial’ (2017: 100). This is understandable and necessary but the need to insist upon this cannot overcome the potential problem of the unreal nature of this exercise. Work by Cheryl Thomas, for example, has shown that ‘mock jury research and public opinion polls conducted with volunteers, not real serving jurors at court, is a fundamentally flawed method of understanding what real jurors think and how real juries work’ (Thomas 2020: 987).
With regard to methodological problems in other ‘rape myth’ research (much of which is included in Leverick's paper about ‘overwhelming evidence’), Willmott notes that his PhD was developed after ‘directly considering the limitations which exist within past research’, where, for example we find ‘student samples [that are] yet to have been reliably shown to exhibit external validity’. With regard to the central role of deliberation in trials Willmott also notes that ‘group deliberation within any mock jury research is always required in order that the study can be considered to exhibit adequate external validity’ (2017: 205) (my emphasis). Overall, Willmott explains that ‘the present study sought to vastly improve upon the ecological validity of much previous jury research’ (2017: 115).
Despite the inevitable limitations that Willmott had in attempting to make his research realistic and as representative as possible, problems that could only be resolved by carrying out work with real juries, his work is some of the best to date. Willmott also found that there was a relationship between rape myths and how individuals relate to rape cases, although as work by Tinsley, Baylis and Young (that we will discuss below) has indicated, this relationship may not prove that ‘rape myths’ necessarily lead to bad decision making by jurors.
The critics
Another significant problem with the rape myth research is that it is based on an invented scale or rather scales, that claim to be able to identify individuals who believe in rape myths. Before looking at this issue, it is worth looking at some of the other critical issues that have been raised about rape myths.
At the start of 2023 the Labour shadow justice secretary stated that as ‘barely one in a hundred reported rapes ever results in conviction’ this means that in the UK rape has effectively been ‘decriminalised’ (Sleigh, 2023). The number of reported rapes has increased significantly in the last few years, but the numbers of those convicted has remained relatively constant. As a result, the idea that there is a ‘justice gap’ appears to be more true than ever before. This problem of a justice gap was being discussed in 2005 by researchers led by Liz Kelly. In a Home Office research study called A Gap or a Chasm?, it is explained that there has been a fall in the rape conviction rate to 5.6 per cent; here it is noted that this ‘represents a justice gap that the government has pledged to address’ (Kelly et al., 2005: ix). Adding to the concern about the justice gap, Joanne Conaghan and Yvette Russell note that many laws and practices have changed over the last few decades to deal with perceived problems in rape cases but ‘it becomes increasingly apparent that the global transformation in rape law regimes has failed to hold in check the widening “justice gap”’ (Conaghan and Russell, 2014: 26).
The idea of a justice gap highlights the specificity of rape cases as different to other types of crimes. In particular, as we have seen, a key concern is that there are rape myths in society that have created this gap. However, questions have been raised about the way rape cases are discussed as being so distinct.
For example, the often-repeated idea that the number of rape convictions is so low, whether that be 1 in 100 or around 5 per cent, is a constructed notion based on all reported cases to the police rather than conviction rates in court. Rarely is this the way conviction rates are discussed or understood in relation to other crimes. Evolutionary psychologist Paula Wright notes that: ‘Feminists reach the shockingly low figure by conflating all complaints made to the police with all eventual convictions. If other crimes were calculated this way, the overall conviction rate for all crimes would hover around 6 per cent. Yet, only rape is calculated this way.’ She elaborates, noting that in England and Wales, ‘When compared to other crime statistics, the rape conviction rate is higher than that for threatening to kill, attempted murder, manslaughter and GBH. Why isn’t this common knowledge?’ (Wright, 2023). Similarly, Cheryl Thomas, a professor of judicial studies at University College London, raised concerns about this figure, noting that in terms of how conviction rates are generally discussed, in England and Wales the actual conviction rates in court cases for adult women is 67 per cent. The dramatically low representation of the conviction rate, Thomas believes, is a problem in that what could be described as a myth about convictions being so low may in fact result in women feeling that it is pointless going to the police in the first place (House of Commons, 2023).
Cheryl Thomas’ work is particularly interesting in terms of jury research because, unlike almost all other research in this area, Thomas’s work is with actual juries. She is sceptical about the claims regarding rape myths and has noted herself that it is not only rape conviction rates that are low but there are many different types of offences that have relatively low conviction rates. This is something that is rarely discussed by those carrying out rape myth research, who continue to assert the special nature of rape cases. In her 2010 paper Are Juries Fair?, for example, Thomas notes that conviction rates for threatening to kill were only 36 per cent, compared with death by dangerous driving, which at the time of writing was at 85 per cent. This she explains is at least in part due to some cases having more direct evidence, compared to cases where, like threatening to kill (and often in rape cases), you ‘must be sure of the state of mind of the defendant’ (Thomas, 2010: iv). 3 More generally, we find concerns raised about what some see as the simple reality that comparing different crime conviction rates is like comparing apples and oranges. Why, for example, Kapil Summan, editor of Scottish Legal News asks, should murder and rape conviction rates be the same: ‘Aside from other differences between the two…the commission of a crime in cases of rape is often the very point of contention whereas in homicide cases a major clue of criminality comes in the form of a dead body’ (Summan 2018).
Thomas also notes in her paper that conviction rates are actually lower for men who have allegedly been raped than for women, which she observes, ‘challenges the view that juries’ failure to convict in rape cases is due to juror bias against female complainants’ (2010: v). In 2023, Thomas again notes that ‘Some of the highest jury conviction rates are in rape cases with female complainants (rape of a female under 16 and under 13 on both contemporary and historic charges) and some of the lowest jury conviction rates are in cases with male complainants (rape of a male 16 or over on both contemporary charges and historic charges)’ (Thomas 2023: 216).
Research into rape myths often notes that rape is different to other offence because the behaviour of the complainant is sometimes seen as a problem by jurors and used against the complainant. If the woman in a rape case is drunk, for example, we find that there are some issues raised by mock jurors regarding the believability of the person. However, work carried out by Baumer looking into the victim behaviour in murder cases similarly found that: ‘In sum, our analysis indicated that victim characteristics affected the processing of murder case….killings of disreputable or stigmatized victims tend to be treated more leniently by the criminal justice system’ (Reece, 2014: 17). In other words, the behaviour and believability of complainants is raised in many other jury situations and is not specific to rape or to those who are said to believe in ‘rape myths’.
Furthermore, recent research by Cheryl Thomas with real jurors contradicts Leverick's findings. Thomas’s research was based on surveys with 771 jurors who made up 65 trial juries (Thomas, 2020: 11). From this work Thomas concluded that: [H]ardly any jurors believe what are often referred to as widespread myths and stereotypes about rape and sexual assault. The overwhelming majority of jurors do not believe that rape must leave bruises or marks, that a person will always fight back when being raped, that dressing or acting provocatively or going out alone at night is inviting rape, that men cannot be raped or that rapes will always be reported immediately. The small proportion of jurors who do believe any of these myths or stereotypes amounts to less than one person on a jury (2020: 20). Regardless of how demographically representative a group of volunteer ‘mock’ jurors are, the very fact that they have volunteered to take part in a mock jury study means they cannot be representative of the vast majority of those who actually serve on juries in England and Wales…. What this in turn means is that the data from mock jury studies will be biased because those who choose to participate in these studies (and opinion polls) do not and cannot represent the overwhelming majority of actual serving jurors (2020: 27).
Some valid questions are raised by Leverick and others regarding the research methodology used by Thomas, and as Thomas uses a very different form of questions it can be argued that this work cannot simplistically be used to invalidate the ‘rape myth’ research discussed by Leverick (Chalmers et al., 2021; Daly et al., 2022). Nevertheless, her work is useful, at the very least, because it raises some doubts about the certainty of the idea that jurors are seriously prejudiced and that rape trial juries should be abolished.
James Chalmers, Fiona Leverick and Vanessa Munro also draw our attention to recent research in New Zealand with real jurors that did involve examining deliberations in real sexual offence cases. Here they point out that ‘plenty of evidence’ was found that ‘false beliefs about sexual violence were present in jurors’ discussions’ and so once again, they argue, ‘the evidence that jurors hold false beliefs about rape and rape victims is overwhelming’ (Chalmers et al.,. 2023a).
However, this research by Yvette Tinsley, Claire Baylis and Warren Young is far more nuanced than Chalmers, Leverick and Munro suggest. Indeed, by carrying out research with real juries, here we get a far more balanced understanding of ‘rape myths’, the conclusions of which raise some doubts about the methods and findings on the ‘overwhelming evidence’ from mock jury research. Moreover, it is worth noting that the New Zealand research does not quantify the scale of rape myth acceptance and consequently the extent of the problem is unclear. As a result, we do not know if this research backs the idea of there being a significant number of jurors for every jury who believe in myths or whether, as Cheryl Thomas argues, the numbers are relatively small.
This study starts by noting that ‘rape myth acceptance scales give an incomplete view of when and how jurors might be influenced by cultural misconceptions’. Indeed, rather than adding to evidence that pushes for policy changes and the radical abandonment of jury trials, the paper concludes: ‘While our study confirms that jurors are susceptible to cultural misconceptions, it also demonstrates the complexity of assessing the extent of their influence and the difficulties in designing reforms to reduce their use’ (Tinsley et al., 2021: 463).
Usefully, this paper looks not only at ‘rape myths’ but also, and importantly, if we are to draw conclusions about jury decision making, it attempts to assess what impact, if any, these misconceptions have upon this decision making (2021: 467). They do this by not only looking at potential misconceptions but also at the extent to which these misconceptions dictate the outcome of juror decision making. Even here, again showing the nuance of the paper, they recognise that ‘there is often no way to determine the degree to which illegitimate reasoning affected the outcome in these cases’ (2021: 479).
What Tinsley, Baylis and Young do is to look at not only the existence of rape myths but also at the extent to which fallacious, erroneous or problematic reasoning exists in jurors. Do jurors not only believe certain rape myths, they ask, but do these myths result in a one-dimensional and myopic way of thinking that ultimately means that an individual's decision making at the end of the trial can said to be clearly prejudiced?
Here, for example, we get a taste of the more balanced and nuanced approach being adopted: In some cases where jurors have doubts for other reasons about whether the offence has been proved beyond reasonable doubt, it may be understandable and legitimate for them to take into account the absence of injuries or evidence of resistance. However, if that translates into a belief that a rape cannot be proved beyond reasonable doubt, or indeed, a belief that it is unlikely to have occurred in the absence of injuries or resistance, that is clearly ascribing undue weight to that evidence and results in fallacious reasoning (2021: 473).
Taken as a whole, this paper is useful because it shows the complexity of decision making in rape cases, the overlapping and at times contradictory ideas, ideals and realities of trying to come to a just decision based on the evidence—something that goes way beyond an RMA survey with volunteers that often lacks the complexity that is demonstrated here.
The ‘scientific’ RMA and AMMSA scales
Key to many of the studies about rape myths is the RMA or rape myth acceptance scale. Many research projects have been carried out using an RMA scale, the claim being that this scale measures problematic attitudes related to rape myths. Fiona Leverick describes the RMA scale as ‘scientifically validated’ (Chalmers et al., 2021). It is unclear who gave the scale this scientific validation, or indeed what is meant by this. IQ tests were said to be scientific, and this is arguably a far more rigorous test than the RMA scales, but social scientists over the years have usefully challenged this idea about IQ tests and questioned the idea that there is an innate level of intelligence based in part on race and gender (Ceci and Williams, 2009). Arguably, the same rigour is needed in examining what exactly the RMA scales are and, indeed, what it is that they measure.
One of the early creators of the RMA scale is Martha R. Burt. Writing in 1980, Burt describes her scale, where each statement is measured from 1 to 7, as ‘a first effort to provide an empirical foundation for a combination of social psychological and feminist theoretical analysis of rape attitudes’ (Burt, 1980: 229). Using Burt's method, those who answer with higher numbers (from 1–7) to each of the statements in the RMA scale are subsequently said to have problematic ‘rape attitudes’. The logic of this approach is that those who answer with lower numbered responses are giving unproblematic, or good, answers. If you answer ‘7’ to a lot of the questions, for example, you will be understood to be part of the problem of, ‘prejudicial, stereotyped, or false beliefs about rape, rape victims and rapists’ (1980: 217). Those who answer ‘1’, on the other hand, are understood to not have false or prejudicial beliefs.
As well as being founded in feminist theory, Burt's research was also using ‘research on reactions to victims’, comparing those who ‘deny or reduced perceived injury’ or ‘blame the victim for their own victimisation’ and would subsequently be expected to answer the RMA with higher numbered responses (1980: 217), compared to those people who are more understanding, sympathetic and empathetic to victims. Furthermore, part of the framing of this research was to assess ‘sexual conservatism’, as opposed to ‘liberal’ attitudes towards sex, in an attempt to find evidence of a ‘pervasive ideology that effectively supports or excuses sexual assault’ (1980: 218). As a result, what we find is that this RMA scale is developed within a particular ideological feminist framework, one that also has a clear political orientation. It also, and increasingly, as we will see, not only measures what it sees as negative behavioural attributes, but necessarily measures positive attributes that are more ‘liberal’ and victim-oriented. In this respect, part of the RMA scale is an empathy test.
It is worth bearing in mind that this type of test, that has gone on to be the backbone of a significant number of research projects, is a test made up of 15 statements, or later, in the case of the AMMSA scale, 30 statements. Following these statements, the researcher attempts to show that those people giving what could be described as the wrong, or bad answers, are not only prejudiced towards women (or at least rape victims) but are prejudiced to an extent that in a courtroom situation, they will find rapists not guilty. This is quite some ask from a 15 or 30 statement questionnaire.
As it happens, reading Burt's statements, compared with the AMMSA scale that came later, many of them are relatively straightforward and a strong argument can be made that whatever else it does or does not do, it will be likely to demonstrate attitudes that are deeply problematic with regard to women and rape. For example, the statement, ‘Any healthy woman can successfully resist a rapist if she wants to’, is simply not true. Likewise, it would be difficult to know what to say to an individual who agreed with the statement, ‘Women who get raped while hitchhiking get what they deserve’ (1980: 223).
However, there are other questions that are not clearly true or false, and not clearly based on an attitude that can be described as necessarily sexually aggressive. For example, the first of Burt's questions is, ‘A woman who goes to the home or apartment of a man on their first date implies that she is willing to have sex’. We’ll come back to this statement when looking at the AMMSA scale, but it is worth noting that answering with a high number to this question, when calculating the result, has the same effect as someone answering with a high number to the idea that hitchhiking women deserve what they get. Burt even uses this example of ‘going back to the home or apartment’ and claims that those who agree with this and other statements are part of a problem where ‘the world is indeed not a safe place for rape victims’ (1980: 229). But are these statements equivalent, and how confident are we in the ‘scientific’ nature of the conclusions drawn from those giving ‘bad’ answers to the ‘home or apartment’ question? At the very least there appears to be an ideological feminist dimension to the RMA scale, which Burt recognises herself.
The idea of rape myths was developed by Susan Brownmiller in her 1975 book Against Our Will (Brownmiller 1975). Writing in 1980, Martha Burt, like Brownmiller, was concerned about cultural attitudes towards women and rape. As Reece correctly notes, ‘historically attitudes to rape both reinforced and reflected women's subordinate societal role’ (2013: 446). However, Reece also argues that times, and attitudes, have changed somewhat, and that ‘the regressiveness of current public attitudes towards rape has been overstated’, often by feminist academics who promote the idea of rape myths today (2013: 446). If we look, for example, at the British Social Attitude survey question regarding what could be described as a traditional or conservative view of women's role in society, this idea of changing attitudes is borne out.
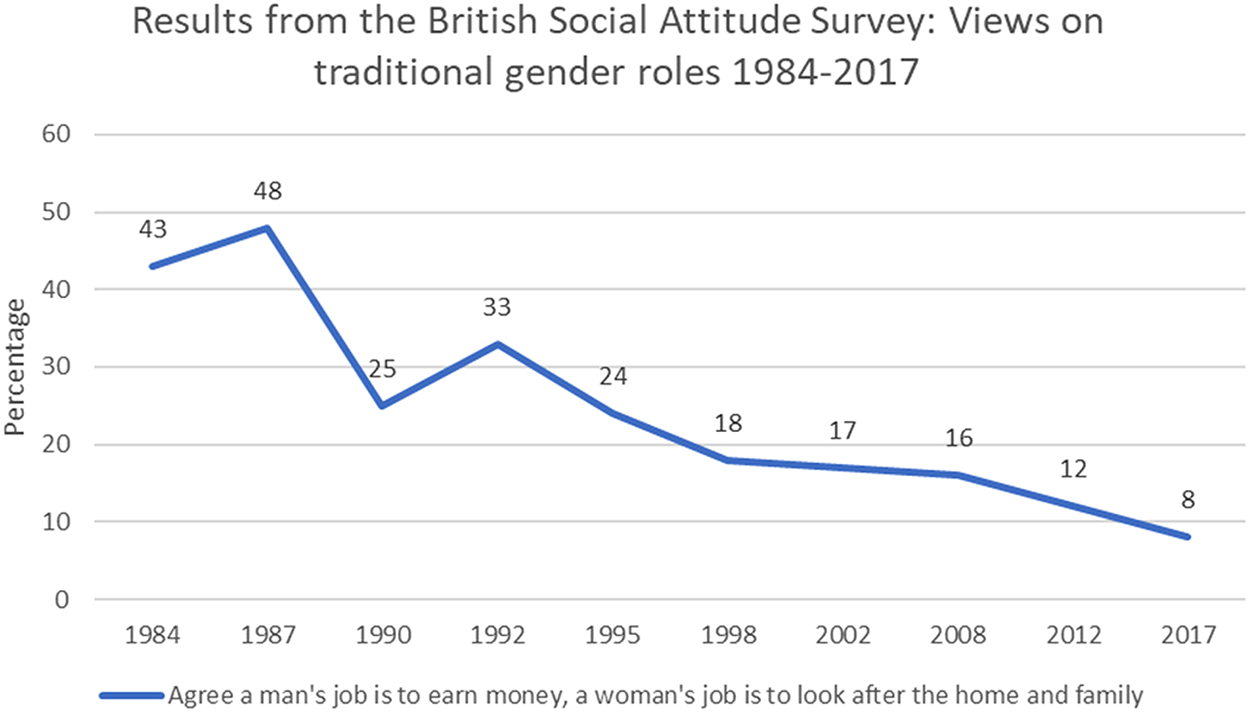
In 1987, 48 per cent of those surveyed in the British Social Attitude survey agreed with the statement, ‘a man's job is to earn money, a woman's job is to look after the home and family’. By 2017, this idea had fallen to such an extent that only 8 per cent of people agreed with it (Phillips et al., 2018). These changing outlooks do not necessarily relate to violence against women but would appear to reflect a changing sense (and also a changing reality) regarding women's dependence upon men, as well as a growing sense of equality between the sexes that may impact on men's attitudes.
As attitudes changed, concerns were raised about the efficacy of Burt's original RMA scale and the extent to which the statements remained useful. In particular there was a concern that the public were now aware of what ‘correct’ and ‘incorrect’ answers to give to the RMA statements, and so it was changed. Heike Gerger, Hanna Kley, Gerd Bohner and Frank Siebler, for example, designed the Acceptance of Modern Myths About Sexual Aggression (AMMSA) scale, noting that ‘respondents nowadays may have become more aware of the politically correct answers to the most explicit and obvious items used in typical RMA scales’ (Gerger et al., 2007: 424). There is likely to be some truth to this perspective. It is also possible that attitudes had improved, but rather than engage with this possibility, an alternative scale was developed, in part due to the belief that rather than sexist attitudes declining, ‘sexist beliefs may have become increasingly subtle and covert’ (2007: 424–5). Now, rather than sexism being about traditional gender roles, stereotypes and discrimination, it was repackaged as ‘the denial of continued discrimination, antagonism towards women's demands, and a lack of support for policies designed to help women’ (2007: 425). There is something rather circular about this argument, so that even if women's equality becomes more of a reality, the act of questioning or ‘denying’ this inequality itself becomes a new form of sexism. Consequently, for academic feminists at least, sexism and gender inequality can always be discovered.
From this particular feminist perspective, sexism had not gone away or declined, it had simply changed, and as such, ‘we decided to develop a new scale assessing the acceptance of modern myths about sexual aggression’ (2007: 425). In other words, because RMA scores were getting lower (2007: 424), i.e., fewer numbers of people were ‘failing’ the test, a new test was created to boost the scores based on a new, modern feminist interpretation of what constituted problematic attitudes. For critics like Helen Reece, the attempt to inflate the figures was, ‘as fallacious as making the driving test practically impossible to pass, then treating the resulting failure as evidence of appalling driving’ (Reece, 2013: 456).
Gerger, Kley, Bohner and Siebler are quite explicit about the changing nature of the scale. Rather than empirically measuring statements that are clearly true or false, they note, ‘it would be more expedient to define rape myths not as false, but rather as “wrong” in an ethical sense’ (2007: 423). Consequently, the AMMSA scale is an explicit ethics test, with a scale of rightness or wrongness depending on the score that an individual gets from completing the survey.
Again, a key dimension of this ethical outlook was related not only to sexist attitudes, or sexually aggressive attitudes, but also to empathy as opposed to antagonism, towards victims. As they explain, ‘sexual aggression myths can be thought of as covering aspects of both the '“belief in a just world” and a lack of empathy’ (2007: 426).
The difficulty here, in terms of thinking about this rape myth scale as scientifically validated, is that it is almost entirely bound up in a theoretical or ideological starting point about ethics. It is in part a test of ‘correct’ or new feminist attitudes, attitudes that include an attempt to measure empathy levels that reflect or do not reflect a victim sensibility. It is both a therapeutic and also a politically loaded scale that attempt to measure ‘right wing authoritarianism’ and a ‘social dominance orientation’ (2007: 426). As a result, the authors of the AMMSA scale could be said to be measuring, in part at least, a social justice sensibility, one that problematises those who ‘believe in a just world’, while celebrating and seeing those individuals as correct who demonstrate ‘the trait of empathy’ (2007: 433). It does much more than this, but in part the new AMMSA scale was a measurement of how ‘progressive’ and ‘aware’ a person you are in relation to gender-based attitudes.
The AMMSA scale also measures answers from 1 to 7 where 1 = completely disagree and 7 = completely agree, 4 = neutral. 4 The scale is based on 30 statements and is therefore a scale based on a combined score. Following the ethical logic of the scale, where ethics relates to a person's ‘moral principles’, 5 one can infer that to answer 1 to any of the statements means you are ‘right’ and you are a moral person (at least with regards to sexual aggression and rape myths), whereas if you answer 7, you are morally ‘wrong’. So, let us look at some of these questions.
When we examine the statements in the AMMSA scale it is clear that they are often not fact-based but are a test of a person's opinion and their sentiment regarding relationships and victims of rape. Some of the statements are also open to interpretation and at times, are potentially contradictory, even at the level of a feminist interpretation of the ethically ‘correct answer’. For example:
Statement 1. reads: ‘When it comes to sexual contacts, women expect men to take the lead’. Statement 7. reads: ‘After a rape, women nowadays receive ample support’. Statement 9. reads: ‘If a woman invites a man to her home for a cup of coffee after a night out this means that she wants to have sex’. Statement 13. Reads: ‘Most women prefer to be praised for their looks rather than their intelligence’.
When using the AMMSA scale, researchers imply that to answer with a high number to any of these questions is ethically wrong rather than factually wrong, although the latter is also arguably implied. Researchers do not go on to prove that an answer is factually incorrect because it is not known in any detail or with any certain which of these statements are correct or incorrect. Additionally, only one of the questions above is specifically about rape. Some of the statements, like no. 7, use ambiguous terms like ‘ample’ that again can be interpreted differently by different individuals and at least in part what we end up with is a test of ‘correct’ thinking, in terms of relationships and victim empathy.
For example, statement 1, ‘When it comes to sexual contacts, women expect men to take the lead’, is understood to be testing for sexually aggressive attitudes and is also relating to the understood problematic idea of the passive woman. But what if this is what individuals have experienced in their lives? Perhaps there is a class and educational level bias built into this question. As a non-fact-based question that could be answered in very different ways based on many different factors, whatever the benefit or usefulness of the AMMSA test, it is difficult to call it scientific. It is also questionable, the extent to which you could call someone unethical for answering this question with a high number. It may be an answer that sexist people give, but it may also be an answer that all sorts of people give who are not ethically problematic, even based on the ethical code of the AMMSA scale.
Furthermore, and somewhat ironically, from a feminist perspective you could actually answer yes to this statement about men ‘taking the lead’, based on the understanding that we live in a patriarchal society that oppresses women and pushes them to be passive in sexual relationships. This is also the case for statement 13, where one could argue that a patriarchal society results in women being objectified and this encourages them to be more concerned with their looks than with their perceived intelligence: Again, answers to this statement could reflect different class and educational backgrounds and experiences.
As Reece notes, with regard to the ‘coffee’ question, this statement can also be interpreted in many ways depending on how definitive you interpret what is being asked. For example, if someone thinks that coffee = sex, no questions asked, and that no rape can apply in this situation, then one would reasonably think that this person has a problem. It is possible and arguably likely, however, that when answering, participants think about the probabilities of the statement being true, rather than the absolute truth or falsity of it (2013: 462). As Reece notes, researchers do not know (statistically speaking at least) how the general public negotiate sex, ‘and even if there were solid research, such norms would be quintessentially contingent and contextual’. Rather than presuming that there is a problem with people who believe this statement is generally true, Reece suggests that perhaps the answers being given are treated with some respect and potentially taken on board as evidence of this being the case (2013: 463), rather than presuming that this is necessarily a myth or prejudice ‘propagated by the media’ (Conaghan and Russell, 2014: 26).
In terms of statement 7 regarding the idea that there is or is not ample support for rape victims, this again, at a factual level, is open to interpretation. In theory, following the ethical scale, the correct answer is 1, i.e., I completely disagree that there is ample support for rape victims, and the incorrect answer is 7, I completely agree that there is ample support. Remembering that this scale is used across the world, one assumes that different countries and even different cities have a differing amount of rape support. 6 Additionally, in terms of the ambiguous nature of the question, it is not clear what, ‘ample support’ means. Again, following the ethically implied correct approach, from an empathetic and victim framed sensibility, the correct answer is that there is not enough support; after all, as the authors of the AMMSA scale argue, to deny discrimination or to question the need for more ‘support for policies designed to help women’, is sexist. Even where factually and practically improvements have been made—more money is provided to third-party providers and better practices are adopted by criminal justice services—following AMMSA's ethical logic, the correct answer would remain 1 = I completely disagree that there are amble services.
The AMMSA scale is one of many newer surveys that attempt to assess rape myths. Some, like the Illinois Rape Myth Acceptance Scale,
7
break down the statements into a subscale where we find categories of statements lumped together that test the idea that: ‘She asked for it’. ‘He didn’t mean to’. ‘It wasn’t really rape’. ‘She lied’.
Again, however, while answers to these questions may identify ‘sexist’ attitudes, and attitudes that could mean that an individual is likely to be biased in a jury situation, it is likely also to identify other types of individuals who may be seen as problematic, from an ethical feminist perspective, but may not mean that these individuals are problem jurors.
The ‘she asked for it’ statements, for example, could well find individuals with deeply prejudiced views about women who ‘wear slutty cloths’ (Elmore et al., 2021), or who get ‘drunk’, or ‘hook up with lots of guys’. 8 But high answers to some of these questions may simply reflect a conservative or old-fashioned view about ‘how to behave’, that may or may not have an impact in a jury situation. A traditionalist, for example, may have a strong sense of personal responsibility and be critical of the way some women behave, but they may equally have a strong sense that men should act like gentlemen and consequently be more rather than less inclined to judge male behaviour harshly: Conservative-minded individuals are also often understood to be more, rather than less, inclined to judge immoral behaviour harshly and to support the use of punishment and prison.
These questions in the RMA scales can therefore also be a ‘conservative’ test with regard to the idea of a ‘just world’ and of personal responsibility, and while they may identify individuals who are essentially excusing rape based on a woman's ‘immoral’ behaviour, they are also likely to capture more traditional or less victim-oriented individuals, people with views about ‘being sensible’ and ‘not putting yourself in a situation’, an approach that may reflect more conservative ideas about personal behaviour and personal responsibility but that do not result in excusing rape.
With the subcategory of—‘He didn’t mean to’—we find statements that explain rape in terms of sexual desire that has gone too far, where guys get ‘carried away’. There is a reasonable question here with regard to the idea that rape is about power rather than sex, but it would be difficult to assert or prove that rape never includes ‘when a guy's sex drive gets carried away’. To some extent, these statements demand an answer of 1, i.e., that this is never true, based, again, less on facts than upon a perceived ‘correct’ sentiment or outlook.
There are questions in RMA scales and indeed in wider research about rape myths that address the idea that ‘she lied’ 9 or that women often or sometimes ‘cry rape’ that relate to the big question of false allegations (Gunby et al., 2012).
The issue of false allegations is a significant one with regard to feminist research and there is an implicit and sometimes explicit assumption that false allegations of rape are rare. This may be true, but we don’t know this for sure, and the language used to assess how people think about this ‘rare’ occurrence is often ambiguous.
False Allegations of Rape, written in 2006, notes that in the past there was a pre-judgement that assumed false rape allegations were rare, but now, Rumney argues, the reverse is the case: Just as early legal commentaries uncritically adopted psychoanalytical theories of why women make false complaints, along with claims that false allegations were common, in the last three decades there has been a lack of critical analysis by those who claim a low false reporting rate and the uncritical adoption of unreliable research findings (Rumney, 2006: 157).
Helen Reece notes that, like many of the RMA questions, it is not entirely clear what is being asked and answered. For example, she notes that: Turning first to the proportion of women who people believe cry rape, the AMMSA scale measures this by asking people whether they agree that women ‘often’ do so, but the frequency indicated by ‘often’ is contextual and subjective: participants who agree with the AMMSA statements may mean any proportion ranging from ‘almost always’, through ‘more often than not’, to ‘too often for their testimony to prove the matter beyond reasonable doubt’ (Reece, 2013).
A false reporting level of 0.2 per cent would mean that 1 in every 500 allegations is false, whereas 8 or 9 per cent of false allegations is closer to 1 in 10. In other words, it is not clear what the level actually is, and if the level is closer to 1 in 10, would it be justifiable to classify this as something that ‘often’ happens?
Reece notes that ‘It is hard to say that ‘women cry rape’ is a myth when we do not know the rate of false allegations of rape’. She adds that Westmarland and Graham unwittingly sum this up when they argue: ‘The myth that women frequently lie about rape continues, with posters [on an internet forum] even stating that it was increasing. … It is a myth that can be particularly difficult to rebut…because of disagreement between academics about what proportion of rape reports are “false”’ (Reece 2013: 461).
However, RMA scales that address the question of false allegations are often not testing the truth or false nature of the answers being given; as Gerger notes with reference to the AMMSA scale, this is really a matter of ethics or of what is perceived by feminist academics in particular to be a ‘test’ of correct or incorrect thinking, or a test of a more victim empathetic sensibility, a sensibility that may be lacking in more conservative or less ‘liberal’ individuals (Gerger et al., 2007).
Tragically, the promoted idea that ‘conviction rates’ for rape are incredibly low, sitting at between 1 and 5 per cent of cases, may have elevated this idea that false allegations are common. Amongst ‘conservative’-minded individuals who still have some faith in the police and the justice system, the apparent ‘fact’ that 95 per cent of rape allegations do not lead to a conviction may have increased the popular understanding that false reporting must be high.
As we have shown, the mock jury trials that most research is based upon has serious methodological problems. Above, we have suggested that the RMA and AMMSA scale have other problems as regards their ‘scientific’ nature and the potential that there is an ethical, perhaps even a political, and even class-based bias built into the questions/statements being asked. However, taken on its own terms, it is possible and even likely that within the potential confusion of these rape scales, they do identify individuals with problematic attitudes towards relationships and rape. But what they also do, which is never addressed or discussed, is potentially identify a ‘progressive’ bias at the ‘correct’ end of the scale—a bias that could also suggest that there is a new and different type of pre-judgement, or prejudice that will result in miscarriages of justice that see innocent men convicted of rape.
The one-sided interpretation of RMA scales
Despite the questions raised so far about the methodological flaws with RMA scales and the work with mock juries, the results of the mock jury trials consistently find a relationship between certain attitudes and how mock jurors (if perhaps not real juries) make decisions about guilt and innocence. Even Cheryl Thomas, working with actual juries, found that around one in 12 people on a jury could be said to have some rape myth prejudices. 10 One of the problems, however, is that, as we have suggested, as well as finding individuals who have significant prejudices, RMA scales are also likely to problematise conservative or more traditionally minded individuals who may not be biased when adjudicating on the matter of rape. This is arguably something that has become more problematic following the changes to RMA scales that are less inclined to use clear statements about rape and sexist attitudes—like the idea that a woman hitchhiking got what she deserved.
But if we take the results of the mock jury trials at face value and accept that at least some of the individuals with high RMA scores have problematic values, why do we not also take the same critical approach to those with particularly low scores e.g., on the AMMSA scale?
What if the AMMSA scale, for example, is not only demonstrating some evidence of a rape myth bias but is also showing a feminist or therapeutic bias with regard to rape victims? Logically, what we would find here is that some individuals on mock juries are finding men guilty of rape based not on the evidence but because they have a tendency to (perhaps uncritically) empathise with and believe the ‘victim’.
When we look at the results of this research—this is exactly what we find.
If we look again at the Willmott studies, the studies that Leverick argues was some of the best research to date, what we find is that men who should be found innocent are indeed, on a number of occasions, actually found guilty.
We know that this is the case because a core dimension of the rape myth research is that for the study to be effective, researchers create scenarios where there is a lack of external evidence that would allow jurors to make clear decisions about rape. This is a necessary part of this research because if there was external evidence, forensic evidence, eye-witnesses or CCTV footage, jurors would use this evidence to make their decisions. This is not what the mock trials are there to find out. Rather they are set up in a way to make the decision-making process based almost exclusively upon the testimony of the complainant and the accused. 11
Willmott explains that the rape cases that he used in his research were ‘largely evidentially ambiguous, meaning that roughly equal information corroborated and contradicted both parties’ accounts of what happened’ (2018: 10). Because these trials are ‘lacking compelling evidence, including CCTV or eyewitness testimony’ and jurors are left with ‘one version [of events] put forward by a defendant and an alternative account put forward by a complainant, individual jurors construct differing narrative interpretations of what they believe actually occurred’ (2018: 4).
If there is ‘evidential ambiguity’ and a ‘lack of compelling evidence’, given that juries are supposed to have a starting point of innocent until proven guilty and to only find guilt when the evidence allows you to come to this conclusion beyond reasonable doubt, all of the mock juries in Willmott's studies should have found the defendant not guilty. I raised this with Willmott, noting that: In the scenarios you gave to the jurors you understandably set it up so that there is no clear or obvious innocent or guilty verdict, thus allowing for the factors you are interested in to be examined. You talk of there being equal evidence on both sides and no eyewitness, CCTV etc. Given this, I initially presumed that the verdict would be not guilty on every occasion—based on my understanding that to convict someone you had to be beyond all reasonable doubt. However, this was not the case, and I was wondering what you thought about that and why this was the case. I ask because if all that someone is going by is who you believe, and no other definitive evidence, it almost feels like those who decided on guilt were really weighing up the balance of probabilities rather than using the reasonable doubt framework. In short, you’re absolutely right and I agree with your assessment of what jurors appear to be doing. The findings are evidence that jurors don’t work as presumed by the CJS as they appear to make decisions based on some sort of Bayesian probabilistic weighting based on each piece of evidence. In fact, if jurors are not sure beyond reasonable doubt (this is a determination that they could arrive at based on the evidence as they interpret rather than its objective factual basis) then they should indeed arrive at a not guilty verdict even if they think he may have, possible have or probably did it. We found, as you indicate, this wasn’t the case.
12
Discussing the reasons for the guilty verdicts, Taylor and Joudo note that this appeared to be because the participants coming to a guilty conclusion, ‘hold favourable attitudes toward rape victims in general; believe the complainant to be highly credible; empathise more with the complainant; empathise less with the accused [and] personally believe that the accused was guilty both prior to and after jury deliberation’ (2005: 48). Here, because the ethically correct approach is said to be one where you empathise with the victim (but where no empathy is considered for the accused), there is no question raised about a potential problem or a potential bias in this decision-making process.
Willmott does note that low AMMSA scores did indeed mean that there also appears to be a ‘predispositional bias’ (2017: 194) at the low end of scale, and in his final conclusion noted that isolating biased jurors from court cases could improve verdicts for both complainants and defendants (2017: 213) (my emphasis). However, the overall emphasis in Willmott's work that relates to ‘rape myths’ means that little is made of this. In the end, he concludes that there is a problem of ‘rape attitudes’ and with those with a ‘decreased belief in the complainants account’. Consequently, it is those potential jurors who exhibit ‘incorrect’ rape myth attitudes who he focuses on and believes should potentially be ‘screened out of the jury trial process’ (2017: 200).
He further notes that ‘education appears to be an important prerequisite in the acceptance of such [rape myth] attitudes,’ whereby those with a university degree have lower AMMSA scores and those without a degree have relatively high scores. This he attempts to explain by noting that: ‘It is possible that the role of intelligence may be accounted for in terms of critical thinking capabilities in that, those with greater educational attainment are both more able and willing to critically appraise, rather than passively accept, preconceived attitudes that are common place in society’ (2017: 193).
However, given that those with lower scored were more likely to find the accused guilty based on what Willmott himself called a form of ‘Bayesian probabilistic weighting’, despite the lack of clear evidence of guilt, it is difficult to know how he came to identify this group as being more ‘willing to critically appraise’. The presumption appears to be based on an idea that ‘less intelligent’ people, or at least those who do not have a university degree, are more passive and prone to ‘preconceived attitudes’, unlike the seemingly more critical university-educated participants. However, perhaps the opposite is the case, and in fact it may be that university-educated individuals have been ‘trained’ in correct thinking with regard to a dominant discourse and an ‘elite’ narrative about gender, victimhood and the ethically and empathetically correct attitude that is desired by academics.
Part of the process of mock jury trials is an assessment of the extent to which participants believe the complainant. Based on the ethical nature of the RMA scales, those who empathise with and to some extent ‘believe’ the ‘victim’ are thought to have the better attitudes. This sense of the ethically correct attitude to ‘believe the victim’ has become significant over the last few decades, helped in part by the #MeToo movement (Soave, 2020).
Well before this movement, Liz Kelly was arguing that the police should instil ‘A culture of belief’ when dealing with individuals who claim to have been raped (Kelly et al., 2005: 87). Somewhat surprisingly, given her position as Lord Advocate—the chief legal officer of the Scottish government—Dorothy Bain has similarly promoted the idea that in some sexual abuse cases it is right and good that ‘People are being encouraged to report sexual crime and people are being told that they will be believed’ (Taylor, 2021). Suggesting an institutionalised dimension to believing the victim, we also find that Police Scotland promote the idea that ‘Officers know how difficult it is for people to report rape, they will respect you and believe you’. 13
Kapil Summan, editor of the Scottish Legal News, has noted that part of the problem is that senior Scottish legal figures now use the term ‘victim’ when they should be referring to the complainant. He notes that, ‘In Scotland we consistently see the strange and persistent dithering between “victim” and “complainer” from the mouths of the Justice Secretary and Lord Advocate in Scottish government and Crown Office media releases, in contexts where they in fact simply mean “complainer”’. The point being that to call someone a victim is to accept that a crime has taken place even before a verdict of guilt has been found. Additionally, he notes that the ‘England and Wales’ Victims’ Commissioner, Baroness Newlove, tweeted in June: “I strongly disagree with judges who demand rape victims are referred to as complainants. A victim is a victim from the moment the crime is committed”’ (Summan 2018).
In the literature on rape myths, it is rare to find any concern being raised about those who believe the ‘victim’ and much concern is raised about those who believe the defendant. To say that this is a one-sided approach to the issue is to undersell the significance of this problem. However, from a feminist perspective, where there is at times a belief in the patriarchal nature of society and a presumption that false allegations are rare (despite the contest evidence of this), the ethically correct perspective is one that starts from an assumption that it is good to have an empathetic attitude to the complainant. In other words, those mock jurors who believe the ‘victim’ tend to be either ignored as a potential problem for justice or are seen in a positive light. Consequently, when guilty verdicts are given by participants of mock jury trials, despite the lack of clear evidence, little or nothing is said about this, and there is almost no concern raised about the fact that some people may be too empathetic, or too victim-centred, to the extent that if replicated in a court of law we could find an increasing number of miscarriages of justice.
With researchers dealing with mock juries there is a presumption that individuals with a high score are prejudiced whereas those with a low score are not. But this conclusion can only be arrived at if you have no critical engagement with the ethical norms around which the scales have been developed. Arguably, what we are actually seeing here is an ‘elite’ section of society—criminologists and feminist academics (backed up, in Scotland at least, by the police and the Lord Advocate)—who are unable to see the prejudices of low-scoring mock jurors precisely because they have the same ‘educated’ prejudices.
To use what is admittedly one of the worst questions in an RMA scale, from the Illinois subscale, we find a statement that reads: ‘Girls who are caught cheating on their boyfriends sometimes claim that it was rape’. 14 I have come across no rape myth researcher who argues that women never lie. It is also a fact that some women caught ‘cheating’ on their boyfriends claim that it was rape and end up in prison (Evening Standard 2012). But from an ethical RMA point of view, the ‘correct’ answer to this question is 1. completely disagree. That this is factually incorrect is irrelevant because what is being adjudicated upon here, and arguably is being adjudicated upon within RMA scales more generally, is not something that is true or false, or something that is ‘scientifically validated’, but the ethical goodness of a person as decided by a one-sided and therapeutically oriented feminist worldview.
Final thoughts and conclusions
Each jury is a little parliament. The jury sense is the parliamentary sense. I cannot see the one dying and the other surviving. The first object of any tyrant in Whitehall would be to make parliament utterly subservient to his will; and the next to overthrow or diminish trial by jury, for no tyrant could afford to leave a subject's freedom in the hands of twelve of his countrymen. So that trial by jury is more than an instrument of justice and more than a wheel of the constitution: it is the lamp that shows that freedom lives (Devlin 1956:164).
We started this paper by noting the influence of academics, and in particular Fiona Leverick's work that argued there was ‘overwhelming evidence’ of rape myths. Leverick has gone on to argue that this evidence justifies a pilot project in Scotland to abolish juries in rape cases (Chalmers et al., 2023). However, as we have seen, much, indeed almost all, of this ‘overwhelming evidence’ used by Leverick is methodologically flawed and lacks statistical veracity due to the non-random samples that are used. Despite some of the interesting findings in this research, the ‘mock’ nature of the juries raises serious doubt about the reliability of the findings with regard to actual juries, as does the almost total lack of deliberation that takes place in these experiments. Jurors treated as isolated individuals rather than as part of a collective decision-making body cannot be realistically discussed as being part of a jury.
In an article written by Fiona Leverick, James Chalmers and Vanessa Munro, that critiques the work of Cheryl Thomas, the correct observation is made that ‘Juries do not vote: they deliberate. No research which relies solely on polling individual jurors can provide answers about what is said and discussed behind the closed doors of the jury room’ (Chalmers et al., 2021) (my emphasis). This is an important and valid point, but it did not stop Leverick using a whole body of research that overwhelmingly did not include any juror deliberation but rather left the jurors as individuals whose role was simply to ‘vote’. Indeed, much of the research used in Leverick's seminal paper was carried out in conditions that lacked any reality to a trial process, and the variety of RMA scales used across the research examined by Fiona Leverick makes it difficult to use this research as a collective body of work.
Willmott's work attempts to resolve many of these methodological problems, but his sample remains problematic due to the non-random nature of the participants. Indeed, Leverick highlights Willmott's research because she recognises that most of the other studies ‘suffered from methodological weaknesses’ (Leverick 2020: 266). If there are methodological weaknesses in these studies, bringing them all together and representing them to us in a table form does nothing to resolve this problem. It may look impressive because now we have a large number of pieces of research saying similar things, but simply by giving us a large number of problematic pieces of research does not stop them from being problematic. Based on this alone, one would have to question the extent to which the claim of ‘overwhelming evidence’ about rape myths can be justified, and more particularly, it raises serious questions about the use of such evidence as a basis for policy changes. As we noted above, McEwan and Kapardis argue, it would be ‘dangerous’ (McEwan 2000: 111) to use ‘unrealistic’ mock jury research ‘as the basis for policy changes’ (Kapardis 2010: 162).
At times, Leverick cites more recent research to back up her argument about ‘overwhelming evidence’, but even here, for example in the work of Tinsley, Baylis and Young with real juries, we find contradictory or inconclusive evidence regarding how ‘rape myths’ work in practice, where ‘there is often no way to determine the degree to which illegitimate reasoning affected the outcome in these cases’ (2021: 479).
The impetus for the rape myth research stems from a belief that there is a ‘justice gap’ i.e., where relatively low conviction rates in rape trials are understood to be at least in part related to juror ‘false and prejudicial beliefs’ (Chalmers et al., 2021). The belief is that rape trials are peculiar in terms of the number of convictions but as we have seen, a variety of other crimes (in England and Wales) where one ‘must be sure of the state of mind of the defendant’ have even lower conviction rates than rape trials (Thomas 2010: iv). Further evidence of this was found by Thomas’ extensive research in 2023, where she explains that: When all criminal offences deliberated on by a jury are combined, the average rate of conviction is 64%. However, this is not a very helpful statistic because it conceals the fact that jury conviction rates vary substantially by one key factor: the offence. This means the jury conviction rate for rape needs to be seen in relation to the jury conviction rate for other offences. [T]he highest jury conviction rates are for making indecent photographs of children (89%), death by dangerous driving (85%), drug possession with intent to supply (84%), murder (76%), handling stolen goods (73%). The lowest jury conviction rates are for threatening to kill (33%), attempted murder (47%), manslaughter and GBH (48%); for all of those offences a jury is more likely to acquit than convict. Over the 15-year period the jury conviction rate in rape was 58%, meaning juries were more likely to convict than acquit on rape charges in this period (Thomas 2023: 216).
One of the key myths to do with rape, we are told, is the belief that some or many rape allegations are false allegations. But again, as we have seen, academics themselves differ markedly on what they belief the accurate figure of false allegations actually is. In other words, one of the key ‘myths’ about jury trials is based upon the idea that false allegations are rare when in fact the actual rate of false allegations is ‘unknown’ (Tinsley, 2021: 466). 15 Furthermore, research with actual jurors carried out by Cheryl Thomas (2020) raises some serious doubts about the extent to which we can talk about a problem of jurors having false and prejudicial beliefs. Additionally, the popularised idea that the rape conviction rate is around 5 per cent (or 5.5 per cent as Leverick argues (Chalmers et al., 2023)) is deeply problematic, when the actual rate of jury trial convictions in Scotland (for all rape cases) is 51 per cent and in England and Wales (for adult women) is 67 per cent. Indeed, the promotion of this very low figure, as with the discussion about false allegations, or the specific nature of rape trails and prejudiced jurors, could itself be described as something of a myth. 16
The methodological flaws in the mock jury trial research are enough in and of themselves to seriously question the idea of ‘overwhelming evidence’ of jury myths. The legitimate concerns that have been raised about the asserted idea of a ‘justice gap’ add to the problematic nature of the ‘rape myth’ idea. On top of this, however, we find that the idea of ‘rape myths’, and the invented rape myth acceptance (RMA) scales, are not based upon a test of true and false beliefs but, especially in their later forms, like the AMMSA scale, are in fact a series of ethics statements or tests, developed and indeed changed over time by feminist academics with a specific ideological outlook. 17 Rather than the RMA scales being scientific, as Leverick asserts, they are better understood as a test of a correct outlook or sensibility that is victim-oriented, based upon an empathetic sensibility.
Based upon a presumed ethical correctness of those who give low scores to RMA scales, we find that there is a serious blind spot in almost all of this research. Even when there is not enough clear evidence to convict in mock jury trials, up to a quarter of participants find the defendant guilty (Taylor and Joudo, 2005: 46–8), and yet little or nothing is said about this. It would appear that because the researchers are so fixed upon the ideal of a victim sensibility that they are blind to the reality that what they are also discovering is in fact a different bias, one that is too empathetic to the alleged rape victim and that would, in a real jury situation, potentially result in a miscarriage of justice.
From a victim-oriented perspective and one that identifies a positive attitude amongst those who are empathetic towards the alleged victim of rape, rape myth researchers fail to notice that there may be another victim in the room, the man who may be falsely accused, or who is found guilty despite the lack of clear evidence.
That the idea that rape myths have been proven by ‘overwhelming evidence’ appears, in Scotland at least, to fit into a perspective that has become part of a dominant discourse. 18 Similarly, we can see the promotion of an empathetic ideal, within the criminal justice system itself, where there is a drive to ensure that judges are ‘trauma-informed’. 19 Here, it is presumed that the public can no longer adjudicate on rape trials because they lack the ‘trauma-informed’ expertise necessary to understand rape victims—even though the individual in a trial is not known to be a rape ‘victim’ until after the verdict: The judges in question are likely to also be ‘educated’ about rape myths, even though, as we have shown here, the reality of these myths is highly questionable.
Much of the research with mock juries looking in to rape myths presumes that empathising with the victim reflects a positive and good ethical starting point: empathising with the rape victim is not the same as believing, but in a court case where we do not know who the victim is, having this as a starting point could be a problem for justice and indeed, could be seen as turning criminal justice ideals on their head. As Baroness Helena Kennedy, for example, has herself argued, ‘In the adversarial criminal justice system we do not start off from a position of neutrality. We start off with a preferred truth—that the accused is innocent—and we ask the jury to err on the side of that preferred truth, even if they think she (sic) probably did do it.’ Furthermore, she notes, ‘The criminal justice system is based on the fundamental value that it is far worse to convict an innocent person than to let a guilty one walk free’ (Kennedy, 2005: 11).
The ‘overwhelming evidence’ provided by Fiona Leverick has helped to create a new system of justice in Scotland where there, in theory at least, will be no juries and only judges (who may be trained to be ‘trauma-informed’) adjudicating on the innocence or guilt of alleged rapists. However, abolishing juries arguably tilts the balance of justice in favour of the alleged victim. Helped by the ideas of a ‘justice gap’ and of ‘rape myths’ that have been developed by academic feminists, we find a new ethical position developing, assisted by the RMA research, that encourages a sensibility of believing the victim. As such, based on this ‘overwhelming evidence’ the ideal of justice described by Baroness Kennedy above would appear to have been inverted.
When we look in detail at some of the research with real juries, like the work by Tinsley et al. (2021), what we actually find are jurors in real-life situations who are desperate for evidence. For justice to be served in rape cases, both for the defendant and for the accused, there are no shortcuts that can or should be used to avoid this objective necessity, and future research would be well placed to focus upon this as an area for improvement, rather than attempting to undermine the democratic ‘little parliament’ called a jury.
Footnotes
Acknowledgements
Thanks goes to my colleague Donncha Marron, who was, as ever, enormously generous with his time and comments about this paper. I am also grateful to reviewer suggestions about this paper.
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author received no financial support for the research, authorship, and/or publication of this article.