
Abstract
This article is situated in ongoing discussions about the influx of images of police violence. To date, much scholarship has centred on Foucauldian notions of knowledge-power and sousveillance. Alternatively, I attend to how video evidence produces understanding of police violence in court through a case study of the murder trial of Officer Michael Slager who shot and killed Walter Scott in North Charleston, South Carolina. While audio and video direct evidence of the moments leading up to Slager's decision to shoot was presented, cross-examination focused more explicitly on post-shooting conduct as circumstantial evidence. This approach highlights an issue for video evidence, that what is to be settled at trial may not be directly re-presented in video. Gurwitsch's notion of Gestalt and Garfinkel's adaptation thereof are proposed as an alternative means of interrogating video evidence.
Introduction
Moore and Singh's (2018) recent discussion of ‘data doubles’ (Haggerty and Ericson, 2000) is a marked step forward to understanding how video evidence produces new problematics for notions of justice. Here, I take up and extend their analysis in relation to another perplexing matter for video evidence: polarized, divergent interpretations of police violence captured on video. How to theorize video evidence has been a matter of concern for this journal since its inception (i.e. Mathiesen, 1997) but has gained recent attention again, in part through the proliferation of videos of police work (Sandhu and Haggerty, 2017; Stalcup and Hahn, 2016). This work intersects with concerns about how to deliver public accountability for police violence (Deuchar et al., 2020; Stone, 2007) in light of the ‘new visibility’ of police work (Goldsmith, 2010).
Goodwin's (1994) paradigmatic study of the Rodney King assault by Los Angeles Police Department (LAPD) officers should disavow readers that video unproblematically re-presents the circumstances of police violence (see also Schwartz, 2009; Vertesi, 2015). His exposition of the ‘coding schemes’ employed by police training officer/expert witness Charles Duke showed how an ‘expert’ in police practice produced officer intent through the recorded images and still photos. That the same video evidence led to acquittals for the four officers involved in the criminal trial, but convictions for two of the four in the federal civil rights trial only adds to the complexity of visual jurisprudence (Biber, 2009; Marusek, 2014; Mezey, 2013). Contemporary trials for police violence have proved equally problematic for situating the ‘truth value’ of video presented as evidence (Bosman et al., 2017).
I start this article by revisiting Moore and Singh's (2018) discussion of KGB statement videos in criminal trials. I then go on to argue that an ethnomethodological adaptation of gestalt contexture (Garfinkel, 1967, 2002, 2021; Garfinkel and Livingston, 2003; Watson, 2009; Wieder 1974) gives purchase on understanding how video functions as evidence in court. Garfinkel's approach lends itself to video analysis, for as Goodwin's discussion of the King beating demonstrates, there is interpretive flexibility and extraneous information that incorporates meaning into video evidence (see also Schneider, 2016). Settling the ‘truth’ of images, aside from being contentious, is procedural (McHugh, 1970), and this article explores how that procedure is enacted.
Trials for on-duty police shootings are perspicuous settings (Lynch, 2007; Wittgenstein, 1953) for the study of video evidence given that on the rare occasions police officers are criminally charged (see Stinson, 2017), the actus reus is not typically in question; officers concede the ‘facts’ that are readily depicted in video—that the accused used violent force against the victim at the time and location re-produced in moving images. The trier of fact is instead asked to adjudicate mens rea, whether or not an officer acted reasonably when using violent force (Alpert and Smith, 1994; Klinger and Brunson, 2009); for example, that they were motivated by a reasonably perceived imminent threat to themselves or others and not motivated by malice, revenge, anger or racial animus. Therefore, what is at issue in trial (motive) can only be deduced from video; it is not self-evidently present within video evidence. Video is used to produce this gestalt (reasonable vs. malicious) and provides the contexture to the gestalt in such a way that as meaning is given to some piece of evidence, so too does other evidence gain a corresponding alignment with that sense (Watson, 2009: 481).
After revisiting Moore and Singh (2018) and adding Garfinkel's adaptation of gestalt contextures to their discussion, I will progress to a case study analysis of the use of video evidence in cross-examination at the criminal trial for Officer Michael Slager. Slager was accused of intentional homicide (murder) in the on-duty shooting of Walter Scott on 4 April 2014 in North Charleston, South Carolina. The incident occurred following a traffic stop for a non-functioning tail light in Scott's vehicle. It was infamously caught on bystander cellphone video, which contributed to the investigators’ decision to charge Slager. The case is interesting on the grounds that there is compelling direct evidence that implicates Slager for unlawful arrest, which would then implicate him for intentional homicide. Despite this, prosecution counsel focused their cross-examination on post-shooting conduct as circumstantial evidence centred on Slager's state of mind and intentionality. The decision highlights the complexity of using video evidence to establish criminal intent, particularly for law enforcement officers and use-of-force incidents.
KGB statements and gestalt contexture
Out-of-court statements are usually inadmissible under the rules of hearsay evidence. Moore and Singh (2018) discuss a Canadian exception to this rule: 1 the decision by the Supreme Court of Canada in R v KGB 2 that permits out-of-court statements to be considered for ‘truth value’ when a witness recants previous statements made to the police under certain circumstances (i.e. (i) a statement is made under oath; (ii) it is video taped in its entirety and; (iii) the opposing party can cross-examine the witness, see Nowlin and Brockman, 2018: 288). Prior to KGB, there were some occasions where video statements may have been deemed admissible for their value in impeaching the credibility of a witness (see Brannigan and Lynch, 1987; Lynch, 2015; Lynch and Bogen, 1996 for analysis of how past contradictory statements are used to impeach current credibility), although a trier of fact would be given instructions not to interpret the contents of the video as ‘true’.
The practice of gathering so-called KGB statements has become pervasive in Canadian law enforcement. It is systematically used following calls for service and laying of charges in domestic assault cases, in anticipation of victims/complainants presenting contradictory testimony at trial (although KGB statements can be used in any case where a witness recants a recorded statement made to police). The practice is generally done by interviewing and video recording the victim/complainant either at the scene or at a police station in the immediate aftermath of an assault, producing a spectacle of the injured and emotionally distraught victim. If such a statement is gathered by police it is admissible for both probative ‘truth’ value and assessing witness (i.e. the victim's) credibility.
Moore and Singh (2018) show how this practice creates a data double of the individual making some statement before trial but then recanting that statement in trial, although they quite rightly refrain from asserting that video statements are received unequivocally as ‘the truth’. Instead, triers of fact are left to decide which of the two competing statements to believe, if either. Indeed, the use of KGB statements is limited to occasions where witnesses do change their testimony, as the video statements would be redundant if testimony were consistent. In arriving at a verdict, triers of fact are therefore inevitably tied to, and empowered to weigh, any evidence against the case or narrative (Jenkings, 1997; Rossmath, 2013; Scheffer, 2010; Suresh, 2018) that produces the sense and meaning of evidence. Video evidence does not stand apart from all other evidence as a unique and incontrovertible truth, but rather in a self-same circumstance, gains status as truth when weighed in reflection of all accompanying evidence and the narratives counsel overlay to furnish their arguments. The data double produced through video statements is subject to the same scrutiny as the witness (albeit the visceral nature of the images may be particularly persuasive, as Moore and Singh discuss).
The issue of persuasion that Moore and Singh (2018) introduce benefits from further analytic attention than afforded in their analysis. Moore and Singh primarily attended to the discomforting nature of the data double for the witness/victim—the data double serves to displace and discredit their current testimony by showing previous statements as inconsistencies. The consequence, they argue, is further victimization of these witnesses, who at the time of trial face ‘antagonistic’ (2018: 117) use of video evidence, forced to re-experience images of their victimization while being discredited. Moore and Singh contrast the experience of the ‘actual victim’ (2018: 119), which they conceptualize as the witness on the stand, with the video ‘doppelganger’ (2018: 129) recorded at/near the time/scene of the incident. The analysis is based in a feminist criminology that critically appraises the effect of the data double on victims, not how sense is attributed by triers of fact to either the ‘actual victim’ or ‘doppelganger’. How image evidence and testimony produce an accepted narrative goes unattended in Moore and Singh's discussion. This is not to fault them—their interest lies elsewhere—but it does leave a compelling question open to further theoretical consideration: how does either side of the adversarial circumstance in court use video to produce narratives that are persuasive to their position?
Consider here Garfinkel's (1967, 2002, 2021) adaptation of Gurwitsch’s (1964) notion of gestalt. In the famous ‘duck/rabbit’ diagram no part of either the rabbit or the duck stands out as the unique indicator of duck-ness or rabbit-ness, but rather the totality of the diagram indicates what the viewer is seeing—a bill or ears, a nose or an indent and so on (Figure 1).
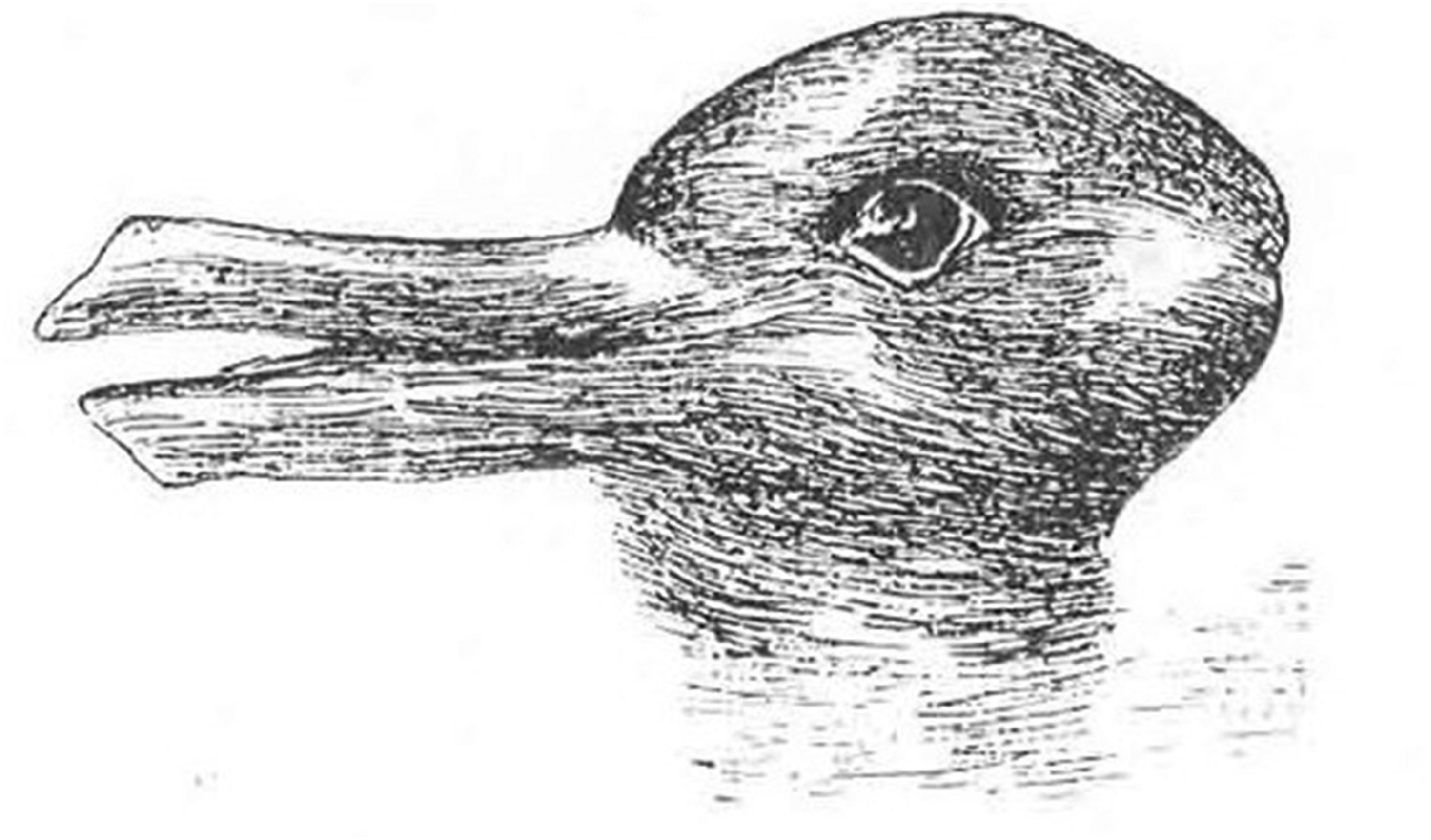
Duck/rabbit gestalt image. https://images.app.goo.gl/Cuz5HvxLAJwDwyn5A.
The notion of gestalt contexture applies to Garfinkel’s (1967: 114) study of jurors, where he states: jurors did not actually have an understanding of the conditions that defined a correct decision until after the decision had been made. Only in retrospect did they decide what they did that made their decisions correct ones. When the outcome was in hand they went back to find the ‘why’, the things that led up to the outcome, and then in order to give their decisions some order, which names, the ‘officialness’ of the decision.
If Garfinkel's observations hold, then despite the primacy of visual information in our culture (‘seeing is believing’), the meaning of actions depicted in video gain their sense through an overall assessment of all evidence and the trier of fact's ultimate finding. Video evidence is just another means of determining what really happened. The consequence for a trier of fact is not that there is an ‘actual victim’ and ‘doppelganger’ in front of them, but rather that they must weigh the probative value of the two statements as they pertain to the charges—which of the statements seems to fit within the other case circumstances such that one is seen as more ‘truthful’? This does not diminish the disempowering and discomforting circumstances witnesses must experience when faced with prior statements that contradict what they intend to say in court, and where their credibility stands in question. It does provide further conceptualization of how video evidence is used in court. Garfinkel's adaptation of gestalt contexture dissolves the conceptualization of ‘actual victim’ as current and present and ‘doppelganger’ as previous and removed, setting such determinations aside to be made by triers of fact.
The question of theoretical and empirical interest becomes ‘how do parties to a legal proceeding employ video evidence, ambiguities and all, to persuade the trier of fact?’ The extent to which there is a ‘true’ gestalt, for Garfinkel, is not a matter to be settled by the analyst, but by participants to the scene—marking his contrast with Gurwitsch who argued for a ‘true’ gestalt. There can be no abstracted ‘actual’ versus ‘doppelganger’ because deciding what is ‘true’ is part of the setting. Instead, the role is attending to how legal counsel append narratives to video and testimonial evidence to support their partisan position and produce the favourable gestalt from the collection of evidence presented.
While any case where video evidence is present could be used to demonstrate the above discussion, instances of police violence stand out as particularly relevant. Collins (2008) and Doyle (2003) have demonstrated that absent accompanying narratives, it is often difficult or impossible for outside observers to make sense of videos of violence. Interpreting videos of police violence is further complicated by the fact that police are both ‘dirty workers’ while simultaneously the symbolic standard-bearers for ‘law and order’ (Goldsmith, 2010). The moral obligation for police to be as restrained as possible when using (lethal) force while at the same time being obliged to use force in protection of the public results in confusing parameters for post hoc analyses. Stoughton et al. (2020: 125) refer to the phraseology common in law enforcement: ‘awful but lawful’.
In the case of Slager, two competing narratives, both seeking to define the same choppy, distorted and inconclusive video evidence present the opportunity to examine how ambiguous videos of violence gain meaning in court. While the case arguably had elements that strongly implied guilt for Slager, what garners ultimate analytic interest is how state prosecutor Bruce DuRant cross-examined Slager, using the video to confront the narrative favourable to Slager. Examining how DuRant performed this work, and how Slager resisted it, will help us further understand what role video can play in settling such disputes. That the trial resulted in a hung jury and Slager later pleading guilty further demonstrates the complexity of deciding what actually happened in video renditions of violent events.
The prima facie case against Slager
Slager shot Scott on the Saturday morning of the Easter long weekend, shortly after 9.30 a.m. Slager had enacted a traffic stop to investigate a non-functioning taillight, and Scott parked his vehicle in the lot of an auto parts store. The store was located close to a pedestrian pathway referred to locally as the ‘Yellow Brick Road’. Slager's dashboard camera recorded both audio and video. Slager requested to see Scott's licence, insurance and registration, and explained his reason for pulling Scott over. Scott informed Slager that he did not have insurance or registration because he was in the process of purchasing the car and had yet to take full possession. Slager re-requested Scott's driver's licence and, upon receiving it, returned to his patrol car to run a background check. Eighteen seconds later, Scott opened the door of his vehicle and stepped out, making a gesture as if to ask Slager a further question. Slager testified in court that he instructed Scott to get back in his car (the audio on Slager's dash cam cuts out at this moment) to which Scott complied and shut the door, until a further 17 seconds passed, and the door swung open and Scott ran towards the pedestrian pathway. Slager exited his patrol car and pursued Scott on foot. Slager's car was stationary so the dash-cam video remained focused on the back of Scott's car, but the audio track recorded Slager radioing his foot pursuit, shouting ‘TASER! TASER! TASER!’ (in court testimony, Slager stated he used his Conductive Energy Weapon (CEW) as many as four times on Scott, although his memory was not precise) and ordering Scott to ‘GET DOWN ON THE GROUND NOW!’ before the two ran out of radio range and the audio cut out. 3 At some point following this interaction, Slager shot and killed Scott.
Following the shooting, Slager informed investigators from the South Carolina Law Enforcement Division (SLED) and the Federal Bureau of Investigation (FBI) that Scott had engaged Slager in a physical altercation (a fight), during which Scott took Slager's CEW. Slager attested to shooting Scott as an act of self-defence. However, after these statements were publicized and Slager had effectively been exonerated, Feidin Santana shared his eye-witness video which showed Slager shooting Scott in the back as he fled. Santana testified in court that he believed Slager had control of the situation prior to shooting Scott, and that Scott never possessed Slager's CEW. The bystander video depicts the moments just before Slager opens fire; Slager and Scott are both on their feet and appear to be grappling with each other. The moment the camera focuses on the two, Scott breaks away from Slager as Slager draws and aims his firearm. As Scott is running away, Slager shoots at him eight times. Scott falls to the ground, Slager walks towards Scott, reports on his radio ‘shots fired, subject is down. He grabbed my Taser’, orders Scott to ‘PUT YOUR HANDS BEHIND YOUR BACK NOW! PUT YOUR HANDS BEHIND YOUR BACK!’ handcuffs Scott and then immediately runs-walks back to collect his CEW. At trial, a forensic video analyst testified that Scott was at least 18 feet from Slager and had his back turned to Slager as the shots were fired. The coroner's report indicated five bullets hit Scott in his back, buttocks and ear (Schmidt and Apuzzo, 2015).
In post-incident statements, Slager told FBI and SLED investigators he feared the CEW might be used by Scott to incapacitate him (Waters, 2016). If this were the case, it would be arguable that, even though Scott was fleeing and Slager shot him in the back, Scott could have been perceived as an imminent threat and lethal force could have been justified despite the prima facie breach of the fourth amendment articulated in the Supreme Court of the United States (SCOTUS) decision Tennessee v. Garner (471 US 1 [1985]; a federal prohibition against shooting fleeing suspects in the back). However, if Scott was unarmed, and Slager did not have reasonable grounds for mistakenly believing Scott to have taken the CEW, then Slager would have been acting unlawfully when he decided to shoot Scott, and would have been motivated by ‘malice aforethought’ 4 or callous disregard for human life. 5
Increasing the prima facie grounds for Slager's guilt, South Carolina state courts have taken the strongest interpretation of Bad Elk v. United States (177 US 529 [1900]) of any state in the Union (Clark, 2017). This leading SCOTUS decision ruled that individuals are empowered to use whatever force is necessary to resist unlawful arrest. While Scott did have an outstanding warrant for missed child support payments, Slager did not know this when he pursued Scott. Whether Scott knew or did not know Slager's reasons for arresting him are not determinate, as only officer conduct is in question. North Charleston Police Department's policy permits CEW use ‘when [it] is required to use physical force for protection from assault and/or take a person into custody’ 6 (Blinder et al., 2015). Resisting law enforcement is a misdemeanour offence with a min/max fine of US$500–1000 and no more than one month in prison (SC [South Carolina] Code 16-9-320, 2013), making it questionable that Scott would have been taken into custody since he had already identified himself when he submitted his driver's licence to Slager.
In Illinois v. Wardlow (528 US 119 [2000]) the SCOTUS asserted police rights to pursue a citizen on the simple grounds that they appeared to flee police, although Wardlow was brought into compliance without use of violent force (Capers, 2018). Direct evidence of Slager's prima facie offence against Scott was readily re-presented in video evidence (the traffic stop, the incomplete background check using Scott's driver's licence, the declared use of the CEW). Slager's conduct captured on video could have constituted important aspects of the prosecution's case because Scott's decision to flee, and Slager's decision to use violent force to bring him into compliance, arguably produces conditions of unlawful arrest thus absolving Scott of any culpability in resisting that arrest. It places civil liability to damages, if not criminal culpability, at Slager's feet for attempting to enact an unlawful arrest through excessive force. However, during the cross-examination of Slager, the prosecution instead focused on post-offence conduct to demonstrate their interpretation of Slager's state of mind.
Producing motive: The gestalt contexture of video evidence
Slager's narrative was that his decision to shoot was based on having a good-faith mistaken belief that during the fight, Scott took Slager's CEW. The prosecution sought to demonstrate that Slager's testimony did not accurately reflect the moments leading up to and following the shooting, using the video evidence to draw Slager's account into question. At the core of both cases is a simple question: what motivated Slager to shoot, fear or malice? How to understand the images depicted in the video hinges on the overall impression, the gestalt, compiled through the totality of evidence (i.e. what the video depicts and Slager's explanation for what is depicted).
This gives us occasion to consider how motive functions within legal and societal circumstance. In ‘Situated actions’, Mills (1940) notes that an individual's own synopsis of motive is itself an interested and motivated act. Slager had a vested interest in his motive being perceived by the jury as ‘fear’ to avoid criminal conviction. However, for social scientists, this orientation to motive assumes a realist ontology. This is a practical necessity for legal practitioners—motive is a real thing that exists in the mind of the accused but can be perceived in the depicted actions on video. However, as Blum and McHugh (1971) argue, motives are observer's rules. As they put it, with light modification: motives are used by [jurors] to link particular concrete activities to [specifically] available [legal] rules. Motive, then, is one collective procedure for accomplishing [legal decisions], and for sorting out the various possibilities for [trial outcomes] by linking specific acts and [legal] rules in such a way as to generate the constellation of social actions that [jurors] call [‘guilt’ or ‘not guilt’].
(1971: 98)
If motive exists only in the mind of the accused, it is not available to direct scrutiny. While this is not a problem for jurors who are charged with deciding what a motive may have been, it is for social scientists who, if they follow the realist ontology of motive, neglect the complexity of how a motive is produced. While motives almost certainly govern conduct in some sense, what counts as a plausible and/or reasonable motive is not decided based on the objective contents of an individual's mind, but how triers of fact decide the veracity of an account that attributes motive to action (see also Scott and Lyman, 1968). Triers of fact rely on common-sense knowledge of actors to come to those conclusions (see Garfinkel, 1967, especially ch. 4). The ethnomethodological alternative to examinations of motive is articulated by Sharrock and Watson (1984: 439): Ethnomethodology is interested in analyzing the ways in which actors assign motives to each other … and has no interest whatsoever in constructing motivational schemes on its own behalf. In order to [do so] it will have to engage, at one point or another, in making ascriptions of motives but this will not involve any special, general or specially sociological problems. Its doing will rely upon the analyst’s ‘vulgar competence’ (to borrow a phrase of Garfinkel’s) upon the ordinary capacity to make out what people are doing things for.
Taking note of Garfinkel's discussion of jurors' decision-making practices, the consequence is: whatever meaning is ascribed to actions depicted in video evidence gains its sense in accordance with the assemblage of all evidence, testimony and narrative, which together produce the gestalt contexture of the scene. The following three examples, drawn from Slager's trial as re-presented through courtroom video posted to YouTube, will demonstrate this.
The gestalt contexture furnished through video evidence and testimony
During cross-examination of Slager, state prosecutor Bruce DuRant progressed through several topics, at points questioning actions depicted in the bystander video, at others attending to matters unrelated to the video or the shooting itself. Here, I attend strictly to the arguments made through the video depictions, and Slager's response, noting how DuRant and Slager each attempt to give meaning and motive—control the narrative—of what is seen.
Using a courtroom video of Slager's trial posted to YouTube, I have transcribed two separate sections of the cross-examination where DuRant interrogates Slager's attestations to what he experienced during the incident. For each excerpt presented, I have included time markers for the YouTube video as well as the New York Times edited bystander video. The full transcript is available on the author's ResearchGate webpage. Readers can open the two videos and follow the transcript to see and hear the courtroom interaction and the moments in the bystander video interrogated. After some preliminary questions that demonstrate alignment between the parties as to what can be seen in the video (see Drew, 1978; Lynch and Bogen, 1996; Mair et al., 2013) DuRant begins probing candidate motives.
At line 109 of the transcript, DuRant questions Slager's post-shooting approach to Scott's supine body without Slager's gun raised to the ready position. Slager had testified at this point to the belief that Scott had taken the CEW; DuRant implies that if Slager feared Scott was still armed, then Slager should have approached Scott with his weapon raised. Slager insists that further context is required to comprehend his state of mind in the video:
Excerpt 1, lines 109–123, court video 0:22:29–0:23:05, NYT video 0:25–0:42

DuRant posits a ‘reasonable officer acting on a good-faith mistaken fear’ would approach a suspected armed subject by remaining in the ‘ready’ position—they would continue to be afraid. DuRant uses the images to draw Slager's candidate motive into question; ‘reasonable fear’ ought to be excluded as a motive if Slager's conduct does not exhibit fear. For his part Slager prioritizes an interpretive asymmetry (Coulter, 1975; Mair et al., 2013) between the video and his lived experience. DuRant and the jury are looking at the video with 20–20 hindsight, knowing the outcome. Viewers do not experience any of the physical conditions Slager experienced at the scene (see Mieszkowski, 2012). For Slager, his conduct can be explained by error given the nature of the physical struggle. DuRant turns this around on Slager in line 121, questioning ‘you were in the fight still?’ implying that as much as motive can be read into the conduct depicted in the video, anger is a more appropriate interpretation than fear.
In lines 124–158, DuRant asks a series of questions that further expand on Slager's state of mind and whether Slager was ‘provoked’ which Slager denied. 7 DuRant then moves on to Slager's procedure in handcuffing Scott, before arriving at perhaps the single most damning aspect of the video for contradicting Slager's testimony that he had perceived Scott to be holding the CEW when he shot:
Excerpt 2, lines 154–184, court video 0:24:20–0:25:38, NYT video 0:39–1:09

Slager acknowledged that he did not follow his active shooter training, which instructed him to aim his firearm at a subject he believed to be armed. DuRant also notes that the very moment Slager finishes handcuffing Scott he begins to run-walk back to where he had fired the eight shots without searching Scott's body for the CEW. Instead, Slager immediately returns to collect the CEW from its resting position some 50 feet away, as if Slager knew where it was without searching Scott. In line 179 Slager makes another appeal to asymmetry between lived experience and what is seen on video, which DuRant outright rejects by instructing Slager to only comment on what is visible in the video.
The video is far from unequivocal in its depiction of motive in the moments following the shooting. The two competing gestalt contextures, furnished in part by these narratives of motive, take their form in relation to what might reasonably be determined from post-shooting conduct. For DuRant's case, the video should furnish a motive of ‘malice aforethought’ on the grounds that Slager's narrative does not align with the post-shooting images. DuRant uses ‘reasonable officer’ criteria such as training regimens to demonstrate how a ‘good-faith mistaken officer’ ought to react in the same circumstances, contrasting this with Slager's recorded conduct. Since Slager exhibits no evident fear of Scott being in possession of the CEW, nor does he search Scott for the CEW upon handcuffing him, DuRant indicates there was no reasonable fear of a weapon.
For his part, Slager contends that the actions should be ascribed the motive of ‘reasonable officer with good-faith mistaken belief, and whose non-conforming post-shooting conduct should be accounted for through disorientation having just been in a fight’. Slager contends that what can be seen on video looks bad, but it is not a fair depiction of what was going on for him on the scene. The video does not settle this contention itself, but rather gains its meaning through the interaction between Slager and DuRant: each side argues a narrative of what ought to be known from the scene, relying on video to furnish that narrative, but also building out the interpretation of the video through the candidate narrative in a self-same procedure. Jurors are left to decide not only which of the gestalts is the correct one, but to interpret the meaning of each depicted action in relation to that ‘correct’ gestalt.
In a crescendo point in his cross-examination, DuRant attends to what is likely the most publicly scrutinized element of the post-shooting conduct, the dropping of the CEW next to Scott's body—an action widely interpreted as ‘planting’ the weapon. DuRant opens this phase of building an account of Slager's actions and motives by stating that what is seen on the video is ‘hard to miss’:
Excerpt 3, lines 191–204, court video 0:26:15–0:26:48, NYT video 1:30–1:45

DuRant first mentions the dropping of the CEW in question form to Slager, stating rhetorically that the action is ‘hard to miss isn’t it sir?’ (lines 193–194). Slager does not acknowledge recognition of what is to have been missed, replying ‘I’m sorry?’ to which DuRant repeats his inquiry. Slager arguably feigns ignorance of the ‘planting’ narrative by redirecting to another aspect of the video, Officer Habersham administering first aid to Scott. DuRant rejects the redirection by stating ‘No miss what you did with that taser’ and replays the one-second moment of the CEW being dropped three times consecutively before advancing the video frame-by-frame pressing the forward arrow key, and stating ‘this is the part I’m talking about thet's pretty easy to miss’. 8
Just under 20 seconds after the dropping, Slager is seen picking up the CEW. This action would nullify the strict legal significance of dropping the weapon a propos obstruction of justice or disturbing the scene. However, DuRant redirects attention to another aspect of the video, the perception Slager may have of the bystander, Mr Santana, filming the incident:
Excerpt 4, lines 206–222, court video 0:26:48–0:27:48, NYT video 1:45–2:12

Through this exchange, DuRant produces the ‘planting’ narrative, and gives explanation for the aborted attempt. DuRant argues the decision by Slager to pick up the CEW was motivated by the bystander's position relative to that of Slager and Officer Habersham. Santana's original vantage point was behind trees set back from the incident itself. As the incident unfolded, Santana moves closer to the scene, out from the trees and apparently into view of Slager and Habersham. DuRant uses this prospective revealing to infer motive for Slager's picking up the CEW. Slager, somewhat non-committedly, responds with ‘appears to be’ twice and ‘that's when I picked up the taser, yes’, conceding some form of agreement with DuRant.
The problem of understanding Slager's situated motive(s) is not resolved through the video alone, and contextualization produces the candidates for motive. Slager is non-committal, treating the action as inadvertent and unthinking (this is affirmed in the following section). DuRant argues the action is evidently meaningful, a meaning that gains its sense when the impact of the camera's presence imposes upon Slager as the operator reveals himself from his covert position. For DuRant, Slager should be seen as motivated by his own perception of guilt and attempting to hide that guilt by ‘planting’ the CEW. Motive for collecting the CEW is best interpreted as a reaction to the realization of the video's presence. At this stage, Slager merely concedes that what DuRant sees on the video is what he also sees.
DuRant then departs from the video and the ‘planting’ narrative until 0:43:11 on the courtroom video when, in pursuing a line of questioning pertaining to what Slager told investigators directly following the incident, he asks:
Excerpt 5, transcribed separately, court video 0:43:11–0:44:40

Here we see the explicit effort by both Slager and DuRant to place motive onto conduct through the video. Slager frames the ‘planting’ as inadvertent and without memory (line 13), something he just did after following the reasonable action of ‘policing [his] gear’ (line 20) and the potential threat that the passenger or another passer-by might pose in collecting the CEW in an uncontrolled crime scene. Later, although unthinking, he corrected the action (line 19). DuRant agrees that it was appropriate to collect the CEW in the active crime scene and ‘consolidate your gear’ but contests whether dropping the CEW close to Scott's body, as opposed to simply holstering the weapon, is consolidation (lines 22–24). DuRant demonstrates his incredulity with Slager's statements by following Slager's assertion that one might ‘consolidate the scene’ on lines 25–26 with the prolonged and purposeful pause on line 27, followed by the pronounced ‘whut?’ on line 28. Finally, DuRant definitively addresses the issue in the final exchange ‘sir, if you’re going to secure your taser, you pick it up from the ground and put it where?’ to which Slager answers ‘in my holster’, thus conceding there is no reasonable reason to have put it on the ground close to Scott's body.
Through these lines of questioning, the notion of gestalt contexture takes its significance for interpreting video evidence, particularly of police action. The circumstances depicted in these videos are often difficult to interpret on either ground of unfamiliarity with what a ‘reasonable officer’ is or that action depicted in video is itself confusing (Collins, 2008; Doyle, 2003; Manning, 2010). Both conditions are present in this video, which is what makes it such a compelling document to consider the notion of gestalt. Through the adversarial trial process, viewers (triers of fact) are given the same type of object (the video) as the exemplar duck/rabbit diagram. On one hand, conduct is argued to be in accordance with a reasonable, if not flawless, officer. On the other, conduct is depicted as emblematic of malicious intent, an officer whose actions are so far removed from what a reasonable officer would conventionally do if fearing for their life that fear must be excluded as the motivation for lethal force, leaving only malice or callous disregard in its place. Narrative clarifies how the video ought to be seen; the two competing narratives are each built out of the video and in turn gain credibility through video, the accompanying invocation of rules for crime scene management and candidate explanations for derivations from rule-following conduct. Seeing motive in the video requires aligning the various elements of the gestalt contexture to interpret the state of Slager's mind as he shot Scott. It is only through situating the action-depicted-on-video through the broader gestalt contexture of evidence and testimony that the meaning of the action gains its sense for triers of fact.
This discussion does not exclude the possibility that viewers see what is on video and immediately draw their conclusions. Video can be a particularly persuasive type of evidence, especially under the current conditions of ‘racial reckoning’ (Capers, 2018; Romano, 2017) in the United States and elsewhere, and in a case where race is such a glaring element of the interaction depicted—Slager being White and Scott Black. This fact was repeatedly addressed in news media coverage of the incident. That said, the options for what might be seen and interpreted are limited by the circumstances in which viewing takes place. The dropping of the CEW is seen either as an intentional planting or an unthinking event. Deciding this in turn gives meaning to the testimony that accompanies the video—either Slager or DuRant are misrepresenting the significance of the action. That meaning takes its form in reflection of the culmination of evidence, producing, and a product of, that constraining condition for seeing and sense making. Contrasting these observations with Moore and Singh's (2018) formulation of viva voce testimony as ‘actual’ and video as ‘doppelganger’ would leave us in a position where we would have to diminish the implications of video evidence. Would an officer's motivated and partisan testimony formulate the ‘actual’ conditions to be considered, the video a mere ‘doppelganger’ thereof?
There is some risk here that the banal invocation of the duck/rabbit diagram downplays the complexity of the racial politics presented in the scene. I would argue the opposite is true. Should a viewer decide that racial animus is the appropriate motive to assign Slager, that work is done through specific references to elements of the video, testimony or other considerations that help them make sense of the video. In the Canadian Broadcasting Corporation (CBC) documentary Frame 394, Muhiyidin D’Baha, a Black Lives Matter organizer from North Charleston, problematized the micro-analysis of individuals' movements depicted on video, stating ‘the fact that Michael Slager pulled his trigger eight times and the holes in the back of Walter Scott, those are the types of things that can’t be interpreted’. For D’Baha, Slager's actions on video are evaluated quite differently than in court, and the gestalt of ‘guilt’ is defined in reference to the value of Scott's life, not the perception of Slager. New York Times columnist Charles Blow is also featured in the documentary arguing: we’re getting to a point of fatigue of trying to analyse individual videos of individual cases arguing about ‘in this moment of the video I see this and in this moment of the video I see that.’ We can’t keep having that kind of argument.
For Blow, the implication is analysis must occur at a much higher level, attending to the risk to democracy when democratic institutions such as the police and the courts expend such effort explaining away the disproportionate death of Black men at the hands of police officers. Attending carefully to how these gestalts take their form, in court or otherwise, gives us greater purchase to delve into officer propriety and the assumptions built into law and police conduct.
Conclusion: Theorizing video evidence in court
As changes to technology and culture create more and different kinds of video, it is increasingly important to understand what kind of thing video evidence is, and how ‘truth’ may be derived from it in court. Moore and Singh’s (2018) discussion of data doubles provides significant headway for analysing video's contribution to the gestalt interpretation of guilt or not-guilt produced at trial. The central problem for both analyses is coming to terms with how ‘truth’ is derived from video evidence. Moore and Singh's (2018) positioning of the ‘actual victim’ versus their video ‘doppelganger’ creates a reasonable contrast for a critical feminist criminology, but leaves aside issues of how triers of fact assess conflicting testimonial and video evidence. KGB videos can be treated as ‘truth’, but doing so is not necessarily the case. It is certainly relevant to ask: ‘what kind of impact does this practice have on individuals subjected to it?’ But a further question remains: ‘when this practice is applied, how do individuals do the work of arguing which of two competing versions is the correct one?’ (see Cuff, 1993; Pollner, 1975). KGB statements and videos of police violence may each be compelling, visceral forms of evidence, although their candidate meanings are structured by the conditions of their use, and their ‘truth value’ is both informative of, and informed by, those conditions and narratives in a mutatis mutandis manner—as the video is found convincing (or not) so too will be the interpretation of accompanying evidence and trial outcomes. Oppositely, if a compelling reason is presented to distrust video then video's ‘truth value’ is diminished.
It is perhaps a unique feature of criminal trials for police on-duty use-of-force incidents that officers are, if not compelled, at least well advised to provide some defence of their actions rather than simply contesting that the state has not made the case. As such, these trials are venues where two contesting gestalt contextures are advanced, of which video plays some role in establishing which narrative aligns with a candidate verdict. We must be cautious about what we presume video does in these circumstances; video may indeed be a compelling aspect of the gestalt, even the most compelling aspect, but the criminal trial for the four LAPD officers accused of unlawful use of force in confronting Rodney King demonstrates the folly of assuming video speaks for itself. If it is the case that a video is the definitive piece of evidence that convinces a jury's verdict, then all other contesting evidence takes its meaning and significance through that gestalt. By attending to how such ‘truths’ are arrived at, we help demystify the role of video evidence, shaking ourselves of the assumption that video re-presents ‘truths’. Video does not stand alone as an unquestioned, objective epistemic object, but gains its meaning through proceedings.
My objective here is to keep moving the ball downfield on analyses of video in legal circumstances. Prior studies, including Moore and Singh (2018), Sandhu and Haggerty (2017) and Stalcup and Hahn (2016) have theorized video, to varying degrees, from perspectives outside of the practical use of video in deciding cases. Moore and Singh (2018) attend to how the KGB video data double disempowers and discredits a witness. Sandhu and Haggerty (2017) produce ideal-typical categories for police officers’ experiences and perceptions of video evidence and themselves being video recorded (see also Sandhu, 2019). Stalcup and Hahn (2016) are likely most aligned with this article in their endorsement of video pragmatism over video optimism or pessimism. Conforming with Stalcup and Hahn's (2016) classifications, this study proposes a ‘video praxeology’ (see also Kolanoski, 2017; Mair et al., 2012, 2013; Watson, 2018a, 2018b; Wilke, 2017), a study of how arguments in court are advanced with video evidence, and how video evidence gains its sense in court while also informing the sense of other evidence and the eventual verdict.
This article examines how video evidence features in criminal trials, with a specific focus in the Slager trial on how post-shooting conduct as circumstantial evidence was used to interrogate Slager and impeach his testified-to motives. It incorporates phenomenological philosophy of Gurwitsch and the ethnomethodological use of gestalt contexture to consider how ‘truth’ is derived from and instructive to video interpretation. I contrasted my approach with that of Moore and Singh (2018) by attending to how the data contained within a ‘data double’ is made salient to a trier of fact. Instead of contrasting an ‘actual’ witness with a video ‘doppelganger’, I have argued in favour of examining how arguments made in court produce ‘truth’ without granting epistemic primacy to one form of evidence or another. By considering how video gains and produces ‘truths’ in a self-same procedure with accompanying evidences in court, we further dispel the common cultural cliche that ‘seeing is believing’.
Footnotes
Acknowledgements
I would like to thank Carmen Nave, Wes Sharrock, Michael Lynch, Michael Mair, Albert J Meehan and Stacy Burns for their comments on this and previous drafts, as well as the suggestions from the anonymous reviewers of Theoretical Criminology.
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
This article draws on research supported by the Social Sciences and Humanities Research Council.
Notes
Author biography
Patrick G Watson is assistant professor of Criminology at Wilfrid Laurier University.