
Abstract
The formation of autism advocacy organisations led by family members of autistic individuals led to intense criticism from some parts of the autistic community. In response to what was perceived as a misrepresentation of their interests, autistic individuals formed autistic self-advocacy groups, adopting the philosophy that autism advocacy should be led ‘by’ autistic people ‘for’ autistic people. However, recent claims that self-advocacy organisations represent only a narrow subset of the autistic community have prompted renewed debate surrounding the role of organisations in autism advocacy. While many individuals and groups have outlined their views, the debate has yet to be studied through computational means. In this study, we apply machine learning and natural language processing techniques to a large-scale collection of Tweets from organisations and individuals in autism advocacy. We conduct a specification curve analysis on the similarity of language across organisations and individuals, and find evidence to support claims of partial representation relevant to both self-advocacy groups and organisations led by non-autistic people. In introducing a novel approach to studying the long-standing conflict between different groups in the autism advocacy community, we hope to provide both organisations and individuals with new tools to help ground discussions of representation in empirical insight.
Lay Abstract
Some autism advocacy organisations are run by family members of autistic people, and claim to speak on behalf of autistic people. These organisations have been criticised by autistic people, who feel like autism charities do not adequately represent their true interests. In response to these organisations, autistic people have come together to form autistic self-advocacy organisations, or groups in which activists can spread awareness of autism from an autistic point-of-view. However, some people say that autistic self-advocacy organisations do not sufficiently represent the needs of all autistic people. These tensions between organisations and individuals have made it difficult to determine which organisations can make the claim that they represent all autism advocates individuals equally, instead of showing preference to a sub-group within the autism community. In this study, we try to approach this issue using computational tools to see if, in their Twitter posts, both kinds of organisations show a preference for the interests of autistic people or parents of autistic children. We do so by comparing a large body of Tweets by organisations to Tweets by autistic people and parents of autistic children. We find that both kinds of organisations match the interests of one group of autism advocates better than the other. The insight we provide has the potential to inspire new conversations and solutions to a long-standing conflict in autism advocacy.
Introduction
The initial period of autism advocacy was heavily influenced by autism organisations founded by families of autistic children, which have been described as being managed without the input of autistic individuals (McCoy et al., 2020; from this point onwards, organisations that are not self-designated as led by autistic people will be referred to as non-self-advocacy groups, or nASA for short). 1 In the early days of their existence, nASA organisations often adopted a biomedical view of autism, conceptualising it as an illness that – with adequate research – could be treated to lessen the severity of its symptoms, or cured entirely (Krcek, 2013). Communications from these were often targeted at family members of autistic children to supply parents with resources, information and support as they navigated their children’s diagnosis. In public statements, prominent charities have described autism as a ‘national emergency’ and a ‘monumental health crisis’ (Wilson, 2013), characterising it as a condition that greatly obstructs the ‘hopes’ and ‘dreams’ of those afflicted and causes severe ‘struggle’, ‘embarrassment’ and ‘pain’ for the families involved (Autistic Self Advocacy Network (ASAN), 2009).
nASA groups have drawn criticism from autistic self-advocates, who object to what they have described as nASA groups’ stigmatising depictions of autism, as well as their failure to include autistic people in decision-making processes within their organisations (ASAN, 2016). Autistic self-advocacy (ASA) organisations emerged in the 1990s, challenging the dominance autism charities had over popular narratives of autism (Ortega, 2009). Drawing from the broader disability advocacy movement (Ne’eman & Bascom, 2020), autism self-advocates adopted the social model of disability rather than the biomedical construction of autism (Krcek, 2013). Instead of characterising autism as inherently pathological and thus requiring a cure, the social model promotes neurodiversity, or a desire for autistic people to be included into society without changing aspects of their cognition or behaviour to be accepted (Kapp et al., 2013; Pellicano & den Houting, 2022). ASA organisations maintain that autistic people, and not their neurotypical family members, should be at the forefront of decisions on research, policy and public communication surrounding autism (Bertilsdotter Rosqvist et al., 2015; Ne’eman & Bascom, 2020).
The popularity of ASA groups and the views they express prompted a debate around the question of which groups speak for autistic individuals. Since their inception, ASA organisations have asserted that nASA groups make wrongful claims of representativeness, as the views of autistic people were scarcely considered in their initiatives (Chapman & Veit, 2020; Fellowes, 2020; Rosenblatt, 2018). However, family members of autistic children have raised doubts about ASA organisations’ claims of representativeness (Richardson & Sharp, 2020), arguing that ASA groups, as spokespeople for the entirety of the autistic community, have a responsibility to represent a diverse – and occasionally conflicting – set of interests (McCoy et al., 2020).
Parents of autistic children with more severe intellectual, social and behavioural impairments have reported feeling alienated by ASA organisations (Haney, 2018), in large part due to their vocal opposition to policies aimed at addressing parents’ supervision and safety concerns. For example, a proposal to subsidise personal locating devices for families with autistic children prompted an outcry from leading ASA organisations, amid parental insistence that such devices could prevent children from getting lost or wandering into dangerous situations (Joseph, 2011). In prioritising autonomy and independence outcomes for autistic adults, parents maintain, ASA organisations neglect to consider the unique needs and concerns of autistic people unable to speak for themselves (Richman, 2020).
In an exploration of what it means for an organisation to ethically advocate for the autistic community, McCoy and his colleagues (2020) suggested that ASA and nASA organisations – as parties assuming a representative role not through electoral means, but through self-appointment – engage in practices of ‘partial representation’. For example, while ASA groups claim to speak for all autistic people, they may be preferentially amplifying the voices of autistic people who are capable of speaking for themselves. To ensure that they do not overlook autistic people with greater support needs in their advocacy, McCoy et al. recommended that organisations seek endorsement from parents and caregivers with ‘firsthand knowledge of the needs of autistic people with severe disabilities’.
In response to this recommendation, some argued that parents could not reliably represent their autistic children’s interests (Benjamin et al., 2020), suggesting that, for organisations, representational priorities should lie with amplifying the expressed views of autistic people. Others argued that parents deserve to be represented in their own right, not solely as proxies for their children (Buturovic, 2020), affirming the role of the parent as a stakeholder in autism advocacy. It is clear, then, that the community has yet to reach a consensus on what constitutes ethical, fully representative autism advocacy, leaving a legacy of contradictory arguments for organisations to follow. The question remains: who speaks for the autistic community?
This study introduces a new approach to investigating this critical question. By analysing social media data with natural language processing (NLP) tools, we compare the online expressions of autistic self-advocates and parents of autistic children with messages from organisations that engage in self-appointed representation practices: nASA groups and ASA organisations. While this method cannot definitively prove nor disprove claims of partial representation, the many comparisons drawn between language used by individuals and organisations may capture a snapshot of representational patterns in online advocacy. This method allows us to explore criticisms against both ASA groups and nASA organisations, providing empirical evidence to support or challenge these claims. The empirical methods introduced are not infallible: social media data may not fully reflect the diversity of the autism advocacy community, and language modelling results introduce ambiguities in interpretation. Even so, we believe the study offers a valuable methodological contribution to the field, providing a new way to explore the complex dynamics of representation within the autism community.
Autism advocacy on Twitter
The focus of this work is on online autism advocacy, and in particular, advocacy on the platform Twitter (now known as X). The advent of Internet-based communication created widely accessible channels for disability advocacy, enabling users to bond over shared experiences and rally against the stigmatisation, prejudice and exclusion they face in a largely able-bodied and neurotypical society (Bowker, 2008; Bowker & Tuffin, 2004; Jaeger, 2022). Online spaces dedicated to the discussion of autism by autistic people allowed individuals to forge a positive autistic identity centred around the celebration of their neurodiversity. In Internet forums, autistic people embraced their idiosyncracies rather than framing them as symptoms that must be remedied; asserted agency over their way of life in a rejection of the viewpoint that they are victims of their condition; and developed new terminology to distance themselves from language that positions them as lesser than their non-autistic peers (Parsloe, 2015).
Although autism advocacy is represented across many social media platforms, Twitter was selected for this study for three reasons: (1) at the time the study was conducted, it offered generous API (Application Programming Interface) access for academic researchers, allowing us to efficiently collect large-scale datasets; (2) its API supported features such as keyword-based searches of users and Tweets that were critical to the design of the study; and – most critically – (3) Twitter has long been a critical platform for online autism advocacy. As online advocacy spread from lesser-known forum boards to mainstream social media networks, Twitter emerged as a space for autistic individuals to make themselves heard by other autistic people, non-autistic people and autism organisations alike (Trevisan, 2016). Using the #ActuallyAutistic hashtag, Twitter users publicly identify themselves as autistic, sharing personal experiences with the intention of countering overly medicalised narratives that dominate public perceptions of autism ([@autisticadvocacy], 2014). Critically, Twitter is a powerful tool for dissent and protest, providing autistic individuals with a platform to express collective opposition to social and medical policies that they consider harmful to autistic people. In recent years, autistic individuals have popularised the #SayNoToABA hashtag to highlight the underexplored adverse effects of applied behavioural analysis (ABA), a controversial autism treatment ([@AutSciPerson], 2021). Similarly, the #StopTheShock hashtag gained prominence in response to reports of an institutional care centre routinely administering electric shocks to its autistic in-patients as a method of behavioural control (ASAN, 2022). This study leverages ‘Tweets’ (short public messages on the Twitter platform) by autistic users to capture overall patterns in their language use, which may be indicative of their public values and beliefs.
Much like autistic individuals, parents of autistic children rely on Internet-based communication in their research into their children’s diagnoses. Parents may turn to other parents of autistic children on the Internet for educational resources and emotional reassurance, building a community based on their shared experiences of parenting autistic children (Fleischmann, 2005; Reinke & Solheim, 2015) and forging new identities as ‘autism parents’ (Hall et al., 2016). On Twitter, parents have established hashtags such as #AutismMom, #AutismDad and #AutismParent to document their experiences, promote their interests and make their needs known.
Corporate social responsibility
Organisations are also users of Twitter. Organisations seeking to communicate their commitment to conducting business in an ethical manner commonly do so on social media platforms, allowing for highly visible displays of corporate social responsibility (CSR). Companies that broadcast CSR-related messaging do so to cultivate the belief among stakeholders that their engagement with CSR is authentic (Hur et al., 2020; Lock & Seele, 2017). In a comprehensive study exploring the virtual avenues for CSR-related messaging, it was found that a majority of corporations use Twitter to keep stake-holders informed of their CSR activities (J. Yang et al., 2020). Within companies in the non-profit sector – an umbrella term under which many registered ASA and nASA organisations fall – negative perceptions of CSR have been found to decrease the perceived trustworthiness of the organisation (Lin-Hi et al., 2015). This erosion of trust may have significant ramifications for stake-holders’ willingness to support the organisation’s activities, an effect that is particularly detrimental for organisations that are financially reliant on their stake-holders’ goodwill. A company using social media to appeal to an audience may benefit from demonstrating that its social responsibilities are aligned with those that it positions as stake-holders (Connelly et al., 2011); establishing a ‘good fit’ with key actors may be especially critical for organisations whose mission is centred around the promotion of an altruistic social cause (Graff Zivin & Small, 2005; Jamali & Mirshak, 2007), such as autism awareness and acceptance.
Applying the lens of CSR requires the identification of a body of stake-holders, to whom the organisation tries to appeal to through its social media activity. However, identifying the primary stake-holders of autism advocacy organisations is not a trivial task. Some organisations may describe their constituents as a narrower group than all people involved in autism advocacy. For example, in their page on ‘What We Believe’, the Autistic Self-Advocacy Network states ‘that autistic people need to be involved whenever autism is discussed’, centering autistic self-advocates in their mission. Other organisations may make implicit claims of inclusiveness: the Autism Speaks home page features resources for both autistic people and parents of autistic children side-by-side, which could be interpreted as an intention to equally represent and service both interest groups.
We do not have insight into an organisation’s internal decision-making processes beyond materials they choose to externalise, so we cannot make definitive claims of who organisations intend to represent. Considering claims of biased advocacy and exclusionary attitudes have been levied against both ASA and nASA organisations; however, it may be argued that some hold an expectation that both kinds of organisations should aim to represent a broad range of stake-holders, encompassing many groups implicated in autism advocacy, research and policy. In our methodology, we compare organisational Tweets to Tweets by both groups of individuals to capture potential displays of preferential alignment, whether this alignment is intentional or not.
Drawing on foundational theories from the organisational CSR literature (Graff Zivin & Small, 2005; Jamali & Mirshak, 2007), we assume that ASA and nASA groups alike are motivated to display alignment with whichever group they consider their core audience members. Accordingly, if nASA groups deem parents of autistic children to be their most important audience members, their values – as reflected by the language used in their Tweets – should overlap more significantly with those of parents than autistic individuals. Likewise, if ASA groups are primarily interested in appealing to autistic Twitter users, their expressed values would likely register as more similar to the beliefs of autistic individuals than to parents of autistic children.
Informed by the direction in which criticisms of partial representation have been raised, two specific predictions are made: (1) the online expressions of ASA organisations will be more similar to expressions of autistic self-advocates than to those of parents of autistic children and (2) the online expressions of nASA organisations will be more similar to the expressions of parents of autistic children than to those of autistic individuals. Because the chosen NLP method represents semantic patterns in language use (Goldberg & Levy, 2014), rather than syntactic or frequency-based approaches, we posit that groups whose language use is ‘more similar’ make expressions that are ‘closer in meaning’, though we are unable to collect additional evidence – such as self-report data – to support this claim.
Methods
We gauged the alignment of an organisation’s public messaging with different groups by analysing how similarly they use language in their Tweets. Specifically, we derived a measure of similarity between the semantic contexts in which shared words occur across the Tweets of organisations and individuals. We produced measures of semantic similarity in three steps: (1) constructing a corpus of Tweets for each organisational and individual group of interest; (2) generating word embeddings as a means of calculating semantic similarity between groups; and (3) conducting a specification curve analysis (SCA) as a robustness check of the hypothesis testing procedure. For a visual summary of methods, see Figure 1.
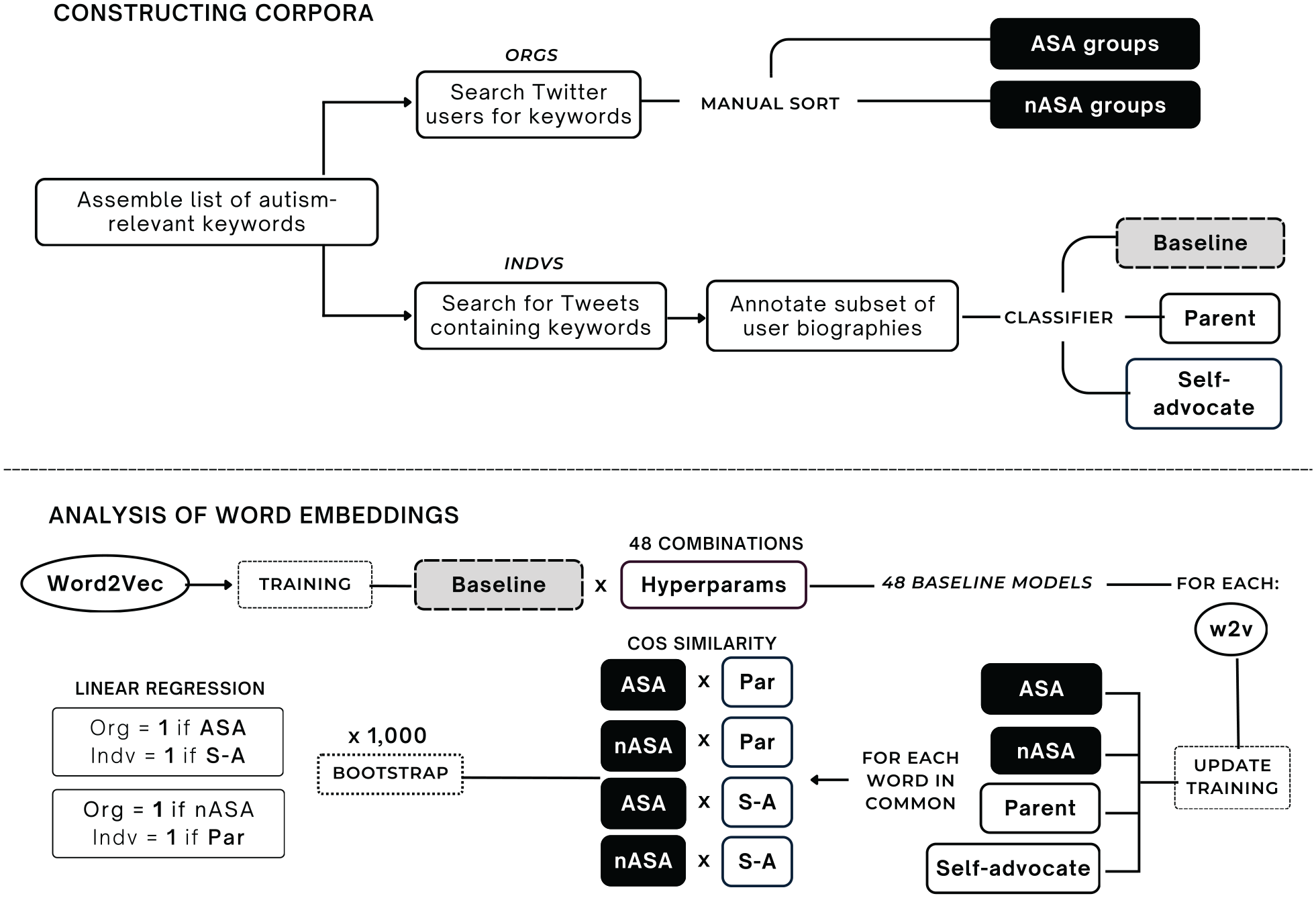
Summary of procedure for finding semantic similarity between common words in Tweets across autism-relevant organisational and individual groups. ‘w2v’ refers to a Word2Vec model.
Constructing corpora
For comparisons across organisational and individual online expressions to be made, four distinct corpora of Tweets were obtained, each authored by one of the four groups of interest. Because no such corpora are readily available, they were constructed for the purposes of the study. All data were collected between March and August of 2022.
First, it was necessary to establish a dictionary of words and phrases used in reference to autism, both by autistic people engaging in self-description and by non-autistic people describing autistic others. A list of autism-relevant keywords was compiled through an informal survey of graduate students at an autism-centred research group (who were both autistic and non-autistic). For the full list of keywords and more detail on the selection process, see Supplementary Materials A.1.1.
To construct a corpus of Tweets by organisations, autism-relevant keywords were applied to the Twitter API’s ‘user search’ function, a relevance-based search that returns a 1000 public user accounts per keyword. Twitter accounts were manually labelled as ASA groups if their biographies (1) did not contain references to the account being owned by an individual (e.g. account name or biography contains personal details) and (2) contained references to self-advocacy. If a Twitter account did not belong to an individual but did not mention self-advocacy, it was labelled as a nASA group. Twitter accounts belonging to users identified as individuals were discarded. We note that although this process introduces the possibility of misclassification – that ASAs are labelled as nASAs – we chose to take a conservative approach with identifying self-advocacy groups, as they generally adhere to more specific criteria on who can assume a representative role over the autistic community (Ne’eman & Bascom, 2020; Zuber & Webber, 2019). We also acknowledge that our approach of distinguishing between groups and individuals may increase the possibility of false positives: that non-groups are labelled as groups. We choose this approach because, at the time the data were collected, Twitter API limit restricted researchers to collecting up to 3200 of a users’ most recent Tweets, so we employ a more permissive selection approach for groups to ensure that we collect a sufficiently large sample of Tweets on which to fine-tune word embedding models. These Tweets were then sorted using the manual labels provided to create two distinct corpora: Tweets by ASA and nASA groups. The public Twitter handles of accounts that constituted our organisational set are available upon request, which is a measure we take to preserve the privacy of users.
While it could be presumed that the majority of Tweets published by autism-centred groups would pertain to topics relevant to autism, the same assumption cannot be extended to autistic individuals and parents of autistic children. Consequently, the procedure for constructing Tweet corpora differed for individuals. First, a large number of Tweets containing autism-relevant keywords were collected, excluding re-tweets (re-posts of another user’s materials) and Tweets not authored in the English language. The biographies of the Tweets’ authors were retrieved. A random subset of 20,165 user biographies were labelled by a human annotator, such that each biography was deemed to belong to a user who self-identified as autistic, a parent of an autistic child or neither. Twitter users already represented in corpora of organisational Tweets were excluded from this sample.
Next, a number of supervised classification models were trained on the labelled examples to identify which category a user belonged to based on their biography (for more detail on the annotation and model selection process, see Supplementary Materials A.1.2 and A.1.2.1). The model with the highest test accuracy (the highest proportion of correct labels assigned to biographies that it had not been trained on) was used to classify the rest of the user biographies. The corpus designation of each Tweet’s author – autistic, parent of autistic child or non-autistic – was therefore determined by a human rater, or by a model trained on human ratings.
At the end of the corpus construction process, discrete collections of Tweets were available from the four groups of interest: ASA groups, nASA groups, autistic self-individuals and parents of autistic children. Tweets that were retrieved during the keyword-based Tweet search, whose authors did not belong to any these groups, were stored in a separate ‘baseline’ corpus for later use in pre-training the language model.
Word embeddings
Advances in the field of NLP have produced sensitive methods of generating numerical representations of words to capture their underlying semantic qualities. Within these methods, a word’s ‘embedding’ – a vector representation that reflects the many contexts in which it occurs – can be thought of as its coordinates in a hyperdimensional semantic space, where each dimension reflects a semantic quality (Kusner et al., 2015). Words that have a tendency to occur near each other are far likelier to have a stronger semantic relationship than words that rarely inhabit the same context; this property of language can be envisioned as the physical distance between two embeddings, such that the closer together two embeddings are situated in a semantic space, the more shared meaning exists between the words.
A word’s embedding is not fixed and unchanging: a language model determines a word’s embedding by analysing where it occurs ‘within the corpus on which it is trained’. This dynamic property of language models has been leveraged by social scientists to capture sociocultural attitudes and trends through language use. Findings that a language model trained on mainstream news sources produces associations between occupations and gendered words along stereotypically gendered lines, such that ‘woman’ relates more closely to ‘secretary’ than ‘engineer’, have shed light on a collective culture of gender bias (Caliskan et al., 2017). A powerful example of a language model’s ability to parallel the attitudes, sentiments and concerns of its training documents was also presented in the study by Garg et al. (2018), in which embeddings trained on 19th-century American literature demonstrated an increased association between Asian-related terms and derogatory adjectives following waves of Asian immigration into the United States.
A language model’s unique ability to capture the meaning of words within a corpus has also been used to compare attitudinal similarities and disparities between groups. Lawson et al. (2022) illustrated the effect that hiring female chief executive officers (CEOs) can have on gender stereotypes in organisational language, such that positive associations between words pertaining to femininity and agency emerged in organisations that experienced a leadership transition to a female CEO, relative to organisations that did not.
As embedding representations, words that frequently share the same context are positioned closer to one another in semantic space. It follows that if identical words trained on two distinct corpora are situated close to one another, there is a great overlap in the contexts in which these words are used between corpora. Furthermore, greater similarity in the positions of an identical word between Corpus A and Corpus B, as compared to Corpus A and Corpus C, suggests that there is greater shared meaning in the way the word is used in Corpora A and B. If, for example, the word ‘autism’ frequently occurs in a biomedical context in the Tweets of nASA groups and parents of autistic children, but not in the Tweets of autistic individuals, this would be reflected in the greater distance between embeddings of ‘autism’ in nASA and self-advocate, relative to nASA and parent, comparisons. Thus, disparities in organisational representativeness could be illustrated through organisation/individual comparisons for each identical word across the four corpora of interest.
Estimates of shared meaning between autism-relevant words in comparisons across organisational and individual corpora were recovered in the following steps. Prior to training, a text-cleaning procedure was applied to all Tweets (more details in Supplementary Materials A.1.3). Baseline embeddings for many words were generated using the gensim package on Python (Rehurek & Sojka, 2011) to train an unsupervised NLP algorithm, Word2Vec (Mikolov et al., 2013), on the baseline Tweet corpus. Word2Vec produced an equal-length multi-dimensional vector for unique words in the baseline corpus. Next, the baseline model was trained on each of the corpora of interest separately, yielding four distinct sets of word embeddings. In this step, the pre-trained language model will adjust the semantic placement of words from the baseline corpus depending on how the word is used in the new training corpus; words used in similar contexts across two corpora are adjusted in similar directions, resulting in smaller distances between embeddings.
Embeddings of words not present across all corpora were removed, and the distances between embeddings of identical words between organisations and individuals (nASA groups × parents of autistic children, nASA groups × autistic individuals, ASAG groups × parents of autistic children, ASAG groups × autistic individuals) were computed. Cosine similarity, or the cosine of the angle formed by two numerical vectors, served as the distance metric and was calculated between each identical word embedding pair using the SciPy package on Python (Virtanen et al., 2020). Cosine similarity can assume any value between –1 and 1, such that a cosine similarity of –1, 0 or 1 represents an opposite, orthogonal or identical relationship between two vectors. Note that, while negative cosine similarities indicate that two word embeddings are semantically dissimilar, values close to zero signal a lack of semantic similarity and dissimilarity.
Following this procedure yielded a set of cosine similarities, such that each similarity metric was associated with a single word for a given individual and organisation comparison. Inspired by the analyses in the study by Lawson et al. (2022), a linear regression analysis was applied to test Hypothesis 1 – that the Tweets of ASA groups organisations are closer in meaning to (and therefore have greater, more positive cosine similarity scores with) the Tweets of autistic self-advocates than to those of parents with autistic children – using the equation and binary coding specification in Equation (1).

Of particular interest is the
To test the second prediction – that the Tweets of nASA groups are closer in meaning to the Tweets of parents of autistic children than to those of autistic individuals – the binary coding specifications are reversed (Equation (2)). The

Specification curve analysis
We note that a word’s embedding depends not only on the training corpus, but also on the hyperparameters that are selected for the language model. A large-scale study of Word2Vec language model performance found that adjustments to a variety of hyperparameters had a pronounced impact on its performance on a recommendation-based task (Caselles-Dupré et al., 2018). Within the context of this study, the possibility that a significant effect is an artefact of hyperparameters of the language model could not be dismissed. An SCA was, therefore, employed to ensure that recovered
First, a number of baseline models were trained, varying across multiple dimensions of hyperparameters. The full hyperparameter space is outlined in Table 1, such that each possible combination of hyperparameter specifications was utilised, yielding 48 (3 × 2 × 2 × 2 × 2) baseline models. Each baseline model was updated on the four corpora of interest separately. For each set of updates on the baseline model, only embeddings of words that occur across all four corpora were retained, and cosine similarities of identical words between corpora pairings (nASA × parent, nASA × self-advocate, ASA × parent, ASA × self-advocate) were produced, yielding four cosine similarity scores per shared word per baseline model.
Hyperparameter space for SCA.

SCA: specification curve analysis.
Negative sampling value set to 10 noise words, as per gensim recommendations.
A 1000 bootstrapped samples were drawn from these datasets of cosine similarities. For each iteration, 10,000 words were sampled and their z-standardised cosine similarities across organisation and individual pairings used to produce two
A total of 48,000 (48 specifications × 1000 samples) pairs of
Statement on community involvement
While there was little community involvement in the design of the study, the authors make every effort to include the viewpoints of autistic self-advocates in the data collection and analyses processes. We do so by ensuring our search word approach for identifying autistic self-advocates on Twitter includes language autistic self-advocates – rather than autism researchers – are likely to use (Supplementary Materials A.2.1). We also devote a significant amount of annotation time (Supplementary Materials A.2.2) to capturing as many self-identifying autistic Twitter users in our scraping dataset as possible to increase the size and diversity of the training, validation and test sets used to develop and evaluate our classification approach.
Results
Pre-registration and code availability
All documents related to the study’s pre-registration can be found on the Open Science Framework. 2 Raw data cannot be shared due to the privacy restrictions imposed by the user agreement for Twitter API Academic Research Access, but cosine similarity scores are made available. All codes can be found on GitHub. 3
Sample
Using Tweets from organisations and individuals in autism advocacy, the z-standardised cosine similarities of shared words across pairings of organisational and individual corpora were retrieved. That is, for a shared word that occurs across all four corpora, we calculate the distance between the way the word is embedded in corpus-specific models. Calculating this distance tells us how different the semantic context in which the word occurs is between corpora. For instance, if the distance between the embeddings for ‘autism’ between ASA groups and autistic self-advocates is smaller than the distance for ASA groups and parents of autistic children, we may conclude that ‘autism’ occurs in more similar semantic contexts in the former pairing than the latter.
The interaction terms from Equations (1) and (2) were computed, indicating the extent to which an organisation had greater semantic similarity with one individual group than the other. As described in the Methods, from our full dataset of all cosine similarity for each shared word, we drew samples of 10,000 words for 1000 attempts, and fitted the samples to Equations (1) and (2). We extracted the
The total number of Tweets, users, words, and unique words in each corpus are summarised in Table 2. In addition, corpus-specific average ratios of words per Tweet and Tweets per user are presented.
Summary statistics of Tweet corpora.
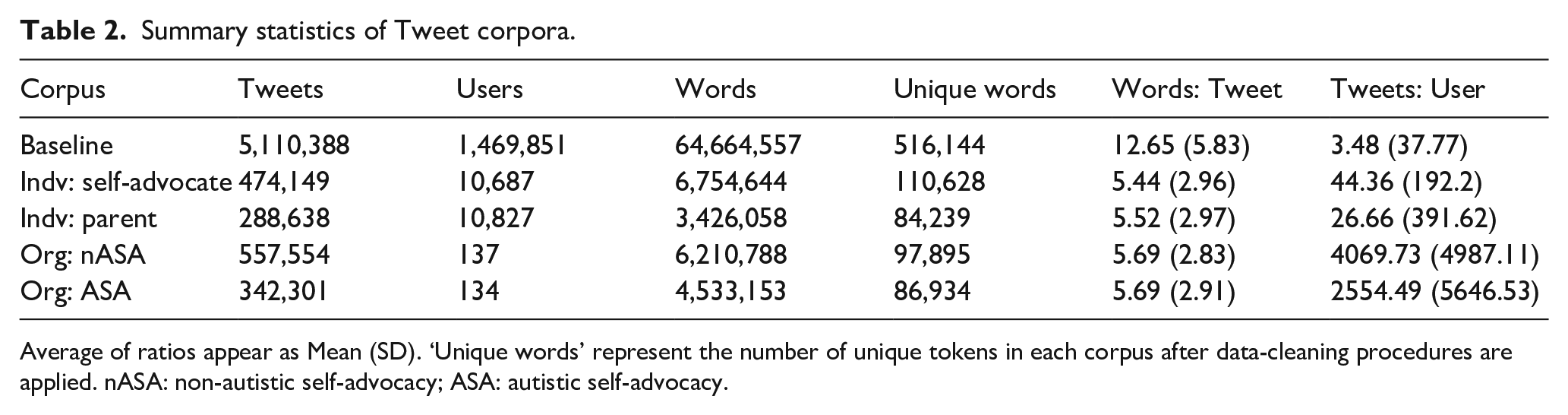
Average of ratios appear as Mean (SD). ‘Unique words’ represent the number of unique tokens in each corpus after data-cleaning procedures are applied. nASA: non-autistic self-advocacy; ASA: autistic self-advocacy.
Specification curve analysis
In Figure 2, interaction coefficients (
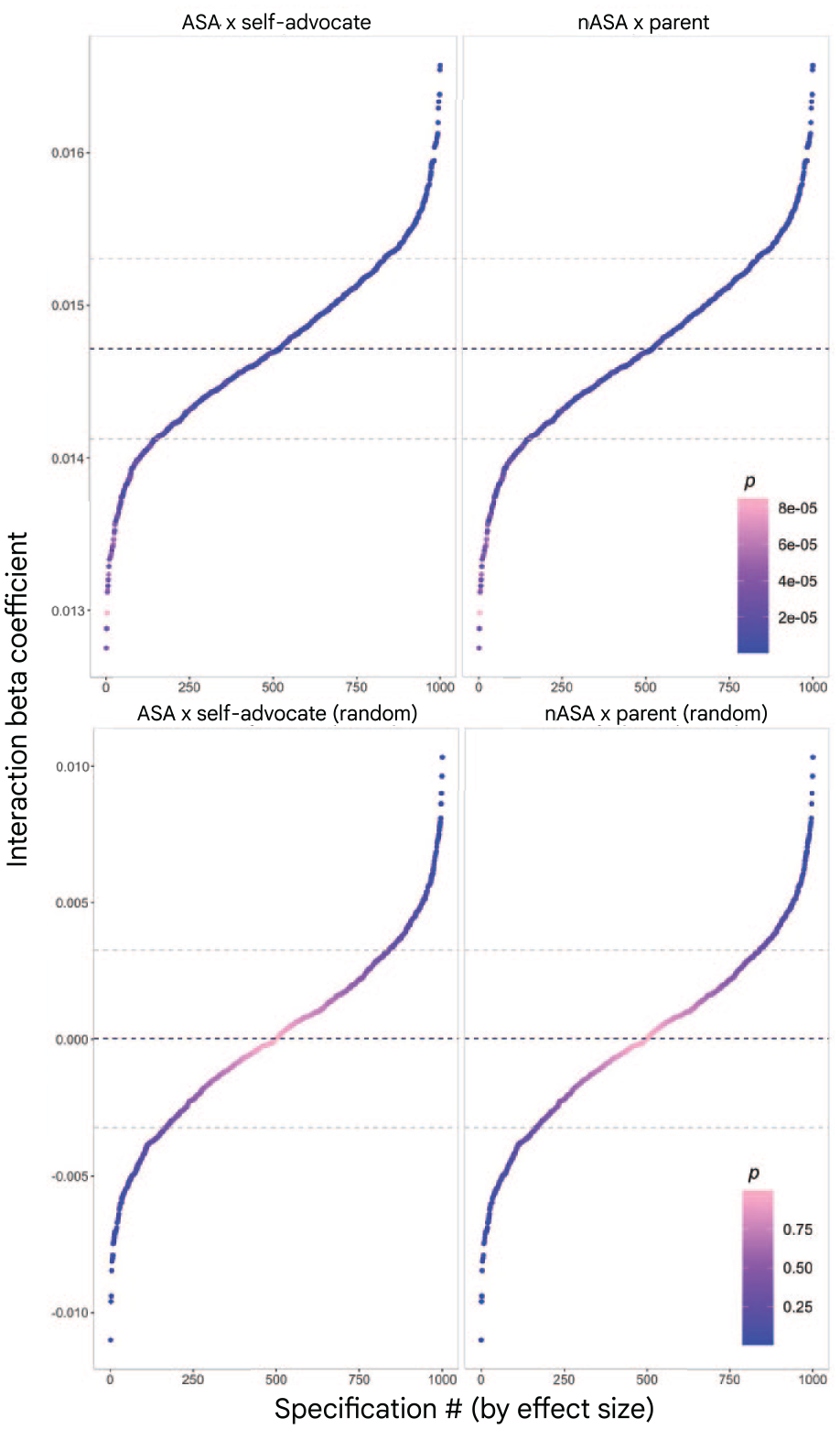
Specification curve of interaction coefficients produced by regressing z-standardised cosine similarity per shared word on binary-coded organisation and individual labels. Below, specification curve of interaction coefficients produced by regressing randomly shuffled, z-standardised cosine similarity per shared word on binary-coded organisation and individual labels is shown. Colour-coded p-values denoted by row. Average of
Interaction terms resulting from the ASA groups × self-advocates binary coding specification (Equation (1)) demonstrate that comparisons of word embeddings between ASA organisations and autistic individuals yielded higher cosine similarity scores than comparisons between ASA groups and parents of autistic children. Simply put, the same words were used in more similar semantic contexts between ASA groups and autistic individuals than ASA groups and parents of autistic children. All
A similar pattern of findings was highlighted by the specification curve for the nASA groups × parent coding specification (Equation (2)), which represented the difference in the cosine similarities between nASA groups and parents of autistic children as compared to nASA groups and autistic self-advocates in the true data. All
Of all
A two-tailed Welch’s t-test indicated a significant difference between the average of the ASA × self-advocate
Discussion
The decades-long conflict between organisations and individuals in autism advocacy has thrust the greater autism acceptance movement into an uncertain future, continuing to impede cooperation within the autism advocacy community and compromising its ability to arrive at mutually beneficial research and policy decisions (Elster & Parsi, 2020; Siegel, 2020; Tabor, 2020). We find that comparing large corpora of Tweets made by organisations and individuals reveals patterns of language similarity consistent with the direction of previous criticisms of organisational partial representation. Adopting the view that word embeddings encode values and attitudes held at the group-level (Caliskan et al., 2017; Garg et al., 2018; Lawson et al., 2022), these findings indicate that ASA groups express more similar views to autistic self-advocates, while nASA groups share values more consistent with those of autistic parents.
Whether or not this study reveals a failure in representation is contingent on many unknown – and, if relying solely on our methods, unknowable – variables. For one, organisations do not always explicitly state the bounds of the representational role in autism advocacy. Without additional insight into organisational decision-making, we cannot conclude if patterns of partial representations are indicative of a failure to meet representational commitments, or a sign of the intentional prioritisation of certain stake-holders over others. We also do not have access to balanced perspectives on the expected level of representation behaviours of autism advocacy groups. If an organisation deliberately and openly prioritises one group over another, is it considered exempt from criticisms of partial representation? On the contrary, if an organisation construes its autism advocacy mission more broadly, is the onus of avoiding partial representation higher than for organisations with more specific inclusion aims? Future studies may build upon the methods introduced in this article by factoring in organisations’ own representational claims (e.g. through mission statements and promotional materials) to highlight the difference between purported and observed representation. They may also incorporate insights on public or group-level attitudes towards expected patterns of organisational representation to add nuance to the implications of our empirical results.
Thus far, contributions to the debate on partial representation were largely based on personal views, requiring many normative assumptions to be made in the process. This work provides a method through which these subjective assertions can be corroborated by real-life data from all groups implicated in the debate. The impact of our methods and findings is twofold: first, we believe the snapshot of autism advocacy on Twitter can help enrich the autism advocacy community’s understanding of representation as it occurs on social media platforms. Second, we hope to provide a reproducible method that allows both organisations and individuals in autism advocacy to monitor the overall state of online organisational representation. For organisations, this method may enable oversight over the alignment of their stated missions with observable instances of representation. This empirically grounded oversight, in turn, may catalyse meaningful reflection and paths of recourse to be taken if inconsistencies between representational goals and outcomes are revealed. Similarly, groups of individuals may benefit from these methods as a means of holding self-appointed representational bodies accountable to their stated representational aims. Before recommending the wide adoption of this method, however, we must consider the limitations imposed by the inherently limited representation offered by sampling from social media. We also discuss difficulties with relying on error-prone machine-learning methods to automatically identify individual stakeholders in the partial representation debate.
Limitations of our sampling strategy
The results offer an insight into discussions of representativeness as expressed through the official Twitter communication of autism-centred organisations and the personal Tweets of users in autism advocacy. As predicted, language in Tweets authored by ASA organisations are more closely associated with language used by autistic individuals than parents of autistic children. Also as predicted, the language used by nASA groups was more similar to language Tweeted by parents of autistic children than to that of autistic self-advocates. Taken at face value, both findings lend weight to claims of partial representation levied against both self-advocacy groups and charities. However, in stating the implications of our findings, we must consider how conducting studies based only on data collected from social media may result in a limited and skewed sample of both autistic individuals and parents of autistic children.
An obvious consideration is the potential exclusion of important subgroups of autistic individuals from the study sample. For those having an issue with ASA groups, one of the most frequently raised points of contention is their purported failure to consider the interests and needs of autistic populations with higher levels of disability (McCoy et al., 2020). Autism – insofar as the term serves as a short-hand for the medical diagnosis of autism spectrum disorder – manifests in a wide range of ‘symptoms, skills, and levels of disability’ (National Institute of Neurological Disorders and Stroke, 2018). Autistic adults may display anywhere from no to severe intellectual impairment (Howlin & Moss, 2012; Lyall et al., 2017), with higher levels of disability resulting in a greater need for external care and support (Sanchack & Thomas, 2016). In their campaigns for increased autonomy, independence and freedom for autistic individuals (Ne’eman, 2011, 2021), ASA groups may have alienated a segment of autism advocates – most notably, parents of children with severe impairments – who hold that self-advocates’ demands are often at odds with legislation, policy and healthcare decisions that would meet the safety and care needs of autistic people with higher levels of disability (Joseph, 2011; Lutz, 2013, 2021). While self-advocates have publicly contested this claim, defending the neurodiversity movement as one that is predicated upon the inclusion of all levels of disability (Des Roches Rosa, 2013; Ne’eman & Bascom, 2020), it remains a highly polarising topic in discussions of organisational representation.
The findings of this study revealed that ASA groups use language in more similar ways to autistic individuals. Given the philosophical underpinnings of self-advocacy, some may argue that self-advocacy organisations justly prioritise autistic over non-autistic interests. Underlying this statement, however, is the assumption that the autistic Twitter users represented in the study, whose Tweets are used to construct the ‘autistic self-advocate’ corpus, accurately reflect the autistic community at large. By virtue of the study design, in which a large volume of Tweets were collected without direct contact between the researcher and Twitter users, it is impossible to determine the extent to which the autistic sample includes autistic individuals with greater levels of disability.
Of adults who are diagnosed with an autism spectrum disorder in childhood, it is estimated that about one-third will experience severe difficulties with communication (Koegel et al., 2020; Rose et al., 2016; Tager-Flusberg & Kasari, 2013), including effective written communication (Dockrell et al., 2012, 2014). Moreover, the lack of accessibility and inclusive design features on social media may feel prohibitive to some autistic people navigating such platforms (Glumbić et al., 2022; Kofmel, 2019). Taken together, these factors highlight several ways in which impairments related to autism may present barriers to engagement with self-advocacy on Twitter, casting doubt on the diversity of the autistic experience that is captured by sampling the Tweets of self-advocates.
Moreover, the views of users who participate in advocacy on social media platforms may deviate substantially from the average view of the wider population from which they are sampled. Previous studies have shown that online activists are likely to display attitudes and behaviours that distinguish them from the average individual. For example, in attempts to characterise voter behaviours by sampling from Twitter, the unusual posting behaviours of ‘hyperactive’ Twitter users was found to obscure the voices of the majority of voters (K-C. Yang et al., 2022). This limitation influences how faithfully our sampling method can be considered to capture the views of both groups of individuals we include in our study: autistic self-advocates and parents of autistic children. Our inclusion criteria mandate that users had both Tweeted about autism and included an autism-relevant self-description in their biography, indicating their likely involvement in online autism advocacy. As such, Tweets sampled from these users may include patterns of language that are not as prevalent outside of online advocacy circles.
Future work can address concerns around the representativeness of sampling methods by using techniques adapted from the minimal intervention literature (Pan, 2006; van der Beek et al., 2021). Minimal participation refers to the process through which participants are contacted for necessary information while safeguarding against high non-response rates by requiring minimal time and resource investment. As it pertains to this study, minimal participation may involve sending Twitter users, whom the predictive model classifies as autistic individuals, a message using Twitter API’s automated messaging function, requesting their voluntary, compensated and secure participation in an abridged version of a suitable autism inventory, such as the Autism Behavior Inventory (Bangerter et al., 2017), or the Adult Executive Functioning Inventory (Holst & Thorell, 2018). Whether or not the sample can be deemed adequately representative can be determined by comparing the results of the survey to data from large samples of autistic adults (Henninger & Taylor, 2013; Howlin & Moss, 2012; Magiati et al., 2014). Similarly, Twitter users identified as autistic self-advocates or parents of autistic children may be asked to report their views, beliefs and behaviours surrounding autism advocacy, which can be compared to previous surveys conducted outside of the online advocacy context to quantify and account for the non-representativeness introduced by the sampling method.
Limitations of imbalanced classification
The second limitation relates to the use of an automatic classification procedure to generate corpora for further language model training. All automatic predictions introduce the risk of incorrect classification. Especially prone to classification error are predictive models trained on imbalanced datasets, in which one class far outnumbers the others, yielding predictions that are biased towards the majority class (Sun et al., 2009). In this study, Twitter users who do not openly identify as autistic or parents of autistic children are over-represented in the training data, resulting in poorer predictive performance for the two populations of interest (more details in Supplementary Materials A.1.2). Such a pattern of classification error may pose a threat to the internal validity of the study. Incorrectly sorting a user that belongs to the minority class into the majority sample, for instance, may taint the common baseline from which all word embeddings across the four corpora are derived, leading to potentially inaccurate or misleading estimates of semantic similarity between organisations and individuals. Fortunately, many courses of action can be taken to boost classification accuracy (Burnaev et al., 2015; Maldonado et al., 2022; Shamsudin et al., 2020), including techniques to produce higher-fidelity predictions by improving the quality of the training data itself.
The present methodology includes several measures to address classification error, such as undersampling the majority class of non-autistic, non-parent users and generating new, synthetic examples of the minority class (Chawla et al., 2002), bolstering the model’s ability to distinguish between the classes (for more details on undersampling and oversampling, see Supplementary Materials A.1.2). The most effective data augmentation technique, however, is simply to retrieve more real-life examples of minority classes. By supplying the predictive model with new training data in which minority classes are more evenly represented, instances of incorrect classification are reduced. An additional benefit of this technique is that the organic variability of user biographies is preserved, which acts as a deterrent against over-fitting in the training stage, allowing the model to produce accurate predictions for biographies external to the training set.
Conclusion
Set against the backdrop of tensions in autism advocacy, this study explored the alignment of language used by autism-centred organisations and the individuals over whom they may have representational duties. By comparing language use in the Twitter expressions of organisations and individuals, the study provided evidence to support criticisms of partial representation that have been faced by both autism self-advocacy groups and autism charities. To our knowledge, this study is the first computational investigation of a conflict that has largely been characterised by qualitative and opinion-based insights. In future applications, the study’s novel methodology and findings may serve as a useful framework to guide organisations and individuals seeking to redress the long-standing conflict in autism advocacy.
Supplemental Material
sj-pdf-1-aut-10.1177_13623613251325934 – Supplemental material for Who Tweets for the autistic community? A natural language processing–driven investigation
Supplemental material, sj-pdf-1-aut-10.1177_13623613251325934 for Who Tweets for the autistic community? A natural language processing–driven investigation by Canfer Akbulut and Geoffrey Bird in Autism
Footnotes
Acknowledgements
We would like to thank Ren Palmer for the substantial help with annotating user biographies, and to all graduate students at the Geoff Bird Lab at the University of Oxford for their help with sourcing autism-relevant keywords. We are also grateful to Brennan Delattre, Graham Reid, Jirko Rubek and Damien van de Berg for their helpful comments on the study design and article.
Author Contributions
C.A. was involved in the conceptualisation, data curation, formal analysis, investigation, methodology, project administration, resources, software, validation, visualisation, writing – original draft, writing – review & editing. G.B. was involved in the conceptualisation, investigation, methodology, supervision, writing – original draft.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Ethics review
Prior to undertaking the research detailed in the article, the authors submitted an ethics review request to an ethics review board at their home institution. The research was determined to be exempt from further ethics review as it involved the analysis of publicly available data with no direct interaction with individuals. The authors adhered to all privacy protections and terms of service stipulated by the Twitter API.
Supplemental material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.