
Abstract
The Language ENvironment Analysis (LENA) system has been used increasingly in research to record and evaluate the everyday speech of autistic children and their families. However, it is unclear how researchers are using LENA and whether the system is well-suited for work with autistic individuals. The purpose of this systematic review is to summarize the use of LENA in autism research, to highlight the strengths and limitations of the system as identified by researchers, and to provide recommendations for future research and clinical use. Forty-two studies that used LENA with samples of autistic children were identified through a systematic database search. Researchers using LENA in autism did so across a variety of ages, settings, and analytical approaches. Most studies used LENA within recommended guidelines. The most common purpose of using LENA was for exploratory research. Noted strengths of the LENA system included ecological validity, cost-effectiveness, and timely clinical feedback. Limitations included lower rates of speaker identification compared to human coders and limited information regarding speech context and language development. This systematic review provides key insights into the methods surrounding LENA use in autism research and serves to inform researchers and clinicians on best practices for future use with this technology.
Lay abstract
In research, language ability has historically been measured using structured tasks in laboratory settings. In recent years, there has been a growing emphasis on the need to instead capture language ability in an individual’s natural setting (i.e. through social interaction or in their home). Considering natural language may be particularly important for the autistic population, as an autistic child’s language ability can be very different depending on the setting. One common tool for capturing natural language is the LENA recording system, which takes audio recordings over long periods of time and provides estimates of children’s and caregivers’ speech. The purpose of this systematic review is to summarize the use of LENA in autism research, to highlight the strengths and limitations of the system as identified by researchers, and to provide recommendations for future research and clinical use. We identified 42 autism studies that used LENA in a variety of ways and settings. Most studies used LENA within the guidelines put forth by its creators, and it was most commonly used to understand speech or speech development for autistic children. LENA is a useful tool for clinicians and caregivers to gain some insights into child speech, but those considering using it should be aware of concerns about its accuracy and limitations about the information it provides. In this review, we supplement the official LENA guidelines with specific suggestions for use with the autistic population.
Despite its removal from the official diagnostic requirements, language continues to be a primary area of challenge for many autistic individuals (Georgiou & Spanoudis, 2021; Tager-Flusberg, 2006; Tager-Flusberg et al., 2009; Wittke et al., 2017) and remains an important area of investigation. Differences in language development are evident at an early age in autistic children, increasing over time relative to neurotypical children (Messinger et al., 2013). Approximately 30% of autistic individuals are minimally speaking (Tager-Flusberg & Kasari, 2013), and concerns about language development are the leading cause for referrals for an autism evaluation (Dillon et al., 2021; Harrop et al., 2021; Matheis et al., 2017; McCormick et al., 2020). Many autistic individuals receive speech-language services for language and communication abilities (American Speech-Language-Hearing Association, n.d.), as these abilities are highly predictive of later social, educational, and vocational success for people on the autism spectrum (e.g. Billstedt et al., 2005; Eaves & Ho, 2008). In addition, language interventions and speech services have been promoted as a high-need area of therapy by autistic adults (Benevides et al., 2020).
Given that language development is so heterogeneous in autism, the ways that language is measured can inform treatment recommendations and how language abilities are characterized in this population. Research on language and social communication in autism has historically been conducted in controlled laboratory settings using structured language assessments or parent-report measures. However, observations of natural, unstructured language have been prioritized by researchers over the last two decades to capture elements of language that may not be present in structured assessment settings (Barokova & Tager-Flusberg, 2020). These short, observational periods of unstructured language production and use typically take place over a 5-to-10-min recorded session of free-play or conversation with a caregiver or researcher (Channell et al., 2018; La Valle et al., 2024). From these samples of language use, researchers and clinicians can derive indices of language such as the rate of speech and conversations, as well as grammatical complexity and grammar and/or speech errors (e.g. Channell et al., 2018; La Valle et al., 2024; Spencer et al., 2023; Winters et al., 2022).
While this extant body of research provides a rich foundation on which the field has characterized language in autism, there has been a growing emphasis on the idea that a child’s communication over a short period in an unfamiliar environment may not be fully representative of their natural language use (Bergelson et al., 2019; Woynaroski et al., 2017). This emphasis has driven researchers to develop innovative ways to capture speech and language in naturalistic, ecologically valid settings. This review focuses on one research tool, the Language ENvironment Analysis (LENA) system, and its use in autism research.
The use of LENA to study language in autism
The push toward the measurement of a child’s natural language environment has resulted in the increased use of daylong recording technology: Non-invasive recording devices that can record audio for considerable lengths of time in everyday environments without the presence of an observer (Cychosz & Cristia, 2021). One such device, LENA, is widely used by researchers and clinicians (Gilkerson et al., 2017). The LENA device allows for up to 16 h of audio recordings, and accompanying software algorithmically categorizes types of vocalizations and other sounds that occur (e.g. child vocalizations, adult vocalizations, nonspeech sounds). The LENA software produces raw counts and summary statistics of each variable of interest (Gilkerson et al., 2017). These automated calculations allow researchers and clinicians to gain information about a child’s language environment without the time and cost of manual transcription and annotation. Although LENA can provide estimates of child speech and the home language environment, it is important to note that it cannot capture more fine-grained linguistic information such as linguistic diversity. In addition, the algorithm normed by the LENA Foundation was trained on a small sample of 94 monolingual, neurotypical, North American children (Gilkerson & Richards, 2020).
Since its development, and despite LENA’s processing algorithms being trained on relatively small sample of neurotypical children, LENA has been advertised as a method of early identification of autism (Gilkerson et al., 2017). Researchers at the LENA Foundation have created the Automatic Autism Screen (AAS), with the goal of objectively distinguishing autistic children from neurotypical children and children with language delay using acoustic information derived from daylong recordings (Richards et al., 2010). However, the AAS was normed on 232 autistic children from ages 16–48 months, which brings into question its ability to predict autism diagnosis earlier than clinicians (Oller et al., 2010). The AAS study reported sensitivity and specificity values for differentiating between neurotypical, autistic, and language-delayed children based on vocal features. When differentiating between autistic and neurotypical the AAS classifier yielded sensitivity and specificity values between .82 and .84, which are values generally considered acceptable for diagnostic purposes; however, the classifier was unable to clearly differentiating between autistic and language-delayed or typical and language-delayed. (Oller et al., 2010). In addition, the AAS has not been independently validated, nor is it currently publicly available, and therefore may have limited utility for researchers and clinicians.
LENA foundation guidelines for use of LENA
Given that LENA is widely used in research, the LENA Foundation has established guidelines to aid in the proper use of the device and accompanying software. First, they recommend that LENA be used with children 2–48 months of age, and within the home environment, as these are the ages and settings on which the device’s algorithm was trained (Gilkerson & Richards, 2020). In addition, they suggest that 16 recording hours, LENA’s maximum recording length, be collected to obtain stable estimates of talk throughout the day. However, it should be noted that a 16-h recording is likely to capture periods when young children are asleep (Paruthi et al., 2016). The LENA Foundation suggests that if fewer than 16 h of data are collected, users should randomly select continuous 10-min intervals to analyze and should sample “varying levels of speech activity” if recording for less than an hour (Gilkerson & Richards, 2020). In addition, recordings should not be “restricted to selections from short recordings made in controlled environments” (Gilkerson & Richards, 2020).
Clarity around use of LENA in autism research
Despite the widespread use of LENA in autism research over the past decade, it is unclear whether researchers are following the guidelines put forth by the LENA Foundation or whether they are using LENA in unique ways. As researchers and clinicians may seek to replicate and/or apply the methods implemented by published studies in the field, it is important to systematically evaluate such methods with respect to the LENA guidelines. In addition, given that LENA’s algorithm was not normed on autistic children, there is still much to be learned about the potential validity and reliability concerns of using LENA in a population where speech and language development is more heterogeneous. Understanding how LENA is being used in autism research is critical, particularly given the need to establish ecologically valid measures of speech production in autism and to capture naturalistic language in a cost-effective manner (e.g. Cychosz & Cristia, 2021; McDaniel, Yoder, Estes, & Rogers, 2020). Researchers and clinicians may be inclined to use LENA within their work due to its unobtrusive properties, automated software, and precedence in the literature for using LENA, however the system may not be the best fit for all intended uses.
Purpose
Existing reviews have examined aspects of language in autism such as parent verbal responsiveness (Edmunds et al., 2019), links to neuroimaging (Butler et al., 2020), and overall intervention efficacy (Sandbank et al., 2020). Past reviews of LENA use in neurotypical children have focused on ethics (Cychosz et al., 2020), validity of automated metrics (Cristia et al., 2020; Wang et al., 2017, 2020) and the overall use of the device in research (Greenwood et al., 2018). However, there is currently no synthesized information, to our knowledge, on how researchers are using LENA specifically to characterize autistic children’s speech input and output.
The purpose of this systematic review, therefore, is to (a) provide researchers and clinicians with a summary of how LENA has been used in autism research, (b) summarize the strengths and limitations of using LENA with this population as identified by researchers, and (c) provide recommendations and considerations for LENA use with the autistic population.
Method
This review was registered online with PROSPERO (registration number: CRD42021255947). We followed the PRIMSA checklist in writing and reporting this systematic review. A trained health sciences librarian STW performed our comprehensive electronic search of publications using the following databases: PubMed, Cumulative Index to Nursing and Allied Health Literature via EBSCO, EMBASE.com, Scopus, PsycINFO via EBSCO, and ERIC via EBSCO. These databases were initially searched in June 2021 and were searched again in March 2023. Our search was not restricted by language.
All database results were collected from January 2008 (after the creation of the LENA device) to March 2023. Search terms were used to retrieve articles addressing the main concepts of the search strategy: LENA/language counts and autism. The search strategy was conducted using a combination of text word searching and the use of subject headings/thesaurus terms, if applicable. The exact search strategy used in each of the electronic databases is reported in Supplemental Information S1. Results were downloaded to EndNote and duplicates removed. All references were uploaded to Covidence Systematic Review software (https://www.covidence.org), a web-based tool designed to facilitate and track each step of the abstraction and review process.
Study selection
Abstracts identified by the search strategy were screened twice and independently by O.C.P. and J.G., who excluded records that did not mention language, autism, or similar broad search criteria. Full texts of the remaining records were independently screened by O.C.P., J.E.M., and J.G., with two people screening each full text. At both stages of the screening process, CH resolved disagreements when needed. All full text articles included in the review were additionally screened using forward and backward citation searching to find any additional relevant articles. Article inclusion criteria included: contain primary data (i.e. not a review article), use the LENA device, and include a group with a diagnosis of autism or a “high likelihood” group. We defined a high likelihood group as any sample that was at an increased likelihood to go on to have an autism diagnosis, such as infant siblings and young children identified to be high likelihood via community screenings (e.g. Messinger et al., 2013; Watson & Crais, 2013). Because our coding scheme was aimed at understanding how LENA has been used in autism research, including whether or not researchers are using LENA within the age groups recommended by the LENA Foundation guidelines, we did not specify a participant age group in our inclusion criteria. To avoid publication bias (Paez, 2017), gray literature (e.g. conference papers, honors, masters, doctoral theses) that were found in our search results were not excluded in our full-text review.
We conducted a separate gray-literature search of proceedings and abstract books of major conferences relevant to language, autism, or both (American Speech and Hearing Association, International Society for Autism Research, Society for Research in Child Development, Symposium for Research in Child Language Disorders) via hand-searching in February 2022 and January 2023 using our key search terms and dating back to 2008 when available. The resulting abstracts were double screened independently by O.C.P. and J.E.M.. All authors of abstracts deemed eligible were contacted for full texts and these abstracts or associated materials were further assessed for eligibility by O.C.P., J.E.M., and J.G. After the screening process, 42 studies met eligibility criteria for inclusion in the current review (31 peer-reviewed journal articles; three doctoral dissertations; eight conference papers, posters, and presentations). See Figure 1 for full screening information.
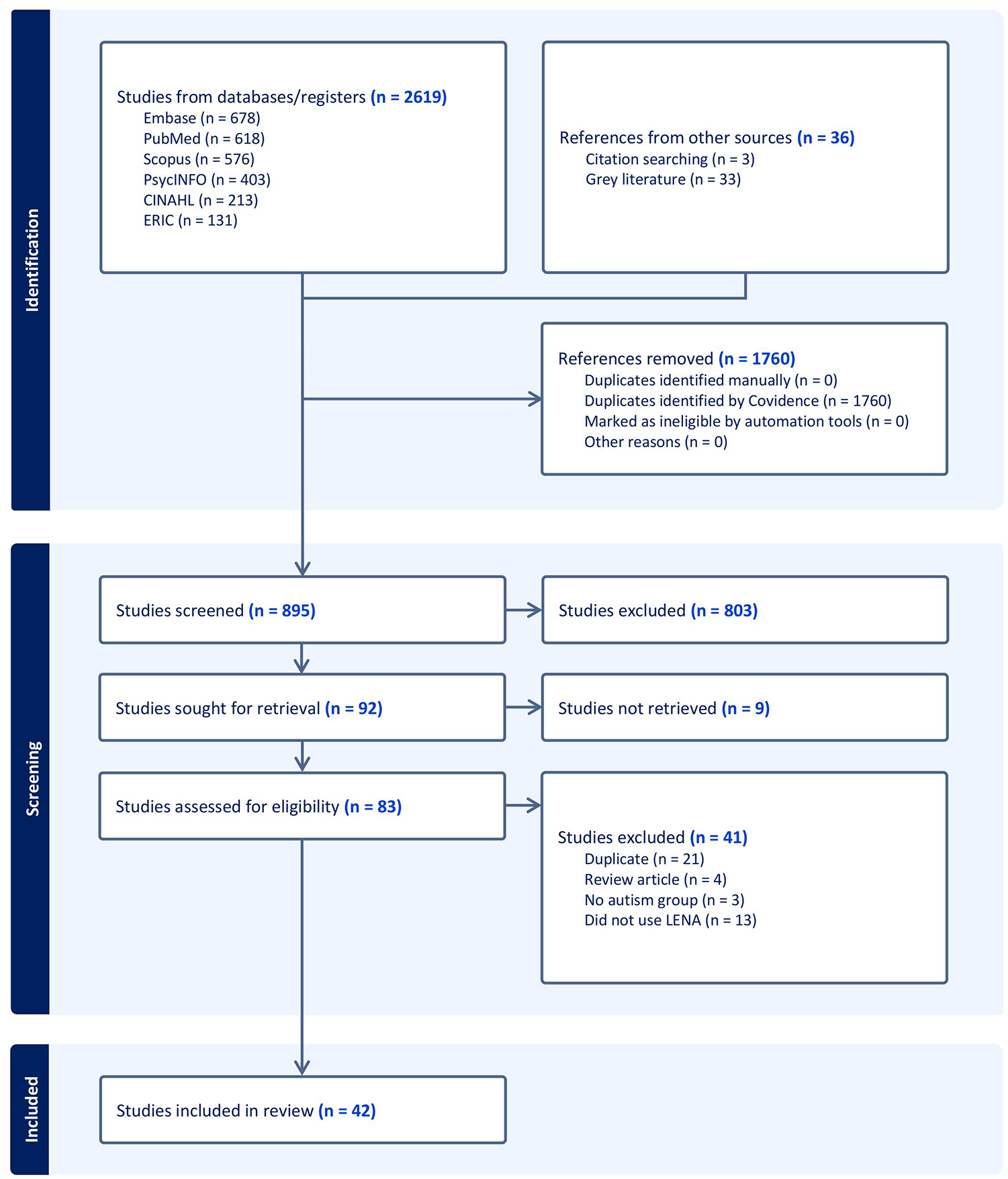
Prisma flow diagram showing study selection.
Coding
A 34-item deductive coding scheme (see Supplementary Information S2 for list of items) was developed by the first two authors, with MRS and CH providing feedback on early versions prior to coding. Data on participant demographics, study purpose, information pertaining to the use of LENA (e.g. variables used from LENA software, average recording length, how the data were used), and identified strengths and limitations of using LENA were extracted from each study. An inductive coding method and semantic approach was used to code and analyze the strengths and limitations noted: Any explicitly-stated strengths, limitations, and recommendations for LENA use were flagged during the initial study coding and agreed upon by the coders, and later grouped into themes that developed as the data were analyzed (Braun & Clarke, 2006; Saldaña, 2016). Authors O.C.P., J.E.M., M.K., and A.N. coded each article independently, with the exception of Markfeld, Feldman, Bordman, et al. (2023), which was independently coded by O.C.P. and J.G. Any disagreement between the two sets of codes were resolved via discrepancy discussions.
Quality assessment
Study quality was assessed for full-text articles (e.g. not conference posters) using the Mixed Methods Appraisal Tool (MMAT; Hong et al., 2018). See full information in Supplemental Information S3.
Community involvement
Autism community members were not involved with this systematic review.
Results
The aim of the current review is to summarize how LENA has been used in autism research and what strengths and limitations of the system have been identified by researchers. The purpose, participant characteristics, location and recording settings, and analytical approach of the forty-two included studies are detailed below, followed by the qualitatively coded strengths and limitations of LENA as described by researchers. See Table 1 for details on each included study.
Study information.
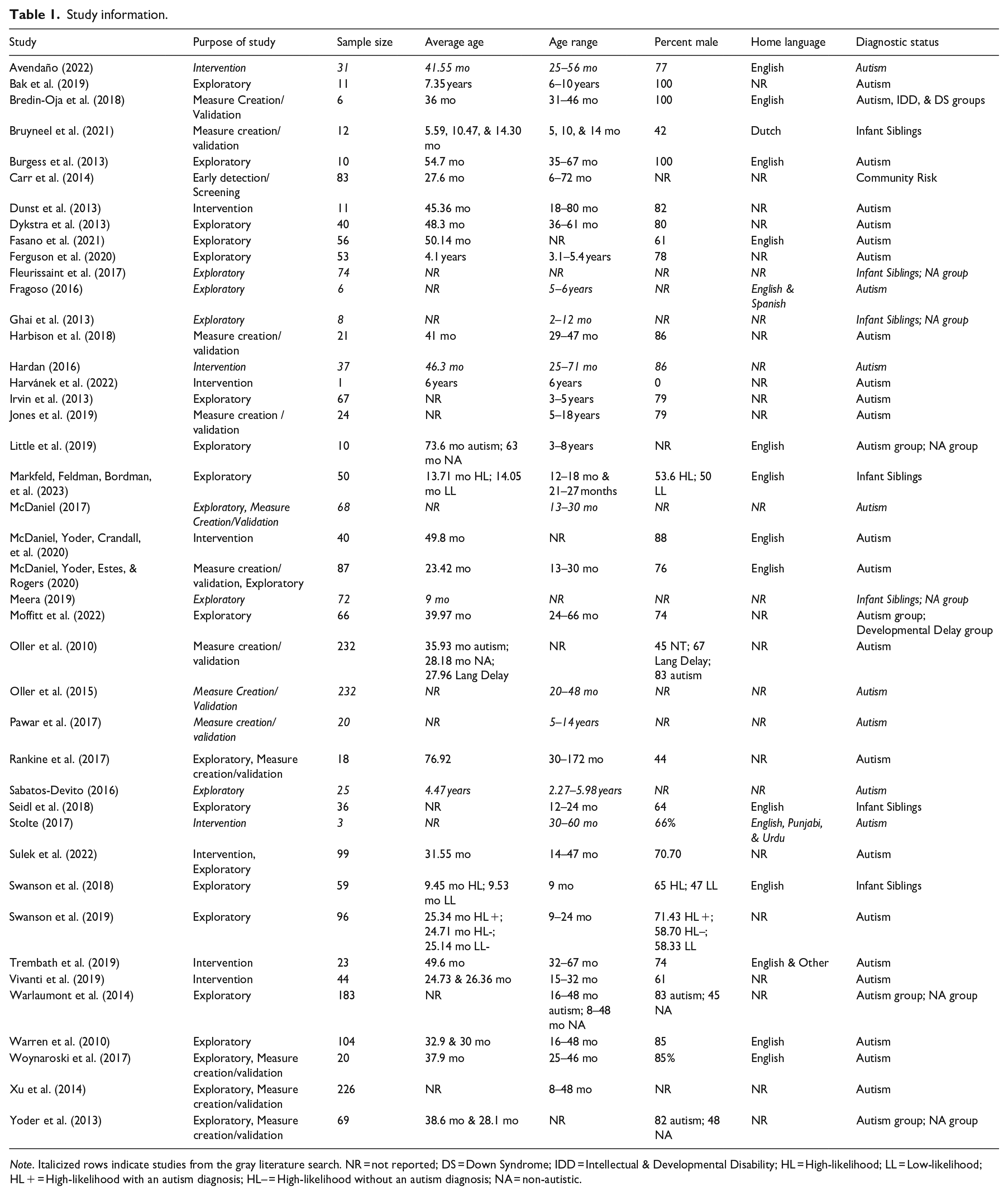
Note. Italicized rows indicate studies from the gray literature search. NR = not reported; DS = Down Syndrome; IDD = Intellectual & Developmental Disability; HL = High-likelihood; LL = Low-likelihood; HL + = High-likelihood with an autism diagnosis; HL– = High-likelihood without an autism diagnosis; NA = non-autistic.
Quality assessment of included studies
Coding via the MMAT (Hong et al., 2018) suggests that full-text studies were overall high quality with some exceptions. Sixteen studies did not report the race and/or sex of participants; therefore, it is not possible to evaluate whether these studies are representative of all autistic individuals (e.g. Steinbrenner et al., 2022). See Supplemental Information S3 for detailed information.
Research purposes
The majority of the studies (k = 26) had exploratory purposes, using LENA to observe and describe speech. Eight of these studies fell under both exploratory and another purpose category. Within exploratory studies, the purpose of LENA use was to understand language development and outcomes in autistic children (Bak et al., 2019; Fleurissaint, 2017; Ghai, 2013; Markfeld, Feldman, Bordman, et al., 2023; McDaniel, Yoder, Estes, & Rogers, 2020; Seidl et al., 2018; Swanson et al., 2019; Woynaroski et al., 2017; Xu et al., 2014) and to better understand the language environment of autistic children (Burgess et al., 2013; Dykstra et al., 2013; Ferguson et al., 2020; Fragoso, 2016; Irvin et al., 2013; Little et al., 2019; Warren et al., 2010). LENA was also used to compare vocalizations of autistic children and children with a high likelihood of autism to non-autistic/low-likelihood control groups (Fasano et al., 2021; Ghai, 2013; Meera, 2019; Seidl et al., 2018; Swanson et al., 2019; Warlaumont et al., 2014; Warren et al., 2010). Finally, LENA was also used to examine the associations between LENA metrics of speech and autistic traits (Dykstra et al., 2013; Ferguson et al., 2020; Irvin et al., 2013; Moffitt et al., 2022; Rankine et al., 2017; Sulek et al., 2022) and clinical measures of language (Dykstra et al., 2013; McDaniel, 2017; Sabatos-DeVito, 2016; Yoder et al., 2013).
Studies using LENA for measure creation and/or validation (k = 13; 6 in combination with exploratory) either tested the efficacy of LENA when used with age ranges or amount of recording time outside the existing guidelines of use (Bredin-Oja et al., 2018; Jones et al., 2019; Yoder et al., 2013), tested the validity of LENA metrics with an autism-specific sample (Bruyneel et al., 2021; McDaniel, Yoder, Estes, & Rogers, 2020; Oller, 2015; Oller et al., 2010; Pawar et al., 2017; Rankine et al., 2017; Sabatos-DeVito, 2016; Woynaroski et al., 2017; Xu et al., 2014), or tested the validity of a new speech metric using LENA equipment (Harbison et al., 2018; McDaniel, 2017; Yoder et al., 2013).
Other studies used LENA to test the efficacy of an intervention (k = 9; 1 in combination with exploratory), or for the early detection/screening (k = 2, 1 in combination with exploratory) of autism in children identified to be at high likelihood of an autism diagnosis.
Characteristics of participants in included studies
The sample sizes across studies ranged from 1 to 232 participants (Msample = 57.92, SDsample = 60.32).
Age of participants
Age ranges of participants ranged from infancy (2 months) to adolescence (Figure 2). Average ages for each study are reported in Table 1. Twenty-one studies included participants that were within the recommended LENA age guidelines (2 to 48 months), and 15 included some, but not all, participants in this range. Of the six studies that did not follow this guideline, one study (Jones et al., 2019) was conducted with the purpose of evaluating LENA outside the recommended age range.
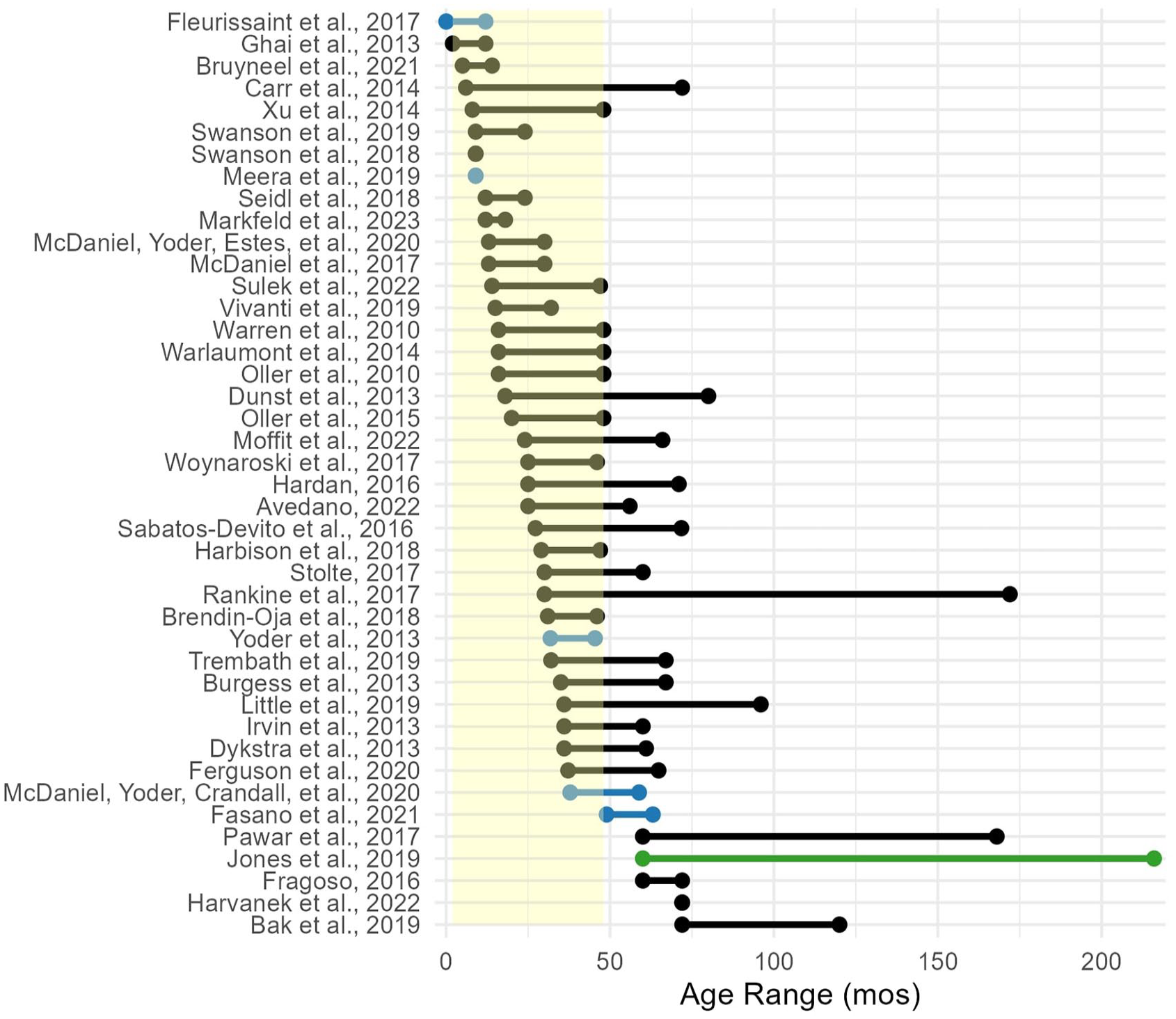
Depiction of age ranges used across studies. The yellow highlighted area of the figure shows the age range that the LENA Foundation recommends for use of the software (i.e. 2–48 months). The study in green (Jones et al., 2019) purposefully used LENA outside of the recommended age range. Blue are studies where age range was estimated, either via mean and standard deviation of child age (i.e. Fasano et al., 2021; McDaniel, Yoder, Crandall, et al, 2020; Meera, 2019; Yoder et al., 2013), or via descriptive text (i.e. Fleurissaint, 2017).
Participant demographics
Of the studies that reported participant sex (k = 31), participants were overwhelmingly male (Msex = 69.4% male, SDsex = 19.67% male). One study (Harvánek et al., 2022) was a case study with one autistic female; the remaining studies reported that 44% to 100% of their samples were male. Of the studies that reported participant race (k = 16), participants were overwhelmingly white, ranging from 11% to 100% across studies (M race = 66.65% white, SD race = 23.1% white). Of the 16 studies that reported the languages spoken in recording environments, 12 reported the home language as English, three reported English and at least one other language (Bruyneel et al., 2021; Fragoso, 2016; Trembath et al., 2019). Bruyneel et al. (2021) featured Dutch speakers, and was the only study conducted with the purpose of validating LENA in another language.
Diagnosis
Most studies using LENA for autism research included participants who had an existing autism diagnosis (k = 31). Of these, participants in four studies were specified to be pre- or minimally verbal (Bak et al., 2019; Bredin-Oja et al., 2018; Harvánek et al., 2022; Jones et al., 2019). Eleven other studies included additional children with other diagnoses (e.g. language delay, Down syndrome), and 10 studies included a non-autistic (often termed “typically developing”) comparison group. Nine studies focused on or included siblings of autistic children. One study (Carr et al., 2014) focused on screening Deaf and hard of hearing children who were being evaluated for autism.
Location and recording settings
Information pertaining to the specific use of LENA is detailed in Table 2.
LENA sampling and analysis.
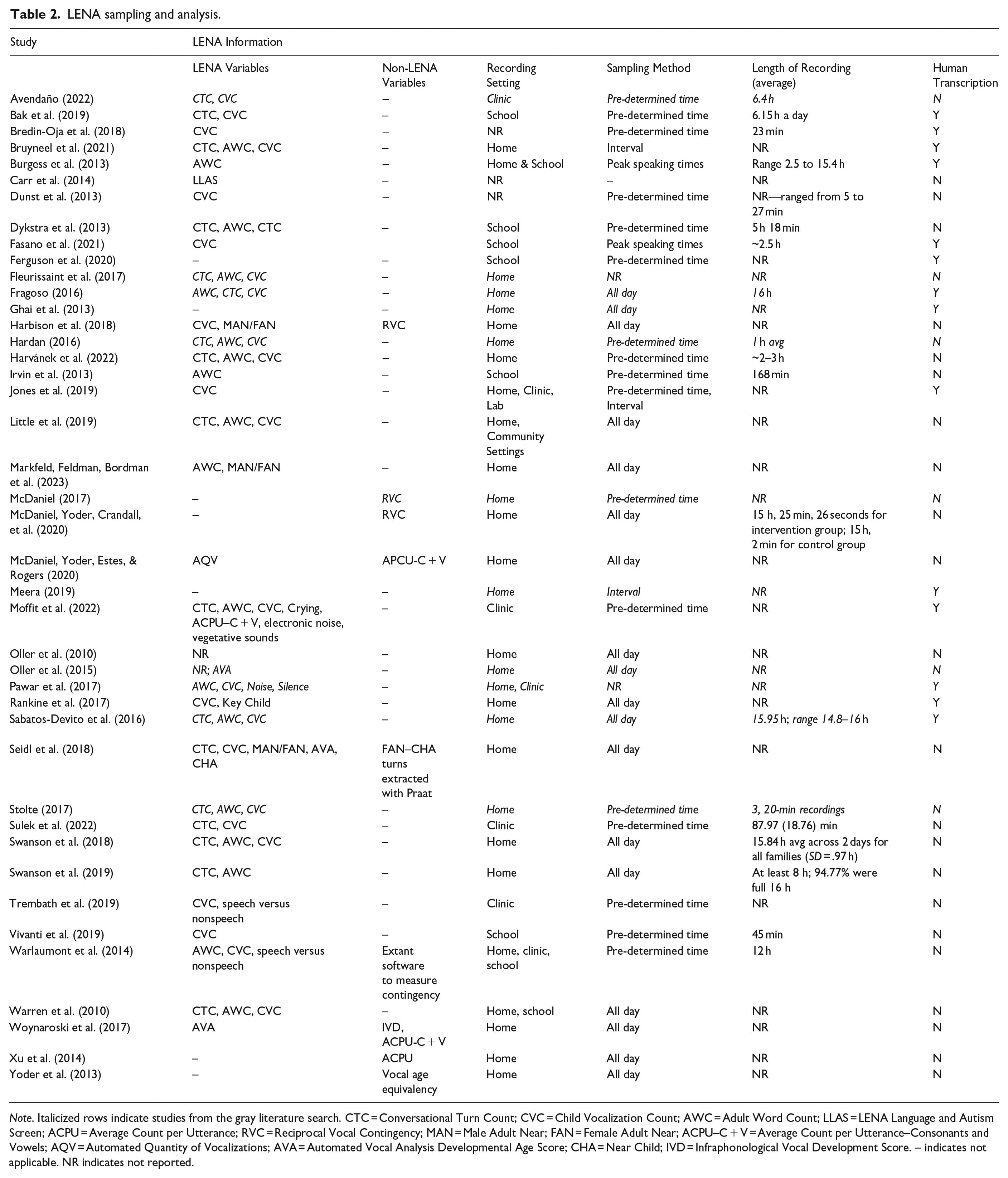
Note. Italicized rows indicate studies from the gray literature search. CTC = Conversational Turn Count; CVC = Child Vocalization Count; AWC = Adult Word Count; LLAS = LENA Language and Autism Screen; ACPU = Average Count per Utterance; RVC = Reciprocal Vocal Contingency; MAN = Male Adult Near; FAN = Female Adult Near; ACPU–C + V = Average Count per Utterance–Consonants and Vowels; AQV = Automated Quantity of Vocalizations; AVA = Automated Vocal Analysis Developmental Age Score; CHA = Near Child; IVD = Infraphonological Vocal Development Score. – indicates not applicable. NR indicates not reported.
Location
Three studies did not report where LENA recordings took place. Among those that did, LENA was used in home (k = 23), school (k = 6), and clinic (k = 4) settings. Six studies reported LENA use across multiple settings. The recording location was central to the aims of seven studies, which examined LENA use in school, intervention, and/or community settings (Burgess et al., 2013; Dykstra et al., 2013; Fasano et al., 2021; Ferguson et al., 2020; Jones et al., 2019; Little et al., 2019).
Length & frequency of recording
Nineteen of the studies used the recommended “all-day” recording length of 16-hours for their analyses: Three of these studies (Harbison et al., 2018; Markfeld, Feldman, Bordman, et al., 2023; Woynaroski et al., 2017) collected two all-day recordings for analysis, and another (Yoder et al., 2013), collected three. Eighteen studies used a structured and/or pre-determined recording time (e.g. the length of a school day or a set number of recording hours). This recording time ranged from 5 min to 12 h. Two studies reported analyzing 5 minute intervals of time rather than the entire recording either for transcription or coding of vocalizations (Bruyneel et al., 2021; Meera, 2019). The remaining 23 studies, representing over half, did not report the average length of their recordings or their sampling procedure (e.g. how they selected units for analysis). No studies discussed the potential influence of varying lengths of waking and sleeping hours in their sample. This may limit findings related to variables that do not inherently control for recording length.
Analysis of LENA data collected in included studies
LENA variables used
Thirty studies utilized the built-in LENA software variables for analysis: Child Vocalization Count (an estimate of the number of times a child produces speech-like vocalizations) was the most widely used (k = 25). Eighteen studies used Adult Word Count (an estimate of the number of words produced by adult males and females in the child’s environment) and Conversational Turn Count (an estimate of the of the number of alterations between the child and adult in the child’s environment that are fewer than five seconds apart). Other variables used included Male/Female Adult Near, which are estimates of the number of adult words produced near the target child, categorized into sexes based on fundamental frequency (Gilkerson & Richards, 2020); Automated Vocal Analysis, which is an estimate of child expressive language based on quantifying speech-like sounds in child vocalizations (Richards et al., 2008); and Nonspeech Sounds, which are instances of burps, cries, and other nonspeech sounds from the target child (Gilkerson & Richards, 2020).
Researchers in nine studies conducted analyses using variables not directly provided by the commercial LENA software (e.g. custom or extant software/algorithms). Common variables derived from extant methods included the Reciprocal Vocal Contingency (RVC) score, which is an index of caregiver-child vocal reciprocity (Harbison et al., 2018); the Average Count Per Utterance (ACPU), which estimates child productions of consonants, vowels, and nonspeech sounds within utterances that are labeled by LENA as being produced by the target child; and the Infraphonological Vocal Development (IVD) variable, which quantifies vocal complexity based on detecting speech-like acoustic parameters in child speech (Xu et al., 2014).
Human transcription and coding
Researchers in fourteen studies manually transcribed and/or coded audio recordings collected using LENA. Two studies utilized human transcription alongside output from the LENA system as part of their analyses. Burgess et al., (2013) transcribed the type of adult words directed at autistic children using audio segments that LENA identified as having the highest Adult Word Count values. Similarly, Fragoso (2016) transcribed adult vocalizations in bilingual households, coding them as English or Spanish to supplement LENA-generated vocalization counts. Three studies reported human transcription and coding as their only analysis, opting not to use LENA-derived indices of speech (Ferguson et al., 2020; Ghai, 2013; Meera, 2019). One such study (Ferguson et al., 2020) provided a rationale for this: Their pilot study revealed that child speech recorded in a school environment was more accurately identified by humans than by LENA, leading the team to use LENA solely for its recording capacity.
Eight studies compared their human transcriptions and codes to LENA output and reported on the findings. The purpose of five of these studies (Bredin-Oja et al., 2018; Bruyneel et al., 2021; Jones et al., 2019; Pawar et al., 2017; Rankine et al., 2017) was to evaluate the accuracy of LENA in identifying and labeling the child language environment, and human transcription/coding was central to their methodology. Researchers in three other studies (Bak et al., 2019; Fasano et al., 2021; Moffitt et al., 2022) manually coded a small portion of their audio segments for quality purposes. Bak et al. (2019) manually coded one-hour samples from their recordings, while Fasano et al. (2021) and Moffitt et al. (2022) coded a selection of LENA-identified vocalizations. Methods for determining agreement between human methods and LENA-derived categorizations varied widely, as did the resulting reports of agreement (agreement between human coded and LENA variables ranged from 23% to 87% across studies and variables coded).
Other measures used alongside LENA
We extracted whether studies used additional measures to capture aspects of language, child behavior, and/or the environment more broadly (e.g. GPS technology). There was a wide range in additional measures used, with 29 different measures used across studies. Thirty studies used standardized (e.g. Mullen Scales of Early Learning) or naturalistic (e.g. communication sample) assessments in tandem with or in comparison to LENA to measure speech and/or language abilities. Eleven of the 42 studies did not use any other measures in addition to LENA. The range of additional measures used across studies was zero to eight, and the average number of additional measures used was 1.95.
Qualitatively coded strengths for LENA use in autism research
Content analysis of explicitly-stated strengths and weaknesses noted in the included studies resulted in the following themes addressing the strengths of LENA use in autism research. These themes are summarized in Table 3.
Strengths and limitations of LENA in included studies.

Note. Italicized rows indicate studies from the gray literature search. LENA = Language ENvironment Analysis System, CVC = Child Vocalization Count. – indicates no strengths and/or limitations reported.
LENA is ecologically valid
A strength highlighted in two studies is that LENA is an objective and ecologically valid measure of speech (Hardan, 2016; Markfeld, Feldman, Bordman, et al., 2023).
LENA provides quick feedback to caregivers and clinicians
Researchers in five studies suggested that with its quick processing and user-friendly output, LENA is a useful tool for giving real-time feedback to give clinicians and caregivers (Irvin et al., 2013; Swanson et al., 2018; Warren et al., 2010; Woynaroski et al., 2017). Automated LENA results may be used in everyday practice to monitor clinical progress and to inform caregiver speech (Bredin-Oja et al., 2018; Swanson et al., 2018; Woynaroski et al., 2017).
LENA is a useful outcome measure in intervention research
LENA was noted as a strong asset to intervention-based research in six studies, with many researchers citing the quantifiable measures of naturalistic speech as a measure of speech and language intervention outcomes (Bredin-Oja et al., 2018; Hardan, 2016; Irvin et al., 2013; McDaniel, Yoder, Crandall, et al., 2020; Sabatos-DeVito, 2016; Warren et al., 2010).
LENA is an informative tool for monitoring speech and autism characteristics
Researchers in four studies suggested that LENA has potential use in informing clinicians of early autism characteristics in child speech (Moffitt et al., 2022; Oller, 2015) and in monitoring speech development in preverbal autistic children (McDaniel, 2017; Woynaroski et al., 2017).
LENA is time- and cost-effective
Researchers in four studies noted that the LENA system is more cost-effective and less time-intensive than manual transcription and coding, providing users with an array of informative measurements without the hours of labor that would be otherwise required to achieve the same results (Fasano et al., 2021; Markfeld, Feldman, Bordman, et al., 2023; McDaniel, Yoder, Estes, & Rogers, 2020; Woynaroski et al., 2017).
LENA is user-friendly
Stolte (2017) noted the accessibility of the software and ease of syncing the data with other software. Not only does the system make measurement of a child’s home language environment easier, but researchers in two studies noted the ease of use for families as well: The recording device is durable with a long battery life, allowing for use throughout daily activities in multiple settings (Ferguson et al., 2020; Stolte, 2017).
Coded limitations and recommendations for LENA use in autism research
Thematic analysis of the included studies resulted in the following themes addressing the limitations of LENA use as explicitly stated by included study authors, as well as recommendations made by those authors to address such limitations:
LENA commonly misclassifies speakers
Among the most commonly expressed limitation of the LENA system was the frequent misclassification of child and adult speakers, resulting in validity concerns for eight studies (Bak et al., 2019; Fasano et al., 2021; Ferguson et al., 2020; McDaniel, Yoder, Crandall, et al., 2020; Moffitt et al., 2022; Pawar et al., 2017; Rankine et al., 2017; Swanson et al., 2018). This concern was cited in toddler-based studies as well as in studies with participants outside the recommended age range of LENA use. Such concerns led to calls for future work to examine the validity of these automated measures (Bak et al., 2019; Bredin-Oja et al., 2018; Swanson et al., 2018; Woynaroski et al., 2017). Researchers recommended using the LENA software either within the recommended age range or alongside human annotation to avoid misclassification errors (Ferguson et al., 2020; Jones et al., 2019; Oller et al., 2010; Pawar et al., 2017; Sulek et al., 2022). Others suggested using data from longer recordings or from multi-day recordings to increase the stability of the estimates (Bak et al., 2019; Harbison et al., 2018; McDaniel, Yoder, Crandall, et al., 2020; Sulek et al., 2022; Trembath et al., 2019; Woynaroski et al., 2017).
LENA does not capture the nature or complexity of child speech
Two main concerns regarding the complexity of child speech arose from nine studies. First, while the system provides users with a quantified metric of speech, LENA does not capture the intentionality of child vocalizations (Avendaño, 2022; Bredin-Oja et al., 2018; Dykstra et al., 2013), or the type and quality of the adult vocalizations directed toward children (Fragoso, 2016; Irvin et al., 2013; Little et al., 2019). Researchers using the software are restricted to viewing frequency data alone without any context (Stolte, 2017). Second, other researchers identified the software’s dichotomous coding (present or not) of child vocalizations as a limitation, as it does not allow for insights into fine-grained language abilities (Markfeld, Feldman, Bordman, et al., 2023; Warren et al., 2010). To address this limitation, researchers suggested the use of LENA in tandem with human transcriptions as well as formal language measures (Bak et al., 2019; Carr et al., 2014; Hardan, 2016; Irvin et al., 2013; Rankine et al., 2017; Trembath et al., 2019).
LENA data does not consider echolalia
The lack of information surrounding the content or complexity of speech from children/adults led researchers in seven studies to warn against the use of LENA variables when working with children with high levels of echolalia in their speech (Dykstra et al., 2013; Little et al., 2019; Rankine et al., 2017; Trembath et al., 2019). Indeed, the use of echolalia or scripting by children was thought to artificially inflate reported CVC numbers (Dykstra et al., 2013; Trembath et al., 2019). In addition, multiple researchers recommended not using LENA variables with minimally verbal autistic children (Bak et al., 2019; Bredin-Oja et al., 2018; Jones et al., 2019; Rankine et al., 2017).
LENA does not capture the holistic language environment
A limitation of LENA, as highlighted by five studies, is that it cannot capture overlapping speech or conversational turns between children (Bruyneel et al., 2021; Ferguson et al., 2020; Irvin et al., 2013). Researchers urged the consideration of the recording setting in analysis, particularly when using LENA in school settings or other environments with multiple children/adults (Bruyneel et al., 2021; Dykstra et al., 2013; Ferguson et al., 2020). Other important aspects of communication in recording environments are not captured by LENA, such as nonverbal communication or the visual, spatial, and sensory environments (Dykstra et al., 2013; Irvin et al., 2013; Warren et al., 2010). This limitation was overcome by the studies that synced LENA data with other devices that recorded the child’s location or the child’s visual environment (Fasano et al., 2021; Little et al., 2019).
LENA does not distinguish between adults and picks up speech not directed toward the target child
Concerns surrounding the interpretability of the Adult Word Count variable were also expressed in eight studies, as LENA software has no way of distinguishing between adults in the home. In environments with multiple children or multiple adults, the LENA system classifies all nearby adult vocalizations when computing Adult Word Count, leaving an unclear idea of which of those vocalizations were directed toward the target child (Bak et al., 2019; Dykstra et al., 2013; Harbison et al., 2018; Irvin et al., 2013; Little et al., 2019; Markfeld, Feldman, Bordman, et al., 2023; Swanson et al., 2018). Moreover, for intervention studies involving caregiver training, it is unclear whether adult speech captured by LENA came from the caregiver undergoing the training, or another adult (McDaniel, Yoder, Crandall, et al., 2020).
Discussion
The purpose of this systematic review was to determine how LENA is being used in autism research. By conducting an in-depth examination into the strategies reported by researchers, we summarized the methods employed with LENA in this field as well as the highlighted strengths and limitations.
How is LENA being used in autism research?
Most autism research employed LENA for exploratory purposes, using LENA recordings and resulting metrics to measure language input and development and to examine autism-specific relationships to LENA metrics. Multiple researchers called for research around additional norming and validation of LENA (Bak et al., 2019; Dykstra et al., 2013; Fragoso, 2016; Markfeld, Feldman, Bordman, et al., 2023; Swanson et al., 2018), which was the second most popular purpose of autism research using LENA. While relatively few studies used LENA in intervention settings, those that did identified the LENA system as a strong asset to their intervention protocols. Despite the promotion of LENA use in the early detection and screening for autism (e.g. Richards et al., 2010), only two of the included studies (Carr et al., 2014; Oller et al., 2010) used LENA for this purpose. While the lack of supporting evidence does not mean that LENA metrics are not useful for discriminating between autistic and non-autistic children, it does suggest that fewer studies have focused on examining LENA’s potential for early detection than expected. This may reflect a hesitancy toward using autism screeners by clinicians (Watson & Crais, 2013) as well as a shift in research priorities in recent years away from identifying causes for autism and toward services and supports for diagnosed individuals (Fletcher-Watson et al., 2017; Gotham et al., 2015; Pellicano et al., 2014).
The majority of included studies had participant samples comprised of autistic children; the remaining studies largely focused on high-likelihood siblings. Very few comparisons between the speech of autistic and non-autistic children were made. Instead, many researchers used LENA to compare the language environments of one child across multiple settings, timepoints, or forms of measurement. These study aims are largely in line with the goal within autism research to have a more ecologically valid understanding of speech and language for autistic children (Bergelson et al., 2019; Woynaroski et al., 2017) and also suggest that autism researchers may be using LENA in similar ways that research with non-autistic children is conducted (Cychosz & Cristia, 2021). More support for this consistency comes from the similar use of LENA variables across studies of autism and neurotypical language development (i.e. CVC, AWC, CTC; Cristia et al., 2020).
Most studies using LENA for autism research did so with samples entirely or partially within the age window LENA variables were normed on (2–48 months). Although a stable autism diagnosis can be obtained as early as 18 months (Hyman et al., 2020; Zwaigenbaum et al., 2016), the average age of diagnosis remains at around four years old or older (Shattuck et al., 2009; Zuckerman et al., 2017), placing the average autistic child at the time of diagnosis outside the recommended age window for analysis using LENA metrics. Future research should aim to extend the benefits of daylong recordings to older children, enabling researchers and clinicians to capture ecologically valid indices of speech without the resources required for human coding.
LENA recordings were most commonly collected in the homes of participating families. This is unsurprising given LENA guidelines to collect data in the home for validity purposes, but, as emphasized by multiple authors of the included studies (Burgess et al., 2013; Dykstra et al., 2013; Ferguson et al., 2020; Little et al., 2019), understanding speech and language of autistic children in school and community settings is critical. For this reason, we join these authors in calling for the continued development of naturalistic and efficient measures of speech and language in multiple settings where the automated LENA software is more prone to speaker misclassification and overidentification of child/adult vocalizations. Much of this work is complicated by the ethical barriers to collecting audio recordings in community settings. A recent article suggests that in addition to following regional third-party consent laws, researchers may provide participants with information cards or short verbal explanations to give to those who may be in range of the recording device, such as visitors to a home, nearby families in public spaces, or classroom staff (Cychosz et al., 2020).
Considerations and recommendations for researchers and clinicians
Compatibility with target child and setting
When deciding whether to use LENA, researchers and clinicians should first consider that compatibility may vary depending on child characteristics. LENA may not be the best fit for all children, and a given child’s age (e.g. is LENA is valid in this age range?), sensory profile (e.g. will the child be comfortable wearing a LENA device for lengthy recording periods?), and frequency of echolalia and/or repetitive speech (e.g. would vocalization counts be higher than expected?) should be considered before use. The anticipated recording environment should also be considered: Automated indices of speech from recordings in settings with multiple adults or children may be less accurate.
As noted in the stated limitations of LENA in the included studies, it is important to consider the large limitation that LENA doesn’t capture the intentionality or content of speech. Specifically, when considering this limitation within the context of speech and language profiles in autism, large amounts of echolalia and/or repetitive speech could inflate CVC. As such, we do not recommend using LENA’s automated child vocalization counts as a primary measure of speech production for autistic children who are reported to produce frequent repetitive speech. To overcome some of these limitations, users may want to integrate data checks such as human transcription or annotation into their methods, especially in samples where there are great individual differences in speech production due to autism features such as echolalia. In addition, users should consider pairing the LENA recording device with alternative processing methods. This is particularly important when studying the language environment of autistic children who are outside the recommended age range of 2–48 months, but may reduce the possibility for speaker misclassification, which was reported in studies with participants both within and outside this window. There are multiple extant automated processing pipelines commonly used in the field, including software from the ChildProject (Cristia et al., 2023; Gautheron et al., 2023), the Automatic LInguistic Unit Count Estimator (ALICE; Räsänen et al., 2021), and a recent algorithm developed by Bang et al. (2022) to classify target child-directed speech and times when the target child is awake versus sleeping. These open-source extant processing methods may overcome age-related limitations of LENA software.
Capturing language
A key limitation noted by multiple studies is that LENA cannot provide all information needed to capture language ability in autistic children. To enrich the information provided by the LENA vocalization counts, we recommend using an additional measure of language or development (Adams, 2002; Tager-Flusberg et al., 2009) such as the MacArthur-Bates Communicative Developmental Inventories (Fenson et al., 2007) or the Preschool Language Scales, 5th Edition (Zimmerman et al., 2011). Using multiple measurements of language may better capture the heterogeneity of language in autism.
Reliability and validity
Not all LENA indices have been validated within the autistic population and some may vary in stability. Although some LENA variables have been validated against human transcription in non-autistic populations (Cristia et al., 2020; Ganek & Eriks-Brophy, 2018; Levin-Asher et al., 2023), the evidence on the validity of LENA variables in autistic and high likelihood children is sparse. One factor that may limit the validity of LENA indices is the stability of these variables. Results from four empirical studies may guide autism researchers on how many daylong recordings are needed to obtain stable estimates of LENA variables, specifically with infant siblings and autistic preschoolers (i.e. Harbison et al., 2018; Markfeld, Feldman, Bordman, et al., 2023; Woynaroski et al., 2017; Yoder et al., 2013). These papers found that multiple daylong recordings are needed to obtain stable estimates of LENA variables, and that the number of recording days recommended varies according to the variable of interest. If researchers are interested in utilizing LENA in other age ranges on the spectrum or in other clinical phenotypes (e.g. school-aged children, adolescents with limited spoken language), we recommend that they first evaluate the stability of these LENA indices in their sample by conducting a Generalizability and Decision study (Cronbach’s et al., 1963). Future data on the stability of LENA variables will allow the field to set more consistent standards regarding how many recording days should be collected.
It should also be noted that stability alone is not sufficient to assume validity of the variables of interest (Yoder et al., 2018). Therefore, stable estimates of variables should not be considered sufficient evidence that these metrics are valid, particularly when other factors (e.g. sleep/wake time, LENA software errors in speaker classification) may be inconsistent and could influence measurement error unevenly across participants. For example, rates of LENA indices (e.g. AWC, CVC) could be underestimated if infant sleeping hours are not removed from recordings prior to the calculation of average counts. Current approaches to account for sleep/wake time include trimming all recordings so they begin after the child wakes and end before the child is sleeping (e.g. Warlaumont et al., 2014), or to individually trim recordings based on when a child wakes up and goes to sleep so that rates are not impacted by sleeping times (e.g. Swanson et al., 2019). Further research will be needed to consider these types of measurement error (see Bang et al., 2022 for potential methodological advances).
Reporting standards for LENA research
As research using daylong, naturalistic recordings in clinically relevant populations progresses, users can take several steps to ensure that their work can move the field forward. When publishing work in this area, we encourage researchers to share specific information regarding the sex, race, home language, and age (average and range) of participants in their study. Age is a critical factor in evaluating the decision to use LENA-measured indices of speech for analysis and can inform the decisions of others aiming to conduct a similar analysis. In addition, fewer than half of the studies included in this review reported the race of their participants, a factor that can provide important cultural context regarding the reproducibility of this work and the possibility that these findings could generalize to all individuals on the autism spectrum (e.g. Millager et al., 2024). A crucial first step to increasing diversity and representation in autism research is to report participant race, and to consider how sociocultural factors may impact findings (Steinbrenner et al., 2022). Further, we encourage researchers to report details regarding their recording and analysis of LENA variables. Although the LENA guidelines encourage recording in the home and for a 16 hour period, these conditions cannot be assumed if not reported. Data transformation practices (e.g. converting raw values to averages, trimming recordings) contributes to the validity of the data, and these practices should be shared to allow for comparison across studies as well as to allow future LENA users to select the most appropriate method of data management.
Strengths and limitations of this review
A significant strength of this systematic review is the inclusion of gray literature and articles published in languages other than English, thus widening the available information regarding use of the LENA system in autism research to date (Konno et al., 2020; Paez, 2017). To our knowledge, this is the most exhaustive list of published studies using LENA; however, there may have been studies not detected using our search terms. In addition, due to the inconsistency of study design, data collection, and reporting across the included studies, we were unable to meta-analyze results of interest such as language growth or outcomes. One potential solution and future direction is for authors to share anonymized .its files to enable further integration of findings across studies. Finally, our qualitative coding of the strengths and limitations of LENA as stated by researchers in the included studies was limited to those that were explicitly provided in the study texts. The LENA technology itself was not mentioned in the discussion of the majority of the included studies, as it is not required in standard manuscript guidelines. As such, it is unclear whether authors that did not explicitly describe a given strength or limitation of LENA would also share these views expressed herein.
Future directions
As stated above, additional work is needed to assess the stability of LENA indices in autism. In addition, researchers should continue to examine how LENA indices are associated with language abilities. Conclusions about these relations have varied widely in existing work both within and outside of autism research (Cychosz & Cristia, 2021), and may be particularly complex for autism. Future research should continue to develop ways to measure language use in older autistic individuals. Finally, when publishing data using LENA, authors should provide detailed information about their methods to increase generalizability and transparency.
Conclusion
This systematic review is, to our knowledge, the first to synthesize methods for using the LENA system in the field of autism research. We found that autism researchers have used LENA for a variety of purposes, but largely to characterize the speech environment of autistic children or children with higher likelihood of autism. For the most part, studies used LENA within the recommended age and recording length/location guidelines. Described strengths of the LENA system included its ecological validity, cost/time-effectiveness, and user accessibility. Described limitations included high rates of speaker misclassification and lack of information surrounding language context/content. This review provides a useful starting point for researchers and clinicians who are using LENA with autistic children, as well as considerations for future directions for those who use LENA in research.
Supplemental Material
sj-docx-1-aut-10.1177_13623613241290072 – Supplemental material for The use of Language ENvironment Analysis in autism research: A systematic review
Supplemental material, sj-docx-1-aut-10.1177_13623613241290072 for The use of Language ENvironment Analysis in autism research: A systematic review by Orla C Putnam, Jennifer E Markfeld, Sarah Towner Wright, Jacob I Feldman, Jessica Goldblum, Maia Karpinsky, Amanda J Neal, Meghan R Swanson and Clare Harrop in Autism
Footnotes
Acknowledgements
The authors thank Tiffany Woynaroski and members of the Daylong Audio Recordings of Children’s Linguistic Environments (DARCLE) group for providing feedback on versions of this manuscript.
Author contributions
O.C.P. and C.H. initiated the idea for this review with consultation from S.T.W. O.C.P. and J.G. completed the PROSPERO registration with supervision from C.H. S.T.W. completed the search strategy and provided the screening infrastructure via Covidence. O.C.P., J.G., and C.H. completed the abstract screening, and O.C.P., J.E.M., and C.H. completed the full-text screening. O.C.P., J.E.M., and M.S. conceptualized the coding scheme. O.C.P., J.E.M., M.K., A.J.N., and J.G. completed the article coding and quality assessment. O.C.P. and J.E.M. drafted the manuscript with edits and contributions from all other authors. All authors read and approved the final manuscript.
Declaration of conflicting interests
The author(s) declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: J.E.M., J.I.F., and M.S. have published work using LENA in autistic populations that were included in this review. They were not involved in the coding or synthesis of results pertaining to their own papers. The remaining authors have no conflicts of interests to disclose.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by training grants from the US Department of Education (H325D180099; O.C.P.) and the National Center for Advancing Translational Sciences (TL1 TR002244; J.I.F.), by a National Institute on Deafness and Other Communication Disorders grant (R01DC020186; J.E.M.), and from a predoctoral fellowship from the Autism Science Foundation (23-003; O.C.P.). Prior to submission for publication, a version of this research was presented as an oral presentation by O.C.P. and J.E.M. at the annual meeting for the American Speech and Hearing Association (ASHA) in 2022.
ORCID iDs
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.