
Abstract
This article introduces the novel mixed language input paradigm (MiLIP), which utilizes language mixing as a pedagogical tool for language learning, and describes the methodology to conduct a longitudinal study using this paradigm. We illustrate the paradigm using the example of intrasententially mixed Greek (target language) with English (familiar language), combined with multimodal input (audio, images, videos, subtitles) over three learning phases. Participants are presented with increasingly complex Greek input as the phases progress: nouns in Phase 1, noun phrases (NPs) in Phase 2, and NPs + verbs in Phase 3. Learning in the proposed paradigm is evaluated through picture selection and grammaticality forced-choice tasks at different stages, and an expressive vocabulary task at the end point of learning. This allows for an assessment of whether learners can arrive at some knowledge of words and grammar in the target language through a scaffolding model of ordered input. Researchers and educators can apply this methodology to investigate language learning utilizing individuals’ existing language knowledge.
Keywords
I Introduction
Learning a second language (L2) or additional language is a common learning experience for the majority of the world’s population. Research on instructed language learning has primarily focused on the type and presentation of the input the learner receives and opportunities for interaction in the new language (Gass, 1997; Krashen, 1985; VanPatten & Williams, 2014). The grounding premise of these studies suggests that input in the developing language must be presented in a unilingual mode, i.e., the modality wherein one language is presented at a time. However, this largely neglects the fact that individuals, particularly from highly linguistically diverse societies often situated in the Global South, not only communicate by naturally mixing the languages they know, but may potentially also learn new languages through such mixed input (Tsimpli et al., 2020).
It has not empirically been established whether learning through such mixed language input can indeed occur or if it is potentially more effective than learning through unilingual input. To address this gap in knowledge, we are running a larger project which aims to experimentally investigate whether mixed language input can be successfully used as a pedagogical tool for language learning. In this article, we provide a description of our novel Mixed Language Input Paradigm (MiLIP) developed for the larger project, which can be used to evaluate short- and long-term effects of learning a new language from carefully structured, mixed language input in adult learners. MiLIP serves not only as a method for vocabulary learning, but, through structured intrasentential mixing, it provides a means of scaffolding such that morphological and syntactic acquisition of a language can develop.
We provide a detailed explanation of the steps taken in stimuli and assessment development, and in doing so, this paper can inform future experimental research wishing to utilize mixed language input as a methodological and/or pedagogical approach.
1 Mixed Language Use
The fluid transition from one language to another has propelled a large body of research in the field of code-switching (CS): the practice of switching between two or more languages, and translanguaging: the pedagogical language practices of bilingual learners and teachers. From the CS literature, languages shared between interlocutors can be mixed within the same sentence/clause (intrasentential CS) or across sentences/clauses (intersentential CS) (Deuchar et al., 2007; Muysken, 2000), with mixing patterns often being structurally and/or pragmatically motivated (Auer, 2013; Stell & Yakpo, 2015). Individual words or whole phrases can be switched with large variation in frequency and pattern (Deuchar, 2020). Insertion, alternation, and congruent lexicalization are types of CS which instantiate overt language mixing, whereby elements from each language are identifiable in the respective utterances (Muysken, 2000). 1
A common analysis of insertions, alternations, and congruent lexicalizations is with reference to Myers-Scotton’s (1993) matrix language frame (MLF), which proposes a distinction between a matrix and an embedded language within each code-switched unit. Put simply, the MLF proposes that the finite verb/auxiliary in a code-switched sentence determines the matrix language. The priority of finite verbal elements is based on inflectional morphological features (tense, agreement) responsible for morphosyntactic agreement between the subject and the verb as well as for the case feature of the subject. Although debate is ongoing about the linguistic restrictions that code-switched sentences abide by and the theories that are best suited to dictate these restrictions (Deuchar et al., 2007; MacSwan, 2014; Poplack, 1980, 2008), several studies show findings compatible with the MLF (Kniaź & Zawrotna, 2021; Parafita Couto & Gullberg, 2019; Vaughan-Evans et al., 2020). MiLIP uses the MLF’s distinction between the matrix and embedded language by introducing a gradual shift in the status of the new language from embedded to matrix and the concurrent demotion of the familiar language from matrix to embedded as learning progresses.
It is worth noting that CS has been considered by some scholars as part of the broader notion of translanguaging (or vice versa). The definition, theoretical underpinnings, and application of “translanguaging” has evolved over time (Balam, 2021; Poza, 2017; Wei, 2018), with its original application in educational contexts (C. Williams, 1994, 2000) and later as a practice of social justice (e.g., García, 2009; García & Lin, 2016). While a lively debate has ensued, there is no consensus about the definition and boundaries of translanguaging, with researchers often having divergent opinions about its scope and application (for a discussion, see Balam, 2021; Treffers-Daller, 2025). For the purpose of this paper and the broad application of MiLIP, we employ pedagogical translanguaging as originally proposed by C. Williams (1994, 2000) and extended by Cenoz and Gorter (2022). Translanguaging is thus viewed as a pedagogical approach which utilizes a learner’s full linguistic repertoire in pursuit of their language improvement and content competence in educational contexts. Here, the characterization of multilingual communication advocates the use of more than one language for better understanding of academic content and learning outcomes more broadly (Cummins, 2017, 2021). Furthermore, translanguaging also defends teacher’s and learner’s production of mixed sentences, not only for learning, but for the sociolinguistic and cultural identity of languages and individuals (Makalela, 2016; Wei, 2011). Unlike translanguaging or CS frameworks that provide descriptive and/or interpretive accounts of naturalistic language use, MiLIP is expressly designed to test structured learning through intrasententially presented mixed input.
2 (Mixed) Language use in additional language teaching and learning
Prescriptive teaching models relying heavily on unilingual instruction practices often fail to mirror the pedagogical realities of multilingual settings. The standard approach to child and adult L2 learning usually endorses a one-language pedagogy (Howatt, 1984; Howatt & Smith, 2014) that (1) relies on the L2 as the exclusive language used without (or limited) recourse to the first language (L1), (2) discourages translation, and (3) enforces a rigid separation between the L2 and L1 (see Cummins, 2007). While there has been a debate disputing the effectiveness of an axiomatic unilingual principle as the sole means to successful language learning (Auerbach, 1993; Cook, 2001; Rolstad et al., 2005; Turnbull, 2001), there is limited scientific investigation of the process and outcomes of L2 learning in contexts where input is not exclusively in the L2. Even in cases of promotion of bilingual education through two-way immersion programs and programs for minority languages (Alanís, 2000; Cummins, 2019), languages are still separated in line with the prevailing principle of one subject–one language (Lambert & Tucker, 1972), largely because of the misconception that mixing languages can lead to confusion or hamper learning (Lara-Alecio et al., 2004).
Against the backdrop of the one subject–one language principle, there is little room for linguistic flexibility, such as language mixing, as a toolkit for deeper learning. Presenting definitions and explanations in another language might be a common pedagogical approach, particularly at earlier stages of language learning, yet this does not reflect the type of naturalistic language mixing that occurs as CS. This is surprising given the lack of empirical support showing that a unilingual approach (i.e., input in one language) is superior for language learning compared with a multilingual one. There is, however, some evidence that language mixing can be facilitative to content teaching and learning (see MacSwan, 2022). For instance, Reyes (2004) showed that during a science project wherein CS was permissible, competent peer interaction involving language mixing was observed in a sample of second- and fifth-grade immigrant Spanish-speaking children in a US classroom. In a mixed methods study investigating the translanguaging practices of eight English teachers in India, Anderson (2022) found that the teachers were open to translingual practices wherein learners’ and teachers’ linguistic repertoires were not restricted to English only. Such inclusive practices facilitated student learning and more broadly mirror the linguistic reality in India (also see A. Lightfoot et al., 2021). It is also evident that all languages can be drawn from in linguistically diverse social contexts (Grosjean, 2010; Wigdorowitz et al., 2022, 2023) and educational settings (Cook, 1995, 2001, 2016; Creese & Blackledge, 2010; Lin, 2013).
What we do know about language learning is that people can learn multiple languages (to varying degrees), without explicit instruction (Morgan-Short et al., 2012; J.N. Williams, 2020), whether the language is natural or artificial (Ettlinger et al., 2015), and whether they have only one or more languages in their repertoire (Bardel & Sánchez, 2020). Furthermore, it is well known that an individuals’ languages are simultaneously activated (to varying degrees) and cannot simply be switched off at will, even in explicitly unilingual environments (Sanoudaki & Thierry, 2015), though they can be pro-actively inhibited (Wu & Thierry, 2017) or integrated, via CS, to meet communicative demands and norms (Green & Abutalebi, 2013). Despite a rich and broad literature on language learning, the utility of mixed input as a pedagogical method for language learning is underexplored. Filling this gap, theoretically and empirically, will allow us to assess the linguistic costs and benefits of language mixing for language learning, and to reexamine the effectiveness of unilingual education for language learners.
Importantly, Anderson (2022) argues that strict unilingual educational policies in contexts where students and teachers share multiple languages are “outdated and counterproductive” (p. 2248). He further recommends that learner inclusion and boosting confidence and participation should be prioritized over maximal target language use. MiLIP takes these recommendations on board and attempts to address them from an experimental perspective; in this way, the present study is methodologically novel and conceptually original as it provides the first concrete way to implement mixing in a language learning context.
3 Language learning considerations
Communication and language acquisition/learning do not occur in a vacuum. Rather, multimodal (contextual) information is continuously integrated (Lazaridou et al., 2017; Spivey & Dale, 2006). In a classroom, for example, a teacher can say a word, emphasize its pronunciation, write the word down, and show an image of the object that the word refers to, all to support the learning of that specific word and its grammatical features. Students are, in turn, evaluated via written and/or oral examination, usually in a single modality at a time in such a way that they abstract away from learning from multiple modalities. The same can be done for remote, web-based learning, where images, videos, sentences, and even stories can be used to relay linguistic information. According to Mayer’s (2009) cognitive theory of multimedia learning, when humans process language across dual channels (auditory and visual), they are cognitively limited by how much information can be processed in each channel simultaneously (Sweller et al., 2011) and need to process information actively in order to adequately attend to and integrate relevant information to achieve learning. Multimodal input enhances learning when visual and verbal input are aligned and nonredundant, but overload occurs if too many competing sources are presented. It has been shown that well-designed multimodal instruction can indeed enhance retention and comprehension (Mayer, 2005). MiLIP takes this multimodality of natural interaction and learning into account in its design. The paradigm presents all input in both oral and written form, accompanied with graphics, to support the morphological and phonological properties of the language to be learned through both the auditory and the written modalities.
An additional consideration in the presented methods, inspired by classroom teaching and learning practices, is the structure of the input. Structuring language input by gradually presenting more complex grammatical structures and inviting the learner to “notice” new linguistic forms has been found to facilitate learning (Robinson, 1995; VanPatten, 1996). This ties in with the idea that language learning is a gradual and ordered process (Tsimpli, 2014). Specifically, nouns precede verbs (Gentner & Boroditsky, 2001), simple sentences precede complex ones (D. Lightfoot, 1989), and active structures are learned before passive ones (Pinker et al., 1987). This orderly development of language is accomplished naturally by a child exposed to L1 input. For the L2 learner, however, it is often helpful to structure the input so that the gradual process of learning is facilitated (VanPatten, 1996). Drawing on this body of literature, we apply such a gradual, ordered input process in MiLIP.
II Methodology
In this section, we present the methodology of a remote, web-based longitudinal language learning paradigm. In our examples, the target language to be learned is Greek, which is embedded into a familiar language, in this case, English. However, the reader can take our proposed method development guidelines and, in theory, apply them to any language combination: Greek and English are illustrative examples used in the design of MiLIP. Ethical clearance for this project was granted from the Faculty of Modern and Medieval Languages’ Research Ethics Committee at the University of Cambridge. All materials are available at https://doi.org/10.17605/OSF.IO/P7JSW.
1 Procedure
MiLIP includes eight different sessions, which are to be carried out online over a four–six-week period. Prior to the start of the main study, a declaration of interest questionnaire can be used to gauge participants’ interest, assess their eligibility, objectively evaluate their English (or relevant language) proficiency, and screen for potential bots and fraudulent cases (for a discussion of the latter, see Vogelzang et al., in preparation). The full procedure is shown in Figure 1.

Procedural overview of the study. There are eight sessions in total (plus a declaration of interest questionnaire), which include a pre-study session, a post-study session, and three learning phases: (1) nouns; (2) noun phrases (NPs); and (3) NPs + verbs. Details of the stimuli in the different learning phases are provided in Section II.3.
Once eligibility has been established, the participant can be invited to the main study. In a pre-study (pre-language learning) session, they are asked to complete a (language) background questionnaire, and subsequently to complete cognitive or other tasks, as needed. The next calendar day, participants were invited to the first language learning session of Phase 1. Each phase consists of 2 learning sessions. All invites to the remaining sessions (Phase 1, Session 2; Phase 2, Session 1; Phase 2, Session 2; Phase 3, Session 1; Phase 3, Session 2) can be sent 4 days after completion of the previous session. We opted for a 4–8-day window between each language learning session to ensure the design is longitudinal and that learning takes place over an extended period, while also being cognizant of the length of participation to minimize attrition. A post-study session follows the final learning session (Phase 3, Session 2) immediately, but could be implemented with a delay to reduce the length of participation in one go and/or gauge retention.
Abilities in the target language are evaluated at different points during the study. Following the presentation of input in Phase 1 (Sessions 1 and 2) and before the start of Phase 2 (Sessions 1 and 2), participants are asked to identify the correct meaning of each newly learned Greek noun from a multiple-choice noun-based picture selection task. This allows the researcher to gauge participants’ learning (Phase 1) and retention (Phase 2) rates. At the end of Phase 2 and Phase 3 sessions, participants additionally perform a grammaticality forced-choice task (GFCT) which assesses participants’ ability to correctly identify grammatical part-learned and part-novel structures in Greek. Finally, an oral vocabulary production task and post-study questionnaire are administered at the end of Phase 3, Session 2. Participants are debriefed with a downloadable handout of examples illustrating what they have learned. The language learning sessions and subsequent tasks take approximately 30 minutes per session to complete, with Phase 3, Session 2 being a little longer due to the additional production task and post-study questionnaire. The study needs to be carried out on a laptop or desktop computer with a stable internet connection, working speakers and microphone. Participants can take notes during the language learning sessions but may not refer to them when performing the assessments. Each task is described in detail below.
All materials have been piloted on L1 English (n = 3), L1 Mandarin–L2 English (n = 2), and L1 Greek–L2 English (n = 1) speakers. The tasks were amended as needed to improve clarity, functionality, and flow, and are found to work as intended. Pilot participants were compensated for their time.
2 Participant and eligibility checks
We urge researchers to consider their participant population in-depth before data collection, as it is known that social and individual variables affect language learning. It is also important to consider how representative a sample is compared with real-world language learners.
a Language proficiency
In our example, participants will be non-native speakers of the familiar language (English) into which the language to be learned (Greek) is mixed. If participants are non-native speakers of the familiar language, proficiency should be assessed. In our example, we therefore include an English proficiency test. 2 In addition, the eligibility questionnaire would ask about previous knowledge of the language to be learned. This is done to ensure participants’ knowledge of and exposure to this language is minimal.
b Other eligibility criteria
We further recommend getting a comprehensive overview of the participants’ demographic and language background, as several background factors could affect their learning. Individuals with substance, language, developmental, neurological, and/or psychiatric disorders should be considered for exclusion, as all of these may affect their learning and/or (neural) processing of language. Finally, the methodology leads to the exclusion of individuals with hearing impairment, color blindness, and/or visual impairments that are not corrected with glasses/contact lenses. This is because the content is presented visually and orally.
3 Learning materials
The mixed language sentences are presented within our novel paradigm, MiLIP. In MiLIP, all input is presented in both oral and written form to support learning of the phonological properties of Greek through oral and written modalities. The language learning task is designed to manipulate the input condition that participants are taught Greek in: mixed input (sentences presented in English with inserted Greek words) or unilingual input (sentences presented in Greek and English separately). The design of the language input is based on the principles of exposure to words, phrases, and sentences in the new language on a gradual basis (Tsimpli, 2014).
The learning of Greek proceeds in three phases of development, as described in the procedure (Figure 1). Materials in each consecutive phase differ in the quantity and quality of mixing per sentence, with the quality following the order of noun (N) → N phrase (NP) → NP + verb (V). In Phase 1, the matrix language (Myers-Scotton, 1993) of the stimuli is English, and concrete Greek nouns of the three different genders (masculine, feminine, neuter) are inserted as the embedded language. In Phase 2, Greek definite and indefinite determiners are inserted together with the nouns. As the Greek nouns and determiners carry markings for gender, case (nominative or accusative), and number (singular or plural), this information has to be extracted and generalized by the learner without any explicit teaching. Verbs, specifically present and past tense action verbs, are introduced in Phase 3. These phases allow the researcher to examine whether learners can arrive at some knowledge of Greek words and grammar through a scaffolding model of ordered input in the new language. In the unilingual input condition, sentences are presented unilingually in Greek through oral and written modalities (with an English translation below), with the target words (N → NP → NP + V) highlighted in bold for each respective phase. Similarly, in the mixed input condition, sentences are presented with Greek words inserted into English sentences, also through oral and written modalities (with an English translation below), with the target words highlighted in bold for each respective phase (see Figure 2).

Example of a sentence in the mixed (left) and unilingual (right) conditions implemented in Gorilla (an experiment builder platform; see https://gorilla.sc/).
In each learning session, learners are presented with the same 12 short stories, each containing six sentences (shown one at a time). The input is presented as a video clip of an L1 Greek–L2 English speaker talking, with a simultaneous written transcription at the bottom of the screen in both conditions (unilingual and mixed). Written Greek is based on a broad transliteration in Roman script supporting phonological rather than graphological properties. Finally, images accompanying the sentences, displaying characters, objects, and scenes, are presented to provide extralinguistic cues to aid learning (generated using Adobe FireFly, 3 see Figure 2). In the mixed condition, the English syntactic frame will allow learners to bootstrap onto their existing knowledge of English to learn the Greek nouns and verbs. This knowledge can support acquisition through several cognitive mechanisms. Positive cross-linguistic transfer of English word order can facilitate the parsing of Greek structures (Schwartz & Sprouse, 1996), whereas determiners can provide early cues for syntactic bootstrapping of gender, number, and case (Foucart & Frenck-Mestre, 2012; Lidz et al., 2003; Wonnacott et al., 2008). In addition, cross-linguistic structural priming can strengthen shared syntactic representations across English and Greek (Schoonbaert et al., 2007). In the unilingual condition, learners largely rely on translations to access meaning.
Twelve nouns are learned in Phase 1 and Phase 2. Multiple occurrences of the same word are crucial for naturalistic and successful learning, and as such each noun is presented to participants six times in different sentential contexts. In Phase 3, we use the same nouns and sentences, now also “revealing” the verbs. Participants are not expected to learn the meaning of each verb (as they are with nouns), but to implicitly infer some of their properties (e.g., number and tense marked with certain morphemes) and agreement with the nouns in subject position.
In each session, sentences are presented in the context of 12 stories, each containing six sentences shown one at a time, as mentioned previously (Table 1 presents an example story). Each story includes two critical nouns (nouns to be learned; Table 2 provides an overview of the nouns in each story). The 12 Greek nouns to be learned were selected based on gender, animacy, and syllable count. The Greek language has three grammatical genders (masculine, feminine, and neuter), and as such, all grammatical genders are presented in the design. In terms of distribution of the grammatical genders across nouns, the neuter is considered the most frequent, followed by the feminine and finally the masculine gender (Mackridge, 1987); however, all three genders are used frequently. We considered it important to expose learners to all three genders in the same frequency in this iteration of the design. This is an aspect that can be manipulated in future research. In MiLIP, there were four of each gender: one animate (two syllables), one animate (three syllables), one inanimate (two syllables), and one inanimate (three syllables). The nouns were selected based on their suffixes, aligning with native Greek speakers’ preference for gender assignment (masculine: -as, -is; feminine: -a, -i; neuter: -o, -i) (Mastropavlou & Tsimpli, 2011). Noun frequency, as indicated by the Hellenic National Corpus, 4 was also taken into account, trying to match nouns of different gender and the same syllable length (e.g., masculine/feminine/neuter two-syllable nouns had comparable frequencies). We tried to avoid Greek–English cognates as much as possible.
Example of a story (story 12) across each phase for mixed and unilingual conditions.
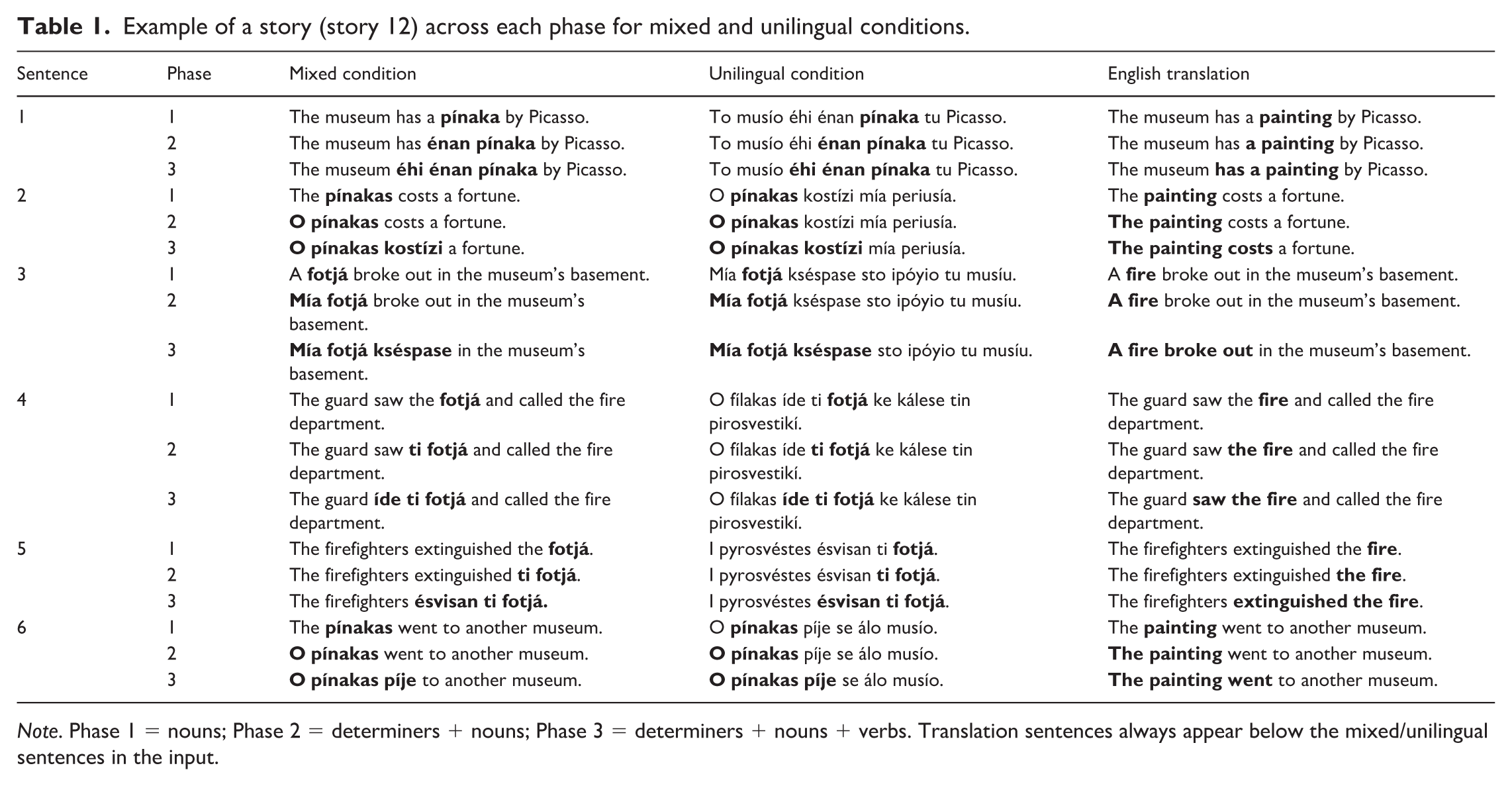
Note. Phase 1 = nouns; Phase 2 = determiners + nouns; Phase 3 = determiners + nouns + verbs. Translation sentences always appear below the mixed/unilingual sentences in the input.
Nouns shown per story with information about their animacy, syllable length, and plurality.
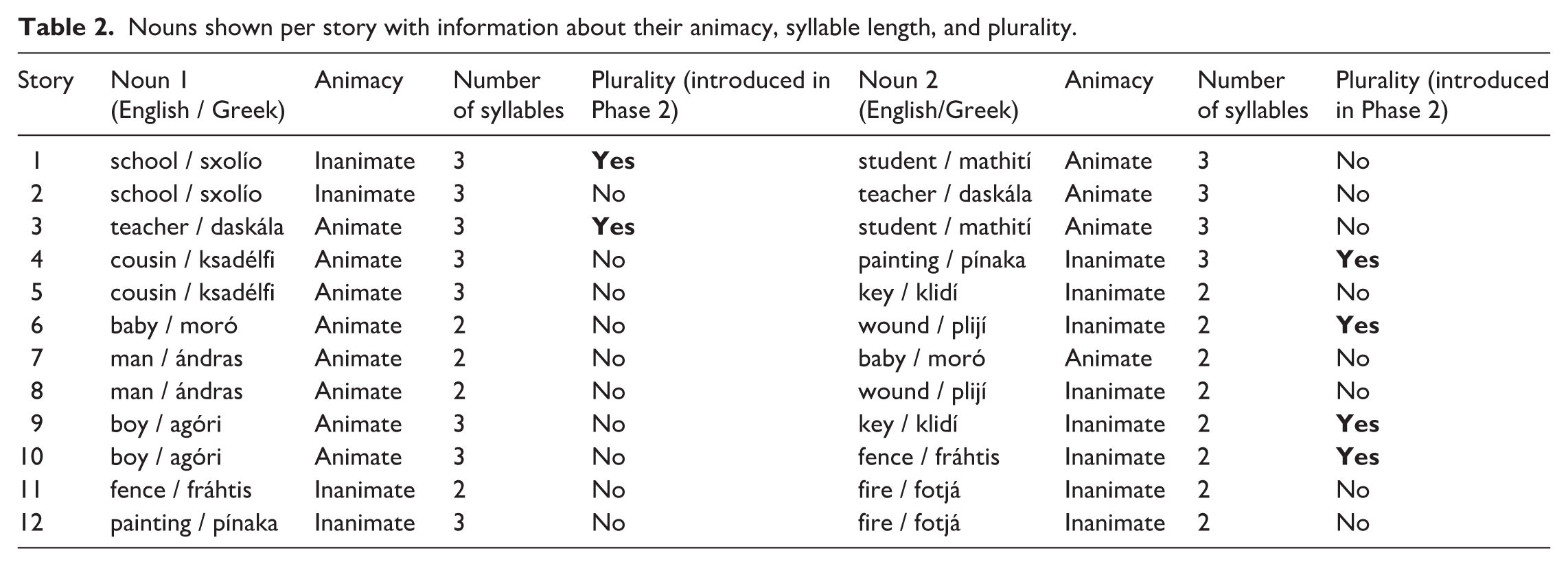
Each noun appears six times, spread across two stories. The first time the noun appears in each story, it is in indefinite form and the other two occurrences are in definite form. The nouns are evenly distributed in nominative and accusative case 5 (three times each). The stories were constructed around the nouns. The verbs used are two-to-five syllables in length, in present or past form, and are all in active voice.
Each session (12 stories) repeats twice, leading to six learning sessions across three learning phases. In Phase 1 (Sessions 1 and 2), all nouns are in singular form. From Phase 2, half of the nouns are also introduced in their plural form (stories 1, 3, 4, 6, 9, 10; 6 see Table 2). We did not do this for all nouns, so we could check participants’ ability to generalize and apply pluralization to forms they have not encountered before. All the information on nouns, determiners, and verbs that participants received is summarized in Tables 3–5, respectively.
Examples of Greek case and number markings learned in Phase 1.

Examples of Greek articles learned in Phase 2.
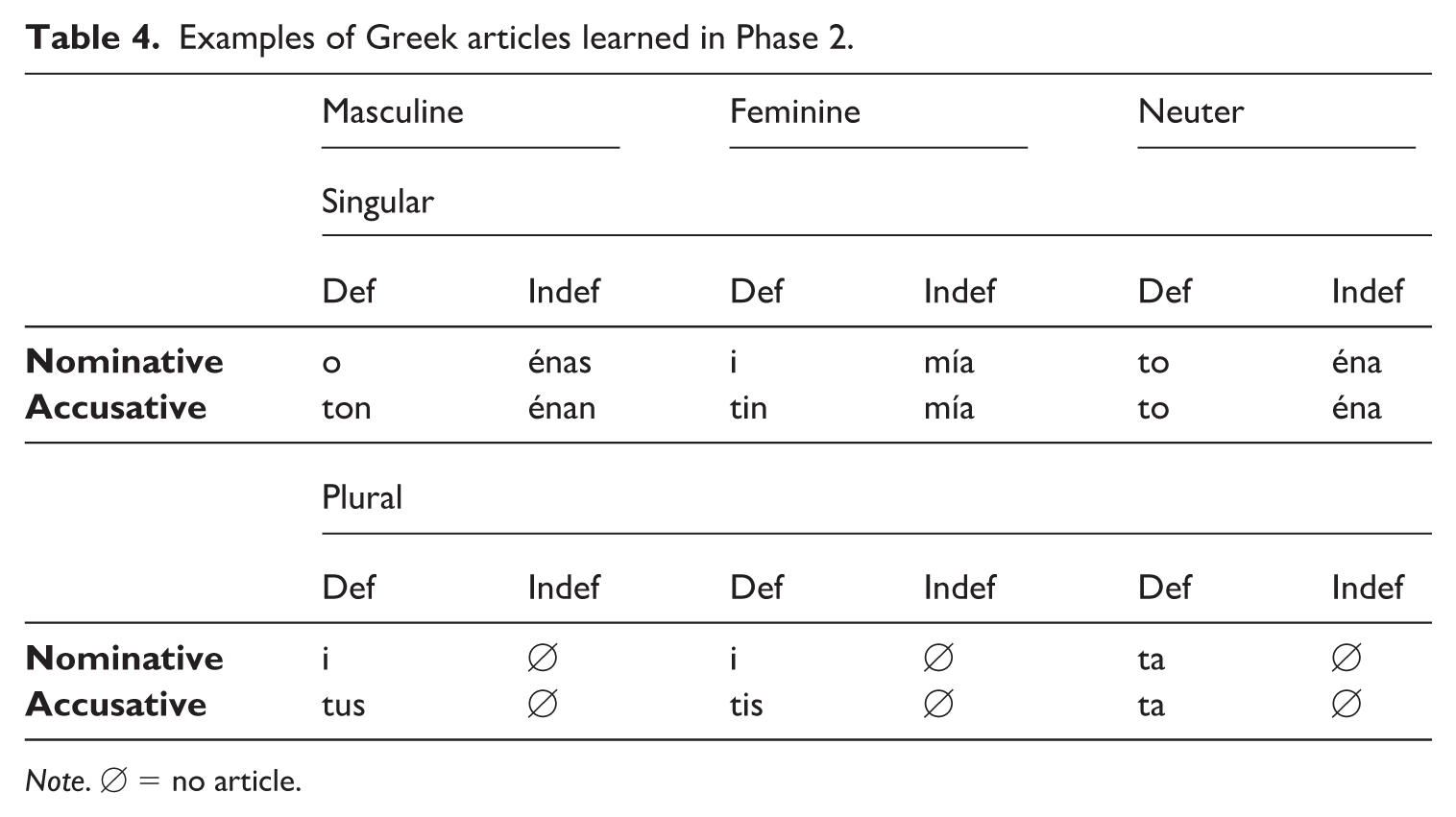
Note. ∅ = no article.
Examples of Greek tense and number markings on verbs learned in Phase 3.

The language input task is designed with block randomization, such that each participant will be randomly assigned to one of two equally sized, predetermined input conditions (unilingual versus mixed). Randomization is also used for the order of the 12 stories in each of the six learning sessions (the sentence order within each story remains the same, however). After each story, a multiple-choice filler comprehension question is posed, asking participants about the content of the story. Responses to comprehension questions are not included in the analysis, but are used to hold participants’ attention and ensure that they are sufficiently engaging with the task.
4 Evaluation measures
a Find the picture: picture selection task
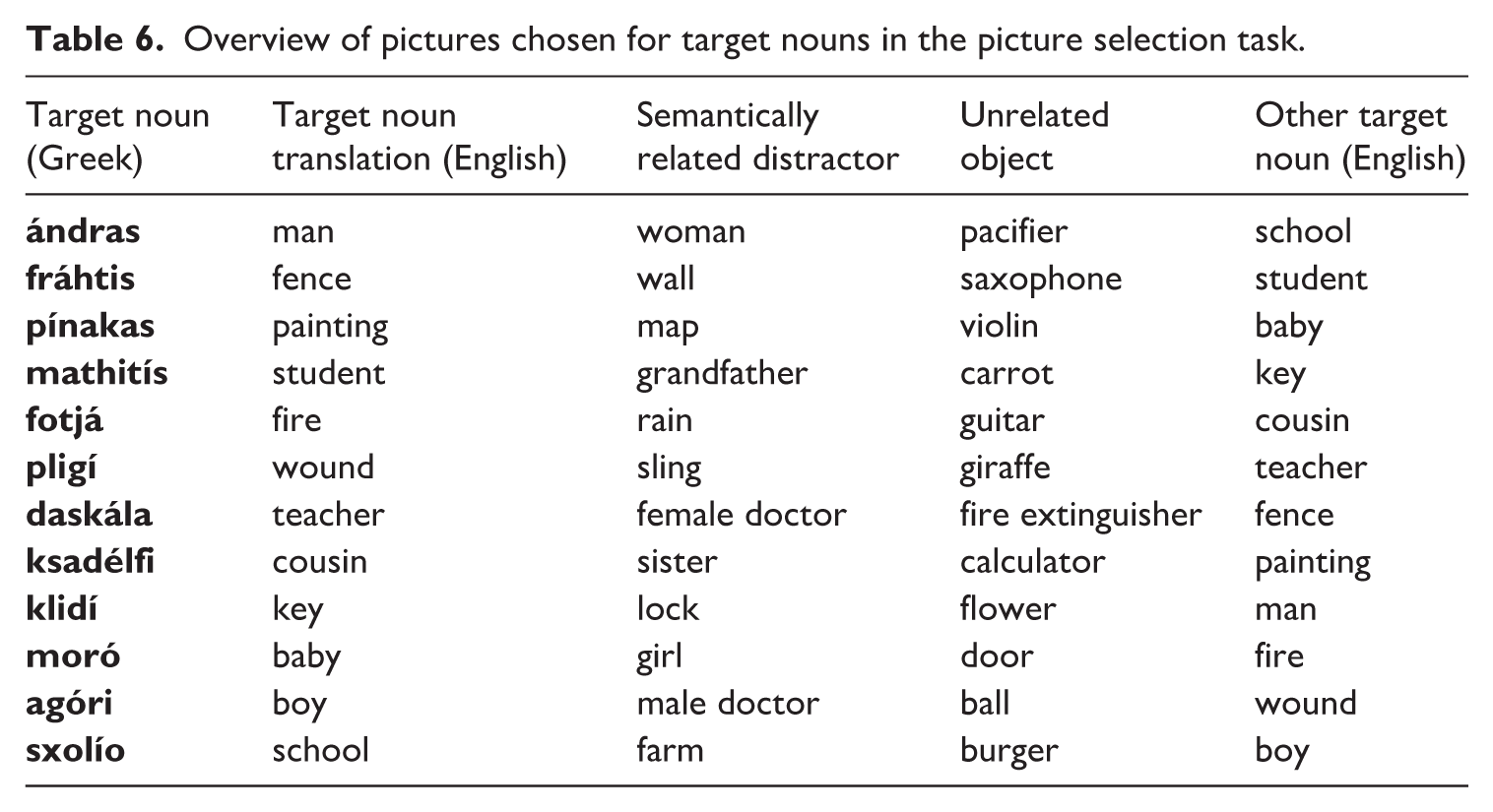
A picture selection task is used to assess participants’ knowledge of the 12 Greek nouns presented in the language-learning part of the experiment. Picture selection tasks are widely used to assess L1 and L2 vocabulary knowledge (Huettig et al., 2011). In this task, participants are asked to select an image of a specific noun with the prompt “Which one is the

Example target item (left) and example filler item (right) from the picture selection task.
Overview of pictures chosen for target nouns in the picture selection task.
Overview of pictures chosen for filler nouns in the picture selection task (always presented in 5th, 10th, and 15th position, respectively).

As mentioned, this task is completed after Phase 1 (at the end of both Session 1 and Session 2) and before the start of Phase 2 (at the beginning of both Session 1 and Session 2) to evaluate Greek learning (Phase 1) and retention (Phase 2). To ensure participants have sufficient exposure to Greek and are indeed learning, they must obtain a score of at least 83.3% (10/12) in Phase 1 to continue to the next session. They are informed of this requirement in the instructions before the task and are given feedback about their performance at the end of the task. If a participant scores below the performance requirement, incorrectly identified words are repeated with their respective stories/materials and are retested up to a maximum of three times. There is no minimum performance requirement for Phase 2, as at this point the task tests retention of nouns learned in the previous phase and takes place before the language learning task. Measures of accuracy on target items (out of 12) and reaction times on accurate items can be calculated per session. Filler items are not included in the calculation of these scores.
b Pick the phrase: a GFCT
The participants were assessed on specific grammatical aspects of Greek through the use of a GFCT four times during the learning process. GFCTs are common assessments of grammatical features in language acquisition (Schütze & Sprouse, 2014). A GFCT is administered as the final task across both sessions of Phase 2 and Phase 3, where participants have been exposed to NPs and Vs in Greek, respectively. Importantly, this task was designed to test participants’ mastering of Greek grammatical features. Their knowledge of the meanings of these words was not assessed. In this task, participants are shown two or three options in Greek (two for case, two for number, three for gender, as appropriate) and need to select the one they think is grammatically correct. When testing knowledge of NPs (agreement with determiner in gender/case), only the Greek text (in Roman script) is used. When testing knowledge of Vs, the English translation is also included. If participants are unsure about their choice, they are encouraged to make a guess. Participants will be exposed to some of the words or word combinations (e.g., in the case of determiner and noun agreement), but will also be tested on novel words and word combinations, although they will have had exposure to all tested grammatical features. By using some novel items, we are able to check participants’ ability to generalize to unseen forms from the input.
The number of items per GFCT varies depending on the features being assessed. Specifically, the GFCT comprises 48 items in Phase 2 Session 1, 48 items in Phase 2 Session 2, 20 items in Phase 3 Session 1, and 44 items in Phase 3 Session 2 (Table 8 provides an overview). Items are randomized per session and not repeated. RTs and accuracy scores as percentages (number of correct responses out of the total number of trials per session or the total number of trials per grammatical feature) can be calculated.
Overview of the features tested in each GFCT, with accompanying examples. Note that Phase 2 Sessions 1 and 2 test the same grammatical features with different items (i.e., no item repetition).
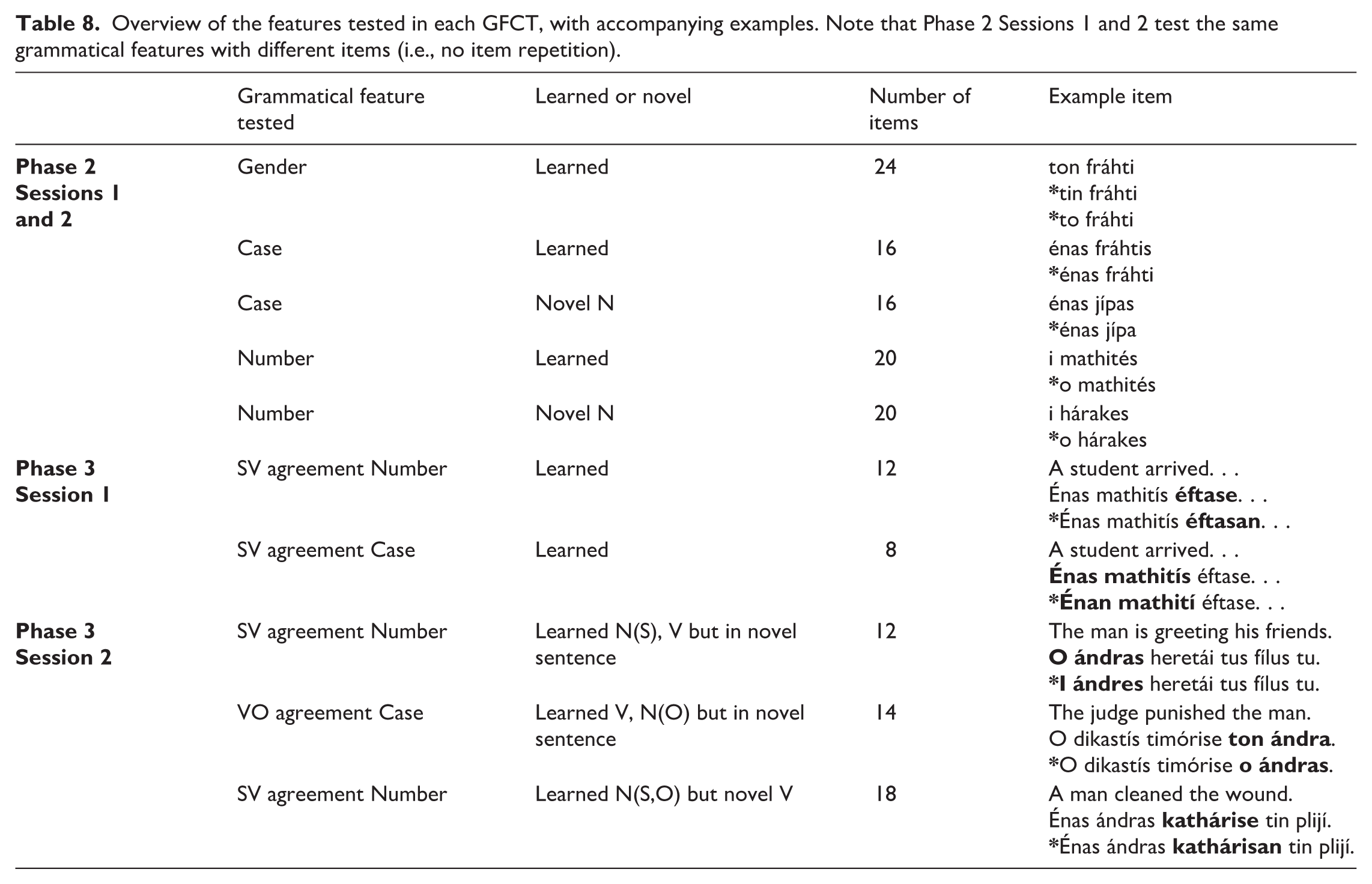
i GFCTs in Phase 2
In Phase 2, participants’ knowledge of agreement between determiner and noun (in gender, case, and number) is tested. For gender, items include only nouns that participants’ have been exposed to. 9 Each of the 12 nouns is tested twice, leading to a total of 24 trials presented with a three-alternative forced choice (3-AFC) design. For case, participants are evaluated on four previously seen masculine nouns and four novel masculine nouns. 10 Each noun appears in four occurrences (nominative-definite, accusative-definite, nominative-indefinite, accusative-indefinite), leading to a total of 32 trials with a 2-AFC design. For number, participants are tested on 12 already seen nouns and 12 novel nouns (which adhered to the same pluralization rules). Each masculine noun is tested in two trials: once manipulating the determiner (definite determiner in plural versus definite determiner in singular + noun in plural) and once manipulating the noun (indefinite determiner singular + noun in singular vs. noun in plural). The same logic is applied to neuter nouns. Because of the simplified spelling (Roman script), this manipulation for the feminine nouns only works with indefinite determiners in nominative case (e.g., mía daskála versus mía daskáles). Hence, for feminine nouns, there is only one trial per noun. The total trials (40 items) for nouns have a 2-AFC design and include: eight trials for seen masculine nouns, eight trials for seen neuter nouns, four trials for seen feminine nouns, eight trials for novel masculine nouns, eight trials for novel neuter nouns, and four trials for novel feminine nouns. Items are randomized and split evenly across the two sessions.
ii GFCTs in Phase 3
In Phase 3, NP + V knowledge is tested. In Session 1, knowledge of SV agreement in number and case is tested. This involves rote learning since participants have been exposed to all the structures they are asked to judge, so do not require generalization or rule application.
11
For SV agreement in number, participants are tested across 12 trials (one for each noun they are exposed to) following a 2-AFC design. For SV agreement in case (the subject always needs to be in the nominative case), participants are tested across eight trials (four masculine, four feminine), also following a 2-AFC design. This manipulation does not work with neuter nouns, because they are identical in surface form in nominative and accusative case. In Session 2, participants’ ability to generalize their V knowledge to new combinations and verbs is tested. SV agreement in number is tested, but this time the combinations between nouns and verbs are novel, i.e., participants have been exposed to the nouns and the verbs but not in the combinations they are asked to evaluate them in. For example, participants have seen the sentence: “To korítsi heretái to agóri” and “Énas ándras éhi,” so they should be able to infer that the singular masculine noun “ándras” should be the subject of the singular verb “heretái” in the following example trial: “ “Thesg. mansg. greetssg. his friends” vs. *’Thepl. menpl. greetssg. his friends”
There are 12 trials in total, one for each noun, following a 2-AFC design. In half of the trials, the target combination involves a singular subject (and verb), and in the other half, a plural subject (and verb). We also test VO constructions (nouns in object position need to be in accusative case in Greek), again using target nouns and verbs that participants have been exposed to but in novel combinations. In singular form, items include: two masculine definite, two masculine indefinite, and two feminine definite nouns (already seen in the input). In plural form, items include: two masculine definite and two feminine definite nouns (participants have seen the plural form in the input), and two masculine definite and two feminine definite (participants have not seen the plural form in the input; see Table 2). 12 This results in 14 trials in total, following a 2-AFC design. Finally, SV agreement in number with novel verbs is tested following the morphological properties of seen verbs. These include six trials with singular S and V and 12 trials 13 with plural S and V, leading to a total of 18 trials with a 2-AFC design.
c Expressive vocabulary task
We designed an expressive vocabulary task to gauge participants’ active knowledge of the 12 Greek nouns from the learning tasks. We are interested in the accuracy of productions, not in terms of prosody but in terms of vocabulary. Participants are presented with an image (from those used in the picture selection task) and are asked to name what it refers to (the noun). Accuracy of the responses can be calculated, for example, with a Levenshtein or Damerau–Levenshtein distance between the produced form and the correct form (e.g., with the “stringdist” R package; Van der Loo, 2014). The Damerau–Levenshtein distance reflects the number of single character (in this case, phoneme) edits (insertions, deletions, substitutions, or transpositions) required to change one word into the other. This should then be transformed into a percentage correct score, reflecting how much of a word was produced correctly. For example, if the target response was mathitís and the participant’s response was mathatí, then one substitution (“a” instead of “i”) and one deletion (of the final “s”) leads to a distance of 2. Because there are seven phonemes in the target word, the Damerau–Levenshtein distance score would be 28.6%. Researchers could also analyze prosodic accuracy or other phonological features of interest.
d Post-study questionnaire
A short 5–10-minute questionnaire invites participants to reflect on their engagement with the study and their language learning behaviors. Specifically, it asks about participants’ learning/response strategies (guessing, intuition, memory, or rule application), confidence in task performance (not very confident, fairly confident, certain, or no observations made), and explicit grammatical rule identification (open-ended). These questions are asked for the picture selection task and GFCT. We also ask whether participants engaged in other methods of Greek learning over the duration of the study, such as through an app, reviewing any notes made, and via media channels. In addition, we ask how helpful each modality (image, audio, video, subtitle) is in facilitating learning. Answers for each modality are on a scale ranging from 0 to 100, where 0 represents “not helpful at all” and 100 represents “extremely helpful”. In addition, we ask about participants’ level of motivation both during the language learning sessions and during the assessment tasks. Answers also range from 0 to 100, where 0 represents “not motivated at all” and 100 represent “extremely motivated”. We can also get an indication of whether participants took and/or used any notes during the learning sessions, whether they felt as though they had learned any Greek, and what this learning experience compares to in terms of how much they learned in this study versus using existing learning apps (if applicable). Finally, participants can share information about their reason for participating, any technical difficulties experienced, and anything else they deem useful to add.
Responses to these questions can be used in several ways, including for clarity, exclusion (e.g., if a participant uses their notes during the assessments), or in-depth quantitative and/or qualitative analysis. In terms of quantitative analysis, we recommend calculating composite scores for (1) helpfulness ratings of each modality (images, audio, videos, subtitles) using Shannon’s entropy (e.g., with the “languageEntropy” R package; Gullifer & Titone, 2018) to get an indication of the utility of each modality on learning; and (2) motivation (story tasks, assessment tasks) by averaging the scores (0–100) across the items. Qualitatively, responses to open-ended questions can be explored.
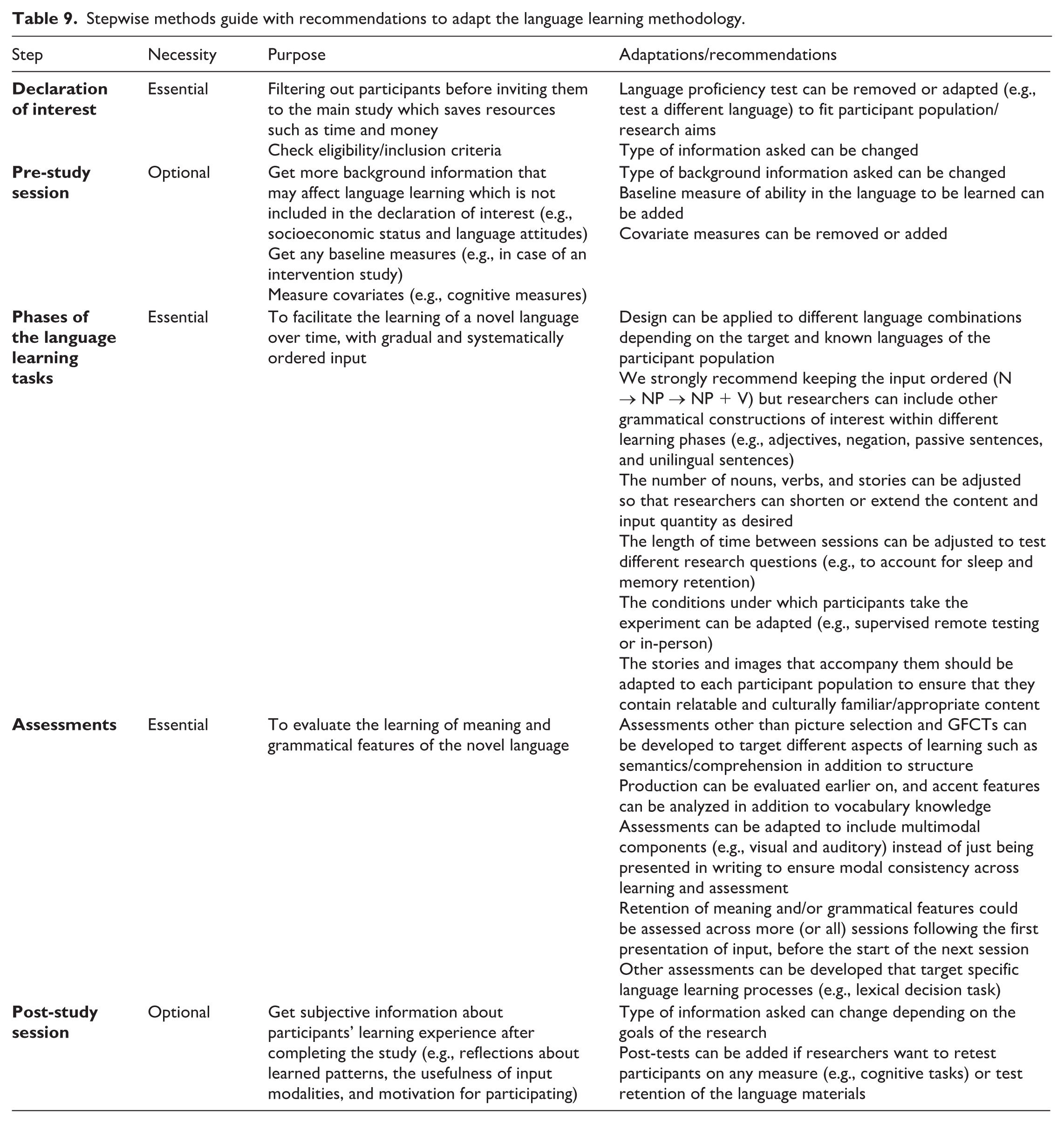
III Stepwise methods guide
Using Figure 1 as a reference, we present a stepwise methods guide in Table 9, which researchers can use to adapt the methodology for their own research. In the table, we indicate which steps are essential (declaration of interest, phases of language learning tasks, assessments) and which optional (pre-study and post-study sessions), as well as which adaptations we recommend other researchers to consider.
Stepwise methods guide with recommendations to adapt the language learning methodology.
IV Limitations
MiLIP, and specifically the presented Greek learning example, has certain limitations. First, the sentences within each story were developed with the nouns (and not the verbs) as the guiding structure. Given the complexities involved in creating 12 completely novel stories that meet several criteria, including that each story contains six sentences comprising two target nouns across three sentences, each sentence is between 4 and 11 words in length, the stories flow in a narrative fashion, and each sentence can have a graphical representation, we chose to develop the sentences around nouns in the first instance. The verbs included in the sentences were used to evaluate various grammatical features of Greek, but never their meaning. In future iterations of sentence stimuli, it could be worth having prespecified criteria for the development of verbs in addition to nouns so that they are more controlled and balanced in number.
A second limitation relates to the distinction between the multimodal presentation of input in the learning phases and the unimodal style of evaluation in the picture selection task and GFCTs (i.e., visual, without audio). Future assessments can be designed to incorporate more multimodal features in the assessments, similar to the presentation of language input received. For example, in the picture selection task, audio could accompany the written text, and in the GFCT, a video of a speaker saying each of the options could be played along with the written text. However, in real-world settings, assessments are primarily presented in a single modality, usually in written form, to evaluate competence (Jamieson, 2011; Yu & Xu, 2024). Our assessments therefore reflect that of real-world language evaluation. In addition, other lexical and grammatical features can be evaluated, including, for instance, the retention of verbs as well as nouns. In MiLIP, limited feedback is provided as there is an emphasis on implicit learning (rather than explicit feedback). In this way, the learning process is similar to naturalistic acquisition rather than classroom learning, and relies less on memory. This was a deliberate choice as it allows researchers to examine whether participants can make generalizations with previously unseen forms, for example with respect to case and number (e.g., in Phase 2). Future work could explore the role of feedback, however, it is important to emphasize that simulating a traditional language classroom environment was neither the aim of MiLIP, nor is it any longer the norm in language learning. Although we acknowledge that our method differs quite drastically from language learning experiences in typical classrooms, it arguably aligns closely with the kinds of informal, technology-mediated, and individual learning environments that many adult learners now engage with, making MiLIP a relevant tool for investigating contemporary language learning processes.
Finally, the audiovisual recordings and image generations were limited by budgetary constraints. The recordings were carried out by the research team in a sound-treated booth. However, to improve the quality of the recordings, a sound engineer or equivalent expert should be consulted where possible. AI was used to generate the images, which made it difficult and time-consuming to keep characters and objects consistent throughout a story. More advanced AI or images sketched by an artist could prevent these issues.
V Future applications
Our methodology seeks to establish the efficiency of mixed language input for language learning in controlled language learning contexts by using a familiar language in order to scaffold new language knowledge. Future applications of this methodological design are vast and wide-reaching. They can be applied to language learning for different language pairs as well as investigations of language learning with different and diverse populations situated in a variety of sociolinguistics contexts. For example, children (over the reading age) could be assisted by the multimodal design, and learning aptitude of older adults could be investigated. In theory, this method can be applied across typologically (dis)similar language pairs differing in, for instance, script and typological distance, as well as to speakers with different L1–L2(–Ln) linguistic profiles, and sociolinguistically diverse learners, such as bidialectal and heritage speakers. The tweaks to scaffolded language input lie in the researchers’ knowledge of the grammatical features of the languages which will need to be taken into consideration as the learning sessions progress. The paradigm can also be used to assess language learning in classroom settings compared with remote web-based settings, since learner experience (e.g., autonomy of the learner, number of learners present, predictability, and uniformity of content) between these contexts differs quite substantially. We are not claiming that MiLIP resembles classroom interactions generally, but, rather, we have drawn inspiration from how (linguistically diverse) classroom settings facilitate language learning.
This method also has the potential to transform our current thinking on how languages are learned by implementing mixed language methods inspired by effortless multilingual practices found in non-Western societies (A. Lightfoot et al., 2021). Findings from such efforts may provide alternative support, complementing pedagogical translanguaging research, to the unilingual and separationist norm currently adopted in global language teaching and learning practices that are guided by evidence for optimal learning strategies. Furthermore, our design takes into account and contributes to existing evidence showing multi-language activation when more than one language is available to learners (Soares & Grosjean, 1984; Wu & Thierry, 2017). The underlying idea of mixing languages to support learning, therefore, has the potential to be formally and more broadly applied as a beneficial pedagogical practice both in and outside the classroom. We encourage researchers and educators to adapt this methodology to their contexts and learning goals so that empirical evidence can guide effective language education.
Footnotes
Acknowledgements
We thank the pilot participants for their time in completing this study and for providing valuable feedback. Furthermore, thanks go to John Williams for giving us input about the design of the language learning conditions. We also thank the reviewers for their valuable feedback.
Data availability
All materials are available on the OSF, https://doi.org/10.17605/OSF.IO/P7JSW.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research is supported by a Cambridge Humanities Research Grant (CHRG).
Ethical approval and informed consent statements
This study received ethical approval from the Ethics Committees of the University of Cambridge. All pilot participants provided written informed consent prior to enrolment in the study. This research was conducted ethically in accordance with the World Medical Association Declaration of Helsinki.