
Abstract
According to Hopp’s Lexical Bottleneck Hypothesis, difficulties in second language (L2) lexical processing may lead to non-target syntactic computations. In line with this hypothesis, cognates – which are processed faster than non-cognates, as defined by the cognate facilitation effect – can ease L2 syntactic processing. In order to investigate whether cognates additionally facilitate L2 syntax learning, we had two groups of Spanish natives learn an artificial language drawing on Basque. Each group explicitly learnt a set of either Spanish–Basque cognates or non-cognates and a word order grammatical rule. Then, two sentence–picture matching tasks tested their ability to apply the rule (1) with cognates vs. non-cognates and (2) with novel cognate words. Results showed that, in both cases, cognate learners were better at applying the rule than non-cognate learners. This finding suggests that the cognate facilitation effect and its role in the Lexical Bottleneck Hypothesis can be extended from L2 processing to L2 learning. We end by mentioning possible implications of our results for second language teaching in adulthood.
I Introduction
The acquisition of the native language (L1) is a complex process which requires infants to acquire/learn its phonemes, parse the speech stream into words, associate lexical items with meaning and extract and generalize grammatical rules (de Diego-Balaguer & Lopez-Barroso, 2010). Similarly, learning a second language (L2) in adulthood also involves associating a large set of lexical items with their appropriate semantic content, learning to pronounce them according to the phonemes of the L2 and assimilating syntactic structures of the target language which are not present in the L1 and which are, therefore, more costly to learn and process (Díaz et al., 2016; Zawiszewski et al., 2011). For decades, the focus on how speakers learn and process a second language has inspired a large body of research in the fields of bilingualism and L2 acquisition. The underlying motivation for this research is that, while babies acquire the L1 in a natural and apparently effortless way, learning an L2 is much more challenging for adults and only a few reach native-like proficiency (R. Ellis, 2004; Housen & Simoens, 2016). In light of this finding, the question of how second language learning can be eased becomes highly relevant. In this study, we investigate whether L2 syntax learning can be facilitated by the use of a cognate vocabulary.
Cognates are words which share both form and meaning across two or more languages (e.g. guitarra and guitar for Spanish–English). Over the last 20 years, a large body of studies has focused on bilingual retrieval of individual words from the mental lexicon through cognates (for a review, see Kroll et al., 2015). These studies have found that cognates are produced, recognized and read faster than non-cognates, a phenomenon known as the ‘cognate facilitation effect’.
This effect has been taken as evidence that the two languages of bilinguals are activated during lexical access. Specifically, it has been argued that the cognate facilitation effect occurs because, due to cross-linguistic formal similarity, the orthographic and/or phonological representations of the cognate in the two languages of the bilingual activate during lexical access, but this cross-linguistic activation does not occur with non-cognates, which do not have similar orthographic/phonological forms across languages. In both cases, activation spreads to a semantic representation shared for translation equivalents, which, receiving activation from two word forms as opposed to one, is more strongly activated when the word accessed is a cognate than a non-cognate. The activation of the semantic representation feeds back to phonological and orthographic representations, so that the phonological and orthographic forms of cognate words are also more strongly activated than those of non-cognate words. The overall stronger activation of cognates compared to non-cognates causes the former to be processed faster than the latter (Dijkstra & Van Heuven, 2002).
Several studies have reported that cognates ease bilingual lexical production and comprehension. For instance, cognates are recognized faster and more accurately than non-cognates in progressive demasking and lexical decision tasks (see, amongst many others, Dijkstra, Grainger, & van Heuven, 1999; Dijkstra, Miwa, et al., 2010; Duyck et al., 2007; Lemhöfer & Dijkstra, 2004). Bilinguals have been shown to be faster at naming pictures with cognate than with non-cognate names (e.g. Costa et al., 2000; Gollan et al., 2007). Gullifer et al. (2013) demonstrated that English–Spanish bilinguals name highlighted words in sentences more quickly when these are cognates than non-cognates, irrespective of the language in which sentences are presented, and Van Assche, Drieghe, et al. (2009; Van Assche, Duyck, et al., 2011) found that bilinguals read cognates in sentences faster than non-cognates, both in the L1 and the L2.
In addition, cognates are learnt more easily than non-cognates, especially at the earliest stages of L2 learning (e.g. De Groot & Keijzer, 2000; N. Ellis & Beaton, 1993; Lotto & De Groot, 1998; Rogers et al., 2015). This is arguably because, when L2 cognates are first encountered, they can be readily processed by accessing the phonological and/or orthographic representations of formally similar L1 cognates, linked in turn to lemmatic and conceptual information. By contrast, since L2 non-cognates share no formal similarity with their L1 counterparts, learners must acquire the phonological/orthographic representations of these words and then link them to the lemma and conceptual representations of their L1 translations, a process that is naturally more costly (Parasitic Model of vocabulary development; see, amongst others, Ecke & Hall, 1998; Hall, 1996, 2002).
Although most studies examining the cognate facilitation effect have focused on its role in lexical processing, cognates can also facilitate syntactic processing. Here, we briefly report the results of three studies looking into this topic: Miller (2014), Hopp (2017) and Soares et al. (2018).
Miller examined the role of lexical access in the reactivation of the antecedent during English–French bilinguals’ reading of wh-dependencies, i.e. sentences in which the wh-filler – in brackets in example (1) – has moved from its canonical position (the gap) to an earlier position in the sentence: (1) Charlotte critique le papillon [à qui] Robert a offert le nouveau ballon dans le jardin lundi soir. ‘Charlotte criticizes the butterfly to whom Robert gave the new ball in the garden Monday evening.’ (Miller, 2014, p. 181)
Crucially, Miller had the antecedent of the wh-filler be either an English–French cognate animal (e.g. gorille ‘gorilla’) or non-cognate animal (e.g. papillon ‘butterfly’). While reading the sentences, bilinguals saw a picture of an animate or inanimate entity in gap position that matched the antecedent on half of the occasions. In a probe classification task, they had to decide whether the picture depicted something alive or not. Miller found that sentences were read faster when the picture matched a cognate antecedent, indicating that this type of words facilitated the reactivation of the antecedent at gap position.
Similarly, in two eye-tracking experiments Hopp examined how German–English bilinguals processed sentences containing L1–L2 cognate and non-cognate verbs. The structures tested were English reduced relative clauses – in brackets in example (2) – the surface word order of which partially overlaps with German embedded clauses (OV): (2) When the doctor [Sarah ignored] tried to leave the room the nurse came in all of a sudden. (Hopp, 2017, p. 105)
According to Hopp, when reading these structures L1 German learners of English temporarily activate the canonical word order of German embedded clauses. Hence, the L1 structure competes with the L2 structure and potentially interferes with an L2 target syntactic parse. The results of the study indicated that bilinguals’ first-pass reading times were faster for sentences with cognate verbs than with non-cognate verbs. This indicates that, when the sentences contained cognates, it was easier for learners to inhibit the competing L1 structure and focus on the L2 target structure.
Finally, Soares et al. (2018) compared how European-Portuguese–English bilinguals resolved relative clause (RC) syntactic ambiguities in the L2 when cognates and non-cognates were embedded in the first or second position of the noun phrase (NP) preceding the RC. Participants were asked to read and complete sentence fragments such as ‘Britney recognized the guard of the prisoner who . . .’ (in this case, the two nouns in the NP preceding the RC are cognates with the L1: guard–guarda and prisoner–prisioneiro). Crucially, native speakers of European Portuguese generally attach the RC to the highest element of the complex NP (high attachment, HA), while English natives tend to attach the RC to the lowest element of the complex NP (low attachment, LA). Soares et al. found that when cognates were embedded in the first position of the NP preceding the RC, English learners chose to resolve RC ambiguities using LA, just like English natives would do. In other words, cognates mitigated the interference from L1 attachment preferences (i.e. HA) and allowed learners to achieve a native-like processing of ambiguous RC.
In sum, these studies show that cognates can facilitate L2 target syntactic computations. This finding aligns with the Lexical Bottleneck Hypothesis (Hopp, 2014, 2018), 1 according to which delays or difficulties in L2 lexical processing may lead to non-target syntactic processing. Specifically, the less costly lexical processing is, the more resources may be available for subsequently computing target syntactic relations. Since the processing cost of cognate retrieval is smaller than that of non-cognate retrieval, processing a given syntactic structure could be easier in sentences with cognates than with non-cognates.
Previous research on the impact of the cognate facilitation effect on language processing has examined the behavior of speakers who had already acquired their L2 to a higher or lower degree of proficiency, neglecting the extent to which cognates could ease L2 syntax learning. In this study, we tackled this issue by investigating whether the explicit learning and subsequent application of an artificial language’s grammatical rule could be facilitated by the cross-linguistic activation of the lexicon through cognates. In addressing this goal, it was hoped that this study would provide an answer to the question of how second language learning can be eased, informing as such previous research on L2 learning and contributing to a better understanding of how vocabulary and syntax interact in the course of L2 acquisition.
II The current study
The current study aimed to answer the following research question:
• Does the use of cognates facilitate the application of an explicitly learnt L2 grammatical rule?
To address this question, we designed two versions an artificial language drawing on Basque, which differed on the status of their vocabulary: cognate with Spanish or non-cognate. We assigned 40 participants – Spanish natives with no previous knowledge of Basque – randomly and evenly to one of these two versions, with 20 participants assigned to each version. The language depended on just one grammatical rule, which was shared for both of its versions (a word order rule; see Section III.2). First, to make sure that participants truly had no knowledge of Basque, they all conducted a pre-test consisting of a non-cognate sentence–picture matching task. Then, the two groups of participants were taught either the cognate or the non-cognate vocabulary of the language, and learning was evaluated by means of a picture–word matching task. Finally, we instructed cognate and non-cognate learners on the rule of the artificial language and tested their ability to use it or apply it in two sentence–picture matching tasks: a test with cognate or non-cognate words and a post-test with novel cognate words for the two groups of learners. This was done on the grounds that successfully learning a grammatical rule requires not only having explicit rule-based knowledge, but also being able to transfer this knowledge into real-time language processing, a process which has been shown to take some time (McLaughlin et al., 2010). Our approach to L2 learning in this study resonates with the Skill Acquisition Theory, according to which learning a language, like learning other skills, could be seen as a process that starts with the learner obtaining declarative or explicit knowledge about the language (e.g. in the form of rule presentation). Then, as the learner practices using this knowledge, it becomes proceduralized or routinized, gradually turning into a more implicit knowledge that can be used automatically (DeKeyser, 2015).
First, we predicted that, if participants truly had no knowledge of Basque before the experiment, in the pre-test they would answer randomly to the sentence–picture matching task and performance would be comparable for both groups of learners.
Second, we hypothesized that, in line with the cognate facilitation effect, learning cognates would be easier than learning non-cognates. In fact, since cognates could simply be processed by co-activating their formally similar L1 translations (i.e. as if they were equivalent to their L1 counterparts), then it could be argued that only non-cognates – and not cognates – had to be acquired. In any case, we predicted that accuracy in the picture–word matching task could be higher for cognates than for non-cognates.
Third, and considering the above, we hypothesized that the learning load of the experiment would be smaller for cognate learners than for non-cognate learners. That is, cognate learners would only need to learn the grammatical rule, but non-cognate learners would need to learn the non-cognate vocabulary and the grammatical rule. Consequently, in the test’s sentence–picture matching task, lexical processing would be easier for sentences made up of (already known) cognates than of (recently acquired) non-cognates. This would allow cognate learners to dispose of more resources to access their explicit rule knowledge and use it to process sentences and perform the sentence–picture matching task, which would help proceduralize rule knowledge as part of the learning process. Importantly, the cognate facilitation in rule application we hypothesize is somewhat different from the cognate facilitation in processing predicted by the Lexical Bottleneck Hypothesis, since the latter would be the result of an easier lexical processing easing syntactic structure building. If our hypothesis was correct, we predicted that cognate learners would be better at applying the grammatical rule than non-cognate learners, as indicated by higher accuracy in the sentence–picture matching task.
Finally, the post-test aimed to further test the hypothesis that cognates would ease the application of an explicitly learnt L2 rule. Participants performed a sentence–picture matching task with previously unseen cognate words, and no vocabulary-learning phase preceded this task. We hypothesized that the L2 cognates would be processed without difficulty as if they were equivalent to their L1 translations, and that, just as in the test, this easy lexical processing would leave many resources left for rule application. Accordingly, we predicted that the mean accuracy rate of participants who had learnt non-cognates would increase from the test to the post-test. As for participants who had learnt cognates, two different scenarios were hypothesized. On the one hand, their accuracy rate could be similar or even better than in the test due to the experience accumulated in the previous part of the experiment. On the other hand, since participants would be confronted with new lexical items, applying the rule of the language could become more challenging. If this was the case, participants’ correct responses could be lower than in the test.
III Method
1 Participants
Forty Spanish speakers (36 female) took part in the experiment. Their ages ranged from 18 to 30 years (M = 22, SD = 3.25) and they were all students at the University of the Basque Country (UPV/EHU) who came from other regions of Spain where Basque is not spoken. Thirty-nine of them were native speakers of Spanish and one was a native speaker of Catalan who had started learning Spanish at the age of 3 years. 2 All of them reported having no previous knowledge of Basque nor any verb-final or case-marked languages in a linguistic background questionnaire filled out prior to the experiment. All participants reported having normal or corrected to normal vision and hearing. Before the experiment began, they read and signed an informed consent. The present study was approved by the Ethics Committee of the University of the Basque Country (UPV/EHU, M10_2019_167). Participants were paid 10 € for their participation.
2 Materials
a The artificial language
As mentioned, two versions of an artificial language were created. Each version of the language counted on 30 lexical items: 20 animate nouns and 10 verbs. In one of the versions, the lexical items were cognates in Spanish and Basque (e.g. Basque bonbero vs. Spanish bombero, ‘firefighter’). In the other version, the vocabulary was made up of non-cognates (e.g. the Basque word suhiltzaile also corresponds to the Spanish word bombero). The cognate and non-cognate nouns and verbs were matched in length (nouns, p = .84; verbs, p = .36). These words were used to create transitive sentences to be listened to in the pre-test and the test. For the pre-test, we created eight Subject–Object–Verb (SOV) sentences and eight Object–Subject–Verb (OSV) ones shared for the two versions of the language, all made up of non-cognate words. For the test, we created 40 different SOV sentences plus a set of 40 OSV ones, derived from the SOV items. The sentences of the cognate version of the language were made up of cognate words, and the sentences of the non-cognate version of the language were made up of the equivalent non-cognate words. Four different lists were generated to prevent participants from listening to both versions of the same sentence. During the test, every participant listened to 20 SOV sentences and 20 OSV ones presented in a randomized order.
In addition, 30 extra cognate words – 20 animate nouns and 10 verbs – shared for the two language versions were used to create 40 transitive sentences (20 SOV and 20 OSV) to be listened to in the post-test. In this case, two different lists were created to prevent participants from listening to both versions of the same sentence. Thus, all participants listened to 20 sentences (10 SOV and 10 OSV) made up of previously unheard cognates in the post-test carried out immediately after the test (the materials of the study can be consulted in the OSF repository: https://osf.io/zwm7r/?view_only=5c259bde7fd147acbbb474cc7a21d670).
As previously stated, in the artificial language verbs had to be placed in the final position of the sentence, but the order of subject and object noun phrases was free. Case markers attached to the nouns indicated whether these were the agent (-ak) or patient (-a) of the action. Mirroring Basque grammar, verbs were followed by the auxiliary du (‘to have’) to conform with grammatically correct sentences. Due to experimental restrictions such as cognateness of the lexicon and imageability of the stimuli, most sentences were semantically unusual, i.e. they related agents and patients who would not normally interact in the real world (for an example of test sentences, see Table 1; for the whole set of experimental sentences, see the Appendix in supplemental material). Participants were informed about the nature of the sentences before the experiment began.
Example of SOV and OSV test sentences for the cognate version of the language (Version A) and the non-cognate version of the language (Version B).

Note. All four sentences mean ‘The actor has painted the doctor.’
b Audio files
The vocabulary items and the experimental sentences of both versions of the artificial language were recorded by three female native speakers of Basque aged 22 to 24 years. Speakers recorded (1) the pre-test sentences, (2) the test sentences and (3) the post-test sentences and lexical items, respectively. Recordings took place in a soundproof booth using a Tascam voice recorder (DR-100 MKII model, frequency sampling of 44,100 Hz). Speakers were asked to read the stimuli at a normal pace and with natural intonation. Once the audios were recorded, they were matched in length and intensity (dB) using Praat (Boersma & Weenik, 2018, version 6.0.37).
c Pictures
Pictures corresponding to the lexical items of the artificial language were bought from 123RF Image Bank (https://www.123rf.com/) and further edited to make them depict transitive actions (for an example, see Figure 1). In total, 120 pictures were created. Each picture corresponded to a pair of SOV–OSV sentences. The order in which the subject and the object appeared in the pictures was counterbalanced, so that in half of the pictures the subject appeared on the right and in the other half, on the left.

Example experimental picture.
3 Procedure
We conducted the experiment using E-Prime software version 2.0 (Schneider et al., 2002) and described it to participants as ‘a study of Spanish speakers’ capacity to learn Basque’. The experiment included four stages: (1) a pre-test, (2) a vocabulary and rule learning phase, (3) a test and (4) a post-test. We informed participants that, in all the stages but the learning one, they would see two mirror pictures depicting transitive actions and they would hear a sentence describing one of the two. They were told that their task was to pair each sentence with its picture. In addition, they were made aware that the words they learnt would be included in the test sentences, but not in the post-test sentences, which would be made up of new words. Crucially, we did not explicitly refer to the cognate or non-cognate nature of the vocabulary items. Once participants had completed the experiment, they were additionally tested on their working memory capacities by means of a digit span test (Gathercole et al., 2004; Jarvis & Gathercole, 2003), to ensure that the capacities of both groups of participants were comparable. The experiment lasted for a maximum of an hour.
a Pre-test
The pre-test was designed to make sure that participants’ knowledge of Basque was non-existent. Participants sat at approximately 65 cm from a monitor set to 1920 × 1080 pixels in a soundproof booth and were informed through instructions on the screen that they would be simultaneously presented with two pictures and an auditory sentence in Basque. All sentences were constructed using non-cognate words from the non-cognate version of the language. Pictures occupied most or all of the screen. For each trial, the pictures depicted two characters performing an action and the only difference between them was that the agent–patient relationship was reversed from one picture to the other (for an example, see Figure 2). Participants’ task was to select the picture that matched the sentence heard by pressing either the right or the left button on a game controller. As they did this, the next trial began. In this part of the experiment, eight SOV and eight OSV sentences were played in a randomized order for each participant. In order to be fit for the experiment, participants had to answer randomly.

Example experimental trial in the pre-test.
b Learning phase
Following the pre-test, each group of participants was explicitly taught the vocabulary of their version of the artificial language and the grammatical rule. For vocabulary learning, participants saw in a randomized order the pictures corresponding to the 20 nouns and the 10 verbs that would appear in the test, with the name of each item written below the pictures. Participants also listened to the word associated with each picture. Each word could be played again by pressing the left button on the game controller. To move on to the next picture, participants pressed the right button on the controller. After a first familiarization with the items, participants performed a picture–word matching task. They saw two pictures depicting either two nouns or two verbs and listened to a word naming one of the two. They had to select the picture that matched the audio by pressing the right or the left button on the game controller. Each button press replaced the pictures with a new pair and a new trial began. In order to move on to the test, participants had to obtain a minimum of 25 correct responses out of 30. If this was not the case, they were indicated to repeat the task. Participants received feedback on their responses.
Following the picture–word matching task, learners were explicitly taught the grammatical rule of the language. 3 The rule was visually presented on the screen and accompanied by example cognate or non-cognate SOV and OSV sentences not included in the test stimuli. Learners of the cognate version of the language were presented with example sentences made up of cognate words – see example (3) – and learners of the non-cognate version of the language were presented with the equivalent example sentences but made up of non-cognates. To make sure that, even if there were group differences in rule instruction, cognate and non-cognate learners understood the rule equally well and that this did not affect their performance in the test, the experimenter explained the rule in person to participants and clarified any terminological or other questions that they had.
(3) In this language, sentences are always transitive and verb-final. The subject is marked with -ak and the object is marked with an -a. For example, saying Pilotuak enfermera pintatu du is the same as saying Enfermera pilotuak pintatu du. In these sentences, pilotu is the subject and enfermera is the object of the verb pintatu.
c Test
Just as in the pre-test, in the test the two groups of participants were simultaneously presented with two mirror pictures and an auditory sentence and had to select the picture that matched the audio using the game controller. Crucially, the same characters appeared in the two pictures that conformed to each trial (see Figure 2), so that the only way to successfully match a sentence with its picture was to apply the grammatical rule responsible for subject–object assignment. Overall, participants listened to 40 sentences (20 SOV and 20 OSV) made up of cognates or non-cognates, depending on the version of the language being learnt. All sentences were grammatically correct. We decided not to use a test including ungrammatical sentences (e.g. with a word order or case marking different from the one participants were taught) so that they could focus on deriving the correct interpretation of each sentence based on their grammar knowledge, as they would naturally do when exposed to their native language. Test trials were preceded by four practice trials (including two sentences from each condition not present in the test stimuli) to make sure that participants understood how to apply the rule learnt to perform the task. In this part of the experiment, participants did not receive feedback on the correctness of their responses.
d Post-test
In the post-test, both cognate and non-cognate learners again completed a sentence–picture matching task, but this time sentences were made up of cognate items different from the ones used in the test. Before the post-test, participants did not receive any vocabulary training. The procedure of the post-test was exactly like that of the pre-test and the test.
e Digit span test
Once the experiment was completed, participants were asked to carry out a digit span test based on the one used in Bild et al. (2002); the pdf of the digit span test is available in the OSF repository: https://osf.io/zwm7r/?view_only=5c259bde7fd147acbbb474cc7a21d670. Participants had to repeat by heart a set of increasing sequences of numbers verbally administered by the experimenter. Participants were asked to repeat a maximum of nine numbers and they had to do so first forwards and then backwards. The test finished either when participants repeated the whole list of numbers or when they failed to do so on two consecutive trials of the same length.
IV Data analysis
We used the programming environment R (R Core Team, 2022, version 4.2.2) to analyse the data yielded by the experiment (the data can be consulted in the OSF repository: https://osf.io/zwm7r/?view_only=5c259bde7fd147acbbb474cc7a21d670)
The results of the pre-test, the vocabulary learning stage, the test and the post-test were analysed using a series of generalized linear mixed-effects models. All models were fitted using the function glmer in the package lme4 (Bates et al., 2015). For the pre-test, we tested whether accuracy in the sentence–picture matching task was significantly higher for one of the two groups of learners. We fitted a model with Accuracy as dependent variable, Group (cognate learners vs. non-cognate learners) as independent variable, random intercepts by participant and item and a random slope of group by item. Contrast coding was used for the variable Group (with cognate learners coded as 1 and non-cognate learners coded as −1). For the vocabulary-learning phase, we tested whether accuracy in the picture–word matching task significantly differed for cognate and non-cognate learners. As in the previous analysis, the model fitted had Accuracy as dependent variable, Group as independent variable (with cognate learners coded as 1 and non-cognate learners coded as −1), by-participant and item random intercepts and a random slope of group by item. Models with the same specifications tested for an effect of Group of learners on accuracy in the sentence–picture matching tasks carried out in the test and the post-test. In the test, we additionally assessed whether cognate learners, on the one hand, and non-cognate learners, on the other hand, obtained comparable accuracy when matching SOV and OSV sentences to pictures. For each group of participants, we fitted a model with Accuracy as dependent variable, Word order as independent variable (OSV coded as 1 and SOV as −1), random intercepts by participant and item and a random slope of word order by participant.
Next, we examined whether accuracy for cognate and non-cognate learners significantly differed (1) from the pre-test to the test and (2) from the test to the post-test. In the first case, the model used had Accuracy as dependent variable, the interaction between Group (cognate learners vs. non-cognate learners) and Stage (pre-test vs. test) as independent variable, random intercepts by participant and item and two random slopes, of stage by participant and of group by item. Contrast coding was used for the variable Group (with cognate learners coded as 1 and non-cognate learners coded as −1). Treatment coding was used for the variable Stage with pre-test taken as reference level. In the second case, the model fitted had the same random and fixed effects structure, only that in this case the variable Stage (test vs. post-test) took test as its reference level.
Finally, we examined participants’ performance in the digit span test. Learners were given 1 point if they repeated correctly a sequence of numbers and 0 points otherwise. The highest possible score was 30 points. We used an independent-samples t-test to analyse the results of the task. To assess the magnitude of the effect of the t-test, we computed Cohen’s d. Following Cohen (1988), we considered a d of 0.2, 0.5 and 0.8 to be small, medium and large, respectively. Additionally, we calculated if working memory significantly affected cognate vs. non-cognate learners’ accuracy in the test and the post-test. To this aim, we fitted two generalized linear mixed-effects models (one for the test and one for the post-test) with the following structure:
We report the coefficients and their level of significance for each independent variable in each analysis. For all analyses, the significance threshold was set at p < .05.
V Results
The full output of all the statistical models conducted can be consulted in the OSF repository: https://osf.io/zwm7r/?view_only=5c259bde7fd147acbbb474cc7a21d670
1 Overview of cognate and non-cognate learners’ accuracy performance in the experiment
Table 2 presents descriptive statistics for cognate and non-cognate learners’ accuracy performance in the different stages of the experiment. As shown, the mean accuracy rate of both groups of participants increased throughout the experiment, with cognate learners consistently showing higher percentages of correct responses than non-cognate learners. Our research question investigated the effect that the use of a cognate or non-cognate vocabulary had on the application of an explicitly learnt L2 grammatical rule. In what follows, we examine whether, as suggested by the descriptive statistics, the status of the vocabulary significantly interacted with participants’ accuracy in their use of the rule throughout the experiment.
Descriptive statistics for the accuracy rates of both groups of participants throughout the stages of the experiment.
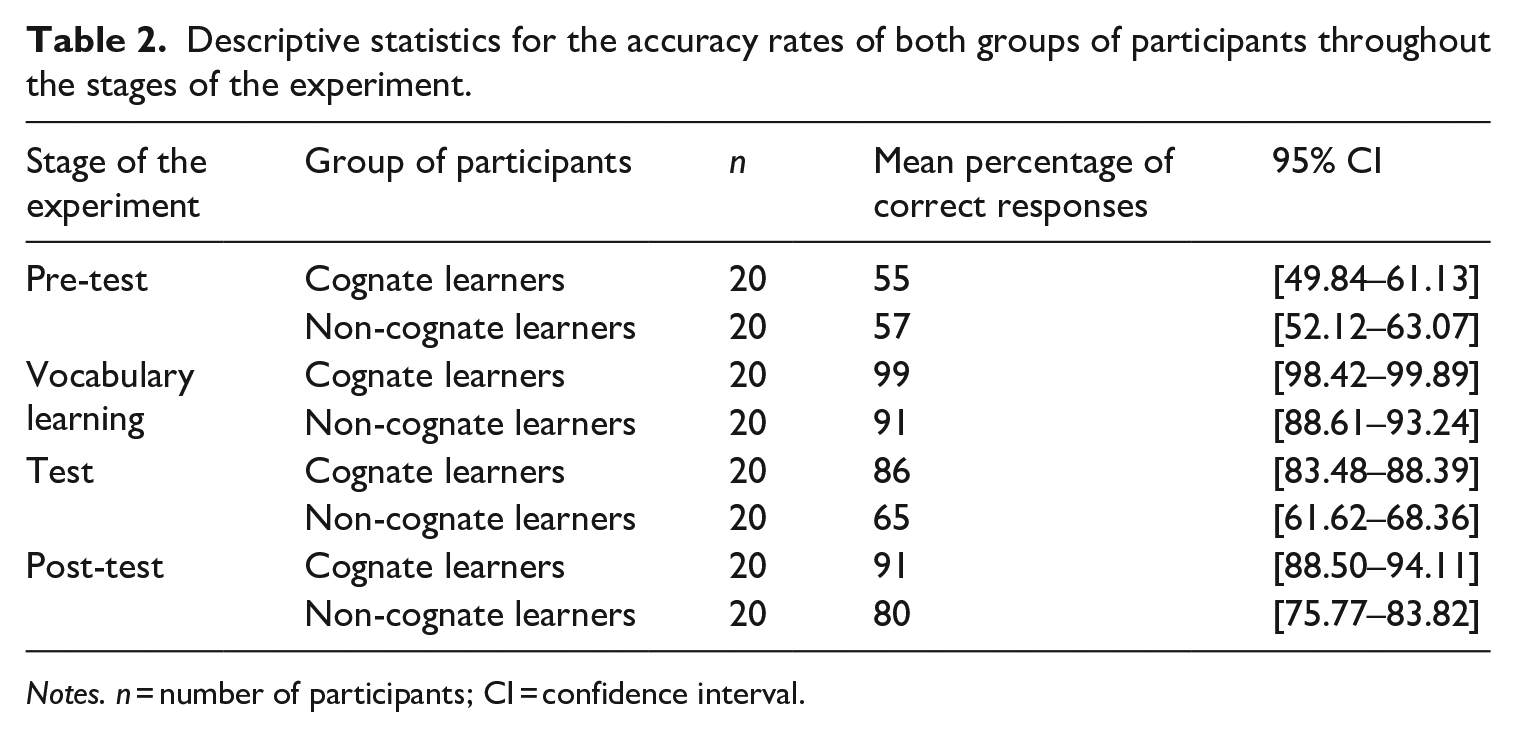
Notes. n = number of participants; CI = confidence interval.
2 Pre-test
The regression analysis yielded no significant effect of group of learners on accuracy (β = −0.05, SE = 0.11, z = −0.48, p = .63). This indicates that both groups were comparably accurate in the sentence–picture matching task. Since participants were Spanish natives without knowledge of Basque, we expected them to answer randomly to the task, i.e. we expected that cognate and non-cognate learners’ mean percentage of correct responses was close to 50%. As illustrated in Table 2, the two groups’ mean accuracy percentages were 55% and 57%, respectively. Given that participants came from parts of Spain where Basque is not spoken and that they reported never having been instructed in the language, we considered that, as required, they responded to the task randomly. The moderately high percentages obtained were attributed to the small number of items in the pre-test (n = 16).
3 Vocabulary learning stage
In terms of vocabulary learning, Table 2 shows that both groups of participants were highly accurate in the picture–word matching task testing vocabulary knowledge (mean accuracy percentage for cognate learners, 99%; for non-cognate learners, 91%). Yet, as hypothesized, matching cognates to pictures was easier than matching non-cognates to pictures, as shown by the fact that (1) accuracy was significantly higher for cognate than for non-cognate learners (β = 1.20, SE = 0.30, z = 4.06, p < .001) and (2) out of the 40 participants tested, just four non-cognate learners failed to achieve the minimum of correct responses in their first attempt to the task and had to perform it a second time.
4 Test and post-test
An analysis of participants’ performance in the remaining stages of the experiment indicated that cognate learners were significantly more accurate at applying the grammatical rule of the artificial language than non-cognate learners both in the test (β = 0.69, SE = 0.12, z = 5.53, p < .001) and in the post-test (β = 0.51, SE = 0.16, z = 3.18, p = .002). This suggests that, as hypothesized, cognates eased grammatical rule application.
5 Processing SOV and OSV word orders with cognates and non-cognates
In order to test whether the two word order conditions – SOV and OSV – were processed differently in sentences made up of cognates and non-cognates, accuracy in the test was calculated for each condition in both versions of the artificial language. When participants processed sentences with cognates, the mean accuracy rate for SOV (86.13%) and OSV (85.75%) sentences did not significantly differ (β = 0.05, SE = 0.13, z = 0.38, p = .71). When participants processed sentences with non-cognates, SOV sentences were on average more accurately matched to the corresponding picture (75.97%) than their OSV counterparts (63.39%). This time, the difference in performance was marginally significant (β = −0.30, SE = 0.16, z = −1.94, p = .05). This suggests that the general tendency to interpret the first animate noun in a sentence as the agent (agent-first preference), which usually makes agent-first sentences easier to process than non-agent-first ones (e.g. Gómez-Vidal et al., 2022; Zawiszewski et al., 2022), was more salient when lexical processing was harder.
6 Comparison of performance across the pre-test, test and post-test
Based on the hypothesis that processing sentences with cognates as opposed to non-cognates would facilitate the application of explicit knowledge of the rule, which is a necessary step for this knowledge to become proceduralized as part of the learning process, we made two predictions. First, we predicted that cognate learners would outperform non-cognate learners from the pre-test to the test. Second, we predicted that performance from the test to the post-test would improve more for non-cognate learners than for cognate learners, since the former went from processing non-cognate sentences in the test to processing cognate sentences in the post-test, but the latter already processed cognate sentences in the test.
a From the pre-test to the test
A generalized linear mixed effects model indicated that there was a significant interaction between the effect of Group of learners and Stage of the experiment on accuracy, β = 0.69, SE = 0.19, z = 3.60, p < .001. Post-hoc comparisons revealed that the accuracy rate significantly improved for both groups of participants but, as predicted, the improvement was significantly higher for cognate learners, β = 1.64, SE = 0.21, z = 7.95, p < .001 than for non-cognate learners, β = 0.36, SE = 0.17, z = 2.18, p = .03.
b From the test to the post-test
In this case, there was not a significant interaction between the effect of Group of learners and Stage of the experiment on accuracy, β = −0.13, SE = 0.18, z = −0.74, p = .46. There was a significant effect of Stage (β = 0.75, SE = 0.19, z = 3.97, p < .001), which suggests that accuracy from the test to the post-test statistically improved for both groups of participants. This was confirmed by post-hoc tests (cognate learners, β = 0.59, SE = 0.24, z = 2.45, p = .01; non-cognate learners, β = 0.79, SE = 0.17, z = 4.61, p < 001). As predicted, the magnitude of the improvement was higher for non-cognate learners than for cognate learners, as indicated by a larger estimated logit coefficient of the effect of Stage on accuracy for the former than for the latter. However, the lack of an interaction indicates that the difference between groups did not reach statistical significance.
7 Digit span test
The digit span test revealed that cognate and non-cognate learners had similar working memory capacities: cognate learners, M = 16.9, SD = 4.09, 95%CI = (14.96, 18.81); non-cognate learners, M = 18, SD = 3.89, 95%CI = (16.18, 19.82). An independent samples t-test confirmed that there was not a statistically significant difference between groups, t(38) = −0.87, p = .39, d = −0.28. In addition, working memory did not significantly affect cognate vs. non-cognate learners’ performance nor in the test nor in the post-test, as indicated by the non-significant interactions of the effect of Group of learners and Working memory scores on accuracy (test, β = 0.01, SE = 0.03, z = 0.22, p = .82; post-test, β = −0.01, SE = 0.04, z = −0.30, p = .77).
VI Discussion and conclusions
In this study, we showed that the application of an explicitly learnt L2 grammatical rule is eased by cognates. 4 Previous studies had only demonstrated the facilitative role of cognates on syntax processing (e.g. Hopp, 2017; Miller, 2014; Soares et al., 2018). This study expands these findings, for the first time, to syntax learning.
Prior to being explicitly taught the lexis and the rule of the artificial language, both groups of participants performed the pre-test’s sentence–picture matching task similarly. After explicit teaching of the cognate or non-cognate vocabulary and the rule of the language, participants’ performance significantly improved, with cognate learners outperforming non-cognate learners in the test. The versions of the artificial language learnt by the two groups of participants were identical except for the status of their lexical items, and participants’ working memory capacities were comparable and did not significantly affect cognate vs. non-cognate learners’ accuracy in the test. Considering this, the difference observed in the performance of both groups of learners can only be attributed to retrieval of the vocabulary items.
The cognate facilitation effect establishes that cognates are recognized and processed faster than non-cognates, and this is arguably the result of cross-linguistic activation (Costa et al., 2000; Dijkstra et al., 1999; Santesteban & Schwieter, 2020). The facilitatory effect of cognates has direct implications for the Lexical Bottleneck Hypothesis (Hopp, 2014), which assumes that the cost associated with L2 lexical processing could influence syntactic processing. More precisely, the hypothesis states that, in language processing, some aspects of lexical access precede syntactic structure building, so that a costly lexical processing may result in non-target syntax processing. In this sense, cognates might reduce demands on lexical processing, freeing the resources necessary for (successful) structure building.
Although the Lexical Bottleneck Hypothesis was postulated based on language processing evidence, according to Hopp (2018, p. 18) ‘the core tenets of the hypothesis can be incorporated into existing models of L2 sentence processing and acquisition’ (our emphasis). Hence, the facilitatory effect of cognates on syntax learning found in our study could generally be explained by Hopp’s hypothesis, even if some differences between the cognate effect on processing and on learning as studied in this experiment must be noted. In our study, we do not assume that cognates facilitated processing by freeing more resources for structure building, as in previous research. Instead, we argue that cognates alleviated demands on lexical learning and processing, allowing for more resources to access and use the (declarative) knowledge of the case-marking rule to process the sentences in the sentence–picture matching task, a process which, according to the Skill Acquisition Theory, would help internalize this knowledge (DeKeyser, 2015).
To be more specific, we argue that L2 non-cognate words had to be acquired from input, but L2 cognate words could simply be processed by co-activating their L1 translations, which were very well learnt in learners’ minds. This reasoning matches the view on lexical acquisition held by the Parasitic Model of vocabulary development (see, amongst others, Ecke & Hall, 1998; Hall, 1996, 2002). This model claims that the first step to learn an L2 (or L3) word is to establish a phonological and/or orthographic representation of it. On the one hand, if the learner’s lexicon does not contain a similar L1 word form, as in the case of non-cognates, a new phonological and/or orthographic representation will be created. Then, this L2 form will be connected to the lemma of its L1 translation equivalent, linked, in turn, to a conceptual representation. The lemma and conceptual representations of the L1 word will be accessed when processing the L2 non-cognate. On the other hand, if the learner’s lexicon contains an L1 word form similar to the one in the input, as in the case of cognates, the phonological and/or orthographic representation of the L1 word will be attached to a representation of the L2 word including only those features in which the two word forms differ, if any. When processing the L2 cognate, the lemma and conceptual representations of the L1 word will be accessed via the direct link between the L1 and the L2 word forms. Crucially, most or all of the cognate form will already be established in learners’ minds, but a new formal representation will have to be created for non-cognates.
Considering the above, we argue that cognate learners only truly needed to learn the artificial language’s grammatical rule, but non-cognate learners needed to learn the vocabulary and the rule of the language. Following explicit rule presentation, in the test’s sentence–picture matching task learners needed to process the cognate and non-cognate words and apply the rule learnt. We argue that processing the recently acquired non-cognate words required more resources than processing cognates, which benefited from the cross-linguistic activation of their formally similar L1 counterparts. Consequently, non-cognate learners had fewer resources left to apply the grammatical rule than cognate learners did. This would explain why non-cognate learners’ performance in the test was less accurate than cognate learners’ was.
Before turning to the results of the post-test, it is worth reflecting on how the vocabulary learning and the sequencing of tasks in the experiment could have affected the results of the test.
Cognate and non-cognate learners first learnt the cognate or non-cognate words. Then, they learnt the rule with example sentences made up of cognates or non-cognates, respectively. Finally, they had to apply the rule to cognate or non-cognate sentences in order to perform the sentence–picture matching task. Due to this order of tasks, successful rule learning and application was dependent upon learners remembering the meaning of the lexical items to which the morphological markers -ak and -a were added. First, to be able to correctly interpret the example sentences during rule presentation. Second, to be able to interpret the sentences and pair them with the corresponding pictures during the test. Accuracy in the picture–word matching task testing vocabulary learning was significantly higher for cognates than for non-cognates. This is not surprising, since, as mentioned in the introduction, cognates have been found to be learnt more easily than non-cognates throughout the learning span (De Groot & Keijzer, 2000; N. Ellis & Beaton, 1993; Lotto & De Groot, 1998; Rogers et al., 2015) and, in fact, we have even argued that, strictly speaking, the former do not need to be learnt. Yet, in light of this result, one could think that the advantage of cognate learners over non-cognate learners in rule application was due to differences in word knowledge. In other words, non-cognate learners could have learned the rule and could have known how to apply it just as well as cognate learners, but their poorer vocabulary knowledge may have caused them to perform worse in the sentence–picture matching task.
Before jumping into this conclusion, several points have to be considered. First, both groups mastered the vocabulary to a high degree of proficiency, i.e. they obtained more than 90% accuracy in the picture–word matching task, which shows that they were very good at associating the cognate or non-cognate words with their pictures. This suggests that cognate and non-cognate learners’ lexical knowledge was great and that the group difference in rule application observed was not due to differences in this measure. In line with this, learners’ accuracy in the picture–word matching task and in the test’s sentence–picture matching task was non-significantly correlated (cognate learners, r(18) = .05, p = .82; non-cognate learners, r(18) = .25, p = .30). Additional evidence comes from the analysis of cognate and non-cognate learners’ accuracy on SOV vs. OSV sentences. Cognate learners were comparably accurate when matching SOV and OSV sentences with pictures. By contrast, non-cognate learners were marginally more accurate when matching SOV sentences with pictures than when matching OSV ones. If the overall group difference observed in the test was simply a consequence of non-cognate learners having weaker lexical knowledge than cognate learners did, then there would be no reason to expect a difference in non-cognate learners’ accuracy on SOV vs. OSV sentences. That is, it should have been equally challenging to identify the non-cognate words in the two types of sentences and, thus, perform the task accurately. Conversely, non-cognate learners’ marginally more accurate performance on SOV sentences than on OSV ones suggests that applying the rule was more difficult when sentences did not follow the default agent-first preference. In other words, this result suggests that the difficulty that non-cognate learners faced in the sentence–picture matching task was applying the rule, rather than identifying the lexical items. All in all, it is unlikely that poorer lexical knowledge explains the main group difference observed in the test.
Finally, the performance of both groups of learners significantly improved from the test to the post-test, when participants performed a sentence–picture matching task with novel cognate words. Yet, the difference in accuracy was more pronounced (even if not significantly) for non-cognate learners. While the amelioration attested in cognate learners was probably due to the fact that they were quite familiar with how to perform the task by the time they got to the post-test, the improvement attested in non-cognate learners can only be attributed, again, to cognates. In other words, when liberated from the cost of retrieving the recently acquired non-cognates, the task of applying the rule of the language to disambiguate the mirror pictures became much easier. In the present study, we wanted to conduct an experiment that allowed the testing of our hypotheses in a single experimental session, and, hence, we did not test longer-term effects of learning, for instance, by including a post-test with novel non-cognates. Still, this interesting question could be addressed in future studies.
In sum, this study provides an answer to the question of how second language learning can be eased and suggests how the cognate facilitation effect and its role in the Lexical Bottleneck Hypothesis could be extended from L2 processing to L2 learning. The finding that the use of cognates can facilitate the application of explicitly learnt L2 syntactic structures could have pedagogical implications for the teaching and learning of second languages. For instance, it could be appropriate to recommend the use of cognate words when grammatical structures are introduced for the first time in the L2 classroom. However, it is worth noting that this recommendation may not drastically alter current teaching practices or textbook designs, as established pedagogical wisdom already encourages the presentation of new grammar in easily comprehensible contexts, often utilizing familiar vocabulary. In spite of this, we would like to highlight the importance of emphasizing these established principles and extending them to encompass the role of cognates in L2 syntax learning.
Supplemental Material
sj-pdf-1-ltr-10.1177_13621688241254617 – Supplemental material for The impact of cognate vocabulary on explicit L2 rule learning
Supplemental material, sj-pdf-1-ltr-10.1177_13621688241254617 for The impact of cognate vocabulary on explicit L2 rule learning by Noèlia Sanahuja and Kepa Erdocia in Language Teaching Research
Footnotes
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported in part by grants from the University of the Basque Country (PIF19/08), the Basque Government (IT1439-22) and the Ministry of Science, Innovation and Universities of the Spanish Government (PID2021-124056NB-I00).
Supplemental material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.