
Abstract
Can we explain individual outcomes by referring to patterns observed in populations? Social scientists generally assume that we can, at least to a certain degree, and they study populations partly with that goal in mind. However, while patterns can be observed on the population level, which suggest that, on average, certain segments of the population are more likely to experience some outcome, it is impossible, on the individual level, to predict who will actually experience the outcome, even if the individual’s relevant characteristics are known. Thus, an interesting tension emerges: on the one hand, individual action and experience produces population-level patterns, while on the other hand, individual experience appears to be ‘inherently underdetermined’ and partly or largely due to luck or chance. Accordingly, this article considers the relationship between regularities and individual outcomes and to what extent it is desirable to construct models which can explain all the variance in outcomes, and the roles of true chance and what one might call ‘as-if’ chance in this. An empirical demonstration based on ALLBUS data explores these issues further. It uses the example of the graduate premium to discuss that, while there is a pattern where, on average, graduates earn more than non-graduates, there is a certain degree of individual-level deviation from this pattern (even after taking account of other relevant factors) which is partly due to chance. Patterns identified in data can provide the upper and lower bounds within which chance plays its part. The article closes with a discussion of implications for research and policy, and for the understanding of research findings by the general public.
Keywords
Introduction
Can we explain individual outcomes by referring to patterns observed in populations? Assuming that we can, at least to a certain degree, social scientists study populations partly with that goal in mind. One of the early scholars to consider patterns in populations was the 19th-century Belgian scientist Adolphe Quetelet who turned his attention to regularities found in data aggregated from individual actions. Goldthorpe (2007) described these patterns as ‘probabilistic regularities’ which are ‘observable only at the level of the aggregate or “mass”, and relating to phenomena that, when viewed more locally, appeared as being inherently underdetermined’ (p. 194). An example is suicide, an early sociological topic analysed by Durkheim, amongst others. Any individual suicide was difficult if not impossible to predict – hence ‘inherently underdetermined’ – but patterns emerged suggesting that suicide was more common in certain groups or cultures than others. Such regularities, rather than the ‘states and behaviour of the particular individual members of such populations’, form the explananda of sociology which Goldthorpe (2015) considers to be a ‘population science’ 1 (p. 12), while noting that the population-level regularities stem from individual actions.
Other population sciences such as epidemiology grapple with similar issues: while patterns can be observed on the population level which suggest that, on average, certain segments of the population are more likely to develop certain forms of cancer, it is impossible (at least on the basis of current knowledge), on the individual level, to predict who will actually get cancer, even if the relevant characteristics are known. This makes it seem, from the perspective of an individual, as though luck or chance are the main – or even the only – explanatory factor for disease, notwithstanding the population-level regularity (e.g. Davey Smith, 2011; Davey Smith et al., 2016).
Thus, an interesting tension emerges: on the one hand, individual experience appears to be ‘inherently underdetermined’ and partly or largely due to luck or chance, while on the other hand, individual action and experience produces population-level patterns despite their apparently haphazard emergence. The aim of this article is to explore this gap between population-level and individual-level experience. To do so, I first consider what we can learn from patterns in data, as well as the limits of what they can tell us about individual experiences. One way of framing this is to say that variation in outcomes cannot be (fully) explained by drawing on variation in characteristics of the individuals experiencing them, despite researchers’ best efforts to increase the variance explained by their models. Since chance is one of the reasons why it is impossible to explain all the variation in outcomes, I next discuss the role of true chance and what I will call ‘as-if’ chance in limiting what we can learn from models based on patterns in populations, drawing on existing sociological and philosophical work in this area. This is followed by an illustration of these points by drawing on an empirical demonstration using ALLBUS data. I close with a discussion of implications for research and policy, and for the understanding of research findings by the general public.
Before I go on, a brief comment on the relationship between prediction and explanation, since I use both terms throughout this article: the terms are sometimes used as if they were interchangeable, but they are not: predicting an event or an outcome involves applying the knowledge available about previously studied cases’ outcomes to predict future outcomes in other, similar cases. Given uncertainty about future events, this involves estimating the probability or a range of probabilities with which a future outcome may be expected to occur. Explaining an event or an outcome which has already occurred is to trace the causal processes which led to the outcome of interest. The same factors (independent variables) and population-level patterns formed by them can be used in both activities, and prediction may draw on knowledge about causal processes (even if it often does not do so), but conceptually, they are not the same thing.
Population-level patterns and individual outcomes
Many sociologists are interested in the question ‘of’ how population-level patterns can be explained by referring to social processes, rather than to individual characteristics (e.g. Goldthorpe, 2015: chapter 2). Early on, Quetelet described regularities such as ‘marriage rates, illegitimacy, suicide, crime, and so on’ (Goldthorpe, 2007: 193). These regularities were probabilistic rather than deterministic because it was – and is – impossible to find, in the social domain, patterns and relationships which apply to every individual (or every population, for that matter) without exception. However, to Quetelet (and other early sociologists), it was remarkable that such patterns existed at all, since they had not expected phenomena such as crime rates or suicide rates to be relatively stable over time. Treating them probabilistically allowed for the fact that individuals are subject to more than one causal process, and that causal processes other than the one giving rise to the observed regularity also affect individual outcomes. Thus, while social processes are a core sociological topic, sociologists recognise that ‘socio-cultural phenomena have themselves to be accounted for, in the last analysis, in terms of individual action’ (Goldthorpe, 2015: 32, my emphasis). Theory can be used to account for either population-level regularities or to predict individual outcomes. And of course, whether some explanation based on findings from population-level applies to an individual or not is independent of whether the individual was included in the original study: they may have been among the exception to the probabilistic regularity, a point well-understood by experimental social scientists: Just as there are issues with scaling-up, it is not obvious how to use the results from RCTs [randomized controlled trials, a form of experiment] at the level of individual units, even individual units that were included in the trial. A well-conducted RCT delivers an ATE [average treatment effect] for the trial population but, in general, that average does not apply to everyone (Deaton and Cartwright, 2018: 16, my emphasis; see also Shadish et al., 2002: 247; Subramanian et al., 2018).
One of the reasons an average does not apply to everyone is chance, on which more below. Clearly, as noted in the ‘Introduction’ section, the relationship between patterns and individual is not a unique problem for sociologists; epidemiologists are also among those who face similar issues. As in sociology, attempts to understand individual outcomes by drawing on patterns were made in medicine in the 19th century, though not without resistance from physicians who thought that the individual ought to remain the focus of diagnosis and treatment rather than aggregates, as Hacking describes: a group of four mathematicians, reporting to the Academy of Sciences, concluded that in statistical affairs . . . the first care before all else is to lose sight of the man taken in isolation in order to consider him only as a fraction of the species. It is necessary to strip him of his individuality to arrive at the elimination of all accidental effects that individuality can introduce into the question (Hacking, 1990: 81).
This sums up the tension between the interest in individual outcomes and the use of statistical patterns to understand and predict such outcomes.
A related issue is that understanding how a distribution arises may be helpful for understanding or predicting an individual’s outcome, but the two are not the same thing. Lieberson (1998) comments on this point in the context of rare events, that is, those that occur in only a small minority of cases: understanding why an event is rare and why it happens is not the same thing. For example, illiteracy is fairly rare in Western societies. Reasons for this include universal basic education and the need for being able to read to function in society. But this does not explain why any particular individual does remain illiterate despite the presence of structural factors which make illiteracy rare. Nevertheless, it is necessary first to understand why the event is rare – an explanation on the population level – before we can understand why it did actually come about in any given individual. Thus, it is important always to be clear about the level of one’s analysis: are we trying to explain patterns observed on the population level, or are we trying to explain or predict an individual’s or a type of individual’s outcome? To do so, we may draw on some of the same factors, but some will differ for the two kinds of activity. This point also applies more generally, not just in sociology.
How are these ideas put into practice by quantitative social scientists modelling outcomes of interest? Quantitative social scientists aim to maximise the variation in outcomes
2
explained by their models. This is essentially an attempt to reduce the gap between population-level patterns and individual-level explanations and predictions. By taking account of as many individual characteristics as possible, differences in whether or not the outcome is displayed can be traced back to differences in these characteristics. Thus, the quality of an explanatory model is assessed by reporting the variance it explains using individual characteristics, with ‘better’ models explaining more variance. One way of achieving this is to add more individual characteristics to a model. It is commonly accepted that, in practice, no model will fully explain the variation in outcomes, but an implicit assumption is that this could be achieved in principle using better data, reducing measurement error, including yet more individual characteristics, and so on. However, this may be misguided, since there may be theoretical and substantive reasons why a model cannot explain 100% of the variance, a point well made by Lieberson: How important is it anyway to account for as close to 100 percent of the variation as possible? In particular – above and beyond issues of measurement error, sampling, and other procedural problems – to what degree is it reasonable to expect a perfectly complete theory to account for less than all of the observed variation between units in the dependent variable of interest? (Lieberson, 1985: 93).
Lieberson’s discussion draws partly on Spilerman (1971) who distinguishes ‘structural conditions’ and ‘precipitating incidents’ to explain why a model may not be able to explain all variance. Structural conditions form the context for events, and they can be analysed in terms of ‘community level variables’, while precipitating incidents determine whether an event actually occurs (p. 433). The latter are or can appear to be random which is why, according to Spilerman, explanatory models fall short of explaining the full variance. Lieberson, writing 14 years later, notes that ‘to my knowledge, the style of thinking represented in Spilerman’s (1971) paper has not been taken up’ (p. 96). Arguably, the same might be said now, over 50 years after Spilerman’s paper appeared, since the aim of explaining as much variance as possible rather than considering first how much variance may conceivably be explained seems to be the dominant mode of proceeding.
Assuming then that chance, however, understood, plays a part in human experience, the answer to Lieberson’s question will be that it is perfectly reasonable for a theory not to account for all of the observed variation since chance produces some part of it. Thus, I turn to this issue in the next section.
True chance and ‘as-if chance’
In the previous section, I have described the gap between population-level patterns and individual outcome explanations. One reason why this gap arises is that it is usually not possible to include all relevant factors in a study, so that differences between cases with the same risk factors but different outcomes are in fact due to further risk factors or mitigating factors that also have an impact on the outcome under study. But, as we have seen, even if it were possible to include all relevant factors, a gap would remain, since chance or luck – the focus of this article – are also involved in producing social outcomes. This makes perfect explanations impossible. Chance may be understood either as true, stochastic chance, or as ‘as-if’ chance. Outcomes arising from true chance are those produced by devices such as lotteries, that is, they are completely random and unpredictable. They affect individual outcomes in real life, not just in experimental settings or thought experiments: for example, ‘lotteries are sometimes used as a socially accepted means of distributing resources’ (Shadish et al., 2002: 275), for example, to allocate scarce places at a sought-after school. Winning an actual lottery is of course another example, albeit one that happens to hardly anyone. If it does, it happens at random, that is, it arises from true chance (though conditional on having bought a lottery ticket), but it has the potential to change an individual’s life course profoundly. This is the sort of scenario where a full model would not be able to explain all the variance, as discussed in the previous section: if a lottery is used in allocating scarce school places, no amount of information about the parents or their children would be sufficient for explaining which particular child enters the school, since the lottery introduces a chance element to the process. Salmon (1971) discusses such stochastic processes, noting that having a low expected/predicted outcome probability does not mean something has not been explained. Salmon’s reasoning, applied to the relationship between smoking and lung cancer by way of example, would be as follows: we know that non-smokers only very rarely develop lung cancer, and among smokers, some do and some do not. However, the fact that not all smokers develop lung cancer does not mean that smoking is not a cause of lung cancer. True chance being at play here would mean that, among the smokers, it is impossible to predict who will go on to develop the disease and who will not. Of course other factors are conceivable that characterise a group of smokers who are more susceptible to lung cancer than others, thus increasing the probability for such a sub-group. But Salmon also implies that there are situations where no further subdivisions of groups known to be susceptible to experiencing the stochastic processes are possible. In other words, once we know that someone belongs to such a sub-group, we cannot improve our prediction of whether or not they will experience the outcome beyond the probability of the stochastic process. Knowing that someone is eligible for the school place lottery and that they have entered the draw constitutes the full information available for predicting the likelihood of their obtaining a place at the coveted school, and that likelihood – or the variance explained by the other two factors mentioned – is less than one and will remain so, no matter what additional information we may obtain or how much we improve measurement precision etc.
Stochastic processes are not always as obviously identifiable as in the school place lottery example, and in practice may be indistinguishable from the other form of chance, which I have termed ‘as-if’ chance. This is particularly common. By it I mean chance encounters – coincidences 3 – which appear unpredictable but which are brought about by chains of events which each have their own causal determinants. Thus, they are unpredictable from the individual’s point of view, but they were explicable and predictable considered separately (Bandura, 1982, esp. p.749) (see also Spilerman, 1971: 441, who, drawing on Nagel, refers to as-if chance as ‘relative chance’: ‘Under relative chance, the random behavior observed at one level may have causal antecedents at a different conceptual level’.). As Hacking puts it: ‘We call it chance, but not because the event was uncaused. Chance is a mere seeming, the result of intersecting causal lines’ (Hacking, 1990: 12). So what is ‘chance’ is partly a matter of choice of focus. In addition, chance events – of either type – may be unpredictable, but once they are known to have occurred, their effects are not. For example, while it may be difficult to predict an event such as an accident during childhood, predicting the range of possible effects of such an experience on educational outcomes is easier.
Finally, true chance and as-if chance may have to be treated the same way in practice. Cooper and Glaesser (2016) discuss ‘generative randomness’ using the invented example of a lottery allocating university places to demonstrate that the resulting models retain an element of chance indistinguishable from other sources of error such as omitted variables, measurement, and sampling error. But – as discussed by Spilerman and Lieberson (see above) – this is not a deficiency of the models. Instead, it reflects social processes in the world. Cooper and Glaesser’s (2016) example involves true chance, but they note that as-if chance will have to be treated in the same way as true chance ‘given limited theoretical knowledge and limited access to data’ (p. 4). I close this section by quoting Hacking again to summarise the process of how the notions of chance and probability were introduced into our understanding of social processes:
During the nineteenth century it became possible to see that the world might be regular and yet not subject to universal laws of nature. A space was cleared for chance. . . . Something else was pervasive and everybody came to know about it: the enumeration of people and their habits. Society became statistical. A new type of law came into being analogous to the laws of nature, but pertaining to people. These new laws were expressed in terms of probability (Hacking, 1990: 1).
Data example: graduate premium
I now discuss some of the points made above applied to an example using real data from the ALLBUS. The data were supplied by the Gesis Institute (Gesis Leibniz-Institut für Sozialwissenschaften, 2020). The ALLBUS is a trend survey of the German population, with data collection having taken place every 2 years since 1980. I use all those cases from the ALLBUS who were between 35 and 40 years old in the 2018 wave of the survey. The variables of interest are monthly net earnings as the outcome (or dependent variable) and university degree as the focal causal factor (or independent variable). In addition, I consider gender and whether the respondent lived in West or East Germany. The choice of gender as an additional factor is due to the well-known difference in men’s and women’s earning, the gender pay gap. While its causes are subject to discussion, its existence is well-documented. The regional difference is relevant because, even more than 30 years after unification, there are regional disparities between the former Federal Republic of Germany (West, characterised by democracy and market economy) and the former German Democratic Republic (GDR; East, socialist form of government and planned economy). Dropping cases with missing data on the variables employed in the analyses and all those working less than 30 hours a week leaves 192 cases. 86 of them hold a degree, 106 do not.
The substantive topic is the graduate premium, that is, the amount by which graduates’ earnings are greater, on average, than those earned by non-graduates. Thus, I examine the cause ‘university degree’ and the effect ‘monthly net earnings’. Of course, it is obvious straightaway that even framing the topic in this way is an oversimplification of the complex processes affecting monthly earnings. My aim is to raise some methodological points within a substantive context of general interest rather than contributing to the substantive topic of the graduate premium.
The starting point is that graduates earn more, on average, than non-graduates. Non-graduates have a mean monthly income of €1818.68, for graduates it is €2858.21, that is, a difference of around €1000 a month. But of course, there is a large overlap: some non-graduates earn more than some graduates. Figure 1 illustrates both points for the ALLBUS respondents. In what sense, then, can we say that a degree causes higher earnings? What are the implications of the population-level regularity for the individual? Any individual deliberating whether to go to university may conclude either that doing so will increase their earnings compared to what they would earn if they did not go, or, alternatively, that they may as well not make the effort and suffer foregone earnings while at university since they cannot be sure to earn more money if they do choose to go to university anyway. Either conclusion seems, on the face of it, reasonable. Thus, it is not obvious that having a degree is a cause of higher earnings. For some individuals, it appears not to be. On the other hand, the fact that there is an average difference between the two groups does suggest that there is some connection between educational status and earnings which should not be discounted by individuals faced with the decision of whether to go to university.
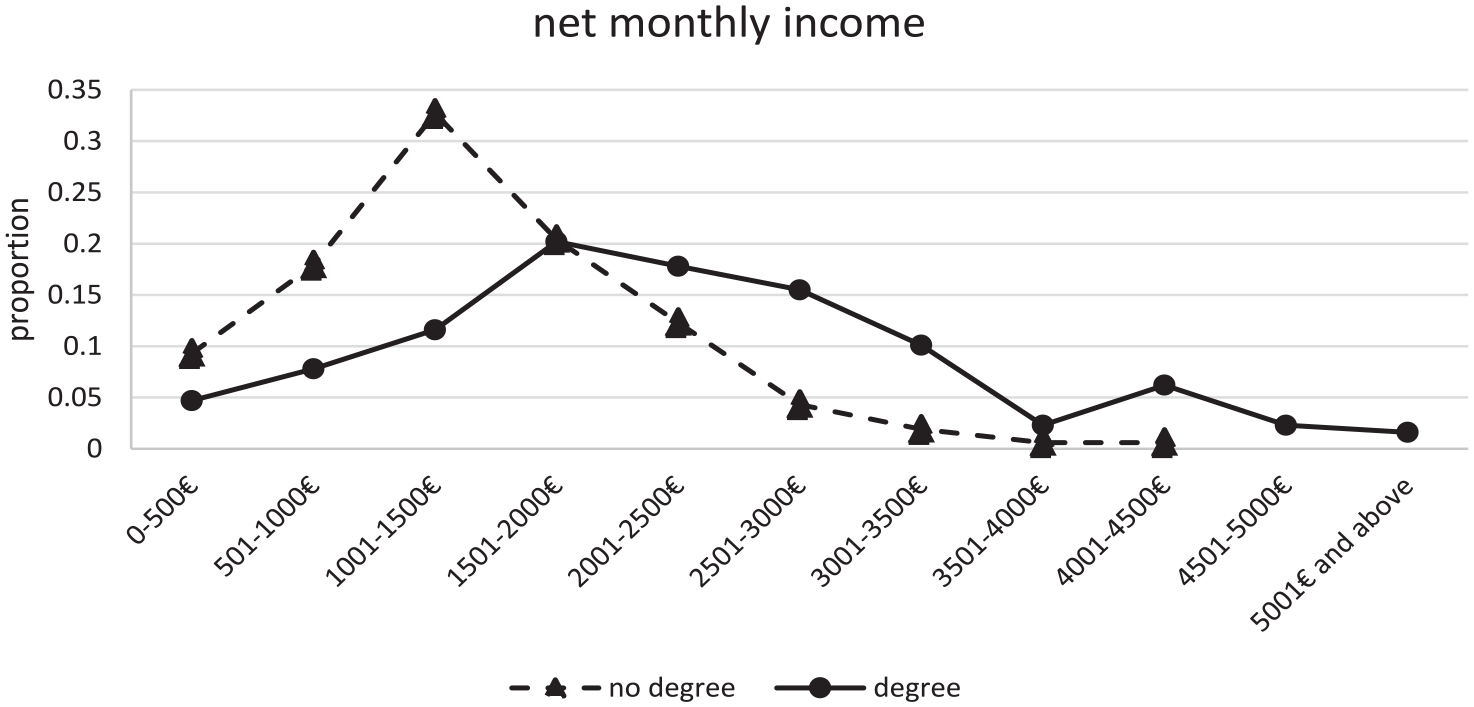
Graduate and non-graduate earnings.
The results of a regression analysis with just educational status as the independent variable and income as the dependent variable are shown in Table 1:
Regression with just degree as independent variable.
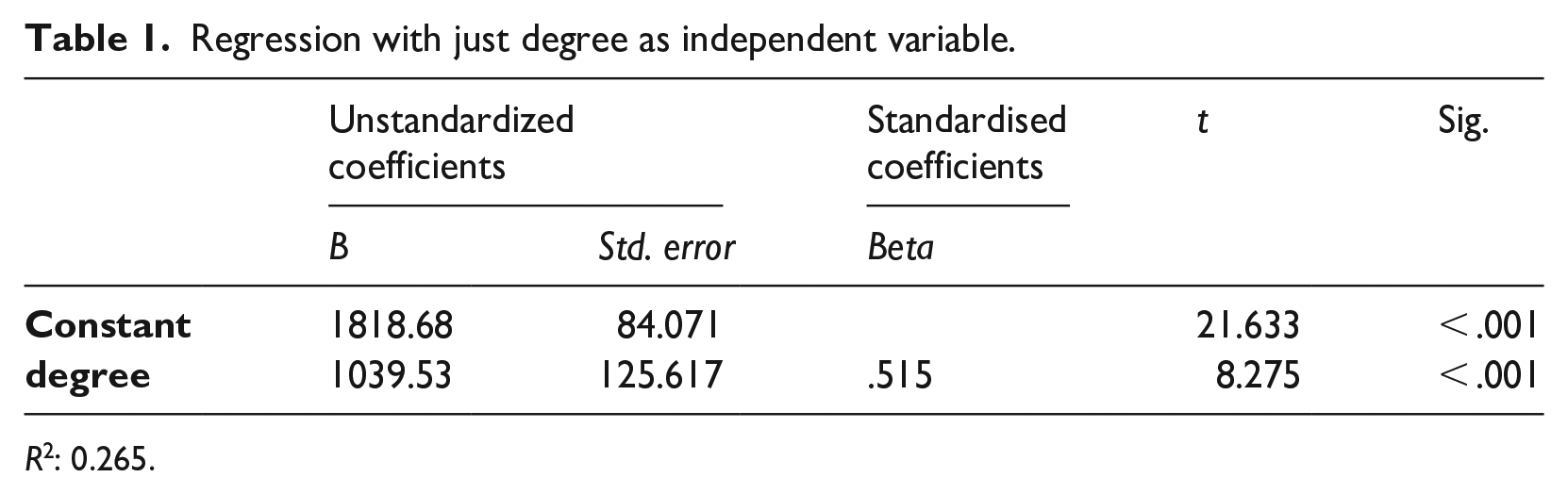
R2: 0.265.
The constant is the mean earnings for non-graduates, the unstandardised B coefficient gives the difference between non-graduates and graduates, that is, it may be said to constitute the graduate premium without allowing for any other factors which also play a part in determining earnings. In a next step, I add just two such additional factors, gender and whether the respondent lives in West or East Germany. Both are known to be associated with earnings, with men earning more than women, on average, and people in the West earning more than people in the East. Table 2 shows the results.
Regression analysis with degree, gender, and West/East.
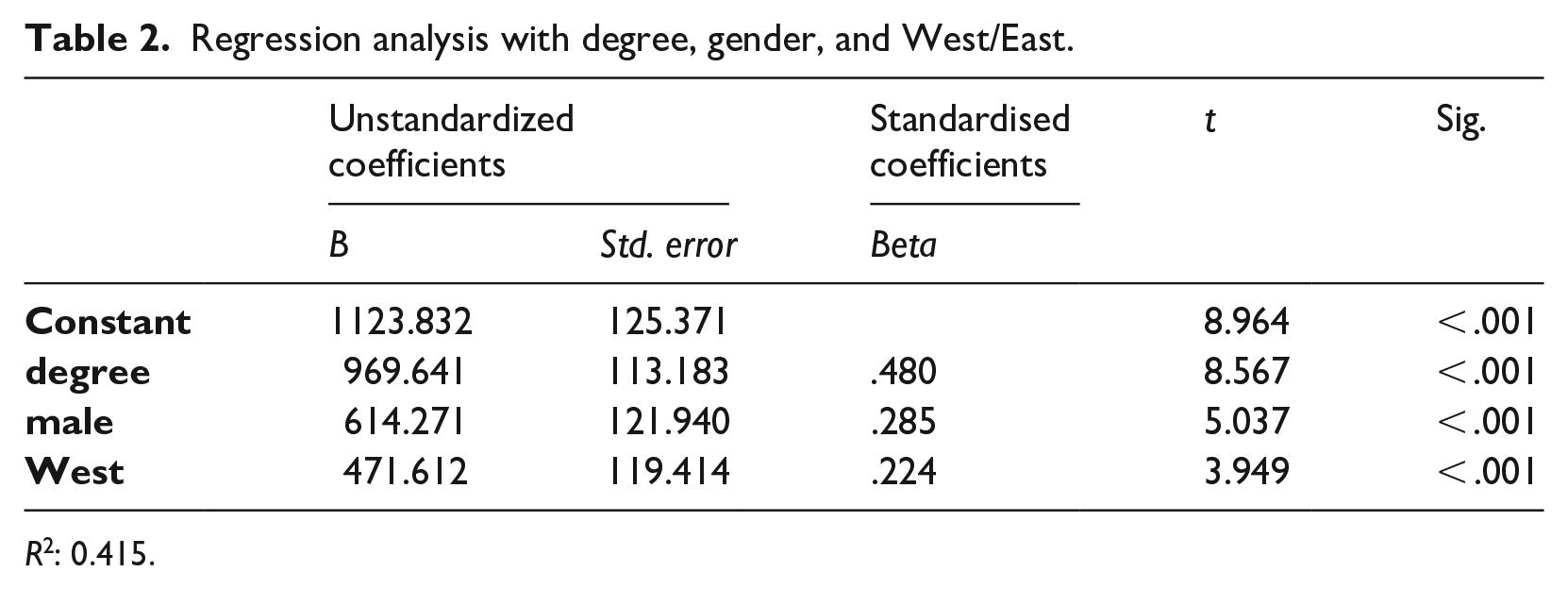
R2: 0.415.
Degree remains statistically highly significant, but the coefficients (B and beta) for degree are slightly reduced compared to the model with just degree as an independent variable. R2 is increased from 0.265 to 0.415. Thus, while this may be considered an acceptable level of model fit in a social science context, over half of the variance is left unexplained by this model. Being female is associated with lower earnings, as is living in the former GDR. The coefficients for all three independent variables are statistically significant. Clearly, the two additional factors I have chosen are also associated with earnings.
I now change my focus from variables to cases to enable me to discuss groups or types of cases. The three binary variables degree, gender, and East/West can be combined in eight different ways, that is, there are eight groups characterised by different combinations of degree, gender, and region. I have calculated the mean incomes for each group as well as the minimum and maximum income within each group. All indices are shown in Table 3, with the rows ordered in descending order by means, so that the groups with higher average incomes are nearer the top of the table.
Mean and range of income for eight groups of interest.
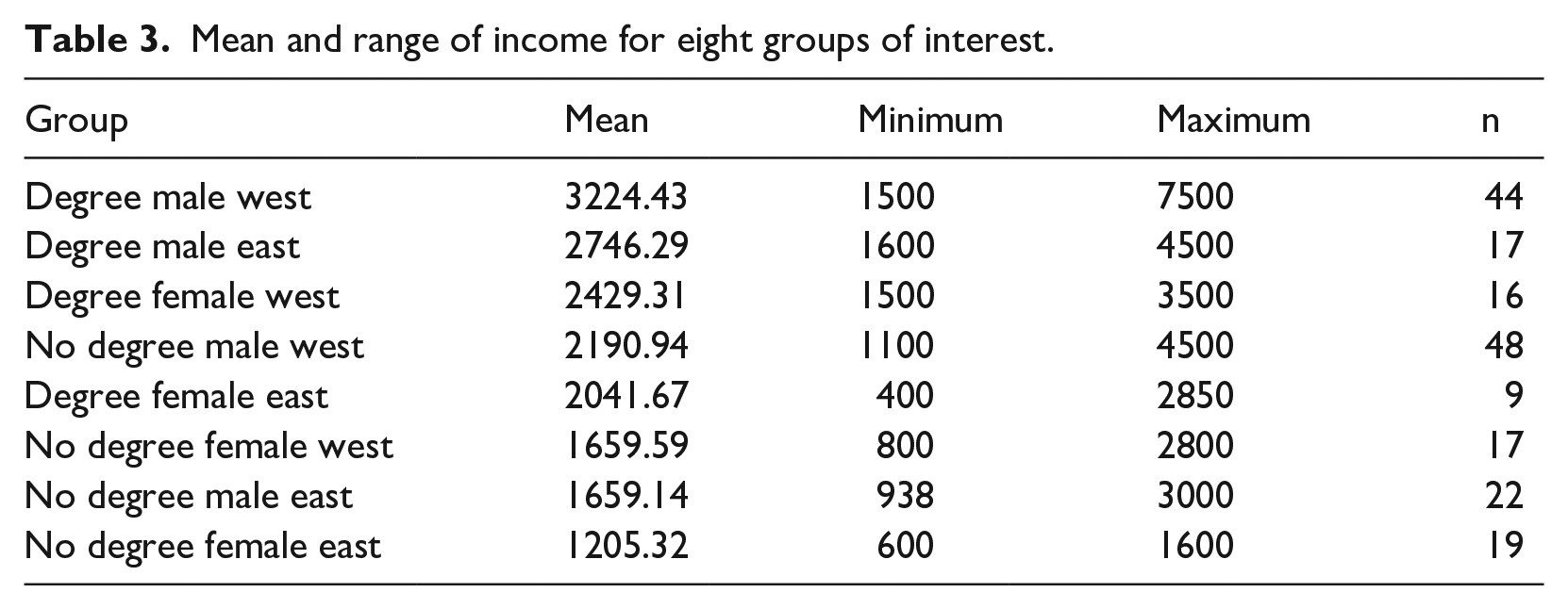
The observed means reflect the findings from the regression analysis: the more favourable characteristics an individual has, the higher their income, on average. Graduates earn more than non-graduates, men more than women, and Westerners more than Easterners, with degree more important than gender and gender slightly more important than region. In addition, the descriptive data shown in Table 3 also illustrate the overlaps between the groups 4 : the highest earner in the group with the lowest mean income, women without degrees from the East, earns more than the lowest earner in the group with the highest income, men with degrees from the West. So, even taking account of two additional factors associated with level of earnings did not eliminate the overlap between the earnings of graduates and non-graduates evident in Figure 1, and I reiterate my comment that, for any individual, a degree is no guarantee that they will earn more than they would without a degree. Making the model more sophisticated, for example, by including career length, occupational sector, region (other than West/East), and so on would, presumably, result in some groups not overlapping with some others. Nevertheless, considering the range of possible outcomes is a useful reminder that averages do not enable precise predictions for individuals. What the minima and maxima do is effectively provide the lower and upper bounds of earnings within which chance (and other factors) can play a part. Even an unlucky graduate man from West can expect to earn at least €1500, whereas even the luckiest non-graduate woman from the East cannot expect to earn more than €1600.
This is an example of a population-level regularity which is well-established and well-understood: the graduate premium has been demonstrated in many countries and at different points in time. The reasons why graduates earn more are to do with their higher and scarcer skills, compared to non-graduates, and the fact that they expect to be compensated for having spent a longer period of time in education, that is, without earnings. But this only goes some way towards explaining why a specific individual graduate earns more than a non-graduate. Other factors, as noted above, can be drawn upon to explain why the graduate earns more, but chance remains a factor, too: to begin with, chance will have played a part in the decision to study for a degree in the first place, but also, given the degree, what job opportunities came to the notice of the recent graduate, whether the industry which provides a good match for their skills happens to have jobs available at the right time, whether they are able and willing to move to a different region, their negotiating skills in setting their salary, and so on. Some of these are difficult to capture on a general, aggregate level, so that they will appear as chance factors in any model applied to the population level. Thus, this example illustrates why it can be impossible, and not actually desirable, to obtain a model that explains all the variance: as well as the structural factors which explain variance, as-if chance and idiosyncratic experiences and characteristics are at play which means that not all the variance can be explained.
Applying Spilerman’s notion of structural conditions and precipitating events to our example would suggest that the mean, minima and maxima identified for each group constitute the structural conditions, that is, the range of possible salaries for an individual of this type, with coincidentally hearing about a job opening, spells of part-time work or career breaks, health problems and the like constituting the precipitating events which determine where within the range an individual’s salary will be (or indeed whether it falls outside the range identified on the basis of other individuals who share the same characteristics). It is worth bearing in mind that of course precipitating incidents include those which produce the observed regularity, that is, the most common experience for graduates (certainly those in good health and full-time work with no career breaks) is to find an appropriately remunerated position, and for non-graduates to be largely restricted to lower-paying jobs.
Conclusion
Discussion
The aim of this article was to discuss the relationship between individual outcomes and population-level regularities. The reason I noted that there is a ‘gap’ and that ‘tension’ arises between the two is that, seemingly, there is a contradiction: population-level regularities are the result of individual actions, and therefore, it ought to be possible to explain them by referring to individual actions. However, individual actions cannot be predicted perfectly from population-level regularities. This is why the latter are best understood as probabilistic regularities, in the sense that they give, for an individual with certain characteristics, the likelihood of him or her experiencing a particular outcome, with the remaining variability in outcomes due to real chance as well as as-if chance.
I noted in ‘Population-level patterns and individual outcomes’ section that understanding how a distribution of some outcome arises is not the same as understanding why a particular individual experiences it. Applied to my example, the graduate premium, it would seem helpful to determine, first, the graduation rate in a particular society and during a particular period. This is not a fixed quantity, and changes in the graduation rate may be explained by referring to factors such as political decisions concerning funding for universities, the availability of a pool of people suitable and willing to take up university study, and the availability of alternative forms of education. Thus, it seems likely that the graduate premium – the focus of interest – is changeable, given that the value of a degree at least partly depends on how common it is, that is, a degree is a positional good (Hirsch, 1976). Only once the size of the graduate premium relevant for the society and historical period the individual finds themselves in has been identified (or estimated, to use a more careful term) can we begin either to predict or explain a particular individual’s level of earnings.
This is where chance comes into play: having considered all other known factors relevant for earnings, we have to allow for the role of chance. Chance will affect all individuals’ experiences, but the way in which it does so will vary. The minima and maxima of earnings for different groups described in ‘Data example: graduate premium’ section (Table 3) set the boundaries within which chance plays out for an individual belonging to the relevant group. Another way of looking at this is described by Bandura (1982: 750) who refers to Pasteur’s adage ‘chance favors the prepared mind’. That is, while chance encounters or events may be random, the effects they have depend on an individual’s characteristics. Some may be more willing than others to change course as the result of a chance encounter, and some – in my graduate premium example – may be more able or willing than others to employ their degree to increase their earnings. On the face of it, the resulting differences look like chance.
Chance in outcomes such as the graduate premium usually takes the form of as-if chance since the chance events affecting earnings will have their own causal explanations. In a previous study (Glaesser, 2015), I used population-level data to identify patterns concerning educational decision-making, and I then interviewed individual cases either conforming to the population-level regularity (‘typical’ cases) or deviating from it (‘deviant’ cases). Once more details were known about the ‘deviant’ cases, it was possible to explain their trajectories and the unexpected outcome did not seem unexpected any longer. But it would be difficult if not impossible to find summarising patterns of all the events or encounters which shaped their trajectories, so that the unexpected outcomes seem to be due to chance while only the population level is considered.
Implications
Generally speaking, models which explain more variance are considered ‘better’ than those explaining less variance. This is because it seems that explaining more variance is equivalent to a better understanding of the causal processes leading to an outcome. However, the danger of attempting to increase variance explained at any cost is that the role of chance for the outcome is underestimated and/or ignored, and that independent variables are included which happen to improve model fit for one particular set of data, but which turn out to have been no more than chance factors once new data are acquired to which the model is applied. This danger is greater if not enough attention is paid to theory and underlying mechanisms. 5 An alternative approach might be to assess the bounds within which chance will play a part for different types of cases, and to consider whether some groups of cases are more likely to be affected by chance. In the medical context, this might mean that non-smokers may be considered fairly unlikely to develop lung cancer (unless they have been exposed to other carcinogenic substances), and if they do, this will be a chance event with a low ceiling on the likelihood of occurring, whereas the ceiling for smokers is higher. But within these bounds, chance plays a part for both groups.
For policy-makers, it is important to be clear about the level any intervention is aimed at. Increasing graduation rates may be desirable because of a society’s needs for a highly skilled workforce, and interventions aimed at achieving this may include improving schooling, so that school-leavers are better prepared for university study, providing counselling, so that university courses can be chosen appropriately, funding universities, so that they are able to teach students successfully, and so on. But the advice given to an individual unsure about whether or not to go to university ought to take account of this person’s particular characteristics and their individual likelihood of success as well as, to stay with the graduate premium example, their likely earning potential given different courses of action, while reminding individuals that even taking account of all these things will not provide certainty as to their particular outcome, and that chance plays a part. In the medical context, there are some interventions known to reduce the incidence of certain illnesses within a population, but medical advice and treatment for an individual will draw on different forms of knowledge. The practitioners giving the advice and treatment will have to remind the individuals (and themselves) that their advice, while based on the best available knowledge, cannot offer certainty regarding the outcome given the role of chance.
Finally, while of course people are well aware of the role of chance, luck, serendipity, fortuity or whatever term is employed, it might be useful to stress the role of chance more when researchers (or science journalists) report scientific findings (see, e.g. Gustafson and Rice, 2020, for an overview of the range of effects of communicating different types of uncertainty). When the Covid vaccines were first rolled out to the general population, some people were surprised and dismayed to find that they had contracted the disease despite their immunisations. A clearer communication of what certain levels of effectiveness mean, and what it means that one’s risk of disease is greatly reduced rather than eliminated, might have been helpful. Similarly, anecdotes abound about lifelong smokers who lived to an old age without developing cancer or any of the other diseases associated with smoking, so that it is important to make clear what it means to be at an increased risk of developing a disease and how to lower this risk (Blastland, 2020). While understanding how scientific knowledge develops and what it is based on is important for anyone, an understanding of the limits of such knowledge is equally important.
Footnotes
Acknowledgements
The author thanks Barry Cooper for his very helpful comments on this paper. The author also thanks the Gesis Leibniz-Institut für Sozialwissenschaften for supplying the ALLBUS data.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.