
Abstract
The use of artificial intelligence in Critical Infrastructure Systems has increased substantially, having evolved to become both technically possible and financially beneficial. Yet there is an emerging consensus that the consideration and management of artificial intelligence-related risks in Critical Infrastructure Systems have not been commensurate with its rapid growth. Our surveys have identified that generalised artificial intelligence principles such as those promoted by the Organisation for Economic Co-operation and Development are alone not fit for purpose in guiding use of artificial intelligence in Critical Infrastructure Systems. Evaluation is an important aspect of that, and we argue for the development of a foundational approach suited to evaluation of artificial intelligence-enhanced Critical Infrastructure Systems as a base to further research and improve practice. This study develops a novel conceptual framework for evaluation of artificial intelligence-enhanced Critical Infrastructure Systems, based on theory adaptation of Value-Focused Thinking. The framework offers simplicity and additional functionality over the default principles-based framework.
Keywords
Introduction
Critical infrastructure is essential to the functioning of society. Without infrastructure such as power, water, sanitation, communications and transport infrastructure, our societies would quickly descend into chaos. Critical infrastructure has been clearly identified under the European Programme for Critical Infrastructure Protection and the U.S. National Infrastructure Protection Plan. Alcaraz and Zeadally (2015) have succinctly summarised the critical infrastructure inclusions for both jurisdictions. This infrastructure is the focus of our study.
The use of artificial intelligence (AI) in Critical Infrastructure Systems (CIS) such as energy (Wang et al., 2019), water (Fu et al., 2022), wastewater (Zhao et al., 2020), food production (Kakani et al., 2020), transport (Nguyen et al., 2018) and service centres (McLeay et al., 2021) has become widespread. McMillan and Varga (2022) provide evidence of an exponential growth in use of AI within transport, energy, telecommunications, water and wastewater infrastructure systems. Their review reveals this rapid and recent increase in AI use within these infrastructure systems is directed towards critical aspects of service provision such as service demand, supply forecasting, forecasting system safety, routing in telecommunications and transport systems, security of infrastructure networks, monitoring infrastructure condition and predicting the need for preventive maintenance. Yet evaluation theory and practice for these AI interventions has not been sufficiently developed, resulting in the possibility of significant risk to society.
Concerningly, the scholarship has focused on the utilisation of AI in the audit or evaluation process rather than evaluation of the impacts of AI utilised in the system (Fedyk et al., 2022; Nielsen et al., 2025; Wassie and Lakatos, 2024) with few exceptions (Leeuw, 2025; Montrosse-Moorhead, 2023; Rinaldi and Nielsen, 2025). AI interventions to critical services offer immense benefits such as efficiency and reliability. However, deficiencies in AIeCIS have the potential for many harmful impacts such as injury, deaths, financial costs, failure to meet social objectives and decay of trust. Consideration of such risks and their management has not been commensurate with the rapid growth in the use of AI (Doorn, 2021). We therefore support the argument, first raised in the evaluation community by Montrosse-Moorhead (2023), that the evaluation literature must similarly move to establish support for the efficient and effective evaluation of AI-enhanced systems and note Rinaldi and Nielsen’s (2025) call for work in this space to continue. Importantly, because of the inherent high risk to human life, well-being and economic prosperity, immediate attention should be given to the evaluation of AIeCIS.
An array of principles to be applied to the design and implementation of AI interventions is emerging (Felzmann et al., 2020; Gabriel, 2020; Hassija et al., 2024; Jobin et al., 2019; Li et al., 2023; Taeihagh, 2021) and there are natural differences in opinion about their usefulness. We have a body of 23 evaluation approaches systematically described by Stufflebeam and Coryn (2014) expanded to 42 approaches distributed across design, use, theory, hybrid and emerging categories (Lemire, 2024), to evaluate various interventions. Notably, principles-focused evaluation (Patton, 2017) has emerged; an approach which aligns very conveniently with the proliferation of principles for design and implementation of AI interventions previously mentioned. In addition, many authors have called loudly for literature to move from merely advocating the principles of AI to practising those principles (Jobin et al., 2019; Kaur et al., 2022; Laine et al., 2024; Palladino, 2023; Thiebes et al., 2021). We also note that traditional systems engineering methods of evaluation during the design phase are considered deficient when applied to AI-enhanced systems (Vanderlinde et al., 2022) because of the probabilistic nature of AI (Hassija et al., 2024; Holzinger, 2021), its susceptibility to learning data quality (Holzinger, 2021), its complexity (Hassija et al., 2024; Holzinger, 2021) and in some instances compromised algorithm transparency (Hassija et al., 2024). These characteristics often result in issues with the explainability and trustworthiness of AI.
CIS are complex human-asset systems essential to the functioning and safety of society and are bestowed trust to perform this important role. Each system is a set of elements standing in interrelation (Bertalanffy, 1969, p 38) that act together to achieve an objective. Accordingly, each of the many elements of these complex systems presents evaluators and investigators with the possibility of deficiencies, particularly for those elements where changes have been applied. A tragic example is changes to the Boeing 737 MAX Maneuvering Characteristics Augmentation System (MCAS), the probable cause of the loss of numerous lives in two separate accidents (Komite Nasional Keselamatan Transportasi Republic of Indonesia, 2018; The Federal Democratic Republic of Ethiopia Ministry of Transport and Logistics, 2022), the basis for the worldwide grounding of Boeing 737 MAX aircraft for an extended period, and the main reason for loss of confidence in Boeing signified by the subsequent fall in Boeing share price.
Although events like this are rare, serious CIS failure modes are abundant. For example, the opportunities for collisions between the trains of a typical large city railway system are copious. Similarly, there are many possible ways for water systems in an urban setting to become dangerously contaminated and there are multiple means of system failure through which city wastewater systems could seriously impact the environment, public health or both. It is the functional integrity, orchestrated system resilience and culture of accountability surrounding the use of these systems that prevent countless serious failures. However, the impending AI enhancements to CIS significantly changes this landscape by introducing new forms of significant risk. Guidance for the evaluation of these risks and their control measures is scarce. Our article is dedicated to addressing this deficit with an evaluation tool backed by theory and example.
These horrific outcomes drive our objective, to propose and validate a conceptual theoretical framework for evaluation of AIeCIS, comprised of factors that matter to stakeholders at the time of evaluation. What matters to stakeholders of critical infrastructure, things like safety, service availability and cost efficiencies, have been explained by a significant body of scholarship (Koppenjan et al., 2008; Van Gestel et al., 2008; Vuorinen and Martinsuo, 2019) as values. A model that systematically and proactively assists decision-makers to achieve a strong alignment between values pertinent to critical infrastructure and the fundamental objectives of that infrastructure, the Value Focused Thinking (VFT) model, was formed by Keeney (1994, 1996a, 1996b) and developed in critical infrastructure case study research (Keeney and McDaniels, 1999; Pudney, 2010; Simon et al., 2014). The VFT model offers convenient insights into our objective of establishing a tool to assist theorists and practitioners evaluating AIeCIS. To meet that objective, our research is guided by the following question: In which ways do Value Focused Thinking (VFT), widely acknowledged governance principles for AI, and studies in critical infrastructure decision-making inform the development of novel conceptual theoretical frameworks for evaluating AIeCIS?
The remainder of this article is structured as follows. In Section ‘Background of the evaluation of AI-enhanced systems’, we set out the extant knowledge on evaluation of critical infrastructure which utilises AI. In Section ‘Methodology’, we explain and justify our research methodology. In Section ‘Findings and discussion’, we propose a framework to guide evaluations of AIeCIS and then we discuss the usefulness of the proposed framework to theorists and practitioners, with an example from Deutsche Bahn. Finally, in Section ‘Conclusions and future research’, we conclude by reflecting upon the extent to which our research has met the needs of evaluation theorists and practitioners, and we propose directions for further research.
Background of the evaluation of AI-enhanced systems
The widespread application of developed forms of AI to operational aspects of CIS has been a relatively recent phenomenon. This section provides a background on evaluation of AI-enhanced systems, currently thought by scholars to be relatively underdeveloped. We do this via a ‘selective review’ (Yin, 2016 [2015]: 72–73) examining reviews by others into the evaluation of AI-enhanced systems.
Arnold and Scheutz (2018) exposed the need for evaluation of modern AI systems and proposed a method for evaluation of AI in parallel with development but stopped short of proposing an evaluation framework. Our background investigations therefore start from 2018.
The evaluation community has proactively raised the need for the evaluation of AI used for policy and programme development. We refer to the workshop ‘Digitalization of Evaluations and Evaluation of Digitalization’ in 2023, and the set of publications dedicated to AI in evaluations (Nielsen et al., 2025).
Montrosse-Moorhead (2023) investigated evaluation criteria for AI use in evaluation. The article has addressed a considerable oversight. There were previously no proposed criteria for evaluating AI use in evaluation yet AI use in evaluation continues to rise. Montrosse-Moorhead applied Teasdale’s Criteria Domains Framework to a group of evaluation studies to arrive at eight criteria domains. We note the author’s comment on the importance of context in deriving appropriate evaluation criteria. Our investigations indicate criteria applicable to the critical infrastructure context would include privacy and security aspects of AI algorithms because of the circumstances where private citizens and other legal entities access critical infrastructure services. These criteria are not considered by Montrosse-Moorhead (2023) and rightly so in that application. In addition, the AI tools being considered for and applied to critical infrastructure have components that require sophisticated AI analysis and coding expertise to assess their trustworthiness. Evaluators could therefore be reliant on a technical expert for critical aspects of an evaluation. We therefore contend that the criteria specified by Montrosse-Moorhead (2023) are unsuitable for evaluation of AIeCIS due to the fact that some important criteria are missing.
Use of AI in evaluations and in evaluating critical infrastructure is interesting for the evaluation community for several reasons. First, low knowledge of AI makes it something evaluators either love or are afraid of. Leeuw (2025) applies the realist evaluation approach to AI from the evaluators’ perspective to shed light on the ‘black box’ in using AI and decrease the unknown. He sees a low understanding of AI among evaluators as one of the main causes of reluctance to use AI in evaluations. Our argument is similar. We believe a sound knowledge of AI is necessary for competent evaluation of AIeCIS and one of the ways to achieve that is to use AI in evaluations. Nevertheless, evaluating AI in critical infrastructure could be a double ‘black box’ for evaluators of AIeCIS. Evaluators need to understand risks associated with critical infrastructure interventions. Second, in sympathy with Leeuw (2025), evaluators should investigate and familiarise themselves with AI used in the CIS they evaluate.
Nielsen (2025) sought to answer two questions: ‘Will emerging technologies (ET) impact the evaluation industry?’ and ‘How will ET impact evaluation practice?’ In answering the first question, the author draws on Raftree’s insights that three waves of diffusion of ET can be distinguished in the evaluation industry. The first wave was characterised by the emergence of new data collection tools, such as mobile phones or geodata, in evaluation activities. The second wave included two main vectors: advanced data collection (e.g. drones, satellites) and data analysis methods (e.g. machine learning). The third wave summarised the previous developments and introduced new disciplines to the evaluation field, such as software development and data science. However, Nielsen (2025) emphasises that evaluation service commissioners play the main role in the development of ET in the evaluation industry. They formulate the demand for specific tools, instruments and technologies in the procurement specifications. If such demand is clearly expressed, ET becomes more widespread throughout the industry.
We examine Nielsen’s response to the first question from the perspective of the evaluand, our main focus. Indeed, we expect the diffusion of ET will occur in a similar way but the procurement of engineering into critical infrastructure, including software and hardware, will determine the rate and extent to which AI becomes embedded into CIS. As such, an evaluation framework directed to the evaluand would need cognizance of approaching waves of ET.
In response to the second question, Nielsen (2025) identifies five main factors on which the development of ET in the field of evaluation depends: (1) Competitive strategies of evaluation service providers, (2) Size and duration of evaluation contracts, (3) Nature of evaluation services, (4) Broadness and depth of capabilities of evaluation service providers and (5) Suitability of technologies for a specific evaluation task.
In addition, price competition and the desire to ensure the highest quality of evaluation also encourage providers to use efficient data collection tools. The application of ET may lead to shorter contract implementation terms, and it may be increasingly difficult for smaller service providers to compete with large companies that have access to advanced technologies and automation solutions. Nielsen (2025) predicts that monitoring systems will likely be automated and replace some of the tasks performed by humans. This is particularly relevant, as evaluators have often complained in the past that data quality in monitoring systems was dependent on the human factor (Dvorak, 2010). In the future, the skills of evaluation teams will be increasingly important, in particular data science.
Critical infrastructure already is experiencing such impacts. Critical infrastructure has embedded systems that continuously collect data, monitor and analyse that data sometimes using sophisticated forms of AI. The outcomes are reported to dashboards with predetermined alarm levels. Hence, the evaluation of AIeCIS requires highly specialised personnel.
Leeuw (2025), has proposed a realist evaluation approach and makes arguments about its relevance to evaluating AI-enhanced interventions in real time. We agree with Leeuw that realist evaluation of AI interventions has the advantage of learning about limitations (and benefits) on the job and that ‘human in the loop’ strategies can substantially mitigate risk. However, when significant risks are presented, as is often the case with critical infrastructure, these human-based strategies by themselves are often insufficient. The opinions about AI in evaluations are divided. Some emphasised the risks and critically argue that AI can deepen social inequality – racial, gender and cultural (Reid, 2023) – pose a threat to marginalised minorities, and erase alternative perceptions of the world (Head et al., 2023). Other evaluators, on the contrary, were more optimistic about the prospects for the application of AI—they emphasised that AI could enhance humanity and encourage trust in it (Sabarre et al., 2023). Meanwhile, Tilton et al. (2023) argued that it is necessary to include AI literacy training in evaluator training so that future and current evaluators can critically evaluate the application of AI models and reflect on the values hidden in AI algorithms.
The application of a set of standardised evaluation criteria in evaluations like those of the OECD’s Development Assistance Committee (DAC) (OECD, 2021) causes some evaluations to be problematic (Qian-Khoo et al., 2022) because top-down implemented evaluation criteria might fail in capturing the specifics of the programmes. Moreover, such frameworks without a flexible application also cause a challenge in that their value content is often only assumed to be understood in the evaluation process (Teasdale, 2021), and the actual understanding can differ.
Evaluators apply different evaluation criteria even if they are from the same field. A recent study by Mavrot et al. (2025) shows that the use of evaluation criteria differs depending on which evaluation teams carry out the evaluation, and for which purpose. It underlines the need for flexibility in how the criteria are applied, which our approach enables. Patton (2020) points out the possible inaccuracy in use of evaluation criteria if the precision of application of evaluation criteria gave the evaluators the illusion of meaningfulness and utility. On the other hand, we see this issue as an advantage enabling the stakeholders to define the importance of each criterion according to their understanding and needs.
Nolt and Leviton (2022) recommend flexibility in defining evaluation criteria and accept that there is a variation in acceptance in their definitions. These should be done before implementation, which should lead to more organic, authentic and transparent practice in applying evaluation criteria. Based on this experience, we define an evaluation framework, but we recommend their flexible application to enable stakeholders to propose their views and needs. It especially concerns complex systems where a large variety of criteria may apply. Numerous AI evaluation frameworks have been proposed in the computing research community since 2018. Nauta et al. (2023) proposed 12 conceptual properties of explainability arising from a review of 312 AI explainability studies, each of which depicts the evaluation of an explainability method. The categories proposed by Nauta et al. are useful for those seeking a deep understanding of the categories of explainability and how each type of explainability may be evaluated but offers no contextualisation of its centrepiece framework to the fundamental objective of explainability, that is, to maintain stakeholder trust in AI. However, from this study, we can observe that the link between each of the 12 forms of explainability and trust in aspects of the services to which the AI is applied, such as safety, reliability, privacy of personal data, autonomy of service users, oversight of automation, trust in the continuing financial effectiveness and viability of the service, remains unaddressed.
Hedström et al. (2023) clearly articulate the fundamental purpose of explainable AI (XAI) and provide descriptions of six evaluative dimensions: Faithfulness, Robustness, Localisation, Complexity, Axiomatic, Randomisation in relation to XAI. Our main concern is that, because of the limited focus to neural network AI, application to broader contexts, such as AIeCIS, may not be valid. Hence, we believe further work is required to align fundamental service delivery objectives with each type of AI explainability to establish their relevance under different contexts.
A review of Trustworthy AI (TAI) literature reveals a relative scarcity of research into evaluation criteria for TAI (McCormack and Bendechache, 2024), especially the development of metrics for evaluating the impacts of AI on society and the environment but also in areas such as evaluating accountability, human agency and oversight. Evaluation of TAI has structural issues in the form of conceptual clarity (Kowald et al., 2024) and there is need to develop methods to evaluate explainability of AI across multiple disciplines to build its trustworthiness in broader domains (Kaur et al., 2022; Kowald et al., 2024).
Ethical principles for the use of AI (EAI), reviewed by Jobin et al. (2019), revealed a significant increase in the number of ethical recommendations for AI proliferating in the public and private sectors over a short time frame. However, solutions to overcome the ethical challenges of AI differ according to context.
Our review of AI evaluation literature has found a dominance of principles-based guidelines promoted by the public sector, intergovernmental organisations and non-governmental organisations. These have become default evaluation frameworks for AI. Given the variety of philosophical standpoints found in XAI, TAI and EAI, and the multiple disciplines involved, it is not surprising that there is a divergence of opinion on the application of those principles and their meaning in different circumstances (Hagendorff, 2020; Jobin et al., 2019; Mittelstadt, 2019). We conclude that there may be a strong need for a more disciplined approach to evaluating AI.
Methodology
Essentially, the methodology of our study is that of conceptual research enabling us to build theory, forming an essential foundation for subsequent empirical research (Jaakkola, 2020). One part of conceptual research, known as theory adaptation, is to introduce an alternative frame of reference to an existing concept (Jaakkola, 2020).
Investigating AI principles in practice
We began by investigating whether the Principles for Trustworthy AI espoused by the OECD are mutually exclusive when applied to real cases. We collated, examined and discussed examples from Deutsche Bahn’s (DB’s) AI-enhanced traffic management system for this purpose.
The methodology continued with capturing and analysing representative data about the guiding principles of AI and associated objectives initiated from those principles. We applied Yin’s (2016 [2015]) selective review approach, essentially a review of highly cited reviews, to curate examples of AI principles-inspired real-world objectives covering each of the prevalent schools of thought on the application of guiding principles (XAI, TAI and EAI) to gain an understanding of the present application of the principles. This was not a systematic review, nor was that level of rigour thought to be necessary given this is not the main output of the study. The search terms ‘AI principl*’ and ‘review’ were applied to the Scopus and Web of Science databases and sorted by citation count. The search results were restricted to those items published since 2019 with citations greater than 100 according to Google Scholar. The only inclusion criterion was that the review had to include reference to examples of the real-world objectives manifested under the guiding principles of AI. Citation searching was then undertaken to locate additional literature, to ensure the main schools of thought were represented. To this, we added the very recent review by McCormack and Bendechache (2024). The list of included studies numbered 15.
Building a VFT based framework
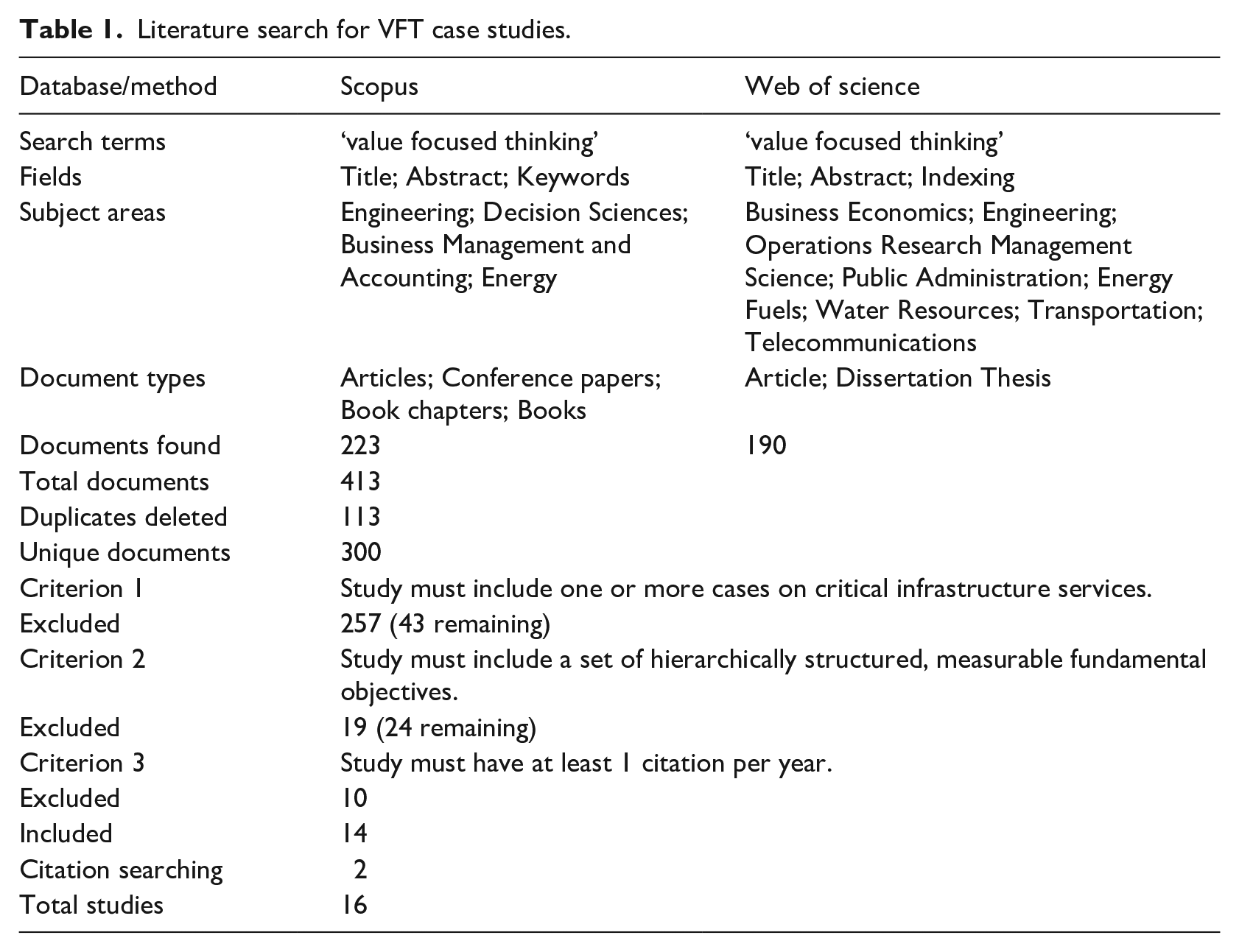
Our next step was to compile an alternative classification framework of fundamental objectives for critical services delivery derived with Keeney’s VFT. To do this, we searched for and reviewed studies where VFT was applied to decision-making in relation to critical infrastructure service delivery. The literature search approach is defined in Table 1. We extracted, from the included studies, the sets of hierarchically structured fundamental objectives, a partial example of which is illustrated in Figure 1. We utilised these to inform the development of an alternative framework comprising seven purposefully designed mutually exclusive classifications and 29 sub-classifications of fundamental objectives and analysed that outcome. We validated these fundamental objectives by checking their alignment with the principles of AI.
Literature search for VFT case studies.
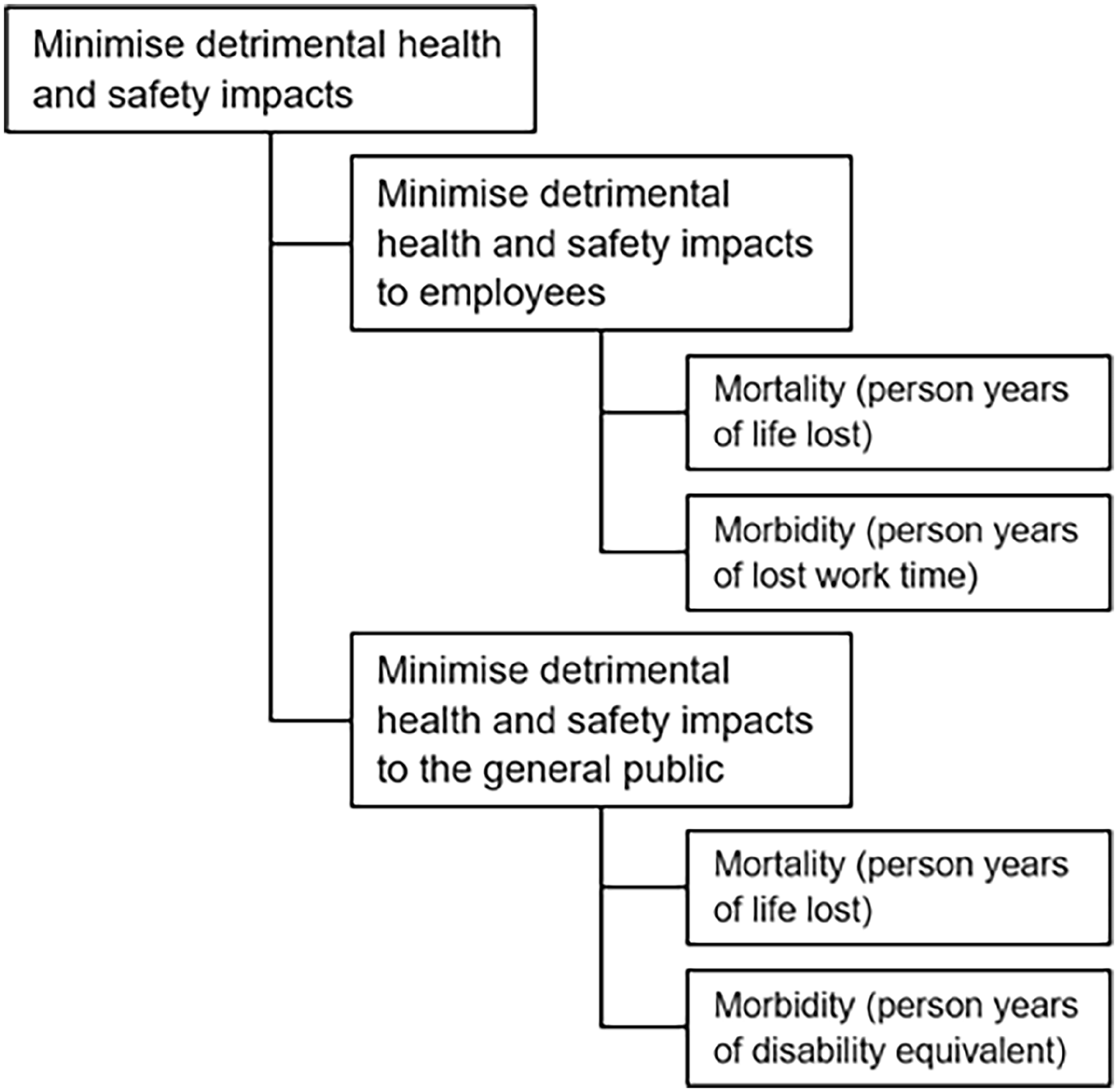
Example of hierarchically structured measurable fundamental objectives.
Within this literature, we searched for the objective or purpose behind applying each of the principles of AI, documenting each objective against the principle to which it is related. These objectives were then assessed as to whether they are means or fundamental objectives according to Keeney’s VFT approach. Fundamental objectives being those that represent core values and means objectives being ways to achieve fundamental objectives.
The final step was to demonstrate the framework with an example. The recently developed Deutsche Bahn (DB) AI-enhanced traffic management system was chosen for this purpose.
Strengths and limitations of this methodology
The methodology consists of a series of data collection and analysis steps progressing from what is currently known about application of principles of AI towards an answer to the research question. The strength of the initial investigation into the application of AI principles at DB is that it is a real and recent case at the cutting edge of AI application. The main limitation is that it is a singular case and hence it is not appropriate to extend the findings to other cases.
The next part of the methodology, to curate examples of real-world objectives inspired by the AI principles, has the strength that the inspiring principles are not just the AI trustworthiness principles promoted by the OECD but also include AI principles emanating from AI explainability cohorts and the ethical AI schools of thought. The main limitation is that we have applied a selective review.
Our search for hierarchically structured, measurable fundamental objectives relating to critical infrastructure was of high quality. However, the data yielded has placed limitations on analysis. The main issue is that the number of conforming studies is so low that some types of critical infrastructure, for example wastewater and telecommunications, are poorly represented. Another limitation is that the included studies are mainly from a time when the use of AI was in its infancy and may not have been considered in the formulation of fundamental objectives and core values.
Findings and discussion
The results of our study are presented and discussed in this section interspersed with findings and discussion about a case study on Deutsche Bahn’s (DB’s) AI-enhanced traffic management system described in Annex 1.
Application of AI principles to Deutsche Bahn
We begin by discussing one of the challenges of using AI principles as the sole evaluative framework for the evaluation of AIeCIS. We introduce a Venn diagram (Figure 2) of DB’s traffic management AI (tmAI). The box represents the universe of actions towards compliance with all AI principles. The black circles represent actions towards compliance with principles applicable to DB’s tmAI, while a faint circle represents actions towards principles that don’t apply to DB’s tmAI such as privacy. The set of actions towards compliance with the principles of robustness of AI and transparency of AI are highly applicable to DB’s tmAI, but they are not mutually exclusive sets. For example, DB requires the tmAI to be robust and tests the tmAI under many varied scenarios to confirm its robustness (Sturm et al., 2024). Confirmation of robustness is achieved at DB through transparency to relevant stakeholders, such as signal engineers and AI designers, involving those experts in selection of test data, design of the tests, carrying out the tests and analysing the results (Schneider et al., 2024). In this case, members of DB’s tmAI development team and their collaborators wrote two separate articles describing DB’s tmAI, subsequently published (Schneider et al., 2024; Sturm et al., 2024).
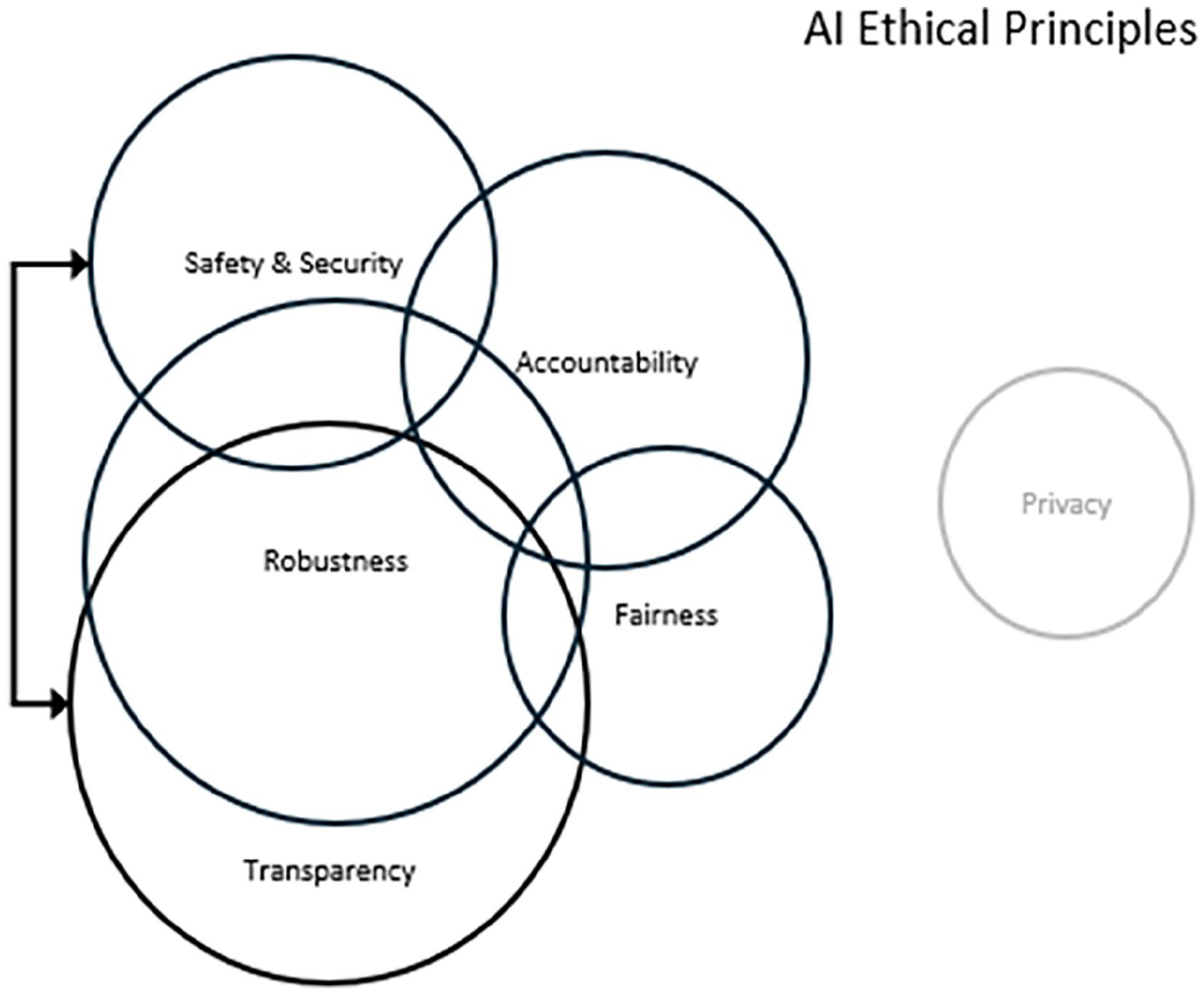
Venn diagram of AI ethical principles applicable to Deutsche Bahn traffic management AI.
Hence, we argue that actions towards transparency of robustness are simultaneously in the ‘robustness set’ and ‘transparency set’. Consequently, an evaluation of DB’s tmAI against the OECD Principles could potentially count the same data twice because of this overlap.
Actions towards transparency in relation to AI overlaps with other principles too. For example, DB is transparent in its 2024 interim report to shareholders about AI diagnostics of images to ensure system safety and security of freight car brakes and roof tarpaulins. The fact that DB’s intentions regarding tmAI and AI diagnostics were reported to shareholders, some of which are done with timeframes, also demonstrates accountability to their stakeholders. So, in relation to DB’s tmAI, our finding is that it is possible for actions in support of the principles of AI to be in more than one set of AI principles.
Investigating the application of AI principles
As a follow up, and in consideration of the fact that the DB case is but a single example, we sought additional data about the application of each of the widely accepted principles of AI. Table 2 was compiled for this purpose. The relevant AI principles, taken from XAI, TAI and EAI literature, are articulated in the first column, followed in the second and third columns by the objectives associated with each principle and their appearance in the literature.
Principles of AI and corresponding objectives according to literature (items marked with # are means objectives).

Note that means objectives indicated with the # symbol in table 2 are defined as ways to achieve fundamental objectives. Fundamental objectives are those objectives that represent core values.
Table 2 provides an accurate representation of the many objectives found in practice that are inspired by the principles of AI. Our first observation is the number of individual principles (20 grouped to 13) that apply to the development and use of AI. These principles are not just convenient categories developed on the run. They originate from governments, agencies of governments and NGOs.
Each objective recorded in Table 2 is inspired by or aligned with a principle and this link originates from the document in which the objective was articulated. Of the 98 individual objectives identified in Table 2, we assess 23 to be means objectives and the remainder as fundamental objectives. These findings paint a picture of multiple principles that overlap in meaning and are interchanged in use. The findings are also indicative of a group of objectives that are not all ideally formulated. From an evaluation perspective, fundamental objectives are preferred because they provide a structure for explaining values expressed by stakeholders and can be used for evaluation against stakeholder values (Keeney and McDaniels, 1992). While research institutions and public sector organisations have generally favoured the use of principles to guide AI development, scholars and theorists warn that this practice on its own has significant shortcomings. Agreement on the precise principles to apply is not straightforward given the diversity of people’s moral beliefs (Gabriel, 2020). Nor can we assume a common understanding of the principles (Jobin et al., 2019). In effect, by adopting AI principles, such as those promoted by the OECD, as the only design guidance, designers are asking stakeholders in AI-enhanced systems to trust their interpretation (Hagendorff, 2020). Under circumstances where AIeCIS has received guidance only in the form of principles, it follows that evaluation is also problematic. Our thoughts on this matter, supported by the findings of this study, go much further. We believe the principles being used to guide development of AI provide an inadequate and confused classification system for evaluations research and practice because they have an overlap in scope exacerbated by the lack of commonly accepted definitions for each of the principles. For example, in Table 2, objectives linked to the principle of Accountability (to identify and rectify processes that could potentially cause harm; to promote diversity) and Beneficence (to promote human well-being; to provide benefit to the environment) are similar to those associated with the principles of Safety (preventing harm to individuals or society), Fairness and Justice (to encourage respect for diversity, inclusion and equality) and Sustainability (to protect the environment and promote environmental well-being). The lack of agreed definition and uncertainty in scope leads to an inability to precisely outline metrics for determining successful application of these principles which in turn impacts the ability to operationalise evaluations. We therefore propose an alternative framework to support a structured evaluation approach. The alternative framework is developed in Section ‘Investigating cases of VFT in critical infrastructure to build an evaluation framework’.
Investigating cases of VFT in critical infrastructure to build an evaluation framework
This section utilises studies that rigorously apply VFT to critical infrastructure intervention decisions to build a novel evaluation framework via a review and analysis of the identified studies. Our review of fundamental objectives for critical infrastructure services is informed by 16 separate studies in decision making in critical infrastructure. The studies included 8 in energy, 2 of which were specifically hydroelectric energy, 2 in transport, 2 in water, 2 in healthcare, 1 in gas infrastructure and 1 in wastewater. A total of 147 objectives were analysed. Our analysis yields 7 classifications and 29 sub-classifications of fundamental objectives, as shown in Table 3 left hand columns. The number of occurrences of each fundamental objective in the 16 items of literature is shown in brackets alongside. Only 9 of the 147 objectives did not align with any of the 29 sub-classifications.
Alignment between fundamental objectives of CIS and principles of AI.
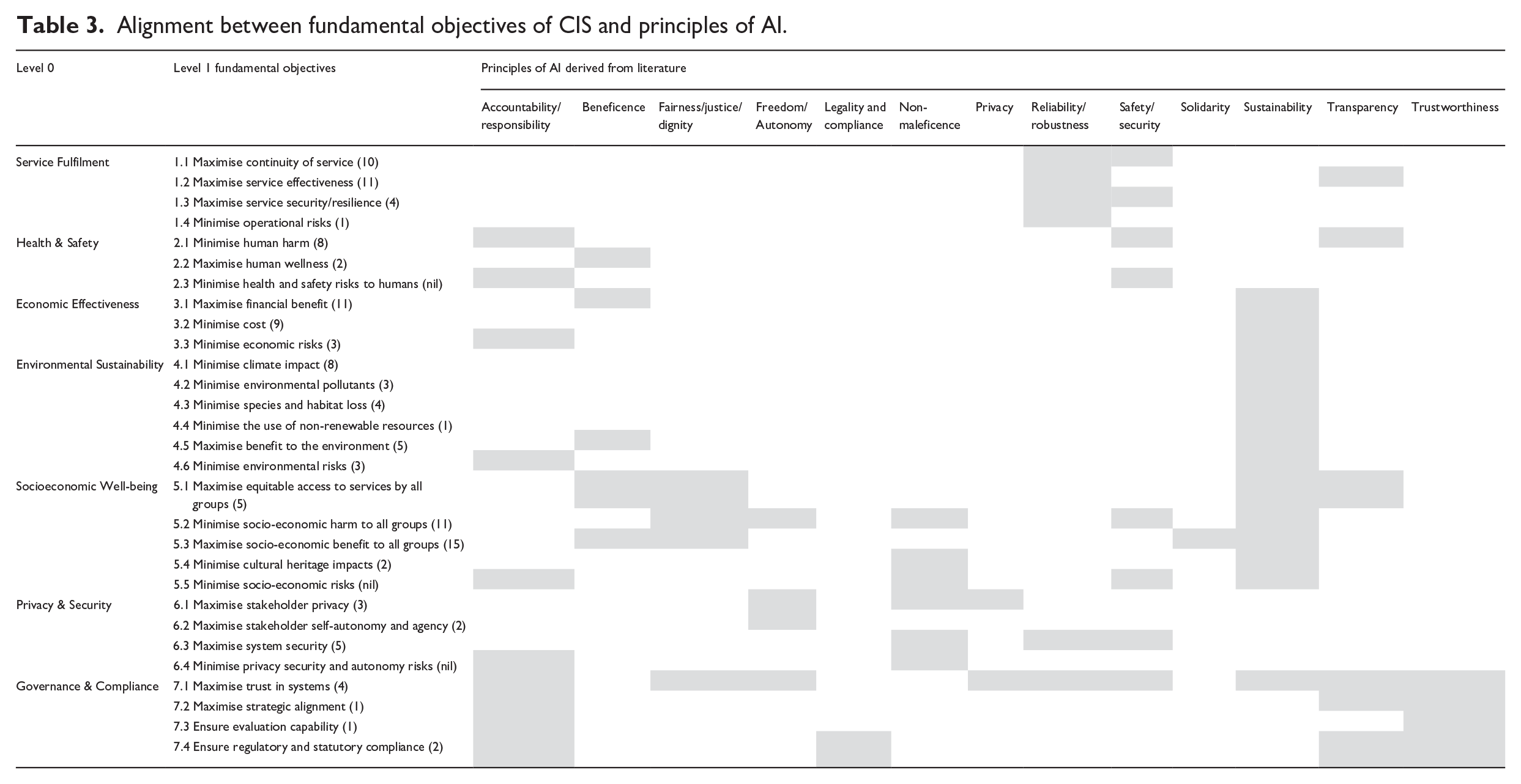
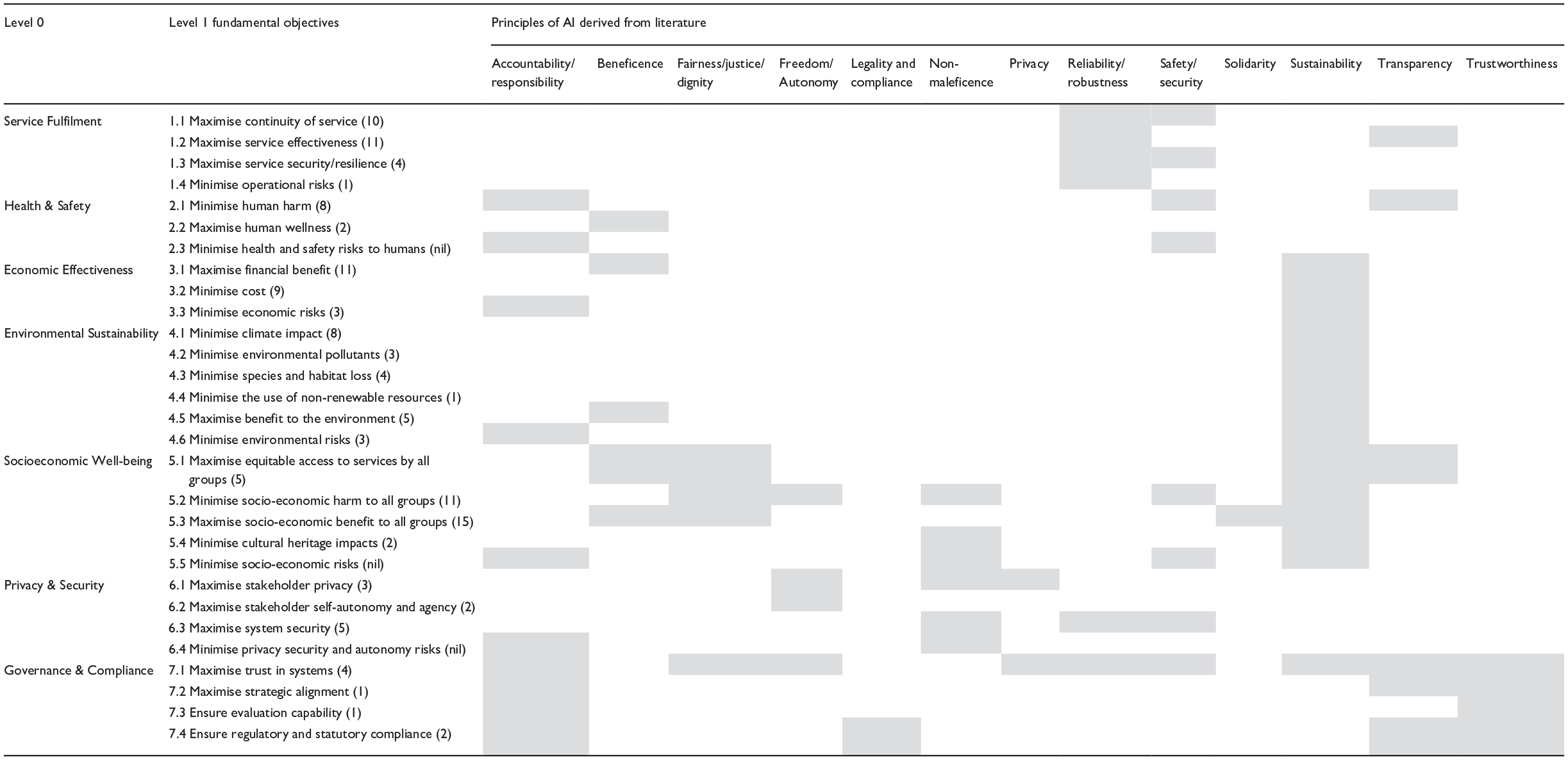
These fundamental objectives are compared with the 20 principles of AI compiled from our initial survey (Table 2) to analyse and assess the alignment between fundamental objectives of critical infrastructure services objectives and principles for the implementation of AI. It is a rudimentary form of validation. We note that as a group, the fundamental objectives cover each of the 20 AI principles. An important point is that while the sub-classifications are typical for critical infrastructure services, we do not imply that they are fixed. They are an example only. The objectives are and should always remain unique to the services provided in response to stakeholder values/requirements and will depend on contextual factors applicable to the situation.
We assert that there is a strong similarity between the fundamental objectives of different types of CIS and our findings support this. The VFT inspired process of eliciting fundamental objectives requires us to engage with stakeholders about their values. It stands to reason that these values remain largely constant regardless of the critical service being accessed. Safety is always a high priority, stakeholders care about sustaining the environment, stakeholders expect the CIS to deliver effective services to a standard that reflects good value and be available when needed.
Of 147 fundamental objectives, only 8 could not be classified into our framework of 7 categories. We list these below:
Promoting attraction of international investment and renewable technology;
Encouraging the equipment industries with a focus on technology and sustainability;
Reducing the institutional and market barriers for new technologies;
Minimise external dependence;
Ensure market transformation;
Maximising control over technology choice;
Improve staff qualifications;
Promote responsible decision making by others.
The first three come from the same study by Bortoluzzi et al. (2021) based on a portfolio of energy generation projects in Brazil. They are part of a drive to introduce distributed energy resources consisting of small-scale solar, wind turbines and energy storage systems, all of which would be located close to the consumer. In effect, these objectives are a means to increasing the availability and continuity of energy to distributed communities of Mato Grosso do Sul, located in Brazil. There are contextual factors relating to the declining capacity of existing hydroelectric sources driving this need (Bortoluzzi et al., 2021). The other five are similarly driven by unique contextual factors. Thus, a significant cause of misalignment of fundamental decisions for the set of CIS studies we examined appears to be the context in relation to those studies. Table 3 demonstrates that each of the fundamental objectives depicted in the proposed framework of fundamental objectives aligns with one or more principles of AI. Moreover, the proposed VFT approach delivers measurable clarity to those principles and provides fundamental objectives aligned with stakeholder values to guide their implementation and evaluation. Consequently, we assert that evaluation of complex AIeCIS is made simpler and more effective by initially identifying fundamental objectives with stakeholder involvement. We offer the framework of fundamental objectives, against which AIeCIS may be evaluated, and the adapted VFT method as valuable outputs of our research.
An evaluation against this framework and in accordance with established and tested VFT practice would normally entail eight components: (1) Review the intervention context, (2) Engage with stakeholders, (3) Establish the intervention objectives, (4) Develop alternative solutions, (5) Develop the utility model, (6) Make the decision, (7) Monitor the intervention and (8) Manage the feedback. This process aligns most closely with the utilisation-focused evaluation model proposed by Patton (2011) in which the evaluator acts as a mentor or trainer of key users. The evaluator identifies and engages influential users to build and use evaluation processes and provides support to those individuals as and when needed. It also aligns with Keeney’s (1994, 1996a, 1996b) VFT method.
The evaluation framework presented in Table 3 combined with the proposed eight-component evaluation process has several valuable features. It is a practical tool for evaluators of AI interventions to CIS locked into compliance with a principles-based edict, such as the IEEE standard for AI transparency. It enables the service provider to set up an evaluation use team and to define measurable objectives for the AI intervention informed by the proposed framework elements. In addition, Table 4 shows references to commonly used metrics for each of the fundamental objectives developed, tested and validated by scholars with appropriate expertise.
Examples of metrics for fundamental objectives.

In conclusion, the proposed evaluative framework demonstrably accommodates the fundamental objectives of 16 critical infrastructure interventions informed by Keeney’s VFT. We posit that the resultant framework adapted from Keeney’s VFT offers structured evaluation guidance in the form of common fundamental objectives aligned with typical stakeholder values and informed by evidence derived from 16 separate critical infrastructure intervention studies. We advance the case that that our fundamental objectives framework aligns with principles of AI derived from literature. Finally, we postulate our framework satisfies objective measurability via references to tested and validated metrics.
Evaluation of Deutsche Bahn AI-enhanced traffic management system
The remaining task of our study is to provide an example of our values inspired framework in action and highlight its advantages for evaluators. We have chosen an AI intervention into CIS for which information is available. We first describe the AIeCIS development and implementation process and then indicate important aspects of evaluating the intervention. Please refer to Table 5 which provides an eight-stage evaluation process beginning with an intervention context review.
Evaluative oversight of AI interventions for critical infrastructure.
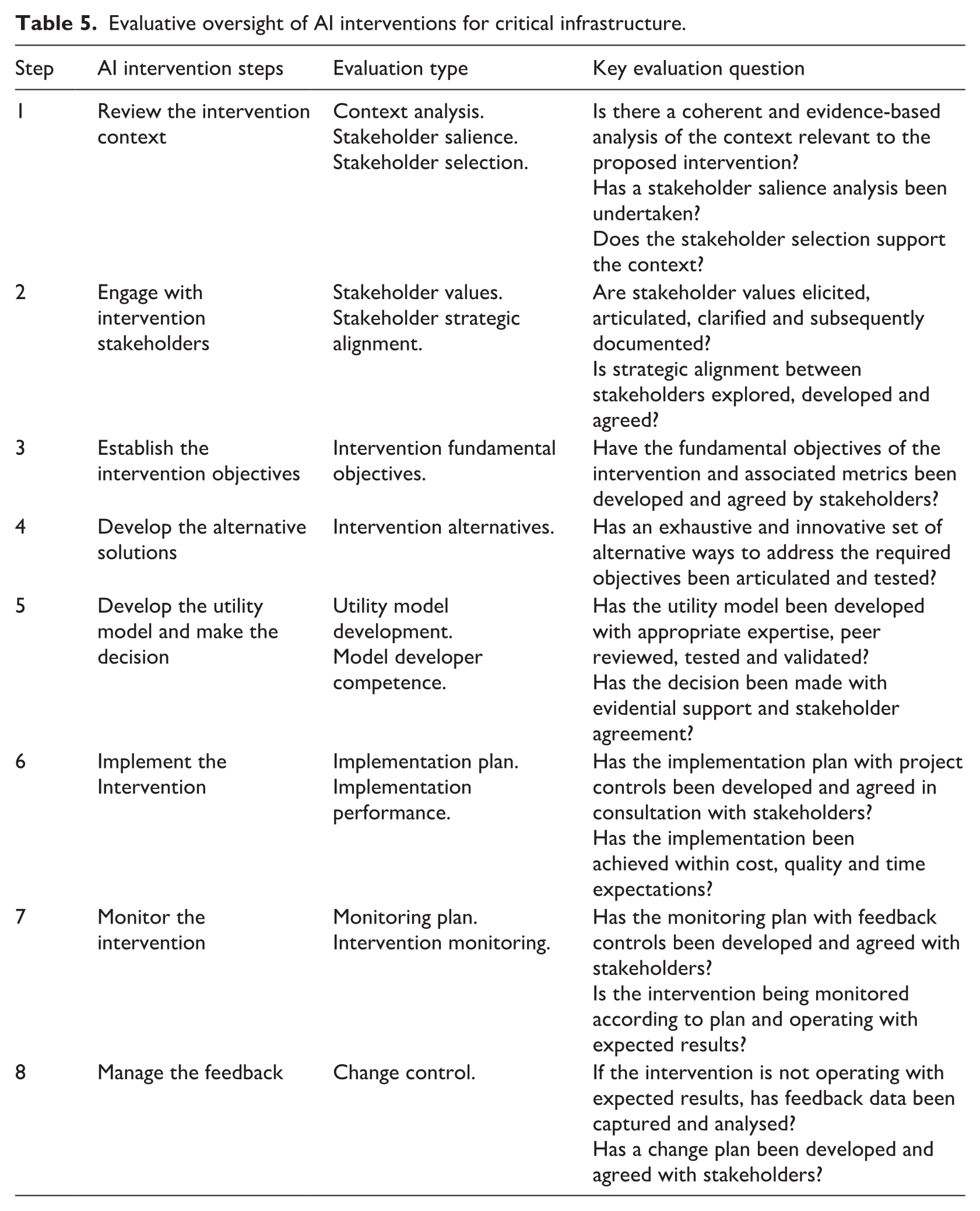
Step 1: We start with understanding the context
Deutsche Bahn (DB, 2024) is Germany’s national railway operating 33,464 km of track, serving 1837 million rail passengers and carrying 197.6 million tonnes of freight in 2023. Over the years, DB’s networks and operations have become increasingly complex with freight traffic in tonne-kilometres predicted to continue to increase 35 per cent between 2019 and 2040 (Kulikowska – Wielgus, 2024) and an average annual passenger growth of 5.1 per cent per annum from 2024 to 2029 (IBISWorld, 2024). As a result, the manual planning and dispatching of trains will reach its limit soon (Digitale Schiene, 2022).
Ensuring its safety and efficiency through optimised traffic management is crucial. DB’s proposed traffic management AI (tmAI) is an AI-based solution for optimising railway traffic management. It is an AI intervention to the manual traffic management system planned for introduction into DB’s Stuttgart Digital Node in 2029 (Digitale Schiene, 2025). At its core, the system employs a Multi-Agent Reinforcement Learning (MARL) approach, where individual trains act as intelligent agents learning to navigate a shared network (Schneider et al., 2024). However, to trust such a complex AI-based system with safety-critical operations, its reliability must be rigorously evaluated. Explainable AI (XAI) methods suitable for Deep Reinforcement Learning (DRL) (Hickling et al., 2023) and MARL (Boggess et al., 2023) provide a pathway to understand, verify and ultimately trust the tmAI.
The German government, as part of its commitment to climate change targets, has committed to using more trains and less road and air traffic. The initiative is known at DB as Strong Rail and the tmAI is an enabler technology to that initiative.
Comments about the evaluation of Step 1
An evaluation of this step must confirm the context is well researched and understood by the implementation team. A key aspect from an evaluative perspective is to ensure the stakeholders are clearly identified and that strategic perspectives of those stakeholders are understood well enough to determine their salience. Therefore, an evaluation would confirm the adherence to an exhaustive process of identifying and understanding stakeholders. Stakeholders are not of equal salience. To this extent, an evaluation ought to confirm that a salience assessment of each stakeholder is completed by examining the dimensions of power, legitimacy and urgency as proposed by Mitchell et al. (1997). This salience assessment would determine which stakeholders must be consulted in the subsequent steps. Our opinion is that the number consulted in the next stages should be in the order of five at most because the level of complexity increases significantly with the involvement of each additional stakeholder.
In the case of DB, the most important stakeholder is the management team. They have the highest level of power due to their position in DB. They have legitimacy due to their responsibility for the viability of freight and passenger operations. They have urgency because the manual traffic management system is fast approaching its scalability limit. Another important stakeholder group, the passengers, have power in numbers and a legitimate need to reach their destinations on time. They also have urgency because the punctuality of passenger services has been declining in recent times. Their interests might best be represented by train traffic controllers. A third stakeholder group, the German government, has a stated interest in achieving greenhouse gas (GHG) reduction targets for 2030 and beyond and have announced their intention to do that through encouraging increased use of rail passenger and freight services. This represents their urgent mission. Their power resides in their being the elected representatives of the people of Germany and their legitimacy comes from their reliance on railways as being the most effective mode of transport from a GHG emission perspective and the only way of reducing GHG emissions at scale in the short term.
The evaluation should reveal sound process, not only in the identification of the three key stakeholders via stakeholder saliency rating, but also confirmation of the corporate strategy supporting why those stakeholders are the most appropriate focus. For example, our case study shows that DB’s corporate strategy supports the choice of the German government as a key stakeholder. In this case, DB’s Strong Rail strategy (DB, n.d.) is intimately tied to the German government’s GHG targets and advocates a growing use of rail transport in support of the achievement of GHG targets.
Consultation with stakeholders to develop a decision model – Steps 2, 3, 4 and 5
The objective of these steps is to arrive at the best intervention solution in consultation with the key stakeholders and in acknowledgement of their values. The process we recommend implementers of the DB tmAI to adopt is to pose a series of questions that reveal the fundamental values important to stakeholders. It is done as a group so that they learn about each other’s values. The values should be articulated, clarified and documented in a shared environment with other stakeholders. This will assist stakeholders to develop, and realise, shared strategic opportunities, which should also be explored and agreed.
The stakeholder participants should then be asked to articulate their fundamental objectives in front of each other and explain how those objectives relate to the values developed earlier. The objectives, developed from critical infrastructure case studies illustrated in Table 3, may be a useful prompt for this process. Keeney (1996a) describes how some objectives are a means to an end and others are an end in themselves (fundamental) and describes the process of stakeholders can be encouraged to identify fundamental objectives. Again, the objectives should be documented noting that there may be different objectives for different stakeholders. Next, the stakeholders should discuss and explore the way their fundamental objectives are or could be measured. The resources identified by Table 4 may assist this process. Often, useful data is already available and it’s a matter of sharing that so that the entire group can understand what is available and discuss metrics that may align more closely with the intent of the fundamental objectives.
An example relating to DB’s tmAI, the fundamental objectives and their metrics taken directly from the Table 4 VFT Framework is given below:
1.0 Service Fulfilment
1.2 Maximise service effectiveness – Measured by percent of services on time (attribute se)
2.0 Health and Safety
2.1 Minimise human harm – Measured by person years of life lost/disability (attribute hh)
3.0 Financial Effectiveness
3.1 Maximise financial benefit – Measured in Euros (attribute fb)
3.2 Minimise financial cost – Measured in Euros (attribute fc)
4.0 Environmental Sustainability
4.1 Minimise climate impact – Measured in tonnes of CO2 equivalent (attribute ci)
7.0 Governance and Compliance
7.1 Maximise trust in systems – Measured with a composite trust metric (attribute ts)
The next part of this phase is to develop a utility model which is a function of individual attribute metrics that represent stakeholder benefit and disbenefit traded off. In this pre-implementation stage of the intervention, there must be intense consultation with key stakeholders with sufficient technical expertise on AI. The stakeholder representatives and implementation team must assign the weights assigned to each attribute.
It is then necessary to determine the most applicable type of utility model (additive, multiplicative or combinatorial). This is done by establishing the nature of independence between the individual model attributes (service fulfilment, health and safety, financial effectiveness and environmental sustainability). Additive independence between attributes implies that stakeholder preferences for the consequences of each attribute depend only on the level of each individual attribute and not on their manner of combination. Note these attribute metrics are probabilistic. They have an expected distribution rather than a discrete value. The correlation between metric distributions also must be determined. The final part of this modelling is to run a Monte Carlo simulation for the utility function of each potential solution and use the result to determine the most beneficial solution. This is a highly technical step, and it is possible that the implementation team does not recognise its own lack of technical expertise. It is critical for evaluators to have confidence in the technical competency of the implementation team in this respect.
The implementation team working with the stakeholders must develop some possible solutions, decide on one of them using the utility model and implement it. In this case, solutions may include variations in the type of AI to use, it may also include a comparative non-AI solution.
Comments about the evaluation of Steps 2, 3, 4 and 5
Evaluation of the design of the AI intervention raises some interesting issues. The evaluation during design must include an assessment of the intervention implementation team’s skills in determining fundamental objectives in consultation with stakeholders, developing a utility model using their input. The components of this evaluation are articulated in lines 2 to 5 in Table 5. One of the largest risks during evaluation of the design stage is whether appropriate expertise is accessed by those implementing the intervention.
Evaluators are advised to ensure a modelling process that is fit for purpose is diligently undertaken and that the process is characterised by genuine collaboration between stakeholders and expert implementers. Evaluators should also check the competence of the people involved, especially where modelling is concerned and that the design stages are peer reviewed by competent reviewers. The models must be correctly designed, executed and analysed. The output of the utility models is stochastic rather than deterministic and must take that into account when being utilised and when the model outputs are being analysed.
DB is taking these steps in accordance with a detailed plan. The modelling includes simulations using real data inputs and will eventually lead to a real trial in Stuttgart Digital Node in 2029 before being implemented more widely across Germany.
Another key aspect is the identification and testing of alternative solutions. Keeney (1996b) indicates that the development and testing of many viable alternatives creates better solutions. Evaluators can check this process is being undertaken by requesting evidence of simulation and testing of alternatives.
In effect, the decision will become obvious through the process of identifying alternatives, modelling those and documenting the results. Stakeholders, some of whom would possess model performance assessment skills, would ideally participate in the decision-making process.
Steps 6, 7 and 8
Technical expertise is also needed in implementing and planning the intervention implementation. There must be an implementation plan developed in consultation with stakeholders with project controls. During implementation, cost, quality and time parameters defined in the plan are checked.
The final steps come after the intervention has been implemented, beginning immediately after the solution is in place. These steps are about monitoring the solution against utility criteria on a regular basis, performing an analysis and making improvements to the AI enhancement if needed.
This step simply involves monitoring the measures that were defined in the beginning, analysing the model outputs and continuous improvement of the AI-enhanced intervention. Again, we recommend a collaborative approach and the involvement of appropriate expertise for modelling and analysis. Any proposed improvements must go through a change management process to control the risks.
Comments about the evaluation of Steps 6, 7 and 8
Evaluators must check that there is a team with sufficient expertise responsible for monitoring the performance of the AI intervention. In the case where modifications to the intervention are to be undertaken, the evaluation aspects covered in Steps 2, 3, 4 and 5 are also applicable here.
Our final finding is that AI trust is a sleeping giant issue (Habbal et al., 2024). There is an enormous quantum of trust the travelling public presently has in DB’s traffic management. This trust is valuable but could be lost with a single accident caused by poor design of AI, poorly trained AI or inappropriate management of AI. The potential downside in relation to trust is so enormous as to potentially cause the DB business to suffer business crippling losses.
Closing comments on the novel values-based evaluation framework
Numerous researchers have applied VFT as a decision-making framework for critical infrastructure cases (Bortoluzzi et al., 2021; Coelho, 2013; de Souza, 2012; Eskafi et al., 2020; Haydt et al., 2013; Höfer and Madlener, 2020; Keeney et al., 1996; Keeney and McDaniels, 1992, 1999; McDaniels, 1994; Morais et al., 2013; Neves et al., 2009; Oliveira et al., 2023; Pudney, 2010; Smith and Dhillon, 2018; Smith et al., 2018). Their work has informed the development of the Table 3 fundamental objectives. Of these, none have adapted VFT as an evaluation framework. We posit that these examples support the adaptation of VFT, a stakeholder values-based multi-criteria decision analysis method, to evaluation of AI interventions in critical infrastructure systems. We summarise the guidance for evaluative oversight derived from this theory adaptation in Table 5.
While Keeney’s VFT inspired approach provides an encouraging framework of fundamental objectives for reference by evaluators, our research is somewhat limited by the scarcity of evaluative studies of the application of AI in critical services and the lack of data in relation to that. Consequently, a repeat of this study when more data is available would be advisable. This is, after all, the early stages of implementing AI technology into society’s critical services.
Conclusions and future research
Our conceptual evaluation framework and eight-step approach is the first to align evaluation of an intervention to stakeholder values using Keeney’s value-focused thinking. We demonstrate the potential impact of this novel framework through a specific focus on evaluation of AI-enhanced Critical Infrastructure Systems interventions, which we know to be on an exponential growth trajectory.
We established through a review of literature that a substantially common group of AI guiding principles are being promoted through multiple public sector organisations, non-governmental organisations and intergovernmental organisations. These guidelines are being used extensively as default implementation and evaluation frameworks, though scholars warn of problems with doing so. Our Venn diagram analysis of an example from the railway industry revealed that AI guiding principles provide a confusing framework for evaluators because the principles overlap and compound with each other.
By identifying, summarising and analysing the objectives of AI principles extracted from recent literature, we established that, for AIeCIS, the governing principles of AI could be represented under an alternative framework based on Keeney’s VFT. We demonstrated that this alternative framework delivers measurable clarity to those principles, provides fundamental objectives to guide their implementation and evaluation and aligns those objectives with relevant guiding principles of AI. We also demonstrated the use of the framework on a case study from the railway industry. The demonstration illustrated how our values-based framework and eight-step evaluation process can be used to create a self-evaluation tool. It also provided some guidance for evaluator mentors that mentor others using the framework. The alternative framework was therefore found to be simpler and more effective in comparison to the widely available AI guiding principles.
Future research directions
Our novel framework provides multiple avenues for future research into the evaluation of AI trust. The framework has a category within Governance and Compliance, and this could be separated into sub-categories such as trust for (a) service fulfilment, (b) health and safety, (c) economic effectiveness, (d) environmental sustainability, (e) economic well-being, (f) socio-economic well-being, (g) system privacy and security and (h) human autonomy and oversight. Ways to measure each of these forms of trust are yet to be fully developed and it may vary somewhat, according to the type of critical infrastructure, the stakeholder extending trust or lack thereof, and other context information. Further to this, there is a trade-off between trust and other criteria such as how much it costs to develop trust. How do we construct the utility function involving trust and what does it trade off against? Given the uncertainty of risk in relation to trust, and its potential for negative impact, we assert the need for urgent research into measuring trust issues using the proposed conceptual framework.
Another potential research area is related to complexity. We touched on this in the body of our work. Critical infrastructure systems are complex, the ways in which we model simple systems are different from the ways we model complex systems. It is possible, even quite likely, that the framework may need modification to accommodate complexity. One approach would be to consider the effects of feedback and another would be to consider the impact of neighbouring systems.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship and/or publication of this article: This work was supported by the European Cooperation in Science and Technology [grant number CA20112].