
Abstract
Multi-criteria decision analysis is a quantitative approach to the drug benefit–risk assessment which allows for consistent comparisons by summarising all benefits and risks in a single score. The multi-criteria decision analysis consists of several components, one of which is the utility (or loss) score function that defines how benefits and risks are aggregated into a single quantity. While a linear utility score is one of the most widely used approach in benefit–risk assessment, it is recognised that it can result in counter-intuitive decisions, for example, recommending a treatment with extremely low benefits or high risks. To overcome this problem, alternative approaches to the scores construction, namely, product, multi-linear and Scale Loss Score models, were suggested. However, to date, the majority of arguments concerning the differences implied by these models are heuristic. In this work, we consider four models to calculate the aggregated utility/loss scores and compared their performance in an extensive simulation study over many different scenarios, and in a case study. It is found that the product and Scale Loss Score models provide more intuitive treatment recommendation decisions in the majority of scenarios compared to the linear and multi-linear models, and are more robust to the correlation in the criteria.
Introduction
The benefit–risk analysis of a treatment consists of balancing its favourable therapeutic effects versus adverse reactions it may induce. 1 This is a process which drug regulatory authorities, such as EMA 2 and FDA 3 use when deciding whether a treatment should be recommended. Benefit–risk assessment (BRA) is mostly performed in a qualitative way. 4 However, this approach has been criticised for a lack of transparency behind the final outcome, in part due to large amounts of data considered for this assessment, and the differing opinions on what this data means. To counter this, quantitative approaches ensuring continuity and consistency across drug BRA, and making the decisions easier to justify and to communicate, were proposed.5,6 While there is a number of methods to conduct the quantitative BRA, the multi-criteria decision analysis (MCDA) has been particularly recommended by many expert groups in the field.7–10 MCDA provides a single score (a utility or loss score) for a treatment, which summarises all the benefits and risks induced by the treatment in question. These scores are then used to compare the treatments and to guide the recommendation of therapies over others.
Mussen et al. 7 proposed to use a linear aggregation model in the MCDA, which takes into account all main benefits and risks associated with a treatment (as well as their relative importance) to generate a treatment utility score by taking a linear combination of all criteria. This utility score is then compared against the utility score of a competing treatment, and that with the highest score is recommended. This model appealed for numerous reasons, one of which was its simplicity. The proposed method, however, was deterministic, point estimates of the benefit and risk criteria were used, and no uncertainty around these estimates was considered. Yet, uncertainty and variance are expected in treatments’ performances, and must therefore be accounted for in the decision making.
To resolve this shortcoming, probabilistic MCDA (pMCDA) 11 that accounts for the variability of the criteria through a Bayesian approach was proposed. Generalisations of pMCDA for the case of uncertainty in the relative importance of the criteria were developed, named stochastic multi-criteria acceptability analysis (SMAA) 12 or Dirichlet SMAA. 13 However, it was acknowledged that by accounting for several sources of uncertainty, these models become more complex and should be used primarily for the sensitivity analysis.
All the works discussed above concern a linear model for aggregation of the criteria, which is thought to be primarily due to its wider application in practice rather than its properties. One argument against the linear model is that a treatment which has either no benefit or extreme risk could be recommended over other alternatives without such extreme characteristics.14–16 In addition, the linearity implies that the relative tolerance in the toxicity increase is constant for all levels of benefit that might not be the case for a number of clinical settings. To address these points, a Scale Loss Score (SLoS) model was developed. This model made it impossible for treatments with no benefit or extremely high risk be recommended. It also incorporates a decreasing level of risk tolerance relative to the benefits: where an increase in risk is more tolerated when benefit improves from ‘very low’ to ‘moderate’ compared to an increase from ‘moderate’ to ‘very high’. SLoS model resulted in similar recommendations to the linear MCDA model when the one treatment is strictly preferred to another (i.e. has both lower risk and higher benefit), but resulted in more intuitive recommendations if one of the treatments has either extremely low benefit or extremely high risk.
Whilst other methods are discussed in the literature, the only application of a non-linear BRA model to the medical field is made by Saint-Hilary et al., 14 and this only compares the linear and SLoS models. This paper shall build on this comparison by introducing various different aggregation models (AM) to analyse how each work compared to the other in the medical field (by conduction a case study and a simulation study), and allow an informed decision to be made as to which one should be used using the results of an extensive and comprehensive simulations study over a number of clinical scenarios. We will also use a case study to demonstrate the implication of the choice of AM on the actual decision making using the MCDA.
The rest of the paper proceeds as follows. The general MCDA methodology, the four different aggregation models considered, linear, product, multi-linear and SLoS, and the choice of the weights for them are given in Section 2. In Section 3, we revisit a case study conducted by Nemeroff 17 looking at the effects of Venlafaxine, Fluoxetine and a placebo on depression, applying the various aggregation models to a given dataset. In Section 4, a comprehensive simulation study comparing the four aggregation models in many different scenarios is presented, as well as the effects any correlation between criteria may have. We conclude with a discussion in Section 5.
Methodology
All of the aggregation models (referred to as to ‘models’ below) considered in this work are all classified within the MCDA family – they aggregate the information about benefits and risks in a single (utility or loss) score. Therefore, we would refer to each of the approaches by their models for the computation of the score. Below, we outline the general MCDA framework for the construction of a score using an arbitrary model. We consider the MCDA taking into account the variability of estimates, pMCDA. 11
Setting
Consider The monotonically increasing partial value functions The weights indicating the relative importance of the criteria are known constants denoted by The MCDA utility or loss scores of treatment
Within a Bayesian approach, the utility score

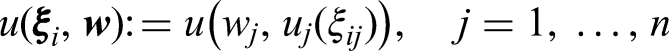
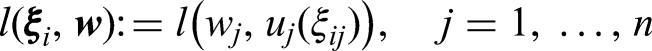




Below, we consider four specific forms of aggregation models, namely, linear, product, multi-linear and SLoS, that were argued by various authors to be used in the MCDA to support decision making.
Linear model
A linear aggregation of treatment’s effects on benefits and risks remains the most common choice for the treatment development.7,12,19,18,13 Under the linear model, the utility score is computed as

As an illustration of all considered aggregation models, we will use the following example with two criteria: one benefit indexed by
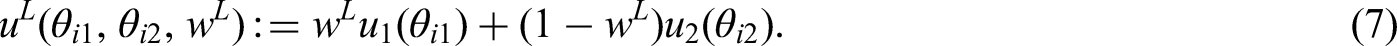

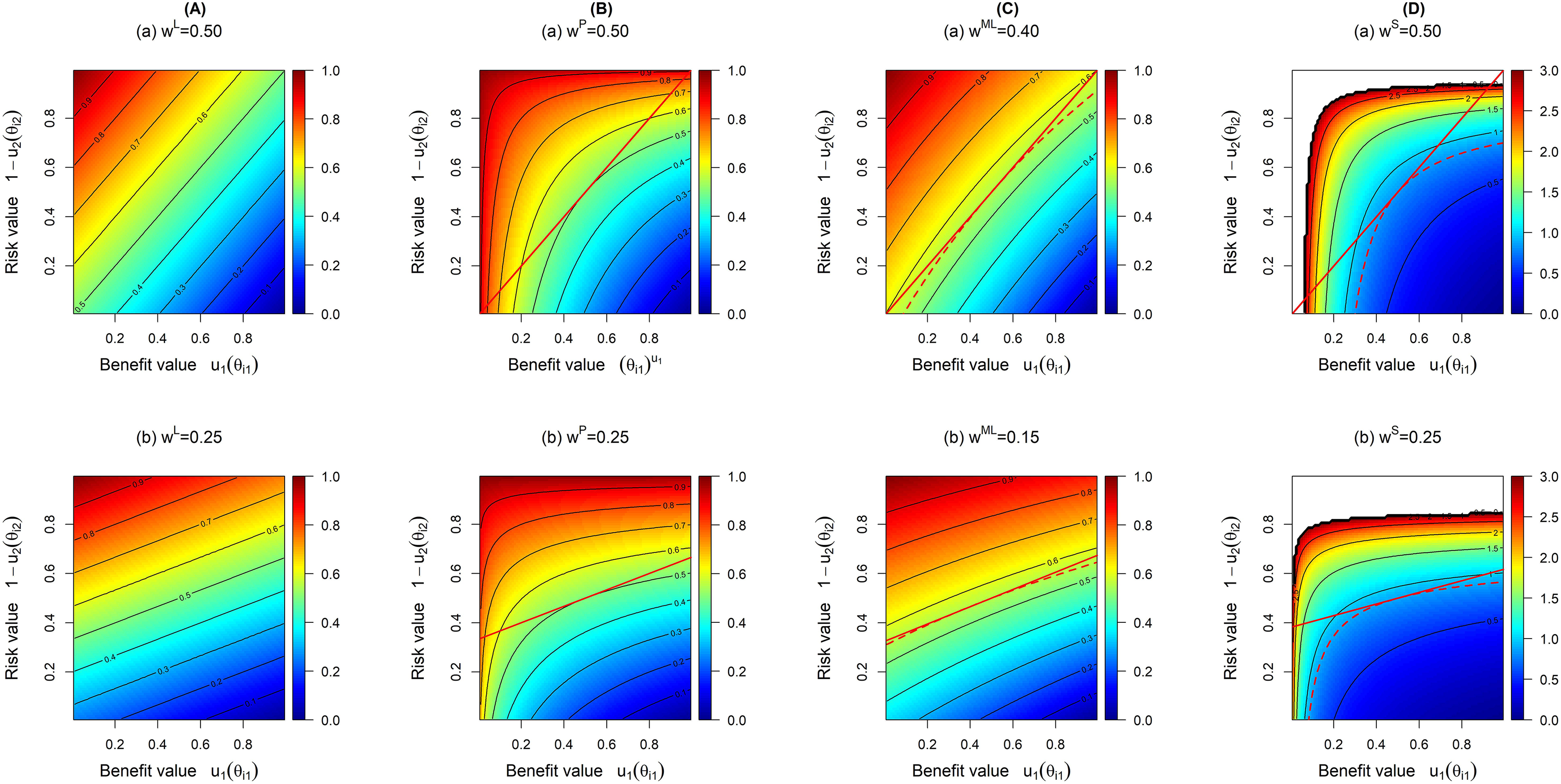
Contour plots for linear (A), product (B), multi-linear (C) and SLoS (D) models with (i) two equally important criteria (top row), and (ii) the risk criterion being twice as important (on average for non-linear model) as the benefit criterion (bottom row). Red lines on panels B to D represent the tangents at the middle point (0.5, 0.5).
The contours represent the loss score for each benefit–risk pair. Lower values of
The major advantage of the linear model is its intuitive interpretation: a poor efficacy can be compensated by a good safety, and vice-versa. However, the linear utility score can result in the recommendation of highly unsafe or poorly effective treatment21,6 and, consequently, in a counter-intuitive conclusion. Moreover, the linearity implies that the relative tolerance in the toxicity increase is constant for all levels of benefit.
14
These pitfalls could be avoided (or at least reduced) by using non-linear models.6,22 Specifically, Saint-Hilary et al.
14
advocated introducing two principles a desirable benefit-risk analysis aggregation model should have:
One is not interested in treatments with extremely low levels of benefit or extremely high levels of risks (regardless of how the treatment performs on other criteria). Decreasing level of risk tolerance relative to benefits: an increase in risk could be more tolerated when benefit improves from ‘very low’ to ‘moderate’, compared to from ‘moderate’ to ‘very high’.
Below, we consider three models having one or both of these properties.
A multiplicative aggregation (known as a product model) is an alternative method of comparing treatment’s effects on benefits and risks.
23
Under the product model, the utility score is computed as

The product utility score for treatment
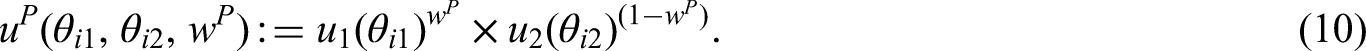

One advantage the product model has over the linear model is that it cannot recommend treatments with either zero benefit or extreme risk. This is because either of these two options would result in a score of zero for the utility function, and as such would make it impossible for such a treatment to be recommended. The contour lines in panel B in Figure 1 demonstrate how the product model penalises undesirable values compared to the linear model. These contours are curved, and are bunched together tightest at points where benefit values are low and where risk values are high. This shows how the penalisation differs this model from the linear model, as under the linear model, an increase/decrease in benefit–risk is treated equally regardless of the marginal values of these criteria, whereas the values of these criteria often have an effect on our decision making under the product model.
A multi-linear model for the aggregation of treatments’ benefits and risks provides a one more alternative for the comparison of two treatments.
22
This model can be seen as attempt to combine the linear and product model. Under the multi-linear model, the utility score is computed as
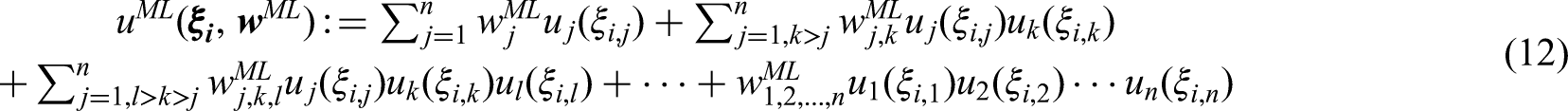
Considering the example with two criteria, the multi-linear utility score for treatment
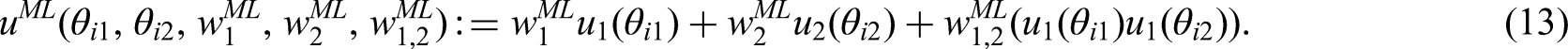
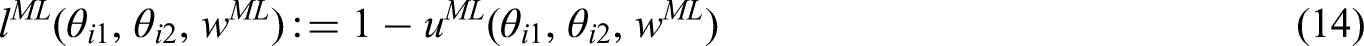
The contour lines demonstrate the almost linear trade-off between benefit and risk, but that there is a slight curvature (which becomes more prominent as it moves further away from more desirable values), indicating a moderate penalisation of extreme values. This shows that while this model attempts to penalise the undesirable criteria values, this effect does not seem to be as strong as in the product model, admittedly due to the chosen value of the weight,
An alternative to the models proposed above is the Scale Loss Score (SLoS) model, which was proposed by Saint-Hilary et al.
14
to satisfy the two desirable properties for an aggregation method. First of all, in contrast to the three models above, SLoS considers a loss score, rather than a utility score, as the output. Therefore, lower values are more desirable. Under the SLoS model, the loss score is computed as

Coming back to the example with two criteria, the loss score for treatment
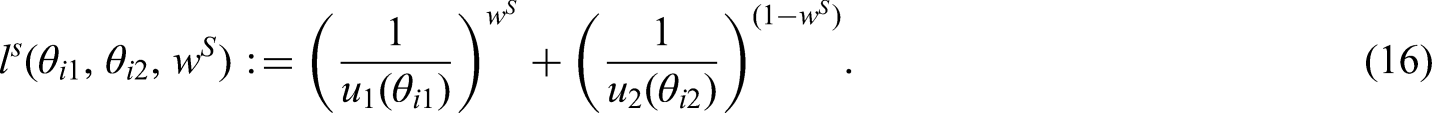
As is the case with the product model, this penalisation makes it impossible for treatments with either no benefit or extreme risk to be recommended over other potential treatments, compared to the linear and multi-linear models (which can recommend such treatments). This is because a treatment that had either of these would return a loss score of infinity (regardless of the values of any other criteria) and would therefore be non-recommendable. On the figure, the white colour at extreme undesirable values (either very low benefit or very high risk) corresponds to very high to infinite loss scores and demonstrate the penalisation effect.
Of note, Figure 1 displays the contours of equal loss score for all the models, so all the plots on this figure could be interpreted in the same way, with lower scores (in blue) corresponding to more desirable benefit–risk profiles. Even when these contour plots concern the same values of weights in the models, the weights themselves are different in each model (represented by different indices). Therefore, when to provide a fair comparison of these models, it is important to ensure that the models carry (approximately) the same relative importance of the criteria defined through the slope of the contour lines. We propose an approach to match the relative importance of the models below.
Methods for quantifying subjective preferences, for example, Discrete Choice Experiment and Swing-Weighting, have been widely studied in the literature.6,7,24,25 Applied to drug BRA, the majority of the weight elicitation methods concern the linear model. In the linear model framework, the weight assigned to one criterion is interpreted as a scaling factor which relates one increment on this criterion to increments on all other criteria.
Note that each of the aggregation models use the individual weights,
Mapping for two criteria
As described in Saint-Hilary et al., 14 formally, the trade-off between the criteria could be represented by the slope of the tangent of the contour lines where the contour line passes through the point (0.5, 0.5) (see the red lines in the contour plot of panels B to D in Figure 1). Therefore, the expressions for the mapping of the linear weight to the competitive models are found through the equality of the slopes of the tangents to the corresponding contour lines.
We start from the setting with two criteria. As stated above, even for the two criteria setting, the multi-linear model requires one more weight to be specified. Therefore, we impose a constraint on the weight corresponding to the interaction term to obtain the unique solution for the mapped weight
Using the utility/loss scores
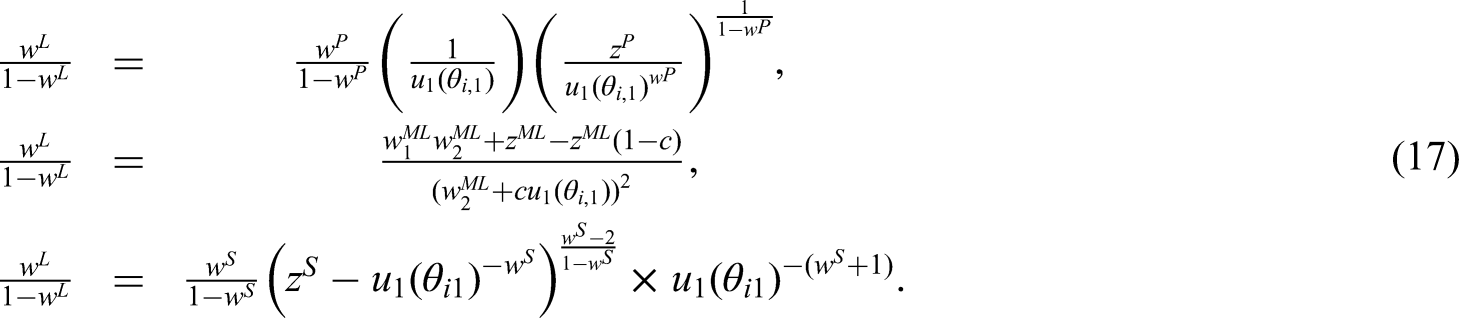
Note, however, that the slope of the tangent of the contours for the linear model are constant for all values of parameters and defined by the weights

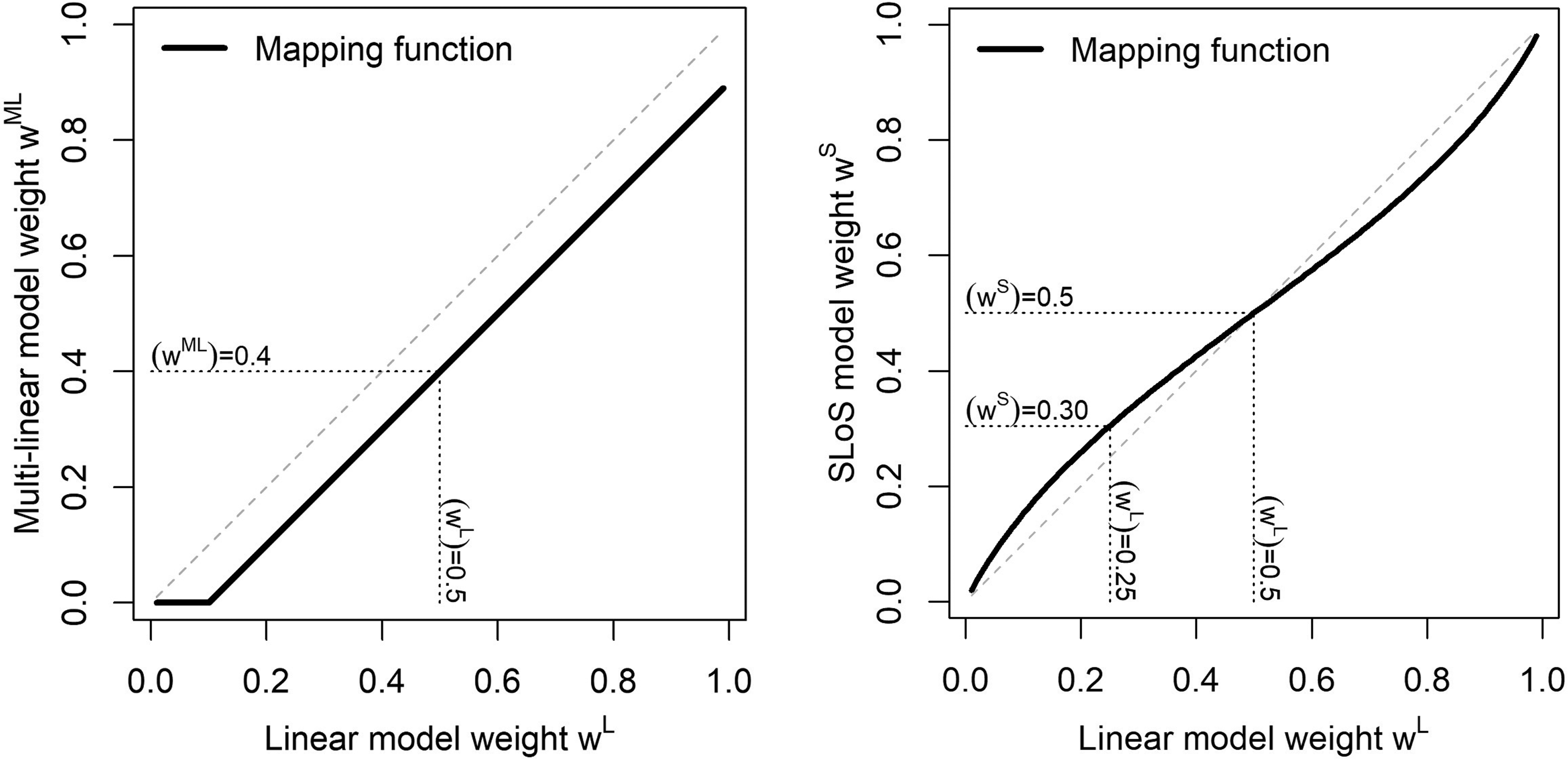
Weight mapping from the linear model to the multi-linear model (left) and to the SLoS model (right).
One can note that for the multi-linear model, the proposed mapping process may result in the obtained negative mapped values of weight. This is because of how the weight mapping function is elicited in the two criteria case: if the value of a weight under the linear model is less than half the value of
The mapped weights for the multi-linear and SLoS models do not have a direct interpretation, and should be back-transformed to linear weights to be interpreted. For instance, with two criteria, a weight of
Proof for the above workings is given in the Supplemental Material.
The derivation above concerns the setting with two criteria only but could be directly extended for the product and SLoS models. Specifically, one can apply the proposed mapping function to each of the weights in the setting with more than two criteria marginally. This would imply that the weights are mapped with respect to the importance of all other criteria rather than a single benefit (or risk).
14
The extension for the multi-linear model, however, is less straightforward. Generally, it would be a much more involving procedure to elicit weights for all the interactions terms as their number increases noticeably if more than two criteria are considered. Specifically, in the case study considered in Section 3, there are four criteria resulting in 11 interaction terms. Following the two criteria setting, we suggest to fix the total weight attributed to all the interactions to be equal to
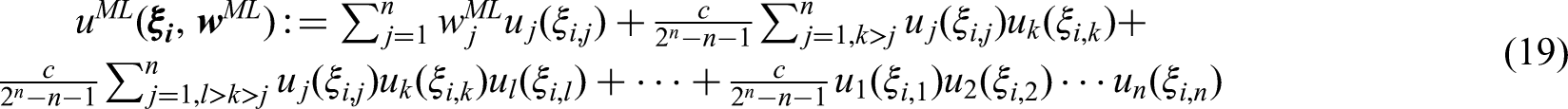
In this section, the performance of the four aggregation models is illustrated in the setting of an actual case study. This will provide an insight on how the various models perform, and what difference in the decision making they induce when applied to real-life data. The case study in question analyses the effects of two treatments (Venlafaxine and Fluoxetine) compared to a placebo, on the effects of treating depression. This study uses data from Nemeroff, 17 and expands on the studies conducted by Tervonen et al. 12 and Saint-Hilary et al. 13
Fluoxetine and Venlafaxine are both treatments used to treat depression. Here, the benefit criterion is the treatment response (an increase from baseline score of Hamilton Depression Rating Scale of at least 50%), and the three risk criteria are nausea, insomnia and anxiety.
Table 1 shows the outcomes of the trial for the two treatments and the placebo.
Number of events and number of patients for each criteria for Venlafaxine, Fluoxetine and Placebo.

Number of events and number of patients for each criteria for Venlafaxine, Fluoxetine and Placebo.
For all criteria, we approximate the distributions of the event probabilities by Beta distributions Most and least preferable values of Most and least preferable values
This case study considers three different weighting combinations, which were used under the linear model by Saint-Hilary et al.
13
These sets of weights correspond to three different scenarios of the relative importance of the criteria for the stakeholders. The first scenario reflects the case when all four criteria are equally important. The second scenario corresponds to the benefit criterion having more relative importance than all risk criteria together. The third scenario can be considered as a ‘safety first’ scenario, in which each risk criterion has a higher weight than the benefit criterion. As discussed in Section 2.3, the weights of the criteria for the product, multi-linear and SLoS models are obtained by mapping. Note, again, that while the multi-linear model might not exactly induce the same average relative importance of the criteria, the proposed procedure suggests to control the contribution of the interaction terms in the decision at the given level of
Table of mapped weights for each of the three scenarios.

Three pairwise comparisons are made: Venlafaxine against Fluoxetine, Venlafaxine against Placebo and Fluoxetine against Placebo. We consider that one treatment is recommended over another if the probabilities defined in (4) or (5) are greater than
Probability of treatment being recommended as the best treatment against another for the three pairwise comparison, using each of the four aggregation models, for each of the three weighting scenarios.

Under the first scenario with the equal weights for all criteria, the treatment with preferable risk criteria values was more likely to be recommended as the three risk criteria altogether have a greater weight than the one benefit criterion. For the comparison between Venlafaxine and Fluoxetine, the probability that Venlafaxine has better benefit–risk characteristics is around 1.7%–1.8% under all four models. For the comparison between Venlafaxine and the placebo, there is only a minor difference in the probability that Venlafaxine has better benefit–risk characteristics (<0.1% in the linear and multi-linear models, 1.6% in the product model and 3.7% in the SLoS model), not enough of a difference to change the recommendation. However, when comparing Fluoxetine to the placebo, a notable difference is observed. Under the linear and multi-linear models, the probability of Fluoxetine having the better benefit–risk characteristics is around 7%–10% (suggesting the placebo is much more preferable), whilst this rises to 37% under the product model and 47.3% under the SLoS model (suggesting near-parity of treatments). This occurs due to the penalisation of low benefit criterion values for the placebo, where the 95% credible interval includes values close to zero (in bold in Table 2). These low values are harshly penalised under the product and SLoS models, as they suggest that the placebo induces no treatment benefit with a non-neglectable probability. The linear model does not account for this and strongly favours the placebo, while the multi-linear does not penalise these values strongly.
Mean (95
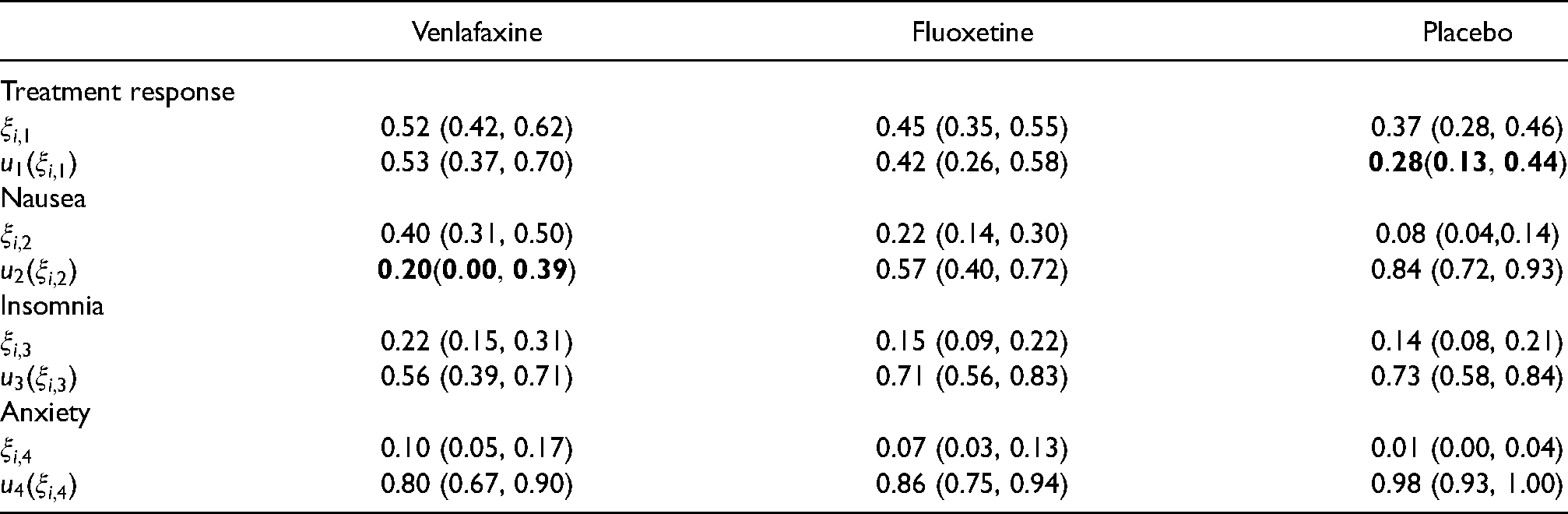
Under the second scenario, the treatment response is considered as the most important factor, and is given a weighting greater than that of the three risk criteria combined. For the comparison between Venlafaxine and Fluoxetine, both the product and SLoS models say that Venlafaxine has inferior benefit–risk characteristics (42.6% and 36.6% probability of being better, respectively). More average results are observed with both the linear model, which gives a probability of 48.0%, and the multi-linear model, which gives a probability of 46.3%. Again, the difference between the probability of the linear model and those of the product and SLoS models is due to the penalising effects of the latter. This occurs because of the nausea risk criterion interval contains zero for Venlafaxine (in bold in Table 2), which causes the product and SLoS models to recommend Fluoxetine more often than Venlafaxine, despite the weighing criteria giving preference to the treatment response (which is greater with Venlafaxine). With the multi-linear model, the penalisation of the undesirable nausea criterion is not as strong as in the product or SLoS models, as the weight mapping induces a drop from 0.11 to 0.06 in the weight given to the corresponding individual term, and the effect of the interaction terms is not enough to overcome this.
For the comparison between Venlafaxine and the placebo, the probability that Venlafaxine has better benefit-risk characteristics is between 63% and 75
For the comparison between Fluoxetine and the placebo, the probability that Fluoxetine has better benefit-risk characteristics is around 65%–80% under all four models, with the probability of Fluoxetine being preferable increasing as the methods increase the penalisation applied to the placebo’s lack of benefit effect. The stronger penalisation occurs under the product and SLoS models, hence why they are both more likely to recommend Fluoxetine.
Across all three comparisons, the multi-linear model is always slightly less likely to recommend the treatment with the greater benefit value than the linear model. As this is the scenario where the benefit criterion is considered to be the most important, this shows that the weight splitting with the multi-linear model induces a loss of the preferences that were given when the weights were originally set out for the linear model, illustrating some of the problems theorised in the methods section.
Under the third scenario, a ‘safety first’ approach is adopted, giving the risk factors a higher weighting. The probability that Venlafaxine has better benefit–risk characteristics is around 0.5%–0.6% when it is compared to Fluoxetine and around 0%–0.6% when it is compared to placebo, under all four models. For the comparison between Fluoxetine and the placebo, the probability that Fluoxetine has better benefit–risk characteristics is around 2.1%–3.0% for the linear and multi-linear models, whilst this increases to 18.5% under the product model and 30.1% under the SLoS model. This increase occurs for the same reasons outlined for the same comparison in scenario 1: The penalisation of the benefit criterion for the placebo, with its 95% credible interval including low values (in bold in Table 2). The linear model does not account for this and strongly favours the placebo, while the multi-linear does not penalise these values sufficiently and still favours the placebo.
Overall, this case study provides us with a number of important observations shedding a light on the differences in the aggregation performances. Firstly, the effects of extremely undesirable outcomes (those highlighted in bold in Table 2) are more significantly and consistently penalised in the product and SLoS models (the penalisation is stronger in the SLoS model than the product model, although they give the same recommendation for every comparison). These examples also help to show that the models provide similar recommendations when one treatment is clearly preferable than its competitor. Lastly, the weight splitting in the multi-linear model induces a change in the relative importance between criteria that may not always reflect the choices of weights as well as other models, highlighted in scenario 2. This makes it less appealing than other models.
To draw further conclusions regarding the differences between models, we conduct a comprehensive simulation study under various scenarios and under their many different realisations.
Setting
To evaluate the performances of the four aggregation models, a comprehensive simulation study covering a wide range of possible clinical cases is conducted. This allows us to investigate many scenarios and their various realisations rather than a single dataset as in the case study. The simulation study is preformed in a setting with two treatments, named
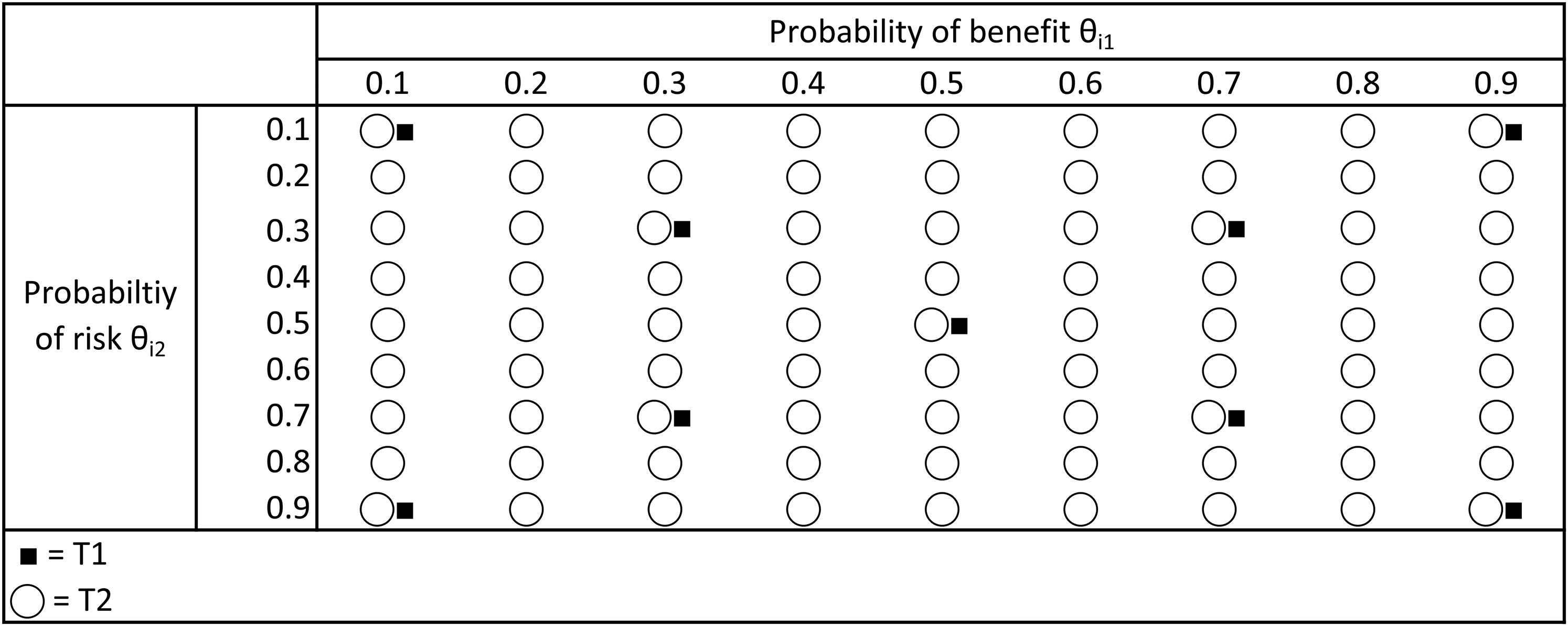
Simulation scenarios for the trial with two criteria.
Figure 3 shows all the different values that the benefit and risk criteria can take for both
Scenario 1:
Scenario 3:
Scenario 5:
Scenario 7:
Scenario 9:
The following Bayesian procedure is used for the simulation study:
Step 1: Simulate randomised clinical trials with two treatments Step 2: Derive the posterior distributions using the simulated data assuming a degenerate prior, Beta(0,0), to reduce the influence of the prior distribution. Draw 2000 samples from each posterior distribution of the criteria and obtain the corresponding empirical distribution for the PVF. Step 3: Use the posterior distributions of the PVF in each of the aggregation models as given in equations 2 and 3 to compute the probability in equations 4 and 5 that treatment Step 4: Repeat steps 1–3 for 2500 simulations trials. Step 5: Estimate the probability that each treatment is recommended
The aggregation models will be compared using
Results
The results are presented on Figures 4 and 5. The first seven scenarios referred to above for treatment
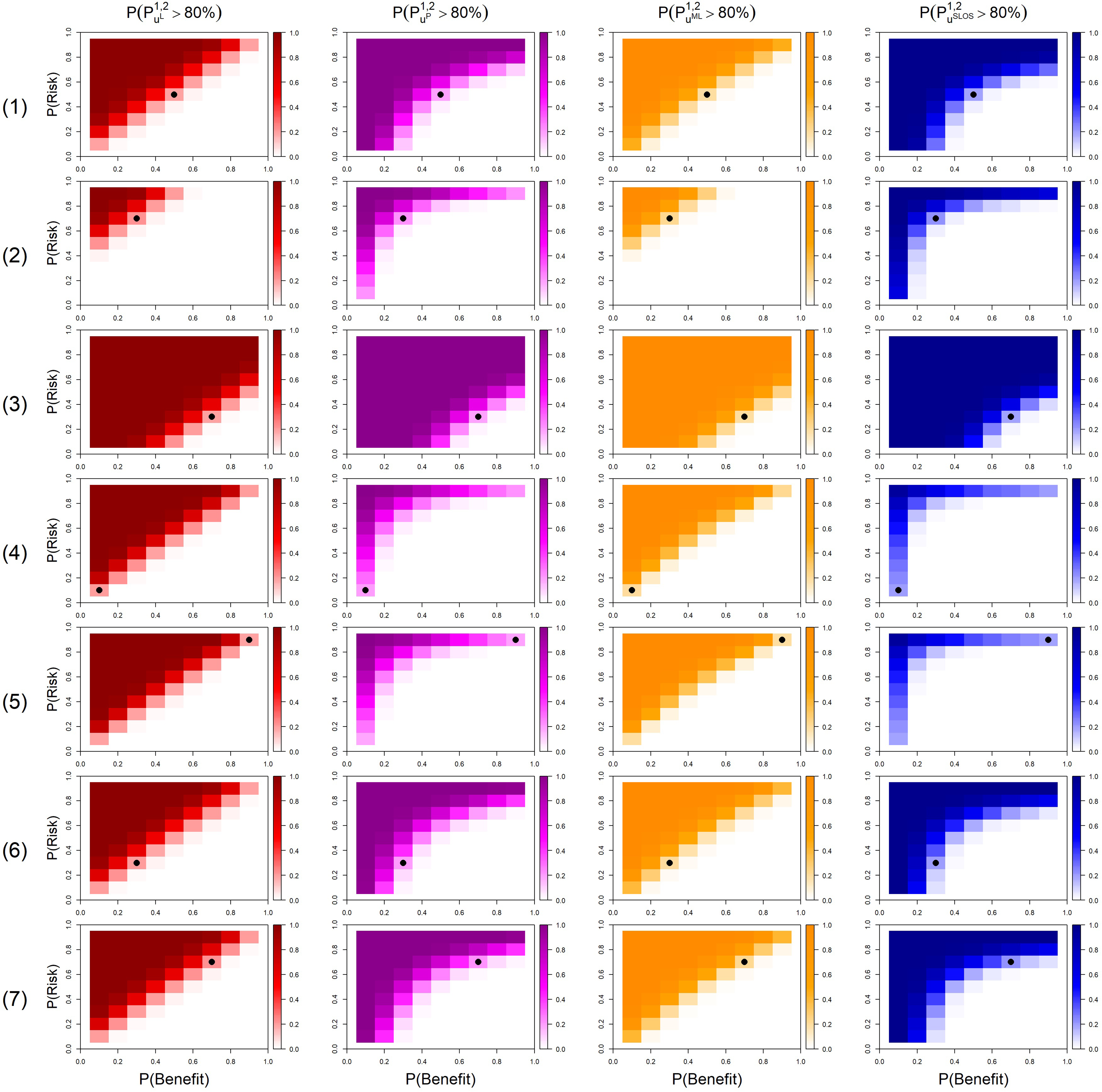
Probability that the model recommends
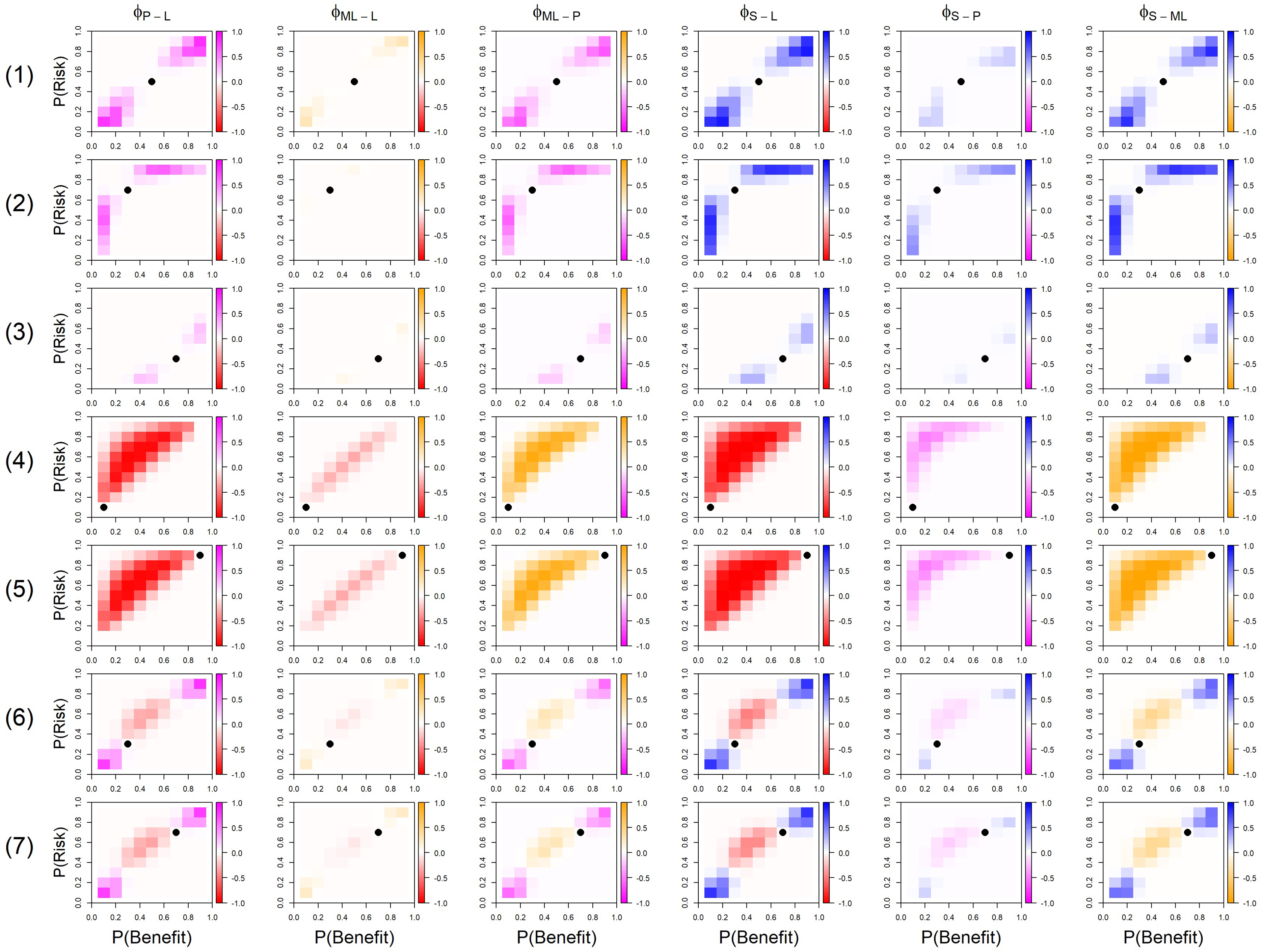
Results of the six pairwise comparisons of the four AM, where a cell being a colour indicates that AM recommended
The probabilities
In Figure 5, a colour of a cell corresponds to the aggregation model of this colour to recommend treatment
In scenario 1, the four models are in agreement to recommend
For example, when
However, a distinguishing difference between the designs under scenario 1 can be found when
In scenario 4, where
It should be noted that poor recommendations can be made under the product and SLoS models if both
In scenarios 6 and 7, all AM recommend
Overall, the simulation study has shown that, for the two criteria having an equal relative importance, SLoS penalises extremely low benefit and extremely high risk criteria the most, whilst the product model penalises these moderately, acting as a sort of middle ground between the linear and SLoS models. The multi-linear model offers a small amount of penalisation (less than the product model), but due to the added complexity of this model when more criteria are added, it should not be recommended over either the SLoS model or the product model. The linear and multi-linear models both recommend treatments with no benefit/high risk over other viable alternatives, which contradicts conditions set out by Saint-Hilary et al. 14 Therefore we can provisionally conclude that the two models that appeal most at this point are the product and SLoS models.
The results above concerned the case with the two criteria being uncorrelated. However, it might be reasonable to assume that the criteria for one treatment might be correlated. In this section, we study how robust the recommendation by each of the four models are to the correlation between the benefit and risk criteria. We consider two cases of the correlation: a strong positive correlation (
We study how likely the correlated outcomes are to change the final recommendation of one of the treatments. Specifically, we study the proportion of cases under each of the scenarios in which the difference in the probability of recommending treatment
Number of times (
) when the difference in recommending
changes by at least 2.5% or 5% between the positively correlated criteria and the non-correlated criteria.
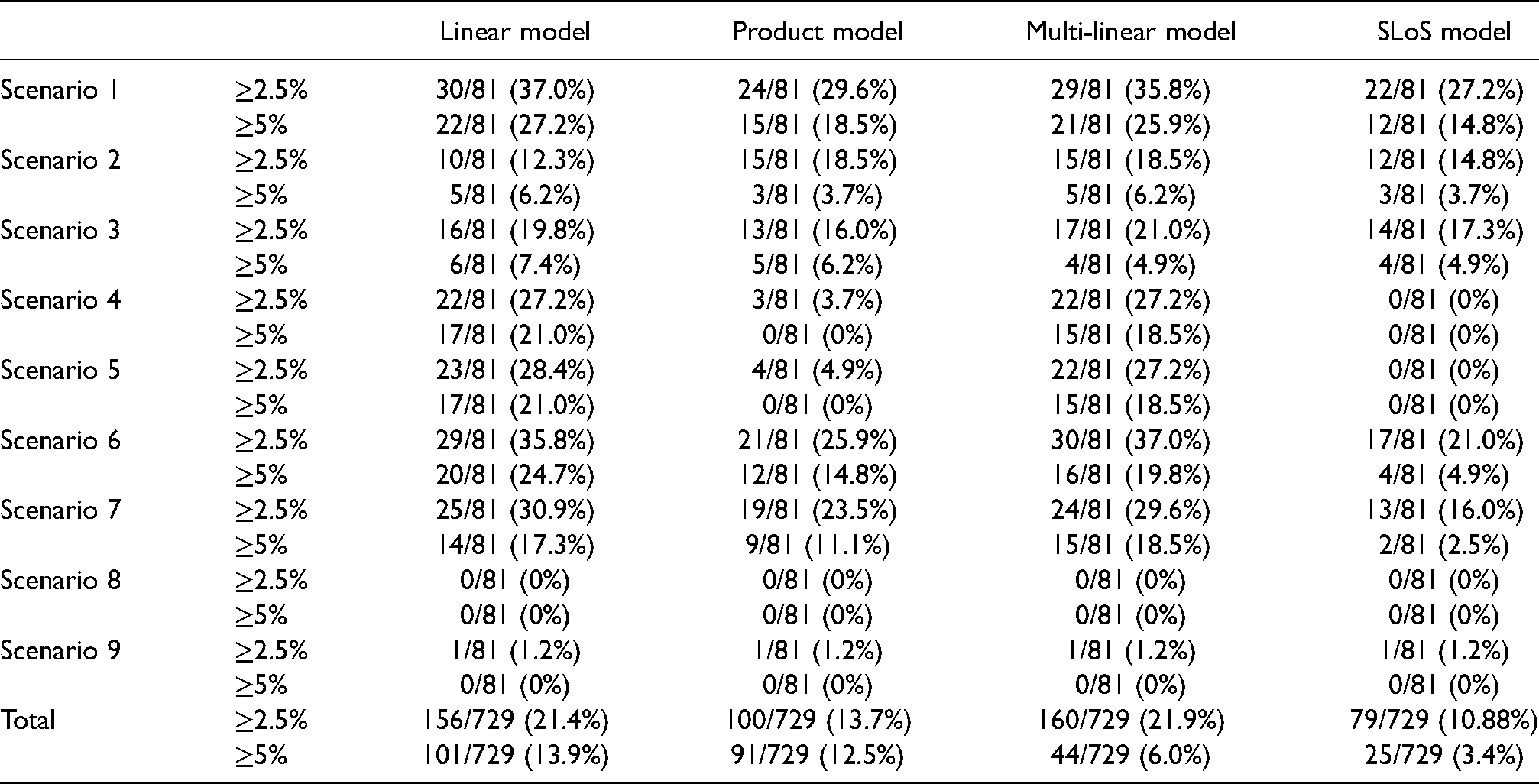
Number of times (
Table 5 shows that all four models are the most affected by correlation under scenario 1 with the characteristics of
Overall, the SLoS model is the least affected by correlation between the criteria, the product model is the second least affected whereas the multi-linear (for the threshold 2.5%) and the linear model (for the threshold 5%) are the most affected ones.
In this article, four potential AM are investigated for use in benefit–risk analyses: The linear model, product model, multi-linear model and the SLoS model. The differences of these models were highlighted in a case-study and a simulation study.
In most clear cases (i.e. when one treatment has more benefit and less risk than the competitor), all AM gave similar recommendations. However, in cases where one treatment had either no benefit or extreme risk, the models which penalised undesirable values more (the product and SLoS models) gave more desirable recommendations: non-effective or extremely unsafe treatments are never recommended. Furthermore, with these models, more risk is accepted in order to increase benefit when the amount of benefit is small than when it is high (or less benefit is desirable to reduce risk when the amount of risk is high than when it is small), which is consistent with the well established assumption of non-linearity of human preferences. 20 It should be noted that these models hardly discriminate two treatments that slightly differ but have both extremely undesirable properties. However, in this case, none of the treatments should be recommended anyway.
The effects of correlations between criteria was also investigated in this study. The overall effect of correlations was small to negligible in the product and SLoS models, showing these AM are not much affected by correlations between the criteria. However, the linear and multi-linear models were more likely to see a 2.5% or 5% change in the probability of recommending one treatment over another, showing that they are more affected by correlations between the criteria.
A simple mapping was applied to obtain multi-linear and SLoS weights from linear weights, so that the models could be fairly compared while preserving the weight interpretation. However, since the mapping is not far from an identity transformation, omitting it would not have a major impact on the results, as demonstrated in Saint-Hilary et al. 2018 14 for SLoS.
Overall, the two models to recommend from this investigation are the product model and the SLoS model, depending on how severely the decision maker whish to penalise treatments with either no benefit or extreme risk (moderate penalisation: product model, strong penalisation: SLoS model). The multi-linear model, whilst acting as a middle ground between the linear model and the product and SLoS models in the simulation study, involves an increased complexity behind the model. These include the increased complexity involved with adding additional terms and increased difficulty in weight mapping. This model also struggled to truly reflect the weightings given in the case study, especially in scenario 2. Because of this, we do not recommend this AM over the product or SLoS models. Additionally, the linear and multi-linear models should not be recommended as both of these models do not contain the two desirable properties outlined in Saint-Hilary et al. 14 : That treatments with no benefit/extreme risk should not be recommended, and that a larger increase in risk is accepted in order to increase the benefit if the benefit is small compared to if the benefit is high – both of which are present in the product and SLoS models.
Footnotes
Acknowledgements
This report is independent research supported by the National Institute for Health Research (NIHR Advanced Fellowship, Dr Pavel Mozgunov, NIHR300576). The views expressed in this publication are those of the authors and not necessarily those of the NHS, the National Institute for Health Research or the Department of Health and Social Care (DHCS). Dr Pavel Mozgunov also received funding from UK Medical Research Council (MC UU 00002/14).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.