
Abstract
In the advent of revolutionary technological change, perpetuated by the publishing of Large Language Models like ChatGPT, the article discusses the transformative effects of artificial intelligence on the application of evaluation standards. Amid a debate on the integration of artificial intelligence technology in evaluation processes, there is a lack of understanding about how artificial intelligence usage impacts adherence to these standards. This article endeavors to bridge this gap by examining the future trends of the ongoing technological revolution, assessing the potential for evaluation tasks to be augmented or replaced by artificial intelligence systems and conducting a thorough opportunity and risk analysis regarding the adherence to evaluation standards. The article addresses both opportunities, such as increased efficiency and analytical depth, and challenges, including structural errors and biases. It concludes with suggestions for evaluators, emphasizing the balance between leveraging artificial intelligence’s capabilities and maintaining critical oversight and ethical responsibility in evaluation practices.
Introduction
The unveiling of OpenAI’s ChatGPT in December 2022 marked a significant milestone in the development of artificial intelligence (AI), especially Large Language Models (LLMs), offering unprecedented human-like language and intelligent behavior (Head et al., 2023). The advent of GPT-4 marks a historic moment in human history, with some commercial researchers suggesting provocatively that “sparks of artificial general intelligence” (Bubeck et al., 2023) have been kindled for the first time. This breakthrough garnered global attention, catalyzing discussions about the opportunities and perils of advanced AI across various sectors, including science, education, the legal system, and the economy. The revolutionary capabilities of machines autonomously understanding, processing, and generating language have also profound implications for the evaluation field, the breadth of which remains to be fully understood.
Throughout history, digitalization has continually shaped evaluation practices. Digitalization is here defined as a transformative sociotechnical process that involves the integration of digital technologies into all aspects of society, leading to fundamental changes in how individuals, organizations, and institutions operate and interact. In the field of evaluation, this has manifested, for instance, through the digitization of documents improving data storage and accessibility, the automation of statistical calculations with analysis software, the development of visualization tools, or the emergence of big data analytics widening the options of data accessibility like social media data. In the past 5 years, significant digital progress has been made through the development of sophisticated machine learning-based analysis methods. These advancements have enabled evaluators to conduct large-scale text analyses (Niekler and Wencker, 2019) or analyze patterns in geospatial data (Purbahapsari and Batoarung, 2022).
The latest development of digitalization within evaluation is shaped by the rise of generative AI systems. Trained on a vast array of data, it enables them to produce tailored outputs in the form of text, audio, and video and can function as a source of knowledge. These advanced AI models execute tasks with a proficiency akin to human intelligence, allowing, for example, to conduct human-like conversation (Liu et al., 2023).
As the technology evolves, evaluators must prepare for a technological shift whose trajectory remains uncertain. Current evaluation literature is discussing the potentials and risks for evaluation practice (Head et al., 2023; Nielsen, 2023), technical constraints (Nielsen, 2023), the need for regulation (Reid, 2023), and the requirements for the professionalization of evaluators to adapt to the technology (Tilton et al., 2023). Furthermore, best practices are shared within the community (Ferretti, 2023; Raftree, 2023).
Following the definition of the European Commission’s high-level expert group on AI, it is defined in this article as a complex sociotechnical system that achieves adaptive problem-solving by analyzing its environment and taking actions:
Artificial intelligence (AI) refers to systems designed by humans that, given a complex goal, act in the physical or digital world by perceiving their environment, interpreting the collected structured or unstructured data, reasoning on the knowledge derived from this data and deciding the best action(s) to take (according to pre-defined parameters) to achieve the given goal. AI systems can also be designed to learn to adapt their behaviour by analysing how the environment is affected by their previous actions. (AI HLEG, 2018: 7)
Definitions of the term vary across science and are fraught with a complex array of expectations, embodying a wide range of both positive aspirations and negative apprehensions.
Many authors share the view that the AI system offers promising prospects to support and enhance evaluation practice (Head et al., 2023). It is recognized for its automation potential, particularly in handling repetitive tasks (Mason, 2023), which could help, for example, to analyze large amounts of data quickly. Moreover, the opportunities of AI tools to derive valuable insights from complex and unstructured data sources are highlighted. By identifying patterns from unstructured data, it enables evaluators to achieve a deeper comprehension of the evaluation subject. AI tools would also offer the opportunity for innovative data collection methods, such as scraping online data or conducting interviews with chatbots (Hassani and Silva, 2023). Finally, it is considered as a tool to enhance visualization and reporting through generating interactive visualizations and automated reports.
However, discussions also highlight the limitations of AI in evaluation practices. Concerns include factual accuracy (Head et al., 2023), potential biases (Head et al., 2023), and the “black box” problem, which refers to the difficulty in understanding how AI models reach certain decisions (Adadi and Berrada, 2018). Ethical considerations are paramount; the need to address potential biases or harms and the broader societal impact of AI was discussed (Bamberger and York, 2020; Head et al., 2023). While there is a consensus that AI tools can automate certain evaluation tasks, it is also acknowledged that some tasks may never be fully automated (Mason, 2023). Within the community, the view is shared that evaluators should proactively engage with AI, learning to incorporate AI tools into evaluation practice, identifying the strengths and weaknesses, while also maintaining a critical stance toward its output (Head et al., 2023).
This article contributes to this ongoing debate by examining the impact of AI through the lens of evaluation standards. Recognizing that this thematic area has not yet been sufficiently explored in the evaluation community, this article aims to bridge the research gap. 1 The following analysis aims to discern how these standards may be bolstered or challenged by incorporating AI systems into evaluation processes, and to identify what measures are necessary to ensure the adherence to standards.
Methods
This contribution utilizes a combination of literature search and conceptual analysis to explore the implications of the emergence of AI systems on the adherence to evaluation standards. Given the rapid advancements in AI and the limited experience in applying the latest technologies like LLMs in evaluation (which differ from older machine learning methods), this conceptual approach was chosen over empirical research methods (e.g. surveys related to organizational practice) to provide timely and relevant insights into the current discourse.
The analysis followed a multistep process. Initially, a comprehensive literature search was conducted to identify key trends in AI development and their potential impact on evaluation tasks. 2 These identified trends were then systematically mapped onto the task-based framework of Autor et al. (2003), which was chosen because it has proven effective in understanding the influence of technological changes on the labor market. This framework provided a theoretical basis to assess how AI tools might automate or augment specific evaluation activities. The mapping of AI capabilities to evaluation tasks was further informed by relevant literature on these activities and supplemented with job descriptions from the O*NET database, particularly those related to social science research and political consulting. This framework provides a foundation for analyzing the implications of AI integration in evaluation structured by opportunities and risks for standard adherence in evaluation.
Future trends in AI
Predicting the future trajectory of AI, especially its impact on evaluation, is challenging due to rapid and often unexpected advancements, such as swift progress in LLMs. While estimates on the arrival of Artificial General Intelligence (AGI)—a stage where AI systems can perform any human task with equivalent proficiency or better than humans (Allyn-Feuer and Sanders, 2023; Grace et al., 2018; Müller and Bostrom, 2016)—vary widely (10−50 years), precise timing may not be essential for understanding AI’s impact on evaluation. Instead, insights can be drawn from past technological evolutions and current trends, five of which are discussed below.
A primary trend in the development of AI is the anticipated continued improvement in the effectiveness and efficiency of AI models (Bubeck et al., 2023). At present, we are witnessing the emergence of language-based AI models, which have reached a performance level rendering them beneficial across a diverse array of societal subsystems. This trend is likely to be propelled further by expected advancements in computing capacities and the deeper integration of this technology in many parts of our society. In addition, professionalization through standardization and specialization in AI development will contribute to enhanced AI performance. Consequently, it can be anticipated that future AI systems will be more adeptly designed and trained, and better equipped to tackle assigned problem-solving tasks. This evolution could manifest as a reduction in errors and higher accuracy in AI outputs.
A second trend in the evolution of AI systems is their expanding capability to perform a diverse array of tasks, marking a shift from more specialized to versatile functionalities. Central to this development is the advancement of multimodal AI systems, which are designed to integrate and process various forms of digital media, including audio, images, and textual data. For instance, these systems are now being used in areas ranging from healthcare diagnostics, where they interpret medical imagery, to customer service bots that can understand and respond to both text and spoken queries (Nicolescu and Tudorache, 2022; Rajpurkar et al., 2022). Furthermore, the realm of AI application is extending beyond the digital space, thanks to significant progress in robotics. AI systems are increasingly being deployed in physical environments, undertaking tasks that require real-world interaction (e.g. autonomous driving).
Building on this, third, AI systems will be able to perform increasingly complex tasks. Intense work could be done on so-called autonomous AI agents, where different AI systems are interconnected (Hao et al., 2023; Wang et al., 2023). These agents are capable of performing not just one specialized activity (such as spam detection) but many strategically coordinated tasks, utilizing specialized data and AI tools. For example, an autonomous agent could be capable of preparing, analyzing, and interpreting data. Furthermore, the capacity for iterative and strategic action is gaining importance in AI-supported or automated decision-making processes, which can be seen, for example, in smart cities (Mills et al., 2022).
Explainable Artificial Intelligence (XAI) can be identified as a fourth central trend in AI development. Scientists aim to make the functioning and decision-making processes of AI systems more transparent and understandable, which are currently opaque due to the black-box nature of neural networks (Adadi and Berrada, 2018; Das and Rad, 2020; Fürst, 2022). XAI focuses on developing AI models that are not only precise and efficient but also yield decisions and actions that are transparent, comprehensible, and verifiable for users. This is particularly important in the field of evaluation, as the traceability of AI-supported analysis processes enables a critical review of the results.
As AI systems evolve and become more integrated into various sectors, the fifth key trend is the increasing focus on the regulation of AI systems and the construction of ethical AI. This trend is a response to experiences with AI systems that have produced ethically questionable outputs, such as discriminatory algorithms used in legal systems (Zuiderveen Borgesius, 2020). For example, the development of trustworthy AI is designed to mitigate these risks by identifying and correcting errors and biases in algorithms. This involves training models on secure and ethically vetted data and incorporating human feedback loops to monitor and sensor outputs that may be ethically hazardous (Thiebes et al., 2021). In parallel, data protection and data security are critical issues in AI deployment. The contradiction between AI systems’ reliance on extensive training data and the principle of data minimization is prompting efforts to devise data protection-compliant (local) solutions. The AI market’s current monopolization by a few major tech corporations, providing the most advanced models, is also a matter of concern. This situation has spurred a broad discourse and political processes advocating for AI regulation based on comprehensive risk assessments (European Commission, 2021). Meanwhile, the vibrant open-source AI community plays a crucial role in democratizing AI development and potentially influencing the direction of ethical AI practices.
In summary, current developments show that evaluators must prepare for significant changes in technology and methodology. Key trends include improvements of AI models leading to more efficient data analysis and text generation, the expansion of AI into versatile functionalities and complex tasks, and a growing focus on ethical AI and transparent decision-making. These developments indicate a transformative impact on evaluation practices, necessitating adaptability and a deep understanding of evolving capabilities of AI systems.
AI and evaluation practice
To understand the potential benefits and risks of using AI in evaluation for the adherence of quality standards, the following chapter examines how technological advancements influence evaluation practice. The ensuing analysis of the impact of AI systems on evaluation practice sets the stage for a detailed exploration of associated risks and potentials for standard adherence.
Understanding technological change through a task approach
To comprehend the impact of AI-driven technological change on the evaluation profession, the task approach developed by economists Autor et al. (2003) provides a valuable analytical lens. Originally employed to assess computerization’s effects on the labor market, this approach offers a nuanced framework to examine occupational changes in the context of digitalization and automation. It enables a differentiated view on the changes within job profiles, focusing on the substitution, augmentation, or generation of tasks. Applying this approach to the evaluation profession involves dissecting job profiles to identify which aspects are susceptible to AI automation and which may evolve or expand.
Autor et al. (2003) structure the activities of professions along two dimensions. On one axis, they are divided into routine and non-routine tasks, on the other axis into analytical, interactive, and manual tasks. Routine tasks are characterized by their high level of predictability and repeatability, involving activities that follow fixed, clearly defined procedures and rules. These tasks are easily standardizable due to their minimal variation and reliance on established protocols. Non-routine tasks, on the contrary, are marked by their unpredictability and the complexity of the challenges they present. These tasks are less standardized and typically require innovative, adaptive approaches.
The second axis is divided into three different task types: analytical, interactive, and manual. 3 Analytical tasks are those that require the processing and interpretation of data or information to inform decision-making, problem-solving, or insight generation. Interactive tasks, in contrast, revolve around communication and interaction with other individuals or groups. Finally, manual tasks involve physical activities or the manipulation of objects, ranging from simple, repetitive actions to complex, skill-requiring procedures.
The task approach can be used to analyze how technological changes historically reshaped occupational profiles. For instance, the advent of the steam engine significantly altered many job roles, as it led to the automation of numerous manual routine activities (Chin et al., 2006). Tasks that were once laboriously performed by humans began to be efficiently executed by machines, signaling a shift in the required skill sets and roles within various industries.
In contrast to the approach of Mason (2023) mapping competencies of evaluators, the task-based approach is preferred as it focuses not only on substitution, but also on the interrelation between AI systems and human evaluators. This perspective is grounded in the co-construction of human action and technology, a concept developed by scholars in Science and Technology Studies (STS; Bijker et al., 1987). In addition to Mason (2023), a manual dimension is added to the framework.
Categorizing evaluation tasks
In the following, evaluation activities will be mapped to the task approach framework, based on activities of evaluators from literature as well as assessments of job profiles of evaluation-related professions (e.g. political consultants, social scientists) (Mason, 2023; O*NET OnLine, 2023a, 2023b, 2023c, 2023d, 2023e) (Table 1). Subsequently, the current research literature on the capabilities of AI systems will be used to investigate the potential effects of the technology on the respective dimensions of the task framework.
Categorization of evaluation tasks within the task framework provided by Autor et al. (2003).
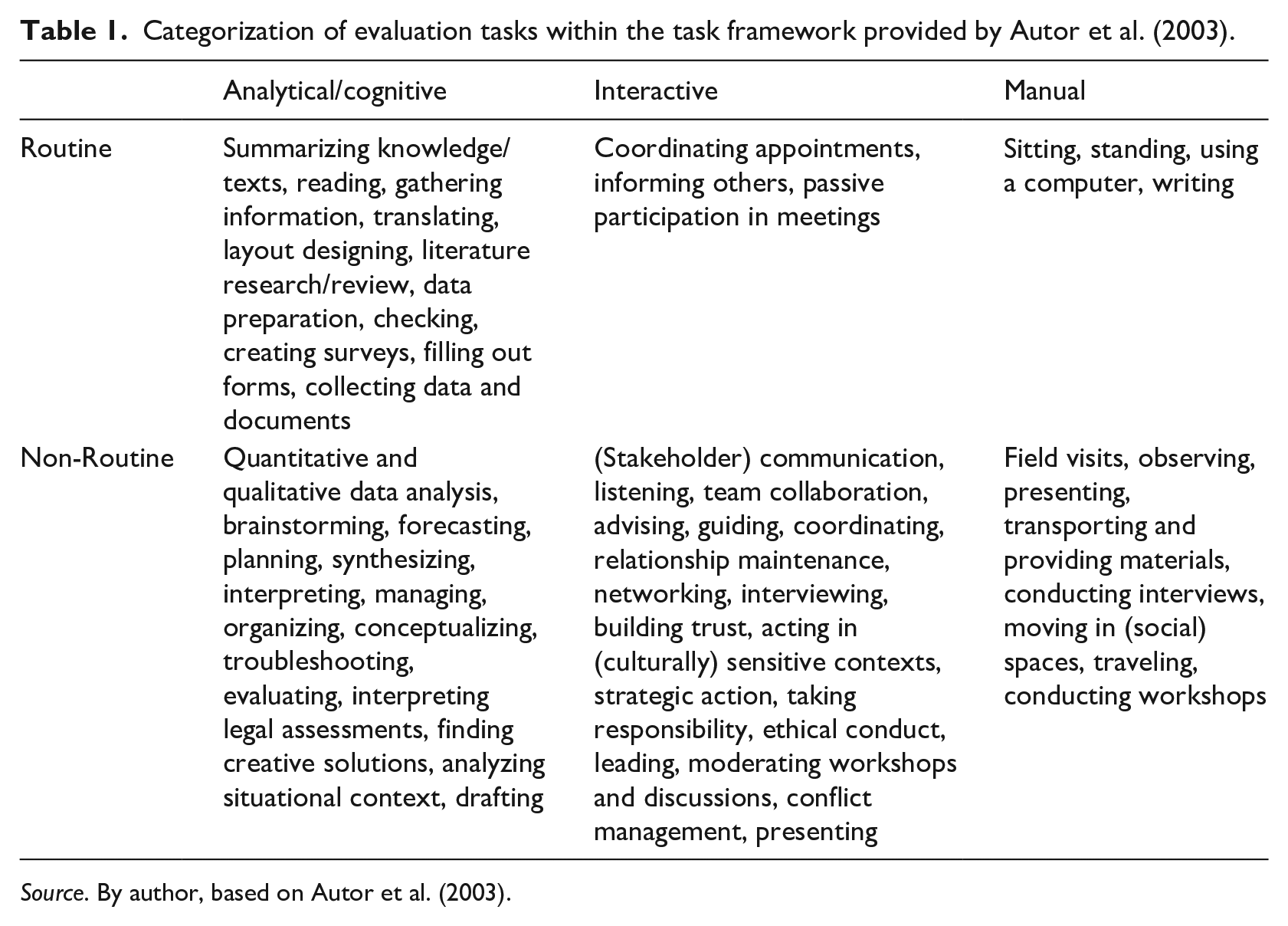
Source. By author, based on Autor et al. (2003).
The categorization of evaluation tasks structured through the framework of Autor et al. (2003) reveals several significant characteristics of this profession. First, the diversity of cognitive, interactive, and manual tasks across both routine and non-routine categories illustrates the complexity and multidimensionality of the evaluator’s role. Particularly notable is the abundance of analytical and interactive non-routine tasks, which underscore the necessity for critical thinking, creative problem-solving, and pronounced interpersonal skills. However, a significant portion of the evaluative work involves routine analytical tasks, such as literature reviews or administrative applications. Some tasks, such as statistical analyses, contain both routine elements (e.g. executing a regression analysis) and non-routine elements (e.g. contextualizing regression results). Furthermore, the overview demonstrates that manual tasks, in both routine and non-routine situations, constitute a significant portion of the work. This emphasizes that physical presence and direct field interaction are key aspects of professional activity.
Which tasks might be augmented or replaced by AI?
After differentiating between the activities, the current research literature is now used to show which type of activities AI tools can already support or replace today or in the near future.
The late 2022 release of GPT-3 marked a significant milestone in AI development, achieving human-level language analysis and generation. This advancement redefined the scope of machine capabilities performing analytical tasks, extending beyond routine tasks (Bubeck et al., 2023; Frieder et al., 2023; Laskar et al., 2023). Despite its proficiency in various benchmarks, GPT-4 still shows limitations in advanced reasoning (Liu et al., 2023). However, as discussed in chapter 2, further enhancements in AI model performance are anticipated. This evolution suggests a gradual increase in AI systems’ competency in executing complex, analytical non-routine tasks. However, the trajectory of this development has an inherent limitation: AI models’ proficiency is confined to analytically tractable tasks based on available data and the ability to digitalize problem-solving processes. For instance, an AI tool generating political program recommendations, relying solely on project documents and interviews, may lack a nuanced understanding of uncodified elements such as power dynamics among stakeholders to formulate context-sensitive recommendations.
In the realm of interactive tasks, new AI systems offer opportunities for expansion or replacement. The currently available chatbots demonstrate the capability to generate situation-specific outputs, with some conversations being indistinguishable from human interactions (Cai et al., 2023). A variety of chatbots have emerged, capable of interacting via text, audio, and even partially through video. However, interactive tasks are inherently complex, requiring a high level of contextual knowledge, such as understanding a person’s placement in a situation or subtle nonverbal communication. These aspects have been challenging to fully digitize and are situated in a dynamic social space that extends beyond digital platforms (Cai et al., 2023; Mason, 2023).
In the area of manual tasks, it is evident that machines are capable of performing routine activities with a high degree of accuracy. This is less a result of the current AI revolution and more due to earlier industrial developments. For non-routine tasks, where machines operate in un-predefined environments, the field of robotics is progressing through innovative leaps (Backer et al., 2018). Despite rapid advancements in the field of humanoid robotics (Ha et al., 2023), as of 2023, there are no machines that exhibit human-like abilities and are capable of performing complex manual non-routine tasks, such as travel activities in a fragile country.
To conclude the analysis of task automatization through AI systems, it is shown that in the future, this technology has a high likelihood to perform analytical non-routine tasks, interactive routine tasks, and manual routine tasks. Nonetheless, further developments are necessary before interactive and manual non-routine tasks can be automated (Table 2). This analysis aligns with Mason (2023) in highlighting that routine tasks will be more impacted by AI, while interactive tasks will remain predominantly human due to the need for interpersonal and contextually responsive skills. However, the presented framework suggests a higher likelihood of AI replacing or augmenting creative tasks, which can be viewed as analytical non-routine tasks.
Likelihood of automatization of task types through current AI technology.
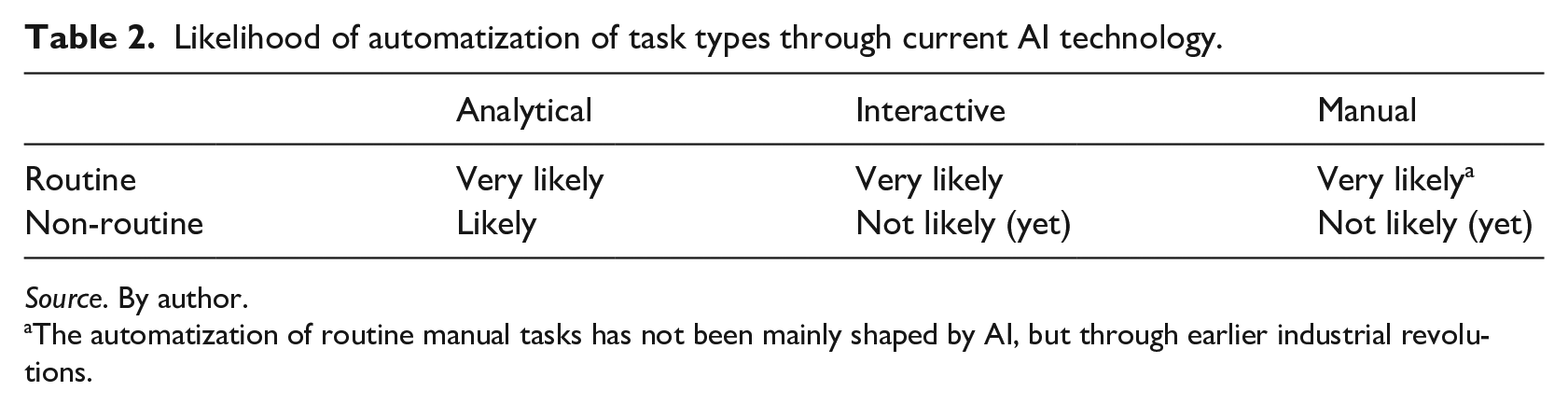
Source. By author.
The automatization of routine manual tasks has not been mainly shaped by AI, but through earlier industrial revolutions.
Opportunities and risks to the standard adherence
Evaluation standards offer guidance for evaluators, ensuring a consistent approach to evaluation processes and quality. Meta-evaluations indicate considerable variation in the adherence and ample room for improvement in adhering to these standards (Guffler et al., 2023; USAID, 2013; Wingate, 2014). In light of this context, the following section will delve into how AI might influence adherence to established evaluation standards. The analysis is based on the projections of the previous chapter, the author’s practical experiences with AI tools, 4 as well as current literature on AI and evaluation. In contrast to Montrosse-Moorhead’s (2023) contribution, which proposes criteria in the form of guiding questions to evaluate the use of AI in evaluation practice, this approach goes a step further by conducting a balanced analysis to identify both potentials and risks related to the integration of AI systems in evaluation practice.
The framework for the analysis is provided by three standard guidelines (DeGEval, 2016; Deutsche Forschungsgemeinschaft (DFG), 2013; OECD, 2010) which are synthesized by Noltze and Leppert (2018) (Table 3). This hybrid framework integrates both nationally and internationally recognized standards and is relevant due to its institutional application. Adopting this framework aims to provide a comprehensive overview of crucial evaluation standards. However, it is acknowledged that individual countries or organizations may place emphasis on aspects unique to their evaluation practices. For instance, not every type of evaluation will include a theory-based approach. Nevertheless, this framework provides a solid foundation for systematically examining the implications of AI in evaluation practice.
Evaluation standards and substandards.

Source. By author (based on Noltze and Leppert, 2018).
Referring to the internationally widely accepted Program Evaluation Standards (Yarbrough et al., 2010), the accountability is not mentioned in the framework but integrated in subsets of the standards, like “quality assurance and systematic error checking,” “completeness of reporting,” and “creating conditions for meta-evaluation.”
Accuracy, scientific rigor, and comprehensibility
Integrating AI in evaluation processes presents a dual prospect of transformative potentials and significant risks for the standards of accuracy, scientific rigor, and comprehensibility. This standard category emphasizes the critical importance of maintaining scientific and methodological rigor in the evaluation process.
AI expands the repertoire of evaluation practice
To maintain accuracy and rigor, evaluators must apply methods accurately, document procedures transparently, and conduct systematic error checking. The capability of AI systems to augment or support analytical tasks is notable (see chapter 3), especially in data collection, processing, and analysis (Christou, 2023; Hassani and Silva, 2023; Polak and Morgan, 2023). Unlike human evaluators, confined to a limited set of methods, AI systems encompass the potential to execute a broader spectrum of digitally documented techniques. Provided with adequate analysis capacities, AI can process and validate diverse data using multiple methods, thereby enhancing accuracy and validity.
In qualitative analyses, AI tools extend the range of analysis methods and coders. Generative AI can offer multifaceted perspectives on material, exceeding human evaluators’ scope. For example, it can simulate interpretations from a diverse range of economists, social, or political scientists on a specific query or transfer knowledge to any given topic.
Against the background of the potential of Big Data for evaluation purposes (Macfarlan, 2015; Picciotto, 2020; UN Global Pulse, 2016), the analytical capacities of AI systems to handle big amounts of data are noteworthy. With the current AI tools, evaluators can collect data on a specific subject without extensive methodological background knowledge, such as programming skills for web scraping. Complex data preparations (e.g. multiple imputations or geospatial analyses) are adjustable through speech commands. The possibility of conducting more analyses, robustness checks, and data processing at a large scale could enhance internal and external validity.
Nevertheless, increased analyses and data volume do not inherently improve validity or evidential rigor. As Azzam (2023) argues, AI systems have limited capacities to ensure internal validity, because they are, for instance, not able to observe the randomization process in the real world. The data quality and its integration into a reliable and valid evaluation design remain pivotal. As evaluation data are subject to interpretation, evaluators must contextualize their analyses, recognizing the dynamics among project stakeholders. This is where the limitations of AI tools in handling interactive, non-routine tasks become apparent (see chapter 3). The reliance of AI models on explicit, digitized knowledge may lead to overlooked nuances or implicit contexts, like power relations, potentially causing a biased or limited perspective. Despite the progress in conducting complex analytical tasks, it becomes clear that the limited capabilities in interactive tasks of AI systems can pose risks to standards adherence.
Automatization sets the ground for standardization
As earlier technological changes proved, automatization may be a key element to contribute to standardized processes and products (Backer et al., 2018). In the current era, the application of AI systems in automating routine analytical tasks holds promise for advancing standardization, especially tasks relying on rules and logic that can be programmed (Mason, 2023). The application of AI tools allows for predefining and documenting analysis procedures and criteria (Yu et al., 2023), which may enhance accuracy, traceability, and replicability. Analytical tasks, therefore, can be executed machine-like repetitively. Therefore, those automated procedures perform free from human cognitive fluctuations 5 and may minimize individual errors, enhancing reliability and objectivity.
However, AI systems may introduce systematic errors and biases that differ from human problem-solving approaches, including so-called hallucinations—instances where AI generates false or misleading information—which can affect the accuracy of analyses (Bubeck et al., 2023). While these errors and biases are inherent in all AI systems, the key challenge lies in understanding the specific types and extent of these errors and biases in influencing outcomes.
Another hurdle associated with AI-driven automation lies in its restricted adaptability and contextual awareness (Raji et al., 2022), which may lead to challenges when adjusting to novel or unforeseen situations, potentially affecting the accuracy and reliability of the outputs.
Credibility
Enhancing evaluators’ competencies and standardizing procedures are vital in bolstering the evaluation team’s credibility. However, overreliance on automated systems might inadvertently atrophy critical human skills, such as critical thinking and domain-specific expertise, which could adversely affect the quality of evaluation outputs. A significant issue in this context is the phenomenon of “automation bias.” This bias involves individuals’ propensity to overvalue decisions and judgments rendered by automated systems, often preferring them over human judgment, even in instances where these systems might be flawed. Consequently, excessive reliance on machine analysis tools could undermine the evaluation team’s credibility. However, in contrast to the assessment of Azzam (2023), there are ways to enhance the credibility of AI use in an evaluation. As he also discussed, there is a need for critical engagement with AI outputs, which can be implemented through robustness checks, or chain-of-thought-prompting. Moreover, working iteratively with AI may enable the development of knowledge, as AI can be used to refine the understanding of existing theories or methods or help to deepen qualitative data analysis. This can also leverage the growing importance of domain expertise of evaluators. Unlike Azzam’s study (2023), this example demonstrates that adherence to evaluation standards cannot be assessed in isolation between the evaluation team and AI system but must always be considered, which is based on a core idea of STS (Bijker et al., 1987).
However, the integration of AI systems in evaluation processes raises significant concerns regarding the “black box” problem, which directly impacts the credibility of evaluation outcomes (Castelvecchi, 2016). Due to the often opaque and complex nature of AI algorithms and neuronal networks, the analytical processes are not transparent. The inability to fully decipher how AI systems reach certain conclusions or analyze data can undermine the trustworthiness of the evaluation outcomes. Evaluators, therefore, face the challenge of ensuring that their reliance on AI systems does not compromise the traceability of their methods. However, there are approaches to addressing this issue through the use of explainable AI. These approaches aim to make the decision-making processes of AI systems more transparent, thereby enhancing traceability and increasing trust in the results.
In today’s post-factual era, characterized by pervasive doubt about facts and widespread misinformation, the credibility of competencies and the evidence presented faces increased scrutiny. With the emergence of generative AI, the creation of texts, images, videos, or audios is virtually indistinguishable from real content. In the evaluation sector, this could entail artificially generated focus group reports, or fabricated images of damaged infrastructure. The growing volume of digital content and its creators may erode trust in well-established knowledge networks.
Usefulness
The following section outlines the contribution that AI systems can make to meet the standard of usefulness. According to the OECD-DAC principles from (1991), evaluations become useful if the following criteria apply:
‘To have an impact on decision-making, evaluation findings must be perceived as relevant and useful and be presented in a clear and concise way. They should fully reflect the different interests and needs of the many parties involved (. . .). Easy accessibility is also crucial for usefulness.’ (OECD, 1991: 7)
Furthermore, these principles state that evaluations have to be timely, so that the results could be implemented in strategic decision-making processes.
AI systems offer opportunities to accelerate evaluation processes and deliver results more promptly, for example, by expediting analysis and quality assurance processes. This can contribute significantly to enhancing the usefulness of results for stakeholders and can be particularly beneficial in formative evaluations.
A significant benefit arises from the use of generative features of generative AI tools. As it allows for the creation and transformation of information in numerous ways (Hassani and Silva, 2023), access to evaluations can be greatly improved. Evaluation reports can be generated automatically as chatbots, simplified language reports, dashboards, or videos. The hallmark of generative AI is its ability to tailor information to individual needs, making it possible to address stakeholders with relevant, customized information. The conventional framework for reporting can be revamped to integrate extensive evaluative knowledge that was formerly omitted from evaluation reports or relegated to the appendix.
Within the evaluation process, AI tools can increase utility by enhancing participation. For instance, questionnaires can be more easily translated into different languages, or opinions from target groups can be analyzed more extensively. As AI tools enable the individualized presentation of evaluation-specific knowledge, it also shifts the competence and knowledge asymmetries between evaluators and relevant actors. By making professional knowledge accessible, AI tools can contribute to the democratization of evaluation processes, making them more inclusive.
While AI systems hold promise for enhancing the utility of evaluations, its integration carries associated risks. Relying on cost-efficient AI systems for evaluation processes could inadvertently lead to diminished human interaction, potentially reducing evaluations to desk studies solely on available digital information about the evaluation subject. Although AI tools facilitate rapid and cost-effective analytical tasks, there is a danger of sidelining interactive, non-routine activities due to the practicality and efficiency of analysis. As a result, there may be an overemphasis on digitally accessible materials at the expense of participatory approaches. This shift could undermine the critical role of interpretive processes in evaluations. The value and applicability of evaluation outcomes might be compromised, as the deeper, often subtle insights and contextual understanding derived from direct human interactions risks being overlooked.
Fairness, independence, and integrity
Evaluators operate in complex environments where actors with diverse agendas intersect and are embedded in power relations. These circumstances challenge evaluators in terms of fairness, independence, and integrity. They must ensure that their work is independent, transparent, and according to ethical principles. Furthermore, by adhering to the do-no-harm principle (CDA, 2012), they must protect vulnerable groups from negative impacts during evaluations.
The current AI technology offers opportunities to strengthen the adherence to those standards. Concerning independence and impartiality, LLMs’ ability to generate and interpret texts from a myriad of perspectives is particularly beneficial. LLMs are trained on a vast array of perspectives and value orientations, representing a significant portion of digitally documented knowledge. Thus, they can broaden human biographically shaped perspectives of evaluators. Alongside existing quality assurance mechanisms, AI systems thus may serve as an additional corrective tool, for example, by generating alternative conclusions on collected evidence or offering different interpretations on conducted interviews.
Integrating AI systems into evaluation practice could enhance the objectivity of evaluations not only by diversifying perspectives but also by standardizing and automating interpretation and evaluation processes. Since AI systems are able to execute machine-like replicable outputs (Ozgor and Simavi, 2024), evaluation criteria, for instance, could be predefined and agreed upon by all relevant stakeholders. Based on the presetting and the delivered evidence, AI models could generate automatically transparent and independent interpretations and evaluations, with less influence regarding the individual biases of evaluators. Although it may still seem distant, algorithm-based tools are already being used for decision support in other professional areas (Barysė and Sarel, 2024). However, this approach is contingent upon the AI systems being provided with all necessary information (e.g. evidence, evaluation criteria) and their ability to draw logical conclusions, interpret, and evaluate at least on par with human evaluators and not to reproduce inherent societal biases.
In addition, AI systems offer further technical solutions for using data from evaluations in accordance with data protection regulations. Especially when using project documents or interviews, AI tools can support automated pseudonymization and anonymization (BRAD, 2020).
A significant challenge to the independence and impartiality of using AI systems lies in the biases inherent in these systems (Head et al., 2023). These biases, originating from training data and processes, can substantially compromise impartiality and independence. For instance, the output of LLMs might replicate gender inequalities or racial biases which are present in their training data. Although efforts are underway to adjust these models to reduce biases and censor responses, evaluators should remain cognizant of these correction processes, which are influenced by humans and (commercial) organizations, so far primarily from the Global North, which represent specific norms.
Another risk to the standards of independence and impartiality lies in the current limited ability of AI systems to perform interactive non-routine tasks (see chapter 3). Evaluators need to comprehend how their actions, reporting, and evaluation outcomes intertwine within a complex social, political, and cultural setting. This requires a context-sensitive perception of dynamic situations and actor relations. However, conversation channels of AI systems are limited because their training data consist of past information and solely digitized data. Although there are attempts to update the knowledge with web information, the knowledge of AI systems is limited to digitized data (e.g. text or images). This excludes, for example, knowledge of implicit power structures or the systematic assessment of nonverbal communication of all relevant actors. 6
A particularly high risk in the realm of AI concerns data protection and the principle of data economy. AI systems demonstrate optimal performance, often provided by commercial vendors through online platforms, which necessitates the sharing of data to utilize their full functionality. Although these providers claim adherence to data protection laws and non-utilization of data for training purposes, the trustworthiness of such large corporations remains questionable, as evidenced by legal breaches in cases like the Cambridge Analytica scandal involving Facebook (Hinds et al., 2020). Moreover, there is an inherent conflict between the substantial data needs of AI systems for their training and the principle of data economy. As AI systems give the opportunity to strive for exhaustive and precise evaluations, evaluators might unintentionally gather more data than what is justified by the principle of data economy.
Evaluability and efficiency
Starting from the premise that AI particularly impacts cognitive/analytical routine and non-routine activities as well as interactive routine tasks (see chapter 3), AI can change the feasibility framework of evaluations. If processes can be automated with enough quality, delegating tasks to AI can make evaluation practices more efficient. AI might automate repetitive and time-consuming tasks such as data collection, data analysis, report generation, and quality insurance. By having the capability to process large volumes of data quickly, it could enable evaluators to analyze and interpret data more efficiently. The resources thus freed could be allocated elsewhere, allowing evaluators to focus on more complex and strategic aspects of the evaluation.
Integrating AI tools in evaluation might also support the expansion of the spectrum of appropriate procedures and methods. As they increasingly take over cognitive/analytical tasks, the repertoire of methods becomes less limited by the capabilities of the evaluating individuals. In addition, the range of possibilities is expanded as unstructured data can be evaluated more effectively. In the context of Big Data, this allows for the expansion of data material to provide evidence for the subject of evaluation (e.g. social media data, automated classification of geodata). Through the automation of processes, analyses can be scaled, for example, expanding sample sizes.
However, the risks of using AI systems for evaluations lie in the standardization of evaluation processes that may not be context-appropriate. When analyses become push-button operations, they may offer plausible but not sufficient insights. Therefore, there is a risk of inappropriate choice of evaluation methods and processes. Especially under the time and resource pressures of many organizations, there might be a tendency to prefer methods that are easier to automate, such as desk studies over participatory methods.
In calculating evaluability when using AI systems, new resources must also be considered. AI systems typically require monitoring and management to ensure the quality of the output (Liu et al., 2016). Particularly in the early stages of the AI era, where new processes are still being developed, a significant allocation of resources is required. However, as automation processes in other sectors, such as the automotive industry, are focused on efficiency gains, a long-term decrease in quality assurance costs could also take place in the evaluation field.
Discussion on the future use of AI
The conducted opportunities and risk analysis indicate that integrating AI systems could significantly impact future evaluation practices concerning central evaluation standards. It is essential for evaluators to harness these potentials and devise secure methodologies for utilizing AI systems. The subsequent discussion offers suggestions for managing this emerging technology effectively.
First, the analysis showed that evaluators should be aware of an impending technological change that has the potential to profoundly alter evaluation practices. As also outlined by Nielsen (2023) or Mason (2023), emerging technologies, including AI, are expected to disrupt traditional evaluation methods by both displacing and augmenting human tasks. The conducted analysis provided a nuanced framework for understanding the types of changes evaluators should anticipate, indicating that both routine and non-routine analytical tasks, as well as interactive non-routine tasks, may be subject to replacement or augmentation. This is in contrast to Mason’s (2023) approach, which, in light of future AI developments, suggests that evaluators should focus on enhancing their skills in non-augmentable activities. Instead, they should comprehensively integrate AI systems within the broader framework of evaluation standards, ensuring a holistic approach to both opportunities and risks. To this end, evaluators should keep abreast of current technological developments, pursue further education, and pilot technical solutions. In order to deepen their understanding of AI in evaluation practices, evaluators should actively explore the possibilities for automating and standardizing evaluation tasks. To achieve this, evaluators should collaborate within the community to exchange knowledge relevant to practice. Only through practical application can the full potential of AI tools be uncovered, along with a clear understanding of the specific risks they may pose.
Second, it is shown that evaluators must make AI applications comprehensible and integrate quality assurance mechanisms into their usage (see also Montrosse-Moorhead, 2023). As outlined, significant risks for accuracy, transparency, traceability, as well as independence and impartiality arise from the black-box nature of AI models. It is worth following technical developments that contribute to more transparent and trustworthy AI. It is not crucial to understand how decisions of neural network’s billions of parameters of AI models are made. Rather, key processes should be made measurable, similar to a production line in a factory. For instance, analysis steps can be split; LLMs can be asked for justifications, the probability of correctness, or assessment bases when creating the output; or the sources of data usage can be made transparent. For automated analyses, it is also important to optimize performance with preliminary analyses before scaling, using representative test data sets. Since it can never be ruled out that AI systems might produce non-human errors or have fluctuating performance, automated processing should always be accompanied by human oversight. Although there are procedures to identify technical errors, evaluators should always be aware of the limited capabilities of AI models to identify errors themselves.
The use of AI models should be, third, made transparent. The application of AI systems can entail several risks, such as in terms of adherence to ethical principles, if discriminatory stereotypes are reproduced. Therefore, evaluators should disclose when and how they have used AI systems. In the case of LLMs, this could involve a disclaimer or documenting all prompts and their outputs. Evaluators’ transparency is also challenged by the increasing possibilities for disinformation and the production of fake facts, whether they are texts, images, or videos. Evaluators must be increasingly prepared to source information whose truthfulness they cannot discern. At the same time, they must anticipate that their evidence base will increasingly be questioned. For example, how does the use of project documents as a data basis change if it cannot be ensured that the reports were not written by an AI model that may hallucinate? The distinction between authentic and AI-generated data could become increasingly complex, and the need for traceable, trustworthy source verification will play an increasingly important role. Therefore, it is essential to develop new techniques in order to ensure the authenticity and reliability of data in the evaluation process.
The conducted analysis reveals that a special focus should be, fourth, placed on data protection and data security. The models’ performance can quickly tempt their use for all potential activities. Before using AI tools, a risk assessment should be conducted to determine whether the tool and data used pose a threat to data protection or security. In addition, risk minimization procedures can be carried out. For instance, only publicly available data and documents can be used for conducting an analysis, or data can be anonymized before entry. Moreover, local or open-source solutions should be considered, where data processing is not outsourced and thus not transmitted to third parties.
Fifth, evaluators should feed AI systems with the most current and relevant contextual knowledge. AI systems are only as good as the data and information they are provided with. This includes data about current developments, trends, and changes in the environment. As Azzam (2023) also highlighted, the lack of access to contextual information can narrow the focus of AI models and lead to flawed internal validity conclusions. In particular, it should be explored whether relevant implicit knowledge (such as information about current dynamics and network relationships) can be made explicit and digitized. This increases the likelihood of improved context sensitivity and thus contributes to the standard adherence in areas such as accuracy, independence, and impartiality. A widely spread approach to strengthen the validity of outputs can be achieved through Retrieval Augmentation Generation (RAG), a method that enhances AI responses by retrieving relevant information from external databases or documents before generating an output (Lewis et al., 2020).
Finally, it is crucial for evaluators to acknowledge that the automation offered by AI systems does not diminish their responsibility to uphold evaluation standards. Evaluators must understand that they hold complete accountability for any analyses and recommendations that emerge from AI outputs. All decisions, even those augmented by AI, have to be grounded in human judgment and adhere to ethical guidelines. The evaluators bear the responsibility for quality assurance, verifications, and ensuring the harmlessness of outputs, regardless of the level of automation involved. There are already valuable frameworks available for evaluating AI systems. For example, Montrosse-Moorhead (2023) offers a framework with guiding questions to assess AI performance, while Reid (2023) provides a crucial framework that addresses ethics and equity in the use of AI in evaluation. Evaluators must meticulously assess which tasks can be effectively replaced or augmented by AI, and where robust human−AI interaction loops are essential to ensure adherence to evaluation standards.
Conclusion
Society is at the onset of a technological revolution, the consequences of which are not yet fully understood. However, the integration of AI systems in evaluation practice represents a significant shift, offering both immense opportunities and substantial challenges. AI’s capabilities in automating analytical non-routine and interactive routine tasks promise to revolutionize evaluation activities. The capabilities of AI tools to standardize and automate tasks can lead to increased efficiency and accuracy in evaluations. Their ability to handle large data sets and provide diverse analytical perspectives can enhance the quality and depth of evaluations. This could lead to more robust and comprehensive evaluations.
However, the integration of AI systems also presents risks for the adherence of central evaluation standards that must be carefully navigated. The “black box” nature of AI systems can lead to a lack of transparency and traceability in the evaluation process, challenging the credibility and reliability of the results. While AI tools can enhance evaluators’ competencies, there is also the risk of over-reliance on these technologies, potentially leading to automation bias and failures in handling complex, context-sensitive evaluation scenarios. Furthermore, the introduction of AI in evaluations brings ethical and data protection concerns to the fore. AI models could inadvertently perpetuate biases and violate data privacy norms. The possibility for AI systems to produce ethically questionable outputs or to be exploited for purposes beyond the original intent poses a significant challenge to maintain fairness, independence, and integrity in evaluations.
In light of these considerations, evaluators must adopt a cautious and informed approach to integrating AI into their practices. This involves staying abreast of technological advancements, understanding the capabilities and limitations of AI tools, and critically assessing the appropriateness of their use in various evaluation contexts. Although it was not the primary focus of this analysis, it should be noted that there are scientists (e.g. Bamberger and York, 2020) who also emphasize the importance of systematic capacity development to enhance evaluators’ skills for responsibly working with AI tools.
While AI systems offer promising avenues for enhancing evaluation practices, its integration into this field must be approached with a critical eye, ensuring that the benefits are harnessed without compromising the integrity and credibility of the evaluation process. The evaluators’ role, therefore, shifts toward one of careful oversight, ethical responsibility, and maintaining a balance between technological innovation and human judgment. The conceptual analysis demonstrates that existing evaluation standards already offer a robust framework for guiding the responsible use of AI in evaluations. Building on this foundation, future contributions could develop orientation guidelines that address the specific challenges of using AI systems, as suggested by CNIL (2024).
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.