
Abstract
Historically 3D effect in film has been used as a relatively superficial aesthetic attraction. Here we consider and test the idea that 3D can be used to guide viewer attention and narrative interpretation in film. The current study used self-report measures in conjunction with eye-tracking technology to record attention, memory and narrative interpretation of 32 participants (25 female). Eye-gaze behaviour was recorded while half of the participants were randomly assigned to watch Michel Gondry’s The Green Hornet (2011) in 3D and the other half watched the same film in 2D. We concentrated on a particular moment where the use of 3D technology brings some aspects of the image to the forefront, such as a prop that might have narrative significance for the story as it unfolds. We were unable to confirm that 3D effect in Gondry’s film is effectively used to direct viewers’ visual attention towards narratively relevant information. Also, we found no evidence that the 3D version of Gondry’s film contributes to better memory or narrative interpretation of this particular scene. In discussing our findings, beyond the technical conditions of our eye-tracking research, we consider the role of film genre, narrative mode, viewers’ expectations and media literacy in shaping such visual attention and narrative interpretation.
Introduction
For his 3-D “Titanic” rerelease, Mr Cameron said he had approached seven companies about working on the film, testing each by asking it to convert about a minute of movie footage before he chose the best two or three efforts. “All seven of the vendors came back with a different idea of where they thought things were, spatially,” he said. “So it’s very subjective” (Itzkoff, 2010).
There is a scene in Quentin Tarantino’s cult hit Reservoir Dogs (1992) where a well-placed orange coloured balloon whirls after a speeding car (at 45:55, see Figure 1). Still from Reservoir Dogs (Tarantino, 1992).
The car is driven by gangster Nice Guy Eddie Cabot (Chris Penn) while having an upset phone conversation about a bank heist gone wrong. The balloon is well placed and timed as it appears on screen at the very moment when Eddie, in his getaway car, describes how the robbery turned into a police trap with a “fucking bullet festival”. At this point of Tarantino’s disjointed narrative, neither Eddie nor the viewer knows the identity of the traitor; only later (at 59:43) do we learn that Freddy Newandyke, alias Mr Orange (Tim Roth), is an undercover cop.
The orange balloon is an example of a traditional, visually foregrounded but rather subtle clue in a 2D film. In a hypothetical 3D-version of this film, such foregrounding could be achieved with stereoscopic effect, and like that, we assume, it could make a less subtle but more salient hint in terms of the viewers’ narrative orientation.
Stereoscopic 3D
Cinematic 3D imaging technology makes use of the optical and neural disposition of human stereoscopic vision. Stereoscopic vision or stereopsis is a result of the horizontal separation of the human eyes. Seeing with two spatially separated eyes causes small differences in the field of vision, referred to as binocular disparity. This slight optical mismatch appears as depth perception in the brain. Imitating humans’ binocular physiology and stereoscopic vision, 3D imaging technologies record through two horizontally separated lenses. As a result, 3D projection produces images that prompt the viewer’s brain to perceive three-dimensionality on a two-dimensional screening or display surface. To make the 3D illusion work, such stereoscopic image needs to be transported to the human perceptual system by wearing particular glasses (anaglyph or polarized glasses), or by projecting it on a specially constructed screen (autostereoscopy).
Although the first stereoscopic viewing device, Charles Wheatcroft’s stereoscope, dates back to 1838, and the first stereoscopic film screenings were already held at the end of the 19th century, the use of 3D technology shows no steadiness in film history. As film historian Ian Christie puts it “3D is perhaps best understood as something like a comet, returning at periodic intervals to light up the sky of cinema with a spectacular display, before retreating into darkness” (Christie, 2013: 128). In the past the decline was more caused by technologically determined economical factors: in the 1950s slow technological innovation and exhibitors’ reluctance in risk-taking (they were putting their faith – and money – into extending the size, instead of the depth, of their screens) led to 3D’s fate. Recently, piggybacking on the digital revolution, 3D bypassed the technological bottleneck. The success of James Cameron’s Avatar (Cameron, 2009), certainly in financial terms, reinstated the format and persuaded exhibitors to upgrade their projection rooms.
1
Even though it seemed that the post-2010 period would finally bring about the format’s sustained flourish, by “2012, the initial excitement and box-office results of 3D had waned significantly” (Bordwell, 2012: 74). As we argued elsewhere (Kiss, 2016), the main reason behind the recurring decline is the one-sided address through which 3D is approached, both in terms of its creative production and regarding its critical valuation: 3D imaging technology, from early stereoscopic cards to the latest generations of digital 3D exhibition, is commonly used for enhancing immersion, refining the illusion of reality, or improving representational fidelity. In its relation to cinema, it is praised as well as despised to similar extents, but it is consistently judged as having the sole function of a mere – visual – attraction. (ibid, p. 315)
Considering its latest failure as a meagre perceptual feature, we extended the ultimate question – ‘Will the 3D revolution happen?’ – by contemplating: ‘Will the 3D revolution happen if 3D remains a visual-aesthetic attraction?’ (ibid: 313). 2 By drawing a lesson from the technology’s previous miscarriages, we have been sketching a radically new prospect, considering a possible transition from 3D’s visual celebration to its narrative appropriation, that is, the use of 3D as a narrative device, to support the “telling” of the story. With time, we presume, 3D’s visual novelty will wear off, and, as we have seen by the narrative solidification of sound and colour, in order to endure, it might need to be brought into motivated relation with viewers’ main concern, that is with the story. Although this question is part of a larger debate within both the industry and academia, we tend to agree with Adam May’s (head of production at Vision 3 where the 3D effects of Alfonso Cuarón’s (2013) Gravity were made) prediction: “seeing what is possible with 3D – in terms of driving story – will start to resonate with audiences and the perception will shift from 3D just being utilised for tentpole blockbusters” (3D Focus, 2013).
3D’s narrative appropriation
Having the idea of 3D technology’s narrative utilization in mind, one might be struck by a specific scene in Michel Gondry’s (2011) The Green Hornet. The film tells the story of Britt Reid (Seth Rogen) who, when becoming the sole inheritor to his father’s large company, bands together with his late dad’s personal assistant Kato (Jay Chou) to turn into a superhero crime fighting team. The scene in question is around 15 min deep in this story, showing the exact moment when the protagonist realizes the immense weight and responsibilities that comes with the massive heritage (Figures 2–5 Stills from The Green Hornet (Gondry, 2011). Stills from The Green Hornet (Gondry, 2011). Stills from The Green Hornet (Gondry, 2011). Stills from The Green Hornet (Gondry, 2011).



Staging the scene in depth, the 3D technique gives special attention to certain elements of the image. Among these a little statue stands out strikingly, representing the figure of Atlas from Greek mythology, who, as a punishment of Zeus, is forced to carry the Earth on his shoulders (Figure 6).
3
Key still from The Green Hornet, displaying the statue of Atlas (our highlight).
The statue’s connection to the unfolding story seems to be clear: as a narratively motivated prop, it literally foregrounds both the dramatic point (a massive heritage and the responsibility that comes with it, landing on the shoulders of the lazy and empty-headed protagonist, feels more like a punishment) and the emotional tone of the situation (the recognition is distressing – see Figure 5). Nevertheless, one might wonder whether immersed viewers actually see the little statue, moreover, whether they see it as a narratively motivated prop of an on-going story? Turning these questions into a case study project, we have been wondering whether – and how – such a 3D foregrounded prop could act beyond a mere visual attraction, and start to function as a narrative clue? To answer these questions (before advising the creative industry), first one has to have a thorough understanding of the perceptual and meaning-making mechanisms of stereoscopic film viewing. We explore psychological theory of viewer-engagement with film and empirical evidence that may point towards the potential of 3D communication in narrative cinema.
Empirical psychology of viewer engagement with 3D
Various theoretical models of how viewers engage with film and other media recognise the contributions from both internal and external influences that shape the experience (e.g. Grodal, 2009; Lang, 2000; Shimamura, 2013; Tan, 2008). These models generally conceptualise the experience as involving a dynamic interaction between the film content and its formal features (genre, lighting, soundtrack etc.) and viewer variables (emotional arousal, motivations for viewing, etc.). These theoretical models converge on the idea that viewer experience is shaped by both automatic and controlled attentional processes.
Emerging evidence suggests that the structural aspects of film have a particularly strong influence on viewer attention. Hollywood cinema tends to be highly choreographed to present useful information in a predictable way (Smith, 2012). Over the years, as filmmaking techniques and film language have become more sophisticated, filmmakers have used lighting, motion, cuts and shot length to exert more control over the attention of film viewers (Cutting et al., 2011). Specifically, research evidence has demonstrated that different viewers attend to film images in consistent patterns (Mital et al., 2011; Smith and Mital, 2013). Loschky et al. (2015) argue that this phenomenon of film related attentional synchrony is evidence of what they have dubbed the tyranny of film. It is by using such tyrannical film techniques that filmmakers can guide the viewers’ attention to best tell a story. Research has shown how these features can shape comprehension of visual scenes (Magliano and Zacks, 2011) and the unfolding narrative (Hutson et al., 2015). Here we ask if 3D can be added to the list of techniques used to manipulate attention.
To date, there have been few empirical comparisons of viewer (cognitive or emotional) engagement with 2D and 3D film, and of those in the literature, mixed results have emerged. For example, some studies have observed significant differences between the formats in terms of their effects on viewers’ physiological arousal (Dores et al., 2013, 2014; Rooney et al., 2012), perceived realism (Rooney et al., 2012; Rooney and Hennessy, 2013) and feelings of presence (Ijsselsteijn et al., 2001), while others have shown no significant difference between the formats in terms of their effects on physiological arousal (Rooney et al., 2012; Rooney and Hennessy, 2013), self-reported emotional engagement (Ji and Lee, 2014; Ji et al., 2013; Rooney et al., 2012; Rooney and Hennessy, 2013), or enjoyment (Ji et al., 2013; Ji and Lee, 2014; Rooney et al., 2012; Rooney and Hennessy, 2013). One possible explanation for the varied results is that the research studies each use various types of films or film clips and evidence suggests that film genre matters when it comes to the effect of 3D (Bride et al., 2014; Ji and Lee, 2014; Pölönen et al., 2012).
Similarly, the research exploring 3D effect on viewer attention is scant and mixed. While Ji et al. (2013) showed that 3D viewers in a controlled laboratory setting reported being no more focused on the film than 2D viewers, Rooney and Hennessy (2013) showed that 3D viewers reported being less distracted than 2D viewers in a field study of real cinema patrons. In both studies attention was operationalised using self-reported measures and, to date and to our knowledge, no research has compared 2D and 3D film viewing using behavioural measures of attention, such as eye-tracking.
Further to this line of inquiry, when contextualizing the question in the film history of the technology, we need to ask whether 3D can also contribute to story comprehension by visually triggering viewers’ narrative interpretations. We conceive of narrative interpretation as an integrated representation of (an element of) the story that incorporates meaning beyond basic comprehension (Dixon et al., 1993). In film, according to Bordwell, interpretation is an inference-driven “construction of meaning out of textual cues” (Bordwell, 1989: 3). This idea places importance on the act of “showing” the viewer (i.e. directing viewer attention towards) elements that may contribute to the meaning-making, including comprehension, “concerned with apparent, manifest or direct meanings”, and interpretation, “concerned with revealing hidden, nonobvious meanings” (ibid: 2). Again, to date and to our knowledge, no research findings directly address this question in the context of 3D film. It is highly plausible that directing viewers’ attention to a narrative clue like the statue identified in The Green Hornet would trigger narrative interpretation, and by that aid viewers’ story comprehension. Specifically, directing attention to the narrative clue may mean that participants are more likely to meaningfully integrate it into the meaning-making process in a way that would drive their story construction. This prediction is supported by research exploring engagement with literary fiction. In their research, Mullins and Dixon (2007) demonstrated readers remembered information better and were more likely to predict the solution to the crime when critical information was marked by the narrator. However, recent psychological research using 2D film suggests that just because viewers look somewhere in a film, doesn’t mean that they will remember, comprehend and interpret what they viewed. For example, Hutson et al. (2015) observed synchronous eye-movements in viewers watching scenes from an edited version of Orson Welles’ A Touch of Evil (1958), despite differences in narrative comprehension. This demonstrates that there is not a one-to-one correspondence between what we look at in a film and what we “see”.
The present study
The general context of our project is in the intersection of cognitive psychology, film studies (narrative theory) and film technology and industry (3D production and projection). The drive is to explore the idea of how 3D imaging technology can be conducive to the kind of visual foregrounding and narrative appropriation that Tarantino’s 2D cinema has played upon (see introduction). Answering the broader question ‘In what way can 3D effect in film contribute to the comprehension of the story?’, our project’s ultimate aim is to understand the perceptual and cognitive differences between 2D and 3D viewing processes. The findings from this project will allow us to add to the theoretical recommendations, through which the industry could stabilize 3D’s currently fading position in the film business. At the same time, this study aims to make a contribution to the exploration of the psychological mechanisms involved in visually processing complex emotional narrative and other information.
Contributing to this wide-ranging project, the current study examines a concrete manifestation of the idea of narratively motivated 3D by analysing the scene described above from Michel Gondry’s The Green Hornet featuring a statue prop with narrative relevance. Using eye-tracking and self-report measures, the present research compares 2D and 3D film viewing and comprehension processes through patrons’ attention, memory, and narrative interpretation. Thanks to the dual format of the film’s Blu-ray release (Columbia Pictures Industries, Inc.; Sony 2011), we were able to present, within identical conditions, two different versions of the first 15 min and 20 s of the film for two different groups. We randomly assigned participants to view the film in either 2D or 3D format. The current research aimed at testing three hypotheses that were built on each other. We predicted that viewers of the 3D version will pay more attention to the prop than the 2D viewers [H1]. We further hypothesised that viewers of the 3D version will be more likely (than the 2D viewers) to remember the prop [H2], and that they will be more likely to recognise and interpret it as a symbolic clue [H3] that supports the story’s narrative comprehension. We tested these hypotheses using two types of measures. In order to test our first hypothesis [H1], we tracked participants’ eye-movements and compared their gaze locations from the 2D and 3D versions. To our knowledge, this is the first study to use eye-tracking technology to explore viewers’ visual attention towards 3D film. Additionally, we tested the second and third hypotheses [H2 and H3] using a series of open and closed form questions, with standard self-report scales to explore visual attention, memory, and symbolic-narrative interpretation.
Method
Research design
The study utilised an independent group experimental design, in which participants were randomly allocated (using a random number generator) to watch the film in either 2D or 3D. In order to explore viewer engagement and experience a mixed measures design was employed; this design included open-ended and closed form self-report measures and eye-tracker recordings.
Participants
Overall sample size and demographic information (bold) and broken down by condition (italics).

Stimuli
Participants viewed the first 15 min and 20 s of Michel Gondry’s The Green Hornet, which could be played in either 2D or 3D format. At this point in the film (Figures 2–5), Britt’s father, James Reid (Tom Wilkinson), has recently passed away and our protagonist is set to inherit his late dad’s media empire. During the scene of interest, Britt and Axford, the managing editor of the empire’s newspaper the Daily Sentinel, enter the father’s abandoned office and discuss taking on the responsibility of managing the paper that is part of the inheritance. Figure 6 highlights a specific prop in the office, the statue of Atlas holding the world on his shoulders. It features prominently in the 3D version of the film (due to the emergence effect of negative parallax) but less so in the 2D version (visual foregrounding only by traditional staging in depth). 4 While portions of the film were shot in 2D and converted to 3D in post-production, 3D effects, including those for the target scene, present a striking illusion of depth (Crust, 2011).
Measures
Gaze behaviour
Participants’ eye-movement behaviour was monitored using a pair of Tobii Glasses V1, which track movements in the right eye and have a sampling rate of 30 Hz. In order to analyse gaze behaviour, eye-tracking data were imported into Tobii Studio Version 3.3.1. Gaze data were recorded for the entire time participants watched the film (15 m and 20 s). From these data, we focused only on the 16-s period that the prop was on screen. Within this time period, we isolated the part of the screen that contained the prop as our “area of interest” (AOI) and limited our analyses to the gaze data within this AOI. In the current study we use three indices of gaze behaviour; the number of times the participant’s eye fixates on the AOI (fixation count), the total duration of time that a participant’s eye is fixated on the AOI (fixation duration) and the total duration of time that a participant’s eye is either fixated or moving within the AOI (visit duration).
Recall and interpretation
To test the relevant hypotheses, we needed to see if participants recalled the presence and interpreted the possible relevance of the prop. In the first instance we were interested to see if participants might do this spontaneously, without directive or leading questions, and if not, then to see how much direction it would require before participants would demonstrate memory and interpretation. Our approach was to embed relevant questions (target questions) within an array of distractor or “smoke-screen” questions about the film and then, once participants had responded, to probe their memory and understanding in a systematically more directive way.
Initially, participants rated the film’s use of symbolism on a scale (target question) among items about various other qualities such as acting, cinematography and set design (smoke-screen questions). For each of these items (target and smoke-screen), participants also responded to an open-ended question calling for particular examples to support their choice, such as “Can you think of any symbols that were used in the film? What did these symbols represent and did this symbol relate to the narrative (events in the film)?”. Responses to smoke-screen questions were not analysed. For open ended target questions, a response was coded as a “hit” every time a participant answered the question in a way that indicated recollection of the prop or using the target interpretation e.g. “I saw a statue of a man carrying the world on his back” or “the statue of Atlas symbolised the responsibility placed on the main character”. All other responses were coded as a “miss”. All responses were coded by two independent researchers who were blind to the participant’s experimental condition. Cohen’s kappa revealed over 95% agreement between the raters (κ = 0.797). Where the two coders disagreed on a particular response, a third coder was used.
Following the initial free-recall questions, participants were asked a more directive set of target questions to probe their memory and interpretation. For this we used a partly occluded version of the scene as a prompt (see Figure 7). Participants were asked to describe what had been covered up. At this point, participants were also asked “Do you think the object is placed here for a reason? Why?”. Responses to these open questions were coded in the same way as described above. Key still from The Green Hornet, occluding the statue of Atlas (our manipulation).
Attentional focus
Participant self-reported attention was measured using seven items that comprise the attentional focus subscale of the Narrative Engagement Scale (Busselle et al., 2009). These items, for example “I had a hard time keeping my mind on the film” and “I was NOT distracted during the viewing” were rated on a seven-point scale, where higher scores were indicative of higher levels of attention. This scale demonstrated high levels of reliability in the original samples (Cronbach’s α = 0.79 to 0.85), and in the current sample (α = 0.839).
Enjoyment
Participant enjoyment of the film was assessed using four items generated for this study (and taken at face validity) that explore both attitude and behavioural intention: “I would recommend this movie to others”; “At some suitable point in the future, I would like to see the rest of this movie”; “I really did not like this film” (reverse scored); and “I would pay to see this movie (in full) in the cinema”. All four items were on a seven-point scale, with items coded so that higher scores were indicative of higher levels of enjoyment. Reliability analysis for the current sample revealed very high levels of reliability in this scale (α = 0.917).
Negative effects of presence
Previous research has reported various negative effects of 3D film viewing such as dizziness, eye fatigue, and headache, particularly with poorly composed 3D film (Banks et al., 2012; Solimini, 2013). For this reason it was important to account for any potential differences between the groups in terms of negative effects of viewing. To this end, an adapted version of the negative effects subscale from The ITC-Sense of Presence Inventory (ITC-SOPI; Lessiter et al., 2001) was used. Four items (e.g., “During the film I had a headache”) using a seven-point scale were used, where higher scores were indicative of more negative effects of presence.
Individual differences
It was also important to ensure that the groups did not differ in terms of other important individual differences such as viewing habits or film preference. A number of control questions were included so as to measure preference for “movies that have profound meanings or messages to convey”, movies “that make me think” and immersive features such as 3D or HD format. Participants also indicated their perceived “ability to interpret film themes” and their “ability to decode a film’s deep meaning”. Information on viewers’ frequency of screen time and whether or not they had seen the film before was also collected. All of these individual-difference items (target questions) were embedded in smoke-screen questions about their preferences for other types of movies and their perceived ability for other tasks such as recognising celebrities and following subtitles in a film.
Procedure
The study was carried out in the university eye-tracking laboratory in Dublin. The film was played using a 3D-ready Blu-ray player (Panasonic DMP-BDT120) and presented on a 47-inch Smart 3D LED TV (LG 47LB65). The Tobii eye-tracking glasses were positioned on a desk 120 cm away from the screen. They were attached to a fixed support, with 3D lenses fitted to the front of their frame, and an adjustable chin rest placed underneath.
Upon arrival to the laboratory, individually, participants took the time to get comfortable using the adjustable seat and chin rest to fix their head in place. The lights were then switched off and participants’ eyes were calibrated using a nine-point field. After calibration, the Tobii Glasses provide a calibration rating out of a total of five stars. Where the calibration was poor (i.e. below 3 stars), the calibration process was repeated until the rating was acceptable. Following calibration, participants watched the first 15 min and 20 s of the film.
Participants were told that they would watch the film for approximately 20 min. The only other information provided about the film was that it was “from mainstream cinema” and that “the footage is entirely fictional and generated for commercial purposes”. The scene of interest occurs 14 min and 43 s into the film’s running time and lasts approximately 16 s. After 15 min and 20 s of viewing (21 s after the scene of interest is over), the film and the eye-tracker recording was stopped. At this point participants sat at a different desk and completed the measures described above.
First, participants completed the scale items that captured participants’ ratings of various qualities of the film such as use of symbolism (target) acting, cinematography and set design (smoke-screen). For each of these items, participants also responded to an open-ended question calling for particular examples to support their choice. After participants had responded to these, they completed the attentional focus scale. Next they were asked to complete the more directive set of questions using the occluded scene images.
For control purposes, it was important that we gauged participants’ ability and agreement with the target interpretation. Two questions were used to do this. First, the prop was revealed to participants and they were asked whether it was included “for no particular reason”, “as a symbol to do with the story”, “for aesthetic/visual reasons”, or “to make it seem like a real office”. Then participants were presented with the following statement “This ornament is a man carrying the world on his back, which could represent the weight and responsibility that the main character is feeling now that his father has died” and asked to indicate their level of agreement. The remaining measures described above were then administered via online survey. On completion of the measures, participants were provided with a debrief form, outlining the true nature of the study, and provided the opportunity to ask questions. Ethical approval for all aspects of the study was granted by the relevant institutional ethics committee.
Results
Means (M), standard deviations (SD), t-tests and effect sizes for quantitative dependent variables by group.
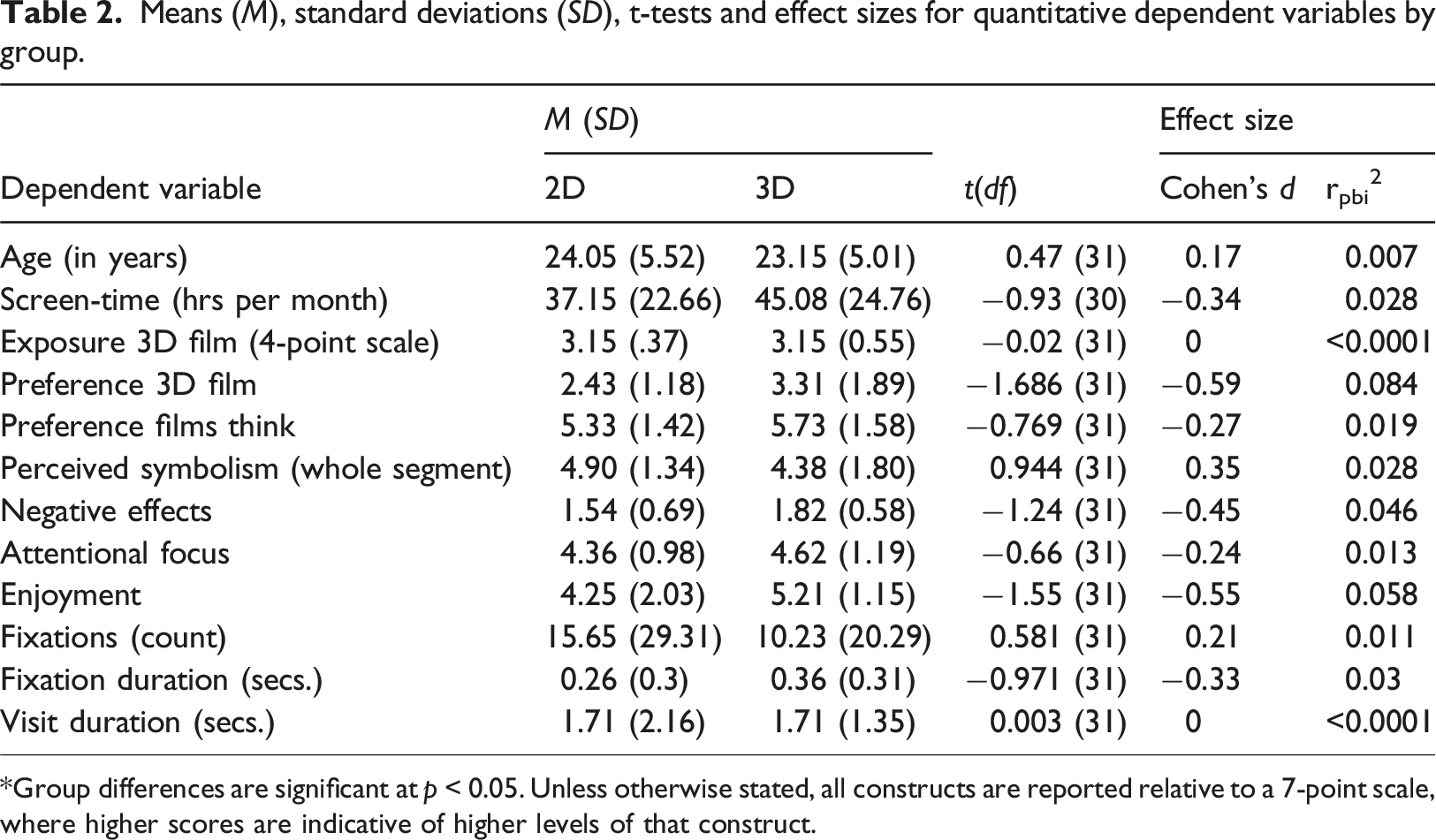
*Group differences are significant at p < 0.05. Unless otherwise stated, all constructs are reported relative to a 7-point scale, where higher scores are indicative of higher levels of that construct.
Hypothesis 1 [H1] predicted that due to the emergence effect of negative parallax viewers in the 3D condition would pay more attention to the prop than those in the 2D condition. Firstly, results revealed that viewers in the 3D condition did not make significantly more fixations on the prop (see Table 2 for descriptive statistics) than viewers in the 2D condition. Nor did they spend more time fixated on the prop and they did not demonstrate a significantly higher visit time in the AOI. Thus hypothesis one was not supported by the results, that is, participants in the 3D condition presented no differences in their viewing behaviour than those in the 2D condition.
Hypothesis 2 [H2] predicted that viewers of the 3D version will be more likely (than the 2D viewers) to remember the prop after viewing the film, and hypothesis 3 [H3] predicted that participants in the 3D condition would be more likely to interpret the prop as a symbol pertaining to the film’s narrative themes. Various measures and analysis contributed to testing these hypotheses. Using an indirect quantitative scale measure of participants’ perceived use of symbolism for the entire (15 min 20 s of the) film, no significant difference was observed between the 2D and 3D conditions (see Table 2 for results – labelled “Perceived symbolism”). That is, participants in the 3D condition did not report that the film (for the entire 15 min and 20 s segment that they viewed) used symbolism significantly more than those in the 2D condition (see Table 2). While this question is directly relevant to the hypotheses, it pertains to perception of the entire film. Further analysis focused on the scene and more specifically the target prop.
In testing hypothesis 2 and 3, participants were afforded the opportunity to freely recall the presence of the prop and identify it as a narrative cue (coded: hit). Results revealed no participant (in either condition) spontaneously recalled the prop and thus no participant spontaneously interpreted it as symbolic. Building on this we tested to see if 3D participants were more likely to recall the prop and interpret it as a narrative symbol when prompted by the occluded scene image (see Figure 7). Here, once again, no participants (in either condition) could recall what was occluded and thus no participant interpreted it as meaningful. Thus hypotheses 2 and 3 were not supported by the results of this study.
To add validity to our findings, we needed to ensure that participants were able to identify the prop and appreciate its significance when faced with the full image, and importantly, that this ability did not differ between groups. Once the prop was revealed, 61.5% of participants’ in the 3D group and 75% of participants in the 2D group responded with the target interpretation. Analysis revealed no significant effect of condition in these responses (see Table 2). Finally, participants were asked to read the following statement and indicate their agreement: “This ornament is a man carrying the world on his back, which could represent the weight and responsibility that the main character is feeling now that his father has died. Do you agree?”. Here, 30 participants (of 33) agreed with the presented interpretation (1 participant in the 2D condition disagreed and 2 in the 3D condition disagreed). Again, analysis revealed no significant effect of condition in these responses.
Discussion
The current study compared the attention, memory, and narrative interpretation of 2D and 3D film viewers as they watched a target scene from Michel Gondry’s (2011) The Green Hornet. The mise-en-scène (staging and parallax) of the target scene was such that we predicted 3D viewers would pay significantly more attention to a particular prop than their 2D counterparts. We further predicted that the 3D viewers would be more likely to remember the prop and more likely to interpret the prop in a particular way.
Testing our first prediction, in line with previous research (Cutting et al., 2011; Loschky et al., 2015; Magliano and Zacks, 2011; Mital et al., 2011; Smith and Mital, 2013) we tried to demonstrate that structural aspects of film have a particularly strong influence on viewer attention. Building on this work, our research was an attempt to show that 3D effect can be used to direct viewer attention (relative to the ability of 2D film), however, we were unable to verify such influence through stereoscopic manipulation. Against our hypothesis [H1], results revealed that 3D viewers looked at the prop no more times, and for no longer duration, than the 2D viewers. Additionally, in line with Ji et al. (2013), we report no difference between viewers’ self-reported overall attentional focus towards the 3D and 2D versions of the film. This finding is perhaps not surprising given that participants were alone in a dark room, seated 120 cm from the screen and thus all participants’ attention (in both conditions) was high.
We also predicted that once 3D participants viewed the prop, they would be more likely to remember it and to interpret it as a cue to the film’s unfolding narrative theme. Results revealed that 3D participants were no more likely to remember the prop (recall or recognise), and no more likely to interpret it as a symbol or narrative cue. This was found when measures recorded spontaneous responses and when responses were given to directive prompts, demonstrating that interpretation of narrative cues involves much more than simply looking at them. These findings support those of Hutson et al. (2015), who showed that there is not a one-to-one correspondence between viewer attention and comprehension. Together these findings have important implications for the use of eye-tracking technology as a research method, highlighting as others have argued before (Russo, 1978) that this research tool is limited in its ability to access the processing behind an eye-fixation. For this reason, many researchers (see Sirois and Brisson, 2014) have begun to use measures of pupillometry (the relative diameter of the pupil) as an index of cognitive processing. Future research can build upon the current findings by incorporating measures of pupillometry (or other physiological measures) to explore the current questions further.
Looking at the current research findings from within their original context and drawing conclusions for film studies, film technology and industry (3D production and projection), a general question arises: ‘Was Gondry expecting too much of the viewer?’. Here we have a scene that calls upon the viewer to register and then interpret a narratively charged prop in a way to which they did not respond. Perhaps this is a task only achievable by the media and film literate scholar? While participants in the current study considered themselves to be proficient and experienced with sophisticated films (see Table 2), this study included no way to measure the participants’ ability in this regard. Thus it is possible the groups of participants may not have been extremely media literate, at least not on the level of being able to read such subtlety of visual foregrounding (they were male and female students, mostly students of psychology, between the ages of 18 and 48). Nevertheless they are typical of the target audience for the film. Even though The Green Hornet is a movie by Michel Gondry, from whom auteur literate viewers might expect playful creativity, it is clearly a 3D superhero blockbuster film, regarding to which sub-genre and narrative mode and style few viewers would expect such inventive artistry, let alone subtle symbolism (a claim that seems to remain true despite the involvement of a variety of directors in contributing the superhero genre since the release of this film). As for the latter, it is not only that the film’s prominent sub-genre and narrative mode do not invite symbolic reading, but also that the target audience of a Hollywood superhero movie does not expect to exercise any symbol-literate skills (e.g., knowledge of and experience in Greek mythology). It is reasonable to assume that the visual spectacle was an important part of the experience (an experience that involved action scenes, explosions and fast car chases), regardless to its subtle narrative potential.
Future research might shed light on the role of genre and narrative mode as the primary framing condition of viewers’ expectations. Questions like ‘Would Gondry’s subtle symbolism work in art-cinema narration (with more auteur and narrative literate audience)?’ would lay out a relevant follow-up exploration. Further to this, manipulation of certain elements of film language might enhance salience, providing higher exposure for the prop, and, by ensuring awareness beyond attention, improving the chance for symbolic reading. Specific recommendations are beyond the scope of this initial exploration of how 3D effects may or may not prompt processes of narrative engagement. Future empirical research on altering the position of props within the frame (central positioning) and in the setting (foreground staging), changing their colour or the scene’s lighting scheme, applying virtually or physically mobile framing (zoom or pan and tracking shots), and on other techniques of visual highlighting could not only upgrade our knowledge about the complementary effect of 3D among the traditional elements of perceptual hierarchy, but also provide recommendations for fine-tuning film language in order to contribute to aimed (narrative) effects.
All things considered, the question of whether Gondry was asking too much of the viewer could be modified, asking ‘Is film studies expecting too much of the viewer?’. It is plausible to assume that our second and third hypotheses, without their empirical support, could form a valid argument within the merely theoretical branches of film studies, celebrating Gondry’s subtle symbolism and trailblazing genius in 3D’s narrative appropriation. One of the complementary upshots of this present study is a reminder that media-, symbol-, narrative-, and auteur-literate professional viewers, when posing otherwise valid assumptions, often reach beyond the actual experiential context of a film, therefore are not representative to target audiences of films with different entertainment aims.
An alternative interpretation is that the current study, in the measures it employed, did not capture the way in which viewer engagement with the narrative was shaped by the 3D effect. That is, the level at which this may have occurred. Perhaps an attempt to draw viewers’ attention to the prop led to differences in the way the viewers construed the narrative mood, or their empathic response to Britt Reid’s overwhelming feelings of burden. The current study was limited in that it did not collect data about participants’ feelings towards the characters and narrative themes, nor did it employ physiological measures of emotional response. Future research would benefit by asking questions about the participants’ feelings towards the characters or the scene, for example, seeing whether viewers attribute more stress to the character in the 3D condition than in the 2D condition. In this regard, the use of qualitative research methods (audience interviews or focus groups) may also be illuminating. There is also scope to couple these data with a complimentary deeper analysis of the film’s narrative themes and symbolism. Indeed we invite researchers to extend these questions beyond the current study to other films and 3D effects, and in more ecological viewing settings. The current study makes an initial exploration using Gondry’s The Green Hornet, which uses negative parallax to achieve the depth illusion of interest. To build upon this work, researchers can test the extent to which the findings generalise to other film genre, directors, styles, viewing contexts, with other sorts of 3D visual effects (e.g. positive parallax, stereopsis, binocular rivalry). In that way, the body of research findings, combined with those studies reported in the introduction, can build a more complete understanding of both the ontological and phenomenological differences between stereoscopic 3D and flat 2D. For example, research is currently underway to explore the extent to which perceptual versus conceptual forms of “realism” might be associated with automatic or controlled neural processes of entertainment engagement (see, for example, Christophers et al., 2023 or Christophers et al., 2024).
Conclusion
To our knowledge, this is the first study to compare eye-movement behaviour of 2D and 3D film viewers. We aimed to explore the way in which 3D effect in film (relative to 2D film) might be used to direct viewer attention towards a narrative clue, and consequently increase the likelihood that a viewer will remember it. Furthermore we wished to explore if the attention towards the narrative clue would trigger interpretive activity, facilitate the meaning making process and drive story comprehension. Here we report that viewers who saw the film in 3D looked at the prop no more than their 2D counterparts (no more times, for not a longer period). As a consequence, they were no more likely to remember the icon (recall or recognise), and no more likely to interpret it as a symbol or narrative cue. Thus, in this particular case study, we failed to demonstrate that 3D effect is successful at directing attention of viewers, and viewers reported enjoying the experience more. However there are outstanding questions about the use of 3D as a tool to increase narrative interpretation. In the current study we used measures of viewers’ high level interpretation of narrative themes. Future research may benefit from exploring how 3D can be used to improve automatic processing of social information and affective interpretation.
As to our original question ‘Will the 3D revolution happen this time?’, our preliminary conclusion suggests that it might, perhaps only if 3D technology’s unique affordances find their way to a perceptually salient representation, fitting context (genre and narrative mode) and audience expectation.