
Abstract
Research on the electoral personalization of politics has stressed a trend towards a greater role of top prominent political figures (party leaders and ministers). This trend was described as centralized electoral personalization. Yet, this trend is merely one side of a more complex story. No leader attracts all voters’ support, and other candidates manage to stand out despite lower resources and visibility. Using a unique dataset of 47,239 actual ballot papers cast for the 2018 Belgian local elections, we show that candidate-level, list-level and district-level factors result in distinct preference voting behaviour. While these factors lead to unmistakable forms of (de-)centralized personalized forms of elections, we furthermore, show that intermediary situations distinctively emerge. A significant number of ‘subtop’ candidates stand out among candidates, by attracting support from voters who do not support the mere leader of the list. This ‘oligarchized personalization’ would deserve greater attention in the literature.
Introduction
One of the prominent trends in contemporary democracies has been the growing personalization of politics. This evolution – defined as ‘the notion that individual political actors have become more prominent at the expense of parties and collective identities’ (Karvonen, 2010: 4) – has been affecting various facets of politics (Cross et al., 2018; Rahat and Kenig, 2018). Yet, some authors have argued that personalization has not affected all politicians identically. Party leaders were the great winners of this trend, resulting in a ‘centralized personalization’ of politics – as opposed to ‘decentralized personalization’ (Balmas et al., 2014). It has translated in a rich literature looking at the importance of leaders, especially in elections and within political parties (Aarts et al., 2011; Bittner, 2011; Clarke et al., 2004; Clarke et al., 2009; Kriesi, 2012; Garzia 2012; Lobo and Curtice, 2014; Pilet and Cross, 2014; Poguntke and Webb, 2005; Wauters et al., 2018).
Another line of research has shown that the centralized personalization of politics, and of elections in particular, is merely one side of a more complex story. Party leaders may have grown in importance, but they do not fully dominate election processes. Several studies have shown that some voters simply do not care about the party brand or its leader (Marsh 2007; Van Holsteyn and Andeweg 2010, Mattes and Milazzo 2014). For those voters, the main driver behind electoral choice is the personality of local candidates. Beyond the few political leaders, other politicians still find their way and attract voters’ attention (30; Holtz-Bacha,et al., 2014: 164).
In this wake, a few studies have shown that the type of electoral systems, and especially the type of preferential-voting list PR systems, critically affect the concentration of votes on a few top candidates and/or the spread of preference votes across a wider spectrum of less prominent candidates (Dodeigne and Pilet 2021). In particular, it appears that “subtop” politicians – defined as politicians who are not the main leader of their party but who still enjoy a good visibility among voters (like less senior minister at national level, or deputy-mayor at local level) – remain crucial actors in the electoral personalization of politics. Those “subtop” politicians contribute to a form of personalization that is situated between “centralized” and “decentralized” electoral personalization. Dodeigne and Pilet (2021) defined this trend as “oligarchized” electoral personalization. In electoral systems where voters are allowed to cast multiple preference votes, “subtop” politicians can counter the predominance of leaders (i.e. centralized personalization). While a few studies have sought to identify factors explaining (de)concentration of preference votes (Wauters, 2021), a systematic analysis is still lacking. In this study, we analyze how preference votes are spread (or not) across multiple candidates at local Belgian elections where multiple preference voting is allowed. We test how candidates-level, lists-level and districts-level factors affect the dispersion of preference votes across candidates. In other words, we seek to identify the factors that resist the overarching trend towards centralized electoral personalization. Within the symposium in which this article is published, our study looks at the electoral stage of intraparty competition, and examines the distribution of intraparty preference votes as the results of the strategies of both candidates and voters.
For that purpose, we rely on a unique dataset from the 2018 Belgian local elections (Wallonia). Local elections in Wallonia are organized under a PR system with open lists. It means that voters first decide which party list they want to support, and then they can mark their preference for one or several candidate(s) within the list. Seats are then allocated between lists, and then within lists solely on the basis of the preference votes received by each candidate. Ballot position has no effect on the allocation of seats within list, even if parties can still decide which candidates occupy which position on the list. For these elections, we have been – for the first time ever – authorized by the regional administration to directly record official ballot papers cast by voters. The direct access to real paper ballots is extremely rare for researchers. A few earlier studies used mock ballot in survey research (Jacobs et al., 2014; Erzeel and Caluwaerts, 2015; Marien et al., 2017; Janssen, 2020), but with all difficulties related to correct reporting and limited number of observations for systematic analysis. In this study, we have access to more reliable data from real electoral ballots cast by 47,239 actual voters, covering 4,906 candidates on 188 lists of candidates across 49 municipalities. Each of those municipalities constitutes a distinct electoral race, with a few lists running and one leader for each list.
The article is structured as follows. We start by a review of past research in order to identify the main factors explaining the candidates’ electoral performance thanks to a concentration of votes on their single name or rather multiple preference votes cast in combination with other co-partisan candidates. Second, we present in detail the Belgian case and its electoral system that is covered in this article. We then turn to the presentation of our data and method. The fourth section presents and discusses our main findings. And we then conclude by discussing their implications for the scholarly debates on the personalization of elections.
Theoretical framework and hypotheses
The literature on preference voting under list PR systems is already well consolidated, especially in Netherlands and Belgium (see Wauters et al., 2020 for a review), but also in some other countries (Katz and Bardi, 1980; Wildgen, 1985; Holli and Wass, 2010; Christensen et al., 2021; Söderlund et al., 2021). In a systematic comparative study using candidates’ electoral results, Dodeigne and Pilet (2021) examined electoral intraparty competition in four countries using list PR systems allowing for intraparty choice, namely Belgium, the Czech Republic, Finland and Luxembourg. One of their core findings is that the electoral system, and especially the number of preference votes that the electorate can cast, is a key factor in broadening the scope of intraparty competition. When voters are allowed to cast more preference, they tend to use this opportunity to spread their preference votes. It contrasts with systems that allow to cast a single preference vote in which incentives to concentrate that vote on the party leader are greater. In the same vein, Wauters and his colleagues (2015) have shown that voters could be divided between those casting a vote for the leader only, those casting multiple votes for the leader a few candidates, voters casting preference votes for one or several less visible candidates. The latter two behaviours concur to resisting the full centralized electoral personalization under multiple preference voting.
Yet, we still know little about what factors other than the electoral system are associated to single or rather to multiple preference voting. In one of the rare existing studies, Wauters, and colleagues (2021) have shown that the age of the party is a key factor has voters cast more often single preference vote for the leader when the party is newer, and has therefore less well-known candidates on the list. We will therefore build on earlier studies on preference voting to develop a set of hypotheses on factors concurring to single versus multiple preference voting. We present our hypotheses at three levels of analysis: (1) candidate-level, (2) list-level and (3) district/municipality-level.
For the candidate-level factors, we hypothesize three types of candidates’ characteristics affecting preference voting behavior, but in diverging directions. First, some characteristics seem to contribute to single preference voting, i.e. specific candidates manage to perform at elections thanks to their capacity to attract votes under their own candidacy only. It is especially the case for leadership characteristics such as party leaders and cabinet members. In particular, when a prominent leader – like a minister or the party leader – is on the list, it leads to more voters voting for that candidate only (Wauters et al., 2018), and to a stronger concentration of preference votes within the list (Dodeigne and Pilet 2021). We might therefore expect that being a prominent politician would lead to attract more votes from single preference voters. In the context of local elections, it would apply to two sorts of prominent politicians: the incumbent local mayor as well as national or regional politicians (MPs, ministers, and party leaders) running for local elections.
Mayors attract more single preference votes than multiple preference votes.
National and regional politicians attract more single preference votes than multiple preference votes. Complementary to these highly prominent figures, we, furthermore, expect that lower prominent characteristics (as incumbent local councillors or aldermen) would still play out but less markedly. There is indeed a wide literature showing that incumbents tend to attract more preference votes (Van Holsteyn and Andeweg, 2010; Thijssen, 2013; Maddens and Put 2013; Górecki and Kukołowicz 2014). Hence, Aldermen (deputy-mayors) and local councillors should also be able to play out their incumbency card. However, their incumbency advantage would be less strong than for mayor or national and regional politicians. They could therefore also attract preference votes but potentially less often single preference votes. Voters who just want to vote for such candidates and do not consider other candidates like upper levels politicians should be rarer.
Incumbent aldermen and incumbent local councillors attract less single preference votes. Second, we consider as another influential candidate’s characteristic that affects preference voting the position of candidates on the list as attributed by the party. Several studies have shown that candidates that are positioned higher on the list benefit from a competitive advantage over other candidates placed at lower positions on the ballot (Van Erkel and Van Aelst 2016; Söderlund et al., 2021). Many voters use list position as a shortcut to identify more competent candidates (Devroe and Wauters, 2020). Futhermore, candidates positioned higher on the list tend to enjoy greater visibility in the media (Van Erkel et al., 2017). Therefore, we expect that these candidates positioned higher on the ballot will benefit from a greater competitive advantage which will result in a greater capacity to attract single preference votes. By contrast, candidates positioned lower on the list tend to stand out only via multiple preference voting.
Candidates positioned higher on the list attract more single preference votes. Third, research has identified that candidates from some specific social groups may attract more preference votes. It is especially the case for female candidates and for candidates from ethnic minorities (Teney et al., 2010; Marien et al., 2017). Such candidates may gain electoral support from voters who seek to boost the election of candidates from groups that are often under-represented in representative institutions. Yet, such voting behavior would rather be associated to group voting, i.e. supporting multiple female candidates or ethnic minority candidates. There is no reason for voters with such motivations to cast a vote for one candidate only. And indeed, research has shown some forms of block voting for female or ethnic minority candidates (Jacobs et al., 2014; Marien et al., 2017; Janssen, 2020.
1
). Therefore, we expect that female candidates and ethnic minority candidates will be more often associated to multiple preference voting, and therefore to concur to deconcentrating intraparty competition.
Female candidates attract more multiple preference votes.
Candidates from ethnic minorities attract multiple preference votes. Next to candidates’ characteristics, we expect that list-level factors are influential for the casting of single or multiple preference votes. Wauters and colleagues (2018) have demonstrated that established parties were associated with a lower concentration of preference votes on their lists. It could be due to their greater number of incumbents (see H3), but also to their party organization. In comparison to established parties, newer parties present organisations that are less structured. This tends to favour single preference voters, especially towards prominent candidates as the latter benefit from a greater margin of actions during the electoral campaign. Furthermore, we hypothesize that a list party magnitude also impacts voting behaviour in terms of strategic considerations (Thijssen, 2013). In comparison to smaller party lists, larger party lists favor the electoral emergence of a greater number of candidates, which provide greater incentives for voters to cast multiple preference votes for a wider share of potentially successful candidates (see also Dodeigne and Pilet, 2021). On the opposite, voters are strategically incited to support a limited number of candidates on smaller party lists (if not only their preferred candidate), as hardly a few candidates will get access to office.
Candidates running on established party lists attract fewer single preference votes than multiple preference votes.
Candidates running on smaller party lists (in terms of seats gained) attract fewer single preference votes than multiple preference votes. Finally, we expect that the municipality context matter. Dodeigne and Pilet (2021) have shown that races in smaller districts tend to show higher levels of concentration of preference votes. In the specific context of local elections, this should be reinforced the diversity of political dynamics between large urban centres and small rural municipal contexts. The latter, which are characterised by less densified territorial environment, the seminal “friends and neighbor” effects are the strongest, which results in a larger voters’ familiarity with candidates. This results in greater preference voting in smaller municipalities (André et al., 2012; Put and Maddens, 2015). On the opposite, large urban municipalities tend to favor electoral subcommunities, splitting electoral linkages between candidates and voters into specific neighborhoods and urban communities (Dodeigne et al., 2021). In this context, we expect that voters will specifically target certain candidates, resulting in a greater share of single preference votes.
Candidates running in larger municipalities attract greater single preference votes than multiple preference votes, and vice versa for candidates in smaller municipalities.
Case study: the 2018 local elections in Wallonia (Belgium)
Local elections in Wallonia (Belgium) are organized using list PR systems allowing voters to cast preference votes in 253 municipalities. In each of them, elections are held every six years to elect members of the local council. Each municipality constitutes a single electoral district. The number of local councilors to be elected ranges between 7 in the smallest towns up to 47 in the largest ones such as Liège. On the day of elections, voters must first decide the party lists they want to support. Then, within the list of their choice, voters may either cast a list vote by marking a vote in the box situated on top of the list (i.e. no preference votes towards any candidates of the list), or they can cast a preference vote for one or multiple candidates (up to the number of seats to be allocated).
The allocation of seats to the local council proceeds in two steps. First, seats are allocated between party lists. Each ballot marked by a vote for a list (either with a list vote or with one or several preference votes) is counted as one vote for the list. On the basis of the number of votes received by each list, seats are allocated via the Imperiali method of seat allocation (with successive divisors starting with 1, 1.5, 2, 2.5;…). This method is one of the variants of proportional representation and tends to slightly favor larger lists (Pilet et al., 2020). Then, seats are allocated to candidates within lists according to the number of seats obtained by each of these lists. Since the 2018 elections, the Walloon local electoral system uses an open list system. List votes do not count for the allocation of seats within lists. Parties can determine the position candidates occupy on the ballot but this position does not affect the allocation of seats within lists. And the seats are attributed to the candidates with most preference votes by decreasing order until all seats are allocated.
The structure of party systems and party competition greatly varies across the 253 municipalities. In larger urban municipalities, the local party systems tend to mirror the national party system, with four to five parties running under their national party brand, leading to local executive coalitions. In smaller rural municipalities, party competition tends to be restricted to 2 or 3 lists, with fewer lists running under national party labels and more ‘pure’ local lists (Dodeigne et al., 2019), and often with one list gaining a majority of seats. Overall, the large diversity of local party systems and electoral competition offer a fruitful empirical ground to test the effects of our varying factors presented above.
Data and method
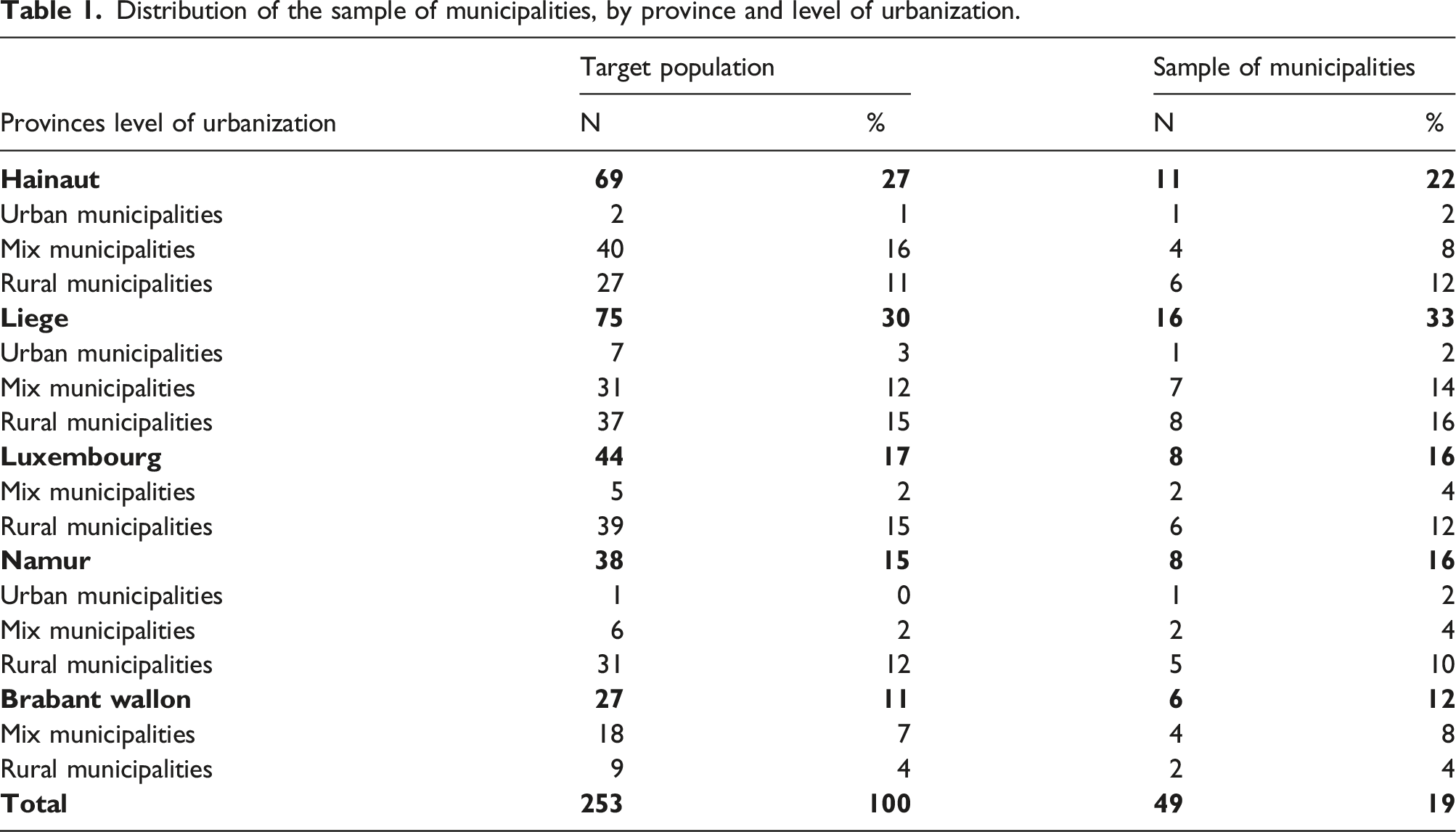
Distribution of the sample of municipalities, by province and level of urbanization.
Distribution of preference votes cast according to different voting categories.
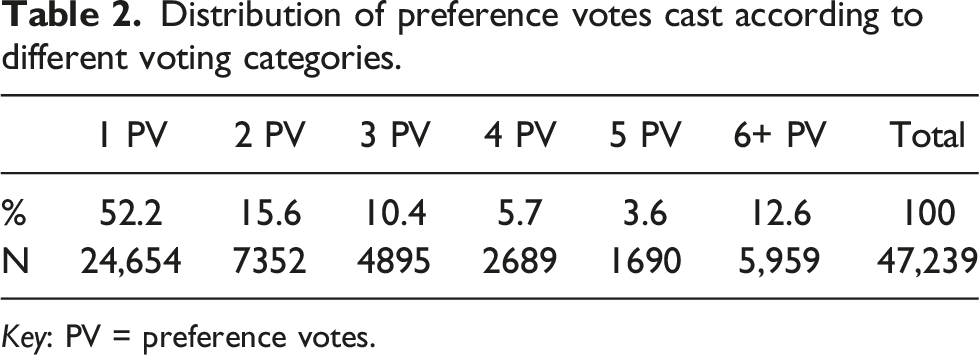
Key: PV = preference votes.
Descriptive statistics for the dependent and independent variables.
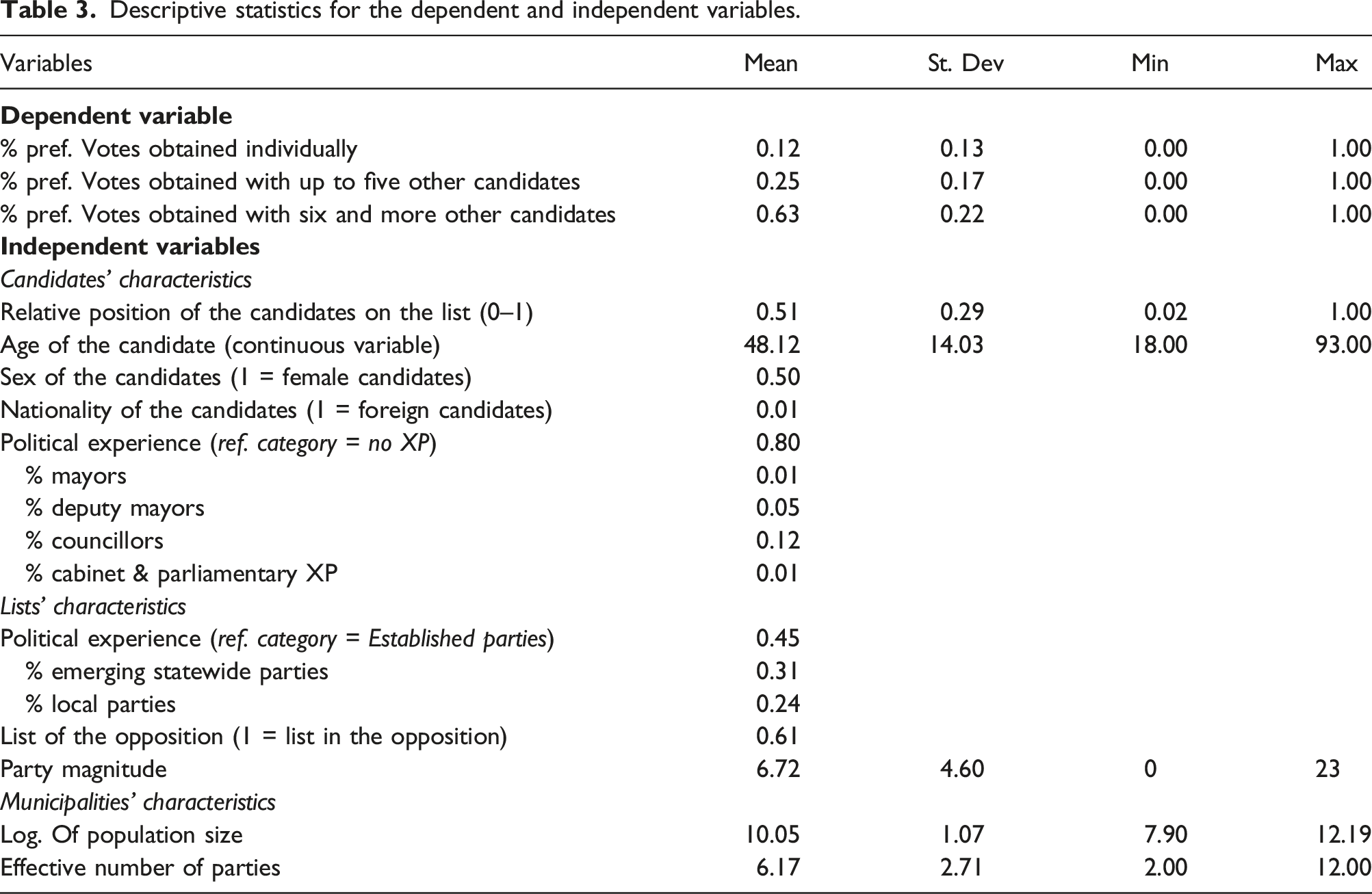
Regarding our independent variables (see Table 3), we gathered official electoral information published by public authorities with previous studies about candidates’ characteristics and party lists in competition at the 2018 Walloon elections (Close et al. 2020; Dodeigne, 2018; Dodeigne et al., 2020). The first six hypotheses are candidates-level factors. For officeholders (H1, H2, H3), we operationalized candidates’ political background as a categorical variable, where no experience at all is the reference category (80% of all candidates in our sample). Candidates that are serving at upper levels of government include members of regional and national parliaments and cabinet ministers. The list position (H4) is operationalized as a relative position according to the absolute number of candidates. This allows us to provide a unique standardized indicator of positions, irrespective of the list length (which greatly varies across municipalities). A higher score on this continuous variable (0-100 percent) indicates that candidates are positioned by their party at the bottom of the list (100 being the latest position), and vice versa for candidates positioned higher on the list 2 . For sex (H5), we use official information to distinguish male and female candidates. Table 3 indicates a mean of 50 percent which perfectly reflects the electoral regulation that imposes gender parity since 2018 (see Pilet et al., 2020). As non-Belgian foreigners can be candidates at local elections, we use the candidates’ nationality as proxy for candidates’ ethnicity (H6) 3 .
The second set of hypotheses are related to party lists-level factors. Following H7, we first distinguish the local branches of established national party lists from emerging parties (respectively 45 and 31 percent). We also, account for local lists which cover 24 percent of all lists. Furthermore, party magnitude is operationalized as the total number of seats obtained by the party lists at the elections. As a control, we also identify list of the opposition which indicate that candidates were running on a list that was not part of the local majority before the 2018 elections.
The third and final set of variables are related to municipalities’ characteristics. On the one hand, size significantly differ across the 49 municipalities, with the largest municipality (Liège) being 73 times bigger than the smallest one (Tinlot), creating a strong skew to the left towards smaller municipalities (the median value being 18,552 inhabitants and the mean 42,150). We thus log transformed the variable. We also control for the structure of the local party system following Laakso and Taagepera (1979)’s seminal concept of effective number of parties in each of the 49 municipalities.
Findings
Considering the structure of the data (4,906 candidates are nested in 188 lists across 49 municipalities), we specified a multilevel linear regression where level-I covers candidates and level-II are lists nested in municipalities. Our model includes a varying intercept for our three dependent variables, i.e. the average percentage of preference votes obtained individually, with two or four co-partisans and five and more other co-partisans. In this regression equation, γ00 is the intercept while γ01, γ02, γ03, γ04, γ05 are the regression slopes for explanatory factors varying across electoral lists in municipalities (Incumbent majorities, ENP, Party types and magnitude as well as population size), while γ10, γ20, γ 30, γ 40, γ50, γ60 cover presence of specific candidates’ profile varying across electoral lists (nationality, sex, age, political capital and list position). Finally, εij and δ
oj
are the residual error terms. The subscript j is for the lists within municipalities (j = 1…J) and the subscript i is for candidates running on lists (i = 1…n
j
)
4
.
Multilevel linear model predicting share of candidates’ preference votes obtained individually and with other co-partisans.
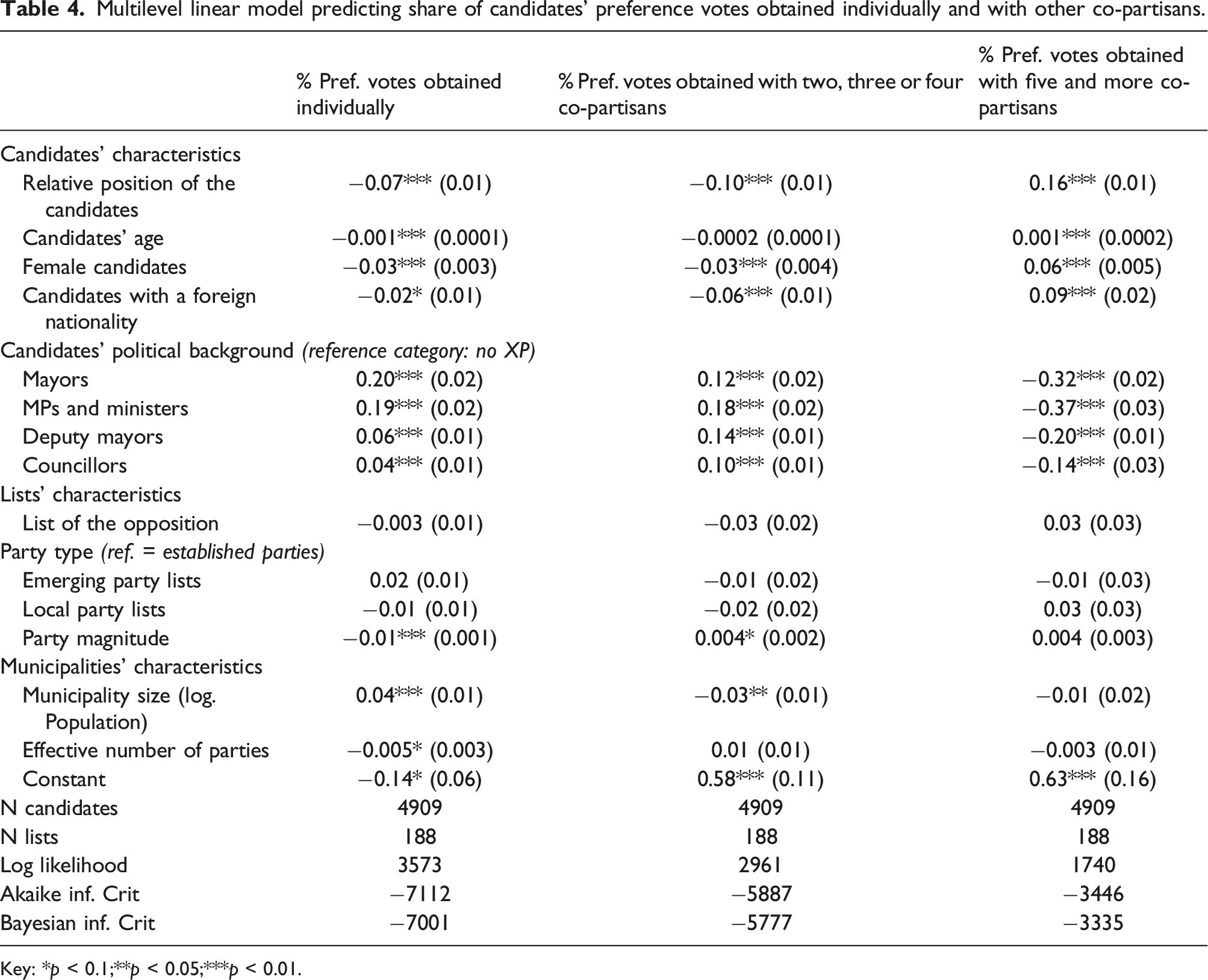
Key: *p < 0.1;**p < 0.05;***p < 0.01.
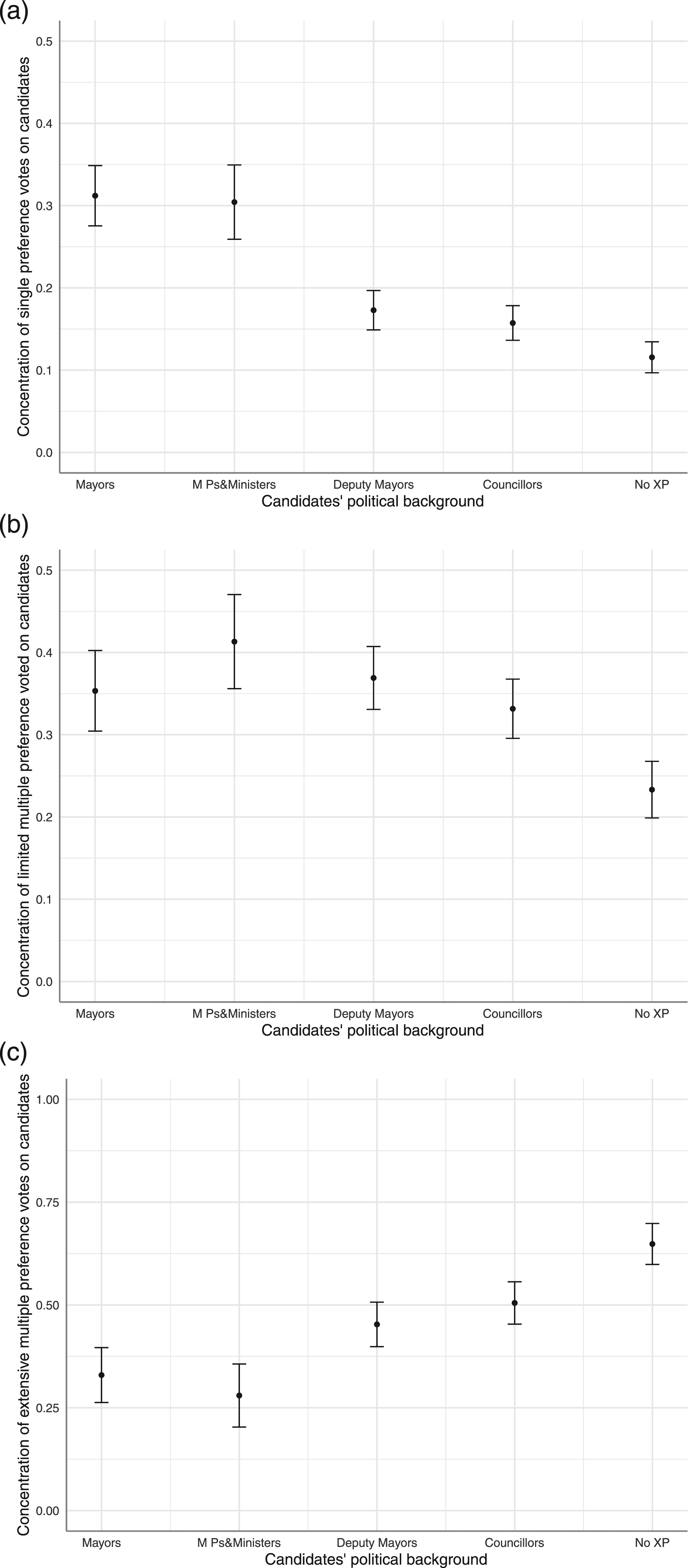
(a), (b) and (c). Marginal effects of political background on candidates’ concentration of preference votes according to single, limited and extensive preference voting categories.
Those “sub-top” politicians attract substantially more votes than inexperienced candidates and concentrate a fair share of preference votes cast on their unique candidacies or with a restricted number of co-partisans. Yet, they do not manage to concentrate most of their preference votes on their mere names as do mayors, MPs and ministers. By contrast, candidates without any political capital are those who obtained the greatest shares of preference votes when voters supported five or more other co-partisans. These lay candidates concur to deconcentrate intraparty competition and to a more decentralized form of personalization. In other words, the ‘forces resisting centralized personalization’ can be explicitly identified in the candidates’ political background confirming H1, H2 and H3. Yet, the results cannot be summarized as a mere dichotomous phenomenon between centralization or decentralization of personalized electoral competition. Complex and intermediary situations are clearly observable with middle-range candidates emerging in between these two ‘extreme’ personalized forms.
The same kind of logic is observed with the candidates’ relative position on the list (H4). We observe that this variable has a negative effect on the proportion of preference votes received from ballot with one or a limited multiple preference votes. By contrast, the relative position on the list has a positive effect on the candidates’ percentage of extensive multiple preference votes. In other words, candidates with lower positions on the lists concentrate more votes because of group voting. On the opposite, candidates with better positions on the list tend to secure a higher percentage of votes by their own name only. H4 is, therefore, confirmed.
Finally, the multivariate regressions confirm that female and ethnic minority candidates receive mostly preference votes from voters casting extensive multiple preference votes (H5 and H6). By contrast, these candidates receive relatively fewer votes from ballot with single preference votes. Because they struggle to concentre preference votes on their mere candidacies, female and ethnic minority candidates face more challenges to emerge vis-à-vis their co-partisan candidates. And contrary to some expectations, the higher proportion of multiple preference votes is not necessarily an electoral advantage for those female and ethnic minority candidates: they hardly benefit from “bloc voting” (i.e. voting only for female candidates or ethnic minority candidates). In our sample, we even observe that there are slightly more preference votes for ‘men only’ (2.8 percent of the voters), than for ‘women only’ (2.3% of the voters).
Our second set of hypotheses are related to the nature of the list on which candidates are running. We expect candidates campaigning on lists from establishing and emerging party lists (H7), and from smaller lists (H8) to present a relatively larger share of their preference votes from a single or a few preference votes. Here, our findings are less neat. While the sign of the coefficients for emerging parties are positive, showing that candidates from emerging party lists receive relatively more votes from single-preference voters, they are not statistically significant. It is also not significant for the negative sign of multiple preference votes. However, party magnitude shows clear and significant effects confirming H8: as party magnitude increases, the percentage of single preference obtained by candidates substantially decreases (Figure 2(a)). On the opposite, greater party magnitude favours extensive multiple preference votes, although the confidence intervals are significantly larger. Finally, our expectations vis-à-vis municipal-level factors are confirmed (H9). In larger municipalities, candidates receive a greater share of their preference votes thanks to single-preference votes whereas smaller municipalities favour the opposite. Results are significant in all models but for extensive multiple preference votes. (a) and (b). Marginal effects of party magnitude on candidates’ concentration of preference votes according to single and extensive preference voting categories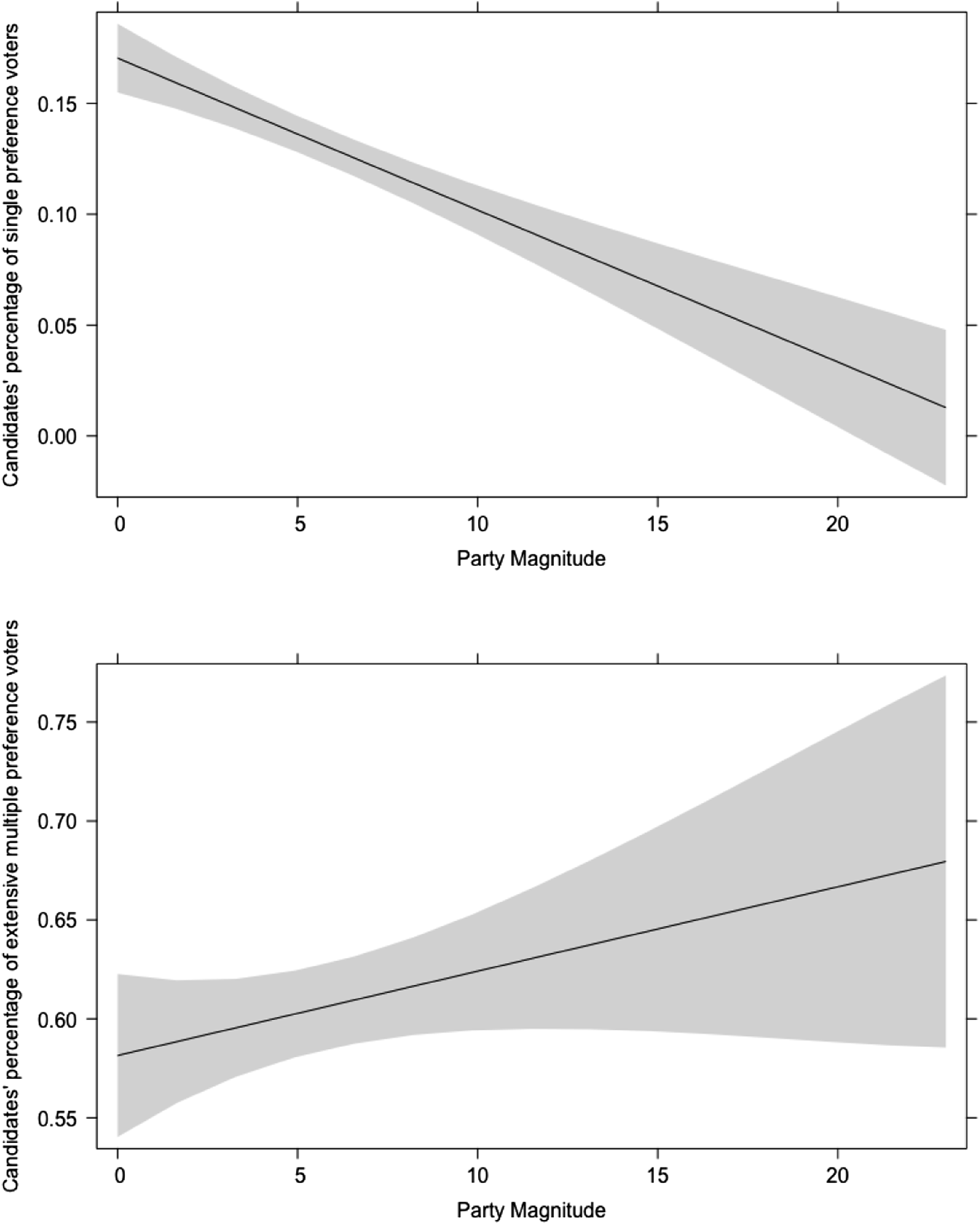
Discussion and conclusion
The empirical goal of this study was to determine the effects of candidates-level, lists-level and municipalities-level factors upon candidates’ capacity to earn votes on their own name only, or in support with other co-partisan candidates. By doing so, we seek to theoretically contribute to ongoing debates regarding centralized and decentralized electoral personalization.
Our findings have first shown a stark difference between candidates attracting mostly single-preference votes and those receiving mostly multiple preference votes. In line with the centralized personalization thesis, prominent political figures (mayors, MPs, ministers) stand up among other candidates and attract preference votes on their mere names. Candidates attracting mostly single preference votes are also favored by the higher position they occupy on their list. And they come from smaller parties with fewer other prominent politicians who cannot contest their leadership. By contrast, candidates that are supported by voters making an extensive use of preference voting have a very different profile. They are lower on their party list. They come from larger parties. And they can mobilize identity-based block voting based upon their gender and their nationality (other than Belgian). These findings indicate that a first set of factors contributing to resisting the overarching trend of centralized personalization by fostering multiple preference votes are related to identity politics, and to the electoral mobilization of sociodemographic traits related to traditionally underrepresented groups (Holli and Wass, 2010; Teney et al., 2010).
But the most original contribution of our study is probably related to the analysis of a third profile of candidates. In a context where Belgian voters tend to cast a limited number of preference votes (35.3 percent of all ballots examined), an intermediate profile of candidates stand up vis-à-vis top and lower political figures discussed above. Candidates attracting these voters are often “subtop” politicians. They can be ministers, MPs or mayors, but they are also very often deputy-mayors and local councilors. They are also placed in the highest positions on the list, albeit not necessarily on the very top position. And they come from a party who obtain more seats and have, therefore, a greater range of candidates with some political capital. We can therefore conclude that those candidates contribute to limiting a full centralized personalization of electoral competition, but with a rather different logic. They confirm the idea that there was something in between centralized and decentralized personalization (Balmas et al., 2014), what earlier studies have defined as an “oligarchization” or an “elitization” of politics (Lindqvist, 2018; Dodeigne and Pilet, 2021). Next to the main leaders, there are “subtop” politicians that have some visibility and that may survive in multiple preference voting systems by attracting support from voters who would not vote for them only, but for them and a few additional candidates, often the main leaders. They can make a career in the shadow of the most prominent politicians from their party, and contribute to a total concentration of electoral politics around (local) party leaders only. Such findings concur to debates in other settings, and especially to the necessity to pay more attention to those mid-level or “subtop” politicians in order to better understand how they build up their electoral and political capital, and how they might also contribute to resisting the centralized personalization of politics.
Finally, future research could further investigate the implications of our findings about differences in lists and parties. Parties develop specific electoral strategies during candidate selection processes in PR systems (Hazan and Rahat, 2010; Vandeleene et al., 2016). They try to reach an ideal equilibrium between different types of candidates who could appeal to different subsets of the electorate. Different profiles of candidates – with different levels of political seniority, with specific sociodemographic traits – result in different patterns of preference voting behaviour. Some attracted single-preference voters, other multiple preference voters. We have also seen that those patterns might different according to the type of party, or to the local context. The next logical step would be to go for analyses at list-level, revealing how the combination of different types of candidates within a single list might lead to different patterns of preference votes at list-level. This would contribute to unveiling the dynamics of multiple preference votes in relationship to the debate about the personalization of elections.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Fonds De La Recherche Scientifique - FNRS grant no 40003171.