
Abstract
Intraparty candidate selection methods are the drivers of many topics of interest to political scientists. Their operationalization, however, is made complicated because they tend to involve multiple selectorates that differ in their levels of inclusiveness and centralization and that play various roles within the process. This complexity poses a challenge for large-n comparative studies. Drawing on the Political Parties DataBase Round Two to analyze candidate selection methods in 184 parties from 35 democracies, we highlight the inadequacy of the currently available measures to correctly account for this complexity in large-n studies and offer improvements on this front. Specifically, we propose a continuous measure of inclusiveness that better captures the complexity of candidate selection methods and a new measure of complexity to facilitate future analyses into this feature. We recommend that scholars in other cross-national projects consider adopting similar or improved coding strategies in order to better capture these complexities.
Introduction
Candidate selection methods are the “choice before the choice” (Rahat 2007:157), the first of the two institutional hurdles that a politician faces on the path to power in a democracy (the second is the electoral system). Often—for candidates who hold safe seats or high positions on party lists—selection is the election. Thus, candidate selection methods are key to explaining many political phenomena, such as women’s representation (Kittilson 2006; Pruysers et al., 2017; Aldrich 2020; Krook 2010), party unity (Itzkovitch-Malka and Hazan, 2017; Shomer, 2016; Sieberer, 2006) and satisfaction with democracy (Shomer et al., 2016). They are also seen as valuable components, for example, in the study of intraparty democracy (Cross and Katz 2013), representation style and legislative behavior (Crisp 2007; Fernandes et al., 2020).
And yet, challenges abound in the research of candidate selection methods. To wit: candidate selection methods frequently include several selectorates, each playing various roles in the selection process. This complexity is well known and has received some scholarly attention (e.g., Hazan and Rahat 2010; Rahat and Cross 2018). However, large-n comparative studies tend to ignore it due to a lack of cross-national standardized coded data. Instead, they rely on measurements that are incapable of capturing important information concerning the nature of the process.
Our dual goals in this note are to demonstrate the inadequacy of available measurements to correctly account for this complexity in large-n studies, and to offer improvements. We open with an overview of the state of the research and reveal a gap between the complexities that are detailed in small-n studies and their oversimplification in large-n studies. Next, we show how the Political Party Database Project (PPDB R2) data-coding scheme accounts for these complexities. In the third section, we present data on 184 parties in 35 democracies, highlighting how prevalent complex methods are. Finally, we propose two innovative measures: (1) an improved inclusiveness measure that is more sensitive than existing ones and, given data availability, easier to compute consistently across a large number of cases; and (2) a complexity measure, which may trigger a new path for comparative research into this subject which, although long known to scholars, has not been systematically analyzed beyond a few country studies.
The state of the research
Intraparty candidate selection is not a new topic to political scientists. Ranney (1981), Gallagher and Marsh (1988) and, more recently, Rahat and Hazan (2001) and Hazan and Rahat (2010) all created common concepts and undertook operationalizations in their work. These were then used in studies that analyzed the determinants of candidate selection methods (Barnea and Rahat 2007; Gauja 2016), their development patterns (Bille 2001; Scarrow et al. 2000; Kittilson and Scarrow 2003) and their consequences (Cross et al., 2016; Sandri et al., 2015; Cordero and Coller 2018; see also above).
The most widely studied elements of candidate selection methods are the selectorates, specifically their inclusiveness (or size) and geographic centralization (Rahat and Hazan 2001). These are seen as important in explaining political phenomena. Variance in the selectorates creates diverse incentives that produce an array of political consequences in terms of participation, representation, competitiveness, and responsiveness (Hazan and Rahat 2010).
Parties tend to employ several selectorates that may vary in their levels of inclusiveness and centralization and, compounding the complexities, may also play diverse roles in the selection process. The resulting processes may be designated as multistage, where each selectorate performs a distinct role in the process; assorted, where different candidates face different selectorates; or weighted, where multiple selectorates share roles in selecting the same candidates (Hazan and Rahat 2010).
Many existing works consist of case studies or focused comparisons between a few parties (Cordero and Coller, 2018; Narud et al., 2002; Siavelis and Morgenstern, 2008). These acknowledge and account for the complexities of candidate selection methods, while large-n comparative studies have hitherto failed to do so. Yet as we show below, complex processes are the norm rather than the exception. Indeed, large-n comparative studies will never be as sensitive to nuances and detail as case studies are. Any coding entails standardizing and simplifying complex phenomena and structures. But the gap found in candidate selection research is too large to ignore (Rahat and Cross, 2018). Previous studies demonstrated that complex selection methods have different consequences from simple selection methods (Rahat 2009; Vandeleene 2014). Hence, oversimplification is expected to affect the findings of large-n studies.
Previous cross-national large-n analyses of candidate selection methods (treating them either as the dependent or independent variable) ignored all or most of the complexities of the process. Some of these coded candidate selection as involving only a single selectorate at a single particular level (Chiru et al., 2021; Cordero et al., 2018; Shomer, 2016; Shomer et al., 2016); others allowed for only a few specific combinations (Lundell 2004; Shomer 2014, 2017). Part of the problem may stem from data availability issues, a challenge that ongoing cross-national collaborative projects seek to resolve. Yet new data also require improved measurements in order to be optimally utilized. In what follows, we discuss the two prevalent approaches to measuring candidate selection methods’ inclusiveness, which is the main feature of interest to political scientists.
The first group of studies used ordinal measurements. It includes Lundell (2004), Shomer (2017), and Chiru et al. (2021), who applied the Comparative Candidate Survey (CCS), and also V-Dem’s new V-Party project (Lührmann et al., 2020). The CCS and V-Party datasets allow their respondents and coders, respectively, to designate only one selectorate. Relying on multiple candidates from each party, the CCS can therefore account for assorted methods, where some candidates within the same party are selected differently than others, but not for the other types of complexity. Shomer (2017) accounts for five selectorates and includes three specific combinations while Lundell (2004) accounts for five and includes two specific combinations. However, as we show below, this accounts for a very small fraction of all possible—and actual—combinations of selectorates.
The second type of measurement is an interval scale, suggested by Hazan and Rahat (2010) and used, for example, by Itzkovitch-Malka and Hazan (2017). This scale can account for combinations of two selectorates and may be sensitive to the degree of influence of selectorates in the process. However, lacking predetermined guidelines for combining selectorates, it becomes unwieldy when more than two selectorates are used (a frequent occurrence), and requires expertise rarely found beyond single-country studies to determine weights for each selectorate.
Complexity in candidate selection data
In this study, we utilize the second round of the Political Party Database Project (PPDB R2). The PPDB “is a cross-national initiative to establish and update an online public database as a source for key information about political party organizations” (PPDB R2 2021). It provides standard coded variables, covering “party resources, party decision processes, and the outcome of decision-making procedures for parties in many representative democracies” (ibid.). The data were collected by established and renowned political scientists and their teams, each in their country of expertise. The full overview of the project and its members is available in Poguntke et al. (2016) and on the project’s website.
The PPDB R2 country coordinators and their teams gathered relevant data on a battery of 28 items. These pertain to seven selectorates: individual members; local-level organizations; regional- or state-level (subnational) organizations; national collective bodies; the national party leader(s); non-member supporters; and affiliated or other (non-party) organizations. Since only three parties used the last type of selectorate and gave it a marginal role, we excluded it from our analyses. For each selectorate, it is indicated whether it was involved in at least one of four roles: suggesting/proposing candidates for internal consideration; screening/filtering (prior to decisions by other parts of the party); selecting/deciding (de facto decision, even if another party body needs to rubber-stamp it); and vetoing (following decisions by other parts of the party) (PPDB R2 2021). The use of standardized categories for defining the role(s) of each selectorate allows us to separately assess their weight in the process.
Figure 1 details the selection process captured by the PPDB R2 and the numerous possible resulting combinations of selectorates and roles. With up to seven possible selectorates and up to four roles for each, and considering that these possibilities are not mutually exclusive, the theoretically possible combinations are in the hundreds. The resulting data structure can therefore, undoubtedly, depict even extremely complex processes. The earlier studies mentioned above did not, and could not, do so. Possible selectorates and selection roles in the PPDB R2.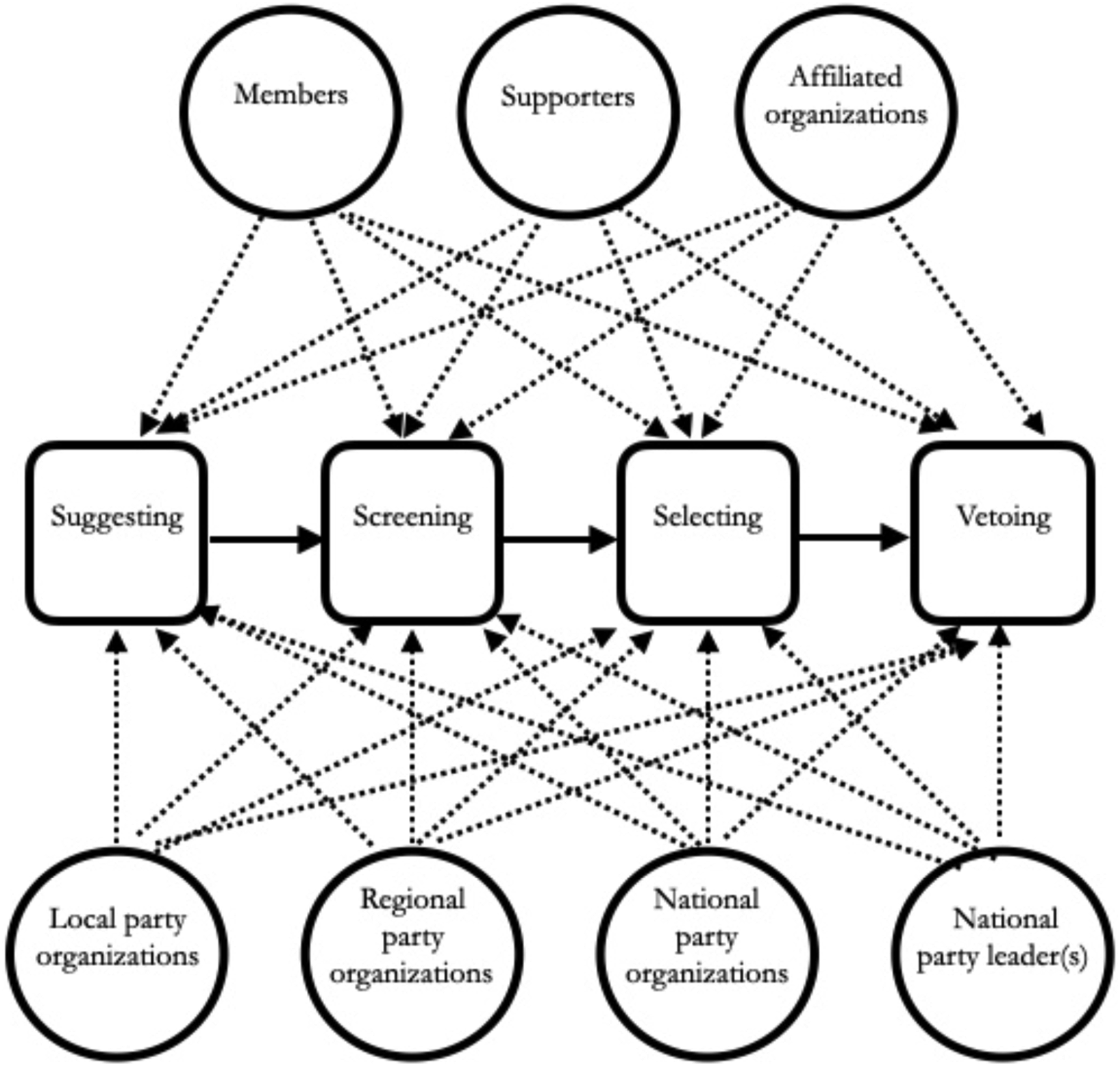
The PPDB data have some limitations. For one, they represent a cross-national “snapshot” of political parties between 2016 and 2019, preventing inferences about longitudinal developments. Additionally, they do not provide information on the degree of centralization of member and supporter selectorates, or on the exact size and nature of party organs involved. More importantly, since the data were collected at the party level, there is no way to distinguish between assorted and weighted methods. 1 These limitations notwithstanding, the PPDB presents a substantial improvement in detail and refinement over previous endeavors.
Candidate selection methods: a complex picture
Figure 2 presents an “upset plot” (Lex et al., 2014), created with the UpSetR R package (Conway et al., 2017), displaying the various combinations of selectorates used by 184 parties
2
from 35 democracies (according to Freedom House in 2017 and 2018) between 2016 and 2019, for which the coders indicated at least one positive answer per at least one selection role.
3
The horizontal bars on the left show how many parties employ each type of selectorate. The vertical bars, in conjunction with the connected dots below them, show the frequency of each possible combination. Selectorates involved in candidate selection in 184 parties.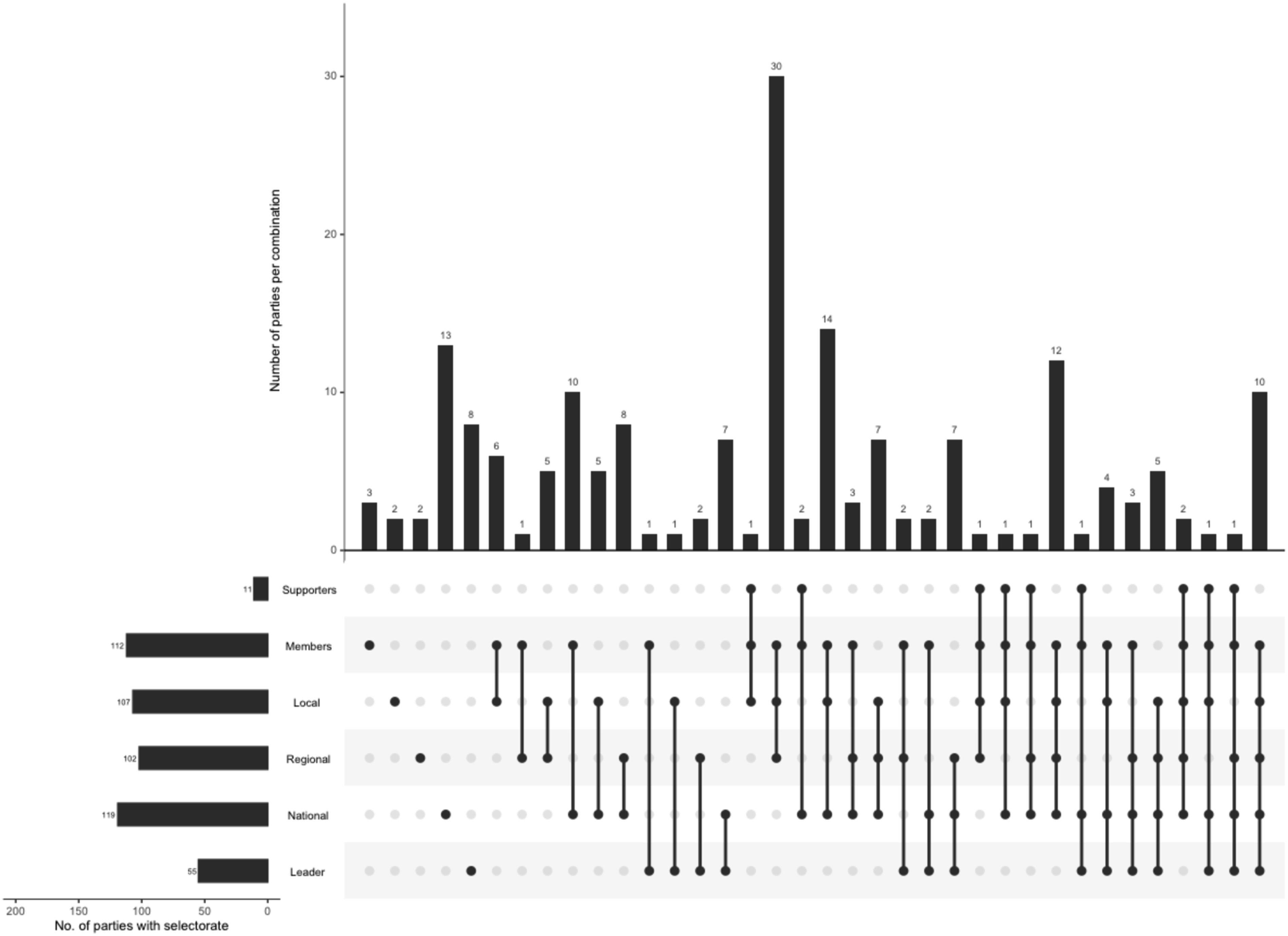
In the vast majority of cases (84.8%), parties used multiple selectorates to select candidates. The average number of selectorates in our data is 2.7, while the median is 3. Importantly, Figure 2 presents a somewhat simplified picture in that it does not show which role each selectorate performed, and thus does not fully distinguish between different combinations involving the same selectorates. The actual combinations of selectorates and roles are many; the 184 parties in our data use 139 distinct combinations, making almost every party unique in its selection method. In essence, as discussed, most parties meaningfully employ at least two selectorates, and multiple combinations must be taken into account if one wishes to capture a majority of the cases. This simple finding highlights the shortcomings of current approaches to operationalize candidate selection methods and the need for more nuanced measurements. We further elaborate on the shortcomings of existing measurements, and on the improvements that the proposed new measures suggest.
Accounting for complexity
We now return to the two main types of measurement that previous studies used and address the complexity uncovered by our analysis above. The CCS and V-Party, as noted, allow respondents or coders to choose only one selectorate out of six options. In contrast, in our analysis only 28 parties (15.2%) employ a single selectorate. Indeed, one selectorate may be more influential than others in a given party, for example, the selectorate which solely performs the screening of candidates or their selection (composing the actual list). However, in our data, substantial shares of the parties have multiple selectorates performing the screening (34.8%) or selecting (46.2%) roles.
Shomer (2017) does allow three combinations between the five selectorates she includes in her measure, with the national party approving the selection of the local leadership, local delegates or primaries. But parties employ numerous other combinations. For example, even if we consider only the two most important roles in our view (screening and selecting), 46 parties in our data (25%) involve both primaries and local party organs. Moreover, many of them also employ a third selectorate, as 27 involve the national party organ (e.g., the British Labour), and 12 the party leader (e.g., the Canadian Liberal Party). Having to pick a single category on an ordinal scale that does not account for such combinations may impact the result of research in unpredicted ways, depending on the researcher’s arbitrary choice of category.
Finally, while Hazan and Rahat’s (2010) scale does allow the weighing of several selectorates, it is unclear how this is achieved with more than two, whereas 107 parties (58%) in our data use three or more selectorates. Consider, for instance, that among the 30 parties in nine countries that employ the same three selectorates—primaries, local, and regional selectorates—we find nine different combinations of these selectorates. These combinations result in different degrees of inclusiveness, ranging on our measure (see below) from 0.583 (Norway’s Centre Party), which is at the 62nd percentile within our data, to 0.83 (British Green Party), which is at the 95th percentile. Even if one would rely on an existing dataset such as the PPDB, Hazan and Rahat’s scale does not provide a systematic formula to account for these differences.
We thus propose two innovative measurements: first, an inclusiveness measure which improves on Hazan and Rahat’s scale; second, we present a new complexity measure that will enable the inclusion of this feature of selection methods in large-n studies and explore its impact. In the online Supplemental Material Appendix B, we also suggest a decentralization measure, structured similarly to the inclusiveness one. Our calculation of these measures draws on the PPDB data, but they could in fact be applied to any comparably detailed data, whether based on an expert’s survey, candidates’ responses or self-gathered information.
We compute our inclusiveness measure by first calculating the weight of each selectorate (i) by adding up the number of roles (j) it plays (see Appendix C in the online appendix for an example of the calculation).
4
We divide the selectorates into three levels of inclusiveness, captured by X
ij
in equation (1): inclusive selectorates that include members and supporters (X
ij
= 1); middle-of-the-road selectorates that include local, regional and national party organs (X
ij
= 0.5); and the party leader, that is, the exclusive selectorate (X
ij
= 0). Future improvements to the PPDB or other datasets may of course enable even greater differentiation. We then sum these weights, each multiplied by X
ij
, and divide the result by the overall number of roles played by all selectorates (N): equation (1)
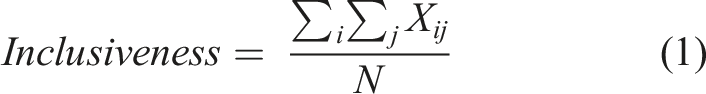
To test this measure’s validity, we compare it to two others with available data: Itzkovitch-Malka and Hazan’s (2017) and the CCS. The PPDB overlaps with the former on 29 parties. The correlation between their inclusiveness measure and ours is strong and significant (r = 0.58, p < 0.001), despite a substantial difference in the time the data were gathered. The overlap with the latter is larger and covers 65 parties. We compute for each party’s respondents in the CCS the mean score for the relevant question (B3). The correlation between that value and our measure is also strong (and negative, because the direction of the question is opposite) and significant (r = −0.55, p < 0.001). We view these results as evidence that our measure works as expected, while producing values that are different enough from other existing measures and, as explained, express a valuable improvement.
We now turn to complexity. One straightforward way to measure complexity is to count the number of selectorate-roles performed (N). However, there is a difference between a method that involves five selectorate roles, with one selectorate performing all possible four roles and another performing just one, and a method that involves five selectorates, with each performing one role. To capture this difference, we suggest computing the effective number of selectorates (ENS), taking into account both the number of selectorates in each party and their respective “weight” in the process (S
i
),
5
as indicated by the number of roles each selectorate performs out of all selectorate roles in the process (N) (cf. Laakso and Taagepera, 1979) (see Appendix C in the online appendix for an example of the calculation). Equation (2) is therefore:
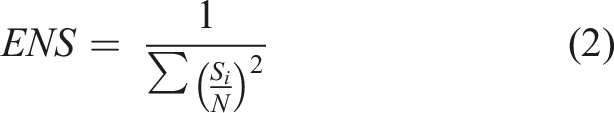
Complexity is not restricted to certain kinds of parties or systems; rather, it is prevalent across all of them. It does not significantly correlate with any of several system- and party-level factors, either in pairwise comparisons or in a multivariate analysis (see Supplemental Material Table A2 in the online appendix for more details). 6 These are: democratic regime type (parliamentary, presidential or hybrid); federalism; electoral incentives to cultivate a personal vote and the logged average district magnitude; wave of democratization; party family; party size and party age; and geographic region. Crucially, across all examined types of political systems and parties, the mean effective number of selectorates is over 2.
Figure 3 presents the distribution of our complexity and inclusiveness measures utilizing the PPDB data. It drives home two main points: that most parties employ complex selection methods, with more than two selectorates involved (mean = 2.52, median = 2.67); and that our inclusiveness measure is much more fine-grained and sensitive to this complexity than any other existing measure. Distribution of complexity and inclusiveness in the data.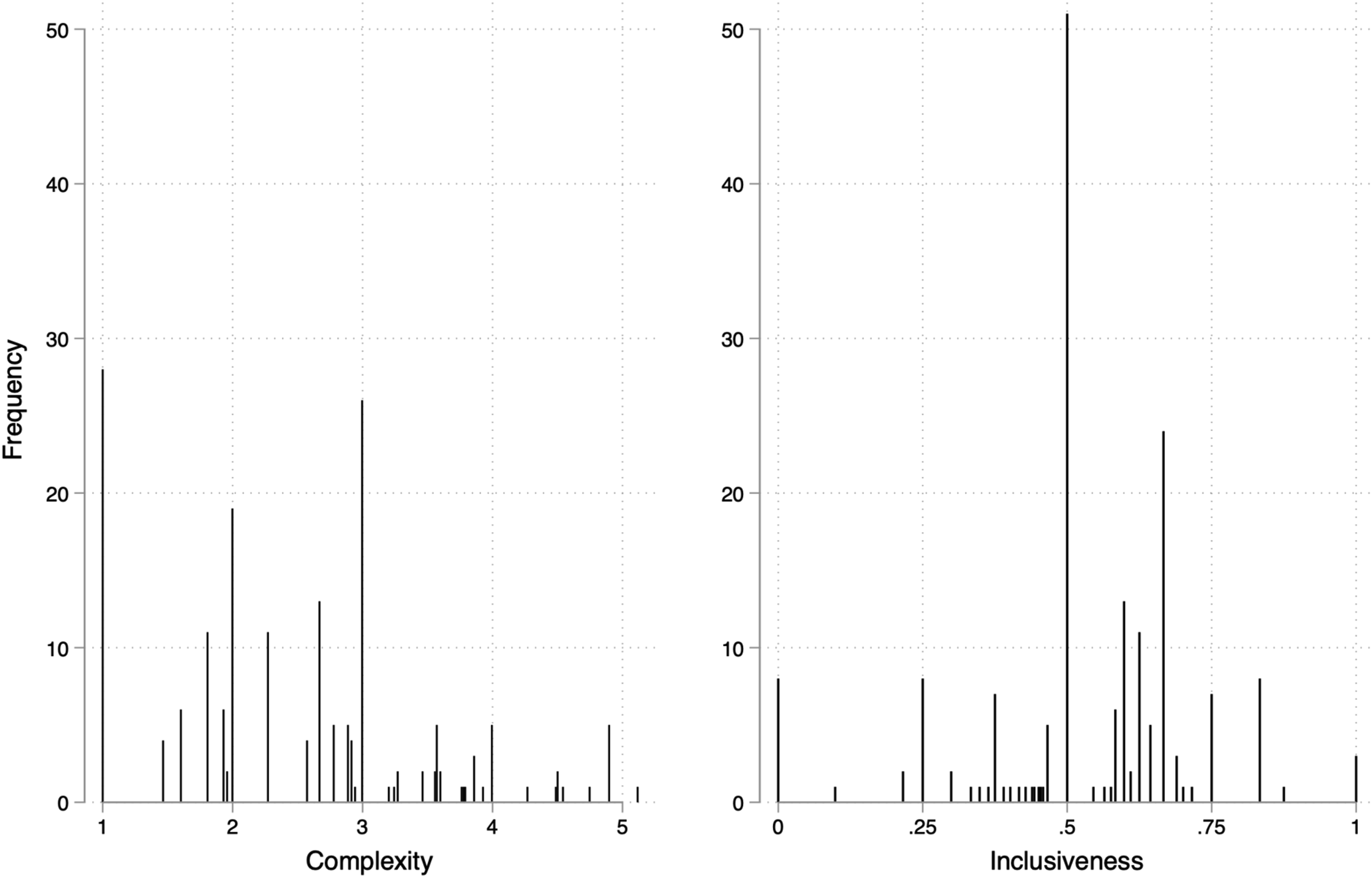
Conclusion
Parties often use multiple selectorates that play various roles in the selection process. There are numerous observed combinations. We hold that a more nuanced operationalization of the main characteristics of selection methods is sorely needed. Such an advancement was always an aspiration—now it is also possible. Relying on a newly available dataset, we suggest a nuanced measure of inclusiveness as well as a brand-new measure of complexity.
Using the same (or improved) battery of questions in other large-scale collaborative projects, such as the Comparative Candidate Survey or V-Party, may deepen our knowledge about candidate selection and enhance our understanding of the topic. With better tools in hand, scholars could re-explore the determinants and consequences of selection methods with greater sensitivity and broader samples. They may break new frontiers, especially when assessing the impact of complexity. We call on any scholar investigating candidate selection methods to take advantage of these new opportunities and challenges, either in conjunction with the PPDB or with any comparable dataset in the future.
Supplemental Material
sj-pdf-1-ppq-10.1177_13540688211060658 – Supplemental Material for Servants of two (or more) masters: Accounting for the complexity of intraparty candidate selection methods
Supplemental Material, sj-pdf-1-ppq-10.1177_13540688211060658 for Servants of two (or more) masters: Accounting for the complexity of intraparty candidate selection methods by Or Tuttnauer and Gideon Rahat in Party Politics
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by the Israel Science Foundation (grant No. 1835/19).
Supplemental material
Supplemental material for this article is available online.
Notes
Author biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.