
Abstract
Anthropogenic environmental pollution is a known and indisputable issue, and the importance of searching for reliable mathematical models that help understanding the underlying process is witnessed by the extensive literature on the topic. In this article, we focus on the temporal aspects of the processes that govern the concentration of pollutants using typical explanatory variables, such as meteorological values and traffic flows. We develop a novel technique based on multiobjective optimization and linear regression to find optimal delays for each variable, and then we apply such delays to our data to evaluate the improvement that can be obtained with respect to learning an explanatory model with standard techniques. We found that optimizing delays can, in some cases, improve the accuracy of the final model up to 15%.
Introduction
Anthropogenic environmental pollution is a known and indisputable issue. Every day, the human body is exposed to harmful substances in various ways, including by ingestion of food and drink and by absorbtion with breathing. While it is possible to limit the ingestion of harmful chemicals, it is impossible to choose the air we breathe. Chemicals dangerous to health (or that become so if absorbed over certain amounts) include suspended particulate matters, nitrogen oxides,
Predicting the value of a time series, such as the concentration of a certain pollutant in time, is a very well-known problem. The usual statistical approach to its solution requires the use of moving average models, or, more generally, of Autoregressive Integrated Moving Average (ARIMA) models, that define the problem as an autoregressive one (see Box et al 13 for a comprehensive introduction). The underlying idea is that the past values of the predicted variable, for example, the pollution concentration, can be used to predict future values. The implicit assumption is that the behavior of the predicted variable remains somewhat constant, and such models are designed to identify, and describe, such behavior. A different approach, more typical of machine learning, consists of enhancing a static model learner (eg, linear regression, tree regression, neural network) with lagged variables, that is, variables with the past values of the predictors. A classical regression model is designed to extract a (implicit or explicit) function of the (current) predictors that explains the (current) value of the interesting variable; a lagged regression model acts in the same way, but using, as predictors, both the current and the past values of the explanatory variables. The so-called ARIMAX models mix these 2 ideas, and are designed to extract functions of both the current and past values of both predicting and predicted variables. The most relevant drawback of ARIMA-type frameworks is that the resulting models are, in a way, implicit. As a matter of fact, in most natural phenomena, the variable to be predicted has enough slow-changing behavior for the past values to be very good predictors, so good that the real predictors cease to have relevant roles. As a consequence, with ARIMA-type methods, one obtains very good predicting models that offer no explanation of the underlying process, which cannot be used for the purposes of serving as basis for (T)LURs. Pure lagged models, such as those offered by typical learning packages (see Hall, 14 for example), bypass this problem when the past values of the predicted variable are not used, but raise other issues. In particular, a typical lagged model (both explicit or implicit) uses tens of lagged variables per each explanatory parameter; this proliferation of columns makes it very difficult, or impossible, to interpret the underlying process even when explicit functions are used. As a consequence, the most successful lagged models are based on neural networks, which are already implicit. The form of the regressed function is, per se, an additional problem of classical approaches. ARIMA-type models and linear regression are designed to extract a linear function, which is, typically, a good first approximation of the underlying behavior. As we have recalled, lagged models can be also tree-like, that is, layered functions, or even highly nonlinear, such as in neural networks. But these approaches do not allow to explicitly model the nonlinearity level, so to say, in search for some simple, albeit nonlinear, behavior. 15
In this article, we present a methodology to select, at the same time: (1) predicting variables, (2) the amount of their lag, and, if necessary, (3) their nonlinear contribution. By using a multiobjective optimization algorithm, we produce a set of potential solutions. In some sense, each solution can be thought of as a temporal convolution vector that highlights the contribution of each predictor by taking into account the temporal component and their nonlinear contribution. Any such vectors can be applied to the original data, to test the effect of the transformation with different regression algorithms. A temporal convolution vector contains an optimal lag and an optimal nonlinear transformation for each variable, and it not only allows the induction of a better explanation model, but it is also interpretable per se, as it shows exactly the delay after which each predictor is most influential. Optimizing lags solves, in a way, both problems of ARIMA-type models and lagged models: the temporal convolution vector allows one to better understand the necessary delay for an explanatory variable to take effect, and, if it is the case, its nonlinear contribution.
To test our methodology, we considered a data set containing
Background
Mathematical models for air quality prediction and explanation
The relationships between concentrations of air pollutants in the urban agglomeration and meteorological factors, traffic flow, and other elements of the environment have been described using many different modeling techniques. However, taking into account the interpretative usefulness of the results obtained, they can be categorized into (1) interpretable models, including explicit function (linear, polynomial, exponential, and other nonlinear functions),16-19 clustered models, 20 and probabilistic models,21-23 and (2) noninterpretable models, including those based on neutral networks, 24 forests of decision trees or regression trees,25-27 and ensemble models.28,29
The relationships between concentrations of air pollutants, traffic flow, and meteorological conditions based on the same hourly data used in this article were already analyzed. An interpretable simple probabilistic model was built for
Time series and lagged models
A time series is a series of data points labeled with a temporal stamp. Time series arise in multiple contexts; for example, in our case, data from environmental monitoring stations can be seen as time series, in which atmospheric values (eg, pressure, concentration of chemicals) change over time. If each data point contains a single time-dependent value, then the time series is univariate; otherwise, it is called multivariate. In our case, we refer to a multivariate time series in which precisely 1 variable is dependent; for other applications, it makes sense to consider multivariate time series with multiple dependent variables. There are 2 main problems associated with time series: time series explanation and time series forecasting; these problems are usually associated with different contexts and approached with different tools. In particular, time series forecasting emerges in the realm of statistical economics, and, more recently, has found applications to other contexts. Time series explanation, on the other hand, is related to machine learning processes, and it is not linked to a particular field of application. The different approaches to time series analysis have, clearly, nonzero overlapping.
The typical statistical-based time series forecasting approach is based on autoregressive models. The simplest univariate forecasting approach is commonly known as simple moving average (SMA) model: an SMA is calculated over the time series by considering its last
In the machine learning context, there are 2 influential approaches to time series analysis: recurrent neural networks34-36 and lagged models. In the former case, neural networks are adapted to the specific form of a time series to be trained for forecasting. In the latter case, on the other hand, data are systematically transformed by adding a delay, so that a classical, propositional learning algorithm can be then applied; among the available packages to this purpose, we mention Weka timeseriesForecasting. 14 Lagged models are flexible by nature, as they are not linked to a specific learning schema, and their focus is on time series explanation. In some cases, lagged variables have been used for neural network training, increasing their performances. While explicit models can be used for forecasting, it is not their focus, considering that their forecasting horizons are limited to the maximum lag in the model; time series forecasting models, on the other hand, allow long-term predictions, at the expenses of the interpretability of the models. Different, yet related, approaches include, 37 in which a modified decision tree learner has been used to model air pollution using lagged versions of the predicting variable in the form of univariate time series. Lagged models, and more in general, models that include consideration on the past values of the predictors, have been mainly used in dealing with issues related to the analysis of factors affecting health and human life. In studies on the impact of air pollution on mortality, lagged variables are used to consider the duration of the exposure. Effect of exposure to high concentrations of particulate matter has been studied in previous studies,8,10,38 among others. The effect of exposure to ozone, including lagged variables, was analyzed, inter alia, in previous studies.39,40 As for concentration of pollution models, lagged variables are considered in forecasting models such as Catalano et al, 41 but such models are definitely different from those developed in this work in many perspectives. Similarly, multiobjective optimization processes are used to solve various types of optimization problems also in the environmental context, for example, in allocation of sediment resources, 42 long-term ground water monitoring systems, 43 calibration of rainfall-runoff model, 44 optimal location and size of the given number of check dams, 45 or studying the problem of mitigating climate effects on water resources. 46
Feature selection
Feature selection (FS) is defined as the process of eliminating features from the data base that are irrelevant to the task to be performed. 47 Feature selection facilitates data understanding, reduces the storage requirements, and lowers the processing time, so that model learning becomes an easier process. Feature selection methods that do not incorporate dependencies between attributes are called univariate methods, and they consist in applying some criterion to each pair feature-response, and measuring the individual power of a given feature with respect to the response independently from the other features, so that each feature can be ranked accordingly. In multivariate FS, on the other hand, the assessment is performed for subsets of features rather than single features. In our case, multivariate FS may be paired with optimal lag searching, so that not only the delayed effect of each variable but also its actual need in the explanation model is taken into account. Relevant to this study are FS techniques based on multiobjective problems, reviewed in the next paragraph.
Multiobjective optimization
A multiobjective optimization problem (see Collette and Siarry
48
) can be formally defined as the optimization problem of simultaneously minimizing (or maximizing) a set of

where
Feature selection can be seen as a multiobjective optimization problem, in which the solution encodes the selected features, and the objective(s) are designed to maximize the performance of some classification/regression algorithm in several possible ways; this may entail, for example, instantiating equation (1) as:

where
Data
There is only 1 communication station for measuring the air quality in the city of Wrocław, and it is located within a wide street with 2 lanes in each direction (GPS coordinates: 51.086390 North, 17.012076 East, see Figure 1). The center of 1 of the largest intersections in the city with 14 traffic lanes is located approximately 30 m from the measuring station, and is covered by traffic monitoring. The measurement station is located on the outskirts of the city, at

Aerial view of the monitoring station.
Descriptive statistics.

Method
Lagged regression
Linear regression is the most immediate approach to explicit modeling of a multivariate time series. In our case, for example, one can denote by:
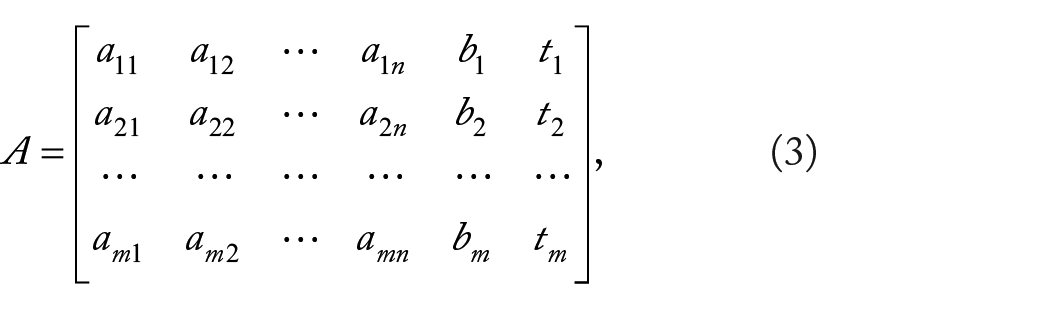
the set of preprocessed data, in which

Solving this problem entails finding

In other words, we use the value of each independent variable
Lagged regression can be performed with other, more complicate, model extraction methods that may not allow explicit representation, such as random forest or neural networks of any type. The underlying idea is the same: enhance the independent data by adding lagged versions of each variable
Optimizing a lagged model
Both standard and lagged linear regression are classical, simple approaches to the problem of explaining the value of
We work under the additional assumption that, for each

Our methodology can be described as follows: (1) we split the original data set
Having separated the optimization part from the training part, we can now arbitrarily complicate the model. For example, in some contexts, such as pollution concentration modeling, a super-linear explanation model may fit better than a linear one, yet preserving the possibility of an intuitive interpretation. From the mathematical point of view, the inverse problem that corresponds to searching for a super-linear model is a simple generalization of equation (6):
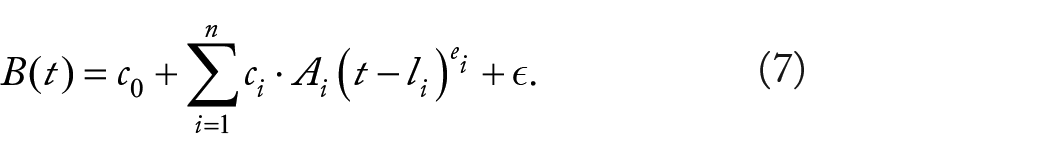
Thus, in the optimization part of our methodology, we can optimize coefficients

A simple schematic of the proposed methodology.
Solving the optimization problem
Deciding the best lag and the best exponent for each variable is an optimization problem. Formally, given a multivariate time series

The transformation equation (8) works for every

A simple numeric example of such a transformation can be seen in Figure 3. In this example, we start off with 5 observations and 5 independent variables (the sixth column indicates the time of observation); the left-hand side (that contains the lags) of the decision variables vector contains 0 for the first and the fourth variable, 1 for the second variable, 3 for the fifth variable, and −1 for the third variable (which entails that this variable is not selected); the right-hand side (that contains the exponents) contains 1 (linear behavior) for every variable except the third one (which, by the way, is eliminated) and the fifth one, in which the exponent is 2 (quadratic behavior). The original data set, therefore, must contain 3 less observations because in this example, we are assuming that to explain the current value of

Example of transformation. The original data set (top) is transformed by the pair
Solving the optimization problem entails evaluating a vector

and, on the other hand, we want to minimize the complexity of the extracted model, using:
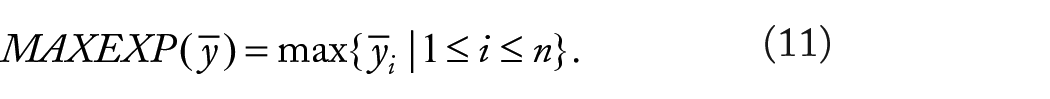
Thus, solving our optimization problem means instantiating equation (1) with:

Clearly, other objective functions can be designed that may or may not improve the quality of the solutions.
Implementation
Multiobjective evolutionary algorithms are known to be particularly suitable to perform multiobjective optimization, as they search for multiple optimal solutions in parallel. In this experiment, we have chosen the well-known Nondominated Sorted Genetic Algorithm II, 49 which is available as open source from the suite jMetal. 62 Nondominated Sorted Genetic Algorithm II is an elitist Pareto-based multiobjective evolutionary algorithm that employs a strategy with a binary tournament selection and a rank-crowding better function, where the rank of an individual in a population is the nondomination level of the individual in the whole population. As black box linear regression algorithm, during the optimization phase, we used the class LinearRegression from the open-source learning suite Weka, 63 run in 10-fold cross-validation mode, with standard parameters and no embedded FS. We have represented each individual solution (gene) as an array:

with values in
The initial population has been generated randomly, in each execution, and the fitness functions reflect the objective functions of equation (12) in the obvious way; in particular, Weka implementation of any regression extraction algorithm returns, among other measures, the Pearson correlation coefficient of the extracted model. Mutation and crossover operations have been adapted to the form of the gene. To mutate an individual
Experiment
According to the methodology described in Figure 2, we prepared the data sets
Training results for

We use exec. to indicate the execution number and exp. to denote the exponents. The variables are denoted as in Table 1.
Training results for

We use exec. to indicate the execution number and exp. to denote the exponents. The variables are denoted as in Table 1.
As for the test phase, we have operated as follows: first, we have used the original test data set
Test results for

We use exec. to indicate the execution number, and corr. (mean a.e., root m.s.e., root a.e., and root s.e.) to denote the correlation index (the mean absolute error, the root mean squared error, the root absolute error, and the root standard error, respectively).
Test results for

We use exec. to indicate the execution number, and corr. (mean a.e., root m.s.e., root a.e., and root s.e.) to denote the correlation index (the mean absolute error, the root mean squared error, the root absolute error, and the root standard error, respectively).
Discussion
In view of the results that have been obtained, 2 important elements emerge: first, how lags and nonlinear contributions are explained in the physical process, and, second, how the transformations improve the synthesis of regression models. As much as the first point is concerned, it is important to understand that different executions may give rise to different results and yet similar performances. On one side, some lags are consistent in all executions, which indicates that the temporal component of their contribution is stable and clear. On the other side, some lags and some individual coefficients do show certain variability: we believe that in such cases, more experiments are necessary to fully understand the underlying mechanisms. All notwithstanding, it is clear how convolution vectors have a clear positive effect on the cross-validated performances across the entire spectrum of algorithms for regression that we have tried. The following considerations can be done.
Traffic influences the amount of pollutant concentrations in a positive way, and with 1 hour of delay; this delay can be explained by the fact that the effect of exhaust gases needs some time to accumulate (observe, also, that we are limited by the granularity of observations: if sensors had collected data with granularity, say, 1 minute, we may have seen shorter delays for this variable).
Higher air temperatures are associated with a decrease in
Wind always affects concentration in a negative way, with a constant (across different executions) delay of 2 hours. This is probably due to the distance between the intersection and the meteorological station; the average wind speed of 3 m s−1 and the roughness of terrain explain the amount of the delay.
Higher humidity may cause a decrease in
High solar duration and high temperature favor the transformation of nitrogen oxides into secondary pollutants, which include ozone, and this implies a decrease in
Of how the transformation influences the synthesis of good regression models, we can observe what follows. First, not all models show the same improvement, but all models show some improvement. In the case of
Comparing our results from the statistical point of view with those that can be obtained by other, well-known, methods is quite difficult. Take

While the coefficients are not too dissimilar from those obtained with the transformations, the reduced correlation shows that delays must be taken into account. Running full lagged models, on the other hand, leads, in some cases, to higher correlations. Unfortunately, the resulting models are impossible to be interpreted from the environmental point of view. Just for example, the simplest full lagged model that we tried, with 6 hours of maximum delay for each variable (ie, with 36 independent variables), already leads to positive and negative coefficients of the same independent variables at different delays: the variable temperature, for instance, presents positive coefficients for lag 0, 4, and 6, and negative ones in all the other lags. A possible explanation of this phenomenon is that by artificially increasing the number of independent variables (such as it is done when several lagged variables are added for each parameter), one allows regression algorithms to find artificially good solutions by using many hyperplanes; in other words, the solution tends to overfit even in presence of several thousands of data instances. Overfitting models are less reliable explanatory models because they tend not to be associated with physical explanations.
Conclusions
In this article, we have approached the problem of devising an explanation model for
Footnotes
Funding:
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The authors acknowledge the partial support from the following projects: Artificial Intelligence for Improving the Exploitation of Water and Food Resources, founded by the University of Ferrara under the FIR program, and New Mathematical and Computer Science Methods for Water and Food Resources Exploitation Optimization, founded by the Emilia-Romagna region, under
Declaration of conflicting interests:
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Author Contributions
GS: experiment’s conception and design, results’ technical interpretation, and text writing. EL-S: implementation, test, and text writing. JK: data providing, results’ physical interpretation.