
Abstract
Targeting ads based on consumers’ real-time locations has evolved into a practice worth billions of dollars in the advertising industry. Yet, the implications of repeated mobile ad exposure are poorly understood, primarily due to the confounding effects of locational context. This research seeks to bridge this gap. Using two large datasets comprising more than three million observations from a major European mobile telecommunication company, the authors investigate how ad repetition and location revisits (i.e., returning to a previously visited location) jointly determine consumer response to mobile display advertising. The empirical strategy leverages coarsened exact matching combined with a logit model with fixed effects at the consumer-location level. The results show that the ad click-through rate is more than 26% higher at revisited locations than at locations visited for the first time. However, mobile ad repetition decreases click rates, and this effect is amplified at revisited locations. The results contribute to the theory and practice of mobile advertising.
Keywords
During the last decade, smartphone penetration in the United States has more than tripled, predicted to reach 97% by 2025 (Statista 2024). Responding to this trend, marketers have reallocated advertising budgets from desktop to mobile devices. In 2025, U.S. mobile ad spending will exceed $228 billion, with approximately 80% ($188 billion) attributed to in-app advertising and the remaining 20% ($40 billion) to mobile web advertising (Wurmser 2024).
The unique characteristics of smartphones—including portability and real-time location sensing—provide opportunities for new types of (mobile) ads (Grewal et al. 2016). In particular, location-based advertising (LBA) enables marketers to take into account consumers’ location context when targeting ads (Shankar and Balasubramanian 2009). In the United States alone, LBA spending was estimated to amount to $32.7 billion in 2023 (Statista 2023), a significant portion of all mobile ad spending. However, most applications of LBA rely on rather simple, mechanistic implementations, which may not fully utilize its potential (Ghose 2017). Therefore, a better understanding of how consumers respond to location-based ads—enabling advertisers to improve the performance of geotargeted campaigns—is of key interest to the mobile advertising industry.
Most LBA applications only use consumers’ real-time location to deliver ads sent as push notifications when they are in the vicinity of a store, a practice referred to as “geofencing” (Luo et al. 2014, p. 1754). However, as geofencing ignores the heterogeneity of consumers at a given location, it is bound to leave money on the table (Ghose, Li, and Liu 2019). For example, familiarity with a certain physical location might increase the relevance of and, thus, the response rate to ads from local stores, compared with that of ads received at unfamiliar locations. Exploring how smartphone users’ location histories may account for heterogeneity in their response to LBA is therefore an important prerequisite for precise mobile geotargeting. Conversely, prior work on digital advertising indicates that the effectiveness of mobile advertising may drop sharply after the first impression (Chatterjee, Hoffman, and Novak 2003). Since common geofencing applications implement a one-to-one mapping between geographic locations and ads, data from such platforms do not allow for separating the effects of previous location visits and previous exposures to the ad. Likely owing to such data limitations, academic research has yet to discuss the impact of repeated exposure to mobile advertising.
In this article, we aim to fill this gap and analyze consumer response to repeated exposures of mobile advertising, focusing on the case of mobile pull advertising (where consumers initiate the request for ad content; Molitor et al. 2020). We do so by studying the interplay of ad repetition and location revisits on mobile advertising response. We propose that consumers’ prior visits to their current location—inferred from their location histories—may reveal their familiarity with their current environment, and we link the notion of location familiarity (Desai and Hoyer 2000) to mobile ad response. We expect that location familiarity both increases the relevance and facilitates the processing of the ad and that this leads to a higher overall ad effectiveness as well as a fast onset of wear-in, that is, increased response to the first few impressions of the ad and an earlier overall peak in the ad response curve (Pechmann and Stewart 1989). However, in line with the effects documented in Bleier and Eisenbeiss (2015) and Dahlén (2001), we posit that the fast onset of wear-in may accelerate wearout, possibly resulting in a stronger negative effect of repeated exposure to an ad delivered at a familiar location (relative to the same ad delivered at an unfamiliar location).
To conduct our investigation, we use two separate datasets collected from an LBA application that belongs to a large European telecommunications company. The app connects consumers with ads from a variety of offline stores, presenting offers in consumers’ vicinity in a scrollable ad feed. Importantly, it is the consumer who initiates the interaction with this ad feed, aligning the app's ad delivery mechanism with what is commonly termed a “pull” mobile advertising (Grewal et al. 2016; Molitor et al. 2020). This ad delivery mechanism enables us to observe all possible combinations of our primary constructs, location revisits and ad repetition, across both studies. In Study 1, we analyze a large dataset of approximately 3 million ad exposures collected from 146,139 users over a period of eight months. In this study, ads were presented in ascending order of the physical store distance from the users’ real-time location (i.e., ads from the closest stores were shown first). In Study 2, we conduct a robustness test using a dataset on an entirely different set of 2,009 new app users who were exposed to approximately 190,000 ad impressions over a ten-week period. In contrast to Study 1, the ads in Study 2 were delivered using a mechanism that displayed them in a randomized order. This randomized allocation of ads helps minimize any potential bias arising from the proximity-based ranking used in Study 1, enabling us to further validate our results.
Our empirical analysis aims to understand how ad repetition and location revisits jointly determine ad clicks. We apply consumer-location fixed effects to account for time-invariant unobserved heterogeneity in the location-specific preferences of consumers, including preferences for (stores at) a given location. In addition, we use coarsened exact matching (CEM) to reduce the potential imbalance between consumers who revisit a specific location and consumers without location revisits (Blackwell et al. 2009).
Our key findings include the following: First, we show that mobile ad repetition tends to decrease consumers’ click rates. This finding stands in contrast with the prevailing consensus in the ad repetition literature that ad response usually increases over the initial ad impressions and decreases subsequently. To reconcile this tension, we carefully reexamine the theoretical underpinnings of the predicted shape of the ad response curve and discuss how the decline of click rates may be caused by the ways in which “pull” mobile advertising—where the consumer initiates the interaction with the ad feed—differs from advertising in other media previously investigated. Second, and in contrast, we show that location revisits are indeed positively related to consumers’ click rates, even after accounting for time-invariant unobserved heterogeneity in the location-specific preferences of consumers and for observable ad characteristics such as discount depth, store distance, and display rank. Specifically, location revisits are associated with a click rate approximately 26.1% above the click rate corresponding to the same ad by a consumer visiting the same location for the first time.
Our study contributes to the evolving literature on mobile advertising by providing the first theoretical discussion and empirical investigation of ad repetition in mobile advertising. Prior research on ad repetition has focused on TV, print media, and (banner ads on) the web. In contrast, we focus on the role of location, a factor unique to the mobile channel. To this end, we account for consumers’ location histories and analyze how consumer reactions to repeated ad exposures at geographic areas visited for the first time differ from those at revisited locations. In addition, our analysis also highlights how the higher consumer involvement in mobile “pull” advertising may lead to a declining ad response curve.
Our results also provide important implications for marketers as well as advertising platforms and regulators. Advertising platforms (e.g., those operated by mobile operators or social networks) with access to rich data on consumers’ location histories can learn about location-specific familiarity to improve their targeting accuracy (Yun et al. 2020). However, given that repetition may lower ad effectiveness, marketers may also want to set limits on the number of times the same ad should be displayed to a consumer.
Prior Research on Location-Based Mobile Advertising
Since the launch of the iPhone in 2007, the promise of mobile advertising has been twofold: On the one hand, consumers tend to carry their mobile devices with them wherever they go. This portability enables marketers to deliver ads to consumers throughout the day, irrespective of their physical location. On the other hand, smartphones are equipped with various sensors capable of collecting data about consumers and their environment. Tapping into these data may, in turn, enable marketers to personalize their interactions with consumers based on their behavior, environment, and psychological state (Cooke and Zubcsek 2017; Ghose 2017). How the locational context of the ad recipient may drive heterogeneity in mobile ad response has, therefore, been a central question in the mobile advertising literature.
Depending on the application, recipients’ locational context may play different roles in mobile advertising. Location sensors built into smartphones enable marketers to detect how far a mobile consumer is from the nearest point of sale, to cross-reference the consumer's location with other data to learn about their immediate physical environment, and to learn their mobility patterns over time. Of the approaches within this scope, the overwhelmingly most popular mobile marketing technique is geofencing (Ismail 2019), which targets consumers with ads sent as push notifications when they are in the vicinity of a store. The prominence of this approach is also reflected in academic research: The strong negative effect of store distance on ad response has been demonstrated both inside shopping malls (Danaher et al. 2015) and in general urban environments (Fong, Fang, and Luo 2015; Molitor et al. 2020).
Research has also studied other determinants of ad recipients’ locational context. Ghose, Li, and Liu (2019) find that people commuting between home and work were up to three times more likely to redeem mobile offers. In a similar setting, Andrews et al. (2016) find that among commuters, those on more crowded subway trains were more likely to respond to mobile advertisements. Another stream of research has considered longer patterns of consumer location dynamics. Using methods akin to collaborative filtering, this line of work has argued that commonalities between consumers’ mobility patterns may correspond to commonalities in their ad response (Ghose, Li, and Liu 2019; Zubcsek, Katona, and Sarvary 2017).
Regarding the timing of mobile advertising response, most research has focused on direct responses on the same day an ad is delivered. Looking at the longer-term dynamics, Fang et al. (2015) and Luo et al. (2014) conclude that the same-day scope is, in fact, an important boundary condition to the store distance effect. In addition, Park, Park, and Schweidel (2018) note that free sample coupons increase purchases even after the offers expire. This result is echoed by Osinga, Zevenbergen, and Van Zuijlen (2019), who observe the strongest response to a large-scale regional mobile banner advertising campaign in the offline (vs. online) channel. However, these articles are similar to the work looking at same-day conversions in that they study the impact of a single ad exposure. 1 To our knowledge, no prior research has studied the impact of repeated exposure to geotargeted mobile advertising. Given that in a typical geotargeting application, any consumer who returns to a previously visited location may be delivered the same ad multiple times, this is an important gap in the literature.
Effects of Mobile Ad Repetition: Hypotheses
Main Effect of Ad Repetition
To develop our hypotheses, we draw on prior work studying the effects of ad repetition. The dominant paradigm in this literature, shaped by the seminal works of Berlyne (1970), Cacioppo and Petty (1979), and Belch (1982), posits a nonmonotonic advertising response across various dependent measures (such as brand attitudes, ad recall, or purchase intentions). According to this view, the ad response function consists of an increasing “wear-in” stage taking place during the first few exposures, followed by a gradual decline in ad effectiveness—referred to as the “wearout” stage—evidencing consumer reactance to advertising beyond a certain degree of repetitive exposure (Pechmann and Stewart 1989; Tellis 1988).
While the research paradigm on repeated ad exposure has changed little over the past four decades, the interactivity of online advertising has made click-throughs an important measure in evaluating ad performance (Hoffman and Novak 1996; Sismeiro and Bucklin 2004). Focusing on click-throughs also addresses a long-standing criticism of early advertising research: Whereas laboratory studies can only collect measures at the point of exposure to the ad instead of at the point of purchase (Baker and Lutz 2000; Kronrod and Huber 2019), for digital advertising these two locations are often the same (Manchanda et al. 2006; Sahni 2015). Notwithstanding these adjustments, academic research on the repetition of digital advertising has generally replicated the same patterns documented in traditional media: Both brand attitudes and click-throughs in response to online advertising have been documented to decrease after, at most, a few exposures, reaching negative returns on additional ad impressions beyond a certain degree of repetitive exposure (Chae, Bruno, and Feinberg 2019; Chatterjee, Hoffman, and Novak 2003; Dahlén 2001). In line with this, we expect that ad repetition will trigger an adverse reaction from consumers, leading to a decrease in mobile ad effectiveness. Formally:
Contextual Moderators
Behavioral research has long held the view that when consumers engage in processing new information, the outcome of this process may be affected by information present in their immediate physical environment (Gregory, Lichtenstein, and Slovic 1993). Along these lines, Feldman and Lynch (1988) argue that contextual cues present in consumers’ immediate surroundings may affect the accessibility of their preferences. Testing this notion in a large-scale field study, Berger, Meredith, and Wheeler (2008) demonstrate that being assigned to vote in a polling location at a school increases voters’ likelihood of supporting a school initiative.
Naturally, such contextual effects are not homogeneous. In their review of the ad repetition literature, Pechmann and Stewart (1989) note that the timing of the wear-in stage (and, consequently, the dynamics of the rest of the ad response curve) depends on the recipient's motivation and ability to process the message (with both factors related to a faster onset of ad wear-in). The marketing literature has studied a broad range of behavioral and technological moderators affecting these factors. Herein, we focus on brand familiarity and ad relevance.
Brand familiarity
In one of the earliest explanations of the heterogeneity of consumer response to repeated advertising, Sawyer (1981) argues that the ads of familiar brands may get more attention from the recipient after fewer repetitions, accelerating the habituation stage and bringing a faster wear-in to ads of familiar brands, a notion later confirmed by Batra and Ray (1986) and Tellis (1988). In the digital advertising realm, Dahlén (2001) observes much higher initial click-through rates for ads by familiar brands, which dropped rapidly after the first impression, while in the same study, ads by unfamiliar brands produced click-through rates increasing through as many as five ad exposures.
Ad relevance
Consumers’ increased addressability on the internet relative to traditional media has enabled marketers to leverage the moderating effect of brand familiarity on ad repetition, leading to the emergence of a technique known as retargeting (Helft and Vega 2010). Retargeting campaigns usually contain specific products or services that consumers have browsed before—in other words, brands that are familiar to the ad recipient, increasing the effectiveness of online advertising (Van Doorn and Hoekstra 2013). Despite the relatively greater homogeneity of the target audience, the retargeting literature has shown that the relevance of retargeted ads, which in turn may depend on the evolvement of consumers’ product preferences, may affect both wear-in and wearout. For instance, Lambrecht and Tucker (2013) find retargeting to be more effective than generic advertising only when consumers have already progressed in their decision-making process and are closer to the actual purchase. Similarly, in an interesting parallel to the results on how brand familiarity moderates consumer response to repeated ads, Bleier and Eisenbeiss (2015) find that a higher degree of banner personalization increased retargeting effectiveness. However, this effect decreased faster over time compared with less-personalized banners, rendering less-personalized ads optimal starting about three weeks after the consumer's visit to the marketer's website.
Role of consumers’ locational context
We argue that response to repeated mobile advertising will also be informed by both brand familiarity and ad relevance, and we tie the strength of both effects to consumers’ location histories. Based on Desai and Hoyer (2000), we contend that location familiarity moderates the strength at which consumers’ environment influences their cognitive processes. This may happen for at least two reasons. First, location familiarity facilitates the processing of physical surroundings, enabling consumers to rely on more information drawn from their task environment. Second, location familiarity might also account for a greater degree of prior knowledge about stores in consumers’ surroundings, enabling recipients to more efficiently process the information contained in the ad. 2
In the setting of mobile advertising, we expect both moderating roles of location familiarity to be present. We expect that consumers can process the information content of (mobile) ads pertaining to stores at familiar (vs. less familiar) locations more easily: They may recognize the brand from prior experience as well as be able to identify the address of the store more quickly. To arrive at our second hypothesis, we add the observation that marketers with longitudinal data on ad recipients’ location patterns can associate differences between visitation patterns of the same geographic location with differences in consumers’ familiarity with that location. Moreover, since more frequent prior visits are also an indicator of more frequent future visits to the same location (De Montjoye et al. 2013), we conclude that ads pertaining to stores at previously visited locations will not only be easier for consumers to process but (on average) also more relevant to them.
In sum, we predict that familiarity with a given location, inferred from the observation of repeated visits to that location, is positively related to both participants’ ability and motivation to process ads relevant at that location. Combining this prediction with the findings of Bleier and Eisenbeiss (2015), Dahlén (2001), and Tellis (1988), suggesting that easier-to-process ads reach peak wear-in both after fewer repetitions and at a higher level, enables us to formulate hypotheses concerning additional characteristics of the mobile ad response curve. We predict that ads delivered at previously visited locations will elicit a stronger response (H2), and that ad repetition at such locations will evoke a faster wear-in followed by an accelerated wearout—a decline in ad response that sets in sooner and at a more rapid pace than that of ads displayed at locations visited for the first time (H3). Formally:
We empirically test our hypotheses on data from a European mobile telecommunications company. We describe the research setting in more detail next.
Research Setting
We use data from a large European mobile telecommunications company. The company has introduced an LBA application that connects consumers with product-specific ads from various offline stores. Consumers download the app to be informed about offers in their vicinity. The ads do not have a specific brand or industry focus but come from various stores and product categories.
Once opened, the application determines the consumer's location via the smartphone's built-in location-tracking capabilities (e.g., a GPS system), enabling consumers to find nearby offers. Based on the device's location, ads are presented in a scrollable feed in ascending order of distance from a consumer, with the nearest ads appearing first. It is crucial to note that the order of ads is solely based on the device's location relative to stores, with no additional forms of personalization. Thus, using the app at different physical locations will most likely lead to a different selection of ads. In turn, repeatedly using the app at approximately the same physical location will result in a similar selection of ads, assuming that the temporal spacing between different logins is relatively low and most offers remain valid.
In the app, the ads include the exact distance information and a short description of the promotion, including the name of the offline store and, if applicable, the discount depth offered. Figure 1 offers a stylized screenshot of the focal app's interface. Besides browsing the list of ads, consumers can click on any of the ads to receive more detailed information, such as the offer's expiration date and the code to redeem it at the store.
Stylized Screenshot of the Focal App's Interface.
Our data contain observations of in-app advertising exposures to promotional ads from participating retailers. Each observation corresponds to one ad displayed. The data contain the offer details, information on how the ads displayed in the same session were rank-ordered, and users’ responses (“ad click”). Users could click on multiple ads within a session, as well as click on the same ad in multiple app usage sessions. Since only the first click on any specific ad revealed new information to a consumer, we only include observations up to the first click on each ad in our analysis. 3 Nevertheless, if a user clicked on multiple ads for the first time within a single session, each such click would still be accounted for in our sample. In addition, we also have users’ GPS location information and second-by-second time stamp data. Note that location information is only recorded when the application is running in the foreground.
A key advantage of proprietary data from a mobile application, compared with browser-based cookies, is that we observe unique user IDs, which can neither be altered nor deleted by users of the focal application. This enables us to connect repeat observations of the same consumer throughout the entire period studied. We use repeat observations to measure (1) if a consumer was exposed to a specific ad more than once, referred to as ad repetition, 4 and (2) if consumers revisited the same location(s), referred to as location revisit. Similarly to Zubcsek, Katona, and Sarvary (2017), we map physical locations to a grid of 500 m spacing based on a standardized coordinate-specific reference system. A location observation is then defined as a cell in this grid (that a consumer's GPS coordinates map to), and a location revisit is observing a consumer in a previously visited cell.
Figure 2 depicts our conceptual approach to identifying locations on a grid. In this example, we observe three hypothetical consumers at times t1 and t2 > t1 in the vicinity of store S (in cell A3). Based on Figure 2, we can distinguish between a consumer (123) who revisits the same grid cell (B2) and is targeted with a repeat ad for store S at time t2, a consumer (445) who is not revisiting the same location at t2 but is targeted with a repeat ad, and another consumer (875) who is revisiting the same location at t2 but does not receive ads for store S (due to being in a nonadjacent grid cell). The case of a consumer that revisits a (grid) location without being reexposed to an ad would be represented by consumer 123 if, for example, store S only advertised at t2 but not at t1.
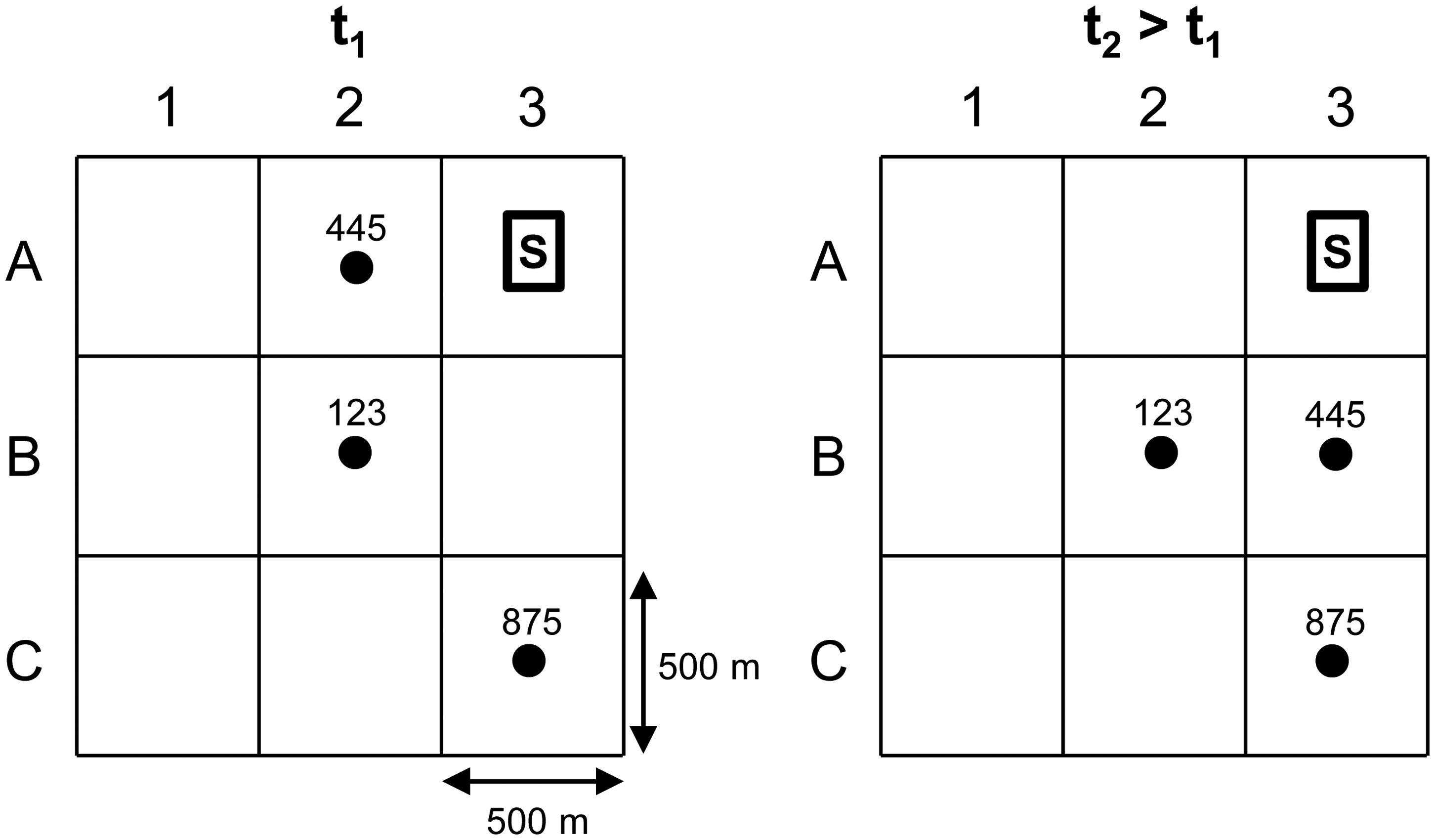
Illustrating Our Approach of Identifying Locations on a Grid.
We test our hypotheses on two separate datasets collected via the same LBA application and the same geographic location—a large European country—two years apart. In Study 1, we leverage a comprehensive dataset spanning the first eight months following the app's launch, comprising over 3 million observations. In contrast, Study 2 was conducted over 2.5 months and consists of approximately 190,000 observations. Unlike in the main field study, however, ads were displayed to app users in Study 2 in a randomized order. This design feature enhances our ability to disentangle the individual effects of ad repetition, location revisits, and their potential interaction. We begin with the details of Study 1.
Study 1
Our first study utilizes information on all in-app usage activity from the first eight months of the app after its launch. The data contain observations of in-app exposures to 1,003 different ads, which were available in 1,589 different brick-and-mortar stores. The data on 146,139 consumers’ app usage activity throughout the observed period correspond to 3,012,090 ad exposures and 51,545 ad clicks recorded in 66,354 distinct grid locations in one large European country.
Measurement and Descriptive Statistics
Table 1 describes our data. Our dependent variable, ad click, measures a consumer's binary response to the displayed ad. We define multiple variables to measure ad repetition: Ad repetition is a binary variable that indicates whether or not a user had previously been exposed to an ad campaign, and ad repetition count captures the frequency of repeated exposures to the same ad campaign. Location revisit, a binary variable inferred from each app user's entire observed location history, indicates whether or not a user had visited the same location on the grid prior to the given observation. The distance variable (measured in kilometers) shows the distance between consumers and stores. Display rank indicates the presented order of ads, where rank 1 is the highest and rank 10 is the lowest. 5 The discount variable quantifies the value of an offer in percentages. Finally, we include the cumulative usage frequency—representing the count of prior app logins—to account for a user's experience with the app.
Descriptive Statistics (Study 1).
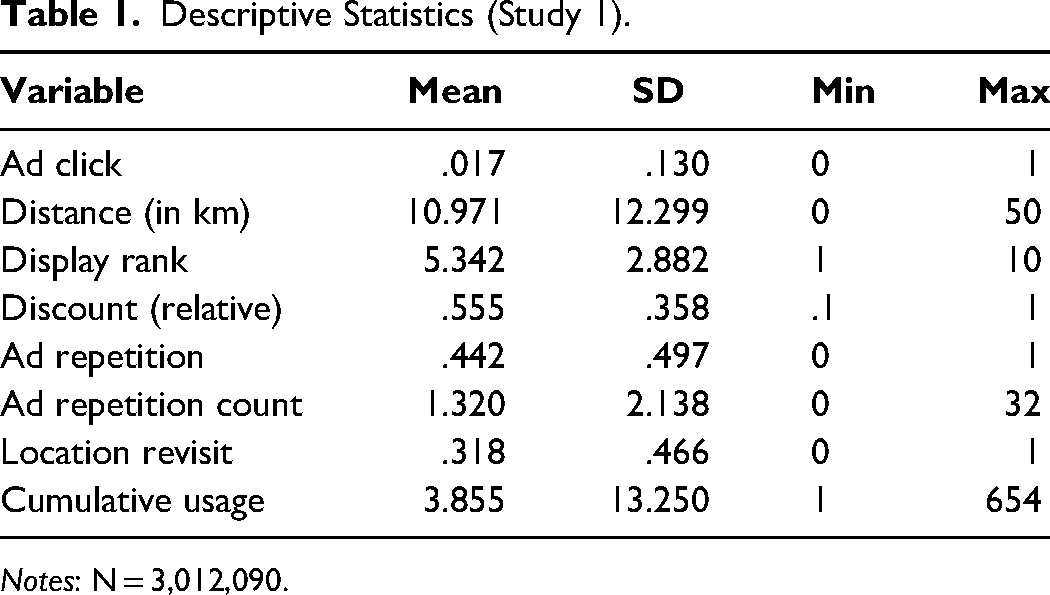
Notes: N = 3,012,090.
Approximately 44.2% of observations correspond to repeated ads, 27.3% correspond to revisits, and 22.8% correspond to repeated ads at a revisited location. 6 (The pairwise correlations of all variables can be found in Table W1 in the Web Appendix.) The overall click rate is 1.73%, with click rates of 1.62% and 2.72% for ad repetition and location revisit, respectively (and 1.56% for repeated ads displayed at revisited locations), whereby 87.67% of sessions are without an ad click. Grouping all observations by all possible combinations of the ad repetition and location revisit indicator variables, the overall difference in click rates is significant (χ2(3) = 942, p < .001). Figure 3 shows the relationship between ad repetition and click rate for observations with and without location revisits. It indicates significant differences in click rates between observations with and without location revisits, with peak click rates occurring at the first exposure (zero repetitions) for both types of observations. We note that, while the observed patterns are in line with H2 and H3, they also stand in clear contrast with H1 in that we do not observe increased click rates even over the initial repetition (i.e., from the first to the second ad exposure).
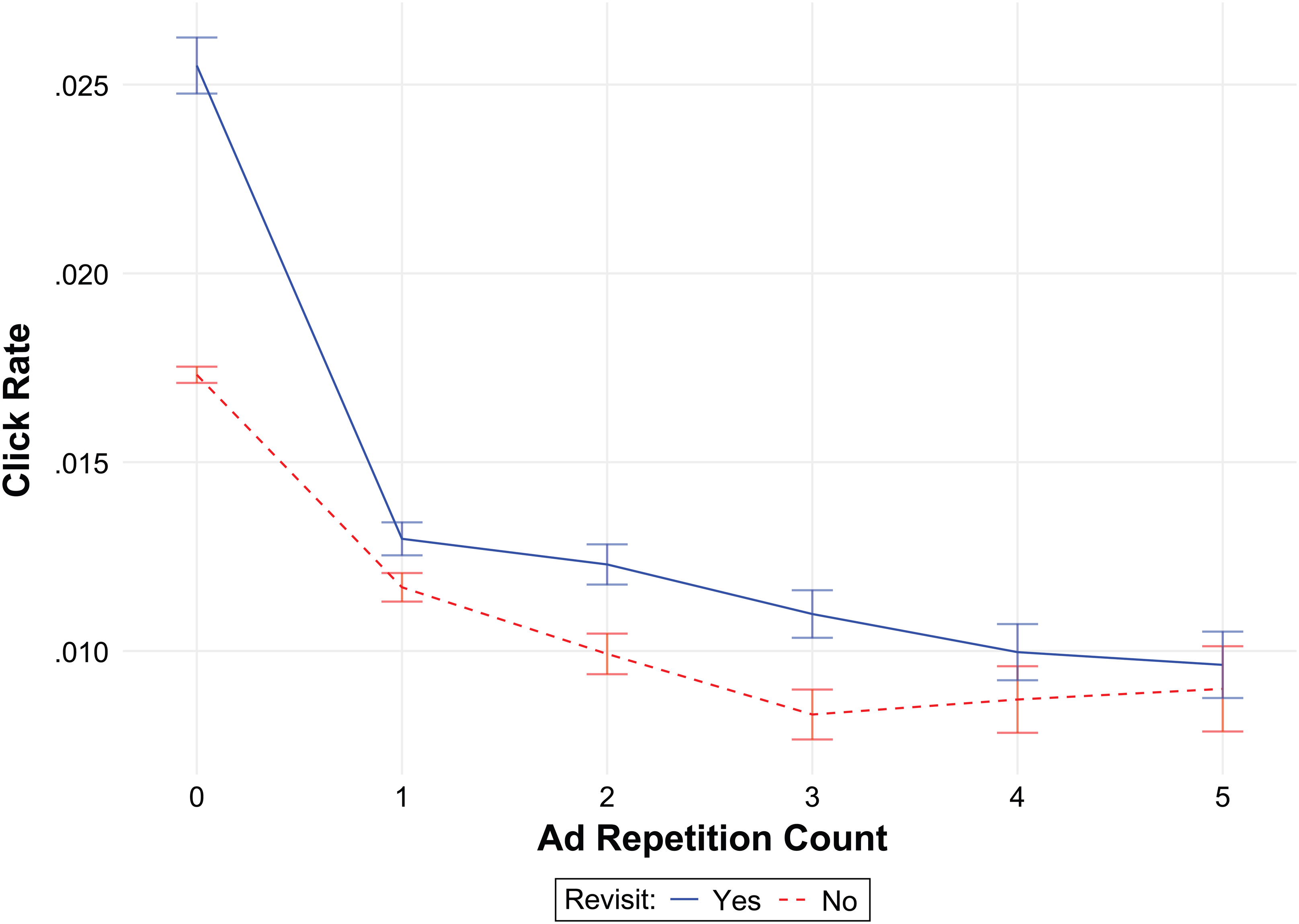
Click Rates by Ad Repetition Count and Location Revisit Status.
While these descriptive findings provide valuable insights into the relationship between ad repetition, location revisits, and click rates, it is crucial to account for potential differences in the baseline behavior of consumers who exhibit different location revisit behaviors. To address this issue and ensure a more rigorous comparison between the presence and absence of revisits for consumers, we utilize a matching and weighting approach, as described in the following section.
Matching and Weighting
In our context, the preferences of consumers who revisit specific locations may differ from those of users who do not engage in location revisits. To account for these differences, we use CEM, which enables us to reduce the imbalance in covariates between consumers with and without location revisits. It is important to clarify that matching is a preprocessing procedure to improve inferences from observational data (Abadie and Spiess 2022). While fixed effects can adjust for unobserved, time-invariant heterogeneity, matching techniques like CEM add robustness by ensuring that the treatment and control groups are more comparable based on observed characteristics (Rubin 2006). Thus, combining CEM with fixed effects enables us to address selection issues more comprehensively than solely relying on fixed effects.
CEM is a nonparametric matching method that aims to reduce imbalance between groups. Unlike other methods that rely on trial-and-error and iterative reestimation, CEM selects the balance between users who have and have not experienced location revisits beforehand (Blackwell et al. 2009). CEM has been increasingly popular in the marketing (Osinga, Zevenbergen, and Van Zuijlen 2019; Wies, Moorman, and Chandy 2022) and information systems (Kumar, Mehra, and Kumar 2019) literatures, as it reduces model dependence and bias in settings with larger datasets. Specifically, a key advantage of CEM is that it approximates a fully blocked experiment that attempts to arrange observations in groups (blocks) that are similar to each other, enabling it to achieve lower levels of imbalance than other matching methods (King and Nielsen 2019). In applying CEM to our data, we consider various covariates. These include consumer-specific factors, such as the device's operating system, and location-specific factors, consisting of store density and average income for the postal code where a given user was using the app for the first time. Additionally, we use three behavioral variables to capture users’ location preferences and temporal patterns: the types of locations they visited (i.e., urban, suburban, rural) and the times of day and days of the week when users were actively using the app. 7 Each of these three behavioral variables is represented by a binary indicator that takes the value of 1 if the first and second observation for a user align in terms of location type (e.g., both occur in urban locations), time of day (e.g., both occur in the morning), and day of the week (e.g., both occur on weekends), respectively, and 0 otherwise.
We note that one-time app users could not be observed to revisit any location and would, hence, all be assigned to the “no-revisit” group. To avoid misattributing time-invariant differences between one-time and repeat users of the app to differences characteristic of repeat app users who revisit specific locations versus repeat app users who do not, we take the conservative approach and omit all one-time app users from the matching procedure. Thus, our analysis only considers consumers with at least two observed app logins. Following the matching procedure, we retain 63,646 matched consumers, 38,859 with and 24,787 without an observed location revisit. We report the summary statistics and t-tests in Tables W2 and W3 in the Web Appendix. While the numbers in Table W2, showing the covariate balance before matching, indicate that the iOS share, store density, and income variables were statistically different between the two groups, the results in Table W3 indicate that our matched sample is balanced.
Next, we estimate our main model using the matched and weighted CEM sample. In doing so, we derive weights for each observation based on the CEM procedure, which we then directly feed into the logit model, which is described next.
Model
Using a logit model, we model consumers’ ad clicks as a function of ad repetition, location revisits, and their interaction. As the tension between H1 and the click pattern displayed in Figure 3 calls for a model specification that can flexibly estimate ad response dynamics over repeated impressions, we include both the binary ad repetition and the interval-scaled ad repetition count and squared ad repetition count variables. To capture the heterogeneous preferences of consumers for ads served at different grid locations (see Figure 2), we estimate our model using a conditional logit framework with consumer-location fixed effects (Chamberlain 1980). These fixed effects capture time-invariant unobserved heterogeneity in consumers’ location-specific preferences, such as their preferences for (stores at) a given location. In addition, based on the CEM procedure, the model includes specific weights for each observation that determine how much it influences the final parameter estimates, which is referred to as regression adjustment (Rubin 1979). 8
The probability that a consumer i at location j clicks on ad k (from a set of N ads) at time t is given by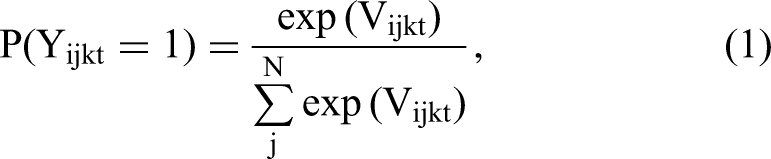
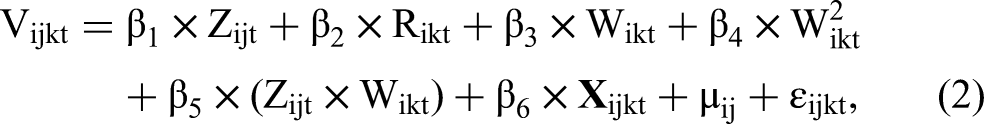
Estimation Results
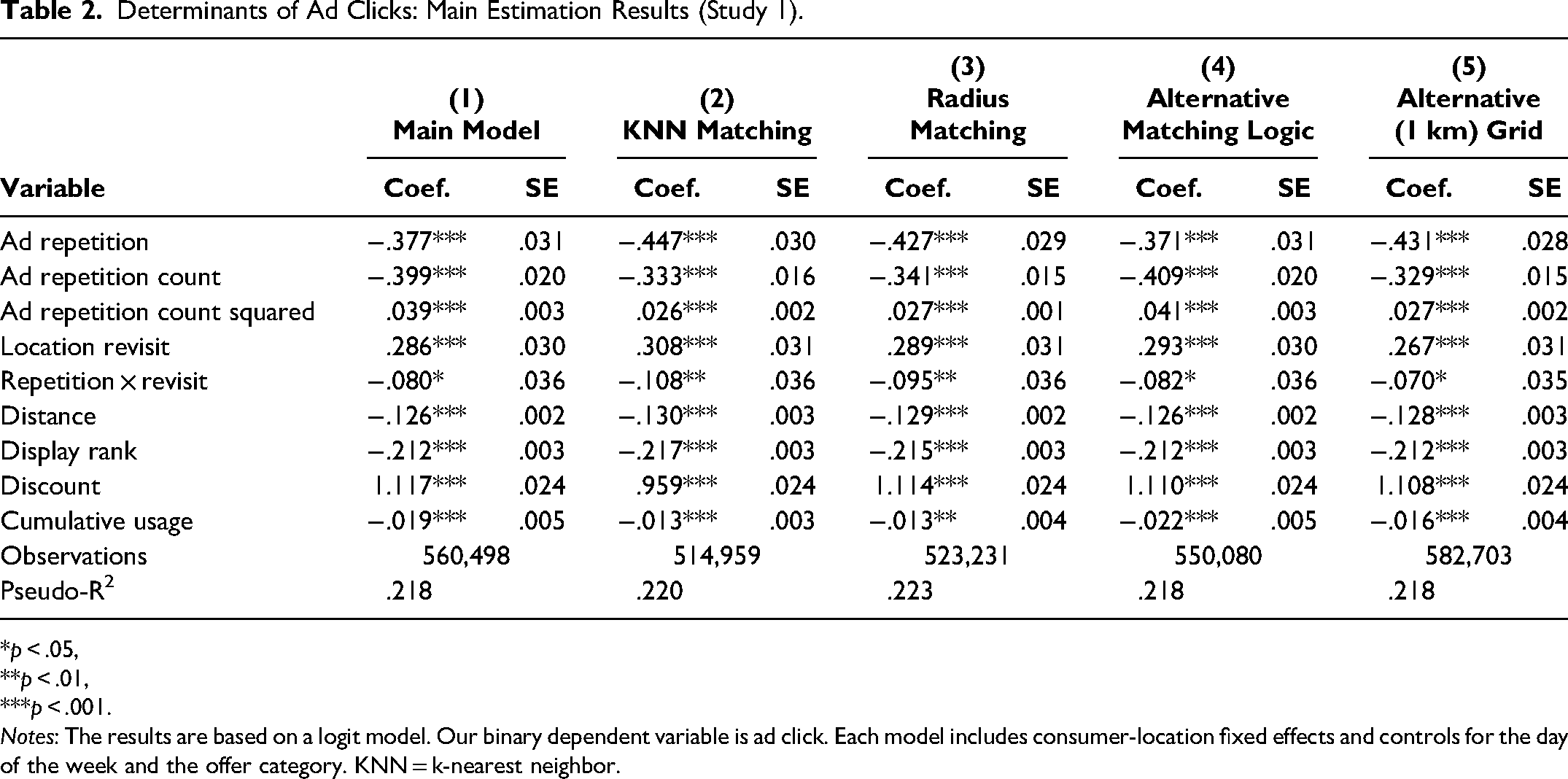
The results are shown in Table 2, Column 1. Consistent with Figure 3, the model estimates suggest a unimodal relationship between ad repetition and click rate. Specifically, we find that ad repetition is negatively correlated with click rates (B = −.377, p < .001). Similarly, the number of times an impression is repeated also exhibits a negative relationship with ad clicks (B = −.399, p < .001). However, the squared term for ad repetition shows a positive association with ad clicks (B = .039, p < .001), suggesting a flooring effect whereby ad response approaches zero more slowly as the number of prior ad exposures increases. Overall, the three coefficients imply a declining click rate with repeated impressions of the same ad, and we do not find statistical support for the increase in ad click-through put forward in H1, even at low levels of ad repetition. Given the unimodality of the ad response curve, we nevertheless note that this pattern is consistent with a rapid onset of wearout documented in some of the earlier studies on digital advertising (Chatterjee, Hoffman, and Novak 2003; Dahlén 2001), which is likely amplified by the increased involvement that ads delivered through the “pull” mechanism may command (Molitor et al. 2020).
Determinants of Ad Clicks: Main Estimation Results (Study 1).
*p < .05, **p < .01, ***p < .001.
Notes: The results are based on a logit model. Our binary dependent variable is ad click. Each model includes consumer-location fixed effects and controls for the day of the week and the offer category. KNN = k-nearest neighbor.
In contrast, we find that location revisits are associated with a higher click rate (B = .286, p < .001). Thus, our data support H2. Finally, the interaction of ad repetition and location revisit also has a negative effect on ad response (B = −.080, p = .024). We conclude that H3 is also supported: Increased familiarity with a location seems to amplify the negative effect of ad repetition. Overall, these results indicate that the repetition-induced tedium kicks in fast, even for ads at familiar locations.
Turning to the other covariates, we find that distance and display rank are negatively related to consumers’ ad click likelihood, respectively (distance: B = −.126, p < .001; display rank: B = −.212, p < .001), which is plausible and consistent with previous literature (Ghose, Goldfarb, and Han 2013). The coefficient of discount is significant and positive (B = 1.117, p < .001). Finally, consumers’ increased cumulative usage of the application exhibits a small but significant negative relationship to ad clicks (B = −.019, p < .001).
Figure 4 shows the predicted click probabilities based on the main model (Column 1 of Table 2). After accounting for time-invariant heterogeneity in consumers’ click behavior at each location (shown in the figure by normalizing fixed effects to zero), we observe an average lift of 26.1% in the probability of an ad click for the first impression at a revisited location (solid blue line) compared with a location visited for the first time (dashed red line). As the frequency of ad exposures increases, the probability of an ad click decreases at a diminishing rate for both revisited and nonrevisited locations.
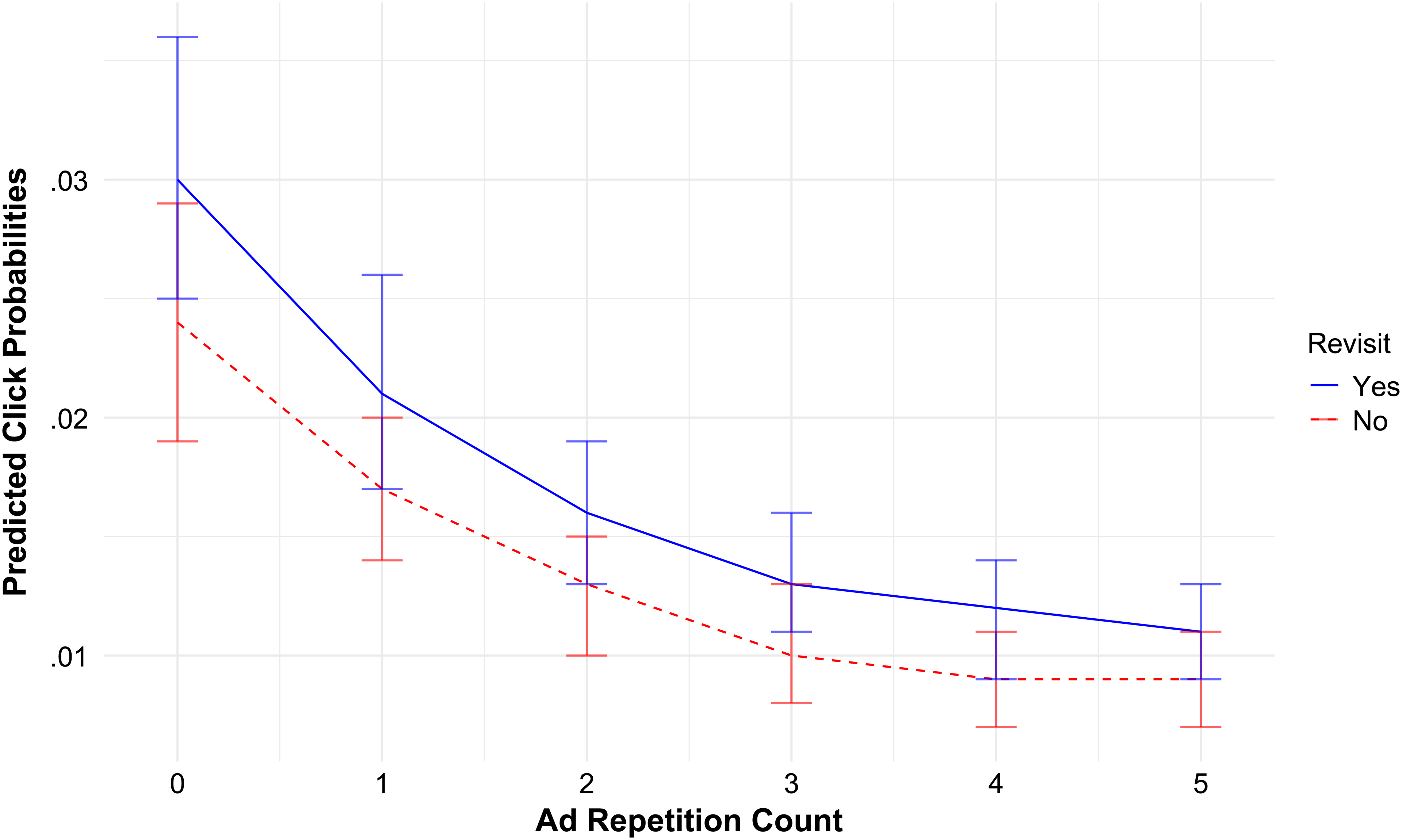
Predicted Click Probabilities by Ad Repetition Count and Location Revisit Status.
Robustness Tests
To assess the robustness of our results, we employ a multipronged approach that encompasses multiple matching algorithms (Columns 2 and 3 in Table 2), an alternative matching logic (Column 4 in Table 2), and an alternative model specification using a 1 km grid spacing (Column 5 in Table 2). First, we test the impact of replacing the CEM algorithm with the k-nearest neighbor (KNN) matching for propensity score matching (PSM). In addition, we test an alternative matching logic that contrasts observations with and without ad repetitions using CEM. Our analyses also include alternative specifications of our primary logit model, as well as a linear probability modeling approach. These additional robustness checks are provided in the Web Appendix. All validity tests are based on the model specification detailed in Equation 1. Our findings are presented subsequently.
PSM
PSM has been the most commonly used matching procedure in observational studies (Pearl 2010). Conceptually, PSM estimates the probability that a consumer engages in location revisits (as a dependent variable) based on the selected matching variables (i.e., users’ mobile operating system, store density per postal code, and average income per postal code) using a logit (or probit) model, which differs from the (less model-dependent) CEM approach. Within the PSM framework, we employ two different matching algorithms: KNN and radius matching, both with caliper sizes δ of .001 and common support to balance the matched groups (Pearl 2010). The coefficients from our model are presented in Column 2 for KNN and Column 3 for radius matching in Table 2. Despite the underlying differences between PSM and CEM, which are also reflected in the sample sizes, we are able to recover almost identical coefficients, supporting H2 and H3 at p < .001, while replicating the finding of a unimodal relationship between ad repetition and click rate but, contrary to the first half of H1, showing no increase in ad response with ad repetition. The consistency of results across different matching procedures suggests that our findings are robust and unlikely to be driven by the specific matching algorithm employed.
Alternative matching logic
To address the concern that our results may be influenced by the initial choice of matching variables outlined in the “Matching and Weighting” section, we employ an alternative matching logic within our CEM framework. In this refined approach, we match individuals based on whether they have been exposed to repeated ads and then reestimate our main model. The results of the key coefficients and hypothesis tests remain robust in terms of magnitude and effect size, as illustrated in Column 4 of Table 2, thereby reinforcing the validity of our findings.
Larger grid spacing
Larger grid spacing may be more appropriate in rural areas as well as in cases where location detection is only possible through cell tower position (a method that is far less accurate than the GPS-based approach). To test whether our choice of grid spacing affects our results, we therefore extend the definition of locations to cells of a grid of 1 km spacing. The coefficients of this estimation are presented in Column 5 of Table 2. As all coefficients are virtually indistinguishable from the results in Column 1—supporting H2, and H3 at p < .001 but not finding support for the initial increase in ad response put forward by the first half of H1—we conclude that our results were not affected by the chosen grid spacing.
Study 2
For the second study, we obtained information on all usage activity of a sample of first-time app users over a period of 2.5 months, collected by the same mobile communication company in the same geographic area two years after Study 1. There is no overlap between the consumers observed in each study because Study 2 is limited to consumers who downloaded the app for the first time.
A key feature of Study 2 is that the sorting of ads in the feed was randomized at each login session, which enables us to disentangle the stand-alone effects of ad repetition and location revisits, respectively, from the interaction of these two factors. 11 To implement this randomization, at each login, mobile ads were randomly drawn from all stores within 50 km from the app user's real-time location, assigned, and displayed to consumers. Consequently, the probability of a user being exposed to the same ad, displayed at the exact same display rank, is lower in this randomized setting compared with the probability resulting from Study 1's distance-based presentation order.
The corresponding data, described in Table 3, contain observations of in-app advertising exposures to 3,275 different ads, which were available in 2,920 different brick-and-mortar stores. The data on 2,009 consumers’ app usage activity throughout the observed period correspond to 190,032 ad exposures and 2,096 ad clicks recorded in 1,979 distinct grid locations in one large European country. (The pairwise correlations of all variables can be found in Table W4 in the Web Appendix.) The baseline click rate is 1.1%, while the click rates are .77% and 1.35% for ad repetition and location revisit, respectively (and .9% for repeated ads displayed at revisited locations). The overall difference in click rates between all observation types is significant (χ2(3) = 68.79, p < .01).
Descriptive Statistics (Study 2).
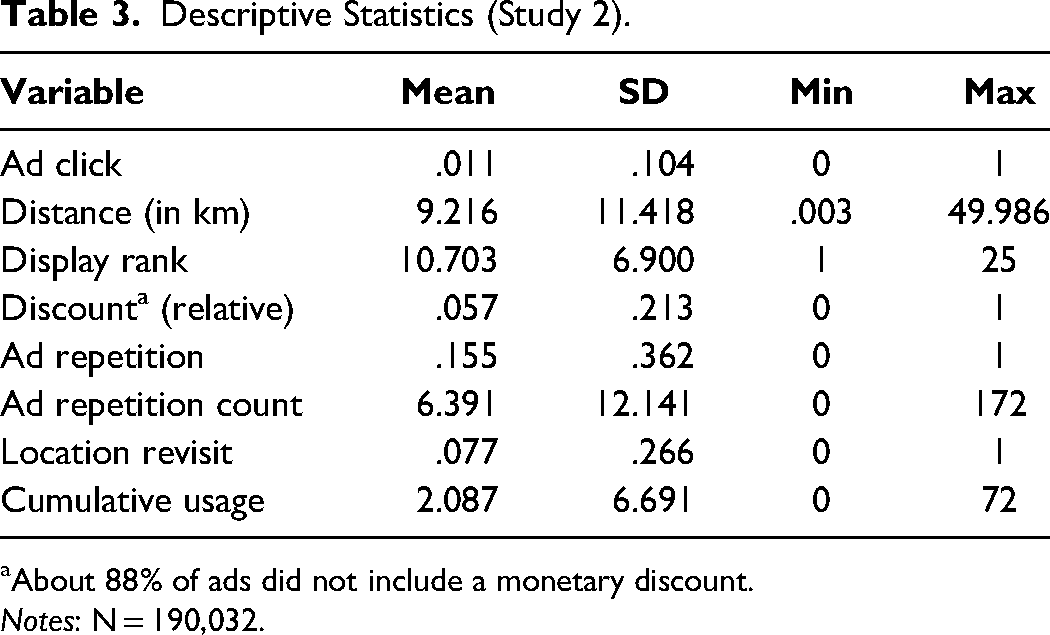
About 88% of ads did not include a monetary discount.
Notes: N = 190,032.
Just as in Study 1, we combine matching and weighting using the CEM procedure. 12 Specifically, based on the matched and weighted sample from Study 2—where we also match the variables of users’ mobile operating system, store density per postal code, and average income per postal code—we reestimate the focal logit model with consumer-location fixed effects, detailed in Equation 1.
The estimation results, shown in Table 4, are as follows. We find that ad repetition is negatively related to ad clicks (B = −.659, p < .001). Similarly, we also find a negative impact on ad clicks for ad repetition count (B = −.074, p < .001), while the result for the squared term for ad repetition count is positive (B = .0004, p < .001). Moreover, location revisits are positively related to consumers’ ad click likelihood (B = .914, p < .001). The interaction of ad repetition and location revisit is significantly negatively related to ad clicks (B = −.398, p < .001). In summary, the results of Study 2 align closely with Study 1, further substantiating our initial findings.
Determinants of Ad Clicks (Study 2).
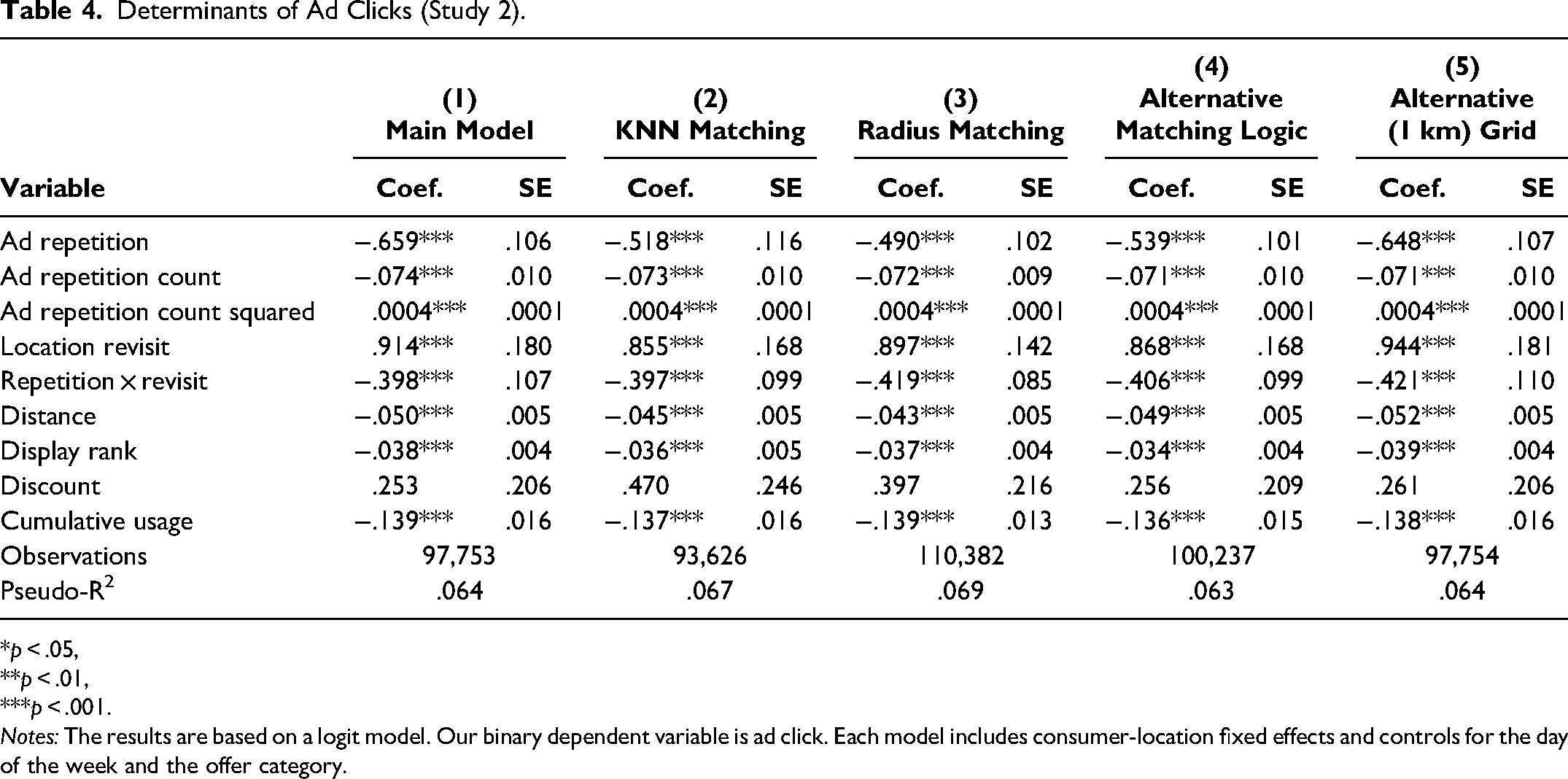
*p < .05, **p < .01, ***p < .001.
Notes: The results are based on a logit model. Our binary dependent variable is ad click. Each model includes consumer-location fixed effects and controls for the day of the week and the offer category.
Regarding the covariates, we find that distance and display rank each have a negative sign (distance: B = −.050, p < .001; display rank: B = −.038, p < .001), which indicates a decreasing ad click likelihood with increasing store distance and lower ad position in the app's display. In addition, discount has a positive sign (B = .253, p = .218). Finally, cumulative usage is also negatively related to ad clicks (B = −.139, p < .001), suggesting that users’ engagement with the app declined in the long run.
In addition to our main model, we conducted a series of robustness tests, mirroring those in Study 1, which are shown in Columns 2–5 of Table 4. Across all tests, the focal coefficients remain qualitatively similar in terms of both effect size and significance level.
Discussion
Taken together, our tests on two datasets provide strong evidence regarding the role of ad repetition and location revisits on mobile advertising response. In support of H2, we find that location revisits increase response rates; that is, consumers are more likely to respond from locations that they visit more often (and are hence more familiar with). However, while we find that this effect is weaker at higher levels of ad repetition—supporting H3 in Study 1—we also document a clearly negative main effect of ad repetition in both studies. We thus do not find statistical support for the increase in ad click-through put forward in H1. This negative main effect of ad repetition, therefore, appears to stand in contrast with the literature that, across various print and digital media, has consistently documented an initially increasing and subsequently decreasing response to repeated advertising.
To reconcile our results with the literature, we note that in their meta-analysis of prior research on advertising response, Schmidt and Eisend (2015, p. 421) show that “when [consumers are] highly involved, only a small number of exposures is needed to become fully familiar with the stimulus and boredom occurs.” This echoes the findings of Cauberghe and De Pelsmacker (2010), who show that the impact of ad repetition varies based on the level of consumer involvement with the product. For high-involvement products, high levels of ad repetition resulted in a level of brand recall similar to that achieved with low levels of ad repetition but led to a more negative brand attitude. In contrast, while high levels of ad repetition increased brand recall for low-involvement products, they resulted in a brand attitude similar to that seen with low levels of ad repetition (Cauberghe and De Pelsmacker 2010).
Importantly, we note that in both of our studies, the peak click-through response is consistently achieved at the first impression—regardless of whether ads are served at locations the consumer is revisiting or visiting for the first time. This observation suggests that the declining ad response is not solely due to an accelerated wear-in at revisited locations but rather to the way the advertising channel facilitates the processing of ads. The “pull” mechanism of the LBA mobile app that is central to our two studies may uniquely influence ad involvement by (1) allowing the consumer to initiate the ad exposure sequence—unlike traditional or digital advertising formats—and (2) making the ad itself the primary content consumed, as opposed to the ad being displayed alongside some other content (Grewal et al. 2016; Molitor et al. 2020). These characteristics of the ad consumption process should naturally increase consumer involvement, making it easier to process the ad content. 13 Thus, the high involvement afforded by the mobile “pull” channel could explain the decline in click-through rates after the first impression.
Notwithstanding the impact of higher consumer involvement (afforded by the “pull” mechanism) on consumers’ ability to process ads, we note that higher involvement may also increase the contribution of ad relevance to the higher click-through rate observed at revisited locations. Testing recall for TV ads in a high-involvement setting, Burke and Srull (1988) find that participants with higher purchase intentions in the category had lower memory interference (by competing ads). This suggests that the high involvement and ease of processing provided by the context of the mobile app should be further enhanced for more relevant ads, nuancing how location familiarity (Desai and Hoyer 2000) may influence response to mobile ads delivered via a “pull” mechanism—similar to the effects of brand familiarity documented in prior research (Batra and Ray 1986).
Notably, our results contribute to both mobile advertising theory and practice. Whereas the predominantly negative link between repeated exposures and advertising response has been documented in the online advertising literature, state-of-the-art methods in mobile advertising often not only overlook the impact of repeated ad exposures but also commonly assume that the impact of visited locations on mobile advertising response is the same for any consumer at any time (Ismail 2019; Luo et al. 2014).
By accounting for both idiosyncratic and dynamic patterns linking specific locations to mobile advertising response, our work follows in the footsteps of Ghose, Li, and Liu (2019). However, whereas Ghose, Li, and Liu’s method hinges on vast amounts of data fed to a black-box machine-learning algorithm to cluster consumer mobility patterns before producing ad targeting recommendations, our results are stated in terms of simple constructs that emerge from academic research in marketing and are straightforward to adapt to any LBA application.
Our findings are most applicable to “pull” mobile advertising strategies where consumer interaction initiates the ad sequence. Within this context, we propose a novel geotargeting method: displaying mobile advertising offers to consumers who revisit the area surrounding a particular offline store. Specifically, our results indicate that response rates can be boosted by reducing ad repetition and displaying mobile ads only in areas that consumers, based on their observed mobility patterns, appear most familiar with. Regarding the generalizability of our results, we note that the contextual factors governing ad response dynamics under a “push” mobile advertising strategy should be exactly those discussed in our theorizing. However, depending on consumers’ degree of involvement with push mobile ads, some of our findings may not be directly transferable to that context.
We assess the potential economic benefits of this new LBA method based on the click rate at revisited locations. Our results in Table 2 indicate a lift of more than 26% in clicks compared with the baseline. This number may translate into a substantial profit increase for a cost-per-click-based advertising model such as the one used by the LBA provider in this study. In this context, we note that even a single-digit percentage lift in advertising effectiveness can have a substantial economic impact in the mobile display advertising market, which will exceed $228 billion in the United States in 2025 (Wurmser 2024). As we cannot provide actual numbers for confidentiality reasons, we use an illustrative example: For a monthly reach of 10 million offer-based impressions, a predicted click rate of 2.02% (based on the estimates reported in Table 2) for revisited observations would result in 202,000 clicks. Assuming an average cost per click of $1, the optimal utilization of revisited observations would generate yearly revenue of $2,424,000. In contrast, the baseline scenario without location revisits or ad repetitions, with a predicted response likelihood of 1.60%, would yield $1,920,000 annually. 14 The resulting revenue difference would be $504,000 per year.
These numbers may not apply universally to all marketers. One commonly voiced criticism of our recommendations is the argument that the cost of a mobile ad impression is so low that there is no need for methods more sophisticated than geofencing. However, this argument completely ignores the possibly high cost of false positives. In many markets, consumers are already protected from being overwhelmed by unsolicited mobile ads, such as the requirement of explicit consumer consent in the European Union's General Data Protection Regulation (Bender 2024). Therefore, the return on high click rates is further amplified by the high opportunity cost of bad targeting (Goldfarb and Tucker 2011). In addition, while better insights about consumers’ location-specific preferences potentially benefit consumers by reducing the number of irrelevant ads, even anonymized location histories might reveal personally identifiable information based on frequently used residential or workplace locations. Hence, consumers may be inclined to provide (or, equivalently, not remove) their consent if the ads they receive are more relevant to them.
Concluding Remarks
Mobile sensing technologies in smartphones have enhanced the potential of geotargeting by providing access to consumers’ physical location histories. Such data enable marketers to personalize consumers’ mobile browsing experiences by including offers from stores based on consumers’ current and previous locations. However, prior work has mainly focused on naive targeting practices at consumers’ real-time locations—often in the context of geofencing—which do not allow for separating the effects of previous location visits and previous exposures to the ad. In our empirical study, we aim to fill this gap in the literature and measure the interplay of ad repetition and location revisits on mobile ad response.
To conduct our analyses, we use two separate datasets collected from an LBA application of a large European telecommunications company that connects consumers with ads from a variety of offline stores. In Study 1, we test our hypotheses using a large field dataset spanning a period of eight months. In our econometric model, we incorporate consumer-location fixed effects to account for time-invariant unobserved heterogeneity in the location-specific preferences of consumers, including their interest in stores at each location, while further enabling us to test our hypotheses based on variation in ads and revisits within consumer-location pairs. Our empirical approach combines matching with weighting for regression adjustment (Rubin 1979), which addresses the potential imbalance of covariates related to location revisits. Specifically, to reduce the imbalance in covariates between consumers with and without location revisits, we utilize CEM. To assess the generalizability of our results, we replicate our analysis in Study 2 on data collected from a different set of app users to whom the ads were displayed in a randomized order. This randomization enables us to disentangle the stand-alone effects of ad repetition and location revisits, respectively, from the interaction of these two factors.
Our results are consistent between the two studies. Relative to the baseline scenario of the first exposure to an offer at a location visited for the first time, location revisits correspond to higher click rates—in contrast to ad repetition, which decreases click rates. Thus, we find that consumers who previously visited a given location respond more favorably to novel offers at the same location. Introducing the ideas of Desai and Hoyer (2000) to the theoretical framework based on Berlyne's (1970) two-factor theory, our theorizing explains the positive relationship between location revisits and ad response by consumers’ familiarity with previously visited locations. Specifically, we argue that revisits reveal consumers’ familiarity with the given location and that location familiarity positively impacts ad wear-in by increasing the relevance of and thereby facilitating the processing of information contained in ads pertaining to the revisited location. However, we also find that merely repeating ad exposures—the norm in the digital advertising industry—decreases click rates. Importantly, this finding differs from the majority of ad response patterns documented in the literature; typically, ad response only starts to decline after an initial increase over the first few ad impressions. We argue that this difference can be explained by the higher level of (ad) involvement afforded by the “pull” mobile advertising mechanism (Banerjee, Xu, and Johnson 2021; Molitor et al. 2020).
One key implication of these findings is that firms with access to consumer location data, such as LBA providers, have the option to move beyond the static use of location—just sending out ads to consumers in close proximity to stores—and additionally make use of consumers’ location histories in their future targeting activities. Besides the theoretical importance of our findings, such novel approaches may also provide sizable economic benefits to firms. To assess these benefits, we demonstrate the potential economic impact of location data. Our analysis suggests that the usage of revisited locations can increase the revenue of LBA platforms by up to 26.1%. In addition, our findings also highlight the importance of the novelty of ads. To leverage this insight, retailers may need to think about the strategic usage of (shorter) offer expiration dates that are tailored to their stores’ locations (as store traffic and repeat visits may vary by location).
Naturally, collecting and processing consumers’ longitudinal location information is a prerequisite for applying our methods, and this may raise consumer and/or regulatory concerns about privacy (Landau 2015; Toti and Steils 2024). However, concerns (e.g., the revelation of home and work locations) regarding the privacy of consumer data in mobile advertising ecosystems may be offset by marketers’ ability to serve more relevant ads. In this regard, our results should help consumers and regulators alike gauge the benefits of ad relevance and compare them with the drawbacks of reduced data privacy. Furthermore, the tension between ad relevance and data privacy can be lessened by technical solutions such as privacy by design (Langheinrich 2001) that may enable location targeting while protecting consumers’ privacy. For example, solutions based on the privacy by design principle are already being implemented by manufacturers such as Apple by keeping certain types of privacy-sensitive information only locally on a user's mobile device (without sending the sensitive data to any central server; Hoepman 2018).
Our results are not without limitations. First, we study a pull-based approach of advertising where consumers decide to use the app. Future research could compare the impact of accounting for location histories in pull versus push-based advertising approaches (Molitor et al. 2024). Second, in a related manner, our results are based on users with an interest in local stores. To extend the applicability of our findings, it may be beneficial to randomly induce and measure consumers’ deal-seeking propensity and reception toward location-based ads. Third, we only observe in-app ad clicks. Future research may investigate other dimensions of consumer response, for example, in-store purchase data. Fourth, additional covariates could further capture location familiarity. These could include data on individuals’ residential and work locations, common trajectories (Shoshani, Zubcsek, and Reichman 2024), and detailed frequency of visits. Additional mobility measures and data on app activities would also help enrich the matching procedure. Although such data might be obtainable by mobile service providers, potential privacy issues could persist. Therefore, a plausible direction for future research may involve conducting field experiments, which could help collect more nuanced data on location familiarity while better preserving privacy. However, this would necessitate a sufficiently large sample with low attrition rates.
To summarize, we believe that our results have a variety of implications for marketers, (mobile) ad platforms, and regulators. Our results enable regulators to assess the benefits of relevant ads, for example, by using click rates to calculate individual valuations of (increased) ad relevance that could be compared with estimates of the potential costs of reduced data privacy (Acquisti, John, and Loewenstein 2013). For platforms and marketers, the rapid technological developments in the area of Internet of Things applications, including connected (and self-driving) cars, wearable devices, and even smart home appliances, will continue to increase the possibilities to track and/or target consumers at different locations (Cooke and Zubcsek 2017; Grewal et al. 2020). Thus, platforms and marketers will increasingly require a better understanding of the interplay between consumers’ location and consumption choices in order to improve the effectiveness of their mobile communications to consumers through increased personalization.
Supplemental Material
sj-pdf-1-jnm-10.1177_10949968241300063 - Supplemental material for Does Location Familiarity Increase Response to Mobile Ads?
Supplemental material, sj-pdf-1-jnm-10.1177_10949968241300063 for Does Location Familiarity Increase Response to Mobile Ads? by Dominik Molitor, Peter Pal Zubcsek, Martin Spann, and Philipp Reichhart in Journal of Interactive Marketing
Footnotes
Editor
Peeter Verlegh
Associate Editor
Steven Bellman
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research of this article: Financial support by Deutsche Forschungsgemeinschaft (project no. 414986791) is gratefully acknowledged. Peter Pal Zubcsek also acknowledges the generous support of the Israel Science Foundation (grant no. 2160/21), the Coller Foundation, and the Henry Crown Institute of Business Research in Israel at Tel Aviv University.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.