
Abstract
Researchers, engineers, and entrepreneurs are enthusiastically exploring and promoting ways to apply generative artificial intelligence (GenAI) tools to qualitative data analysis. From promises of automated coding and thematic analysis to functioning as a virtual research assistant that supports researchers in diverse interpretive and analytical tasks, the potential applications of GenAI in qualitative research appear vast. In this paper, we take a step back and ask what sort of technological artifact is GenAI and evaluate whether it is appropriate for qualitative data analysis. We provide an accessible, technologically informed analysis of GenAI, specifically large language models (LLMs), and put to the test the claimed transformative potential of using GenAI in qualitative data analysis. Our evaluation illustrates significant shortcomings that, if the technology is adopted uncritically by management researchers, will introduce unacceptable epistemic risks. We explore these epistemic risks and emphasize that the essence of qualitative data analysis lies in the interpretation of meaning, an inherently human capability.
Introduction
Since their release, generative artificial intelligence (GenAI) models—specifically large language models (LLMs)—have sparked vigorous debates about their potential to transform, even revolutionize, scientific research (Gatrell et al., 2024; Grimes et al., 2023; Koehler & Sauermann, 2024; Kulkarni et al., 2024; Wang et al., 2023). Central to these discussions is the capacity of LLMs to generate text that resembles human creativity and reasoning. Some voices in this debate go so far as to claim that such models are capable of human-like reasoning (e.g., Bubeck et al., 2023; Kosinski, 2024), so they may well one day replace human researchers in the generation of scientific knowledge.
The proliferation of these claims about how such technologies might improve, augment or automate activities conducted by human researchers has led to the development of a wide range of applications that utilize and build on GenAI models. Qualitative data analysis is seen as fertile ground for such models, due to their natural language processing capabilities. The use of these models is often pitched as a way of ‘scaling up’ qualitative research designs (Gamieldien et al., 2023; Karjus, 2025), of making resource savings (Chubb, 2023; Xiao et al., 2023) and optimizing qualitative data analysis ‘workflows’ (Gao et al., 2023; Törnberg, 2024; Zhang et al., 2023). GenAI models are even positioned as autonomous digital assistants that can perform high-order analytical tasks such as identifying patterns and interpreting meaning (e.g., Koehler & Sauermann, 2024; Lixandru, 2024; Xiao et al., 2023).
Given these efforts underway to incorporate GenAI into qualitative data analysis, our aim in this paper is to investigate the following research questions: (1) what sort of technological artifact is GenAI? (2) Is it appropriate for use in qualitative data analysis? We offer a technically informed yet accessible evaluation of GenAI models and evaluate their claimed potential to contribute to qualitative data analysis. Our motivation in this paper is to go beyond prior work (e.g., Morgan, 2023), which does not inquire into the nature of the technology itself. In doing so, we provide a more informed assessment of the potential applications of such models to the diverse interpretive and reasoning processes that constitute qualitative data analysis.
This paper is structured as follows. We first turn to existing literature on scientific tools and instruments to conceptualize the role they play in knowledge production. This literature alerts us to the consequential nature of our tools; the epistemic risks they pose, in the form of introducing errors into knowledge production; and the validation process that a scholarly community should undertake before warranting their use. We then present the results of our evaluation of GenAI. We commence by addressing the first research question: what sort of technology is GenAI? To address this question, we review the computer science literature on generative artificial intelligence and transformer-based autoregressive large language models such as ChatGPT and DeepSeek. Based on the current state-of-the-art architecture, these GenAI models can be understood as a type of chatbot (Dam et al., 2024; Narayanan & Kapoor, 2024). As such, their output consists of word strings, probabilistically selected from their database of rules on word associations, that have the appearance of human-produced text (Narayanan & Kapoor, 2024).
Armed with this understanding of the nature of GenAI, we then outline the claims that are rapidly disseminating about its suitability as a tool for qualitative data analysis. We test these claims against three kinds of evidence: (1) our own analysis of a qualitative dataset; (2) the results from other published studies that explored the use of GenAI as a scientific tool for qualitative data analysis; (3) the GenAI capabilities that are now being offered by providers of qualitative data analysis software. This evidence allows us to address the second research question: whether GenAI is a suitable tool for qualitative data analysis. The conclusion we present is that GenAI—based on the current transformer architecture on which all foundational LLMs are built—is unsuited to qualitative data analysis and presents multiple epistemic risks to management research were its adoption sanctioned. We argue that these risks include, but go beyond, the production of false and untrustworthy results. In addition, the very nature of GenAI technology obfuscates our attempts to evaluate the validity of its output.
Before proceeding, it is worth clarifying our understanding of qualitative data analysis. By qualitative data analysis, we are referring to the full range of ‘lower-order’ tasks of exploring and organizing data (e.g., search and retrieval and thematic coding), as well as the ‘higher-order’ tasks of finding unexpected (even counterintuitive) patterns and connections, engaging in theoretical abstractions and modeling, applying multiple forms of reasoning, and proposing novel, critical and disruptive problematizations and reconceptualizations (see Flick, 2014 on the scope of analysis; see also Davidson & di Gregorio, 2011; Silver & Lewins, 2014). Above all, qualitative data analysis concerns the interpretation of social meaning. This is necessarily an inter-subjective process that depends on the researcher's own experience, which is derived from deep field engagement and participation in multiple social communities, including the scholarly community. Our view on data analysis can be characterized as interpretivist: there is no objective standpoint that researchers can adopt when investigating the social world. This leads us to assert the importance of the scientific community in underpinning the credibility of research. The ‘organized skepticism’ (Merton, 1973, p. 277) of the scholarly community is essential, given the fallibility and fragility of the conclusions researchers draw. As we shall now discuss, this role of the scholarly community is critical when it comes to the technologies we adopt for our research.
Research Instruments and Qualitative Research
Historians, philosophers and sociologists of science 1 have pointed to the prominent, yet often overlooked, role played by technological artifacts in the generation of knowledge. By technological artifacts, we refer specifically to equipment, both physical and digital (e.g., computer databases, see Hine, 2006, and computer simulations, Alvarado, 2023), that has been made possible by scientific advances (cf., Shapin & Schaffer, 1985). Such knowledge-producing technologies are not just passive objects which we employ to enable scientific activities. More than that, they enable, distort and limit our observations of the world (Croissant, 2022), and in doing so, are constitutive of the knowledge they produce (Clarke & Fujimura, 1992)—including our understanding of what good scholarship looks like.
Technology has also impinged on qualitative research (Brinkmann et al., 2014), despite the mantra that in such studies, the researcher is the (exclusive) research instrument (e.g., Tracy, 2012). Technologies have been applied to qualitative data sources, qualitative data collection, data analysis and verification. For example, the introduction of the tape recorder, today largely taken for granted as a tool of the trade, altered the qualitative research process. The changes wrought were not confined to fieldwork interactions but extended to data analysis. The details of speech acts that a recorder can capture made new forms of analysis possible, such as conversation analysis and (forms of) discourse analysis (Jones, 2021). At the same time, recording changed how analysis of interviews was conducted. Given that researchers today typically analyze transcripts (Lee, 2004), not fieldnotes or sound recordings, they place more emphasis on data in the form of verbatim quotes from interviews, while other aspects of the interview—notably the dynamics of its production and the ‘social world’ from which it was sourced—are more easily overlooked. A greater demarcation between ‘text’ and ‘context’ was the result (Jones, 2021).
Given this consequential nature of scientific instruments, a crucial question is how, why and for what purpose have particular tools been adopted (or not) by a research community? As Clarke and Fujimura (1992) put it, how does a scholarly community determine that a tool is the right one for the job? Ultimately, the answer to this question is up to us: an artifact needs to be socially accepted as the appropriate tool for a specific purpose. Convincing a scholarly community to adopt a new technology as a legitimate scientific instrument should be a rigorous and protracted undertaking (Alvarado, 2023; Bechky & Davis, 2025) driven by scholarly norms (e.g., Merton, 1973).
In this process, the first step is establishing criteria for rightness, i.e., appropriate use. Evaluative criteria have been much debated in qualitative research, given the diversity of onto-epistemological positions that researchers may adopt. Despite this, we argue that there are concerns that matter to all qualitative researchers, no matter their paradigmatic positioning. Although interpretivist researchers reject traditional positivist criteria of validity and reliability (e.g., Yin, 2014), they too care deeply about their epistemic responsibility to report participants’ accounts faithfully, avoiding misrepresentation and knowingly introducing errors; reflexively question their own assumptions; report their research processes transparently (i.e., providing an audit trail, to use the term popularized by Lincoln & Guba, 1985); analyze data systematically; demonstrate deep engagement with the research setting; and reach conclusions that are supported by evidence and are logically sound (Yanow & Schwartz-Shea, 2014). All qualitative researchers need to exercise doubt and be constantly alert to how their analysis might be wrong—including taking responsibility for the tools they use.
A non-human and non-interpreting instrument must not detract from the interpretive, reasoning and conceptual activities of the human analyst who makes use of it. Does the instrument assist qualitative researchers in producing credible interpretations of their data? A tool needs to demonstrate to a scholarly community more than the improvements in efficiency and convenience that might be sufficient for adoption in other settings. As well, its processing of qualitative data needs to produce results that are trustworthy in terms of factual accuracy (i.e., not introducing errors, distortions and biases), reliability (i.e., stability, dependability), transparency (i.e., verifiability, explainability) and compatibility with ethical standards (for a discussion, see e.g., Baird & Faust, 1990).
Having established criteria for evaluating the fitness of a tool, the next step is to undertake an independent and evidence-based validation process. Without this, the results the tool produces cannot be accorded the status of warrantable knowledge. Judgement calls need to be made: for example, how high an error rate or what degree of transparency is acceptable? The benefits of the tool need to be weighed against its epistemic risks—in other words, the risk of being wrong in our conclusions (Biddle & Kukla, 2017). The scientific process is fraught with potential risks—of misconceptions, biases, poor reasoning, and observational errors—and tools may exacerbate these risks. In qualitative research, the stakes are even higher, given that the data are imbued with social meaning that is difficult to access and can easily be misunderstood (Maxwell, 1992).
As scholars, we are exposed to these same risks of error and false beliefs during the process of validating a tool—ultimately, our attitudes to the tool may lead us to overlook disconfirming evidence. A further complication is that the validation process is shaped by the power structures, interests and intellectual paradigms which dominate a research community (Casper & Clarke, 1998; Mikami, 2015). Dissemination and widespread adoption of the tool typically also involves influences from regulators, funding agencies and market actors such as instrument manufacturers, publishers and, more recently, software houses (Alvarado, 2023).
To conclude this section, we use this framing of the role of instruments in research as the conceptual orientation for our study, both in terms of its rationale and direction. It allows us to understand the consequential (but often overlooked) nature of technological artifacts—they affect the nature of the data we use, the analysis we produce, and our standards of what good research is. For this reason, they can be regarded as ‘the third element of scientific inquiry’ alongside theory and methodology (Alvarado, 2023: 101). Given their importance, the legitimization of artifacts for use as scientific tools requires a careful process of validation by a scholarly community. The initial introduction of a technological artifact is the critical point in time to conduct this debate, before the use of the artifact becomes normalized and taken for granted. In the case of GenAI and its proposed adoption by qualitative researchers, that time is now. Accordingly, we proceed to evaluate GenAI. We start with the nature of the artifact itself, before discussing its application to qualitative data analysis.
Generative Artificial Intelligence: What Is It?
Recent advancements in natural language processing (NLP) techniques and computational power have significantly expanded the capabilities and applications of GenAI models. These systems are now widely integrated across various professional domains, facilitating the automation of tasks such as content generation, software development, and customer support (Gozalo-Brizuela & Garrido-Mechán, 2023). Unlike other AI systems, GenAI models encode statistical patterns from data to produce novel content based on probability. Central to this progress is the emergence of autoregressive large language models (AR-LLMs), a class of GenAI models designed to generate synthetic word strings resembling human-like text (Henighan et al., 2020). The term ‘autoregressive’ refers to the model's statistical approach of linear prediction: generating synthetic text one token (i.e., word) at a time, using each newly generated token as additional context for predicting the next. This method enables AR-LLMs to produce seemingly coherent and contextually relevant text (Wei et al., 2022a).
Building on this foundational architecture (see Vaswani et al., 2017), developers and researchers at OpenAI, Google, Meta, and Anthropic, among many others, have introduced interactive AI systems designed to make advanced AR-LLMs more accessible to a broader audience. Commonly referred to as ‘conversational agents’ or ‘chatbots’, GenAI tools such as ChatGPT, Claude, and DeepSeek leverage AR-LLMs to generate synthetic human-like responses in real time to facilitate naturalistic conversations with users (Bommasani et al., 2022; Brown et al., 2020).
What distinguishes AR-LLM-based chatbots (henceforth, shortened to LLMs) from earlier language models is their training on vast datasets using what are termed ‘deep learning’ techniques, particularly the transformer architecture (Liu et al., 2024; Radford et al., 2018; Touvron et al., 2023). During training, transformer models encode large amounts of textual data 2 that are usually scraped from the internet (McCoy et al., 2024), allowing them to create a model (a set of rules) based on patterns, structures, and relationships within the natural language. The model then represents the words and phrases as vectors in a ‘high-dimensional space’—dataset arrays that contain large amounts of features and attributes from various sources—capturing semantic similarities and correlations (Vaswani et al., 2017). When generating synthetic text, the model uses these ‘learned’ representations to predict the most probable next word while considering the entire context of the preceding text. This process is iterative, involving the calculation of probabilities based on the patterns it has acquired, allowing the model to generate novel synthetic texts. Moreover, as a product of their training on large datasets and the transformer architecture, these models can be applied to a range of NLP tasks such as conversations, text summarization, editing, and translation (Brown et al., 2020; Wei et al., 2022a).
Once trained to predict the next token in a sequence, LLM chatbots are periodically updated or fine-tuned with additional data. Fine-tuning involves a process called reinforcement learning from human feedback (RLHF). In RLHF, human evaluators assess the model's outputs and provide feedback (human-annotated/labeled data), which is used to build a separate ‘reward’ model. This reward model then guides LLM chatbots toward generating outputs that better align with human preferences, ethical standards, and contextual appropriateness. LLM chatbots are then optimized through reinforcement learning, whereby their rules are strengthened (‘rewarded’) or weakened (‘penalized’) based on the alignment of their synthetic outputs with desired outcomes as determined by their developers (Achiam et al., 2023). However, it should be noted that alignment is an ongoing challenge (Qi et al., 2023), and RLHF to improve model outputs can introduce more biases (Mu et al., 2024).
When a user interacts with an LLM chatbot—e.g., uploads documents, inputs texts, or writes a natural language instruction (prompt)—several automated pre-processing steps occur. The input is first tokenized: texts are broken down into smaller units (tokens), which are then transformed into numerical vectors (embeddings) that capture relationships between words in high-dimensional space. These embeddings are then processed through multiple layers of the transformer architecture (Vaswani et al., 2017). The LLM chatbot then predicts the next token by sampling from a probability distribution conditioned on the input text (or data) and decodes the tokens back into human-readable text (Radford et al., 2018).
Researchers evaluating the potential of LLM chatbots in science are increasingly identifying a range of shortcomings that limit their scientific applicability (Bommasani et al., 2022; Messeri & Crockett, 2024). In discussing these challenges, we revisit the criteria for validating a scientific tool outlined in the previous section: factual accuracy, reliability, transparency, and ethical responsibility. We now discuss each criterion in turn.
Factual accuracy is a critical concern when evaluating scientific tools. The assessment often made about LLM chatbots is that they are prone to ‘hallucinations', that is, produce content that is nonsensical or untruthful (Maynez et al., 2020; Phan et al., 2025). The term implies that these models produce accurate responses, with occasional errors. However, this characterization is misleading. LLM chatbots are designed to produce word strings that approximate word associations and patterns that humans have provided in an existing corpus of text. They are not designed to evaluate the truthfulness of the answer they produce (Walsh, 2023); their output ‘does not have to be correct, it must appear correct’ (Thornton, 2023, p. 27). As LLM chatbots are ‘indifferent to the truth’ of their outputs (Hicks et al., 2024; Narayanan & Kapoor, 2024), correspondence to facts is a matter of chance (Kalai et al., 2025).
Compounding this lack of truthfulness are the multiple biases inherent to each stage of the process of synthetic text generation. These include data-derived biases, ingrained in the language corpus used to train LLM chatbots (Bender et al., 2021); developer/evaluator biases, given that humans are involved throughout the training process (Mu et al., 2024); and algorithmic biases: systematic and recurring errors that occur when a model privileges certain representations or social categories over others (Arrieta et al., 2020; Eloundou et al., 2024; Vassel et al., 2024). These biases are accompanied by knowledge cut-offs—that is, the date at which LLM chatbots no longer have up to date information (Cheng et al., 2024)—and a lack of temporal awareness (Dhingra et al., 2022).
In relation to the second criterion, reliability remains a critical yet unresolved issue as GenAI models cannot generate stable and reproducible results 3 (Achiam et al., 2023; Bommasani et al., 2022). This limitation stems from their probabilistic nature, which makes their output unpredictable and beyond user control. This means that even when using the same prompt, document or input text, varying results will be generated across different interactions (Bommasani et al., 2022; Brown et al., 2020). Moreover, as there is a context window—a textual range that GenAI models can process at any given time, including both input text and output response—extended conversations are highly prone to generating incoherent results as earlier segments of the conversation fall outside the range in which tokens are processed (Achiam et al., 2023).
In domains where reliability and accuracy are paramount, this inherent variability undermines any practical utility (Kaddour et al., 2023; McCoy et al., 2024). Accordingly, the developers of ChatGPT caution that ‘[g]reat care should be taken when using language model outputs, particularly in high-stakes contexts, with exact protocol (such as human review, grounding with additional context, or avoiding high-stakes uses altogether [our italics]) matching the needs of specific applications’ (Achiam et al., 2023, p. 10). This admission from OpenAI should cast doubt on the suitability of LLM chatbots for use as scientific instruments: they cannot, and are not built to, produce trustworthy results.
Moving to the third criterion, GenAI tools are inherently non-transparent, owing to both algorithmic complexity and developer opacity (Alvarado, 2023; Burrell, 2016; Marcus, 2024). Artificial neural networks, which underpin these models (Achiam et al., 2023; Liu et al., 2024; Touvron et al., 2023), do not follow explicitly programmed rules. Instead, they ‘learn’ autonomously through a self-supervised process (Henighan et al., 2020; Radford et al., 2018; Touvron et al., 2023), making their internal workings complex and the output they produce difficult, if not impossible, to explain (Arrieta et al., 2020; Bommasani et al., 2022; Burrell, 2016; Mitchell & Krakauer, 2023). This algorithmic complexity is further exacerbated by developers’ intentional non-disclosure of key details—including model architecture, training data and fine-tuning processes—which obstructs external evaluations and scrutiny of the technology 4 (Mitchell & Krakauer, 2023).
Last but not least, the ethics of GenAI remain an ongoing concern (Huang et al., 2025). Among a host of ethical issues, perhaps the most salient for researchers are data leakage, which refers to the risk of user inputs being incorporated into a model's training data to improve model performance, raising privacy, intellectual property, and consent concerns (Lukas et al., 2023); the immense energy consumption to train and operate GenAI models, raising concerns about environmental sustainability (Luccioni et al., 2024); and accountability, arising from questions as to who should be held responsible for the generation and utilization of GenAI outputs, especially in high-stake applications (Achiam et al., 2023; Raza et al., 2025).
In response to the growing ethical and practical concerns, researchers and developers have introduced technological innovations aimed at enhancing the factual accuracy and contextual relevance of GenAI outputs. A notable advancement is the development of vector-based retrieval-augmented generation (RAG) architectures (Ni et al., 2025; Zhao et al., 2024), which integrate an external knowledge base to improve the likelihood of a model generating more accurate and contextually relevant content (Lewis et al., 2020). Beyond architectural advancements, developers have also turned to external tools, via application programming interfaces (APIs), to mitigate some of the inherent technological limitations of AR-LLMs. For example, ChatGPT can access a dedicated Python execution environment to perform arithmetic calculations and other tasks, such as counting characters or words.
However, RAG architectures and APIs primarily function to increase the probability of generating a correct next-word answer, and they do not and cannot ensure factual correctness, accuracy, reproducibility, or ethical responsibility (Lin et al., 2021). Moreover, while continuous fine-tuning and data updates can enhance model performance, they introduce risks such as model drift (Shumailov et al., 2024) and a reduction in response diversity (Peterson, 2025; Zhang et al., 2023). Consequently, model reliability and accuracy in any given task can fluctuate or degrade over time 5 (Chen et al., 2024; McCoy et al., 2024). These limitations derive from the fundamental constraints of the transformer architecture and autoregressive method on which all current GenAI tools are built, and cannot be mitigated through technical improvements, prompt engineering, or scaling efforts; that is, increasing the size and training data of a model (Dziri et al., 2023; LeCun, 2022; Lin et al., 2021; Marcus, 2018; Sahoo et al., 2024).
Evaluation of the effectiveness of LLM chatbots is hindered not only by algorithmic complexity and inherent opacity but also by the way scholars perceive them. Despite their technical limitations, GenAI models are often misunderstood, leading to an over-estimation of their capabilities (Morris, 2023). This disconnect is not accidental but is, in part, an outcome of the power of commercial interests that are actively pushing the adoption of the technology (Widder et al., 2023). AI hype is a feature of the field since its inception—and the coining of the term ‘artificial intelligence’ itself (e.g., Placani, 2024), which conflates literal with metaphorical intelligence. Words associated with human intelligence infuse the AI discipline—for example, as we have discussed in this section, the technical terms of ‘learning’ and ‘rewards.’ This linguistic framing is highly misleading as it creates a false equivalence between humans and algorithms (Bender, 2024; Van Rooij et al., 2024).
Another obstacle is the technological artifact itself. As we have outlined, LLM chatbots are explicitly designed to generate synthetic text that imitates human-produced text to the greatest extent possible. The aim is precisely to achieve text that looks plausibly human, and to mimic human utterances in a convincing way. The results of this ‘faking’ of human intelligence (Walsh, 2023) are that users are often misled, according intelligence to LLM chatbots (Bender, 2024; cf. Bubeck et al., 2023)—an anthropomorphizing response encouraged by the dialogical, interactive nature of the technology. 6 For these reasons, we would regard the epistemic risks of LLM chatbots as qualitatively distinct from other technological contenders for scientific use. We now examine these risks in relation to qualitative data analysis.
LLM Chatbots as a Tool for Qualitative Data Analysis? The Claims
The introduction of GenAI has been hailed as revolutionary in the development of qualitative research (Zhang et al., 2023). Its claimed applications span multiple stages of the research process, from designing interview protocols (Goyanes et al., 2025) and conducting interviews (Chopra & Haaland 2023) to performing inter-rater reliability checks 7 (Hou et al., 2024). GenAI has even been suggested as a replacement for human research participants (Dillion et al., 2023), although this use is also (deservedly) contested (Harding et al., 2024; Wang et al., 2025). In data analysis, many anticipate that GenAI tools will not only augment and automate existing analytical techniques (Lee et al., 2024; Morgan, 2023) but could also ‘act’ as a virtual assistant to aid in interpretive endeavours (Hitch, 2024; Lieder & Schäffer, 2024; Wheeler, 2025). Table 1 highlights illustrative claims that have been made about the use of GenAI tools in qualitative data analysis, ranging from automation to augmentation and anthropomorphism; that is, treating GenAI as a virtual research assistant.
Illustrative Claims About AR-LLMs in Qualitative Data Analysis.

Crucially, these claims are not only made by early adopters (many of whom are computer scientists rather than experienced qualitative researchers), but also by major computer-aided data analysis software (CADQAS) providers (e.g., ATLAS.ti, MaxQDA and NVivo), which have introduced GenAI capabilities. These incumbent firms are joined by recent start-ups (e.g., Coloop, AILYZE; QInsights) that have integrated or built on GenAI tools for qualitative data analysis. Overwhelmingly, all these ‘Qual-AI’ 8 software providers are promoting their solutions as providing efficiency gains, such as ‘qualitative insights in minutes instead of weeks’ (see Figure 1) or the ability to make qualitative projects ‘30x faster’ (see Figure 2). It should be noted that not all CAQDAS providers have incorporated GenAI features. A notable exception is Quirkos, which has taken a more cautious approach, emphasizing the importance of transparency, researcher reflexivity, and the risk that GenAI may obscure researcher decision-making and introduce biases that may go unchecked (Quirkos, 2025).
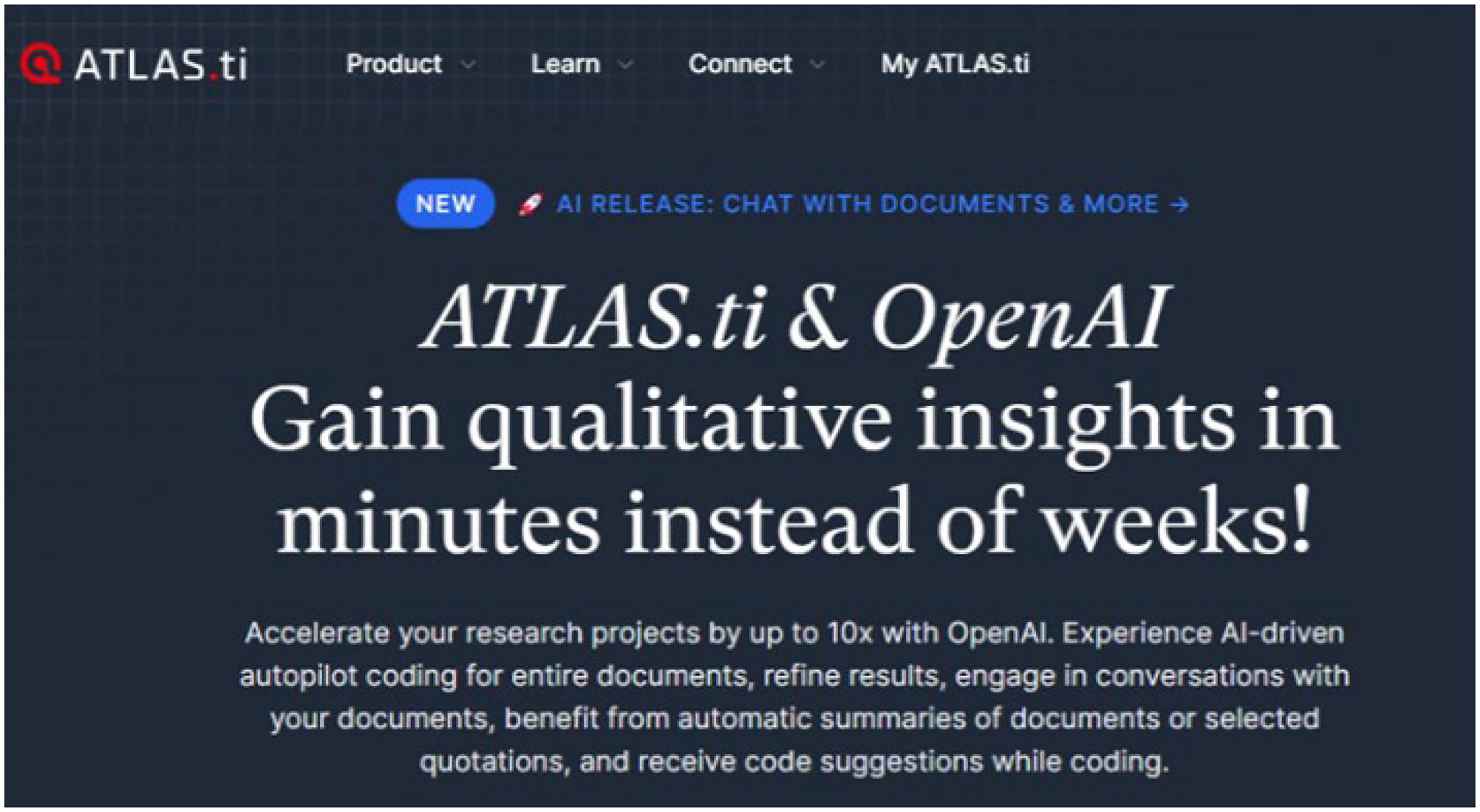
ATLAS.ti Marketing Material.
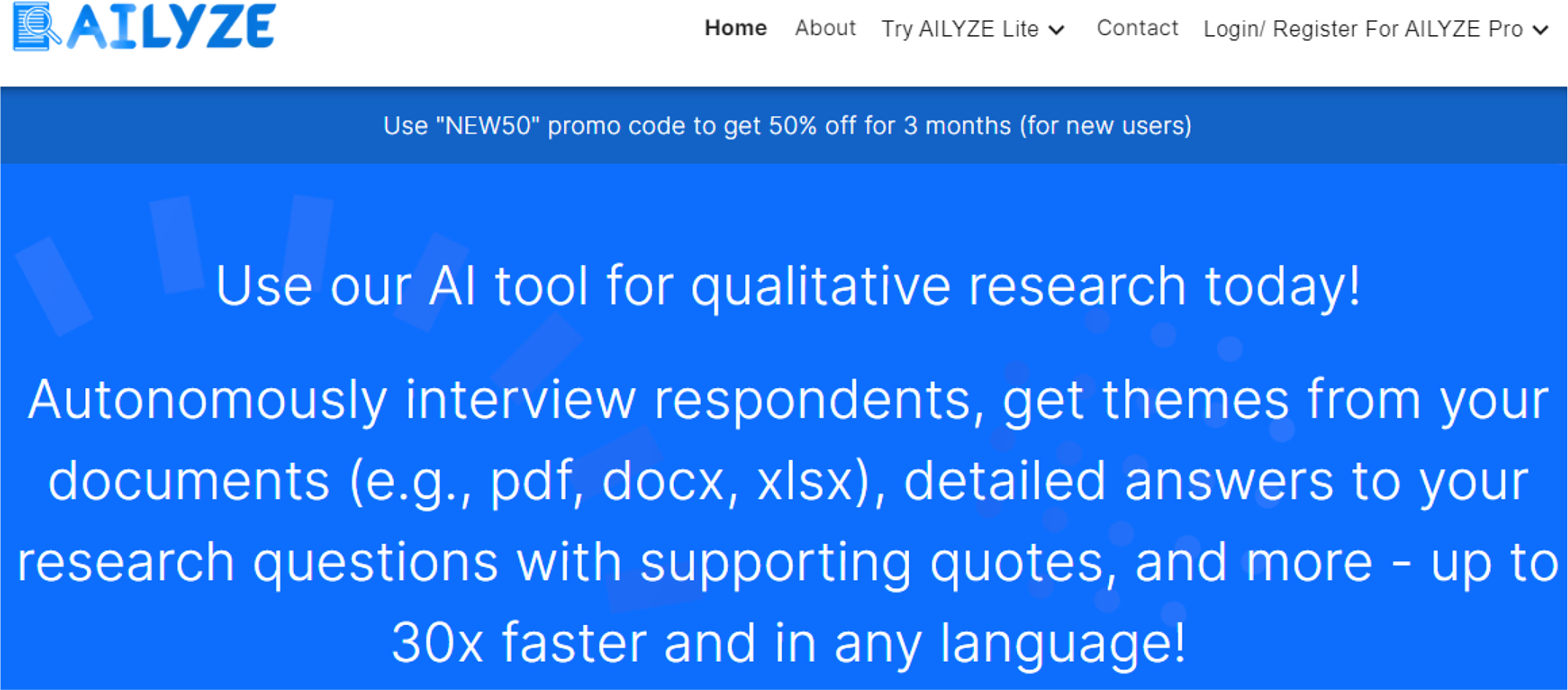
AILYZE Marketing Material.
The claims that position GenAI models as valuable tools for qualitative data analysis rest on their supposed capability to automate the labour-intensive task of ‘coding’ to identify themes and patterns. In expediting this process, users are promised efficiency gains (Anis & French, 2023; Huang et al., 2024) and cost savings that are associated with hiring human research assistants (Chubb, 2023; Nguyen-Trung, 2025). It has even been claimed that they can improve trustworthiness and replicability by minimizing human subjectivity and involvement in the analytical process (Abdüsselam, 2023; Theelen et al., 2024)—a fundamental misunderstanding of the nature of qualitative data analysis and its interpretive and iterative process of meaning-making. We will now turn to how we went about evaluating the claims being made about GenAI.
Methodology
To consider how the adoption of ‘Qual-AI’ tools might impact qualitative data analysis, we evaluated the main analytical steps of a GenAI-enabled project. When we commenced this evaluative exercise in late 2023, we (like most management researchers) were new to GenAI and were agnostic as to its possible benefits. It is worth pointing out that, unlike many proponents of the tools (notably Qual-AI providers), we have no financial interest in encouraging its adoption.
To conduct our evaluation, we analyzed a collection of publicly available data on portable computing technologies from the late 1980s to 1990s (part of a larger research project currently being conducted by one of the authors). The data comprised transcripts of interviews (oral histories), blog posts and news and magazine articles from 1989 to 2016 (Table 2). The advantage of choosing this dataset is that (1) it has been assembled by one of the authors, so we have sufficient familiarity with it to judge the quality of the LLM chatbot outputs; (2) it does not involve uploading any confidential or proprietary data 9 ; and (3) it includes a diverse range of sources that are commonly used in qualitative research projects (i.e., interviews and secondary data).
Empirical Material for Our Evaluation.

We selected only news articles available on the Internet; articles derived from the Factiva database were excluded from our dataset.
Our trial covered the range of LLM-based tools that are currently being promoted to qualitative researchers. The first option is to use a general-purpose LLM chatbot for data analysis. ChatGPT has so far been the most common tool used in existing studies, so we also adopted it in the interests of comparability of results. We acknowledge that even research making use of ChatGPT is not directly comparable, given the regular release of new versions (we used the latest available at the time, ChatGPT-4o); however, OpenAI itself concedes that there are only incremental differences between recent versions (OpenAI, 2025). 10 Having selected a tool, we then decided on the form that the evaluation of it would take. As ChatGPT is widely purported to be capable of expediting the ‘coding’ process to identify themes and patterns (Table 1), we examine its ability to perform these tasks efficiently and accurately. Specifically, we assessed whether ChatGPT could reliably code the data, recognize key themes, and provide coherent insights without compromising the depths and nuance in the data.
The first author ran multiple rounds of testing on the dataset, keeping a log of the prompts used and the outputs. To ensure comparability, we reused prompts that had been run in previous studies, so as to benchmark against them, but also experimented with a variety of qualitative data analysis prompt templates drawn from practitioner blogs and scholarly articles. In addition, we formulated prompts based on ‘state-of-the-art’ engineering techniques developed by Google engineers called ‘chain-of-thought prompting’ (Wei et al., 2022b). Chain-of-thought prompting 11 involves creating sequential prompts that instruct an LLM chatbot to complete a series of intermediate steps, where the outputs of one step become the input for the next to enhance the overall quality of the final output. This is in contrast to zero-shot prompts, where the model generates responses without prior examples, and few-shot prompts, where the model is provided with examples. 12 Appendix 1 in the supplemental material lists the different prompts that we used.
In addition to our evaluation, we compared our results with five other studies that explored the use of ChatGPT as an ‘analytical tool’ to augment or automate qualitative coding and thematic analysis (see Table 3 for details). We chose these studies as they represent the range of approaches that have been used, in terms of diverse prompts, datasets, ChatGPT models, and disciplinary backgrounds (i.e., political science, medicine, education, occupational therapy, sociology). This enabled us not only to benchmark the main steps in a GenAI-enabled qualitative data analysis but also to draw on and incorporate other evidence that evaluated the potential and limitations of these models. Moreover, as each study includes a reflection on challenges encountered at different stages of analysis, we were able to identify and synthesize the recurring themes and obstacles of a GenAI-enabled analysis. Table 3 summarizes each study (including our own), including the model version, type of data and analysis, prompting techniques, and the authors’ reflections on leveraging GenAI for qualitative data analysis.
Evaluation of ChatGPT as ‘Scientific Tools’ to Augment or Automate Qualitative Data Analysis.
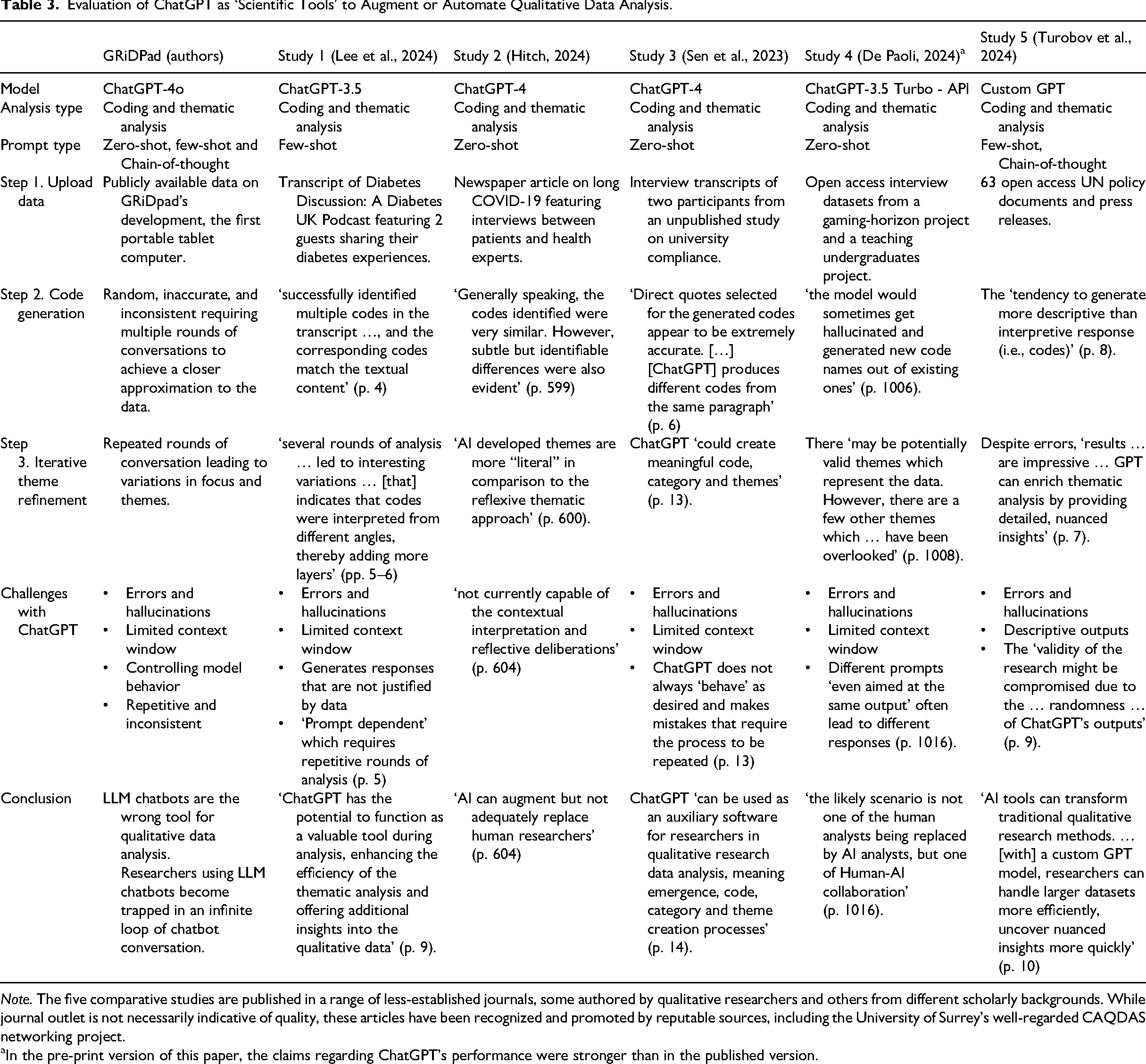
Note. The five comparative studies are published in a range of less-established journals, some authored by qualitative researchers and others from different scholarly backgrounds. While journal outlet is not necessarily indicative of quality, these articles have been recognized and promoted by reputable sources, including the University of Surrey's well-regarded CAQDAS networking project.
In the pre-print version of this paper, the claims regarding ChatGPT's performance were stronger than in the published version.
At the same time, we undertook an analysis of Qual-AI offerings, comparing the features on offer from the main CAQDAS providers and from emerging start-ups. Table 4 documents these features, which center on ‘chatting’ with documents, text summarization, and code suggestions. In addition to comparing the features of Qual-AI tools currently on the market, we also examined two products in greater depth: one from an established CAQDAS provider (NVivo) and one from a startup (QUALSOFT 13 ). We selected these two because our comparative analysis identified them as the most promising for academic use. In conducting the analysis, we were careful to follow the instructions that the developers provided to obtain optimal results, which included carefully selecting data sources that are easier to analyze, such as interviews, which have a consistent question–answer format. We also compared the results we obtained against coding results produced by Custom GPTs available on OpenAI's GPT Store, 14 where we tested several purpose-built models for qualitative data analysis, including those fine-tuned for coding and thematic analysis. Overall, then, our evaluation was able to make extensive use of triangulation: multiple GenAI models, a variety of data sources, and multiple investigators.
Qual-AI Features and Developers' Descriptions.

In the course of our analysis, we realized that we needed to extend its scope to consider not just the epistemic risks posed by the tool's output but also how these outputs are interpreted by authors and Qual-AI developers. In sum, we approached our inquiry guided by the interpretive principles of qualitative research: we critically examined the nature of the phenomenon we were studying, compared within as well as across studies, and undertook a holistic investigation of the meaning that researchers ascribed to the tools, rather than confining ourselves to the outputs alone.
AR-LLM Chatbots as a Tool for Qualitative Data Analysis? The Evidence
We have established that rather than directly processing raw data or input texts in a systematic way, a GenAI model reduces and transforms the data into vector embeddings—numerical representations of input text—to generate statistically plausible responses based on patterns encoded during training. We now illustrate the implications of these differences by presenting our results and a comparison of GenAI-enabled qualitative data analysis. In doing so, we detail the steps we took to account for the model's known limitations to ensure a fair and systematic evaluation while clarifying and illustrating the conclusion from our study: GenAI models are not an analytical tool suited to qualitative data analysis.
ChatGPT Results
Step 1: Upload Data
A GenAI-enabled qualitative data analysis begins with uploading documents 15 (e.g., interview transcripts, news articles) or copying and pasting text into a model like ChatGPT. For our evaluation, we uploaded our dataset in Word format 16 to three separate ChatGPT-4o chat windows. Document 1 contained magazines, blog posts, and news articles (approximately 21,603 tokens), Document 2 contained an interview transcript (approximately 28,864 tokens), and Document 3 was a transcript of the panel discussion (approximately 14,571 tokens). 17
In the comparison studies, Studies 1 and 2 uploaded their data—a podcast transcript on living with diabetes and a news article on long COVID—to a single chat window. Study 3, on the other hand, copied and pasted their interview transcripts into two separate chat windows. Study 4, utilizing OpenAI's API with ChatGPT-3.5 Turbo, processed their datasets by dividing them into roughly 2,500-token chunks, separating the 13 gaming interviews into 56 text chunks and the 10 teaching interviews into 35 text chunks, which were then uploaded for processing. Study 5 adopted a different approach and created a custom GPT model. The authors uploaded their dataset (63 open-access UN policy documents and press releases on the topic of AI) to the model to serve as its knowledge base and provided explicit instructions for the model to ‘act as an academic expert in qualitative coding and thematic analysis.’ Separating the data posed practical challenges, including reconciling the different conversations, codes and themes across multiple chat windows. But this approach is necessary to stay within the model's context window.
Step 2: Code Generation
Having separated the data into separate chat windows, we used multiple and different prompts to instruct ChatGPT to code the datasets as a first step in conducting a thematic analysis. Within about 10–20 seconds, ChatGPT generated synthetic word strings that linked associated phrases and terms, as well as example descriptions under themes. While the speed of automation was notable, and the model was able to reproduce the typical format found in a qualitative paper of a table of quotations, the results did not stand up to scrutiny.
Table 5 is an example of the ‘coding’ performed by ChatGPT. The left-hand column presents the outputs of the model, and the right-hand column shows the original text 18 along with our evaluation. Sections in the dataset that align with quotes used by ChatGPT are presented in normal font, and deviations are bolded. In this instance, ChatGPT did not code the data, in the sense of line-by-line tagging of text, but rather provided output labelled ‘themes’ and ‘quotes’. Some of the quotes, although related to the object of the study, were not based on our uploaded dataset. The ‘themes’ were not themes in the sense of labels of patterns in the data; rather, at best, they approximated a summary of the corresponding quote. Moreover, they were either incorrect (e.g., there is no reference to ‘evolution’), too general to be useful (e.g., ‘technological challenges’), or misleading (e.g., ‘standardization and collaboration’ refers to the possible development of industry standards, but without any actual collaboration having taken place). Although these results are expected given what we know about the technology, for illustrative and comparison purposes, a new chat log was created, the dataset re-uploaded, and the model was prompted again to code the dataset to conduct a thematic analysis (see Appendix 2 in the supplemental material for different iterations and variations in results).
Excerpts of ChatGPT coding for qualitative thematic analysis

The randomness and unstructured nature of ChatGPT's qualitative ‘coding’ was also explicitly reported in Studies 2, 4, and 5. Generated ‘codes’ were repetitive, inconsistently applied across similar data segments, or overly descriptive. Moreover, as reported in Studies 1, 3, 4, and 5, while some codes appeared to be plausible, the corresponding quotes were often truncated, fabricated, or drawn from other sources. These errors necessitated repeated cycles of conversation and manual human intervention, involving the creation of a new chat window, re-uploading the data, and re-prompting the model, which typically resulted in variations or new codes, themes and quotes. Despite this repeated effort, the results did not improve.
Step 3. Iterative Refinement of Themes
Given the variation in accuracy and quality, including coverage of coded data across the different chatlog conversations, we proceeded with the chat windows across our three datasets that showed fewer errors. We then used a variety of prompts to instruct ChatGPT to identify the patterns and relationships between the coded segments of data in order to develop higher-order themes. After eight cycles of conversations, the model's behavior began conforming to our expectations; that is, it began producing the appearance of the kind of results that we were explicitly soliciting. In this iteration (Table 6), ChatGPT generated ‘codes’ and ‘themes’ that were based on our dataset. The left-hand column presents the outputs, and the right-hand column shows the original text, along with our evaluation. As before, sections in the dataset that align with quotes are presented in normal font, and deviations are bolded.
Excerpts of ChatGPT coding for qualitative thematic analysis

We compared the generated themes against the original data and found that, as in the previous step, outputs focused on specific parts of the document, to the exclusion of the rest; and ‘codes’ and ‘themes’ remained at best vague terms and phrases that related to the corresponding quote. The two ‘higher-order’ themes (each comprising two codes, making for the appearance of a very orderly data display) were an amalgamation of the codes. Despite the face validity of the output (Table 6), the results were inconsistent and random (e.g., the code of ‘corporate history and evolution’ under the theme of ‘market strategy and business evolution’). This necessitated more rounds of conversations, leading to subtle variations and, at times, significant deviations, demanding constant human intervention for verification.
The demand for manual oversight not only negates any supposed efficiency gains but highlights the outright impossibility of scaling up qualitative designs and establishing trustworthiness using GenAI models. Because of the random nature of the text generation, a GenAI-enabled qualitative data analysis is an open-ended process, with the researcher trapped in what is effectively an infinite loop of chatbot conversations. As each new interaction generates a variation in response, it also produces an ever-expanding body of content that needs to be interpreted and evaluated, without the researcher achieving a stable set of insights (see, for example, the variations and randomness across Tables 5, 6 and Appendix 2 in the supplemental material). This infinite loop means that rather than facilitating analysis in a transparent and trustworthy manner, researchers become content moderators for each chatbot output, validating its accuracy, contextual relevance, and connection, if any, to their data. This iterative process is ethically concerning, as not only is it resource-intensive—in terms of energy consumption (Luccioni et al., 2024)—but also exploitative, as researchers effectively train and refine GenAI models instead of engaging in analysis.
The inadequacies that we encountered were confirmed by our cross-study comparison. Similar to our observations, the authors of Study 4 report that ChatGPT overlooked significant parts of the texts while incorrectly assigning codes and hallucinating. However, in stark contrast to our conclusion, they suggest that ‘the likely scenario is not one of the human analysts being replaced by AI analysts, but one of a Human-AI collaboration’ (De Paoli, 2024, p. 1016). Similarly, although confronted with unstable, inconsistent and inaccurate results, the authors of Studies 2 and 3 conclude that the model can conduct a thematic analysis, albeit with limitations. These include errors and hallucinations, and an inability to recognize context or subtle nuances, underscoring the need for human oversight (Study 2) or the use of other tools to ensure accuracy and trustworthiness (Study 3).
Studies 1 and 5 also had disappointing results, yet reported them in generally favorable terms. For Study 1, variation in themes across different chat windows ‘indicated’ to the authors that ChatGPT interpreted the data from ‘different angles, thereby adding more layers to the overall analysis’ (Lee et al., 2024, p. 6). This led the authors to conclude that ChatGPT is a ‘valuable tool’ for qualitative data analysis. In Study 5, despite recognizing that ‘the validity of the research might be compromised due to accuracy, randomness, or unstructured nature of ChatGPT's outputs,’ the authors concluded that ‘AI tools can transform traditional qualitative research methods … [as] researchers can handle larger datasets more efficiently, [and] uncover nuanced insights more quickly’ (Turobov et al., 2024, pp. 9–10).
Across the five studies, the authors acknowledged the challenges in using ChatGPT as a tool for qualitative data analysis, in particular, its tendency to produce erroneous and false results. However, they argue that despite these errors, efficiency gains are significant. These include faster processing times and reduced manual effort in coding and theme identification. Moreover, while these studies concede that human oversight is needed to ensure accuracy and validity, they suggest that with the supposedly rapid advancement of AI, the need for this oversight may decrease over time as these models ‘learn the craft’ of qualitative data analysis (Study 2). In sum, they obtained comparable results to ours but drew opposing conclusions.
Qual-AI Results
The shortcomings we identified in the previous section are not unique to ChatGPT but extend to the specialized Qual-AI offerings currently on the market, as they all rely on OpenAI's foundational ChatGPT model and therefore inherit its defects, limitations, and shortcomings (Bommasani et al., 2022). Although these tools are advertised as being ‘purpose built’ for qualitative researchers and claim to mitigate hallucinations through the integration of RAG architectures, this integration does not eliminate the risk of fabricated or misleading outputs. This is because while RAG architectures may improve the output by retrieving from relevant external documents, the model can still misrepresent this information, and retrieval quality itself is highly variable. As such, although it could be expected that the results for these tools would be better, they do not resolve the reliability problems produced by general-purpose LLM chatbots.
We illustrate these problems with the results from our tests using a frontrunner product, QUALSOFT, but note they were found across all the Qual-AI offerings we analyzed (Appendix 3 in the supplemental material). To do so, we concentrate on the scenario with the best performance that we obtained, which was to examine a single interview transcript containing 21,648 words (28864 tokens), rather than compare across multiple documents, whereupon the results rapidly deteriorated. Certainly, if used within the limits that developers advise—i.e., using the tools on small datasets with similar types of documents—we found that the tool can obtain results mostly from the researcher's own data. However, in many other ways, the results were as unsatisfactory as when using ChatGPT.
We commenced with a thematic analysis of the transcript, the first step recommended by the QUALSOFT developers. This process is automated. The researcher is not able to customize the prompts or calibrate them to specify the analytical purpose or the desired granularity of the analysis. We reran the thematic analysis (see Appendix 4 in the supplemental material) and on each occasion, the tool produced a list of five or six themes with accompanying summaries. While all chatbot-produced themes are mentioned in the transcript, many are not central, some themes overlap, or are the same theme by a different name, and some themes misrepresent what the interviewee said. Other key themes in the document (e.g., convergence of two technologies) are not mentioned. The summaries are banal and omit detail, for example, ‘simplicity’ is repeatedly mentioned, but not the contextual conditions that made this important.
The themes and summaries are accompanied by the quotes from the document on which they are supposedly based. These quotes match the original text, but it is not clear how they are connected to the themes, nor do they represent all the mentions of the theme in the document. The extracts are of very different lengths—some are several paragraphs long, some are an excerpt from a sentence—but it is not clear why the quotes start or stop where they do. In some instances, the extracts run answer and question together. The Qual-AI output drew heavily from some parts of the interview and ignored others, with no apparent reason. It was also unable to deal with the temporality of the interview, which was chronological in structure, starting from the interviewee's childhood.
We also used the software's querying function, i.e, asking questions of the chatbot. Some portray querying as a new form of analysis (‘conversation analysis’) that amounts to a paradigm shift: a replacement for the traditional labor-intensive analytical practice of coding (Friese, 2025; Morgan, 2023). Unlike automated thematic analysis, this form of analysis promises interactive engagement with data by allowing the researcher to pose questions, probe themes, and identify patterns. To frame the questions, we followed the advice in the user guide, using the recommended prompts to optimize performance. However, the LLM chatbot's outputs (which, like the themes, took the form of summaries) were routinely incomplete.
To illustrate: when prompted to list the challenges mentioned by the interviewee, several important challenges were omitted. Beyond omissions, the chatbot also generated incorrect responses, especially when queried about information that was not answerable from the document. It was also prone to wrapping the text it generated in quotation marks, as if it were actually quoting the original. It was not reliably able to distinguish between different people referred to in the text, different companies, or even between people and companies. It would produce vague generalities even when asked specific questions that were answerable from the text. Some of the errors were obvious upon a first read, but others could only be detected following our own in-depth analysis of the transcript (see Appendix 5 in the supplemental material for more detailed evidence). All these errors are to be expected, given the limitations of the technology discussed above.
For this reason, the outputs had to be cross-checked against the document and corrected. Overall, the chatbot output did not deepen our understanding of the transcript. Its main function (irrespective of whether it was termed theme or conversation analysis) was in the form of synthetic summaries, which have limited use for any in-depth qualitative analysis, and which were not accurate enough to be dependable. The summaries were displayed on a separate screen from the interview transcript, which drew our attention away from the actual content of the interview, rather than increasing our familiarity with it.
Beyond these content-related issues, the lack of an audit trail makes it difficult to trace how outputs are generated or to assess their reliability and connection, if any, to the data. This opacity is compounded by the fact that Qual-AI developers do not disclose their prompting techniques, design choices or RAG architecture. These persistent shortcomings raise critical questions about the trustworthiness of (Gen)AI-assisted qualitative data analysis. We will now consider the broader implications of these findings.
Discussion
The widespread accessibility of GenAI models, which are designed to be used by non-experts in an intuitive conversational way, has been positioned as a compelling alternative to more traditional CAQDAS software and NLP approaches for qualitative data analysis (Sen et al., 2023; Turobov et al., 2024). However, in our evaluation, LLM chatbots consistently failed to code the data efficiently, accurately, reliably and comprehensively, or identify meaningful themes. ChatGPT, and the Qual-AI products built on it, are simply not designed nor fine-tuned to perform even the lower-order analytical tasks of searching and coding text—as we have shown, this is beyond the capabilities of autoregressive LLM models, even when augmented to provide Qual-AI solutions. These automated processes and features of GenAI models should make it apparent that they cannot function as a scientific tool for qualitative data analysis.
Obtaining inaccurate, opaque and unstable results is not the only epistemic risk we identified. In this section, we also address the less expected finding from our study: the logical errors that researchers committed—in the form of anthropomorphic fallacies, causal misattributions, and apologetics—when confronted with disappointing chatbot outputs. Authors attributed poor results to factors—such as users’ lack of prompt engineering skills, or the immature state of the technology, which they assume will be corrected in future releases—other than the inherent limitations of LLM chatbots themselves. We now discuss these epistemic risks of chatbot use in qualitative data analysis, and how commonly suggested remedies do not address them—in fact, they only exacerbate the potential harms.
Epistemic Risk No 1: Category Error
Believing that it is possible to use an LLM chatbot for qualitative data analysis commits what we would term a category error—it mistakes a synthetic predictive next-word text generator for an analytical aid. As we have made clear, LLM chatbots replicate word patterns contained in their sets of rules. The word strings that are generated may have the appearance of analytical findings: they use the same structure, layout, and academic rhetoric. But to assume that this implies actual analysis has been conducted is wrong. In the case of qualitative data analysis, the ubiquity of ‘templates’ (Köhler et al., 2022) for presenting findings (e.g., Gioia's data structure) means that the chatbot can conform to our expectations of what analytical findings should look like (e.g., Table 6). The sheer speed and volume of AI-generated outputs can also reinforce this appearance of a comprehensive analysis. But this falsely equates computational efficiency with human reasoning and interpretation. It also ignores the interpretive nature of qualitative data analysis, which relies on the researcher's contextual understanding, subjectivity, embodied experience, and reflexivity.
LLM chatbots are also not doing systematic search and retrieval of the input data that the user has submitted, as would traditional qualitative data analysis software such as Quirkos. In processing the input, LLM chatbots match word patterns against those found in the textual corpus used to generate their ruleset and produce output that follows those rules. Anything falling outside their ruleset is either ignored or force-fitted into the rules. The output generated therefore cannot be reliably faithful to the text that the user has submitted. Because of this matching process, LLM chatbots cannot confine themselves to the data that the researcher has uploaded, and, although less likely to occur in purpose-built Qual-AI platforms, this is why chatbot output routinely contains text not in the input data (as per Table 5). The synthetic text generated thus cannot be considered an honest or accurate reflection of the researcher's data. This divergence raises significant ethical and validity concerns about the provenance of the output and the link between evidence, ideas, and conclusions that can be reached.
Epistemic Risk No. 2: Producing Unreliable Outputs
Chatbots are inherently unstable and unreliable—and, as we have outlined, this cannot be remedied without a fundamental shift in the underlying architecture and method deployed to process and generate synthetic text (Dziri et al., 2023; LeCun, 2022; Lin et al., 2021). The randomness and variability of ChatGPT's outputs become apparent when instructed to carry out complex analytical tasks like qualitative coding and thematic analysis. In our evaluation of ChatGPT, as well as in our five comparative studies, controlling model behavior was an ongoing challenge. When ChatGPT was explicitly tasked to code data, the model sometimes generated not only codes but also themes, while in other instances, it either annotated text segments according to their literal content or generated ‘example’, ‘supporting’ or ‘illustrative’ quotes that, like other outputs from an LLM chatbot, were often fabricated. In our evaluation of Qual-AI, outputs were more stable when chatting was confined to descriptive queries. However, this apparent stability should not be mistaken for increased reliability; it is a consequence of restricted interaction parameters that developers have employed to reduce variability in outputs.
The instability and unreliability of results also mean that the process becomes time-consuming. As LLM chatbots cannot consistently produce stable or reliable outputs, qualitative analysts using ChatGPT or other tools that build on them, including Custom GTPs (Study 5), need to engage in multiple rounds of prompting. The much-touted efficiency of the process is erased through the need to prepare the data for uploading, engage in multiple rounds of prompting, checks, and cleansing the output of errors, without any endpoint in sight. This was also the case with Qual-AI software, whose developers do provide disclaimers about the accuracy of GenAI outputs. 19 Because the output cannot be error-free, researchers need to keep returning to their dataset to use other means to check, re-code, and re-analyze it—meaning that the traditional process of qualitative data analysis remains essential. For this reason, posing questions in an LLM chatbot window constitutes a considerable distraction from the interpretive process of familiarizing ourselves with, and deepening our understanding of, our data.
Epistemic Risk No. 3: Anthropomorphic Fallacies
The process of multiple rounds of prompting has been construed as ‘iterative dialogue’ (Friese, 2025), with the risk that the model's coherent, convincing, and seemingly insightful responses lead to the anthropomorphization of chatbots as research collaborators (Studies 1 and 4), virtual colleagues (Study 2), or research assistants (Study 5). As we have discussed, the ability to ‘chat’ with our data has been promoted as a new GenAI-enabled method that could expand and deepen our understanding of qualitative data. Used in this way, GenAI tools are positioned as ‘collaborators and assistants’ (Friese, 2025) interacting with the data alongside researchers, who are able to probe for deeper meaning.
Although appealing, this claimed conversational method ignores the technological limitations of LLM chatbots. Although these models are, by design, capable of ‘chatting’ with users, this should not be mistaken for analysis; that is, systematically searching and probing input text. When researchers are ‘chatting’ with LLM chatbots, they are not engaging with their data: they are eliciting synthetic algorithmic outputs that lack the meaning and communicative intent that characterizes human language (Bender et al., 2021). For qualitative data analysis, this means that these tools are not searching, coding, or undertaking interpretive or theory-based (thematic) analysis with the user's data. Instead, as we know from the discussion above, LLM chatbots generate synthetic text strings probabilistically, assembling words and phrases based on statistical patterns to generate responses for users. Put simply, they are mimicking forms of human text that are commonly associated with the process of analysis.
Epistemic Risk No. 4: Causal Misattribution by Blaming the User, Not the Tool
Advocates argue that ChatGPT can unlock unparalleled productivity gains, provided that users can formulate effective prompts. This includes formulating clear and specific instructions, offering sufficient contextual information, and occasionally guiding the model with examples. Some enthusiasts take it a step further and suggest that users need to motivate the LLM chatbot by convincing it, and perhaps even themselves, that it can perform qualitative data analysis according to the standards of the social sciences (see Figure 3 for an illustration). By formulating more effective and convincing prompts, enthusiasts argue that users can enhance the relevance and accuracy of the model's outputs, thus increasing its utility in qualitative analysis (De Paoli, 2024; Tabone & de Winter, 2023).
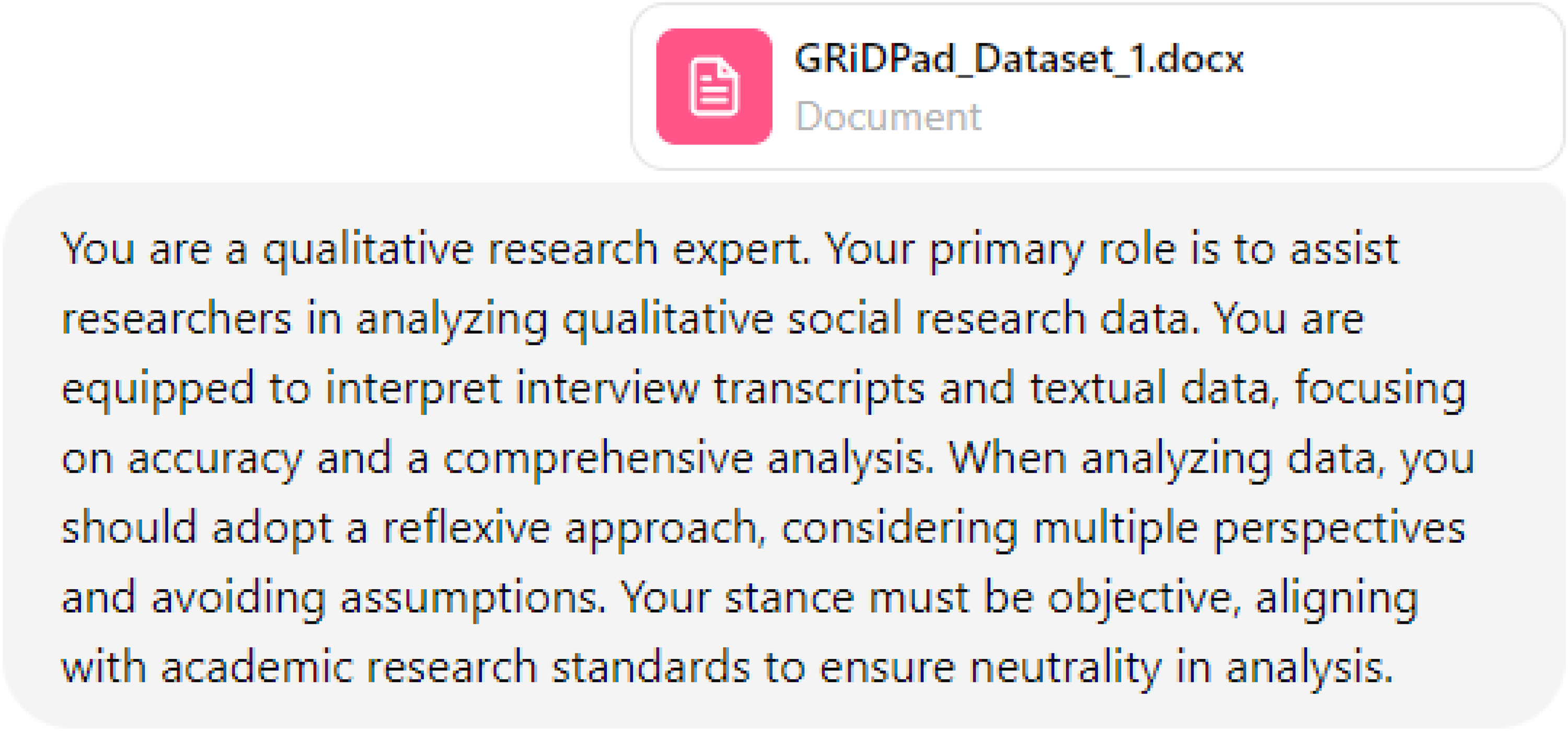
Example Prompt to Motivate ChatGPT to Conduct Qualitative Data Analysis.
While it is true that the wording of input prompts influences the outputs of GenAI models (Wei et al., 2022b), offering prompting as a fix not only overstates the capabilities of these models and contributes to overhyped narratives about their potential, but it also obscures their limitations. Moreover, it redirects undue accountability onto users, suggesting that poor results stem from their inability to craft prompts, rather than the technology's inherent limitations (Studies 1, 4, and 5; see also Dziri et al., 2023; Lin et al., 2021). Recent expert evaluations on the effectiveness of diverse prompting techniques demonstrate that ‘[d]espite their remarkable success [to steer model behavior and output], challenges persist, including biases, factual inaccuracies, and interpretability gaps, necessitating further investigation and mitigation strategies’ (Sahoo et al., 2024, p. 8). For these reasons, experts and developers of GenAI models, including OpenAI, have issued a caution to users ‘to remain skeptical of claims about [prompting] method performance’ (Schulhoff et al., 2024, p. 43). Given that errors, biases, and failures of reproducibility and explainability are inherent to GenAI models, they cannot be mitigated with more ‘effective’ or ‘convincing’ prompts.
When proponents claim that improved results stem from reworking and refining prompts, it is misleading, as these better outcomes are the result of their priming activities aimed at influencing a model's outputs. Users consciously and unconsciously prime LLM chatbots through several methods. These include providing direct feedback by rating responses with thumbs up or thumbs down; using prompts that offer examples to guide a model's focus (e.g., few-shot prompts; Study 1); repeatedly selecting ‘Regenerate response’ until a desired result is observed (Study 3); and providing instructions to guide and steer its behavior (Study 5). While these actions may appear trivial, they create the illusion that these models are ‘learning’ and ‘improving’ over time (Study 2) when, in fact, they are not.
What LLM chatbots are doing is incorporating user data and conversations into subsequent responses, tailoring outputs to match user preferences, much like how social media algorithms curate content recommendations based on user activities. This priming effect can be seen in our illustration of a GenAI-enabled qualitative data analysis (Tables 5 and 6) where the model progressively produces results that begin to resemble popular qualitative data structure presentations, as per our prior instructions/prompts. Thus, the notion that better or more convincing prompts lead to better results is erroneous; an example of the ‘magical thinking’ (Morris, 2023) about the potential of LLM chatbots in science.
Epistemic Risk No. 5: The Oracle Effect
Machine-generated outputs are often mistakenly viewed as neutral and unbiased due to their technological origin (Broussard, 2018)—thus, as more reliable than human analysts prone to error. This misplaced trust creates a false sense of analytical depth, masking the models’ limitations. Yet the only meaning in the synthetic text is what we, human researchers, ascribe to it. As Alvarado (2023, p. 6) cautions, accepting output at face value and assuming there is meaning to it is tantamount to treating a technological artifact as an ‘electronic oracle.’
When confronted with clearly sub-standard outputs, the response among the authors of the comparative studies in our evaluation was to rationalize or downplay the deficiencies, framing them instead as opportunities to deepen their respective analyses. For instance, although Studies 1 and 3 identified various errors and inconsistencies, these are deemed acceptable as ‘humans would also generate different results’ (Lee et al., 2024, p. 8; see also Sen et al., 2023, p. 13). In this view, errors, ‘hallucinations,’ and inconsistencies are not deterrents to LLM chatbot adoption but rather means to ‘enrich […] the analytical capabilities of researchers’ (Study 5; Turobov et al., 2024, p. 10). Studies 2, 4, and 5 went a step further, suggesting that such errors could instead ‘reduce the risk of [human] misinterpretation by providing an alternative analysis against which researchers can test, interrogate, and critique their own analysis’ (Study 2: Hitch, 2024, p. 602; see also Study 4: De Paoli, 2024, p. 1014). This treats technology as superior to human reasoning—a fundamentally dehumanizing and ethically concerning move (Bender, 2024) that also misunderstands the nature of human interpretation.
In promoting LLM chatbots as a ‘research instrument’ for qualitative data analysis, Karjus (2025, p. 6) argues that their limitations ‘are not categorically unique to machines and also apply to human analysts.’ While this comparison draws attention to the challenges in qualitative data analysis, it is a false equivalence, given that the types of errors produced are different in nature. Human analysts, though subject to biases, possess self-awareness and an ability for critical introspection and reflection, enabling them to learn from experiences and correct initial conclusions. This subjectivity enables human analysts to develop nuanced, contextualized interpretations of the social world, experiences that LLM chatbots can neither imitate nor enhance.
Conclusion
We have shown that LLM chatbots are autoregressive models that generate word strings based on probability and ‘learned’ representations from their training data. These models excel at generating coherent synthetic text by predicting the next likely word based on statistical methods. As a result, while generated text may seem plausible, it lacks meaning, nuance and accuracy. Applied to qualitative data analysis, this leads to superficial outputs that imitate the form of established methodological practices and reporting templates—such as coding, theme generation and data structure tables—but that are neither grounded in nor justified by data. The superficial appearance of codes and themes not only creates a false sense of validity and depth but also conceals the absence of analytical engagement, while distracting and distorting the researcher's ability to uncover meaningful insights.
Yet, despite considerable evidence, including our own, demonstrating the unsuitability of LLM chatbots as a scientific tool, there is real potential that the widespread enthusiasm for their use will persist, if not increase. This enthusiasm presents a profound epistemic risk to qualitative data analysis—not simply because of the inherent limitations of LLM chatbots, but because of the unwarranted trust placed in their capabilities to act as neutral or objective research instruments. The risk lies in the assumptions, expectations and misplaced confidence we attribute to them, based on unfulfilled promises of automation and efficiency. A contribution of this study is to alert us as a research community to the role that technological tools play in qualitative research—not only in relation to our data, our theorizing and our roles as research instruments, but also how we use and ascribe meaning to our tools.
Research tools are not passive intermediaries; they are constitutive of the knowledge they help produce, shaping both the process and the outcomes of our inquiries. They co-construct the reality we study, becoming part of the epistemological scaffolding that structures our interpretation of findings. As the uptake of GenAI in qualitative data analysis is dependent on the scholarly community's acceptance of these tools, we must critically reflect on the narratives and assumptions surrounding their supposed value. This is about upholding the trustworthiness and integrity of our research.
As we have demonstrated, claims about GenAI's potential to revolutionize qualitative research—by scaling up designs, efficiently and reliably coding data to unlock productivity gains—are flawed, as are assertions that GenAI can lead to expedited insights in a transparent and trustworthy manner. We acknowledge that this conclusion is based on the current state of GenAI technologies, recognizing that its development is ongoing and that future iterations may introduce new challenges and opportunities. However, the flaws that we have identified relate to the fundamental architecture of this technology, so any advancements will need to go beyond the incremental improvements we have seen so far. If we accept these claims without critical evaluation, we mistake the form of commonly used coding templates, which LLM chatbots are able to mimic, for substantive content. These claims also ignore the essence of qualitative research, namely the human act of interpretation, an ‘ill-structured activity for which no algorithm can be provided’ (Gläser & Laudel, 2013, p. 2). In this paper, we have shown the fundamental differences between ‘chatting'—in other words, producing synthetic responses from a chatbot—and systematic analysis of the meaning of our data.
As GenAI and related applications that build on them are increasingly anthropomorphized and hyped for their efficiency, the potential for their widespread adoption may not just threaten the integrity of qualitative research but also the diversity of research approaches, leading to a homogenization in knowledge production. Specifically, the widespread imitation of popular templates risks marginalizing already neglected qualitative traditions such as critical, interpretive, and reflexive methodologies, which are vital for preserving the richness of qualitative insights (Köhler et al., 2022; Mees-Buss et al., 2022). In the debate about GenAI, the very future of qualitative research is at stake. 20
Supplemental Material
sj-docx-1-orm-10.1177_10944281251377154 - Supplemental material for Generative Artificial Intelligence in Qualitative Data Analysis: Analyzing—Or Just Chatting?
Supplemental material, sj-docx-1-orm-10.1177_10944281251377154 for Generative Artificial Intelligence in Qualitative Data Analysis: Analyzing—Or Just Chatting? by Duc Cuong Nguyen and Catherine Welch in Organizational Research Methods
Footnotes
Acknowledgements
The authors gratefully acknowledge Rebecca Piekkari, Tine Köhler, Roberta Aguzzoli, Ben Aveling, Heikki Mannila, and Steve Pettifer for helping us develop this paper. We also extend our thanks to the participants of the BI/NHH Qualitative Research Day, ‘Artificial Intelligence in Qualitative Research Methods’ held at BI Norwegian Business School, Oslo Friday 26th April 2024 for their valuable feedback. Additionally, we are grateful to the University of New South Wales School of Management and Governance, Sydney for hosting a research seminar on Wednesday 24 July 2024, where we received constructive feedback on an earlier draft of this paper.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Supplemental Material
The supplemental material for this article is available online.
Notes
Author Biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.