
Abstract
Current supercomputers often have a heterogeneous architecture using both conventional Central Processing Units (CPUs) and Graphics Processing Units (GPUs). At the same time, numerical simulation tasks frequently involve multiphysics scenarios whose components run on different hardware due to multiple reasons, e.g., architectural requirements, pragmatism, etc. This leads naturally to a software design where different simulation modules are mapped to different subsystems of the heterogeneous architecture. We present a detailed performance analysis for such a hybrid four-way coupled simulation of a fully resolved particle-laden flow. The Eulerian representation of the flow utilizes GPUs, while the Lagrangian model for the particles runs on conventional CPUs. Two characteristic model situations involving dense and dilute particle systems are used as benchmark scenarios. First, a roofline model is employed to predict the node level performance and to show that the lattice-Boltzmann-based Eulerian fluid simulation reaches very good performance on a single GPU. Furthermore, the GPU-GPU communication for a large-scale Eulerian flow simulation results in only moderate slowdowns. This is due to the efficiency of the CUDA-aware MPI communication, combined with the use of communication hiding techniques. On 1024 A100 GPUs, an overall parallel efficiency of up to 71% is achieved. While the flow simulation has good performance characteristics, the integration of the stiff Lagrangian particle system requires frequent CPU-CPU communications that can become a bottleneck, especially when simulating the dense particle system. Additionally, special attention is paid to the CPU-GPU communication overhead since this is essential for coupling the particles to the flow simulation. However, thanks to our problem-aware co-partitioning, the CPU-GPU communication overhead is found to be negligible. As a lesson learned from this development, four criteria are postulated that a hybrid implementation must meet for the efficient use of heterogeneous supercomputers.
Keywords
1. Introduction
The Top500 list reports the most powerful supercomputers worldwide. The number of heterogeneous supercomputers, i.e., systems with additional accelerators such as Graphics Processing Units (GPUs), in the Top500 list has steadily increased in the last years, accounting for roughly 39% in June 2024. 1 Each node of such a heterogeneous supercomputer typically consists of one or many Central Processing Units (CPUs) and GPUs (Kim et al., 2012). Numerical multiphysics simulations are a powerful technique for conducting in-depth investigations of complex physical phenomena by providing detailed data, which is challenging, if not impossible, to collect in experiments. A significant challenge with these simulations is that they are computationally costly, which is why they are often run on supercomputers. Especially supercomputers containing GPUs have become increasingly popular for numerical simulations in recent years (Oyarzun et al., 2017; Rohr et al., 2014; Shimokawabe et al., 2017) as they offer unprecedented computing power. A common approach in the literature for utilizing such heterogeneous supercomputers for multiphysics simulation is hybrid implementation (Feichtinger, 2012; Kotsalos et al., 2021; Xu et al., 2012), i.e., different simulation modules running on different hardware. Several reasons are predestinating or sometimes even forcing hybrid implementations in the context of multiphysics simulations. First, the various combined methodologies in such multiphysics simulations may exhibit distinctly contrasting computational properties, e.g., problem sizes, parallel and sequential portions, conditionals, and branching. Therefore, the best-suited hardware architecture can differ between the simulation modules. Second, if one simulation module dominates the overall run time of the simulation, accelerating only this part using GPUs is a straightforward, pragmatic, and development time-saving alternative to porting the whole code base to GPU. Third, practical limitations can challenge multiphysics simulations: not all coupled software frameworks and modules may support the same hardware, e.g., if parts of the simulation use commercial software. While hybrid implementations are commonly used in practice for the aforementioned reasons, they introduce inherent challenges in performance and scalability.
A prominent example of multiphysics simulations is coupled fluid-particle simulations with fully resolved particles (i.e., multiple fluid cells per particle diameter, see Rettinger, 2023). Such simulations have been used in the literature, among others, to understand the formation and dynamics of dunes in river beds (Kidanemariam and Uhlmann, 2014; Rettinger et al., 2017; Schwarzmeier et al., 2023), analyze the chimney fluidization in a granular medium (Ngoma et al., 2018), investigate the erosion kinetics of soil under an impinging jet (Benseghier et al., 2020) and to analyze mobile sediment beds (Rettinger et al., 2022; Vowinckel et al., 2014). One encounters some of the previously mentioned reasons for hybrid implementations in the context of coupled fluid-particle simulations with fully resolved particles. First, when coupling a particle simulation with a fluid simulation using a fully resolved approach, the number of particles is typically at least three orders of magnitude smaller than the number of fluid cells, leading to an imbalance in the workload, where the fluid simulation can overwhelmingly dominate the total run time of the simulation. Therefore, accelerating only the fluid simulation using GPUs is a pragmatic approach for this application. Second, while the fluid simulation employed here uses a structured, cartesian-grid-based methodology and is therefore ideally suited for GPU parallelization (Holzer et al., 2021; Kuznik et al., 2010), the situation is more complex for the particle simulation. One extreme is molecular dynamics simulations using millions of particles but relatively simple and uniform particle-particle interactions, which are well suited for GPUs (Machado et al., 2021). The other extreme is particle simulations consisting of few but large particles with complex shapes and sophisticated and diverse particle-particle interactions (Iglberger and Rüde, 2010), assumably better suited for CPUs. The particle methodology of this paper lies somewhere in between. While spherical particles are used, the number of particles is comparably small (due to being fully resolved), and the particle-particle interactions are more sophisticated (e.g., lubrication corrections) than the typical molecular dynamics or Discrete Element Method (DEM) simulation on GPUs in the literature. This effect will increase when introducing more complex particle shapes or additional particle-particle interactions (such as cohesion) in the future.
Numerous fluid-particle simulations in the literature use hybrid parallelization in one way or another, of which we present a representative selection in the following. One example is simulating deformable bodies (using the finite element method) in a fluid, i.e., blood cells in cellular blood flow (Kotsalos et al., 2021). Here, the focus is more on structural mechanics, as the finite element method dominates the overall run time and is, therefore, the accelerated part of the code. Hybrid approaches have also been used in the literature to couple commercial Computational Fluid Dynamics (CFD) solvers on the CPU such as Ansys (He et al., 2020; Sousani et al., 2019), or AVL fire (Jajcevic et al., 2013) with the DEM on the GPU. Furthermore, simulations have been accelerated using hybrid parallelization to gain a deeper understanding of fluidized beds (Norouzi et al., 2017; Xu et al., 2012), or the effects of porosity and tortuosity on soil permeability (Sheikh and Pak, 2015). Another variant is to use the GPU for both the fluid and the particles, but the CPU supports the particle dynamics through collision detection (Junior et al., 2010). Furthermore, we point the reader’s attention to a related work utilizing a heterogeneous-hybrid approach, i.e., CPUs for the particles, while the fluid simulation is distributed on both the CPUs and GPUs (Feichtinger, 2012).
We chose the Partially Saturated Cells Method (PSM) for the coupling between the fluid and solid phase as it has been used successfully in the context of GPUs (Benseghier et al., 2020; Fukumoto et al., 2021) due to its Single Instruction, Multiple Data (SIMD) nature.
In this work, we postulate several performance criteria that a hybrid implementation has to meet in our opinion for an efficient use of a heterogeneous supercomputer without misusing resources. First, the overhead introduced by the hybrid implementation (i.e., the CPU-GPU communication) must be negligible compared to the overall run time. Second, the performance-critical part (in our case, the fluid simulation) should show good performance on the GPU. Third, the share of the GPU run time of the total run time must be sufficiently high to justify using a heterogeneous cluster. Fourth, it has to show a satisfactory weak scaling performance for the efficient use of multiple supercomputer nodes. One of the main contributions is introducing a multi-CPU-multi-GPU implementation for fully resolved fluid-particle simulations, fulfilling the four criteria stated above. To evaluate the presented implementation, an in-depth performance analysis on a state-of-the-art heterogeneous supercomputer is provided, comparing two contrasting cases of a fluidized bed simulation, namely in dense and dilute states of the solid granular phase. The paper focuses on the experience with the performance and scalability of the presented hybrid implementation on supercomputers rather than on the exposition of physical results. Coupled fluid-particle implementations in the literature using a comparable particle methodology still are often limited to CPUs (Kidanemariam and Uhlmann, 2014; Rettinger et al., 2017; Vowinckel et al., 2014). With this work, we report and study the experience with the performance and scalability of the presented hybrid implementation on a supercomputer to allow other researchers to make an informed decision if such a ‘partial’ acceleration might be a suitable approach for their codes.
2. Numerical methods
Generally, fully resolved coupled fluid-particle simulations consist of three modules: fluid dynamics, particle physics, and fluid-particle coupling. In this section, we introduce the background of the methods based on the work of Rettinger and Rüde (2017, 2022). Figure 1 illustrates coupled fluid-particle simulations using the PSM, as it will be explained in the upcoming sections. Two-dimensional sketch of coupled fluid-particle simulations using the PSM.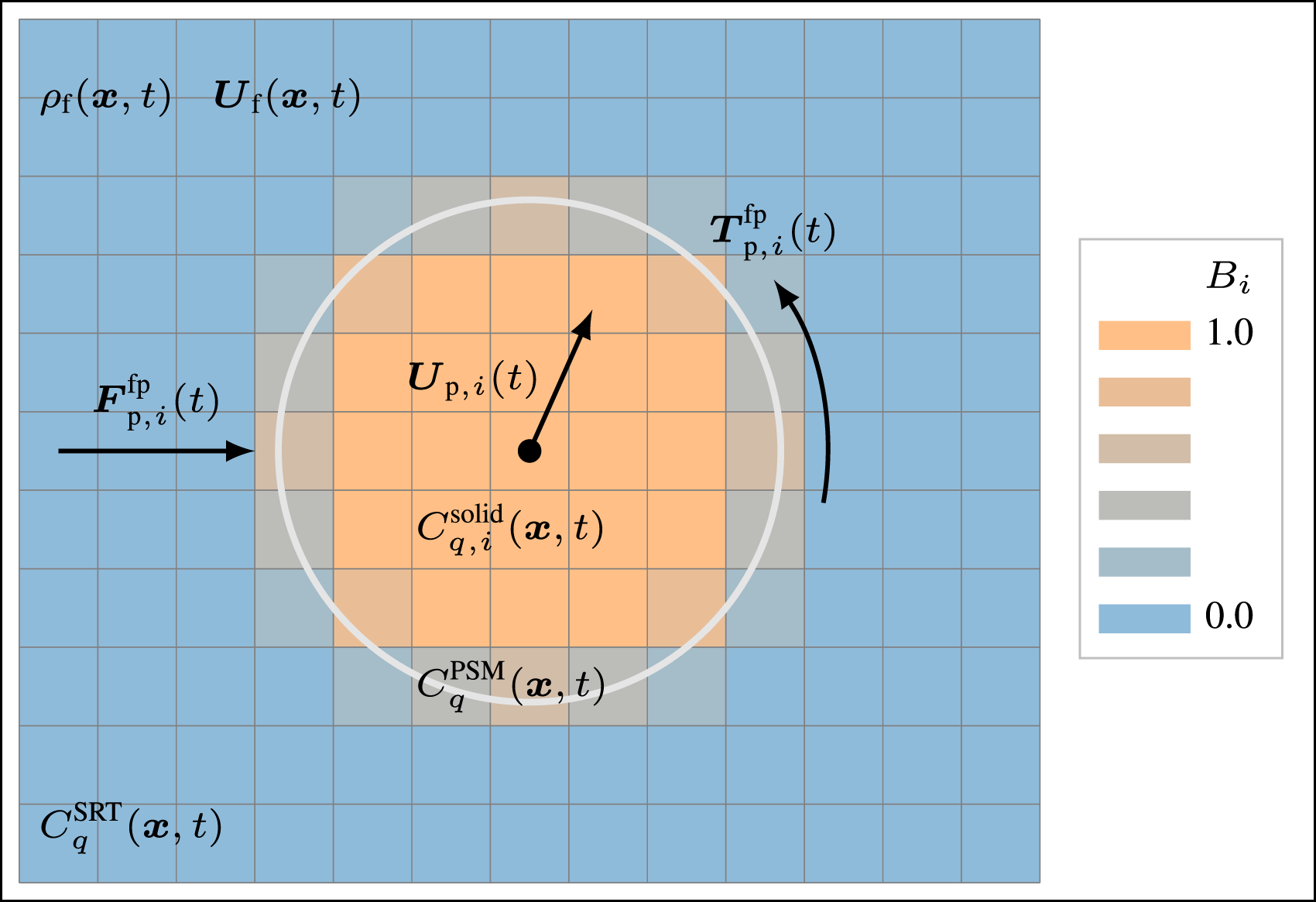
2.1. Lattice Boltzmann method
We use the Lattice Boltzmann Method (LBM) with the D3Q19 lattice model for the hydrodynamics simulation, an alternative to conventional Navier-Stokes solvers (Krüger et al., 2017). We evolve 19 Particle Distribution Functions (PDFs)
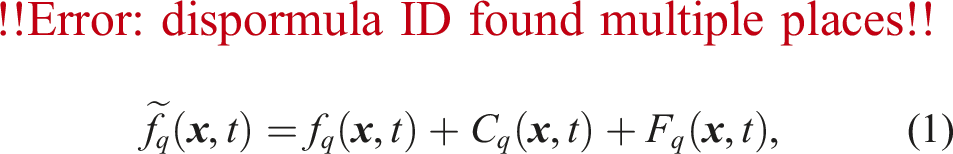
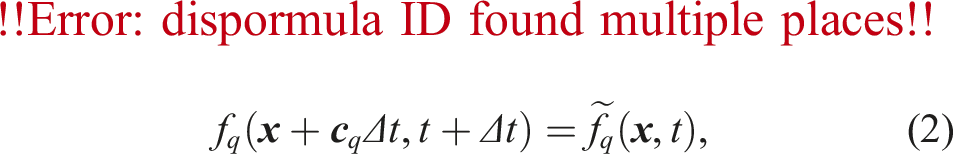
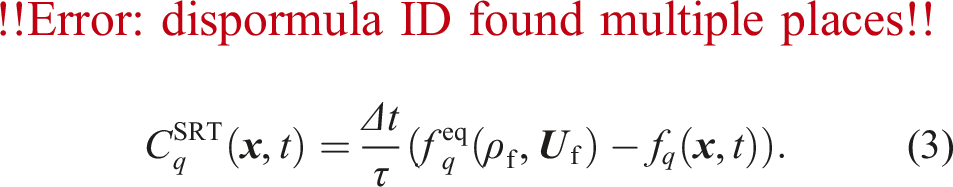
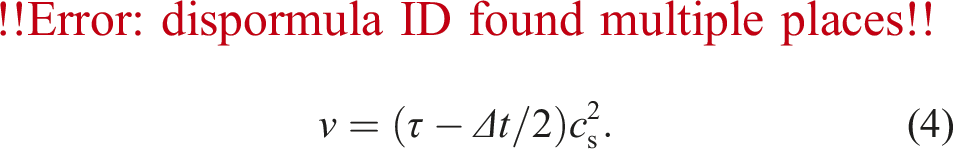

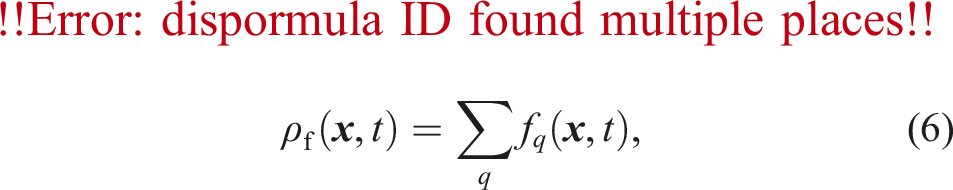
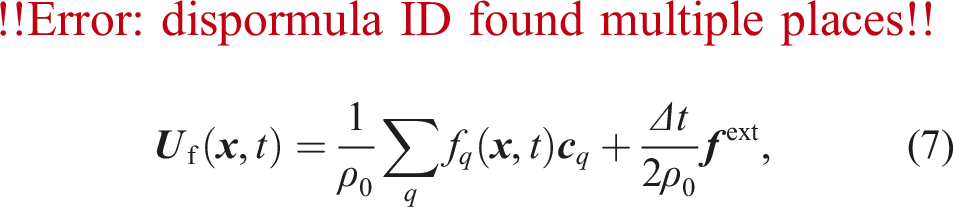

2.2. Particle dynamics
The behavior of the particles is modeled using the DEM (Cundall and Strack, 1979). The total force
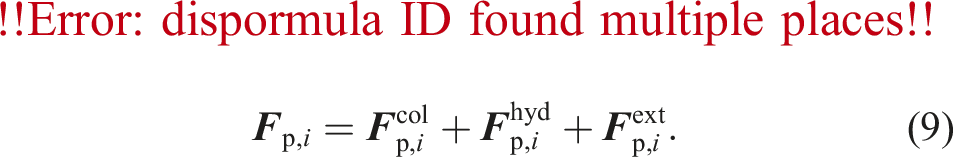
2.2.1. Particle interactions using the discrete element method
The collision between particle

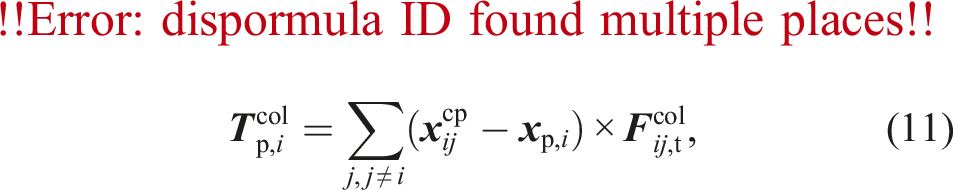
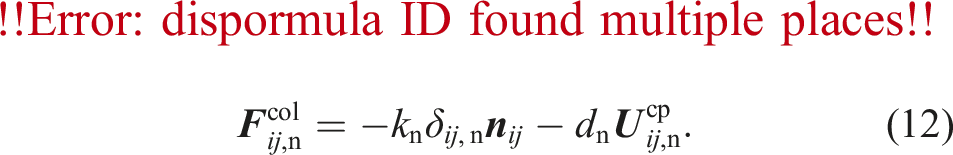
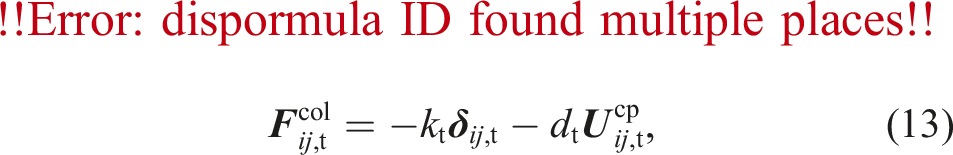

2.2.2. Integration of the particle properties
We update the particle’s position and velocity by solving the Newton-Euler equations of motion using the Velocity Verlet integrator:


2.3. Fully resolved fluid-particle coupling method
The task of the coupling is to perform momentum exchange between the fluid and the solid phase. We use the PSM for the fully resolved fluid-particle coupling (Noble and Torczynski, 1998). It modifies the LBM collision step from equation (1) by introducing the solid volume fraction

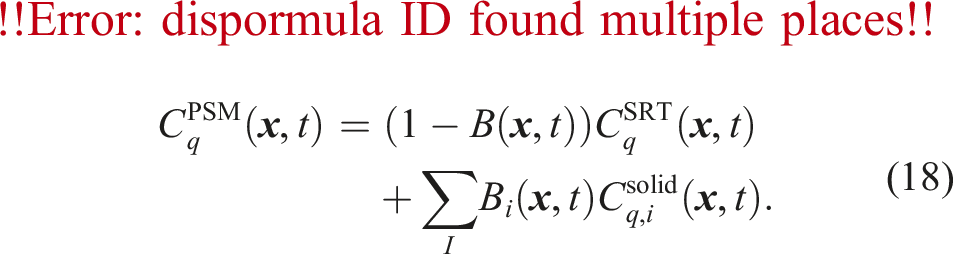

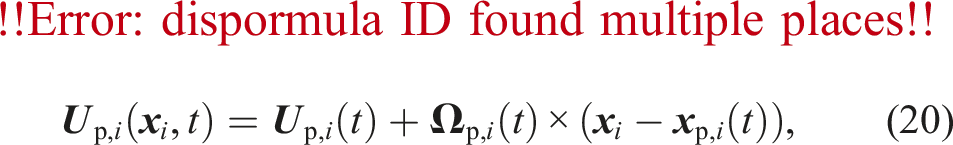
So far, we have only considered the influence of the particles on the fluid. However, the fluid also influences the particles through hydrodynamic forces. We compute the force


2.3.1. Lubrication correction
The lubrication force and torque act on two particles approaching each other. The two particles squeeze out the fluid inside the gap, which exerts a force in the opposite direction of the relative motion. However, this effect would only be covered correctly by the fluid-particle coupling for a very fine grid resolution, which is computationally too expensive. As the lubrication force has a significant influence, we compute lubrication correction force terms to compensate for the inability of the coupling method to represent these forces correctly. We compute lubrication correction terms due to normal- and tangential translations and rotations. Therefore, the total hydrodynamic force
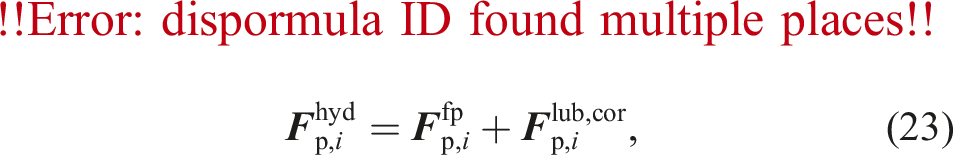
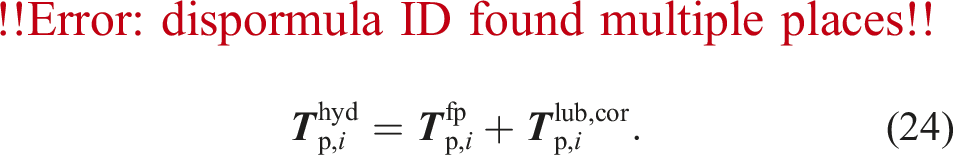
2.3.2. Particle mapping
A coupled fluid-particle simulation using the PSM requires the computation of the solid volume fraction
In Figure 2, the overlap fraction The linear approximation yields the analytical solution for the blue cells. The particle is represented by the orange circle. Note that the grid is coarsened for better clarity.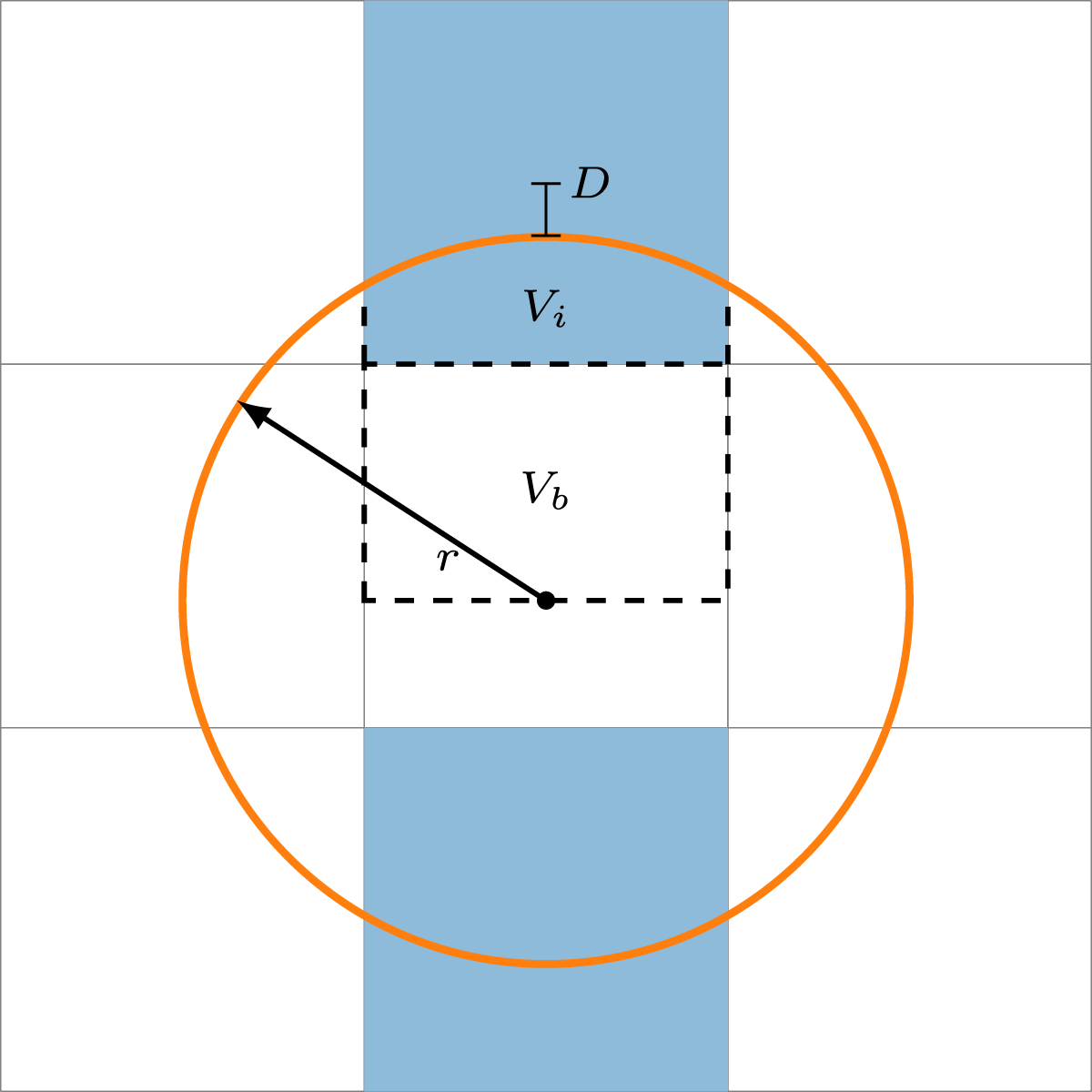
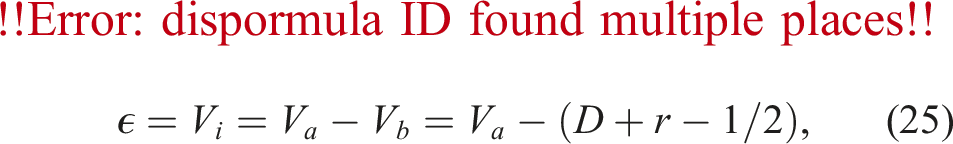
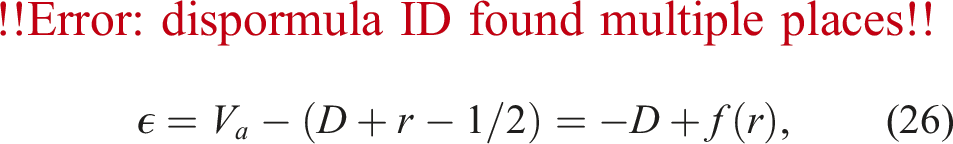

3. Implementation
We implemented our hybrid coupled fluid-particle simulation within the massively parallel multiphysics framework Partitioning of a 2D simulation domain into four blocks. The circles with ID 0 to ID 9 indicate the particles, and the blue cells are the fluid. One GPUx for updating the fluid cells is assigned to each block x, and the corresponding CPUx cores are responsible for the particle dynamics. CPUx represents the CPU cores having a direct connection/affinity to GPUx. MPI rank x is assigned to CPUx, distributes the particle computations among CPUx using OpenMP, and uses GPUx for the fluid dynamics.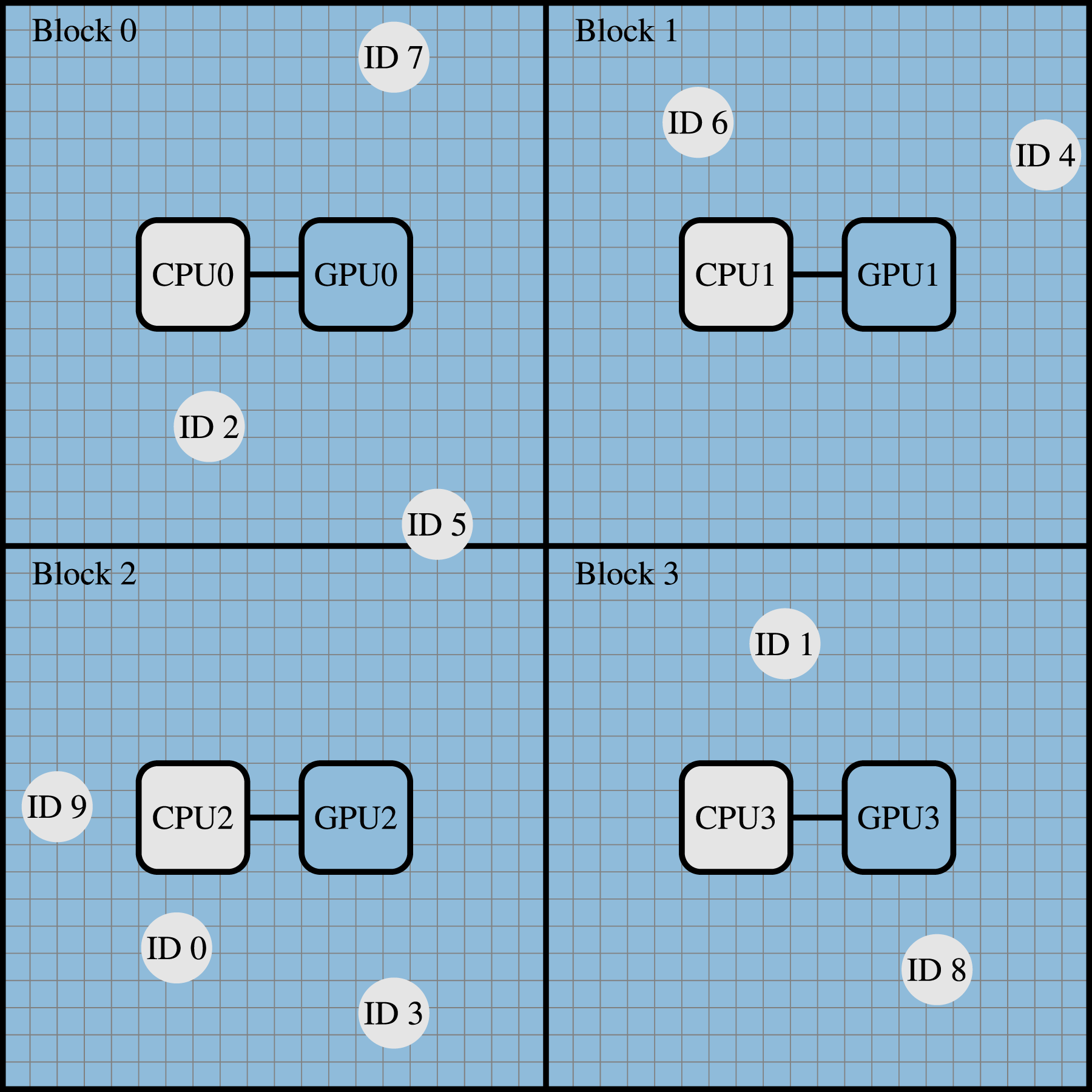
We want to highlight that the particle simulation is not a standalone framework, but for the particles and the fluid that are physically close to each other (i.e., in the same block), one MPI process is responsible for both the particle and fluid dynamics and the CPU and GPU have a direct connection/affinity. The CPU cores belonging to the respective GPU are responsible for updating the particles whose center of mass lies inside that block (local particles). In Figure 3, CPU0 is responsible for the particles with ID 2, 5, and 7. Additionally, particles can overlap with a given block whose center of mass lies in another block (ghost particles). In Figure 3, the particle with ID 5 is local for block 0 and ghost for block 2. This overlapping causes the need for communication between the CPUs. The particle computations within a block are parallelized among the CPU cores using OpenMP. The communication between neighboring blocks is implemented using the CUDA-Aware Message Passing Interface. On clusters with multiple GPUs sharing a node and NVLinks between the GPUs, NVIDIA GPUDirect is used for direct GPU-GPU MPI communications between the GPUs on the node. Figure 4 illustrates the different modules of the simulation, on which hardware they are running, the workflow, and the necessary communication steps. We will explain the figure in detail in the following sections. Generally speaking, the GPU is responsible for all operations on fluid cells (i.e., the LBM and the coupling), whereas the CPU performs all computations on particles. The associated data structures are consequently located in the respective memories (fluid cells in GPU memory, particles in CPU memory). Flowchart of our hybrid CPU-GPU implementation from the perspective of a CPU and GPU responsible for the same block. The color coding indicates the communication types required within each step.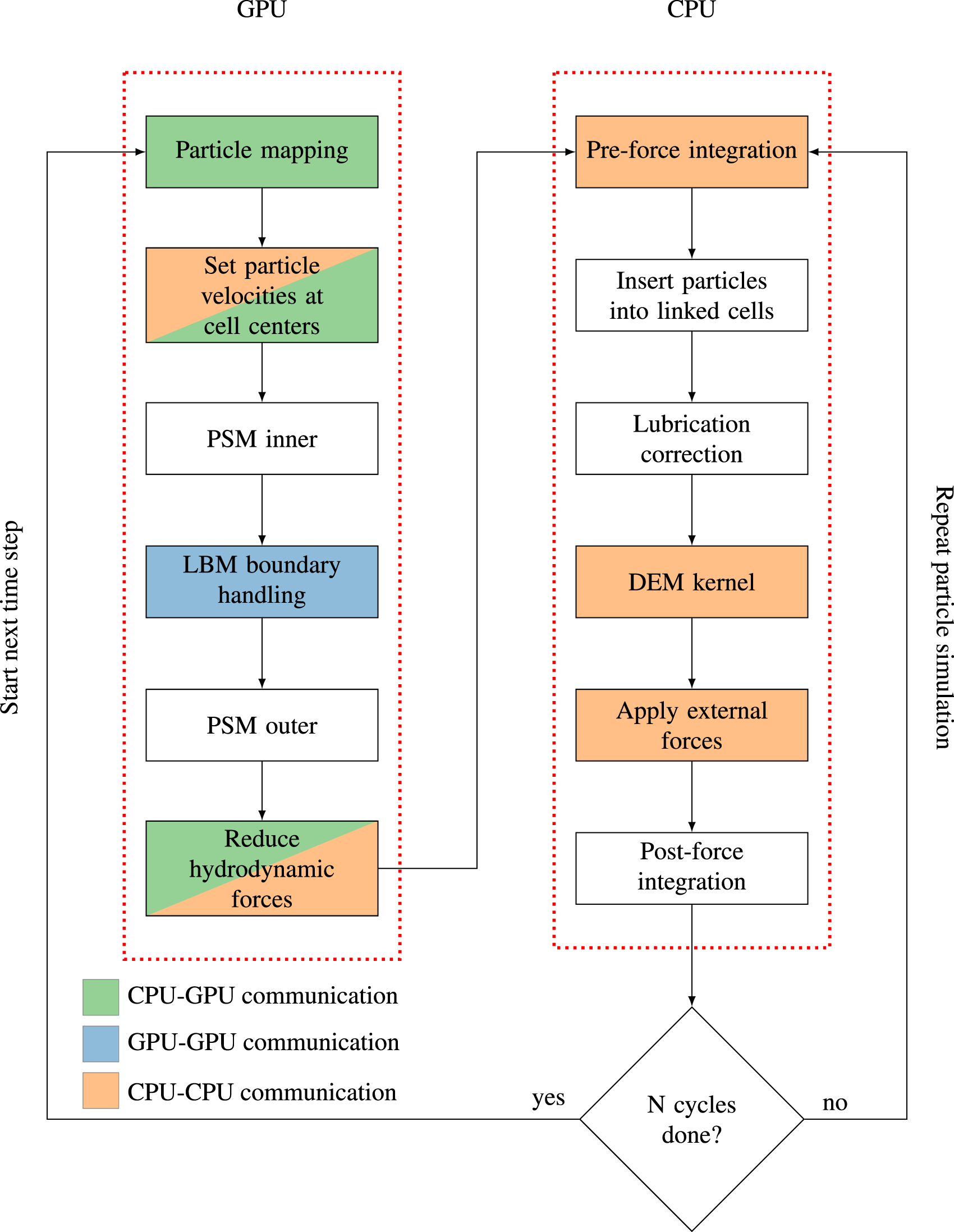
3.1. Fluid dynamics and coupling on the GPU
Performing an LBM update step requires the communication of boundary cells between neighboring GPUs. However, the first three kernels do not need neighboring information. Therefore, the communication is hidden behind those kernels by starting a non-blocking send before the particle mapping. A time step begins with the coupling from the particles to the fluid.
3.1.1. Coupling from the particles to the fluid
For the particle mapping, the GPU has to check overlaps for all cell-particle combinations, even though there is no overlap for most cell-particle combinations. This check quickly becomes very computationally expensive. Therefore, we reduce the computational effort by dividing each block into Overview of the different communication steps from the perspective of a CPU and GPU responsible for the same block.
3.1.2. Fluid simulation
Next, the PSM inner kernel is performed. The term ‘inner’ indicates that this kernel updates all cells except the outermost layer of cells. Skipping the outermost layer ensures that this routine can be called without waiting for the previously started GPU-GPU communication to finish. The PSM kernel creates the highest workload of the entire simulation. It is, therefore, performance-critical. We use the code generation framework lbmpy (Bauer et al., 2021b; Hennig et al., 2023) to obtain highly efficient and scalable LBM CUDA kernels. lbmpy allows the formulation of arbitrary LBM methods (such as the PSM) as a symbolic representation and generates optimized and parallel compute kernels. We integrate those generated compute kernels within the simulation in
3.1.3. Coupling from the fluid to the particles
Finally, the GPU reduces the forces and torques exerted by the fluid on the particles
3.2. Particle dynamics on the CPU
The first step of the Particle Dynamics (PD) simulation on the CPU is the pre-force integration of the velocities to update the particle positions (equation (15)). The latter particle movement requires synchronization between the CPUs to account for the position update, which potentially moves particles from one block to another, making other CPUs responsible for the particles. Computing particle-particle interactions by iterating over all particle pairs can quickly become very expensive due to its
Running the fluid dynamics and coupling on the GPU first and the particle dynamics on the CPU second seems to be a promising candidate for overlapping the CPU and GPU computations to gain some performance improvements. Therefore, we elaborate on this possibility in the remainder of this section. The following will refer to the different simulation modules as they are named in Figure 4.
Under the condition that the numerical error must not increase, only some parts of the CPU and GPU computations can overlap, others cannot due to the dependencies of the two-way coupling. There are two ways of overlapping the CPU and GPU parts: within a time step or between subsequent time steps. Only the post-force integration step of the particle simulation on the CPU in time step
4. Performance analysis
We use the Juwels Booster cluster for the performance evaluation. Each GPGPU node consists of four Nvidia A100 40 GB GPUs, two AMD EPYC 7402 CPUs (24 cores per chip), and eight NUMA domains. Thus, each CPU is shared by two GPUs and is divided into four NUMA domains, with six cores belonging to one NUMA domain. Four out of the eight NUMA domains have independent PCIe lanes to the four GPUs on Juwels Booster, ensuring that CPU-GPU communications do not interfere between the GPUs. The following will refer to a GPU and an associated (i.e., directly connected via a PCIe lane) NUMA domain with its six cores as a CPU-GPU pair. All GPUs within a node are connected via NVLinks, allowing direct GPU-GPU communication. For communication between GPUs not sharing a node, PCIe lanes connect each GPU to its own Mellanox HDR200 InfiniBand ConnectX 6 adapter. A SCALE kernel (i.e., a 1:1 read/write ratio) yields a memory bandwidth of about 1400 GB/s for the A100 40 GB (Ernst et al., 2023). We use 20 cells per diameter to geometrically resolve the particles (Rettinger et al., 2022; Rettinger and Rüde, 2022; Biegert et al., 2017; Costa et al., 2015). The upcoming sections first introduce the computational properties of the simulated cases, followed by their performance results.
4.1. Simulation setups
In order to study the performance of the here introduced hybrid coupled fluid-particle implementation, we are using a fluidized bed simulation. We compare two cases: the dilute case and the dense case. They exhibit different characteristics regarding the number of particles per volume and the number of particle-particle interactions. We choose these two cases to investigate how different particle workloads on the CPUs influence the overall performance of the hybrid CPU-GPU implementation. We use 10 particle sub-cycles (Section 3) per time step. We discretize the domain using Visualization of the consolidated fluidized bed setup running on one CPU-GPU pair. For the fluid field, only a two-dimensional slice is visualized.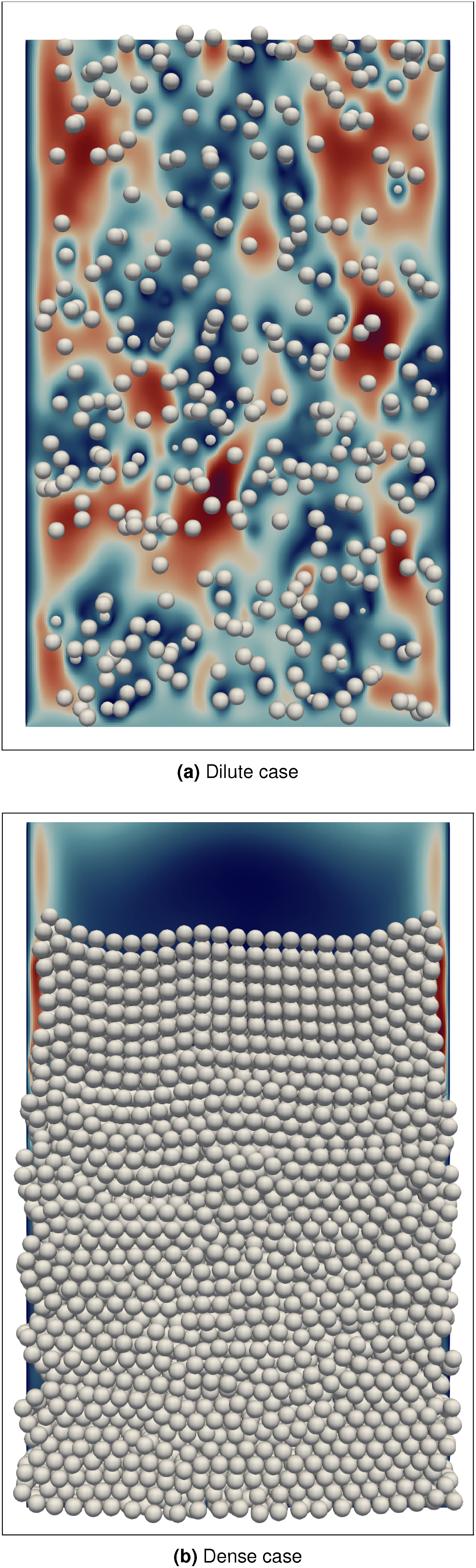
4.2. Performance results
In this section, we present and analyze the performance results. We first look at the individual run times of the different simulation modules to understand the bottlenecks. Furthermore, we present a weak scaling benchmark for both cases up to 1024 CPU-GPU pairs. In addition, we show strong scaling results for three different problem sizes up to 1024 CPU-GPU pairs. Finally, we demonstrate the acceleration potential of hybrid implementations by comparing it to a large-scale CPU-only simulation from the literature. For all results, we average over 500 time steps. In the following, we will refer to the performance criteria formulated in Section 1.
4.2.1. Run times of different simulation modules
We investigate the run times of the different simulation modules to analyze the overhead introduced by the hybrid implementation, i.e., the CPU-GPU communication, assess the GPU performance, and detect the overall bottlenecks. To evaluate the performance of the PSM kernel on the GPU, we employ a roofline model (Hager and Wellein, 2010) for the LBM kernel. We determine the maximal possible performance for the given kernel and hardware when exploiting the maximal memory bandwidth (i.e., the performance ‘lightspeed’ estimation). The PSM kernel comprises the LBM kernel plus additional memory transfers depending on the number of overlapping particles. As this number differs from cell to cell, the PSM roofline model would not be straightforward. Therefore, we analyze the LBM model only, keeping in mind that this is a too optimistic performance estimation. Since we use the D3Q19 lattice model, we read and write 19 PDFs per cell and time step. This results in 19 reads and 19 writes (double-precision), i.e., 304 bytes to update one lattice cell (Feichtinger et al., 2015). The domain consists of 8e7 fluid cells. This results in the following minimal run time per time step according to the roofline model:

We divide the total run time into the following modules: the PSM kernel (PSM), the CPU-GPU communication (comm), the particle mapping (mapping), setting the particle velocities (setU), reducing the hydrodynamic forces Individual run times of the different simulation modules on a CPU-GPU pair.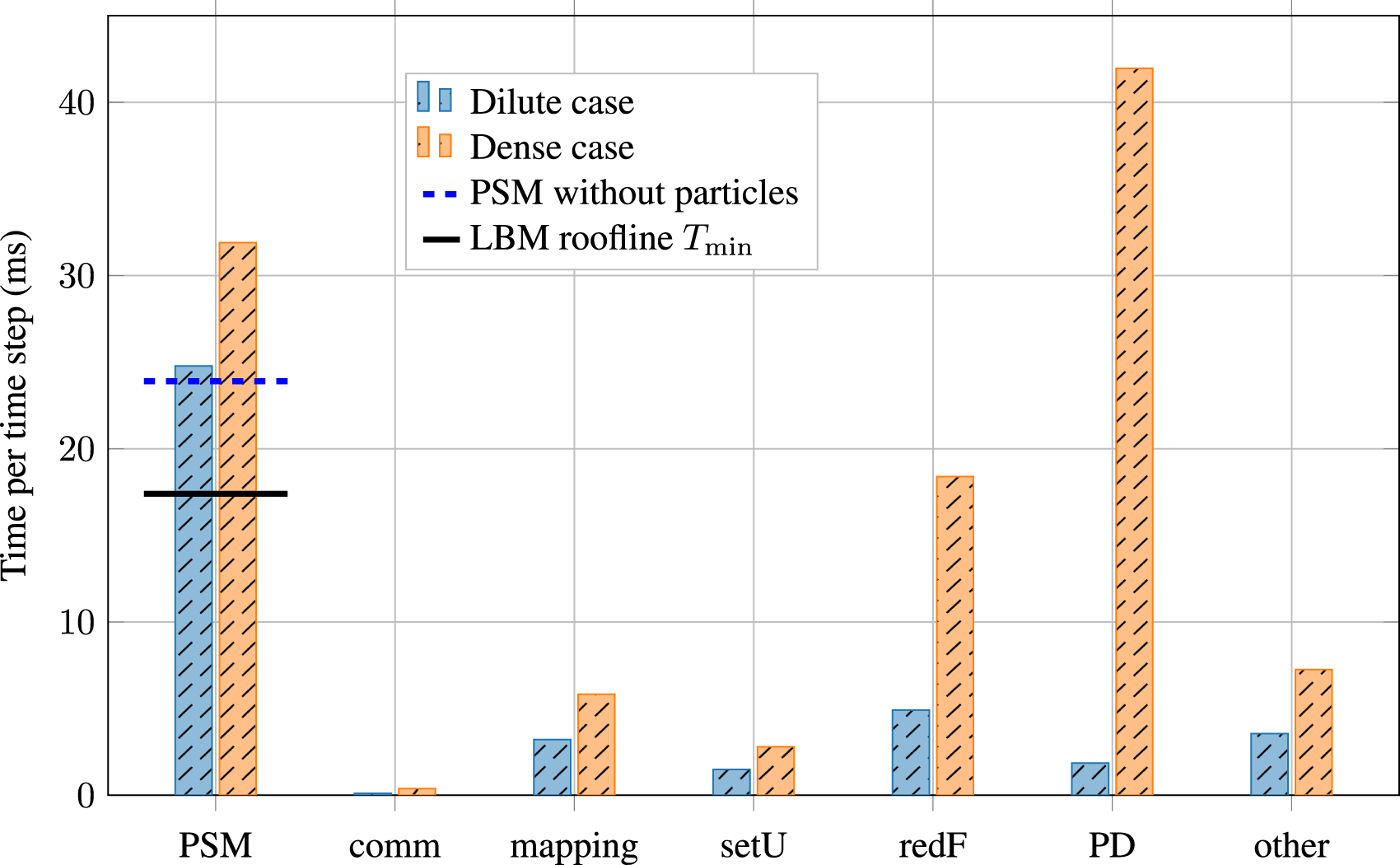
In the dilute case, the PSM kernel needs about 42% more time per time step than the LBM lightspeed estimation, and the dense case 83% more time. Compared to the PSM kernel without particles, the dilute case needs about 4% more time per time step, and the dense case 34% more time. The CPU-GPU communication is negligible for both cases. All modules take longer in the dense case than in the dilute case. While in the dilute case, the PSM kernel accounts for the majority of the run time, the PD simulation needs more time than the PSM kernel in the dense case. Still, most of the run time is spent on GPU routines in the dense case.
The overhead introduced by the hybrid implementation is negligible because we only transfer a small amount of double-precision values per particle but no fluid cells, and thanks to the problem-aware co-partitioning. The overhead, therefore, shows that a hybrid parallelization with the presented technique is a viable approach, and the first criterion is met. The performance of the PSM kernel is close to utilizing the total memory bandwidth of the A100, especially considering that the given roofline model does not take the memory traffic due to the solid part of the PSM kernel into account. Therefore, the second criterion is met. There is a significant performance gain for the PSM kernel on the GPU compared to a CPU-only implementation since the PSM kernel is utilizing almost the entire memory bandwidth, which is significantly lower on CPUs. Even in the dense case, the GPU run time accounts for most of the total time because the fluid and coupling workload is much higher than the particle workload, even though we use 10 particle sub-cycles. Therefore, the third criterion is met. The PSM kernel exhibits two remarkable effects that we analyze in detail below using NVIDIA Nsight Compute. 2
First, the significant difference between the LBM main memory roofline (horizontal line) and the PSM kernel without particles (dashed horizontal line) in Figure 7 indicates that the PSM kernel cannot fully utilize the main memory bandwidth as the memory transfers of the PSM kernel in the absence of particles are very similar to the ones assumed in the LBM main memory roofline. This is noticeable because the PSM is an extension of the LBM, and it is known that the LBM can nearly fully utilize the main memory bandwidth on the A100 architecture (Holzer et al., 2024; Lehmann et al., 2022). The PSM kernel uses 196 registers per thread. This large number of registers per thread heavily limits the number of warps per Streaming Multiprocessor (SM), leading to a maximum possible occupancy of the SMs of only 12.50%. This low occupancy is insufficient to issue enough load/store instructions to fully exploit the main memory bandwidth, resulting in a difference between the PSM without particles and the LBM memory roofline.
Second, while the PSM kernel is in the dilute case only slightly slower than without particles, this difference gets more significant in the dense case. Several effects differentiate the dilute and dense cases. First, more particles increase the unfavorable GPU workload, i.e., warp divergence and coalesced access. The branch instructions increase by 2.06% in the dilute case and by 18.18% in the dense case compared to the PSM kernel without particles. The number of excessive sectors due to uncoalesced global accesses increases by 78.49% from the dilute case to the dense case resulting in 21% of the total sectors in the dense case. Besides that, the number of instructions issued increases by 4.32% in the dilute case and 39.51% in the dense case, which is in a similar range than the run time increase, corresponding to the instruction boundness of the code mentioned in the first effect (i.e., the low occupancy of the SMs limits the issued instructions). Since the increase in main memory traffic is 0.98% (dilute case) and 12.15% (dense case) and therefore smaller than the run time increase, the main memory utilization drops from 65.85% (dilute case) to 52.56% (dense case).
4.2.2. Weak scaling
When increasing the simulation domain further to simulate physically relevant scenarios, using a single CPU-GPU pair is often insufficient. Instead, multiple pairs or even multiple nodes of a supercomputer must be used. Therefore, a satisfactory weak scaling is desirable. For weak scaling, the problem size is increased with an increasing number of CPU-GPU pairs, keeping the workload per CPU-GPU pair constant. When having a perfect weak scaling, the performance per CPU-GPU pair stays constant, independent of the number of CPU-GPU pairs used. In the context of LBM, MLUPs is a standard performance metric for weak scaling (Holzer et al., 2021), meaning how many lattice cell updates the hardware performs per second. We use the total run time for computing the MLUPs, containing both the CPU (particles) and the GPU (fluid, coupling) time. For the weak-scaling plots, we have conducted at least three benchmarking runs and will use the best sample in the following. We start with a single CPU-GPU pair and a single domain block as described in Section 4.1. We then double the number of CPU-GPU pairs successively until we reach 1024. At the same time, we double the domain blocks/size alternately in each direction: Weak scaling performance for both cases up to 1024 CPU-GPU pairs. Weak scaling parallel efficiency for both cases up to 1024 CPU-GPU pairs.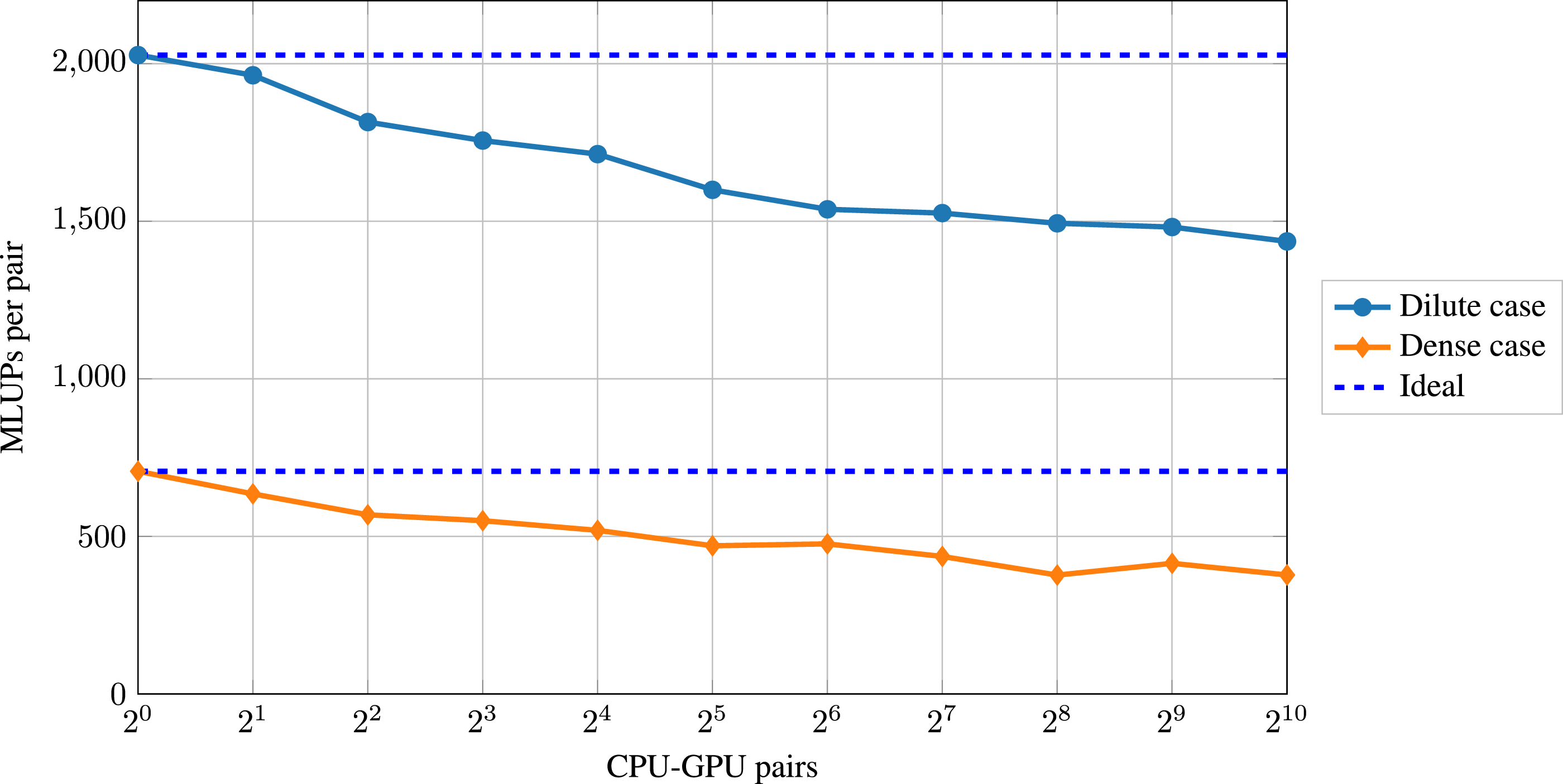
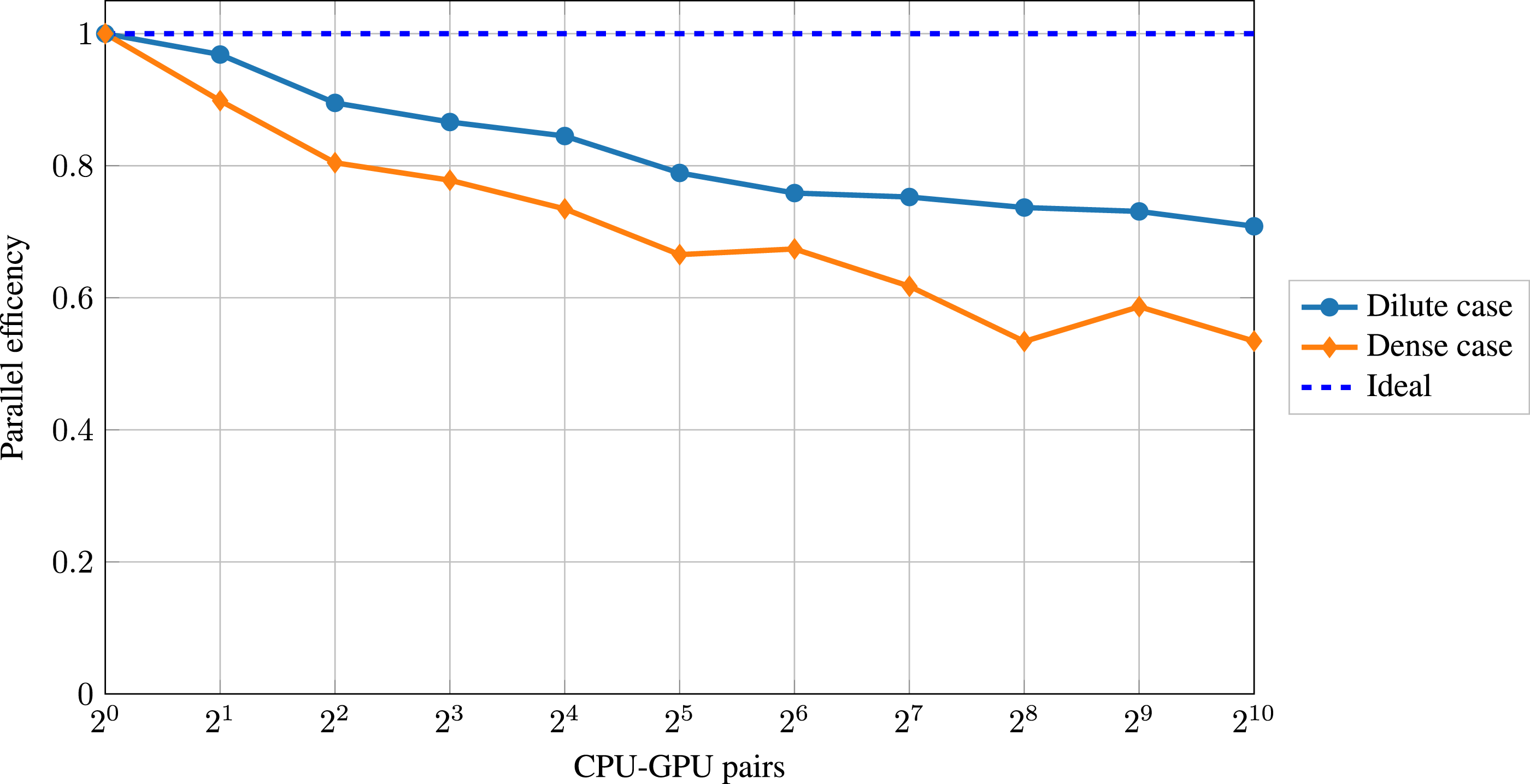
We observe a roughly three times higher performance for the dilute case than for the dense case. Both cases show a parallel efficiency decrease particularly strong in the beginning. The parallel efficiency is 71% in the dilute case and 53% in the dense case when using 1024 CPU-GPU pairs, which corresponds to a domain size of
Interpreting the overall weak scaling behavior requires more detailed analysis of the scaling of the different simulation modules. When using a single CPU-GPU pair, the dominating routines are the PD, the PSM kernel, and the coupling (i.e., particle mapping, setting the particle velocities and reducing the hydrodynamic forces Weak scaling performance of the dominating modules for the dilute case up to 1024 CPU-GPU pairs. Weak scaling performance of the dominating modules for the dense case up to 1024 CPU-GPU pairs.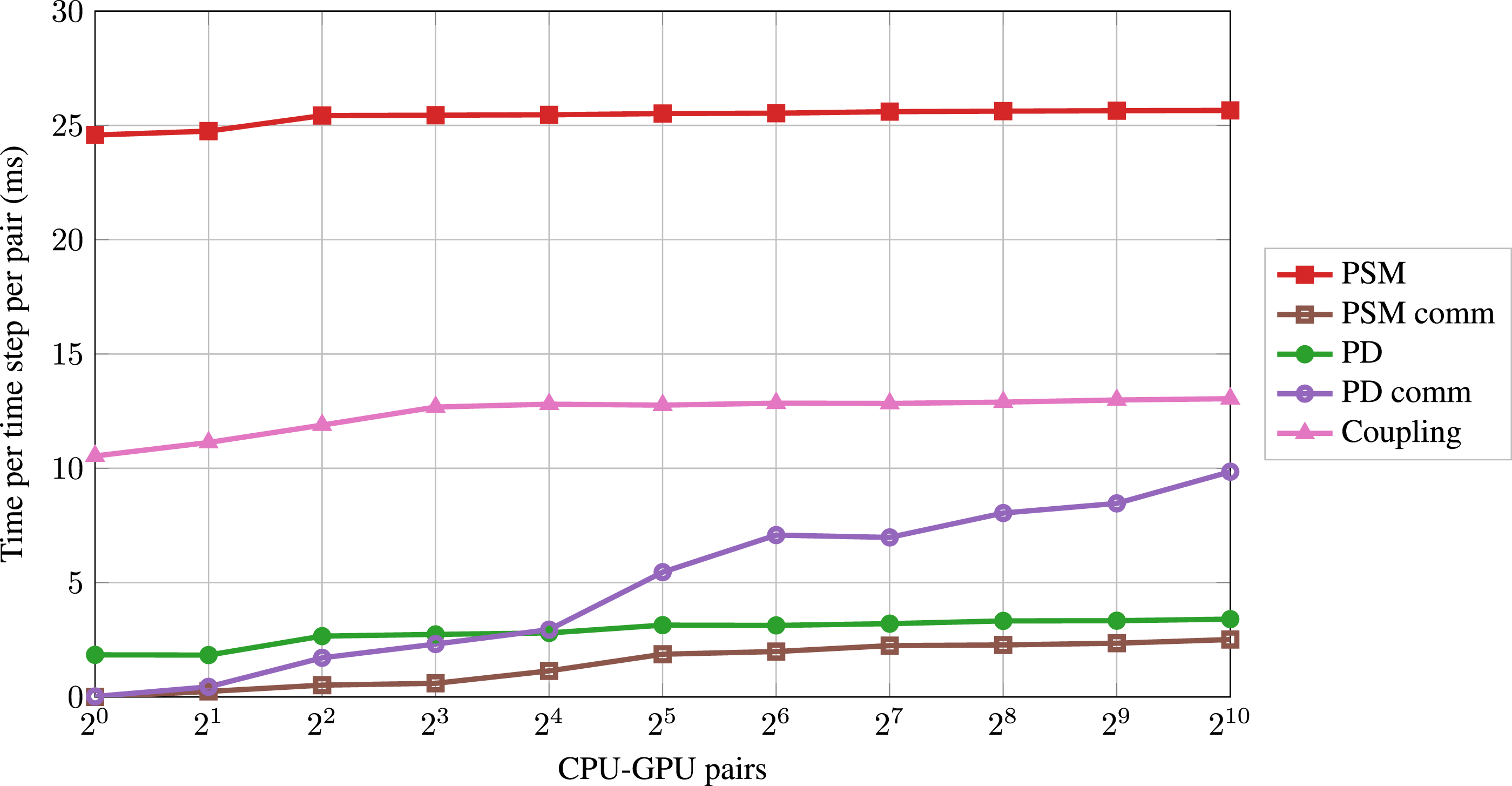
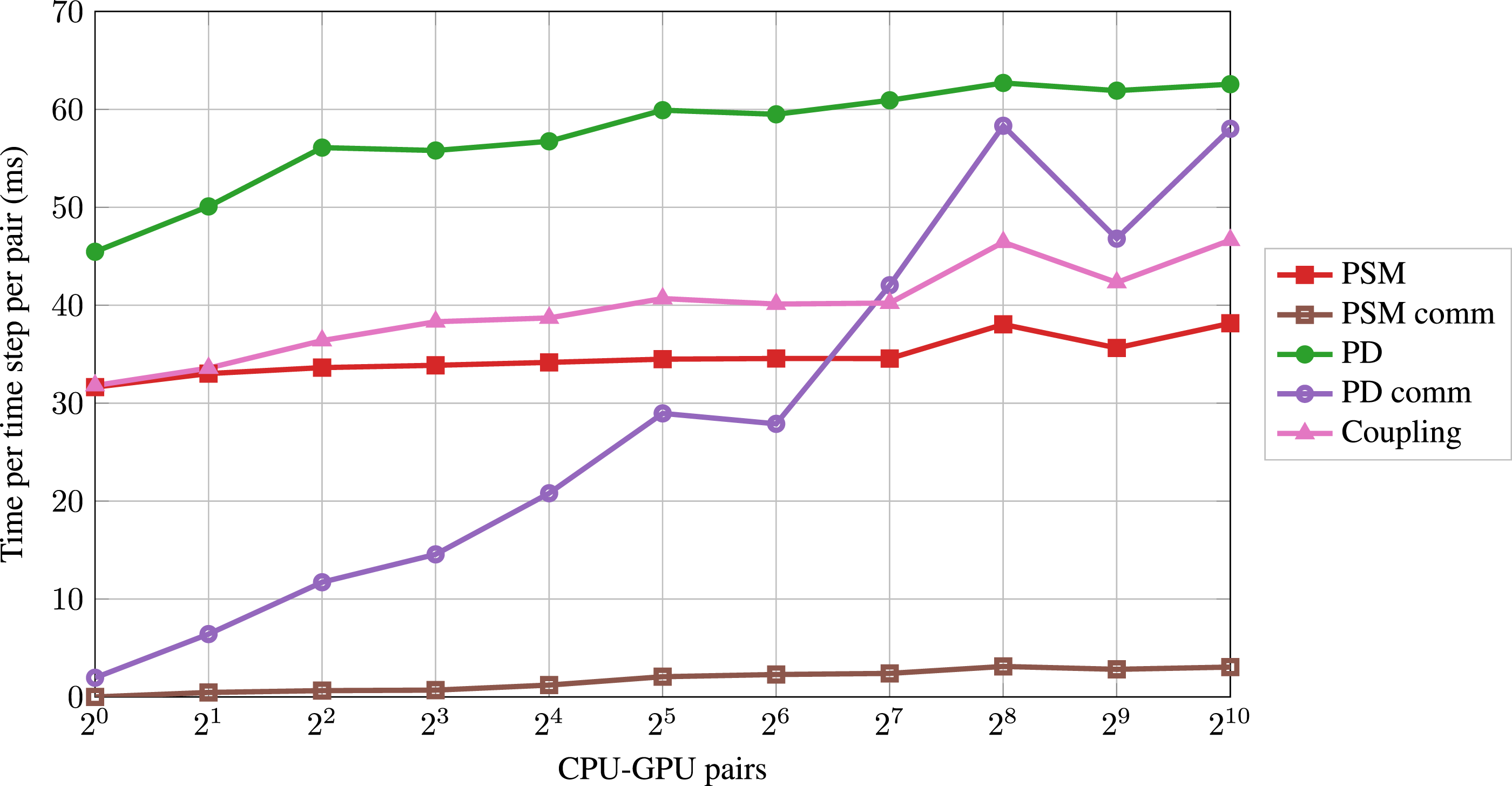
The different modules show similar qualitative scaling behavior when comparing the two cases. The PSM kernel scales quite well in both cases. The corresponding GPU-GPU communication (PSM comm) is negligible. The PD run time increases initially and then shows saturation. The CPU-CPU communication (PD comm) increases drastically, surpassing the run time of the PSM kernel and the coupling in the dense case. The PD and the corresponding communication are more relevant for the overall scaling in the dense case than in the dilute case. The coupling scales similarly to the PD.
The PSM workload per GPU stays constant in the weak scaling, explaining the nearly perfect scaling. Since we are hiding the PSM communication (Section 3), we expect it to be negligible. We expect the PD and the coupling run time to increase initially because the number of neighboring blocks increases. More neighboring blocks lead to more ghost particles per block, resulting in a higher workload. This effect decreases when blocks have neighbors in all directions, resulting in an almost linear scaling from this point on. This phenomenon has been reported in the literature (Rettinger et al., 2017). The methodology requires 10 particle sub-cycles per time step and three communication steps per sub-cycle for a physically accurate simulation. Additionally, the simulation requires two CPU-CPU communication steps per time step apart from the sub-cycles (Figure 4). We have 32 CPU-CPU communication steps per time step, which cannot be hidden behind other routines. This becomes the dominating factor for the decrease of the overall weak scaling performance in both cases.
To gain more profound insights into the reasons for this significant increase of the PD comm time in the weak scaling and to estimate the scaling behavior beyond 1024 CPU-GPU pairs, we investigate the data transfers of the PD comm in more detail for the dense case. The PD comm consists of two parts: the synchronization of particle quantities between processes and the reduction of particle quantities (Section 3.2). In the following, we focus on the dominating part, the synchronization. Figure 12 plots the maximum and average amount of data a process either sends to or receives from its neighboring processes per synchronization call. The two arrows indicate the steps in which the weak scaling doubles the domain in the y-direction (the out-of-plane direction normal to the cross-section in Figure 6(a)) for the first two times. Furthermore, the figure illustrates the maximum number of synchronization (i.e., communication) partners per process. Weak scaling of the particle synchronization in the dense case up to 1024 CPU-GPU pairs. Both the maximum and average amount of data (in bytes) a process either sends to or receives from its neighboring processes per synchronization call are illustrated (left y-axis), and the maximum number of synchronization partners (right y-axis).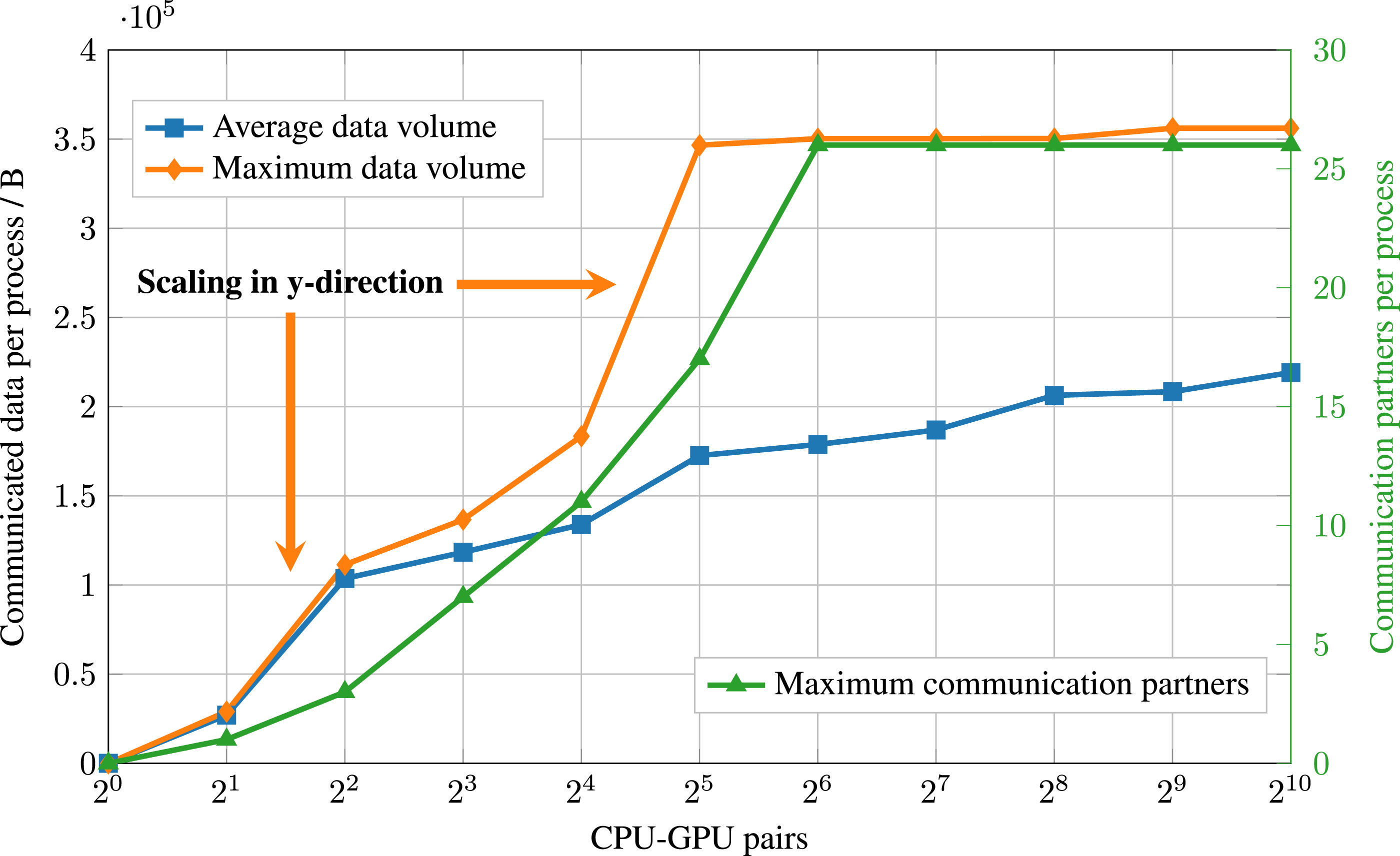
The maximum number of communication partners increases initially, reaching 26 starting from
The maximum number of communication partners is bounded from above at 26 because this is the maximum number of neighboring blocks in 3D (including blocks that only share a corner) because a
4.2.3. Strong scaling
For strong scaling, the problem size is fixed with an increasing number of CPU-GPU pairs, decreasing the workload per CPU-GPU pair. When having a perfect strong scaling, the run time decreases to the same extent as the number of CPU-GPU pairs increases. We present strong scaling results for three problem sizes: small, medium, and large. The small problem consists of Strong scaling performance for both cases and three different problem sizes up to 1024 CPU-GPU pairs. Strong scaling parallel efficiency for both cases and three different problem sizes up to 1024 CPU-GPU pairs.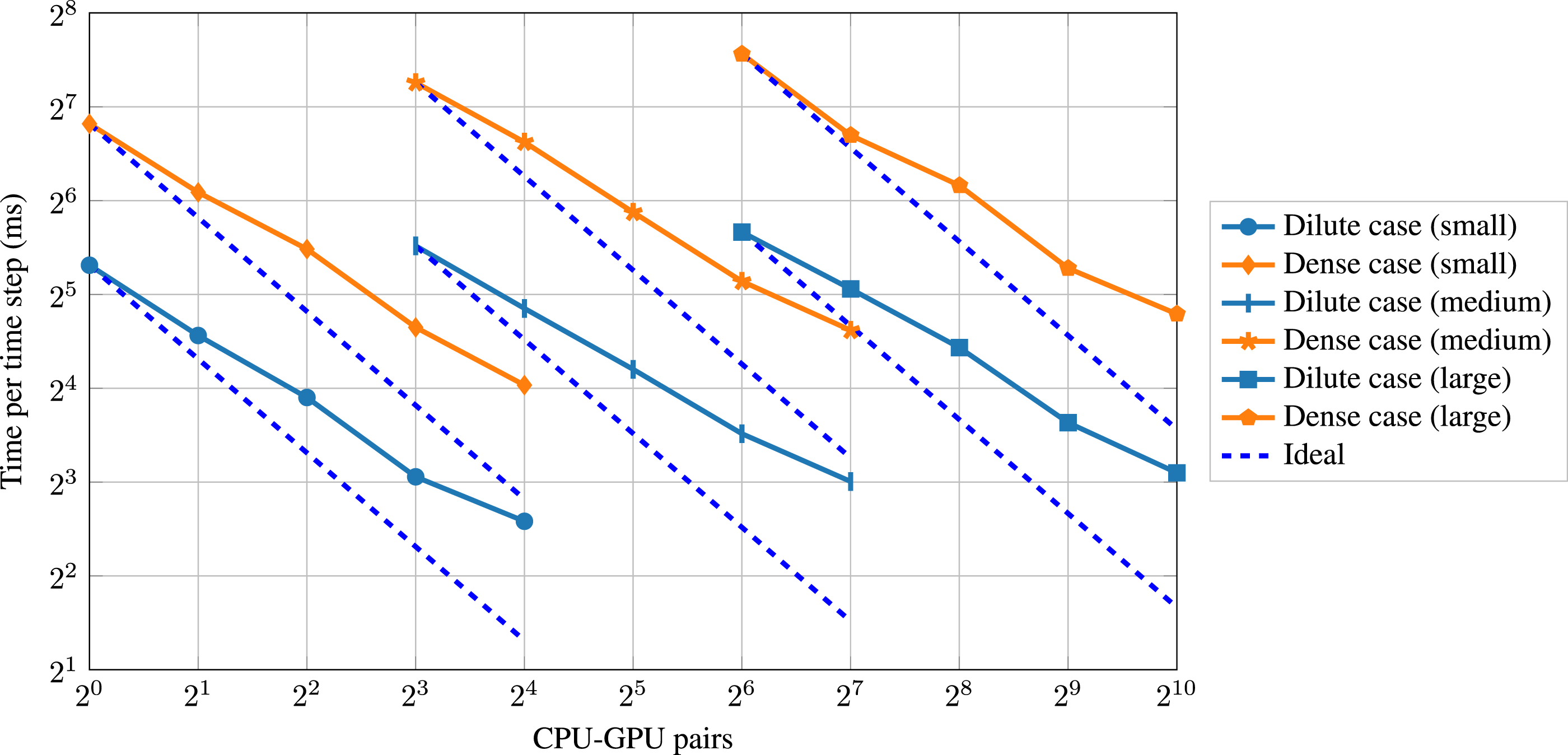
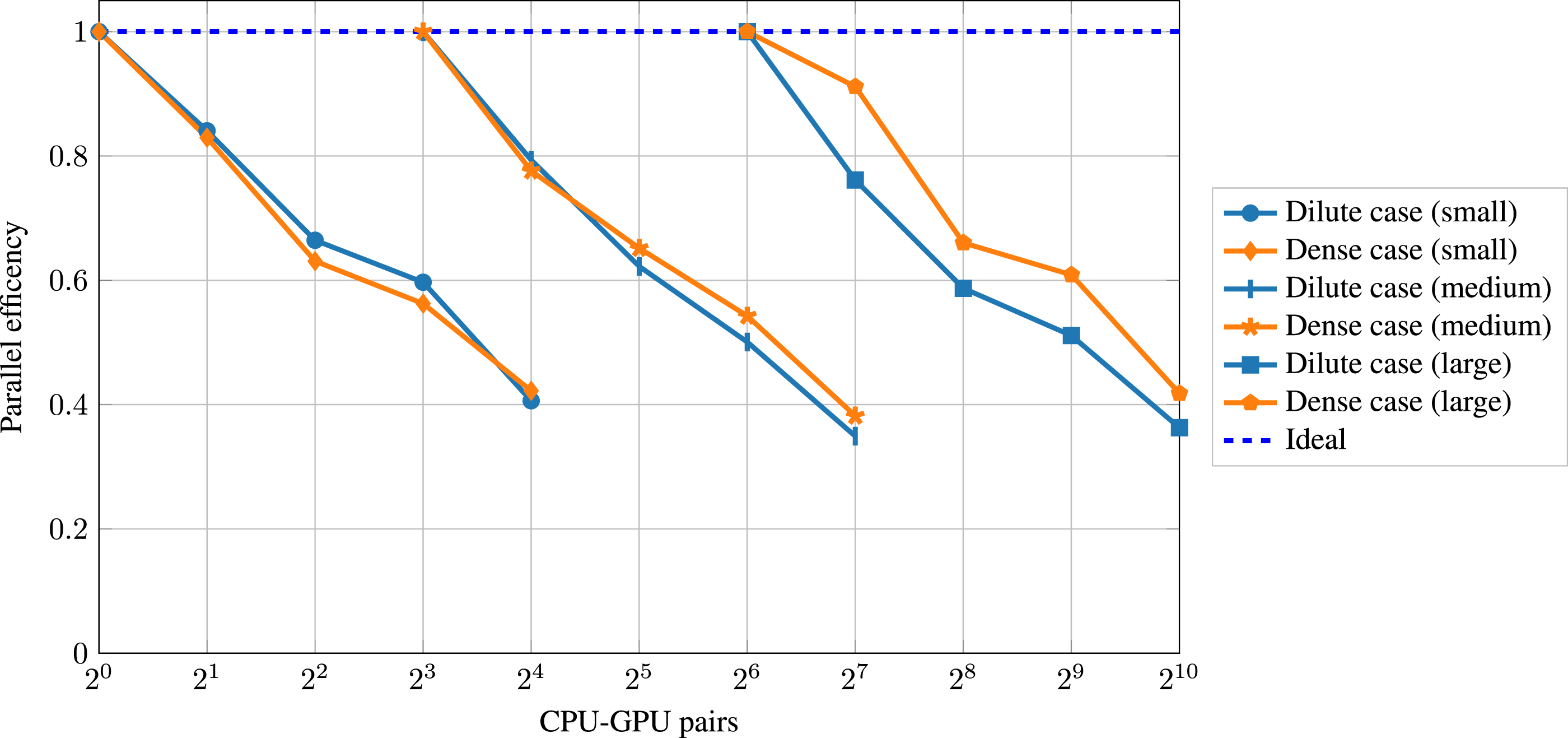
The dilute and dense cases exhibit a similar strong scaling behavior for all three problem sizes. In contrast to the weak scaling, the dense case does not show an overall lower parallel efficiency in the strong scaling. In all cases, the time per time step decreases when doubling the number of CPU-GPU pairs. However, the decrease is less than a factor of 2, resulting in a deviation from the ideal curve. The corresponding parallel efficiency is around 60% in all cases when doubling the number of CPU-GPU pairs twice, whereas it drops to about 40% when doubling the number of CPU-GPU pairs four times. The decrease in parallel efficiency is expected in strong scaling since, eventually, the problem size becomes too small to effectively utilize the computational resources while the communication overhead increases. The most relevant driving force for the decrease in parallel efficiency in the strong scaling originates, similar to the weak scaling analysis (Section 4.2.2), from the frequent synchronizations of the particle properties (PD comm). Similar strong scaling behavior, in particular the decrease in parallel efficiency, has been reported in the literature for other CFD codes on different supercomputers (Karp et al., 2023; Min et al., 2024).
4.2.4. Potential speedup of hybrid implementations
We expect that the speedup of the hybrid implementation compared to a CPU-only code

5. Implications and lessons learned
As a lesson learned, we discovered that the relatively small data transfers between CPU and GPU can become negligible for coupled applications exhibiting a significant imbalance of the data exchange between the coupled modules and the computations inside the modules in favor of the computations, making hybrid coupling a feasible approach. This is particularly true for the application used in this work, as only the several orders of magnitude smaller particle data need to be exchanged, not the entire fluid field processed by the GPU. As a result, only 0.35% of the total run time is devoted to CPU-GPU communication in the dense case. These findings can also be applied to other applications that exhibit this desired imbalance between computation data size and data transfer between the coupled modules. Other coupled applications, such as a huge flow field around complex deformable geometries like the deformation of blood cells in cellular blood flow, which is referenced in Section 1, can also exhibit this imbalance. Since the surface data acts as a boundary condition for the deformation simulation, just this surface data needs to be exchanged between the fluid and solid phases. Approaches with a high ratio of data exchange to computations (i.e., exchange entire fields between CPU and GPU in each time step) have been found in the literature to perform undesired on previous architectures, this may change in the future due to new hardware developments. High bandwidth memory transfer between CPU and GPU main memory is the trend of architectures like the NVIDIA GH200 Grace Hopper, which makes hybrid implementations promising for more applications (even up to transferring the entire GPU data in every time step) and should be further studied in the future.
The advantages of code generation (Section 3.1.2) are the subject of another lesson learned. We discovered that code generation adds an extra overhead during the implementation stage, which is only beneficial in a framework with long-term support if one depends on highly optimized similar codes, portability to other architectures, and a certain form of expandable, sustainable approach. However, because code generation is used, the code functions flawlessly with different LBM variations on other modern GPU architectures, such as the AMD MI250X, which uses the HIP API, as well as on consumer GPUs. Subsequent work will encompass a systematic performance comparison.
6. Conclusion
On heterogeneous systems, it is pragmatic and, therefore, attractive to use a hybrid parallelization, i.e., different simulation modules running on different hardware. However, hybrid implementations increase the complexity of achieving good performance and scalability, especially on large-scale systems. In this paper, we have examined a hybrid coupled fluid-particle simulation with geometrically resolved particles. We use GPUs for the fluid dynamics, whereas the particle simulation runs on the CPUs. We have reported and studied the performance of this approach for two cases of a fluidized bed simulation that differ in terms of the number of particles per volume. The overhead introduced by the hybrid implementation (i.e., CPU-GPU communication) is negligible because we are transferring only a small amount of data per particle but no fluid cells. The performance of the fluid simulation is close to utilizing the full memory bandwidth of the A100, implying that using the GPU is a good choice for the fluid simulation. In both cases, the GPU routines take most of the run time. In a weak scaling benchmark, the hybrid fluid-particle implementation reaches a parallel efficiency of 71% in the dilute case and 53% in the dense case when using 1024 CPU-GPU pairs. The current PD methodology requires 32 CPU-CPU communication steps per time step, which is the driving force for the decrease of the overall parallel efficiency. Our results are limited insofar as different numbers of particle sub-cycles, fluid cells per diameter, etc., will result in different performance results. We have formulated four criteria that a hybrid implementation must meet to be suitable for the responsible use of heterogeneous supercomputers. The performance results have shown that our hybrid implementation fulfills all criteria, making it suitable for large-scale simulations on heterogeneous supercomputers. In the future, we plan to investigate the particle communication steps in more detail regarding the bottleneck and optimization possibilities. We are employing sub-cycles to increase stability for stiff systems. Using other integrators may permit longer time steps and thus less communication due to sub-cycles. We have shown the acceleration potential of hybrid implementations. Therefore, we plan to run coupled fluid-particle simulations of even larger scenarios to better analyze, among others, the physical phenomena of erosion in sediment beds.
Footnotes
Acknowledgements
The authors gratefully acknowledge the Gauss Centre for Supercomputing e.V. (![]() ) for funding this project by providing computing time on the GCS Supercomputer JUWELS at Jülich Supercomputing Centre (JSC). The authors gratefully acknowledge the scientific support and HPC resources provided by the Erlangen National High Performance Computing Center (NHR@FAU) of the Friedrich-Alexander-Universität Erlangen-Nürnberg (FAU). The hardware is funded by the German Research Foundation (DFG).
) for funding this project by providing computing time on the GCS Supercomputer JUWELS at Jülich Supercomputing Centre (JSC). The authors gratefully acknowledge the scientific support and HPC resources provided by the Erlangen National High Performance Computing Center (NHR@FAU) of the Friedrich-Alexander-Universität Erlangen-Nürnberg (FAU). The hardware is funded by the German Research Foundation (DFG).
Author contributions
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The authors thank the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) for funding the project 433735254. The DFG had no direct involvement in this paper; and this work has received funding from the European High Performance Computing Joint Undertaking (JU) and Sweden, Germany, Spain, Greece, and Denmark under grant agreement No 101093393.
Notes
Author biographies
Samuel Kemmler is a Ph.D. student at the Chair for System Simulation at the Friedrich-Alexander-Universität Erlangen-Nürnberg (FAU) and a research assistant at the Federal Institute for Materials Research and Testing (BAM) in Berlin. He holds an M.Sc. degree in Computational Engineering and is one of the core developers of the
Christoph Rettinger studied Computational Engineering at the FAU. In 2023, he finished his Ph.D. on fully resolved simulation of particulate flows at the Chair for System Simulation.
Ulrich Rüde heads the Chair for System Simulation at the FAU. He studied Mathematics and Computer Science at Technische Universität München (TUM) and the Florida State University. He holds a Ph.D. and Habilitation degrees from TUM. His research interest focuses on numerical simulation and high-end computing, particularly computational fluid dynamics, multilevel methods, and software engineering for high-performance computing. He is a Fellow of the Society of Industrial and Applied Mathematics.
Pablo Cuéllar studied Civil Engineering at the Universidad Politécnica de Madrid and received his Ph.D. in Civil Engineering from Technical University Berlin in 2011. He is a guest scientist at BAM.
Harald Köstler got his Ph.D. in Computer Science in 2008 on variational models and parallel multigrid methods in medical image processing. 2014, he finished his habilitation on Efficient Numerical Algorithms and Software Engineering for High-Performance Computing. Currently, he works at the Chair for System Simulation at the FAU. His research interests include software engineering concepts, especially using code generation for simulation software on HPC clusters, multigrid methods, and programming techniques for parallel hardware, especially GPUs. The application areas are computational fluid dynamics, rigid body dynamics, and medical imaging.