
Abstract
Parallel implementations of Krylov subspace methods often help to accelerate the procedure of finding an approximate solution of a linear system. However, such parallelization coupled with asynchronous and out-of-order execution often makes more visible the non-associativity impact in floating-point operations. These problems are even amplified when communication-hiding pipelined algorithms are used to improve the parallelization of Krylov subspace methods. Introducing reproducibility in the implementations avoids these problems by getting more robust and correct solutions. This paper proposes a general framework for deriving reproducible and accurate variants of Krylov subspace methods. The proposed algorithmic strategies are reinforced by programmability suggestions to assure deterministic and accurate executions. The framework is illustrated on the preconditioned BiCGStab method and its pipelined modification, which in fact is a distinctive method from the Krylov subspace family, for the solution of non-symmetric linear systems with message-passing. Finally, we verify the numerical behavior of the two reproducible variants of BiCGStab on a set of matrices from the SuiteSparse Matrix Collection and a 3D Poisson’s equation.
1. Introduction
Solving large and sparse linear systems of equations appears in many scientific applications spanning from circuit and device simulation, quantum physics, large-scale eigenvalue computations, and up to all sorts of applications that include the discretization of partial differential equations (PDEs) as described by Barrett and et al. (1994). In this case, Krylov subspace methods fulfill the roles of standard linear algebra solvers (Saad, 2003). The Conjugate Gradient (CG) method can be considered as a pioneer of such iterative solvers operating on symmetric and positive definite (SPD) systems. Other Krylov subspace methods have been proposed to find the solution of more general classes of non-symmetric and indefinite linear systems. These include the Generalized Minimal Residual method (GMRES) by Saad and Schultz (1986), the Bi-Conjugate Gradient (BiCG) method by Fletcher (1976), the Conjugate Gradient Squared (CGS) method by Sonneveld (1989), and the widely used BiCG stabilized (BiCGStab) method by Van der Vorst (1992) as a smoother converging version of the above two. Moreover, preconditioning is usually incorporated in real implementations of these methods in order to accelerate the convergence of the methods and improve their numerical features.
One would expect that the results of the sequential and parallel implementations of Krylov subspace methods to be identical, for instance, in the number of iterations, the intermediate and final residuals, as well as the sought-after solution vector. However, in practice, this is not often the case due to different reduction trees – the Message Passing Interface (MPI) libraries offer up to 14 different implementations for reduction, data alignment, instructions used, etc. Each of these factors impacts the order of floating-point operations, which are commutative but not associative, and, therefore, violates reproducibility. We aim to ensure identical and accurate outputs of computations, including the residuals/errors, as in our view this is a way to ensure robustness and correctness of iterative methods. In this case, the robustness and correctness have a threefold goal: reproducibility 1 of the results with the accuracy guarantee as well as sustainable (energy-efficient) algorithmic solutions.
The implementation of Krylov subspace methods on massively parallel systems reveals their scalability problems. Mainly, because the synchronization of global communications, especially the reductions, delays parallel executions. The most common solution has been the developments of communication-avoiding and communication-hiding methods and, also, the use of new MPI functions to hide the communications, overlapping their execution with the computation of iterative methods. In Cools and Vanroose (2017), the authors propose a general framework for deriving pipelined Krylov subspace methods, in which the recurrences are reformulated to make the parallelization easier. Again, these changes impact on the robustness and correctness of the iterative methods.
In general, Krylov subsbpace methods are built from three components: sparse-matrix vector multiplication Ax (
In this paper, we aim to re-ensure reproducibility of Krylov subspace methods in parallel environments. Our contributions are the following: • We propose a general framework for deriving reproducible Krylov subspace methods. We follow the bottom-up approach and ensure reproducibility of Krylov subspace methods via reproducibility of their components, including the global communication. We build our reproducible solutions on the ExBLAS (Collange and et al., 2015) approach and its lighter version. • Even when applying our reproducible solutions, we particularly stress the importance of arranging computations carefully to be executed deterministically, for example, avoid possibly replacements by compilers of a*b + c in the favor of fused multiply-add ( • We optimize the • We verify the applicability and performance of the proposed methodology on the preconditioned BiCGStab (PBiCGStab) and the pipelined PBiCGStab method. We derive two reproducible variants of each method and test them on a set of large SuiteSparse matrices and a 3D Poisson’s equation.
This journal article extends our previous conference paper (Iakymchuk et al., 2022). In particular, we include the pipelined preconditioned BiCGStab as another test case, optimize SpMV and reduce the number of global collectives in reproducible versions, as well as validate the implementations on larger matrices. Other information is also added to make the paper self-contained.
This paper is structured as follows. Section 2 reviews several aspects of computer arithmetic as well as the ExBLAS approach. Section 3 proposes a general framework for constructing reproducible Krylov subspace methods. Section 4 introduces the PBiCGStab and the pipelined PBiCGStab methods, describing their MPI implementation in detail. Later, we evaluate the two reproducible implementations of PBiCGStab and pipelined PBiCGStab in Section 5. Finally, Section 6 reviews related work, while Section 7 draws conclusions and outlines future directions.
2. Background
At first, we briefly introduce the floating-point arithmetic that consists in approximating real numbers by numbers that have a finite, fixed-precision representation. These are composed of a significand, an exponent, and a sign:
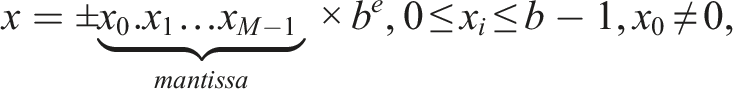
Parameters for three IEEE arithmetic precisions.

The IEEE 754 standard requires correctly rounded results for the basic arithmetic operations (
There are two approaches that enable the addition of floating-point numbers without incurring round-off errors or with reducing their impact. The main idea is to keep track of both the result and the error during the course of computations. The first approach uses EFT to compute both the result and the rounding error, storing them in a floating-point expansion (FPE). This is an unevaluated sum of p floating-point numbers, whose components are ordered in magnitude with minimal overlap to cover the whole range of exponents. Typically, FPE relies upon the use of the traditional EFT for addition that is
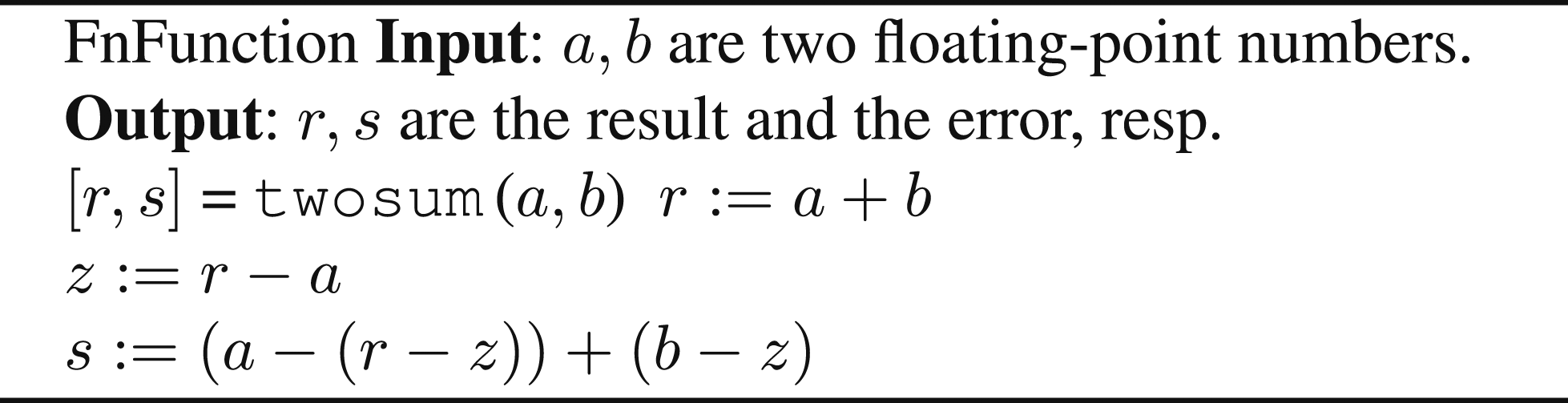
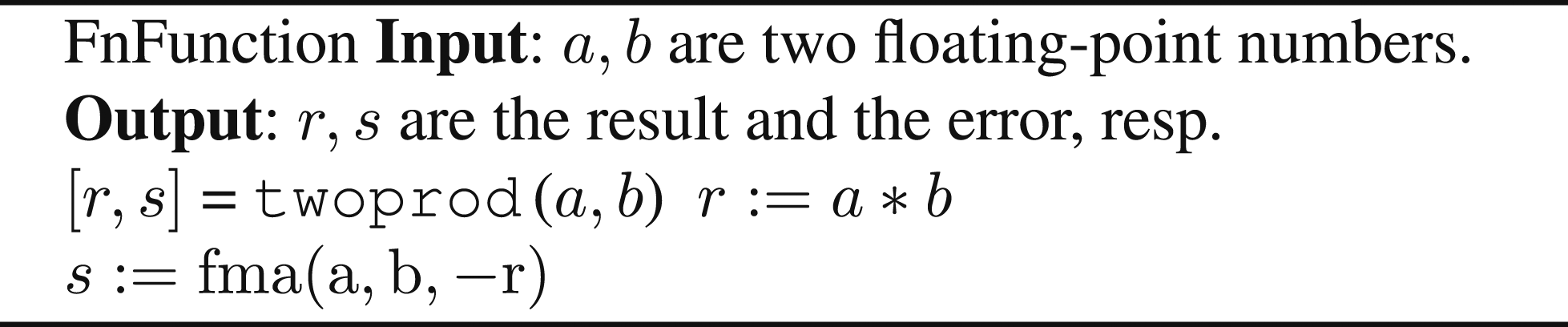
The ExBLAS project (Iakymchuk et al., 2015) is an attempt to derive a fast, accurate, and reproducible BLAS library by constructing a multi-level approach for these operations that are tailored for various modern architectures with their complex multi-level memory structures. On one side, this approach is aimed to be fast to ensure similar performance compared to the non-deterministic parallel versions. On the other side, the approach is aimed to preserve every bit of information before the final rounding to the desired format to assure correct-rounding and, therefore, reproducibility. Hence, ExBLAS combines together long accumulator and FPE into algorithmic solutions as well as efficiently tunes and implements them on various architectures, including conventional CPUs, Nvidia and AMD GPUs, and Intel Xeon Phi co-processors (for details we refer to Collange et al., 2015). Thus, ExBLAS assures reproducibility through assuring correct-rounding.
The corner stone of ExBLAS is the reproducible parallel reduction, which is at the core of many BLAS routines. The ExBLAS parallel reduction relies upon FPEs with the
3. General framework for reproducible Krylov solvers
This section provides the outline of a general framework for deriving a reproducible version of any traditional Krylov subspace method. The framework is based on two main concepts: 1) identifying the issues caused by parallelization and, hence, the non-associativity of floating-point computations and 2) carefully mitigating these issues primarily with the help of computer arithmetic techniques as well as programming guidelines. The framework was implicitly used for the derivation of the reproducible variants of the Preconditioned Conjugate Gradient (PCG) method in Iakymchuk et al. (2020a, 2020b).
The framework considers the parallel platform to consist of K processes (or MPI ranks), denoted as P1, P2, …, P
K
. In this framework, the coefficient matrix A is partitioned into K blocks of rows (A1, A2, …, A
k
), where each P
k
stores one row-block with the k-th distribution block
3.1. Identifying sources of non-reproducibility
The first step is to identify sources of non-associativity and, thus, non-reproducibility of the Krylov subspace methods in parallel environments. As it can be verified in Figure 1, there are four common operations as well as message-passing communication patterns associated with them: sparse matrix-vector product ( Preconditioned conjugate gradient method with annotated BLAS kernels and message-passing communication.
In general, associativity and reproducibility are not guaranteed when there is perturbation of floating-point operations in parallel execution. For instance, invoking the
3.2. Re-assuring reproducibility
We construct our approach for reassuring reproducibility by primarily targeting • exploit the ExBLAS and its lighter FPE-based versions to build reproducible and correctly rounded • extend the ExBLAS- and FPE-based • rounding to double: for long accumulators, we use the ExBLAS-native
It is evident that the results provided by ExBLAS
3.3. Programmability effort
It is important to note that compiler optimization and especially the usage of the fused-multiply-and-add (
Another important observation is to carefully perform divisions and initialization of data. For instance, the choice of b in the Krylov solvers is the value b = Ad, with
4. Reproducible BiCGStab
The classic Biconjugate Gradient Stabilized method (BiCGStab) by Van der Vorst (1992) was proposed as a fast and smoothly converging variant of the BiCG (Fletcher, 1976) and CGS (Sonneveld, 1989) methods. We present here the preconditioned BiCGStab (PBiCGStab) and the pipelined preconditioned BiCGStab (p-PBiCGStab), their design and implementation with Message Passing Interface (MPI).
For both methods, we consider a linear system Ax = b, where the coefficient matrix
Additionally, and for simplicity, we integrate the Jacobi preconditioner (Saad (2003)) in our implementations, which is composed of the diagonal elements of the matrix (M = diag(A)). In consequence, the application of the preconditioner is conducted on a vector and requires an element-wise multiplication of two vectors.
4.1. Message-passing parallel PBiCGStab implementation
The algorithmic description of the classical iterative PBiCGStab is presented in Figure 2. The loop body consists of two Formulation of the PBiCGStab solver annotated with computational kernels and communication. The threshold τmax is an upper bound on the relative residual for the computed approximation to the solution. In the notation, ⟨⋅, ⋅⟩ computes the 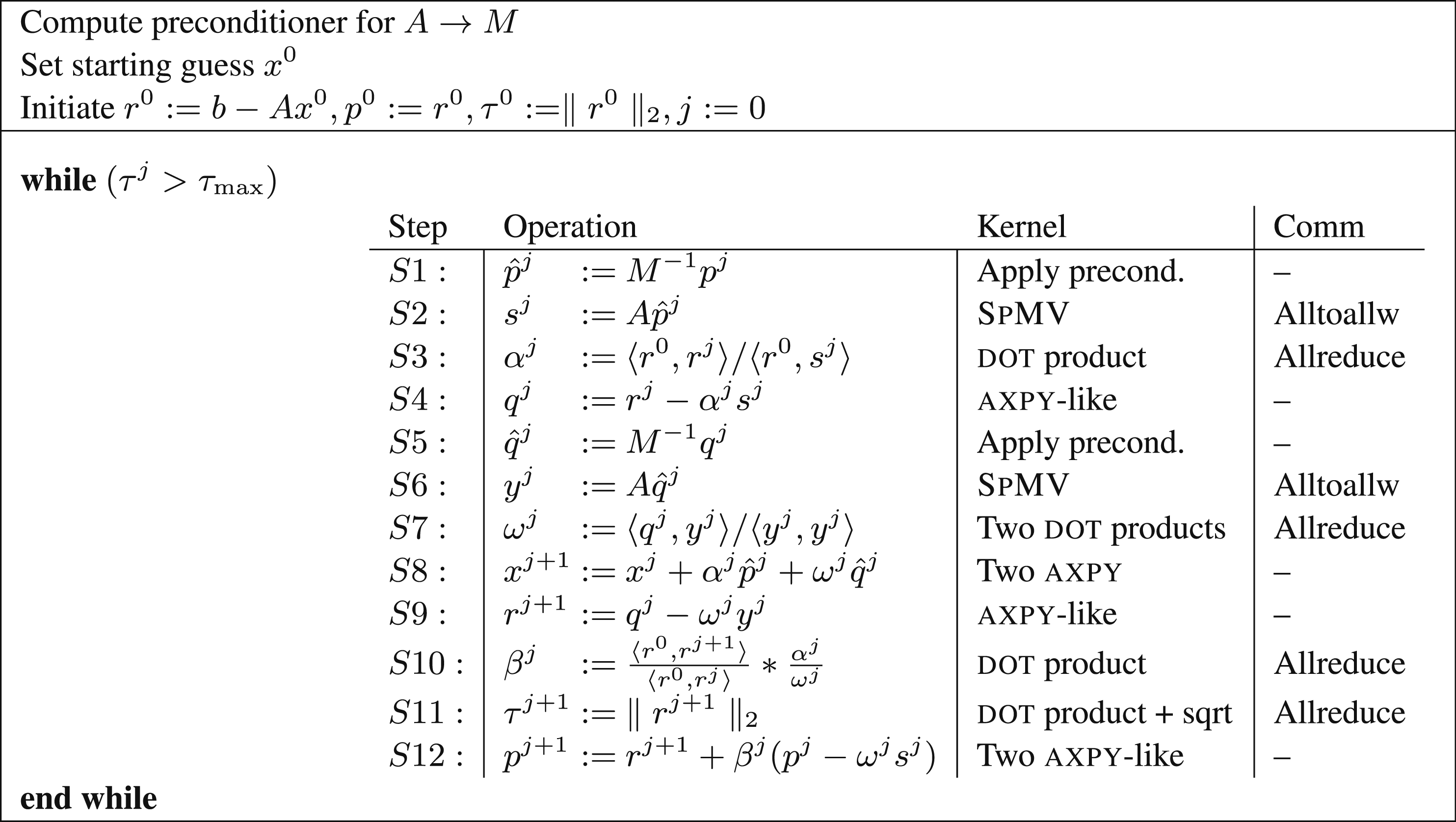
As described in Section 3, the framework includes a reproducible implementation of the most common operations in a parallel implementation of a Krylov subspace method. Therefore, we next perform a communication and computation analysis of a message-passing implementation of the PBiCGStab solver. From there, we derive the reproducible version by following the guide from Section 3.
For clarity, hereafter we will drop the superindices that denote the iteration count in the variable names. Thus, for example, x j becomes x, where the latter stands for the storage space employed to keep the sequence of approximations x0, x1, x2, … computed during the iterative process. Taking into account these previous considerations, we analyze the different computational kernels (S1–S12) that compose the loop body of a single PBiCGStab iteration in Figure 2.
4.1.1. Sparse matrix-vector product (S2, S6)
This kernel needs as input operands: the coefficient matrix A, which is distributed by blocks of rows, and the corresponding vector (
In theory, prior to computing this kernel, we would need to obtain a replicated copy of the distributed vector
The computation can then proceed in parallel, yielding the vector result s in the expected distributed state with no further communication involved. At the end, each MPI process owns the corresponding piece of the computed vector. To ensure the reproducibility of this computation, the local
4.1.2. Dot products (S3, S7, S10, S11)
The next kernel in the loop body is the
The easiest solution to compute ρ
k
is to call to the
While
4.1.3. Application of the preconditioner (S1, S5)
The kernel in the step S1 consists of applying the Jacobi preconditioner M, scaling the vector p by the diagonal of the matrix. Therefore, it can be executed in parallel by all processes because each of them stores a different set of the diagonal elements (those related with the piece of the matrix that it stores) and the corresponding set of the vector elements:
There is no routine in the MKL library to implement the element-wise product of two vector, therefore, an ad hoc implementation has to be done. Reproducibility is ensured if this code is based on
4.2. Message-passing parallel p-PBiCGStab implementation
Cools and Vanroose (2017) propose two main steps for deriving the pipelined version of a Krylov subspace method: • Communication-avoiding: In which the number of global communications is reduced, rearranging the original recurrences. Usually more terms appear in the new recurrences and, therefore, there are more vector operations. • Hiding communications: Since global communications are the most time-consuming component of Krylov subspace methods at large scale, the alternative to reduce their impact on the performance of parallel implementations is their simultaneous execution (overlapping) with
The algorithmic description of the pipelined preconditioned BiCGStab (p-PBiCGStab) is presented in Figure 3. The loop body consists of two Formulation of the 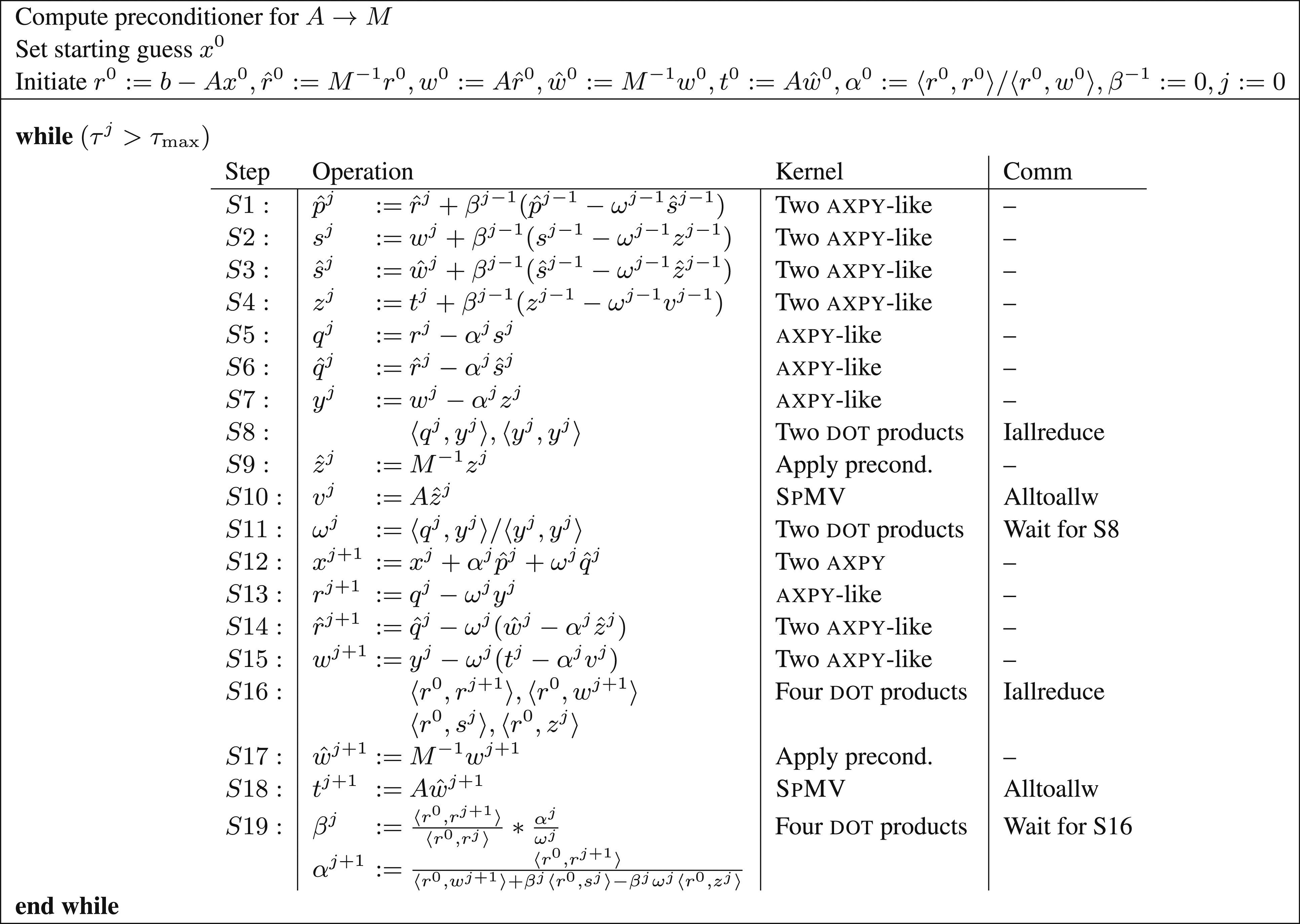
The analysis of the computational kernels of the algorithm is very similar to the described above for the parallelization of PBiCGStab in Section 4.1. The only difference is how the
4.2.1. Dot products (S8 ∪ S11, S16 ∪ S19)
Although, there are six
5. Experimental results
In this section, we report a variety of numerical experiments to examine the convergence, scalability, accuracy, and reproducibility of the original and two reproducible versions of PBiCGStab and p-PBiCGStab. In our experiments, we employed IEEE754 double-precision arithmetic and conducted them on the dual Intel Xeon Gold 6240R CPU @2.4 GHz nodes with 48 cores and 384 GB of memory each at Fraunhofer ITWM. Nodes are connected with the HDR Infiniband.
5.1. Evaluation on the suitesparse matrices
Convergence of the
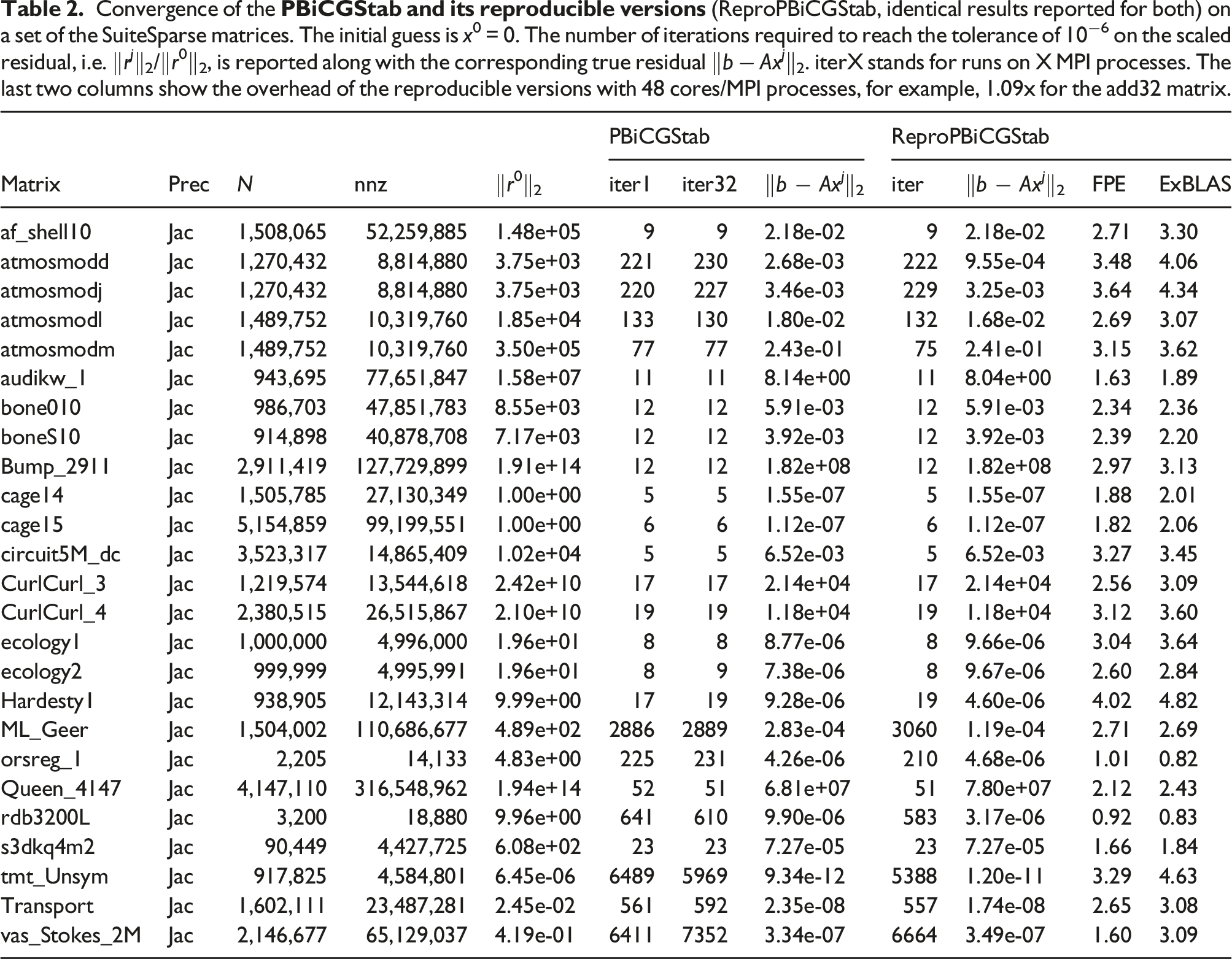
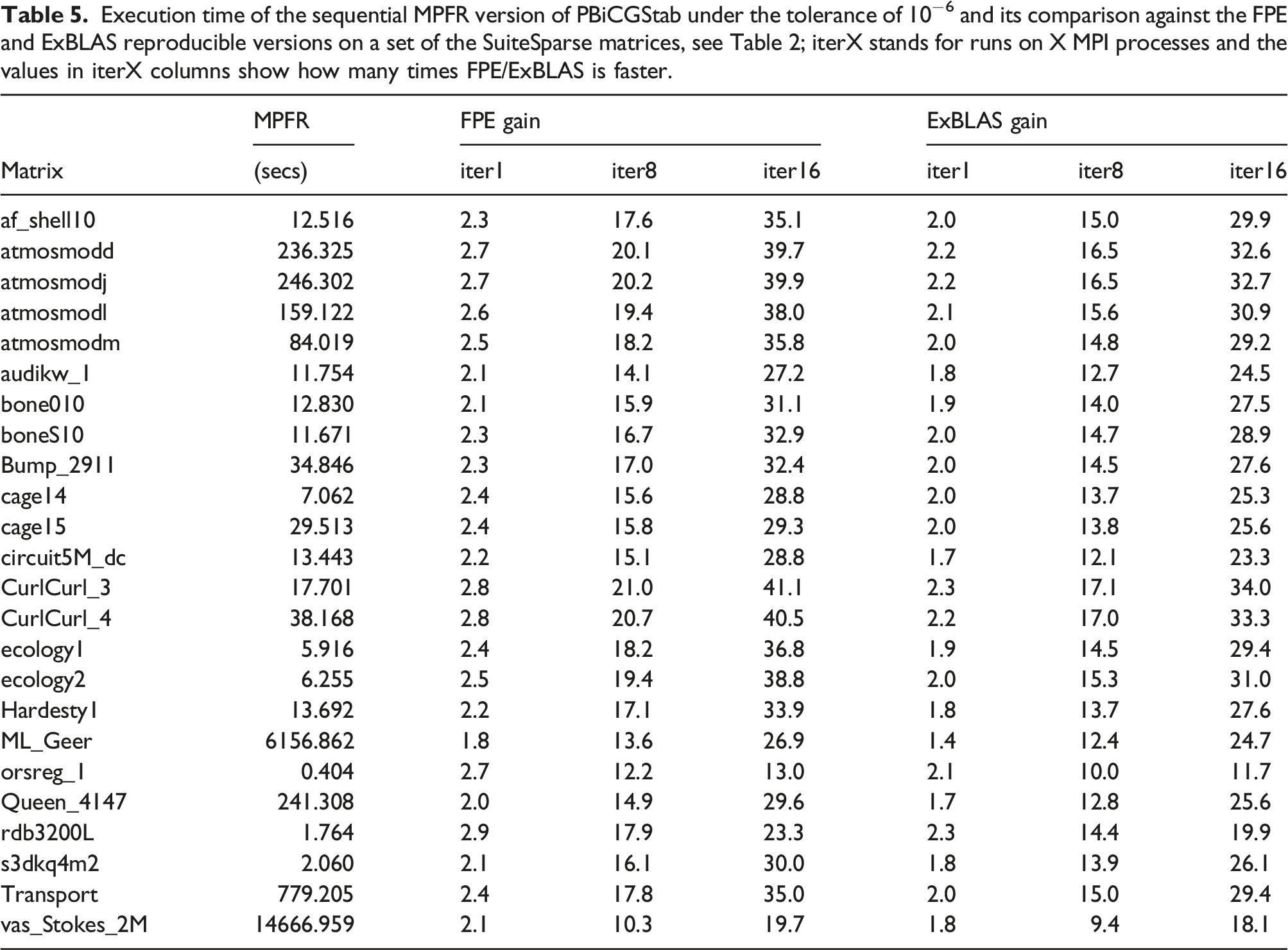
Table 2 reports the number of required iterations to reach the stopping criterion as well the final true residual for PBiCGStab and ReproPBiCGStab; the latter marks both ExBLAS- and FPE-based variants as they report identical results independently from the number of cores/MPI processes used. We also report the initial residual (‖r0‖2) which can serve as an indicator in combination with the final true residual of how the convergence unfolds. For the original version, we display the number of iterations on one (iter1) and 32 cores (iter32) as they differ. In fact, there is a variability of the results between the other core counts too. Notably, the two reproducible variants show a tendency to deliver more reliable accuracy of the approximate result (the final true residual) and/or converge faster. For instance, the reproducible variants require significantly less iterations for the vas_stokes_2M, orsreg_1, rdb3200L, Transport, tmt_unsym matrices. The reproducible variants are slightly slower for only two matrices, namely ML_Geer and atmosmodj. For the other matrices, mostly symmetric matrices, the results are comparable between reproducible and non-reproducible versions in terms of the number of iterations; however, there is a fluctuation in the final true residual for the original non-deterministic version.
The table also reports the overhead of the reproducible versions against the original non-deterministic version as the normalized mean time on 48 MPI processes. The two reproducible versions perform well with the overhead under 3x for the majority of the test matrices. The FPE version generally shows better performance than the ExBLAS version: one third of the test matrices show the overhead under 2x.
Convergence of the
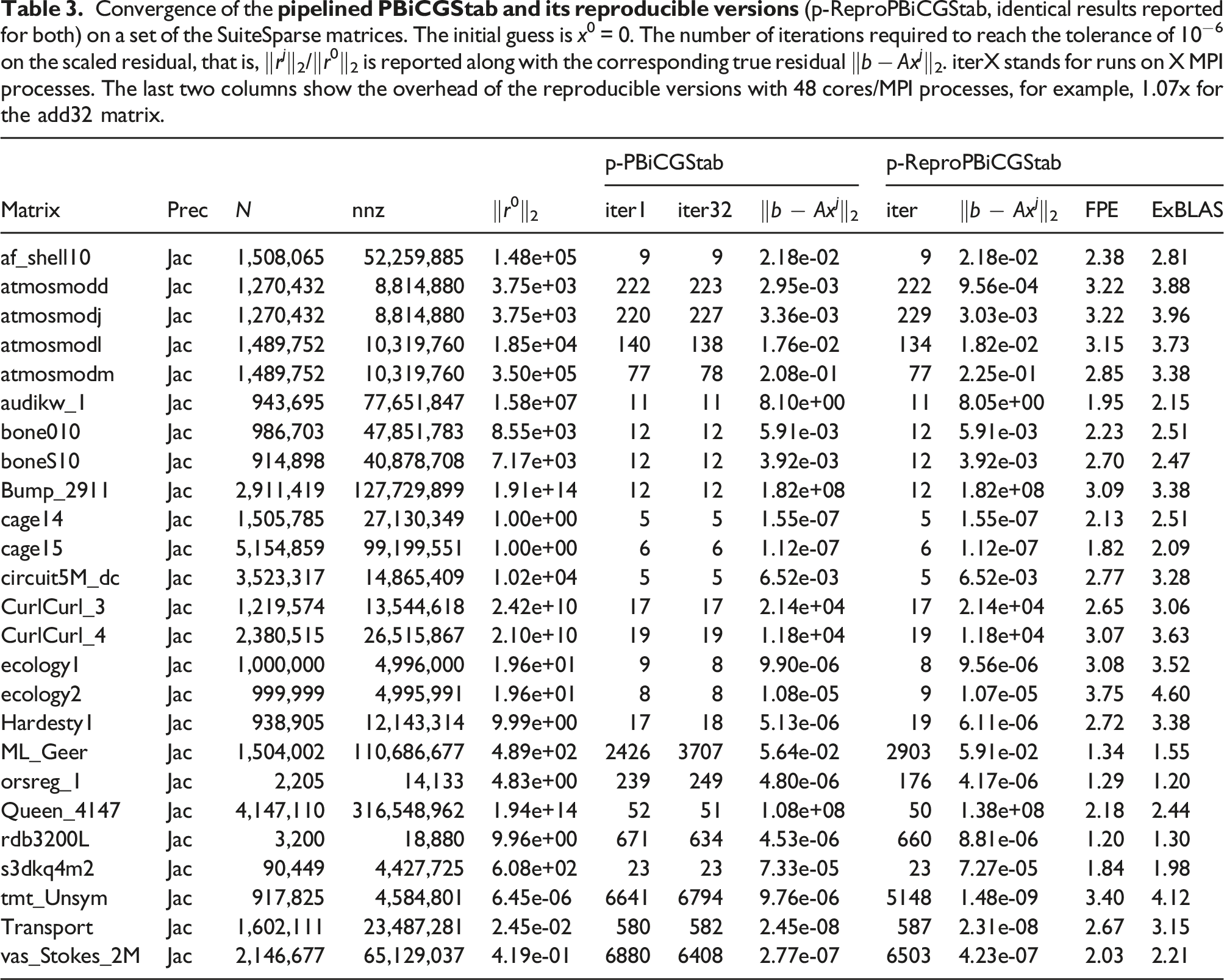
In addition, the table exhibits the overhead of the reproducible pipelined BiCGStab variants against the original version on 48 MPI processes. The two reproducible versions show the overhead of 3x for most of the tested SuiteSparse matrices. As for the standard BiCGStab method, the FPE version generally shows better performance than the ExBLAS: three quarters of the cases exhibit the overhead under 3x; for the rest, the overhead never exceeds 4x.
Figure 4 presents the convergence history in terms of the residual computed at every iteration of both the standard and pipelined PBiCGStab methods. The depicted two matrices, namely orsreg_1 and tmt_unsym, represent the beneficial scenarios for the reproducible variants, when they reach the approximate solution in significantly less iterations than their non-deterministic variants. In fact, these results demonstrate a sort of desired scenario when the reproducible variants converge to the solution faster despite yielding more costly computations per each iteration. In the case of these two matrices, which may not be generic, the standard and pipelined PBiCGStab non-deterministic variants require more iterations on various MPI processes. Moreover, the number of iterations to reach the approximation of the solution fluctuates significantly among runs of the same non-deterministic variant on a different process count. Residual history of the standard PBiCGStab and its reproducible variants (first row), and the pipelined PBiCGStab and its reproducible variants (second row); orsreg_1 results are shown in the first column, while tmt_unsym in the second column, see Table 2 for details on matrices. Note that the last iteration is not shown.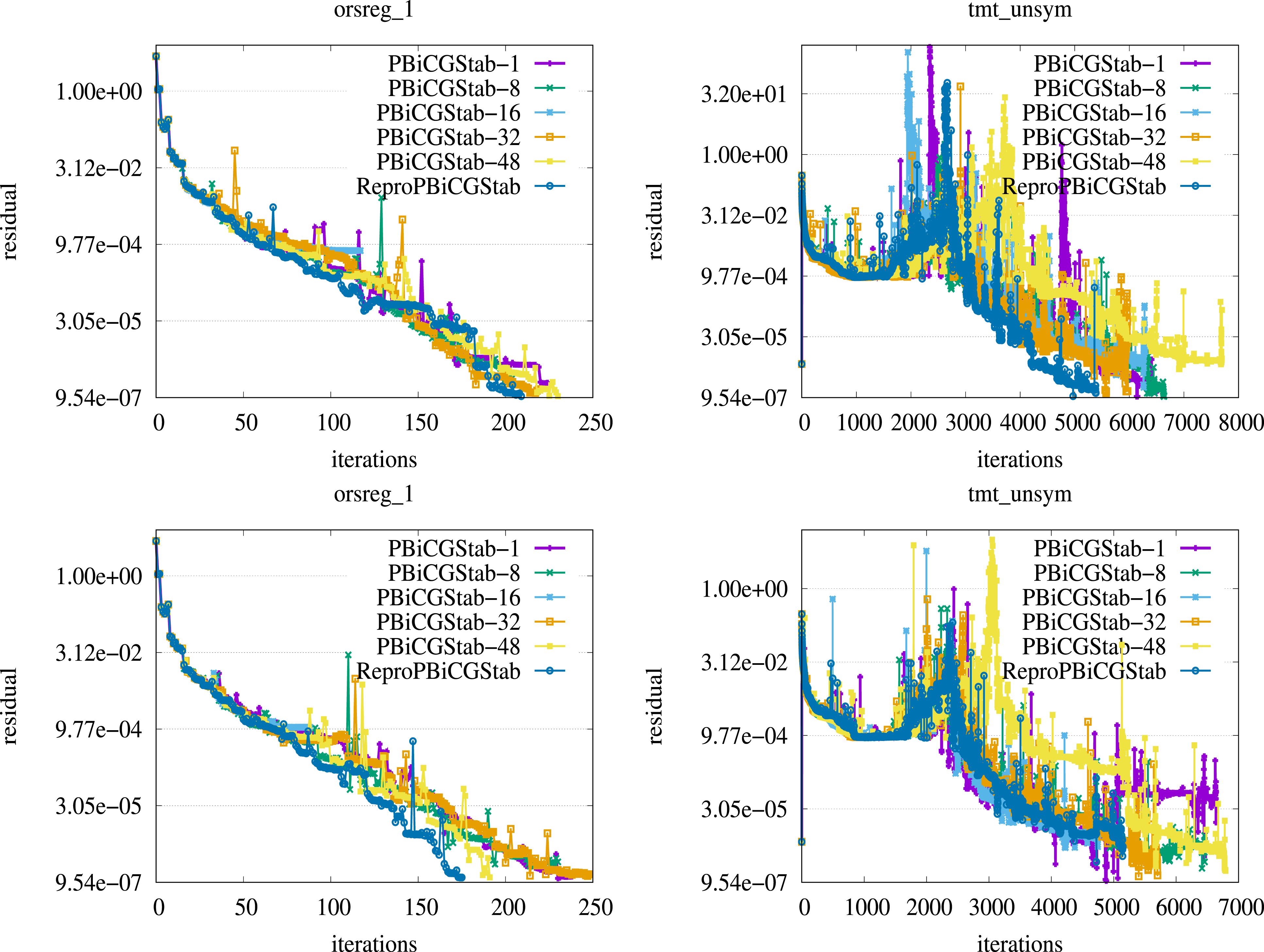
Figure 5 demonstrates the strong scalability results – when the problem is fixed but the number of allocated resources varies – for the original and both ExBLAS- and FPE-based standard and pipelined PBiCGStab variants on the Queen_4147 matrix. The figures in the left column report the mean execution time for the entire loop of the solver among five samples, while the figures in the right column show the performance overhead of the reproducible versions. We select the Queen_4147 due to the large number of nonzero elements, 316 millions. As we observed, the smaller number of nonzeros leads to the worse scalability, especially on the large core count, and higher overhead for reproducible variants, but never more than 8x. For small matrices like orsreg_1, a lower number of cores is a preferable option to reach an approximation to the solution with the sustainable resource utilization. In these experiments, MPI communication is performed within a node, most likely being exposed to intra-node communication via shared memory. All variants show good scalability results for Queen_4147 with 28x (24x), 29x (29x), and 31x (31x) speed up on 48 MPI processes, when compared to the one process runs, for the original, FPE, and ExBLAS variants of the standard PBiCGStab (pipelined PBiCGStab), respectively. The reproducible variants demonstrate higher/better speedup due to extra floating-point operations. The overhead of the ExBLAS and FPE variants compared to the standard variant is reduced to nearly 2.5x and 2.3x, accordingly, on 48 MPI processes; the pipelined versions exhibit slightly higher overhead on the small core count. The scalability on the other matrices from Tables 2 and 3 shows variable patterns and overhead. Strong scaling results of the standard PBiCGStab and its reproducible variants (first row), and the pipelined PBiCGStab and its reproducible variants (second row) for the Queen_4147 matrix, see Table 2; plots in the first column report the measure time, while plots in the second show the overhead.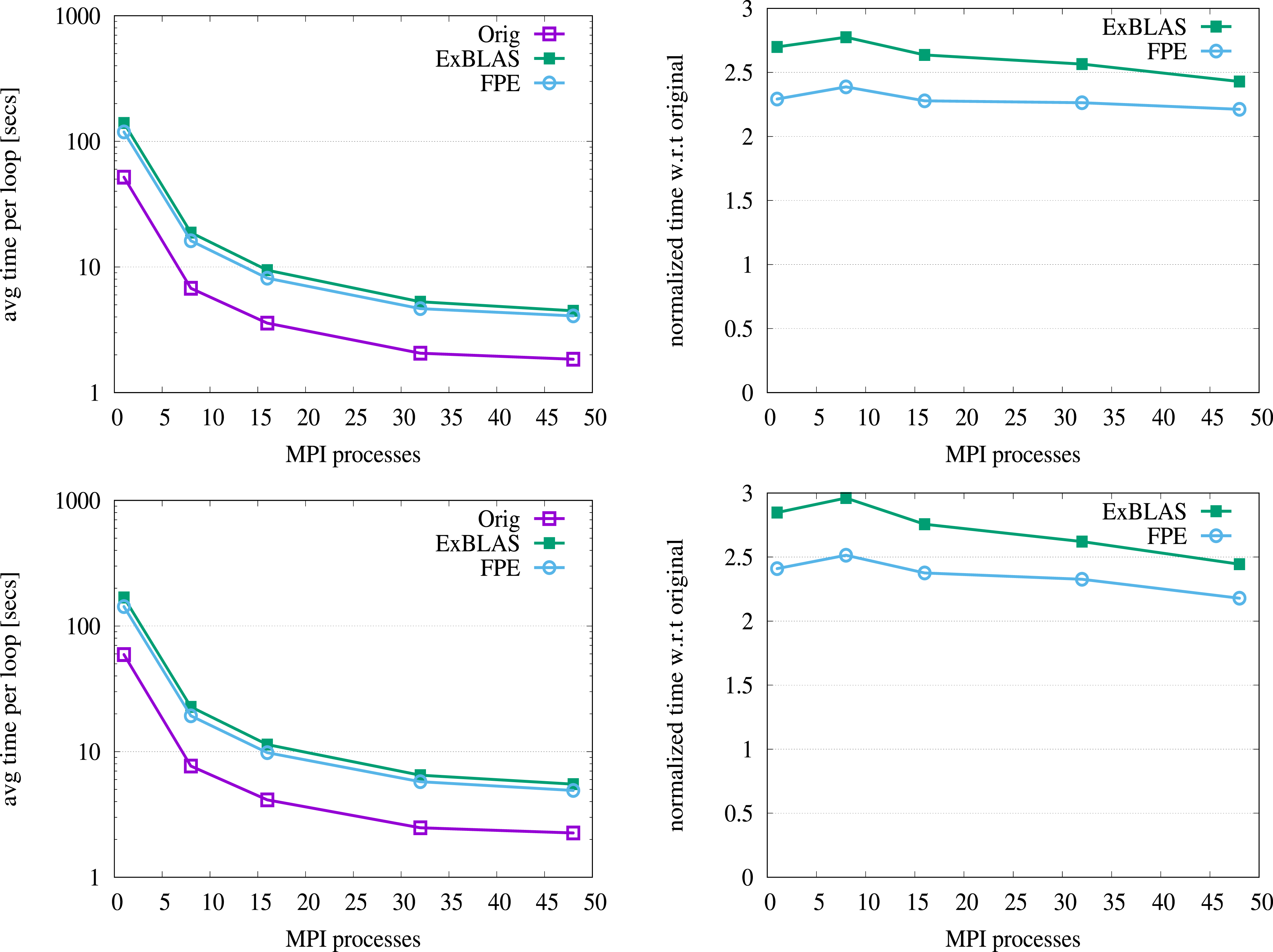
Note that the average execution time per loop for many matrices from Tables 2 and 3 is not sufficient for distributed memory computations. This is due to the fact that the potential performance gain from extra nodes is demolished by communication.
5.2. Scalability
We leverage a sparse SPD coefficient matrix arising from the finite-difference method of a 3D Poisson’s equation with 27 stencil points. We perturb the matrix with the values 1.0 − 0.0001 below the central point to create the unsymmetric 27-point stencil aka the e-type model (Cools and Vanroose, 2017). Given that the theoretical cost of PBiCGStab is t
c
≈ 4nnz + 26n floating-point arithmetic operations, where nnz denotes the number of nonzeros of the original matrix and its size n, the execution time of the method is usually dominated by that of the 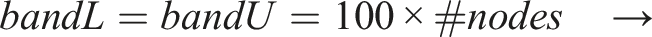
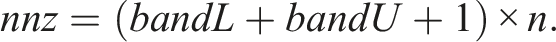
The right-hand side vector b in the iterative solvers was always initialized to the product of A with a vector containing ones only; and the PBiCGStab iteration was started with the initial guess x0 = 0. The parameter that controls the convergence of the iterative process was set to 10−6.
Figure 6 reports the results of both strong and weak scaling for the reproducible variants against the original version. For the strong scaling, we fix the problem to 64M nonzeros and vary the number of nodes/cores used, while for the weak scaling the work load per node is kept constant as 4M nonzeros by varying the bandwidth with respect to the number of nodes involved; presumably, there is enough load to hide the impact of communication. We select median time among five runs to limit the impact of the outliers. We run the tests within a single allocation for 32 nodes to make sure that there is no additional unnecessary perturbations to the measured time. For the strong scaling tests, the standard and pipelined PBiCGStab variants show a similar convergence behavior. However, for the standard variants the global reductions are not overlapped with computations and may show higher overhead in case of the FPE reproducible version due to a more complex reduction operation. For the standard reproducible versions, the overhead on 32 nodes is 37.8% and 40.2% for the FPE and ExBLAS versions, accordingly. For the pipelined reproducible versions, the performance penalties are similar with 38.0% for the FPE version and 35.9% for the ExBLAS. The weak scalability experiments show expected behavior with the slightly declining line of the execution time and the overheads around 35%. Strong (top row) and weak (bottom row) scalability of the reproducible PBiCGStab variants; the standard PBiCGStab results are shown in the left column of plots, while the pipelined PBiCGStab results in the right column.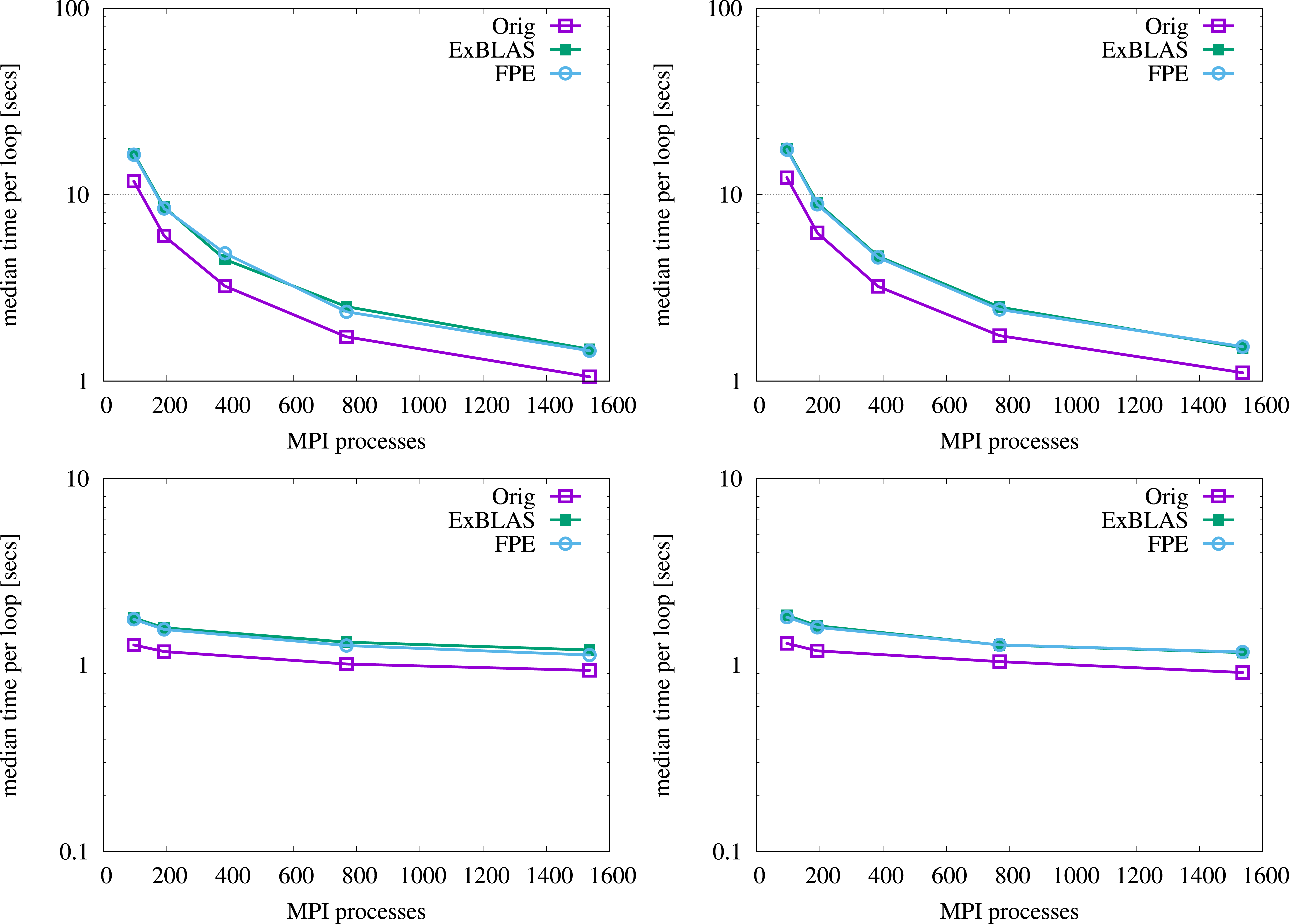
5.3. Accuracy and reproducibility
In addition, we derive a sequential version of the PBiCGStab as in Figure 2 that relies on the GNU Multiple Precision Floating-Point Reliably (MPFR) library (Fousse and et al. (2007)) – a C library for multiple (arbitrary) precision floating-point computations on CPUs – as a highly accurate reference implementation. This implementation uses 2048 bits of accuracy for computing
Accuracy and reproducibility of the intermediate and final residual against the Multiple Precision Floating-Point Reliably (MPFR) library for the orsreg_1 matrix, see Table 2.

Execution time of the sequential MPFR version of PBiCGStab under the tolerance of 10−6 and its comparison against the FPE and ExBLAS reproducible versions on a set of the SuiteSparse matrices, see Table 2; iterX stands for runs on X MPI processes and the values in iterX columns show how many times FPE/ExBLAS is faster.
6. Related work
To enhance reproducibility, Intel proposed the ‘Conditional Numerical Reproducibility’ (CNR) option in its Math Kernel Library (MKL). Although CNR guarantees reproducibility, it does not ensure correct rounding, meaning the accuracy is arguable. Additionally, the cost of obtaining reproducible results with CNR is high. For instance, for large arrays the MKL’s summation with CNR was almost 2x slower than the regular MKL’s summation on the Mesu cluster hosted at the Sorbonne University (Collange and et al., 2015).
Demmel and Nguyen (2013, 2015) implemented a family of algorithms – that originate from the works by Rump et al. (2010, 2008) – for reproducible summation in floating-point arithmetic. These algorithms always return the same answer. They first compute an absolute bound of the sum and then round all numbers to a fraction of this bound. In consequence, the addition of the rounded quantities is exact; however, the computed sum using their implementations with two or three bins is not correctly rounded. Their results yielded roughly 20% overhead on 1024 processors (CPUs only) compared to the Intel MKL
The other approach to ensure reproducibility is called ExBLAS, which is initially proposed by Collange et al. (2015). ExBLAS is based on combining long accumulators and floating-point expansions in conjunction with error-free transformations. This approach is presented in Section 2. Collange et al. (2015) showed that their algorithms for reproducible and accurate summation have 8% overhead on 512 cores (32 nodes) and less than 2% overhead on 16 cores (one node). While ExSUM covers wide range of architectures as well as distributed-memory clusters, the other routines primarily target GPUs. Exploiting the modular and hierarchical structure of linear algebra algorithms, the ExBLAS approach was applied to construct reproducible LU factorizations with partial pivoting (Iakymchuk et al., 2019).
Mukunoki and Ogita presented their approach to implement reproducible BLAS, called OzBLAS (Mukunoki et al., 2019), with tunable accuracy. This approach is different from both ReproBLAS and ExBLAS as it does not require to implement every BLAS routine from scratch but relies on high-performance (vendor) implementations. Hence, OzBLAS implements the Ozaki scheme (Ozaki et al., 2012) that follows the fork-join approach: the matrix and vector are split (each element is sliced) into sub-matrices and sub-vectors for secure products without overflows; then, the high-performance BLAS is called on each of these splits; finally, the results are merged back using, for instance, the NearSum algorithm. Currently, the OzBLAS library includes dot products, matrix-vector product (gemv), and matrix-matrix multiplication (gemm). These algorithmic variants and their implementations on GPUs and CPUs (only dot) reassure reproducibility of the BLAS kernels as well as make the accuracy tunable up-to correctly rounded results.
The proposed framework was implicitly used to derive the reproducible preconditioned Conjugate Gradient (PCG) variants with the flat MPI (Iakymchuk et al., 2020b) and hybrid MPI plus OpenMP tasks (Iakymchuk et al. 2020a). The reproducible PCG variants were primarily verified on the 3D Poisson’s equation with 27 stencil points showing the good scalability and low performance overhead (under 30% for both the ExBLAS and lightweight variants) on up to 768 cores of the MareNostrum4 cluster.
7. Conclusions
Parallel Krylov subspace methods may exhibit the lack of reproducibility when implemented in parallel environments as the results in Tables 2–4 confirm. Such numerical reliability is needed for debugging and validation & verification. In this work, we proposed a general framework for re-constructing reproducibility and re-assuring accuracy in any Krylov subspace method. Our framework is based on two steps: analysis of the underlying algorithm for numerical abnormalities; addressing them via algorithmic solutions and programmability hints. The algorithmic solutions are build around the ExBLAS project, namely: ExBLAS that effectively combines long accumulator and FPEs; FPEs for the lightweight version. The programmability effort was focused on: explicitly invoking
As test cases, we used the preconditioned standard and pipelined BiCGStab methods and derived two reproducible algorithmic variants for each of them. It is worth mentioning that the two BiCGStab methods are in fact different algorithms with different set of operations yielding non-identical computation path and the divergent way rounding errors are propagate; this difference can be witnessed by the convergence history in Figure 4 even when using the reproducible variants. The reproducible variants deliver identical results of the standard and also pipelined PBiCGStab, which are confirmed by its MPFR version, to ensure reproducibility in the number of iterations, the intermediate and final residuals, as well as the sought-after solution vector. We verified our implementations on a set of the SuiteSparse matrices, showing the performance overhead of nearly 2.0x for the ExBLAS and FPE-based versions, with a noticeably lower overhead for the latter. Tests with the 27-point stencil on 32 nodes show a low performance overhead of 35 %–40%. The code is available at https://github.com/riakymch/ReproPBiCGStab.
With this study we want to promote reproducibility by design through the proper choice of the underlying libraries as well as the careful programmability effort. For instance, a brief guidance would be 1) for fundamental numerical computations use reproducible underlying libraries such as ExBLAS, ReproBLAS, or OzBLAS and 2) analyze the algorithm and make it reproducible by eliminating any uncertainties and non-deterministic order of computations that may violate associativity such as reductions and use/non-use of
Our future work is to investigate the residual replacement strategy in the pipelined Krylov subspace solvers such as the pipelined PBiCGStab (p-PBiCGStab) (Cools and Vanroose (2017)) and to study if such strategy can be mitigated by the higher precision provided by long accumulator and FPEs. We believe that there is a potential of using higher precision provided by long accumulator and FPEs in order to mitigate the different way rounding errors are propagate as well as to cope with the attainable precision loss in p-PBiCGStab.
Footnotes
Acknowledgments
We acknowledge the usage of computing resources kindly provided by Fraunhofer ITWM.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Department of Computing Science at Umeå University; the EU H2020 MSCA-IF Robust project (No. 842528); the French ANR InterFLOP project (No. ANR-20-CE46-0009). The research from Universitat Jaume I was funded by the project PID2020-113656RB-C21 via MCIN/AEI/10.13039/501100011033 and project UJI-B2021-58.
Notes
Author biographies
Roman Iakymchuk is Associate Professor at the Division of Scientific Computing, Department of Information Technology, Uppsala University (UU), Sweden. He is also Associate Professor at the Department of Computing Science at Umeå University (UmU), Sweden. At UmU, he is a co-Principal Investigator of EuroHPC JU Center of Excellence in Exascale CFD (CEEC) and leads the work package on Exascale Algorithms. Roman develops the Exact BLAS (ExBLAS) library for fast, accurate, and numerically reproducible computations. He extended this idea to Krylov type solvers in hybrid parallel environments. He conducts his research on numerical linear algebra, accuracy and precision of computations, parallel programming models as well as enabling sustainable computations.
Stef Graillat received his PhD degree in 2005 from Université de Perpignan, France. He is Professor in Computer Science at Sorbonne Université and a deputy director of LIP6 laboratory. His research interests are in computer arithmetic, floating-point arithmetic, and validated computing.
José I. Aliaga is Professor in the department of Computer Science and Engineering in the University Jaume I (UJI), Castellón. His main research interests include the application of high-performance computing on sparse numerical linear algebra and Krylov subspace methods, improving both the performance and the energy efficiency of the parallel implementations in hardware accelerators, shared-memory multiprocessors and clusters. Nowadays, all these techniques are being applied in the field of machine learning, particularly in medical image processing. José has published more than 75 papers in journals and conferences, and has also participated in over 40 research projects funded by both national and private organizations (in Spain or within the EU), leading 10 of these projects. He was also involved in five technology transfer contracts (three in Spain and two within the EU), leading four of them.