
Abstract
Malleability is defined as the ability to vary the degree of parallelism at runtime, and is regarded as a means to improve core occupation on state-of-the-art multicore processors tshat contain tens of computational cores per socket. This property is especially interesting for applications consisting of irregular workloads and/or divergent executions paths. The integration of malleability in high-performance instances of the Basic Linear Algebra Subprograms (BLAS) is currently nonexistent, and, in consequence, applications relying on these computational kernels cannot benefit from this capability. In response to this scenario, in this paper we demonstrate that significant performance benefits can be gathered via the exploitation of malleability in a framework designed to implement portable and high-performance BLAS-like operations. For this purpose, we integrate malleability within the BLIS library, and provide an experimental evaluation of the result on three different practical use cases.
Introduction
Task-level malleability is a well-appreciated property in cloud computing, where it refers to the capability of expanding/shrinking the number of resources allocated to a certain job during its execution. Process-level malleability can also offer significant performance benefits for distributed MPI scientific applications though, in that context, it is considerably more challenging due to the necessary re-distribution of the workload and data; see Iserte et al. (2017), Iserte et al. (2018) and the references therein.
In contrast, the concept of exploiting thread-level malleability inside an application may seem simple, both when using POSIX threads (pthreads) or a high level parallel application programming interface (API) such as OpenMP (OpenMP Architecture Review Board, 2018), but there are still relevant challenges that must be addressed to demonstrate its benefits. In particular, many applications rely on Linear Algebra threaded libraries (TLs), such as the Level-3 Basic Linear Algebra Subprograms (BLAS) (Dongarra et al., 1990), which are internally parallelized to optimize performance on multicore processors (Intel, 2020; OpenBLAS, 2015; Van Zee and van de Geijn, 2015).
TLs can exhibit three different degrees of flexibility to determine the number of threads that execute a specific kernel: • Static TLs, in which the number of threads is decided at the program level, and hence it cannot vary throughout the execution of the complete program. Therefore, the number of threads is constant across all kernels within the execution. • Moldable TLs, in which the number of threads executing a kernel can be varied dynamically across different kernels, but in all cases before the execution of each individual kernel starts. • Malleable TLs, in which the number of threads executing a kernel can vary dynamically and upon request while the kernel is under execution. Currently, the support for malleability in TLs is scarce or non-existent on both commercial and open-source TLs.
Additionally, applications where each task basically requires the execution of a kernel from a linear algebra library can exploit parallelism either (1) from within the application only, (2) from inside the library kernels only, or (3) a combination of both (that is, application + library) (Dolz et al., 2015). In this paper, we revisit the third approach, exploring the performance benefits of composing a task-parallel Application (TA) with a thread-level malleable BLAS (MLB). Concretely, our TA + MLB approach divides the existing threads into t App teams, handled by the application, where each team (comprising one or more threads) is in charge of executing a single task/linear algebra kernel. Alluringly, in our TA + MLB approach, the number of threads in each team cannot only vary dynamically during the timespan of the application, but also during the execution of each individual linear algebra kernel.
Our dynamic approach at the kernel level is built on top of an instance of MLB developed using the Basic Linear Algebra Instantiation Software (BLIS) (Van Zee and Van de Geijn, 2015). In Catalán et al. (2019, 2020) this solution was reported to deliver considerable benefits for the execution of the (dense) LU factorization on current multicore processors in comparison with classical solutions that exploit parallelism only within the BLAS (as, for example, is done when combining the legacy LAPACK with a multi-threaded realization of BLAS) as well as more modern realizations of this factorization, via a rutime, that exploit parallelism only at the task/application level (Buttari et al., 2009; Quintana-Ortí et al., 2009; Badia et al., 2009).
In this paper we progress a significant step forward toward demonstrating the benefits of the TA + MLB approach via the elaboration and analysis of a collection of three cases beyond the simple LU matrix decomposition. In particular, we develop TA + MLB implementations of the following case studies, investigating different parallelization strategies, gaining insight on applicability/advantages, and reporting the performance of this approach: – QR factorization for the solution of (full rank) linear least squares problems (Golub and Loan, 1996). – Matrix inversion via Gauss-Jordan elimination (Householder, 1964). – Inference with deep neural networks (Sze et al., 2017).
The rest of the paper is structured as follows. After a general overview of the mechanisms to exploit parallelism in task-parallel applications, we then assess the benefits obtained from the introduction of the malleability mechanism in dense algebra applications and deep learning. We close the paper with some concluding remarks and proposal for other applications of malleability.
Exploiting parallelism in task-parallel applications
Let us consider an application composed of a collection of tasks, intertwined via task dependencies, and where each task basically requires the execution of a kernel from a linear algebra library (e.g., BLAS). The left-hand side panel in Figure 1 displays a simple workhorse example for the following discussion, consisting of four tasks, numbered as Task-parallel application and parallelization schemes. SA + TL and TA + TL(1) use static TLs; TA + TL(2) is an example of the application of moldable TLs; TA + MLB requires a malleable TL.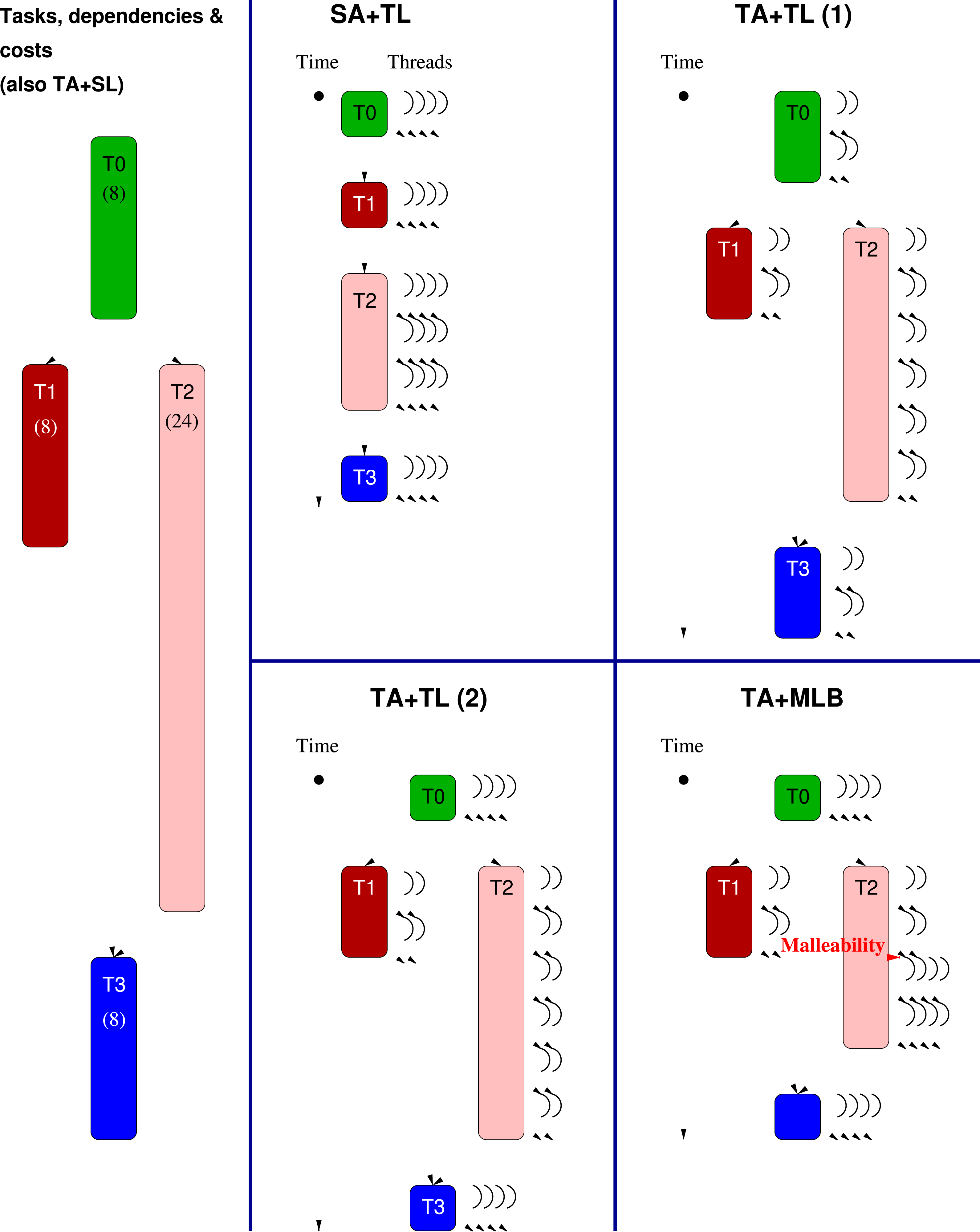
This type of application can be parallelized via one of the following three schemes, each presenting some advantages and caveats (Dolz et al., 2015): • A performance pitfall appears for applications that involve, as part of their computation, a non-negligible number of sequential kernels, which cannot benefit from a multi-threaded execution. For example, this is the case when the sequential kernels present a high computational complexity since, with this scheme, their cost cannot be hidden by overlapping their execution with that of other (independent) kernels. In the simple example in Figure 1 this would occur, for example, if task • A caveat of this scheme is that it requires decomposing the application into a “sufficient” number of tasks of the “appropriate” granularity, exposing a delicate balance: – On the one hand, if the tasks are too coarse, there may be too few of them, limiting the parallel scalability (at the application level). Also, dividing the tasks into finer-grain sub-tasks can be infeasible for some applications. – On the other hand, creating too many tasks increases the overhead introduced by the runtime in charge of controlling task dependencies. Furthermore, it may result in suboptimal execution of the sequential linear algebra kernels, which may be too small to properly exploit the memory hierarchy of the system (Low et al., 2014). – Finally, for TAs comprising large, compute-intensive linear algebra kernels with few dependencies (such as those in the Level-3 BLAS), the • However, each task is now executed using (a fixed number of) two threads. This case is an example of the use of a static TL, where the number of threads per task is defined on a per-application basis, and does not vary neither across kernel invocation nor inside kernels. This option should be adopted with care as it is prone to incur in thread over-subscription, (that is, creating more threads than physical cores) which, for task-parallel applications involving linear algebra kernels, often results in low performance on modern multi-core processors.
In this paper we revisit the
The approach proposed in this paper progresses one step further in the direction of malleability to allow that the number of threads that participate in the execution of a task varies during the execution of the corresponding linear algebra kernel. This is illustrated in the panel labelled as
Our dynamic, kernel-level malleable scheme tackles the two following scheduling-related problems. Consider a task-parallel application to be executed by a runtime using a number of “application thread teams” T
A
, T
B
, T
C
, …, with each application team in charge of executing a single task at any given moment. (For example, in the – The application team T
A
could benefit from a larger number of threads than those currently allocated to it. However, its peer application teams T
B
, T
C
, … are currently executing other linear algebra kernels and, with existing non-malleable libraries, will not release their resources until they complete their job. Should application team T
A
wait until this occurs or commence the execution of – Assume that, for this kernel
To avoid these problems, we adopt a dynamic solution, where the threads migrate between application teams on-the-fly, during the execution of the kernels, using a particular MLB built on top of BLIS (Van Zee and Van de Geijn, 2015). In the next few sections, we illustrate the benefits of this approach using three relevant cases from dense linear algebra and deep learning, running on multicore processor architectures.
Integrating malleability in BLIS
The malleability mechanism that we integrated into BLIS v0.5.1 is described in detail in Rodríguez-Sánchez et al. (2020) together with an analysis of the overhead introduced by this mechanism. For brevity, we only summarize next the most relevant aspects of this integration.
In order to introduce malleability the key is to leverage (and modify) the BLIS API to distinguish in the library between 1) the maximum number of threads and 2) the active number of threads. The former parameter specifies the amount of threads that are initially active when invoking a routine, and it typically matches the number of cores of the machine. The latter parameter specifies the number of threads that participate in a given computation at a specific time, and can be modified asynchronously at any time by any application thread.
Using these two parameters, the workload for each of the nested loops (which corresponds to the iteration space for that loop) in the BLIS routine is distributed among the threads. As a result, those threads without any workload assigned to them in a given loop immediately proceed to the end of that loop, where they remain blocked (in a passive wait, to avoid wasting resources) till all the active threads that participate in the execution of that loop complete their part of the work.
Dense linear algebra
QR factorization with look-ahead
Algorithms Consider the QR factorization (Golub and Loan, 1996) of an m × n nonsingular matrix A, given by A = QR, where the m × m matrix Q is orthogonal and the m × n factor R is upper triangular. For simplicity, hereafter we assume that n is an integer multiple of the algorithmic block size b. Furthermore, we consider a column partitioning of A into s = n/b blocks, of b columns each. In our notation, A(:, c1 : c2) refers to the submatrix of A that spans the c1, c1 + 1, …, c2-th panels (or column blocks) of A, comprising columns c1 · b, c1 · b + 1, …, c2 · b − 1. (Note that, in our notation, the indices for blocks and elements start at 0.)
Listing 1 and the accompanying Figure 2 shows a (simplified version) of a blocked algorithm that computes the QR factorization of a square n × n matrix A expressed with a high level of abstraction. This formulation corresponds to a blocked algorithm that offers high performance provided b is moderately large, by reducing the ratio between flops and memory accesses. The algorithm performs s iterations, with the loop body first computing the factorization of the “current” panel (that is, the k-th column block); and then updating the panels to its right with the corresponding orthogonal transforms (trailing update). For simplicity, these two operations are encapsulated inside routines PF and TU, respectively. They are also quite different: PF is mostly a sequential operation while TU can be performed via highly parallel Level-3 BLAS. Partitioning of a matrix consisting of s × s blocks, with s = 5, and operations performed at iteration k = 1 of the algorithm for the QR factorization in Listing 1.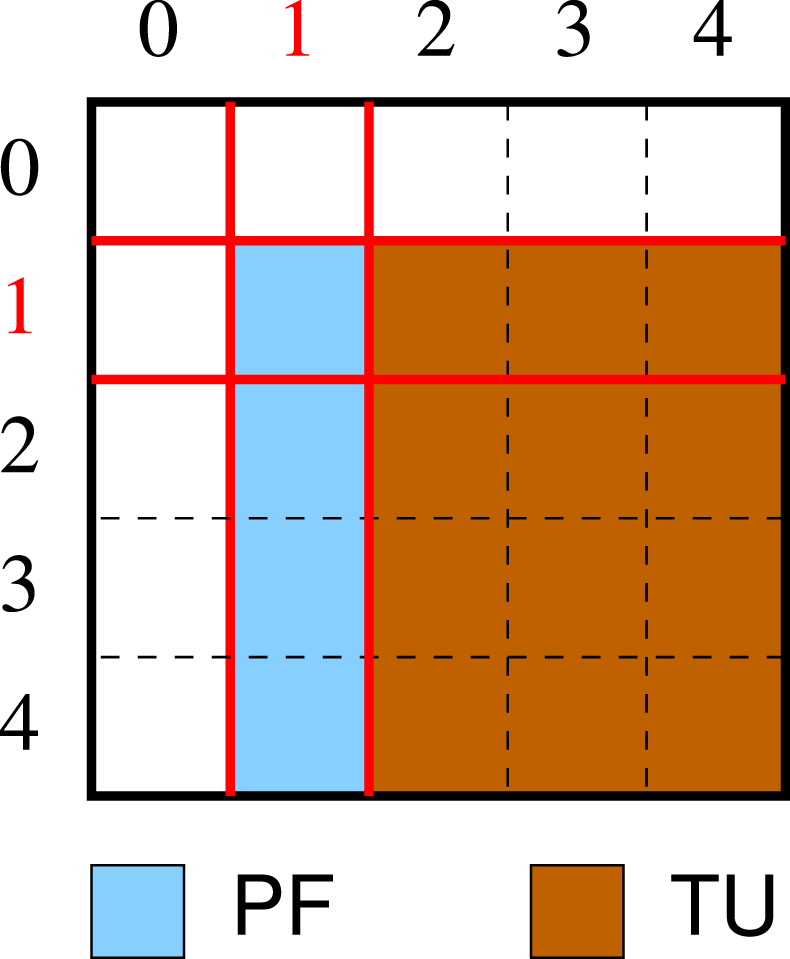

Listing 1: Simplified routine for the QR factorization.
The conventional approach to parallelize this matrix factorization is to exploit loop-parallelism from within the (Level-3) BLAS only, which corresponds to the
In our work, we follow an alternative nested-parallel
In order to expose nested parallelism for the

Listing 2: Reformulated QR factorization.
For simplicity, let us aggregate the update of the trailing (k + 1)-th panel and the subsequent factorization of the same panel in this code excerpt into a single operation, hereafter named panel update (and encapsulated inside PU). This results in the simplified algorithm for the QR factorization with look-ahead in Listing 3.

Listing 3: Simplified routine for the QR factorization with look-ahead.
Compared with the conventional algorithm for the QR factorization (that is, the realization without look-ahead in Listing 1), the variant with look-ahead features a loop body consisting also of two tasks: PU and TU, where the former is still mostly sequential while the latter can be performed via highly parallel Level-3 BLAS. However, in contrast with the standard algorithm, the two tasks in the loop body are now independent and, therefore, they can be executed in parallel. The main advantage of the look-ahead reformulation of the algorithm is that, because of the independence between the two operations in the loop body, it can overlap the execution of the small, sequential panel update with that of the large parallel trailing update. This is relevant since, as the number of cores grows, the panel update cannot take advantage of the increasing volume of hardware resources, and eventually becomes a performance bottleneck.
In order to exploit the task independence in the look-ahead variant via nested parallelism (
During the factorization, the ratio between the floating point operations (flops) performed inside the PU and TU vary, introducing two sources of workload imbalance: To tackle this problem, we can apply an early termination mechanism (developed in Catalán et al. (2019) for the LU factorization) that quits the execution of PU (and delays the pending part of the panel factorization to the subsequent iteration) as soon as the team in charge of TU notifies it has completed its job. This is equivalent to a dynamic, adaptive tuning of the algorithmic block size b. In the case, we leverage MLB to enforce that, as soon as the threads in team T
P
are finished with PU, they join those in team T
T
for the collaborative execution of TU.
In Catalán et al. (2020), we analyzed how to integrate task-parallelism with MLB, from the point of view of parallel programming. That work evaluated this solution for three matrix factorizations: LU (with partial pivoting), QR, and reduction to symmetric band form. However, the study performed there had a few relevant simplifications: 1) the team in charge of the panel factorization comprised a single thread only; 2) the solution did not include early termination; and 3) the malleability mechanism was not integrated into BLIS. In this paper we overcome these simplifications to offer a more complete experimental assessment of the benefits of nested
Performance evaluation
The following experiments (and those in the second use case in this section) were carried out on a platform equipped with a 20-core Intel Xeon Gold 6138 processor (Skylake micro-architecture). The reference codes were compiled with icc version 18 and linked with OpenMP 4.5 and either BLIS v0.5.1 or MKL 2018.1.163, and the malleability mechanism was integrated into BLIS v0.5.1 (Rodríguez-Sánchez et al., 2020). All experiments were performed in double precision. In addition, in order to avoid the performance distortions caused by the aggressive utilization of the power modes (and associated frequencies) featured by Linux governor for the Intel® Xeon® Gold 6138 processor (Intel, 2019), the operating frequency for all cores was set to 1.7 GHz.
Figure 3 reports the performance of the following codes for the QR factorization of square (m = n) matrices: – – – – Performance of the QR factorization.
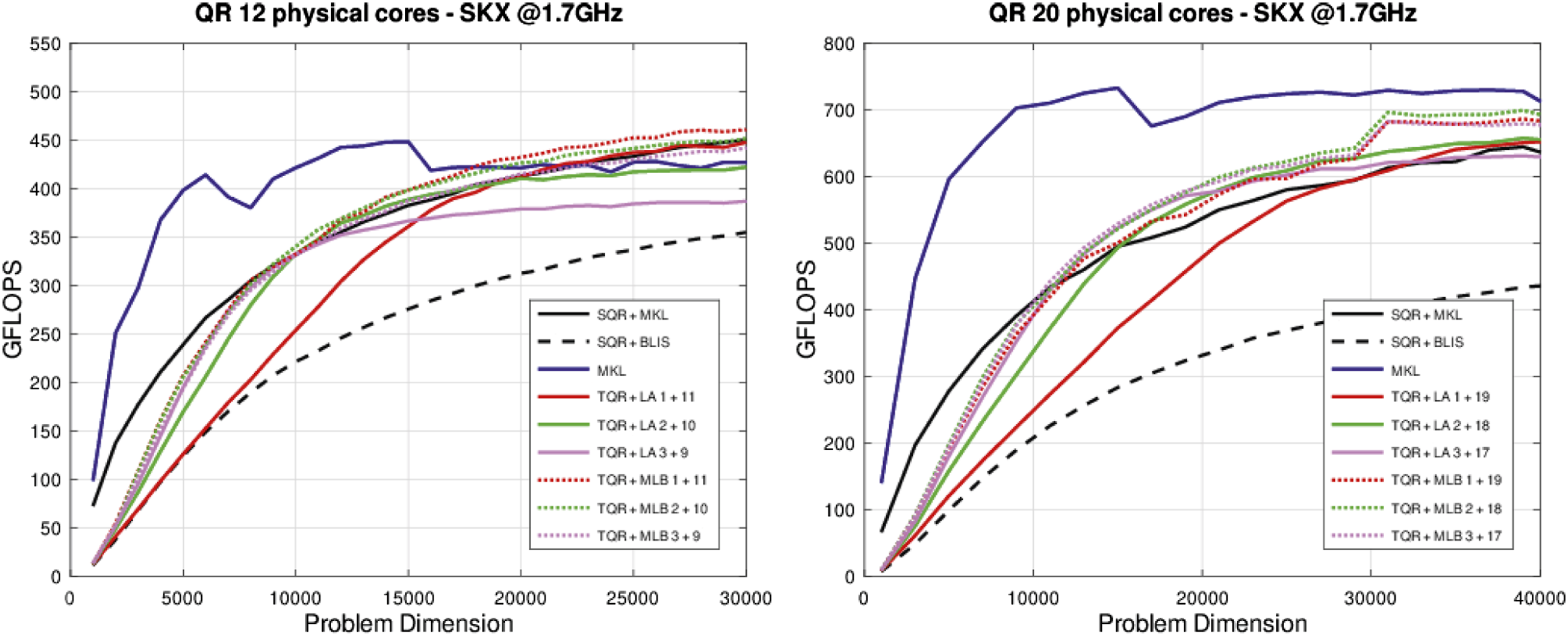
Figure 3 reports the results of the execution of the routines for the QR factorization using 12 and 20 cores (that is, the full socket in the latter case). Focusing on the
Matrix inversion via GJE with look-ahead
Algorithms. The Gauss-Jordan elimination (GJE) can be leveraged to build a direct procedure to compute the matrix inverse (Householder, 1964) that offers remarkable efficiency on modern multicore and manycore architectures (Benner et al., 2013). Moreover, similarly to the classical multi-stage matrix inversion algorithm via the LU decomposition (Golub and Loan, 1996), the practical numerical stability of the GJE-based procedure can be ensured via the introduction of partial pivoting (Higham, 2002). For simplicity, we do not include pivoting in the following description of the inversion algorithms though all our practical implementations evaluated in this section include this technique.

Listing 4: Simplified routine for matrix inversion via GJE.
Consider a nonsingular n × n matrix A. Listing 4 illustrates the procedure for matrix inversion via GJE adopted the same notation introduced for the presentation of the algorithms for the QR factorization. At each iteration of the loop in the blocked algorithm, indexed by k, the procedure first computes the “factorization” of the k-th (column) panel of the matrix. Once this panel is processed, via routine PF (for panel factorization), the inversion procedure updates the leading submatrix (panels) to its left via routine LU (for leading udpate); and the trailing submatrix (panels) to its right via routine TU (for trailing update). Here, the degree of parallelism of PF is scarce, while both LU and TU are composed of highly parallel matrix multiplications.
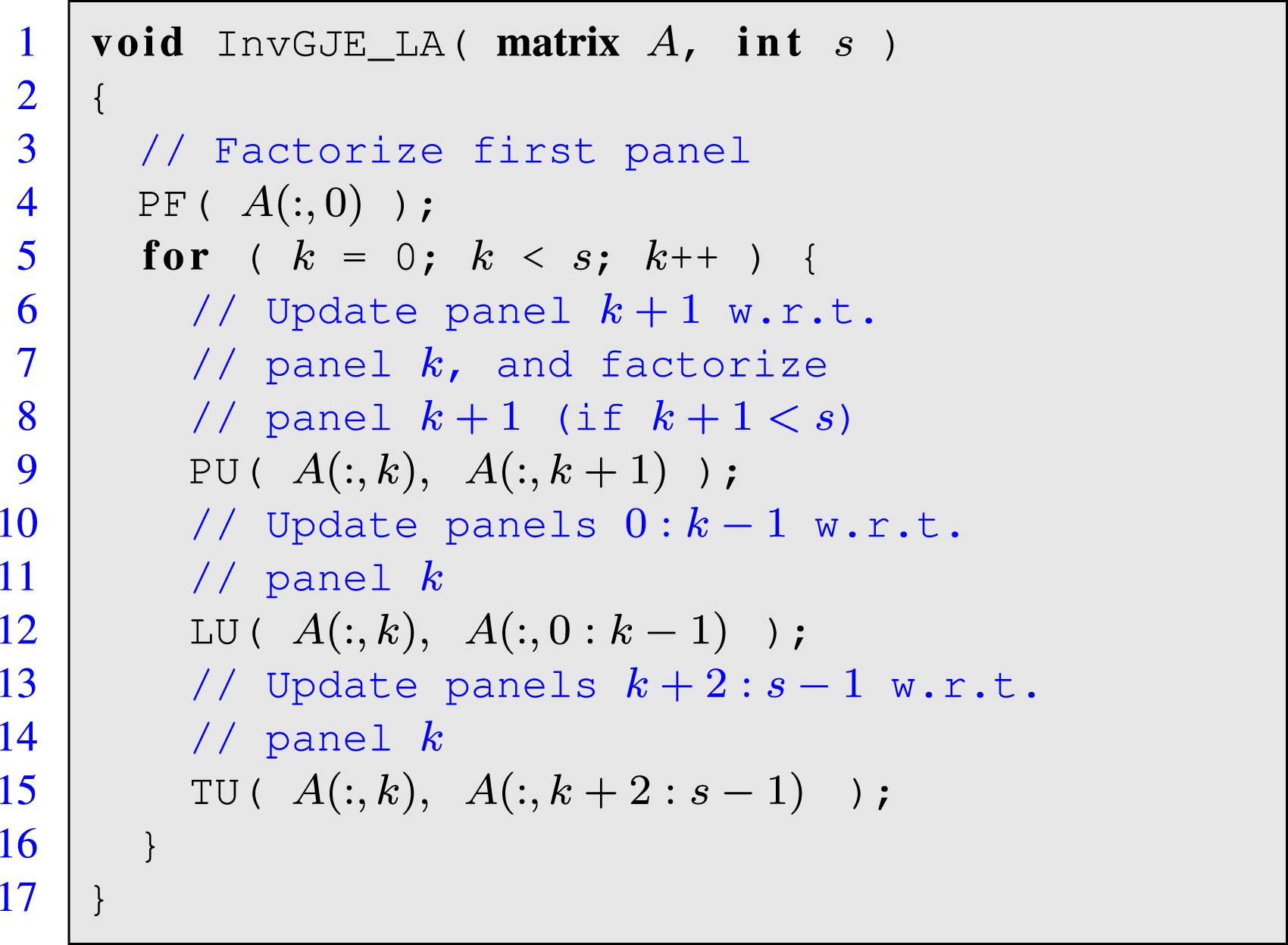
Listing 5: Simplified routine for matrix inversion via GJE with look-ahead.
As for other conventional panel factorizations, such as the LU, QR or Cholesky decompositions, the application of look-ahead (Strazdins, 1998) overcomes the strict dependencies present in the loop body of the matrix inversion procedure via GJE. For this purpose, the trailing submatrix needs to be split into two panels, and the algorithm has to be (manually) re-organized, applying a sort of software pipelining strategy in order to perform the panel factorization of the (k + 1)-th panel in the same iteration as the updates of the leading and trailing submatrices with respect to the factorization k-th panel. These changes allow to overlap the sequential factorization of the “next” panel with the highly parallel update of the “current” leading/trailing submatrices in the same iteration. This is illustrated in the re-organized variant of the algorithm with look-ahead in Listing 5.
The GJE-based algorithm for matrix inversion enhanced with look-ahead features three independent operations per loop iteration: PU, LU and TU. On a multicore processor, the question that arises in this case is how to execute these operations (tasks) in parallel. An straight-forward scheme is to dedicate all threads/cores to computing each operation in a sequential order. That is, all threads compute PU in parallel; upon completion, they next collaborate to compute LU; and, finally, they work on TU, also in parallel. This corresponds to
The approach we follow in this work is to divide the collection of threads into three application thread teams, assigning a team consisting only of a few threads to the execution of PU; while dedicating the bulk of the threads, distributed between the remaining two teams, to the execution of LU and TU. Note that, as the iteration progresses, the width (i.e., number of columns) of the submatrix involved in LU increases while that of TU diminishes. In this scenario, the use of a MLB for the execution of the operations underlying LU and TU can allow to shift the threads from one team to the other(s) as soon as they complete the execution of their kernel.
Performance evaluation
Figure 4 compares the following codes for the inversion of an n × n nonsingular matrix: – – – – Performance of the matrix inversion.
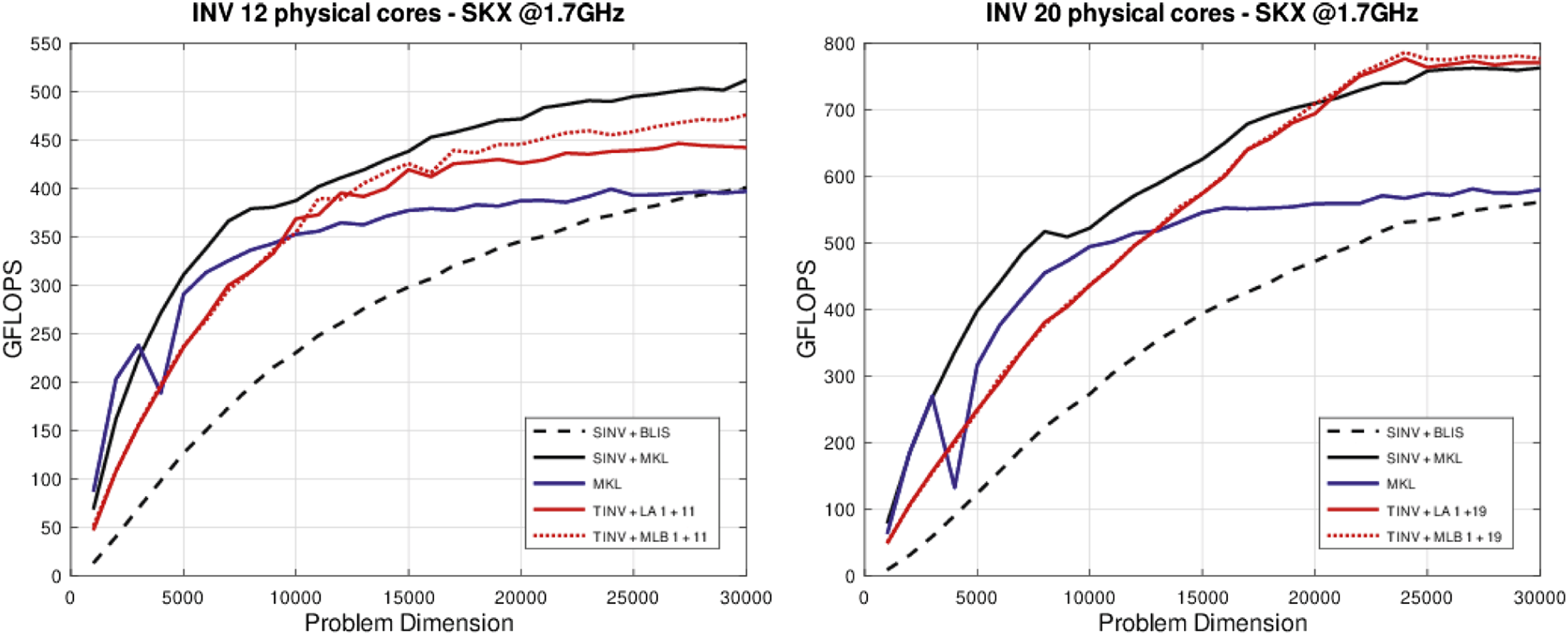
For the last two options we assign a single-thread team to the panel “factorization”; the remaining threads are then split among the two other teams, in charge of the left and right panel updates, depending on the cost of these operations. We also evaluated other options with 2 and 3 threads mapped to the team in charge of the panel, but they showed inferior performance for this operation. Both
Figure 4 shows that the variant
Deep learning inference
Inference algorithms
Deep neural networks (DNNs) consist of a large collection of interconnected neuron layers, where each layer performs an operation on its inputs to produce the output activations that are passed to the next layer. In the inference process for convolutional neural networks (CNNs), to a large extent these computations are equivalent to a general matrix-matrix multiplication (GEMM) or a convolution (Higham and Higham, 2018), followed by the elementwise application of a non-linear function. Furthermore, under certain conditions, the convolutions can be efficiently cast in terms of an enlarged GEMM via the im2col transform (Chellapilla et al., 2006).
The inference algorithm is illustrated with a high level of abstraction in Listing 6. There, it consists of an “endless” loop that commences with a blocking call to extract a sample (or collection of samples) from the input buffer I into the activation buffer A1 (layer 1 or input layer). These data are then serially processed by the sequence of layers that define the model: For l = 2, 3, …, L, layer l receives the input activations Al−1 and applies the transforms defined by the model in that layer, given by W l , to produce the outputs for that layer, A l , which will then become the input activations for the subsequent layer. The final result is passed to the output buffer (layer) O.

Listing 6: Simplified routine for inference with a DNN consisting of L layers.
The scenario we target in this case study reflects a high-performance inference server operating on the edge, which remains inactive till it receives a sample, e.g., from one among several connected devices, via the input buffer. The server then has to apply a specific DNN model to the batch of samples to produce an output under certain time constraints. While this occurs, new samples can arrive, from the same or other source, being enqueued into the input buffer till the server is ready to process them.
Now, as argued at the beginning of this section, when dealing with CNNs most layers involve a convolution, and this type of kernel dominates the global cost of the inference. For example, a fully-connected (FC) layer with nl−1 inputs and n l outputs, that receives a batch of b samples, boils down to a GEMM of dimensions defined by these three parameters: nl−1, n l and b. On the other hand, consider a Convolutional layer that comprises a convolution operator consisting of k n filters (or kernels) of dimension k h × k w × c i each. Assume the layer receives b tensor inputs (or samples) of dimension h i × w i × c i each; and produces b tensor outputs of size h o × w o × k n each. Using the im2col transform, the convolution can then be applied in terms of a GEMM with the dimensions defined by k n , (h o · w o · b) and (k h · k w · c i ). Other types of DNN layers, such as batch normalization, regularization, flatten or pooling present a minor contribution to the arithmetic cost and execution time of a DNN.
The challenges for the inference process on a multicore process arise from the constraints on the response times for many practical applications (e.g., real-time object recognition), the unpredictable arrival time of the batches (and sometimes even the number of samples of each batch), and the unbalanced computational costs of the distinct layers. Under these conditions, an
Performance evaluation
The experiments for the deep learning (DL) use case in this section were carried out in a platform equipped with a 48-core ARMv8 processor (Huawei Kunpeng 920). As in the previous cases, the malleability mechanism was integrated into BLIS v0.5.1 (Rodríguez-Sánchez et al., 2020). On this platform, gcc 7.5.0 was used as the compiler and the codes were linked with OpenMP 4.5. All experiments were performed using 24 cores and IEEE 32-bit floating point arithmetic. The operating frequency for all cores was set to 2.6 GHz.
The DNN model that is employed for the following evaluation corresponds to ResNet-50 (He et al., 2016) (but Similar results were obtained for AlexNet as well as variants of VGG models). We analyze two variants of an scenario that emulates, for example, an autonomous car equipped with several cameras that capture and send images to a centralized inference server (in the vehicle). In both cases, the server processes the images (samples) in batches, with each batch comprising the samples received in the last 0.1 s. In the first case, each batch contains the same number of samples: either 1, 2, 4 or 8 in our experiments. In the second case, each batch may now consist of a distinct number of samples: between 1 and 8. These two variants reflect cases where all the cameras capture images at the same rate or at different rates, respectively. (The inter-batch period was selected to emphasize the differences between the distinct parallelization schemes presented next.)
We consider 7 parallelization schemes for the DL case study: the baseline configuration (labelled as
We analyze the performance of the previously-described schemes using three key metrics: 1) the total execution time necessary to process a certain number of batches; 2) the execution time per batch; and 3) the waiting time per batch (that is, the time from the moment the batch arrives to the input queue till it is processed). The total execution time highlights the benefits of a concurrent execution of multiple batches. On the one hand, the execution time per batch illustrates the performance hit due to the increase of the number of teams (which results in a decreasing number of threads per team). On the other hand, the waiting time per batch shows the real benefits of the multi-team execution from the point of view of satisfying a given constraint in the time response.
The top two plots in Figure 5 demonstrate that increasing the number of concurrent teams reduces the total execution time for inference with batches of both fixed and variable size. The reason is that the layers of RestNet-50 are not complex enough (from the computational perspective) to fully profit from the 24 cores. As a result, the execution of several inference processes in parallel reduces the total execution time by a factor of 1.85× when using two teams, 2.4× with three teams, and a factor of 2.7× with four teams, for both fixed and variable batch-size scenarios. Malleability contributes a performance gain of up to 5% (two teams), 10% (three teams), and 13% (four teams) in the case of fixed batch size, and up to 4% (two teams), up to 3% (three teams), and up to 4% (four teams) in the case of variable batch size. Total execution time, average execution time per batch, and average waiting time per batch (top, middle and bottom, respectively) to perform inference for ResNet-50 with 50 batches of various sizes (left) and three workloads of batches with random sizes (right).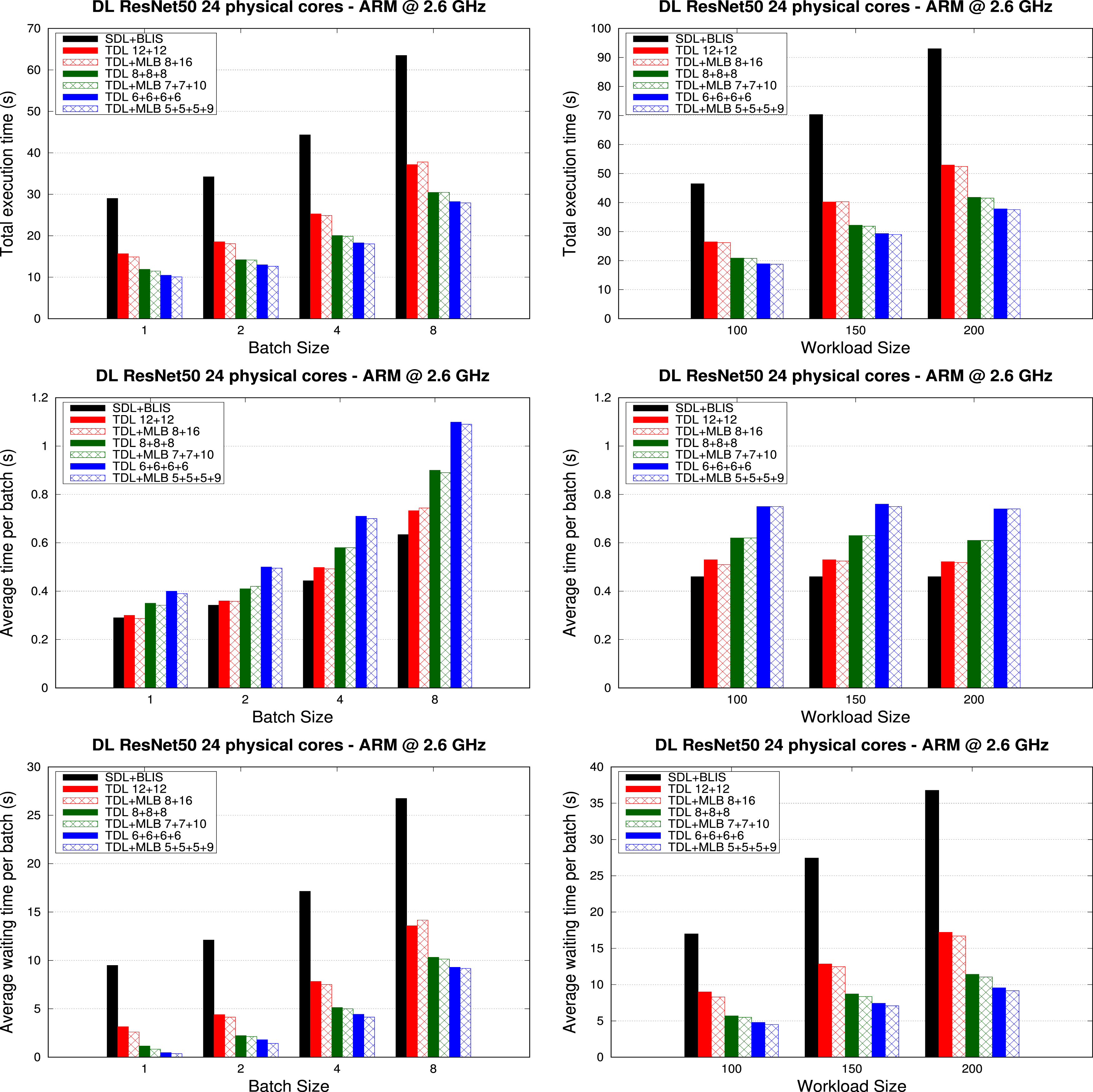
The plots in the middle row of Figure 5 report the average execution time. The results there show that adding more teams (which implies reducing the resources per team), increases the execution time per batch. This growth is not linear with the batch size, because some layers involve memory bound computations, with reduced parallel scalability. Moreover, we observe that dividing the resources between two teams does not increase the execution time per batch. The reason is the low complexity of the individual layers, which does not permit that the two-team scheme benefits from all the computational power of the processor. However, adding the third team results in an increment of the execution time per batch. The effect of the malleability is visible when compared with its corresponding non-malleable counterpart, with a reduction time for the two-team scheme of up to 11% and batch size of 4 and up to 7% with a random batch size. For the three-team scheme, the performance gain is up to 4% in the former scenario and up to 3% with the random batch size. For the four-team scheme, malleability adds a 4% of improvement for fixed batch size and up to 5% for the random scenario. There is also a performance loss for the two-team scheme when the batch size is fixed. This may be due to the negative effect of one team stealing a thread from another team which may be also executing a critical layer. This performance penalty is compensated not only in the total execution time but also in the average waiting time per batch. (That is, the time spent since the batch arrival to the start of its execution.)
Finally, the bottom two plots in Figure 5 illustrate the benefits of increasing the number of concurrent execution teams in the waiting time per batch: Using two, three and four teams diminish the average waiting time by factors up to 3×, 8× and 26× when the batch size is fixed; and up to 2.13×, 3.22×, and 3.8× when the batch size is variable; respectively. As in the previous tests, the malleability delivers an extra performance gain, of up to 12%, 14% and 23% for two, three and four teams, respectively.
Conclusions
In this paper, we have assessed the benefits of integrating malleability into the BLIS framework to avoid the rigidity of current instances of BLAS, for which the number of threads used for the execution of a routine is fixed from the beginning to the end. In practice, this new functionality is exposed to the programmer via a minimal modification of the BLIS expert API. The programmer just needs to identify where the distribution of the computation threads must be modified and the change is seamless.
The performance results demonstrate that the benefits of this approach are widely appealing in scenarios where the parallelism is extracted at both application- and library-level. More specifically, when the workload is not equally balanced at application-level, the malleability allows us to modify, at runtime, the parallelism at the library-level with the purpose of improving the overall core occupation.
Considering future work, we believe that malleability can also offer significant advantages in runtime-based task scheduling or popular task-based programming models such as StarPU (Augonnet et al., 2011) and OmpSs (Duran et al., 2011). There, the scarce task-level parallelism in some parts of the application (Dolz et al., 2015) can be by-passed by means to dynamically increasing the parallelism within the tasks. Hence, a fully malleable underlying library becomes mandatory.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is supported by grants PID2020-113656RB-C22, RTI2018-093684-B-I00 and PID2021-126576NB-I00 funded s MCIN/AEI/10.13039/501100011033 and by “ERDF A way of making Europe,” grant S2018/TCS-4423 of the Comunidad Autónoma de Madrid, by the Multiannual Agreement with Complutense University in the line Program to Stimulate Research for Young Doctors in the context of the V PRICIT under project PR65/19-22445, and project Prometeo/2019/109 of the Generalitat Valenciana. A. Castelló is a FJC2019-039222-I fellow supported by MCIN/AEI/10.13039/501100011033.
Author biographies