
Abstract
The advancement of modern processors with many-core and large-cache may have little computational advantages if only serial computing is employed. In this study, several parallel computing approaches, using devices with multiple or many processor cores, and graphics processing units are applied and compared to illustrate the potential applications in fluid-film lubrication study. Two Reynolds equations and an air bearing optimum design are solved using three parallel computing paradigms, OpenMP, Compute Unified Device Architecture, and OpenACC, on standalone shared-memory computers. The newly developed processors with many-integrated-core are also using OpenMP to release the computing potential. The results show that the OpenACC computing can have a better performance than the OpenMP computing for the discretized Reynolds equation with a large gridwork. This is mainly due to larger sizes of available cache in the tested graphics processing units. The bearing design can benefit most when the system with many-integrated-core processor is being used. This is due to the many-integrated-core system can perform computation in the optimization-algorithm-level and using the many processor cores effectively. A proper combination of parallel computing devices and programming models can complement efficient numerical methods or optimization algorithms to accelerate many tribological simulations or engineering designs.
Keywords
Introduction
Theoretical development, experimental investigation, and numerical simulation are the common approaches adopted in tribological studies. A study can combine the three methodologies for achieving an intended goal. While most often one of the methodologies is used at initial stage to deal with the problem in hand. A subsequent study 1 may be required to further examine the subject with some knowledge previously obtained. Since 2004, the central processing units (CPUs) in general-purpose computers started to have more than one processor core. In an era of abundant parallel computing devices, a lubrication engineer performing numerical computation is essential to adapt to the computing hardware advancement. When a tribological simulation is properly modeled with parallel computing codes, the benefit of reduced simulation time will be extended with little additional efforts as the improvement of the computing hardware continues.
In many tribological studies of fluid-film lubrication optimization, the bottleneck usually is in solving the underlying lubrication model. For instance, the main computational loading in using DIviding-RECTangle method2–4 or genetic algorithm5,6 for bearing designs is dealing with many iterative computations of lubrication models. An effective optimization algorithm is mainly capable of reducing the number of searches in the process. More importantly, the parallel computing can easily accelerate the search process which may be many folds faster than applying an improved optimization scheme. Similarly, a powerful computation may alleviate the need for an efficient numerical methods or algorithms in many tribological simulations or designs. A recent study 7 combines two programming languages, MATLAB and OpenMP Fortran programming, for fluid-film lubrication optimization. The goal was to take the advantages of effective multithreaded computing of OpenMP and MATLAB’s graphical interface and real-time display capability. The approach obtained accelerated results by combining the useful features of the two computing paradigms.
In 2011, several popular iterative methods for finding the solution of air-lubricated bearing models are compared. 8 The methods being examined are successive-over-relaxation (SOR), preconditioned conjugate gradient (PCG), and multigrid (MG) methods. However, all the methods compared in that study were conducted in serial (sequential) computing using a single processor core. Hence, the presented execution efficiency of the methods might be significantly different when parallel computing is being used. This is also subjected to the methods can be easily implemented with little modification in parallel computing.
A new numerical method for analyzing lubrication of rough surface was proposed recently. 9 The calculations in that study were all conducted using the MATLAB in a four-core CPU system. The execution time was effectively minimized compared with the serial computing. It was noted that the execution time could be further deceased using more processor cores. Several recent studies10–16 also show a few bearing analyses and optimum designs using OpenMP in Fortran coding. It was found that the execution time of the numerical simulations can be significantly reduced with a small amount of time and effort spent in code revision for parallel computing.
In an iterative solution method for various forms of Reynolds equation, the selection of relaxation factor and stopping criteria in iterative procedure is very important in terms of computational efficiency. It is found that the speed-up of the RBSOR (red-black successive-over-relaxation) method is superior to the standard SOR method in serial computing. 16 A stopping criterion for iterative solution methods, which is based on a truncation error analysis of Taylor series expansion, in lubrication analysis was presented. 17 The iterative methods used to validate the stopping criterion were SOR, PCG, and successive-under-relaxation for solving compressible- and incompressible-fluid Reynolds equations. The study shows that a proper stopping criterion for iterative methods can prevent excessive computations with satisfactory results.
The execution time of the standard SOR method cannot be effectively minimized in a parallel computing, while the RBSOR is much better in that regard. Although the RBSOR method is a well-known parallel computing scheme for solving lubrication models of elliptic partial differential equation, it is not necessary the best one in terms of efficiency. But, the use of RBSOR method is advantageous in terms of its easy to understand and straight-forward to implement. In this study, the RBSOR method is selected to assess the characteristics of the parallel programming paradigms with their respective computing devices.
Currently, the processors being applied to execute the parallel computing in a shared-memory workstation or server can be classified into three types. These are multicore processors (MCPs), graphics processing units (GPUs), and the more recently developed processors with many-integrated-core (MIC, that is, Intel Xeon Phi CPU). The main differences between MCP and MIC processors are the latter has poor single-thread performance, but with a large number of threads which is suitable for highly parallel workloads. The processor bandwidth of MIC is also several (5 to 6) times higher than that in MCP, with the expense of about twice power consumption in full load. 18
For shared-memory systems, both the open architecture of parallel programming paradigms, namely OpenMP and OpenACC, are under active development in recent years. The OpenACC is a new programming model (started in 2011) for GPUs, while the OpenMP (started in 1997) has long been used in parallel programming for MCPs. The MIC processors are also relied on the OpenMP to release the full computational potential. These two directive-based programming models are easy to implement, which enable the lubrication engineers to focus on the numerical models to be solved. And the modification of a serial code to a parallel one can be executed incrementally. This is contrary to an extensive coding revision required in using CUDA (Compute Unified Device Architecture, for Nvidia GPUs only) or MPI (message passing interface, which can be used in distributed- or shared-memory systems).
In this study, the parallel computing part of the Fortran programs for tribological simulation is coded by either CUDA, OpenACC, or OpenMP. 16 A counterpart coding can be constructed using C or C++ language, on most platforms. Initially, the effect of the cache size of CPU and GPU on the OpenMP and OpenACC performance for fluid-film lubrication is investigated. The performance comparison of CUDA, OpenMP, and OpenACC is also carried out in the cases where the cache size of respective device is sufficient. The usefulness of the MIC system for handling simultaneously independent computing tasks is also investigated in an air bearing optimization study.
Methodology
Lubrication models
In this study, the performance and characteristics of the multithreaded (MCP and MIC) and GPU computing for lubrication analysis are assessed using two lubrication models. A simple model is an inclined-surface slider lubricated with incompressible fluid (equation (1)). Equation (1) is discretized by the standard second-order accurate difference equations to form the difference equation
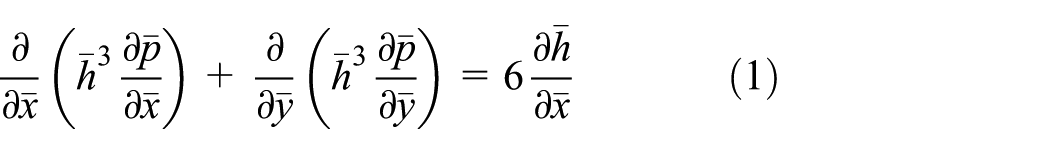
The dimensionless groups used in equation (1) are as follows

The second case deals with the optimum design of an air-foil bearing. 19 The film pressure of the air-foil bearing is modeled by equation (2), which is linearized by Newton’s method and solved iteratively with an elastic boundary to simulate the supporting bump foils. 19 The dimensionless groups are the same as used in equation (1)
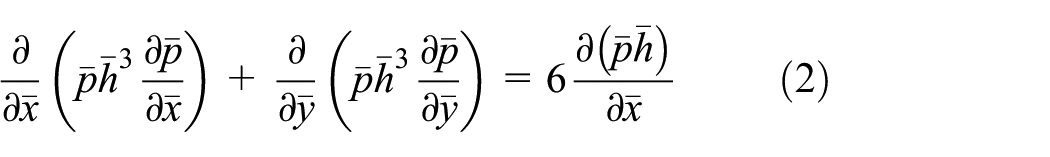
To determine the foil deformation in the bearing with a known eccentricity ratio, the air film thickness is defined by the elastic foil model (equation (3))

The bump foil compliance number

The design variables and parameters of the air-foil bearing.

Computational setting
Three iterative methods, SOR, RBSOR, and SPSOR (strip-partition successive-over-relaxation), are applied in this study in serial computing as well as in parallel. In this study, equations (1) and (2) are discretized and solved by the standard second-order accurate five-point stencil finite difference method. Since the programming language used is Fortran, the column-wise processing of arrays is applied in the nested loops, either in serial or parallel computing. The first method being used is the standard point SOR with natural ordering. The other two domain decomposition methods 12 , the RBSOR and SPSOR, are also applied. In the RBSOR method, the computation is divided into a two-partition layout (Figure 1), and each partition is denoted by red or black points. If the computation starts from the red points, then this five-point stencil computation depends on the values of the adjacent four black points. Other than the values of boundary points are given, the values of the black points are from a previous iteration or initial guess. The computation of all red points can be executed in parallel among the available processor cores. To complete the whole domain computation, the black-point calculation is then performed. The updating of the black points is based on the newly computed red points.

The layout of the standard RBSOR method. 12
Figure 2 shows the computational layout of the SPSOR method when two strips are employed. In this study, the systems have various processor cores and the number of strips in the SPSOR is always equal to the number of available processor cores to maximize the workload. Since the boundary pressure data for each strip are taken from a previous iteration, the computation of the pressure in each strip, thus, can be conducted simultaneously. Note that the domain stripping computation is performed in the direction in which favors the data access in using Fortran; thus, the required amount of CPU cache can be minimized.
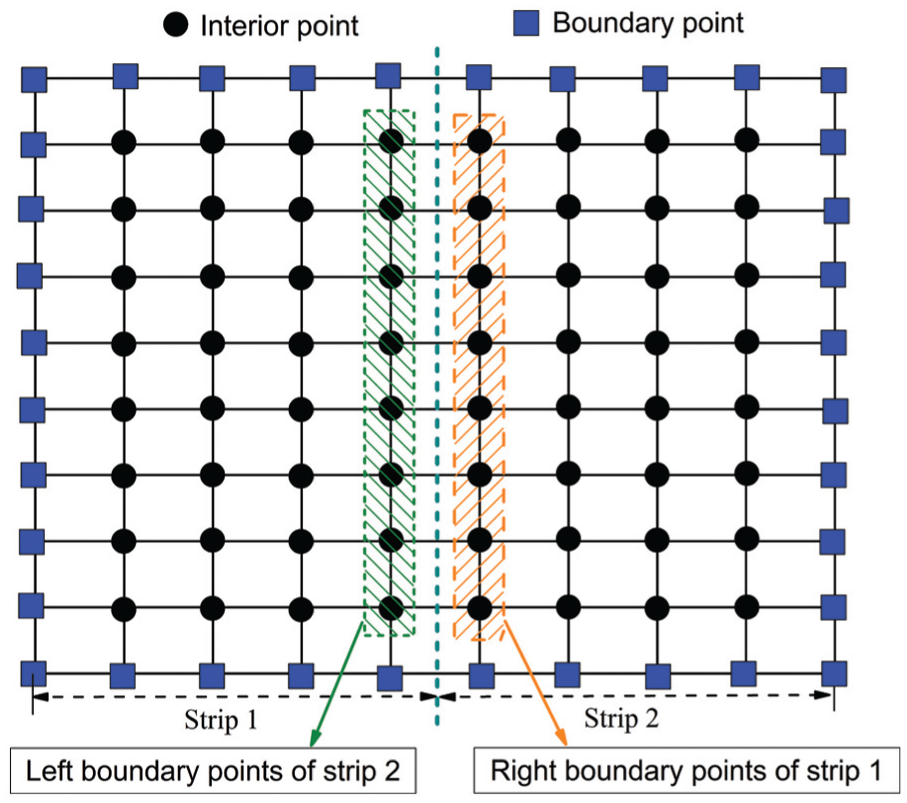
The layout of a two-strip partition of SPSOR method. 12
In the cases of parallel computing, the OpenMP and OpenACC directives are applied in Fortran 95 coding to speed up the computation. In the OpenMP computing, the number of processor cores to be used concurrently in a computation can be assigned at run-time and easily monitored. But, this is not the case for GPU computing. Also, the logical processor cores (Hyper-Threading of Intel) in the MCP or MIC system are not used in this study, which have only a fraction of computing capability of physical processor cores. The concurrent use of logical processor cores may present adverse effects in parallel computing. When the OpenACC computing is used, the bottleneck tasks (i.e. solving equation (1) or (2)) is offloaded to the GPU via a bus interface in the computer. The calculated results are then returned and collected by the main CPU via the same bus interface.
In this study, four computers (CMP1 to CMP4) are used. Table 2 shows the parallel programming paradigms used and the corresponding device, operation system, and compiler. Table 3 lists the main specification of the four computers as well as the computing devices installed. The number of processor cores of the MCP/MIC system ranges from 4 to 64 and the number of GPU cores are from 448 to 768. Also note that the cache of the computing devices varies in a wide range, which may affect the computing performance significantly. 12 Note that the CMP3 is tested with three GPUs, one GPU at a time, to evaluate the computing performance using the same platform. The PGI compiler for Fortran 90/95 language is selected for its ability to support CUDA, OpenACC, and OpenMP. The CUDA and OpenACC programming models are implemented on Nvidia GPUs while the OpenMP coding is operated on Intel MCPs or an MIC. Currently, the new Intel MIC processor is supported by the MS-Windows Server 2013 or 2016.
Setup of the parallel programming environment.

CPU: central processing unit.
Configuration of the computing machines.

MCP: multicore processor; MIC: many-integrated-core; GPU: graphics processing unit.
Particle swarm optimization
The PSO method is a population-based stochastic optimization technique,14,20 which emulates the social behavior of a group of individuals (particles) in search of an objective with high merit. In this study, each particle represents a bearing design; the objective of the optimization is to maximize the bearing stiffness, eccentricity ratio, and the reciprocal of the attitude angle simultaneously. The two decision variables are the radial clearance of the bearing and the ratio of the bearing width and length for a fixed projected area.
The essence of a global optimization, such as using the PSO, is to conduct a few searches at the same time to maximize the chance to locate extremes and also guided by some algorithm-specific group effort. The simultaneous searches are natural to parallel computing. The main bottleneck of the air-foil bearing optimization conducted in this study is in solving the underlying lubrication model, which is the compressible-fluid Reynolds equation (equation (2)). There is no difference in this regard in the other global optimization studies. As always, an effective optimization algorithm is mainly to reduce the number of searches in the process.
In a PSO simulation, the simultaneous computing using the available processor cores can be conducted either in the lubrication model (iterative-solution-level) or in the search method (optimization-algorithm-level), each of which has different characteristics in parallel computing. If a search (mainly to compute the numerical model based on a set of predetermined design variables) is handled by a thread (an independent task performed by a core), the parallel computing is operated in the optimization-algorithm-level. Otherwise, a search can be accelerated by performing parallel computing in the iterative solution methods for equation (1) or (2) with all the available processor cores. The algorithm-level parallelization is only applicable if several concurrent independent simulations are needed, such as computing different bearing designs in an epoch of the PSO analysis. Thus, the analysis can be run in parallel. While the approach of parallel computing conducting in the solution-level consists in splitting the solution domain of a single simulation in several partitions (e.g. using RBSOR and SPSOR), each partition being solved in a separate computation thread handled by a processor core.
It is shown that a PSO simulation performed in the algorithm-level (coarse-grain computing) is much more efficient than in the solution-level (fine-grain computing). 14 The drawback of fine-grain computing using OpenMP is a potentially large latency (communication and synchronization) requirement in the fork-joint process of threads. On the other hand, the parallel computing using CUDA and OpenACC suffers two latency related bottlenecks in each parallel execution, which are the fork-joint process and the CPU to GPU two-way communication. Nevertheless, the OpenACC can only be applied in the solution-level. As a result, only OpenMP is used in the PSO simulation in the algorithm-level and the performance of the MCP and MIC computing is compared.
In this study, the two design variables are radial clearance (c), and the aspect ratio (

Note that the use of equation (5) is an easy means to transform the optimization of three independent objectives to only a single objective. The drawback is that a highly nonlinear relationship among the objectives may be resulted if any of the three objectives approaches its extreme values during the optimization process.
Parallel optimization analysis
In an optimization analysis when the computation is conducted in the algorithm-level, the number of total processor cores in the system affects the overall parallel computing performance. If the number of required searches in a generation (epoch) exceeds the number of available processor cores, two or more batches of parallel computing are required. And the execution time of the optimization analysis is basically proportional to the total number of computing batches required. For most global optimization algorithms, the ability to conducting search with more designs at a time usually provides a better result. Therefore, in theory a machine with more processor cores can be more effective for performing a global optimization analysis.
Table 4 shows the parameter setting for the eight optimization tests, PSO1 to PSO8. The goal is to study the effect of total number of function evaluations (product of number of particles and number of epochs) as well as the number of available processor cores on the performance of optimization. The parallel programming paradigm used for both the MCP and MIC systems is OpenMP. In the first three cases, PSO1 to PSO3, the numbers of particles and epochs vary, but with the same total number of function evaluations (i.e. 400). The other cases (PSO4 to PSO8) have about 800 function evaluations. In a PSO analysis, the number of computing batches required in one epoch is the number of particles divided by the number of available process cores, which should be a whole number.
Parameter settings in the particle swarm optimization (PSO) analysis.

Since the number of particles in an epoch of PSO analysis is usually greater than the number of available processor cores, more than one batch of parallel computing tasks may be required. For instance, in the case of using 10 particles running 40 epochs (PSO1), the use of CMP1 (having four processor cores) requires three batches of parallel computing tasks. At the first two batches of computing all four cores of CMP1 are occupied. In the third batch for the last two tasks two cores are used whereas the other two cores are just idling. While the other two cases (PSO2 and PSO3) have no core-idling in each epoch. Also, the computing tasks in a batch usually are not completed at the same time, and a batch execution time is determined by the task with the longest time in that batch. The execution time variations among the tasks are mainly due to the solution time difference in iterative process.
Results
In the initial test of using one processor core, a much faster execution was obtained by the RBSOR method when compared with the standard SOR and SPSOR methods (Figure 3). Figure 4 shows the performance of the three iterative methods for solving equation (1) using CMP1 with four physical processor cores. Note that in each method, the relaxation factor is optimized and the convergence criterion for the same solution accuracy is used. Next, the OpenMP computing of RBSOR and SPSOR using CMP3 is conducted (Figure 5). The numbers in the parenthesis in Figure 5 are the number of iterations for each respective case. Note that the numbers of iterations for the same gridwork are different in RBSOR and SPSOR, and the latter requires more iterations due to less efficient in the solution (film pressure) updating process. From these preliminary results (Figures 3–5), it can be concluded that (1) the SOR method cannot be effectively accelerated in parallel computing (limited improvement) due to the data race problem in the iterative procedure; (2) the RBSOR and SPSOR can be accelerated effectively by the four-core parallel computing; (3) the performance of the RBSOR is slightly better than that of SPSOR. Hence, the RBSOR is used in the following studies to compare the performance gain using OpenMP and OpenACC programming models.

The performance of the SOR, RBSOR, and SPSOR methods for solving the Reynolds equation (equation (1)) by serial (single core) computing.

The performance of the SOR, RBSOR, and SPSOR methods for solving the Reynolds equation (equation (1)) using four physical processor cores.

Comparison of OpenMP computing of RBSOR and SPSOR in parallel computing.
Figure 6 shows the comparison of OpenACC computing performance on various GPUs. The performance of the OpenACC computing is basically a function of clock-speed of the GPU and its number of cores, except in the case of Tesla C2075. The high-performance Tesla C2075 is designed mainly for GPU computing; in this case, the CPU–GPU communication bandwidth is another important factor affecting the computing performance.

Comparison of OpenACC computing performance on various GPUs.
On CMP2, the three parallel programming paradigms (OpenACC, CUDA, and OpenMP) are used in the RBSOR method to speed up the calculation of the discretized equation (1). The results for various grid sizes are shown in Figure 7. In the test conditions, the OpenACC of GPU computing has a significantly better performance than the multithreaded OpenMP computing for the cases having a large number of numerical grids. Figure 8 shows the computational performance of OpenACC, CUDA, and OpenMP programming conducted on 10-core CMP3. The performance of the OpenMP computing is worse than that of either of GPUs running OpenACC. It can be seen that the CUDA computing requires a better CPU-GPU communication, in which the Tesla C2075 is much better performed than that of Quadro K2200 (both are using the same base system).

Computational performance of OpenACC, CUDA, and OpenMP programming on CMP2.
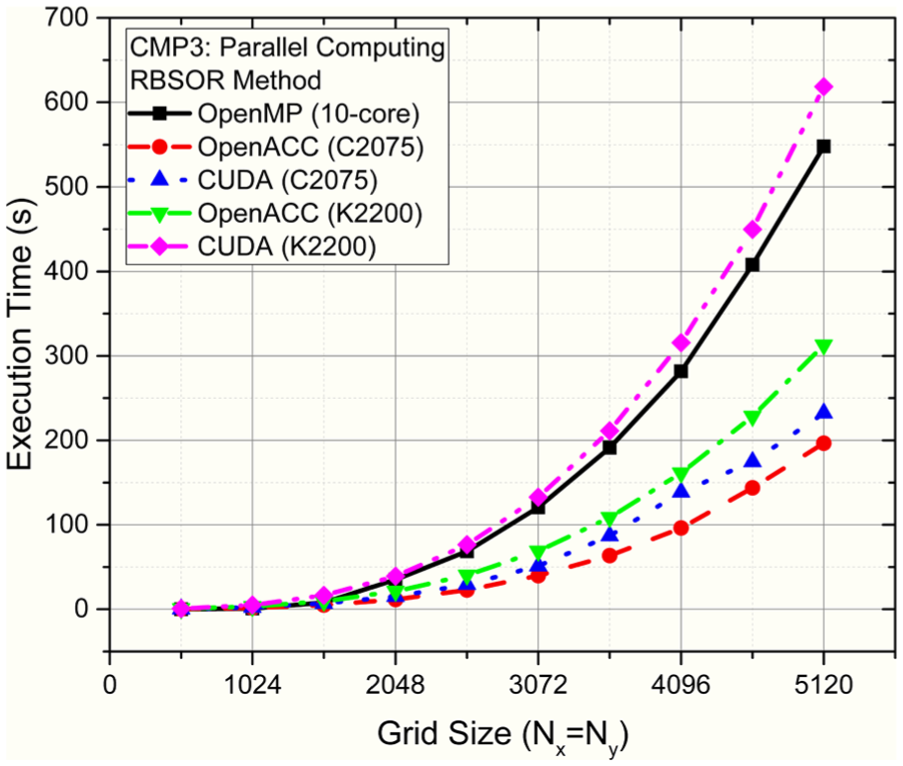
Computational performance of OpenACC, CUDA, and OpenMP programming on CMP3.
In the next two graphs (Figures 9 and 10), the performance of the computing is normalized to show the execution time required for a grid in iteration. This is obtained by dividing the overall execution time by the total number of the grids and the number of iterations conducted. Also, the amount of the cache required in an iterative computation is estimated using the total number of film-pressure grids (Nx × Ny), which is represented by a double-precision real number (occupying 8 bytes). Thus, the maximum grid size, for Nx = Ny, to fully utilize the high-speed cache is 866 and 1768, for a CPU with cache of 6 and 25 MB, respectively. When the available cache is exhausted in a computation, the performance is level-off at a larger computing time (Figure 9). It is found that the size of the cache in modern CPUs confines the performance when a computing requirement exceeds the limit. Due to the data access primarily from the slower main memory, a reduced performance is resulted. Figure 10 shows the comparison of computing performance of the OpenACC and OpenMP. The poor performance in the cases of smaller grids by OpenACC computing is due to a frequent data exchange at the low-speed GPU bus interface.

The effect of cache size on the computing performance shown in normalized execution time.

Typical computing performance of OpenACC for GPUs and OpenMP for multicore CPUs.
The data of the computing time required for various numerical grids (Figure 10) were obtained empirically. Since the computations were performed in the same computer, when the GPU or CPU cache was exhausted (for the grid size large than 2048, Figure 9), the slowest part of I/O (CPU or GPU–CPU to main memory) governs the performance. Thus, the amount of normalized computing time levels off when the grid sizes are greater than 2048.
The simulation results of the cases listed in Table 4 are tabulated in Table 5. In the first three cases (400 functions evaluations) of using CMP3, the resulted minimized execution time is due to the number of required epochs is reduced. While in the last three cases (800 functions evaluations), the execution times required for the 40 and 80 particles are about the same. As both cases have the same number of total parallel computing batches (which is 20). While in the cases of having 20 particles 40 parallel computing batches are required. As for the CMP4, the simulation time also increases as the number of computing batches increases. Note that the CMP4 has 64-core, which requires two computing batches in an epoch of PSO4. This results a total of 20 computing batches. For all the cases in Table 5, a given computer has a similar execution time per computing batch. Thus, the case of PSO1 has the shortest execution time by CMP4. The best optimization result in the PSO simulations is by using 80 particles (vs 40 in PSO1) in 10 epochs. Therefore, a system with more processor cores can allocate more particles in one search and a better optimization result can be obtained with reduced execution time.
Results of the parallel PSO simulations shown in Table 4.

PSO: particle swam optimization; CPU: central processing unit.
Objective: maximize
Discussion
The speedup of using parallel computing versus serial computing depends on the numerical methods used and the size of the problem. Some studies may apply Amdahl’s 21 law to estimate the speedup, if the parts in a computing can be clearly distinguished between parallelizable and non-parallelizable. But, modern multicore CPUs usually have variable clock rates. Therefore, if only one core is used, the CPU clock-speed in execution is higher than that of concurrent use of all cores. This makes the estimation of parallel speedup difficult. In this study, the multicore CPUs have the variable clock-speed (speed-step) option enabled.
A serial version of computing code for modeling fluid-film lubrication may differ from an effective parallel version for the same task. In some cases, a parallel algorithm may have to do some extra work, compared to an optimal serial algorithm, in order to be executed in parallel. A practical strategy is to incrementally treat the bottleneck(s) in a numerical simulation by OpenMP or OpenACC. This may involve the change of the code in the underlying code segment(s). The ability to modify code incrementally and to enable or disable OpenMP/OpenACC during the program compilation are the main features of these two directive-based programming models.
The simultaneous computing of using more than one processor core can be useful in many tribological optimization studies. A highly efficient lubrication model can be used as a slave program by accepting some data inputs and then return calculated results to the calling (master) program. The exchange of data between the master and slave programs can be easily accomplished by writing and reading data files from the system disk or storage device. The master program can be written in Fortran, C, or C++with OpenMP to deal with multiple launches of slave program at the same time. Currently, the application of multiple starts is not supported by OpenACC. The slave program is an executable program and can be written by any language. A commercial program can also be invoked in a similar way with known format of data inputs and outputs. Note that this is different from performing multitasking on one device, in which multiple users are supported and each user usually has a different objective.
Conclusion
Tribological simulation, as in many other scientific and engineering fields, is in an era of ubiquitous parallel computing. To effectively deal with iterative methods used in fluid-film lubrication analysis, the computing device is to be selected with a matching parallel programming model. The newly developed OpenACC standard is a programming model for GPUs, while the OpenMP has long been used in parallel programming for MCP, and now for the processors with MIC. An appropriate stopping criterion for iterative methods is also an influential factor for computational efficiency.
In this study, the GPU (OpenACC) computing can have a better performance than the multithreaded (OpenMP) computing in the cases with fine grid size (at iterative-solution-level). This is mainly because a larger cache is available for the GPUs in the tested cases. It is also found that the computing capability of a GPU in the same class is proportional to its clock-speed and the number of cores. It is expected that the combination of the fast developing GPUs and the OpenACC standards can facilitate the numerical simulations in many lubrication analyses.
For the cases where nested loops in iterative methods are the bottlenecks, the use of OpenMP parallel computing may not benefit from using a system with many processor cores. On the other hand, if the computing tasks can be treated by independent slave programs (as in the case of PSO analysis, each slave program computes a design), then the OpenMP programming is the only and effective choice. In this case, a machine with MIC installed may have advantage over the MCP system in global optimization studies. The reduced execution time is mainly due to a better computing load balance. It is also noted that the price versus performance of a computing device may be an influential factor in some tribological simulations, which is a subjective matter.
Footnotes
Handling Editor: Noel Brunetiere
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was supported by the Ministry of Science and Technology of ROC, contract number MOST 105-2221-E-182-019 and Chang Gung Memorial Hospital of Taiwan, project number BMRP 375.