
Abstract
This study examined potential differences in vocabulary found in picture books and adult’s speech to children and to other adults. Using a small sample of various sources of speech and print, Hayes observed that print had a more extensive vocabulary than speech. The current analyses of two different spoken language databases and an assembled picture book corpus replicated and extended these findings. The vocabulary in picture books was more extensive than that found in child-directed speech (CDS) and even adult-directed speech (ADS). The likelihood of observing a rare word not contained in the most common 5,000 words in English was more likely in a corpus of picture books than in two different corpora of CDS. The likelihood of a rare word in the picture books was even greater than that found in ADS. It is proposed that these differences are more indicative of informal versus formal language rather than the spoken versus written modalities per se. Nonetheless, these results highlight the value of rich read-aloud experiences for vocabulary development and potentially for reading comprehension once written language is acquired. These findings are described in terms of a distinction between formal and informal language, which has implications for views of literacy, cognitive and linguistic development, and learning to read.
Keywords
Most educators, regardless of theoretical orientation, recommend reading books to children to nourish language development (Dickinson, Griffith, Golinkoff, & Hirsh-Pasek, 2012; Duursma, Augustyn, & Zuckerman, 2008; Sénéchal & LeFevre, 2014; Wells, 1985). Most child care and preschools have reading time devoted to a teacher reading aloud picture books to children. It is not always obvious, however, why the recommendation of this type of shared reading is so ubiquitous. There might be many good reasons but the goal of this article is to assess a specific one. The research determines whether popular picture books read to children extend their linguistic and cognitive experience beyond what usually occurs in day-to-day spoken language exchanges. As will be addressed in the “Discussion” section, it is important to acknowledge that children might also acquire the same linguistic and cognitive experience from oral speech alone depending on genre of the language experience.
Picture Books
Picture books are usually described in terms of possessing two forms of communication: iconic and symbolic (Levin, Anglin, & Carney, 1987; Nikolajeva & Scott, 2001). Pictures are iconic because they resemble objects or scenes depicted, and the text is symbolic because it narrates a linguistic description related to the pictures. There is an art to composing picture books beyond the scope of this contribution. At the minimum, successful picture books require a seamless link between pictures and narrative text. Not surprisingly, children being read to look at pictures and not text (van Kleeck, 2003). Evans and Saint-Aubin (2005) measured eye fixations of 4-year-old children as they were read to. Results revealed that the children spent about 95% more time looking at pictures than text. Thus, during shared picture book reading, the child is actually listening to the story while looking at pictures in the book. Thus, although children are not obtaining direct experience with written letters and words, they are benefiting from the language of the story.
Vocabulary Knowledge
Words and language provide a “cognitive niche,” which expands a person’s cognitive capacities (Clark, 2013), and the earlier children are equipped with this linguistic savvy, the more they will benefit from everyday experiences. Few people would argue with the importance of language in achieving success in society today (Ritchie & Bates, 2013). A direct measure of language quality is the amount and nature of the vocabulary it contains. Research has shown that a child’s vocabulary is fundamental to his or her perceptual and cognitive development (LaSasso & Davey, 1987; Massaro, 2006a, 2006b; Waxman, 2002).
Vocabulary knowledge is positively correlated with both listening and reading comprehension (Anderson & Freebody, 1981; National Reading Panel, National Institute of Child Health and Human Development, 2000). It is not only critical for language competence, but it also plays an important role in understanding the world. Very young children more easily form conceptual categories when category labels are available than when they are not (Waxman, 2002). Even children experiencing language delays because of specific language impairment benefit once this level of word knowledge is obtained (Massaro, 2006b). Given this evidence,
. . . it follows that increasing the pervasiveness and effectiveness of vocabulary learning offers a timely opportunity for improving conceptual knowledge and language competence for all individuals, whether or not they are disadvantaged because of sensory limitations, learning disabilities, or social condition. (Massaro, 2006a, p. 228)
The present research reveals a vocabulary advantage of picture books over spoken language directed to children and therefore the possibility of picture books accelerating and enhancing vocabulary development.
The widely cited research by Hart and Risley (1995) discovered that before the age of 3, children heard many more words in high than in low socioeconomic status (SES) families. In an important follow-up study, Hoff (2003) demonstrated that “quantity, lexical richness, and sentence complexity of mother’s speech to their children” of the language also differed between these two types of families. Thus, it appears that quality as well as quantity of language is important in children’s language development. Analogously, I make the argument that reading picture books to children provides a similar advantage over the usual speech parents and others direct at children.
Although researchers and educators agree that children should acquire strong vocabularies and use them often, there is less consideration of when and how they should acquire them. Vocabulary should be acquired early in life because a word appears to be better learned the earlier a child learns it. As expected, competence in word recognition is also a function of how frequently the word is encountered (Petrova, Gaskell, & Ferrand, 2011). Age of acquisition is positively correlated with frequency of occurrence, however, making it difficult to isolate their effects.
In a large-scale project, age of acquisition and word frequency had very large and roughly equivalent correlations with reaction time and accuracy in a lexical decision task (Kuperman, Stadthagen-Gonzalez, & Brysbaert, 2012; Kuperman & Van Dyke, 2013). In addition, age-of-acquisition ratings accounted for a substantial percentage of variance after effects of log word frequency, word length, and similarity to other words were accounted for (Kuperman et al., 2012). In another informative study, there was an advantage of high-frequency over low-frequency words acquired fairly late, but early acquisition of words eliminated any frequency advantage (Stadthagen-Gonzalez, Bowers, & Damian, 2004). Thus, experiencing broader vocabulary early in life is beneficial for conceptual and linguistic learning and performance.
Research Goals
Nature of input is important for vocabulary and language development. A child is exposed to a variety of inputs, including exchanges with caregivers, television and related media on mobile devices, and shared picture book reading in which a book is read aloud to the child. The goal of this research is to assess the nature of language the child experiences in most spoken and written contexts. Significant language and vocabulary differences between these two modalities would be informative for both research inquiry and development of educational applications.
A layperson might think of written language as simply spoken language written down, especially with increasing popularity of automated dictation programs and instant text messaging in which speech is accurately converted to text (e.g., Dragon Dictation, 2015). Similarly, the seamless conversion of written text to speech blurs the distinction between these two modalities. Upon analysis, however, important differences between spoken conversations and written media have been found.
Donald P.Hayes’s Study
Hayes (1988) took on at that time a momentous task of collecting and analyzing language occurrences from printed magazines, newspapers, and books, television and natural conversations. Given these samples of speech and writing, Hayes analyzed the variety of words that occurred. Hayes (1988) analyzed what he called the lexical pitch of the vocabulary used to describe word usage as in “The speaker was able to pitch her remarks to the level of her audience.” The words occurring in these contexts were evaluated against frequency of occurrence in the American Heritage Dictionary study (AHD; Carroll, Davis, & Richman, 1971). The AHD was at that time the most comprehensive digital database of written language, with a corpus of more than 5 million tokens.
The question Hayes addressed was the degree to which word tokens found in his specific set of samples overlapped with the most common 10,000 word types in the AHD. (When language occurrences are analyzed, a distinction is made between word types and word tokens. A type is a unique word category, whereas a token indicates an occurrence of a particular type. A count of word types gives the number of unique words that occur, whereas a count of word tokens gives the total number of word occurrences.) As might be expected, the results showed a direct correspondence between frequency of word occurrences in magazines, newspapers, and books and rank order frequency in the AHD, derived from written language. Occurrence of words in samples of these three forms of written media roughly replicated the frequency of occurrence of written language from the much larger AHD. Numerically, about 90% of word occurrences in the samples of newspapers and magazines overlapped with the 10,000 most frequent word types in the AHD.
In contrast to the written language samples, however, the spoken language databases showed a significantly different pattern of results. The most frequent 10,000 word types from the AHD corpus occurred much more often in the spoken language samples than in the written language samples. This was particularly true for words ranked between 300 and 3,000 in the AHD. The 1,000 highest frequency words made up about 85% of the spoken language samples and only about 60% of the written language samples.
These results make the salient point that word occurrences in spoken language appear to differ from those in written language, with a bias for occurrence of high-frequency words in spoken language. Hayes concluded that lexical pitch (richness) of spoken language is aimed significantly lower than lexical pitch of written language (see also Halliday, 1987). Another way to view the results is that spoken language, with its heavy use of high-frequency words, tends to preclude occurrence of novel, less frequent words.
Current Replication Study
Hayes’s seminal work sets the stage for additional analyses with larger and more accessible databases. To address language use and vocabulary acquisition, contrasting picture books with conversational speech is a valid inquiry into their properties and differences. Hayes (1988) found that lexical pitch of his sample of books to be read to preschool children was somewhat intermediate between the spoken and written language samples. However, Hayes and Ahrens (1988, Table 2) reported roughly equivalent results for these books and college graduates speaking to spouses and friends. This difference is most likely due to Hayes’s use of 10,000 versus Hayes and Ahrens’s use of 5,000 most frequent word types in the AHD as the normative baseline. To address this apparent discrepancy and the question of the richness of the two genres of language more thoroughly, I compared word occurrences in picture books, child-directed speech (CDS), and adult-directed speech (ADS).
An extension of the Hayes study is also called for given that his analyses were based on very small samples, especially given today’s availability of databases of spoken and written language. The different categories in his spoken language corpora consisted of only about 1,000 words each, made up of 10 subsamples of 100 or more words. Only 21 books were recorded for the sample of books to be read to preschool children. In the present constructive or conceptual replication (Makel & Plucker, 2014; Schmidt, 2009) and analysis, the written language sample consisted of the complete text of 112 picture books for a total of more than 57,000 words. There were two spoken language databases used in the present study. The first had more than 15,000 words for CDS and more than 65,000 words for ADS. The second had more than 2.5 million words of parental speech in the company of children.
Method
Databases
Picture book database
The picture book database was obtained from a shared picture book reading application called Read With Me! (2012). The text from 112 popular picture books was transcribed for the application, although the text is hidden and not accessible by the user. The choice of picture books involved selections by the author, three experienced librarians working in the children’s section of two regional libraries, and several undergraduates. The goal was to choose their favorite picture books as well as those frequently read. As can be seen in the appendix, many of the picture books are well known and consist mostly of “storybooks” rather than “information books.” Thus, any advantage in the vocabulary of picture books would be expected to be even larger if “information books” were used. The genre of these books, however, makes a reasonable comparison with the speech corpora, which were collected in an informal conversational setting.
CDS
For the first corpus of CDS, I analyzed a database collected by Dr. Patricia K. Kuhl at the Institute for Learning and Brain Sciences (formerly the Center for Mind, Brain and Learning) at the University of Washington (Kirchhoff & Schimmel, 2005). The corpus was obtained to evaluate possible differences between acoustic characteristics of adult speech directed to children and to other adults. It consists of 64 conversations that included 32 different mothers solicited from neighboring communities. Each mother had two conversations, one with an adult experimenter and the other with her infant (age 2-5 months). Conversations were recorded using a far-field microphone (suspended from the ceiling near speakers’ heads). The recorded speech thus reflects natural conversational conditions. The recorded speech was time segmented and transcribed orthographically by phonetically experienced transcribers at the Department of Electrical Engineering at the University of Washington. These transcriptions were double-checked and serve as the corpus for the present analysis.
The CDS was recorded while the mother was interacting and playing with her child in a playroom situation with a variety of toys. The mother was instructed to simply play with her child as she would normally in a 20- to 30-min play session. (The child’s speech was not transcribed.) This produced an average of 520 CDS words from each of the 32 mothers. The topics of conversation were very broad, including discussions of animals, body parts, cartoons, colors, cooking, clothes, eating, emotions, family members, family activities, moods, places to visit, shapes, toys, and similar subjects.
ADS
The ADS came from the same collection as the CDS and consisted of both the mother’s and experimenter’s speech during a casual conversation. Much of the speech for the ADS corpus included discussions about the mother’s child and their various day-to-day activities. Similar to the CDS, the ADS conversation was open-ended although prompts were given by the experimenter when necessary to continue the conversation. The ADS therefore came from both mother and experimenter in each of the 32 sessions. These sessions produced an average of 2,182 words per session. The topics of conversation were similar to those observed in the CDS sessions. The data collection was also designed to elicit nine cue words, containing the most distant points in the vowel triangle, either by toys being played within the CDS session or prompts by the experimenter in the ADS session. The words were key, sheep, bead, boot, shoe, spoon, pot, top, and sock.
Corpus of Contemporary American English (COCA)
The COCA (1990-2012) was used to obtain a measure of common and rare words. This corpus is evenly balanced between spoken and written English. The corpus contains more than 450 million words from unscripted radio and TV shows, books of fiction, short stories, and movie scripts, and more than 100 popular magazines, 10 newspapers, and 100 academic journals. More than 150,000 samples contribute to the complete database.
Child Language Data Exchange System (CHILDES) Corpora
A subset of the CHILDES corpora (MacWhinney, 2000) was also used in the analyses. This CHILDES Parental Corpus database consists of contributions of 27 individual corpora provided by 27 different investigators (ParentFreq, 2015). The total number of lexical items in this parental corpus is 2,579,966 word tokens, with 24,156 word types (counting all inflected forms of a word as separate types). It consists of spoken utterances from parents, caregivers, and experimenters in the presence of children (age = 0;7-7;5; M age = 36 months). This corpus provides a huge sample of speech that children are exposed to (e.g., dinner table talk, talk during free play, and storytelling), even though not all of the utterances are strictly child-directed.
Procedures/Analyses
Using Unix utility programs sort (2015) and uniq (2015), I analyzed transcriptions of the spoken language corpora and the text in the picture books to count total number of words (tokens) and number of unique words (types). Given that the size of the databases differed, I took a subset of the picture books to create a sample to give a comparable contrast between the picture books and the CDS corpora. To increase reliability of the analyses, I repeated the sampling of words from two additional subsets of books in the picture book database. The three subsets were created by randomly sampling from the books making up the complete picture book database. Two samples had 32 books, and the remaining sample had 38 books to create samples comparable with the CDS database. All 112 books were used in the comparison with the ADS database. The appendix lists titles of the 112 books and an indication of which books were contained in each of the three samples.
Results
Picture Books Versus CDS
The current databases were analyzed to determine whether picture book and spoken language vocabulary differed significantly. Table 1 lists the number of types and tokens for the CDS database and three samples of the picture book database along with number of unique words in each database. As seen in the column of the Number of Types in Table 1, there were significantly more word types in the three samples of the picture book database (average = 2,504) than in the CDS database (1,017), even though their token counts were fairly equal. This result means that the sample of picture books had a larger vocabulary than found in the sample of CDS.
Number of Tokens, Number of Types, Type/Token Ratio, Number of Rare Types, and Ratio Advantage of Books Over the CDS Corpus.
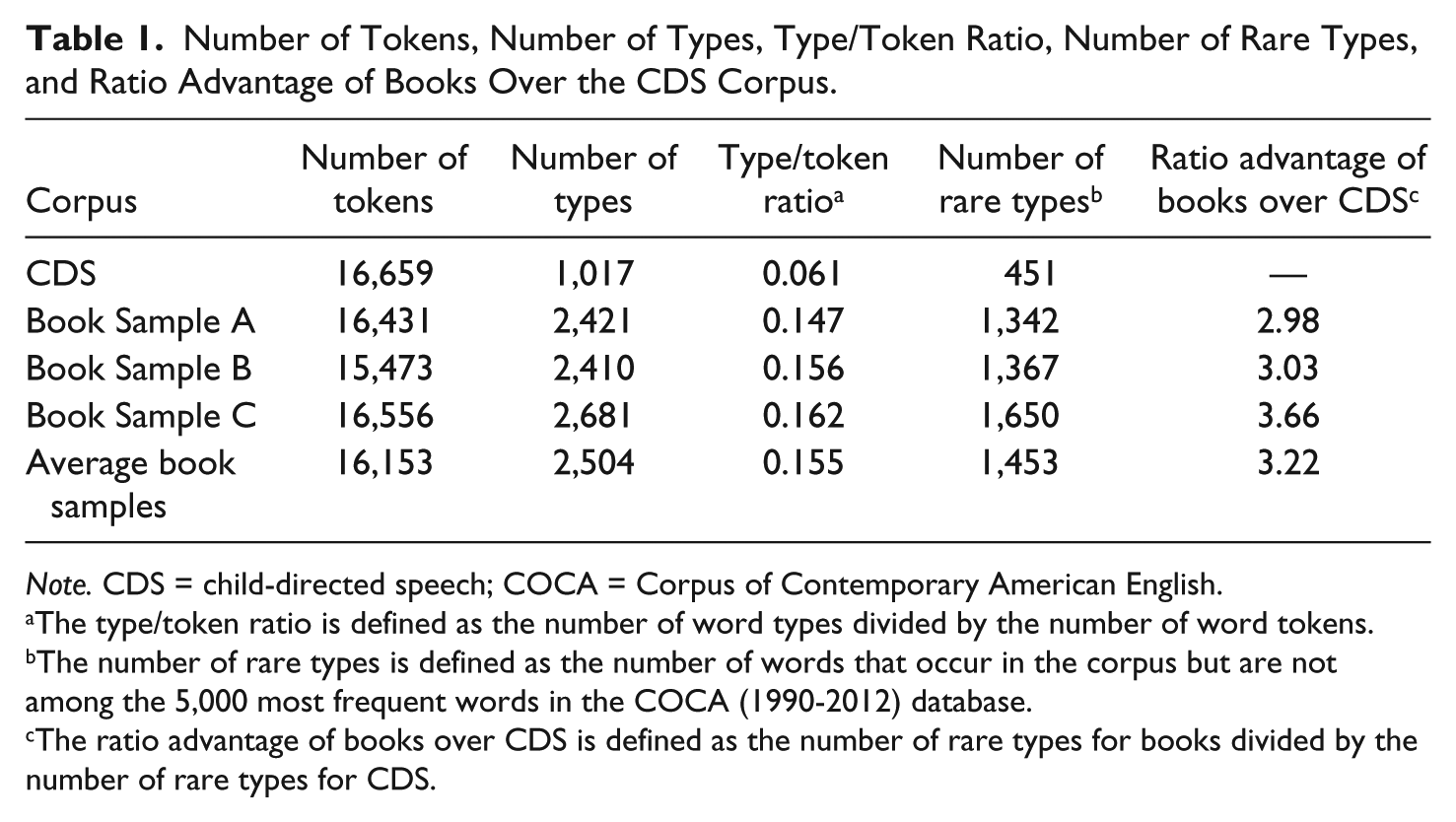
Note. CDS = child-directed speech; COCA = Corpus of Contemporary American English.
The type/token ratio is defined as the number of word types divided by the number of word tokens.
The number of rare types is defined as the number of words that occur in the corpus but are not among the 5,000 most frequent words in the COCA (1990-2012) database.
The ratio advantage of books over CDS is defined as the number of rare types for books divided by the number of rare types for CDS.
The type/token ratio gives a measure of how often word types occur relative to the total number of word tokens. A larger ratio means that the database has a larger number of different words relative to the total number of word occurrences. Table 1 shows that the type/token ratios for the three samples of picture books were 0.147, 0.156, and 0.162, respectively, much larger than the CDS corpus ratio of 0.061. Thus, there are about 2½ times as many word types in the picture book corpus relative to the CDS corpus. This initial result, however, is not sufficient to demonstrate that picture books have a more widespread and challenging vocabulary than CDS. It might be the case, for example, that the picture books might simply contain more common word types than those in the CDS sample. Following the procedure used by Hayes (1988), it is necessary to determine how vocabulary in the current samples compares with the most frequently used words in English. Given Hayes’s findings, picture books should have a more extensive vocabulary over and above frequently used words.
The picture book, CDS, and ADS samples were evaluated with respect to the 5,000 most frequently used spoken and written words in the COCA (1990-2012). The COCA list of the 5,000 most frequent words distinguishes among identically spelled words corresponding to different parts of speech. Given that part of speech is not available in the picture book, CDS, and ADS databases, it had to be ignored in the analysis. Combining words that had the same spelling in the COCA list reduced it from 5,000 to 4,353 uniquely spelled words. Given the enormous COCA database, this list provides a robust measure of the most common or frequently used words in the English language. In the present analysis, a rare word is defined as one not occurring in the list of common words.
The column of the Number of Rare Types in Table 1 eliminated words in the samples that overlapped with the most frequent words in the COCA database. This column shows that there were roughly 3 times as many rare word types (average 1,453 vs. 451) in the picture book word corpus than in the CDS corpus. This result means that children listening to a reading of a picture book are roughly 3 times more likely to experience a new word type that is not among the most frequent words relative to the situation of listening to their caregiver’s speech. Thus, children experience a greater number of rare words and supposedly a more extensive and challenging vocabulary with picture books than with CDS.
Picture Books Versus ADS
In the next analysis, vocabulary in the picture books was contrasted with ADS. Given that the number of words in the ADS database was similar to the complete picture book database, the full corpus of picture books was compared with ADS. Results in Table 2 show that picture books have a more extensive vocabulary than that observed when two adults are talking to each other. The column of the Number of Rare Types in Table 2 shows that there were roughly 1 and 1½ times as many rare word types (3,672 vs. 2,227) in the picture book word corpus than in the CDS corpus. Thus, the advantage of picture books over spoken language was about half the size for ADS than for CDS. Thus, the analysis shown in Tables 1 and 2 confirms the conclusion by Hayes (1988) that lexical pitch of written language is aimed higher than lexical pitch of the spoken language of conversations. Given that text complexity is correlated with word difficulty, it is reasonable to expect that a more challenging text exists when there is a larger number of word types not found in the most frequent words in the language.
Number of Tokens, Number of Types, Type/Token Ratio, Number of Rare Types, and Ratio Advantage of Books Over the ADS Corpus.
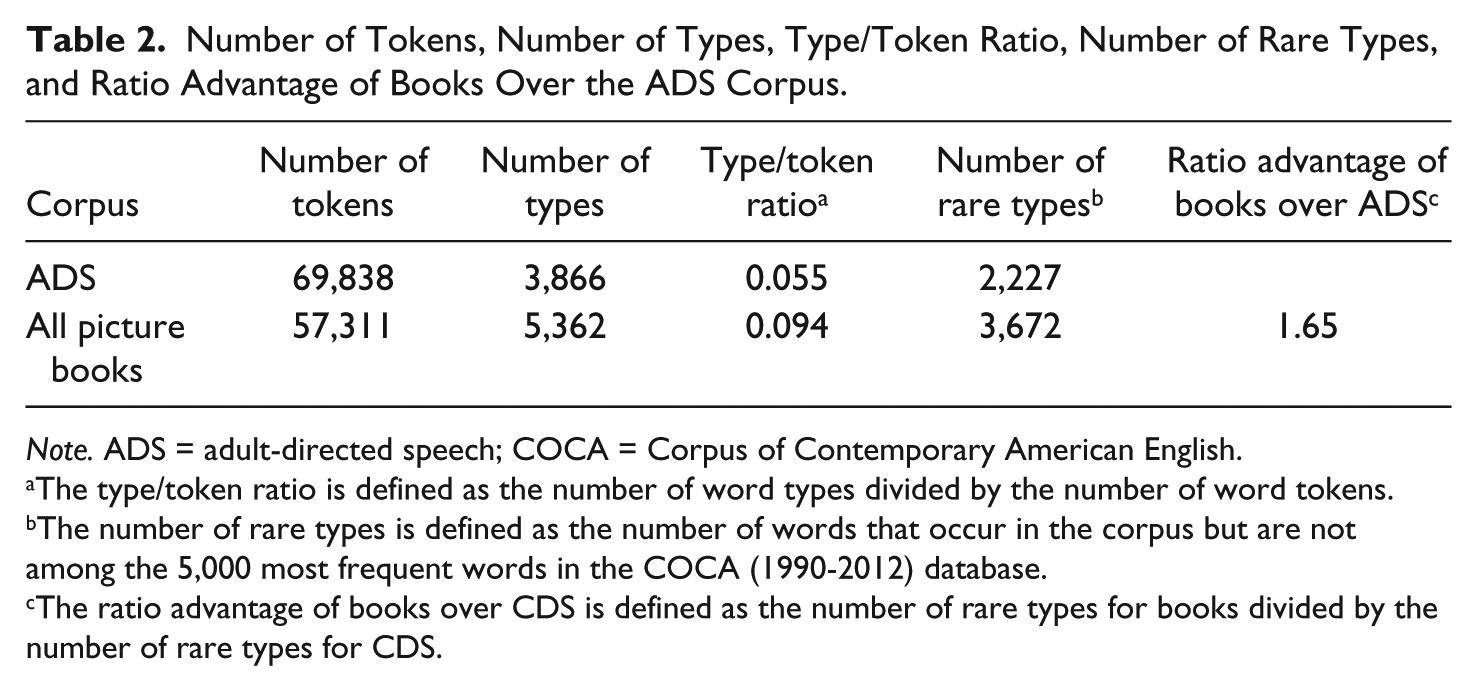
Note. ADS = adult-directed speech; COCA = Corpus of Contemporary American English.
The type/token ratio is defined as the number of word types divided by the number of word tokens.
The number of rare types is defined as the number of words that occur in the corpus but are not among the 5,000 most frequent words in the COCA (1990-2012) database.
The ratio advantage of books over CDS is defined as the number of rare types for books divided by the number of rare types for CDS.
CHILDES Parental Corpus
It might be argued that the current CDS speech samples might not be representative of spoken language to children in general. To address this issue, I determined whether my conclusions would hold up with an extremely large database of CDS by analyzing a subset of the CHILDES corpora (MacWhinney, 2000). To test whether the picture books have a more widespread and challenging vocabulary than the CHILDES parental corpus, I took three independent samples from the CHILDES corpus and compared these with the current picture book sample. Following the previous analyses, it is necessary to determine how vocabulary in these samples compares with the 5,000 most frequently used words (COCA, 1990-2012). The column of the Number of Rare Types in Table 3 shows that there were roughly 1 and 1½ times as many rare word types (3,672 vs. 2,118) in the picture book word corpus than in the CHILDES corpus. The results show an advantage of picture books over the CHILDES parental corpus. Eliminating words in the samples that overlap with the most frequent words in the COCA database, the Ratio Advantage column shows that there were roughly 1.73 times as many rare word types in the picture book word corpus than in the CHILDES corpus. There are three likely explanations why this result shows a smaller advantage than the comparison in the first CDS corpus. First, the children were younger in the first CDS corpus, and second, the CHILDES corpus also contained parental speech not directed at children. However, Hayes and Ahrens (1988, Figure 1) found that the parental speech to children did not differ across their first 12 years. A third possibility is that CHILDES corpus is highly correlated with ADS. Evidence for the third possibility is that the CHILDES corpus and the ADS corpus gave essentially identical results (see Tables 2 and 3 of the present article).
Number of Tokens, Number of Types, Type/Token Ratio, Number of Rare Types, and Ratio Advantage of Picture Books Over Three Samples of the CHILDES Parental Speech Corpus.
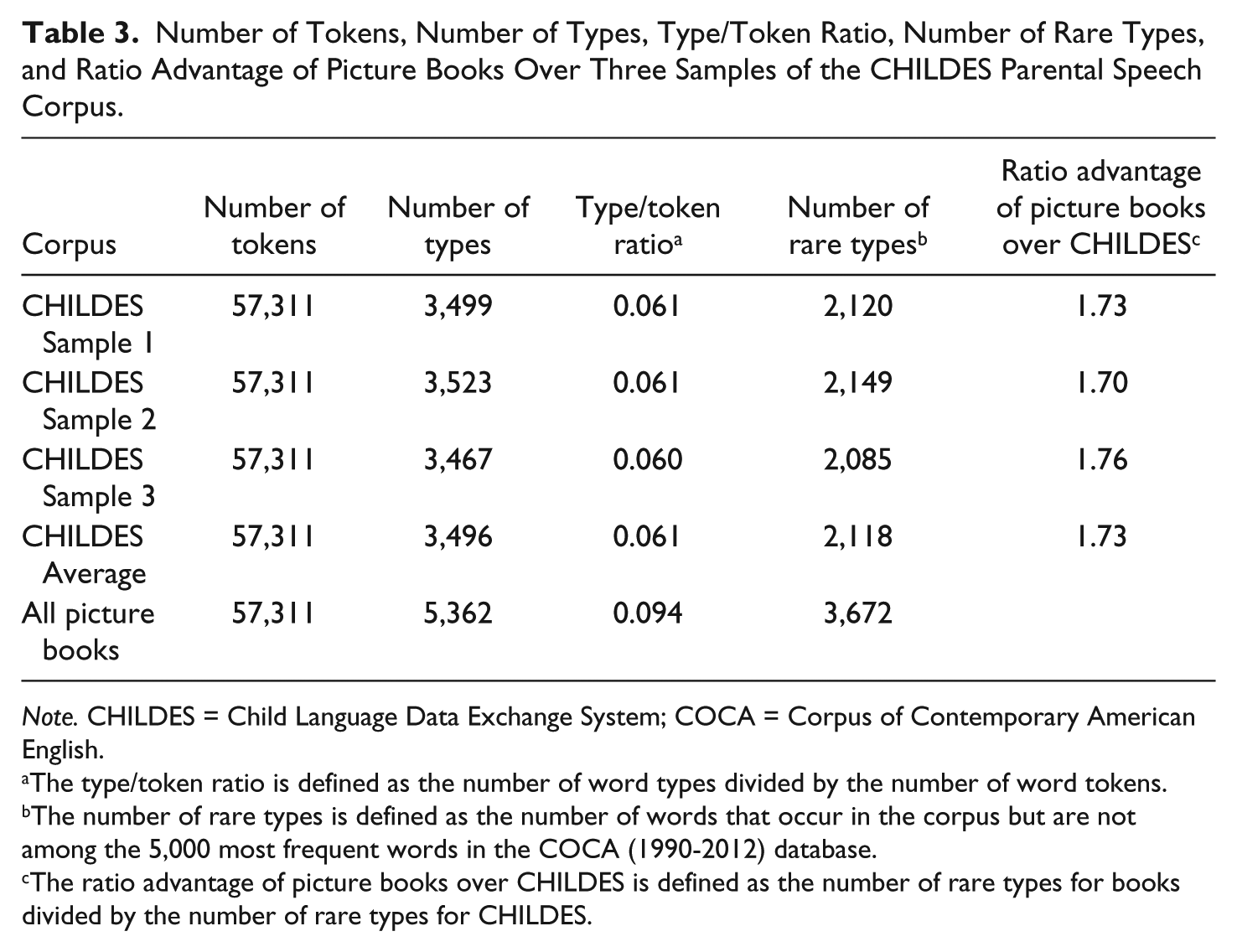
Note. CHILDES = Child Language Data Exchange System; COCA = Corpus of Contemporary American English.
The type/token ratio is defined as the number of word types divided by the number of word tokens.
The number of rare types is defined as the number of words that occur in the corpus but are not among the 5,000 most frequent words in the COCA (1990-2012) database.
The ratio advantage of picture books over CHILDES is defined as the number of rare types for books divided by the number of rare types for CHILDES.
To provide another test of the hypothesis that the type/token ratio is larger in print than in spoken language to children, the CHILDES parental spoken corpus (MacWhinney, 2000) was contrasted with the AHD print corpus (Carroll et al., 1971). (The AHD corpus is the appropriate comparison because the larger COCA corpus contains both spoken and written languages.) The type/token ratio in the CHILDES parental corpus is 0.0093 compared with a type/token ratio of 0.017 in the AHD print corpus. Assuming that the number of word types will remain fairly constant with increases in sample size from around 2.5 million to 5 million, a new word type would occur about 3.6 times more often in print than in spoken language to children (the ratio of 86,741/24,156 word types). This result based on much larger databases replicates the differences found in Tables 1 to 3 with the derived CDS, ADS, CHILDES, and picture book corpora.
Another measure of vocabulary size in picture books relative to CDS is to determine number of word types that occurred in the picture book database that did not occur in the CHILDES parental corpus. There were 1,274 words that occurred in the picture book database that did not occur in the CHILDES parental corpus. This is an impressive result given that there were 2,579,966 words in the CHILDES parental corpus and only 57,311 words in the picture book database, a factor of 45 in corpus size. It is also useful to compare these results with those from ADS. In this case, there were only 541 word types that occurred in the ADS database that did not occur in the CHILDES parental corpus. This result is much lower than the 1,274 words that occurred in the picture book database that did not occur in the CHILDES parental corpus. It is also consistent with the result that the likelihood of a unique word was significantly larger in picture books than in ADS (see Table 2).
In summary, several measures from several databases indicate that picture books are generally composed of less frequent and more complex vocabulary relative to the speech of caregivers to children.
Discussion
In the present research, the vocabulary found in three corpora of spoken language and an assembled picture book corpus was evaluated. Rare vocabulary words were more characteristic of print in picture books than in spoken language. There was a larger likelihood of observing a rare word (not one of the most common words) in picture books than in spoken language. These results extend and refine the earlier finding of Hayes (1988) who was limited by much smaller samples of speech and print.
An analysis of words that occurred in the picture books that did not occur in speech indicated that the child is exposed to challenging words in picture books that are not commonly found in speech. It has also been shown that the earlier the age of acquisition of words, the better their memory and processing in adulthood (Kuperman et al., 2012). Thus, with picture books, the child benefits not only from being exposed to infrequent and challenging words but also from being exposed to them early in life.
Differences Between Speech and Writing
It is not surprising that the linguistic content of speech and writing differs from one another because usually their goals differ. Most speech occurs in contexts in which interlocutors are cooperating with one another to construct meaningful conversation. Spoken dialogues usually require rapid exchanges, and the interlocutors find high-frequency words more accessible. Some of Paul Grice’s (1975) maxims for good conversations help highlight how spoken word choice is somewhat constrained. The interlocutor’s contributions should be efficient, informative, relevant, and unambiguous. Compared with traditional writing, which requires rewriting and even external editing, speaking must be initiated fairly rapidly and is in most cases off the cuff.
Evidence for the different requirements of spoken and written language can also be seen in the occurrence of the dozen most frequent ranked words in English. These occurred more often in written language than in spoken language. Table 4, showing the 12 most frequent words in the Google Books database (Norvik, 2012), reveals that these words are mostly articles, propositions, and conjunctions. These words occur more often in written than spoken language, most likely because they are currently considered more essential for written language than for spoken language, whereas these words can be dropped in casual speech without harm. In contrast to most written language, spoken language is usually “face-to-face” so that gestures and context can substitute for these words. These differences between use of spoken and written language indicate why the most frequent dozen or so words in the language will occur more often in print than in speech.
Twelve Most Frequently Occurring Words and Their Proportion of Occurrence in the Google Books Database, Which Consisted of 97,565 Distinct Words That Occurred a Total of 743,842,922,321 Times (After Norvik, 2012).

The percentage of occurrence of each of the words corresponds to the percentage of times that word occurred in the Google Books database.
In contrast to the more frequent use of the most common articles, propositions, and conjunctions in written language, common nouns and verbs tend to be used more often in spoken language. One reason is that speech production in dialogues is partially constrained by how quickly conversationalists can access words. It is well documented that time required for lexical access is dependent on both familiarity and age of acquisition (Kuperman et al., 2012; Kuperman & Van Dyke, 2013). These constraints can bias word choice to more frequent and early-acquired words. The context of conversations also limits word choice; for example, interlocutors tend to repeat words that have been recently uttered and use deictic gestures in place of content words. All of these constraints bias spoken conversations to use more common words than would be found in written language that does not normally have these constraints.
Genre of Language Use
The present comparisons between written and spoken language were necessarily confounded with genre of the linguistic content. The language in picture books is qualitatively different from most speech that parents address to their children, but the difference is not because it is written versus spoken language. In fact, children are actually hearing speech when books are read to them. Most importantly, well-scripted spoken language can be rich in word choice and grammar, as in prepared talks (Stand Up to Bullying, 2015; Talks to Watch With Kids, 2015). If parents and caregivers give a formal lecture to their children or narrate true or fictional stories, properties of the utterances in these talks should be more similar to those in picture books than to CDS.
The goal of this article was not to argue in favor of one language modality versus another but to simply assess the nature of language that is currently found in picture books versus speech. It is understood that different contexts require varying intentions, purposes, and manners of speaking. Thus, some conversational speech might be more sophisticated than conversation in storybooks (Hayes & Ahrens, 1988, Table 2). However, the current statistical analyses indicate that, as expected, picture books will usually offer more extensive language than conversational speech.
Rather than considering any observed difference between speech and writing as a difference due to sensory/motor modality, a distinction between informal and formal language might be more germane. Traditionally, most speech has been viewed as informal and most writing as formal. However, recent rapid changes in technology and social media are blurring this long-accepted difference between speech and writing. With current editing and recording technologies, the impermanence of speech and the permanence of writing are not any longer a distinguishing factor. The Internet has co-opted differences in time and space as either media can reach across the world (Socialnomics, 2015). With texting and Skype, immediacy can be a feature of either medium. Complexity can vary in either medium with nonfiction books and oral lectures as examples of complex instances. Speech is usually a dynamic interaction between two or more people but there are frequent occurrences of teenagers and even adults texting to each other across a shared table. Even emotional content and paralinguistic cues found in speech can be approximated in writing with emoticons and other embellishments of text.
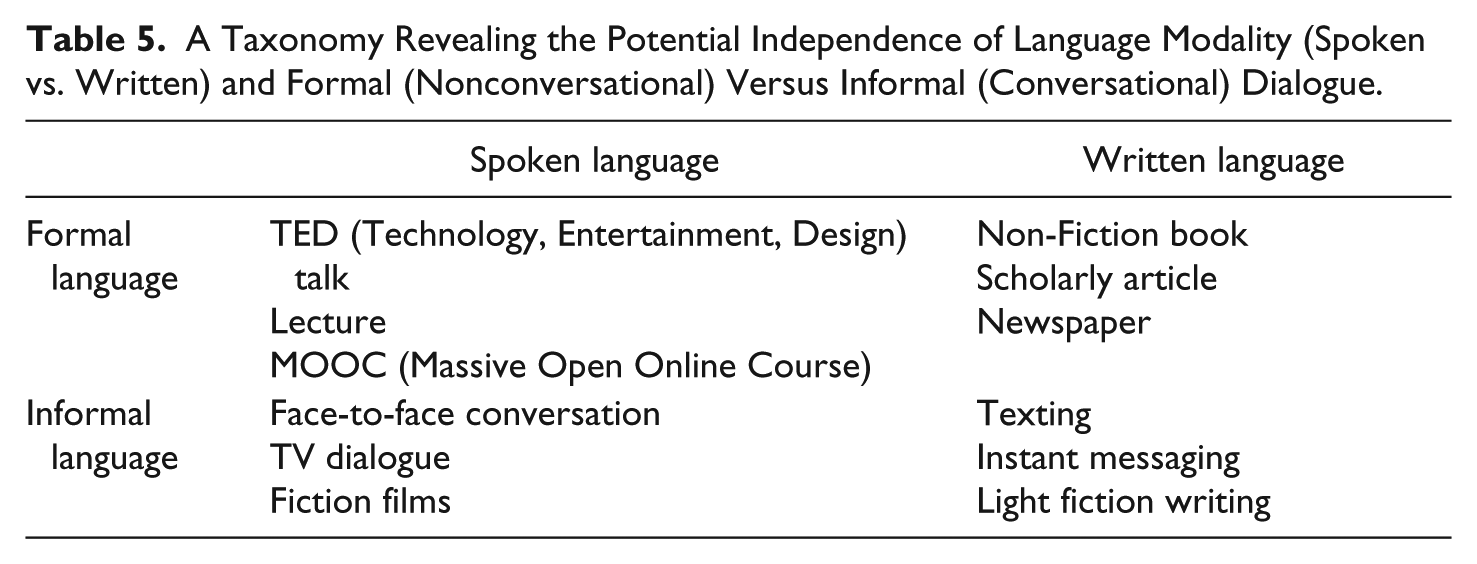
Given that both spoken and written languages can be naturally used in most situations, it might be reasoned that it is the formal versus informal genre of linguistic occurrence rather than its oral or written medium that is important. Table 5 provides a taxonomy revealing the potential independence of language modality (spoken vs. written) and formal (nonconversational) versus informal (conversational) dialogue. Categorizing linguistic occurrences as formal versus informal provides a framework that gives some predictability of complexity of vocabulary that would be found. More rare and complex vocabulary should be found in the formal relative to the informal instances of language use in Table 5. Although there is currently no direct evidence to substantiate this categorization, future research could sample vocabulary found in these instances. For example, frequent occurrence of the 12 most frequent words from the Google Books Database shown in Table 4 should occur much less in texting and instant messaging. In addition, there should be more rare and complex vocabulary in more formal instances of language use regardless of whether they are delivered via speech or writing.
A Taxonomy Revealing the Potential Independence of Language Modality (Spoken vs. Written) and Formal (Nonconversational) Versus Informal (Conversational) Dialogue.
Implications of the Research
Views of literacy
There has been continuing discussion since Plato’s (1925) Phaedrus about differences between spoken and written language. Socrates bemoaned loss of the human skill of memory with the advent and use of print. Beginning with Plato, scholars have delineated the many values that print provides. Havelock (1986) proposed a qualitative change in the form of thought beginning in ancient Greece with the transition from orality to literacy. Ong (2002) described writing as a technology that must be laboriously learned, and which effects the first transformation of human thought from the world of sound to the world of sight. Ong sought to identify distinguishing characteristics of thought and its verbal expression in societies with and without literacy in most of the population (see also Olson & Torrance, 1991).
Considering the genre of language being used, however, differences observed between speech and print might be more adequately explained by a distinction between formal and informal language. Scribner and Cole’s (1978, 1981) research in Liberia was able to distinguish between school effects and literacy effects. They evaluated three different scripts and literacy traditions: school literacy in English, religious literacy in Arabic script and, third, an indigenous script used by individuals for letter writing and record keeping in the local language. They found that cognition, reasoning, and memory benefited most from school experience not from literacy itself. Although literacy correlates positively with income, wealth, and health at both individual and societal levels (Prinsloo & Baynham, 2013; Ritchie & Bates, 2013), there may be nothing special about written language itself as much as various societal practices such as schooling. Additional discussion and evidence for the bridging of a divide between oral language and literacy can be found in Prinsloo and Baynham (2013). Given electronic media, for example, reading and writing can be easily combined with speech to communicate with friends and teachers, engage in learning sessions, and create scholarly projects. Shared reading of picture books can be viewed as embodying a component of school practice not found in typical spoken language. If so, this experience not only contributes to children’s language but also prepares them for school’s didactic practices.
Cognitive and linguistic development
The current analysis of spoken and written language corpora indicates that the picture books contain a more extensive vocabulary than speech. A primary supposition of this article is that the more extensive language found in picture books relative to spoken language directed at children has important consequences for linguistic and cognitive development. It is well documented that word learning is positively correlated with word frequency and age of acquisition. In turn, oral language competence and vocabulary knowledge are positively correlated with learning to read and reading ability (National Early Literacy Panel, 2008; National Reading Panel, National Institute of Child Health and Human Development, 2000). Just recently, results have shown that breadth and depth of vocabulary knowledge as measured by the amount of information known about a word are correlated with the reader’s ability to make global coherence inferences from text (Oakhill, Cain, & McCarthy, 2015).
More generally, vocabulary growth is positively correlated with understanding more complex language. Children’s understanding of and use of grammar is positively correlated with their vocabulary (Bates, Bretherton, & Snyder, 1988). There is also good evidence that children tend to produce language that they hear (Cameron-Faulkner, Lieven, & Tomasello, 2003). To test the relationship between the words children produce and the words they hear, I correlated the log10 frequency of 2,797 words from the CHILDES parental corpus with the log10 frequency of these words from another CHILDES corpus of children’s speech (Baath, 2014). This set of words was chosen because they had both concreteness and imagery ratings from another database (MRC Psycholinguistic Database, 2015). The correlations were extremely large: .812, .900, and .869 for children aged 18, 36, and 60 months, respectively. Thus, young children’s language reflects the language they hear from their parents. Given the higher lexical pitch of picture books, children hearing these books read by their parents will promote language use to a greater degree than their experience with most other spoken language.
There has been renewed interest in enriching a growing child’s language by increasing the amount of language the child hears (Talbot, 2015). The present research, however, questions the value of simply talking more to children without any concern with what is communicated (Massaro, 2015). A recent project by the City of Providence, called “Providence Talks,” is designed to automatically record words being spoken to children with the goal of increasing the amount of language children hear (Providence Talks, 2014). As indicated by research reviewed in this article, language quality is critical in providing vocabulary necessary for children to develop into good readers and competent learners. Given the fact that word mastery in adulthood is correlated with early acquisition of words, shared picture book reading offers a potentially powerful strategy to prepare children for competent literacy skills.
Learning to read
One controversial line of thinking in the psychology and pedagogy of reading either implicitly or explicitly conceptualizes successful reading as an act in two stages (Gough & Tunmer, 1986). When schooling begins, the child owns an impressive facility in spoken language making it valuable to have reading further build on that facility. To exploit this facility, the child’s task is to “decode” printed language into spoken language (Gough, Juel, & Griffith, 1992). Once decoded, the child’s ability to comprehend written language is roughly equivalent to their listening comprehension. This traditional conceptualization of learning to read expects the child to associate or bridge written text to spoken language. The present analyses indicate, however, that much of written language is not found in day-to-day spoken language. When children begin reading independently, they will encounter many new words that they have not experienced in spoken language. Thus, spoken language alone does not prepare the child for written language of books. It might be appropriate to rethink the standard model that makes reading and learning to read parasitic on speech.
I believe that learning to read requires two fundamental skills: the mechanics of processing written language (e.g., recognizing written letters and words) and language understanding. Research by Sénéchal and colleagues supports this distinction. They have shown that shared storybook reading predicts vocabulary acquisition, whereas teaching written language predicts alphabet knowledge and even future reading fluency. One study (Sénéchal, 2006) found that parents teaching the alphabet, reading words, and printing words predicted kindergarten alphabet knowledge and Grade 4 reading fluency. Shared storybook reading, however, predicted kindergarten vocabulary and frequency with which children reported reading for pleasure in Grade 4.
Sénéchal and LeFevre (2014) were able to study children who were schooled in French but spoke English at home. This assessment tested how English home literacy activities influenced their progress in English literacy independent of school-based English language instruction. They found that an informal literacy environment (e.g., parents reading to their children at home) predicted growth in English receptive vocabulary from kindergarten to Grade 1, whereas parent reports of a formal literacy environment (consisting of parents teaching the alphabet, printing words, and reading words) predicted growth in children’s English early literacy between kindergarten and Grade 1 and growth in English word reading during Grade 1. Other contributing factors to literacy acquisition include parents’ didactic activities, their expectations about learning early literacy at home, as well as their child’s interest in learning literacy (Martini & Sénéchal, 2012). Although parental teaching activities help guarantee the child’s direct experience of written language, it is important that shared storybook reading contributes to growth of the child’s receptive vocabulary.
A relatively recent U.S. national research review panel on reading was aimed at children from birth through age 5 (National Early Literacy Panel, 2008). Predictors of reading acquisition included written language knowledge, cognitive skills, and memory. Five more moderately correlated factors also revealed the importance of written language. Factors included concepts about print and print knowledge, early decoding, reading readiness, oral language, and visual processing. Most interesting for our purposes, however, was the overall correlation of early oral language development with later reading achievement. When oral language was measured with complex measures (such as using multicomponent tests that included knowledge of syntax, ability to define word meanings, and listening comprehension), this variable explained roughly 50% of the variation in later reading comprehension. A possible implication of this finding is that the richer language of storybook reading can provide young children a richer oral language that will make a positive contribution to their future reading skill.
The present research documented that picture books will necessarily have greater lexical pitch than found in most conversational spoken language. An important caveat is whether children will be able to understand and learn challenging vocabulary and concepts of picture books without guidance (Schleppegrell, 2012; Snow, 2002). Children will usually receive appropriate guidance in shared picture book reading. When reading independently, children necessarily benefit when given guidance via print, speech, or other media such as pictures, animations, or videos. There are several interventions that provide this type of support (Glenberg, 2008; Glenberg & Gallese, 2012; Tecwave, 2013), and there should be more of these as technology and reading science evolve.
In conclusion, very little inquiry has addressed the issue of how picture books and conversational spoken language differ from one another. In this article, I show that picture books embody a lexical pitch that would support learning of new and challenging vocabulary. This vocabulary is particularly valuable because an extensive vocabulary is positively correlated with reading comprehension (National Reading Panel, National Institute of Child Health and Human Development, 2000). Most parents are advised that they should read to their children. As far as I know, no one previously has substantiated an important reason why this advice is particularly valid: The books read to children are usually more linguistically and cognitively enriching than everyday speech.
Footnotes
Appendix
Names of the books in the picture book database taken from transcriptions of the books used in Read With Me! (2012). The letters A, B, and C refer to the samples used in the child-directed speech (CDS) comparisons (as shown in Table 1).
17 Kings And 42 Elephants (C)
A Place For Ben (C)
A Pocket For Corduroy
All The Colors Of The Earth (C)
All The Places To Love (A)
Amazing Grace (A)
Animalia (C)
Are You My Mother? (A)
Arthur Babysits (C)
Arthur Writes A Story (A)
Arthur’s Tooth (C)
Arthur’s Underwear (C)
Arthur’s Valentine (A)
Ask Mr. Bear (A)
Barbapapa Zoo (C)
Bark, George (C)
Below (C)
Boats (C)
Brown Bear, Brown Bear, What Do You See? (C)
Charlie Needs A New Cloak (C)
Counting Kisses (C)
Curious George (C)
Dear Zoo (C)
Doctor De Soto (C)
Don’t Frighten The Lion (C)
Duck For President (A)
Duck On A Bike (A)
Earth Dance (A)
Everyone Poops
Fancy Nancy And The Posh Puppy (A)
Five Little Monkeys Jumping On The Bed
Frederick
Freight Train
George And Martha (A)
George And Martha One Fine Day (A)
George Shrinks
Good Night Gorilla
Goodnight Moon
Grabby Pup
Grandfather’s Journey (A)
Green Eggs And Ham
Guess How Much I Love You
Harold And The Purple Crayon (A)
Hattie And The Fox
Have You Filled A Bucket Today? (A)
Hop On Pop
How Do Dinosaurs Say Good Night? (A)
How I Became A Pirate
If You Give A Mouse A Cookie
In My Heart (A)
Inch By Inch
Jamberry (A)
Jumanji
Kitten’s First Full Moon
Leaf Man
Library Lion
Little Bear’s Little Boat (A)
Little Cloud
Little Gorilla (B)
Little Pea (B)
Llama Llama Red Pajama (B)
Love You Forever (B)
Madeline (A,B)
Martha Speaks (A,B)
Matthew’s Dream (A,B)
Mike Mulligan And His Steam Shovel (B)
Milk And Cookies (A,B)
Miss Nelson Is Missing (A,B)
Miss Rumphius (B)
Mr. Gumpy’s Motor Car (B)
Oh, The Places You’ll Go! (B)
Olivia And The Missing Toy (B)
Over In The Meadow (B)
Owl Moon (B)
Pancakes, Pancakes! (A,B)
Panda Bear, Panda Bear, What Do You See? (B)
Pig On The Titanic (A,B)
Polar Bear (B)
Qwerty The Computer (B)
Round Trip (B)
Shadow Play (B)
Shake My Sillies Out (B)
Sheep In A Jeep (B)
Somewhere In Africa (B)
Stellaluna (B)
Swimmy (B)
Tar Beach (A,B)
Teeny Tiny (B)
Ten Nine Eight (B)
Ten Oni Drummers (B)
The Carrot Seed (C)
The Cat In The Hat (C)
The Giving Tree (A,C)
The Grandad Tree (C)
The Little Engine That Could (C)
The Napping House (C)
The Polar Express (C)
The Story Of Ferdinand (C)
The Very Busy Spider (C)
The Very Hungry Caterpillar (C)
There’s A Wocket In My Pocket (C)
Time To Sleep (A,C)
Tough Boris (C)
Two Little Trains
What Do Ducks Dream? (C)
What Happened To Patrick’s Dinosaurs? (A,C)
Where Are You Going? (C)
Where Once There Was A Wood (A,C)
Where The Forest Meets The Sea (C)
Where The Wild Things Are (C)
Whistle For Willie
Wombat Walkabout (A,C)
Acknowledgements
The author would like to thank Dr. Patricia Kuhl of I-Labs and Katrin Kirchhoff at the University of Washington for making the child-directed speech available to him. He also thanks the editors and the reviewers for their very helpful comments and guidance on the research.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: A portion of the data entry described in this article was supported by a grant from the Academic Senate of the University of California, Santa Cruz.