
Abstract
Adhering to PRISMA guidelines, this study systematically reviews the reliability and validity evidence of two prominent sentence completion tests (SCT): the Rotter Incomplete Sentences Blank (RISB) and the Washington University Sentence Completion Test (WUSCT). SCTs have often been conceptualized as projective tests and summarily dismissed as lacking efficacy in psychological assessment, though this characterization is not entirely accurate. Conceptually and methodologically, SCTs are more aptly characterized as performance-based measures. Interest in potential applications of SCTs with clinical populations continues to persist. This review incorporated 51 studies conducted in the United States that met rigorous reliability and validity criteria. Although there is evidence to support the reliability and validity of the RISB and WUSCT, results vary widely depending on sample characteristics (e.g., age, race/ethnicity), study context, and the purpose of score interpretations examined in the study. Therefore, practitioners who utilize results from SCTs should consider these characteristics when engaging in interpretation.
Public Significance Statement
This article systematically reviews studies on the reliability and validity of two widely used sentence completion tests (SCTs) in psychological assessment: Rotter Incomplete Sentences Blank (RISB) and the Washington University Sentence Completion Test (WUSCT). Despite significant skepticism surrounding this genre of assessment instrument, their clinical use persists. The variability in evidence supporting scores across assessment use and client characteristics underscores the critical need for nuanced and context-sensitive interpretation.
SCTs occupy a distinctive position within the broader domain of personality assessment, a position that calls for systematic evaluation of the empirical evidence relevant to their application. They are designed to elicit self-expressive responses that reflect individuals’ characteristic ways of perceiving themselves and others (Loevinger, 1957; Rotter & Rafferty, 1950). Responses generated through open-ended sentence stems rather than direct questions position SCTs as performance-based measures (PBMs). In Weiner’s (2013) characterization, PBMs are assessment methods that require individuals to demonstrate psychological processes through their performance, thereby providing information that surpasses what can be obtained through self-report. Although SCTs have historically been classified as projective techniques, this terminology oversimplifies their methodological and theoretical nature. The term “projective” derives from Frank’s (1939) hypothesis that individuals project unconscious internal needs and meanings onto ambiguous stimuli—but it does not define a distinct category of assessment.
Contemporary scholarship calls for conceptualizing SCTs as PBMs of personality that sample behavior, cognition, and affect under standardized conditions (McGrath & Carroll, 2012; Meyer & Kurtz, 2006). Building on Meyer and Kurtz’s (2006) call for more informative taxonomies of assessment methods, subsequent commentaries have emphasized differentiating techniques according to the psychological processes they engage—such as expressive, perceptual, narrative, or self-evaluative operations (Bornstein, 2011; Schultheiss, 2007). Bornstein (2011) has suggested that personality assessment methods should be classified not by presumed theoretical allegiance but by the mechanisms through which examinees generate responses. Within this perspective, SCTs represent a distinct methodological class that engages controlled verbal expression and reflective meaning-making, distinguishing them from the perceptual processing demands of inkblot methods or the narrative construction required by storytelling tasks.
In the absence of a consensus term, we adopt PBMs because it aptly captures the methodological essence of SCTs by eliciting observable performance under standardized conditions while avoiding the historical and theoretical assumptions associated with the term projective. Personality assessment tools vary in the degree to which they structure or constrain a respondent’s behavior, forming a continuum that ranges from highly structured self-report inventories to minimally structured expressive tasks. Although PBMs are less structured than self-report inventories or rating scales completed by collateral informants, there is no sharp subjective/objective divide; assessment instruments are best conceptualized as differing in the degree of stimulus ambiguity (Meehl, 1945).
Although survey data indicate that their overall use has declined (Benson et al., 2019; Piotrowski, 2015; Wright et al., 2016), PBMs continue to represent significant components of practice in certain specialties such as inpatient, forensic, and educational settings (Wright et al., 2016). For example, PBMs, such as SCTs, are used in approximately 11.3% (vs. 22.6% for the Wechsler Intelligence Scale for Adults) of child custody evaluations (Mathy, 2019). Given that custody evaluations are widely viewed as among the most complex, technically demanding, interpersonally challenging, and legally contentious types of psychological assessments (Benjamin et al., 2017), the continued allowance of PBMs by the courts is noteworthy. At the same time, PBMs of personality continue to attract scholarly attention, though often within the context of long-standing debates about the scientific credibility of projective methods. Influential critiques have questioned their empirical foundation relative to self-report inventories (e.g., Stemplewska-Żakowicz & Paluchowski, 2013; Weiner, 2013). However, these critiques frequently treat projective techniques as a monolithic category. While such scholarship is valuable for highlighting psychometric concerns, it tends to overgeneralize, obscuring important distinctions among subclasses such as storytelling, inkblot, drawing, and SCTs. The conceptual shift toward PBMs provides an opportunity to reconsider these instruments within a methodological framework that emphasizes observed performance, standardized administration, and empirically testable constructs (Bornstein, 2011; Meyer & Kurtz, 2006). Within this framework, SCTs represent a distinctive PBM subclass that operationalizes personality assessment through structured verbal production. Far from being obsolete, SCTs remain in active use across clinical, educational, and research contexts, particularly for assessing ego development, psychological adjustment, and personality integration (Lambie, 2007; McCloskey, 2014; Piotrowski, 2019, 2024).
Surveys of practitioners consistently identify SCTs as among the most frequently used performance-based techniques (Holaday et al., 2000), and they have been embedded for decades in personality assessment courses, developmental research programs, and applied evaluations. Among the wide range of SCTs developed over the past century, RISB (Rotter & Rafferty, 1950) and WUSCT (Loevinger, 1957, 1998) stand out as the two most extensively researched and widely applied instruments. Among SCTs, only the RISB and WUSCT possess sufficient empirical foundations, standardized scoring systems, and decades of validity research to support a systematic evidence review.
The RISB was designed to assess personal adjustment through respondents’ attitudes, conflicts, and affective concerns expressed in sentence completions (Churchill & Crandall, 1955; Rotter & Willerman, 1947). Its standardized scoring system classifies individuals as “normal,” “maladjusted,” or “questionably adjusted” based on the coherence, emotional tone, and defensiveness of responses (Lah & Rotter, 1981; Rotter et al., 1954). Later work has broadened interpretive applications to include interpersonal functioning, affect regulation, and psychopathology (Ames & Riggio, 1995; Fuller et al., 1982; McCloskey, 2014; Torstrick et al., 2015; Weis et al., 2008). Survey research with members of the Society for Personality Assessment found that the RISB was the most frequently used SCT, administered to nearly half of respondents’ adult clients and one third of adolescents (Holaday et al., 2000).
The WUSCT, by contrast, was developed as a measure of ego development grounded in Loevinger’s structural model of personality organization (Hoppe & Loevinger, 1977; Loevinger, 1957). The WUSCT is the most extensively studied and widely used standardized measure of ego development (Jorgenson, 2017; Manners & Durkin, 2001). Decades of research have extended the measure’s applications to domains such as identity status (Adams & Fitch, 1981; Adams & Shea, 1979), object relations and social competence (Avery & Ryan, 1988; Larson et al., 2007), and adaptive functioning in clinical and community samples (Jennings & Armsworth, 1992; Lambie, 2007; Wilber et al., 1982).
Collectively, the WUSCT and RISB possess stronger empirical foundations, clearer interpretive frameworks, and broader applications than other SCTs. Both instruments benefit from decades of psychometric research, replicable scoring procedures, and well-articulated theoretical underpinnings, contributing to their enduring relevance in contemporary personality and developmental assessment (American Educational Research Association [AERA] et al., 2014; Holaday et al., 2000; McGrath & Carroll, 2012). Despite their widespread use and substantial research history, no systematic review has synthesized the evidence on reliability and validity for the WUSCT and RISB, leaving the field without an integrated evaluation of the empirical foundations of these extensively studied and widely applied SCTs.
Purpose of the Study
The primary aim of this study was to systematically review and evaluate the evidence supporting the reliability and validity of scores derived from two of the most extensively researched SCTs: the WUSCT and the RISB. Despite limited recent publications, these measures remain among the most psychometrically developed and conceptually coherent PBMs, offering structured yet expressive indices of personality functioning. As the field increasingly emphasizes evidence-based standards, renewed evaluation of these measures is essential to determine their current scientific and applied value. To address this need, we conducted a comprehensive systematic review to synthesize empirical findings accumulated over several decades, clarifying the reliability, validity, and interpretive foundations of the WUSCT and RISB. The review identifies strengths, limitations, and gaps in the literature to inform contemporary assessment practice and guide future research on sentence completion methodologies within an evidence-based framework consistent with the Standards for Educational and Psychological Testing (AERA et al., 2014).
Method
This systematic review adhered to Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) guidelines (Page et al., 2021). The initial step involved formulating a plan designed to uphold the scientific integrity of the process, as described below.
PICOT Statement
A PICOT statement (Haynes, 2012) was generated as part of the study plan and prior to the search. A PICOT statement offers a specialized framework that serves to aid researchers in formulating questions and facilitating the literature review, and it is easily modifiable to account for other variables. The search plan was developed in alignment with the study goal of systematically reviewing evidence of reliability and validity for scores derived from projective tests. The following PICOT (Population, Instrument, Corroboration, Outcome, Time Frame) statement guided the study: P- Population: Included participants of any age, sex, race, or ethnicity living in the US I- Instrument: Sentence completion tests C- Corroboration: Evidence of reliability or validity O- Outcome: Decisions regarding score interpretation or use T- Time: Is there a difference in study results over time?
To identify studies for inclusion, several databases were searched: PsycINFO, Embase, Scopus, Web of Science, and Medline PubMed through EBSCO. Alternative search approaches to identify relevant articles not available in the above databases were used: (a) hand searching of the references of included articles identified in the searched databases and (b) conducting citation tracking of published articles. A formal meta-analysis could not be conducted due to the significant variability in the methods, purposes, and projective measures used in the studies that were included in this review.
Search Terms
The databases were searched using various combinations of the following search terms: “interrater agreement,” “interrater concordance,” “interrater reliability,” “intercoder reliability,” “test-retest,” “test-retest reliability,” “test retest reliability,” “result reliability,” “test reliability,” “reproducibility of results,” “predictive validity,” “concurrent validity,” “convergent validity,” “discriminant validity,” “clinical utility,” “classification accuracy,” “diagnostic accuracy,” “diagnostic utility,” “treatment utility,” “test validity,” “face validity,” or “result validity” and “projective,” “apperception,” “projective test,” “test validity,” “projective technique,” “sentence completion,” “human figure drawings,” “projective personality test,” “thematic apperception test,” “children’s apperception test,” “house-tree-person,” “draw-a-person,” “Rotter,” “Rorschach,” or “Miner.” Although the reliability and validity of projective techniques other than SCTs were not directly analyzed, it was important to consider a broader range of projective techniques in the search terms to identify studies that may have compared these measures to SCTs.
Inclusion/Exclusion Criteria
Inclusion and exclusion criteria were established for reliability and validity with each psychometric property considered separately. For a study to be included in the analysis of reliability it had to meet the following criteria: (a) involve administration of the RISB and/or the WUSCT and (b) report correlation coefficients to estimate reliability, rather than merely reporting percent agreement between raters (Cronbach & Shavelson, 2004; McCrae et al., 2011). Studies that met these criteria are presented in Figure 1.
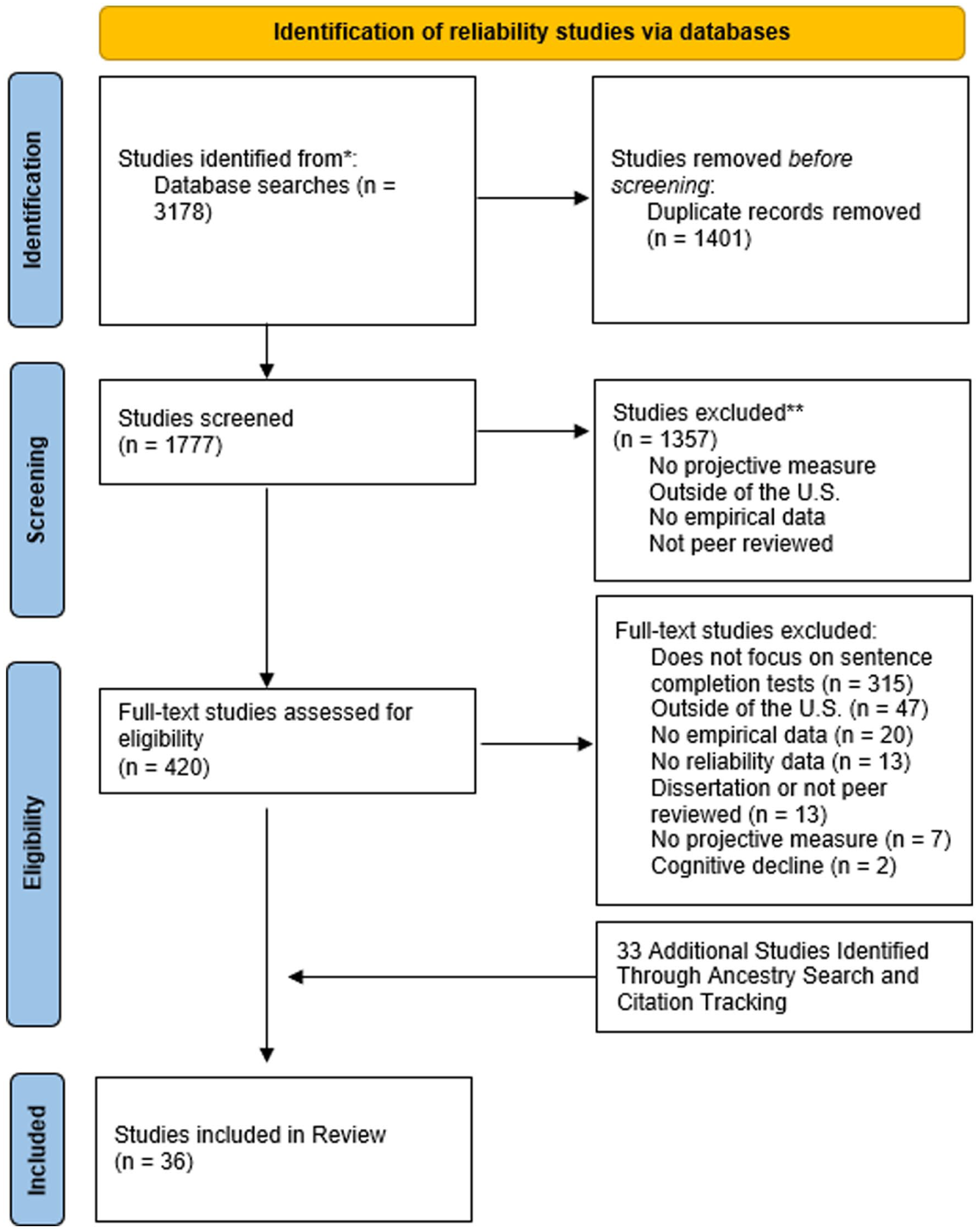
Flowchart of Studies Identified That Discussed Reliability.
For a study to be included in the analysis of validity, it needed to meet the following criteria: (a) involve administration of the RISB and/or the WUSCT, (b) report an interrater reliability in projective test scoring greater than .80, and (c) report one or more of the following: correlation coefficients used to estimate validity, effect size metrics based on differences between means or the information needed to calculate them, effect size metrics for associations among categorical variables or the information needed to calculate them, confidence intervals by means of two related groups, or diagnostic utility statistics (Frick & Loney, 2000; Smith & Smithson, 2015). Studies that met these criteria are presented in Figure 2.
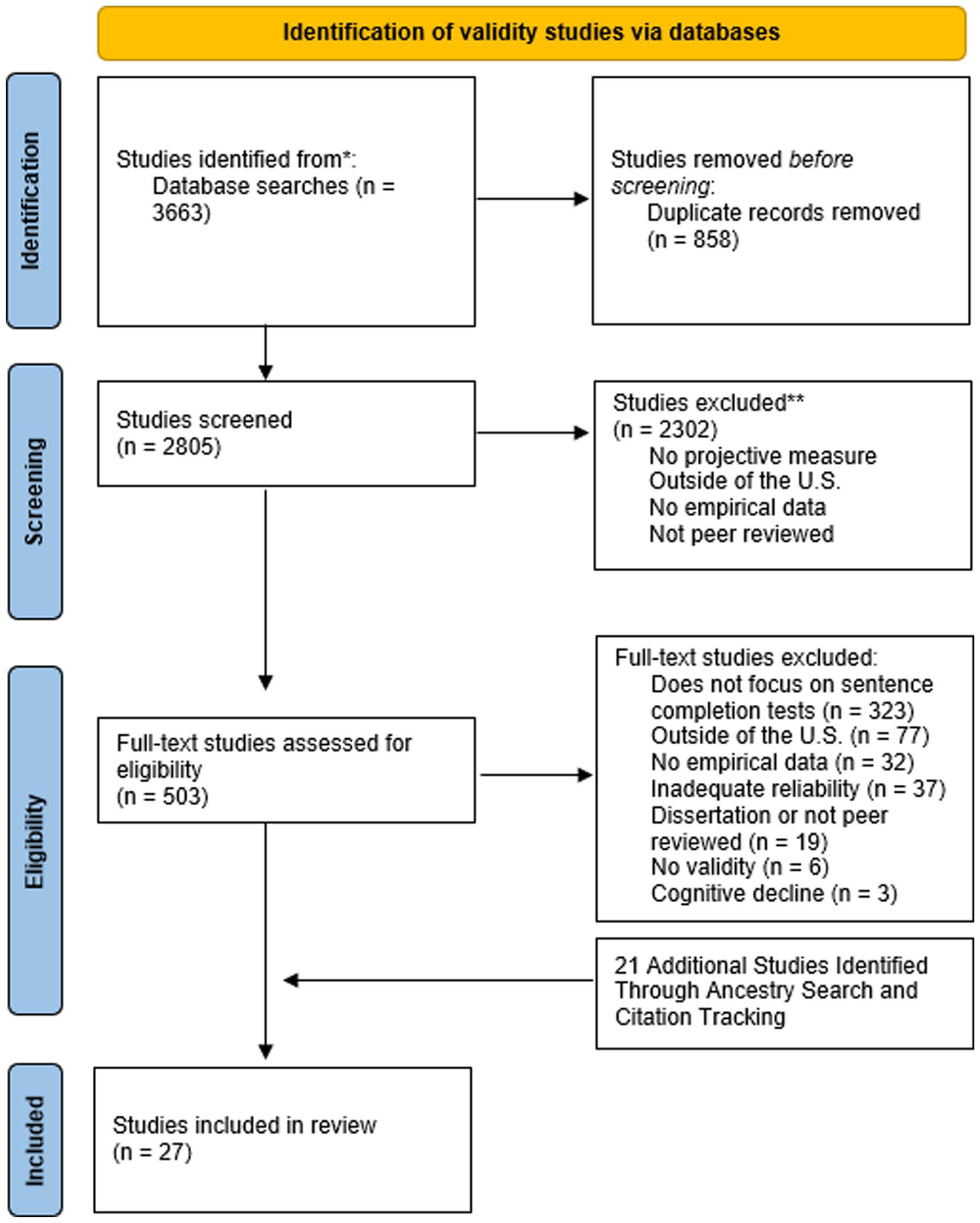
Flowchart of Studies That Discussed Validity.
Studies were excluded if they met any of the following criteria: (a) participants were sampled exclusively from a country outside of the United States, (b) the study was a dissertation, (c) the information reported focused exclusively on projective techniques that were not being compared with an SCT, (d) the study focused on cognitive problems related to aging, (e) the study was a case report, and (f) the study was nonempirical.
Exclusion criteria were designed to ensure that the synthesized evidence was methodologically rigorous and relevant to the intended context. Studies conducted outside the United States were excluded because validity is specific to particular scores, uses, and populations; cultural and linguistic differences can alter item functioning and score interpretation (AERA et al., 2014). Dissertations were omitted because they rarely affect review conclusions and often provide incomplete or inconsistently reported data, adding workload with minimal evidentiary benefit (Briscoe et al., 2023; Vickers & Smith, 2000). Studies of other projective techniques were excluded to maintain conceptual focus (Frank, 1939; Teglasi, 1998; Weiner & Kuehnle, 1998). Investigations centered on cognitive decline or aging-related processes were excluded because they predominately address neurocognitive rather than personality or psychological adjustment constructs, making their score interpretation and validity evidence distinct and not commensurate with the adjustment or ego-development focuses of the review (Caselli et al., 2016). Finally, nonempirical studies (e.g., theoretical reviews, commentary pieces) were excluded because validity and reliability arguments require empirical data to support score interpretation, and nonempirical sources cannot provide the statistical evidence necessary for a rigorous systematic review.
Coding of Variables
The titles, references, and abstracts from the EBSCO search results were uploaded to Covidence (2023), a web-based collaboration software platform that streamlines the production of systematic and other literature reviews. The authors of this study completed article screenings and reviews. Articles pertaining to reliability and validity were screened separately and were independently coded by two reviewers to mitigate any inclusion/exclusion bias. A third reviewer examined articles for which there was a disagreement about whether the article should be included. After the initial screening, full texts of the articles were uploaded into Covidence and further screened independently by two reviewers for inclusion in this review. Variables coded included the study design, reliability or validity evidence reported, participant ages, total sample size, clinical disorder discussed, effect size, mean, and standard deviation. Each article included in the review was coded by one or more authors.
Inclusion and Coding Agreement
Four authors independently reviewed the studies returned through the search procedures to determine which articles met this study’s inclusion criteria. Each article was reviewed and coded by two authors. Cohen’s kappa was used as a measure of interrater reliability to ensure that chance agreement did not overly impact the inclusion of studies in this article (McHugh, 2012). When a disagreement occurred between two authors on whether a study should be included, a third author reviewed the article to resolve the disagreement. While the overall interrater reliability among the reviewers was generally high, it is important to note that lower agreement rates involving one of the reviewers contributed to some lower interrater reliability metrics. This discrepancy may be attributed to differing interpretations of the evaluation criteria and highlights the importance of having a third reviewer resolve potential disagreements regarding inclusion of articles. In addition, this review was limited to studies conducted in English that occurred in the United States to help ensure relevance to populations, policies, and health systems within the United States. The authors were only able to review studies that were published in English, and translating non-English publications was beyond the scope of the review at this time.
Transparency and Openness
Materials and analysis information for this study are available by emailing the corresponding author. No elements of this study were preregistered. This paper was a systematic review that involved no additional analysis of new data. Artificial intelligence, specifically ChatGPT (OpenAI, 2025), was used to help generate the tables included in this article based on numerical data written in paragraph form by the authors. Prompts provided to ChatGPT included only data and statistical results (e.g., “please create an APA style table that summarizes the following descriptive statistics:”) that were already reported in the manuscript, and no new data or additional analyses were generated by ChatGPT. All use of artificial intelligence occurred after the manuscript was written, and all content generated in any way by artificial intelligence was checked for accuracy, clarity, and adherence to APA standards by the authors before being included.
Results
Five hundred and seventy-seven studies met the initial search criteria based on their titles and abstracts and were coded for subsequent analysis. Ultimately, 51 studies met the full-text inclusion criteria. The independent review of the articles resulted in adequate interrater reliability, both when coding the title/abstracts (Table 1) and in coding the full text of the articles (Table 2). Consensus coding was used to address and agree upon any differences in coding that occurred between raters.
Title/Abstract Interrater Reliability (IRR).
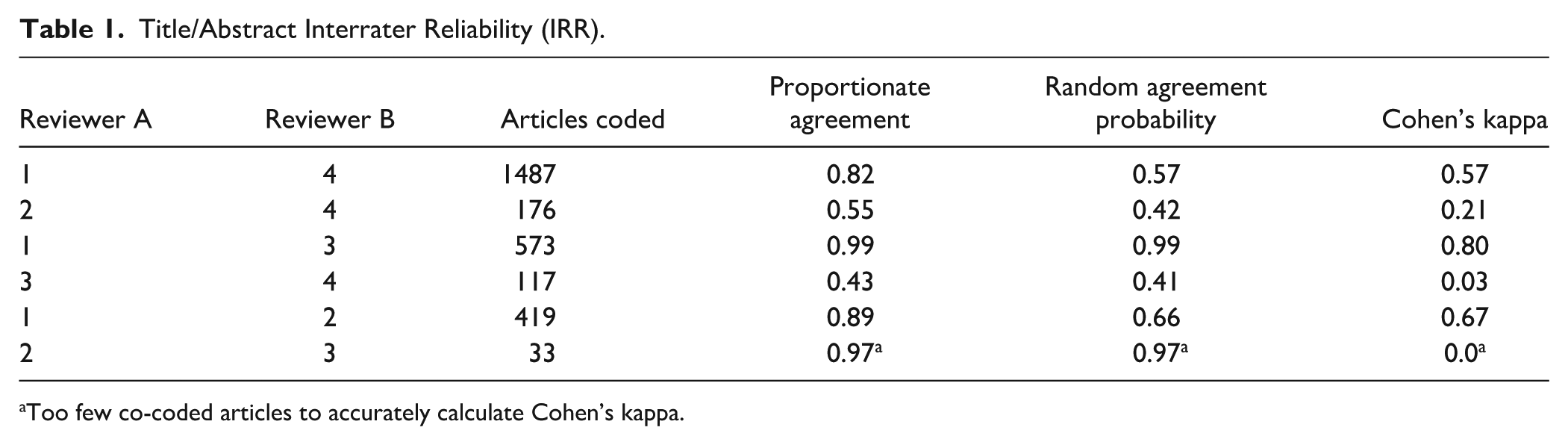
Too few co-coded articles to accurately calculate Cohen’s kappa.
Full Text Interrater Reliability (IRR).
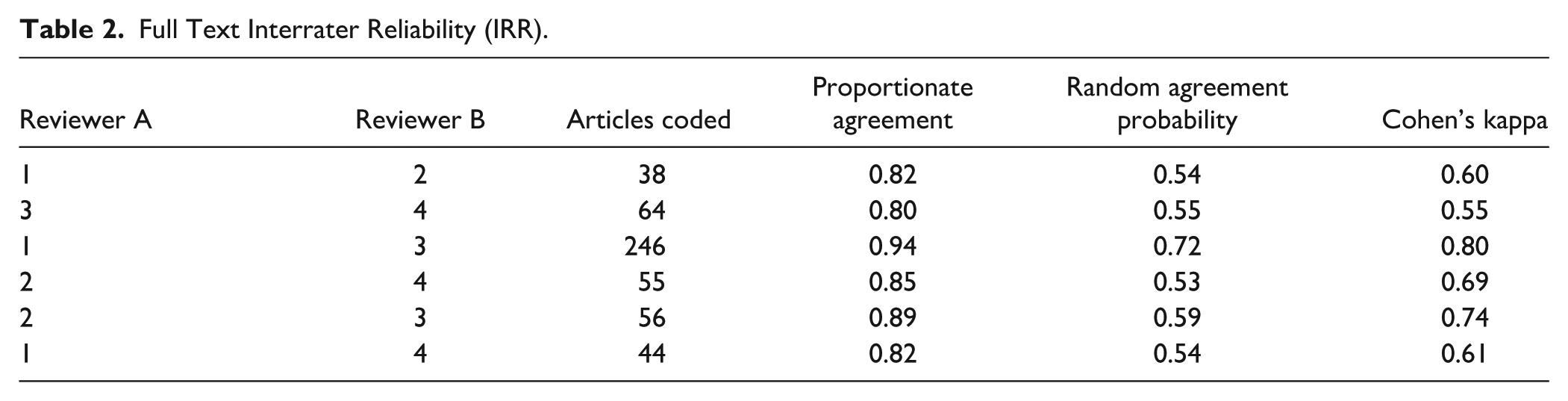
Articles that met inclusion criteria for this study reported measures of reliability such as interrater reliability, split-half reliability, Cronbach’s alpha, and test–retest reliability (Table 3). In addition, the articles that met inclusion criteria for this study reported measures of validity such as concurrent validity, predictive validity, construct validity, discriminant validity, and convergent validity (Table 4).
Types of Reliability Reported by Articles Included in This Study.

Source. AERA et al. (2014).
Types of Validity Reported by Articles Included in This Study.

Source. AERA et al. (2014); Campbell and Fiske (1959); Fornell and Larcker (1981).
RISB
The RISB (Rotter & Rafferty, 1950) is an SCT that was first developed in 1950 as a way of evaluating psychological adjustment and personality. It consists of sentence stems that participants are asked to complete, and their responses are scored to provide a score that indicates their level of “adjustment” or “maladjustment” (Torstrick et al., 2015). The RISB remains one of the most used sentence-completion tools because of the simplicity of its administration, the flexibility of its use, and the level of nuanced information it can provide to a psychological evaluation (Holaday et al., 2000).
Studies of RISB Reliability
Four studies examined the reliability of the RISB when used with populations of school-age children. One such study found high reliability (r = .94) based on raters’ initial scoring and rescoring of RISB records (Kennedy et al., 1963). Two studies reported Cronbach’s alpha values that ranged from .78 to .93 (Fuller et al., 1982; Weis et al., 2008). The development of the scoring manual for the high school RISB form found that split-half reliability ranged from .74 to .86, and interrater reliability ranged from .96 to .97, with females having the higher reliability in both cases (Rotter et al., 1954).
Four studies examining the reliability of the RISB in a mix of adolescents and adults found that interrater reliability ranged from .88 to .95 (Ames & Riggio, 1995; Arnold & Walter, 1957; Jessor et al., 1963; Lah & Rotter, 1981), while reliability across initial and rescored records ranged from .90 to .95 across “many” years, to .97 after a four-week interval (Arnold & Walter, 1957; Jessor et al., 1963). Arnold and Walter (1957) found that split-half reliability was .76. Ames and Riggio (1995) found a Cronbach’s alpha of .91 for internal consistency.
Twelve studies examining the reliability of RISB scores using samples of adults found that interrater reliability of the total scores ranged from .81 to .98 (Baker & King, 1970; Edwards & Sapp, 2002; Gardner, 1967; Jessor & Hess, 1958; Lah, 1989; Logan & Waehler, 2001; McCloskey, 2014; Rotter et al., 1949; Rotter & Willerman, 1947; Tempone & Lamb, 1967; Torstrick et al., 2015). Split-half reliability ranged from .77 to .96 depending on the gender of the study participants, with females tending to have the higher split-half reliability (Gardner, 1967; Rotter et al., 1949; Rotter & Willerman, 1947; Torstrick et al., 2015). Test–retest reliability ranged from .38 to .54 (Churchill & Crandall, 1955). Gardner (1967) found an interrater reliability of .80 across an eight-month interval. Torstrick et al. (2015) found a Cronbach’s alpha of .81 for internal consistency.
Across 20 studies examining RISB reliability (Table 5), a clear consensus emerges for strong interrater reliability, which was reported in 16 studies and consistently exceeded .80 across age groups. Test–retest reliability was examined in only three studies and yielded highly variable coefficients, limiting firm conclusions about temporal stability. Overall, the available findings indicate that RISB scoring procedures yield reliable estimates across developmental levels, but longitudinal research is needed to clarify stability over time.
Reliability and Validity Metrics for RISB Studies.
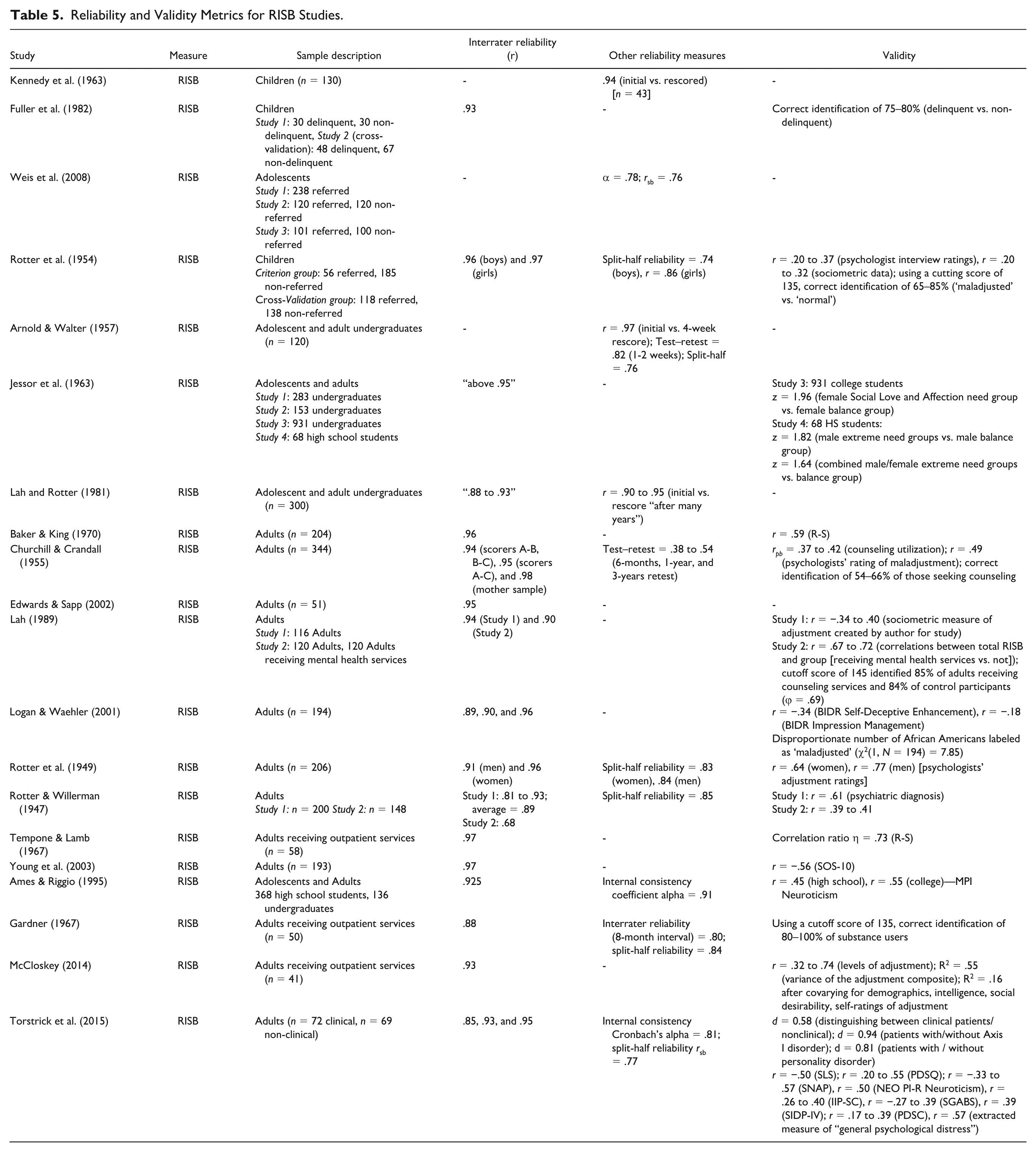
Studies of RISB Validity Using Samples of School-Age Children
Two studies were identified that examined the validity of the RISB in school-aged children. Rotter et al. (1954) developed a scoring manual for a high school RISB form to differentiate between clinic-referred “maladjusted” adolescents and their non-referred peers. The criterion group included 241 adolescents (56 referred, 185 non-referred), while the cross-validation study involved 256 adolescents (118 referred, 138 non-referred). For females, RISB scores were found to correlate positively with both psychologist interview ratings (n = 48; Pearson r = .37, biserial correlation = .58) and sociometric data (n = 70, r = .32). For males, the correlations with interview ratings (n = 45; Pearson r = .20, biserial correlation = .20) and sociometric data (n = 68, r = .20) were somewhat weaker. A cutting score of 135 correctly identified 78% of male participants who had been classified as “normal” based on psychologist interview ratings, 65% male participants who had been classified as “maladjusted,” 85% of females classified as “normal,” and 85% of females classified as “maladjusted.”
Fuller et al. (1982) studied a “delinquent” group consisting of 30 adolescent male students who had been placed in a residential treatment center and a “non-delinquent” group consisting of 30 randomly selected male high school students. They then developed a short RISB form with a revised maladjustment score which was cross validated with 48 male high school students and 67 male “delinquent” students. The form accurately identified 82% of the original 60 participants, 75% of the high school students, and 80% of the “delinquent” students in the cross-validation sample.
In summary, validity evidence for the RISB in school-age samples supports its utility for group discrimination. Across studies, RISB scores differentiated delinquent or clinic-referred adolescents from non-referred peers with moderate-to-high classification accuracy (approximately 65–85%), while concurrent validity correlations with interview and sociometric criteria were small to moderate, particularly for males. Gender differences were evident, with stronger associations and higher classification accuracy for females, suggesting that RISB validity in youth may be influenced by developmental and gender-related factors and may be strongest when used for categorical screening purposes.
Studies of RISB Validity Using Mixed Samples of Children and Adults
Ames and Riggio (1995) produced the only study examining the validity of the RISB in a mixed sample of children and adults. Their study examined the correlation between RISB scores and the Maudsley Personality Inventory (MPI) in high school (n = 368) and college (n = 136) students. The correlations between RISB scores and MPI Neuroticism scores were .45 for high school students and .55 for college students. The authors also found that high school students often scored significantly higher on the RISB and the MPI Neuroticism scale compared with norms from when the RISB was initially validated, while college students' scores on both measures remained relatively consistent over time. In addition, a greater percentage of female high school students were classified as “maladjusted” compared with their male counterparts.
In summary, the limited evidence from mixed-age samples suggests that RISB validity may strengthen with age, as reflected in higher associations with neuroticism among college students compared with high school students. Findings suggest that adolescent RISB scores may differ from original validation samples, with higher rates of maladjustment classification among female adolescents. These patterns indicate that developmental context may influence score interpretation and that caution is warranted when applying uniform norms and cutoff scores across age groups.
Studies of RISB Validity Using Samples of Adults
A series of eight studies examining the validity of the RISB in adults were reviewed. Rotter et al. (1949) examined the RISB as a measure of maladjustment in college students. Criterion groups included 42 women (20 classified as “normal,” 15 as “maladjusted,” and 7 as “questionably adjusted”) and 33 men (13 classified as “normal,” 15 as “maladjusted,” and 5 as “questionably adjusted”). Separate scoring manuals for males and females were developed, with common scoring issues addressed using an additional 16 women and 20 men. In total, 58 women and 53 men were included in the development of the manuals. Additional analysis of records from 82 females and 124 males demonstrated strong correlations between RISB scores and psychologists’ adjustment ratings (“adjusted” or “maladjusted”) for both males (r = .64) and females (r = .77).
Gardner (1967) administered the RISB to 50 outpatients at a narcotic rehabilitation center (20 male heroin users, 20 male pill users, 10 female heroin users). Using a cutoff score of 135, the RISB correctly identified 80% of male heroin users, 90% of male pill users, and 100% of female heroin users.
Churchill and Crandall (1955) studied the use of the RISB with college students and mothers. For 65 women and 24 men who entered counseling, and 123 women and 132 men who did not, biserial correlations between RISB scores and counseling utilization were slightly higher for females (rpb = .42) than they were for males (rpb = .37). For mothers (n = 44), there was also a correlation between RISB scores and psychologist ratings of maladjustment (r = .49). Using the cutoff score provided by the manual, the RISB correctly identified only 54% of male and 66% of female students who sought counseling.
Torstrick et al. (2015) studied 72 individuals either currently or previously receiving psychiatric treatment and 69 nonclinical undergraduate college students, finding that RISB scores effectively distinguished between the groups (d = 0.58). Scores also differentiated clinical patients with or without an Axis I disorder (d = 0.94) and those with a personality disorder (d = 0.81). The RISB scores inversely correlated (r = −.50) with the Satisfaction with Life Scale (SLS) created by Diener et al. (1985). A positive correlation was reported with the Psychiatric Diagnostic Screening Questionnaire (PDSQ) (r = .39) created by Zimmerman (2002) and with the Structured Interview for DSM-IV Personality (SIDP-IV) (r = .39) created by Pfohl et al. (1997). High RISB scores were linked to negative affect, anxiety, depression, irrational thinking, and interpersonal problems. Women regularly received scores that were significantly higher than men on the RISB.
McCloskey (2014) administered the RISB and six tests of adjustment to 41 recent admissions to psychotherapy at community mental health centers. The overall RISB score had a range of correlations (r = .32 to .74) with levels of adjustment. Hierarchical regression revealed that the overall RISB score explained 55% of variance of the adjustment composite, but this dropped to 16% after accounting for factors such as demographics, intelligence, social desirability, and self-ratings of adjustment.
Tempone and Lamb (1967) examined adult outpatients at a mental health clinic (n = 58) and found that scores on the RISB had a correlation ratio (η = .73) for the regression of conflict scores on a measure of repression-sensitization (R-S) developed by Byrne (1961). Similarly, Baker and King (1970) examined the relationship between the RISB and R-S scale in undergraduate students (n = 204). They found that the overall RISB score correlated with the R-S scale to a slightly lesser degree (r = .59).
Lah (1989) examined the RISB using 116 undergraduate students involved in sororities and fraternities and found that the RISB total scores correlated with a sociometric measure of adjustment created by the author for the purpose of the study. The highest correlations were for items associated with aspects of adjustment (r = −.34 to −.40). The second experiment recruited 240 undergraduate students, half of whom received on-campus mental health services and half of whom were controls. Pearson correlations between total RISB scores and group were higher for female participants (r = .72) than for male participants (r = .67). The author also found that a cutoff score of 145 achieved the best overall identification rates, which accurately identified 85% of undergraduate students receiving college counseling services and 84% of control participants (ϕ = .69).
Logan and Waehler (2001) examined potential influences of racial group and socially desirable response tendencies on the RISB in 94 African American and 100 White undergraduate students. The authors found that overall RISB scores had a negative correlation (r = −.34) with the Balanced Inventory of Desirable Responding (BIDR; Paulhus, 1994) measuring self-deception enhancement. Although mean overall RISB scores of African American and White students were comparable, the use of the recommended cutoff score of 135 resulted in a disproportionate number of African American students being labeled as “maladjusted” (χ2(1, N = 194) = 7.85, p < .0125).
In summary, adult studies provide the strongest and most consistent evidence of RISB validity, with scores showing moderate to strong associations with clinician ratings, psychopathology indicators, and related personality constructs, as well as moderate-to-large group differences between clinical and nonclinical samples. Classification accuracy was often high in clinical contexts, though performance varied by setting and criterion. At the same time, adult findings revealed systematic demographic effects, including higher maladjustment scores among women and disproportionate classification of African American participants when standard cutoffs were applied, indicating that while RISB validity is most robust in adulthood, interpretive caution remains necessary.
Overall Summary of RISB Validity Findings
In summary, the preponderance of the studies suggests that the RISB demonstrates acceptable internal consistency, as well as convergent and predictive validity. Internal consistency estimates for total scores and maladjustment indices, most often reported as Cronbach’s alpha, generally fell in the acceptable-to-strong range, with coefficients ranging from approximately .78 to .93 across studies. Convergent and predictive validity were supported through associations with clinician adjustment ratings, neuroticism, repression-sensitization, counseling utilization, indices of psychopathology, and life satisfaction, with validity coefficients typically ranging from approximately r = .32 to .77. However, some studies reported reliability and validity estimates—such as split-half reliability coefficients and selected convergent validity correlations—that fell below generally accepted standards (see Tables 3 and 4). Validity coefficients varied substantially across studies as a function of sample characteristics, criterion measures, and analytic approaches, reflecting notable methodological heterogeneity in the literature.
Across school-age, mixed-age, and adult samples, RISB scores demonstrated meaningful discriminant validity, consistently differentiating referred from non-referred participants, counseling seekers from non-seekers, and clinical from non-clinical groups. Across studies, classification accuracy for these distinctions typically ranged from approximately 54% to 85% when established or empirically derived cutoff scores were applied, with several investigations reporting moderate to large group differences (e.g., d ≈ 0.58 to 0.94). Discriminant validity was further supported by the measure’s ability to distinguish adjustment-related constructs from theoretically unrelated traits, with correlations with unrelated constructs generally falling in the small range (approximately |r| ≤ .30), although effect sizes varied across samples and criteria. Demographic patterns also emerged across multiple studies, with women more frequently receiving scores in the maladjusted range and African American participants disproportionately classified as maladjusted when standard cutoffs were used. Taken together, the available evidence indicates evidence of validity across developmental levels, though variability in research design, quality, and reporting practices underscores the need for more methodologically rigorous and demographically sensitive validity studies.
Washington University Sentence Completion Test (WUSCT)
The WUSCT (Loevinger, 1957, 1998) was initially designed to use sentence-completion stems to assess an individual’s ego development. The WUSCT was based in Loevinger’s stage theory of ego development, and its continued use is based in its status as one of the premiere tools for evaluating ego development and on the additional nuance that many providers believe adds to a psychological evaluation (Manners & Durkin, 2001).
Studies of WUSCT Reliability
Nine studies examined the reliability of the WUSCT using school-age participants. These studies found that interrater reliability ranged from .57 to .96 (Avery & Ryan, 1988; Borst et al., 1991; Frank & Quinlan, 1976; Holt, 1980; Hoppe & Loevinger, 1977; Maron & Rock, 1984; Noam et al., 1984). Test–retest reliability ranged from .14 to .92 (Frank & Quinlan, 1976; Kitchener et al., 1984; Redmore & Loevinger, 1979). A significant portion of the variability in test-retest reliability was reported by Redmore & Loevinger (1979) (Table 6).
Test–Retest Correlations Reported by Redmore and Loevinger (1979).
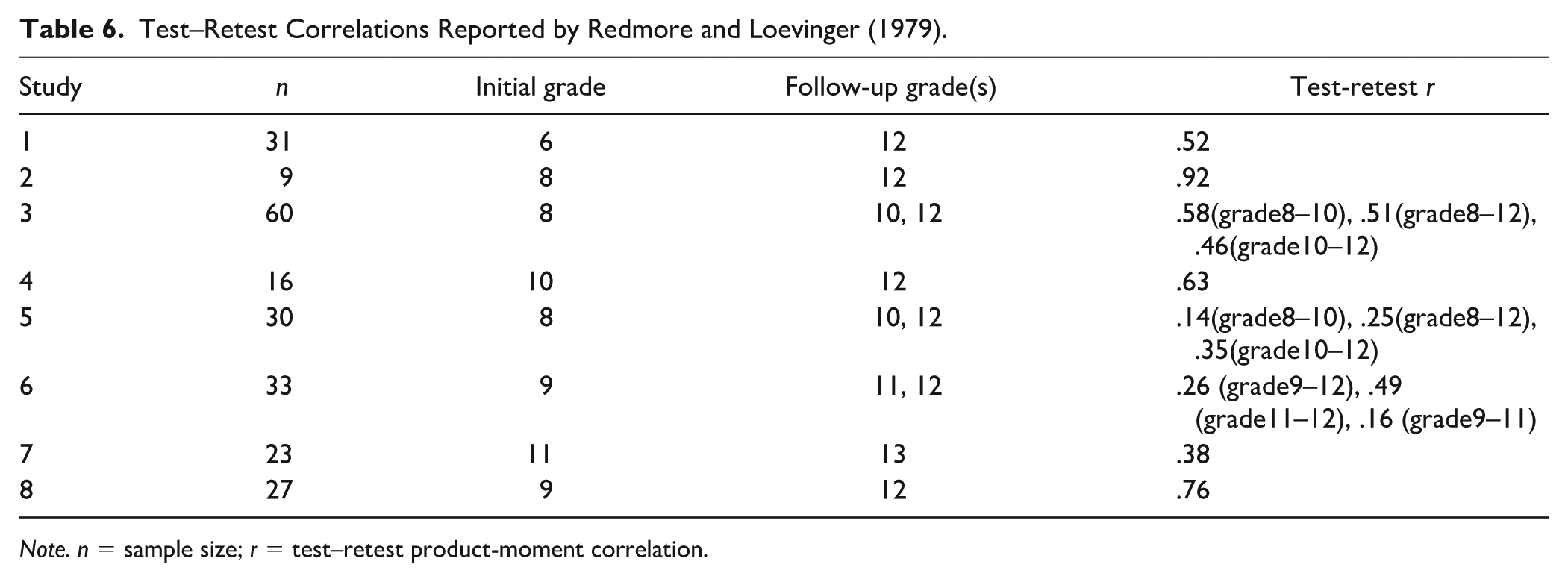
Note. n = sample size; r = test–retest product-moment correlation.
A study examining the reliability of the WUSCT with a mix of adolescent and adult participants found that interrater reliability was .93 for the Total Protocol Rating (TPR) and .88 for the item sum scores (Sutton & Swensen, 1983).
Nineteen studies examined the reliability of the WUSCT with adult participants. These studies found that interrater reliability for TPR and item sum scores ranged from .70 to .94 (Adams & Fitch, 1981; Adams & Shea, 1979; DeMoss & McCann, 1997; Jennings & Armsworth, 1992; Lambie, 2007; Lambie et al., 2010; Lambie & Ieva, 2012; Lanning et al., 2007; Larson et al., 2007; Loevinger et al., 1985; Luthar et al., 2001; Novy, 1993; Novy & Francis, 1992; Picano, 1987; Shea et al., 1978; Waugh, 1981; Welfare et al., 2013; White, 1985; Wilber et al., 1982).
Considered collectively, the 29 available studies provide moderately strong evidence of scoring reliability for the WUSCT across age groups, with interrater coefficients commonly falling in the acceptable-to-strong range (.70–.94) despite variability across studies and samples. Test–retest reliability was reported far less frequently and showed substantial fluctuation, with coefficients ranging from very low to very high values (approximately r = .14 to .92), making it difficult to draw firm conclusions about temporal stability. Across developmental levels, interrater agreement appears to be the most consistently supported index of reliability, whereas stability over time remains insufficiently established. Overall, the available findings indicate that WUSCT scoring procedures can yield reliable estimates when applied by trained raters, but more methodologically consistent longitudinal research is needed to clarify the measure’s temporal stability.
Studies of WUSCT Validity Using Samples of School-Age Children
Six studies examined the validity of the WUSCT in childhood. Avery and Ryan (1988) recruited 92 children in grades 4 to 6 with no known disorders at an urban magnet school. The WUSCT TPR was examined for relationships with the Blatt Parent Nurturance Scores of the Blatt Object Representation Scale (BORS) created by Blatt et al. (1981), the Teacher Rating Scale of Achievement and Social Adjustment (TRS) created by Ryan et al. (1985), the Child Rating Scale (CRS) created by Hightower et al. (1987), the Gesten Class Wheel (GCW) created by Gesten (1979), and the Metropolitan Achievement Tests (MAT) created by Durost et al. (1970). Scores on the WUSCT correlated with the Academic Competence subscale on the TRS (r = .26), the Reading Achievement Score on the MAT (r = .33), and inversely correlated with the Social Perceived Competence subscale on the CRS (r = −.22). No significant correlation was found with the overall scores for any of the assessments or other subscales of the assessments.
Frank and Quinlan (1976) recruited 66 Black and Puerto Rican “inner-city” adolescent girls: 25 “delinquents” from a city institution, 25 “nondelinquents” from a settlement house recreational program, and 16 from the settlement’s leadership training program. When WUSCT scores were adjusted for intelligence as measured by the Peabody Picture Vocabulary Test, “delinquent” girls, F(2, 62) = 7.79, p < .001, had lower ego development levels than “nondelinquent” girls (χ² (6) = 31.11, p < .001). Ego stage significantly correlated with the overall number of deviant behaviors (r = −.45), measured by self-report and corroborated by social workers, counselors, and administrators. The strongest correlation was with fighting behavior (r = −.52), with other significant correlations for running away, promiscuity, homosexuality, and alcohol abuse (r = .25 to .29). Correlations between drug abuse and pregnancy were found to be trivial.
Borst and colleagues (1991) recruited 219 adolescent psychiatric inpatients with an affective disorder, conduct disorder, or mixed conduct-affective disorder. Participants were classified as either “suicide attempters” or “non-suicidal.” Chi-square analyses showed a relation between suicide attempts and ego development on the WUSCT (χ2(1) = 8.65, p = .003). Stepwise logistic regression showed that level of ego development, gender, and specific diagnosis significantly contributed to prediction of suicide attempts. In addition, ego development remained a significant predictor of suicide attempts even when accounting for variance due to gender and diagnoses.
Hoppe and Loevinger (1977) studied 107 boys from grades 8, 9, and 11 at a private school to explore the relationship between ego development and conformity using a self-report measure of conformity developed by Hoppe (1973). Their analysis revealed a significant quadratic trend in self-report conformity scores based on the item sum, F(4, 105) = 5.1, p < .03, even after controlling for age, grade level, IQ, and GPA (F = 3.93, p < .05). They also found that ego development correlated with the number of demerits received over the past 90 days, with the highest proportion of “conformers” (students with perfect compliance) falling within the Conformist range of the WUSCT (χ2(1) = 4.36, p < .05). However, ego development did not correlate with peer ratings of conformity or an experimental measure of conformity (Willis & Hollander, 1964).
Maron and Rock (1984) recruited 17 adolescent girls at a coeducational Orthodox Jewish high school. Ego development, as measured by the WUSCT, was related to two of the three scales of religiosity derived from a structured interview: God’s Relationship to Man (χ2 = 12.9, p = .01), and Behavior versus Belief (χ2 = 12.9, p = .01). It was not significantly related to View of Religiosity.
In summary, validity evidence for the RISB in school-age samples supports its utility for group discrimination. Across studies, RISB scores differentiated delinquent or clinic-referred adolescents from non-referred peers with moderate-to-high classification accuracy (approximately 65–85%), while concurrent validity correlations with interview and sociometric criteria were small to moderate, particularly for males. Gender differences were evident, with stronger associations and higher classification accuracy for females, suggesting that RISB validity in youth may be influenced by developmental and gender-related factors and may be strongest when used for categorical screening purposes.
Studies of WUSCT Validity Using Mixed Samples of Children and Adults
Sutton and Swensen (1983) recruited 70 participants made up of children and adolescents from a juvenile detention center, a junior high school, and a high school, as well as adults from a university, a group of college graduates and graduate students, and a group of retired university professors. All participants completed the WUSCT, the Thematic Apperception Test (TAT; Murray, 1943), and an unstructured interview. The authors used Loevinger and Wessler’s developmental framework (1970) to score participant responses for level of ego development and achieved high interrater agreement for item scoring (r = .95: .96). The score of the WUSCT correlated with the mean of the individual item scores for the TAT (r = .79) and unstructured interview (r = .89). Newman-Keuls Sequential Range Tests were used to test significant differences between the mean ego level scores of each group by instrument. There were no statistically significant differences for the three adolescent groups. For the three adult groups, the item sum score on the WUSCT was significantly lower than the mean interview and TAT scores, although no effect sizes are provided.
In summary, the limited evidence from mixed-age samples suggests that RISB validity may strengthen with age, as reflected in higher associations with neuroticism among college students compared with high school students. Findings suggest that adolescent RISB scores may differ from original validation samples, with higher rates of maladjustment classification among female adolescents. These patterns indicate that developmental context may influence score interpretation and that caution is warranted when applying uniform norms and cutoff scores across age groups.
Studies of WUSCT Validity Using Samples of Adults
Five studies examining the validity of the WUSCT in adulthood were reviewed. Welfare and colleagues (2013) recruited 120 counselors-in-training and practicing counselors with no known disorders. Items on the WUSCT that seemed specifically relevant to the work of counselors were used to assess overall cognitive complexity. In a linear regression, the WUSCT was statistically significant as a predictor for two of the four variables: positive client traits identified by the counselor for clients they felt effective (r2 = .02) and negative client traits identified by the counselor for clients they felt less effective (r2 = .04). However, both analyses had low effect sizes as reported in Table 7.
Reliability and Validity Metrics for WUSCT Studies.
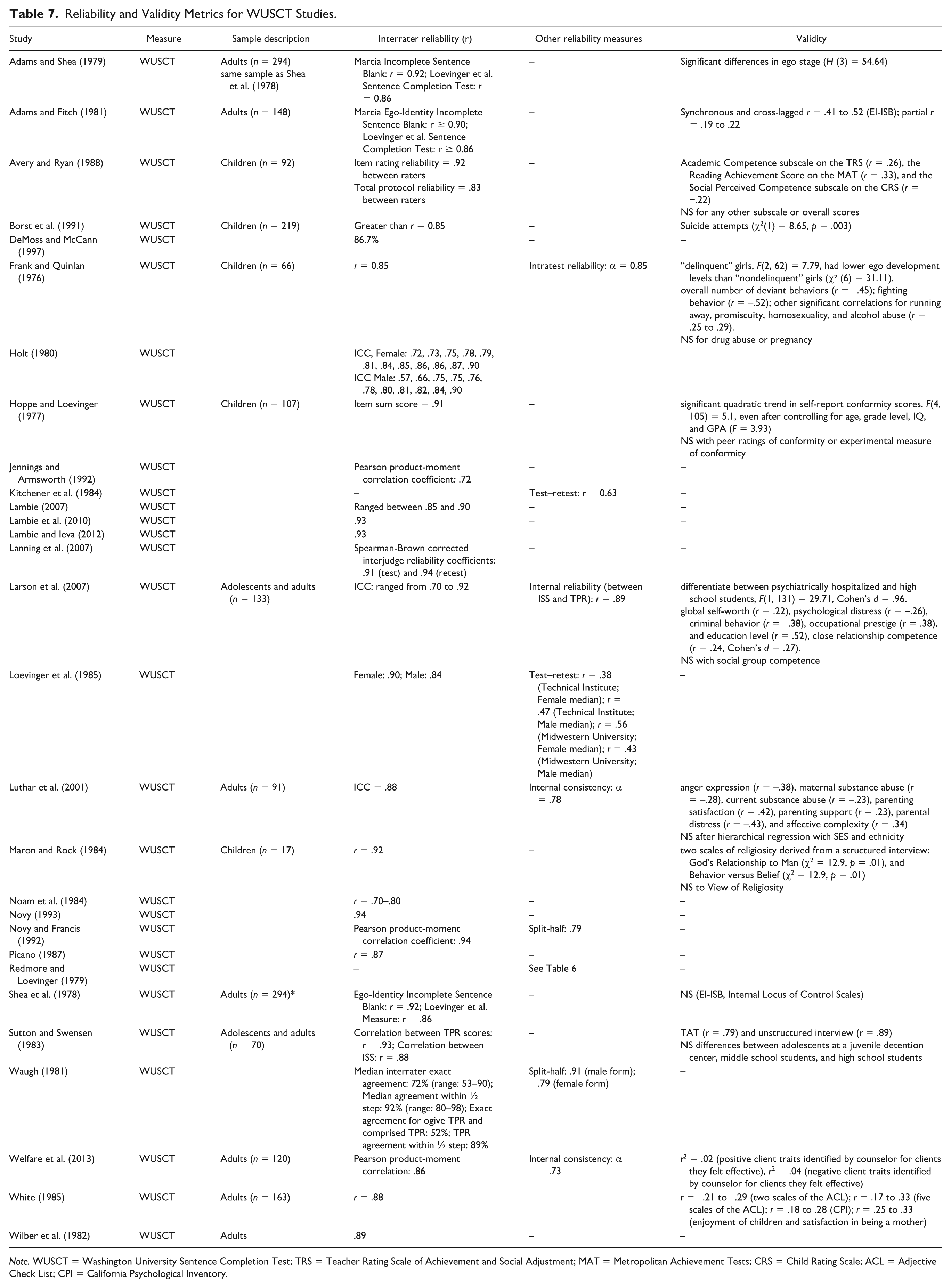
Note. WUSCT = Washington University Sentence Completion Test; TRS = Teacher Rating Scale of Achievement and Social Adjustment; MAT = Metropolitan Achievement Tests; CRS = Child Rating Scale; ACL = Adjective Check List; CPI = California Psychological Inventory.
Larson et al. (2007) evaluated 133 participants who had initially been recruited as adolescents for a longitudinal study of psychosocial development. This study took place 11 years after the participants had been recruited. Seventy-four participants had been hospitalized as adolescents for anxiety, depression, behavioral, or other disorders, and 59 participants were originally recruited from a demographically matched control group of high school students. Ego development was able to differentiate between groups, F(1, 131) = 29.71, Cohen’s d = .96, even after 11 years. When examining intercorrelations among indices of functioning, ego development correlated with the other five: global self-worth (r = .22), psychological distress (r = −.26), criminal behavior (r = −.38), occupational prestige (r = .38), and education level (r = .52). While ego development did not correlate with social group competence, it did correlate with close relationship competence (r = .24, Cohen’s d = .27).
White (1985) recruited 163 women from a nurse practitioner training program and administered various personality tests, including the Adjective Check List (ACL) created by Gough and Heilbrun (1965), the California Psychological Inventory (CPI) created by Gough (1957), and the Rotter Internal-External Locus of Control Scale (LCS) created by Rotter (1966). A questionnaire on attitudes toward children and childrearing experiences was also given, assessing satisfaction related to rearing children, being a mother, whether the children were planned, and the number of children. Higher ego levels were positively related to five of the eight scales on the ACL (r = .17 to .33) and negatively related to two of the eight scales (r = −.21 to −.29). They were also positively related to all twenty of the CPI scales (r = .18 to .28) and the external control scale of the LCS (r = .19). In addition, higher ego levels correlated with enjoyment of children and satisfaction in being a mother (r = .25 to .33). Thus, higher ego levels were associated with adjustment, nurturance, responsibility, tolerance, enjoyment of children, a sense of inner control, lack of aggression, and leadership.
Luthar and colleagues (2001) recruited 91 mothers from the community. Participants were given several measures to assess difficulties toward mothers’ feelings in the maternal role including the Brief Symptom Inventory (BSI) developed by Derogatis (1993), the State-Trait Anger Expression Scale (STAXI) developed by Spielberger (1996), the Addiction Severity Index (McLellan et al., 1990), the Parent-Child Relationship Inventory (PCRI) developed by Gerard (1994), the Parenting Stress Index Short Form (PSI) developed by Abidin et al. (2006), and vignettes on family relations designed for this study. Ego development was related to six of the seven variables: anger expression (r = −.38), maternal substance abuse (r = −.28), current substance abuse (r = −.23), parenting satisfaction (r = .42), parenting support (r = .23), parental distress (r = −.43), and affective complexity (r = .34). However, after considering ethnicity and SES via hierarchical multiple regression analyses, the main effects of ego development were no longer significant. Interactions between ego development and psychological difficulties indicated trends that the advantages of high levels of ego development decreased when mothers reported adjustment problems, and higher levels of ego development correlated with more variability in maternal functioning.
Shea and colleagues (1978) recruited 294 undergraduate students. Participants completed the Marcia Ego-Identity Incomplete Sentence Blank (EI-ISB) developed by Marcia (1966) and the Internal Locus of Control Scales (Levenson, 1974). Analyses of variance found that ego development, as measured by the WUSCT, had no significant relationship with scores on the other measures. The same sample and measures were used in a follow-up study conducted by Adams and Shea (1979). Using a Kruskal–Wallis one-way analysis of variance, they found that students in the four identity status groups had significant differences in their ego stage distributions (H (3) = 54.64, p < .0001). A series of one-way analyses of variance between ego level and locus of control revealed no significant associations. Adams and Fitch (1981) used the same sample and followed up with 148 of the original 294 undergraduate students a year later to have them complete the EI-ISB and WUSCT. All synchronous and cross-lagged correlations were significant (r = .41 to .52). To rule out a possible spurious relationship in the cross-lagged correlations, partial correlations with control for measurement of one source of spuriousness were computed: both were significant (partial r = .19 to .22).
In summary, adult studies provide the strongest and most consistent evidence of RISB validity, with scores showing moderate to strong associations with clinician ratings, psychopathology indicators, and related personality constructs, as well as moderate-to-large group differences between clinical and nonclinical samples. Classification accuracy was often high in clinical contexts, though performance varied by setting and criterion. At the same time, adult findings revealed systematic demographic effects, including higher maladjustment scores among women and disproportionate classification of African American participants when standard cutoffs were applied, indicating that while RISB validity is most robust in adulthood, interpretive caution remains necessary.
Overall Summary of WUSCT Validity Findings
In summary, the preponderance of the studies suggests that the WUSCT demonstrates acceptable internal consistency as well as convergent and predictive validity across age groups, albeit with slightly stronger evidence of validity in use with adult populations. Several investigations reported adequate internal consistency for total protocol ratings and item sum scores, with coefficients typically ranging from .70 to .94. These results support the coherence of the ego development construct in applied validity contexts. Convergent and predictive validity were reflected in associations between WUSCT scores and a range of theoretically relevant indicators, including academic competence, reading achievement, deviant behaviors, psychosocial functioning, parenting satisfaction, and maternal distress, with reported validity coefficients most often falling in the small-to-moderate range (approximately r = .22 to .52), and several studies reporting moderate-to-large group differences for clinically relevant outcomes (e.g., d ≈ 0.96).
Evidence of concurrent validity was supported by associations between WUSCT scores and theoretically related measures administered within the same assessment context, including structured interviews, other sentence completion measures, and performance-based assessments of ego development and personality functioning. In these studies, concurrent validity coefficients were generally moderate to strong, with correlations ranging from approximately r = .41 to .89, depending on the criterion measure and scoring method. However, the strength of concurrent associations varied across samples and comparison instruments, and some studies reported weaker or nonsignificant relations with selected constructs, underscoring variability in concurrent validity as a function of criterion selection and study design.
Across school-age, mixed-age, and adult samples, WUSCT scores demonstrated meaningful associations with external indicators of developmental maturity, behavioral functioning, adjustment, and interpersonal competence. Ego development differentiated “delinquent” from “nondelinquent” adolescents, psychiatric inpatients with and without a history of suicide attempts, adults originally hospitalized as adolescents from matched controls, and individuals at different levels of occupational, relational, and educational attainment, with reported group differences ranging from moderate to large in magnitude (e.g., χ² values reaching statistical significance and effect sizes as large as d ≈ 0.96). Associations between WUSCT scores and external criteria typically fell in the small-to-moderate range (approximately r = .22 to .52), including correlations with deviant behaviors, psychosocial functioning, occupational prestige, and educational attainment.
Discriminant validity was supported in studies showing that ego development correlated with unique aspects of functioning, such as conformity patterns, religious beliefs, maternal role stress, and affective complexity, but not uniformly across all domains (e.g., peer-rated conformity or locus of control in some samples). Taken together, the available evidence indicates that the WUSCT demonstrates meaningful evidence of validity across developmental levels, although the variability in effect sizes, sample characteristics, and analytic strategies highlights the need for more methodologically rigorous and consistently designed validity research.
Discussion
The RISB and WUSCT are two SCTs that have been studied extensively for their reliability and validity across various populations and age ranges, although many of these studies are now several years to several decades old. Both assessment tools have shown some degree of potential in assessing psychological adjustment and personality development, but they also have limitations that practitioners should consider when interpreting results and forming diagnostic conclusions about a patient. Of course, reliance on a single instrument for purposes of conceptualization and classification of a clinical condition is a practice to be eschewed (e.g., Dombrowski, 2020) but the two SCTs under review have demonstrated potential for clinical use when considered in the context of a comprehensive evaluation.
For the RISB, studies generally reported high interrater reliability and moderate internal consistency. However, test–retest reliability is much more variable, indicating inconsistency in the stability of test scores over time. Demographic factors like gender and age appeared to influence the reliability of the RISB to some extent. Still, the instrument generally appears to demonstrate sufficient reliability for cautious use when acknowledging the impact that gender and age can have on the results.
In terms of validity, there is some evidence that scores on the RISB correlate with various other psychological measures demonstrating adequate concurrent validity. However, the RISB has shown potential shortcomings regarding its sensitivity to demographic variables of the participants included in the studies. This can contribute to overidentification of African American and female individuals as “maladjusted,” raising concerns about its appropriateness for these populations. Overall, while the RISB shows some potential value as a tool for assessing psychological adjustment, its results should be interpreted cautiously when used with diverse populations considering its lack of demonstrable validity for populations from diverse racial and gendered groups. This issue is not limited to sentence completion tasks (Bornstein, 2011; Putnick & Bornstein, 2016); the impact of cultural biases on test scores represents a field-wide concern, as even the most consequential instruments (e.g., intelligence tests) often lack investigations of measurement invariance (e.g., Dombrowski et al., 2021) and long-term stability (e.g., Watkins et al., 2022) with diverse populations.
The WUSCT has also been studied for its reliability and validity across populations. In studies with school-age children, interrater reliability was generally high. Although some studies involving both adolescents and adults as study participants reported high interrater reliability, there was much more variability in these values. Test–retest reliability estimates varied considerably across studies, indicating inconsistent stability over time. Based on our review, results varied markedly based on characteristics of the sample as well as the specific conditions of the study. This finding poses problems for consistent interpretation. If an interpretation suggests maladjustment at time 1 but then indicates normal functioning at time 2, then it can be difficult to establish interpretive consistency and therefore veracity. Overall, the preponderance of the WUSCT reliability evidence suggests adequate reliability, but the results also seem to vary significantly based on the sample population and the specific conditions of the study.
Various forms of validity have also been explored for the WUSCT. There is evidence that it has some predictive validity in terms of academic attainment, intelligence, and certain behaviors (e.g., aggression, suicidality). However, these associations appear to be influenced by demographic factors such as socioeconomic status, age, gender, and ethnicity. Despite this, the WUSCT has demonstrated evidence as a tool for measuring an individual’s personality and identity development over time.
Future research aimed at improving the clinical utility of the RISB and WUSCT should prioritize two interrelated directions. First, studies should examine the incremental validity of SCT scores within multimethod assessment batteries, clarifying whether these measures provide clinically meaningful information beyond routinely used procedures such as interviews, rating scales, and cognitive tests. Second, research should focus on developing context-sensitive interpretive frameworks, including revised cutoff scores, demographically informed norms, and explicit decision rules linked to specific clinical questions. Together, these efforts would shift SCT research from establishing psychometric adequacy toward determining how, when, and for whom these instruments enhance clinical judgment.
There are several limitations to this review that should be considered when interpreting the results. First, there was significant variability in the sample sizes, methods, and populations of the included studies which may impact the generalizability of the findings. Second, it is possible that studies relevant to this review were missed when searching the databases outlined in the methods section. Third, there is the potential that despite using a comprehensive and systematic approach to the review, publication bias may have impacted the studies that were included. Fourth, both tests showed variability in test–retest reliability, reflecting inconsistencies in the stability of measured constructs over time. Fifth, the evidence reviewed indicated limitations concerning demographic factors, including age, gender, race, and ethnicity. Sixth, studies have revealed a tendency for overidentification or misclassification of maladjustment. Finally, many of the studies that initially evaluated the reliability and validity of these assessment measures were conducted decades ago, and few studies include current populations to determine how the tools, presently still used in clinical practice, hold up over time While there is evidence of reliability and validity of the use of SCTs for select purposes, these findings strongly suggest a need for careful contextual interpretation of results and underscore the ethical requirement for practitioners to use SCTs, and any assessment instrument for that matter, in the context of a multi-informant, multimethod evaluation process when arriving at diagnostic decisions.
Conclusions
Adhering to PRISMA guidelines, this study systematically reviewed 51 studies that examined the reliability and validity of the RISB and WUSCT. The evidence reviewed supports the use of these measures as part of a comprehensive assessment when evaluating ego development, exploring cognitive styles, and conceptualizing personality structure. In addition, results from these measures can complement interviews and rating scales in treatment planning, goal setting, and monitoring therapeutic progress. These tests are particularly promising for specialized clinical populations, such as individuals with substance abuse issues, psychiatric conditions, adolescents with delinquent behaviors, and those at risk for suicidality.
The results of this study have important implications for applied psychological practice. Practitioners must recognize the nuanced nature of SCTs and their place within a broader multimethod assessment battery. These instruments are most beneficial for exploring specific aspects of personality, cognitive styles, or ego development, rather than serving as standalone diagnostic tools, a stricture not only specific to SCTs but also imposed on any assessment instrument. Because these measures provide a level of nuance and the ability to probe responses that is not always afforded by using more standardized broadband measurement tools, many providers still choose to use these assessments within their psychological evaluations. Given the need for additional evidence to support their widespread use across diverse purposes and populations—a requirement of almost all assessment instruments—training programs will need to promote a more nuanced understanding of SCTSs and consider whether teaching about them represents the most efficient use of instructional time and resources. However, if practitioners choose to use the two SCTs reviewed in this study, they should familiarize themselves with the available evidence concerning reliability and validity to recognize each instrument’s limitations, apply critical interpretive judgment, and remain attentive to demographic diversity and cultural sensitivity when interpreting results, an admonition that is applied to any instrument used in the assessment process (Dombrowski et al., 2022). Future directions for the use of SCTs should include the development of revised, valid scoring systems and supplemental interpretive guidelines tailored explicitly to demographic subgroups. In addition, it would be beneficial to include detailed procedures for training coders and for monitoring interscorer reliability. Future research into these measures and SCTs in general would benefit from a thorough evaluation of their reliability and validity in relation to current populations and with other updated assessment tools. While instruments like the RISB and WUSCT may provide valuable insights into psychological adjustment and personality structures, additional research is necessary to determine their incremental value and ensure their ethical use in psychological practice. However, the results of this study suggest that SCTs may provide a degree of incremental validity for specific assessment purposes and should not necessarily be summarily dismissed as being devoid of an evidentiary basis.
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.