
Abstract
Research demonstrates that people can fake on self-rated emotional intelligence scales. As yet, no studies have investigated whether informants (where a knowledgeable informant rates a target’s emotional intelligence) can also fake on emotional intelligence inventories. This study compares mean score differences for a simulated job selection versus a standard instructed set for both self-ratings and informant-ratings on the Trait Emotional Intelligence Questionnaire—Short Form (TEIQue-SF). In a 2 × 2 between-person design, participants (N = 81 community volunteers, 151 university students) completed the TEIQue-SF as either self-report or informant-report in one of two instruction conditions (answer honestly, job simulation). Both self-reports (d = 1.47) and informant-reports (d = 1.56) were significantly higher for job simulation than “answer honestly” instructions, indicating substantial faking. We conclude that people can fake emotional intelligence for both themselves (self-report) and on behalf of someone else (informant-report). We discuss the relevance of our findings for self- and informant-report assessment in applied contexts.
Keywords
Emotional intelligence (EI) has been identified as a key skill required for future employability (Alawadhi, 2021; McIntyre, 2018). EI is related to performance outcomes in both education (MacCann et al., 2020; Perera & DiGiacomo, 2013) and work (Edelman & van Knippenberg, 2018; O’Boyle et al., 2011; Schutte & Loi, 2014), with tests of EI widely used in selection processes for education and employment (Edelman & van Knippenberg, 2018). However, there is evidence that test-takers can “fake good” on self-reports of EI, resulting in inaccurate measurement (Choi et al., 2011; Day & Carroll, 2008; Tett et al., 2012). In fact, several studies show that test-takers can distort their responses to self-rated EI measures when instructed to do so, producing moderate to very large mean score changes (d = 0.57–0.94; Day & Carroll, 2008; Grubb & McDaniel, 2007; Hartman & Grubb, 2011; Whitman et al., 2008). These effect sizes are consistent with meta-analyses of instructed faking on personality rating scales, which show large to very large mean score changes to both Big Five (d = 0.48–1.65) and Dark Triad (d = 0.39–0.96) domain scores (Viswesvaran & Ones, 1999; Walker et al., 2022).
While EI researchers have suggested that informant-reports could supplement or replace self-ratings (Choi & Kluemper, 2012; Libbrecht et al., 2010), recent research has shown informants can also fake on personality scales (König et al., 2017; Walker, 2021). That informants may distort their responses on EI measures has implications for employee selection across a range of industries including the military (Alawadhi, 2021; Bar-On, 2010; Bar-On et al., 2006; Daly, 2022; McIntyre, 2018). Given the rise of interest, and use of EI measurement within both industry and research, it is vital to understand the extent to which informants can distort their responses on EI measures, and whether this response distortion adversely impacts the validity of these scales, and how they are interpreted. As yet, there have been no studies examining the extent to which informants also “fake good” on EI rating scales. The major aim of the current study is to address these questions by comparing self- and informant-faking on EI rating scales on a standard instruction set versus job simulation instruction set.
Emotional Intelligence
There are multiple models of EI which can be broadly understood by the type of measurement technique used. Ability scales (ability EI) use maximum performance test items requiring information processing or knowledge to answer (e.g., “How much sadness does this facial expression portray?”). Rating scales instead ask test-takers to evaluate themselves (for self-ratings) or another person (for informant-ratings) in terms of how well as statement describes them (e.g., “Expressing my emotions with words is not a problem for me”; Petrides, 2009).
One of the dominant EI models assessed with rating scales is Trait EI. This model is operationalized using the TEIQue (Petrides, 2010) which comprises 16 EI facets organized into four overarching EI domains (well-being, self-control, emotionality, and sociability). These domains can be aggregated into a single “trait EI” score.
There is substantial evidence that trait EI predicts performance at work and school, and this evidence underpins the widespread use of EI in selection. EI is associated with higher academic performance (MacCann et al., 2020; Perera & DiGiacomo, 2013; Petrides et al., 2016), job performance (O’Boyle et al., 2011), job satisfaction (Schutte & Loi, 2014), work engagement (Akhtar et al., 2015; Barreiro & Treglown, 2020), and organizational citizenship behavior (Miao et al., 2017), and with lower burnout (Mikolajczak et al., 2007), and counterproductive workplace behavior (Miao et al., 2017). High EI leaders tend to be more well-liked by their employees and tend to be effective leaders (Edelman & van Knippenberg, 2018; Hopkins & Bilimoria, 2008; Walter et al., 2011). As such, it is not surprising the use of trait EI assessments has become an increasingly important component of the selection decision-making process in organizations (Edelman & van Knippenberg, 2018; Miao et al., 2017). A 2019 survey from career builder found that 71% of employers prioritized employee EI over IQ (Melnichuk, 2021), and EI was listed as a top 15 skill required by organizations by the year 2025 (Zahidi et al., 2020). Globally, military recruitment frequently uses EI assessments (e.g., Australian Government Department of Defence; Bar-On, 2010; Daly, 2022) with U.S. Department of Defense estimating that implementing EI selection measures within the Air Force alone will save approximately $190 million (Bar-On, 2010). However, the self-reported nature of self-reported EI measures has raised concerns that test-takers may attempt to make themselves look more emotionally intelligent than they really are to “get the job” (Christiansen et al., 2010; Grubb & McDaniel, 2007).
Faking and EI
Given the widespread use of self-report EI measures, it is important to understand the extent to which test-takers can distort (fake) their responses on these rating scales (Van Rooy & Viswesvaran, 2007). A common method for examining whether people distort their responses is by using an instructed faking paradigm. Instructed faking paradigms compare scores obtained under standard instructions to scores obtained under instructions that simulate a high-stakes setting (usually job selection). Such paradigms examine the extent to which test-takers can distort their responses in a socially desirable way to present create a more favorable impression (faking good; Arthur et al., 2010; Donaldson & Grant-Vallone, 2002; Furnham, 1990; Rogers et al., 2003). For example, a job applicant may try to enhance their positive qualities to obtain a job (Birkeland et al., 2006). There is evidence from instructed faking studies of self-ratings that people do “fake good” on EI rating scales (Day & Carroll, 2008; Grubb & McDaniel, 2007; Hartman & Grubb, 2011; Whitman et al., 2008).
Specifically, the Emotional Quotient Inventory (EQ-i) shows large mean score differences when participants were instructed to fake compared with answer honestly, for both the full form (d = 0.57–0.94) and the short form (d = 0.51–0.83) (Day & Carroll, 2008; Grubb & McDaniel, 2007; Hartman & Grubb, 2011). Tett et al. (2012) found small to very large mean score differences between faking and honest conditions on the Multidimensional Emotional Intelligence Assessment (MEIA; d = 0.17–2.01). Very large mean score differences (d = 1.08) between honest and faking conditions were also found when using the Emotional Inventory Scale (Whitman et al., 2008), the Self-report Emotional Intelligence Test (d = 1.00) (Christiansen et al., 2010), and the Wong and Law Emotional Intelligence Scale (d = 1.12) (Lievens et al., 2011). In contrast, Choi et al. (2011) found only a small effect of faking when using the Emotional Intelligence Scale and the Self-report Emotional Intelligence Scale. Although it is one of the most commonly used EI assessment frameworks, there have as yet been no studies assessing the effect of faking on the TEIQue. This is one of the gaps the current study will address.
Overall, there is evidence that test-takers can “fake good” on self-report EI scales. Critically, Hartman and Grubb (2011) show that not everyone fakes good to the same extent—faking can change the rank order such that people who fake the most rise to the top of the applicant pool. In addition, Tett et al. (2012) demonstrated that test-takers can fake 26% more successfully when traits are job relevant highlighting a potential threat to the accuracy of selection decisions. These issues are consequential for selection, and promotion decisions within both organizational and educational contexts, as people who would otherwise not have been selected can fake to artificially out-rank other applicants (Zickar & Robie, 1999). In addition, people who fake their EI scores to successfully get the job may be the very people the selection process had intended to screen out (Ellingson et al., 2001).
Informant-Reports
Informant-reports involve a knowledgeable other (i.e., colleague, friend, family member) rating a target to provide an alternative source of information about a target beyond what the target self-reports about themselves (Vazire, 2006). However, the informant’s rating informant can be influenced by the extent to which the informant likes the target, or the closeness of the target/informant relationship (Beckman et al., 2020; Hollander, 1956; Leising et al., 2010). Leising et al. (2010), and Furnham and Treglown (2021) demonstrated that the extent to which the informant likes the target will alter the informant’s rating of the target. Similarly, Beckmann et al. (2020) found that informants rated the target more favorably than the target rated themselves across all Big Five traits with Grös et al. (2007) demonstrating this effect was most prevalent on evaluative traits. Importantly, the concept that informants may rate their targets favorably is not a new idea with research as early as Allport (1928) and Hollander (1956) expressing concern about the potential for biases such as the friendship effect and halo biases impacting informant-ratings. However, there has been very little research examining the extent to which informants can distort their responses.
Walker et al. (2022) found very large effects of instructed faking for informant-reports on the Dark Triad of personality such that informant-ratings were more favorable than self-ratings. Given the conceptual similarity between rating scales of EI and personality, we expect that faking will also occur on informant-report measures of Trait EI. In fact, given the close relationship between the informant (the test taker) and the target (a friend), it is feasible that informant-ratings will result in even greater faking than self-ratings, due to a friendship effect. Despite the conceptual similarity between rating scales of EI and personality, it is not assured that informants will distort their responses in the same way on EI measures as on Big Five measures. They are distinct constructs and should be considered such when examining the extent to which response distortion may occur and impact the interpretability of the EI scales. That is, evidence that people can fake on a Big Five measure does not negate the importance of examining or collecting evidence of response distortion on measures of related constructs.
That informants may fake on behalf of others may seem intuitive, but intuition alone is not evidence, nor does intuition extend to understanding the extent to which an informant may distort their responses. Given existing evidence that informants rate their targets more favorably than targets rate themselves, there is a substantial empirical basis with which to investigate informant-report faking with the same vigor previous decades have dedicated to understanding self-report faking. Furthermore, this research is iterative in nature such that the first step is to determine how much people can fake on EI measures before moving on to looking at whether people do fake EI measures in practice. With increasing interest in implementing EI assessments across a range of industries and educational programs and the rising use of informant-report measures, it is vital to understand the extent to which informants may distort their responses, their motivations for doing so, and how much this happens in practice.
The Current Study
The aim of the current study is to examine how much people can fake self- and informant-ratings of EI under simulated “high-stakes” conditions of obtaining employment (instructions are available in supplementary materials). We use a 2 × 2 between-personal design crossing the target (oneself vs. a friend) with the motivational condition, or stakes of the assessment (no stakes vs. wanting a desirable job).
Our expectations for the extent of faking on self-report scales are based on prior work examining faking on EI questionnaires. Large effects of faking good have been demonstrated across several EI measures such that when instructed to, people can distort their self-reported scores. Therefore, we expect to replicate prior findings that people can “fake good” on self-reported EI. That is, trait EI scores will be higher in the job simulation than “answer honestly” condition, indicating the degree to which test-takers are “faking good” (Hypothesis 1).
Our expectations regarding the effects of faking on informant-report scales are based on prior research showing that informants inflate their target’s positive characteristics (Furnham & Treglown, 2021; Leising et al., 2010), and results demonstrating large score differences for informants under fake good instructions (Walker et al., 2022). As such, we expect informants can fake on informant- and self-report EI measures when instructed to do so. That is, informant-ratings will result in increased faking relative to self-ratings (Hypothesis 2). Finally, people will fake more for others than for themselves such that mean score differences between the job simulation and “answer honestly” conditions will be moderated by ratings of source (self vs. other) such that the difference is large for informant-reports than for self-reports (Hypothesis 3).
Method
Preregistration and Open Science
This study and hypotheses were preregistered (https://aspredicted.org/blind.php?x=sj95qz). The preregistration includes four sets of hypotheses presented along with a data analysis plan including a moderation analysis of rater characteristics that may influence the extent to which people fake for themselves or others. Three of those hypotheses are presented here, and the fourth is included in supplementary materials. The rater characteristic hypotheses, method, analyses, and tables can be found in supplementary materials. The data, codebook, R code, and SPSS syntax for this study are available (https://osf.io/gjdf3/?view_only=6f1419e6a936404aa5f1943782a8533b).
Participants
There were 232 participants, aged 18 and 72 years (M = 25.81; SD = 11.13). Participants were 81 community volunteers (49 female, 30 male, two nonbinary; Mage= 36.12; SD = 13.26) recruited through social media (Facebook, Twitter, and LinkedIn), and 151 undergraduate psychology students (101 female, 50 male; Mage = 20.28; SD = 2.99) from the first author’s university. The undergraduate students received course credit for taking part in this study.
An additional 45 participants completed study protocol but were excluded from the study based on per preregistered data cleaning procedures (failing two or more attention checks, taking less than a third of the median response time to complete the study, selecting “not well” or “not well at all” from the demographic question “how well do you speak English,” or including random text in the free-text fields were excluded from this study). A power analysis for a 2 × 2 analysis of variance (ANOVA) suggests that 128 participants are required to detect a medium effect size with 80% power.
Materials
Trait Emotional Intelligence Questionnaire—Short Form (TEIQue-SF; Petrides, 2009) is a 30-item scale measuring global EI and four subscales including emotionality (e.g., “Expressing my emotions with words is not a problem for me”), sociability (e.g., “I can deal effectively with people”), self-control (e.g., “I’m usually able to find ways to control my emotions when I want to”), and well-being (e.g., “I feel that I have a number of good qualities). Items are rated on a 7-point scale ranging from “completely disagree” to “completely agree.” Informant-reported EI was measured by adapting the TEIQue-SF from first to third person (i.e., “I feel that I have a number of good qualities” becomes “They feel that they have a number of good qualities”).
Procedure
Participants completed this online study (MTime = 33 minutes) on a personal computer at a time and location of their choosing. All participants completed a demographic questionnaire and the self-/other-interest questionnaire. Participants were then randomly assigned to one of four conditions using Qualtrics randomization: informant/fake good, informant/honest, self/fake good, self/honest. In the “informant-report” conditions, participants were asked to think of a peer of the same sex and age (not a romantic partner). The specific instructions for each condition are given in the supplementary materials (https://osf.io/eb49g/?view_only=28d4eceb865049558c8b1818596cb684). The “fake good” instructions framed the personality ratings as part of a job selection process for a job you/your friend really wanted.
Following the instruction screen, participants were asked “what did the instructions ask you to do?” and participants had to select a response from nine options (e.g., “Rate myself honestly,”“Complete some intelligence tests”). If they did not answer correctly, the instructions were displayed a second time. There were four manipulation checks, all of which were data check items, in place to ensure attention to the task and instructions (see supplementary materials). All protocols were approved by the Human Research Ethics Committee of the first author’s institution.
Analysis
Hypotheses 1 to 3 were tested using 2 × 2 ANOVAs. An ANOVA was conducted for total TEIQue scores. Four separate ANOVAs were conducted for each of the four domains of the TEIQue and these results can be found in the supplementary material. We evaluated the effect size with respect to
Results
Reliability and Descriptive Statistics
Table 1 presents the reliability and descriptive statistics for TEIQue scores. Mean differences across conditions are also shown. Internal consistency reliability of EI was good across honest, and fake good conditions. These reliability estimates are consistent with prior research on these measures (O’Connor et al., 2017; Petrides, 2009). Effect sizes (Cohen’s d) were large for faking good on self-ratings (d = 1.47), and large for faking good on informant-ratings (d = 1.56). Although we refer to Cohen’s d effect sizes in terms of small (d = 0.2), medium (d = 0.5), and large (d = 0.8) based on Cohen (1988), these effect size values are arbitrary and should be considered within the context of effect sizes found in prior faking research (Thompson, 2007). Prior faking studies in EI and meta-analytic results in personality research (Big Five and the Dark Triad) have found Cohen’s d effects ranging from small-moderate (d = 0.48) to large (d = 1.65).
Reliability and Descriptive Statistics for Global EI and Each Facet Under Answer Honestly, and Fake Good Instruction Conditions for Self-Report and Informant-Report (Cohen’s d Compares Faking Conditions to Answer Honestly).
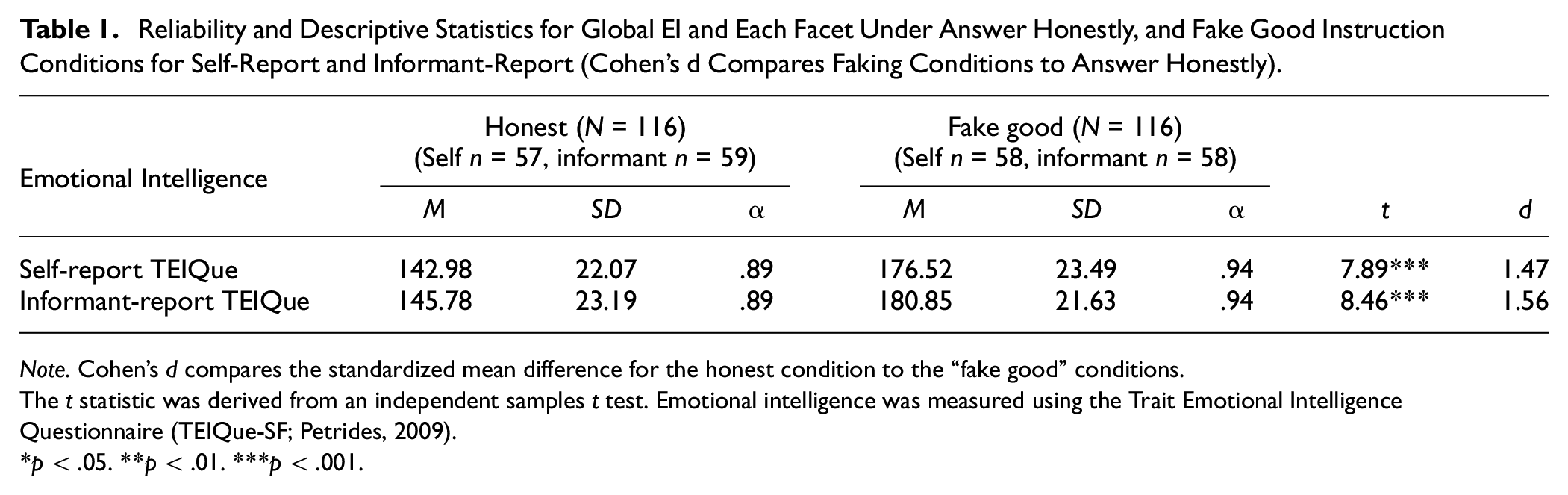
Note. Cohen’s d compares the standardized mean difference for the honest condition to the “fake good” conditions.
The t statistic was derived from an independent samples t test. Emotional intelligence was measured using the Trait Emotional Intelligence Questionnaire (TEIQue-SF; Petrides, 2009).
p < .05. **p < .01. ***p < .001
Hypothesis Testing
Table 2 reports the ANOVAs (testing Hypotheses 1–3).
Results of the 2 × 2 Between-Subjects ANOVA Testing Instruction Condition (Fake vs. Honest), Source (Self vs. Informant) and Instruction-by-Source Interaction.
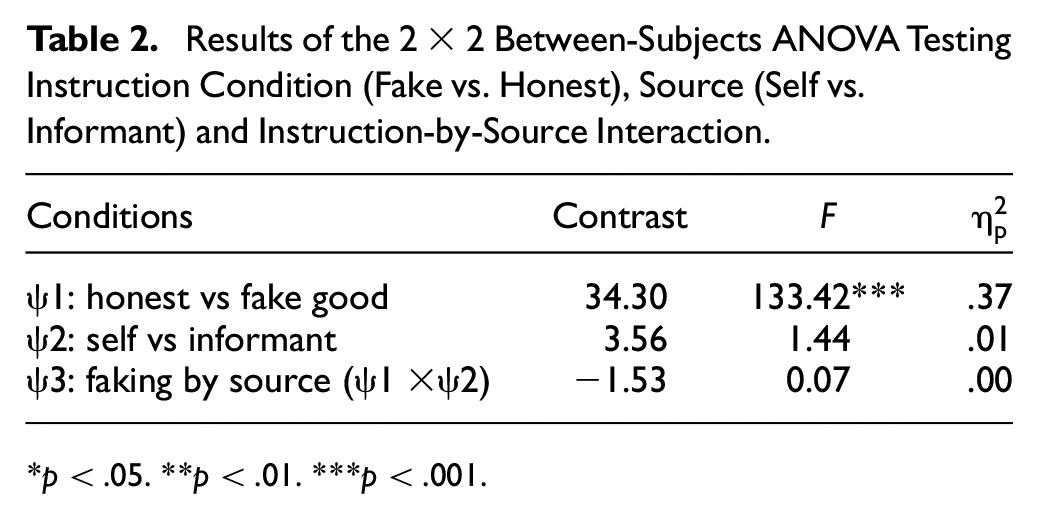
p < .05. **p < .01. ***p < .001
Hypothesis 1: People Will “Fake Good” on the TEIQue
Contrast 1 tests whether mean scores significantly differ for the “answer honestly” versus job simulation conditions. Scores were significantly higher for job simulation than “answer honestly” conditions, with a large effect size
Hypothesis 2: Informant-Ratings Will Result in Increased Faking Relative to Self-Ratings
Contrast 2 tests whether mean differences between self- and informant-ratings differ significantly from zero. There was not a significant difference between self- and informant-ratings providing no support for Hypothesis 2
Hypothesis 3: People Will Fake More for Others Than for Themselves
The interaction effect of instruction type (“answer honestly” with “fake good”) with rater-type (self vs. informant) was not significant. That is, the extent of faking for self-reports (d = 1.47) and informant-reports (d = 1.56) was not significantly different
Discussion
The results of this study demonstrated two things. First, people can fake on self-report trait EI when instructed to answer as part of a job selection simulation. The magnitude of faking on EI was substantial and consistent with past EI faking studies (Christiansen et al., 2010; Day & Carroll, 2008; Grubb & McDaniel, 2007; Hartman & Grubb, 2011; Lievens et al., 2011; Tett et al., 2012; Whitman et al., 2008). Second, informants fake just as much as people providing self-reports, in contrast to assumptions that informants have no reason to fake (Connelly & Ones, 2010).
EI tests are often used during the recruitment and selection process given that EI predicts workplace behavior, staff retention, and leadership quality (Akhtar et al., 2015; Barreiro & Treglown, 2020; Miao et al., 2017; O’Boyle et al., 2011). In fact, large organizations such as PricewaterhouseCoopers and Oracle have identified EI as a key skill required for future employability (Alawadhi, 2021; McIntyre, 2018), as has the Australian Defence Force (Application and Selection Process, The Australian Government Defence Force, n.d.; Daly, 2022) and the United States Air Force (Bar-On, 2010; Bar-On et al., 2006). As such, a clear understanding of whether and how much job applicants can distort their responses on EI questionnaires is important. While test-takers have been shown to fake on a range of self-report EI scales in prior research, the current study shows that people can also fake on behalf of someone else. That is, if a job applicant is required to nominate a person (informant) to complete a survey that relates to the EI of the applicant, it is possible the informant will inflate their responses about the applicant. Until recently, it has been assumed that informants do not have a reason to engage in faking on behalf of someone else despite early concerns that friendship biases may influence informant responses (Allport, 1928; Hollander, 1956; Leising et al., 2010, 2013). As a result, informant-reports are widely used not only to collect information about a target, but also to confirm the veracity of the target’s self-reported scores (Connelly & Ones, 2010; Kim et al., 2019). If informants, as the result from this study suggests, also distort their responses, then this has serious consequences related to the utility using informant-reports as part of a recruitment strategy.
At a practical level, this study provides a warning relating to the implementation of self- and informant-report EI measures into recruitment and selection practices, and highlights the practical limitations of relying heavily on rating scales for assessment. These results emphasize the need to examine the appropriateness of alternative approaches that could be used to help reduce the influence of faking on EI evaluations. The predominant methods for assessing EI include rating scales (e.g., self- and informant-report measures like the TEIQue) and ability EI measures (e.g., maximum performance tests such as the MSCEIT or situational judgment tests) (O’Connor et al., 2017). Additional methods of measurements used in personality assessment merit consideration and may include the use of assessment centers and other behavioral observation methods (Borkenau et al., 2001; De Los Reyes & Kazdin, 2005), functional magnetic resonance imaging (fMRI) to study the neural underpinnings of EI (Killgore et al., 2017), and interview-based assessments (Kessler & Üstün, 2004). Taking a multi-method approach that integrates various assessment techniques, especially in selection processes where faking can alter applicant rankings (Hartman & Grubb, 2011), may be advantageous. Experience sampling methodologies whereby participants are required to answer short questionnaires multiple times per day may also provide a more information about a person's true EI score. Although rating scales remain the most prevalent means of evaluating EI, incorporating alternative methods could help mitigate the risks and consequences of faking associated with self- and informant-report measures. However, it is crucial to ensure selected measurement methods are feasible and fit for purpose (i.e., job selection).
This study provides the first comprehensive assessment of instructed faking investigating the extent to which faking can occur on both self- and informant-reports of EI. Our data demonstrate that informants can fake and lay the foundation for future research to continue to explore informant-faking, and the practical implications of informant-faking. In particular, do informants fake in a high-stakes real-world context, and what are the implications for score interpretation if they do fake. In order for the confidence in informant-reports to continue, a similar level of scrutiny that has been applied to self-reported EI must be applied to examining the psychometric properties of informant-reports of EI.
There are limitations that warrant comment. The informant design of this study was such that participants imagined a friend of their choice in a between-subjects design. Although the results were consistent across self-versus-informant conditions, it is possible that there may be systematic bias in participants’ selections of their identified peer (e.g., downward social comparison) that may influence the pattern of results. As such, future research may employ a design where each participant nominates a person of their choice to provide an informant-report. This would provide a more fine-grained approach to examining the differences between faking on self- versus informant-reported EI. In addition, given that 360° reports of EI are common in the workplace (Sala, 2003), future research may also use 360° assessments within a faking paradigm to determine whether all raters of a single person fake to the same extent and whether this might provide an additional avenue for detecting faking. That is, do multiple informants rating a single target show agreement even when they are faking. Given that agreement between raters is often used as evidence that informants do not fake, it would be prudent to confirm this assumption.
This study is the first to assess the extent to which faking can occur on informant-reports of EI. We replicated prior findings that people substantially fake on self-report EI scales. We also present the first evidence that people fake just as much on informant-reports of EI—using informant-reports will not reduce the extent of faking. Before this study, evidence that informants are unlikely to fake was purely anecdotal. These results demonstrate the importance of closely examining the extent to which response distortion is relevant for self- and informant-reports. If people self-report themselves favorably and informants also rate their targets favorably, then the utility of EI assessment is diminished for high-stakes applications. Although self-report scales continue to undergo intense scrutiny regarding their accuracy as a result of response distortion, there has not been the same scrutiny for informant-reports.
This study has established that informants can fake and lays the foundation for future research to continue to explore informant-faking. In particular, do informants fake in a high-stakes real-world context, and what are the implications for score interpretation if they do fake. In addition, future research should consider alternative methods for assessing over- or underreporting on self- and informant-report questionnaires to avoid inaccurate or misinterpreted self- and informant-reported EI. For example, (a) implementing social desirability scales or impression management measures to identify participants who may be prone to over- or underreporting their characteristics (Paulhus, 2002); (b) developing ipsative assessments to reduce the likelihood of over- and underreporting by requiring participants to choose between equally desirable options, thereby increasing the difficulty of favorable self-presentation; and (c) using advanced statistical methods, such as term frequency-inverse document frequency (TF-IDF) to identify patterns or inconsistencies in the responses that may indicate over- or underreporting (Purpura et al., 2022). In order for the confidence in informant-reports to continue, a similar level of scrutiny must be applied to examining the psychometric properties of informant-reports of EI.
Supplemental Material
sj-docx-1-asm-10.1177_10731911231203960 – Supplemental material for Faking Good on Self-Reports Versus Informant-Reports of Emotional Intelligence
Supplemental material, sj-docx-1-asm-10.1177_10731911231203960 for Faking Good on Self-Reports Versus Informant-Reports of Emotional Intelligence by Sarah A. Walker and Carolyn MacCann in Assessment
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.