
Abstract
To interpret a person’s change score, one typically transforms the change score into, for example, a percentile, so that one knows a person’s location in a distribution of change scores. Transformed scores are referred to as norms and the construction of norms is referred to as norming. Two often-used norming methods for change scores are the regression-based change approach and the T Scores for Change method. In this article, we discuss the similarities and differences between these norming methods, and use a simulation study to systematically examine the precision of the two methods and to establish the minimum sample size requirements for satisfactory precision.
This article concerns the practical use of change scores (e.g., posttest score minus pretest score) obtained from psychological tests or questionnaires for drawing inferences about change at the level of the individual. For example, if a patient is in treatment, the clinician may want to evaluate how this patient responds to the treatment in terms of change of mental health, distress, quality of life, or general functioning. Important questions include the following: Has the patient improved at all? Is the patient’s improvement on track? Is the observed change practically important? The answers to these questions may be used to tailor future treatment of the patient.
Change scores often are based on counts of correct answers or sums of scores on rating scales observed at two measurement occasions. Without a frame of reference, scores are not directly usable for practical measurement (Angoff, 1984). For example, knowing that John had 18 out of 28 arithmetic items correct or that Mary scored 37 scale points out of 60 on an introversion scale means little if anything as long as their test scores cannot be related to a distribution of test scores or a performance standard with a well-established meaning. The same goes for change scores. Without an interpretative context, it is hard to say whether observed change of an individual is small or large, consistent with natural recovery, or lagging behind compared with the change of other patients undergoing the same treatment.
To provide a frame of reference, one needs transformed scores, known as norms (Allen & Yen, 2002). A well-known type of transformed scores is norm-referenced norms (Allen & Yen, 2002), locating an individual amid a norm group. Another type of transformed scores, criterion-referenced norms (Allen & Yen, 2002), refers to diagnostic cutoffs that patients have to pass to be admitted to a course or a therapy, or to qualify levels of severity (e.g., mild vs. strong depression). In change assessment, criterion-referenced norms include the minimal clinical important difference, which is the minimum change a patient must show to qualify change as having practical impact. In this article, we focus on norm-referenced norms and study two often-used regression-based norming methods for change scores. Study of criterion-referenced norms deserves full attention in a separate article.
The construction of norms is known as norming. Norming methods for change scores have received surprisingly little attention so far. In this study, we consider the simplest change score possible, which is the difference between the test score obtained after a treatment and the test score obtained prior to the treatment, known as posttest and pretest scores, respectively. Norming change scores can be challenging for at least two reasons. The first challenge is that, pretest scores, posttest scores, and consequently change scores contain measurement errors and therefore may be unreliable (Bereiter, 1963; Cronbach & Furby, 1970; Linn & Slinde, 1977; O’Connor, 1972). In practice, interindividual change typically has small variance (Gu et al., 2018), which may also cause low change-score reliability. The second challenge, in particular in the context of mental health care, is the heterogeneity of a group of patients. Often one cannot simply compare the change of one patient to the change of all other patients. To monitor a patient’s change, ideally the patient should be compared to patients of the same age, the same gender, the same comorbidity, or other relevant background variables. This means that researchers may need to take such information into account when constructing norms. Ideally, data are collected within all relevant subpopulations based on the relevant background variables, but because this approach may require a huge sample, it may be practically infeasible. A solution to the problem is continuous norming (Gorsuch, 1983), which results in norms for subgroups using statistical control, based on a relatively small sample.
The goals of this study were to gain more insight in the precision of norms for change scores and to derive sample size requirements for deriving reliable norms for change scores. The structure of this article is the following. First, we present a general, regression-based framework for norming change scores, which includes two popular norming methods for change scores as special cases. The two methods are the regression-based change approach (Van der Elst et al., 2008) and the T Scores for Change method (McSweeny et al., 1993). Second, using a simulation, we study the precision of norms developed by means of the regression-based change approach and the T Scores for Change method. Finally, we discuss the results and provide recommendations for minimum sample size needed to produce sufficiently precise norms.
Norming Methods for Change Scores
First, to provide an overview of the field and also as a precursor for the two methods we study in this research, we briefly discuss two approaches to quantifying individual change in the pretest–posttest design, which are the classical change-score approach (i.e., using the classical change score to quantify individual change) and the residual change-score approach (i.e., using the residual change score resulting from a regression model). Second, we present a general framework of norming change scores, which includes the regression-based change approach and the T Scores for Change method as special cases.
Two Approaches to Quantifying Individual Change
The classical change-score approach and the residual change-score approach (Willett, 1988) are widely adopted methods. Caruso (2004) discussed other methods for quantifying change that were used less frequently. For the classical change-score approach, we use the observable classical change score
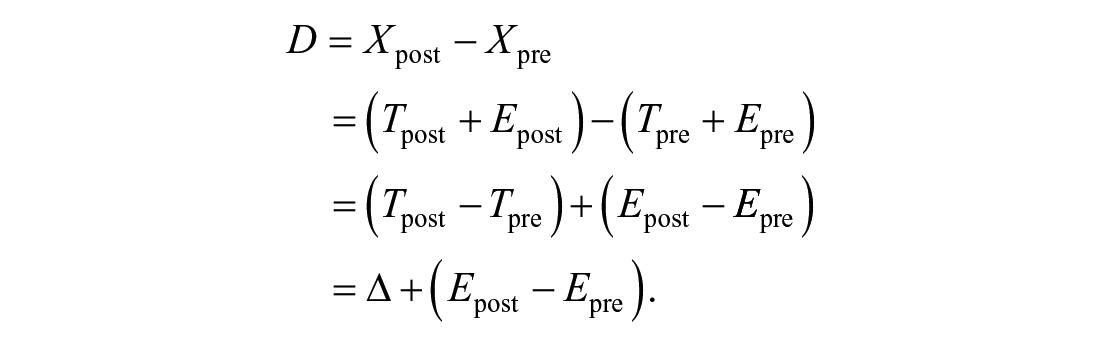
Because
The residual change-score approach, also known as residual gains or base-free measurement of change, intends to correct for the correlation between pretest score and change score (Cronbach & Furby, 1970; Manning & Dubois, 1962; Willett, 1988) by means of the residualized posttest score. Let
Regression-Based Norming for Change Scores: A General Framework
Regression-based norming for test scores (Van Breukelen & Vlaeyen, 2005; Zachary & Gorsuch, 1985) generates the reference distribution of test scores by means of regression analysis. Let the random vector
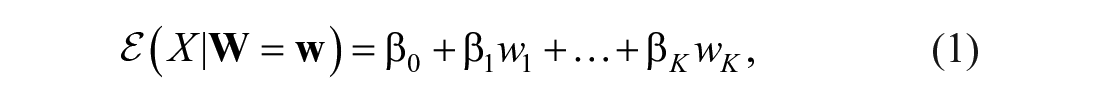
where
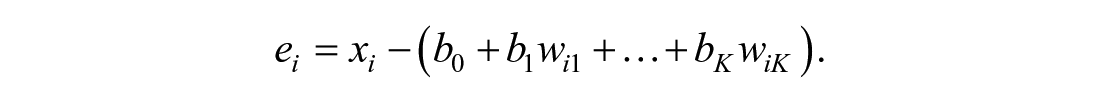
The distribution of
Regression-based norming for test scores can readily be extended to norming change scores. Replacing
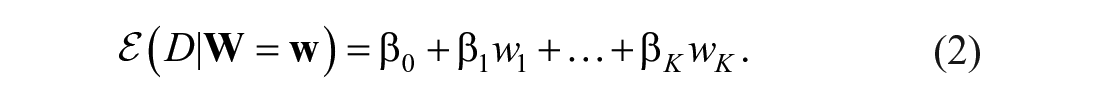
An observable change score, denoted by
One may notice that Equation (2) is a general framework for norming change scores, and that we have not discussed which covariates
The regression-based change approach (Van der Elst et al., 2008) assumes that change scores can be predicted by means of a few relevant covariates, and that the pretest score is not included as one of the covariates in Equation (2). The model used is
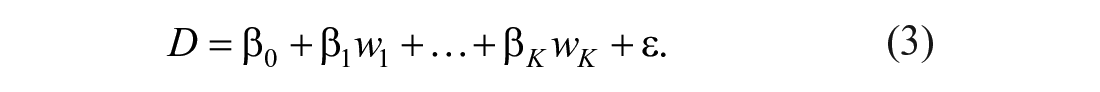
Because Equation (3) directly models the change score, the regression-based change approach follows the classical change-score approach to quantifying individual change. The T Scores for Change method (McSweeny et al., 1993) requires that the pretest score is included as a covariate in Equation (2), so that
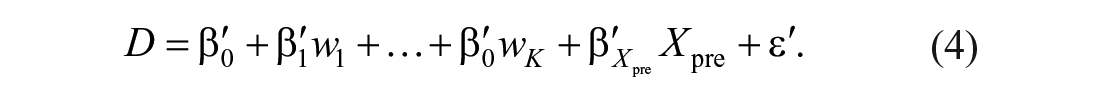
Adding
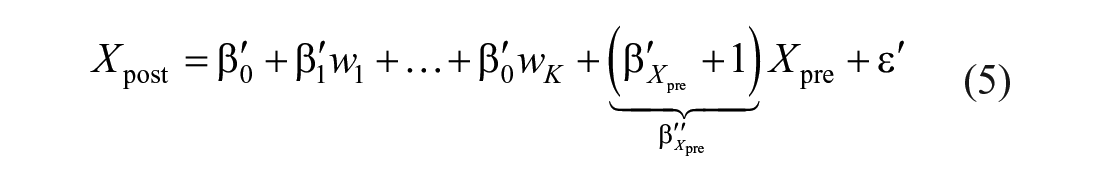
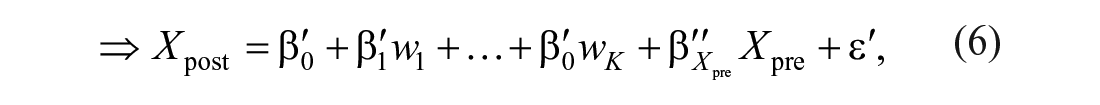
which is the model McSweeny et al. (1993) proposed. Equation (6) shows that the T Scores for Change method follows the residual change-score approach to quantifying change, which at first glance appears to be different from the regression-based change approach. However, as we have shown from Equations (4) to (6), the T Scores for Change method and the regression-based change approach together define a general framework for norming change scores (Equation 2), and the only difference between the two methods resides in the inclusion of
Here, we notice a special case of including
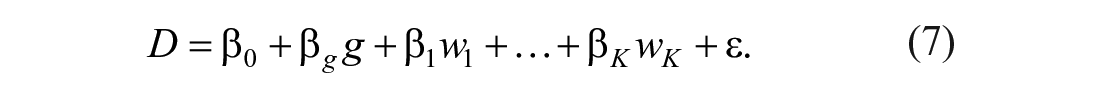
Equation (7) often is referred to as CHANGE, which is a method using the classical change score as the dependent variable to analyze the pretest–posttest control-group design (Van Breukelen, 2013). On the other hand, suppose that the T Scores for Change method (Equation 6) includes a categorical variable, so that Equation (6) becomes
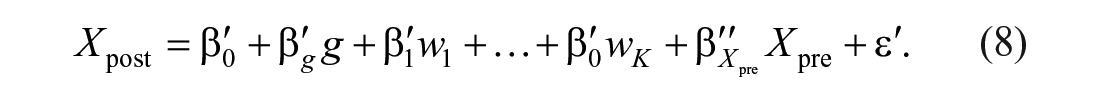
Then Equation (8) becomes the analysis of covariance (ANCOVA) model. CHANGE and ANCOVA may cause contradictory results with respect to group-mean differences in nonrandomized studies when groups differ on average at pretest, where ANCOVA indicates a mean effect, whereas CHANGE does not, which is known as Lord’s paradox (Lord, 1967; Van der Elst et al., 2008). Van Breukelen (2013) formally examined this issue and showed that applying ANCOVA and CHANGE to the same data could result in completely different conclusions, because ANCOVA assumes absence of such a group effect at pretest and CHANGE assumes presence of a group effect (Van Breukelen, 2013). The implication of Van Breukelen’s research for our study is that, when using the T Scores for Change method, one may find that
Before concluding the section, we remind the reader that regression-based norming requires the assumptions associated with regression analysis to hold for the application of interest. For detailed discussions on this topic, we refer the reader to Oosterhuis (2017).
Deriving Norm Statistics
The two norming methods produce norm statistics in the same manner. To describe the procedure, we use the regression-based change approach as an example. The steps are the following.
Step 1: Compute for each person
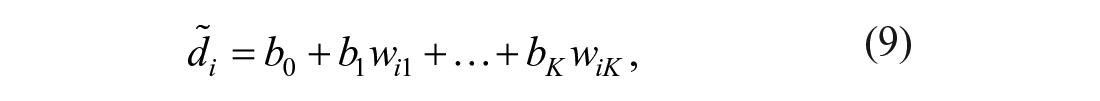
where
Step 2: Compute residual

where
Step 3: One may use the distribution of
Step 3*: Compute the standardized

where
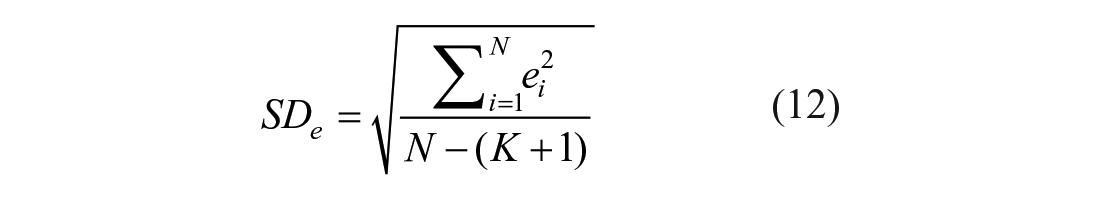
A few remarks are in order. First, when the T Scores for Change method is used, in Step 1, one computes the predicted posttest score
In this article, we used a simulation study to examine the two norming methods under various conditions and investigate the precision of estimated norms and the minimum sample size needed to obtain norms of high precision.
Method
Data Generation
Population Model
We assumed that pretest score,
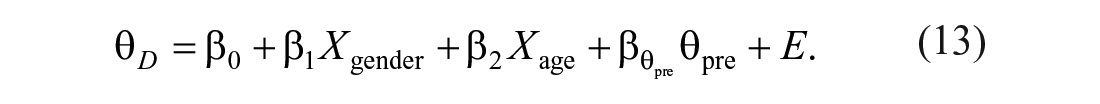
Thus, we assumed that the variance of
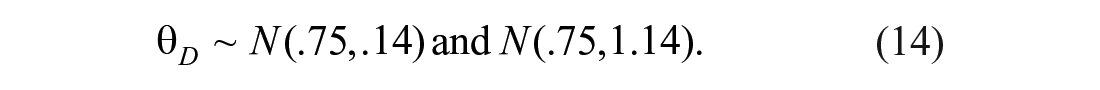
Gu et al. (2018) showed that the choice of
We further assumed that posttest score,
Correlation
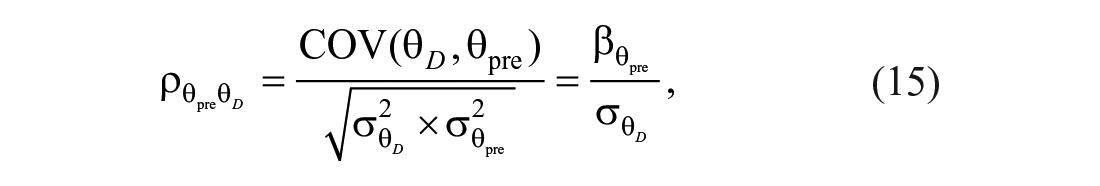
where
Consistent with Oosterhuis et al. (2016), we assumed that covariate
Test Characteristics and Item Parameters
We considered tests containing 10, 20, and 40 items (Jabrayilov et al., 2016; Kruyen et al., 2013). Polytomous items were simulated using the graded response model (GRM; Samejima, 1969), which is a common choice in simulation research, because the GRM enables the easy manipulation of a test with desirable features. Because the GRM assumes that latent variable
Suppose item
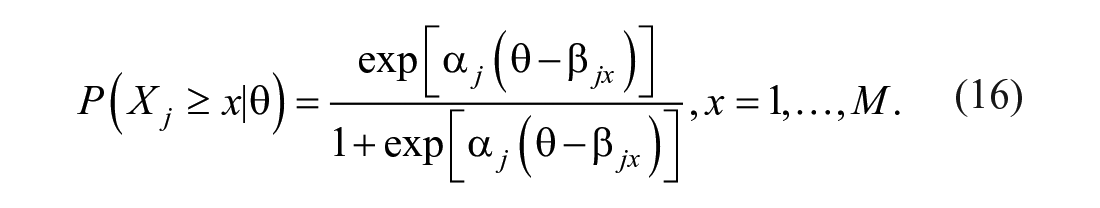
Slope parameter
Simulation Design
The completely crossed design had
Test length: 10, 20, and 40 items.
Number of item scores: 2 and 5.
Sample size: 100, 200, 300, 400, 500, 600, 700, 800, 900, 1000, 1100, 1200, 1300, 1400, and 1500.
Effect size of covariates:
Correlation between
Variance of θ change:
For each cell, we generated data using the following steps.
Step 1: Item parameters were sampled.
Step 2: A sample of person parameters at pretest were randomly drawn from the
Step 3: For each design cell, we repeated Step 2 1,000 times, and as a result, 1,000 item-score data sets of pretest and posttest administrations were generated.
Step 4: For each data set, we computed standardized residuals based on the regression-based change approach and the T Scores for Change method.
Dependent Variables and Data Analysis
Rank Correlation
Using Kendall’s tau (Kendall, 1938), we computed three different rank correlations. They are (a) Rank correlation (denoted by
Precision
We considered the precision of the 1st, 5th, 10th, 25th, 50th, 75th, 90th, 95th, and 99th percentiles of the standardized residuals generated by the regression-based change approach and the T Scores for Change method. Precision expressed by the standard deviation of the sampling distribution is not suitable for percentile estimates that typically are not normally distributed. Alternatively, we used the 95% interpercentile range (IPR), which is a distribution-free measure defined as the difference between the 97.5th percentile and the 2.5th percentile of the distribution of standardized residuals, based on 1,000 data sets in each design cell. The higher the IPR, the lower the precision.
Results
Rank Correlations
Figure 1 presents boxplots of
The Median Values of Estimated Rank Correlations, Estimated Change-Score Reliability (
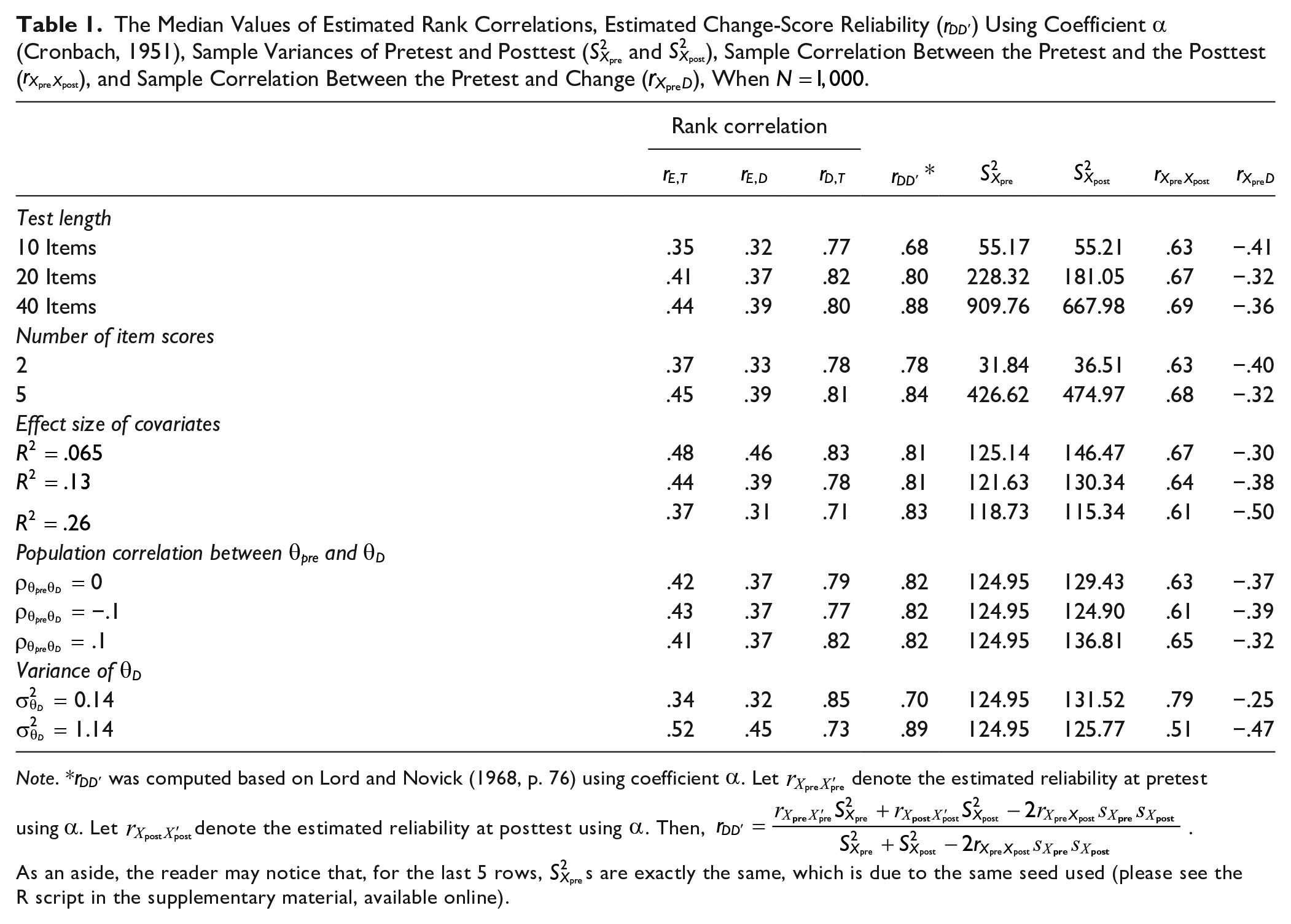
Note. *
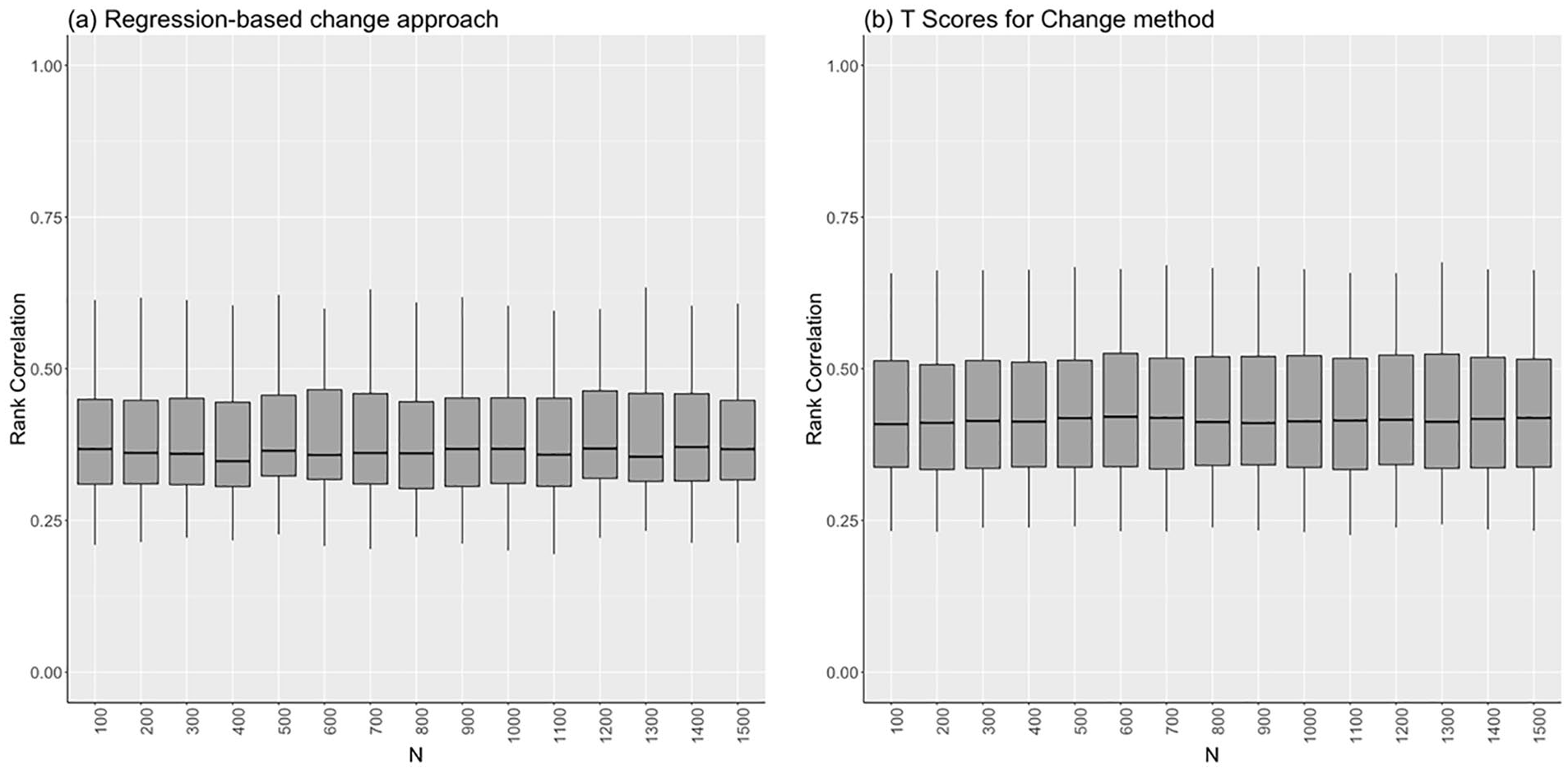
Boxplots of
Based on Table 1, we made the following observations. First, the median of
Relationship Between IPR and Sample Size
For each percentile and for the T Scores for Change method, Figure 2 shows the box plots of IPR against sample size across all 1,620 cells. We chose not to plot the percentiles generated by the regression-based change approach because the results were similar to Figure 2. The figure shows that, as sample size grew, the norms were more precise, which reflects the well-known, inverse relation between sample size and sampling variance for all statistics based on a sample of independent observations. Specifically, estimation precision sharply increased as sample size increased from 100 to 500. As sample size reached 1,500, the increase of precision leveled off. The figure suggests that, when designing a study for normative data, a sample size between 500 and 1,500 may be desirable, but based on this study suggestions for exact sample sizes do not seem to be realistic.
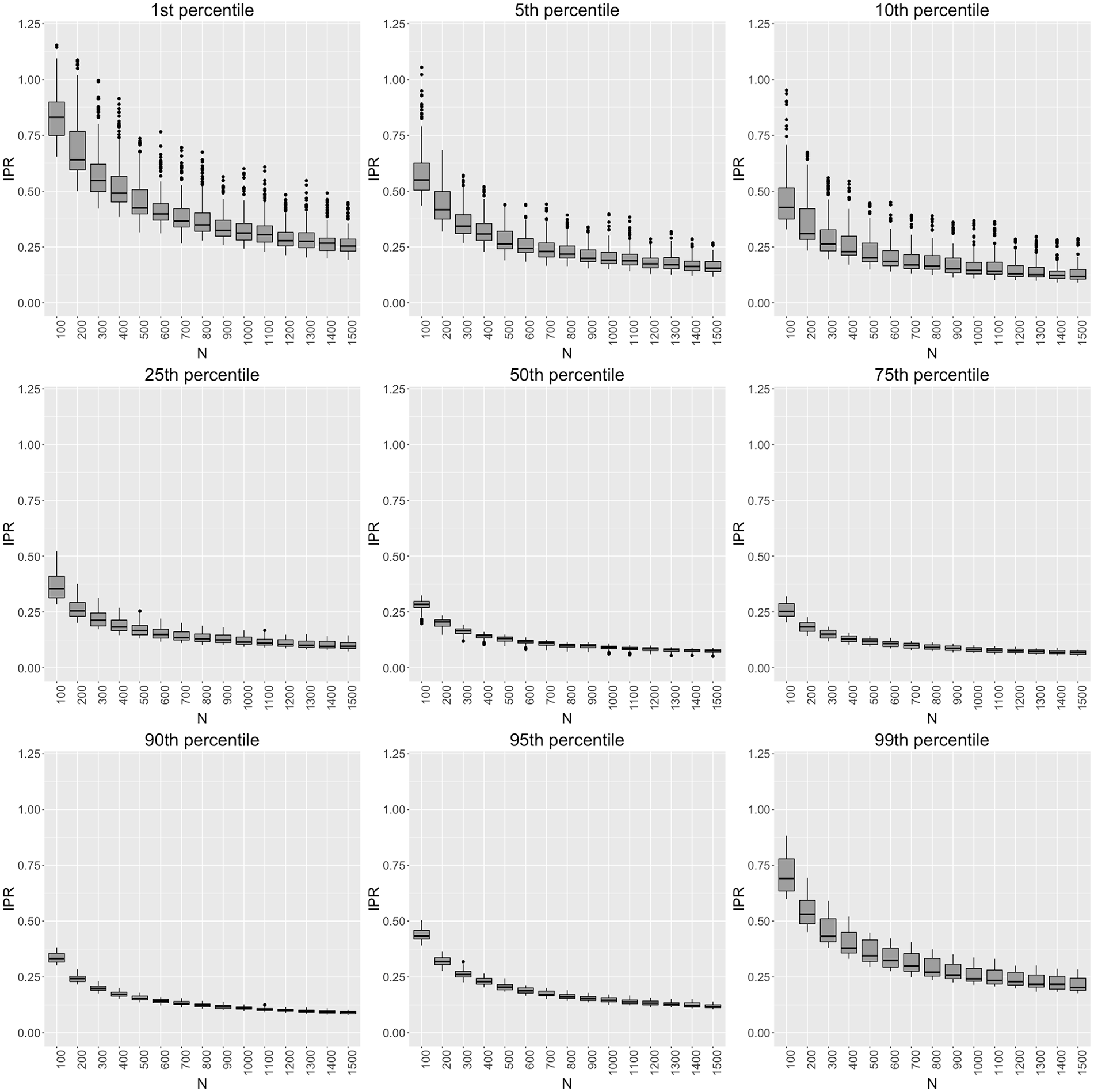
Relationship between sample size (N) and interpercentile range (IPR) for the 1st, 5th, 10th, 25th, 50th, 75th, 90th, 95th, and 99th percentiles generated by the T Scores for Change method.
Relationship Between IPR and the Other Five Design Factors
Figures (3) through (7) present the relationship between IPR generated by means of the T Scores for Change method and the other five design factors, which were test length, number of item scores, effect size of covariates, correlation between
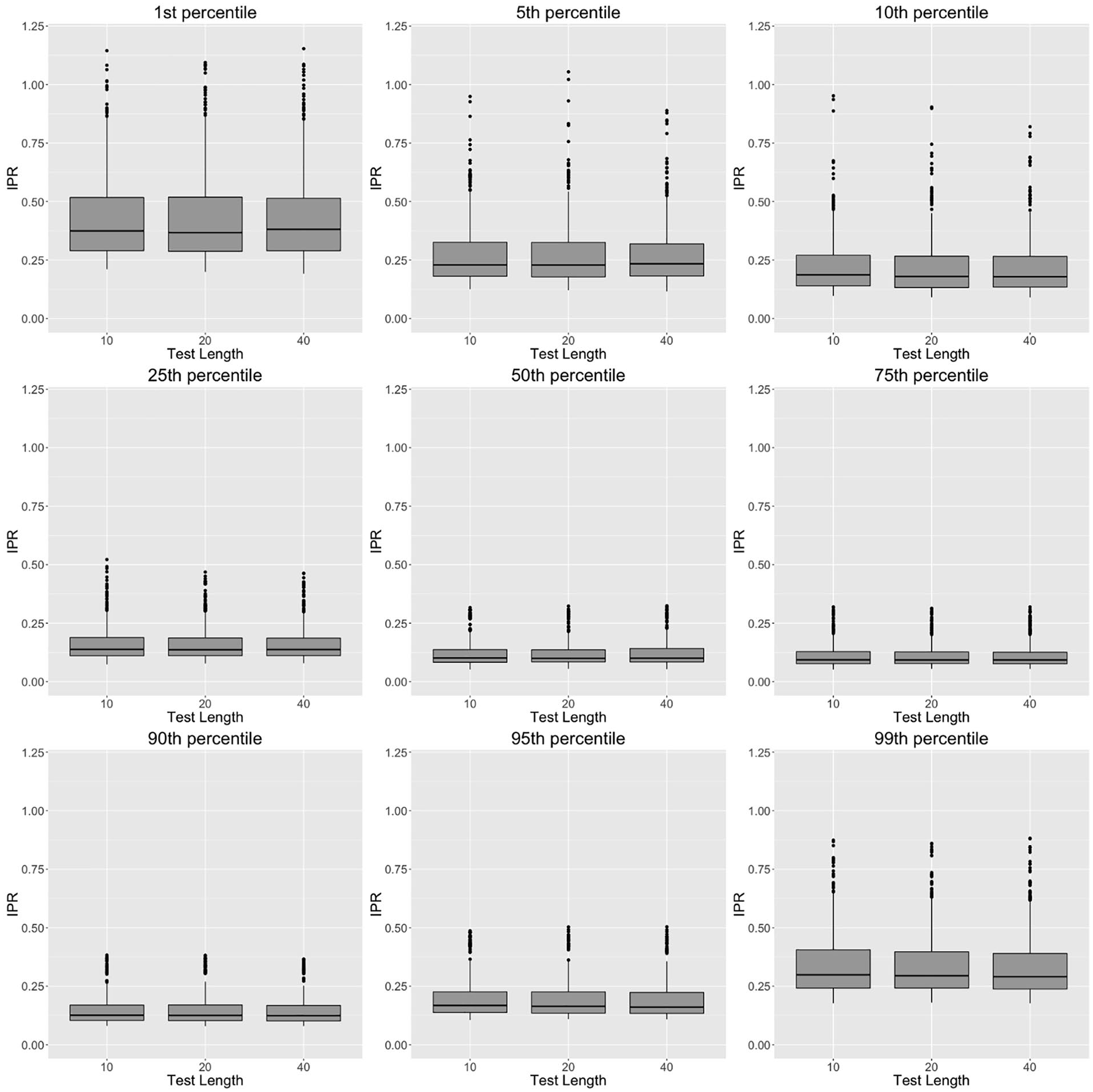
Relationship between test length and interpercentile range (IPR) for the 1st, 5th, 10th, 25th, 50th, 75th, 90th, 95th, and 99th percentiles generated by the T Scores for Change method.
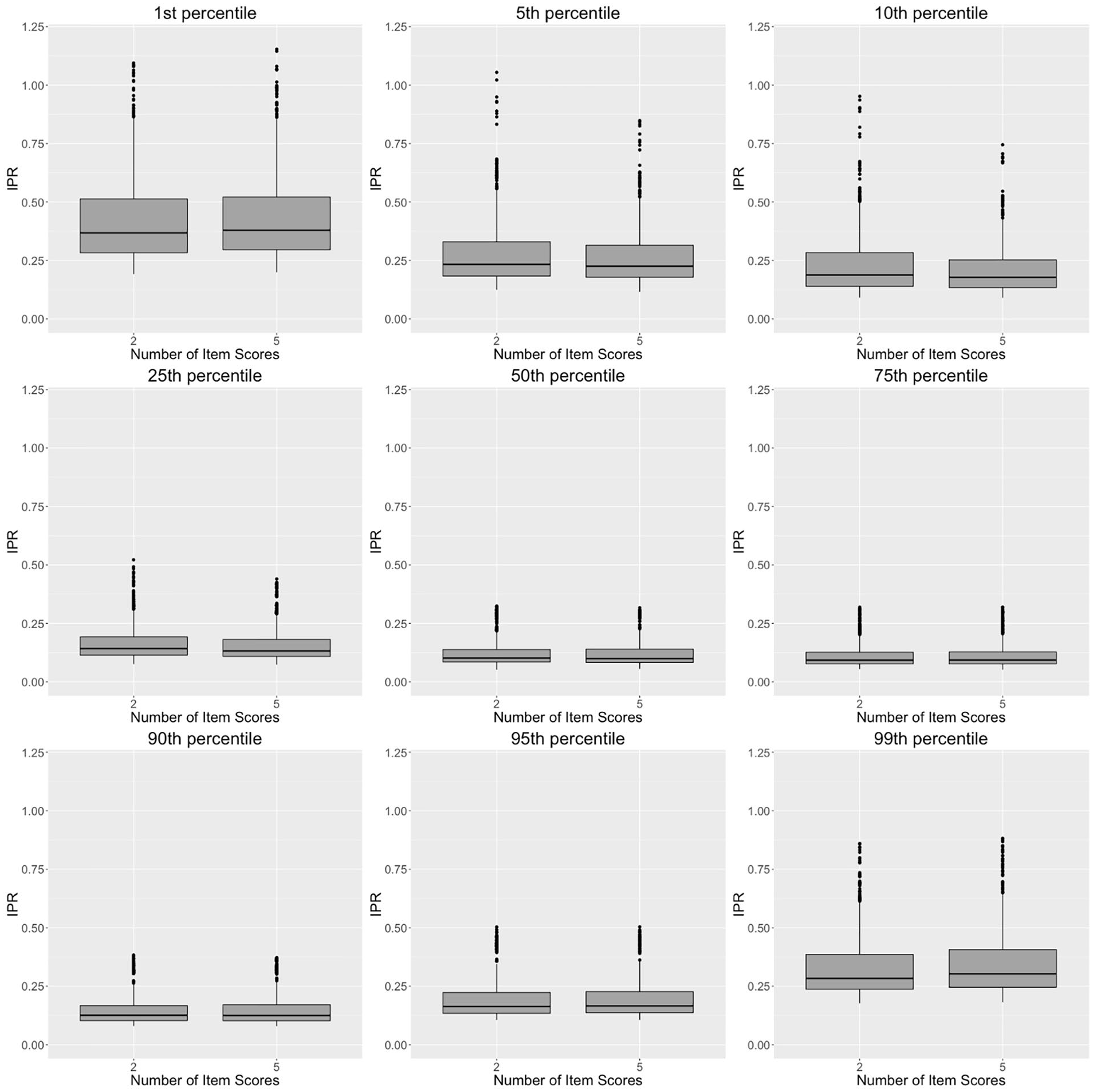
Relationship between number of item scores and interpercentile range (IPR) for the 1st, 5th, 10th, 25th, 50th, 75th, 90th, 95th, and 99th percentiles generated by the T Scores for Change method.
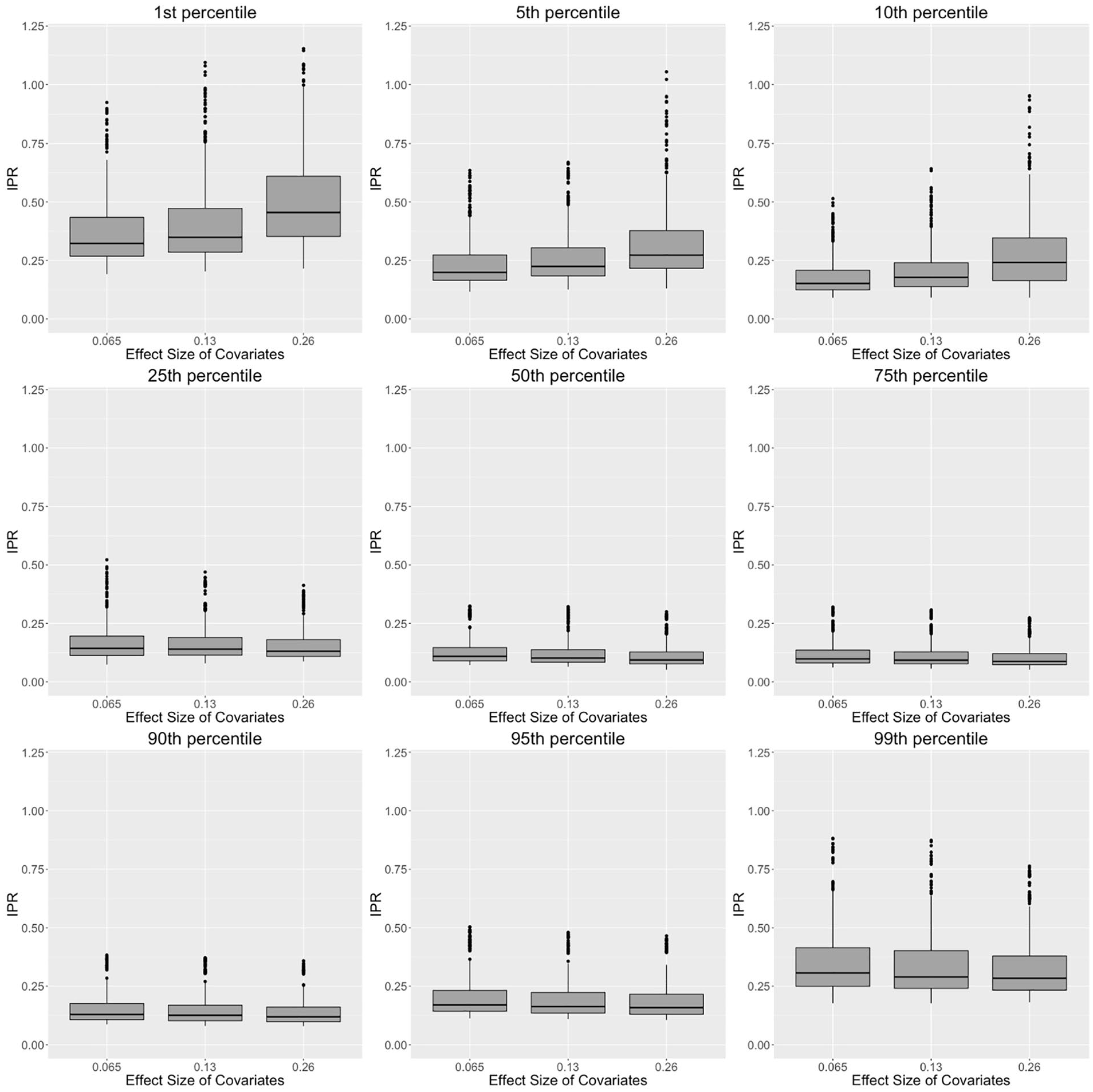
Relationship between effect size of covariates and interpercentile range (IPR) for the 1st, 5th, 10th, 25th, 50th, 75th, 90th, 95th, and 99th percentiles generated by the T Scores for Change method.
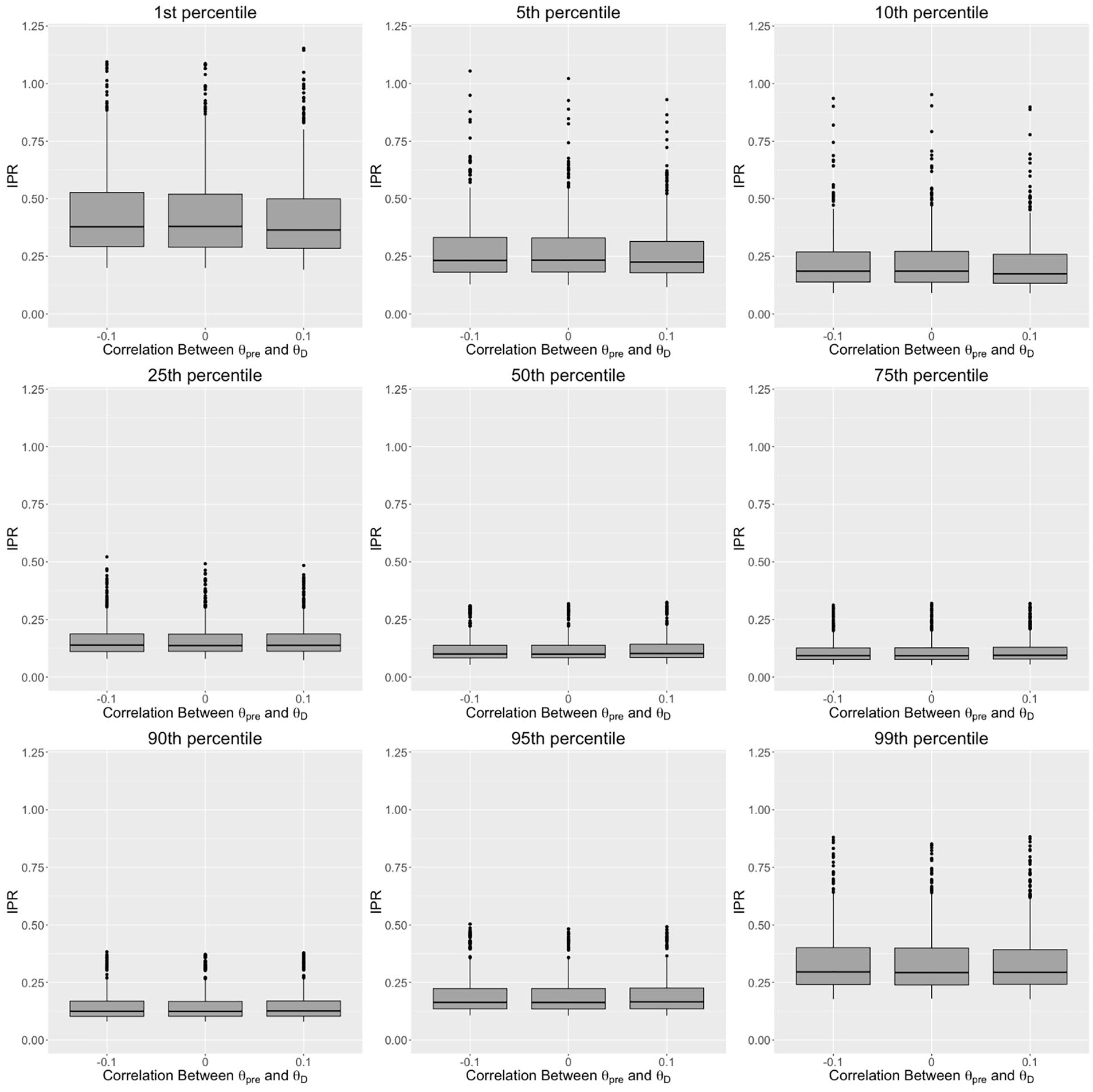
Relationship between correlation between
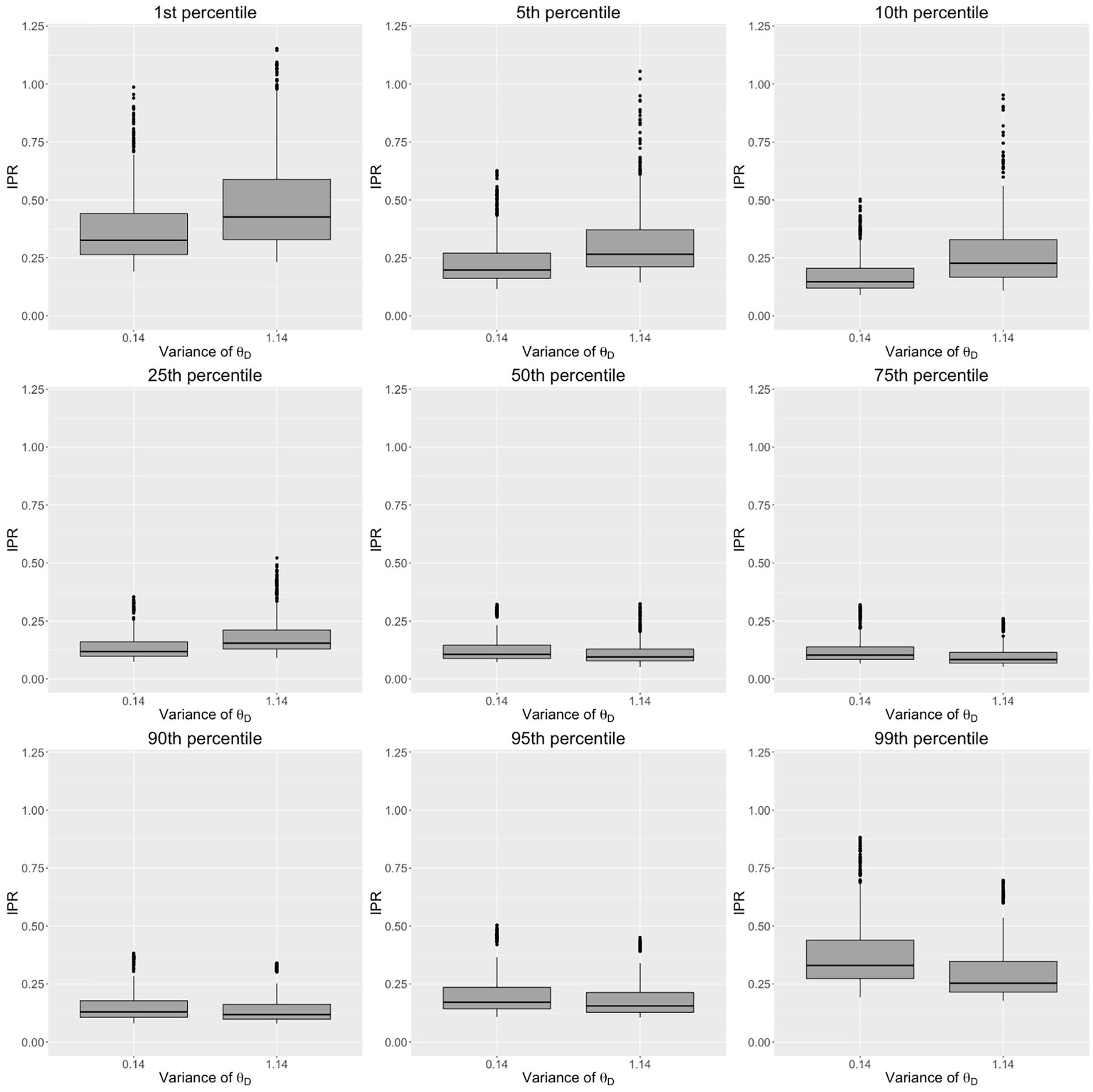
Relationship between variance of θ change and interpercentile range (IPR) for the 1st, 5th, 10th, 25th, 50th, 75th, 90th, 95th, and 99th percentiles generated by the T Scores for Change method.
Although the simulation was a fully crossed factorial design, we chose not to use analysis of variance (ANOVA) to analyze IPR results. The reasons are that, first, the normality assumption of ANOVA was severely violated, and second, although the log-transformed IPR to some extent reduced the problem of nonnormality, ANOVA results showed that almost all the design factors were significant. The reasons for significance were considerable sample size, hence large power, and outliers, of which there were quite a few; see Figures (3) through (7).
Discussion
Because of their simplicity and popularity, we limited attention to change scores obtained from pretest–posttest designs, but change scores are not limited to such designs. For example, to monitor cognitive decline in elderly people, norms developed for repeated administration of neuropsychological tests can offer diagnostic assistance. We showed that the regression-based change approach and the T Scores for Change method originated from the same general, regression-based framework for norming change scores. We advise test constructors to make critical decisions about the covariates, such as the pretest score, that they decide to include in the model.
Norming change scores is a challenging task. Our simulation study showed that the relative position of persons in the sample norm-distribution produced by the two norming methods largely differed from the relative position of persons in the error distribution, as witnessed by the low rank correlations. This suggests that decision-making (e.g., whether a patient’s health condition has improved compared with a normative sample) solely based on norm statistics may lead to biased conclusions. More studies are needed to understand the cause of low rank correlations to improve the norming methods.
Increasing sample size greatly improved the precision of norms, but the benefit of a larger sample size diminished quickly as the sample grew larger than 1,500 observations. Our simulation study suggested that a sample size of 500 is a reasonable minimum for norming change scores. Increasing the sample size to about 1,000 is still beneficial, but samples larger than 1,500 offer little improvement.
In the simulation study, we assumed that
The two regression-based norming methods for change scores assume a linear relationship between observed change scores and covariates. In the simulation study, we used a linear model to model the relation between
In recent years, new methods have been applied to norming test scores. For example, the Box-Cox Power Exponential model, which is based on the Generalized Additive Model for Location, Scale, and Shape (GAMLSS; Rigby & Stasinopoulos, 2005), has been used to norm IQ scores (Voncken et al., 2017). GAMLSS-based models allow for the flexible specification of a raw test score distribution, including the mean, variance, skewness, and kurtosis and therefore may be better suited in practice where the empirical item-score data set does not show desirable features such as a normal distribution of residuals. Thus, for future research, it might be interesting to investigate how new methods, such as the GAMLSS-based models, can be used to norm change scores.
Supplemental Material
Appendix_A – Supplemental material for Precision and Sample Size Requirements for Regression-Based Norming Methods for Change Scores
Supplemental material, Appendix_A for Precision and Sample Size Requirements for Regression-Based Norming Methods for Change Scores by Zhengguo Gu, Wilco H. M. Emons and Klaas Sijtsma in Assessment
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.