
Abstract
Future crewed deep space missions will be challenged by substantial communication latency with Earth. Autonomous systems will likely augment the role of mission control, enabling a more Earth-independent crew. To improve the performance of human-autonomy teams, autonomous systems can adapt in real-time to accommodate changes to an operator’s cognitive states caused by dynamic spaceflight events. The aim of this work was to determine the most important feature categories to accurately predict an operator’s cognitive states in real-time as they work with an autonomous system. We utilized data from a human-autonomy teaming experiment in which trust, mental workload, and situation awareness were predicted as participants completed a spaceflight-relevant task. In cognitive state predictions of unseen operators, a model with no operator background information or eye-tracking data outperformed models that included these features. These simplified models enhance feasibility for an autonomous system to adapt in real-time to accommodate an operator’s cognitive states.
Keywords
Introduction
Future crewed missions to deep space will present a challenging operational environment in part due to substantial communication latency with Earth. While previous NASA human spaceflight missions have relied on NASA’s Mission Control Center (MCC) for troubleshooting time-critical problems, the communication latency for long-duration space missions will make it cumbersome, and at times, hazardous, to rely on mission control in these situations (Frank et al., 2016). In deep space missions, autonomous systems will likely augment the role of MCC, enabling a more Earth-independent crew (Anderson et al., 2020, Rollock & Klaus, 2022). To improve the performance of both human crews and their autonomous teammates, autonomous systems should understand and account for the operators they work with, whether the operators are remotely interacting with the autonomous system or co-located. Autonomous systems that can adapt in real-time to accommodate an operator’s cognitive states, performance on the task, and environment in which they are working are of particular interest in operationally dynamic environments (Feigh et al., 2012). Transient events and problems in spaceflight can dynamically alter an operator’s cognitive states, and a future autonomous system that predicts and accounts for these changes could enable better outcomes for the human-autonomy team. Operator trust, mental workload, and situation awareness (TWSA) are particularly relevant in spaceflight scenarios (Anderson et al., 2020, Parasuraman et al., 2008). This work focuses on the accurate predictions of an operator’s cognitive states.
To enable TWSA predictions, data from unobtrusive measures can be collected and fed into models (Kintz, Buchner, Anderson, et al., 2023, Richardson et al., 2024). For example, “embedded measures” (i.e., actions and inactions by the operator) can help infer operator cognitive states unobtrusively, without interrupting an operator’s focus with a questionnaire. Models that require fewer measures to accurately predict an operator’s TWSA are preferred in operational environments where additional sensors needed to estimate cognitive states, such as eye tracking glasses, may affect the feasibility of implementation. The aim of this work is to determine the most important types of features for accurately predicting an operator’s cognitive states in real-time as they work with an autonomous system. We utilized data from human-autonomy teaming experiments in which trust, mental workload, and situation awareness were predicted as participants completed a spaceflight-relevant task, employed by Kintz, Shen, Buchner, et al. (2023). Various models containing subsets of features were used to find the model that satisfied both the requirement of simplicity and accuracy in prediction. We hypothesized that a model with access to only a subset of features could achieve a similar cognitive state prediction accuracy as a model with access to all features.
Methods
In the supervisory human-autonomy teaming experiment, participants worked with a simulated autonomous system to troubleshoot various problems with a remote spacecraft Environmental Control and Life Support System (ECLSS) with a 10 s latency (Kintz, Shen, Buchner, et al., 2023b). The data from 14 participants (7 M/7 F) was used in this analysis ( Kintz, Buchner, Anderson, et al., 2023a). The experiment had CU-Boulder IRB approval.
As in Kintz, Buchner, Anderson, et al. (2023a), prior to beginning the experiment, participants completed training for the simulated spacecraft ECLSS and completed questionnaires to account for display experience, video game experience, and predisposition to autonomous systems using the Automation-Induced Complacency Potential (AICP) score (Merritt et al., 2019). The participants also completed a 3-min Psycho-Motor Vigilance test to measure reaction time on the day of the experiment (Basner et al., 2015). During the experiment, participants wore Pupil Labs Pupil Core eye-tracking glasses. Each participant completed 15 trials working with the simulated autonomous system. Of the 15 trials each participant completed, the simulated autonomous system offered incorrect solutions in four randomly selected trials to replicate a real-world imperfect autonomous system and elicit realistic trust dynamics (Lee & See, 2004; Wickens & Dixon, 2007). The simulated autonomous system has five modes of operation, with varied levels of autonomy and transparency. In each trial, the system remained in one autonomous mode. After a trial was completed, participants reported their trust using a questionnaire for querying trust (Jian et al., 2000), workload using a modified 10-point Bedford workload scale (Roscoe & Ellis, 1990), and situation awareness using the Situation Awareness Rating Technique (SART) (Selcon & Taylor, 1990). The trust scale ranges from 12 to 84, the workload scale ranges from 1 to 10, and the situation awareness scale ranges from −14 to 46. For each of these questionnaires, higher values correspond to a higher degree of trust, mental workload, or situation awareness.
The data collected and used in the TWSA predictions consisted of five feature categories: operator background information, autonomous system mode (agent mode), simulation events, operator actions, and operator eye-tracking. The data streams in each feature category can be seen in Figure 1. With the feature categories defined, nine simplified models, referred to as Models 1 to 9, were created to include data from subsets of the feature categories. A tenth model, referred to as Model 0, was created to include all feature categories and is identical to the model developed in Kintz, Buchner, Anderson, et al. (2023a). The feature categories allocated to each model type can be seen in Figure 1 with red X’s or green ✓’s. By comparing the performance of the nine simplified models to the complete model, the feature categories critical to accurately predicting an operator’s cognitive states can be identified.
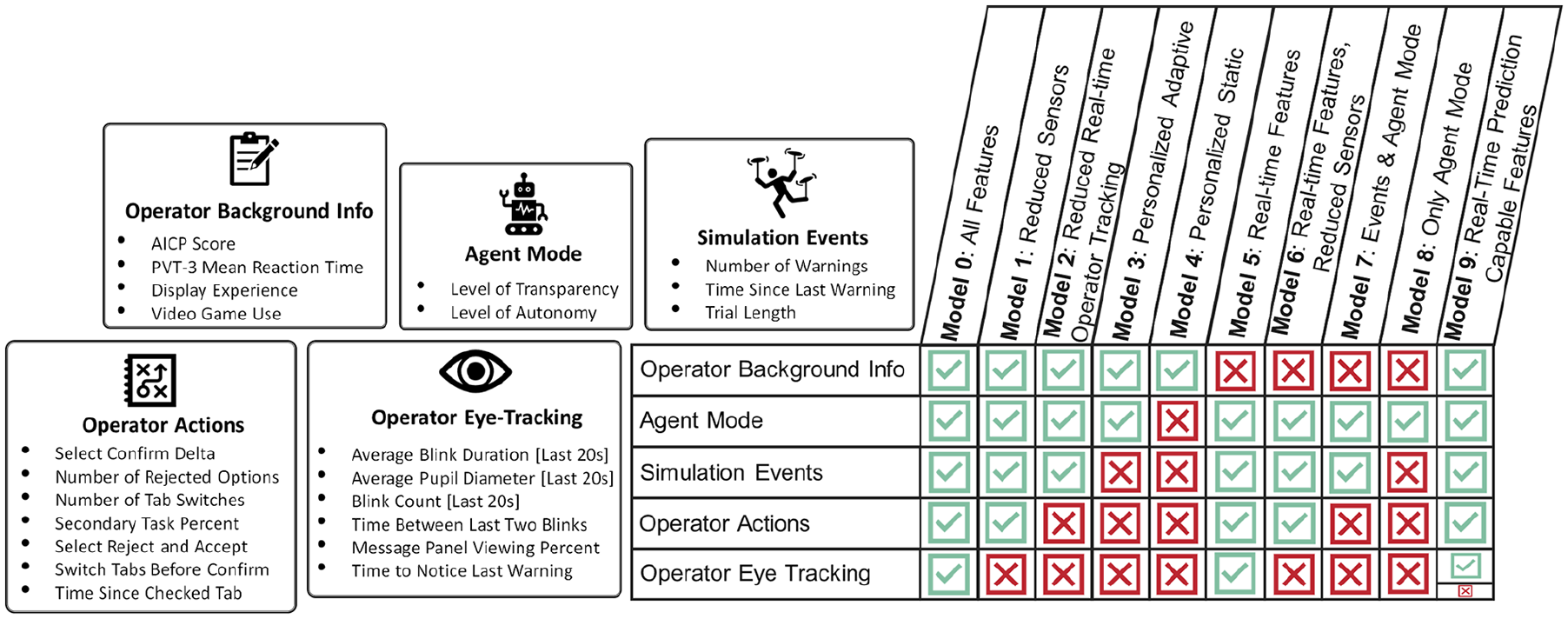
Categories of features and types of models explored to predict trust, workload, and situation awareness.
Once defined, each model’s performance against unseen participants was assessed using Monte Carlo cross validation (MCCV). For each model, 100 iterations of MCCV were completed, and for each iteration, a training set of ten participants was randomly selected and used for feature selection and coefficient fitting, and then a test set of four participants was used for performance assessment. To rigorously assess the performance of models on completely unseen participants, all 15 trials for a given subject were assigned to either train or test sets.
Within one iteration of the MCCV, feature selection used only the training data. Stepwise linear regression was used for both trust and situation awareness feature selection. Stepwise ordinal regression was used for workload feature selection, since the Bedford workload scale is ordinal. For all three cognitive states, an exhaustive search was performed to seed the stepwise model, as described in Kintz, Buchner, Anderson, et al. (2023a), to reduce the likelihood of finding local minima. The two Agent Mode terms were forced to be included in all models except Model 4, since the feature subset did not include agent mode. These terms correspond to the level of transparency and autonomy of the autonomous system. The terms were forced due to a desire to compare to other experiments on adaptive autonomy. During the feature selection process, the Bayesian Information Criterion (BIC) was used to select the final features of the model, penalizing the addition of new terms (Gelman et al., 2014). However, the BIC metric optimizes for descriptive fit on the training data but does not optimize for predictive performance. With features selected, the coefficients of the regression models were fit based on the ground truth questionnaire values for trust, mental workload, and situation awareness from the training data.
Once the models were fit, predictions were made for the unseen test data and compared to the ground truth TWSA values to assess model predictive performance. Specifically, for each iteration of MCCV, the Mean Absolute Error (MAE) was computed. For this calculation, the scale for predictions was bounded to the maximum and minimum of the scale.
Results
The resulting distribution of MAE for each of the models and cognitive states can be seen in the violin plots in Figure 2, where each data point represents the MAE from one iteration of MCCV. A lower MAE indicates better model accuracy, and a narrower spread corresponds to a more robust model for consistently predicting the cognitive states of unseen participants. The interquartile range (IQR) was computed to assess the spread of the data due to skew in the distribution.
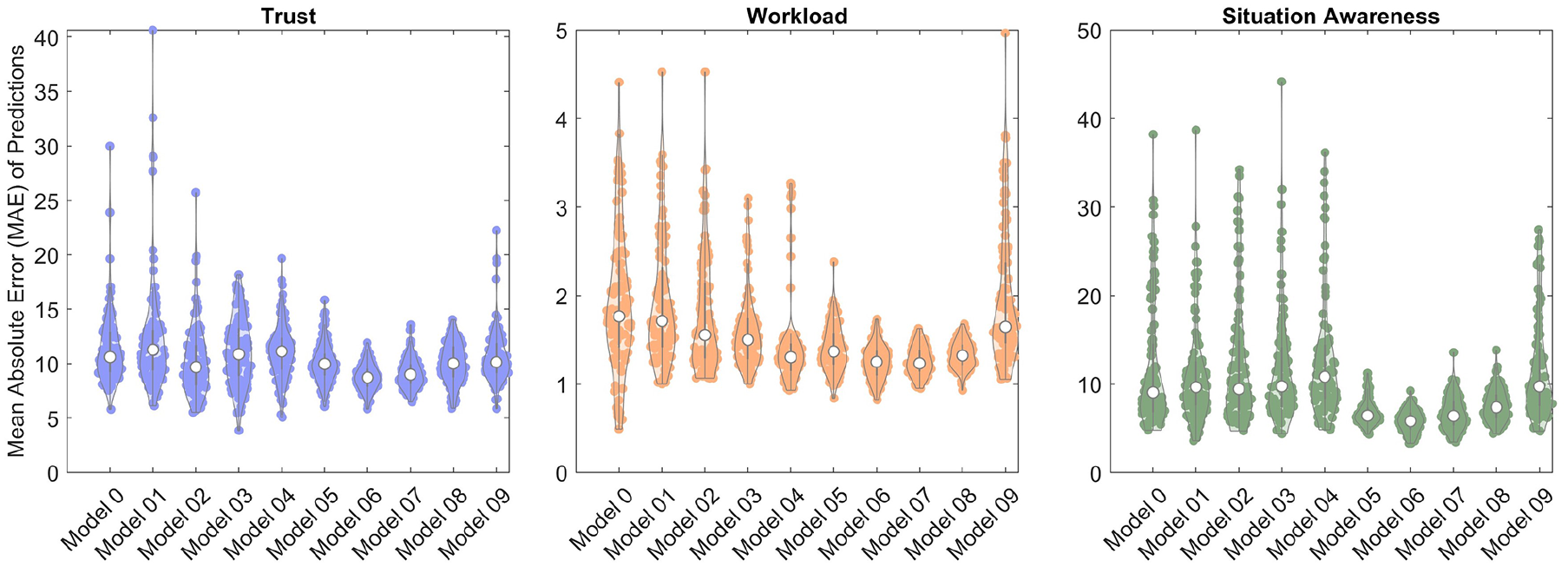
Violin plots, using code from Bechtold (2016), of mean absolute error in predictions of trust, workload, and situation awareness from 100 MCCV iterations for models 0 to 9 with each data point corresponding to 1 iteration of MCCV.
Trust Model Performance
When assessing the cross-validated performance of operator trust prediction, Model 6 was shown to have the lowest median MAE (8.72), corresponding to high accuracy, followed closely by Model 7 (9.00). This is of particular note, as these are lower than the Model 0 MAE (10.60). In addition, less variation across MCCV iterations was observed for Model 6 (IQR: 1.57) and Model 7 (IQR: 1.69) when compared to Model 0 (IQR: 3.66).
Mental Workload Model Performance
When assessing the performance of Models 0 to 9 for operator mental workload prediction, Model 7 had the lowest median MAE (1.23), corresponding to the highest accuracy, followed by Model 6 (1.25). Model 0 had a median MAE of 1.76. For workload, Model 8 had the lowest IQR (0.22), followed by Model 7 (IQR: 0.24) and Model 6 (IQR: 0.27). Model 0 had an IQR of 0.98.
Situation Awareness Model Performance
The MCCV results for situation awareness indicate Model 6 had the lowest median MAE (5.81), corresponding to the highest accuracy, followed by Model 7 (6.39) and Model 5 (6.43). Model 0 had a median MAE of (9.05). The greatest robustness was observed in Model 5 (IQR: 1.51), followed by Model 6 (1.78). Model 0 had an IQR of 7.66.
TWSA Combined Model Performance
To understand the ability of a given model to predict all cognitive states accurately, a matrix of scatter plots was created with the median MAE for each cognitive state, as seen in Figure 3. To compare cognitive states, the medians were normalized to the trust, mental workload, and situation awareness survey ranges. The plots compare two cognitive states at once to increase interpretability when compared to a three-dimensional plot. The best models are in the lower left corner of each plot, as this indicates a low median Mean Absolute Error for two cognitive states at once. Of the models analyzed in this study, Models 6 and 7 had the best prediction accuracy for unseen participants across all three cognitive states.
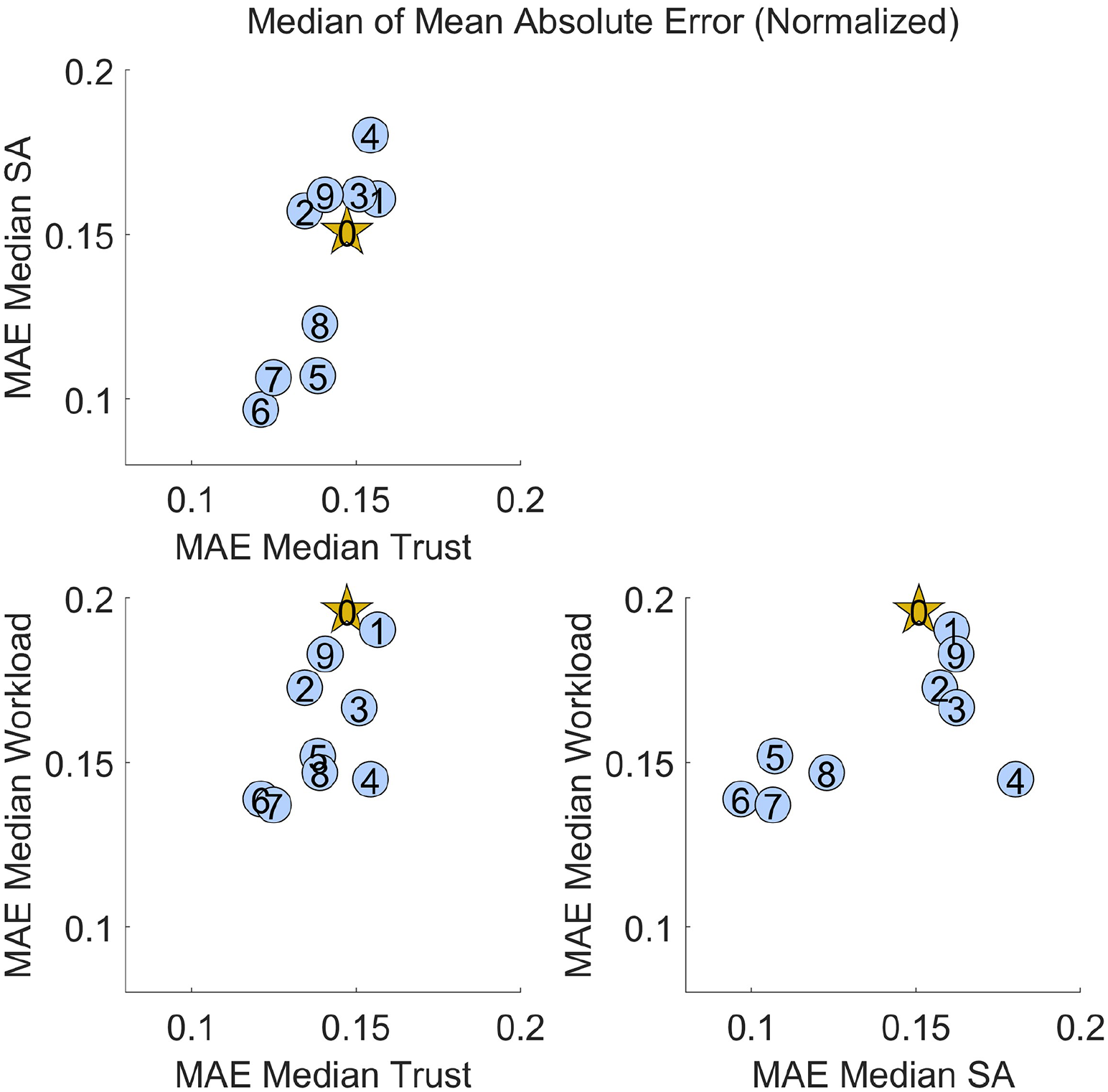
Comparison of median MAE for two cognitive states, each normalized to the scale of its respective cognitive state questionnaire, where each blue dot represents a simplified model, and the gold star represents the complete model (Model 0). Models in the lower left corner of each plot have low cross-validated median MAE in predictions of both cognitive states.
Discussion
The performance of Model 6 and Model 7 compared to Model 0 highlights an opportunity to simplify cognitive state prediction models while achieving better accuracy and robustness. Models 6 and 7 include only embedded measures and no additional sensors (i.e., eye tracking glasses not required), which could reduce encumbrance and improve adoption in operational environments. Additionally, the performance of the simplified models indicates the importance of simulation events and agent mode in predictions of an operator’s trust, mental workload, and situation awareness. Notably, however, the cognitive state predictions that were only a function of the agent mode (Model 8) were less accurate than those that leveraged simulation events and operator embedded measures (Model 6). This motivates adapting an autonomous system to an informed cognitive state prediction rather than using simply the mode or events as a proxy for operator cognitive state.
Some models have greater variance and were not robust to all training/test splits, while other models, specifically models 5 to 8, seem to be robust to the training-test splits across iterations of MCCV. We have attributed this variance to the operator background information since highly variable data from one participant to the next was observed in this category of features. This causes the training/test splits to have a large impact on the coefficients of the model, which is likely to predict TWSA along the full range of the scale. Comparatively, the models with less variable features, such as simulation events or agent mode which were consistent across participants, robustly remained accurate across iterations of MCCV. It is important to note that the variability within a feature, though detrimental for predictions for unseen operators, may substantially improve a model which is trained on a given subset of operators and applied to their future interactions with an autonomous system.
Though it has been concluded that Model 6 and 7 performed well in the context of this experiment, these models have not been applied to data from different experimental conditions and are not necessarily generalizable. There may be other tasks or scenarios in which additional feature types enable better predictive performance.
Conclusion
While there are improvements to be made in the accuracy of the TWSA prediction models, this work demonstrates the feasibility of embedded predictions of operator cognitive states in real-time, even with few measures of the operator themselves. In some instances, greater predictive accuracy and model robustness can even be achieved with fewer sensors and measures of an operator. Reduced sensor requirements enhance the real-world feasibility of implementing this framework in operational environments. This would be beneficial in spaceflight where strict mass and volume constraints can limit the space for additional equipment, but also in military applications and search and rescue operations where equipment must be carried. The ability to make cognitive state predictions with embedded measures and reduced sensors would allow for future autonomous systems to adapt in real-time based on a human operator’s cognitive state without taking an operator’s focus away from a task. Real-time adaptation to an operator’s TWSA provides an opportunity to improve human-autonomy teaming and may positively influence the performance of an operator.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This project utilized the University of Colorado, Boulder Alpine Supercomputer, which is funded by University of Colorado Boulder, the University of Colorado Anschutz, Colorado State University, and the National Science Foundation (award 2201538). Thanks to the National Science Foundation Graduate Research Fellowship Program for funding this effort. This work was also supported by the Space Technology Research Institutes grant from NASA’s Space Technology Research Grants Program.