
Abstract
We extend previous work on applying computational linguistics in understanding distributed sensemaking. In an experiment, teams of three respond to incidents in the C3Fire simulation under different levels of shared information, and radio communications were automatically transcribed (with an overall accuracy of around 80% for these recordings). The transcription was analyzed by computer to classify speech acts. We compared heuristics and regular expressions, supervised machine learning (using linear SVM), and unsupervised learning (using BERT). For this small corpus of utterances, SVM provides acceptable performance (around 79% accuracy) with minimal computational demand compared with the other approaches. In terms of team communication, differences in information conditions are identified (particularly in terms of speech acts relating to statements about “fire” and “rescue,” and statements about “reasoning and planning”). The study demonstrates the potential of automated analysis of team communications and indicates when teams might struggle with sensemaking.
Introduction
In a previous study, we analyzed communications of three-person teams performing a military map exercise (Baber et al., 2022). Manually derived transcriptions were classified, by computer, using manually defined regular expressions (as indicators of speech acts) and topic-spotting. In this paper, we automate the transcription of audio with teams conducting an exercise using the C3Fire micro-world (see Method) and apply Machine Learning and Artificial Intelligence approaches to speech act classification. Our aims are to:
Explore Distributed Sensemaking in teams performing a dynamic task with differing information.
Demonstrate the potential of a semi-automated pipeline (from capture of audio to transcription to classification) to classify speech acts in terms of sensemaking in teams.
Distributed Sensemaking
Teams need to understand the current situation, to develop and adapt plans appropriate to that situation, and to know what actions each team-mate is performing. In such situations, teams need to engage in sensemaking. Individual sensemaking is well understood (Klein et al., 2006). We are interested in the ways in which sensemaking can be distributed across a team (Attfield et al., 2021).
“Common ground” (Clark & Brennan, 1991) is a core element of distributed sensemaking. As such, we expect this to be reflected in communications between team-mates and this could be reflected in the speech acts the team uses.
Defining Speech Acts
A “speech act” is a way of doing things with words (Austin, 1962), that is, using speech to produce an effect on listeners. Searle (1969) argued that “the unit of linguistic communication is not, as has generally been supposed, the. . .word or sentence. . . but rather the production of the . . .word or sentence in the performance of the speech act. . .[S]peech acts. . .are the basic. . .units of linguistic communication.” (p.16, emphasis added). To date, there is no agreed standard as to how best to define speech acts. Searle (1969) estimated there could be up to 10,000 speech acts in English.
Analysis of speech acts could use performative verbs, for example, “please,” “would you,” “could you,” “shall we” etc. (in these examples, the speech act might relate to a request or invitation to perform an action). However, the definition of a speech act depends on its social and linguistic context, which makes their precise identification challenging.
Searle (1969) suggested that a focus on sentences might be preferable to individual words. In machine learning, linguistic context is obtained from short phrases (n-grams). Moldovan et al. (2011) used the first 2 to 6 words of online posts. F1 (weighted average of Precision and Recall) was around 0.6 for Naïve Bayes and 0.7 for Decision Trees (average accuracy 65% for Naïve Bayes and 72% for Decision Trees). Bayat et al. (2016) used a Support Vector Machine with n-grams (on text messages in German) and report F1 average 0.69 with accuracy of 74%. Using a Multi-Channel Deep Attention Network, Ghosh and Ghosh (2021) achieved around 90% classification accuracy.
Paul et al. (2023) applied a transformer-based approach (using a pre-trained T5 model) to identify speech (dialogue) acts in military communication. This study had nine dialogue acts (e.g., provide information, command, greeting etc.) in two forms of information flow (up or down the chain of command). Classification of the best (i.e., top 5) dialogue acts ranged from Command (F1 0.8) to Request information (F1 0.7). Confusion arose from similar dialogue acts, for example, “provide information up” versus “provide information down.”
Speech Acts for Distributed Sensemaking
We define sensemaking in terms of themes relating to common ground (Figure 1). Figure 1 reflects the specific circumstances of this experiment, and we expect different relations between sensemaking themes for other contexts. Messages could be about Situation Awareness, for example, location of fire, vehicles, people; Reasoning, for example, proposing hypotheses or explaining requests; Action, for example, searching the environment, movement of responders or the fire, rescue of people. In terms of speech acts, messages relate to “Communication,” that is, the radio protocol that the teams use, such as using call-signs, using words to indicate receipt of the message (“ack” or “roger”), or using terminators such as “over.” The message content can be a “statement” of, or a “request” for, information or action, for example, a statement of Reasoning could be “large buildings contain more people than small buildings” and this could lead to a request for Action, for example, “<call-sign> search large buildings,” and this action will modify situation awareness which, in turn, could modify Reasoning, for example, large buildings might not always contain lots of people.
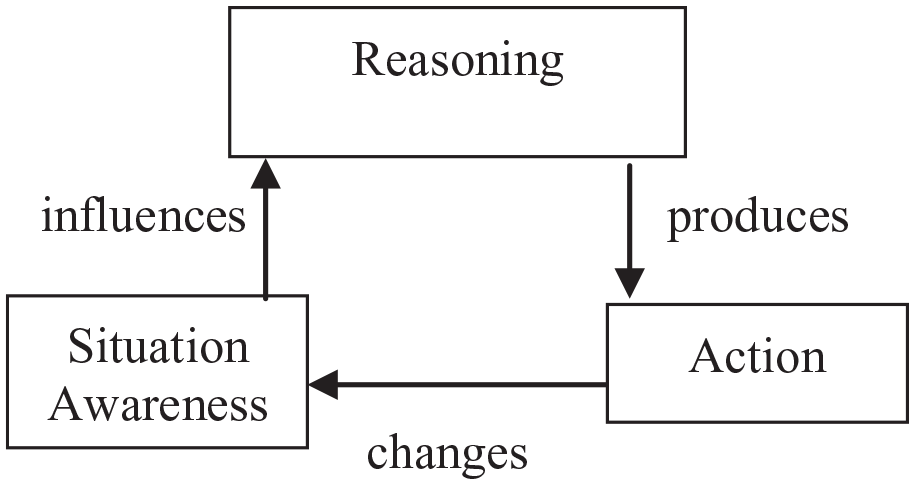
Model of sensemaking in this experiment.
Method
In this experiment, the primary manipulation is the level of detail that is shared between team members from the game. We also explored interventions to encourage sensemaking in teams and this is reported in Gibson et al. (2024).
Participants
Thirty-six participants (with knowledge of military operations but no experience with C3Fire), in teams of three people, participated in trials using the C3Fire micro-world.
C3Fire
C3Fire (Johansson et al., 2003) is a micro-world which involves response to a simulated forest fire (Figures 2 and 3). Previous C3Fire experiments have identified that changing the information that participants view impacts on performance (Berggren et al., 2017). In our experiment, we used three conditions: (a) a Unit Only view that displayed the environment around the units under a call-sign’s immediate control (Figure 2); (b) a Shared Unit view that displayed that environment as seen by all call-signs (not shown due to space limitations); (c) a “God’s Eye” view that displayed the complete environment (Figure 3). We hypothesize that the degree of shared information influences the communications of teams and that this will result in observable differences in speech act.
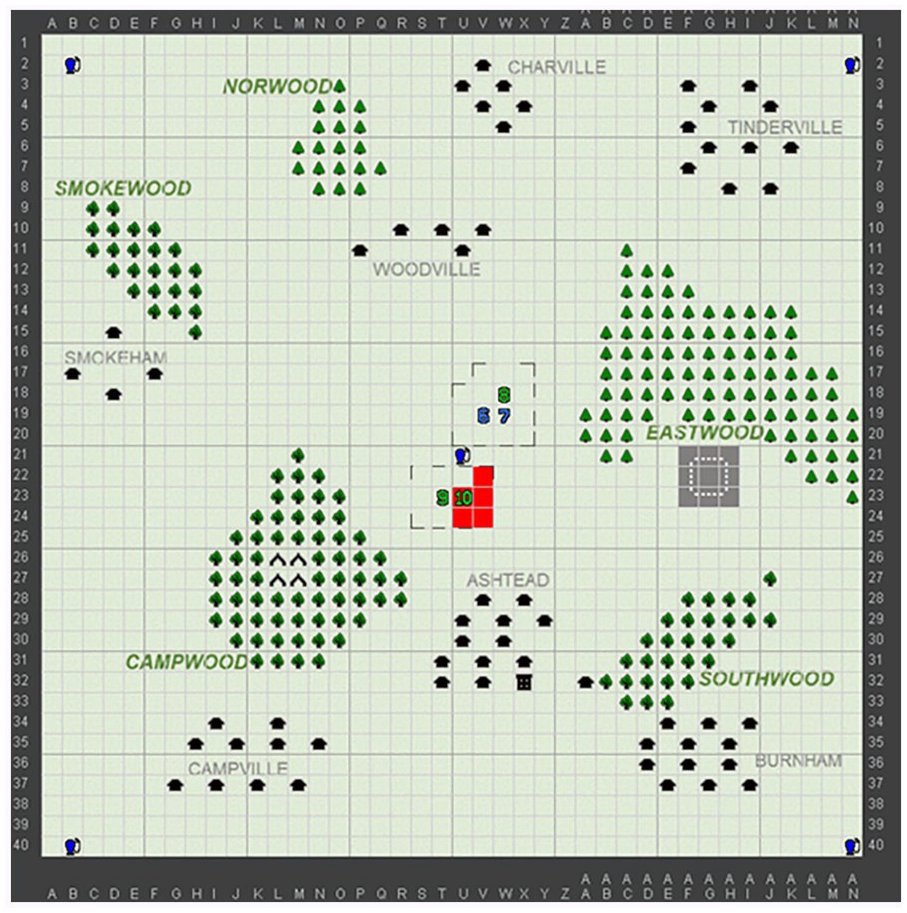
Unit-only views showed the position of units under the control of a call-sign (indicated by the numbers in the centre of the screen) and the fire visible to these units (in red).

The “Gods Eye” view showed the position of all units in the team and the full extent of the fire in the environment.
Procedure
The experiment was run at Dstl Portsdown West. Ethics approval was obtained from the MoD Defence Science Advisory Committee (20230316_01_DSAC). For each trial, a team of three participants, the C3Fire System Controller, C2EL system manager and analysts were present.
C3Fire ran on networked laptops. Each participant interacted with the micro-world using a computer mouse connected via laptop to a visual display unit. CalytrixCNR radios supported communications via microphones and noise cancelling headphones. The radios were “push-to-talk,” operated via a button on the interface. Only one participant could talk on the radio at the same time, but headphones connected to the radio network could hear all messages.
Teams were allocated (using Graeco-Latin squares) to one of the three conditions for user interface and one of two Sensemaking intervention conditions. In each team: call-sign Alpha commanded three firefighting units; call-sign Bravo commanded one firefighting unit and two rescue units; call-sign Charlie commanded one firefighting unit and two logistics units.
Following a familiarization exercise, each team undertook three scenarios (counter-balanced across teams) with different fire spread. After each scenario, teams completed questionnaires (Sensemaking Assessment Questionnaire (SMAQ) and DSM Worksystem Screening Tool (DSM-WST) developed for this project, see Leggett et al., 2021 for details). At the end of all scenarios, teams engaged in a group discussion with the experimenters.
Speech transcription and text analytics
The focus of this section will be on the transcription of the audio recordings and their analysis.
Transcription
GoogleLanguageR, developed by Edmondson 1 , was used to process each audio file. Audio files, recorded at 16 kHZ, were converted from stereo to mono (using tuneR). Following this, we ran GoogleLanguageR in discrete mode. This meant that, rather than uploading the full audio file to the Cloud (which we were reluctant to do) we segmented (using tuneR) the recording into chunks of 30 s and batch-processed these locally. An initial test of this pipeline was conducted on a good quality audio recording of e e cummings poem “Pretty How Town” (selected because of the unusual combinations of words). We compared the transcription with the original text to calculate a Word Error Rate of 11.5%. Correcting the transcription for homonyms, for example, “there” for “their,” improved this to 6.6%. This suggests, for good quality audio recording, with minimal manual intervention, we can expect a transcription accuracy of around 90%. However, in the experiments, participants will be producing spontaneous speech which is likely to include dysfluencies that could affect recognizer performance (in poem-reading, the source material is provided). In poem-reading, the focus of the person’s attention is solely on the production of speech, that is, reading the poem. In the experiment, the demands of the C3Fires task might affect speech quality and intensity. In poem-reading, the person reading the poem maintains a constant distance from the microphone and constant level of speech (i.e., both in terms of volume and tempo). While the experiment uses close-talking microphones, there might be movement of the microphone or there might be problems with the Press-to-Talk switch needed to activate the microphone. Each of these factors could impair transcription (even in the benign ambient conditions in which the experiment took place).
When applied to the audio recordings from the experiment (without manual intervention) the Word Error Rate was 34.9 (±9.9)%, which is clearly much worse than the poem-reading baseline. However, some words were consistently misrecognized, for example, “ricky” for “recce”; “brother” for “bravo,” as well as several place-names. Applying a global search and replace for common misrecognitions reduced the word error to just under 20%, giving an accuracy of 80%.
For each audio recording, this process took up to 10 min and the manual correction (performed on the total corpus) took a further 15 min which meant the process followed for this report took approximately 6 hr to transcribe all 36 recordings (or 540 min of audio).
By comparison, manual transcription takes approximately 15 times recording time (Baber et al., 2022) which would involve 8,100 min (135 hr, 5.6 days) effort to transcribe by hand. Following this transcription, labelling of speech acts was performed.
Manual Classification of Speech Act Types
A sample (15%) of messages, decomposed into sentences, was given to four of the authors (CB, HG, SA, AL) with the following codes: Statement of Objective, Statement of Situation, Statement of Action, Request for Objective, Request for Situation, Request for Action, Other. In this instance, the “objective” refers to Commander Intent, Mission goal, or other form of reasoning. Table 1 gives examples of sentences and their classification.
Example Sentences and Their Classification.

Messages could belong to more than one class, manual classification was challenging, with only modest agreement between pairs of raters (Cohen’s Kappa ranged from 0.39 to 0.49). We also fed the coding and samples into a Large Language Model (Claude from Anthropic) which had a slightly better agreement with human raters (around 0.55). Raters discussed discrepancies until consensus was reached for each sample sentence. Once we had a set of sentences that had been classified, we inspected each of these to identify keywords that occurred in each class.
At the start of each run, teams discussed the intelligence, provided in the form of newspaper reports, and we categorized this as “Discuss intel.” We separated speech acts relating to fire and rescue responses, although these intersect with Situation Awareness and with speech acts relating to “Action,” for example, “recce,” “moving” etc. The justification for this is that C3Fire emphasizes responding to fires and rescuing civilians and we felt that this needed to be reflected in the granularity of the analysis. Speech acts relating to planning or defining an intent were grouped under the heading of “reasoning” and were characterized by words such as “agree,” “think,” “believe.”
Heuristic Classification
Transcripts were split into sentences and regular expressions used to extract sentences for each speech act (using R libraries dpylr, stringr, and tidytext).
Extraction involved specifying regular expressions for each type of speech act. For example, speech acts relating to “statement of Situation awareness” were extracted using the following expression (not all place-names included in this example): SAwords = c("^north$", "^south$", "^east$", "^west$", "^locat$", "hospital", "^camp$", "police", "building", "wind", "DraysEnd", "Charville", "Firwood", "GreenHill". . .) and applied using the command:
Topics were derived for each condition (using Latent Dirichlet Allocation, as previously applied in Baber et al., 2022, with the R library topicmodels).
Machine Classification
The labels from manual classification of sentences were used as the basis for training machine learning classifiers. Machine learning was implemented using Python’s sci-kit learn.
As noted in the manual classification exercise, many sentences contained words that related to more than one class and some classes (such as Situation Awareness and Communications) were over-represented. This created a class imbalance that could skew classification. To handle this, we defined a “priority labelling” approach, in which a sentence was labelled by the class that appeared most in the labelling (where there was a tie, we weighted “communications” as lower than other classes as this was less discriminative).
Once training sentences had been labelled, the corpus of messages was transformed using Term Frequency Inverse Document Frequency (TF-IDF) and each sentence represented as a feature vector. The corpus was split into 80% training and 20% testing sets and fed into Naïve Bayes, Support Vector Machine (SVM), and Convolutional Neural Network (CNN) classifiers. We will not report the Navie Bayes results as the various permutations of this approach resulted in weighted F1 of 0.45 (37% accuracy). Using the priority labelling approach, accuracy for SVM, using 10-fold validation, was 80% (with weighted F1 85%) and CNN accuracy was 78% (weighted F1 60%). These values suggest that our approaches reach comparable levels of performance to those reported by Paul et al. (2023) for their “top 5” dialogue acts.
We applied a pre-trained BERT (Bidirectional Encoder Representations from Transformers) model to the corpus. We fed the corpus directly into the BertTokenizer to generate word embeddings and then a DataLoader is utilized to input to BERT and train the model in batches. At first, with initial (multiple instances) labelling, BERT struggled to classify the sentences (with an average F1 below 0.3). The problem might have stemmed from the ambiguity of the priority labelling or might be a consequence of limited training data when utilizing the priority labelling method. BERT is unable to learn the nuances of the speech acts in the given training data. Consequently, we used multi-label classification in which any of the possible classes for a given sentence could be applied. This had little effect on the performance of the SVM (accuracy 78%, weighted F1 0.92). For the CNN, multi-label classification (with training epochs of 100) increased accuracy to 88% and weighted F1 to 0.77 (albeit with a tendency to overfit smaller classes). BERT, optimized using Binary Cross Entropy loss function, Adam optimizer and learning rate of 0.01 over 50 epochs, had F1 scores ranging from 0.54 to 0.94; average weighted F1 0.83 (62% accuracy).
Results
Comparison of Teams
A key performance indicator in C3Fire is the average “casualty rates” (i.e., the number of people not rescued) and these were highest in the Unit-Only view condition (Unit Only view = 50.2; Shared Unit view = 27.5; God’s Eye View = 17.3). In terms of self-reported Sensemaking performance (using SMAQ) there was a slightly lower average rating, 72%, for the Unit-only view, compared with the Shared Unit view (76%) and the God’s Eye view (75%).
In terms of high-level communication measures, an initial comparison of conditions, is shown in Table 2.
Comparison of Conditions Using High-level Measures of Communication.
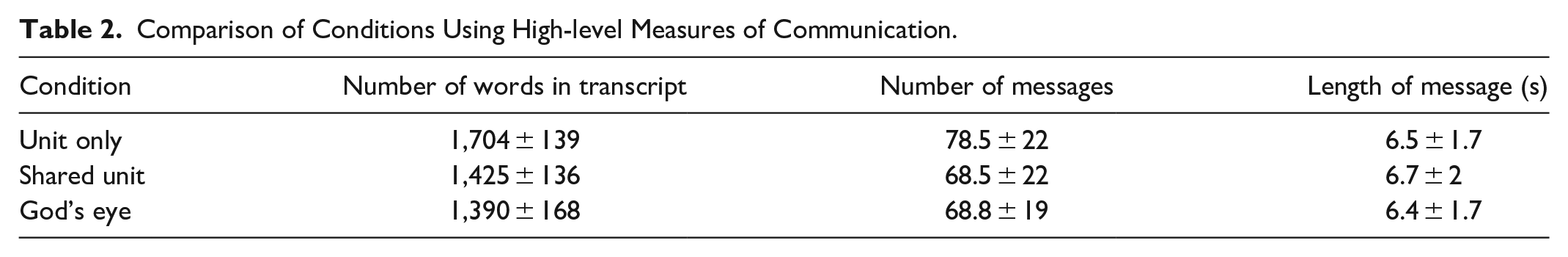
Table 2 shows that the Unit-only view has a greater number of messages which, given that messages had a similar length of 6 to 7 words per condition, explains why Unit-only also has a higher number of words in the transcript. This suggests that, as one might expect, restricting their view of the environment leads participants to communicate more. What this does not tell us is how the communications differed and this is why speech act analysis becomes relevant.
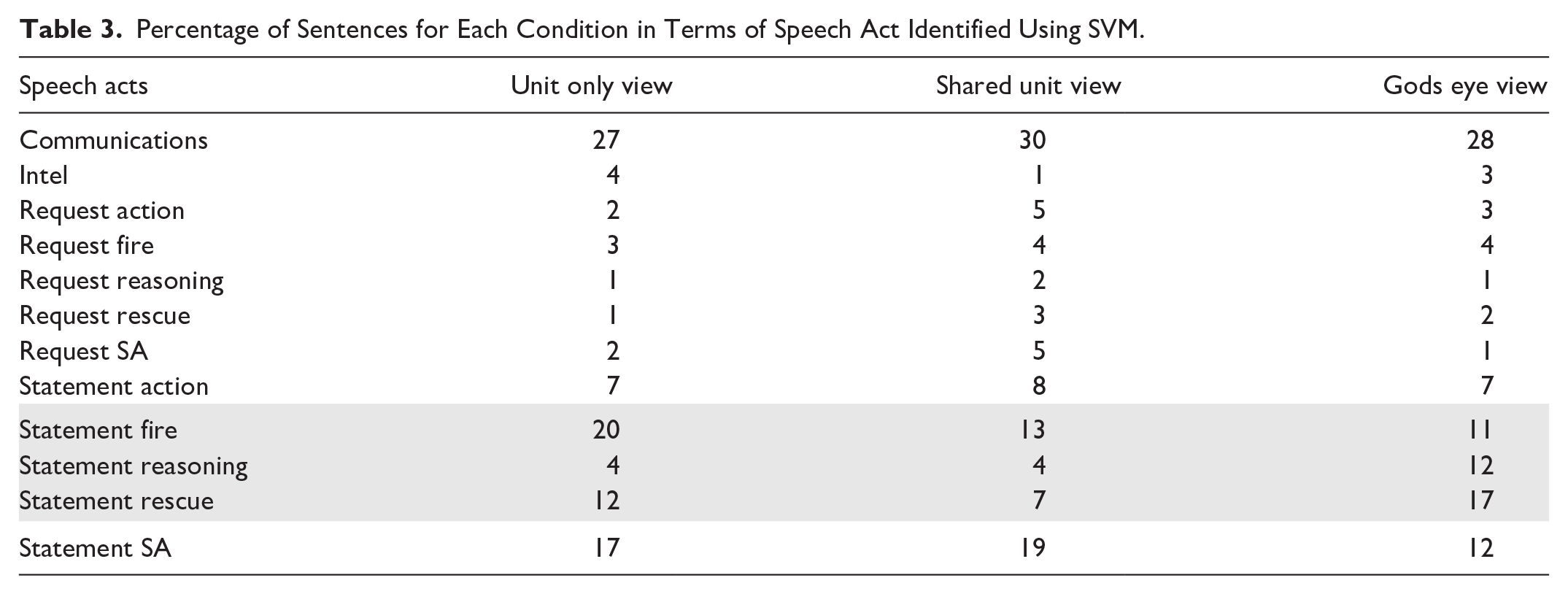
In Table 3, we summarise speech acts (identified using priority labels with SVM) focussing on Statements and Requests for each category of message. The percentages of speech acts varies across conditions, although there are too few “Requests” to draw conclusions. In terms of “Statements,” we highlight three rows in Table 3 where there are notable differences: the Unit Only view has the highest proportion of statements of “fire” and, with “Shared Unit” view, the lowest proportion of sentences relating to statements of “Reasoning.” In contrast, the “God’s Eye view” had highest proportion of statements of Reasoning. The “Shared Unit View” has the lowest proportion of Statements relating to Rescue.
Percentage of Sentences for Each Condition in Terms of Speech Act Identified Using SVM.
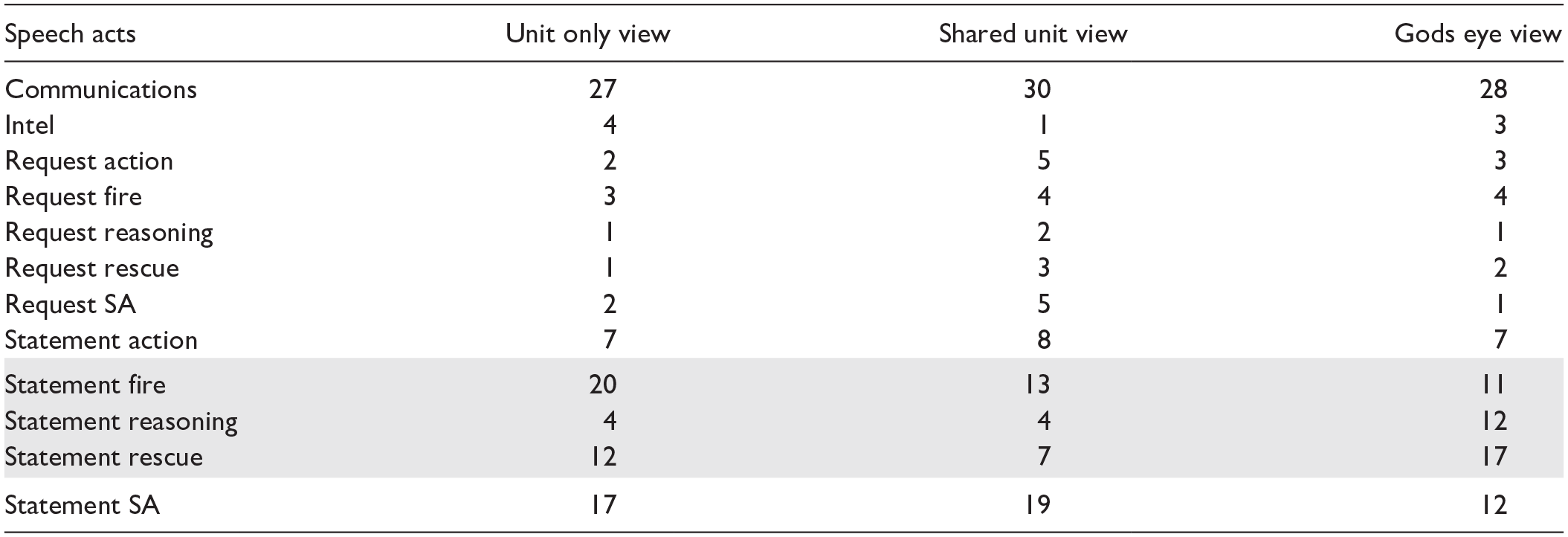
While we have not reported (due to space limitations) the results of the Latent Dirichlet Allocation analysis of Topics identified, we note that the Unit-only view tended to focus on uncertainty over location of units or the fire. In contrast, the Shared Unit view focused on rescue, for example, search for people, or moving water supplies. Topics in the God’s Eye view place greater emphasis on agreeing action and defining objectives.
Discussion
We demonstrate how speech acts can be specified from a Distributed Sensemaking framework; how such speech acts can be automatically identification in spoken communications; and how this process can differentiate between teams performing under different conditions.
Transcription performance, even with some manual intervention, is 80%. Our analysis is performed on this data. This might mean that the classifications are not completely accurate (given the quality of the input to this process). However, we assume that errors in transcription are evenly distributed across conditions and, therefore, differences between conditions (in terms of speech acts) are more likely to arise from the messages in that condition rather than any systematic bias in the recordings.
Classification of the sentences, in terms of speech acts, was challenging for human analysts (because many of the sentences could be defined as more than one speech act). Using labels from human raters, we trained machine learning algorithms. A Support Vector Machine with 10-fold validation produced a classification accuracy of around 80%. This was comparable to more sophisticated Convolutional Neural Network and superior to the use of a transformer-model (BERT) on this limited corpus of sentences.
The distribution of speech acts identified by SVM and the topics identified (through LDA) show that the limited view of the environment afforded to the “Unit Only” view had an impact on their ability to make sense of the task, both in terms of the recognising what was happening on a global scale (rather than focusing on their own, local views) and their ability to plan.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The work reported in this paper was partly supported through UK Defence Science and Technology Laboratory SERAPIS project Lot 3 D37 “Improving and measuring distributed sensemaking in command and control: an experimental study.”