
Abstract
For human-agent teams, it is as important for agents to have models of their human teammates as it is for humans to have models of their agent teammates. However, approaches to knowledge elicitation have wrestled with the problem of capturing human knowledge when much of it is tacit and difficult to verbalize. By observing the choices that people make under different conditions we can infer the choice structure they appear to be following. In this way, observations could allow the agent to predict its human team-mates’ choices and actions. We report an experiment in which eye-tracking is used to capture choices in a constrained task and then develop a decision model that can replicate aspects of these choices. We propose that such a model can support human-agent teams by enabling inferences of some aspects of human decision-making.
Introduction
The success of human-machine cooperation depends on human’s ability to understand the goals of autonomous agents and for autonomous agents to infer a human’s goals. In this paper, we focus on the latter. We believe that autonomous agents could infer the goals of their human teammates by considering the features of the situation to which the human is attending and, from such observations, predict which actions a human will take.
We accept that most concepts of a “team” assume that members have some mental model of their team-mates’ knowledge, skills, abilities, preferences, behavior, etc., acquired through interactions. For this paper, the question is how a computer agent might acquire a “model” from observing its human team-mates. To simplify this question, our focus is on a dyad in which two agents will choose to cooperate or not. We consider cooperation from a game-theoretic perspective and seek to identify when human participants choose between cooperative or individual options. To capture the information to which people attend, we use eye-tracking due to its non-invasive means of indicating the strategy the decision making.
“Stag Hunt” as a Cooperative Game
Stag Hunt is popular in game theory to explore cooperation between pairs of players. The motivating story (originally proposed by Jean-Jacques Rousseau) is that two hunters can either work separately to each catch a hare that can feed one person or can cooperate to capture a stag that can feed several people. Choice (between collecting a hare or hunting a stag) depends on a payoff matrix (Table 1).
Example of Payoff Matrix for Stag Hunt.
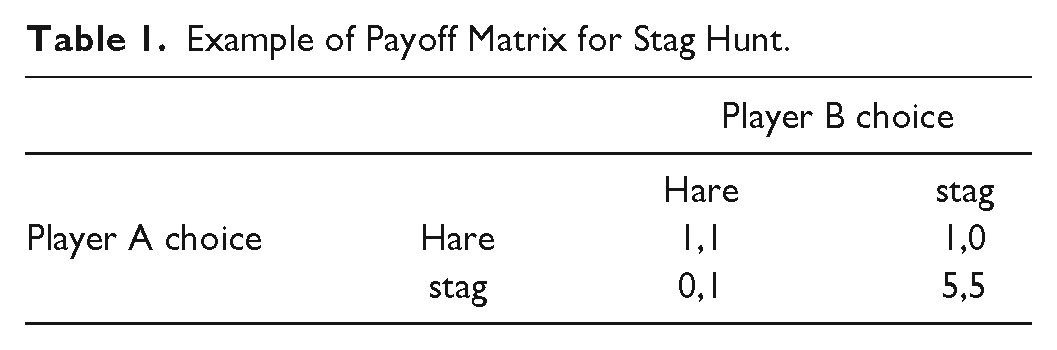
In contrast with other game-theory payoff matrices, Stag Hunt has two Nash equilibria: one that is risk-dominant (i.e., both players choose hare which has a low but guaranteed reward) and one that is payoff-dominant (i.e., both players choose stag which has the highest Reward).
In Stag Hunt, the payoff-dominant strategy is also the cooperative one. Given two Nash equilibria, rational choice is based on the expectation of what the other player is likely to choose (Skyrms, 2001). In Table 1, the difference between rewards might suggest that a cautious (risk averse) player would always hunt hare. A player who has little knowledge or trust of the other player would also hunt hare. In order to shift to a cooperative strategy, it is necessary to form a model, or gain some experience, of the other player (Al-Ubaydli et al., 2013). Playing the game with the same player can also increase the likelihood of both players choosing stag. Alternatively, one can invoke “the shadow of the future” (Axelrod, 1984), that is, a discount factor. One way to define the discount factor is by estimating the likelihood of encountering the other player again. Only when the number of encounters cannot be estimated (but is more than one) is choosing stag preferable, on the assumption that the other player will eventually choose stag. In one-shot versions of the game (where you only make a single choice) the dominant choice is hare.
Eye tracking can be used to explore information acquisition as people make decisions (Costa-Gomas et al., 2001). In typical game-theory experiments, participants view a payoff matrix, for example, Devetag et al. (2016) show that a naïve (level 1) player fixates on the rows in a payoff matrix that relate to their own payoff, and a more experienced (level 2) player fixates across rows and columns to predict the other player’s most likely payoff (and therefore the other player’s most likely choice). In a game where players only see a payoff matrix, estimating the other players strategy requires a mental model based on the relative differences in the payoff matrix and an understanding of game-theory logic. In a grid world, the choice can be estimated by relative distance to objects.
We use a grid-world version of stag Hunt adapted from Nesterov-Rappoport 1 (in this version, the low-reward “hunt for rabbit” is replaced with “forage for fruit”). Hence, from here we refer to low reward choices as plant (rather than hare).
Figure 1 shows the relative positions of self (blue, on left) and other (red, on right) players along with two plants and one stag. In Figure 1, other is adjacent to the stag but four squares from a plant. From this, we might infer that other will choose stag as their goal. Self is five squares from the stag but three squares from the nearest plant. Depending on self’s appetite for risk or desire for reward, self could move to the nearest plant, knowing that they would reach this before other was able to reach their closest plant, and guarantee a small reward for self. Alternatively, self could move to stag in the hope that other would remain in its vicinity (and self also has the option to shift to plant if other moves past stag).

A grid-world stag hunt.
Method
We simplify the game environment in Figure 1 so that participants only respond to still images and do not see the players move. This makes it easier to record eye movement relative to Areas of Interest that correspond to grid location. A consequence of simplifying the interaction in this way is that we do not an iterative game. This means that the game in our experiment is a series of one-shot versions of Stag Hunt, which, as noted above, increases the likelihood of choosing plant rather than stag.
The design of the experiment was approved by University of Birmingham (ERN_22-1145). Thirty 2 participants (11 female; 19 male students in MSc Human-Computer Interaction) were recruited from a class of 48 students on an experimental design and statistics module. Participation was voluntary. Participants had no previous experience of the game and most (24) had minimal knowledge of game theory.
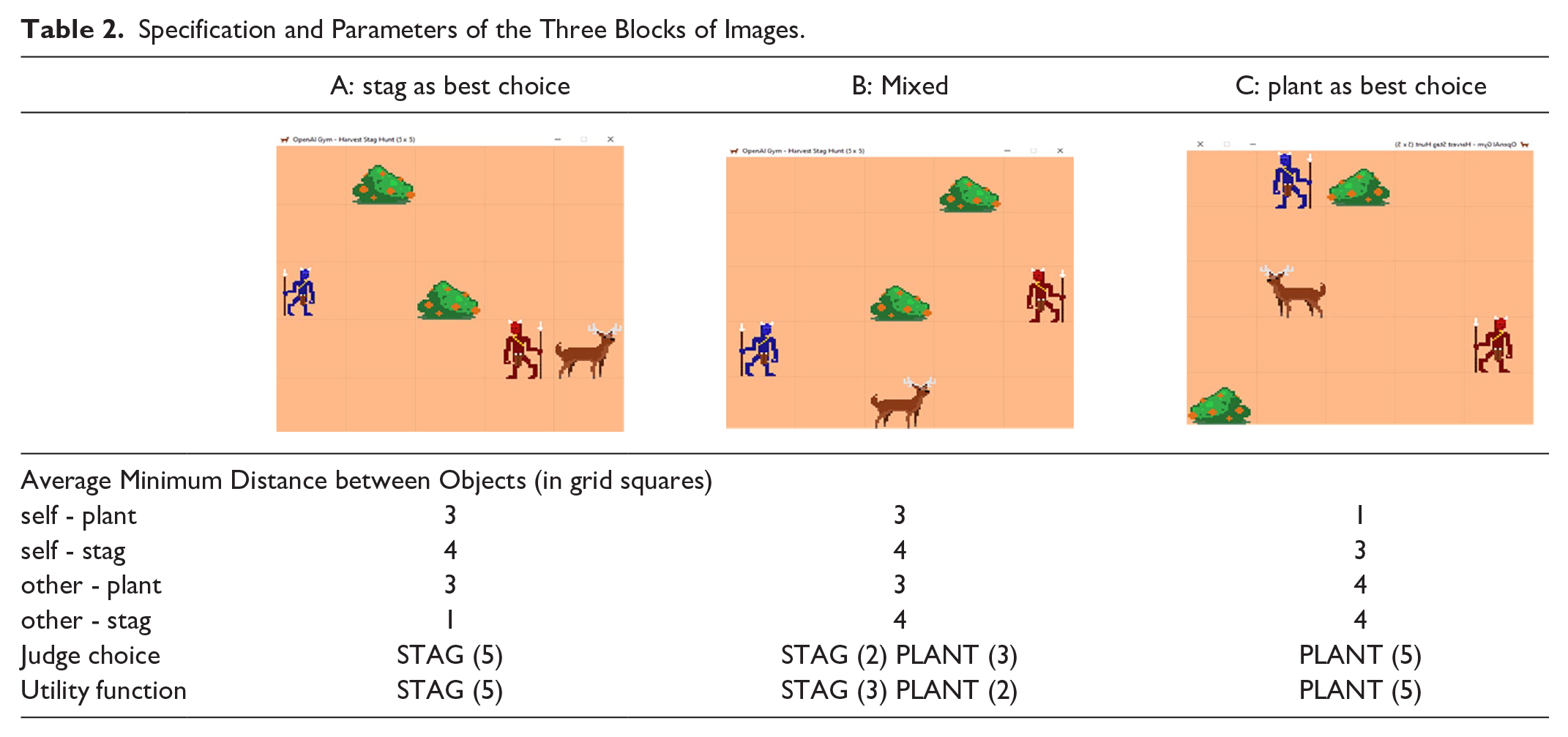
Participants are shown the image and asked whether they choose to hunt stag or forage for plants. In each image, two hunters (self, blue, and other, red) appear on a grid. Participants always played as self. Two participants with knowledge of Stag Hunt and game theory completed the task. Their choices defined the Judge choice for each block (Table 2). Note, the judges achieved consensus on 10 of the 15 images. Where there was discrepancy, the judges discussed to agree a judge’s choice.
Specification and Parameters of the Three Blocks of Images.
A Tobii Pro Fusion eye-tracker (running at 120 Hz) recorded gaze data (number of fixations, average fixation duration, time to first fixation) for each Area of Interest (where each Area of Interest contained objects in the grid-world, i.e., self, other, stag, or two plants).
We had three dependent variables to evaluate performance:
• Mean Time for Fixation on Objects: We defined a ‘fixation’ as an event with a time above 100 ms. Anything below this was either a “glance” (75–100 ms) or “ignored” (0–75 ms), and anything over 3500 ms is “long.” Our mean time for fixation only included times above 100 ms.
• Number of Visits to Objects: Each time an Object was fixated (using a definition fixation as being >100 ms), it counted as a visit;
• Time to First Visit to an Object: The average time to first visit an Object indicates the order of Object fixation. We assume that fixations were unlikely to be repeated viewing of an Object, that is, we assume that participants did not look at an Object, look away and then look back at that Object. As with the definition of mean time for fixation, we set a minimum cut-off of 100 ms to define a first fixation.
Preparation of Data
We used agreement with Judges’ choice to split the data into two groups: those that agreed with the Judges and those that disagreed. The idea is that participants who have a decision that matches the judges (for a given image) are likely to be applying a game-theoretic approach. Post-task discussion with participants supported this assumption as some participants said they were “just guessing,” “kept changing my mind,” or “wasn’t sure what the best answer was.” This gives four categories for comparison: Judge chooses stag, Participant chooses stag; Judge chooses stag, Participant chooses plant; Judge chooses plant, Participant chooses plant; Judge chooses plant, Participant chooses stag.
Analysis was based on the mean across participants for images in each category.
Model of Visual Sampling and Game Play
Following the approach of resource-rationality (Oulasvirta et al., 2022) we assume that humans are rational with respect to their internal processing limits and the limits imposed by the environment. This provides a perspective on Simon’s notion of bounded rationality and assumes that people sample information that is useful in decision-making.
Prior work has shown that eye movements can be treated in terms of information sampling by a Markov decision process (Acharya et al., 2018; Chen et al., 2017, 2021). We formulate the visual search as a Partially Observable Markov Decision Process (POMDP). The agent needs to learn a policy that allows it to sample the visual scene in order to produce a decision. Visual sampling is defined using the EMMA model (Salvucci, 2001). At each step, the agent learns to map the history of past interactions with the environment to a distribution over actions for the current time step, while adhering to the constraints imposed by human vision. The policy is represented by a recurrent neural network (RNN).
Results
Mean Time for Fixation on Objects
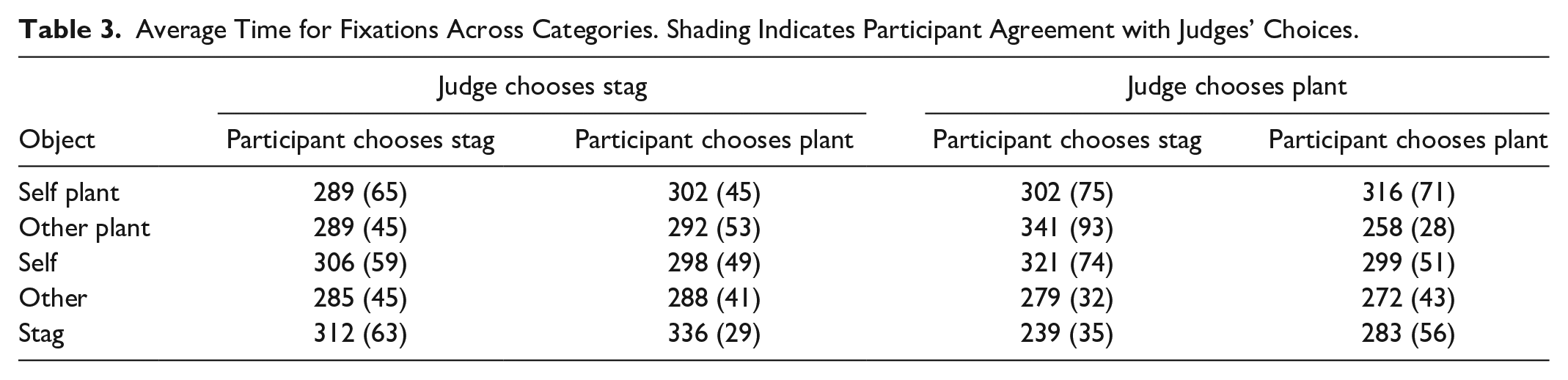
A two-way Analysis of Variance (Object × Agreement) showed no effect of Object or Agreement on the mean fixation on Objects. Table 3 shows that average fixations are in the region of 300 ms for all objects.
Average Time for Fixations Across Categories. Shading Indicates Participant Agreement with Judges’ Choices.
Number of Visits to Objects
Table 4 shows average number of visits to objects for all participants (using the same categories as above). A two-way ANOVA (Object × Agreement) gives significant main effect of Object (F[4, 120] = 9.93, p < .0001) but not for agreement and no interaction effect.
Visits to Objects.
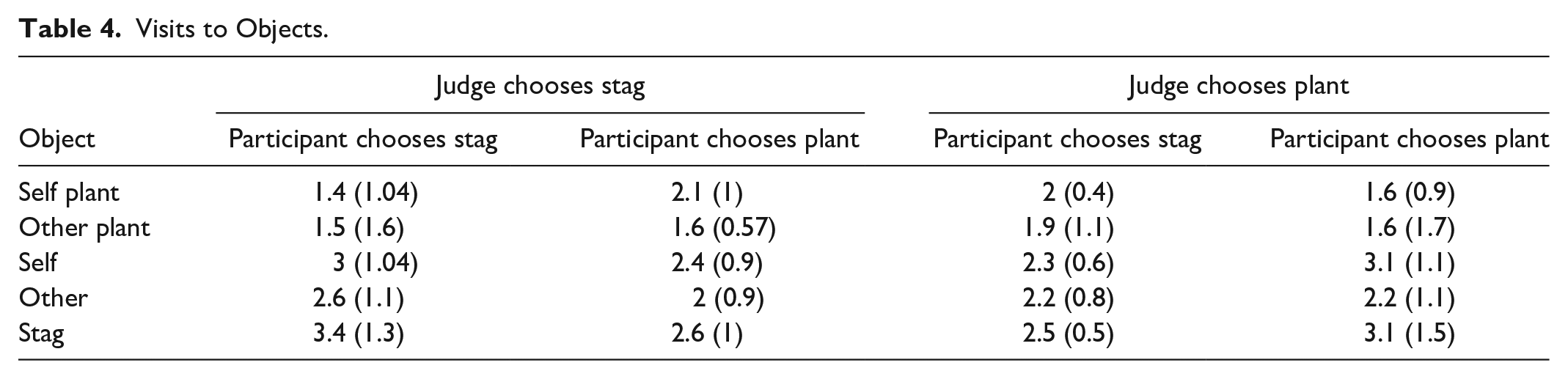
The mean count of visits to Objects was between 1.4 and 3.4. Across categories, stag is visited the most, followed by self, then other, with self plant and other plant having similar numbers of visits. This is borne out by the fact that the only post-hoc pairwise comparisons that are not significant are self and stag and self plant and other plant.
Time to First Visit to an Object
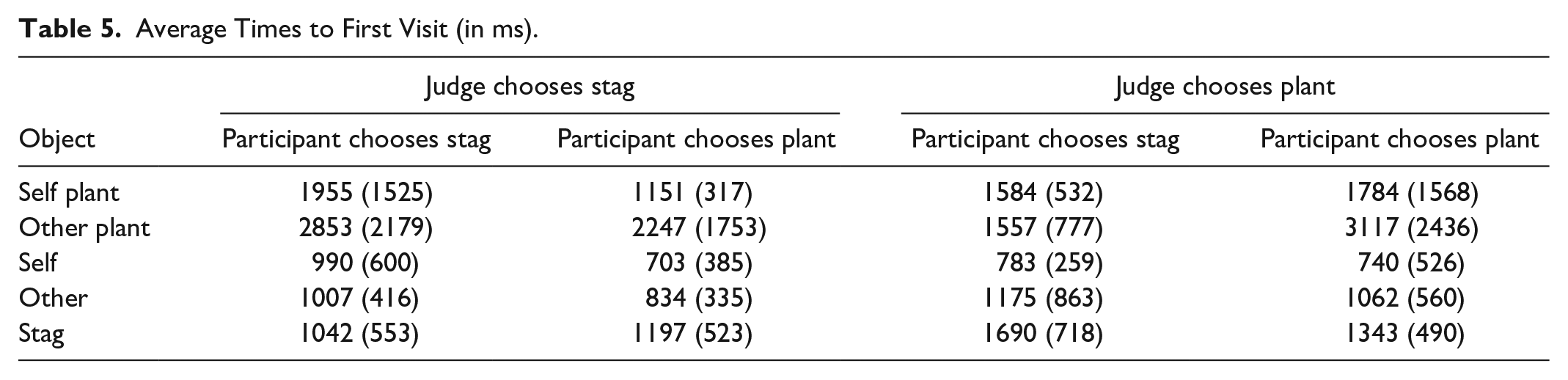
Table 5 summarizes time to first visit. A two-way ANOVA shows a main effect of Object (F[4, 12] = 7.3, p < .0001]) but not of agreement and no interaction effects. Post hoc, pairwise comparisons show significant differences across all pairs, except for self plant and stag, self and other, other and stag.
Average Times to First Visit (in ms).
Defining Participant Strategies
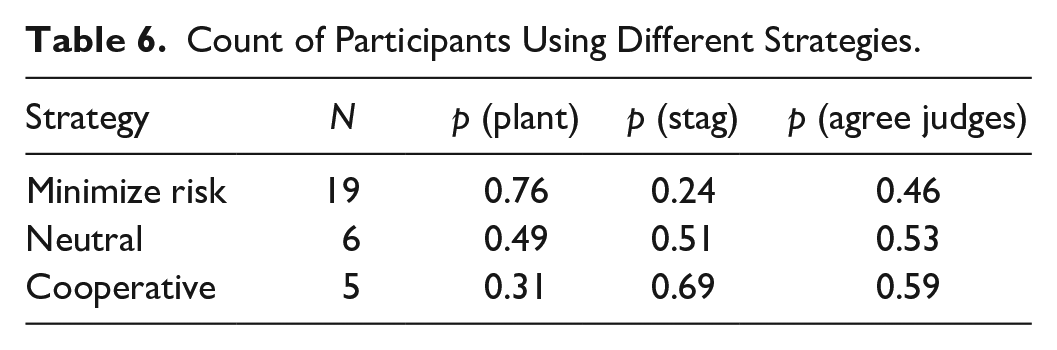
The definition of “strategy” is based on the proportion of choices made by each participant for stag or plant. If participants were more likely to choose plant (irrespective of the “correct” answer), we assumed they were following a Minimize Risk strategy. If participants were more likely to choose stag, we assumed they were following a Maximize Reward (Cooperative) strategy. If there was minimal difference (e.g., <0.1) between proportions, we defined this as “Neutral.”
Table 6 suggests that the majority of participants were treating this as a one-shot game. Given the lack of feedback, this is not surprising. Participants who used a Cooperative strategy tended to have a slightly higher probability of agreeing with the expert scores, but the numbers are too small to draw meaningful conclusions.
Count of Participants Using Different Strategies.
Relating Strategy to Fixation Type
We analyzed the proportion of fixation types (as defined above) across images for the three strategies (Table 7).
Proportion of Fixations by Strategy.
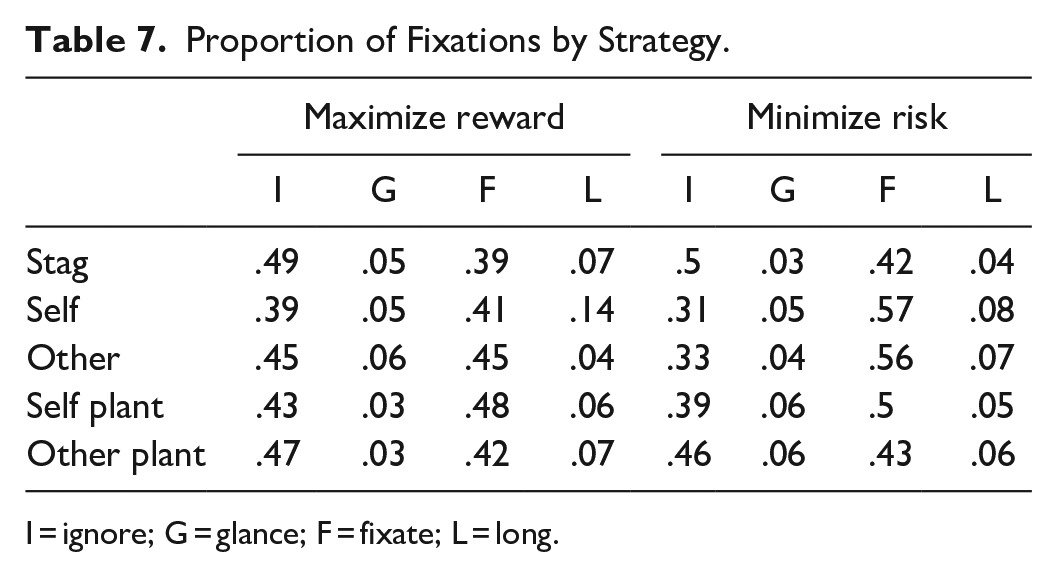
I = ignore; G = glance; F = fixate; L = long.
In Table 7, there are notable differences. This suggests that participants who adopted Minimal Risk strategies were more concerned about the activity of other than those who adopted the Cooperative strategy. Perhaps participants who opted for Cooperation were more trusting of other?
Modelling Information Sampling
Would a computer model of a human decision maker (with similar approach to visual sampling) exhibit comparable information sampling as reflected in the distribution of fixations on objects? The model was trained to output decisions that agree with the judges.
Figures 2 and 3 show the time to first fixation for the computer model when it can make 1, 3, or 5 fixations. With 5 fixations, the model will have sampled every object on the screen and these times are comparable to those in Table 5. For example, if we consider the time to first visit to the other player (player red in Figure 2), when the correct choice is plant, this is 1062 (±560) ms in Table 5 and is 1200 (±625) ms in Figure 2 (for 5 fixations). We propose that these timings overlap sufficiently to imply similar constraints on visual search for the “average” participant and the model. This does not mean that the model is behaving in an manner that is identical to people, but that the limits that we have imposed on the ways in which objects in the scene are attended has some similarity to human performance (and is, by definition, very different from the ways in which a conventional Reinforcement Learning model would sample all objects in the scene simultaneously).
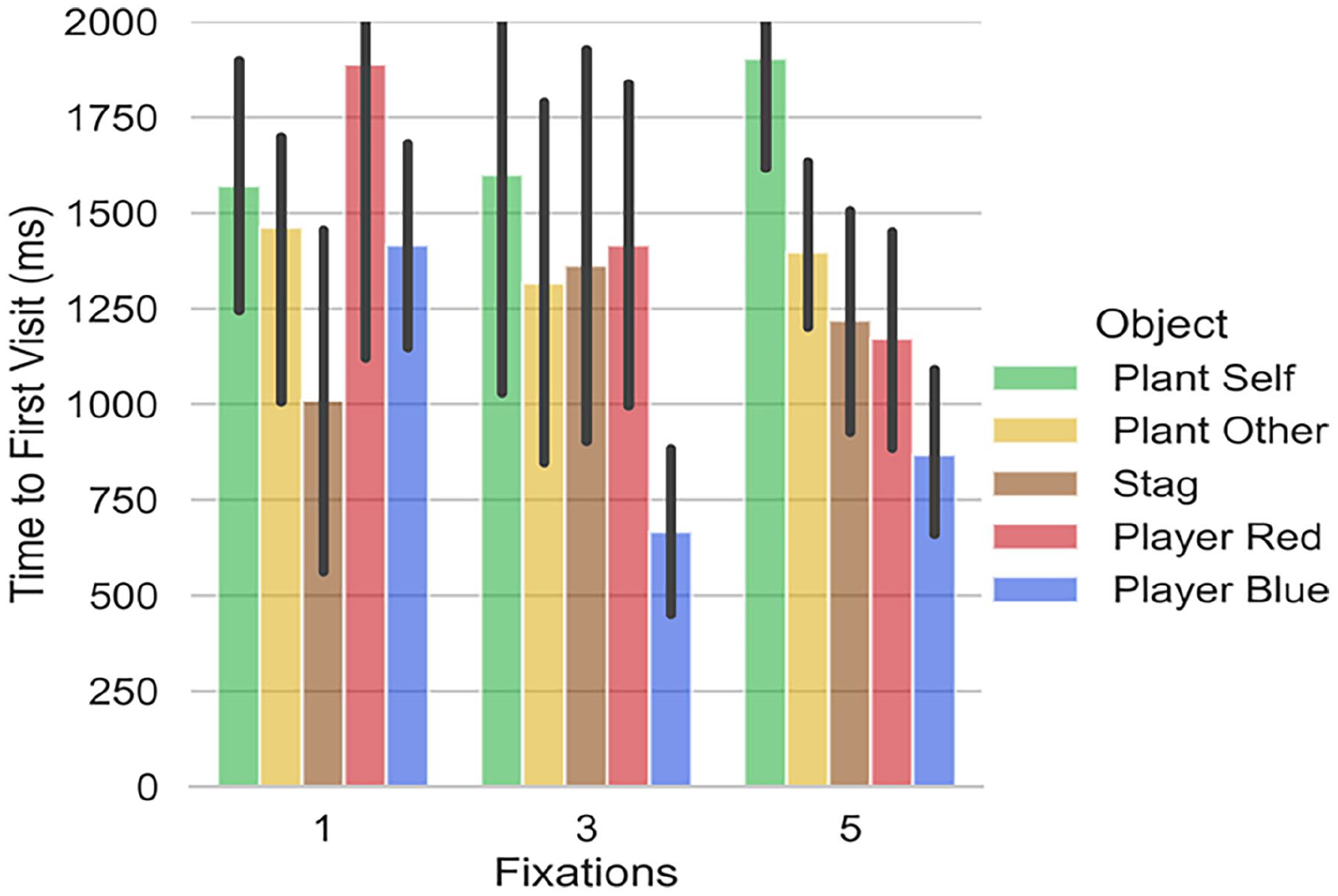
Visit to first object when decision is PLANT.
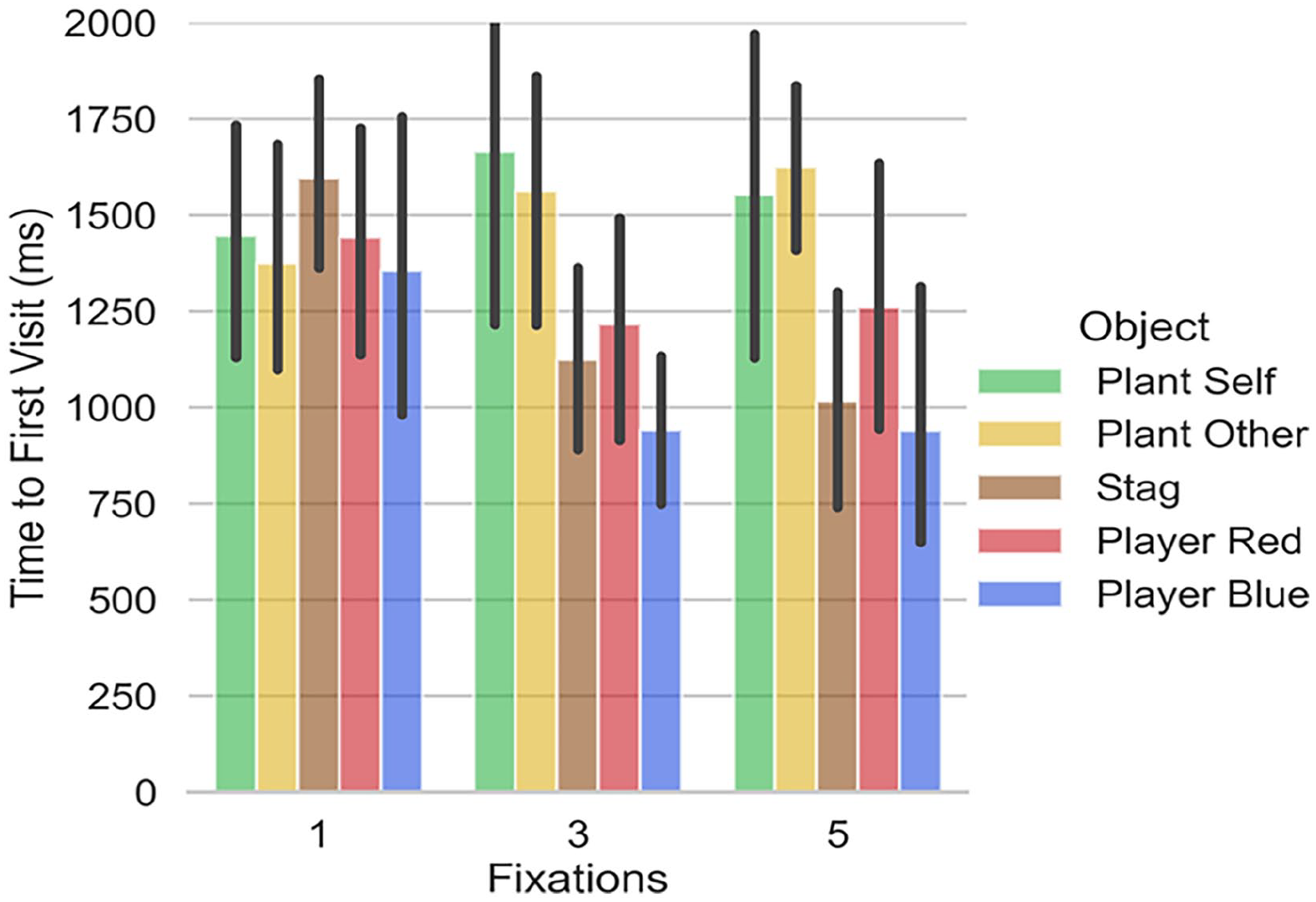
Visit to first object when decision is STAG.
Table 5 suggests that participants sample the objects in the order: self, other, stag, self-plant, other plant (although the standard deviations hint at some variation across participants). Figure 2, where the decision is plant, shows the computer order: self, other, stag, other plant, self plant (so the difference between this and the human data relates only to the plants). In Figure 3, where the computer decision is stag, the order is: self, stag, other, self plant, other plant. Here, the difference is when the stag is sampled.
While the model does not fully align with the average human data, it does indicate an information sampling strategy that responds to the reward of the objects (stag attended before plants) and the potential for cooperation or defection of the other player.
Discussion
Even for a simple task like the one used in this study, there are benefits to developing human-like agents. A Reinforcement Learning agent with full access to the environment (i.e., with no restrictions on sampling of objects) is unlikely to require sequential sampling of objects. While it would derive the salience of objects for its decisions, it would do so in a way that is quite different to human decision making. Thus, our approach allows us to model human decisions in terms of information sampling strategies.
In game theory settings, people find it difficult to imagine how the other player might act (and people typically rely on simplifying assumptions that the other player will use the same strategy as themselves). The model could show the likely strategy of the other player (and the user could decide whether this differs from their own). We could, separately, model own and other player strategy and have the agent compare these. In this case, the agent would alert the user to potential differences in strategy. Models could reflect a range of different strategies, for example, ones that prioritize Reward or ones that minimize risk. As the person plays the game, the models could continually monitor the information sampling and predict which of them is most likely to reflect the user strategy. This could allow the agents to predict their human team-mates activity and aid in deciding whether to intervene, provide support, or draw the human’s attention to specific information.
We aim to use the computer model as a proxy for human decision-makers when training Multi-Agent Reinforcement Learning (MARL). Clearly, having humans participate in the millions of trials required to train MARL is impractical. There is a tradition of using humans to manually intervene in MARL training, for example, having human feedback shape the reward signal (Christiano et al., 2017) or having human experts modify the reward space (goal map) that trains MARL (Nguyen et al., 2019). Our approach introduces human-like qualities into the agents themselves. Having agents that could represent some aspects of human decision behavior (in this case, the manner in which information from a display) can allow other RL agents to learn to interact with “human-like” agents. We also aim to use human-like agents to identify the most probable strategy that a person is following in a decision task.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The work reported in this paper was partly supported by an award from the US Army Research Laboratories to the Alan Turing Institute and University of Birmingham.