
Abstract
Prior research on trust in automation has primarily focused on instances where decision aids form predictions based on the same raw input information as humans. This study extends the paradigms into the human-processed input framework, where machine predictions are based on human-processed data, instead of the raw input. The human-processed input framework introduces a unique error pattern, “incorrect reassurance,” where faulty automation prediction erroneously validates users’ initial errors. This study examined the impact of “incorrect reassurance” on human trust in automation in the human-processed input framework. Thirty-five participants completed a Mental Rotation Task (MRT), using an imperfect automated decision aid. Results show that incorrect reassurance patterns led to larger trust decrement, lower final performance, and quicker final reaction time compared to other performance patterns. The findings emphasize the importance of understanding trust in automation in the context of the human-processed input framework.
Introduction
Automation has the potential to enhance safety and efficiency in various industries, such as healthcare, transportation, warehouses, and construction. Human trust in automation has been identified as a key factor for the successful implementation of these technologies (Bhat et al., 2024; Guo & Yang, 2021; Guo et al., 2023; Hoff & Bashir, 2015; Lee & See, 2004).
Prior research on trust in automation has primarily focused on instances where decision aids form predictions based on the same raw input information as humans. For example, in the X-ray luggage screening task used by Merritt et al. (2013), participants made an initial unaided decision in parallel to the automated aid scanning the luggage to predict whether the bag required a search or not. In this scenario, both humans and the automation used the same initial X-ray image to make judgments. Then participants made their final decision after viewing the aid’s advice.
Alternatively, automated systems may operate on human-processed input data. In the healthcare sector, for example, to reduce medication errors (patients receiving and taking the wrong pills), automated pill-recognition technologies have been introduced for verification (Caban et al., 2012; Lester et al., 2021; Reiner et al., 2020). In this process, pharmacists first select the medication based on prescriptions (raw input), automation then predict the human-selected medication (human-processed input), and finally, the pharmacist decides whether or not to give it to patients after viewing the prediction. The human-processed input framework introduces a unique error pattern, “incorrect reassurance,” where faulty automation prediction erroneously validates users’ initial errors.
This study extends the trust paradigms into the human-processed input framework, introducing unique error patterns that must be extensively explored. Kim et al. (2023) developed a simulation testbed called Mental Rotation Task (MRT). In the experiment, participants first viewed the reference shape and made an initial selection from five answer choices. Participants were then shown the automated aid’s prediction of their initial choice. After that, they confirm whether their initial response was correct or not. Results show that in the incorrect reassurance cases, where the automated aid’s erroneous prediction could potentially mislead participants to confirm their wrong initial response, there is a notable decline in both the performance and trust levels.
Methods
This study complied with the American Psychological Association code of ethics and was approved by the University of Michigan’s Institutional Review Board (HUM00230326).
Participants
Thirty-five university students (average age = 22.06, SD = 3.11), all with normal or corrected to normal vision, completed the experiment. Participants were compensated with a $10 bonus rate, with a chance to earn up to another $10 as a performance bonus.
Apparatus and Stimuli
The experimental display was presented on a Dell 23.8-inch monitor, with a 1,920 × 1,080 resolution. Each participant performed 60 trials of a mental rotation task (MRT), which consisted of initial answer selection without automation help and a final verification with the help of an imperfect automated aid (Kim et al., 2023).
Mental Rotation Task
During each trial, participants first viewed the reference shape and made an initial selection from five answer choices. After rating their confidence, participants were shown the automated aid’s prediction. On this page, participants were asked to confirm the validity of their initial response. They were then shown the performance feedback on the validity of their initial response, the machine aid’s prediction, and their final response (bottom of Figure 1), along with the points gained or lost for the trial and the cumulative points up to the current trial.

On the final selection page (top), the automated aid’s prediction was provided to the participants. Participants’ task was to determine whether their initial answer was right or wrong, compared to the reference. The performance feedback page (bottom) showed the validity of the initial choice, automation prediction, and final choice. If the initial choice was incorrect, the correct answer was highlighted in green.
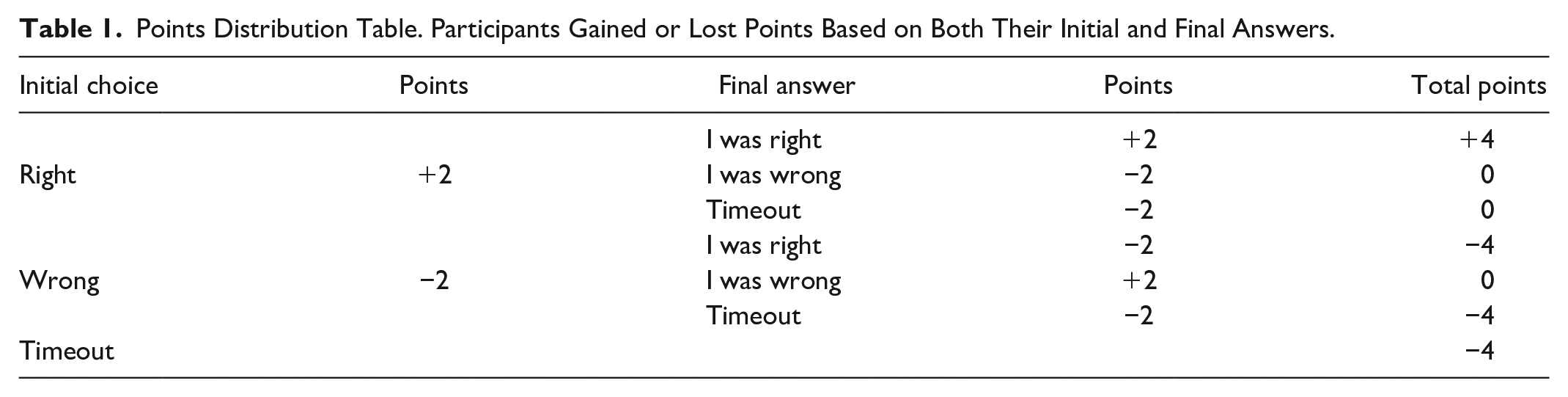
Participants gained 2 points for right initial or final answers and lost 2 points for wrong initial or final answers. If the answer was not selected within the time limit, they lost points for the trial. For each trial, the possible points were either +4, 0, or −4 (see Table 1 for details). This point system was used to keep the participants engaged throughout the 60 trials.
Points Distribution Table. Participants Gained or Lost Points Based on Both Their Initial and Final Answers.
One change made to the study by Kim et al. (2023) was that we included feedback on the validity of the machine aid’s prediction in green color when correct and red color when incorrect (see Figure 1). This was changed to explicitly let the participants know of the machine prediction validity, which could be missed if the shapes seem similar.
Automated Aid
For the mental rotation task, participants were supported by an imperfect automated aid designed by Kim et al. (2023), with reliability between 70% and 80%. The reliability followed the suggestion of synthesizing literature that if automation performance falls below 70% reliability, the costs will outweigh the benefits (Wickens & Dixon, 2007).
The automated aid aimed to help achieve the goal of determining the validity of the initial choice by predicting the initially selected shape (machine prediction is shown below the participants’ initial answer [highlighted in yellow] in Figure 1). However, the participants were ultimately responsible for selecting the final answer: to determine whether their initial answers were right or wrong.
Out of the 60 trials, there were 42 correct predictions and 12 incorrect predictions. The machine validity for the remaining six trials depended on participants’ initial answers. These were the potential incorrect reassurance cases that if the participants’ initial answer was right, it would appear as a correct automation prediction and if the participants’ initial answer was wrong, it would appear as an incorrect automation prediction.
Procedure
Participants were recruited via email and invited to the lab. Upon arrival, they reviewed and signed an informed consent form. After completing a pre-experiment survey, they were then shown a 5 minute introduction video that went over the experiment and began training to become familiar with the scenario. During training, participants completed four practice trials of MRT. Afterward, participants completed 60 trials of MRT, followed by a post-experiment questionnaire, and received compensation based on their performance.
Independent and Dependent Variables
A within-subject design was utilized, with an independent variable, performance patterns. This variable captures the combinations of participants’ right or wrong initial responses (indicated by the first letter) and the automated aid’s correct or incorrect prediction (indicated by the second letter). Five patterns were: RC (Right-Correct), RI (Right-Incorrect), WC (Wrong-Correct), WI (Wrong-Incorrect), and WI_Ref (Wrong-Incorrect that matches the reference image; see details in Table 2). The occurrence of each pattern was dependent on participants’ initial responses, which could not be manipulated.
Performance Patterns With Descriptive Names. Each Pattern Captures the Combinations of Participants’ Right or Wrong Initial Responses (Indicated by the First Letter) and the Automated Aid’s Correct or Incorrect Prediction (Indicated by the Second Letter).
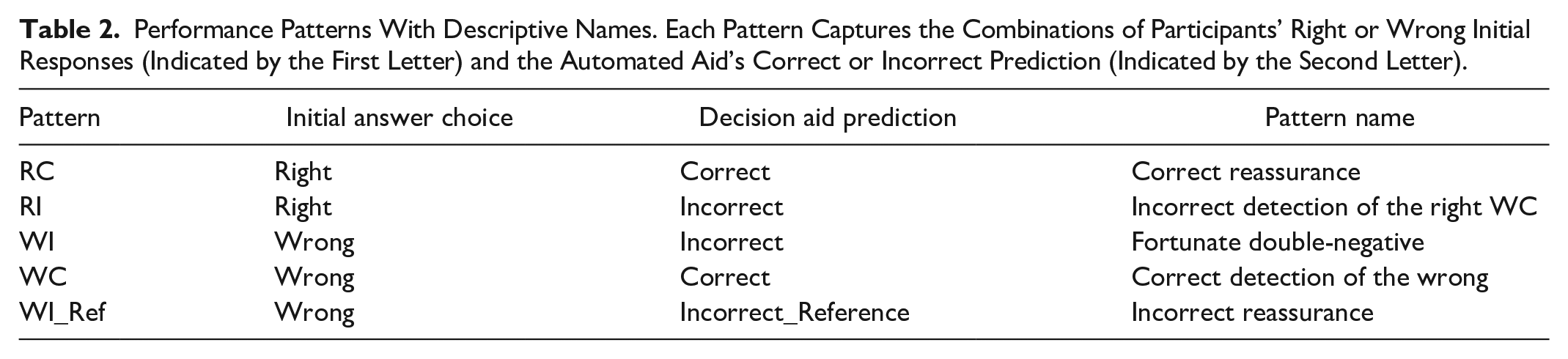
The wrong-incorrect pattern, where a human’s wrong initial choice is followed by incorrect machine prediction, can be subdivided into two different kinds of advice. When the incorrect prediction doesn’t match the initial choice or the raw input, the machine prediction would suggest the initial choice was wrong. However, if the automated aid’s incorrect prediction corresponds to the reference image, the incorrect prediction could potentially mislead humans to confirm their wrong initial choice. Kim et al. (2023) labeled this pattern (WI_Ref) “incorrect reassurance.”
Other performance patterns were also assigned a descriptive name to facilitate clear reference. We labeled pattern RC as “correct reassurance,” as automation prediction accurately affirms participants’ right initial response. Pattern RI, termed “Incorrect Detection of the Right,” occurs when the automation erroneously flags participants’ right initial response as incorrect. Pattern WC is designated as “Correct Detection of the Wrong” and represents scenarios where participants’ wrong initial response is correctly detected by the automation. Lastly, pattern WI is described as the “fortunate double-negative” because the automation’s incorrect prediction does not align with either the reference or the participants’ wrong initial choice, which could be interpreted as providing an unintended beneficial recommendation toward detecting the initial mistake.
The subjective measure, trust rating, was measured on a 0 to 100 visual analog scale after each trial. The moment-to-moment trust change was computed by comparing the trust ratings of the trial (i) with the previous trial (i-1).
Objective performance metrics were the accuracy of participants’ final verification (final performance) and the duration of the final verification, measured from the moment the automated aid’s prediction appeared until participants clicked either “I was Right” or “I was Wrong” in seconds (final reaction time).
Data Analysis
We used a one-way repeated measures Analysis of Variance (ANOVA) test along with Tukey’s Honestly Significant Difference (HSD) for post hoc pairwise comparisons between the performance patterns. To investigate trust stabilization and negativity bias, mixed model Generalized Linear Model (GLM) tests were conducted using the “lme4” package (Bates et al., 2014). Two mixed linear models were constructed (one for automation success and another for automation failure) and compared using the Welch two-sample t-test. Both analyses were conducted using R statistical software, version 4.2.2 (R Core Team, 2013).
Results
We first calculated the frequency of the observed occurrence of performance patterns. The incorrect reassurance pattern (WI_Ref) was absent for one participant (n = 34), while the remaining patterns were exhibited by all participants (n = 35) (see Table 3).
Results Table Summarizing Dependent Measures by Performance Pattern.
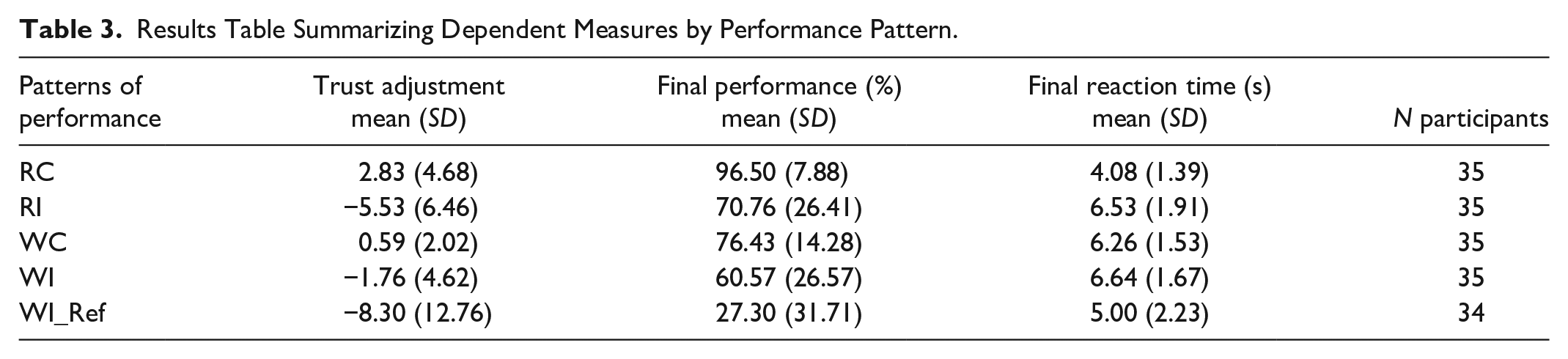
One-way repeated measures ANOVA revealed trust change (F[4, 169] = 14.14, p < .001), final performance (F[4,169] = 41.83, p < .001), and final reaction time (F[4,169] = 13.93, p < .001) were influenced by performance patterns.
Trust Change
Positive trust change was observed for the two correct automation prediction patterns, RC and WC. Following incorrect automation predictions, trust change resulted in negative outcomes (Figure 2). Incorrect predictions led to a greater trust drop in magnitude than gains observed in correct predictions (t = −4.33, df = 705.84, p < .001).
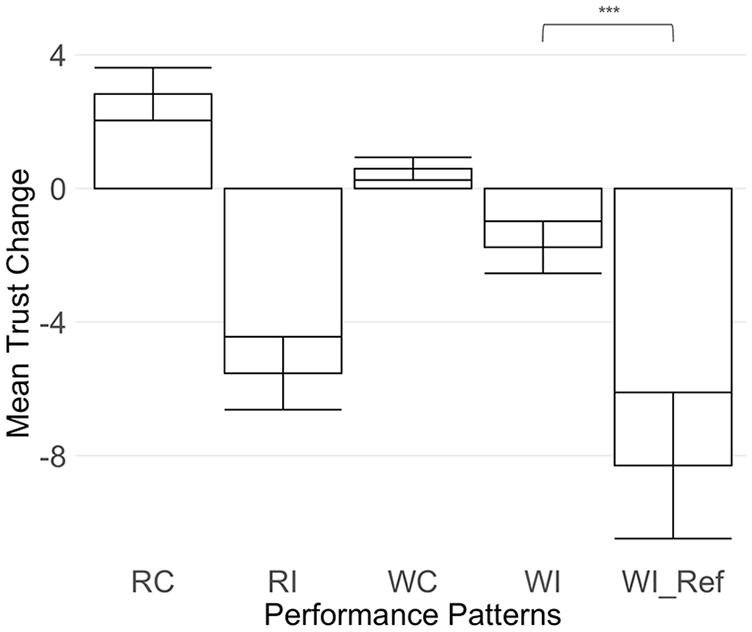
Bar chart illustrating mean trust change (Y axis), for each performance pattern. Significance indicator is displayed to highlight the significance within incorrectly predicted patterns (RI, WI, and WI_Ref).
The trust change results are presented in Table 3. The largest trust decrement occurred when participants encountered the pattern WI_Ref (Incorrect reassurance), as depicted in Figure 2. This pattern led to a significantly lower trust change compared to the other incorrect machine prediction pattern, WI (fortunate double-negative; difference = 6.54, p < .001). However, trust change of incorrect reassurance was not significantly different compared to pattern RI (incorrect detection of the right). Furthermore, pattern RI was not significantly different compared to pattern WI (fortunate double-negative).
There was no statistically significant difference in trust change between the two correct machine prediction patterns, RC (correct reassurance) and WC (correct detection of the wrong).
Analysis of trust change as a function of time revealed the magnitude of participants’ trust increment from experiencing correct predictions decreased over time (t = −4.18, df = 1466.53, p < .001), decreasing by 0.044. When participants experienced incorrect predictions, the trust decrement marginally decreased in magnitude over time (t = −1.66, df = 464.50, p < .001), decreasing by 0.048.
Final Performance
Final performance was significantly lower for the incorrect reassurance pattern (WI_Ref) compared to other incorrect machine prediction patterns RI (difference = 43.45%, p < .001) and WI (difference = 33.27%, p < .001; see Figure 3).
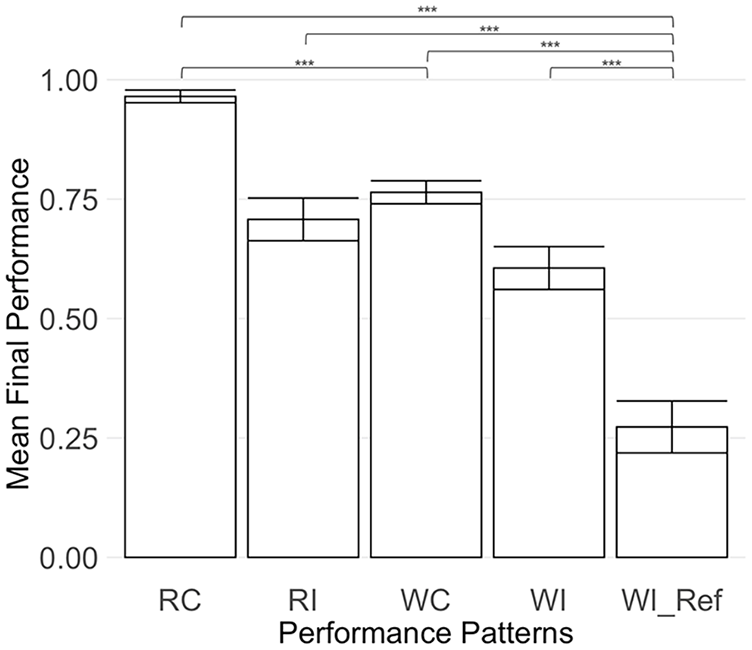
Bar chart illustrating mean final performance (Y axis), for each performance pattern. Significance indicators are displayed to highlight the statistical significance between performance patterns.
Pattern RC showed significantly higher final performance than pattern WC (difference = 20.08%, p < .001).
Final Reaction Time
Furthermore, the final reaction time for the incorrect reassurance pattern (WI_Ref) differed significantly from patterns RI (difference = 1.53, p < .01) and WI (difference = 1.63, p < .01). No significant differences were found between patterns RI and WI.
Pattern RC showed a significantly shorter final reaction time compared to pattern WC (difference = 2.18, p < .001).
Discussion
Kim et al. (2023) highlighted the negative implications associated with the “incorrect reassurance” pattern, noting the worse outcomes and greater trust decrement compared to the “fortunate double-negative” pattern (described in their study as the “simply incorrect” pattern). This study investigated the incorrect reassurance more deeply by comparing it with other performance patterns arising from the human-processed input framework. We predicted that the incorrect reassurance pattern (WI_Ref) would lead to poor performance, which would ultimately lead to a greater trust decrement compared to other patterns. To study this, we examined participants’ trust change, performance, and reaction time.
The final performance results indicated that among the five performance patterns, RC (correct reassurance) resulted in the highest rate of final correct answers. On the contrary, the incorrect reassurance pattern (WI_Ref) resulted in the lowest rate of correct final answers compared to all other patterns, as shown in Figure 3. The lowest rate of final correct answers indicates the dangerous aspect of incorrect reassurance: when automated aid validates participants’ wrong initial response as correct, it is more likely that participants will be misled into believing their initial error to be accurate.
Consistent with our predictions, the poor final performance observed in the incorrect reassurance pattern was followed by a greater trust drop relative to the fortunate double-negative pattern (WI), which aligns with the findings reported in Kim et al. (2023)’s experiment. The incorrect reassurance pattern also led to a greater trust drop compared to patterns RC (correct reassurance) and WC (correct detection of the wrong; see Figure 2).
Pattern RI (incorrect detection of the right) also resulted in a larger decrease in trust compared to RC (correct reassurance) and WC (correct detection of the wrong). However, for pattern RI, the final performance outcome was significantly higher (as shown in Figure 3), and the final reaction time was notably slower (as shown in Figure 4) when compared with the incorrect reassurance pattern (WI_Ref). These results in performance and reaction time suggest that participants were capable of recognizing the inaccuracies in the automation’s predictions for the pattern RI and consequently could disregard the automation’s incorrect advice.
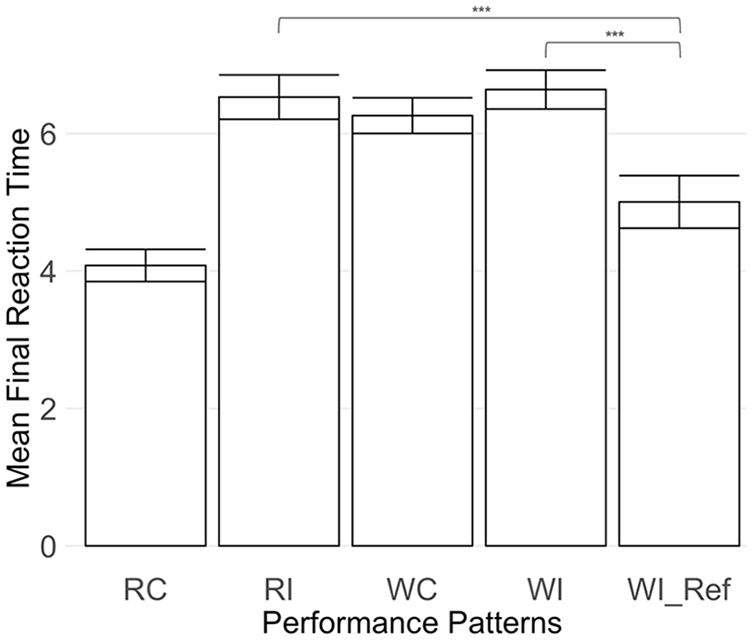
Bar chart illustrating mean final reaction time (Y axis), for each performance pattern. Significance indicator is displayed to highlight the significance within incorrectly predicted patterns (RI, WI, and WI_Ref).
Existing literature on trust indicates that trust tends to decrease after incorrect recommendations and increase following correct recommendations (Lee & Moray, 1992; Yang et al., 2017). The research conducted by Lee and See (2004) and Yang et al. (2022) explored the concept of negativity bias within trust in automation and suggested that negative experiences have a stronger impact on trust in decision aids than positive experiences. The direction of trust change observed in our study followed this trend, showing that incorrect automation predictions (RI, WI, and WI_Ref) resulted in a more significant trust drop compared to the increase in trust from correct automation predictions (RC and WC).
Additionally, we observed that as participants became more familiar with the automation’s correct predictions, the magnitude of trust increment significantly lessened over time. Similarly, the decline in trust due to incorrect predictions showed a marginal reduction over time. The marginal significance observed from incorrect predictions could be associated with the limited frequency of incorrect prediction trials incorporated within the experiment. These trends align with existing research findings that point to a stabilization of trust over prolonged interaction with automated decision aids (Du et al., 2020; Yang et al., 2022).
Participants demonstrated significantly quicker reaction times in the incorrect reassurance condition (WI_Ref) in comparison to patterns RI and WI (see Figure 4). The quick response times were similar to the reaction times of pattern RC (correct reassurance), which occurs when a correct automation prediction confirms the right initial selection. The automated aid’s incorrectly reassuring predictions caused participants to rapidly reach a consensus with the automated aid, erroneously affirming that their initial wrong choice was correct.
Even though the fortunate double negative pattern (WI) is an incorrect automation prediction, this pattern could be interpreted as providing a beneficial recommendation. Therefore, the incorrect reassurance pattern and the pattern RI (incorrect detection of the right) are the two fully incorrect recommendations. In our study, the incorrect reassurance pattern (WI_Ref) resulted in a significant decline in trust compared to all other patterns except pattern RI, as illustrated in Figure 2. Despite this, pattern RI showed higher performance and longer reaction time, suggesting that prolonged engagement with these patterns may lead to a wider gap in trust change results. Furthermore, in real-world applications, pattern RI might prompt unnecessary and redundant repetition of the initial task. In contrast, the incorrect reassurance pattern could lead to false validation of an initially wrong action. The primary consequence related to pattern RI is an elongation of task completion time, whereas the ramifications of incorrect reassurance patterns could be as serious as the delivery of incorrect parcels or medication. Therefore, when the severity of outcomes is incorporated, the decrease in trust due to incorrect reassurance patterns could potentially be magnified.
In environments where safety is the priority, such as in healthcare, automation providing incorrect reassurance could be particularly damaging, as it may lead to outcomes that harm patients (Reiner et al., 2020). Studies have indicated that trust is more negatively affected by automation failure than it is improved by automation success (Manzey et al., 2012; Yang et al., 2022). Therefore, it is essential to develop a deeper understanding of human trust behavior in response to unique errors that arise within the context of the human-processed input framework.
To ensure that the accuracy of the automation remained above the effective threshold (Wickens & Dixon, 2007), we were limited to incorporating only 6 trials of the incorrect reassurance pattern out of 60 trials. Moreover, since participants’ initial responses could not be manipulated, the occurrence of patterns was participant-dependent. In our study, only one participant did not encounter the incorrect reassurance pattern. Despite the varied group sizes across the five patterns and the limited number of incorrect reassurance patterns, these factors did not heavily impact our analysis. We employed one-way repeated measures ANOVA, which analyzes the mean responses of each participant. For future research, expanding the number of overall trials could allow for more extensive investigation into the effects of incorrect reassurance patterns. However, study designs should consider the possibility of participant fatigue associated with extended experimentation duration and the risk of automation disuse that could arise from exposing participants to excessive instances of incorrect reassurance patterns.
Conclusion
The objective of our study was to investigate trust in automation within the context of a human-processed input framework, wherein machine predictions are based on human-processed data, instead of the raw data observed by humans. We examined the influence of a unique error pattern from this framework, referred to as incorrect reassurance. Our findings indicate that incorrect reassurance patterns led to lower performance and larger trust decrement, indicating the dangerous nature of this error pattern. Future research should expand to examine how incorrect reassurances influence human trust in various settings, especially in safety-critical environments. By understanding the human-processed input framework, we can enhance the design and effectiveness of semi-automated decision aids across various sectors, contributing to improved safety.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was partly supported by the University of Michigan Rackham Graduate Student Research Grant awarded to the first author.