
Abstract
Emerging digital technologies and the ubiquity of social media have accelerated the spread of manipulated media, which includes the deliberate alteration of audio-visual content to mislead or influence public opinion. This study compares human and analytical approaches to detect, attribute, and characterize manipulated media across diverse platforms. As part of the Semantic Forensics (SemaFor) program, we assessed human baseline performance against advanced analytics in tasks involving text and image manipulations within news articles. Results indicate that while analytics excel in detecting and localizing manipulations, human performance remains vital for handling nuanced or context-heavy tasks. This research underscores the need for combining human expertise with technological solutions to effectively counteract media manipulation threats.
Keywords
The Rise of Manipulated Media: Challenges and Responses in the Digital Age
Emerging digital technologies and the ubiquity of social media platforms have accelerated the spread of manipulated media, news, and technical information in both size and scale. Manipulated media refers to the use of digital tools and technologies to deliberately alter, distort, misrepresent, or fabricate visual or audio content. This media may be used to influence public opinion or sway social outcomes, mislead, or deceive the audience, or to simply create confusion and undermine trust in legitimate sources.
Journalists, media organizations, and policymakers can advocate for ethical guidelines and best practices in digital media consumption, fact-check and debunk misinformation, and encourage constructive dialog with audiences. However, the increasing ease of producing and disseminating manipulated media has sparked a demand for technological solutions capable of swiftly and autonomously countering this growing threat. Technological solutions that can detect, attribute, and characterize manipulated media provide a scalable and automated method to limit, mitigate, and prevent its spread. Despite analytics not reaching perfect accuracy, prior research has shown that algorithms can obtain higher accuracy in detecting manipulated news than humans (Zhou & Buyya, 2018). These solutions may be able to contain and combat these threats more effectively than human moderation alone.
Advancing Media Integrity: DARPA’s SemaFor Program and the Battle Against Manipulated Media
The Semantic Forensics (SemaFor) program funded by the Defense Advanced Research Projects Agency (DARPA)—aims to develop foundational technology to refine and extend analytics for detecting, attributing, and characterizing semantic inconsistencies in manipulated media at scale. SemaFor analytics were evaluated through a series of rolling tasks focusing on the evolving threats of synthetic and manipulated information across a variety of modalities. The goal of the present research is to provide a baseline of human performance for comparison with the SemaFor analytics developed to address detection and characterization demands across diverse manipulated media tasks. Direct comparison with technological approaches to detecting and characterizing manipulated media are relatively few. It is evident that human and analytical approaches to understanding and processing manipulated media differ not only in their performance outcomes but also in their fundamental methodologies. As media manipulations become more technically advanced and semantically complex, enhancing analytical performance becomes increasingly challenging.
Method
The present work provided a baseline of both typical human performance (N = 299) and subject matter expert (SME) performance (N = 9) in comparison to SemaFor analytic performance. The nine SMEs were individuals with experience in the generation, detection, and manipulation of media and associated with the broader SemaFor program that were not involved in the production of the specific manipulated media probes used for the study. Media manipulations were embedded within multi-media news articles and comprised both visual and text manipulations. Humans and analytics were provided with matched probes across different tasks, comprising text detection and localization, image detection and localization, propaganda tactic characterization (e.g., bandwagoning), and semantic inconsistency detection.
Sample Demographics
The SemaFor Human Baseline Evaluation used Prolific—an online panel company similar to MTurk—to recruit a US citizen sample of participants who then completed the tasks on the Qualtrics survey platform. At the completion of the study’s tasks, participants were provided with a code to report, and the experimenters reviewed their data (e.g., attention checks). They were then paid $12.00 (US) for their participation through the Prolific platform. A total of 308 participants participated, comprising 37% female, 60% male, and 3% not reported. Ages ranged between 18 and 72 (M = 37, SD = 11).
Types of Tasks
Across tasks, participants were shown the media stimuli and asked to identify whether each item was genuine or manipulated. The order of the media stimuli was randomized to control for order effects. These tasks reflect real-world scenarios where distinguishing manipulated content from authentic information is crucial.
For image detection and localization, participants reviewed the news article (with an image) and indicated whether or not they detected an image manipulation. If a manipulation was detected, they were prompted to draw a box around the manipulation. This task was designed to mimic the challenge of identifying doctored or manipulated images that might influence public perception. For generated text detection, participants reviewed a news article probe and asked to determine whether or not it was entirely synthetically generated (or not). Probes were a few paragraphs. This task mirrors the real-world necessity of identifying news articles that are produced of whole cloth using large language models that could mislead readers.
For propaganda tactic characterization, participants were asked to detect and characterize a specific propaganda tactic in the news article (e.g., scapegoating, hate speech, bandwagoning, and dictat). Participants received instructions and definitions for each tactic before they began and could reference this information while completing the task. This task underscores the importance of accurately understanding and characterizing the meaning and intent of media artifacts. For semantic inconsistency detection, participants were provided with the news article and responded whether the elements in the news article were consistent in meaning across the headline, image, and body. This simulates real-world scenarios where often a headline is taken out of context with the body of the article, or the caption of the image. These inconsistencies can signal attempts to mislead readers and emphasize the importance of holistic media literacy as a critical skill.
Measures
We use metrics like the probability of detection and balanced accuracy to measure performance on these tasks because they provide a comprehensive evaluation of a system’s ability to accurately identify manipulated content, while accounting for potential biases and imbalances in the data, thus offering a more nuanced understanding of the model’s real-world effectiveness.
The probability of detection p(D) is the proportion of actual positives that are correctly identified for a falsification class from the total of true positives (TP) and false negatives (FN).
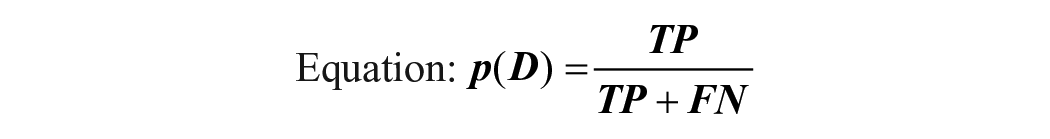
Accuracy is the percentage of correct classifications, specifically called balanced accuracy (bACC) to deal with imbalanced label distribution. Accuracy scores were only applied to the characterization tasks.
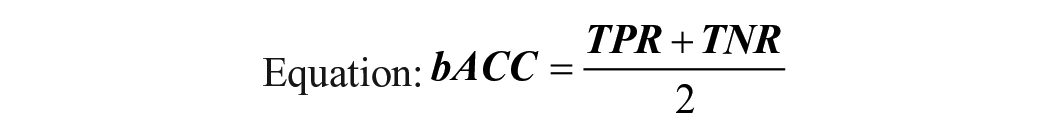
Where:
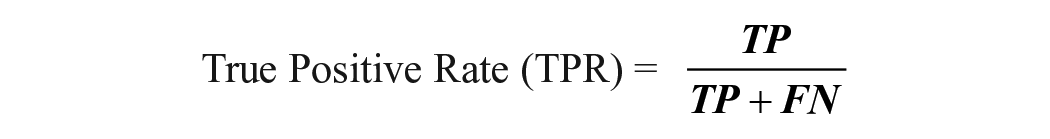
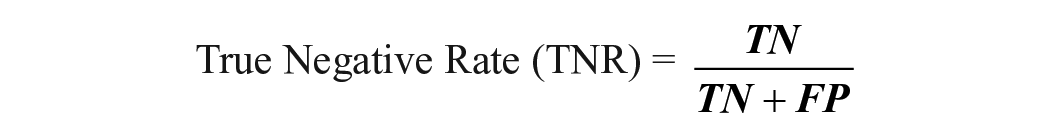
Measuring Human Performance
Each participant completed a subset of the total probes chosen for the human baseline evaluation. To ensure a variety of difficulties and topics were represented across probes, three SMEs reviewed probes with interrater consistency assessed using Fleiss-Kappa agreement (Fleiss et al., 2013). To calculate human performance, each participant’s probe list performance was scored by task. Their performance was then averaged on the probe list among all participants. The classification of the subset of participant probes on an analytic were retrieved and the metric of either bACC or pD were applied on those subsets. This process is repeated for every participant and their probe list and every analytic on the same probe list. These metrics are gathered then averaged to achieve the mean/standard deviation. The bACC metric is used for probe lists containing negative examples where probes were labeled as “pristine” or employing other tactics and intents from the ones being measured.
Measuring Analytic Performance
Multiple analytics competed in detection (i.e., determining if a piece of media is manipulated), attribution (i.e., what tool or generator was used in the manipulation), and characterization (i.e., for what purpose was the media manipulated) tasks. To illustrate trends and facilitate comparisons between human and analytic performance, two operationalizations of analytic performance were examined. First, the mean performance across all analytics that completed a specific task was calculated using the matched probes that the human baseline sample also completed. Second, the best performing analytic’s performance was also used (simple number-right scoring for matched probes). Within the human baseline evaluation, the balanced accuracy (bACC) and probability of detection (pD) were used as metrics. Finally, Cohen’s d was used to help interpret the magnitude of differences in comparing between the human baseline and SME samples.
Results
Human performance was closest to analytic performance in detecting image manipulations—but less so for localizations. The human baseline sample successfully detected image manipulations about two-thirds of the time, whereas SMEs and the mean analytic performance were equal at 75%. Best performing analytics were only slightly better at 78%. When asked to localize the manipulation, performance increased to 85% for the baseline sample and 90% for the SMEs; mean analytic performance reached 98% and the best performing analytic had a perfect score.
There was much variability across human baseline, SME, and analytic performance for the generated text detection task, where full articles were generated. The human baseline sample performed a bit worse than chance (48%), while SMEs were relatively successful at detecting fully generated text articles (75%). Mean analytic performance reached almost 90% and the best performing analytics reached almost 100%.
Performance across the human, SME, and analytic samples showed inconsistent successes across propaganda characterization tasks (see Table 1). In some cases, analytics were able to accurately identify the tactic utilized in the media, while human and SME performance generally was less favorable.
Human Versus Analytic Performance on Characterizing Propaganda Tactics.
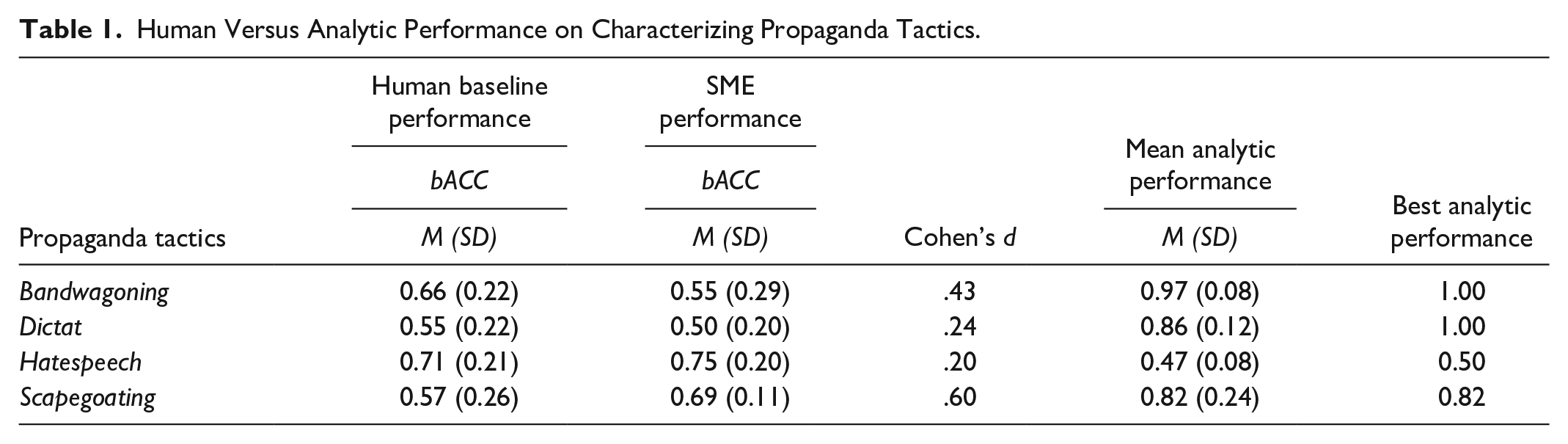
For text inconsistencies, analytics showed the poorest performance in detecting semantic inconsistencies when inconsistencies were present in both the headline and image of an article (see Table 2). However, this performance was only slightly lower than SMEs (67% and 69%, respectively). The human baseline sample performed worse still at 55%. For text and image inconsistencies, analytics outperformed SMEs substantially, and the human baseline even more. For headline inconsistency detection, analytics were equivalent to SMEs, and about 10% better than the human baseline’s performance.
Human Versus Analytic Performance on Detecting Inconsistencies.
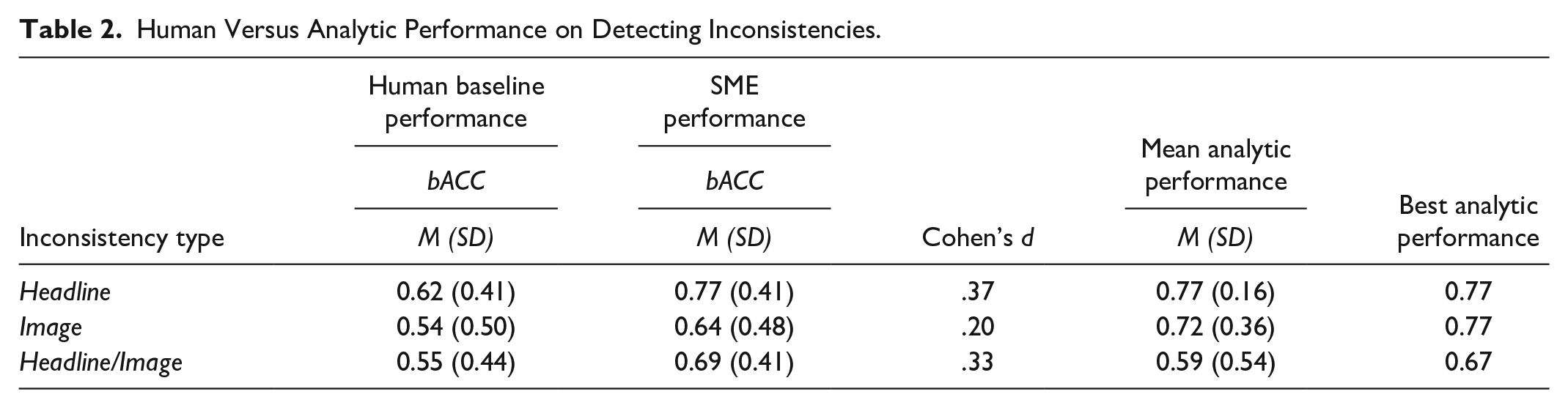
Discussion
Human perception of news can make us vulnerable to misinformation through biases and inaccurate perceptions. Nevertheless, systematic weaknesses in analytic approaches can exhibit their own unique biases—which may or may not overlap. As these results demonstrate, there appear to be systematic differences in performance across not only humans versus analytics, but also a typical baseline sample versus SMEs. Results generally showed analytics’ performance greater than both the baseline and SME samples. That said, there were a few instances where even the best analytics were similar to or even performed worse than baseline and SME samples. Of particular interest are tasks where humans or analytics showed greater success on aspects of the task rather than others. This was mostly true of propaganda tactic characterizations—a task requiring what most humans would say requires subjective interpretation.
Technological advancements in manipulation detection and characterization struggle to keep pace with advances in media manipulation. Understanding the systematic differences between analytics and humans can offer insights into how technology can address pervasive and effective media manipulations. In directly pitting human versus analytic performance across detection and characterization of manipulated media, results suggest that analytics showed substantive if mixed improvement over both the baseline and SME samples.
Application and Future Research
Understanding how analytic approaches complement or hinder human efforts in combating manipulated media highlights the challenges in comparing these fundamentally different methods and the importance of allocating resources wisely. Four cases seem possible. (1) When analytics can outperform human expertise, they offer the greatest benefit, limited risk, and potentially, lowest cost. (2) When analytic and human performance differ in predictable ways—that is, catching what the other might miss—these approaches appear complementary. (3) When analytic and typical human performance are poor, but SME performance is high, SME-driven approaches like fact-checking and debunking false information could be the best recourse. (4) When analytic, typical human, and SMEs all underperform, promoting ethical guidelines for digital media and engaging in constructive dialogs among experts and audiences to promote media literacy and critical thinking skills would appear most viable. This kind of taxonomy can be used to frame not only evaluations, but offer specific recommendations, policy interventions, and media guidelines based on evaluations’ results.
Assuming uniform performance across tasks without assessing characteristics of manipulated media oversimplifies the unique strengths and weaknesses of human and analytic approaches. Indeed, humans and analytic collaboration may even lead to unique interactive effects that may lead to unique advantages in combating misinformation (Snijders et al., 2023). Extending these findings, future research should focus on further disentangling humans’ cognitive factors versus analytic approaches that differentially interact with the characteristics of manipulated media.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This effort was sponsored by the Defense Advanced Research Projects Agency (DARPA), under contract number PGSC-SC-111371-01. The views, opinions and/or findings expressed are those of the author and should not be interpreted as representing the official views or policies of the Department of Defense or the U.S. Government.