
Abstract
The need for automated fact-checking has become urgent with the rise of misleading content on social media. Recently, Fake News Classification (FNC) has evolved to incorporate justifications provided by fact-checkers to explain their decisions. In this work, we argue that an argumentative representation of fact-checkers’ justifications can improve the precision and explainability of FNC systems. To address this challenging task, we present LIARArg, a novel linguistic resource composed of 2,832 news and their justifications. LIARArg extends the 6-label FNC dataset LIAR-PLUS with argumentation structures, leading to the first FNC dataset annotated with argument components (claim and premise) and fine-grained relations (attack, support, partial support and partial attack). To integrate argumentation in FNC, we propose a novel joint learning method combining, for the first time, Argument Mining and FNC which outperforms state-of-the-art approaches, especially for news with intermediate truthfulness labels. Besides, our experimental setting demonstrates that fine-grained relations allow an extra performance boost. We also show that the argumentative representation of human justifications can be exploited in a Chain-of-Thought manner both in prompts and model output, paving a promising avenue for research in explainable fact-checking. Finally, our fully automated pipeline shows that integrating argumentation into FNC is not only feasible but also effective.
Introduction
Social media are the main platforms for online social interaction and transmission of information. While these platforms have democratized access to information and facilitated worldwide communication, they also increased the circulation of online disinformation which refers to all forms of false, inaccurate, or misleading information designed, presented and promoted to intentionally cause public harm or for profit. 1 Fact-checking, i.e., the claims assessment task, is extremely complex and time-consuming to scale with the quantity and speed at which misleading information circulates.
Currently, automated fact-checking methods mainly rely on various pieces of evidence retrieved from the Web to assess the truthfulness of news claims. 2 The use of Large Language Models (LLMs) has significantly improved the task of Fake News Classification (FNC), and most works focused on experimenting with various neural network architectures and training strategies3,4 or how to better combine different pieces of evidence. 5 However, successfully recognizing online disinformation depends not only on understanding whether factual statements are true, but also on interpreting and critically assessing the reasoning and the arguments provided in support of the raised conclusions. 6 In this article, we tackle this challenging issue and we answer the following research question: how to better leverage evidence to improve the performance of automated FNC systems?
Argument Mining (AM)7–9 aims at identifying argumentative spans in natural language texts, classifying each argument component into major types such as claims and premises, and finally, predicting the relations among the classified components. Notable applications of Argument Mining include automated student persuasive essay scoring, where either coarse-grained argumentation features, such as the number of claims and premises, are added,10,11 or an additional dimension of argumentation quality is introduced. 12 AM also enhances the quality of automatic debate systems13,14 and supports collective decision-making processes. 15 In the medical field, AM aids in detecting the effects of interventions (e.g., improved, increased) by incorporating argument features 16 and facilitates the analysis of scientific papers in biomedical text mining. 17 In legal domains, it helps justify decisions 18 and improves legal text summarization.19,20 Two particularly related areas to FNC are argument-based sentiment analysis 21 and stance detection, 22 where identifying a user stance with respect to a certain topic is critical. Combining AM with Fake News Classification to better understand the relationship between a news claim and evidence is a natural step. This integration benefits FNC systems in two key ways: first, it mirrors the work of professional fact-checkers, who analyze claims and premises supporting or refuting the news claim; second, it enhances the explainability of automated FNC systems by allowing argument components to justify the final predicted label. More precisely, our research question breaks down into the following sub-questions: (i) Does an argumentative representation for news claims and human justification profitably impact the task of FNC? and (ii) How to leverage this representation to improve the performance of automated FNC systems?
The main contribution of this article is threefold:
We build a novel annotated linguistic resource called LIARArg, which extends LIAR-PLUS.
23
To the best of our knowledge, LIARArg is the first dataset integrating AM to FNC. It contains 2,832 news claims and justifications provided by professional fact-checkers enhanced with argument components as well as fine-grained argument relations. After establishing strong FNC baselines by combining the strength of recent knowledge-enhanced approaches,24,25 we propose a novel joint-learning architecture to train AM and FNC together to transfer the argument knowledge contained in the annotation to FNC, as well as a novel Chain-of-Thought (COT)
26
based framework to explicitly inject the argument structure into the prompts. These novel approaches outperform SOTA approaches in FNC on the same dataset, especially for news with intermediate truthfulness labels. Through our extensive experimental setting, we demonstrate the crucial contribution of argument relations (particularly fine-grained relations, which allow an extra performance boost on this 6-label dataset) to assist the FNC task, highlighting therefore a promising research direction to tackle the problem of half-truths classification.
27
The remainder of this article is structured as follows: Section 2 provides an overview of existing literature on Fake News Classification. In Section 3, we present the novel LIARArg dataset, including sampling methods, filtering criteria, annotation process, and agreement computation. Section 4 presents the experimental setup, baselines and introduces the two architectures we propose. Additionally, we introduce a fully automated, argumentation-enhanced FNC pipeline. Section 5 presents the key outcomes and insights derived from our experiments. Conclusions end the article with a discussion about the main contributions and limitations of our approach, highlighting directions for future research.
The automated fact-checking process generally involves 4 stages 2 : (i) claim detection to identify or rank the claims to verify; (ii) evidence retrieval to find sources supporting or refuting a claim; (iii) claim verification or FNC to assign truthfulness labels to claims, and finally, (iv) justification production which explains the verdict. This section focuses on works related to the FNC phase, which is the focus of this work.
Early studies on FNC have been conducted using only news claims as input, in a binary classification fashion. 28 FNC has then considerably evolved. Firstly, the input has been enhanced with meta-data such as the speaker’s background and the news context. 29 The evidence has also been incorporated into the input in the form of text, 30 knowledge graphs 31 or tabular data. 32 Secondly, several datasets have employed finer-grained classification schemes, e.g., including the addition of an extra “lack of information” label in FEVER, 33 or more importantly, some supplementary labels to represent degrees of truthfulness such as in LIAR 29 and FakeCovid. 34 Lastly, in terms of modeling strategies, early studies used stylistic features or bag-of-words representation of news claims and metadata without employing external evidence.29,35 Some studies use both claims and evidence as input, and frame FNC as a Natural Language Inference (NLI) problem. In this case, the evidence is used as premise to refute or support the hypothesis represented by a news claim. When multiple pieces of evidence are available, a weighted aggregation 36 is often required to take into account the reliability of the evidence. Another line of research considers the evidence as reliable by default. 37 Early studies used classical methods in Natural Language Inference such as the decomposable attention model of Parikh et al. 38 which scored best on the Stanford NLI corpus. 39 The advent of large pre-trained language models (LLM) such as BERT 40 has garnered attention also in the FNC community3,41,42 and led to significant improvements in FNC systems performances. 43 Most recently, systems based on knowledge-enhanced LLMs such as KnowBert 44 and KEPLER 45 have further improved the classification performance. 25 Rather than using LLMs where the knowledge is injected during the training phase, the SOTA approach in FNC of Ma et al. 24 constructs an entity graph from the news text by aligning entities and their corresponding first-order neighbors in Wikidata. 46 The graph is then fed into a graph attention network 47 to produce a knowledge-enhanced graph representation. Finally, the graph representation is concatenated with a BERT-based textual representation provided as input to a linear classifier. In this article, we leverage the strength of these two knowledge injection methods to set up a strong baseline.
Other approaches aim to enhance the FNC module by linking it with an evidence retrieval module. These approaches have been mostly tested on the FEVER dataset, grounding on the general idea of jointly training the evidence retrieval module and the claim verification module (i.e., FNC). For instance, Yin and Roth 48 proposed CNNs and attentive convolutions to extract sentence representations of the claim and evidence so that the two tasks are trained jointly. Hidey and Diab 49 trained the two tasks jointly by using pointer networks 50 for the sentence selection subtask, and an Multi-Layer Perceptron based architecture for FNC. Finally, Niet et al. 51 used semantic relatedness scores and ontological WordNet features to compare claims and evidence so that evidence retrieval and FNC can be trained together. With respect to these approaches, it is important to highlight that in our work we assume that the right evidence has already been retrieved. Essentially, our module enhances the stage following evidence collection, demonstrating how to effectively utilize this kind of information. We do so by making explicit the inherent argumentative structure within a specific piece of evidence. This assumption ensures that the evidence used is trustworthy and sufficient, thereby averting scenarios where FNC systems appear to improve under false pretenses, namely instances where they correctly predict the veracity of a claim based on incorrect or irrelevant evidence, a typical case of being right for wrong reasons. The disentanglement of the evidence retrieval process from the evidence modeling process permits us to concentrate on how argumentation-based models can support FNC systems without being confounded by evidence quality concerns, thereby reducing the risk of false improvements.
Finally, as for the LIAR-PLUS dataset, 23 several studies have been conducted to improve the FNC performance. Among the approaches employing both claims and justifications as inputs, Sadeghi et al. 52 proposed a BERT-based NLI model which outperformed the baselines of Alhindi et al. 23 However, the full version of the justification texts has been used instead of the simple justifications (composed of some sentences) provided in the original dataset. Mehta et al. 53 proposed a triple BERT network to encode separately news claims, metadata and justifications. However, this approach does not outperform the ngram-based model of Alhindi et al., 23 i.e., 0.70 F1 for binary classification and 0.37 F1 for six-way classification. This highlights the need for improved methods, and particularly, for a more effective representation of justifications on this challenging dataset.
The LIARArg dataset
This section describes the LIARArg dataset which extends the LIAR-PLUS dataset 23 with argumentative labels (i.e., components and relations). To the best of our knowledge, this is the first dataset for FNC annotated with argumentative components and relations (LIARArg and the source code of our experiments can be found at https://github.com/xiaoouwang/argumentation).
Data collection and filtering
LIARArg is built on LIAR-PLUS 23 which is itself an extension of the LIAR dataset 29 consisting of 12,836 news claims taken from POLITIFACT (https://www.politifact.com/) and labeled with truthfulness, subject, context, speaker, state, party, and prior history. We choose LIAR because this dataset is particularly challenging, with six truthfulness labels: Pants-On-Fire, False, Mostly-False, Half-true, Mostly-True and True. The increased number of labels in comparison to datasets like FNC-1 54 (4 labels) and Check-COVID 55 (2 labels) is warranted by the nature of the claims evaluated on POLITIFACT. As shown in Figure 1, claims typically take the form of “X says Y.” The assessment of truthfulness focuses not on the fact that X made the statement, but rather on the accuracy of Y, considering additional contextual factors.

Excerpt from the LIAR-PLUS dataset 23 where each news claim (statement) is paired with an automatically extracted justification provided by fact-checkers.
The extreme categories, such as “Pants-on-fire,” “True,” and “False,” often include factually verifiable statements, for example:
“A photograph of 21-year-old Hillary Clinton featured a Confederate battle flag in the background.” (Pants-on-fire) “When undocumented children are picked up at the border and told to appear later in court “New Hampshire has the third-highest property tax in the country.” (True)
The intermediate labels, however, involve claims that require a more nuanced assessment of plausibility, particularly in cases where:
Causal relationships are examined: For instance, whether a statistic can be attributed to a politician or department’s policy, as in “The Texas Department of Transportation misplaced a billion dollars.” (Mostly-true) Temporal elements are involved: For example, whether a politician has shifted their stance on an issue over time, as seen in “McCain supported George Bush’s policies 95 percent of the time.” (Half-true) Speculative claims about the future are made: As in “It is a fact that it costs more to run the schools in August.” (Barely-true) Positions on controversial issues are considered: As in “Military spending cuts, known as the sequester, were President Barack Obama’s idea.” (Half-true)
As suggested by Uscinski et al., 56 the definition of truth or fact can vary depending on the nature of the claims being evaluated. This layered approach to truthfulness is specific to POLITIFACT and contrasts with datasets like Check-COVID, which focus more on factual accuracy.
Alhindi et al. 23 extended this dataset by automatically extracting for each claim a summary that has a headline “our ruling” or “summing up,” which serves as justification provided by professional fact-checkers. When no summary exists, the last five sentences in the fact-checking article were extracted. Figure 1 shows an instance of the LIAR-PLUS dataset. Note that, in LIAR-PLUS, verdict phrases, such as “it is true” or “this is misleading,” have been filtered to minimize label leakage.
To extend this dataset with the argumentative layer, we first randomly sampled an equal number of news claims for each label. Then we annotate each claim and justification with the following information: argument components (claim and premise), and fine-grained argumentative relations among the identified components (i.e., support, partial support, attack and partial attack).
Besides the additional argumentation-based annotation layer, the filtering of invalid items is also a substantial contribution of our work: the justifications in LIAR-PLUS are very noisy, whether they are summaries or the last five sentences. Furthermore, on many occasions, these justifications are not sufficient to support the truthfulness of the news claim. This quality issue can affect the reliability of our approach. We therefore also annotated the quality of each justification as good, insufficient or incomprehensible. Lastly, we annotated certain news claims as incomplete because sometimes the news comprises only two or three words, and has no meaningful truthfulness. In total, we annotated 3,934 texts of which 1,005 justifications are insufficient, 12 are incomprehensible and 85 statements are incomplete. The final dataset includes therefore 2,832 statements with a valid justification.
Typically, the annotation process in Argument Mining can be divided into three key subtasks: identifying argumentative components and their boundaries, recognizing types of argumentative discourse units (ADUs), and annotating the relationships between arguments. For the boundaries of argumentative components, clauses are typically the units. Discourse markers such as “however” are included in ADUs, as well as prepositional phrases such as “according to X.” As for types of ADUs and relations, early studies have focused on annotating thesis and conclusion statements in student essays 57 and premises and conclusions in legal texts. 58 Peldszus and Stede’s works on the microtext scheme59,60 draw inspiration from Freeman’s theory of argumentation’s macro-structure 61 and introduce a tree-based annotation framework that includes two key argumentative roles: the proponent, who presents and defends claims, and the opponent, who critically questions them. Their schema features fine-grained argument relations, differentiating between simple support (where a single premise suffices) and linked support (where multiple premises must be considered together), as well as rebuttal (where a statement is deemed invalid) and undercutting (where a statement is irrelevant to supporting or refuting another). The persuasive essay scheme annotates, besides claim/premise trees, a central component of student essays named major claim and only distinguishes two types of relations: support and attack. This scheme differentiates between only two types of relations: support and attack. Depending on the specific nature of the texts being annotated and the desired level of granularity, the roles of ADUs (claim or premise) can be omitted, as seen in Kirschner et al. 62 for scientific texts, or more nuanced relations can be incorporated 63 using Walton Argumentation Schemes. 64
We decided to keep the information of argument roles and annotate two kinds of argument components: claim and premise (The detailed annotation guidelines can be found at https://anr-attention.github.io/gd.pdf). The news text is especially well-suited for this dichotomy because each text contains generally some claims which represent statements denoting opinions or standpoints, and premises which contain statements that can be verified to some extent, including typically some quotes from original documents or concrete statistics. Unlike persuasive essays, where identifying the major claim throughout the text is essential, in our case, it is unnecessary to annotate the major claim, as it is always the first claim presented to the annotator. Note that the claim-hood and premise-hood are not intrinsic features of a statement but determined also by the relationships between statements. For example, the same statement the unemployment rate is the highest in 45 years can be annotated as a claim when it is used as a news claim to be verified, but it can also be annotated as a premise when used in a justification, as evidence to support or refute another claim.
Due to the challenging nature of the LIARArg dataset, which includes 6 fine-grained truthfulness labels, we decided to annotate 4 types of argument relations, i.e., support, attack, partial attack, and partial support. Our decision to annotate more than two relations while excluding finer distinctions, such as simple support, linked support, or Walton Schemes, represents a compromise. While greater granularity would add more information, it would also lead to an increase in annotation time, without the certainty to include enough instances for each class to allow the model to learn on them in order to achieve good classification results for this particular corpus. Most crucially, argument relations in LIARArg often follow a one-to-one pattern, with complex structures like linked support being relatively uncommon. That said, incorporating a finer-grained annotation layer to corpora with lengthy and intricate arguments could open new avenues for training more sophisticated models, a highly promising direction for future research. The definitions of these four types of relations are provided below. An argument component supports another when it validates this component, and it attacks another when it contradicts the proposition of the target component. Partial support is used when an argument component validates certain aspects of another component but diverges in some other aspects. Partial attack is used when the source argument component is not in full contradiction, but it weakens the target component. Example (1) shows an instance of support and partial attack (In the examples, claims are in bold and marked by brackets, and premises are denoted in italics in braces. Note that the first line is always the news statement, and the following text is the justification provided by the fact-checker.). In Example (1), Premise
{Another study by EPI concluded Pennsylvania lost another 44,173 jobs between 1993 and 2004 due to NAFTA} Example (2) shows an instance of attack and partial support where Premise One could argue whether it’s wise to meet with leaders of rogue nations. One could also debate whether Obama wrongly downplayed the threat posed by Iran. {But Obama never said the threat from Iran was “tiny” or “insignificant,”}
Two annotators with a background in computational linguistics carried out the first annotation phase. A data sample of 150 texts (i.e., 25 texts per label) was first annotated, followed by a first reconciliation phase to examine the main sources of disagreement, which concerned especially the annotation of partial support and partial attack. Then a second sample of 150 texts was annotated to investigate the effect of the reconciliation phase. After the second round of reconciliation, a last sample of 90 texts was annotated to make sure that the reconciliation led to consistent results. The Inter-Annotator Agreement (IAA) was calculated for each sample, as shown in Table 1. For argument components, IAA is computed for text spans which are identified as argumentative (claim or premise). For relations, all pairs of text spans which are annotated as linked are considered when computing IAA scores. Annotation is considered as agreed when both the relation label and the assigned target components are the same. We achieved a Fleiss’ kappa (Although only two annotators are involved, Fleiss’ kappa is calculated instead of Cohen’s kappa to ensure a certain degree of comparability with other works in the literature where often more than two annotators are involved.) of 0.73 (substantial agreement) for component annotation, and 0.61 (moderate agreement) for relation annotation (We refer to the scale introduced by Landis and Koch in Landis and Koch 65 for interpretation of Kappa statistics where a value above 0.61 is considered to indicate substantial agreement. Since the original score for relation annotation is 0.606, we consider it as a moderate agreement.).
Inter-annotator agreement (Fleiss’ kappa) for argument component and relation annotation.

Inter-annotator agreement (Fleiss’ kappa) for argument component and relation annotation.
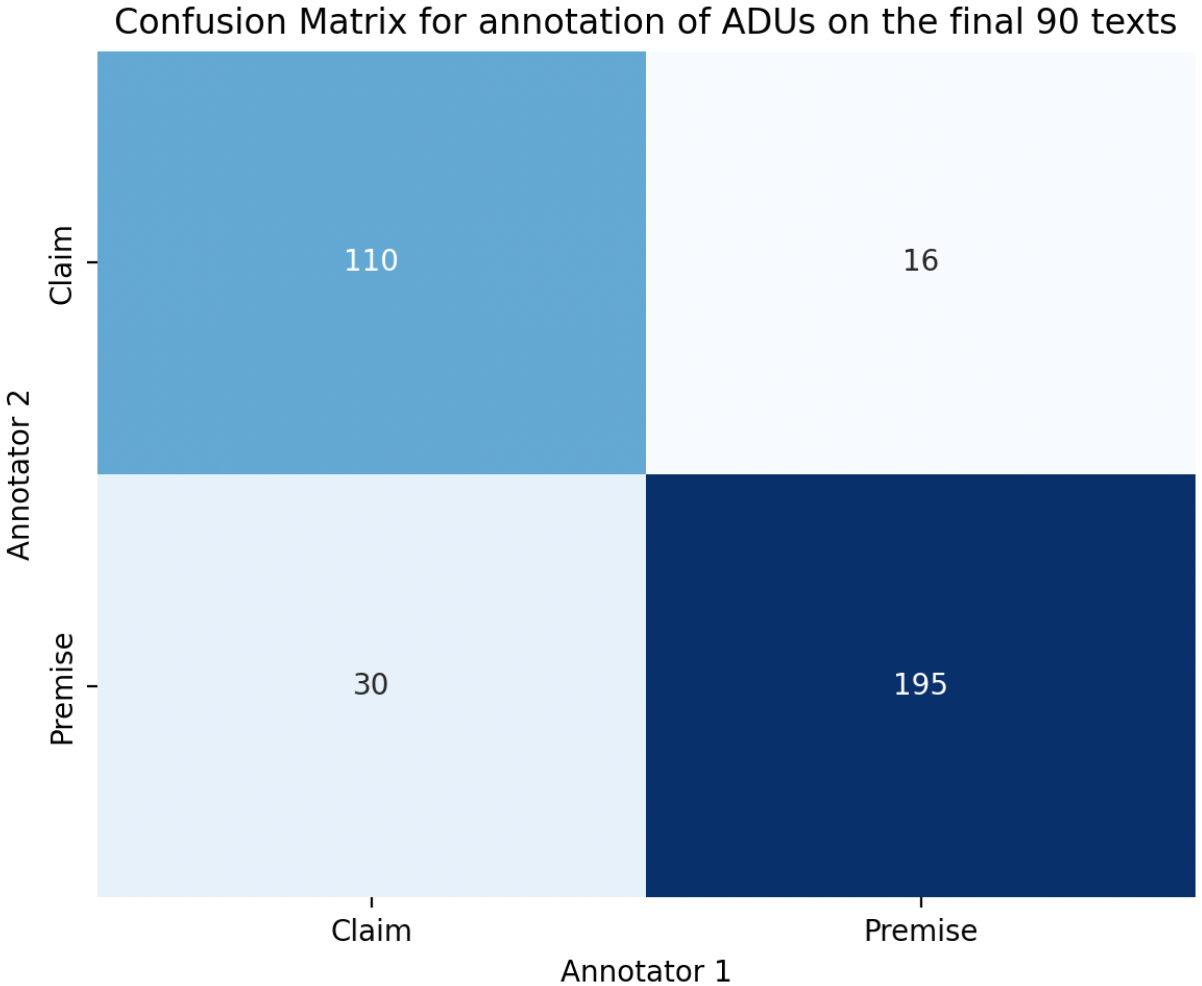
Confusion matrix for two annotators’ annotation of argument components on the final 90 texts.
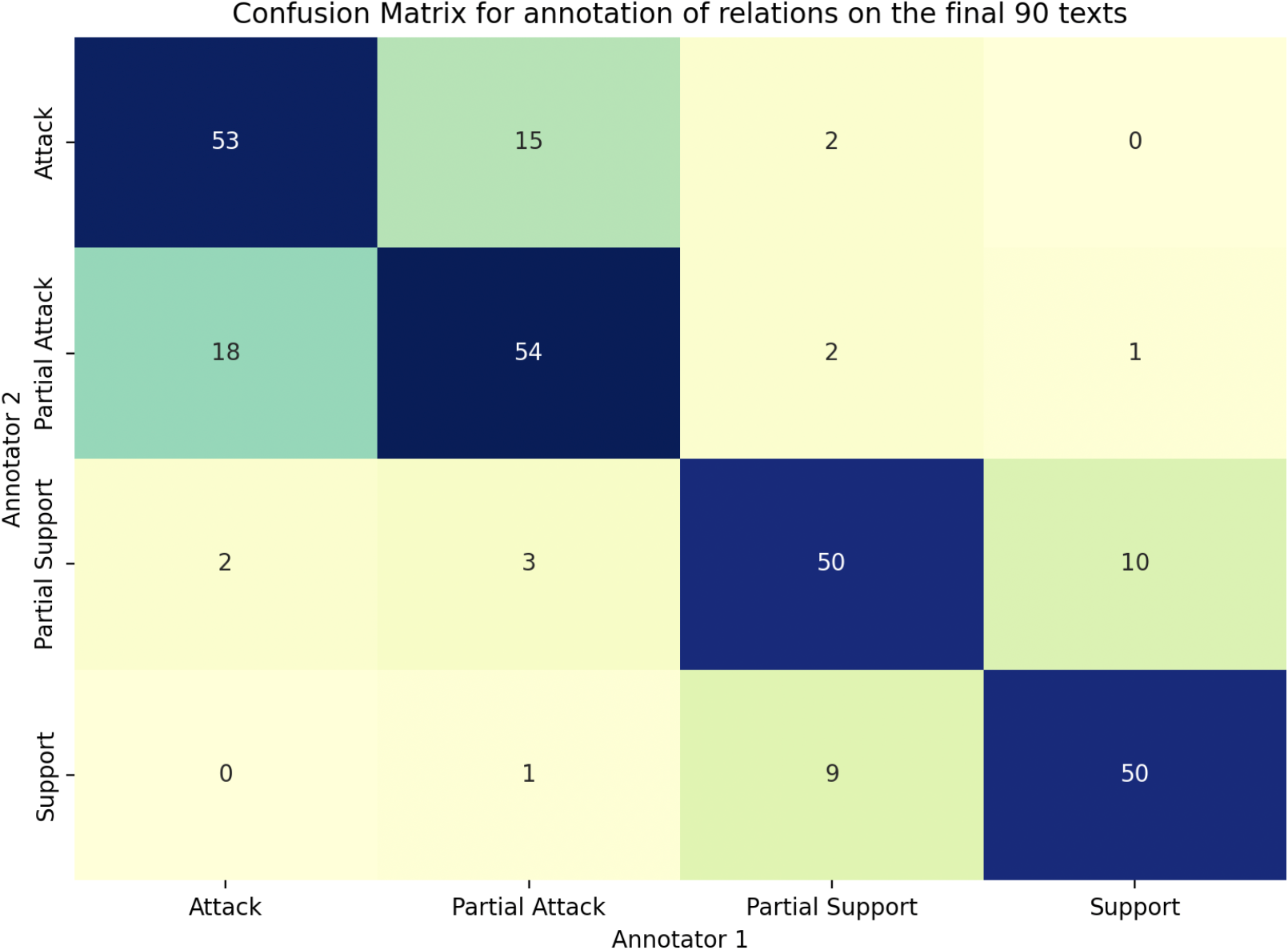
Confusion matrix for two annotators’ annotation of argument relations on the final 90 texts.
Figures 2 and 3 present the confusion matrices for the annotation of argument components and relations on the final 90 texts. 98.6% of the relations contain the same components. The results show that claims and premises are generally well distinguished. The primary disagreements in argument relations, as described at the beginning of this section, occur between support and partial support, and particularly between attack and partial attack.
It is important to note that argument relation annotation is a challenging task. The corpus ComArg, 66 where 3 annotators annotate 2,249 comment-argument pairs with attack/support relations, achieves a Fleiss’s kappa of 0.49. The same Fleiss’s kappa score is calculated for 3 annotators on 30 Randomized Controlled Trial abstracts and is equal to 0.62 (for 2 types of relations). On MicroText, 59 a Fleiss’s kappa of 0.58 is observed for distinguishing attack and support relations. Given these results, and considering that LiarArg involves four instead of two types of relations, we consider a Fleiss’s kappa of 0.61 acceptable in the current work. We obtained a final score of 0.98 for the justification quality, and 0.96 for claim completeness in the IAA assessment, indicating almost complete agreement. This level of agreement is expected as most justifications which are insufficient are the results of automatic extraction of the last five sentences in the fact-checking articles when no human-written summaries are accessible. As for incomplete claims, they are typically truncated sentences consisting of two or three words, making them easy to identify, as discussed in Section 3.1. The annotation task was then completed by one of the two annotators.
Table 2 reports on the number of annotated items per label with the average number of claims and premises for each category. The final dataset is relatively balanced, and the number of claims and premises is similar across the labels.
Average number of claims and premises across the labels.

In this section, we first outline the general settings of our experiments. Following that, we introduce the baselines and describe the architectures we propose.
As mentioned in Section 2, our work centers on the phase immediately following the evidence retrieval process. The whole pipeline of our experiment is illustrated in Figure 4. A news claim paired with an evidence piece forms the primary input. Subsequently, the claim-evidence pair is enriched with argument components and relations. Finally, the classifiers employ Multi-Task Learning or prompting to leverage the argument structure contained in the paired text to improve the FNC task performance.
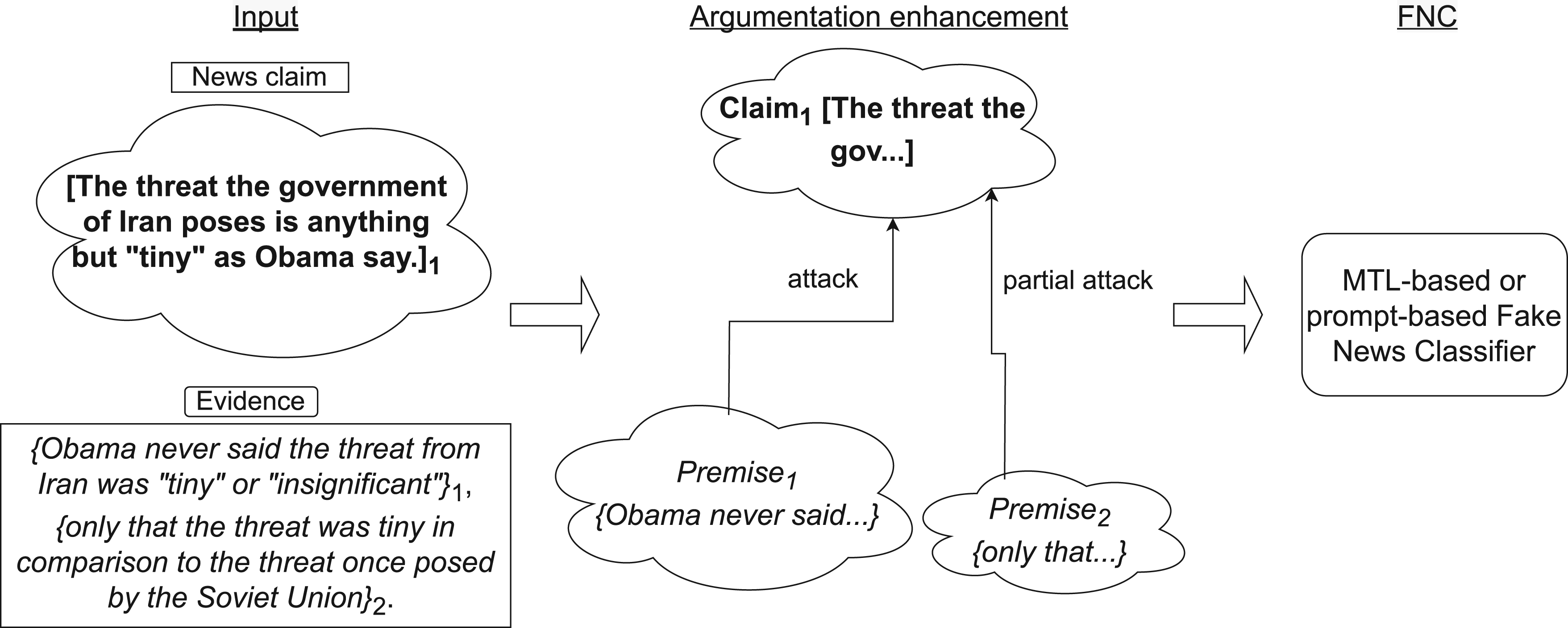
The experimental pipeline.The input consists of a textual claim and a textual justification. The justification is then enriched with the identification of the specific argument components and relations identified in the text. Finally, the classifiers employ Multi-Task Learning or prompting to leverage the argument structure contained in the paired text to improve the FNC task performance.
Our approach for fake news classification is based on two frameworks: Multi-Task Learning to implicitly integrate argumentation to FNC, and Chain-of-Thought to explicitly inject the argumentative information in the input.
Multi-Task Learning or joint learning has been extensively studied and successfully applied in various scenarios in Machine Learning 67 and Natural Language Processing. 68 Multi-Task Learning aims to leverage useful information shared across multiple related tasks to improve the generalization performance on all tasks. 69 A main task is defined with respect to some auxiliary tasks so that the knowledge learned in auxiliary tasks can help the main task, and, at the same time, prevent overfitting. Multi-Task Learning is typically implemented with either hard or soft parameter sharing of hidden layers. The former is applied by sharing the hidden layers between all tasks while keeping several task-specific output layers. In the latter case, each task has its own model with its own parameters, and the distance between the parameters of different models is regularized so that they are encouraged to be similar across models through metrics such as L2 distance. 70
Chain-Of-Thought (COT) is a prompting technique 26 demonstrating a significant performance improvement on a range of arithmetic, commonsense, and symbolic reasoning tasks. The idea is to explicitly decompose the reasoning process such as calculation procedure during the prompting process. For example, instead of asking “What is the sum of 14 and 18?,” and providing “32” as the answer, COT breaks down the procedure step by step: “4 + 8 = 12. Write down the 2 and carry over the 1. 1 + 1 + the carried over 1 = 3. The answer is 32.” Chain-Of-Thought has been shown to elicit reasoning in LLMs as GPT-3, 71 and it is particularly relevant to our scenario since argumentative information can be directly injected into the prompting in a similar manner.
Baselines
Since LIARArg is a subset of LIAR-PLUS, we used the best-performing model on LIAR-PLUS
23
as a simple baseline. Each claim and justification are concatenated, and unigram features of the concatenated text are fed into a Logistic Regression model (
Given the recent advancements in FNC driven by the incorporation of knowledge into LLMs, we establish two other strong baselines by drawing insights from the approaches of Whitehouse et al.
25
and Ma et al.
24
First, we concatenate each claim and justification by inserting [SEP] between the two. A special token [CLS] is then added to the beginning of each sentence pair, from which the final embedding of the input is extracted. The baseline
Proposed architectures
Multi-task learning (MTL)
To fully explore the potential of the justification texts, we adopt the hard parameter sharing and define FNC as the main task. Argument component classification (CC) and relation classification (RC) are considered as auxiliary tasks. Figure 5 illustrates our neural architecture for MTL-based FNC. Each instance of LIARArg is processed into 3 components: concatenated news claim and justification, the argument components (i.e., 3 labels with unknown as an extra component), and argument relation pairs (i.e., 5 labels with neutral as an extra relation (The additional labels are intended solely for training purposes and do not require extra annotation. Neutral relations include all non-linked identified ADUs pairs, while unknown components encompass all non-ADUs.)). Knowledge-enhanced embeddings based on the concatenated text are produced in the same way as for ST classifiers, namely
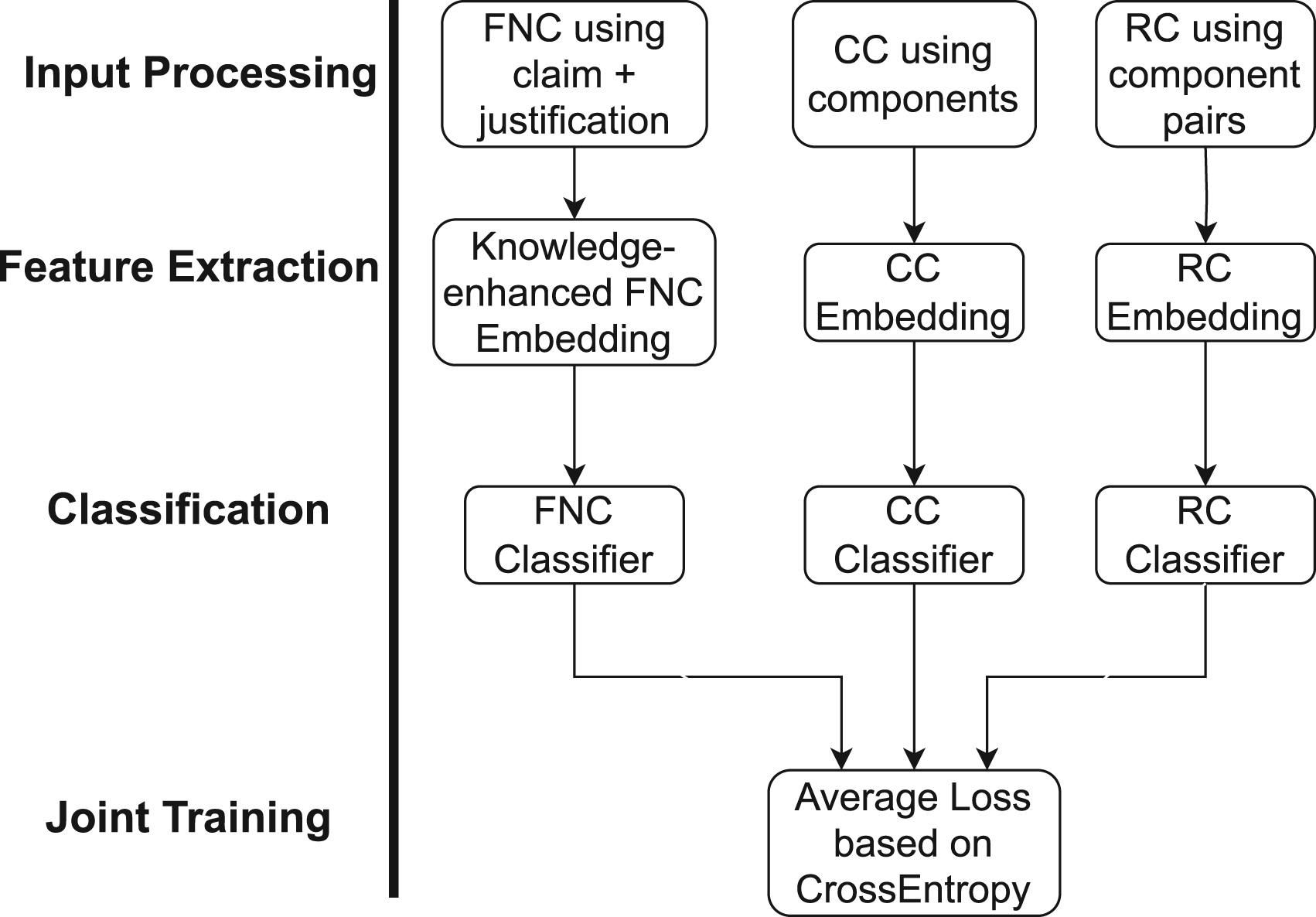
Model architecture for MTL-based FNC. The embedding of the concatenated claim and justification is produced by KnowBert (KB) or KnowBert augmented with graph embeddings. The embeddings of each argument component and relation pair are produced by KnowBert. Each embedding is then fed into a softmax layer to produce the logits for each label.
We use the text-davinci-003 variant of GPT-3 and the publicly available GPT-3 API to make inferences (https://platform.openai.com/docs/api-reference/making-requests). All the prompts start with “The task in question is to assess the truthfulness of a news claim based on a justification text by outputting one of the following six labels: True, Mostly True, Half True, Mostly False, False, Pants on Fire. The definitions of these labels are as follows”:. We used the definitions provided by POLITIFACT (https://www.politifact.com/article/2018/feb/12/principles-truth-o-meter-politifacts-methodology-i/).
To assess the impact of argumentation on FNC, we set up 3 prompting strategies. All the strategies are based on a few-shot setting with 1, 10 and 20 examples for each label followed by a new instance, the difference residing in how the examples and the new instance are presented. To mitigate potential biases in the model arising from specific examples, we construct 10 random samples for the 3 different example sizes used in the few-shot setting. The final evaluation is calculated as the average across 10 trials for each example size, thereby providing a robust assessment of the model’s performance.
In the following, we illustrate these three strategies with a news item containing two claims, as it is the most complex case in LIARArg (The connecting phrases are marked in italics.). The output of COT-based approaches is in Example: The news claims that “Hillary said that I can’t sign money. That’s illegal.” According to the justification, although defacing dollars is illegal, she could have signed that buck New instance: The news claims that Output example: {“label”: “True”} Example: The news claims that “Hillary said that I can’t sign money. That’s illegal.” There are two claims in this news claim. Claim 1: Hillary said that I can’t sign money and Claim 2: Hillary said that that’s illegal. According to the justification, “Although defacing dollars is illegal” is a premise supporting Claim 2, “she could have signed that buck without fear of prosecution” is a premise attacking Claim 1. Based on this justification, the truthfulness of this news should be half true. New instance: The news claims that Output example: {“label”: “True”} Example: the same as in COTP. New instance: The news claims that Output example: {“label”: “True,” “rationale”: “There are 2 claims in
In the subsequent sections, we append 1, 10 and 20 to STP, COTP and COTPS to denote the different number of examples used in the few-shot setting.
A key challenge in the presented approach, with the exception of the COTPS approach, is represented by the required extensive annotation effort. To assess the feasibility of a fully automated FNC pipeline enhanced through the argumentation module, we adapt the SOTA automatic AM parser of Morio et al. 72 to our task. Morio’s et al. 72 parser is trained on various types of data including student essays, 73 argumentative microtexts 59 and scientific articles. 74 We retrain the parser with the same cross-corpora multi-learning approach as in Morio et al. 72 but we add LIARArg as an extra corpus. This fully automated pipeline (Argument Mining parser + FNC classifier) allows us to replicate the methodology discussed above on a significantly larger scale – namely 8,902 texts compared to the 2,832 texts in LIARArg – without requiring further human annotations.
Since the parser of Mario et al. 72 has been adapted to the type of data close to LIARArg, it is important to further assess the effectiveness of this pipeline on out-of-domain data. For this purpose, we conduct an additional evaluation campaign on FNC-1 54 and Check-COVID. 55 The FNC-1 dataset is a well-known benchmark for FNC challenge derived from the Emergent Dataset, 75 containing 75385 labeled headline and article pairs across more than 20 topics. Check-COVID is a benchmark of 1504 claims about COVID-19 where each news claim is paired with evidence from scientific journal articles. We choose these two datasets because both provide claim-evidence pairs that can be used as input to our automated FNC pipeline (see Figure 4). FNC-1 is framed as a stance detection task with 4 labels: agree, disagree, discuss and unrelated, while Check-Covid is a binary classification task with Refute and Support as labels. We employ the state-of-the-art models in the literature for each dataset as baselines: the augmentation-based ensemble learning approach for FNC-1 76 and the dual RoBERTa-based model for Check-COVID 55 where two RoBERTa models are fine-tuned to first select relevant sentences in evidence then to classify the claim-sentences pair.
Considering the large size of these three datasets, we change from GPT-3 to Mistral 7B 77 as back-end for the automated pipeline. Mistral 7B is a recent generative LLM leveraging grouped-query attention 78 for faster inference and sliding window attention 79 to handle longer sequences more efficiently. It outperformed Llama2 13B 80 on a wide range of benchmarks, and Llama2 34B on mathematics and code generation. Its low consumption of hardware resources makes it particularly suitable for large-scale experiments. The official checkpoint on HuggingFace, Mistral-7B-v0.1 (https://huggingface.co/docs/transformers/en/model_doc/mistral), is used with all the default parameters unchanged.
Evaluation setup
We perform 10-fold cross-validation using by StratifiedKFold of Scikit-learn, 81 splitting the LIARArg dataset into 80:10:10 proportions for training, validation, and test sets. Stratified sampling is used to maintain consistent label distribution across all subsets, ensuring that the training, validation, and test sets reflect the overall dataset’s label proportions. For the automated pipeline, we split the rest of the LIAR-PLUS dataset into 80:10:10 with 10 crossfolds. For the two out-of-domain datasets, we adhere to the default data splits as outlined in their respective studies. Specifically, for FNC-1, the split comprises 49,972 instances for training set, and 25,414 for test set. The Check-COVID dataset follows a distribution of 70% for training, 15% for validation, and 15% for testing. Due to the presence of data imbalance in FNC-1, the macro-averaged F1 score is used as metric as in the baseline. 55
Ablation studies are conducted on the MTL setting to demonstrate the impact of argumentative features. We append
Results
In this section, we present the results of the MTL-based and COT-based approaches presented above, as well as those of the fully automated FNC pipeline.
Results of MTL-based FNC
Table 3 reports the results of the MTL approach on LIARArg depending on the number and type of the tasks involved. The two-sided Wilcoxon signed rank test has been performed across the 10 crossfolds and statistically significant improvements have been highlighted in bold. First of all, it can be seen that the LLM-based baselines significantly surpass the LG approach of Alhindi et al., 23 confirming the strong improvement driven by the use of LLMs in the FNC task. Secondly, it is worth noting that combining the graph representation of the entities contained in texts and the KnowBert embedding of the texts themselves produces even better results (KB vs. KGB). The combination of these two knowledge-injected methods provides therefore a strong baseline for our study. Thirdly, adding the argument component classification as an auxiliary task reduces the performance. While we could conclude that adding component information does not aid FNC, we underline that the increasing complexity of the training setup might have counteracted the benefits of the additional information provided by components. Finally, relation classification, despite the strong baselines provided by the knowledge-enhanced representation of news and justifications, clearly improves both binary and 6-way FNC, showing that the information contained in argument relations is crucial for more efficient FNC.
Results of MTL-based FNC models in F1 score compared with LG and single-task based models.
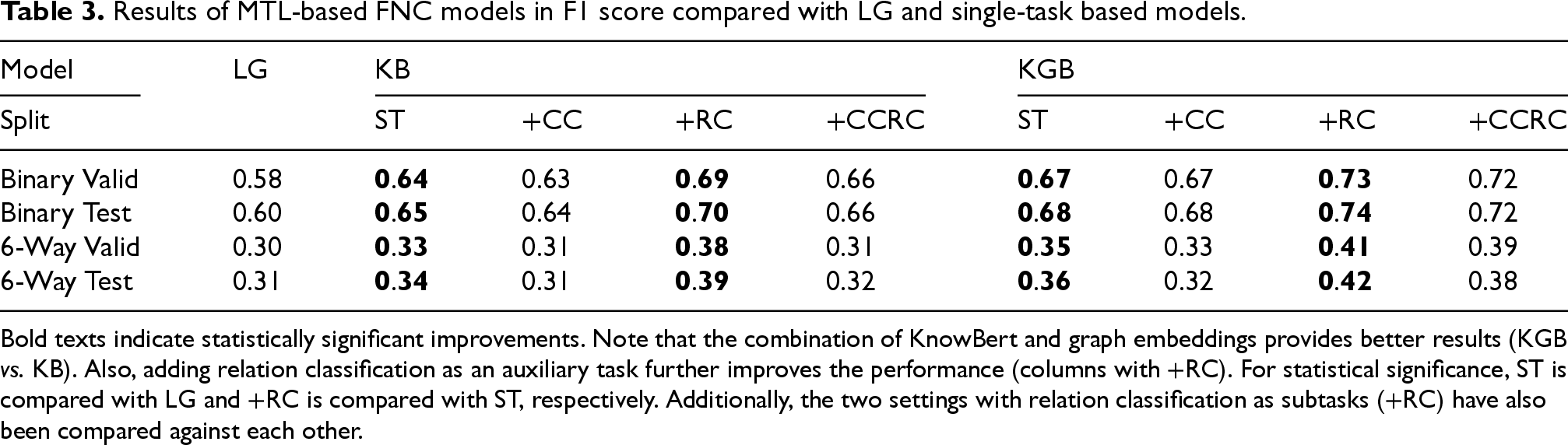
Results of MTL-based FNC models in F1 score compared with LG and single-task based models.
Bold texts indicate statistically significant improvements. Note that the combination of KnowBert and graph embeddings provides better results (KGB vs. KB). Also, adding relation classification as an auxiliary task further improves the performance (columns with +RC). For statistical significance, ST is compared with LG and +RC is compared with ST, respectively. Additionally, the two settings with relation classification as subtasks (+RC) have also been compared against each other.
Table 4 reports the results obtained with the prompting techniques discussed in Section 4, compared to the best MTL setting. 20 examples per label have been used.
Results of prompt-based FNC using 20 examples compared to the best results achieved in the MTL setting.
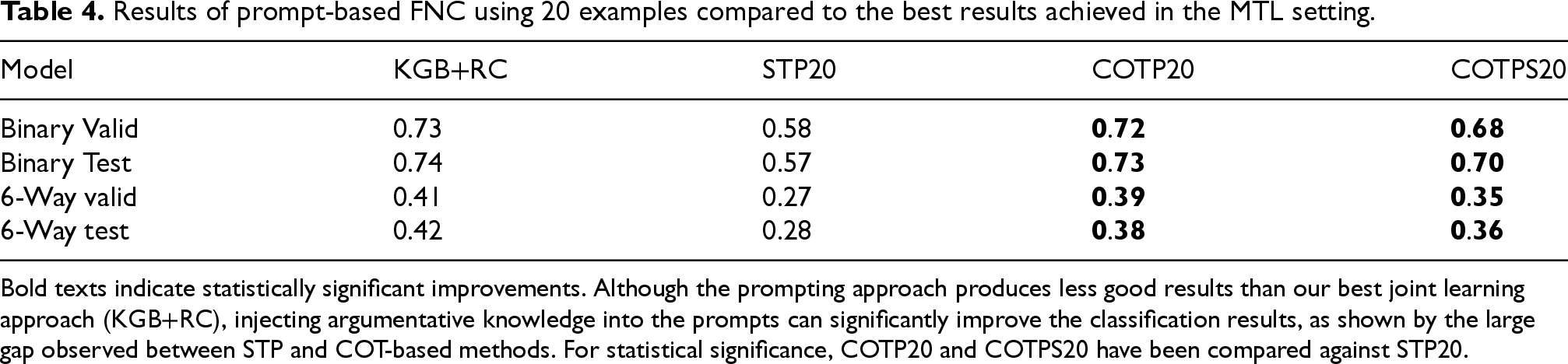
Results of prompt-based FNC using 20 examples compared to the best results achieved in the MTL setting.
Bold texts indicate statistically significant improvements. Although the prompting approach produces less good results than our best joint learning approach (KGB+RC), injecting argumentative knowledge into the prompts can significantly improve the classification results, as shown by the large gap observed between STP and COT-based methods. For statistical significance, COTP20 and COTPS20 have been compared against STP20.
It can be seen that although the prompting approach produces less good results than our best joint learning approach, injecting argumentative knowledge into the prompts can significantly improve the classification results, as shown by the large gap observed between STP and COT-based methods. Indeed, by using 20 examples from each label, COTP achieves an F1-score of only 0.04 under our best model in MTL setting. It could be contented that COTP necessitates annotated new instances which are impractical in real-world settings. Nonetheless, COTPS, which does not require new instances to be annotated as mentioned in Section 4.3, also benefits significantly through argumentative enhancement, producing an F1-score of 0.06 under the best MTL model for 6-way classification. This indicates that using 20 annotations per label in our few-shot setting leads to results comparable to the best joint learning model on LIARArg when argument features are introduced explicitly (COTP). However, without these features, the performance falls short of its potential (COTPS). Furthermore, Figure 6 shows the effect of example size on the performance of COT-based models. We conduct the Wilcoxon signed-rank test on the F1 scores of 10 runs for each model and example size. Significant improvements can be observed for all the models when the number of examples increases from 1 to 10, while the improvement from 10 to 20 is marginal and not statistically significant. This suggests that 10 examples would be sufficient to produce a model with a performance close to our best MTL model. These findings show that COT combined with annotated argumentative information can significantly assist the task of FNC with a very small number of examples, reducing the amount of annotated data needed to train fact-checking systems.
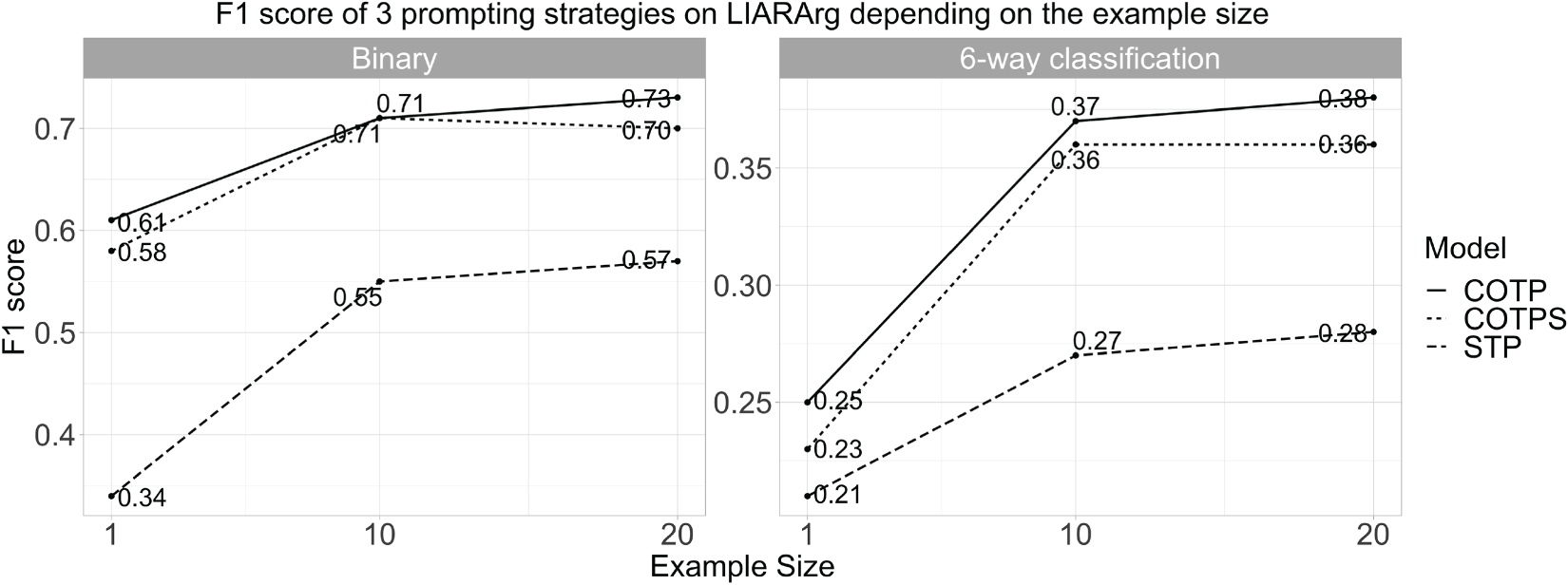
The impact of example size on the performance of COT-based models. Improvements are statistically significant for all the models when the number of examples increases from 1 to 10, while the improvement from 10 to 20 is marginal.
It is important to highlight that, in addition to yielding results comparable to those of COTP, COTPS produces rationals in argumentative form, which can then be used to improve the transparency of automated fact-checking.
82
(For readers’ reference, it is important to highlight that, in our experiments, the inclusion or exclusion of rationales in the output of COTPS did not affect its performance.) In particular, some rationales produced by COTPS are more concise than human-written justifications, as shown in Example (3) (labeled as False). This provides a promising alternative to existing explanatory methods, such as highlighting the salient tokens
83
or extracting sentences.
84
The 4-class relation annotation aims to investigate the role of fine-grained relations in multi-class classification. Table 5 reports the F1-scores of our best-performing models with or without merging fine-grained relations, where “
F1 scores of the ablation study on the impact of fine-grained relations in FNC.
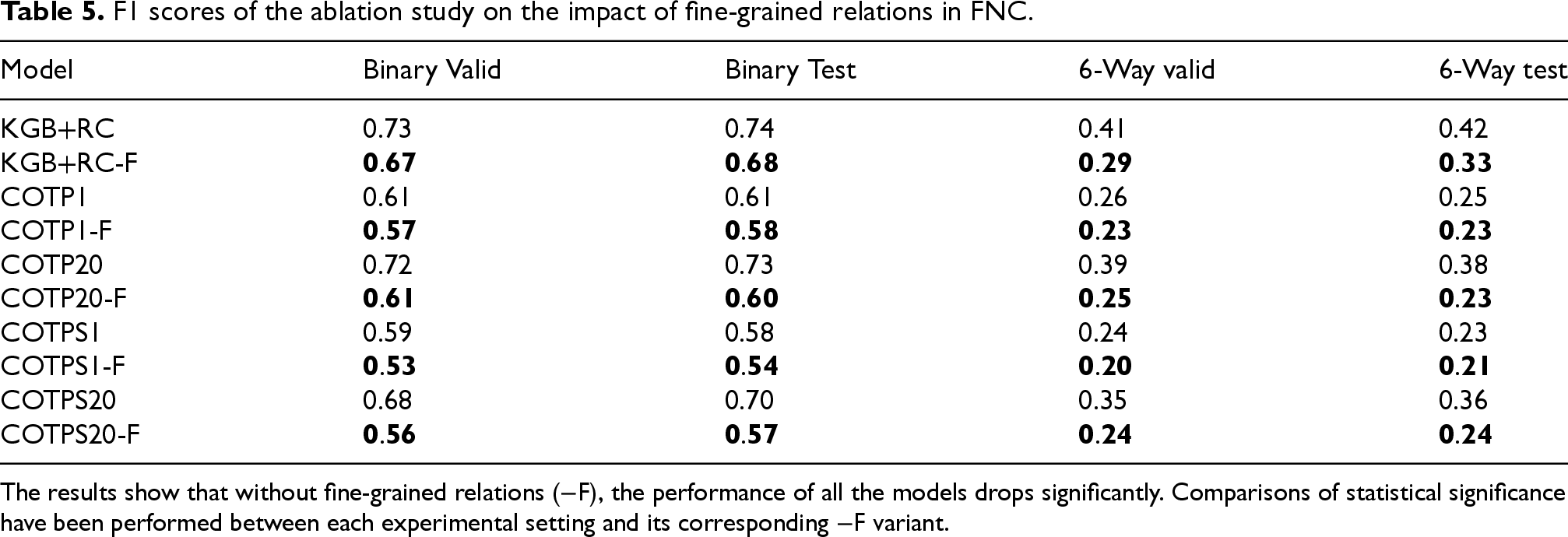
F1 scores of the ablation study on the impact of fine-grained relations in FNC.
The results show that without fine-grained relations (
To evaluate the efficiency performance of Mistral 7B compared to GPT-3, we first run the same COT-based experiments on LIARArg using Mistral 7B. Figure 7 shows the results of both LLMs in the 6-way classification. It can be observed that Mistral 7B generally falls short of GPT-3’s performance in the simple STP setting regardless of the number of examples employed. However, in cases where argument features are integrated, Mistral 7B shows performance on par with GPT-3 when using 20 examples. This suggests Mistral 7B as a relevant alternative to GPT-3 in our setting when the number of examples is large. For this reason, we use 20 examples for the automated pipeline. As described in Section 4.3, 10 samples of 20 examples have been used to provide a robust evaluation.
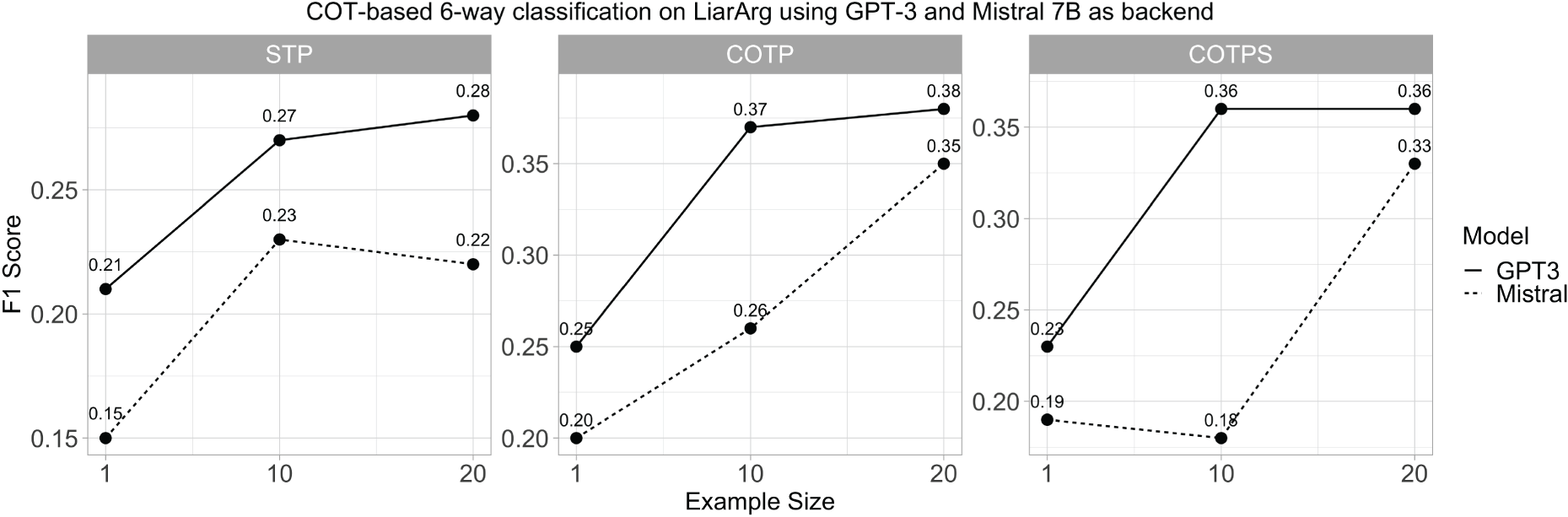
The performance of Mistral 7B compared to GPT-3 in the 6-way classification on LIARArg. Note the comparable performance between Mistral 7B and GPT-3 when the number of examples is 20 and when argument features are provided.
Table 6 reports the results obtained by the fully automated pipeline (i.e., the automatic AM parser paired with the MTL-based or COT-based FNC models) on LIAR-PLUS from which LIARArg has been removed. To the best of our knowledge, our framework is the first one that integrates AM and FC in a pipeline fashion using an MTL approach and COT-based methods. It can be observed that all the variants of our pipeline outperform the previous baseline produced by LG. Knowledge-enhanced LLMs remain strong baselines. The same pattern is observed as in Section 5.1: notably, jointly training argument relation prediction significantly enhances the performance of FNC models. For prompt-based methods, COTP and COTPS outperform STP by a large margin. It is important to note that, for 6-way classification, it is widely recognized that LIAR-PLUS is a challenging dataset, with most works still struggling to achieve F1 scores higher than 0.35. For instance, Koloski et al. 85 cited a SOTA F1 of 0.37, Yang et al. 86 achieved 0.29, and the most recent work by Wang et al. 87 achieved 0.31. The best result to our knowledge is from Sadeghi et al., 52 who achieved 0.41 using full-length justifications. The best F1 score reported in our work (0.44 by KGB+RC) is therefore a significant improvement on LIAR-PLUS.
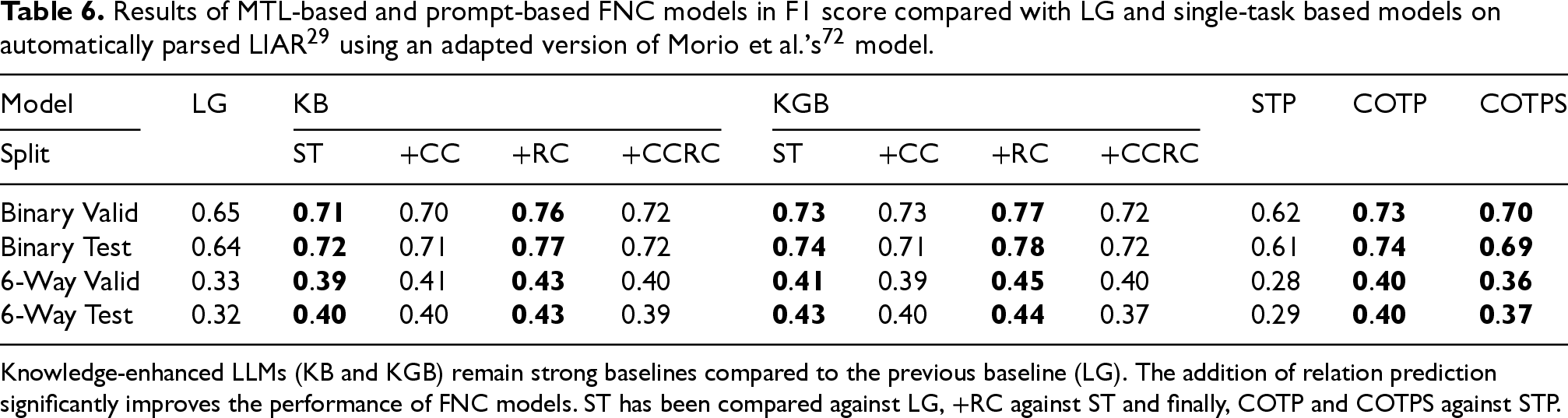
Knowledge-enhanced LLMs (KB and KGB) remain strong baselines compared to the previous baseline (LG). The addition of relation prediction significantly improves the performance of FNC models. ST has been compared against LG, +RC against ST and finally, COTP and COTPS against STP.
Tables 7 and 8 report the results of the automated pipeline on out-of-domain data, namely on the FNC-1 and Check-COVID datasets. It can be seen that the best MTL-based automated pipeline (KGB+RC), using an AM parser trained on data nonspecific to the test data, achieves results nearly matching the state-of-the-art models for both datasets (0.89 vs. 0.90 for FNC-1 and 0.69 vs. 0.72 in the case of Check-COVID), demonstrating the robustness of our approach on out-of-domain data and, more specifically, confirming the relevance of argument relations in the task of FNC. It is important to note that the current best models for FNC-1 and Check-COVID both use specific domain knowledge to enhance the original input, while our automated pipeline is domain-agnostic. Regarding the pipeline employing prompt-based models, although there is a larger gap between the highest F1 score and the previous baseline (0.86 vs. 0.90 for FNC-1, and 0.66 vs. 0.72 for Check-COVID), it is essential to underline that STP is outperformed by a large margin compared to COTP and COTPS, highlighting the valuable improvement brought by the integration of argumentation to the Fake News Classification task. These outcomes demonstrate the relevance and viability of automatically incorporating argumentative information into FNC, setting the stage for a fully automated pipeline devoid of human annotation requirements.
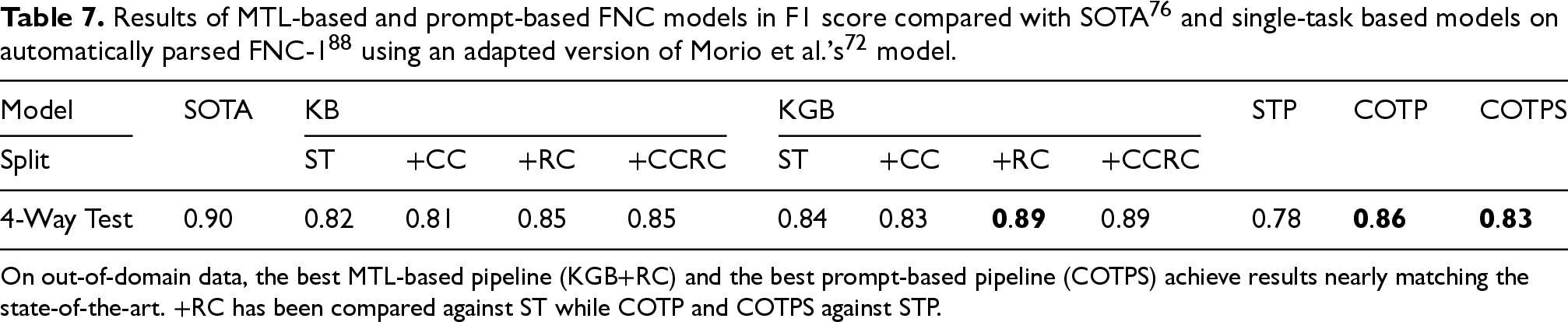
On out-of-domain data, the best MTL-based pipeline (KGB+RC) and the best prompt-based pipeline (COTPS) achieve results nearly matching the state-of-the-art. +RC has been compared against ST while COTP and COTPS against STP.
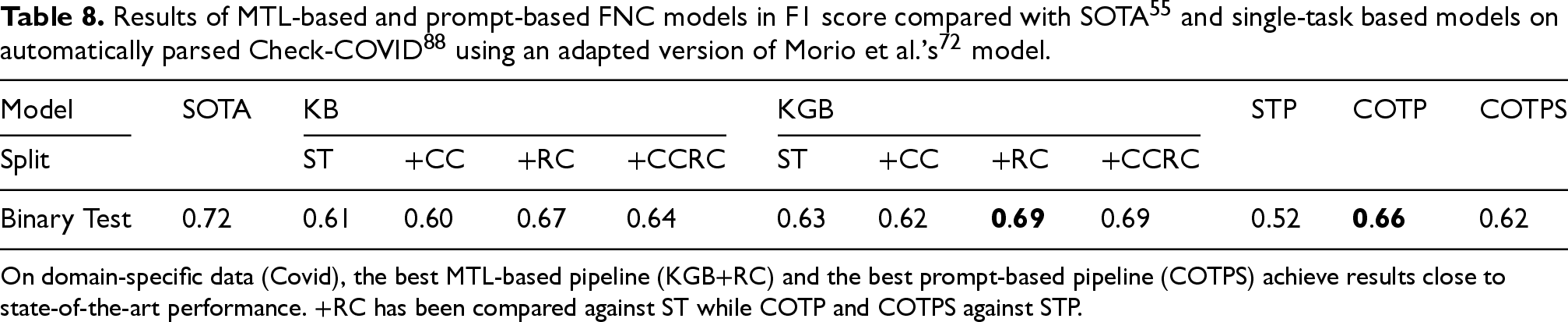
On domain-specific data (Covid), the best MTL-based pipeline (KGB+RC) and the best prompt-based pipeline (COTPS) achieve results close to state-of-the-art performance. +RC has been compared against ST while COTP and COTPS against STP.
We first analyze the error distribution when relation classification is not used as an auxiliary task. Table 9 reports the F1-scores of the 6-way classification produced by the best MTL model (KGB+RC) and two baselines on the test set. It can be seen that without relation information, the improvement induced by KGB is mainly limited to the Pants-on-Fire and True labels, meaning that errors in intermediate labels persist despite the use of knowledge-enhanced LLMs. Indeed, 85% of the erroneous predictions for the intermediate labels remained the same in LG vs. KGB. These intermediate labels, or half-truths, are omnipresent and computationally more challenging to detect than other forms of disinformation, 27 e.g., Monteiro et al. 89 even filter out half-truths before testing.
F1 scores for 6-way classification in two baselines vs. our best joint-learning model.
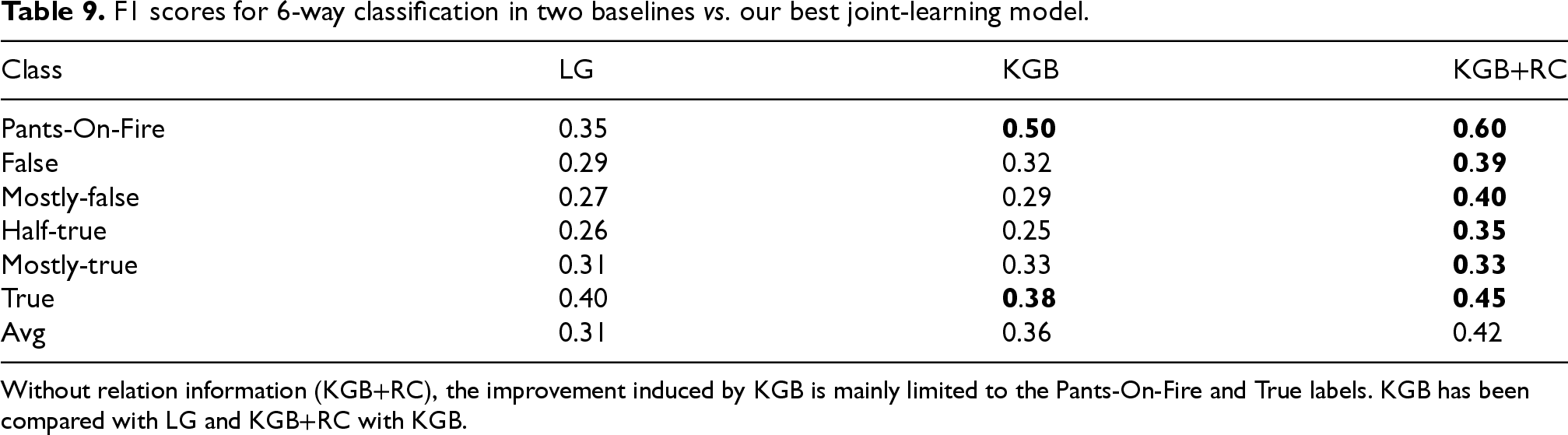
F1 scores for 6-way classification in two baselines vs. our best joint-learning model.
Without relation information (KGB+RC), the improvement induced by KGB is mainly limited to the Pants-On-Fire and True labels. KGB has been compared with LG and KGB+RC with KGB.
Concerning KGB+RC, we notice a strong correlation between the performance in relation classification and FNC. We observe that incorrect relation classification leads to a 45% error rate in FNC vs. 30% error rate when all the argument relations are correctly identified. For intermediate labels, the error rate rises from 40% to 60% when at least one error is made in relation classification. These results further confirm the importance of argument relations in FNC, particularly for intermediate labels. Example (4) shows a typical case of half-true news item where Premise {During Crist’s last year in office, Florida’s economy experienced notable gains in personal income and industrial production, and more marginal improvements in the unemployment rate and in payroll employment}
It is important to highlight two common scenarios where the system tends to misclassify labels. The first occurs when argument components cannot be assessed in isolation. For instance, as demonstrated in Example (5) (True predicted as False), all the three premises must be considered together to accurately classify the claim. The second arises when resolving temporal relations is necessary. For instance, in Example (6) (False predicted as True), humans may clearly recognize that Reagan’s presidency pertains to years before 2008 and 2009 based on the premise provided. However, this understanding may not have been adequately captured by the model.
{As late as 2000, he wrote that he was pro-choice.} {The misery index has been lower – 5.7 in 2008 and 11.8 so far in 2009}
The main goal of this article is to investigate whether the argumentative representation of evidence aids in the fake news classification task. To address this challenging issue, we present LIARArg, the first FNC dataset annotated with argument components and relations. Unlike LIAR-PLUS, in LIARArg we remove insufficient justifications, making it a solid benchmark for future research investigating how the internal structures of evidence can be better leveraged in the FNC task to improve the effectiveness of FNC models. Moreover, we propose a Multi-Task Learning framework to jointly learn FNC, CC and RC, as well as a COT-based framework to explicitly inject argumentative structures in a few-shot learning setting. Knowledge-enhanced embeddings are used to establish strong baselines for comparison.
The reader may argue that GPT-3 or Mistral 7B might have been trained on data comprising the datasets used in our experiments. As highlighted in Zhou et al., 90 the potential risk of data leakage is indeed a growing concern in benchmark evaluation. Unfortunately, the training corpora for both LLMs are not publicly available, making it difficult to confirm or refute this hypothesis.
Our experiments show that argument relations, particularly fine-grained relations such as partial support and partial attack, significantly improve the performance of knowledge-enhanced FNC models. This enhancement is most notable in accurately determining intermediate truth labels, indicating a substantial advancement in the model’s ability to discern complex, graded truth values. The best results are achieved using the Multi-Task Learning framework, outperforming both the SOTA approach on LIAR and most recent approaches in FNC based on knowledge-enhanced LLMs. Under the few-shot setting, COT-based methods yield results comparable to the best results with only 20 examples per label. To the best of our knowledge, this is the first approach showing that Argumentation Mining can be jointly trained with Fake News Classification to improve the latter’s performance. Our work is also the first to exploit argument structures contained in evidence in a Chain-Of-Thought manner both in prompts and model outputs. Finally, we show that the integration of argumentation information into FNC is feasible without human annotations through a fully automated pipeline. This, along with prompting-based approaches, is a promising direction for future research to reduce the amount of annotated data to train fact-checking systems.
More specifically, future works focus on designing new annotation schemes for datasets so that models would be capable of considering multiple argument components simultaneously when classifying argument relations as in Example where all the premises should be considered altogether to determine whether the news claim is attacked or supported, which is typical of temporal events. In terms of prompting, it would be particularly valuable to explore how the types of examples included in prompts interact with the performance of COT-based methods. Also, although weak attack and weak support have been added to the annotation scheme, it would be interesting to see if a more fine-grained typology of argument relations (e.g., classifying attack relations using Walton Schemes 64 ) can be explored to further improve the performance of FNC models. Also, although COT-based models display the potential to produce argument-structure-like explanations (cf. Example (3) in Section 5.2), the extent to which these explanations are understandable to humans and how they can be used to enhance the transparency of automated FNC systems remains to be investigated through an extensive human evaluation. Finally, the combination of evidence retrieval, AM, and FNC presents a fascinating avenue for exploration. However, the corpora analyzed in this study are not particularly suited for such experiments because each news title in these datasets is typically linked to only one fact-checking article, rather than multiple articles. As a result, testing the relevance of retrieving multiple articles is not feasible. If we restrict retrieval to a single article, the correct one is usually retrieved, but this setup fails to reflect a realistic scenario. A more appropriate approach, as in Wang et al., 91 would ideally retrieve multiple fact-checking articles related to the same news title to better simulate real-world conditions.
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work has been partially supported by the ANR project ATTENTION (ANR-21-CE23-0037) and the French government through the 3IA Côte d’Azur Investments in the Future project managed by the National Research Agency (ANR) with the reference number ANR-19-P3IA-0002.
Conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.