
Abstract
Explainable artificial intelligence (XAI) is proposed to improve transparency and performance by providing information about AI’s limitations. Specifically, XAI could support appropriate behavior in cases where AI errors occur due to less training data. These error-prone cases might be salient (pop-out) because of their naturally rarer occurrence. The current study investigated how this pop-out effect influences explainability’s effectiveness on trust and dependence. In an online experiment, participants (N = 128) estimated the contamination degree of bacterial stimuli. The lower occurrence of error-prone stimuli was indicated by one of two colors. Participants either knew about the error-prone color (XAI) or not (nonXAI). Contrary to earlier research without salient error-prone trials, explainability did not help participants follow correct recommendations in non-error-prone trials but helped them correct AI’s errors in error-prone trials. However, explainability still led to over-correction in correct error-prone trials. This poses the challenge of implementing explainability while mitigating its negative effects.
Artificial intelligence (AI) supports human decision-making processes in various tasks and domains. Even though many of the implemented AI systems are highly reliable, humans still need to be in the decision-making loop to evaluate the AI’s recommendations for legal and safety-related reasons, especially in high-risk contexts (e.g., healthcare, employment, and law enforcement; Lai et al., 2021). Human users therefore need to develop an appropriate level of dependence (i.e., the extent to which users follow the AI’s recommendation) when working with the AI systems (Lee & See, 2004). Otherwise, system misuse (being used too much) or disuse (not being used enough) may occur which in consequence could compromise overall safety and the joint human-AI performance (Parasuraman & Riley, 1997).
However, knowing when to follow or not follow the AI’s recommendations can be challenging. That is, humans often struggle to assess if a recommendation is correct or not (Rieger et al., 2023). For instance, previous research has extensively shown examples of system misuse where humans tend to over-rely on the systems and accept incorrect advice (Mosier & Manzey, 2019). Moreover, despite the well-intended efforts to improve an AI decision by manual input, humans also tend to “verschlimmbessern” (actually worsen) the performance by adjusting the system’s recommendation although it was correct (Rieger et al., 2023). Previous research by Rieger and Manzey (2024) showed that humans not only interfered with incorrect but also with correct recommendations, leading to a joint human-automation performance below that of the AI alone.
One approach to help humans distinguish the AI’s recommendations (correct or incorrect) is the implementation of explainability. That is, the system could provide information that helps humans evaluate the quality of the advice, similar to asking a human team member for explanations to determine whether the advice can be relied upon (Schemmer et al., 2022). This is especially important in a high-risk context where humans might be reluctant to follow the system’s recommendations without further justification due to the responsibility and risk involved (Xie et al., 2019). Taken together, explainable AI (XAI) has been proposed as a potential solution to improve human-AI decision quality (Gonzalez et al., 2020; Miller, 2019; Schemmer et al., 2022).
There are different ways in which explainability can be implemented. For example, the system may provide information about different parts of the AI processing (e.g., inputs and outputs) or explain its decision by showing how much each parameter is weighed and added to the final decision (Laato et al., 2022). However, alongside all the proposed advantages of explainability, it can also have downsides. For instance, explainability can also lead to information overload in detecting AI errors (Poursabzi-Sangdeh et al., 2021). Thus, designing an effective XAI can be challenging including determining what, when, how, and how much explanation should be provided to optimize joint performance.
Consequently, instead of providing broad information about the system’s processes, more behavior-guiding explainability could be beneficial. In particular, humans can be provided information about the types of cases that the AI may not work well on because it had little training data (i.e., error-prone cases) and the types of cases that the AI typically works nearly perfectly on because it had a lot of training data (i.e., non-error-prone cases; Rieger et al., 2023). Thus, by communicating the uncertainties involved in the system’s decision-making, it can help users be aware of the probability of the AI making an error for each case (Laato et al., 2022). Consequently, this may help align users’ expectations of the AI system to match with its actual capabilities which can affect users’ behavior when using it.
A strong case study for the potential advantages of providing passive information about the system’s characteristics can be illustrated in the medical field (Challen et al., 2019). For example, some rare cancers with fewer cases being diagnosed might lead to less data being available for AI systems to learn with, compared to more common cancers. This potential imbalance in the training datasets can affect the accuracy of AI systems (Storkey, 2008). Whereas the common cases with large amounts of existing annotated data tend to be evaluated fairly well, the system might be prone to make mistakes for the rare cases. Providing information about the AI’s error-proneness might help users adapt their behaviors. Specifically, users might pay more attention to error-prone cases where they then can correct the AI’s mistakes. In contrast, they might mostly just agree with the AI’s recommendations for non-error-prone cases (i.e., cases with large data).
A previous study (Rieger et al., 2023) found that explainability instructions regarding the AI’s error-proneness could help users follow the AI’s correct recommendations in non-error-prone cases. However, for error-prone cases, this information did not lead to an ideal behavioral adaptation as participants incorrectly worsened correct system recommendations in the subset of error-prone cases that the AI actually assessed correctly (i.e., “verschlimmbessern”). However, in this previous study (Rieger et al., 2023), error-prone cases did not occur less frequently than the different non-error-prone cases, which limits the real-world applicability of the results. As illustrated with the medical case study, non-error-prone cases with large underlying data sets might outnumber error-prone cases such as rare cancers. Error-prone cases might therefore exhibit considerable salience (i.e., pop-out) due to their naturally rarer occurrence.
Given this, it remains unclear how the observed ambivalent effects in behavioral outcomes of explainability would be influenced by this natural pop-out effect. Thus, the current study aimed to investigate whether the results hold true when error-prone cases occur less frequently and are thus more salient compared to earlier research. As our main question was if the results are conceptually replicable with a more realistic pop-out effect of error-prone trials, the hypotheses were stated based on the results of Rieger et al. (2023). Specifically, we expected again ambivalent effect concerning dependence. On the one hand, participants were expected to show higher dependence for non-error-prone trials in the XAI condition as they know about the extensive learning data set for these cases, compared to the nonXAI condition (those not receiving explainability instructions). On the other hand, we hypothesized lower dependence in correct error-prone trials in the XAI compared to the nonXAI condition. Lastly, as participants might notice the AI’s errors regardless of the explainability instructions, especially with the pop-out effect, we hypothesized no difference in erroneous error-prone dependence.
Besides its potential influence on dependence, explainability might also influence trust attitude. Trust attitude, often measured as a subjective construct, is extensively influenced by system characteristics (e.g., the reliability of the system, see Lee & See, 2004). Thus, providing information regarding the AI’s limitation might also affect humans’ trust in the AI system, such that those knowing about the system’s fallibility might initially have lower trust in the system, compared to those not knowing. After interacting with the system, their learned trust might show a reverse pattern if humans perceive XAI as helpful for achieving their goals (Rieger et al., 2023). However, a previous study (Rieger et al., 2023) showed that explainability instructions regarding the AI’s limitation did not influence trust attitude as expected. Although descriptively higher initial trust was found for those without explainability instructions, no difference in learned trust was revealed, challenging the commonly proposed assumption that explainability positively influences trust attitude (Ferrario & Loi, 2022; Shin, 2021). Regardless, because of the awareness of system fallibility in the XAI condition, we hypothesized that participants in the XAI condition would report lower initial trust than those in the nonXAI condition. Moreover, to account for the multidimensionality of trust (Lee & See, 2004; Roesler et al., 2022), we expected that highlighting the fallibility of the AI would reduce the perceived performance of the AI, whereas other facets (e.g., purpose) would not be influenced.
In sum, the goal of the present study was to investigate the impact of explainability instructions regarding specific system limitations that might meaningfully guide behavior (e.g., reduce “verschlimmbessern” for non-error-prone trials) in a simulated medical task. Moreover, we were also interested in whether featuring the limitations through explainability instructions influences trust attitude.
Method
Participants
A target sample size of 128 was calculated based on a priori power analysis to detect a medium effect size of d = 0.50 with a power of 0.80 at the standard .05 alpha error probability for a one factorial between-subjects design. A total of 173 participants were recruited via a local participant portal. Of these, 45 participants were excluded from further analyses due to: (a) failing one or more attention checks, (b) having very good knowledge about AI, and (c) failing a manipulation check. The final sample therefore consisted of 128 participants (33 male, 93 female, 1 non-binary, 1 other) with ages ranging from 18–46 year (M = 21.33, SD = 5.01). Although we initially planned to exclude participants who indicated prior experience in analyzing bacteria, we decided against this exclusion criterion. This decision was made because the predominantly student sample included individuals who answered affirmatively to this question (n = 25), likely due to minimal exposure from a basic biology course.
Task and Materials
Similar to the previous study (Rieger et al., 2023), the current study employed an online experiment programed with jspsych (de Leeuw, 2015) and ran on a JATOS server (Lange et al., 2015). The stimuli (as shown in Figure 1) were microscope images of bacteria adapted from Fahnenstich et al. (2024). The images were resized and recolored to separate the colored bacteria from the background to ensure comparability. Participants’ task was to analyze these microscope images to estimate how much of a sample image was covered by bacteria in percent (see Figure 1). An AI supported participants in this estimation as it provided concrete recommendations (e.g., 27%) which were precisely correct in 87.5% of the cases. To end a trial, participants had to type in their final estimation which could be the same as recommended by the AI or deviate from it.

Examples of the task with a pink-colored stimulus (left) and a blue-colored stimulus (right).
Compared to Rieger et al. (2023), the only difference was that we only used two stimuli colors (pink and blue) instead of four. This was the base to establish the pop-out effect. Error-prone stimuli only appeared in one color which had a lower occurrence compared to the other color which represented the non-error-prone trials. More specifically, out of 40 trials, 30 were non-error-prone trials and 10 were error-prone trials where five were erroneous (i.e., erroneous error-prone) and five were correct (i.e., correct error-prone).
Design and Dependent Variables
A one-factorial design was used with AI explainability (XAI vs. nonXAI) as the between-subjects factor. Based on the previous study (Rieger et al., 2023), we did not expect significant differences between the XAI and nonXAI condition for learned trust, and three sub-dimensions of trust (utility, purpose, and transparency; Roesler et al., 2022). However, to rule out the possibility that the pop-out effect may result in differences in these variables, we analyzed all variables that were analyzed in the previous study. Thus, the analyses for these variables were exploratory.
Dependence
Dependence was measured by the absolute value of how much participants deviated their answer from the AI’s recommendations, with a larger deviation from the recommendation indicating less dependence on the AI.
Trust Attitude
We assessed initial trust (before interacting with the AI) and learned trust (after task completion) with a single item on a scale ranging from 0 (“Not at all”) to 100 (“Completely”). In addition, we used the Multidimensional Trust Questionnaire (MTQ) by Roesler et al. (2022) for the sub-dimensions of trust including performance, utility, purpose, and transparency. The MTQ consists of 12 questions using a four-point Likert scale from 0 (“Do not agree”) to 3 (“Agree”).
Procedure
After giving informed consent, participants were informed that they would be working in a lab, and their task would be to analyze the microscope images of bacteria and estimate how much of a sample image was covered by it in percent. Participants were then informed that the task would be supported by an AI with a reliability of around 90%. In the XAI condition, participants were additionally informed that the AI would perform worse for bacteria in one color due to limited training data, compared to the other color which the AI had more training data for. The error-prone color was randomly chosen to prevent bias for any specific color. Following these instructions, participants answered the initial trust single item.
They then completed four practice trials without the AI’s recommendations where they received performance feedback and the correct answers. After the practice trials, participants completed the main 40 trials. In the erroneous error-prone trials, the AI gave incorrect recommendations with an average deviation from the actual value of 10 (ranging from 8–12 with two over- and three under-estimations).
After these 40 trials, participants completed a questionnaire consisting of a single item for learned trust, the MTQ, and questions regarding perceived involvement and responsibility (later both not reported here). Lastly, participants were debriefed and thanked for their participation.
Results
Manipulation Check
A manipulation check was conducted to investigate if participants noticed the performance differences of the AI between the two colors. We expected that participants in the XAI condition would either answer the correct error-prone color or answer “No,” meaning that they did not notice any difference in the AI performance. This was possible as they might not perceive any difference in the actual AI performance despite knowing the AI’s limitations. Surprisingly, 19 participants in the XAI conditions failed the manipulation check as they answered the non-error-prone color instead of the correct error-prone color which might imply that the framing instruction might be forgotten or overlooked. Thus, these 19 participants were excluded from the analyses as mentioned in the above exclusion criteria. For the XAI condition in the final sample, 43 participants answered the correct error-prone color, while 21 participants did not perceive any performance differences. For those in the nonXAI condition, the majority (n = 38) did not notice any difference in any performance, while the rest reported the AI’s inferior performance for either error-prone color (n = 10) or non-error-prone color (n = 16).
Dependence
The absolute deviation from the AI’s recommendations is shown in Figure 2, with a larger deviation from the system implying lower dependence. Unexpectedly, for non-error-prone trials, there was no significant difference in dependence between the XAI and nonXAI condition, t(126) = −0.06, p = .953, d = −0.01 (MnonXAI = 3.98, MXAI = 4.02).
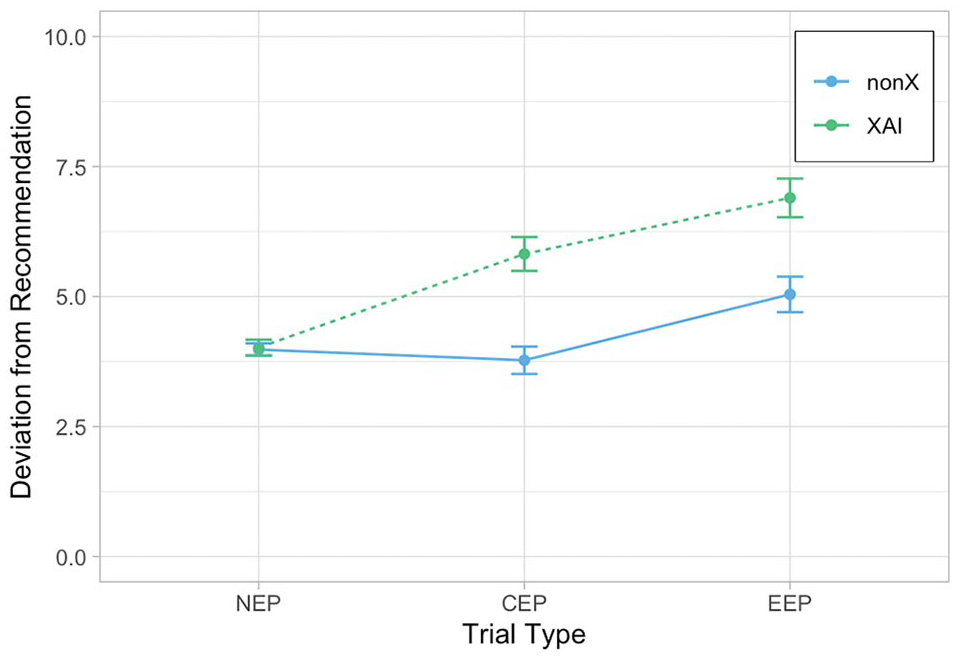
Means and standard errors for the deviation from the AI’s recommendations for the two conditions (XAI vs. nonXAI) across three trial types (NEP = non-error-prone; CEP = correct error-prone; EEP = erroneous error-prone).
For correct error-prone trials, participants in the XAI condition showed significantly less dependence than the ones in the nonXAI condition, t(126) = −3.25, p = .001, d = −0.575 (MnonXAI = 3.78, MXAI = 5.82). In line with our hypothesis, participants who knew about the AI’s limitation over-corrected the correct AI’s recommendations, showing the expected “verschlimmbessern” effect. For erroneous error-prone trials, the preregistered Bayesian independent sample t-test provided small evidence in favor of the alternative hypothesis, BF10 = 2.6, meaning that the data are approximately 2.6 times more likely under the alternative than a null hypothesis. To back up this result we conducted an additional t-test. In line with the Bayesian analysis, participants in the XAI condition showed significantly less dependence than the ones in the nonXAI condition for erroneous error-prone trials, t(126) = −2.42, p = .017, d = −0.428 (MnonXAI = 5.04, MXAI = 6.90). Hence, explainability showed its benefits in erroneous error-prone trials.
Trust Attitude
For initial trust, there was no significant difference between the XAI and nonXAI condition, t(126) = 1.44, p = .154, d = 0.254 (MnonXAI = 68.09, MXAI = 63.08). However, for learned trust, the XAI condition reported a significantly lower learned trust than the nonXAI condition, t(126) = 2.25, p = .026, d = 0.398 (MnonXAI = 69.53, MXAI = 62.92). Both results are in contrast to our expectations which anticipated lower initial trust in the XAI condition and no difference in learned trust.
For the multidimensional trust measurement, there were no significant differences between the XAI and nonXAI condition for all sub-dimensions of trust including performance t(126) = 0.48, p = .631, d = 0.085 (MnonXAI = 2.17, MXAI = 2.12), utility t(126) = 1.03, p = .305, d = 0.182 (MnonXAI = 2.18, MXAI = 2.08), purpose t(126) = 0.78, p = .439, d = 0.137 (MnonXAI = 2.61, MXAI = 2.55), and transparency t(126) = 1.24, p = .218, d = 0.219 (MnonXAI = 2.21, MXAI = 2.05). This is inconsistent with our hypothesis which expected the participants in the XAI condition to report lower trust for the performance dimension than ones in the nonXAI condition.
Discussion
The present study aimed to investigate the impact of explainability instructions on dependence as well as trust attitude. Specifically, the study investigated if the benefits and costs of XAI persist even when error-prone cases visually popped out. On a behavioral level, there was no difference in dependence between the XAI and nonXAI conditions in non-error-prone trials (cases that AI worked well with). This is in contrast to a previous study without the pop-out effect of error-prone stimuli (Rieger et al., 2023) where explainability helped participants follow the correct AI’s recommendations in non-error-prone trials.
This inconsistency might be related to the way the participants constructed their internal rule on which trials need more careful attention (i.e., error-prone trials). Specifically, in the previous experiment by Rieger et al. (2023), participants had to actively match the color of the present stimuli to the error-prone color because rare occurrences could not serve as an additional cue. This might have led to participants actively processing non-error-prone stimuli as non-error-prone—leading to a reduction in “verschlimmbessern.” In contrast, in the present study, this active comparison between the currently presented stimulus color versus the error-prone color was not as necessary given that the error-prone cases visually popped out anyway. Thus, the knowledge of the AI’s error-proneness might not have led to useful behavioral adaptation during the non-error-prone trials in the present study because participants did not need to recall the positive information (i.e., better AI’s performance in the non-error-prone color) throughout the experiment. However, this reasoning is highly speculative and should be investigated in more detail in future research, as we lack insights into whether participants in both experiments approached their tasks with differences in rule set activation.
In the error-prone trials, behavioral adaptations occurred as the XAI condition showed lower dependence than the nonXAI condition for both correct and erroneous cases. Similar to the previous study (Rieger et al., 2023), XAI participants still showed the “verschlimmbessern” effect by worsening correct AI’s recommendations. However, XAI participants in the current study were also better at correcting the erroneous AI recommendations. As the error-prone trials might become more salient and pop out due to rarer occurrences, it might help remind participants in the XAI condition of the AI’s limitation when encountering the error-prone stimuli. Thus, they were able to adjust the wrong recommendations more. Therefore, while providing information about the AI’s limitation in cases where the AI is prone to make errors might help people correct the AI’s errors in those cases, they might also make corrections when the AI is actually correct, resulting in worse performance. One of the greatest challenges in implementing XAI systems will be to harness the positive effects observed in the current and previous experiment (Rieger et al., 2023): increased dependence in non-error-prone cases and decreased dependence in erroneous-error-prone cases. In addition, it is crucial to prevent the negative effect in correctly identified error-prone cases. The speculations regarding potential differences in rule sets already highlighted the necessity to gain a deeper understanding of participants’ internal processes during decision-making together with the system’s recommendation. This understanding is crucial for devising explainability instructions that provide the most effective behavioral guidance. Moreover, the present results show the difficulties of using explainability approaches to foster ideal behavior—a challenge that will likely remain task- and context-dependent.
Surprisingly, XAI negatively impacted trust attitude only after interacting with the AI, but not when participants were explicitly informed about the AI’s limitation before the interaction. This is in contrast to the previous study (Rieger et al., 2023) which found no impact of XAI on learned trust. This implies that the pop-out effect might have brought additional attention to the system’s fallibility during the interaction. Again, this should be interpreted with caution as this could be related to the activated rule set. The visual salience might have led to the focus on the rarer occurring error-prone cases during the current experiment. Thus, participants knowing about the AI’s error-proneness might show a lower trust attitude when they more saliently notice the error-prone trials during the interaction, compared to those not knowing about them. Considering the realistically lower occurrence of error-prone trials, we argue that future research needs to incorporate and systematically investigate the salience of system errors. Our results showed that not all behavioral and attitudinal results revealed for XAI without salient error-prone cases (Rieger et al., 2023) can be transferred to cases where the error-prone cases pop out.
While there are limitations that typically accompany online research, the current study used clear exclusion criteria to ensure the quality of data. However, the prevalence of participants in the XAI condition who indicated the wrong color underscored the importance of conducting thorough manipulation checks in online experiments. This might be particularly crucial when research involves student participants rather than online workers (Hauser & Schwarz, 2016).
Conclusion
While XAI is frequently proposed as a promising approach to enhance human-AI interaction, the current study reinforces the view that XAI should be carefully implemented while considering the behavioral consequences of each specific XAI approach and the task characteristics to achieve optimal behavioral adaptations. A forthcoming challenge in both research and practice involves determining how to implement explainability while mitigating its potential negative effects on trust attitude and dependence.
Footnotes
Data Availability
The preregistration and dataset are available at the Open Science Framework under osf.io/4bgms. Due to the reason of conciseness, the variables perceived involvement and responsibility are not reported here. The analyses of both variables did not reveal significant differences between XAI and nonXAI conditions.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.