
Abstract
Large Language Models (LLMs) with their novel conversational interaction format could create incorrectly calibrated expectations about their capabilities. The present study investigates human expectations toward a generic LLM’s capabilities and limitations. Participants of an online study were shown a series of prompts that cover a wide range of tasks and asked to assess the likelihood of the LLM being able to help with those tasks. The result is a catalog of people’s general expectations of LLM capabilities across various task domains. Depending on the actual capabilities of a specific system, this could inform developers of potential over- or under-reliance on this technology due to these misconceptions. To explore a potential way of correcting misconceptions we also attempted to manipulate their expectations with three different interface designs. In most of the tested task domains, such as computation and text processing, however, these seem to be insufficient to overpower people’s initial expectations.
Introduction
Large Language Models (LLMs) differ from other forms of Artificial Intelligence (AI) mainly in the input modality and in their flexibility across a multitude of task domains. People are not restricted in the kinds of tasks they can try to accomplish with LLMs and can instead freely type any prompt into the system. This leaves them guessing what the proper use of LLM-powered applications is. Potentially unrealistic expectations could then lead to their misuse or disuse (Parasuraman & Riley, 1997). While LLMs have exhibited strong novel capabilities compared to other AI systems, they also have weaknesses that could lead to misuse if not made clear to the users (Bubeck et al., 2023).
This warrants scientific investigations that take inventory of people’s expectations of LLM capabilities and limitations as a proxy for their mental models of how the underlying technology works. To ensure appropriate and safe use we need to understand when and why people trust in and rely on LLM applications and their outputs. This should then inform developers and designers how to enable individuals to correctly calibrate their expectations to the capabilities of the system. With this study we conduct an initial probe into the following two research questions:
Related work
Large Language Model Capabilities and Limitations
A comprehensive investigation by Bubeck et al. (2023) showed how GPT-4 capabilities exceeded those of any previous system. These include text comprehension, image analysis, mathematical problem solving, code generation, recognition of tool affordance, and the development of a theory of mind. However, this varies across different models. For example, many have experienced ChatGPT’s excellence in summarizing or generating texts. However, it routinely fails at even simple mathematical challenges (Kasner & Dušek, 2024). A concern for appropriate use of such technology is when people gather information about or experience with one LLM and then expect others to have the same capabilities. Even with awareness of different models and their weaknesses, it is not always apparent which LLM system is behind the user interface (UI). Providers may also build additional capabilities on top of their LLMs, such as access to web search engines. Such inconsistencies could further cause incorrectly calibrated expectations as people who experienced this with one system might expect all LLMs to have these capabilities.
Calibrating Initial Perceived Trustworthiness
Trust is an attitude (Lee & See, 2004) that can be characterized as an expectation that a system will help achieve a common goal as promised (Jacovi et al., 2021; Zahedi et al., 2023). Since trust is an antecedent to reliance intention (Lee & See, 2004), it is important to assist people in understanding the system’s capabilities and adjusting their expectations. If they rely on a system too much, they might not notice automation failures and produce worse outcomes that might even be harmful (Parasuraman & Riley, 1997). However, the opposite can also reduce performance if people do not take advantage of useful tools because they distrust them.
Previous work has shown the impact of prior information about the quality of a product or brand on the perceived trustworthiness of an automated system (e.g., Kraus et al., 2019; Pataranutaporn et al., 2023). Even without any explicit prior information, the appearance of a system provides implicit trustworthiness cues (Bae et al., 2023). However, these effects appear to diminish as one gathers their own experience with the specific system (Kraus et al., 2019).
Manipulating Expectations Through Design
We suspect that people have high expectations for LLMs’ capabilities in all task domains because they have idealized mental models of how this novel technology works (Kidd & Birhane, 2023). The generation of human-like textual responses by LLMs could have created the conception that LLMs think and process information the same way that people do (Amaratunga, 2023). But since LLMs are accessed through computers and were largely marketed and understood as a form of AI, expectations might also be high for computer-dominated task domains.
To calibrate such expectations to an appropriate level, designers of LLM applications could change the interface appearance to better reflect their system’s strengths. We hypothesize that a design incorporating skeuomorphic metaphors (Ellis & Marshall, 2019) will be perceived as more human-like and will lower expectations for computer-dominated task domains. Conversely, an overly technical design might reduce expectations in human-dominated task domains.
Methods
Procedure
We set up an online survey with three different UI designs as between-subject conditions. In a posttest-only design, all participants evaluated 26 screenshots of a chatbot UI with a different prompt typed in each of them. Depending on the condition, participants saw the prompts typed in either a neutral, a technical, or an analog design. The assignment to conditions and order of prompts were randomized. Afterward, participants were asked about their impression of the system. On average, participants took 10.83 minutes to complete the survey.
Materials
Prompt Selection
We composed a set of 11 capabilities that could be expected from LLMs: text comprehension, text processing, word processing, text production, general knowledge, mathematical reasoning, human intuition, self-explanation, web access, local file access, and memory. This selection was informed by the AI benchmarking literature. For each category, we selected or developed 1 to 3 prompts that reflect a specific use case. All 26 prompts and their respective capabilities are provided in the Supplemental material.
Interface Designs
The different UI designs were non-functional mock-ups of chatbots. The screenshots did not contain the chatbot’s answer or any known branding that could indicate the LLM’s actual capabilities. The neutral design was inspired by common chatbot interfaces such as those of OpenAI’s ChatGPT, Microsoft’s Bing, and Google’s Gemini. It has a plain white background with a gray flat design. The technical design was inspired by the Windows terminal, which is regarded as less user friendly and would usually only be used by experts (Lee et al., 2017 pp. 329–330). It has a white font on a black background. The typeface has been changed to a more technical look and uninformative text such as “system> initializing chatbot v1.1.2 . . . done” has been added. The analog design uses skeuomorphic references to analog devices through a lined paper background, a leather textured sidebar, and images such as sticky notes. Its typeface has been changed to look like handwriting. Screenshots of the three designs are shown in Figure 1. For each prompt, participants were asked to rate the likelihood that the chatbot’s response would “include correct information or achieve the intended goal” on a 7-point Likert scale.
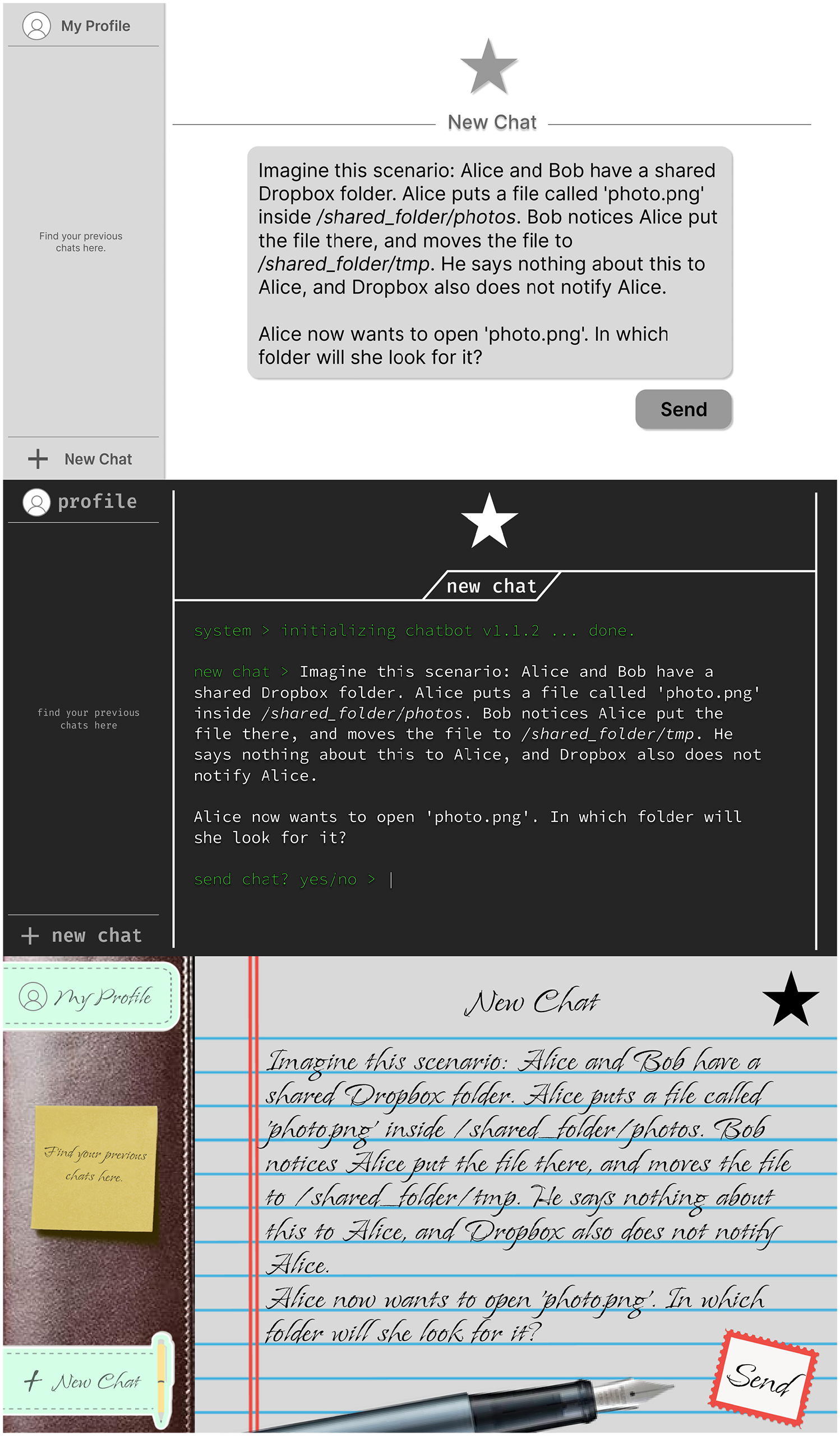
The neutral, technical, and analog interface designs with a sample prompt (theory of mind).
Further Questionnaires
To validate the intended treatments, participants were asked to rate the system’s general capabilities on a similar Likert scale. Participants were also given the System Usability Scale (Brooke, 1996) with slightly rephrased items to assess perceived usability for the UI designs (Ellis & Marshall, 2019). Participants’ perception of the chatbot was assessed with a 5-point semantic differential evaluation for four of the five items of the Godspeed I anthropomorphism scale (Bartneck et al., 2009) and four self-developed items to capture technicalness and familiarity.
Participants
Forty-five participants at least 18 years old and with (self-reportedly) sufficient English proficiency completed the online study. One-third (15) of those were undergraduate students from Arizona State University who were compensated for their time with course credits while the other 30 were people from the United States who were recruited through Prolific and received monetary compensation. Demographic information was not collected due to no underlying studies indicating there might be meaningful differences based on race, gender, nationality, or age.
Results
A correlation matrix of participants’ expectations for specific prompts and the system’s general capabilities is provided in the Supplemental Material. For most of the capabilities, the correlations with their respective prompts were significant. For human intuition, self-explanation, and web access, however, this was not the case. Participants had the highest expectations for the prompts asking for factual knowledge (capital of Portugal, current U.S. president, Olympics in 1992; Figure 2). The lowest expectations were for local file access as well as memory persistence across conversations and users. This is reflected in the expectations for general skills (Figure 3).
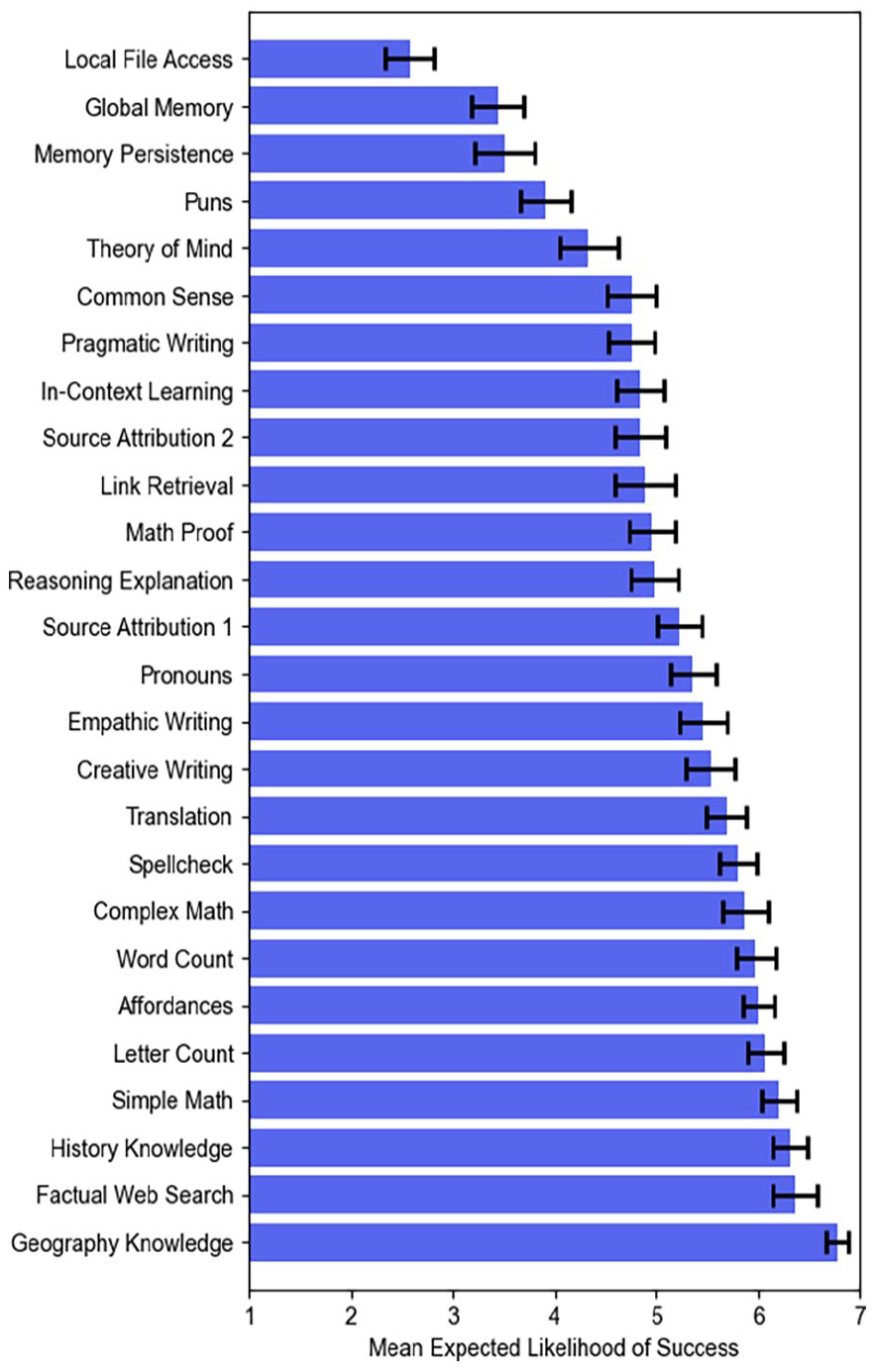
Participants’ expectations for specific prompts. Error bars show standard error for N = 45.
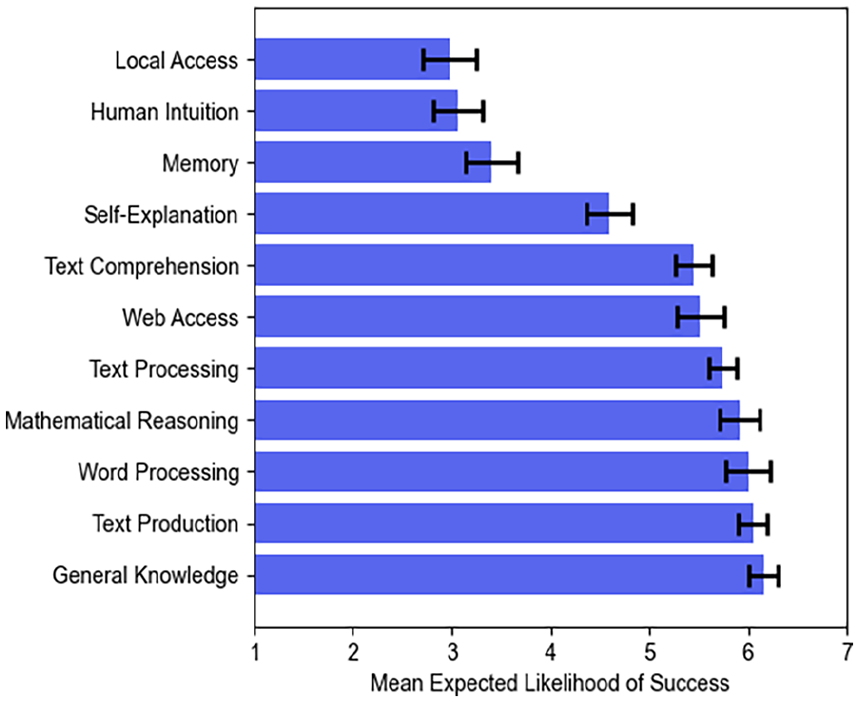
Participant’s expectations for general skills. Error bars show standard error for N = 45.
Participants’ perceptions of the different interface designs are shown in Figure 4. Kruskal-Wallis tests indicated no significant differences in perceived technicalness, χ² (2, 45) = 2.63, p = .268, human-likeness, χ² (2, 45) = 3.15, p = .207, familiarity, χ² (2, 45) = 1.08, p = .582, or usability, χ² (2, 45) = 2.22, p = .330. For all general skills and most prompts there were no significant differences in expectations between the experimental groups. Some examples are shown in Figure 5. Surprisingly, the analog and technical designs which we intended to be on opposite ends of a spectrum sometimes raised similar expectations while the neutral design appeared to be the outlier (albeit not statistically significant). Also contrary to our intuition, participants in the technical condition expected the system to do better on common sense reasoning than those in the analog condition, t(28) = −2.60, p = .015. For factual web search, the picture is similar although not statistically significant. Participants further expected the analog system to be worse at explaining its own reasoning t(28) = −2.18, p = .038.
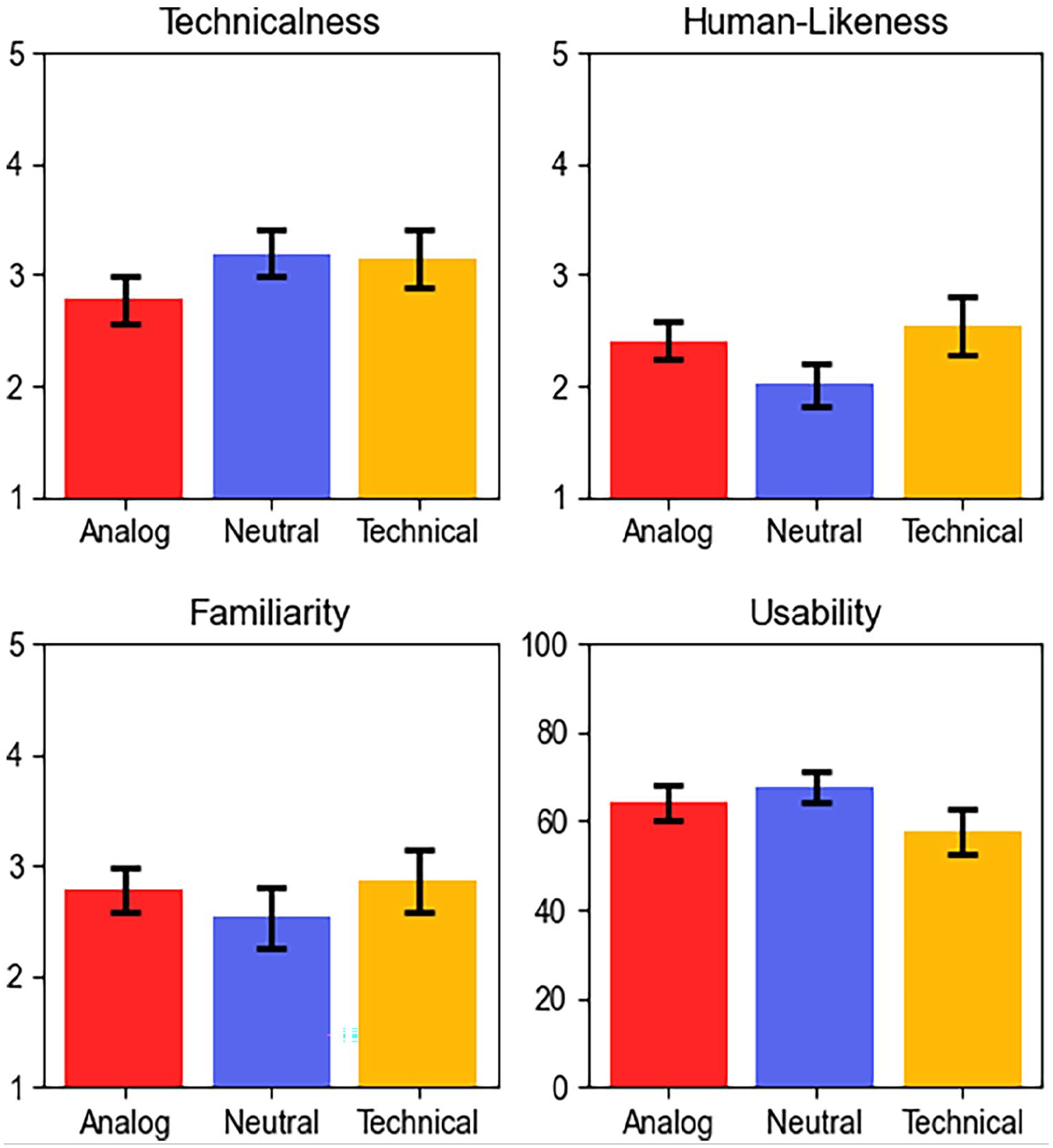
Participants’ perception of the system by condition. Error bars show standard error for n = 16, 15, 14 respectively.
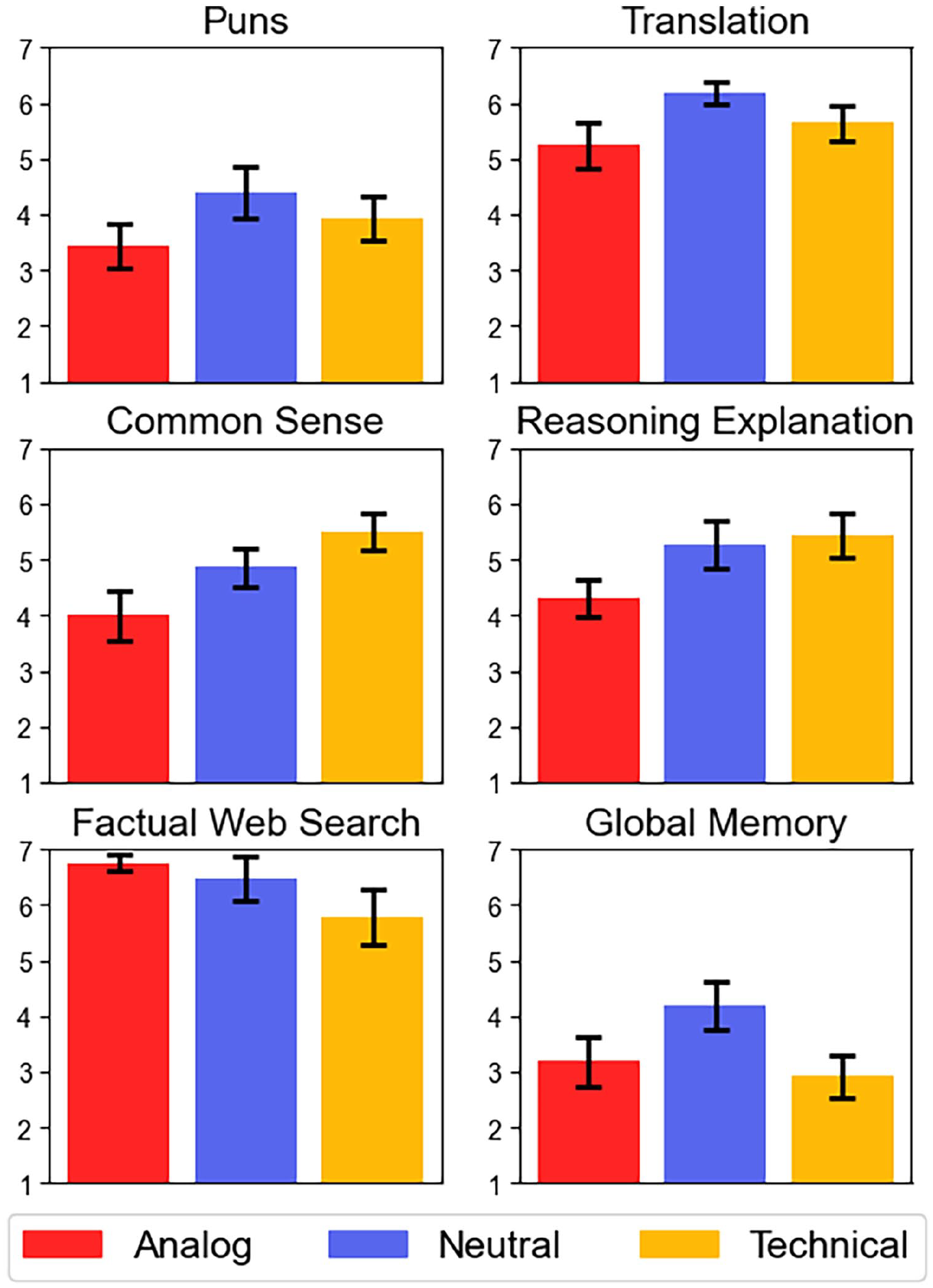
Participants’ expectations for specific prompts per condition. Error bars show standard error for n = 16, 15, 14 respectively.
Discussion
Our results show that people do approach LLMs with general expectations. For example, they do not expect the LLM to be able to access local files or store persistent memories, which might be the case for some systems but not for others. Similarly, participants expected the LLM to have up-to-date general knowledge or the capability to look up this information on the internet. This might be counterproductive if the system does not actually have these capabilities and does not make its knowledge horizon apparent.
Furthermore, for the most part, people’s expectations did not significantly differ between the three interface designs. This could be due to ineffective design choices as participants perceived them to be at similar levels of technicalness. Another reason might be that prior experiences shaped expectations to a degree that could not be overpowered by mere visuals. Future work could further study these reasons. More importantly, however, future research should investigate other ways to correct potential misconceptions, for example through explicit, dynamic, and interactive means of informing people of a systems’ capabilities and limitations.
Limitations
This should be considered an explorative study to inspire future research. Because our sample is small and lacks diversity (e.g., global representation), the findings presented here can probably not be generalized to any larger population. The experimental setup also lacks realism as participants merely reviewed screenshots and did not interact with the system. Finally, the set of prompts used in this experiment was an initial probe and not a complete catalog. We found that some prompts did not capture the general skills they were intended to reflect. This highlights the need for a validated questionnaire with prompts that capture a complete set of skills necessary for an LLM to complete any task.
Conclusion
This online study aimed to identify people’s expectations of LLM capabilities. We report expectations for a broad catalog of prompts and capabilities. These seem to be determined by factors other than the UI design. Future work can build on this to find ways of correcting misconceptions to support calibrated use of LLM systems.
Supplemental Material
sj-docx-4-pro-10.1177_10711813241260399 – Supplemental material for Investigating the Impact of User Interface Designs on Expectations About Large Language Models’ Capabilities
Supplemental material, sj-docx-4-pro-10.1177_10711813241260399 for Investigating the Impact of User Interface Designs on Expectations About Large Language Models’ Capabilities by Felix Gröner and Erin K. Chiou in Proceedings of the Human Factors and Ergonomics Society Annual Meeting
Supplemental Material
sj-xlsx-1-pro-10.1177_10711813241260399 – Supplemental material for Investigating the Impact of User Interface Designs on Expectations About Large Language Models’ Capabilities
Supplemental material, sj-xlsx-1-pro-10.1177_10711813241260399 for Investigating the Impact of User Interface Designs on Expectations About Large Language Models’ Capabilities by Felix Gröner and Erin K. Chiou in Proceedings of the Human Factors and Ergonomics Society Annual Meeting
Supplemental Material
sj-xlsx-2-pro-10.1177_10711813241260399 – Supplemental material for Investigating the Impact of User Interface Designs on Expectations About Large Language Models’ Capabilities
Supplemental material, sj-xlsx-2-pro-10.1177_10711813241260399 for Investigating the Impact of User Interface Designs on Expectations About Large Language Models’ Capabilities by Felix Gröner and Erin K. Chiou in Proceedings of the Human Factors and Ergonomics Society Annual Meeting
Supplemental Material
sj-xlsx-3-pro-10.1177_10711813241260399 – Supplemental material for Investigating the Impact of User Interface Designs on Expectations About Large Language Models’ Capabilities
Supplemental material, sj-xlsx-3-pro-10.1177_10711813241260399 for Investigating the Impact of User Interface Designs on Expectations About Large Language Models’ Capabilities by Felix Gröner and Erin K. Chiou in Proceedings of the Human Factors and Ergonomics Society Annual Meeting
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.