
Abstract
Scandal has been described as socially constructed, in that some combination of the public, the media, and the political elite agrees that a transgression has occurred. This study is among the first to directly observe the “scandal as a construct” premise, using time-series data to estimate how each group’s attention to scandal affects that of every other. These data, collected from Twitter by Barberá et al. (2019), measure the daily tweet volume of media outlets, Members of Congress, and samples of the public in relation to four Obama Administration scandals. Granger causality testing and impulse response functions show, as expected, that a jump in scandal-related tweets by one group affects the tweet volume of every other. But the groups wield unequal influence. Over the long-run, elites drive their supporters’ attention to scandal more than vice-versa. However, in two of the four scandals, the opposite effect was seen in the short-run, opening the possibility of a “sounding board” effect where elites are responsive to the initial reactions of their supporters but lead the conversation thereafter. These results encourage further study into how short- and long-term information flows differ, and why groups may lead in some issue areas but follow in others.
Scandals are important political events because they carry large consequences for the politicians involved (Basinger 2013), their parties (Foresta 2020, Daniele et al. 2020), and the broader policy process (Ferguson 2003, Paschall et al. 2020). But similar incidents of corruption, malfeasance, or immorality do not always lead to the same results (Newmark and Vaughan 2014). Scholars have explained the inconsistency of scandal outcomes by describing these events as being “socially constructed.” For an incident to become a scandal and have a major impact, the alleged transgression must meet with the “general opprobrium” of three sets of actors: the public, the elites, and the media (Thompson 2000). These actors do not behave in isolation, but rather are responsive to cues from one another (Woessner 2005, Entman 2012).
In describing the contours of scandal, and learning about how they emerge, scholars have focused alternatively on each of these three groups. Some have assigned a central role to the public, which is presumably the intended audience for charges of scandal; without its outrage, those charges are unlikely to catch on (Esser and Hartung 2004). Others have focused on the role of the news media, which disseminates information about scandal (Entman 2012, Boydstun 2013), and determines which incidents are newsworthy (Peterson 1956, Nyhan 2017). Finally, a growing set of studies pays attention to the role of political elites, among whom scandal originates, and whose members arguably have most to lose or gain from how an incident plays out (Woessner 2005, Nyhan 2009, Nyhan 2015).
None of these accounts would deny that scandal is largely constructed between the groups. But by focusing only on one or two actors at a time, the literature does not provide clear expectations about whether and when the public, media, or elites will take a “lead role” in scandal construction. A more direct method of studying scandal would use data that represent how each set of actors responds to charges of scandal at multiple points in time. This would allow scholars to observe how one group’s attention influences that of the others, and to probe the conditions under which groups take a lead role in scandal construction.
In this paper, I use data from Twitter to observe how actors respond to one another in terms of the attention they pay to scandal. These data, which were collected by Barberá et al. (2019), represent the daily tweet volume by samples of the public, members of Congress, and major media outlets in relation to four Obama Administration scandals. To estimate the effect of one group’s tweet volume over that of the others, I use two time-series methods—Granger causality and impulse response functions—which measure the day-to-day and long-term effects, respectively.
This analysis advances the literature on scandal in two primary ways and opens the door for a third. First, by incorporating data to represent public, elite, and media attention to scandal over the same time period, I demonstrate that scandals appear to be much more than nominally constructed. Rather, the attention of each group affects that of every other to a substantively important magnitude. But differences do exist. The second major contribution is that in two of the four scandals, Republican Members of Congress influenced the long-term attention of both their citizen supporters and the general public more so than vice-versa, and these effects were greater than any involving the media. Notably, this finding diverges from that of Barberá et al. (2019), who found that the public was more able to drive elite attention than vice-versa, suggesting that certain sets of actors may lead on some topics but follow others. The third result suggests that short- and long-term information flows may differ. In two of the four scandals, public attention had a short-term effect on that of Republicans in Congress, but not vice-versa, even as the latter dominated in the long-term. This result should encourage research into the possibility of a “sounding board” effect, where elites may gauge their supporters’ interest in a scandal in the short-term to determine how much attention to give it in the long-term.
The remainder of this paper is broken into four parts. First, I provide an overview of previous research on scandal. Previous treatments agree that scandals are a constructed phenomenon, but they each focus on how one or two specific groups contribute to the formation of scandal. It is therefore unclear what to expect when the attention of the three main actors is considered together. Second, I describe the data that facilitate this analysis. This project borrows from Barberá et al.’s (2019) data on the tweet volume of elites, the public, and the media as they pertained to four scandals that occurred during Barack Obama’s presidency. Next, I describe the time-series methods that my study uses, and how they alternatively measure the short- and long-term effects of one group’s attention on that of the others. Finally, I present my results, describe what they mean for the study of scandal, and suggest future directions for scholars of scandal to explore.
The Scandal Constructors: Elites, Media, and the Public
Scandal has historically received little attention from scholars, at least when considered relative to its near-constant presence in the political news cycle (Nyhan 2009, 1–3). Cameron (2002) suggests that this may be due to its sensationalized nature. Because news of scandal is shared in part for entertainment purposes, its real-life consequences may go overlooked. Recently, however, scholars have paid greater attention to those consequences, and have found that they are significant indeed. Basinger (2013) finds that congressional scandals lead to resignation 19% of the time and reduces vote share by 5% among politicians who seek reelection, while Paschall et al. (2020) demonstrate that scandal impedes the legislative effectiveness of a politician, even long after the incident has faded from the news.
Adut (2005) breaks the study of scandal into the “objectivist” and “constructivist” approaches. The objectivist approach focuses on the act of wrongdoing itself, supposing the size of a scandal to relate to the severity of the transgression. In this view, scandal is limited to what Adut (2008, 10) refers to as “real misconduct,” such as the crimes committed during Watergate, and outside of politics, this has been the dominant approach in the study of corporate scandal (Clemente and Gabbioneta 2017).
Certainly, over the long-term and across many scandals, the premise that worse crimes lead to greater punishment can be expected to hold true. But even casual observers of politics will note that this is not the full story. To better explain variance in the outcome of scandals, research has increasingly focused on how scandal is constructed by examining the roles that different actors assume in making an incident into a scandal (Entman 2012, Newmark and Vaughan 2014, Nyhan 2015). Of the public, media, and elites, each actor is presumed to have a distinct role in the construction of a scandal.
The public, for one, is generally understood to be the intended audience for charges of scandal. In their analysis of scandal in the German context, Esser and Hartung (2004) distinguish between scandal and the “grievances” that spur them. Only some grievances, they argue, generate the widespread public “indignation and outrage” that makes scandals distinctive. In this way, the public is only the group whose opprobrium is both necessary and sufficient for the construction of a scandal.
At the same time, Esser and Hartung (2004) concede that it is difficult to imagine a scandal that sparks public outrage, but goes ignored by elites and the media. Instead, they posit that the media is instrumental in drawing the public’s attention to a scandal. Boydstun (2013) also contends that media dynamics determine which incidents dominate the political agenda, and which quickly fade away. She describes journalists as varying between “alarm” and “patrol” modes in their reporting. When a story breaks, journalists will immediately shift their attention to it (alarm mode), but between newsflashes, they will continue to probe the implications of the most recent major story (patrol mode). This “patrol mode” reporting can uncover scandalous information, which garners responses from elites, spurring still more coverage of the topic. Boydstun contends that this dynamic explains why, of the many issues and transgressions that may be covered in any given year, only a few are able to claim a spot on the political agenda.
Entman (2012) agrees that the media inform the public about incidents of scandal, but describes it as being more reactive to elites than vice-versa. Entman uses a cascading network model to explain why some charges of scandal sizzle while others fizzle. In this model, once a transgression occurs that violates cultural expectations for our leaders, elites take the first step in condemning the act to news outlets. Only then do the media report on a charge, from which public awareness of the incident follows. Finally, media and public reactions inform elites’ next steps, such that the model incorporates feedback from one actor to another.
While the cascading network model attributes a role to each actor, Entman (2012) is clear that in practice, it places elites in the driver’s seat in terms of constructing scandal. Drawing on reporters’ own accounts, he demonstrates that news organizations have little capacity to root out scandal on their own. In addition, even when information about an improper act is available, journalists are hesitant to report on it without the condemnation of political elites. Entman argues that this may explain why the scandals that capture headlines and lead to resignations are often not about corruption or abuse, but rather sexual and other personal improprieties, committed by relatively minor actors. These incidents are simple for elites to frame as transgressions, involve targets who are easy to “take down,” and pose little threat to aspects of government that elites may wish to protect (e.g., the revolving door of lobbyists and bureaucracy chiefs).
In the digital age, however, it is possible to imagine the elites influencing the public without help from the media. Even two decades ago, Williams and Delli Carpini (2000) surmised that channels of communication between citizens and elites had proliferated to the point that traditional news outlets could no longer suppress charges of scandal. Woessner (2005) experimentally showed that when evaluating the severity of scandal, citizens take their cues directly from elites, whom they trust to contextualize a transgression relative to the normal goings-on of government. Given the rise of social media and the growth in partisan polarization since these studies, it is reasonable to hypothesize that elite influence over public perceptions of scandal has grown larger.
Six Mechanisms of Scandal Construction.

Measuring Attention to Scandal Using Twitter
The data for my analysis come from “Who Leads? Who Follows?” by Barberá and his colleagues at New York University. For each day in the years 2013 and 2014, they collected tweets by mainstream media outlets, Members of Congress (MCs), and various samples of the public. Taken together, their dataset is comprised of roughly 650,000 tweets by MCs, 273,000 tweets by the country’s 36 largest media outlets, and 45 million tweets from a total of 55,000 accounts belonging to private citizens.
The authors used a machine learning method known as Latent Dirichlet allocation, or LDA, to group these tweets into various topics. LDA identifies a user-selected number of topics (here, 100) among the tweets by observing which words appear together in the same context. Then, researchers manually deduce the news item that each topic is about based on the words that are most distinctive to it. 1 Finally, based on the words in each tweet, the algorithm calculates the probability that the tweet belongs to each of the 100 topics. A tweet with the words “Benghazi” and “Jerusalem,” for instance, may be assigned probabilities of 0.55 and 0.45 respectively for the topics on the Benghazi attacks and Israel-Palestine relations. By assigning these probabilities, LDA prevents the information loss that would occur if it categorized them as being about only one topic. To conduct their study, Barberá et al. (2019) calculated the percentage of daily tweets about each topic among accounts in each sample. They did so by adding up the topic-probability estimates for all tweets on a day, divided by the day’s total number of tweets. 2
To measure the relative attention of the public, media, and elites to instances of scandal, my analysis uses the following samples: • Tweets by 10,000 accounts that were randomly selected from all US-based accounts that follow three or more Republican MCs and no Democratic members. • Tweets by accounts tied to the 36 largest media outlets, according to Pew Research Center. These outlets include both mainstream sources (e.g., New York Times) and partisan sources such as Breitbart or Fox News. • Tweets by the official accounts of Republican MCs.
I focus on Republicans MCs because they represented the political opposition when the scandals occurred. I choose supporters of the GOP to represent the public because doing so may provide the clearest results by which to test the mechanisms. If the public is responsive to elites, or if elites are more responsive to the public, those mechanisms would be most pronounced between GOP elites and their citizen supporters. 3
There are four topics in the Barberá et al. (2019) dataset that refer to political scandals. They are the investigation of the Benghazi embassy terror attacks, the IRS targeting controversy, the Veteran’s Health Administration (VA) delays scandal, and the global surveillance leaks by NSA contractor Edward Snowden.
For context, it is worth reviewing the history of these scandals. Controversy emerged around the 2012 attack on the US embassy in Benghazi when 10 federal investigations found that the State Department was unresponsive to requests for additional security prior to the attack. Republican lawmakers charged further that a political cover-up occurred immediately after the attack, but none of the investigations—including two directed by GOP-led congressional committees—supported that charge (O’Toole 2016). The IRS targeting scandal emerged after the agency acknowledged that it had used keywords to identify and scrutinize the tax-exempt applications of political groups (Parsons and Mascaro 2013). While the news met bipartisan condemnation, Republican leaders argued that conservative groups were targeted disproportionately. An FBI investigation found no evidence of “enemy-hunting” (Rappeport 2017), and upon taking office in 2016, Republican president Donald Trump declined to reopen the case (Ohlemacher 2017). The VA delays scandal erupted after CNN reported that 40 patients had died while waiting for care at a Veteran's Health Administration facility in Phoenix, Arizona. The outrage sparked an internal audit that revealed more than 120,000 instances of the VA failing to meet its timely treatment targets, and that schedulers were instructed to falsify records to make wait times appear lower (Cohen 2014). Secretary of Veterans Affairs Eric Shinseki resigned as part of the fall-out. Finally, the Snowden leaks involved the illegal release of over 1.7 million US intelligence files, which led to reports about NSA programs that collected the phone records of US citizens from Verizon; collected the emails and chats of foreigners (primarily) from Microsoft, Google, Facebook, Yahoo, and Apple; and spied on the diplomatic missions of allied countries (Poitras et al. 2013).
As with any set of case studies, certain characteristics of these events make them particularly intriguing to researchers, while others may limit generalizability. To the former, news of these four scandals originated among different sets of actors, allowing us to partially account for whether a group’s role in breaking the news affects its influence later on. 4 To the latter, although scandals come in a few different forms—Thompson (2000) typologizes scandal into personal, financial, and power-related transgressions—all the cases here fall into the third category. Then, there is the more obvious temporal limitation: all the scandals occurred under the Obama Administration, and the outrage over them was most pronounced among congressional Republicans. Future research should re-examine the findings here in different political contexts, and test whether they can be extended to personal and financial scandals.
Other potential limits to generalizability can be assessed empirically. Two of these are the validity of Twitter data as a measure for public, elite, and media attention to scandals, and the extent to which these four cases represent scandals that attracted mainstream attention, as opposed to topics that circulated in a feedback loop among fringe actors. While both Twitter and fringe dialogue may be interesting of themselves, more generalizable data and cases will permit broader claims about how scandals are constructed.
I begin, then, by assessing the validity of Twitter data as a measure of public, elite, and media attention more broadly. Barberá et al. (2019) conducted such a validation for the public attention’s in their supplementary materials. The authors sorted Twitter topics and responses to Gallup’s Most Important Problem question into 19 issue classifications according to the Comparative Agendas Project, creating a month-to-month comparison of Twitter attention and more general issue importance for each of their samples. For Republican supporters, the subset of the public studied here, the relationship was r = 0.70. This indicates that tweets from this group were broadly representative of the concerns that national sample of Republicans had each month during the period under observation.
For other sets of actors—the media and elites—however, the authors did not directly assess how their tweets corresponded with offline attention. To fill this gap, I conduct a simple analysis of Congressional floor speeches (for elites) and Associated Press reports (for media), measuring offline attention by the number of keyword hits for each scandal per week. I compare these counts to the weekly amount of Republican MC and media attention on Twitter given to each scandal, respectively. Across the four scandals, this exercise finds a mean correlation of r = 0.48 for elites and r = 0.63 for the media between weekly Twitter and offline attention. Given that imperfect correlations can result from noise in either X or Y, and that the measures of offline attention I used were necessarily noisy, these results suggest that Twitter data hold a moderate-to-high degree of representativeness of elite and media attention across the scandals under study. A fuller account of this exercise is presented in the online Supplemental Appendix 1.
Next, I address the question of whether these scandals were discussed broadly among elites and the media, or if they occurred more in a feedback loop among fringe actors. While is not a clear-cut distinction to make, we may surmise that if attention to scandals were concentrated among just a few actors—and exclusively in one partisan coalition—then this would be evidence of a fringe dialogue. To facilitate this type of analysis, Barberá et al. (2019) provide an online dashboard that compares actors in terms of how much attention they gave to each topic. It presents the five Members of Congress who tweeted most about each scandal, as well as the overall attention given by members of each party in each chamber.
Across the four scandals, 18 of the 20 members who tweeted most about them were Republicans. This is as expected, and that even two were Democrats may be a surprise (both were in relation to the NSA surveillance controversy). Importantly, each of the 18 Republicans are unique: no one was a top-tweeter on more than one scandal. This indicates that, although some members may certainly take more interest in scandal than others, the information flows that we analyze will not be driven by a tiny cadre of gadfly legislators. Moreover, attention to these scandals across parties was not entirely one-sided. Across scandals and chambers, the mean ratio of Republican to Democratic tweets on these topics was 4.3:1, indicating that nearly one-fifth of attention to these scandals was driven by Democrats.
I also explore the possibility of that discussion of the scandals was concentrated among partisan media outlets, which comprise a minority of the 36 outlets whose tweets are incorporated in the Barberá et al. (2019) data. Expanding on the measurement validity exercise described above and in the Supplemental Appendix 2, I compare Twitter measures of media attention to each scandal with keyword hits in Fox News Network reports, to see whether Fox News (as a partisan outlet) is more predictive of weekly Twitter attention than AP reports are (as a mainstream source). In none of the scandals does attention from Fox News have a significantly stronger relationship with Twitter attention than do AP reports, and in one of them, the relationship between the AP and Twitter is stronger by a statistically significant margin.
The above tests of generalizability show that, for each of the three groups, the volume of scandal-related tweets is at least somewhat indicative of the attention paid to these scandals in other venues. They also provide indirect evidence that attention to these scandals was not driven exclusively by fringe actors but was diffuse enough to merit systematic study. Building on these conclusions, I now turn to the analytic strategy used to evaluate how one group’s attention to scandal affect that of the others.
Assessing Actors’ Relative Influence with Time-Series Analysis
Two time-series analytic methods allow me to test the premise that scandal is constructed by multiple actors—the public, media, and elites—and examine whether one group’s influence predominates over that of the others. The first method, Granger causality, tests for short-term effects between groups, while the second method, cumulative impulse response functions (cIRFs), measures the effect of a spike in one group’s tweet volume on the long-run tweet volume of the other sets of actors.
Both methods require certain preliminary steps. My data are broken into 12 time-series: one for the daily tweet volume of each of the three groups (public, media, and elites) in relation to each of the four scandals. Following Barberá et al.’s (2019) lead, I transform the data in each series into logits. This step is used when data have a long-tailed distribution—there are a few very large values, but most are very small—to keep the few large jumps in values from dominating the analysis, and to avoid violating core assumptions of time-series analysis (Wallis 1987). 5
Next, both Granger causality tests and cIRFs require that I estimate a structural vector autoregression (VAR). These are models that explain the values in one series at t as a function of the values from that and every other series at t-1, t-2, … t-s, where s is the maximum number of lags the model considers. I create a separate VAR for each scandal, checking first that my series are stationary, and confirming that none of the VARs contain serially correlated residuals. 6
The Granger causality test assesses whether one series has a significant, short-run effect on another. When one series “Granger causes” another, its past values explain the present values in the second series independently of past values in the latter. This involves setting up two OLS models and an F-test. To test whether the media’s tweet volume affected that of the public, for instance, I set up one OLS that explains public attention to a scandal at time t with its past values at t-1, …, t-7. Then, I prepare a second OLS that is just like the first, except that it also includes past values for the media’s attention (from t-1 to t-7). Finally, an F-test is run to determine whether the second OLS explains significantly more information about the public’s attention than the first. If that is the case, we can say that media attention to Benghazi had a significant, instantaneous effect on that of the GOP-supporting public.
However, Granger causality only tests for whether an effect exists; it does not estimate the magnitude of that effect. Moreover, it only looks at the short-run impact. A change in one series can have a long-run impact on the values in another because, in the stationary series I analyze, the value of a series at t can impact its value at t + 1, which affects t + 2 and so on. I use a cumulative impulse response function (cIRF) to estimate the effect of a 10% jump in tweet volume among one group on the cumulative tweet volume of another group on the same topic over the following 15 days. 7 If a spike in media attention at t, for example, were to lead to an increase in the public’s tweet volume by 5% at t + 1, 2% at t + 2, and 0% at t + 3,…, t + 15, then the cumulative effect of the original spike would be 7%.
Scandal is Constructed Between Groups, but the Groups’ Influence Varies
In Table 1, I presented six theoretical mechanisms by which scandals are constructed among the public, media, and political elites. While the literature assumes that scandal is constructed between groups, this has rarely been observed in real-time using data. Moreover, the existing literature does not give us clear expectations about who among the groups takes the lead. Since the public is the intended audience for scandal, it is possible that their response to a scandal will direct the other actors’ attention (Esser and Hartung 2004, Entman 2012). At the same time, it is hard to imagine a scandal without a media firestorm around it, and Boydstun (2013) shows that the news media can direct elite attention as well as that of the pubic. Finally, when a transgression occurs, elites have most incentive to quell or fan outrage (Nyhan 2009), and both the public and media may look to them for cues about how to put the incident into context (Woessner 2005, Entman 2012).
I test each of these mechanisms using the methods described in the previous section. Granger causality tests determine whether a short-run effect exists between one group’s attention and another’s. By contrast, cIRFs estimate the long-run effects between groups, added up over time.
Figure 1 illustrates the directions of Granger causality between the three groups for each scandal. The upper-leftmost arrow, from the public to elites on Benghazi, indicates that the percentage of public tweets about Benghazi at time t-1, …, t-7 explains the percentage of Republican Members of Congress’ tweets about Benghazi at time t, independent of past elite behavior. This indicates that in the short-run, public attention to Benghazi drives elite attention, although it says nothing about the magnitude of the effect. Short-term relationship between the tweet volume of three groups.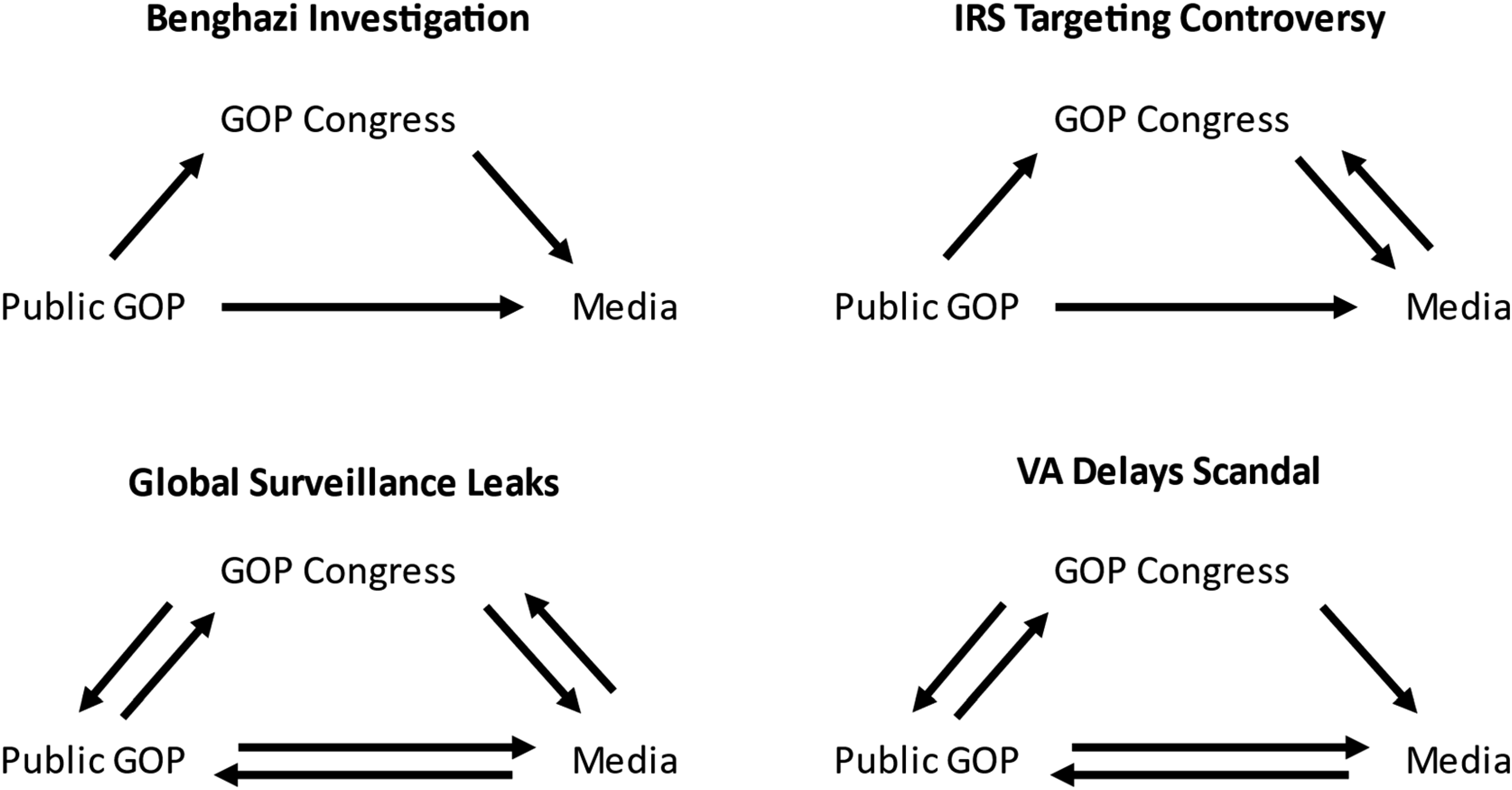
When we compare the arrows to our theoretical expectations, we can begin to draw conclusions. First, as expected, we see evidence of the overall constructedness of scandal. Out of a total of 24 possible short-run relationships, 18 are confirmed by Granger causality tests, and each group influences every other in at least one scandal.
Across scandals and actors, however, we see ample variation. In terms of scandals, some appear to have propelled more active feedback loops than others. The flow of attention to the Benghazi investigation, for instance, does not appear to have been reciprocal between groups in the short-run. Citizen supporters of the GOP affected the attention of both elites and the media, but not vice-versa. Elites affected the media’s attention, but the reverse did not also occur. These results stand in contrast to the instantaneous feedback loops between elites and their supporters, and those supporters and the media, amid the Snowden leaks and VA delays scandal.
We also observe some actors having a more consistent impact in the short-run than others. The media, for instance, only affected the short-run attention of elites in two of the scandals. The partisan public had an unreciprocated, short-run effect on the attention of elites and the media in the Benghazi investigation and the IRS targeting scandal, which are arguably the two cases where the claims of Congressional Republicans deviated most from the established facts.
The partisan public’s short-run influence over Republican MCs stands in contrast to the long-run results. Again, cumulative impulse response functions (cIRFs) allow me to go beyond the effect of one group’s attention at t-1 on another’s at t, by tracing it forward to see how that same jump affects attention at t+1 and onward. Specifically, the model I estimate provides the magnitude of each group’s influence over the others by calculating the effect of a one-time, 10% jump in one group’s tweets about a scandal on another group’s tweet volume over the following 15 days.
Cumulative Responses to a 10-Percentage Point Impulse in Twitter Mentions.
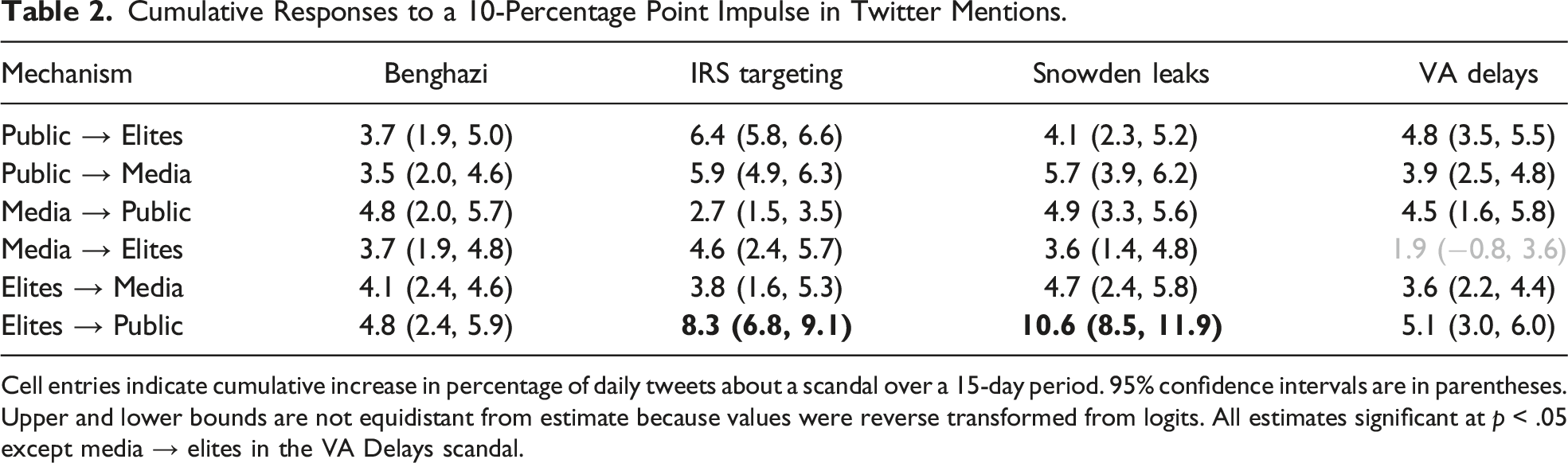
Cell entries indicate cumulative increase in percentage of daily tweets about a scandal over a 15-day period. 95% confidence intervals are in parentheses. Upper and lower bounds are not equidistant from estimate because values were reverse transformed from logits. All estimates significant at p < .05 except media → elites in the VA Delays scandal.
These results, which measure the influence of each group over the others in the long-run, are a clear demonstration of the concept of scandal as socially constructed. All of the response estimates are positive and significant at p < .05, with the exception of the media → elites response in the VA Delays scandal.
A more notable result, however, exists in the mechanism by which elite attention to scandal influences that of the partisan public. In two of the four scandals, the IRS targeting and NSA surveillance controversies, this relationship was stronger than any of the others. A 10% jump in Republican MCs’ tweets about these scandals resulted in a spike of 6.8%–11.9% in the Twitter attention devoted to that scandal among their citizen supporters. These results are replicated in the Supplemental Appendix 3 using a separate, less partisan sample for the public (accounts that followed at least one news outlet). The effect was equally as strong and distinctive.
Taken as a whole, these results advance our knowledge of scandal in two ways. The first is that we have observed that scandal is constructed among actors. This aligns with expectations from prior research. Still, the direct, quantitative observation of each set of actors’ attention over time is useful because it shows us that the construction is far more than trivial. Across all four scandals, all three groups had an impact on at least one other. The relative consistency of this result suggests that a group’s impact is not exclusive to a narrow set of circumstances, but that ceteris paribus, we would expect each set of actors to influence the others.
The second result regards the influence of elites over the long-run attention of their citizen supporters. In two of the four scandals, this relationship was stronger than any other that was observed, and the finding marks a departure from the overall conclusion of Barberá et al.’s (2019) study on a broader range of topics. In that analysis, the authors found that the “partisan public” drove the long-run attention of elites, but here, the opposite is observed in their topics pertaining to scandal.
The last result modifies the above, pointing toward an intriguing avenue for future research. Although elites influence their supporters’ attention in the long-run, a slightly different story emerged in the Granger causality tests of short-run influence. There, in two of the four scandals, the partisan public had an instantaneous effect on elite attention without a reciprocal relationship. Broadly speaking, this shows that short- and long-run information flows can differ considerably, an insight that is worth applying elsewhere. But more narrowly to the topic of scandal, it provides weak evidence of a “sounding board” effect, where partisans tell elites what they wish to hear in the short-run, and elites dominate the flow of attention thereafter. This possibility merits further study on a broader set of topics.
Discussion and Conclusion
In this paper, I contribute to a body of research that understands scandal as a socially constructed event by empirically demonstrating that three key actors—the public, media, and elites—all contribute to placing scandal on the public agenda. This study is among the first to observe the understanding of “scandal as a construct” using data to measure the attention of all three groups over a prolonged period. In doing so, however, we saw that the groups do not hold the same influence—at least not always. Over time, in half of my case studies, elites were able to draw public attention to scandal to a greater extent than vice-versa, and this relationship was greater than any other that was studied.
Again, this finding is essentially the opposite of what Barberá et al. (2019) concluded from their study of a larger set of topics. They found that it was a party’s citizen supporters that wielded most influence over the public agenda, and their party’s elites who responded. Why, then, might information flows between elites and citizens work differently for scandal, relative to other topics?
Research discussed in the literature review suggests two possible answers. One highlights the value of elite cues. Woessner (2005) contends that the public turns to elites to put scandal into political perspective, answering questions such as “How bad is this?” and “Who is to blame?” If elite cues systemically raise the salience of scandal relative to other news and policy items, then this could explain why elites appear to lead the public on scandal. In future research, an experiment may be apt to test this proposition. Using pre-testing, scholars may identify a set of scandals and policy issues that carry the same naïve importance to citizens. Then, a survey experiment can assess whether the treatment of an elite cue affects how respondents perceive the importance of scandals more than it affects that of policy issues.
A second view may emphasize the supply-and-demand of political information. Williams and Delli Carpini (2000) expected that the digital age would blur the line between political news and entertainment, with elites supplying the partisan public’s latent demand for partisan spectacle (which had not previously been supplied by traditional news outlets). On news or policy items, citizens are likely to demand action from elites. This may elicit an initial response, but action being costly—and policy demands being ephemeral—there is less chance that elites will be willing to or successful at driving the public’s attention on these topics. By contrast, scandal is more entertainment oriented (Owen 2000, Vorberg and Zeitler 2019). Citizens may therefore demand relatively less action and more spectacle, which elites may find easier and more advantageous to supply.
Complementary to the finding that elites lead the public’s long-run conversation around scandal was the difference between short- and long-run information flows. The concept of a “sounding board” effect suggests that elites may use channels like Twitter to gauge public interest in a topic before devoting their full agenda-setting power to it. While evidence for this was observed in only two of the four scandals, it is at once an intriguing and plausible dynamic that merits further exploration.
Clearly, this study should not be taken as the last word on scandal, particularly due to the limitations inherent in my case studies. All four of the scandals that I examine fall into a single category of Thompson’s (2000) typology: transgressions that relate to an abuse of power. Further efforts should be made to determine whether my findings hold up when scandals relate to personal or financial transgressions. In addition, all the scandals in my study occurred in a specific political context—under the Obama Administration with Republican control of the House—and reflected outrage in response to institutional policies as opposed to the actions of an individual.
Still, this study represents an advance both on the topic of scandals and in agenda-setting more broadly. We have seen that elites lead on some issues but follow on others. We have seen that short- and long-run information flows between actors can differ significantly. These differences represent fruitful lines of inquiry for scholars of political communication and agenda-setting, and with social media today, data like those collected by Barberá et al. (2019) can allow us to trace the attention of very different sets of actors concurrently and over long periods of time.
Supplemental Material
Supplemental Material - Analyzing Attention to Scandal on Twitter:Elites Sell What Supporters Buy
Supplemental Material for Analyzing Attention to Scandal on Twitter:Elites Sell What Supporters Buy by Seth B. Warner in Political Research Quarterly.
Footnotes
Acknowledgments
The author wishes to thank Suzanna Linn and Eric Plutzer for their guidance and feedback, the authors of “Who Leads, Who Follows?” for making their data available to researchers, and the three anonymous reviewers for their helpful suggestions.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Data Replication
Notes
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.