
Abstract
Evaluation methods emphasizing children’s natural interaction help in getting feedback from children for product development. This paper presents a case study with 9- to 10-year-old children in a school context. The evaluated system was an artificial intelligence–based poetry writing system, and the methods used were peer tutoring with paired interviews and group testing with a new Feedback Game. The evaluation criteria included the number of usability problems, usefulness, and fun. The applicability of the methods is discussed along with the resources required. Peer tutoring revealed numerous problems, whereas group testing and the Feedback Game were quick to conduct and analyze.
Keywords
A case study in 9- and 10-year-olds examines the children’s natural interaction with feedback, and the usability of an artificial intelligence-based computational creativity system called the Poetry Machine.
Usability is a key issue in the success of e-learning resources (Lahti, Siira, & Törmänen, 2012), so their design process should involve the users as early as possible. Gathering feedback from children, however, is challenging, as their language skills, confidence, and self-belief (Read & MacFarlane, 2006) and the presence of adult observers (Höysniemi, Hämäläinen, & Turkki, 2003) may affect their performance. Children are also eager to please (Hanna, Risden, & Alexander, 1997; Höysniemi et al., 2003) and tend to give overly positive feedback (Höysniemi et al., 2003; MacFarlane, Sim, & Horton, 2005).
In this case study, we evaluated a functional prototype of an artificial intelligence–based system called the Poetry Machine with 9- to 10-year-old children. The system is designed to facilitate poetry teaching and writing in Finnish primary schools. It aims to solve the problem of an empty paper by providing pupils with a computer-generated poem excerpt to start with, and rhyme suggestions and new lines as needed. The pupil may modify the excerpt through a user interface similar to poetry fridge magnets by dragging and dropping words, removing or editing them, or adding new words or lines (Figure 1).
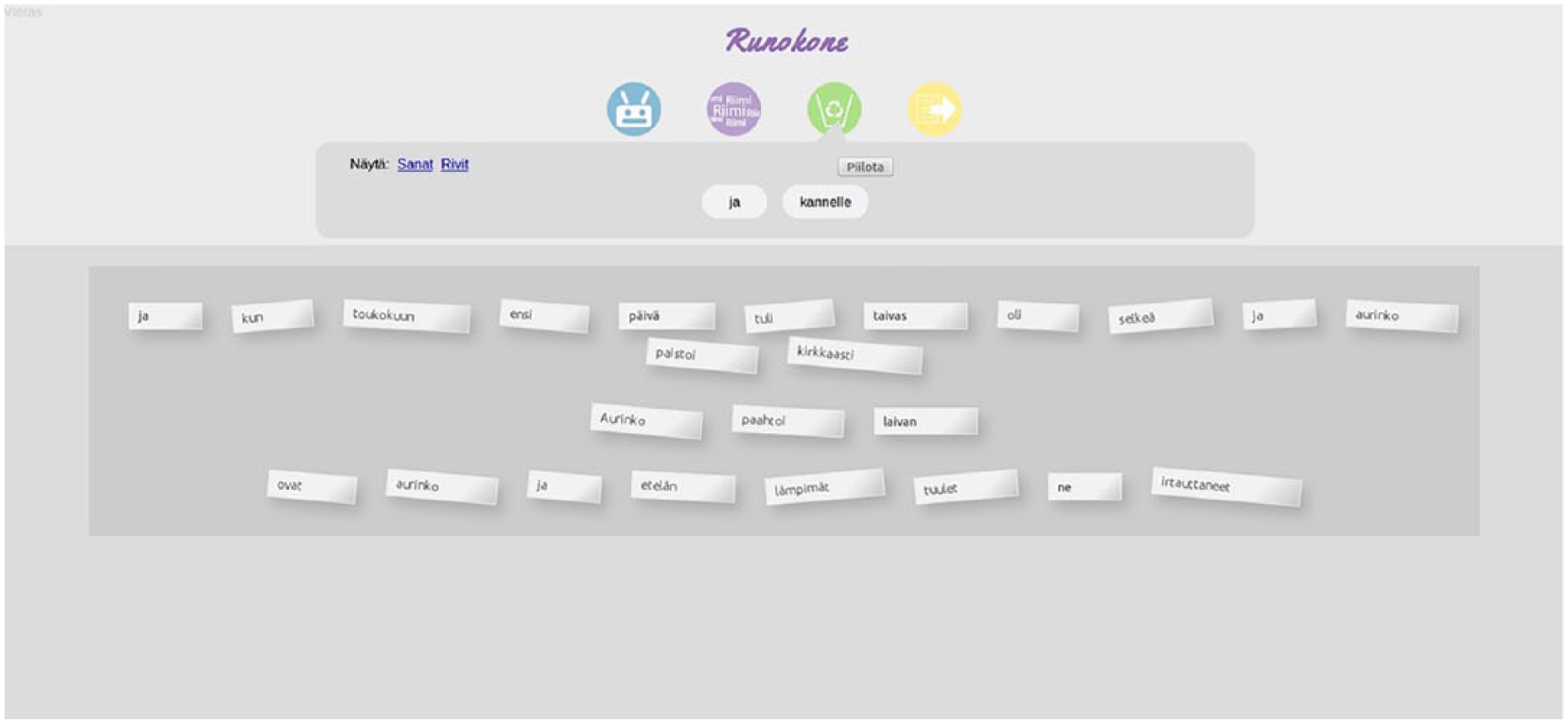
The evaluated version of the Poetry Machine user interface with the fridge magnet metaphor.
We selected three evaluation criteria: the number of usability problems, usefulness, and fun. Usability problems are aspects in the user interface that slow down or complicate task performance, cause usage errors, or make the system look unpleasant (Mack & Nielsen, 1994). Usefulness focuses on the utility of the system in a school context, and fun has been found to correlate well with usability when testing with children (MacFarlane et al., 2005; Sim, MacFarlane, & Read, 2006). We left out efficiency-oriented criteria, as children are not usually productivity oriented (Hourcade, 2008), and speed is generally considered an inappropriate measure with children (Hanna, Risden, Czerwinski, & Alexander, 1999). Based on these three criteria, we selected a multimethod approach using peer tutoring with paired interviews and group testing with a new method called the Feedback Game. We present our experiences with these methods and assess the methods by their ability to give information about the selected criteria, the resources required, and their ability to gather comments from children.
Evaluation Methods
Children in our target age group (9–10 years old) are accustomed to working with adults in a school environment and are able to describe what they see and do (Hanna et al., 1997). Even so, social support and given instructions affect their performance (Hourcade, 2008). For example, children are able to concentrate for a longer time if they are enjoying themselves (Markopoulos & Bekker, 2003). To create an enjoyable and relaxed testing environment and to promote natural interaction between the children, we selected methods involving multiple participants: Peer tutoring and paired interviews involve pairs of users, and group testing and the Feedback Game involve small groups. To provide the children a familiar test environment, we conducted the tests at their school, so we were also able to interview their teacher.
In peer tutoring, a person instructs another person with a similar status. When used as an evaluation method with children, the first child learns to use the evaluated system and then becomes a tutor instructing the other child, the tutee (Edwards & Benedyk, 2007). As children easily emphasize positive features when instructing their friends, supplementary methods are recommended to elaborate negative comments and dislikes (Höysniemi et al., 2003). We used paired interviews, giving the benefit of peer support also in the interview. The questions were open-ended to reduce the children’s tendency to please (Read & MacFarlane, 2006).
We selected group testing as another evaluation method to assess the Poetry Machine in a typical teaching context with a small group of children. Interviewing more than two children simultaneously is challenging, so we studied contemporary alternatives. We did not find a suitable method but found some potential ideas, such as the Fun Toolkit (MacFarlane et al., 2005; Read & MacFarlane, 2006; Read, MacFarlane, & Casey, 2002; Sim et al., 2006), which uses smileys for assessing single products and tactile scales for ranking several products with a single user. We combined these ideas with elements from focus groups, interviews, and board games, producing the Feedback Game. Analogous to board games, it has clear rules facilitating interaction, a physical game board, and game tokens. The Fun Toolkit inspired the game board: a table with eight questions and a 5-point Likert-type scale using smileys from a sad face to a laughing face (Figure 2). This test was the first experimentation with the game and an attempt to validate the method.
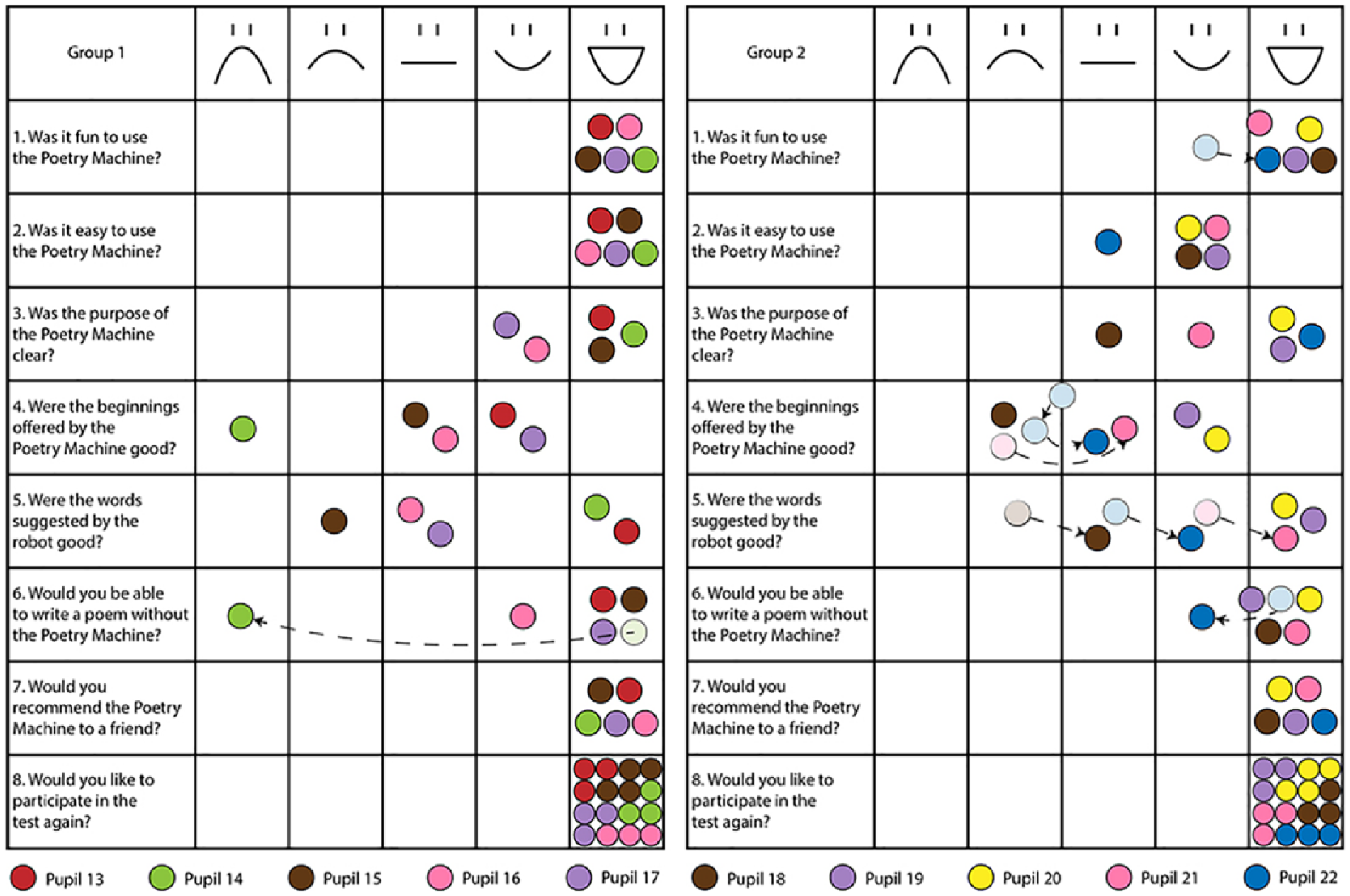
Feedback Game questions and results. Arrows show how the players have changed their minds during the game.
Test Procedure
The evaluations were conducted at a school that had participated in several pedagogical research programs, so the pupils were used to observers in their classes. The school environment may, however, discourage creative thinking (Obrist et al., 2011), so we used paired and group-based methods to facilitate discussions and creativity. We also recruited all the participants from the same class and asked the class teacher to select suitable pairs and groups who were comfortable in working together.
Evaluation With Multiple Users
Evaluating the system with several children at the same time is encouraged to balance out the child–adult ratio in user testing and to give peer support for children. This evaluation used two testing methods involving multiple users at the same time: peer tutoring and group testing.
Involves two children: the tutor and the tutee
The tutor learns the interface
The tutee is instructed by the tutor
Facilitates communication in children’s own language
Involves a small group of children
Resembles a typical classroom use
Children are instructed by their teacher
Children communicate with each other freely during evaluation
Altogether, 22 pupils participated in our tests: six pairs in peer tutoring and paired interviews and two groups of five pupils in group testing and the Feedback Game. Both settings included an equal number of girls and boys, and they were all 9 or 10 years old. We requested parental consent from all the participating pupils with a form sent through the school. We asked the class teacher to form the peer-tutoring pairs from friends of the same sex to ease discussion and to avoid hostility (Höysniemi et al., 2003), whereas close friends were avoided in the group testing, following the instructions for focus groups (Patel & Paulsen, 2002).
We conducted six peer-tutoring and paired interview sessions in 2 days and two group-testing and Feedback Game sessions a week after. We organized the sessions during normal school hours in a small classroom and recorded them with one camera. The children were rewarded with a card, a sticker sheet, and candy.
Peer tutoring and paired interviews
Each peer-tutoring session involved five persons: the tutor and the tutee, one evaluator acting as a facilitator, and two observers. First, we introduced ourselves, presented the test setting, and asked the tutor to fill in a background questionnaire. Then we trained the tutor to write a poem with the prototype, after which the tutor moved aside to read a book, while we introduced the test setting and background questionnaire to the tutee. After that, the actual peer tutoring started, and the tutor instructed the tutee to write a poem with the system. The peer-tutoring sessions lasted on average 33 min, plus 7 min for the paired interviews.
We let the children work independently to promote their natural interactions, so the facilitator helped only when needed. Some pupils also needed encouragement and praise, as Höysniemi et al. (2003) had indicated. Following their instructions, we seated each pair so that the tutee controlled the mouse.
After the peer tutoring, the facilitator interviewed the pair at the same time. We started with warm-up questions asking how many stars the children would give to the Poetry Machine out of five and what was the best or worst thing about it. Then we moved on to specific problems faced during the test. Next, we asked if the children would recommend the tool to their friends and reasons for their choice. Finally, we asked if the children would like to participate in a similar test again.
Group testing and Feedback Game
Each group testing session involved nine persons: five pupils, their teacher, one facilitator, and two observers. First, we introduced ourselves, and the pupils filled in the background questionnaire. Then the teacher showed how to use the system and instructed the children as they wrote their own poems. The group-testing sessions lasted about 45 min, plus 15 min for the Feedback Game.
We played the Feedback Game after group testing to elicit more comments and improvement ideas. First, the players selected the color of their game tokens and thereby also their nickname during the game. The facilitator then explained the rules of the game and started being a game master. The game master started each round by asking a question on the game board, such as “Were the beginnings offered by the Poetry Machine good?” All the players answered at the same time by placing their token on the most suitable smiley column. Next, the game master asked further questions, such as “What was good/poor about them?” Each player answered on his or her own turn, and everyone got to start a round in turn. As Figure 2 illustrates, children were allowed to move their tokens during the game. The used tokens were left on the board to visualize the progress of the game. An ongoing game session is depicted in Figure 3.

A group of pupils playing the Feedback Game.
Analysis
Our evaluation criteria included fun, usefulness, and the number of usability problems. We were also interested in the number of user comments gathered with each method. Therefore, the analyses required several walk-throughs of the collected materials. The usability problems were classified in three levels:
3 = Problem prevents the use of a feature.
2 = Problem complicates the use of a feature.
1 = Problem slows down performance or bothers the user.
The peer-tutoring analysis focused on usability problems, but we also analyzed the behavioral signs, feature usage, and the pupils’ comments. To reduce evaluator effect in the problem detection, we had a pool of three evaluators, from which two evaluators independently analyzed each test recording, as recommended by Hertzum and Jacobsen (2001). One evaluator analyzed the other factors, classifying the behavioral signs as positive or negative based on literature (see, e.g., Hanna et al., 1997; Read et al., 2002). A neutral category was also needed for conflicting signs, such as frowning, which can indicate problems (Hanna et al., 1997) or positive concentration (Read et al., 2002) in the Nordic expressive behavior. This evaluator also counted the feature usage to see what intrigues the children and to assess the test coverage.
The group-testing analysis focused on usability problems and comments, but these recordings did not support the analysis of behavioral signs or feature usage. One evaluator analyzed the recordings supported by in situ notes from all the observers. She also transcribed the paired interviews and the Feedback Game to detect development ideas and comments on the concept and the evaluation criteria.
Test Results and Method Experiences
In the test results, we emphasize our evaluation criteria: number of usability problems found, usefulness of the system, and fun. We also consider how useful the methods were in evaluating these criteria. Because usability evaluation methods with children are often assessed by their ability to detect usability problems and the resources they require (Markopoulos & Bekker, 2003), as well as their ability to elicit authentic comments from the children (van Kesteren, Bekker, Vermeeren, & Lloyd, 2003), we also investigate these factors.
Overall, we found 89 usability problems. Peer tutoring revealed most of the problems (76), giving also detailed information about their reasons. The most frequent problems were related to moving and targeting the words in the poem. The most frequently used features during peer tutoring were editing words (102 times), throwing words into trash bin (88), and moving words (81). The paired interviews revealed 16 problems, of which six were new. Group testing revealed only 18 problems, mainly because our focus had already switched to getting feedback on the system. Only seven problems were new, but they ranked high on the final problem listing by their severity. These problems were related to adding and moving whole lines in the poem. The Feedback Game, as the last debriefing method, revealed only three problems, without new problems.
The most severe problem in both effect and frequency was the limited target area for dropping the words into their new places. This problem was found with all methods, but a similar problem with moving whole rows was found only through group testing. As the group testing included a short introduction to using the tool, it also revealed problems in memorability. For example, the children had problems in recalling how to add new words. The paired interviews, in turn, gave valuable insight into missing features: One pair wanted to remove the whole poem, and another wanted to write their own words into the rhyming tool directly. The Feedback Game did not give new information about the usability problems but emphasized the problems in moving the words in general.
Both the pupils and the teacher found the system useful. The peer-tutoring sessions gave little information about usefulness, so additional information from group testing, the Feedback Game, and teacher interviews was essential. For example, one Feedback Game participant specifically mentioned that the poem excerpt helped in continuing the poem, and the teacher noted that the pupils were faster to get to work, worked more autonomously, and were more engaged than in usual classes. Later on, the teacher also reported that one pupil had started writing poems as a hobby after the test.
Evaluating the criterion fun was complex, as it included the classification of gestures in peer tutoring. The children’s self-reports and comments in the paired interviews and the Feedback Game were an important supplement in this evaluation. We categorized as many as 634 individual gestures in the peer-tutoring sessions into 233 positive, 153 neutral, and 248 negative gestures. Although negative gestures outnumbered the positive, only three children showed negative gestures the most, two neutral gestures, and seven mainly positive gestures (see Figure 4). Also the children’s self-reports imply that the Poetry Machine was fun to use: In the paired interviews, four pupils named fun as a reason to recommend the tool to their friends, and the 10 Feedback Game participants unanimously agreed that the Poetry Machine was fun to use.
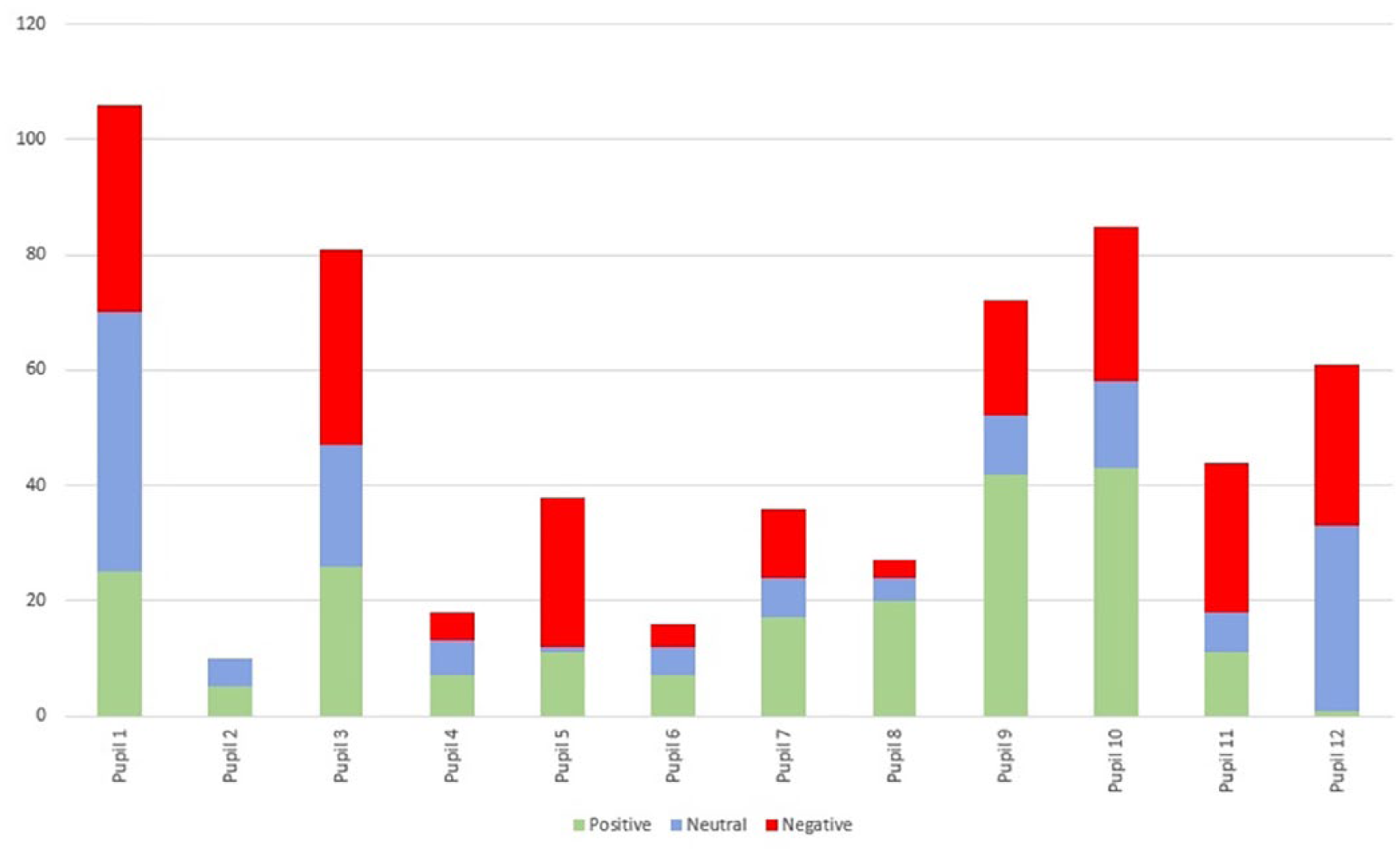
Categorization of the tutors’ (odd-numbered) and tutees’ (even-numbered) facial expressions into positive, neutral, and negative signs. Both the tutor-training and the peer-tutoring phases are counted for the tutors.
Peer-tutoring sessions were cumbersome and time-consuming to conduct and analyze: Conducting the six sessions took about 3 hr 15 min, and the analyses for usability problems took almost 20 hr when done by two evaluators. Analyzing facial gestures, feature usage, and comments took an additional 10 hr from one evaluator. The six paired interviews took about 40 min, and their analyses 4 hr 20 min, also by two evaluators. The two group-testing sessions took about 1 hr, and their analyses 3 hr, from one evaluator. Finally, the two Feedback Games took only 30 min, and their analyses only 1 hr 30 min, also by one evaluator. In addition to being quicker to conduct, the group testing let the evaluators concentrate on observation, as the teacher instructed the pupils. The Feedback Game sessions, on their part, were the easiest to analyze, as the children clearly formulated their answers on top of the previous ones, and the physical tokens made possible biases easy to spot and interpret.
Both in the peer tutoring and the group testing, the pupils’ questions were beneficial in revealing usability problems. Especially the tutors’ answers were helpful, as they revealed also the tutors’ mental models and hesitations. In peer-tutoring sessions, the tutors made 76 comments during tutor training and 124 comments when instructing the tutees, whereas the tutees made only 65 comments. The most useful comments were the tutors’ instructions to the tutees (48) and descriptions of the poem writing process (7). In group testing, pupils made 85 comments: mostly questions for the teacher (34) or comments about the poems (10) but also hints to their friends (6), and some negative comments (4).
Altogether, the pupils gave 10 improvement ideas: six ideas in the paired interviews and four in the Feedback Games. The ideas in the Feedback Game underlined conceptual issues, whereas the ideas in the peer tutoring also dealt specific user interface issues.
If we compare peer tutoring and group testing, although applied with different aims, peer tutoring was very effective in detecting usability problems, revealing 6.3 problems per test user, whereas group testing revealed only 1.8 problems. However, if we take the usability problem analyses into account, it took about 18 min to find a problem in peer tutoring, whereas in group testing, it took only 13 min. On the part of the comments during the test sessions, peer tutoring prompted 265 comments in 3 hr 15 min (82 per hour) with 12 pupils, and group testing prompted 85 comments in 1 hr with 10 pupils. Table 1 summarizes the method comparisons.
Comparison of the Applied Usability Testing and Debriefing Methods
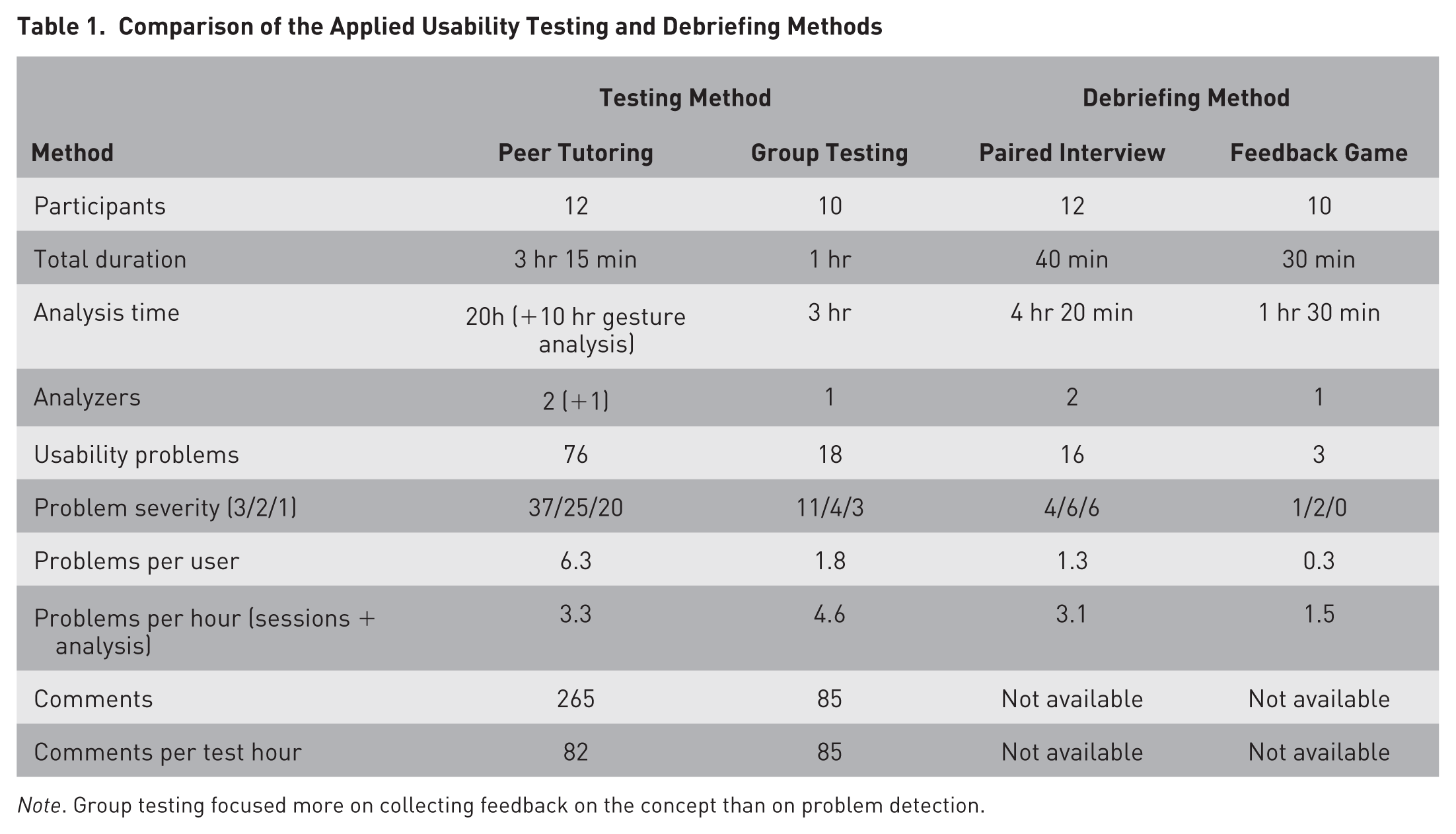
Note. Group testing focused more on collecting feedback on the concept than on problem detection.
Discussion
The number of test participants in our study (22) was in the same size range as in similar studies with children (e.g., Sim et al., 2006; van Kesteren et al., 2003), but it also shared the potential problem of having all the test participants from a limited sample of one class. This is a limitation that we shall address by conducting more tests at other schools.
In peer tutoring, we used only one general task, as open exploration is encouraged for this age group (Hanna et al., 1997). Even so, the test coverage was good, as each feature was tested by at least two pupils. However, the open task seemed to confuse the tutors, and a simple warm-up task might have been appropriate to break the ice. Selecting the more extrovert pupil in each pair as the tutor would also have given them more confidence in instructing the tutee.
Peer bias seemed to be stronger in the paired interviews than in the Feedback Game. In the Feedback Game, the player role and taking turns made it easier for the children to articulate both their agreements and disagreements, whereas in the paired interviews, either the tutor or the tutee usually dominated the discussion. The paired interviews also stressed positive answers, as all the pupils gave one of the two highest ratings for the tool, conforming to other studies with children giving overly positive feedback (e.g., Obrist et al., 2009; Read & MacFarlane, 2006). The answers in the Feedback Game, however, were more varied, including also poor ratings.
The tutors seemed to stress considerably as three adults observed them, whereas children participating in the group testing did not mind the large number of adults. In the analysis phase, having at least two evaluators is preferable to increase the reliability of the findings. For example, our three evaluators were very unanimous, as 86% of the usability problems discovered in peer tutoring were reported at least by two of them. Having fewer evaluators or less analysis time could leave some problems unnoticed, especially minor ones that still disturb the use.
Conclusions
We used a multimethod approach to evaluate an interactive prototype with children. Peer tutoring provided detailed information on the usability problems but was time-consuming to conduct and analyze, whereas group testing confirmed only the most rudimentary usability problems but was more efficient. The new Feedback Game was quick and fun to play and easy to analyze. It was especially helpful in evaluating the criteria usefulness and fun, and in collecting ideas and feedback for the concept. However, the Feedback Game could focus only on a limited set of questions.
The evaluation results clearly show that multimethod approach is beneficial. No method alone could have produced equally useful results for such a broad scope. The various approaches also clearly supported each others’ results. Thereby, our first attempt to validate the Feedback Game seems successful. The results also show that quick and practical results can be obtained even with group-based methods. Therefore, we recommend using a set of group-based methods already in the early phases of development to test new ideas, detect missing features, and focus on specific questions puzzling the development team. Peer tutoring and other, more specific methods are relevant later on in the development process, as the details of the user interface are finalized.
Footnotes
Acknowledgements
We thank Karoliina Tiuraniemi and Mikko Hynninen for assisting with the test sessions and analysis, professor Hannu Toivonen for useful comments, and the pupils and the teacher who participated in the tests. This study was funded by the Academy of Finland (Decision 276897, CLiC) and the European Commission (FET Grant 611733, ConCreTe).
The authors prepared the work as employees of the University of Helsinki.