
Abstract
Animals can navigate through complex environments with amazing flexibility and efficiency: they forage over large areas, quickly learning rewarding behavior and changing their plans when necessary. Some insights into the neural mechanisms supporting this ability can be found in the hippocampus (HPC)—a brain structure involved in navigation, learning, and memory. Neuronal activity in the HPC provides a hierarchical representation of space, representing an environment at multiple scales. In addition, it has been observed that when memory-consolidation processes in the HPC are inactivated, animals can still plan and navigate in a familiar environment but not in new environments. Findings like these suggest three useful principles: spatial learning is hierarchical, learning a hierarchical world-model is intrinsically valuable, and action planning occurs as a downstream process separate from learning. Here, we demonstrate computationally how an agent could learn hierarchical models of an environment using off-line replay of trajectories through that environment and show empirically that this allows computationally efficient planning to reach arbitrary goals within a reinforcement learning setting. Using the computational model to simulate hippocampal damage reproduces navigation behaviors observed in rodents with hippocampal inactivation. The approach presented here might help to clarify different interpretations of some spatial navigation studies in rodents and present some implications for future studies of both machine and biological intelligence.
Keywords
1. Introduction
1.1. Some features of the hippocampus’ role in navigation
The hippocampus (HPC) is a region of the brain that plays a critical role in spatial navigation and also in encoding and recalling spatial information (Burgess et al., 1998; Hartley et al., 2014). Experiments in rodents have advanced our understanding of the neural mechanisms underlying cognitive maps, spatial navigation, and their relationship to learning and memory (Chersi & Burgess, 2015). Historically, several impactful theories suggested that the HPC was crucial for acquiring and storing environmental cues into a map-like representation (Hirsh, 1974; Keefe & Nadel, 1978). Experimental evidence in support of these theories began to emerge with the adoption of the Morris water maze: a spatial navigation task in which rats or mice are trained to swim to a hidden platform in a pool using spatial cues (R. G. M. Morris, 1981). Because they cannot see the platform, animals must rely on a complex “cognitive map” of the environment to reach it. Studies that lesioned or inactivated HPC of rodents found they were impaired in the Morris water maze and showed that the HPC is necessary for the acquisition and retention of spatial information (Gidyk et al., 2021; R. G. M. Morris et al., 1982; Sutherland et al., 1982).
1.1.1. Hierarchical representation of space
Place cells are neurons that represent specific locations in an environment and become active when the animal is there. The spatial region in which a place cell fires is called its “place field.” Place fields vary in size, representing space at various scales. “Place cells” are a key feature of the hippocampus.
The spatial representation found in the HPC is hierarchical in nature, with the hierarchy organized along the dorsal/ventral hippocampal axis (Jung et al., 1994; E. I. Moser et al., 2017). At the lowest level—the dorsal end of the HPC—individual place cells can have highly specific firing patterns tuned to particular locations, providing a “high-resolution” map of the animal’s surroundings. At the ventral end of the HPC place cells operate at a larger scale, forming patterns of activity that represent larger areas and general spatial features of the environment. These multi-scale spatial representations or maps are thought to be one important input to planning and navigation processes (probably involving other brain regions) (Mehrotra & Dubé, 2023; Scleidorovich et al., 2022).
Studies that selectively lesion or inactivate dorsal or ventral HPC show that the ventral hippocampus is important for the early stages of learning in the Morris water task, essentially getting the subject into the general area where the goal can be found. Later in training, the dorsal hippocampus is critical for learning the precise location of the escape platform. This suggests that each level in the hierarchy plays a special role in spatial learning and navigation (Gruber & McDonald, 2012; McDonald et al., 2018; Ruediger et al., 2012).
1.1.2. Acquisition versus expression of navigation behaviors
Activation of the N-methyl-D-aspartate receptor (NMDAR) in the HPC has been proposed to be a key event responsible for the structural changes that occur in neurons during learning and memory formation. Chemically blocking NMDA receptors using peripheral injections of an antagonist has been shown to impair the learning of a new platform location in the Morris water maze task, but rodents were still able to recall previous locations (R. G. Morris et al., 1986). Intraventricular and intracranial injections directly into the hippocampus produce the same effect. This has led to the view that NMDAR plasticity supports the formation of spatial representations and models, that in turn support learning and execution of new behaviors (R. G. M. Morris, 2013). Importantly, it has been shown that NMDA receptor blockade does not impair learning of new behaviors in a familiar environment (though those behaviors cannot be recalled later) but does severely impair learning in a new environment (Bye & McDonald, 2019). This suggests that animals learn a model of the environment that is used in a separate planning process (possibly distributed across multiple brain regions) to learn and plan spatial behavior.
1.1.3. Limitations of lesion/inactivation studies and the opportunity for computational models
Lesion and inactivation studies have been invaluable in studying the role of the HPC in navigation, but they have limitations (Vaidya et al., 2019). Interpretation of the results is sometimes affected by the specificity in space or time of the intervention. For example, the intervention can affect nearby regions so that the results are difficult to attribute solely to the HPC. Moreover, the timing of the intervention can be important, as the HPC is thought to be involved not only in spatial information but also in encoding, consolidating, and retrieval of spatial information. Finally, there are ethical considerations of these approaches as they can be highly invasive.
These difficulties underscore the place of computational modeling in a virtuous cycle along with experimental work. Computational models can be used to test theories arising from experimental work, help interpret experimental data, and generate testable hypotheses for experimental neuroscience to investigate. This article is an example of this virtuous cycle.
1.1.4. Reinforcement learning algorithms as models of spatial learning
Reinforcement learning (RL) is a computational framework that has been extensively used to model biological learning (Botvinick et al., 2020). It models reward-driven learning, in which an agent learns to maximize its reward in an environment through trial-and-error experimentation (Sutton & Barto, 1998). Model-based RL algorithms are particularly useful for modeling spatial navigation (Bermudez-Contreras, 2021) because they learn a model or “cognitive map” of the environment, which they use to learn and execute goal-directed behavior (Botvinick & Weinstein, 2014; Daw, 2012).
1.2. Mismatches between current reinforcement learning algorithms and hippocampal observations
Reflecting on the observations from neuroscience reveals at least two areas of potential mismatch between current reinforcement learning algorithms and the brain’s approach to spatial learning. Reconciling these differences will be important as we search for a full computational account of spatial learning:
A variety of types of hierarchical abstraction have been studied and modeled, including learning action hierarchies (composing sets of atomic actions into useful routines [Eysenbach et al., 2019; Solway et al., 2014; Stolle & Precup, 2002; Xia & Collins, 2021]), learning task hierarchies (composing a sequence of sub-tasks into a larger objective [Dietterich, 2000; Li et al., 2017]), and even using language as a kind of hierarchical abstraction (Frankland & Greene, 2020; Jiang et al., 2019). Some studies have considered abstraction of state or space as the hippocampus seems to do (Dayan & Hinton, 1992; Mao, 2012), but there have been fewer studies of this kind of spatial abstraction (Eppe et al., 2022; Pateria et al., 2021) and they often use manually defined state abstractions rather than considering how the abstractions could emerge in the brain (Dayan & Hinton, 1992; Eppe et al., 2019; Ma et al., 2020; Rasmussen et al., 2017). Since hierarchical abstraction of space seems to be an important feature of animal navigation (Correa et al., 2023; Evensmoen et al., 2015; Jung et al., 1994; Ruediger et al., 2012), hierarchical state abstraction may be undervalued by modern reinforcement learning algorithms. Indeed, Eppe et al. recently identified hierarchical learning as an area where current machine learning and computational models of learning still fall short of biological intelligence (Eppe et al., 2022).
1.3. Contributions of this article
Here, we explore the potential benefits of the principles of learning a hierarchical model of space and separately using it for planning. We propose a computational framework that embodies one possible implementation of these principles. The computational framework includes a novel and biologically plausible state-abstraction approach. We show that this prototype of animal learning produces a hierarchical abstraction of space—like that observed in the hippocampus—and allows efficient learning and planning to reach arbitrary goals. We use the framework to simulate various types of hippocampal impairment that have been studied in mice and show that the simulations reproduce behavioral deficits observed in those mice—strengthening the argument that this framework models the spatial learning and navigation process in the brain. Finally, we explore some implications and considerations for future studies of machine and biological intelligence that involve model-based learning and planning supported by the hippocampus.
2. Results
2.1. Computational setting
To focus on the fundamental concepts being explored here, our experiments use grid world problems as simple analogues of real-world navigation. A grid world consists of a grid of discrete states the agent can occupy, and the agent must learn a route through these states to reach a reward. The agent has no sensors and is only aware of its current location—thus for this study we set aside the role of vision in navigation and focus instead on the learning of a cognitive map. The grid world problem is a simple analogue of the Morris water maze task.
The experiments in this article cast the grid world as a Markov Decision Process and cast spatial learning and navigation as a model-based reinforcement learning problem, and we use a tabular, Dyna-like model-based learning algorithm (Poole & Mackworth, 2017) as the core learning mechanism. The algorithm maintains tables
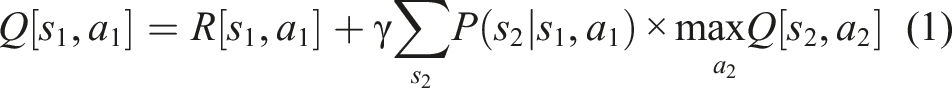
where R[s, a] (the expected reward for executing action a from state s) and P(s 2 | s, a) are estimated by the model and 𝛾 is a discount factor applied to future rewards (creating a preference for immediate rewards). This equation is applied iteratively to propagate value information throughout the states in the world (“value iteration”). To minimize computational effort, we use the prioritized sweeping algorithm (Moore & Atkeson, 1993) to apply equation (1) only to s-a pairs whose estimated value requires updating the most.
2.2. Learning a hierarchical model of the environment
Theories of how the place cell hierarchy arises in the hippocampus are varied, and the underlying mechanisms are complex (M.-B. Moser et al., 2015). Some proposals say place cells arise from the firing of grid cells (which fire in lattice patterns over an environment), but recent computational experiments have also demonstrated the reverse: that functioning place cells can give rise to grid-like cells in recurrent networks (Banino et al., 2018; Cueva & Wei, 2018; Frey et al., 2023; Sorscher et al., 2023) under some specific conditions (Schaeffer et al., 2022). Here, we take inspiration from evidence that spontaneous offline reactivation of place cells (“replay”) is an important part of spatial learning (de Lavilléon et al., 2015) and demonstrates how associations between high- and low-level place fields could arise from such reactivation.
After exploring the environment, our agent uses its learned model of the world (i.e., the state transition table
The aggregation process is based on a hippocampus-inspired algorithm proposed by Chalmers et al. (Chalmers et al., 2023). The architecture involves a two-layer network with the first-layer neurons representing individual places (i.e., specific or “dorsal” place cells) and the second-layer composed of winner-take-all neurons representing larger regions that aggregate multiple places. Random walks activate a particular pattern in the first-layer neurons, and the second-layer neuron that responds becomes more closely tuned to that walk’s constituent places. Since walks that occupy similar regions of space tend to overlap, and since random walks do not cross boundaries, the architecture gradually becomes tuned to clusters of places that “go together” and respect environmental structure. Thus, a meaningful abstraction emerges directly from the random walks. Here, we extend Chalmers’ original work by allowing the agent to simulate the random walks using its learned model of the environment. We further extend the two-layer architecture to multiple layers representing increasing levels of aggregation or abstraction. The result is a hierarchical abstraction of state—similar to that in the hippocampus (see Figure 1, and “Methods” section for more details).
2.3. Using the hierarchical model to plan behavior
By consulting its Q values and model, the agent can identify a previously experienced reward or goal state. At the world-level this goal may be far away, and discounting over great distance dilutes the reward signal such that the route to the goal is not clear from the current position. One solution is to increase 𝛾 and invest more energy in computation (evaluations of equation (1)) to push the reward signal back to the agent. But a hierarchical model allows a better solution: realize that at the highest level of abstraction the goal is only a few steps away (see Figure 2). Thus, information about current and goal states flows upward through the hierarchy to determine relative positioning at each level of abstraction. Plans can then be made recursively from the top down. At the highest level, a plan to reach the goal likely involves only a few transitions between macro-states. Plans to affect each of these transitions are made at the next level down, and this process repeats to the lowest (world) level. The plans are made using the same value iteration approach described above: for each planning sub-problem, an artificial reward function is created that rewards the desired transition at the given level, and prioritized sweeping is used to compute the best way to achieve the transition at that level. Learning a hierarchical model of the environment. The agent learns a low-level world model through exploration of the environment (top left). Abstract macro-states that respect environment structure emerge from simulated random walks in an unsupervised learning process (bottom row). Still higher-level abstract states emerge from the intermediate abstractions. At the highest level the abstract world model contains just four states, representing the four rooms (top right). At this level of abstraction, the goal (green dot in the original grid world) is only a few steps away from the agent (black dot), even though in the actual environment they are separated by many steps.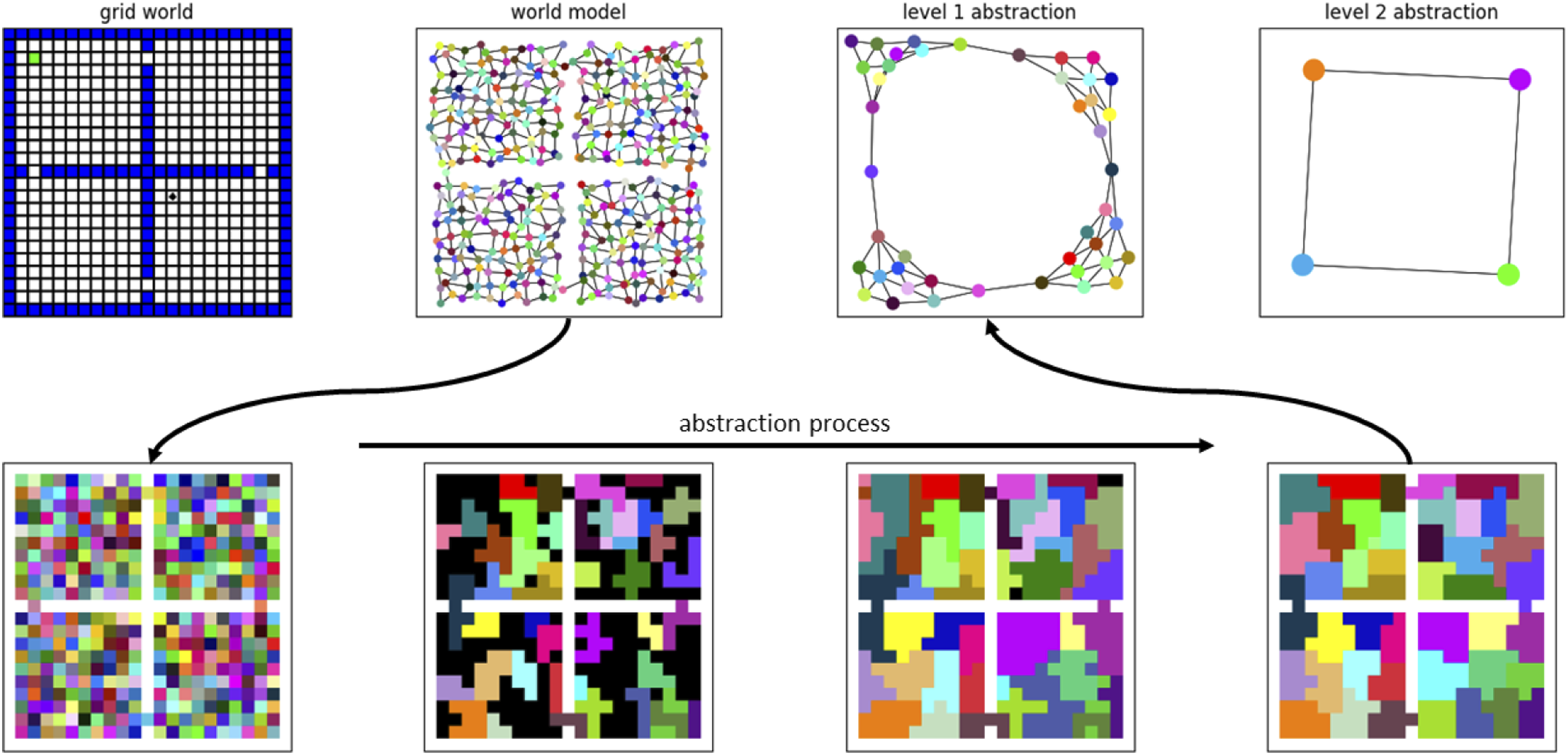
A major benefit of this hierarchical planning is that it avoids the need to propagate value information throughout a vast world model, instead focusing the calculations on a series of small sub-problems. To measure this effect, we use the hierarchical approach to solve randomly generated grid worlds and count the number of evaluations of equation (1). This count serves as a proxy for the agent’s cognitive load—the computational burden of planning rewarding actions. We compare the cognitive load of a conventional (non-hierarchical) prioritized sweeping algorithm and find that the hierarchical agent generally solves problems with less effort (Figure 2). In these experiments, all agents were allowed to self-select the 𝛾 and ϑ parameters that minimized the equation (1) calculations while still allowing them to solve the task (lower discount factor 𝛾 and higher threshold ϑ reduce the distance that value information propagates through the world model—see Methods). Hierarchical planning. At the world-level, a plan to reach the goal would involve dozens of steps. But at the highest level of abstraction—where the world consists of only four rooms—the goal is only two steps away. The first step of a plan at this level indicates an intermediate goal for the level below. The first step of a plan to reach this intermediate goal indicates an even closer intermediate goal for the level below that, and so on.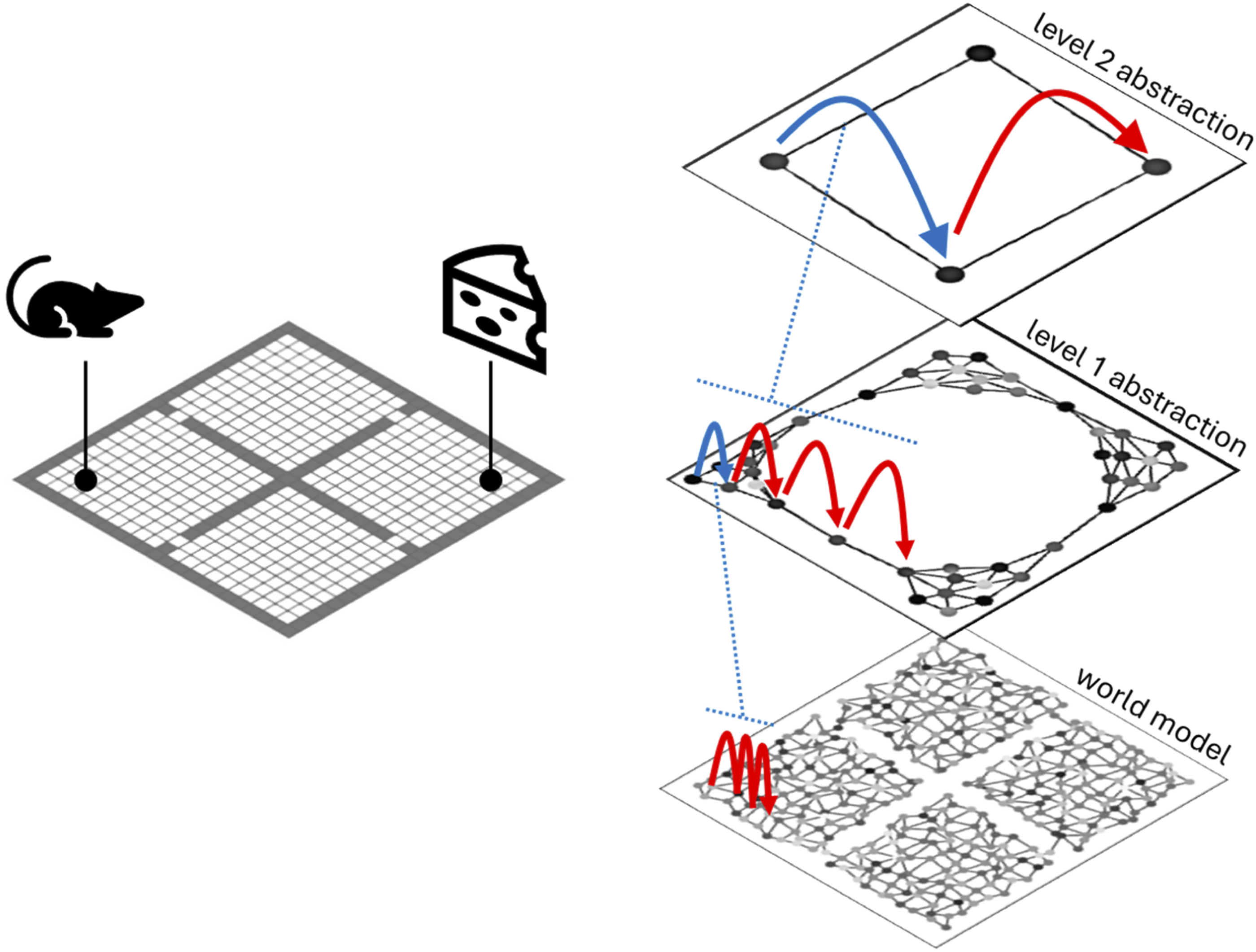
Another benefit of the hierarchical model is that it emerges from random walks in a value-agnostic way. This means that in sparse-reward, goal-seeking situations, it can be used to plan arbitrary behaviors. If the agent has been trained to perform one behavior but suddenly needs to perform a new behavior in the same environment, the new plan can be made efficiently with no additional learning. This sort of context switching would be quite difficult for a model that was tied up with value information and would be expensive without the hierarchical structure. To illustrate this, we present the conventional and hierarchical agents with a new planning problem in the environment they previously learned. The hierarchical model can create the new plan with less effort than is required by the conventional agent’s world-level value iterations. Moreover, the hierarchical plan is refined stage-by-stage, meaning the total effort is amortized over the journey, where the conventional agent must create its whole plan up-front. The trade-off is that hierarchical plans are often slightly suboptimal (Figure 3). This trade-off is probably favorable for animals who must make plans quickly and change them just as quickly when dangers arise. In this experiment, like the previous one, agents were allowed to self-select the 𝛾 and ϑ parameters that minimized the equation (1) calculations while still allowing them to solve the task. Rodents with NMDA receptors chemically blocked can plan new behaviors in familiar environments (but can’t recall them later) but cannot plan in unfamiliar environments. These observations in mice (top row, reproduced from Bye & McDonald, 2019; McDonald et al., 2005) are reproduced when NMDA blockage is simulated in our computational framework (bottom row). These effects suggest that animals learn a hierarchical model of the environment and use it (separately) for planning downstream: when a model cannot be learned, no planning is possible.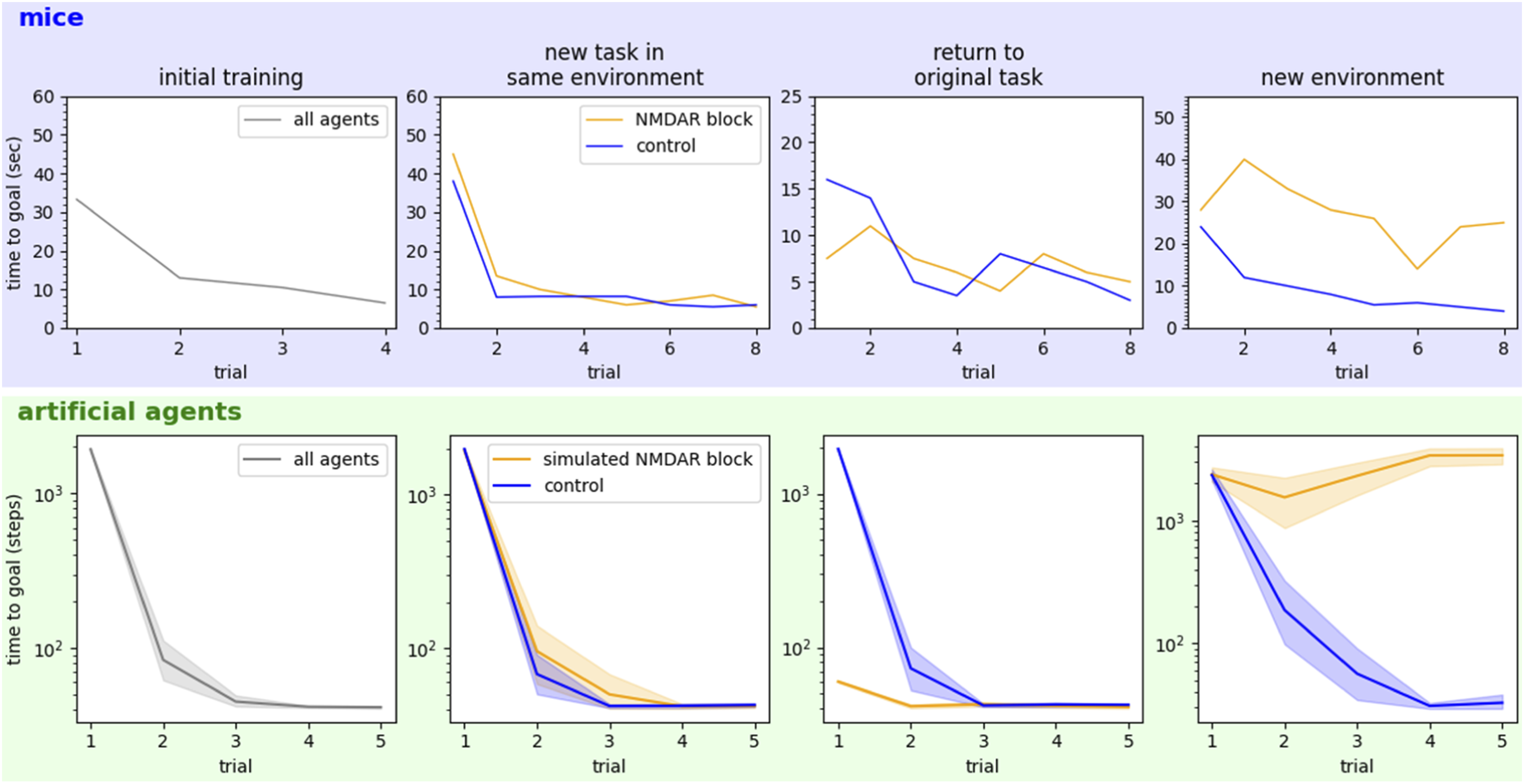
2.4. The framework reproduces observed effects of impairing hippocampus
The previous section explored the potential benefits that animals may gain by learning a hierarchical model of the world and later using it for efficient planning. This section builds credibility for the computational framework by showing that it can reproduce some important observations from neuroscience.
2.4.1. Simulating NMDAR blockage
Based on the results of blocking NMDAR in rodents, we hypothesize that NMDA is required for environment models to be learned, and also for models and planned behaviors to be stored in long-term memory. Memory consolidation in animals largely happens during rest, so we simulate periods of rest by saving our hierarchical agents’ learned models, plans, and Q values to nonvolatile memory. To simulate NMDAR block, we simply prevent both the learning of new world models and the saving of new information gained since the last simulated “rest.”
Agents with and without simulated NMDAR blockage were put through a series of four tasks similar to those used in McDonald, Bye et al. (Bye & McDonald, 2019; McDonald et al., 2005). All agents learn an original task in a novel environment. NMDAR blockage is then applied to some agents, and all learn a new task in the same environment. Agents then return to the original task—it is expected that since the blocked agents did not store the new task in long-term memory, they can resume the original task easier than agents without NMDAR blockage (controls). Finally, agents are made to learn a new task in a completely new environment. Periods of simulated rest—when the control agents save newly learned information to long-term memory—are allowed between each task.
Results are shown in Figure 3 and compared to the original observations from studies of rats with NMDAR block (Bye & McDonald, 2019; McDonald et al., 2005). Upon returning to the original task, healthy animals must relearn the rewarding behavior for that task. But the blocked animals simply resume the original behavior—they do not remember the new task that occurred in between. The blocked animals are severely impaired in the new environment because they cannot create the required world model. The computational framework reproduces both these effects.
2.4.2. Simulating partial hippocampal inactivation
Ruediger et al. studied goal-directed navigation in a water maze and found that the fine-spatial representation of the dorsal hippocampus was required for progression (over repeated trials) from random search strategies to direct swim to the goal. When the dorsal hippocampus was damaged, mice reverted to more random search strategies (Ruediger et al., 2012).
Here, we simulate damage to the dorsal hippocampus by removing a percentage of the lowest-level place fields. That is, a random subset of the lowest-level states was denied representation in the world model. The hierarchical abstractions still form from the remaining place fields, but the loss of low-level information disrupts planning. As the amount of inactivation increases, we see the same reversion to more random searching that Ruediger reported (Figure 4). Trajectories of agents with varying levels of simulated model inactivation (four sample trajectories at each of 0, 30, 50, and 80% inactivation). Agent must navigate from the black dot to the green goal. Ruediger et al. found that inactivating the dorsal hippocampus caused mice to revert to more random search strategies (Ruediger et al., 2012). Removing some states from the lowest level of the abstraction hierarchy in our framework produces a similar effect and sometimes causes navigation to fail.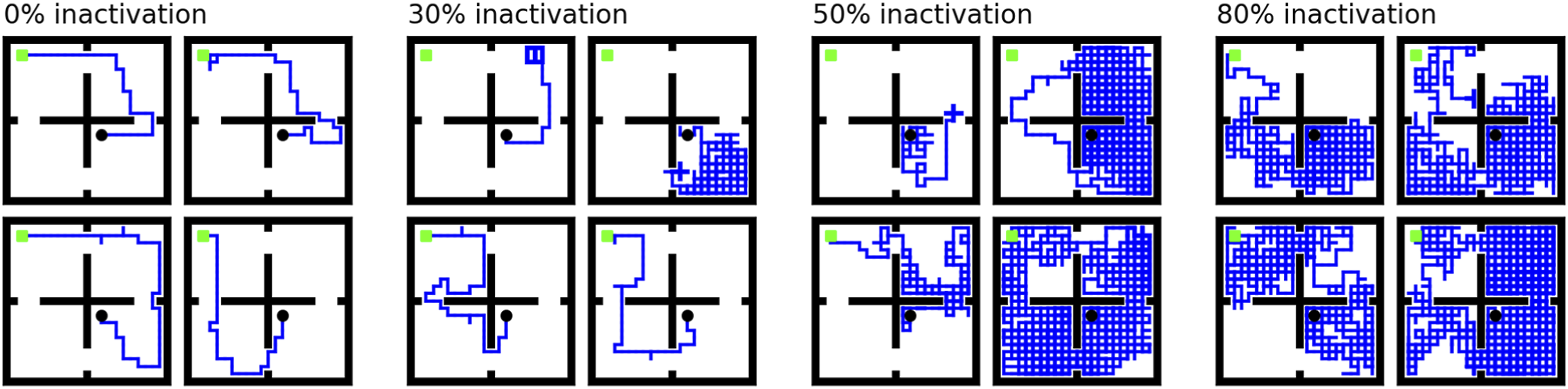
3. Discussion
In this work, we have demonstrated how an agent could learn a hierarchical representation of space as it explores its environment. This hierarchical abstraction resembles the hierarchical representation of space encoded by the hippocampus. Our experiments illustrate that a hierarchical model of an environment can be exploited for highly efficient planning and navigation. We further observe that this computational framework easily explains and reproduces key observations from hippocampal inactivation studies in rodents. Because it sees model-learning and action-planning as separate processes, the framework can explain the observation that blocking NMDAR in mice prevents them from planning in new environments, but not familiar ones: if a model of the environment cannot be learned, no planning is possible. We also reproduce a reversion to random search strategies observed by Ruediger et al. after they lesioned the dorsal hippocampus in mice: knocking out information on a subset of states in the lowest level of our abstraction framework causes a similar reversion.
3.1. Implications of our results
3.1.1. The framework captures principles of efficient, hierarchical learning and planning that the brain values
The fact that the computational framework reproduces some key results from neuroscience is evidence that this framework has captured some key aspects of how spatial learning and planning is affected in the brain. And the efficiency benefits illustrated in Figure 2 (and explored by other researchers [Correa et al., 2023; Tomov et al., 2020]) suggest why the brain works this way to begin with: If an agent can use an existing, hierarchical model for planning, it has the option to solve only the part of the environment currently of interest. In contrast, contemporary model-based algorithms that tightly couple learning and planning must often learn the world model and solve (completely) for a policy simultaneously, sometimes at great computational cost. For an animal, the ability to plan quickly is paramount. Finding food or evading a predator does not demand an optimal plan (indeed, the extra mental effort and time to arrive at a truly optimal solution may make it undesirable). Instead, the brain must find a sufficiently good solution quickly. Does achieving more human-like AI require us to trade in optimality guarantees for efficient hierarchical structures?
3.1.2. The framework makes hypotheses about place cell operation
Theories about place field formation (how place cells become associated with particular physical places) are varied, and the mechanisms are not fully understood (M.-B. Moser et al., 2015). Here, we show how offline reactivation of low-level place cells could influence the tuning of higher-level ones, giving rise to an abstraction hierarchy that respects natural divisions in the environment. But our abstraction algorithm highlights another interesting aspect of place cell learning: how relationships could form between low- and high-level place fields. That is, how a set of low-level fields representing places in a room might become associated with the high-level place field representing that room. This is an aspect of place field operation not often discussed, but these relationships are very important if the hierarchical model is indeed used for planning (to reach a particular region, one must be able to identify the individual places that would satisfy that goal). If neural recordings from rodents show this kind of association between high- and low-level place cells, that would provide further evidence that the hierarchical model supports planning processes.
3.1.3. Learning a world model is intrinsically valuable
Many contemporary model-based RL approaches learn a world model and form a policy simultaneously, and often the two processes are tightly coupled. In contrast, the brain seems to invest energy in understanding the world before it forms policies. This approach may broaden the scope of learning and support transfer between tasks. It should be a consideration in the development of new reinforcement learning algorithms.
3.1.4. Simulating hippocampal inactivation could help explain differing results among inactivation studies in rodents
Results from experimental inactivation of the hippocampus are varied. For example, some studies notice different effects when inactivating dorsal versus ventral hippocampus (Ruediger et al., 2012), while others do not (S. L. (Tommy) Lee et al., 2019). The amount of inactivation achieved affects the results (J. Q. Lee et al., 2017; Lehmann et al., 2007) and can be difficult for the experimenter to control. A computational framework like this one may help explain the varied results. By dialing up the simulated inactivation and experimenting with inactivation at different levels of the hierarchy, it may be possible to reproduce the variety of different results reported in neuroscience literature.
3.2. Limitations and open questions
While it seems this framework captures some key aspects of spatial learning and navigation in the brain, it is also clear that many other aspects remain to be integrated, or remain a mystery altogether.
3.2.1. Bottom-up, top-down, or both?
Our framework learns a model of the environment bottom-up, from world states to highest-level abstractions. In practice, it seems that ventral place fields are active quite early in learning—possibly even earlier than dorsal ones (Ruediger et al., 2012). Given only world-level information from visual and other sensors, path integration systems, and so on, how might an agent learn low-, intermediate-, and high-level abstractions all simultaneously?
3.2.2. The role of sensors in navigation and abstraction
Deep reinforcement learning algorithms have demonstrated that agents can learn complex navigation behaviors using only visual input (Mirowski et al., 2018). But Wijmans et al. demonstrated that maps emerge in the memories of agents even when they are completely blind (Wijmans et al., 2023). Here, we similarly explore behavior in agents without visual capability. In practice though, the brain makes use of both sensory input and cognitive mapping structures, and the interplay between sensation, mapping, and navigation is likely important: by moving around an animal discovers it has some control over its sensor readings, allowing their spatial meaning to be learned. Motion follows sensation and leads to learning and abstraction, which lead to efficient navigation. The older RatSLAM framework began capturing some of this complexity by integrating vision with hippocampus-like mapping (M. J. Milford et al., 2004); perhaps this type of approach should be revisited (M. Milford et al., 2016) and further integrated with modern deep reinforcement learning techniques and hierarchical planning structures.
3.2.3. What other processes does the world model support?
It seems that planning processes exist downstream from NMDA-dependent learning of a world model. That is, the model must be learned before planning can occur. If models are intrinsically valuable, they likely support other processes besides navigation planning. What might those be? Each environment model learned may somehow accelerate the learning of the next, in a meta-learning process. It is also possible that the machinery evolved in the hippocampus for solving spatial navigation problems was later reused for other kinds of perception and conceptual reasoning (Chen et al., 2022; Hawkins & Dawkins, 2021; Hawkins et al., 2018; Wu et al., 2020). If so, studying how the hippocampus learns hierarchical representations and relations of space may help us better understand (and apply, in an engineering or AI context) abstraction in other domains.
3.2.4. Tabular, Dyna-style models
Seem out of place among contemporary, deep reinforcement learning algorithms (Botvinick et al., 2020). Function approximation (e.g., through deep neural networks) is obviously necessary for scalability and generalization, and it is the almost exclusive focus of contemporary model-based RL. Yet, the hippocampus builds a cognitive map that represents discrete places explicitly—like a tabular model. How might the two approaches be combined in the brain? How should they be combined in machine learning algorithms?
3.2.5. What is the interplay between various kinds of abstraction?
Here, we focus on abstraction of space or state. As noted above, significant work has been done on other kinds of abstraction and composition of simple actions or concepts into more sophisticated ones. The brain employs many kinds of abstraction and composition at once (Eppe et al., 2022), and our framework hints at one possible avenue of cooperation between them: low-level plans made to achieve transitions between abstract states could themselves be learned as macro-actions.
3.2.6. How does the hippocampus store multiple hierarchical models?
We have shown how random walks through low-level place fields could drive a hierarchical abstraction process, tuning higher-level place fields to represent larger regions of space. The methods section below details how these associations are stored in a matrix of connection weights between low- and high-level cells. However in biology it seems that a place cell that fires in a particular location in one environment can be recruited to fire in another location in a different environment and then resume its original role when the animal returns to the original environment—a well-known “remapping” phenomenon (Colgin et al., 2008; Muller & Kubie, 1987). Our model does not currently account for this phenomenon, but we note our abstraction algorithm could be easily extended to include multiple parallel weight matrices. External context signals derived from sensory input could indicate which weight matrix is currently active—allowing multiple hierarchical models to be stored in parallel. A biological interpretation would be that multiple possible connections exist between each low- and high-level place cell, and context signals gate these connections such that different sets are enabled or suppressed in different environments, similar to Muller and Kubie’s original proposal (Muller & Kubie, 1987). Thus, the same set of place cells would learn different behaviors for different environments and switch between them appropriately. We leave exploration of this idea to future work.
3.2.7. General limitations of our abstract computational model
As scientists, we often understand complex biological systems through models (e.g., animal models, mathematical/computational models, block diagrams, and pictorial representations). Every model is a sort of metaphor: it is not the complex target system, but it has something in common with—and therefore tells us something about—that system. Like all good models, our computational model abstracts away complexity in order to highlight some general principles. In reality, navigation involves integrating information from multiple sensory processing pathways, head-direction and velocity cells, path integration, and so on. Furthermore, in reality all of this information is noisy and describes a continuous, expansive world (not a discrete grid of states as in our experiments). Our model abstracts away most of this complexity in order to highlight some fundamental principles about hierarchical model learning and planning. While it is common to use simplified reinforcement learning models this way (Bermudez-Contreras, 2021; Botvinick et al., 2020; Botvinick & Weinstein, 2014; Daw, 2012), we hope future work (our own and others’) will build more detailed models that complement (or indeed replace) this one because they include more of the complexity and can therefore say more about neurobiology.
3.3. Comparison to other abstraction-learning approaches
As mentioned in the Introduction section, we believe abstraction of space within a learning framework is somewhat understudied computationally. However, more computational accounts of the space-abstraction process itself are emerging; here, we select a few which seem particularly relevant for comparison and representative of the kinds of work being done.
Tomov et al. recently proposed an interesting Bayesian approach to state abstraction, pointing out that since the abstraction process happens offline (during rest), a more computationally intensive process is warranted. Their method of Bayesian inference over possible hierarchical abstractions produces macro-states that respect task and reward structure. Here, we follow Tomov et al. in seeing the abstraction happening offline. But we don’t suppose this means the abstraction process must be computationally demanding; here, we propose an alternative that is computationally efficient and biologically plausible.
Klukas et al. showed that an agent’s cognitive map of an environment could be partitioned into reusable abstractions based on sensory surprisal (which peaks when passing through natural environmental divisions like doorways). This provides an efficient method for online spatial abstraction. It seems likely that both online and offline abstraction mechanisms are at work in the brain, and their interplay will be an important area for future research. Here, we reproduce Klukas’ intuition that abstractions should respect environmental divisions like doorways. Klukas also illustrates the importance of re-using or sharing spatial abstractions between similar environments, which our framework would support as demonstrated previously (Chalmers et al., 2016).
Recent work by Correa et al. showed that humans create hierarchical abstractions that balance the value of a goal against the computational cost of planning. While it did not propose a specific space-abstraction method per se, Correa’s work did the important service of identifying the general principles that all hierarchical abstractions must fit within.
4. Methods
This section describes in more detail the computational methods used in our experiments. Interested readers are referred to the code repository to see more details. Of course, our implementations realize the principles discussed in this article in a computer processor: presumably the brain implements the same principles in other ways.
4.1. The model-based learning algorithm
We use a Dyna-like model-based learning algorithm (Poole & Mackworth, 2017) as the core learning mechanism in our experiments. The algorithm maintains tables T and R that track state transitions and rewards the agent experiences, respectively. Once populated, these tables together form a model of the environment and can answer questions like “what is the probability distribution over next states after executing action a from state s.” They are also used to calculate Q[s,a], the estimated value of executing action a from state s. These value calculations are applied iteratively to propagate value information throughout the states in the world (“value iteration”). To minimize computational effort, we use the prioritized sweeping algorithm (Moore & Atkeson, 1993) to prioritize calculating values that are most likely to need updating at a given time. The algorithm is described in Algorithm 1.
Algorithm 1. Pseudocode for the basic model-based learning algorithm used in our experiments.

4.2. Learning the spatial abstraction hierarchy
Our approach performs abstraction or clustering using random trajectories through the environment—inspired by the replay phenomenon in which place cell activity plays out previously experienced trajectories during rest. After the agent has explored an environment, it uses its learned model to simulate random walks through the environment. Each walk is encoded as a length-N binary vector, where N is the number of states in the environment. Each element of this vector represents a place cell assigned to a state or place in the environment, and elements representing states in the current random walk are set to one: thus, the vector can be considered a representation of low-level place cell activity for a given random walk.
These vectors create an N-dimensional space where each dimension corresponds to one state/place. Any random walk is a single point in this space, and overlapping walks will have high cosine similarity. Interestingly, all states/places are equidistant in this N-dimensional space: the vector representations for any two nodes have a cosine similarity of zero (or a Euclidean distance of 1.41) between them, regardless of how close or distant they are in the actual environment. Thus, all information about environmental structure now resides in the random walk vectors and the cosine similarities between them: walks with high cosine similarity likely come from the same region of the environment, while walks with low cosine similarly likely do not. An effective clustering can be learned on the basis of this principle.
A second K-dimensional vector represents the activations of a second layer of k cells representing higher-level place fields or clusters. Connection weights between each low-level place cell and each high-level place cell are initially random. The learning process consists of identifying the “winning” high-level neuron that reacts most strongly to each random walk and incrementally strengthening its connection to the places in that walk. We model the relationship between second-layer neurons’ activity and first-layer neurons’ activity as a dot product between the input pattern and the connection weights:
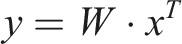
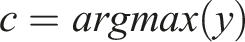
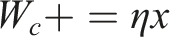
So far we have been discussing a neural implementation of this abstraction or cluster-learning process. But computationally the process can be seen as an application of Online Spherical K-Means clustering (Zhong, 2005) applied in the N-dimensional random-walk space. This approach to clustering turns out to be highly data efficient and can adapt to changes in the underlying environment. For further details and experiments in a graph clustering setting, see Chalmers et al. (Chalmers et al., 2023). By repeated application of the processes (i.e., adding additional layers of cells above the second layer), we create a sequence of abstractions or clusters with increasing spatial scale, as in the hippocampus.
Each macro state created by this process has several lower-level states as constituents. To make the macro-states into a new Markov Decision Process, transitions are added to represent all possible transitions between the constituents of one macro state and the constituents of the other (per the agent’s learned model of the world). Thus each level of the hierarchy consists not only of a set of macro states or clusters but an actual MDP—an abstract version of the original MDP—in which planning can be performed.
Our computational implementation of the hierarchical abstraction process is shown in Algorithm 2.

Algorithm 2. Simplified pseudo-code for the hierarchical abstraction process. For more detail, see (Chalmers et al., 2023) and the provided code repository. The world_model supplied to the learn_abstraction_hierarchy function is the model of the environment learned by the agent during its initial exploration. This algorithm creates a hierarchy of abstract models using that learned model as a base.
4.3. Hierarchical planning
If a goal in the environment (e.g., a previously experienced, high-reward state) is far away, or the environment is vast, it may be very computationally expensive to compute optimal actions using value iteration (equation (1)). Instead, the agent can resort to hierarchical abstractions learned offline to create a hierarchical plan much more efficiently, as in Tomov et al. (Tomov et al., 2020) or Chalmers et al. (Chalmers et al., 2016). While the goal may be distant at the lowest, world-level, at the highest level of abstraction it is likely only a few steps away. Value iteration can easily be applied in the high-level abstract MDP to solve the problem at that level. Then sub-problems of how to affect each high-level state transition are solved at the next level down, again using value iteration (see Algorithm 3). Since each sub-problem is significantly smaller than the full planning problem would be at that level, a hierarchical planning benefit is realized.

Algorithm 3: simplified pseudocode showing how the first step of a hierarchical plan can be formed. The create_plan function is essentially the prioritized sweeping algorithm (Moore & Atkeson, 1993). The create_plan step at each level of the hierarchy is planning to reach an intermediate goal determined by the cleate_plan step from the level above—since this intermediate goal is much closer than the final goal, the plans can be created with computationally conservative values for 𝜗 and 𝛾. Cross reference Figure 5. A hierarchical world model allows efficient planning. During initial learning in a randomly generated gridworld (example shown in panel b—agent must learn a route from black dot to green square), an agent with a hierarchical world model can achieve similar behavior to an agent with a flat world model but with less mental effort (panels a and d—shaded areas represent 95% confidence interval of the mean over 20 repetitions). When a new behavior is needed in a familiar environment (panel c), the hierarchical model allows efficient planning. Panel e shows the cost of planning new behavior for hierarchical-model and flat-model agents in 10 random environments: a hierarchical model allows planning with lower mental effort and amortizes that effort over the journey, whereas a flat plan must be computed up-front. The tradeoff is that hierarchical plans are sometimes suboptimal (longer).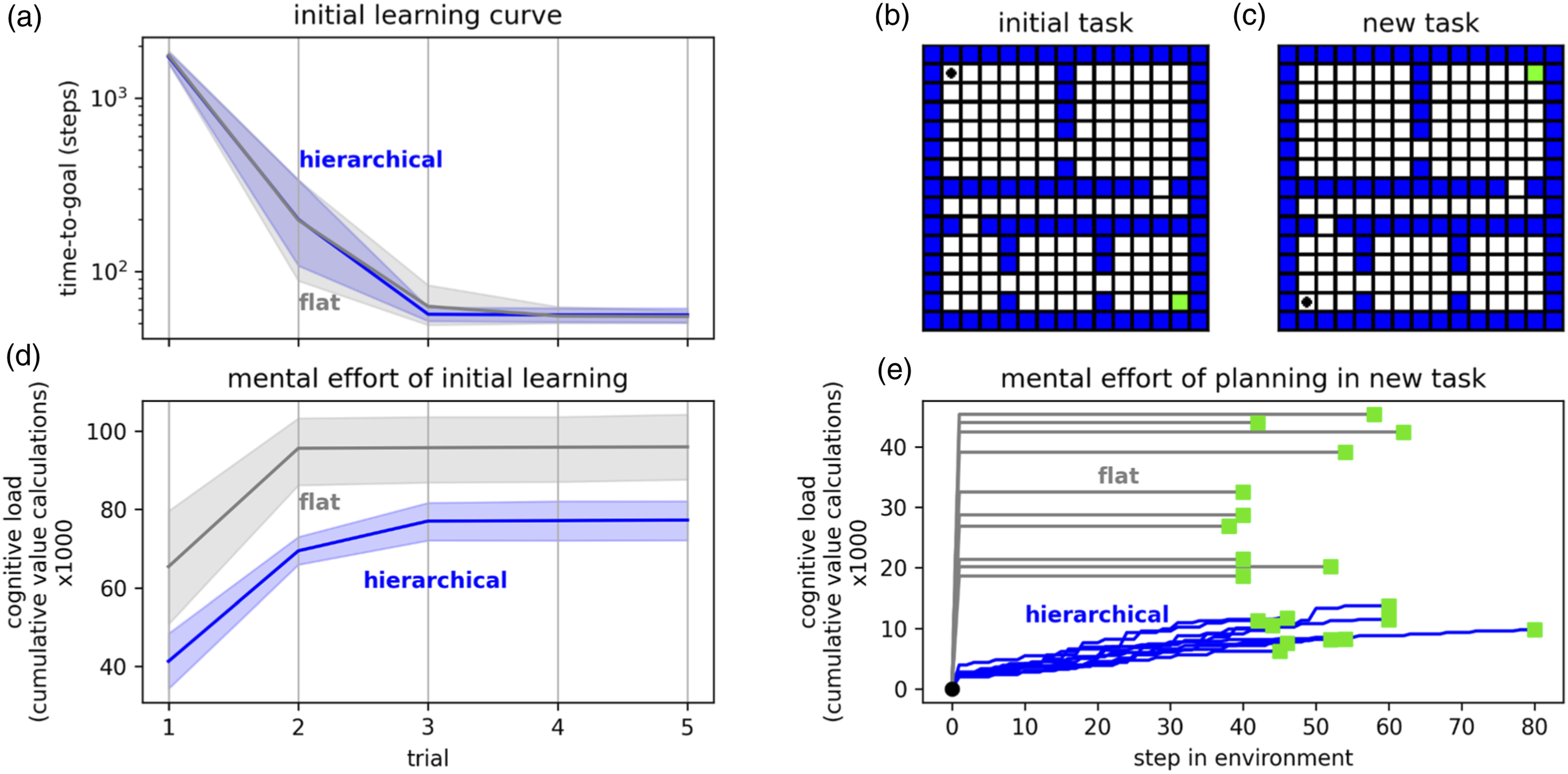
4.4. Simulating hippocampal inactivation
We simulate partial hippocampal inactivation by randomly selecting clusters of world states to deny representation in the world model, as if lesions had knocked out those particular place cells. The percentages shown in Figure 5 indicate the percentage of individual states thus affected. The table updates indicated in Algorithm 1 are skipped for these states—as a result, they cannot participate in learning or planning. Thus when the agent must venture into one of these regions it must either explore randomly or rely on sensory information about the goal, which our agent (like a mouse in a water maze) does not have.
4.5. Simulating NMDAR block and detecting changes in the environment
All of our other experiments imagine a single, standalone learning task. But for the experiments simulating NMDAR blockage, we must imagine the agent learning multiple behaviors and recalling the learned models later. In these experiments, the agents’ learned values (the Q table indicated in Algorithm 1) and world models (i.e., the T and R tables indicated in Algorithm 1), plus the hierarchical abstractions (learned per Algorithm 2), were saved (to disk) after each task and re-loaded before beginning the next task. To simulate NMDAR block, the saving-to-disk was disabled along with hierarchical model construction.
For these experiments, agents were allowed to detect changes in the task and the environment as follows: When an experienced reward did not closely match the current model’s prediction, the lowest-level model and Q values are discarded and the agent begins exploring the environment from scratch. The abstraction hierarchy is kept, however, on the assumption that this is simply a new task in the same environment. If an experienced state transition was unexpected under the current model (i.e., the probability for that transition was low), both value and dynamics information are assumed to be invalid: all models, abstractions, and Q values are discarded and the agent begins learning anew. This approach is appropriate for the sparse-reward, goal-seeking situations considered in this article and a reasonable abstraction of presumably very sophisticated change-detection mechanisms in the brain for our purposes. More sophisticated ways of comparing experience to a model may be necessary for other kinds of Markov decision processes (da Silva et al., 2006; Dick et al., 2020).
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The authors would like to acknowledge financial support from Mount Royal University.
About the Authors