
Abstract
Aggregation, the gathering of individuals into a single group as observed in animals such as birds, bees, and amoeba, is known to provide protection against predators or resistance to adverse environmental conditions for the whole. Cue-based aggregation, where environmental cues determine the location of aggregation, is known to be challenging when the swarm density is low. Here, we propose a novel aggregation method applicable to real robots in low-density swarms. Previously, Landmark-Based Aggregation (LBA) method had used odometric dead-reckoning coupled with visual landmarks and yielded better aggregation in low-density swarms. However, the method’s performance was affected adversely by odometry drift, jeopardizing its application in real-world scenarios. In this article, a novel Reinforcement Learning-based Aggregation method, RLA, is proposed to increase aggregation robustness, thus making aggregation possible for real robots in low-density swarm settings. Systematic experiments conducted in a kinematic-based simulator and on real robots have shown that the RLA method yielded larger aggregates, is more robust to odometry noise than the LBA method, and adapts better to environmental changes while not being sensitive to parameter tuning, making it better deployable under real-world conditions.
1. Introduction
Aggregation, defined as the gathering of individuals into a single group, is beneficial for the survival of animals since it provides protection against predators (Camazine et al., 2003; Grünbaum & Okubo, 1994) and increases resistance to adverse environmental conditions (Krause et al., 2002; Rappel et al., 1999). It is often regarded as a prerequisite for most cooperative behaviors in swarm systems, hence poses a fundamental challenge toward deploying swarm robotic systems in real-world scenarios.
Aggregation behaviors fall into two main categories: self-organized and cue-based. In self-organized aggregation, the location of the aggregate is independent of the environment, as observed in the murmuration of starlings (Goodenough et al., 2017), flocking of birds (Halloy et al., 2007), and it is triggered and governed by the interaction among the individuals. In cue-based aggregation, however, aggregation is triggered by an external environmental cue, such as locations with optimal temperatures within the hive of honeybees (Barmak et al., 2023; Frank et al., 2015).
The development of self-organized and cue-based aggregation behaviors that can be deployed on physical robots is an active line of research (Garnier et al., 2008; Misir & Gökrem, 2021; Na et al., 2021; Schmickl & Hamann, 2011; Sion et al., 2022; Tang et al., 2021). Garnier et al. (2008) modeled a self-organized aggregation behavior of cockroaches and then transferred to a swarm of micro-robots. Inspired by the aggregation behavior of young honey bees (Heran, 1952), a cue-based aggregation method, BEECLUST, was proposed in Schmickl and Hamann (2011). The BEECLUST method imitates the aggregation behavior of honey bees in swarm robots. In this method, a robot moves randomly and stops when it encounters another robot for a particular time. The waiting time depends on the intensity of the cue where robots encountered. It was shown that the BEECLUST method performed well in real-world scenarios such as contamination source detection in extreme environments (Sadeghi Amjadi et al., 2020).
In most studies on cue-based aggregation, the swarm density is chosen high enough to trigger and sustain aggregation. In Arvin et al. (2016), the BEECLUST method was studied under various environmental conditions. Among these factors, swarm density defined as the average number of individuals per unit area, is shown to affect the aggregation performance the most. In high swarm density settings, the probability of robot-to-robot encounters is high enough to support forming and growth of aggregates on the cue. However, in low swarm density settings, robot-to-robot encounter has a low probability; thus, formation and growth of aggregation become a major challenge (Arvin et al., 2016). We aim to overcome this limitation as this would allow implementing, for example, bio-hybrid systems where a few robots interact with the biological agents to influence their behavior (Stefanec et al., 2022). So far, most robot-insect interaction is performed in a centralized way using specially designed manipulators (Rekabi-Bana et al., 2023), which limits the studies to laboratory environments.
An example of a study focused on enhancing aggregation performance is the work conducted by Vardy (2016). In this study, ODOCLUST method was proposed using odometry sensors in the robots. The results showed that the ODOCLUST method outperformed the BEECLUST method. Odometry sensors were also used in a foraging task to boost the performance of the swarm. In Gutiérrez et al. (2010), foraging performance was improved by social odometry in which robots share their odometry data with the other robots locally.
In nature, animals such as honey bees use visual (Collett, 1996) and olfactory landmarks (Reinhard et al., 2004a, 2004b) for navigation in complex environments (Srinivasan, 2010). Robotic systems use landmark-based navigation to move along known landmarks using vision, odometry, and memory-based representations (Kumar et al., 2021; Saleh Teymouri & Bhattacharya, 2021). These systems proved to have better robustness to landmark deficiency, adverse conditions, and environmental change compared to methods based on metric localization and mapping (Furgale & Barfoot, 2010; Halodová et al., 2019; Krajník et al., 2010; Paton et al., 2018). In swarm robotics, such navigation methods were implemented in foraging tasks. As an instance, in Lemmens and Tuyls (2009), an adaptive foraging method was proposed based on landmark-based navigation using RFID tags as landmarks.
In the LBA method (Sadeghi Amjadi et al., 2021), a cue-based aggregation algorithm using landmark-based navigation technique was proposed to increase aggregation performance in low-robot density settings. Despite the increased aggregation performance, the LBA method still heavily depends on odometry for navigation. This dependence is a major drawback since odometry is subject to drift and it is not precise when the robots have to move in uneven terrain, which would limit the use of the LBA in real-world scenarios.
In this article, we propose a new aggregation method, Reinforcement Learning-based Aggregation (RLA) which applies reinforcement learning techniques to choose the optimal action based on the perceived landmarks, removing the dependency on odometry.
The contributions of this article are: 1. A novel reinforcement-learning cue-based aggregation method (RLA) is proposed. To the best of our knowledge, this is the first use of RL for cue-based aggregation in swarm robotics. 2. A cyclical parameter update schedule is proposed to balance exploration-exploitation trade-off of controller update, thereby reducing sensitivity of the performance to the RL parameter choice.
The rest of the article is organized as follows: In Section 2, the BEECLUST method, Landmark-Based Aggregation method, and state-of-the-art on reinforcement learning are discussed. In Section 3, the proposed RLA method and a cyclical parameter update schedule are introduced. In Section 4, the simulation and real-robot experimental setup for evaluating the performance of the proposed method and baselines were introduced. The results of the simulations and real-robot experiments were given and discussed in Section 5. Finally, the conclusion of the work and future works were provided in Section 6.
2. Background
2.1. BEECLUST aggregation
Schmickl and Hamann (2011) modeled cue-based aggregation using three behaviors: (1) move forward, (2) avoid obstacles, (3) wait for w
s
. The focal robot moves forward until it detects an object. If the object is an obstacle, the focal robot avoids it and continues its motion. If the object is a robot, the focal robot stops and waits. The waiting time, w
s
, is calculated as Flowchart of the BEECLUST method.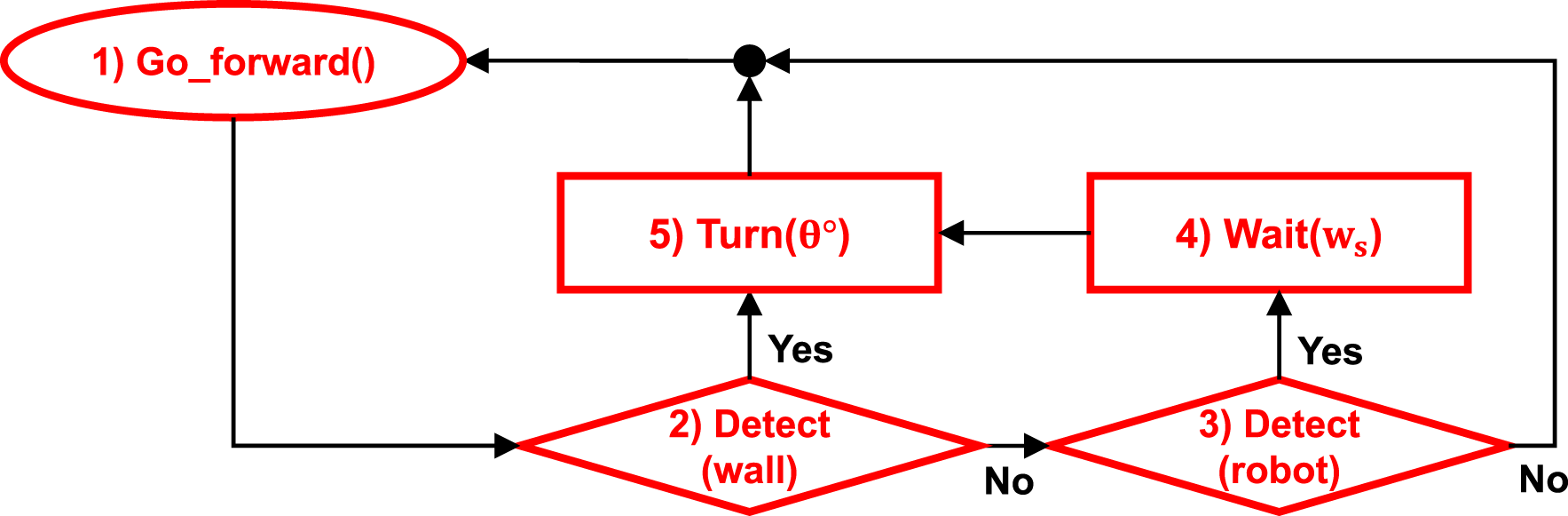
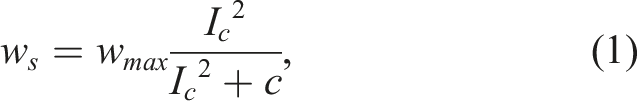
The waiting time is higher inside the cue, where cue intensity is non-zero, causing robots to wait longer there. The higher the cue intensity is, the longer robots wait, and thus, robot-robot encounter probability increases. Consequently, a more stable aggregation is observed in regions with higher cue intensity. Since the BEECLUST method relies on robot-robot encounter probability, in low swarm densities, the probability decreases and affects the aggregation performance adversely.
2.2. Landmark-based aggregation
In the LBA method, when the subject robot detects a landmark for the first time, such as the k
th
landmark, it measures its distance d and angle ϕ with respect to the landmark. Then, it calculates its relative position vector
The robot turns to a random angle and starts to move forward. When it detects an obstacle, it calculates its displacement,
There are three conditions that a robot cannot find the cue by following the previously calculated
2.3. Reinforcement learning in swarm robotics
As RL gained popularity in solving discrete problems, researchers were motivated to study its capabilities in complex real-world cases. However, in complex and continuous real-world problems, dimensionality and scalability of RL methods impose some disadvantages. Modular RL (Doya et al., 2002) was proposed to decompose a monolithic task into simpler sub-tasks that can be solved in parallel. In Wang et al. (2021), a state evaluation-based weighting method was proposed for determining the mixing weights of two sub-policies. Their experiments on maze tasks showed that the proposed method outperformed other studied approaches and improved the training time. In the context of swarm robots and cooperative learning, two fundamental properties of swarm robotics challenge the cooperative learning scheme, which are: (1) interchangeability of agents and (2) irrelevancy of the exact number of agents. In Hüttenrauch et al. (2019), the mean embedding representation of local observation of each agent is used to enable information exchange among agents despite the aforementioned challenges. Young and La (2020) proposed a cooperative RL scheme to flock the swarm away from the predators. In Franzoni et al. (2020), a swarm of hexagonal robots using the Q-learning scheme was used to interact with humans to maintain social distancing in public areas to avoid the spread of COVID-19 disease. Another study in cooperative reinforcement learning is the GridWorld (Pham et al., 2018) and box pushing (Rahimi et al., 2018). Additionally, a reinforcement learning-based controller for a swarm robotic system is proposed in Na et al. (2022) for autonomous operation of the robots in a real-world scenario.
3. Methodology
3.1. Reinforcement learning-based aggregation
The RLA method is proposed to alleviate susceptibility of LBA method on the odometry noise. The essence of the RLA method is the use of reinforcement learning to choose the best action based on the detected landmark. This choice of action leads to higher robustness to sensory noise. In the RLA method, robots move randomly and aggregate, just as in the BEECLUST method (colored in red) as shown in Figure 2. On top of the BEECLUST method, the RLA method incorporates action selection based on the detected landmark and Q-value updates for the selected action. The swarm aggregation is formulated as an episodic Q-learning problem where each state is considered as a separate bandit problem (Sutton & Barto, 2018). Flowchart of the RLA method. Red steps (from 1 to 5) refer to the steps of the BEECLUST method. Snapshots of the kinematic simulation are illustrated in images on the right side. The number specified in the top right corner of the snapshot corresponds to the number of state in the flowchart. (7) A robot detects a landmark and chooses an action. (8) The chosen action of the robot, indicated by the red vector 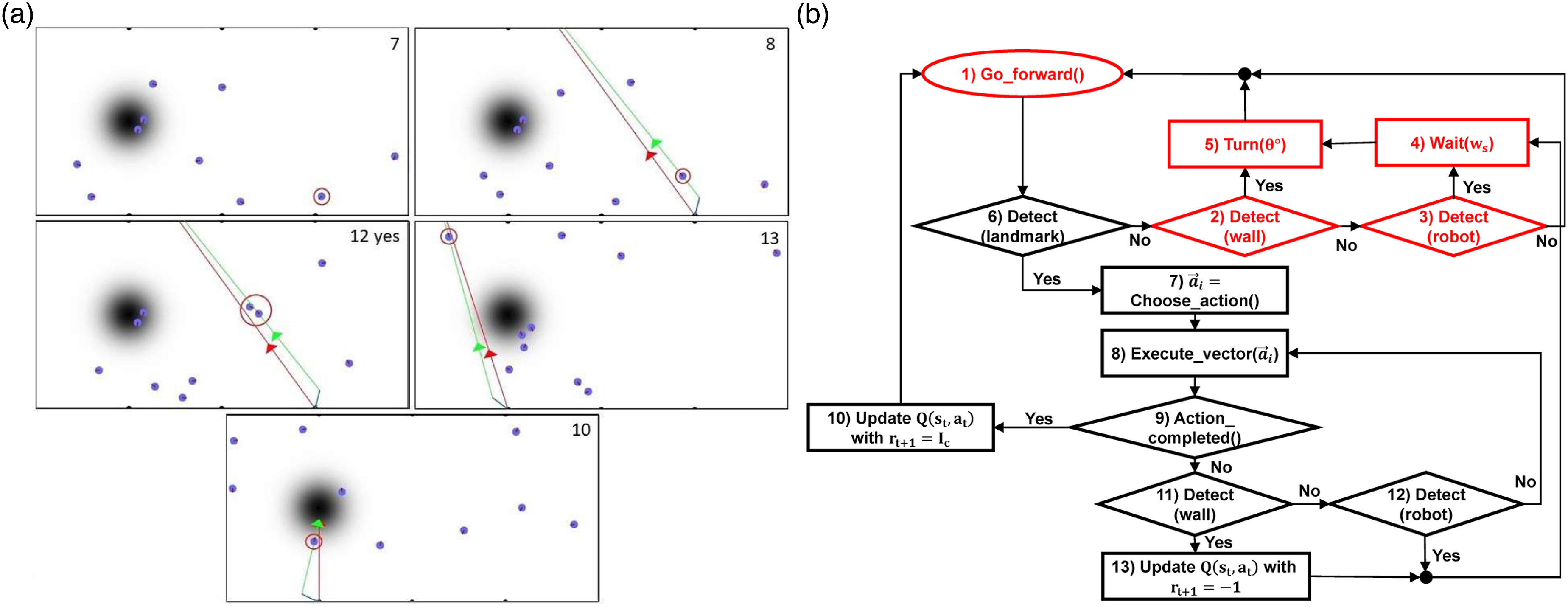
When the focal robot detects a landmark (LM), the landmark is set as the state of the focal robot,
The action space consists of discrete displacement vectors Action space of a robot in the RLA method. The red vector represents the relative location of the robot with respect to the landmark. Each green vector is the action 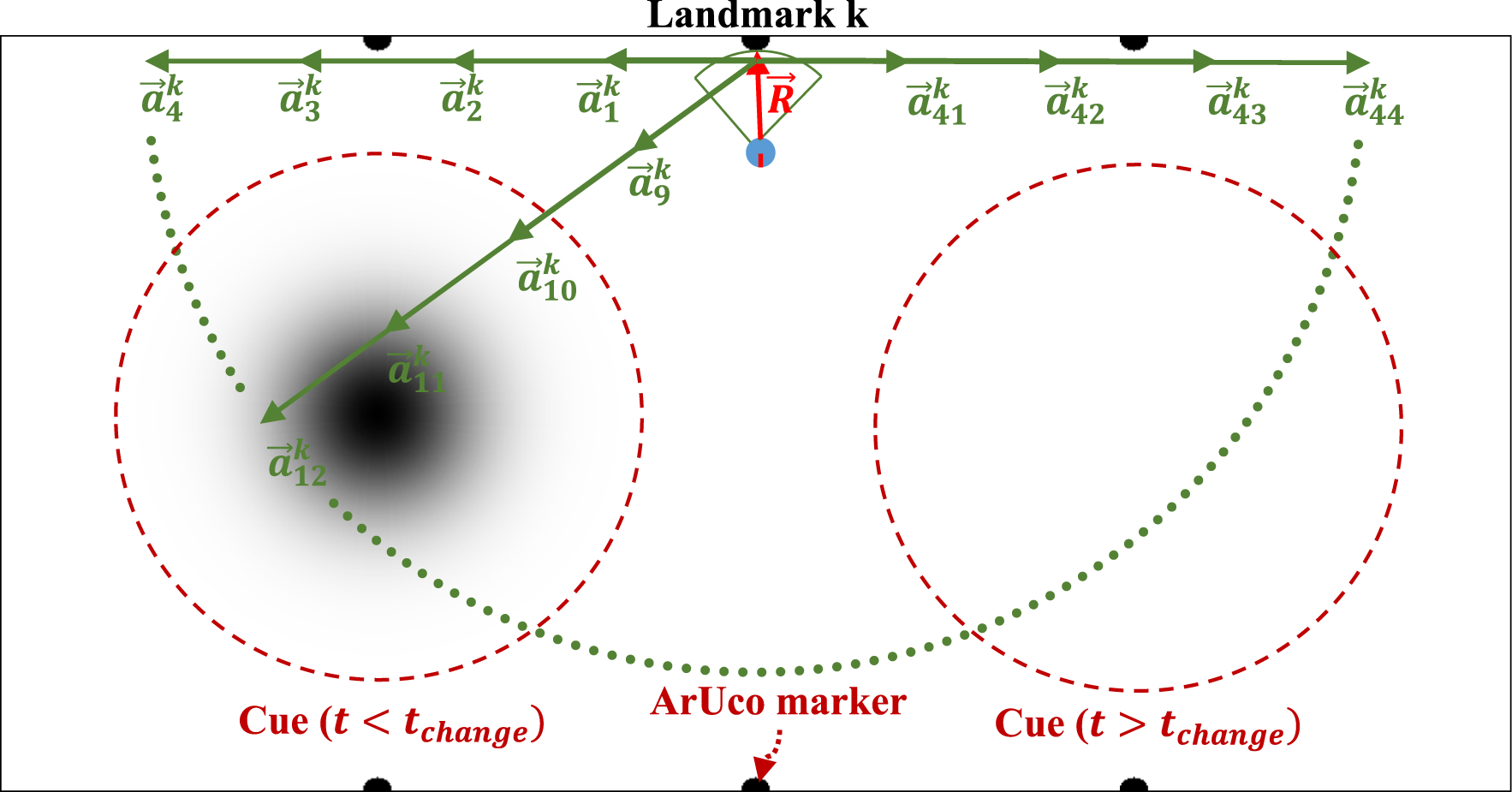
There exist three potential outcomes for the reward received by the focal robot. Upon successfully following target vector
After receiving the reward, the focal robot updates its Q-table using the following recursive update rule
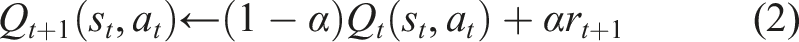
In the BEECLUST method, upon reaching the cue, if a robot collides with another robot, it will wait for a designated duration based on the intensity of the sensed cue at the collision location. In the LBA and RLA methods, extra steps were added on top of the BEECLUST method upon reaching the cue. In the LBA method, in addition to waiting at the cue when encountering another robot, if a robot has previously encountered a landmark before reaching the cue, it will calculate and learn the displacement vector required to navigate from that landmark to the cue. In the RLA method, apart from pausing at the cue when a collision occurs, if a robot reaches cue as a result of executing and action, it will receive a reward based on the sensed cue intensity at the corresponding location.
3.2. Exploration-exploitation dilemma
In order to increase the performance of the RLA method, one of the most important issues is to find the best algorithm for the exploration-exploitation dilemma. In RLA, once a robot detects a landmark, it uses the policy function π
t
(s
t
) to choose an action. A policy function maps the state space to an action space
A simple and effective solution for solving this problem is the ɛ-greedy method (Watkins, 1989) in which the chance of taking a random action is determined by the parameter 0 ≤ ɛ ≤ 1 and the probability of taking a greedy action is 1 − ɛ. In our study, ɛ parameter plays a vital role in the performance of the swarm.
3.2.1. Adaptive ɛ-greedy
In Tokic (2010), an adaptive ɛ-greedy concept called Value-Difference Based Exploration (VDBE) was proposed. In the VDBE approach, an agents’ certainty about the environment is measured by the difference between the value functions of the current and previous steps. Equations (3) and (4) represent the update formula for ɛ in VDBE schedule
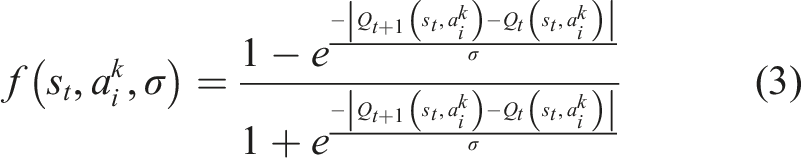
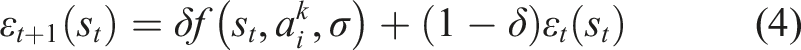
The parameter ɛ is updated using the difference between value functions in two consecutive time steps,
3.3. Proposed ɛ schedule
We propose a new ɛ schedule inspired by the cyclical learning rate changing scheme proposed in Smith (2017). In this schedule, ɛ is changed periodically regardless of the state of the agent
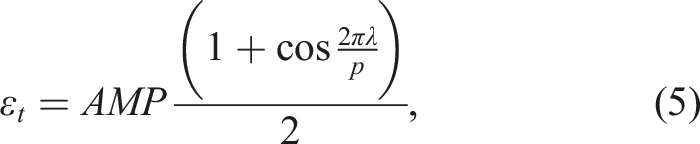
4. Experiments
To evaluate RLA method, experiments on kinematic-based simulator and real-robots were conducted. The experiments were repeated 5 times with randomized initialization conditions.
The learning rate is set to a constant value α = .1; since the environment is non-stationary and noisy, a small, constant value for α will cause slow but guaranteed convergence (Sutton & Barto, 2018).
The performance of aggregation was assessed using the Normalized Aggregation Size (NAS) metric, which is defined as the number of robots inside the cue divided by the population size, NAS ∈ [0, 1].
4.1. Kinematic-based simulator experiments
Kinematic simulation was implemented using Python programming language. Robots were modeled as circles, as shown in Figure 3. The parameters of the robots were chosen such that their size and speed were the same as the Kobot robots (Turgut et al., 2007) used in the real-robot experiments. The radius of the robots were R
r
= .06 m, collision detection range was R
col
= .06 m with a 360° collision detection angle. At each time step k, the location of i
th
robot is updated according to
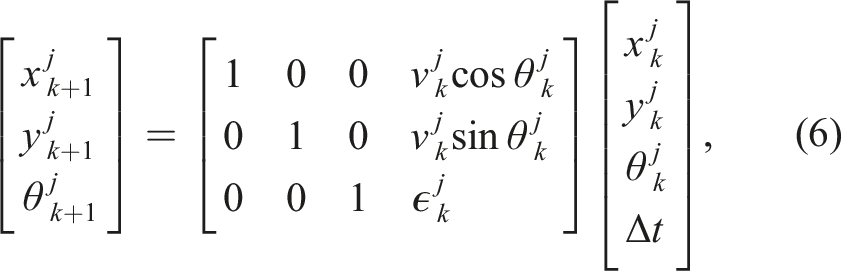
A rectangular arena with dimensions of 2.82 m × 5.65 m was used for all the experiments. The robots were identical and their number was N = 10 in order to create a low-robot density condition. The cue was represented as a dark circle inside the arena with a radius of R c = 1 m. The intensity of the cue reduces towards its perimeter, and its distribution along its radius was considered to be a 2D Gaussian centered at the center of the cue, as shown in Figure 3. In order to test the performance of the methods in non-stationary environments, the location of the cue was moved during the experiment from (1.41 m, 1.41 m) (the left-hand side of the arena) to (1.41 m, 4.23 m) (the right-hand side of the arena) at time t = t change .
The duration of each experiment, denoted as t total , was determined to be sufficiently long for all the methods to reach a steady-state. This decision was made through empirical observation, considering the need for the swarm to achieve a steady-state and maintain it for a certain period. At the same time, it was important to ensure that the experiments could be completed within a reasonable timeframe. The location of the cue was changed at half time of the whole experiment duration, t change = t total /2. For the LBA method, the error threshold parameter was τ e = 4, since this choice has the benefit of both good adaptation characteristics for non-stationary environments and robustness to odometry noise as discussed in Sadeghi Amjadi et al. (2021).
In order to study the robustness of the LBA method to odometry noise, noise was added to the angle of the total displacement as described in Sadeghi Amjadi et al. (2021). If the actual angle of the displacement vector is

In the arena, three landmarks were placed at equal distances from each other on each side of the arena, making a total of six landmarks, m = 6, as shown in Figure 3. It was assumed that robots could detect landmarks up to .5 m.
Parameters and their value used in kinematic simulation experiments.

The following three experiments were performed using the kinematic-based simulator: • Environment Experiment: In this experiment, the BEECLUST, LBA, and RLA (with VDBE and cyclical ɛ schedules) methods were compared. First, this comparison was made without considering any odometry noise. Then, a nominal noise, σ
n
= 15°, was added to displacement vectors based on equation (7). Moreover, the performance of the methods was evaluated in non-stationary environments. Time evolution of NAS values was plotted. • Noise Experiment: In this experiment, the robustness of the methods against noise was studied. Noise was added using equation (7) with σ
n
∈ {0°, 5°, 15°, 30°, 45°, 60°, 90°, 135°, 180°}. For this experiment, the steady-state NAS values were plotted for the sake of clarity of the plots, which were calculated by using the last 100 NAS values of each run. • Parameter Sensitivity Experiment: In this experiment, the sensitivity of ɛ schedules for the RLA method to different parameter values was evaluated. Two schedules were implemented for ɛ, which are VDBE and cyclical schedule. VDBE schedule has only one free parameter σ, whereas the cyclical schedule has two free parameters p and AMP. As in the previous test case, steady-state NAS values were considered. For backing up the statements made in this experiment, the average of rewards that the swarm has received and the change of the ɛ parameter were also plotted over time.
4.2. Real-robot experiment
In real-robot experiments, the Kobot V2 robots (Turgut et al., 2007), a differentially driven CD-sized mobile robot designed specifically for swarm robotic research, Figure 4, was used. Kobot swarm robotic platform. The diameter and height of a Kobot are 12 cm and 11 cm, respectively.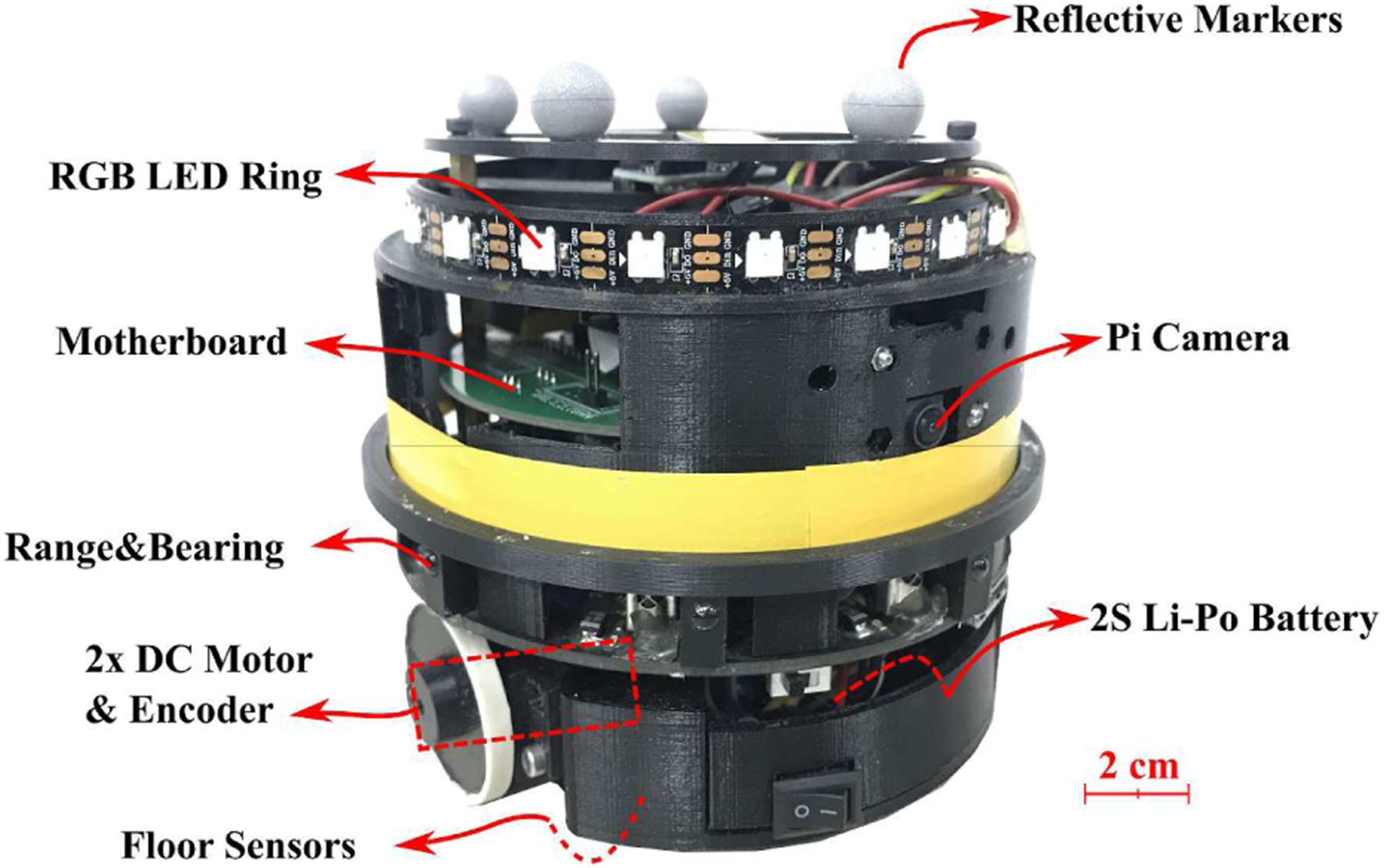
The ArUco markers (Garrido-Jurado et al., 2014) was chosen as the landmarks due to their simplicity, relatively low computational requirements, robustness to occlusion, and low rate of false positive detection. The OpenCV library (Baggio et al., 2012) was used to calculate the position and orientation of the ArUco markers in five steps: (1) Image segmentation: the most distinguishable edges are extracted. (2) Contour filtering: a counter extraction method (Suzuki et al., 1985) followed by a polygonal approximation (Douglas & Peucker, 1973) is applied. (3) Marker code extraction: the internal code of detected regions is analyzed to obtain their internal code. (4) Marker identification and error correction: the environment is distinguished from markers. (5) Corner refinement and pose estimation.
Detection of ArUco markers was implemented on Raspberry Pi 3B + running Raspbian OS and ROS Melodic (Quigley et al., 2009) with the Raspberry Pi Camera v2.1. Kobot robots can detect markers with a .05 m edge up to 2 m distance and from skew angles up to 80°. Nevertheless, detection distance was limited to .5 m to be consistent with the simulations and to avoid detecting landmarks from inside the cue.
Four IR sensors were placed at the bottom of the robot to sense the cue intensity on the floor. IR sensors were calibrated to read 0 from the lowest intensity zone (the carpet on the floor) and 255 from the highest intensity zone (the brightest zone at the center of the cue). Four readings were taken at each location and averaged to compensate for the tilt of the robot and for the non-uniformity of the floor. Optical encoders coupled to the two DC motors were used as odometry sensors. Obstacle and robot detection were performed using the legacy range and bearing system that has 8 modulated IR sensors. The range and bearing system has a range of 20 cm, and it is able to distinguish robots from obstacles.
During the experiments, all robots relied on on-board sensory data and computational resources, and there was no communication between the robots. Only high-level commands such as experiment start, end, and debugging messages were transferred to Kobot robots from the main computer. In terms of battery and power source, 2S (7.4 V Nominal) Li-Po 1300 mAh battery was used in the robots. With this battery, Kobot robots could run up to 2 hours with a CPU load of 50% of the main controller.
In order to calculate the NAS values during the experiment, 2-D poses of each robot were tracked using OptiTrack motion capture system (OptiTrack, US) with 8 USB cameras. The pose information from the camera array was transferred to the main computer running ROS Melodic for real-time NAS calculation and monitoring the current state of the experiment. By observing the real-time NAS value during the experiment, the time at which NAS reached a steady-state value was noted, and the experiment duration was set accordingly. The setup for real-robot experiment is shown in Figure 5. Real-robot experiment setup. Position of each robot is calculated by eight pose cameras (Optitrack) located around the arena. Then, this data is sent to the main computer in order to calculate the number of robots inside the cue for derivation of NAS performance. A webcam is also located in the arena to record the experiments for documentation purposes. Kobots are utilized with on-board camera to detect the ArUco marker, that is, landmarks.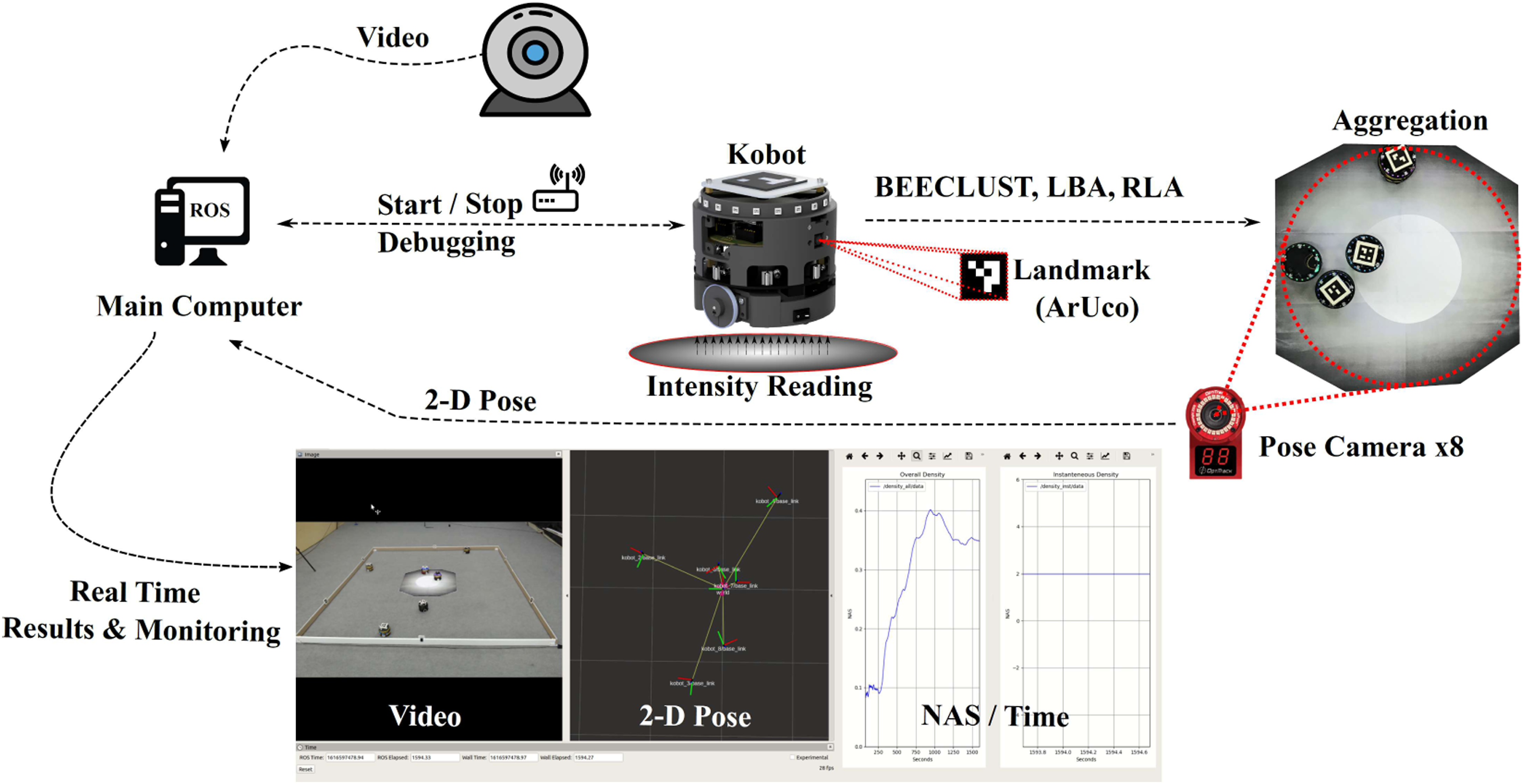
The experimental setup consisted of a rectangular arena with six landmarks placed on the two sides of the rectangle and a circular cue with a white gradient indicating higher intensity regions, as shown in Figure 6. The maximum speed of robots was set to be v
j
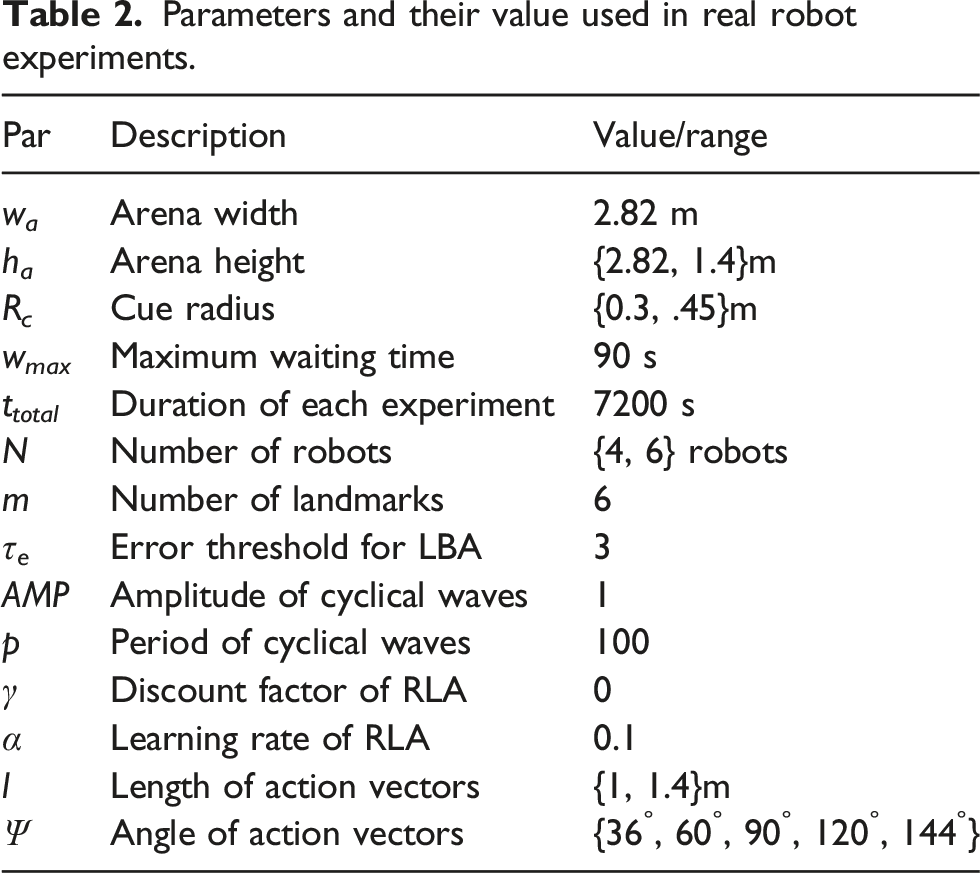
= .14 m·s−1. Real-robot experiments were conducted in two different swarm sizes, N = {4, 6} robots, to study the performance of the methods in two different population densities. The arena for N = 4 robots case was a 2.8 m × 1.4 m with a cue radius of .3 m. For the N = 6 robots case, arena was 2.8 m × 2.8 m with a cue radius of .45 m. The arena for N = 6 robots setup is illustrated in Figure 6. For all three methods, the maximum waiting time was set to be wmax = 90 s. The reason for choosing this waiting time is that a lower waiting time will hamper the aggregation of robots, and no proper aggregation would be formed. On the other hand, time limitation forced by battery life of robots demands a low waiting time. Otherwise, robots would be waiting most of the time inside the cue until their battery dies. Through empirical investigation, we determined that a suitable compromise for the maximum waiting time is 90 s, considering both sufficient lengths of battery life and aggregation performance. Table 2 shows the parameters used in the real-robot experiment. Arena setup for N = 6 robots experiment. A 2.8 m × 2.8 m rectangular arena with six landmarks is surrounded by eight pose cameras (Optitrack) which are used for evaluating the number of robots inside the cue. Robots are calibrated in a way that the grey color of carpet is read as zero cue intensity. Parameters and their value used in real robot experiments.
Three aggregation methods were implemented on the real robots: BEECLUST, LBA, and RLA, with cyclical schedule for ɛ. The error threshold parameter for the LBA method was τ
e
= 3, and for the RLA method, amplitude and period of cycles were chosen as AMP = 1, p = 100, respectively. For the real-robot experiments, only static environment was studied, and no noise was added during the experiment. However, noise still existed due to wheel slippage and odometry errors. Different than the kinematic simulation setup where action space
A new set of kinematic-based simulations were performed with the same settings as the real-robot experiments for comparison. The only difference was that noise of σ n = 30° was added in kinematic-based simulations to match the inherent noise in real robots. Results were reported as steady-state values of NAS. Each experiment was repeated five times to make sure that the results were less dependent on the initial conditions. Thus, the experiments produced total 60 hours of data used for further analysis of the proposed method performance. Such a duration is comparable to experiments in works that explicitly address long-term performance of robotic swarms.
5. Results and discussion
5.1. Kinematic-based simulator experiments
5.1.1. Environment experiments
Time evolution of the NAS values for the three methods with and without odometry noise is plotted in Figure 7. In the experiments without noise, as shown in Figure 7(a), all the methods, except the BEECLUST method, showed a similar steady-state performance during the first half of the experiment reaching a NAS value of .7. When the cue location was changed, the LBA method adapted to the change faster than the RLA method. The BEECLUST method performed worst with a NAS value of .37 since the low-robot density decreased the probability of robot-robot encounters. On the other hand, its performance was not affected by the change of cue. The reason is the random nature of the BEECLUST method; since it does not exploit any information for finding the location of the cue, altering the cue location does not affect the BEECLUST method. Environment Experiments. Time evolution of the NAS values of the BEECLUST method, the LBA method with τ
e
= 4, the RLA method with the cyclical schedule, p = 100, and with the VDBE schedule, σ = 1 are shown. (a) The NAS values without odometry noise and (b) the NAS values with odometry noise, σ
n
= 15°. Shades represent the first and third quartiles, and the solid lines are the median of 5 trials. Duration of each experiment is t
total
= 100,000 s. The location of the cue is changed at t
change
= 50,000 s, indicated by the vertical dashed line. In order to smoothen the results, moving average with a window of [t
s
, t
s
+ 500] is used.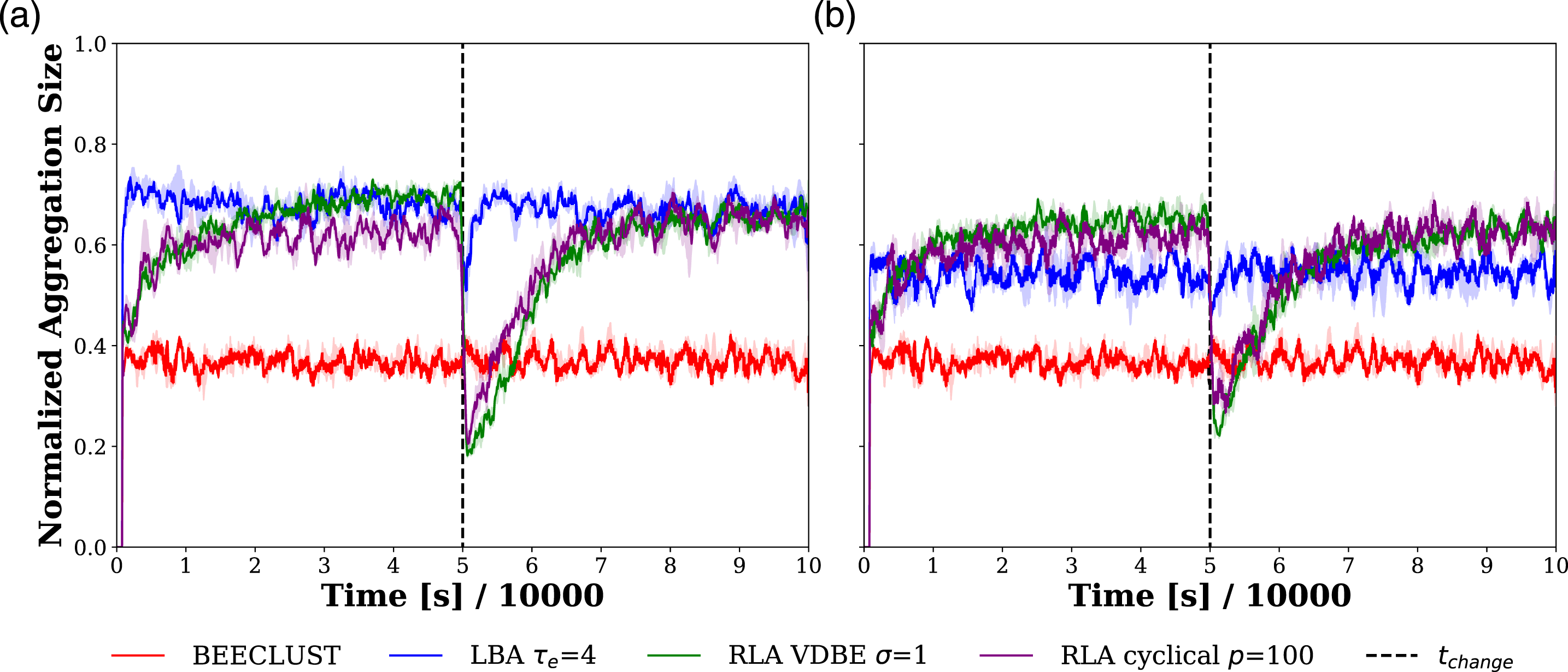
The RLA method with VDBE and cyclical schedule was able to reach the performance of the LBA method. The response of the RLA method is slower than the LBA method, and it also adapts slower to the change of cue position. This is because it takes time for the robots to explore and learn the environment to form the Q-table. In addition, the learning speed is controlled by the learning rate, α, and it is taken as a fixed value, α = .1 in this article.
To further show whether the RLA method allows robots to learn appropriate actions using maximum Q-values, the actions with maximum Q-values for each landmark observation are investigated with an experiment. In the experiment, the robots learn the Q-table implementing the RLA method under the setting of zero noise strength, σ
n
= 0 and with cyclical ɛ schedule with period p = 100 and amplitude AMP = 1. The Q-tables of all robots were averaged at steady-state and for each landmark, action with maximum Q-value was shown as a red vector in Figure 8. The results indicate that the learned actions with the RLA method lead the robots towards the cue region with a higher cue intensity compared to other actions. Representation of the learned actions that yield the maximum Q-value (shown as red vectors) for each state, compared to the other actions (shown as pink vectors) in steady-state.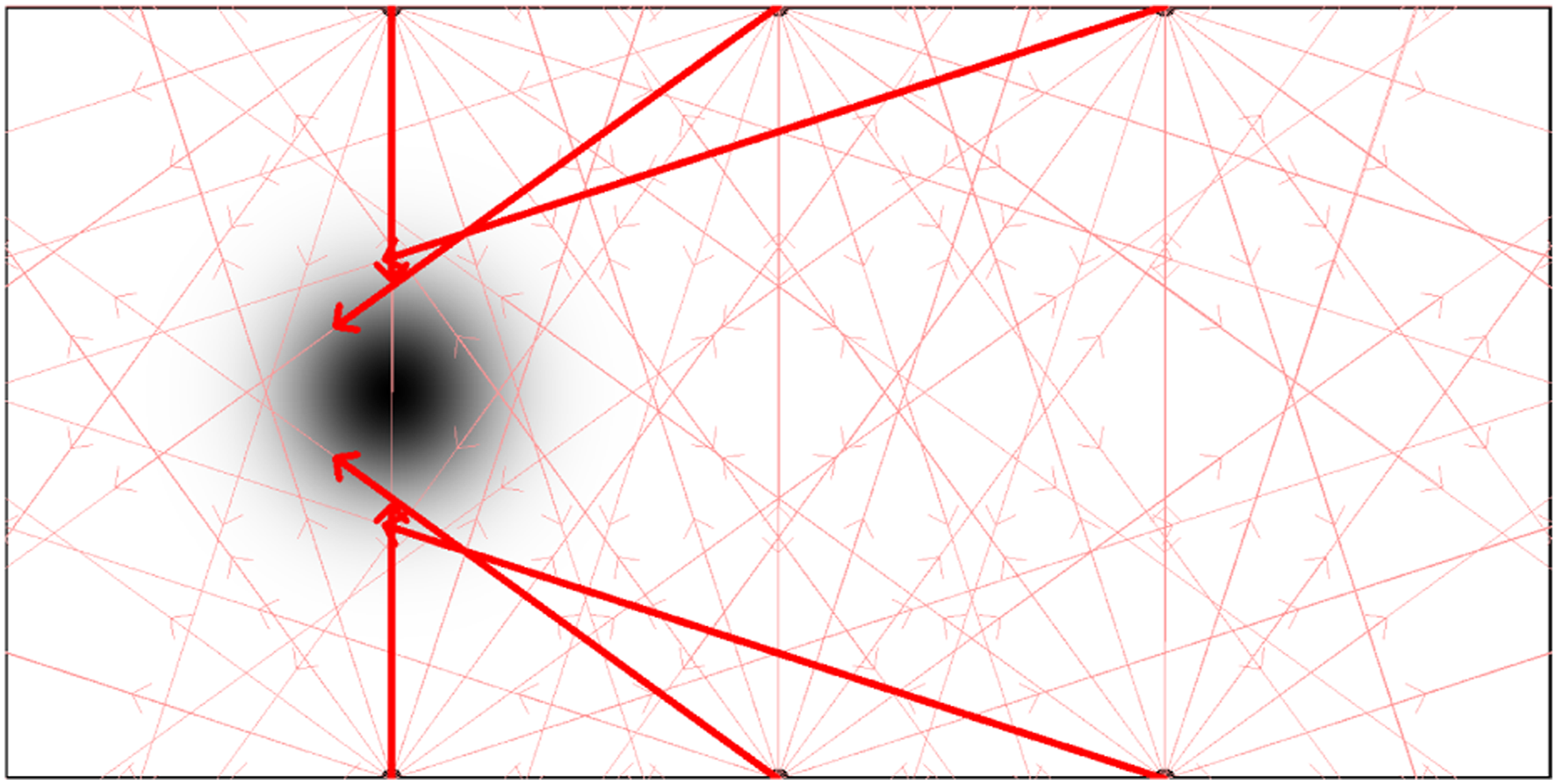
The results of the experiments with odometry noise, σ n = 15°, are shown in Figure 7(b). When compared to the experiments without noise, the performance of all methods except the BEECLUST method decreased. The LBA method has the most drastic decrease from a NAS value of .7 to .55, whereas the RLA method showed a slight decrease from .7 to .67. The reason is the performance of the LBA method depends heavily on the odometry data. Therefore, a slight amount of noise like σ n = 15° affects the LBA method considerably. On the other hand, the RLA method also uses the odometry data to execute an action, but it does not integrate displacement vectors. Therefore, it is more robust to odometry noise.
5.1.2. Noise experiments
The results of the noise experiments are shown in Figure 9. In the zero noise case, the LBA method performed best with a NAS value of approximately .7. However, its performance decreased dramatically as noise increased since the LBA method depends heavily on the odometer readings. The performance of the RLA method also decreased due to noise, especially in higher noise regions, but still, it is more robust to noise than the LBA method. Since the BEECLUST method does not use the odometry readings, its performance did not change and stayed around .37 in all the settings. When σ
n
= 180°, the performance of all methods converged to BEECLUST because the information acquired from landmark is not exploitable anymore due to the intense amount of noise. Noise Experiments. The steady-state values of NAS are shown for the BEECLUST, LBA, RLA with cyclical schedule, and RLA with VDBE schedule methods with respect to the odometry noise, σ
n
∈ {0°, 5°, 15°, 30°, 45°, 60°, 90°, 135°, 180°}. Bars represent the first and third quartiles, and lines are the median of 5 trails. The experiments are static and duration of each experiment is: t
total
= 50,000 s. The x-axis is not drawn to scale.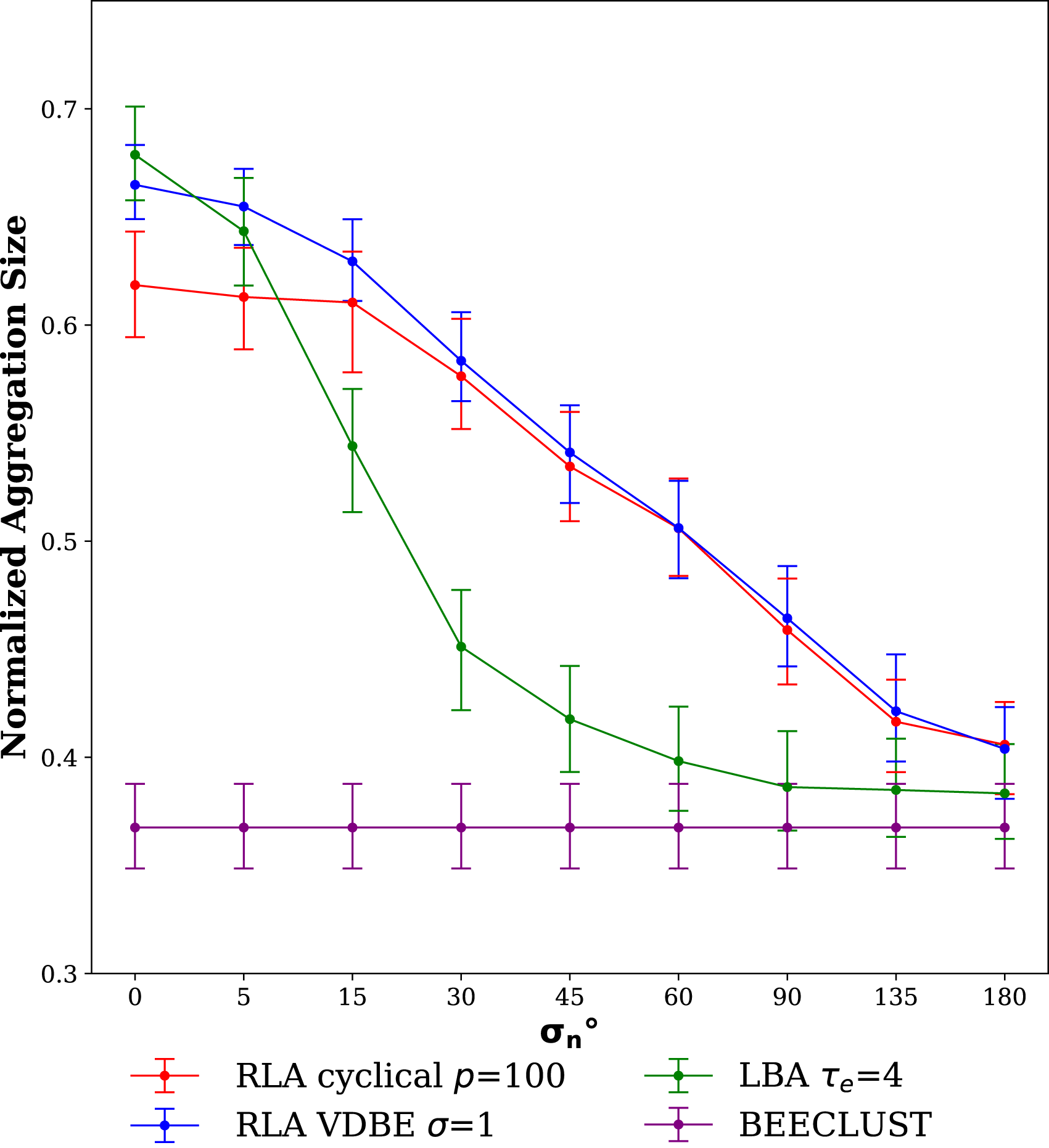
5.1.3. Parameter sensitivity experiments
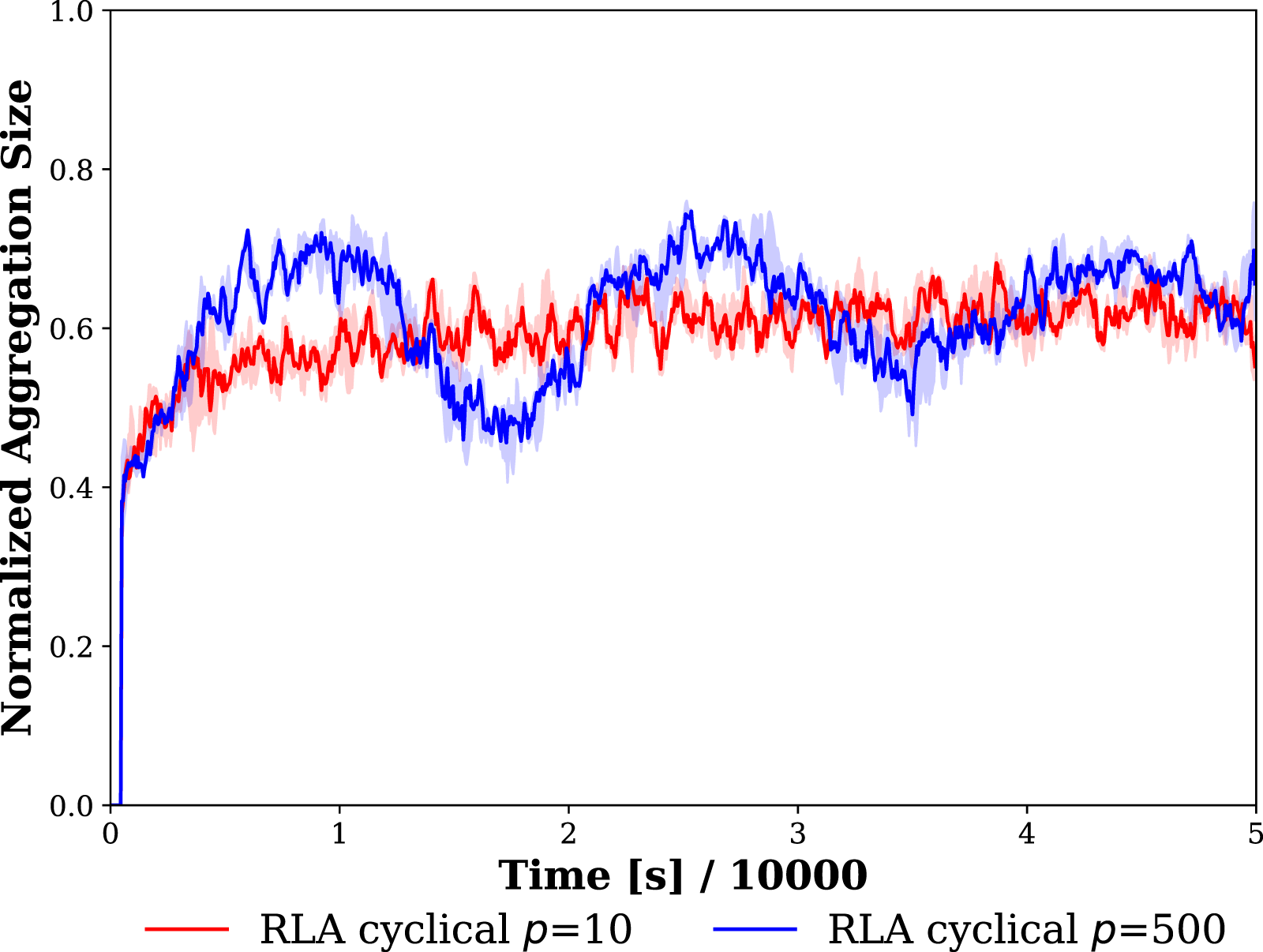
The experimental results investigating the sensitivity of the cyclical and VDBE ɛ schedules with respect to their parameters revealed that the cyclical schedule is less affected by changes in its period and amplitude of ɛ oscillations compared to variations in the σ parameter of the VDBE schedule. The results show that the cyclical scheduling is more effective in the dynamic environments, and the VDBE scheduling is more beneficial with its fine-tuned parameter in the static environments.
The steady-state values of NAS versus the model parameters are shown in Figure 10. The first and second rows plot the steady-state values before and after the change of location of the cue. The leftmost and middle columns are the plots of the period, p, and amplitude, AMP, parameters of the cyclic schedule, and the last column are the plots of the inverse sensitivity parameter, σ for the VDBE schedule. In case of cyclical schedule, the period did not affect the aggregation performance when p ≤ 10. When p ≥ 10, the performance increased considerably and remained around a NAS value of .65, indicating that NAS performance does not change considerably when p ≥ 10. Although large periods did not affect the steady-state value of the performance, they cause oscillations of NAS values as shown in Figure 11. In case of the amplitude parameter, it did not affect the performance for AMP ≥.37, and the NAS value remained around .6. For both cyclical schedule parameters, p and AMP, the results were the same before and after the change of the cue, meaning that the cyclical schedule is adaptive to environmental changes. Parameter Sensitivity Experiments. The steady-state values of NAS are shown for different model parameters of RLA method with cyclic schedule and RLA method with VDBE schedule. Top and bottom rows show the results before and after the change of cue location, respectively. Leftmost and middle columns show the results for the period, p (AMP is taken as 1), and amplitude, AMP (p is taken as 100) parameters of the cyclic schedule, respectively. The rightmost column shows the results for the inverse sensitivity (σ) parameter of the VDBE schedule. Bars represent the first and third quartiles, and lines are the median of 5 trails. Duration of each experiment is t
total
= 100,000 s. The location of the cue is changed at t
change
= 50,000 s. The leftmost and rightmost plots are drawn in semi-log scale. Demonstration of effect of period parameter, p, of cyclical schedule of the RLA method on performance of the swarm. Shades demonstrate the first and third quartiles, and lines are the mean of 5 trials of the experiment.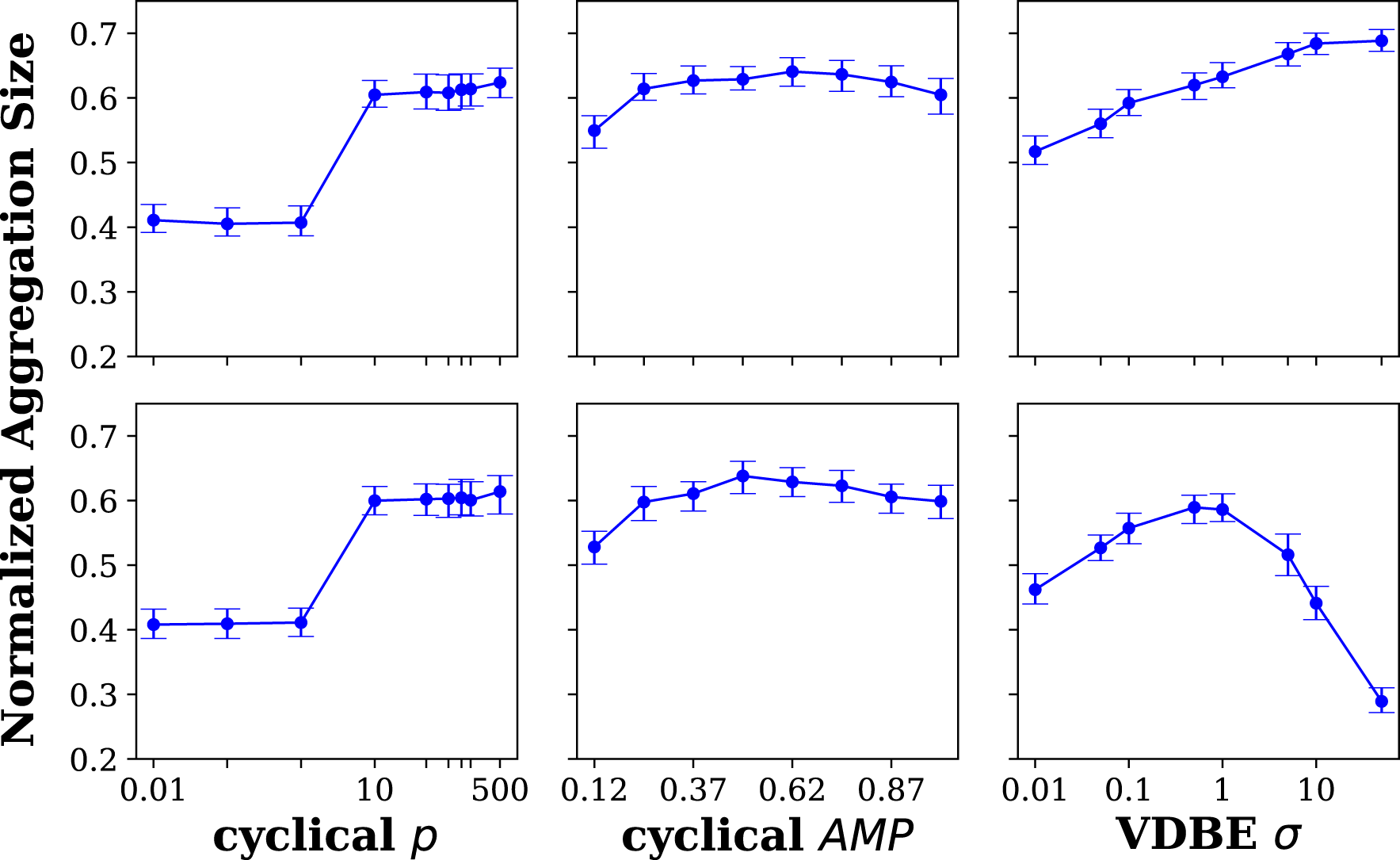
However, in case of the VDBE schedule, σ drastically changes the performance of aggregation. Before the change of the location of the cue, higher σ values yielded better results, indicating better performance of VDBE schedule in static environments. However, after the location of the cue was changed, higher σ values failed to put robots back to the exploration state, decreasing the aggregation performance. For instance, when σ = 50, the NAS value before the change of the cue was approximately .7, and after the change, it dropped to .3, which is even worse than the performance of the BEECLUST method (NAS = .37). This is because robots do not return to the exploration mode; hence, they use the previously learned Q-table in the new environment, and performance becomes worse than the random choice.
In order to understand the performance difference between the two schedules, the time evolution of ɛ for the cyclical schedule with p = 100 and AMP = 1 and the VDBE schedule with σ = 50 using the data from a randomly selected robot is depicted in Figure 12. For the cyclical schedule, ɛ changes periodically based on p and AMP. VDBE schedule updates ɛ for each state separately, one line was drawn for each state making a total of six lines. Evolution of ɛ during time for VDBE schedule with σ = 50 and cyclical schedule with p = 100 for a randomly selected robot. Occasional straight line regions in ɛ is due to the fact that ɛ is updated at every epoch, that is, when the robot detected a landmark. So, ɛ is a function of epoch, not time.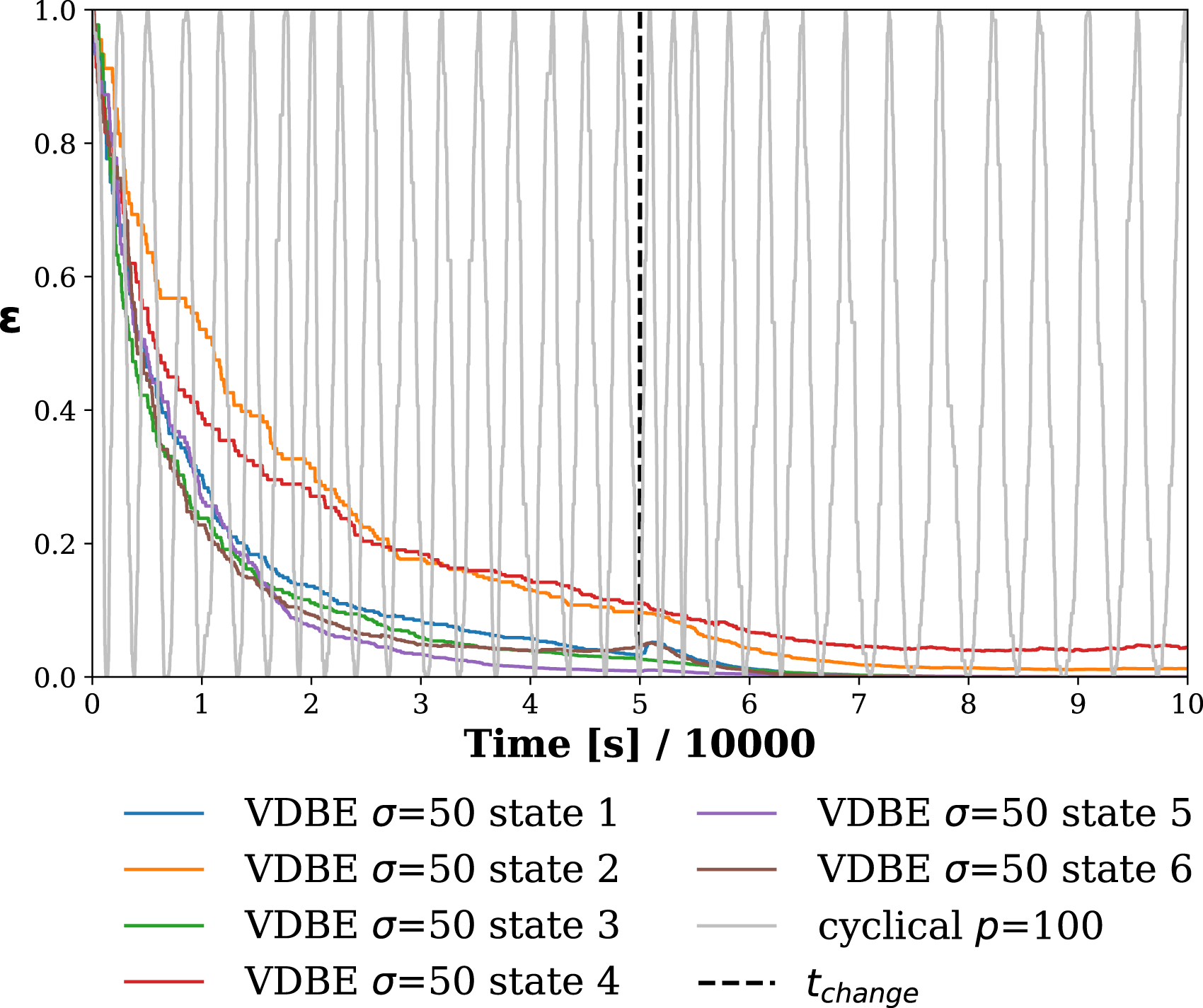
Rewards received by a randomly selected robot for the cyclical and VDBE schedules are depicted in Figure 13. Rewards that VDBE schedule receives were higher than the cyclical schedule before the change of the cue, which indicates superior performance of the VDBE schedule in static environments. However, after environment change, the VDBE schedule keeps ɛ low, as shown in Figure 12 and fails to adapt to the new location of the cue showing better adaptability of the cyclical schedule to dynamic environments. Average reward received by robots during time for RLA method with cyclical ɛ schedule with a period of p = 100 and an amplitude of AMP = 1 and VDBE schedule with σ = 50. Shades represent the first and third quartiles, and lines are the median of 5 trails. Duration of each experiment is t
total
= 100,000 s. The location of the cue is changed at t
change
= 50,000 s, indicated by the vertical dashed line.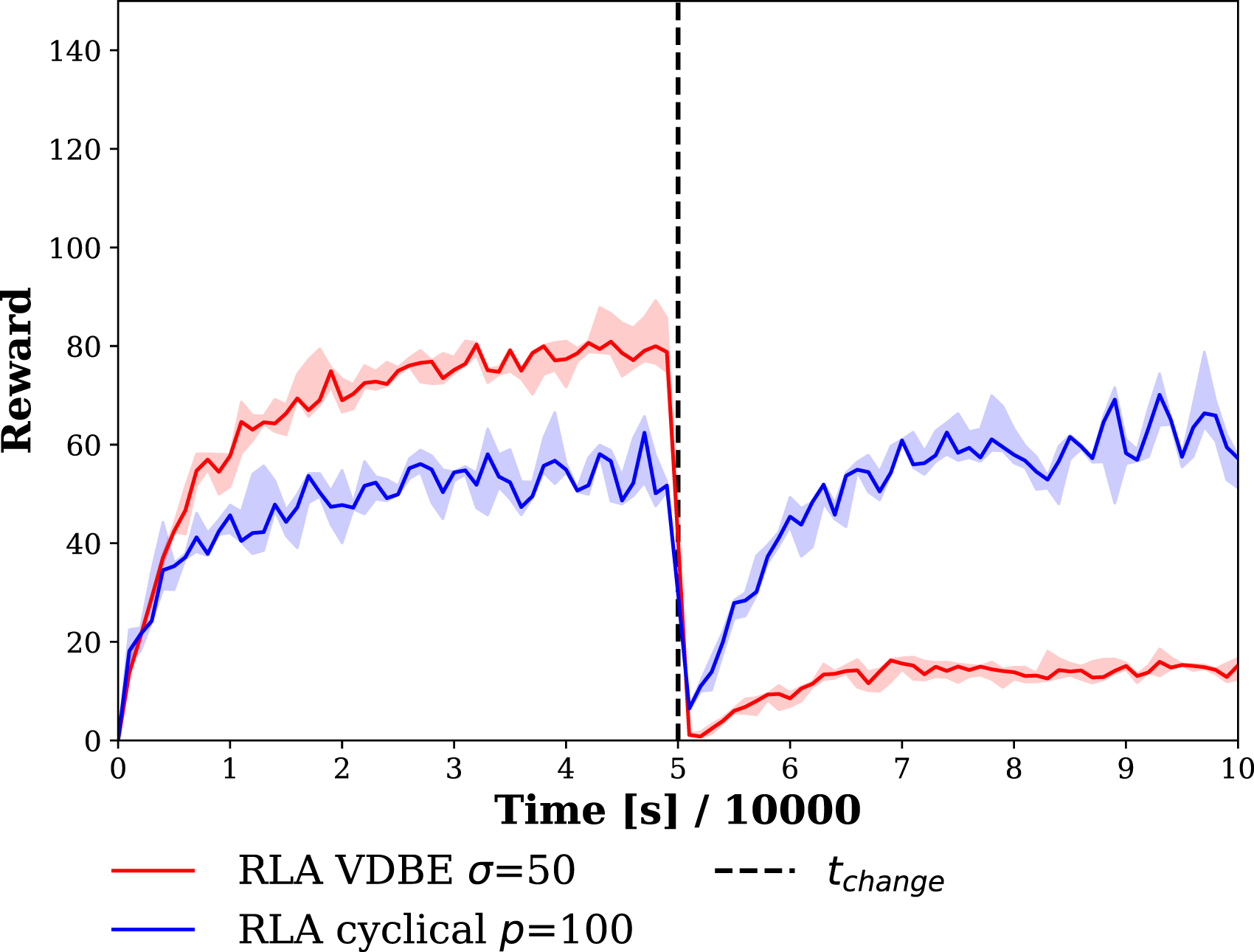
5.2. Real-robot experiments
The BEECLUST, LBA, and RLA methods were implemented using the real robots. For the sake of comparison, the same experimental setup was also implemented using the kinematic-based simulator. The steady-state NAS values for the real-robot and the simulation-based experiments with N = 4 and N = 6 robots are shown in Figure 14(a) and (b), respectively. In N = 4 robots experiment, the BEECLUST method had the lowest performance with a steady-state NAS value of .45, the LBA method had a steady-state performance of .58, and the RLA method had the best performance reaching up to .62. In N = 6 robots experiment, a similar trend in performance has been observed. The results of kinematic-based simulation experiments are in accordance with the real-robot experiments. Steady-state values of NAS performance of the BEECLUST, LBA, and RLA methods for real robots experiments with (a) N = 4 robots and (b) N = 6 robots. RLA method is implemented with cyclic schedule using AMP = 1 and p = 100. The boxes represent the median, first, and third quartiles. Whiskers are the minimum and maximum values. The pink boxes represent the results of kinematic-based simulation results, and the blue boxes are real-robot experiment results. Experiments are repeated five times.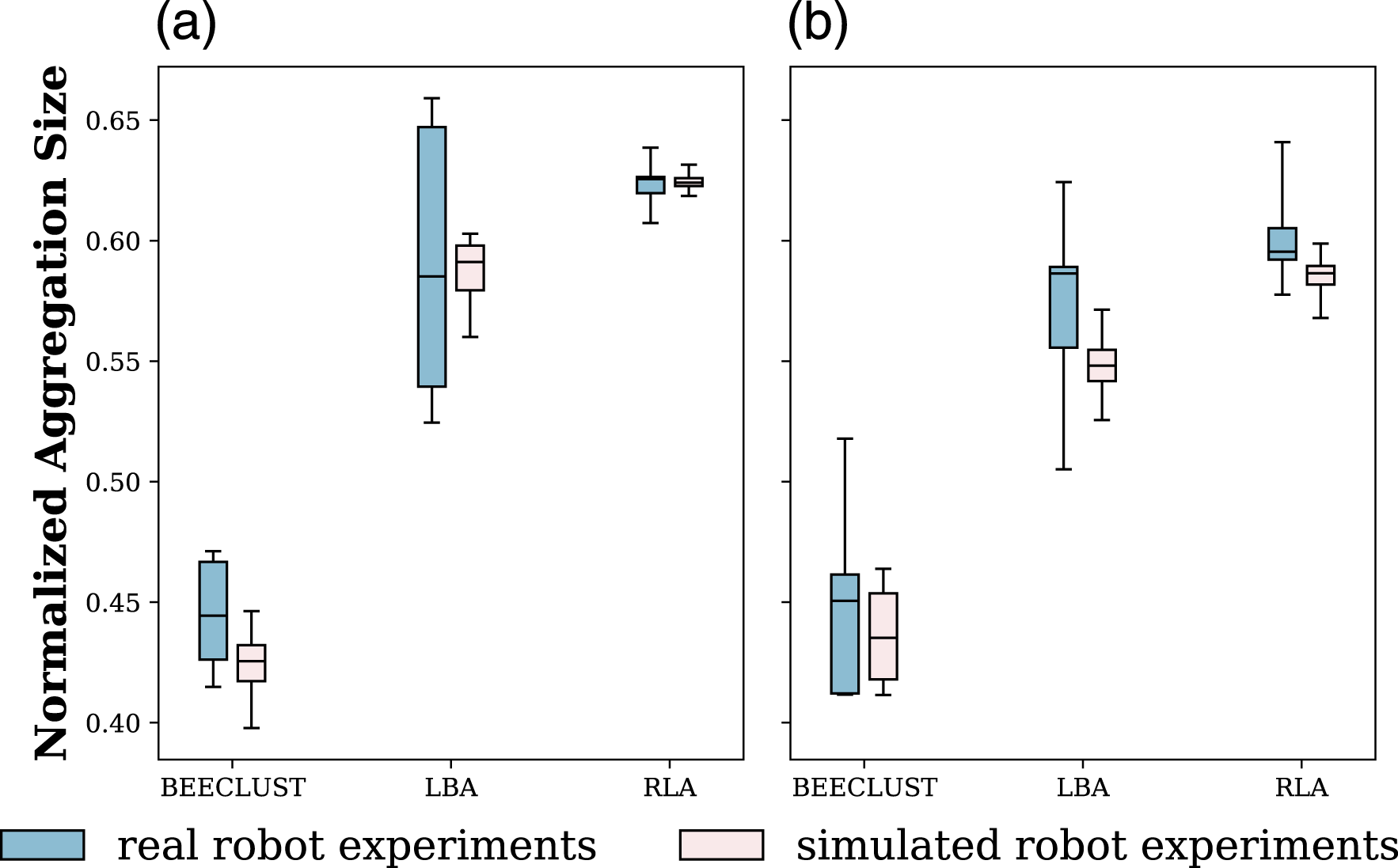
5.3. Discussion
In the environment experiments, since the robot density was low, the BEECLUST method had the worst performance, as shown in Figure 7. For the experiments without noise, the LBA method showed the best performance. However, its performance dropped drastically in the experiments with even a slight amount of noise (Figure 9). The RLA method was more robust to noise than the LBA method. This is also observed in real-robot experiments (Figure 14) where odometry noise was inherently present. From the performance perspective, these results imply that the RLA method managed to aggregate most of the robots on the cue despite the presence of inaccuracy and drift in odometry. This result proves the robustness of RLA method to sensory noise and its applicability in real-world scenarios.
The RLA method uses the Q-learning technique, and ɛ-greedy policy was chosen as the policy to tackle the exploration-exploitation dilemma. In order to use the ɛ-greedy policy effectively in noisy and dynamic environments, ɛ must be scheduled. VDBE (Tokic, 2010) scheduling schemes were implemented, and a new cyclical schedule was proposed using the results in Smith (2017). The RLA method with VDBE schedule achieved the highest performance with proper tuning of the model parameters (Figure 9). However, its performance is very sensitive to model parameters (Figure 10). On the other hand, the RLA method with cyclical schedule is more robust to odometry noise (Figure 9), less sensitive to model parameters (Figure 10), and performs better in non-stationary environments (Figure 7). Furthermore, the cyclical schedule requires less computational power and memory, suitable for simple swarm robots (Figure 14). The result on the cyclical schedule showed that it improves the performance of the RLA method and makes it more applicable in real-world scenarios.
Swarm robotic systems can be used for the tasks dealing with hazardous substances or items that could be dangerous for humans and that are challenging for a single robot (Huang et al., 2019). For example, a swarm robotic system using the RLA method can be used to decontaminate chemical leakage in a damaged factory, where human operators or a single robot are not sufficient to deal with this task. Furthermore, the RLA method is likely to be robust on any sensory noises inside the damaged factory, such as the low quality camera input due to poor light condition and high degree of odometry error due to harsh conditions inside the factory. The advantage of the RLA method in real-world applications is further supported by the research on swarm robotic aggregation for pipeline inspection on water, oil, waste, and chemical reactor vessels. In Duisterwinkel et al. (2018); Andraud et al. (2018), the results suggest that the aggregation of robot swarms for inspection in harsh environments must be robust against sensor noise. The effect of environmental conditions on the robot swarm aggregation is also reported in Na et al. (2021). Therefore, RLA method can provide viable solution for robot swarm aggregation tasks in such hazardous environments under high sensory environmental noise.
In the VDBE schedule, the inverse sensitivity parameter, σ, needs fine-tuning, which is one of the disadvantages of VDBE. The other disadvantage of VDBE is that each state requires its own independent ɛ, which makes ɛ a function of the state, s. Consequently, as the number of states grows, the VDBE schedule will require more memory to store ɛ parameters for each state. For environments with a large state space size, the VDBE schedule consumes a considerable amount of memory to keep track of each ɛ independently.
It should also be noted that the learning rate was set to a fixed value α = .1. Although a constant choice of α will restrict the convergence speed of the model and prevent it from reaching its best performance, studying adaptive and more advanced schedules for α is beyond the scope of this article, and it is considered a future work.
Moreover, the length of action vectors in the RLA method, l, depends on the arena size. More vectors will span the arena better, and chances of finding actions with higher rewards will increase. However, since increasing the size of the action space will increase the Q-table size, training time will grow. On the other hand, a smaller action space size will cause faster learning, but the arena will not be spanned properly. Choosing the size of the action space as 44 is a fair trade-off between not having a large Q-table and spanning the arena sufficiently. In reality, the aggregation problem has continuous action space, but solving the aggregation problem in continuous space is beyond the scope of this article.
It should be noted that since landmarks represent the states of the Q-learning algorithm, increasing the number of landmarks will increase the size of the Q-table hence increasing the training time. On the other hand, choosing fewer landmarks will reduce the probability of their detection and hinder the performance of the LBA and RLA methods. By selecting the number of landmarks as m = 6 for our test cases, the Q-table does not become too large, and still, the performance of the LBA and RLA methods are at acceptable levels.
To address the similarity of the RLA method to Simultaneous Localization And Mapping methods (SLAM), it is worth bearing in mind that the distribution of the landmarks in the arena is sparse, causing the robots to detect them only occasionally and detecting only one landmark at a time. This is analogous to low visibility situations (e.g., in disaster scenarios, adverse weather, or crowded locations), where SLAM struggle (Cadena et al., 2016; Gomez-Ojeda et al., 2020; Li et al., 2020).
6. Conclusion
In this article, a novel cue-based aggregation method was proposed (RLA) based on Q-learning and ɛ-greedy policy. Through systematic analysis with the kinematic-based simulations and real robots experiments, it was shown that the proposed method shows better performance in the presence of odometry noise and environment uncertainties when compared to the BEECLUST method (Schmickl & Hamann, 2011) and the LBA method (Sadeghi Amjadi et al., 2021); and it is applicable in real robots. A new approach to solve the exploration-exploitation dilemma was proposed to schedule ɛ parameter of ɛ-greedy policy. The proposed cyclical schedule was compared to the other state-of-the-art approaches, and it was shown that cyclical updates are less sensitive to model parameters and do not require fine-tuning. Additionally, cyclical updates of ɛ make robots more robust to changes in the environment.
Nevertheless, the proposed aggregation method requires a priori information about the dimensions of the arena. Therefore, as future work, the Deep Deterministic Policy Gradient algorithm (Lillicrap et al., 2015) will be used to avoid requiring a priori information about dimensions of the arena. Furthermore, an adaptive approach will be considered to tune the learning speed of the algorithm.
We plan to deploy the proposed approach in scenarios of robot-insect interaction, where groups of robots aggregate around key agents of social insect colonies to affect their behavior and overall colony activity (Stefanec et al., 2022).
Footnotes
Acknowledgements
The presented work was supported by EU-H2020-FET RoboRoyale project, grant agreement No. 964492 and by the Czech Ministry of Education by OP VVV funded project CZ.02.1.01/0.0/0.0/16 019/0000765 “Research Center for Informatics”.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the EU-H2020-FET RoboRoyale project (964492).
About the Authors