
Abstract
We consider the benefits of dream mechanisms – that is, the ability to simulate new experiences based on past ones – in a machine learning context. Specifically, we are interested in learning for artificial agents that act in the world, and operationalize “dreaming” as a mechanism by which such an agent can use its own model of the learning environment to generate new hypotheses and training data.
We first show that it is not necessarily a given that such a data-hallucination process is useful, since it can easily lead to a training set dominated by spurious imagined data until an ill-defined convergence point is reached. We then analyse a notably successful implementation of a machine learning-based dreaming mechanism by Ha and Schmidhuber (Ha, D., & Schmidhuber, J. (2018). World models. arXiv e-prints, arXiv:1803.10122). On that basis, we then develop a general framework by which an agent can generate simulated data to learn from in a manner that is beneficial to the agent. This, we argue, then forms a general method for an operationalized dream-like mechanism.
We finish by demonstrating the general conditions under which such mechanisms can be useful in machine learning, wherein the implicit simulator inference and extrapolation involved in dreaming act without reinforcing inference error even when inference is incomplete.
1. Introduction
Although dreaming is an everyday aspect of human existence, its precise function, if any, remains uncertain. While some consider it an epiphenomenon with no proper functionality, others see dreaming as having adaptive benefits (see, for example, Zink & Pietrowsky, 2015, for 11 different structural and biological theories of dreaming, which vary greatly in the function they ascribe to dreams).
In particular, it is noteworthy that the phenomenological aspect of dreams – that is, the consciously perceived experience associated with them – is not always central to (or even necessarily considered in) theories regarding their function. For example, a popular idea holds that the primary role is in memory processing (Crick & Mitchinson, 1983, 1995; Hobson, 1994), while others see them as a way to deal with emotional concerns (Hartmann, 1998). Even theories that consider dreams to be a series of events (influenced by the dreamer’s past) within a model of the world in which the dreamer actively participates (Foulkes, 1985) do not necessarily give a role to the phenomenological aspects. As pointed out by Revonsuo (2000), there is no function to the narrative beyond “producing novel and unique mnemonic configurations” in such accounts.
By contrast, phenomenological aspects play a central role in theories that consider dreams to by a simulator of different aspects of life, such as the “immersive spatiotemporal hallucination model of dreaming” (Windt, 2010), the “social simulation theory” (Brereton, 2000; Revonsuo, Tuominen, & Valli, 2015) or the “threat simulation theory” (Revonsuo, 2000; Valli & Revonsuo, 2009). Here, the fundamental tenet is that dreams are not merely replays of previous experiences; instead, dreams contain aspects different from waking life, are less constrained than other thought processes and lack self-reflection and orientational stability (Hobson, Pace-Schott, & Stickgold, 2000).
In general terms, such simulation theories of dreaming propose that dreaming serves as a preparation for future waking interactions – dreams can be understood as the ability to simulate new experiences based on past ones. Such a characterization is also consistent with a predictive coding perspective of cognition: an “REM dream constitutes a form of prospective image-based code which identifies an associative pattern in past events and, therefore, portrays associations between past experiences (rather than the experiences as such)” (Llewellyn, 2016, emphasis in text).
The emphasis here is thus on the sensorimotor oriented nature of dreaming (Svensson, Thill, & Ziemke, 2013). For example, it has been suggested that dreams allow one to rehearse the motor actions necessary for the approach or avoidance behaviours appropriate to the identified patterns in events, and that it is such processing that enables the integration between expectation, perception and action thought to characterize predictive coding while awake (Llewellyn, 2016).
It follows that dream-like simulation mechanisms might also find applications in machine learning, for example for artificial agents that need to learn about both their environment and the consequences of their actions. In general, this remains a relatively unexplored area of research, although dreaming-inspired approaches have previously been used in robotics work (Svensson et al., 2013; Windridge & Kittler, 2008, 2010), and Bojarski et al. (2017), for example, trained a deep network to steer a car by complementing the training data with simulated image-steering pairs. Similarly, data simulation has previously come to the fore among researchers as a means of accommodating the training requirements of deep learning (Bayraktar, Yigit, & Boyraz, 2018; Gaidon, Wang, Cabon, & Vig, 2016; Hinterstoisser, Lepetit, Wohlhart, & Konolige, 2017). In particular, domain randomization (Borrego et al., 2018; Tremblay et al., 2018) has arisen as a data-simulation form of particular recent focus, in which random, non-realistic perturbations are applied to existing data (e.g. via random texture addition) in order to enhance generalisation capability. More recently, Ha and Schmidhuber (2018) and Piergiovanni, Wu, and Ryoo (2018), for example, proposed dream-inspired mechanisms for machine learning.
In this paper, we are concerned with the conditions under which such dream-like mechanisms, that is, the generation of additional training data from past experience, can be of use in a machine learning context. At first glance, it is not obvious that such a utility even exists. If we follow the simulation theories sketched out above, then dreaming may be defined as utilizing a learning agent’s own model of the learning environment in order to generate additional data points, which are then used to further improve the learning model (see also Thill & Svensson, 2011, for a related discussion). This is therefore different from learning by simulation in the more traditional machine learning way (in which the simulation provides the model of the learning environment – but that model is not itself subject to a learning process). Rather, one might consider dreaming as the very specific subset of learning by simulation within which the simulation environment is also learned from real world interaction. 1
However, in terms of classical machine learning, such an implementation, that is, simultaneously learning the world model and its simulation to generate training data, looks seriously conceptually flawed. For instance, if we have a hyperplane-based binary learning model (such as a support vector machine (SVM) or perceptron) trained initially upon the training set of label/vector pairs (where
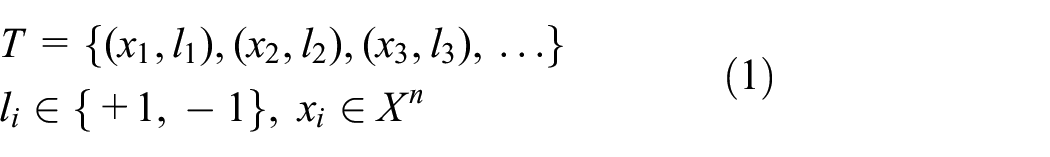
such that the perceptron/SVM learns the hyperplane characterized by weight vector and bias
However, this does not appear to get us very far; the total training set is thus now
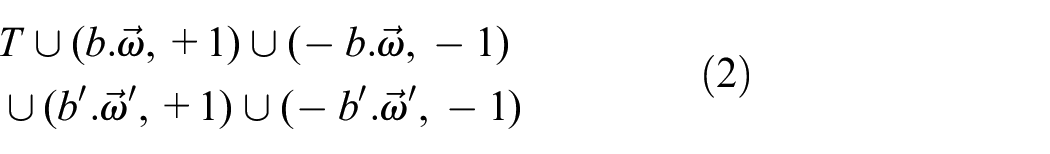
Iterating this process leads to a training set that is dominated by the generated data, which is in effect nothing more than a diary of hypotheses that have been rejected and updated until a (spurious) point of convergence is achieved
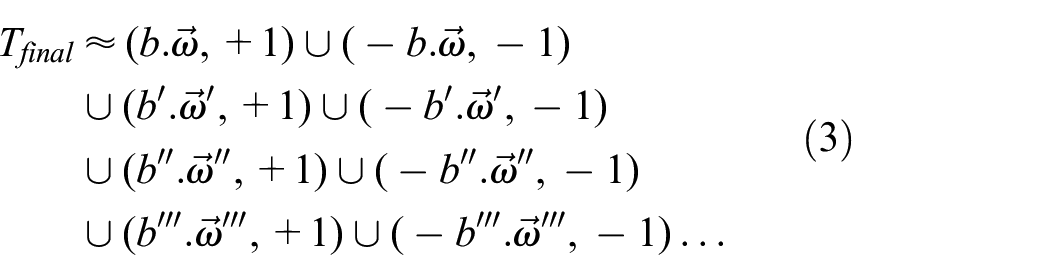
It is therefore not trivially true that something can be gained from dream-like data generation within in a standard supervised learning setting. Nonetheless, Ha and Schmidhuber (2018), for example, have recently demonstrated dreaming within a reinforcement learning context, in which an artificial agent learns to play a computer game utilizing (in addition to the standard mechanisms of reinforcement learning) an offline dreaming mechanism within which the agent plays its own internal representation of the game and thereby refines its own world model, thereby improving learning rates in relation to the non-dreaming variant of the process. In contrast to biological dreaming, however, their model effectively introduces a firewall between learning the world representation and learning the appropriate strategy to act in the world.
Here, we build on this work and the previously discussed biological insights to develop a general model of dreaming for artificial agents. The approach that we adopt will be mechanism agnostic, consistent with a “cognitive systems” approach. We do not assume specialist knowledge of machine learning, but base our discussions on the model by Ha and Schmidhuber (2018) for illustrative purposes.
Before evolving this argument in full, though, we note as an important aside that generative methods have achieved a good deal of attention recently in a game-theoretic/deep-learning context through the successes of Generative Adversarial Networks (GANs) (Goodfellow et al., 2014; Radford, Metz, & Chintala, 2015). Within this paradigm, a generator
The generative aspect of GANs clearly has some connections to dreaming in the sense that randomly instantiated parameters are translated into an input space and then used for further training of the system (in fact, Schmidhuber’s early work was a key inspiration in GAN development). However, there are significant differences; the key aim of a GAN is to parameterize the input domain in order to replicate the source (or, in the case of bidirectional GANs, to compactly feature-encode the input domain), rather than to optimize an agent’s actions with respect to goals within a replicated environment.
A particular GAN variant does exist, however, that can be used in conjunction with environment goal setting, namely, generative adversarial imitation learning (Ho & Ermon, 2016). Here, expert trajectories (i.e. state/action sequences) that are to be replicated by the learning agent are provided in advance, such that the agent seeks to parameterize an optimal policy model that replicates the expert. In particular, for expert trajectories
However, despite these superficial similarities, it is apparent that the states
In principle, though, GAN-based approaches could be fruitfully combined with representation learning of the type to be outlined in order to parameterize a perceptual model; however, as it does not have a bearing on the central argument of the paper, we do not consider it here. In the remainder of the paper, we will thus firstly give an overview of the successful approach by Ha and Schmidhuber (2018) before deriving a more general model of dream-like mechanisms. We then demonstrate under which conditions such mechanisms can generally be useful in assisting a learning process and follow this with an experimental validation of the main finding.
2. High-level summary of Ha and Schmidhuber’s (2018) approach to dreaming
We first give a high-level “bird’s eye” view of the underlying conception behind Ha and Schmidhuber’s (2018) dreaming model in order to be able to abstractly characterize this approach prior to proposing our own general model of dreaming. Note that we will use our own notation in order to later discuss generalizations of this approach.
2.1. Learning
Assume some underlying a priori input world representation
Within this context, and the specific domain context of a computer game, Ha and Schmidhuber (2018) set out firstly to learn a compact representation of
There is implicitly also now an induced mapping in the action space
In the normal (i.e. non-dreamed) mode of learning, Ha and Schmidhuber (2018) learn a predictive mapping between actions and hidden states of the autoencoder – that is, given

where

Thus,
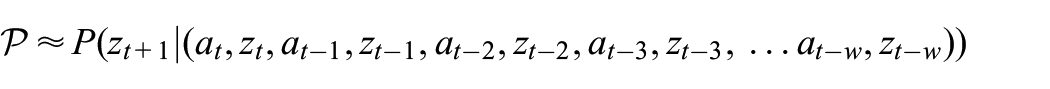
over some temporal window width
For our purposes, we can disregard the parameter
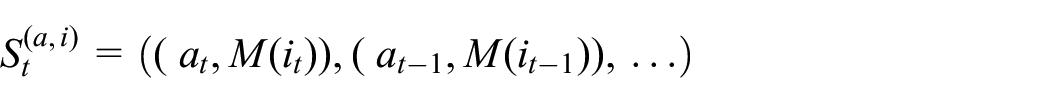
so as to arrive at the modelled probability function

(The RNN component of this process is thus performing the mapping
Ha and Schmidhuber (2018) then learn a simple “Controller” model

which is equivalent to
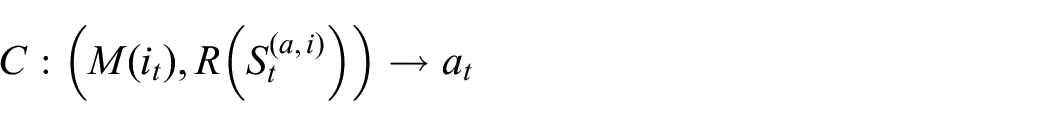
Of course, actually carrying out this action will trigger a transition in the agent’s world as represented within the input domain
2.2. Instantiation of dreams
Thus far, the process outlined is essentially reinforcement learning with an additional autoencoding phase on the input. However, because Ha and Schmidhuber (2018) have learned a predictive model for
Thus, instead of feeding actions back to the environment, it is proposed that learning of
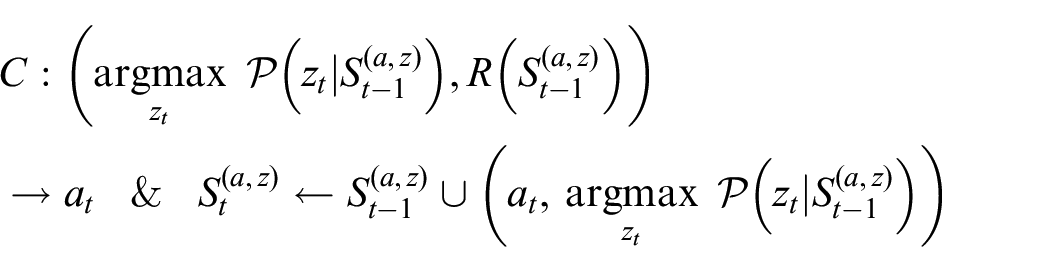
where
For

such that the general dreaming iteration becomes
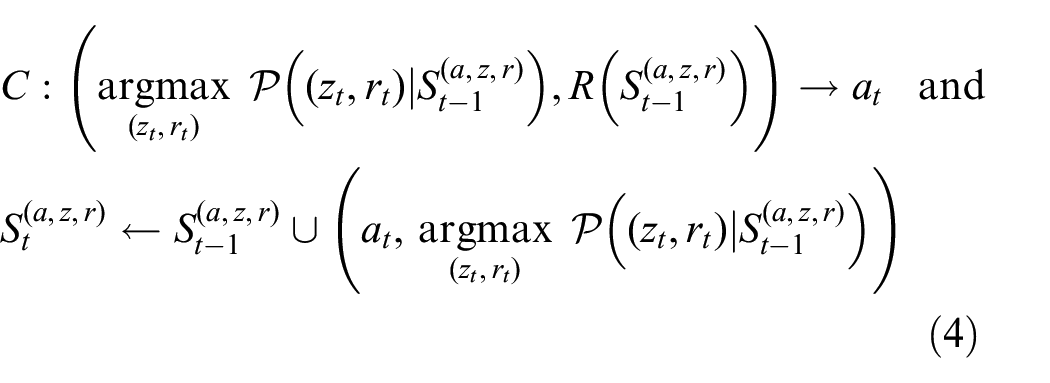
where
Here, the function
To bootstrap this process,
We note, however, that there is no in principle distinction between environmental rewards and environmental observations; the former can in fact be treated simply as a salient subset of the latter (i.e. such that the reward function may be defined
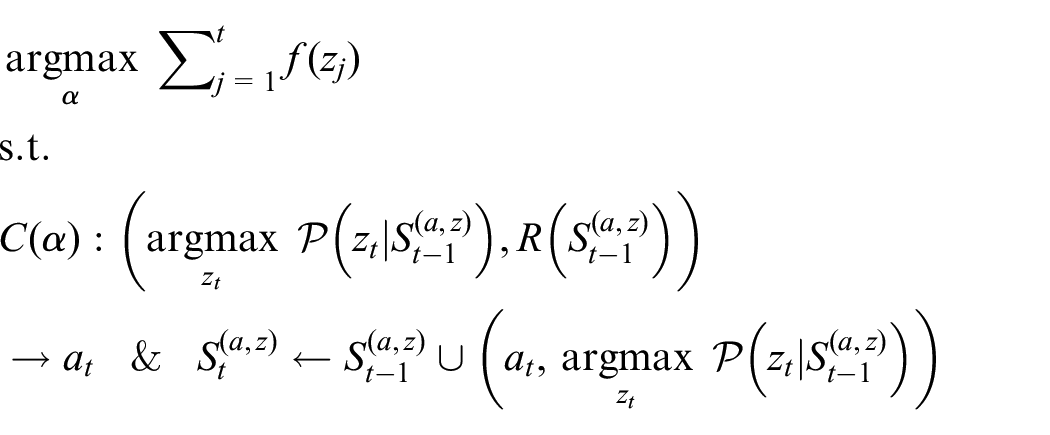
that is, with
3. A general model of dream-like mechanisms
3.1. Recasting the problem in terms of perception–action systems
To summarize the previous, Ha and Schmidhuber (2018) have proposed a successful model for dreaming in which an optimal action response model
To extend the dreaming mechanism discussed so far, a key question is therefore whether some other of the functions it uses, besides
In this case, initial learning again takes place online through motor babbling with respect to a simple input percept space, and progressively builds higher level abstractions of the types of feasible action within this space, aiming to form the most compact hierarchical model of environmental affordances consistent with the active capabilities of the agent, such that high-level exploratory action/perception hypotheses are progressively grounded through the hierarchy in a top-down fashion (consequently, representation is a bottom-up process, and action execution is a top-down process). In this case, there is no explicit reward model or reinforcement learning process required; convergence naturally occurs when the most compact hierarchical PA model is formed of the environment consistent with the agent’s active capabilities.
We can now return to the Ha and Schmidhuber (2018) approach and map this onto a PA framework. By doing this, we can be explicit about how the work is expanded to provide a general dreaming mechanism. To do this, we first group the various functions of the model into two classes based on whether they relate to perception or to action, further splitting the functionality of
In other words, the first group contains functions concerned with the representation of the environment’s affordances (i.e. the response of perceptions to actions, treating the rewards as observations), while the second group is concerned with the planning of actions with respect to these affordance possibilities. We may thus regard the former group as learning an “environment simulator” and the latter group as learning an “environmental strategy” with respect to this simulator.
As an aside, note that this characterization also highlights why dreaming works in this scenario: if we first learn a good simulator– for instance, if we have correctly inferred the rules of chess by observation – then it becomes possible to learn a good strategy offline, that is, without reference to any external observations, by generating our own observations. For example, as long as the domain-rule inference step is correct, we could in principle, if not in practice, exhaustively play chess games entirely offline to find the optimal strategy.
The interesting question, however, arises in relation to the earlier stages of learning, specifically when the “simulator rule inference” is not yet complete. For dreaming-like mechanisms to provide an added value over mere simulation-based learning, dreaming must still be useful when the rules are not completely accurately inferred. Suppose, for example, that we have a partially accurately inferred model of the rules of chess in which every rule apart from that of en passant is known. An offline simulator constructed from this partial rule inference would still be highly capable, and, in particular, would be sufficient to enable the playing of simulated games (i.e. generation of novel training data) that would enable the offline learning of highly effective (if not fully complete) chess strategies (not least because the en passant rule is only rarely deployed). Of course, chess can be characterized as a functionally closed environment; in an open environment, partial rule inference would be the norm, and any simulator rule inference would typically have to be beneficial under partial conditions very far from the convergence asymptote.
3.2. Formalization of the general dream-like mechanisms
We can now consider, given the functional separation into “environmental simulator” and “environmental strategy”, a very generalized dream model consisting of just an online environmental affordance inference model
We can again treat the reward
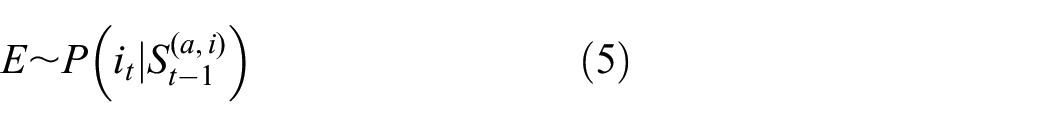
and
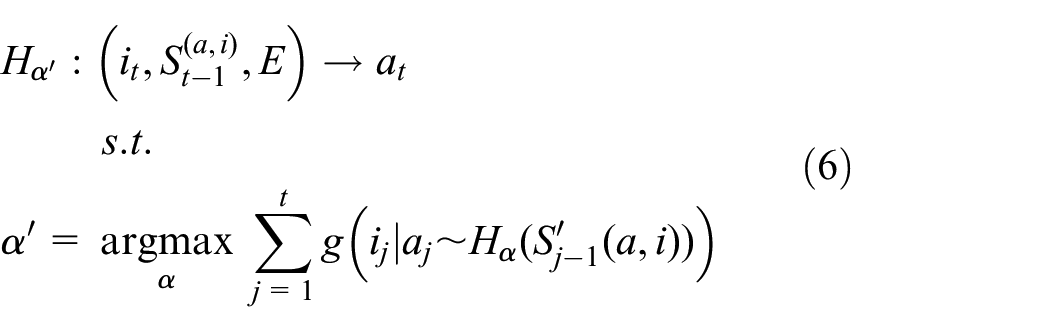
In the offline dreaming mode, the update function for
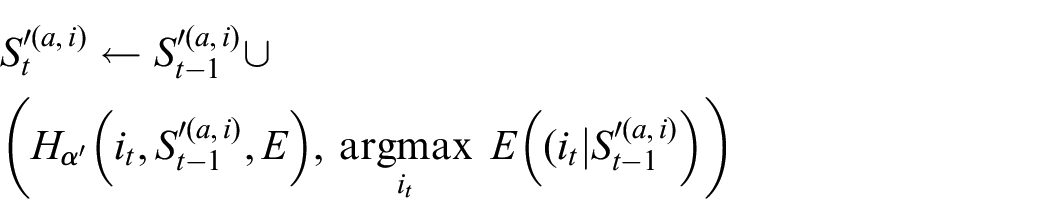
The history
In general,
Note also that this general characterization avoids any explicit mention of intermediate hidden variables, such as those previously deployed for learning temporal and visual configuration states. Such variables can thus be considered here as artefacts of finding accurately generalizing models of
However, given the existence of the possibility of representational compression (as indicated by the autoencoder function

(we may call this requirement with respect to any proposed representational domain remapping a-discernibility). We have thus derived a generalized model of dream-like mechanisms for machine learning in which the role of representation is demonstrated to be ancillary to the crucial aspects of simulation inference and simulation strategy optimization.
As a final aside, although it is not the focus of the present paper, we can note that this also suggests the possibility of stacking intermediate representations hierarchically, such that actions and perceptions are treated subsumptively (again a key component of PA bootstrapping (Windridge & Kittler, 2008, 2010)). Subsumption could thus embody any intrinsic hierarchical modularization of actions (e.g. the notion that “fill container” is necessarily built upon the prior notion of “movable object”), although, in a reinforcement learning context, any stacking would need to respect the reward function,
3.3. Maximizing the utility of a generalized dream-like mechanism
Having arrived at the formulation in the preceding section, we now need to demonstrate that there is a tangible benefit. In other words, we need to verify that we do not simply end up with an elaborate version of the naive example sketched in the introduction whereby we merely end up with a spurious training set that adds no actual benefit.
To begin with, the immediately apparent difference is that here, the learning problem is only partially dream-assisted:
To demonstrate that the model proposed here fulfils this requirement, we begin by drawing an explicit comparison with the spurious example from the introduction. This can be done by rewriting Equation (6) such that the optimization of
The update function for
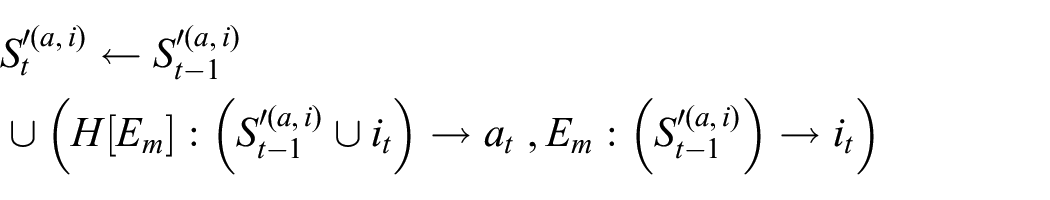
(where it is hopefully clear that
The dreamed sequence
With this, we have now arrived at a formulation that looks similar to the initial example of dreaming that had no discernible benefit. The crucial reason that there is a benefit for the self-generated data in our model is that there is not necessarily a negative consequence to partially accurate inferences of intermediate models of action, even though
This is a consequence of the fact that the sequences
Rather, the only concern is around the ideality of a proposed action with respect to the reward function. It is thus a fundamental aspect of the success of the Ha and Schmidhuber (2018) approach to dreaming that the reward function itself is not learned, but given a priori, without which the learning problem would be entirely ungrounded. Here, again, we can note a parallel with learning in biological entities, for which the “reward function” is provided via the biological necessity of survival within a natural selection context, and is thus external to the agent.
It is hence clear that what dream-like mechanisms offer with respect to optimizing the
Equally importantly, it does not matter if the learned function
We might also, as an extension of this approach, consider further optimization of
The most generalized model of learning for dreaming is therefore a reinforcement learning system in an environment
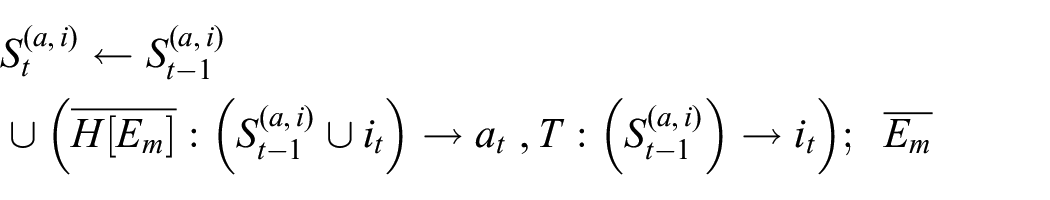
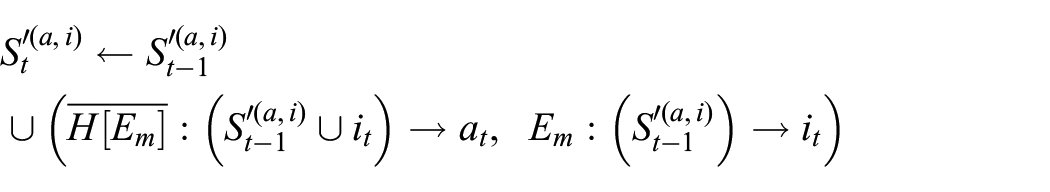
where
Here the bars above
4. Illustrative example
Following the experimental demonstration by Ha and Schmidhuber (2018) of the concrete utility of dreaming in a deep-learning context, we have thus established, on a priori grounds, the necessary conditions under which dreaming can be an effective strategy (in particular the a priori nature of the reward function). Having arrived at a correspondingly generic formulation of dreaming, we can now demonstrate and approximately quantify this utility. We do so using a highly simplified experimental illustration to demonstrate this without reliance on the wider deep-learning context of Ha and Schmidhuber (2018), in which the presence of other factors potentially complicates the understanding of the core dreaming mechanism.
4.1. Agent and environment
The choice of environment model will be as follows. Assume an a priori action set model
An environment model can then be built by greedy accumulation of (percept, action, reward) tuples arising from motor babbling (i.e. such that the tuples form the components of an exploratory sequence
The illustrative example presented here could thus be considered a primordial or proto-biological example of dreaming (although note that the broad conception as formulated in Section 3 is inherently more general, and is able to, for example, apply in arbitrary environments in which no such clear conception of a fixed background space exists). As indicated, our approach to dreaming is much more fundamentally a PA model in which actions are conceptually prior to perceptions and “the world is its own model” (since we do not, in general, explicitly assume
It also greatly simplifies matters in the following to assume that reward scales monotonically with percept values in the simplest manner, that is, such that
To form the action model, the agent seeks to build a bigram model of greedily accumulated action(initial percept, output percept/reward) tuples such that, for a given percept, maximization over a row-normalized histogram acts to select a specific action (percept maximization being equivalent to reward value maximization). To apply the model for a specific input percept (ground truth or dream generated), a nearest-neighbour allocation of the novel percept is made with respect to the existing greedy percept database
4.2. Experimental setup
The spatialized ground-truth domain model (that is to say, the underlying environment of the agent) that we select to govern the intrinsic PA relationship that the learning agent experiences is defined to be the sum over three independently parameterized Poisson functions in order to generate an asymmetric and multi-modal distribution within the finite spatial window in which the agent is constrained to operate
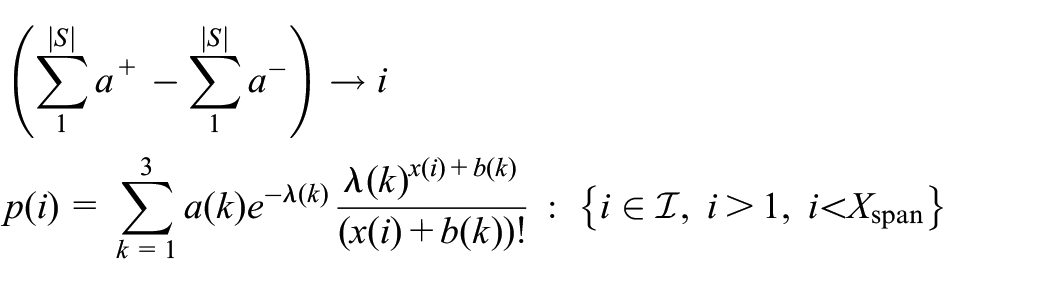
For each distinct experimental run, the above distribution is re-initialized via the following hyper-parametric distributions, which are found to maintain a good range of distributional modalities (i.e. 1, 2 or 3 modes) within the window defined by
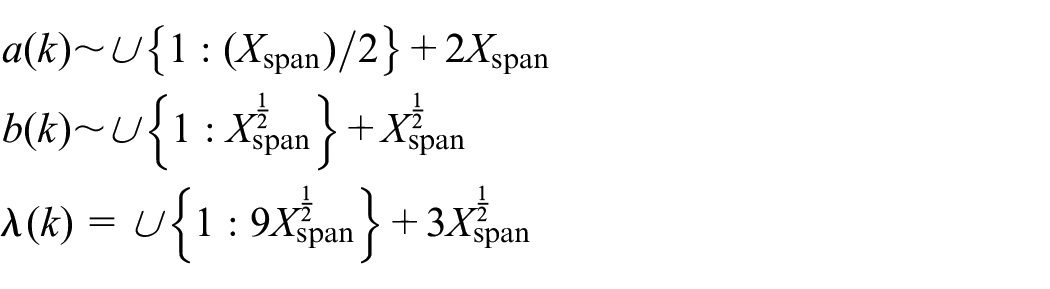
Each experimental run thus consists of 60 alternating cycles of four-sample motor-babbling explorations followed by inference of the perception model, after which an optimal motor action model is calculated such that the agent is capable of attempting to maximize the reward within any given translation scenario (which in this simplified case is equivalent to performing the action that obtains the maximal percept value with respect to the inferred environment model). We hence illustrate the typical situation of partial ground-truth inference due to intrinsic model bias in the initial stages of learning.
The dreaming variant of the agent performs an additional step in which a further set of
For the perceptual inference model, we adopt a piecewise linear-interpolation of percept samples so as to guarantee asymptotic convergence. The model thus constituted is hence inherently capable of generating novel percepts from the discrete percept samples; in particular, the model can generalize over the full range of
During the real/dreamed phases the system thus accumulates generated action(initial percept, output percept/reward) tuples from, respectively, real/imagined motor babbling in order to constitute the action model via greedy bigram histogram accumulation (the simplest possible state–action transition model of
4.2.1. Results
The results are shown in Figures 1–4. An illustration of the relative richness of the dreamed and non-dreamed action models with increasing iteration number is given in Figure 1 (with actions superposed so as to show the aggregate percept transition matrix); the corresponding cumulative reward obtained by the agent for a given action with/without dreaming is presented in Figure 3 (arguably the key result). The benefit of the dream cycle is clearly apparent in both cases. Because of the intrinsic group relationship that exists between actions, percepts and rewards, it is also possible to quantify both a “perceptual error” and an “action error” for any given agent action; for the latter, the average deviation from the maximal possible reward/percept is quantified versus the iteration number in Figure 2 while, for the former, Figure 4 shows the dramatic improvement in input perceptual quantization that arises from the presence of dream cycle motor babbling.
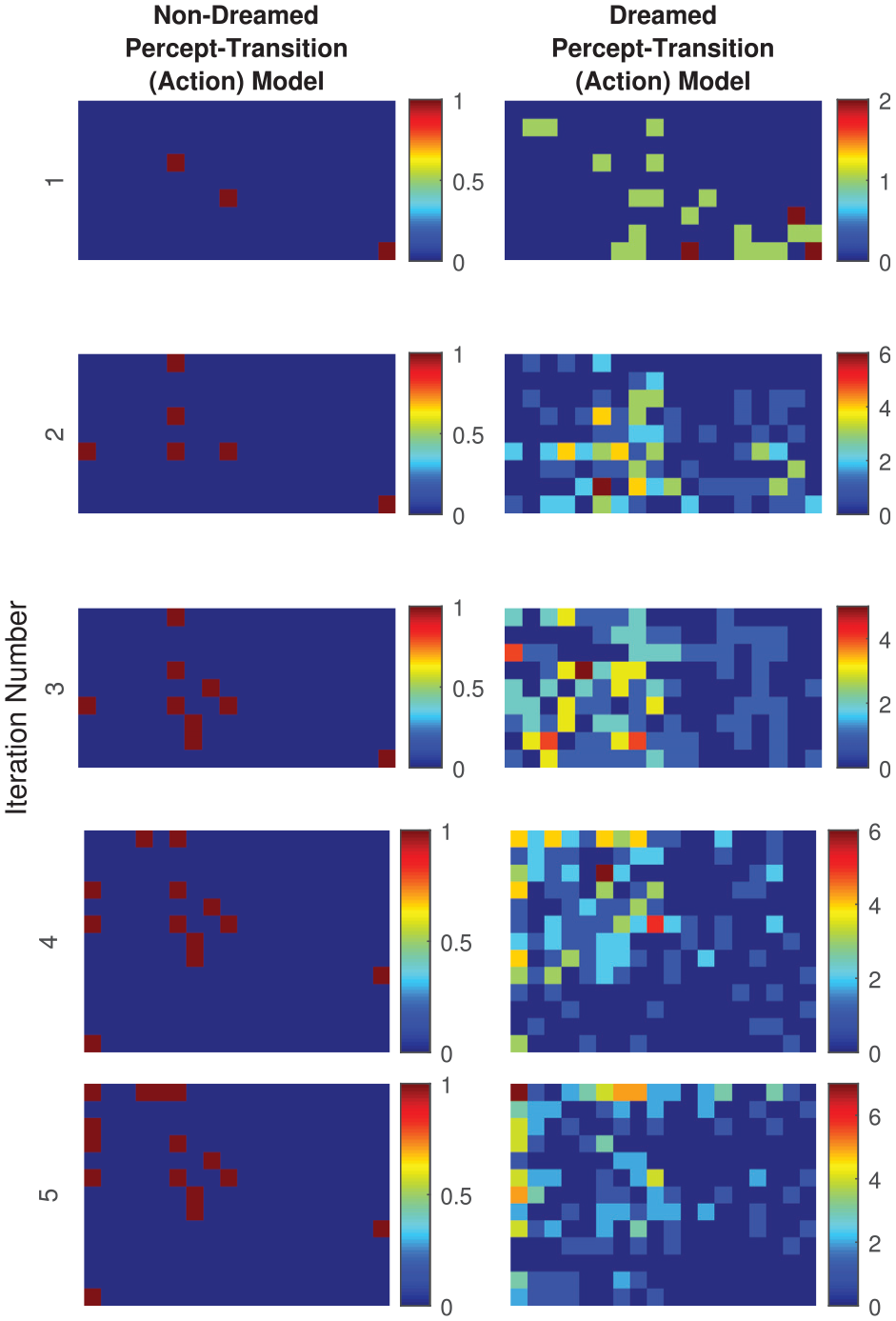
Illustration of relative enrichment of dreamed and non-dreamed action models with iteration number (actions are here superposed so as to form a histogram matrix of possible percept–percept transitions within the model; the vertical colour-bar denotes count number).
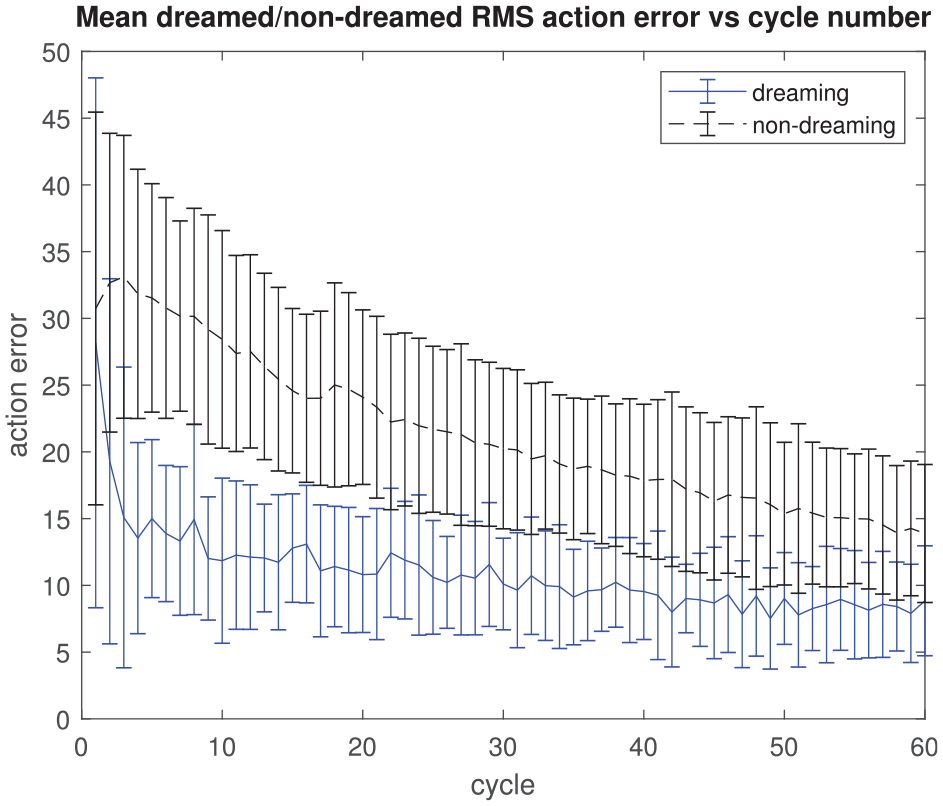
Mean dreamed versus non-dreamed root mean square action error versus iteration number (action error in units defined by
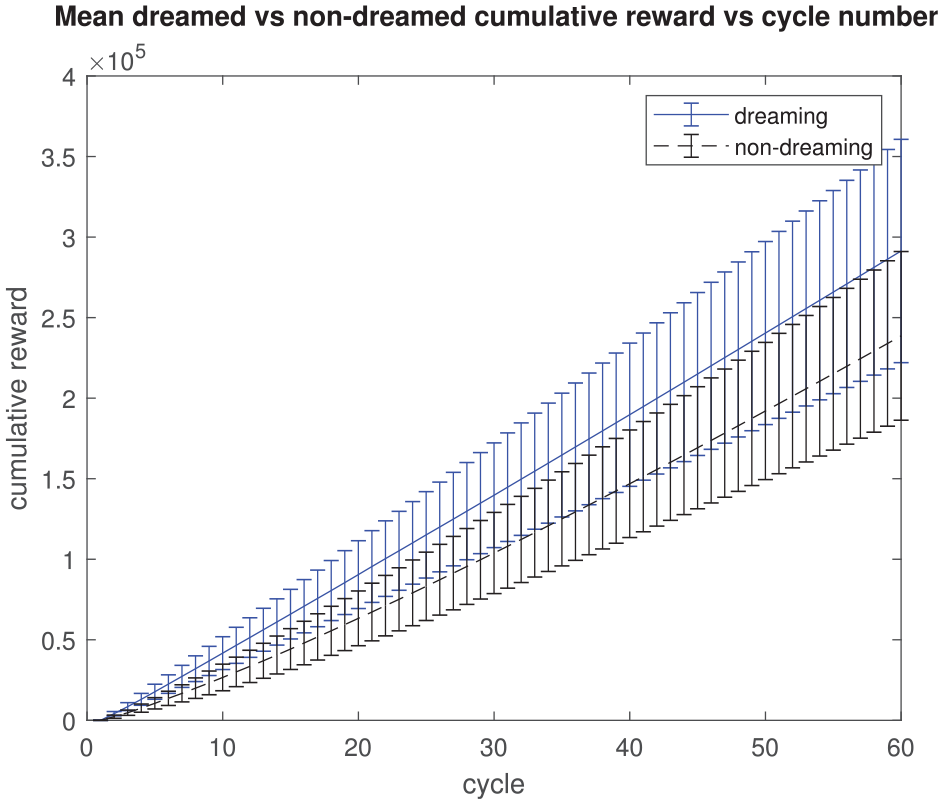
Mean dreamed versus non-dreamed cumulative reward versus iteration number (in units defined by
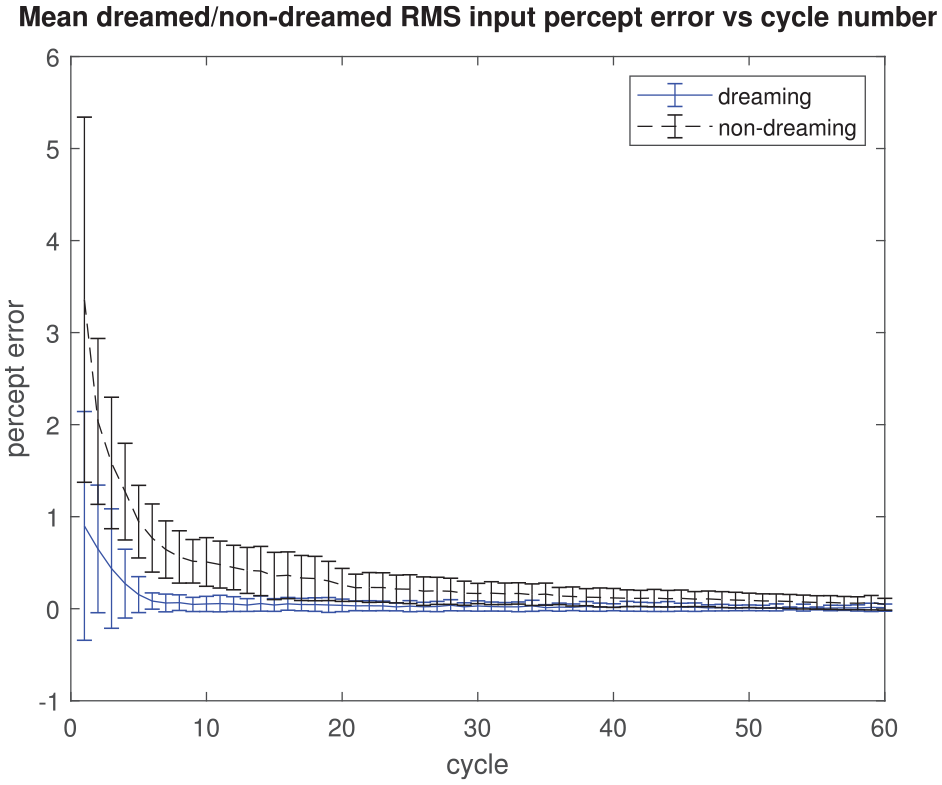
Mean dreamed versus non-dreamed root mean square input percept quantization error versus iteration number (in units defined by the percept group action).
Of course, many other domain examples are conceivable beyond the very simple case illustrated, for instance, those in which percepts do not directly correspond to rewards, but are rather only indicative of a certain likelihood of reward. In this case the environment model would have to additionally characterize the associated percept/reward distribution. The relative efficacy of dreaming will hence vary significantly from domain to domain; the key point, though, is that dreaming can potentially provide utility in any situation in which partially generalized environment models are still capable of providing utility with respect to the domain reward (which will typically be the case in any domains in which the Pareto principle or submodularity applies – that is, in which a “law of diminishing returns” exists).
5. Discussion and conclusion
We have, in the above, provided a general formulation of dream-like mechanisms and set out the conditions under which it has utility for artificial learning. Specifically, we have demonstrated how learning of sequences that were generated offline can generalize to be useful for online learning, concluding that such a dream sequence generation can be used to aid sampling of the
If this were the only relevant aspect of dreaming, it would, in principle, be possible to argue that the proposed system is nothing more than an
However, we have argued that (provided a-discernibility is retained) representation per se is a red herring (at least outside of a PA learning context); the critical aspect that makes dream-like mechanisms as sketched here useful is that useful learning occurs even when the environment and action models
To conclude, we note that the framework we have sketched here has application in deep learning in a reinforcement learning context (Ha & Schmidhuber, 2018; Piergiovanni et al., 2018). Current typical deep neural networks do use a hierarchical distribution of representation but require large amounts of training data to exhaust combinations of modular factors within the data (at whatever level of the hierarchy). Dream-like mechanisms, as we have discussed them here, enable the generation of relevant training data in a way that (as we have seen) can be used to further train the learning model (with the caveats discussed above).
Footnotes
Handling Editor: Takashi Ikegami, University of Tokyo, Japan
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the EC H2020 research project Dreams4Cars (no. 731593).