
Abstract
Objective
To systematically review literature on the use of artificial intelligence (AI) and machine learning (ML) models for detecting velopharyngeal dysfunction (VPD) in patients with cleft palate.
Design
Systematic review conducted in accordance with PRISMA guidelines (PROSPERO CRD420251034524).
Setting
Studies published were identified through EMBASE, ProQuest, Google Scholar, and PubMed.
Participants
A total of 3967 participants contributed 92,323 training samples. Internal validation included 2331 controls and 2449 VPD cases, generating 81,143 validation samples. Ages ranged from 1 to 93 years.
Interventions
ML models were trained on speech features such as mel frequency cepstral coefficients (MFCCs) and constant Q cepstral coefficients (CQCCs) to classify or validate VPD-related speech outcomes.
Main Outcome Measure(s)
Reported performance metrics included accuracy, precision, recall, F1-score, sensitivity, specificity, and Pearson correlation coefficient (PCC). External validation was assessed when reported.
Results
Of 455 screened articles, 34 met the inclusion criteria. Support vector machines were the most commonly used models (16/34, 47.1%), followed by convolutional neural networks (6/34, 17.6%) and deep neural networks (2/34, 5.9%). Across studies reporting performance metrics, midpoint estimates yielded a mean accuracy of 82.9%, precision of 86.7%, F1-score of 0.88, sensitivity of 80.5%, specificity of 82.2%, and PCC of 0.58. Only 3 studies (3/34, 8.8%) performed external validation.
Conclusions
AI/ML models demonstrate promise for VPD detection with encouraging performance. Inconsistent reporting, reliance on engineered features, and limited external validation restrict generalizability. No clinically deployable model has yet been achieved.
Introduction
Velopharyngeal dysfunction (VPD) severe enough to require corrective surgery can occur in up to 20% to 30% of patients after cleft palate repair. 1 When VPD is untreated or when VPD treatment is delayed, severe speech and psychosocial dysfunction can result. 2 The gold standard diagnosis of VPD is resource-intensive, requiring a specialized speech language pathologist (SLP), often with adjunct testing such as videonasoednoscopy (VNE), nasometry, and/or magnetic resonance imaging (MRI). 3 The absence of a universal standardized protocol makes these assessments highly experience-dependent and further constrained by the global shortage of trained SLPs. 4 These challenges are thus particularly pronounced in low- and middle-income countries (LMICs).5,6
In recent years, artificial intelligence (AI) and machine learning (ML) have garnered increasing attention for their potential to address diagnostic challenges in speech disorders, including VPD.5,7 ML models are particularly successful in pattern recognition, which can be extrapolated for image and sound processing. 8 As such, ML models have been used to develop accessible, resource-efficient screening tools. 9 Several studies have already examined their use in the identification of VPD7,10,11 by training models to target hypernasality, formant distortions, nasal emissions, and articulation errors. 8 If validated and deployed effectively, acoustic-based ML models could be used for VPD detection, particularly in areas where access to specialized SLPs is rare or impossible. The development of such screening tools could expedite referrals to SLPs, thereby mitigating the long-term functional and psychosocial impacts of untreated or poorly treated VPD. 12
Over the last decade, there has been an exponential increase in the development of AI/ML models for use in healthcare. 5 The field of cleft lip and palate care has followed suit, with multiple groups publishing on the use of AI/ML for the detection of cleft-related VPD.5,10–41 Previous studies have primarily focused on the development and internal validation of AI/ML tools, leaving a gap in the literature regarding their generalizability, methodological rigor, and clinical deployment in real-world settings. The authors hypothesize that the transition to clinical deployment for AI models for VPD detection has been hindered by fundamental issues in study design, particularly in control group selection, external validation, and handling of acoustic variability. This systematic review aims to address this gap by critically evaluating the aforementioned issues while answering the following question. In patients with cleft palate, do existing AI/ML models for VPD detection demonstrate sufficient external validation and generalizability to support clinical deployment, and what study design limitations may explain barriers to translation?
Methods
This study was exempt from Institutional Review Board (IRB) approval. The review was conducted in accordance with the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) 2020 guidelines and was prospectively registered on PROSPERO (CRD420251034524). Methodological quality and risk of bias were assessed using the QUADAS-AI tool. No amendments were made to the protocol throughout the study.
Eligibility Criteria
Original research articles, including case–control studies, longitudinal observational studies, retrospective cohort studies, and cross-sectional studies, that employed AI or ML methods to develop models or algorithms for the detection of cleft-related VPD using speech samples were included in this study. Included studies were required to validate their models using speech data, regardless of whether performance metrics were reported, and to be published in English. No restrictions were placed on year of publication, patient age, or geographic location.
Studies were excluded if they focused on non-cleft-related causes of VPD, were prior systematic reviews or meta-analyses, were available only as abstracts without accessible full text, or constituted non-peer-reviewed material, including book chapters, magazine articles, blog posts, editorials, case reports, and case series. In addition, reference lists of excluded reviews were screened to identify any additional eligible studies.
Search Strategy
The studies included in this review were identified through searches of EMBASE, ProQuest, Google Scholar, and PubMed. The publishing period was unrestricted. The search strategy incorporated predefined keywords and Medical Subject Headings (MeSH) terms related to ML and velopharyngeal insufficiency (eg, “machine learning,” “deep learning,” “artificial intelligence,” “velopharyngeal insufficiency,” “velopharyngeal dysfunction,” and “hypernasality”), with full Boolean search queries detailed in Supplemental Digital Content 1. All databases were searched from April 16, 2025, through September 11, 2025.
Study Selection and Data Collection Process
The review process was conducted using Rayyan (Rayyan Systems Inc., Cambridge, MA, USA), a web-based systematic review management platform. 42 Rayyan was used for duplicate removal and for the screening of titles and abstracts. All full-text screenings were conducted manually. A total of 427 abstracts were uploaded into Rayyan, after which 143 duplicate records were identified and removed by 1 reviewer, J.I. Following duplicate removal, titles and abstracts were independently reviewed by 2 reviewers, J.I. and S.D. Two hundred and forty-nine abstracts did not meet the inclusion criteria and were therefore excluded from the study. Three systematic reviews were excluded at this stage; however, their reference lists were subsequently assessed for potentially eligible studies by 2 independent reviewers, J.I. and S.D. This process yielded 28 additional articles, which were then subjected to full-text eligibility assessment. Any disagreements or uncertainties at this stage were advanced to full-text screening. Full-text screening was conducted independently by both reviewers, J.I. and S.D, to determine final eligibility. Both authors retrieved full texts of potentially eligible papers and read them individually to identify eligibility. Any discrepancies between the 2 reviewers (J.I. and S.D.) were resolved through discussion and consensus, with consultation of senior authors (Z.Y. and M.E.P.).
Data Extraction
Two reviewers independently extracted predefined data elements from each eligible study using a standardized data collection form. Extracted variables included study characteristics (title, first author, year of publication, country of origin, income classification, language, and study design), participant demographics (age, sex, and whether multiple speech samples were obtained per participant), dataset composition (number of cases and controls, total sample size, and composition of training, validation, and test sets), characteristics of speech tasks, and technical information related to model development (ML model type, software used, extracted features, and recording methodology). Performance metrics (accuracy, precision, specificity, recall, F-1 score, and Pearson correlation coefficient [PCC]) were also extracted. Discrepancies were resolved by consensus. Countries were assigned income classifications according to the World Bank income categories for 2024-2025. 43 When required data were not reported in a study, the item was recorded as not reported.
Risk of Bias Assessment
Risk of bias and applicability was formally assessed in all 34 included studies using the Quality Assessment of Diagnostic Accuracy Studies–Artificial Intelligence (QUADAS-AI) tool. 44 QUADAS-AI is a structured instrument designed to evaluate the methodological quality of AI-based diagnostic accuracy studies across key domains, including patient selection, index test, reference standard, and flow and timing. Risk of bias judgments were categorized by 2 independent reviewers as low, high, or unclear in accordance with QUADAS-AI guidance. Detailed assessment results are provided in Supplemental Digital Content 2.
Data Synthesis
A descriptive analysis was conducted to summarize extracted study characteristics, participant demographics, dataset composition, speech task types, and AI model features. These data were tabulated and used to determine eligibility for inclusion in each synthesis. Extracted performance metrics were reviewed for completeness, and where necessary, missing or inconsistently reported summary statistics were handled by reporting available ranges or marking values as not reported. For each outcome, effect measures consisted of the reported performance metrics from individual studies. Given substantial heterogeneity in study design and reporting practices, performance results were summarized descriptively as ranges with reported standard deviations and confidence intervals when available. To facilitate comparison across studies, medians were calculated, and estimated means were derived using the midpoint of reported ranges. Model performance outcomes, including accuracy, precision, recall, F1-score, specificity, and PCC, were compiled and compared across studies using structured tables to visually display individual study results. Subgroup analyses were performed to explore heterogeneity, including comparisons by external versus internal validation, model type, study design, validation approach, and reported performance metrics.
Results
Study Selection and Characteristics
The initial database search, which included articles from prior systematic reviews, yielded 455 articles. After screening titles and abstracts, 63 studies were selected for full-text review. Of these, 29 studies were excluded for the following reasons: 16 were abstract presentations only, 7 did not use ML or AI-based tools, 3 were systematic reviews, 2 did not utilize speech input, and 1 did not include patients with a cleft palate. Ultimately, 34 studies met the inclusion criteria (Figure 1).
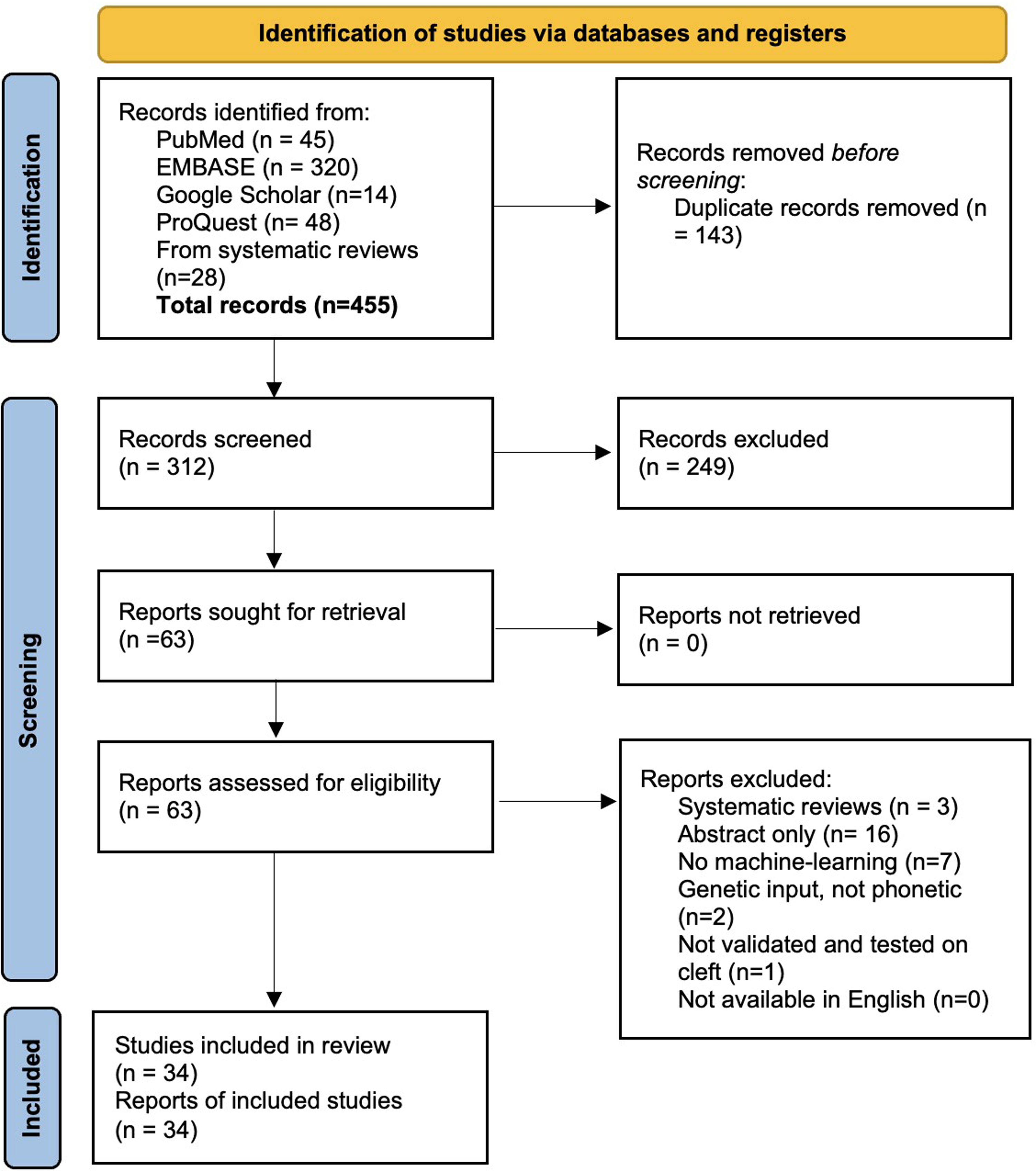
PRISMA flow sheet.
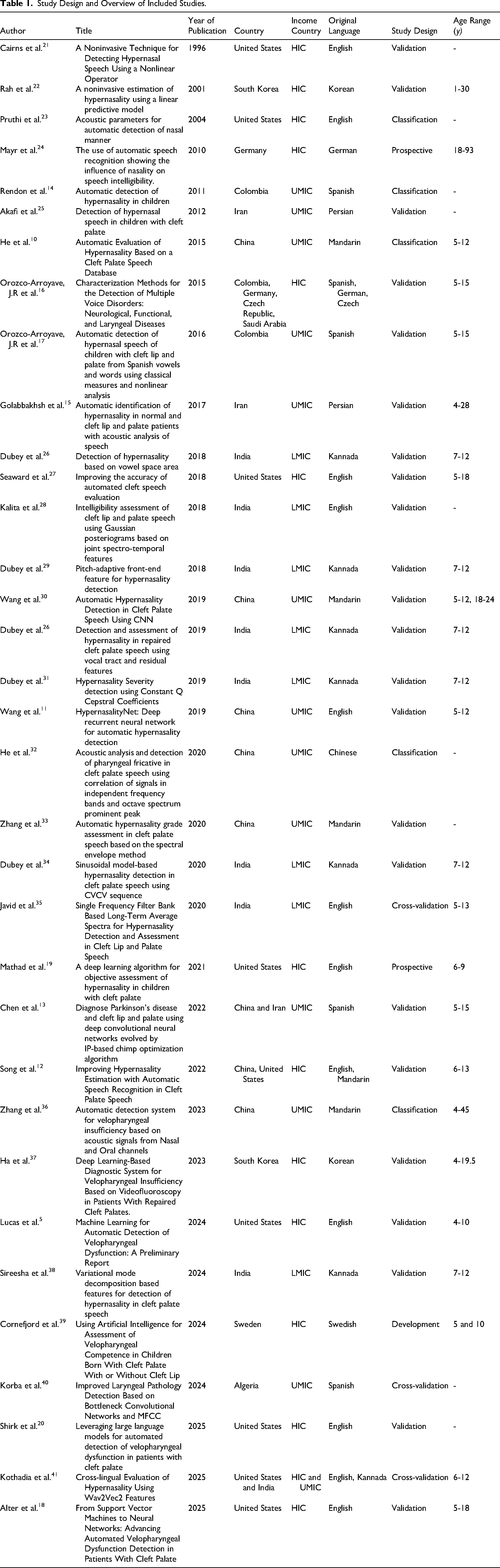
Included studies were published between 1996 and 2025. A positive trend in publication frequency was observed over time, with a notable spike during 2018-2019 and another recent rise in 2024-2025 (Figure 2). Of the 34 studies, 14 originated from high-income countries (HICs), 13 from upper-middle-income countries (UMICs), 8 from LMICs, and none from low-income countries (LICs) (Supplemental Digital Content 3). 43 There were 12 unique countries and 9 unique languages featured across studies. Most (23/34, 68.0%) were validation studies, 15% (5/34) were classification studies, 9% (3/34) were cross-validation studies, 6% (2/34) were prospective studies, and 3% (1/34) were developmental studies. Participant ages ranged from 1 to 93 years (Table 1).
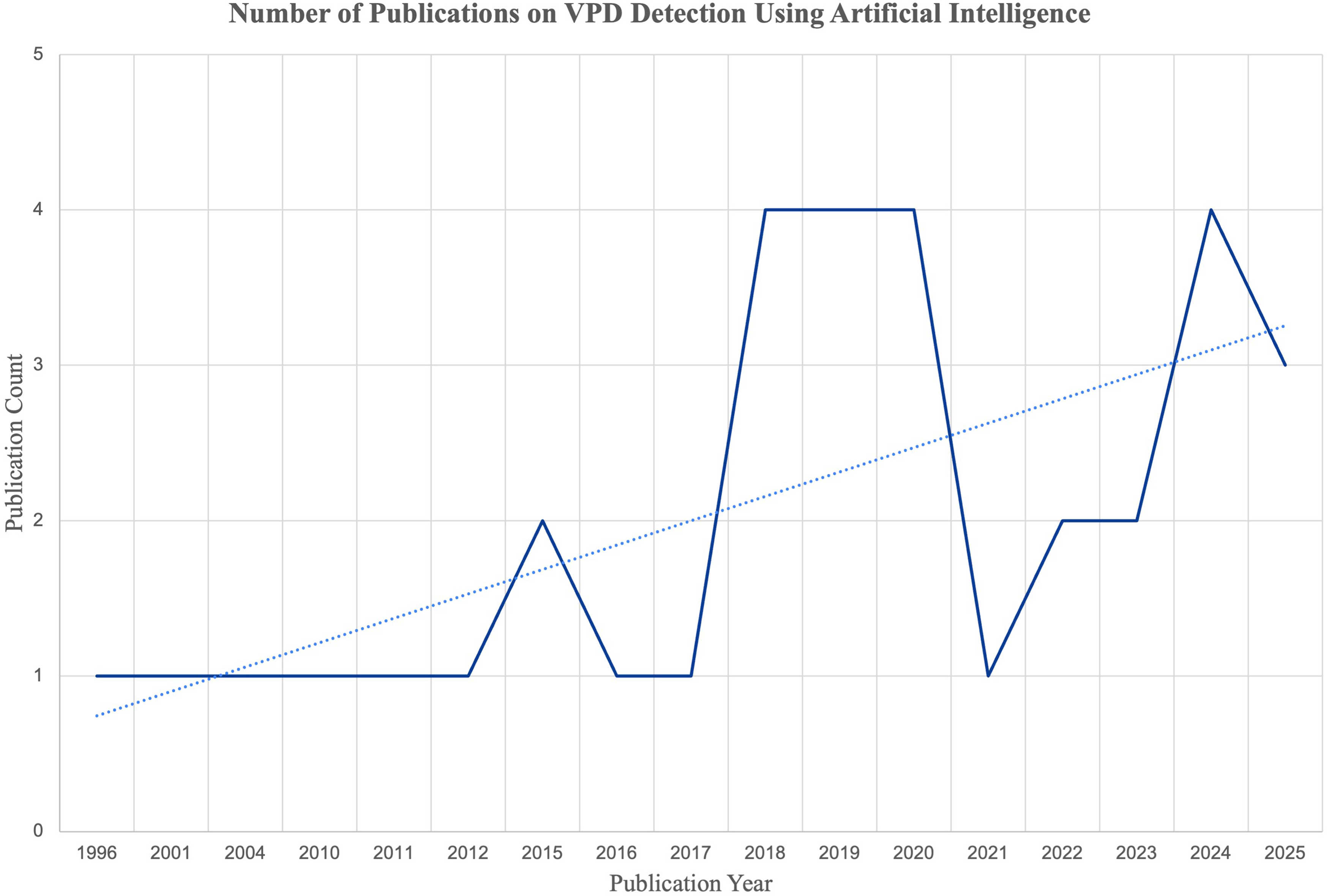
Trend in the number of publications on VPD detection using artificial intelligence.
Study Design and Overview of Included Studies.
Dataset Composition and Validation Strategies
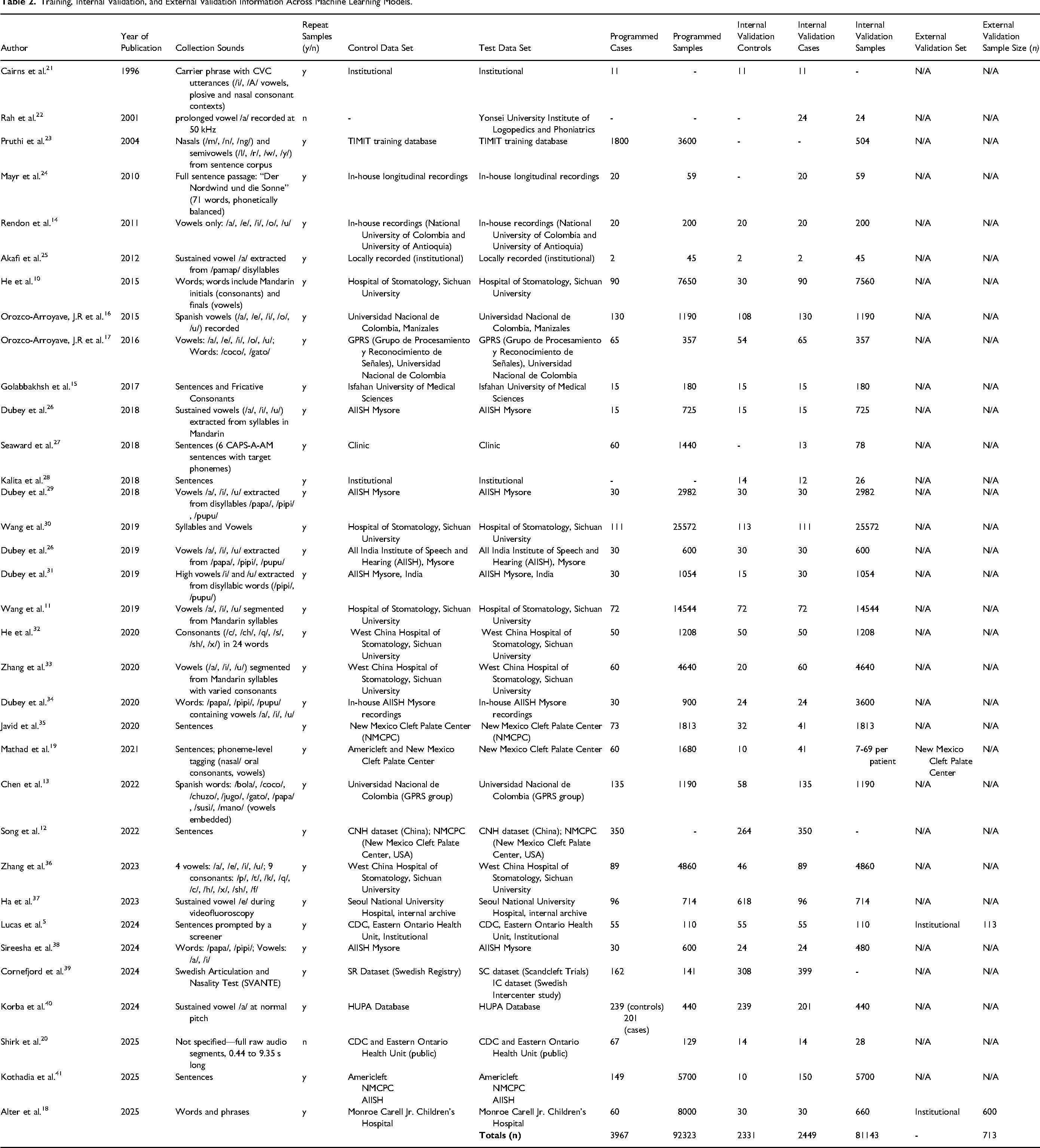
The majority of studies (32/34, 94.1%) reported the number of cases and datasets used for model training and collected multiple recorded samples per participant for model training purposes. Across all studies, 3967 participants contributed 92,323 training samples. Most (31/34, 92.1%) studies completely recorded the number of cases, controls, and datasets used for internal validation. In total, 2331 controls and 2449 VPD cases were used to generate 81,143 internal validation samples. Only 3 studies (3/34, 8.8%) conducted external validation after developing their models. Of these, just 2 (2/34, 5.9%) reported the number of samples used, with Lucas et al. documenting 113 external validation samples and Alter et al. documenting 600 external validation samples.5,6 Of the 34 studies, 28 used institutional databases (28/34, 82.4%), 3 used public databases (3/34, 8.8%), and 3 used a combination of both institutional and public databases (3/34, 8.8%; Table 2).
Training, Internal Validation, and External Validation Information Across Machine Learning Models.
Model Types and Feature Extraction
The most commonly used classifier was the support vector machine (SVM), reported in 16 studies (16/34, 47.1%), convolutional neural networks (CNN) in 6 (6/34, 17.6%), and deep neural networks (DNN) in 2 studies (2/34, 5.9%). The most common speech features that were used include mel frequency cepstral coefficients (MFCCs) (11/34, 32.4%), Shimmer (4/34, 11.8%), and Jitter (3/34, 8.8%). Other commonly used features included spectral entropy and constant Q cepstral coefficients (CQCC). Other models and the corresponding speech features are detailed in Table 3.
Machine Learning Models, Software, and Features Across Studies.
Model Performance
The performance of these models was assessed using a range of metrics across studies, including accuracy, precision, F1-score, sensitivity, specificity, and PCC. Most studies (30/34, 88.2%) did not report mean performance values, instead presenting ranges of values to characterize model performance, as summarized in Table 4. Of the 34 studies, 4 (4/34, 11.8%) studies did not report any performance metrics. The majority (24/34, 70.5%) of studies reported accuracy as a performance metric, with reported accuracies ranging from 37.7% to 100%. Using the midpoint of reported ranges when necessary, the mean accuracy across these studies was approximately 82.9%. Precision was reported in 6 (6/34, 17.6%) studies. Similarly, reported precisions ranged from 55.6% to 100%; the mean precision across studies using midpoint was 86.7%. The F1-score, reported in 7 (7/34, 20.6%) studies, ranged from 0.50 to 1.0. The median F1-score was 0.96, and the average was 0.88. Sensitivity was reported in 16 studies (16/34, 47.1%), with reported values ranging from 32.3% to 100%. The median sensitivity across the 16 studies was 82.9%, and the mean was approximately 80.5%. Specificity was reported across 14 studies (14/34, 41.2%), ranging from 45% to 100%. The median specificity was 82.4%, and the mean was 82.2%. PCC was reported in 3 (3/34, 8.8%) studies, ranging from −0.17 to 0.84. The median of the 3 studies was 0.71, with a mean of 0.58.
Performance Metrics Across Included Studies.
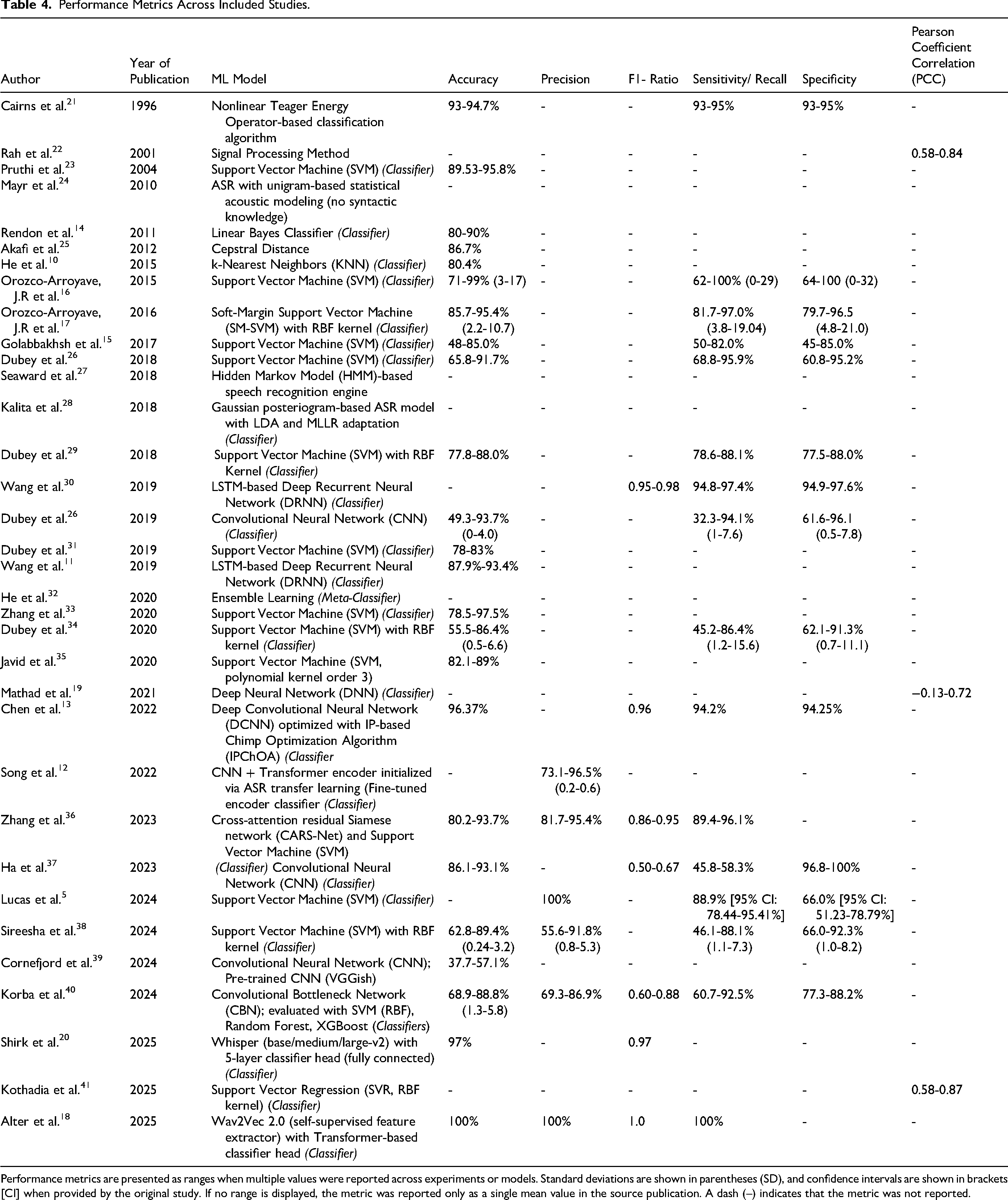
Performance metrics are presented as ranges when multiple values were reported across experiments or models. Standard deviations are shown in parentheses (SD), and confidence intervals are shown in brackets [CI] when provided by the original study. If no range is displayed, the metric was reported only as a single mean value in the source publication. A dash (–) indicates that the metric was not reported.
External Validation and Generalizability
Furthermore, an examination of the subset of studies that performed external validation in addition to internal validation provides insight into how well ML models may generalize to real-world clinical settings (Table 4). Of the 3 studies that included an external validation, each reported different performance metrics. One study reported results using PCC, another reported precision, sensitivity, and specificity, and the third reported accuracy, sensitivity, precision, and F1 score. The externally validated study that reported PCC (Mathad et al.) demonstrated a range of −0.13 to 0.72, indicating variable and in some cases inverse agreement with the reference standard. 19 In contrast, 2 studies that reported PCC without external validation demonstrated higher and more consistently positive correlations, with ranges of 0.58-0.84 and 0.58-0.87, respectively. Comparison of midpoint values between these groups revealed a 59% relative reduction in PCC when external validation was performed, which is to be expected.
Among the remaining externally validated studies, sensitivity was reported as 88.9% (Lucas et al.) and 100% (Alter et al.).5,18 Alter et al. acknowledged that the perfect sensitivity and specificity observed in their model were likely influenced by confounding variables and potential overfitting. 18 When averaged together, these 2 externally validated sensitivity estimates were approximately 17% higher than the mean sensitivity reported by the remaining studies, further suggesting that reported performance may be inflated in the absence of robust external validation. The overall certainty of evidence was judged to be low for all outcomes due to substantial methodological heterogeneity, frequent high or unclear risk of bias on QUADAS-AI assessment, limited use of external validation, and inconsistent reporting of performance metrics across studies.
Synthesis of Findings Relative to the Research Question
Across included studies, AI/ML models demonstrated generally favorable diagnostic performance for the detection of VPD in patients with cleft palate, with mean accuracy, sensitivity, and specificity exceeding 80% among studies reporting these metrics. However, only 3 of 34 studies (8.8%) performed external validation, and reported performance metrics varied across these studies, with inconsistent agreement with reference standards.5,18,19 PCC-based studies reported values from −0.13 to 0.72, while studies reporting accuracy, sensitivity, specificity, and F1 score showed high performance, with sensitivity ranging from 88.9% to 100%.5,18,19
Several recurrent methodological characteristics relevant to barriers to clinical translation were identified. No included study utilized a control cohort consisting of patients with cleft palate without VPD. Most studies relied exclusively on internal validation datasets, with 31 of 34 studies (91.2%) lacking external validation. Substantial variability was observed in recording conditions, speech task selection, and feature extraction methods. Additionally, datasets frequently consisted of multiple recordings per participant rather than independent samples. Reporting of performance metrics was inconsistent, with 4 of 34 studies (11.8%) not reporting any performance outcomes.
These findings demonstrate that limited external validation, absence of appropriate control cohorts, heterogeneity in data acquisition and feature selection, non-independent sampling, and inconsistent reporting are common across studies.
Discussion
The results of this study indicate that current AI/ML models for VPD detection do not demonstrate sufficient generalizability or methodological rigor to support clinical deployment. Although reported diagnostic performance is generally favorable, external validation is rare, and performance is inconsistent when evaluated beyond development datasets. The absence of appropriate control cohorts, reliance on internal validation, heterogeneity in data acquisition and feature selection, non-independent sampling, and the lack of a unified performance metric framework were consistently observed across studies. These are critical barriers to translation. Addressing these limitations will enable clinical implementation of AI/ML models for VPI detection.
Over the last decade, ML algorithm capabilities have progressed remarkably due to the convergence of several key factors: the development of deep learning algorithms, a significant increase in available data, and a rise in computational power. 45 ML algorithms have woven their way into nearly all facets of healthcare, and cleft lip and palate care is no exception.46–49 The surge in AI/ML research is also in part driven by the potential to extend care into rural and low-income areas.46,47 For this potential to be realized, models must be intentionally designed for real-world constraints and rigorously tested in the environments where they will be deployed. Moreover, to effectively control for external confounders and ensure consistency in data collection, prospective studies are particularly valuable, as they allow data to be gathered under conditions that closely mirror the intended real-world use of the device.
ML models have been particularly attractive for the identification of VPD, given their ability to identify other forms of pathological speech.13,50,51 VPD presents with characteristic speech distortions that are audible to the human ear, and it therefore stands to reason that pattern recognition algorithms would succeed in this space. This is evidenced by the recent spike in VPD-related AI/ML publications (Figure 2). Additionally, while some features of VPD are language-specific, most are language-agnostic and predominantly sound-based. 51 This is evidenced by the use of similar modeling techniques in multiple different languages, along with the use of language-agnostic features such as jitter, shimmer, and spectral entropy (Tables 1-3).14–17 Jitter captures small fluctuations in pitch (fundamental frequency), shimmer measures variations in loudness (amplitude), and spectral entropy quantifies how evenly or unevenly energy is distributed across frequencies, with higher values indicating greater vocal noise or breathiness. Considering this, it is theoretically possible that a single ML model could detect VPD in multiple languages. The belief in this concept is supported by the fact that studies have already originated from 12 countries using 9 different languages.5,7,10 Additionally, 3 studies used multiple language inputs to train their models and further increase generalizability.1–3 It should be clarified that the intention of VPD detection models is not to replace specialized SLPs, but rather to extend their reach in areas where access to their expertise is constrained, such as LMICs. However, as with any major technological advancement and the accompanying data surge, quality control is key to ensuring newly developed, complicated methodologies are sound. The results of this study validate this concern, as numerous models have been developed using various techniques, yet a clinically deployable tool has not yet been achieved.
Studies reviewed demonstrated considerable variations in sample size concerning model testing, training, and validation. The lack of standardized sample size calculation is an inherent limitation to AI/ML model studies. While many theories exist, there is no standardized formula for how many “samples” are required to train a diagnostic model. This is complicated by the fact that a single patient can generate innumerable voice samples, and the number of voice samples ultimately depends on the segmentation of voice data. For example, studies that analyze vowels or phonemes can have tens of thousands of samples from only a handful of patients. Importantly, although the studies collected in this systematic review reported a vast number of training and validation numbers, these totals reflect multiple recordings obtained from the same participants rather than independent subjects. This distinction has important implications for model generalizability and the potential for overfitting, especially given the limited use of external validation. Model data augmentation techniques can also expand the quantity of sounds generated from a single patient. Understanding the contributions from each patient to the overall dataset is critical to ensure data balancing. A model that learns based on a dataset predominantly from a single patient is more likely to analyze patient-specific factors, therefore skewing model performance.
The composition of case and control cohorts is equally as important as the quantity of samples in each. No publications reviewed in this study included patients in the control cohort with a history of a cleft palate without VPD. This is a critical error brought to light in studies on the use of AI/ML to detect speech disorders in patients with Alzheimer's disease. 52 Models trained to screen for disease must be tested by those at risk for the disease. For example, a patient not at risk for VPD is highly unlikely to undergo VPD testing. There are obvious differences between the speech of patients with and without a cleft palate, but not all are pathological. In the absence of appropriate controls, models will be unable to determine which components of cleft palate speech are pathologic and which are not. This will result in the models identifying all patients with a cleft palate as “abnormal.” This observation underscores a fundamental design flaw that threatens the clinical validity of most existing models. This is a key reason why model performance declines significantly with external validation. Conversely, external validation results that appear unusually strong should be interpreted cautiously, as they may indicate confounding or overfitting.
CNN, DNN, and SVM were the most frequently used classifiers, though researchers also explored a wide range of other architectures. This diversity in model architectures, often paired with various feature extraction methods like MFCC and CQCC, indicates that no universally effective approach has been established. Although some models show promise, they often rely heavily on extensive preprocessing and manually engineered features.7,20,53,54 While these engineered features are grounded in acoustic science, this reliance creates a significant bottleneck, as the manual effort limits real-world scalability and may fail to capture novel pathological speech characteristics. In contrast, deep learning models such as CNNs can automatically learn features from raw or minimally processed data, but this advantage comes at the cost of requiring larger datasets and often results in less interpretable models. This underscores the complexity of pathological speech and the critical role of SLPs in diagnosing VPD secondary to cleft palate, which makes them in such high demand.
In many reviewed publications, the settings in which voice samples are recorded are highly regulated. While this tactic is seemingly beneficial to standardize data, it can be detrimental to model development, especially concerning external validation. Acoustic models are highly sensitive to all components of a voice sample, including ambient noise, echoes, and other extraneous acoustic artifacts. When these non-vocal features are present in internal samples but absent in external validation samples, model development can be compromised.55,56 Although such regulation may improve internal consistency, it also creates an artificial testing environment that fails to reflect real-world clinical conditions, thereby limiting model generalizability and hindering real-world deployment. The studies reviewed also varied considerably with regard to sound sample composition and feature selection for model processing. Voice samples ranged from vowel-only samples to full sentence analysis (Table 2). In general, for a model to perform robustly in real-world settings, training should be on full sentences with vowel or phoneme analysis used for fine-tuning. 57 The features analyzed in each study were also highly variable. Studies analyzed MFCCs, jitter, shimmer, and many more (Table 3). The complexity of differentiating non-pathologic cleft palate-related speech from VPD should mandate that model development evaluate as many features as possible.
The surge in ML-focused research has led to a lack of standardized reporting across the literature, resulting in substantial gaps that impede meaningful comparisons of models and their efficacies. 58 Notably, performance metrics in this review varied widely among published studies, with 11.8% (4/34) failing to report performance measures altogether. The lack of consistent performance measures across studies severely limited the ability to conclude the various studies. To enable robust cross-study comparisons, the adoption of standardized performance reporting metrics will be essential moving forward. 58 When reporting performance metrics for ML models designed to function as screening tools, best practice is to align with TRIPOD-AI and STARD-AI standards, which emphasize reporting in both prediction-model performance and diagnostic accuracy. The TRIPOD-AI statement recommends presenting discrimination metrics such as the area under the receiver operating characteristic curve (AUROC) and the area under the precision–recall curve (AUPRC); threshold-based measures including sensitivity, specificity, positive predictive value (PPV), negative predictive value (NPV), and F1-score with 95% confidence intervals; calibration statistics such as calibration plots, slope, intercept, and Brier score; and decision-curve analyses. 59 The STARD-AI guideline similarly emphasizes reporting sensitivity, specificity, PPV, NPV, likelihood ratios, and AUROC, accompanied by cross-tabulations of the index test versus the reference standard and confidence intervals for all estimates. 60 While accuracy is often included in studies, it is not sufficient alone in either framework, as it fails to capture performance in imbalanced datasets. The overarching theme between both reporting systems is that disease screening models must be evaluated not only by global measures (AUROC, AUPRC), but also by clinically interpretable outcomes such as high sensitivity/NPV ratios to rule out disease and specificity/PPV ratios to capture false-positive burden.59,60 These tools reduce heterogeneity across the rapidly expanding body of ML models and ensure that meaningful comparisons can be made between studies. Therefore, adherence to these standardized reporting frameworks should be considered a mandatory requirement for future research.
As with any systematic review, the quality of the data is limited by the quality of the studies meeting the inclusion criteria. Outcome metric reporting practices were inconsistent, with 11.8% (4/34) of studies omitting key performance metrics, hindering meaningful model comparisons. The distribution of work was concentrated in HICs and UMICs, limiting applicability to underrepresented populations, particularly those in LICs. Only 3 studies conducted external validation, and just 2 reported sample size, leaving a major gap in assessing generalizability. Most (91.2%, 31/34) of models were tested only internally, risking overfitting to dataset-specific confounders such as ambient noise, recording echoes, and microphone characteristics. Although the results of all these studies are largely theoretical, the successes demonstrated with small-scale external validation testing suggest that model clinical deployment is feasible. Future studies should focus on realistic case and control cohorts, rigorous external validation testing in varied recording environments, and the inclusion of populations who will ultimately benefit from the screening tool.
Conclusion
Over the last decade, there has been a surge of interest in developing AI/ML models to screen speech samples of patients with cleft palate for the presence or absence of VPD. A clinically deployable model could help expand the reach of specialized SLPs, particularly in areas where access to speech care is limited, globalizing VPD care. However, publications on this topic are highly heterogeneous in both design and performance metric reporting, many are vulnerable to acoustic confounding, and few have been externally validated. Despite these limitations, preliminary model data across 9 languages suggest that the development of a clinically deployable screening tool is feasible. Nevertheless, no study has achieved this goal, and substantial work is still required to translate these models into practical, real-world applications.
Future studies should clearly define and include appropriate control cohorts, particularly patients with cleft palate without VPD. Furthermore, external validation should be mandatory using prospectively collected, multi-center datasets with varied recording environments. Adoption of the TRIPOD-AI and STARD-AI frameworks is strongly recommended to promote standardized reporting in ML research, thereby enabling meaningful comparison of models and facilitating their translation into clinical practice. Finally, ML devices should be piloted and further developed in populations they are intended to serve, such as in low-resource settings.
Supplemental Material
sj-docx-1-cpc-10.1177_10556656261445320 - Supplemental material for The Rise in Artificial Intelligence and Machine Learning Models to Screen for Cleft-Related Velopharyngeal Dysfunction: A Systematic Review
Supplemental material, sj-docx-1-cpc-10.1177_10556656261445320 for The Rise in Artificial Intelligence and Machine Learning Models to Screen for Cleft-Related Velopharyngeal Dysfunction: A Systematic Review by Julia Isber, Weixin Liu, Bowen Qu, Shama Dufresne, Amy Stone, Maria E. Powell, Stephane A. Braun, Izabela A. Galdyn, Michael S. Golinko, Zhijun Yin and Matthew E. Pontell in The Cleft Palate Craniofacial Journal
Supplemental Material
sj-jpeg-2-cpc-10.1177_10556656261445320 - Supplemental material for The Rise in Artificial Intelligence and Machine Learning Models to Screen for Cleft-Related Velopharyngeal Dysfunction: A Systematic Review
Supplemental material, sj-jpeg-2-cpc-10.1177_10556656261445320 for The Rise in Artificial Intelligence and Machine Learning Models to Screen for Cleft-Related Velopharyngeal Dysfunction: A Systematic Review by Julia Isber, Weixin Liu, Bowen Qu, Shama Dufresne, Amy Stone, Maria E. Powell, Stephane A. Braun, Izabela A. Galdyn, Michael S. Golinko, Zhijun Yin and Matthew E. Pontell in The Cleft Palate Craniofacial Journal
Supplemental Material
sj-docx-3-cpc-10.1177_10556656261445320 - Supplemental material for The Rise in Artificial Intelligence and Machine Learning Models to Screen for Cleft-Related Velopharyngeal Dysfunction: A Systematic Review
Supplemental material, sj-docx-3-cpc-10.1177_10556656261445320 for The Rise in Artificial Intelligence and Machine Learning Models to Screen for Cleft-Related Velopharyngeal Dysfunction: A Systematic Review by Julia Isber, Weixin Liu, Bowen Qu, Shama Dufresne, Amy Stone, Maria E. Powell, Stephane A. Braun, Izabela A. Galdyn, Michael S. Golinko, Zhijun Yin and Matthew E. Pontell in The Cleft Palate Craniofacial Journal
Footnotes
Ethical Considerations
This systematic review analyzed data exclusively from previously published studies and did not involve any new human or animal participants. IRB approval and informed consent were therefore not required. All studies included in the review were assumed to have obtained appropriate ethical approval and participant consent as reported in their respective publications. The review was conducted in accordance with the PRISMA guidelines and the ethical standards of research integrity and transparency.
Author Contributions
All authors contributed substantially to the conception and design of the study, data collection, analysis, and interpretation. All authors were involved in drafting and revising the manuscript, approved the final version for publication, and agree to be accountable for all aspects of the work.
Consent to Participate
This systematic review analyzed data exclusively from previously published studies and did not involve any new human or animal participants.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.