
Abstract
Reflective narratives contain meaningful information about medical students’ experiences and environments and are a rich source for qualitative analysis. However, analyzing narratives to learn about their content is expensive in terms of time and money. Recently developed artificial intelligence–based tools may help ease the analysis process. This study explored the potential of large language models (LLMs) to facilitate narrative text analysis. The narratives were written by medical students on their observations and reflections on medical encounters in which bad news was delivered. These narratives are challenging for analysis due to their semi-structured nature and medical and emotional content. We compared a former analysis process done manually versus the ability of LLMs to analyze these narratives, across different categories, including contextual (e.g., demographics) and thematic analysis. Our results showed that the LLM effectively processed data and followed formatting requirements. However, the LLM’s performance varied across different categories, showing closer alignment with human analysis in straightforward categories (e.g., age), while struggling with more nuanced aspects of the narratives (e.g., assessing surprise). Ambiguities and complexities in the narratives posed significant challenges for the LLM, limiting its interpretive accuracy needed in such cases. The findings suggest that LLMs could complement human analysis, particularly in extracting explicitly mentioned contextual information, thereby enhancing the efficiency of the analysis process. The research highlights the need for further investigation into the capabilities of LLMs, pointing toward a future where the LLM and human qualitative researchers work in synergy to manage the demand for a timely and accurate narrative analysis.
Keywords
Background
Storytelling is a natural human ability that allows individuals to reflect on meaningful experiences (Zilber et al., 2008). This is evident across various professional fields, including healthcare, where reflective narratives are a rich data source for qualitative analysis, offering insights into complex interpersonal dynamics and professional development (Gregory, 2010; Karnieli-Miller et al., 2017, 2018; Karnieli-Miller, Palombo, et al., 2023; Milota et al., 2019).
Narrative reflective writing creates a space for the students to contemplate their experiences (Chaffey et al., 2012; Wald et al., 2012). It allows them to organize thoughts and feelings about themselves, others, and clinical events (Chaffey et al., 2012; Karnieli-Miller et al., 2018; Kember et al., 2008), to cope with strong emotions (Wald et al., 2010) and to guide future behavior (Aronson, 2011; Novack et al., 1999; Wald & Reis, 2010).
The importance of writing and analyzing narratives is particularly pertinent in medical education, where students’ narratives reveal insights into their experiences and understanding of the hidden curriculum (i.e., norms and informal rules within the clinical environment) (Gaufberg et al., 2010; Hafferty et al., 2015; Hafferty & Gaufberg, 2021; Karnieli-Miller, Taylor, et al., 2010a; Karnieli-Miller, Vu, et al., 2010), and inform educational interventions aimed at both faculty development and student support. Faculty interventions have focused on identifying and addressing problematic aspects of the clinical environment—such as disrespectful communication—with the goal of reducing their occurrence. Student-centered interventions have included educational group meetings to support debriefing, emotional processing, and reflection on professional development (Frankel et al., 2020; Karnieli-Miller, 2020; Karnieli-Miller et al., 2018; Wald et al., 2012).
Despite these narratives’ considerable potential and valuable information, which contain rich personal experiences and insights essential for understanding professionals’ learning, challenges, and development, their analysis presents some challenges. These reflective narratives are diverse in content (e.g., focusing on critical incidents related to professionalism while others focus on a task learned, e.g., breaking bad news or moral courage). They are also written within diverse clinical contexts (e.g., different clerkships) and reflect each student’s unique writing style. Often, they include complex phrasing, medical jargon, and inconsistent formats. Their semi-structured nature, which is important for enabling personal expression and fostering reflection, also makes systematic analysis more difficult. As a result, reviewing multiple narratives becomes a labor-intensive task for educators and researchers. This limitation hinders the ability to fully leverage narrative-based insights, as substantial time and expertise is required for analysis, making timely and practical application more difficult (elaborated later). The recent advancements in artificial intelligence (AI), particularly in large language models (LLMs), present a potential solution to these challenges. However, data are limited about its use and usefulness in research in general (Boiko et al., 2023; Demszky et al., 2023; Hitch, 2024; Jalali & Akhavan, 2024; Xin et al., 2024), and more studies exploring LLMs’ ability to quickly, efficiently, and accurately analyze written reflective narratives are needed.
Large Language Models
LLMs are a ground-breaking advancement powered by deep learning algorithms, trained on extensive datasets comprising texts from various sources (Shanahan, 2024; Vaswani et al., 2017). The training enables LLMs to generate text, understand context, and perform language-based tasks with a proficiency that is often comparable to human intelligence (Lin et al., 2023).
A key feature of LLMs is their ability to handle long-range dependencies in text through their extended context windows, ranging from 8000 to 200,000 tokens (i.e., units of text processed), allowing them to maintain coherence and understand nuanced language patterns across long passages (Anil et al., 2023; Grosse et al., 2023; Head et al., 2023; Song & Dhariwal, 2023; Vaswani et al., 2017). Whereas previously time-consuming tasks (such as topic identification and text summarization) required specialized knowledge, LLMs now offer more efficient alternatives. They also allow for text organization through natural language prompting rather than code-based query syntax. These capabilities broaden access to computational tools, particularly for researchers without technical backgrounds or those working in fields where such methods have been historically underused. With their ability to generate structured outputs and understand contextual nuances, LLMs show increasing potential for qualitative data analysis (De Paoli, 2024; Head et al., 2023; Kasneci et al., 2023; Xin et al., 2024; Yang et al., 2024).
Nonetheless, integrating LLM technology in qualitative contexts is challenging. Issues such as accuracy, bias, ethics, and safety and the ability of LLMs to understand complex human emotions and ethical considerations inherent in medical narratives require careful consideration (Head et al., 2023; Hitch, 2024). Further exploration is needed to verify that automating the analysis is accurate and preserves an understanding of the depth and nuance of these reflections. Therefore, while LLMs are promising, their application must be approached with a critical eye.
Text Analysis and Healthcare Applications Using LLMs
Due to LLMs’ increased relevancy, recent studies have explored LLM applications in qualitative research, including the healthcare context. Researchers have investigated various methodological approaches, from prompt engineering (i.e., refining the instructions to the LLM by humans; De Paoli, 2024) to developing specialized LLM-based software compared with traditional systems like ATLAS (Gao et al., 2024). In some studies, researchers allow LLMs to analyze data before human involvement and found moderate agreement between machine and human coding (Li et al., 2024). Other researchers assigned LLMs specific tasks in analyzing interviews, such as work labeling therapy outcomes from interviews, showing the LLM ability to identify important outcomes in adolescence interviews, compared to binary coding (Xin et al., 2024), while others noted LLMs’ difficulties in understanding nuances when identifying thinking patterns in obesity prevention interviews (Jalali & Akhavan, 2024).
Hitch (2024) shows the potential benefits and limitations of LLM-augmented reflexive thematic analysis. The author describes the AI’s ability to identify patterns and themes that the human researcher may have not noticed, while acknowledging its inability to perform complex contextual interpretations and reflective deliberations essential to reflexive thematic analysis. Hitch proposed thinking about the chatbot as a virtual colleague who may assist in different stages of the qualitative research process (including coding, developing initial themes, reviewing and refining themes, and writing the analytic report). Hitch (2024) sees value in LLMs assisting with simpler tasks in analysis while emphasizing the irreplaceable role of critical human analysis. Within her fascinating work, she calls on further testing the capabilities of LLMs in assisting qualitative researchers. Our work replies to this invitation by comparing human and LLM analysis and helps guide the practical use of LLMs, especially in descriptive analysis. This is done to identify potential advantages and limitations. Thus, in this study, we assess the suitability of LLMs for the final stage of analysis, which is coding students’ narratives in a real-world educational context, requiring both simple and more complex analysis. While Hitch managed to show the power of a hybrid analysis of a single newspaper article based on semi-structured interviews, in English, our study shows the use of LLMs in a larger source of data written by different medical students in diverse medical settings and experiences, including both quantitative (machine-learning performance measures) and qualitative assessment of the results.
The Present Study
This study is designed to compare the effectiveness of LLMs in analysis to traditional human manual analysis. Specifically, we explore here coding, the process of systematically adding labels, tags, or notes to text in order to identify and categorize its elements for analysis purposes. We focused on medical students’ narratives about their experiences of real-life breaking bad news that are provided as part of their learning tasks. The narratives served as educational tools and were previously used in a qualitative study where they underwent manual analysis (Karnieli-Miller et al., 2018; Karnieli-Miller, Palombo, et al., 2023). While this manual analysis was valuable and significant, it proved to be resource-intensive in terms of time and cost, involving three coders working in a consensus-building iterative process. This necessitated a careful examination of the narratives to extract key themes and issues, which resulted in using fewer narratives than those available. Consequently, the need arose to investigate whether LLM-based coding could assist.
The comparison of performance with a thorough human manual analysis is important and interesting as it offers several methodological advantages. First, the manual analysis had been published in medical education journals (Karnieli-Miller et al., 2018; Karnieli-Miller, Palombo, et al., 2023). As such, it serves as a “trusted benchmark,” allowing for a meaningful comparison of the LLM’s output against an expert standard. This enables researchers to evaluate both the accuracy and interpretive alignment of the LLM analysis. Second, using the same dataset for both analyses ensures a controlled comparison, where the only category that is different is the method of analysis (LLM vs. human). This methodological approach ensures that differences observed are attributed solely to the analytical method (LLM vs. human), while simultaneously offering insights into both machine and human capacities for consistency and thematic interpretation (see the Results section). Finally, using existing, previously analyzed data respects research ethics by avoiding redundant analysis of new, sensitive narratives, while also maximizing the value of published material.
But such a comparison is far from straightforward, considering the complexity of analyzing these narratives. First, the narratives were composed by knowledgeable students for their physician small-group facilitators; thus, they contain professional terminology. Assessing whether a general-data-trained LLM can successfully navigate these challenges and analyze the narratives comparably to expert human coders is essential. Second, despite being written under general guidelines, the narratives vary in length and structure, necessitating a balance of consistency and adaptability. This balance refers to the methodological challenge of applying uniform analytical criteria across diverse texts while remaining flexible enough to capture unique insights. For example, while some narratives followed a chronological structure with clearly delineated learning moments, others presented reflections thematically, requiring adaptable coding approaches that maintain analytical rigor across different narrative styles. Third, the narratives were written in Hebrew, with its unique linguistic characteristics (Tsarfaty & Goldberg, 2008). Related to the language, while traditional natural language processing has existed for decades, LLMs are especially promising for languages with limited resources, where even basic tasks like stop-word filtering or named entity recognition can be challenging (Tsarfaty et al., 2019; Tsarfaty & Goldberg, 2008). LLMs show advantages in identification and comprehension tasks when limited labeled data are available (Yang et al., 2024). Thus, this study focuses also on showing whether an LLM accounts for low-resource languages, where LLMs have had less training data compared to widely spoken languages.
Our original human analysis involved two key components: contextual analysis, which provides essential understanding of the background and circumstances of each narrative, and narrative thematic analysis, which identifies emerging patterns and topics. In the current study, we focused primarily on contextual coding, alongside a limited set of thematic codes (e.g., patient’s surprise). Contextual coding is particularly important in qualitative research—it is a labor-intensive process that enables meaningful comparisons. For instance, it allows comparison between narratives about cancer care versus other illnesses, or between cases in which children, rather than adults, received the news. Furthermore, contextual information supports readers in determining whether the findings are relevant to their own settings, contributing to the assessment of transferability. By focusing on these analytic tasks, this study establishes a baseline for evaluating LLM performance in replicating essential components of qualitative research, before extending to more complex narrative thematic analyses. This approach can more easily explore the strengths and limitations of LLM-based analysis in the medical narrative context, providing a stepwise foundation for future, more nuanced applications of this technology.
Therefore, the current study advances understanding of the LLM’s current capabilities and limitations. Practically, it highlights its potential to replace labor-intensive tasks, leading to significant savings of resources and, more importantly, to provide more timely and large-scale analysis of qualitative health research. We address a real-life challenge—analyzing semi-structured professional narratives in medical education—and testing AI tools against human analysis. We set the following goals: (1) To test the LLM’s ability to provide meaningful analysis; (2) To quantitatively assess the LLM’s performance compared to manual coding; (3) To qualitatively evaluate the LLM’s potential to augment the manual coding process and understand the challenges and limitations in the process.
Methods
Participants
Participants were medical students at Tel Aviv University enrolled in a breaking bad news course. As part of the course, students were required to write two narratives. The narratives included a description based on students’ observations of real-life medical teams delivering bad news to patients and/or their families. Students were instructed to (1) describe an event/experience in which bad news was delivered in their presence, (2) analyze the encounter according to a taught breaking bad news protocol (Baile et al., 2000; Meitar & Karnieli-Miller, 2022), (3) reflect on thoughts and feelings that arose during and following the encounter, and (4) reflect on future actions and lessons learned.
Participants were 83 students randomly selected, including 51 females. Their average age was 29.6 years. Each student provided two narratives, resulting in 166 narratives in total. All participants signed informed consent forms for the narratives to be used. The study was conducted with approval from the Tel Aviv University Ethics Committee (approval number 0000355-6), with full details provided in the original research (Karnieli-Miller et al., 2018). The original consent form informed students that their anonymized narratives would be used for research and publications, to be published only after their graduation from medical school, in order to avoid any potential repercussions, as has been done in other studies (Karnieli-Miller, Taylor, et al., 2010b; Wear & Aultman, 2006). Based on this, long rich narratives were published in two leading journals. In 2024, we consulted the Tel Aviv University Ethics Committee regarding our plan for a secondary analysis using LLM technology. To align with ethical obligations, we ensured that all narratives were de-identified, including double checking for erasing any personal information (such as names, hospitals names, and dates) before processing. Furthermore, ethical concerns about data retention and model training influenced our choice of LLM. We chose Claude.ai user interface (Sonnet 3.5 version), released by Anthropic (Anthrop\c, n.d.) based on its robust data handling policies. These included a documented commitment not to use customer data for model training, limited data retention periods (typically 30 days), compliance with SOC 2 and HIPAA standards, and explicit user-permission requirements for data processing. Additionally, Anthropic’s published research on AI safety and transparency regarding model limitations reinforced our choice (Anthrop\c, n.d.). Thus, the committee confirmed the methodology was acceptable without the need for additional consent.
Narratives
The narratives varied in length and style. They ranged from 106 to 1271 words, averaging 472.9 words. While most narratives were written in Hebrew, the students’ primary language, one featured a mixture of Hebrew and English. See an example for a narrative alongside its manual and LLM coding in Figure 1. Illustration of a narrative (translated from Hebrew), alongside its Manual vs. LLM coding.
Manual Analysis
In the original (Karnieli-Miller et al., 2018; Karnieli-Miller, Palombo, et al., 2023), we analyzed the narratives using the qualitative Immersion/Crystallization analysis, a narrative thematic framework developed in medicine (Miller & Crabtree, 1992, 1994), which requires cognitive and emotional engagement, with iterative reading of the qualitative data (Borkan, 2022; Meitar et al., 2009). Our team included a PhD qualitative researcher who is a medical educator and communication expert in breaking bad news, an MD family physician who is also a medical educator, and a PhD candidate in qualitative research. The analysis included several steps. The first step was familiarizing ourselves with the data, by reading the narratives. This was an inductive process to allow a broader understanding of what is present in these narratives. Each team member analyzed a batch of narratives. Then we met as a team, read the same narratives, and compared the coding in an iterative consensus-building process (qualitative inter-rater reliability) (Meitar et al., 2009). This process included a reflective process to further identify when a coding was grounded in the data and when it was based on our interpretations or biases (e.g., believing that the physician specialty, such as being a family physician, would impact the nature of communication in the observed encounter) (Karnieli-Miller et al., 2018; Karnieli-Miller, Palombo, et al., 2023). Within the analysis, as expected in the Immersion/Crystallization method (Borkan, 2022; Miller & Crabtree, 1994), we moved between the entire narrative (the whole story) and its components (e.g., the breaking bad news protocol components analysis). This helped create an exhaustive list of themes and categories entered into a codebook. This process was repeated until saturation and consensus were achieved (Karnieli-Miller, Divon-Ophir et al., 2023; Merriam & Tisdell, 2016; Patton, 2015). In the current study, two additional researchers joined the original research team: one with a PhD in Psychology specializing in data science and another with a PhD in medical education who also focuses on AI tool development and evaluation. They thoroughly studied the categories established in the original research through in-depth discussions with the team that created them, examining various labeling examples for comprehensive understanding. Subsequently, a dialogue emerged aimed at optimizing the “translation” of different categories into model instructions. The entire team participated in the analysis and comparison process, sharing thoughts and insights. The first author (K.M.) calculated the quantitative performance metrics. The qualitative evaluation of the LLM-generated labels and the explanation of differences were conducted collaboratively by the entire team, with the written insights and conclusions synthesizing the various perspectives from the joint discussion.
As required in Immersion/Crystallization (Borkan, 2022; Miller & Crabtree, 1992, 1994), we conducted both vertical analysis learning about each narrative’s nature and horizontal, cross-sectional analysis, of all narratives to identify the issues discussed, the lessons learned, and the potentially enhanced understanding of the protocol taught (Meitar et al., 2009). In addition, we included a contextual descriptive analysis of the narratives focused on the setting in which the events took place; the patient who received the bad news (adults and children); the different participants in the encounter; the type of narrative described: positive, negative, or hybrid; and addressing emotions that arose during the encounter (Karnieli-Miller et al., 2018).
The current analysis focused on the contextual analysis. Thus, the first author of this paper (K.M.), before writing the prompt for the LLM chatbot, inquired about the data and the analysis process. This allowed understanding of the codes needed. Following the LLM analysis, the second and last authors (G.N.-K. and O.K.-M., who were involved in the original manual human analysis) qualitatively analyzed the differences and gaps between the manual versus LLM coding to help explain these differences. This led to a deeper understanding and, at times, refinement of the prompts, leading to fewer LLM “mistakes” (see, e.g., what we described in the analysis of the “specialty” category below). The following section describes our approach to using LLMs to code the same narratives, allowing for a comparison between human and LLM-driven analysis methods.
LLM Analysis
Coding by LLMs was done at the end of August 2024. The LLM analysis was done on seven categories (patient’s age, gender, ethnicity, receiver identity, surprise, illness, setting, and specialty). We chose these as their criteria were straight forward for prompting and coding, focusing on contextual analysis (in contrast to thematic coding) in this stage of proofing the concept of LLM ability to analyze narratives.
As mentioned, we chose Claude.ai user interface (Sonnet 3.5 version), released by Anthropic (Anthrop\c, n.d.), as the LLM coder. The primary considerations in choosing the specific LLM were (1) support for the Hebrew language, (2) a user-friendly user interface, and (3) adherence to ethical and privacy standards.
We also tested sample narratives on other common LLMs supporting Hebrew, as OpenAI’s GPT (access to this model was made through the API, where the data retention policy and non-use of information for training purposes is similar to the Anthropic model policies mentioned above). While both models demonstrated comparable performance in Hebrew text analysis, Claude.ai had some format advantages in producing CSV files and processing Hebrew syntax, and maintaining consistent formatting. We implemented a script in PyCharm (Community Edition 2022.2.4) for data pre-processing and integration, using the pandas library.
Prompting
Variables in the Current Study, With Optional Outputs and Related Prompts.

Comparison Metrics
We compared manual and LLM-based coding on applicable categories using performance measures Cohen’s kappa, accuracy, and F1 score, by Python’s built-in libraries pandas and numPy. One category, specialty, did not fit closed-ended criteria, as its coding included more than five optional categories in the manual coding. Thus, after receiving unmeaningful outputs from the LLM, and in an effort to maximize the LLM’s potential, we decided to use “open-ended” coding for this category: the prompt did not mention the specific coding category constraints but asked for identification of the physician’s specialty in general (see Table 1). In the following Results section, we discuss the results both quantitatively and qualitatively.
Results
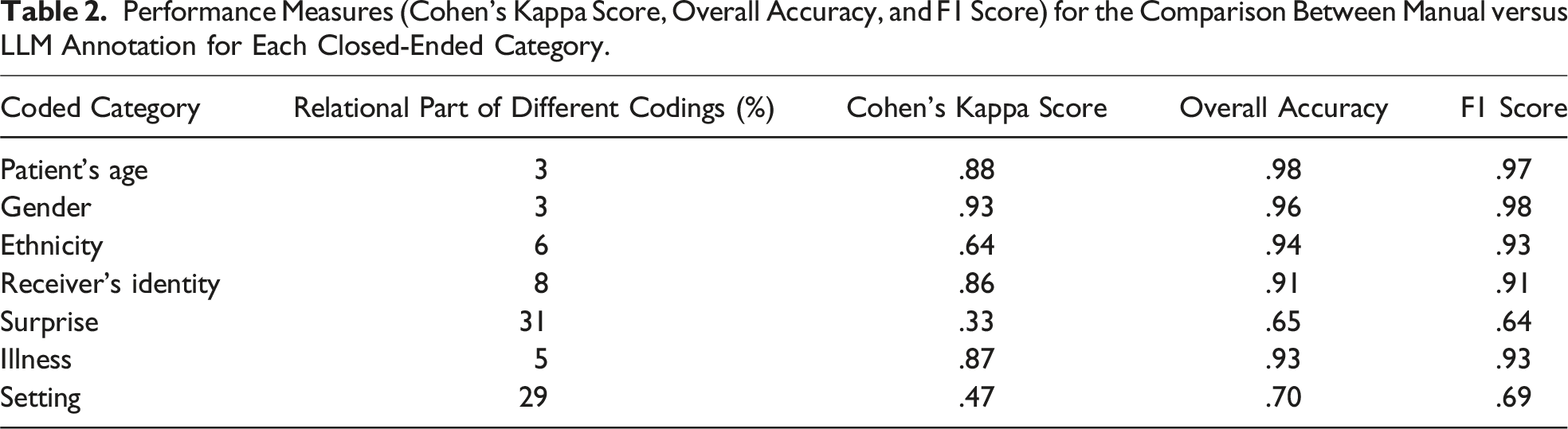
Performance Measures (Cohen’s Kappa Score, Overall Accuracy, and F1 Score) for the Comparison Between Manual versus LLM Annotation for Each Closed-Ended Category.
Patient’s Age
For the age category, the coding was binary: whether the patient was a minor or an adult. Overall, the coding was identical between the manual work and the LLMs, with only four differences (3%). In all four cases, there was the same type of error direction by the LLM: it incorrectly identified a minor as an adult. We assume this is because adults (e.g., parents) were also present at such meetings, and due to the narrative’s somewhat ambiguous nature when describing the participants.
Gender
This category describes the patient’s gender. There were only four differences (3%) in the gender category. In all cases, it was not an error or incorrect identification but a lack of identification: the LLM outputs “no gender.” Analyzing these cases, we noticed that more than one person received the bad news. It’s possible that the fact that they weren’t talking to a specific person led to such an interpretation. However, this is not necessarily understandable given its success in analyzing other personal categories in the same cases, such as age. Moreover, this explanation cannot fully explain the gap because the presence of others was not unique for these narratives only, and the gender was identified well in other narratives describing multiple participants’ encounters.
Ethnicity
The distinction made for this category was whether the patients’ ethnicity was mentioned in the narrative or not. There were ten cases of differences (6%) between the manual and the LLM coding. All errors were in the same direction—the LLM indicated that ethnicity was not mentioned, while ethnicity was identified in the narrative by humans. This may be due to a different interpretation of ethnicity: the reference in these cases was to level of religiosity, language barriers, or country of origin. It is possible that a more detailed definition of what is considered an ethnic mention might have led the LLM to more accurate identification.
Receiver’s Identity
This category reported whether the recipients of the bad news were the patient alone, the patient’s family members alone, or the patient and family members together. There were differences in 14 cases (8%). In almost all cases, the LLM’s different identification was an incorrect identification of “together” versus the other categories—patient alone or family members alone. The gap may have resulted from the difficulty in distinguishing between the presence of the student and additional students at the encounter, whose reference was perceived as the presence of different people. However, in some cases, the confusion was not related to this (e.g., family members were identified as patients), and it was impossible to determine exactly what caused the LLM’s different coding.
Surprise
The distinction for this category was between situations where recipients of bad news were surprised by them or not. Manual and automated coding differed in 55 cases (31%), indicating a relatively large gap. These gaps were not in one direction, but more cases of surprise were identified by the LLM as no surprise. This may be due to the LLM’s difficulty in “reading between the lines” and identifying indirect indications of surprise, for example, different responses of patients or their family members, such as, “not accepting” or arguing with the medical staff member about the diagnosis or outcome. The LLM coded surprise only when it was explicitly, literally, and clearly reported by the narrative writers.
Illness
The coding categorized the patient’s illness as cancer or other disease. There were 11 cases (5%) with a difference between the manual and LLM coding. Except for one case, they were all in the same direction: the manual coding reported “cancer,” while the LLM outputed “other.” This may be because cancer is a complex and multi-stage disease, and in these cases the new malignant diagnosis itself was not the focus of the medical news. Notably, in these same cases, the LLM correctly identified oncology as the medical specialty, indicating it recognized the cancer connection. In other words, it may not be about misidentifying cancer but about cancer’s central emphasis.
Setting
The setting coding referred to the form of the meeting in which the bad news was given: whether it was a planned meeting in the physician’s clinic, a conversation that began during morning rounds in the ward, or other setting. There were 47 incorrect identifications (29%), and their analysis did not reveal a certain trend. It is important to note that this category was not explicitly mentioned in most narratives, which include mostly the content of the meeting. This information is important, as adequate setting plays a role in breaking bad news. However, the LLM’s difficulty in identification reminded us of the difficulty that arose during the manual human analysis: the team included members with research or clinical backgrounds, and the team members who were not physicians experienced more difficulty identifying the setting. It seems that this type of coding requires familiarity with the medical system and daily routine. The human coding identification was made based on various hints (such as the course of the meeting and what preceded the bad news). This may not be apparent to those who are not directly familiar with it—whether they are human or LLM-based.
Specialty
The LLM demonstrated proficiency in identifying a wide range of specialties and sub-specialties, such as obstetrician/gynecologist, radiation oncology, and pediatric emergency medicine, as the open-ended prompt required. The LLM made two clear misidentifications (1.2%), failing to recognize explicitly stated information in both cases: it coded a family physician discussing a meningioma as a neurologist, and incorrectly coded a social worker based on the medical field rather than their explicitly mentioned role. Some cases presented ambiguity rather than clear misclassification. While manual coding by a physician-researcher succeeded in a few cases where the LLM did not provide a specific specialty, this coding relied on prior medical knowledge and assumptions without explicit textual support. This highlights a nuanced aspect of the LLM’s performance: while generally strong in processing explicitly stated information, it occasionally missed clear role designations, and remained limited in making inferences beyond the directly presented narrative.
Discussion
Our study aimed to evaluate the LLM’s capability to analyze semi-structured narratives, based on categories developed by humans, mostly in the contextual analysis of the data. The texts were real-life experiences written by medical students, following some guidelines with instruction but with variability and differences in style and length between them. Human manual analysis is challenging in terms of time and costs; thus, integrating some AI analysis combined with human analysis, specifically by the LLM technology, may be a good solution.
The findings indicate a diverse performance by the LLM in the analysis task. Notably, the LLM correctly identified information for some coding categories. For most categories, the LLM output codes were comparable to the manual human coding. Thus, we compared the LLM’s performance for these categories, in reliability and performance metrics, and found varied levels of agreement. In comparing human and LLM coding for these categories, we found that in patient’s age, gender, ethnicity, and illness, as well as accurate identification of the physician’s specialty in the open-ended coding, the LLM coding closely aligned with human coders. Yet, discrepancies in other areas (receiver’s identity and surprise) underscored the LLM’s limitations and the intricate nature of human-led analysis. These discrepancies reveal challenges in LLM-based analysis, particularly in handling narratives with ambiguous or complex situations where an emotion, feeling, or information is not explicitly stated.
Despite the improvements in LLMs’ ability over time (we even did the analysis with newer versions that were better than those before), human analysis still surpassed LLMs in several crucial aspects. Human analysis demonstrated superior understanding of emotional nuances, as seen in coding for surprise or setting, themes that required interpretive rather than merely descriptive coding. This pattern aligns with the fundamental architecture of LLMs, which excel at pattern recognition but lack true semantic understanding (Ullman, 2023). The LLMs have challenges in “understanding” and identifying subtext (Shapira et al., 2023; Ullman, 2023; Zhang et al., 2024), an important aspect of qualitative studies. Compared to the LLM, humans also excelled in comprehending complex medical situations, such as distinguishing between chronic conditions and current complaints of interpretive categorical distinctions that require domain knowledge beyond pattern recognition. Furthermore, human coders were able “to read between the lines,” for instance, in determining the medical setting (e.g., ward rounds, clinic visits, or other contexts) even when not explicitly stated, a phenomenon also shown elsewhere (Subbiah et al., 2024).
Based on our findings, we propose that qualitative researchers will develop a hybrid “human in the loop” or perhaps actually involving “LLM in the loop” process that leverages the strengths of both LLM and human expertise, as recently suggested in other cases of labeling (Artemova et al., 2024; Jalali & Akhavan, 2024; Ye et al., 2024). Previous analyses of narratives indicated that analyzing approximately 50 (Karnieli-Miller, Vu, et al., 2010) or ∼20% of all existing narratives (whichever is higher) is typically sufficient to identify the main categories and themes (Misgav et al., 2023). This is usually done by a few research team members, followed by a single researcher analyzing the remainder of the data to provide additional examples, a deeper understanding of the phenomena, and quantitative indicators of frequency.
Our findings suggest that a hybrid “LLM-in-the-loop” approach to analyzing students’ narratives may involve the following steps: (1) Initial Exploration for Parallel Category Development: Independent and parallel open-ended category would be created by both humans and LLM on the first ∼50 (or 20%) narratives, to identify possible categories and themes. This phase aligns with the first stage of qualitative analysis, familiarizing oneself with the data, through repeated reading to build a broader understanding of what emerges in the narratives. Conducting this step independently, and then reviewing the categories identified by humans and the LLM, serves as a form of researcher triangulation. It can help surface additional codes, highlight differences, and clarify which codes are grounded in the data versus those shaped by human interpretive bias or AI mistakes. This step was not implemented in the current study, as we focused on comparing with previously coded data. However, we recommend incorporating it in future studies to explore novel insights the LLM might contribute. (2) Targeted Prompt Engineering: Based on the identified categories, prompt engineering (i.e., the human-driven process of refining prompts to improve LLM comprehension and output) would take place. This may involve open-ended questions (to leverage the LLM’s exploratory capabilities) or closed-ended ones (for more structured, quantitative comparison with human coding; De Paoli, 2024; Gao et al., 2024; Hitch, 2024; Jalali & Akhavan, 2024), depending on the category. The LLM would then re-code the same initial 50 narratives. (3) Comparative Analysis and Refinement: The results of the LLM and human analysis would be compared, as done in this study, and codes and prompts will be refined as needed; inter-rater reliability will be assessed at this stage. (4) Scaled LLM Implementation: Once high reliability is achieved, the LLM would be used to code the remaining narratives. (5) Human-led Thematic Deepening: Human researchers would conduct in-depth thematic analysis on selected categories, particularly those excluded from the LLM’s task due to complexity or sensitivity. This stage goes beyond classification, involving interpretation of meaning, identification of subthemes, and integration within broader theoretical or educational frameworks.
This integrated method offers clear advantages, including adding an “AI-qualitative research assistant” in the initial phases to identify additional categories, time savings, response consistency, and reasonable quality of analysis, while still maintaining the depth and contextual understanding that human expertise provides. This process still requires humans to take responsibility in the entire process, including providing clear prompts that encourage identifying subtle signs of more complex categories.
Strengths, Limitations, Further Directions, and Reflection
Our study shows a pioneering exploration of one LLM’s effectiveness in processing and analyzing semi-structured narratives. Besides the theoretical understanding of the current technology status, we illustrate practical implications for researchers considering using LLMs in similar studies. The implications of this research extend beyond immediate methodological improvements. This approach has the potential to facilitate the analysis of a larger volume of student narratives, allowing for real-time adaptation of educational materials to align with students’ concurrent experiences. While these narratives are frequently used for teaching and promoting reflective practice, including individual feedback provided (Frankel et al., 2020; Karnieli-Miller, 2020; Karnieli-Miller et al., 2018; Wald et al., 2012), their use in informing curriculum development or identifying systemic challenges remains limited primarily because they are usually read only by small-group facilitators, restricting broader pattern recognition. Thus, integrating LLMs for initial screening and trend detection could allow for faster identification of problematic issues. Specific narratives flagged by LLMs could then be reviewed in depth by educators, enabling timely educational interventions, not only at the individual level but also at the systemic or curricular level. Furthermore, given the rapid pace of technological advancement, we anticipate further improvements in LLMs’ ability to understand subtleties and nuances in narratives.
Our work extends previous research on prompt engineering (De Paoli, 2024; Jalali & Akhavan, 2024; Li et al., 2024) by implementing a dual-approach methodology. This methodology combines both closed-ended prompts for some categories (enabling quantitative comparison with human coding) and open-ended prompts for other categories (maximizing the LLM’s exploratory coding capabilities), providing a more comprehensive assessment of LLM performance in analyzing medical narratives. The use of Hebrew narratives adds a layer of complexity due to the linguistic nuances and challenges associated with processing Semitic languages, showcasing the LLM’s adaptability to varying linguistic contexts.
However, the study’s scope was limited to a specific language and narrative category, suggesting the need for further, larger-scale research, encompassing other models, languages, and narrative categories. Another limitation of the current study is that we did not attempt to fine-tune the model on labeled data, instead relying on its original training. Future research could explore the possibility of fine-tuning the model on task-specific labeled data, which may improve accuracy and adaptability for complex healthcare coding tasks. This can include the use of an open-ended prompt identified as a helpful and sound methodology in this study, followed by human verification and deciding how to divide these if needed. Another procedure should include the need for clear, at times elaborated, definitions and examples to the LLM, and perhaps the option to mark unclear or non-applicable, and then humans can check these.
Reflecting on the process, this is a study that is done by two different types of researchers—two early adopters of technology—those who are comfortable with taking risks with new approaches (Rogers, 1962), and at least one late, lagged adopter (O.K.-M.) who is very used to and a big believer in the in-depth, iterative qualitative analysis process. This can explain why we focused more on the descriptive, contextual parts that the late/lagged adopter really dislikes in the process though she knows their importance. This approach may have limited the ability of the early adopters to “fly higher” and try more analysis. Thus, future studies are encouraged to try and integrate the LLM in earlier stages of analysis to test its ideas in developing analysis categories.
Conclusion
Our study demonstrates that LLMs show promise in analyzing certain categories of semi-structured medical narratives, particularly for straightforward contextual information. At the same time, human expertise remains superior for tasks requiring nuanced understanding and complex interpretive analysis. These findings suggest that a hybrid approach, LLM in the loop, including human guidance and clear prompts combined with LLM preliminary analysis, followed by human expert review, could offer an efficient solution for contextual qualitative data analysis in medical education research. This method can potentially enable analysis of larger volumes of student narratives, possibly leading to more responsive medical education curricula.
Footnotes
Acknowledgments
We thank the students who shared their stories and experiences with us. Your contributions have enriched our study and provided valuable insights. We appreciate your participation.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by the Israeli Cancer Association grant of the “Ber-Lemsdorf” foundation, in memory of the late Professor Natan Treinin, Chairman of the ICA from 1991 to 1995; and by the Chair of Dr. Sol Amsterdam Dr. David P. Schumann of Medical Education.
Use of Generative Artificial Intelligence
The study, that assesses artificial intelligence analysis versus human analysis, employed two large language models (LLMs): Claude 3.5 Sonnet (Anthropic) and ChatGPT (OpenAI), accessed between July and December 2024. The LLMs served multiple purposes in our research process: (1) supporting the development of Python code for data processing; (2) data processing, as part of our primary research objective comparing human and AI analytical capabilities in qualitative data analysis; and (3) assisting in manuscript writing through suggestions for sentence articulation. All LLM-generated content, including code, analytical insights, and textual suggestions, underwent thorough review and validation by the research team. The LLMs were not used in developing the literature review, methodology section, or discussion. Our approach integrated AI capabilities as a complementary tool while maintaining human oversight and academic rigor throughout the research process.