
Abstract
The impact of ChatGPT and other large language model–based applications on scientific work is being debated across contexts and disciplines. However, despite ChatGPT’s inherent focus on language generation and processing, insights regarding its potential for supporting qualitative research and analysis remain limited. In this article, we advocate for an open discourse on chances and pitfalls of AI-supported qualitative analysis by exploring ChatGPT’s performance when analyzing an interview transcript based on various prompts and comparing results to those derived by an experienced human researcher. Themes identified by the human researcher and ChatGPT across analytic prompts overlapped to a considerable degree, with ChatGPT leaning toward descriptive themes but also identifying more nuanced dynamics (e.g., ‘trust and responsibility’ and ‘acceptance and resistance’). ChatGPT was able to propose a codebook and key quotes from the transcript which had considerable face validity but would require careful review. When prompted to embed findings into broader theoretical discourses, ChatGPT could convincingly argue how identified themes linked to the provided theories, even in cases of (seemingly) unfitting models. In general, despite challenges, ChatGPT performed better than we had expected, especially on identifying themes which generally overlapped with those of an experienced researcher, and when embedding these themes into specific theoretical debates. Based on our results, we discuss several ideas on how ChatGPT could contribute to but also challenge established best-practice approaches for rigorous and nuanced qualitative research and teaching.
Introduction
In November 2022, OpenAI made their chatbot ‘ChatGPT’ (Chat Generative Pre-Trained Transformer, https://openai.com/chatgpt) available to the public, sparking large-scale excitement and discourse regarding the potential of large language models (LLMs) within private and professional spheres. Similar to other LLM-based applications, ChatGPT allows users to interact via a simple online chat interface, utilizing deep-learning algorithms that have been pre-trained based on vast swaths of internet data (Parray et al., 2023; Ray, 2023). Drawing on LLM GPT-3.5 when introduced, ChatGPT can generate human-like text across a broad array of tasks and subjects (Ray, 2023).
In the research context, the introduction of ChatGPT fueled ongoing debates regarding the chances and challenges associated with the rapid development of tools based on deep learning and artificial intelligence (AI) (Feuston & Brubaker, 2021; Jiang et al., 2021; Rahman et al., 2023; Ray, 2023; Sallam, 2023). Since then, several authors have proposed ideas on how ChatGPT might shape academic research and teaching, including idea generation, data management, summarizing research articles and providing additional explanation, or phrasing support for writing up case reports and academic publications (Parray et al., 2023; Rahman et al., 2023; Sallam, 2023). An early 2023 survey among readers of Nature highlighted a majority of participants having already used ChatGPT or similar tools, including for various professional tasks (Owens, 2023).
However, despite the conceptual focus of ChatGPT and other LLMs on text processing and generation, in-depth explorations of ChatGPT’s performance in supporting qualitative data analysis remain, to the best of our knowledge, limited. While this in part might be linked to an understanding of qualitative research as generally open, nuanced, and interpretative (Saldaña, 2011; Tracy, 2010) (tasks in which AI-based language models have historically performed poorly at best), there may also be broader hesitancies linked to a sense that AI-assisted analysis might impede or undercut the human essence of qualitative research: In a pre-ChatGPT study among qualitative researchers from various disciplines on their perceptions of potential AI-assisted analysis, respondents highlighted that despite the ‘messiness’ of qualitative research, they not only considered AI assistance to potentially impede analytic quality and rigor but also voiced concerns regarding stripping the analytic process from its human component (Jiang et al., 2021).
Nevertheless, a number of software providers have introduced or announced for-profit AI-based tools and prototypes to support qualitative analysis [e.g., NVivo’s Autocoding feature (Lumivero, 2023) or MaxQDA’s AI Assist (MaxQDA, 2024)], and while we have yet to meet researchers routinely employing these tools in their own work, the introduction of such tools suggests a growing interest or market for AI-assisted analysis. Qualitative health researchers frequently face a challenge of ensuring high scientific rigor while also contributing to rapidly evolving debates in a timely manner, and AI tools may hold potential to reduce the time needed for in-depth qualitative analysis. At the same time, in qualitative public health research and many other qualitative research fields, for-profit tools are routinely inaccessible for both students and research collaborators working beyond the spheres of well-funded universities in high-income countries. Insights into the opportunities but also challenges of emerging tools such as the free-of-charge ChatGPT remain limited.
The broad availability of ChatGPT, combined with its apparent power and speed in completing a diverse array of tasks (Ray, 2023) but also its inherent inability to move beyond semantic meaning (van Manen, 2023), in our eyes merits an open discourse among qualitative health researchers to gain an understanding of its potentials, challenges, and how it might impact qualitative inquiry. In this article, we contribute to this discourse by exploring ChatGPT’s performance when tasked with analyzing a qualitative transcript, including via a comparison of themes derived by ChatGPT and by an experienced human researcher, as well as by an examination of ChatGPT’s engagement with other steps of the analytic process such as embedding derived themes into broader theoretical discourses.
Methods
To be able to flexibly explore how ChatGPT performs when prompted to analyze qualitative data, an experienced qualitative researcher (JW) conducted a semi-structured interview in English with a fourth-year medical student (LNS). The interview focused on AI in clinical practice, covering themes such as opportunities and drawbacks of digital and AI applications in clinical settings, and potential use cases in specific clinical domains.
The interviewer and first author of this article (JW) has a background in public health, medical anthropology, and psychology, and has several years of experience conducting qualitative research in various settings and on a spectrum of health-related topics. The respondent (LNS) has a background in sociology, public health, and medicine, has previously conducted qualitative research, and was chosen as a respondent due to an inherent interest in both the topic of the interview and the broader purpose of this paper (the potential role of ChatGPT within qualitative scholarship). The rationale underlying our choice of both the interviewer and the interviewee entailed a desire to capture rich dialogue that covered several broad themes, while also giving space for iterative probing and subject matter nuance within the interview encounter. Neither the interviewer nor the interviewee had previously conducted formal research on the use of AI in medical contexts, but both have worked in clinical and public health settings where this issue has been debated vigorously.
The 58-minute interview was transcribed verbatim using the automated transcription tool VINK (Tolle et al., 2024); the transcript was then quality controlled and corrected to ensure accurate transcription. As we do not utilize any real-life data beyond the transcript generated by co-authors of this study, we did not require approval of an ethical review board for this study. The full transcript is included in supplemental file 1, and we invite others to utilize it for their own exploration of ChatGPT’s analytic potential.
Loading the Interview Transcript Into ChatGPT
At more than 7000 words, the full interview transcript exceeded the allowable length for individual ChatGPT prompts. We therefore split it into six parts and loaded it into ChatGPT using the free-of-cost tool ‘ChatGPT Splitter’ (https://chatgptsplitter.com/). ChatGPT Splitter automatically divided longer texts into parts of roughly 8000 characters each and included short prompts at the start and end of each part instructing ChatGPT to treat individual inputs as part of one larger text (see details in supplemental file 1). As of early 2024, the ChatGPT Splitter website is no longer accessible, but several similar tools are available online. In one case, when loading a part of the transcript, instead of waiting for the following part as instructed, ChatGPT manufactured new text to continue the transcript unprompted and without any further input (Figure 1). While an unintended observation, the text created by ChatGPT had considerable face validity and in retrospect highlighted to the study team where lines of probing could have been refined. Additional parts of the transcript as generated unprompted by ChatGPT.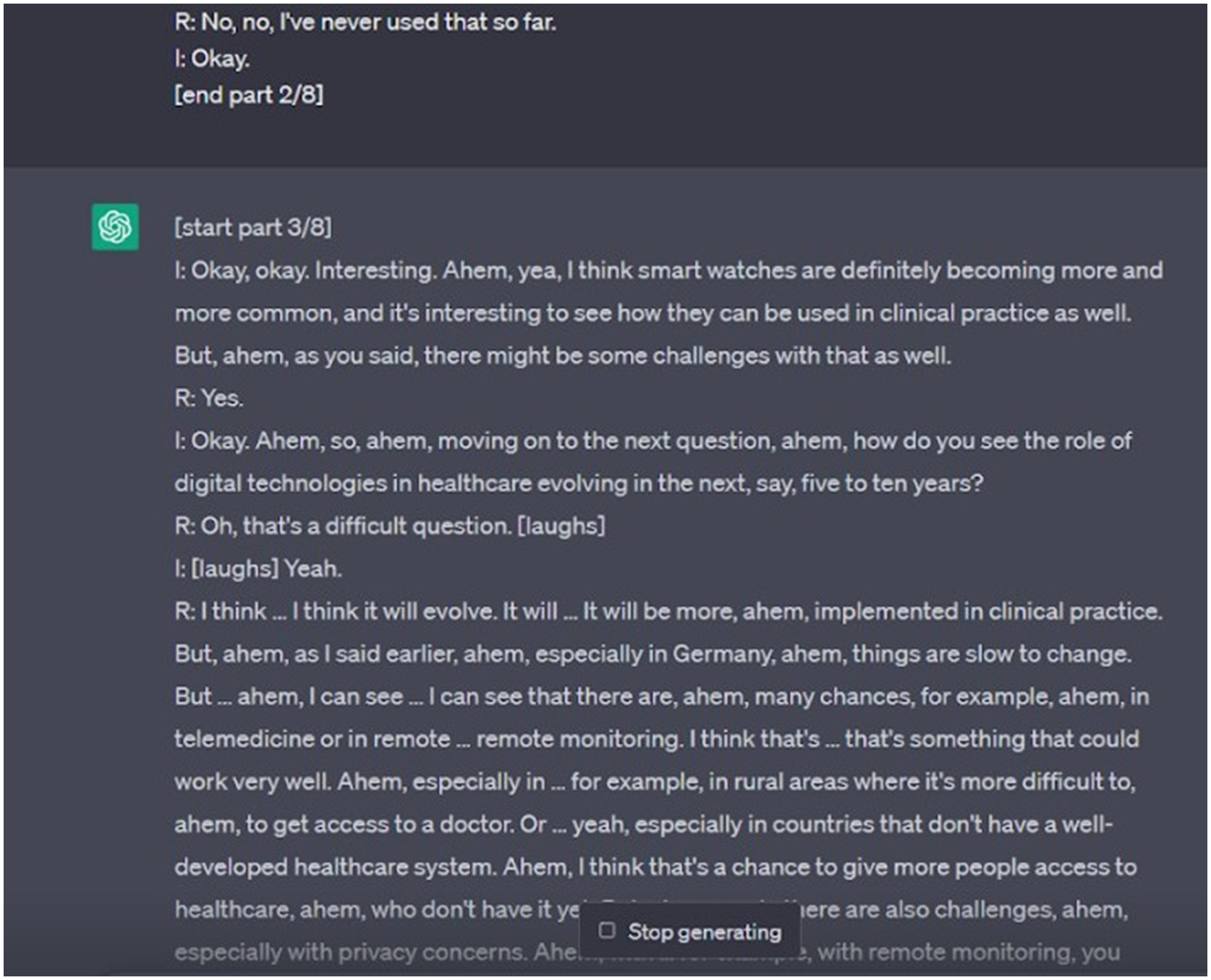
Analysis Performed by ChatGPT
In the first analytic step, ChatGPT (based on GTP-3.5) was given the following analysis instructions: The text I just sent you is the transcript of an interview. Paragraphs starting with “I:” were said by the interviewer, and paragraphs starting with “R:” were said by the respondent. Now please act like a researcher with expertise in qualitative research and thematically analyze this transcript.
We generated a total of three responses to this initial prompt to compare results provided across iterations. We then prompted ChatGPT to provide example quotes for each of the themes identified in the third iteration (“For each of the themes you have identified in the previous step, please provide example verbatim quotes from the transcript.”) and to provide a codebook (“Please provide a qualitative codebook that could be used to thematically code transcripts on the same topic.”).
In a second step after reloading the transcript into new conversations, 1 we prompted ChatGPT to conduct data analysis based on two specific analytic approaches: Grounded Theory as proposed by Charmaz (2014), who posits that the interaction between the researcher and the interviewee is constructed and this construction reshapes how data is collected, interpreted, and reproduced (“Please act like a researcher with expertise in qualitative research and analyze the transcript I have provided you with following the Grounded Theory Approach as proposed by Charmaz.”), and the Five Step Framework Approach (Pope et al., 2000), which is a leading approach for applying the tenets of thematic analysis in qualitative health research (“Please act like a researcher with expertise in qualitative research and analyze the transcript I have provided you with following the five step framework approach as proposed by Pope and colleagues in 2000.”). Initially, when asked to analyze the transcript using Charmaz’s Grounded Theory approach, ChatGPT stated that, as an AI language model, it could not perform the analysis itself and instead provided detailed step-by-step guidance (see supplemental file 2); however, this guidance included steps that aligned moreso with other approaches within Grounded Theory [e.g., using open and axial coding aligning with the steps proposed by Strauss and Corbin (1998) rather than the constructivist approach proposed by Charmaz (2008, 2014)]. To obtain an analysis, we then asked ChatGPT to not only analyze but also to act as a human researcher experienced in qualitative research while doing so. This second request was successful in eliciting an analysis attempt from ChatGPT.
Analysis Performed by an Experienced Qualitative Researcher
As a comparator for the ChatGPT-based analysis, a co-author (KB) with postgraduate education and several years of experience conducting qualitative health research who was not familiar with ChatGPT output or prompts analyzed the transcript. The human analyst was provided with instructions aligning with the initial ChatGPT prompt (to please thematically analyze this transcript), purposively allowing for a more flexible and independent choice of analytic approach. The human analyst chose to follow the tenets of Reflexive Thematic Analysis (Braun & Clarke, 2019) due to the theoretical flexibility and extensive period of data familiarization this approach allows for. The researcher expected these characteristics to bolster the codes and themes developed, given that only one researcher analyzed a dataset consisting of one transcript. Following this approach, the human analyst engaged with the transcript and shared open codes, selected codes, and the broad themes derived from the codes.
Results
In general, ChatGPT provided descriptive analytic insights [insights that manifest content yet miss more latent or interpretative themes (Graneheim & Lundman, 2004)] with a considerable degree of face validity across approaches; ChatGPT further yielded starting points for more interpretative analytic steps. In this section, we first outline and compare the results obtained by ChatGPT and the human researcher when analyzing the interview transcript on AI use in medical practice, and we then provide our experiences when prompting ChatGPT to contextualize findings in broader theoretical discourses.
Comparison of Analytic Approaches
Themes Derived Across All Analytic Approaches.
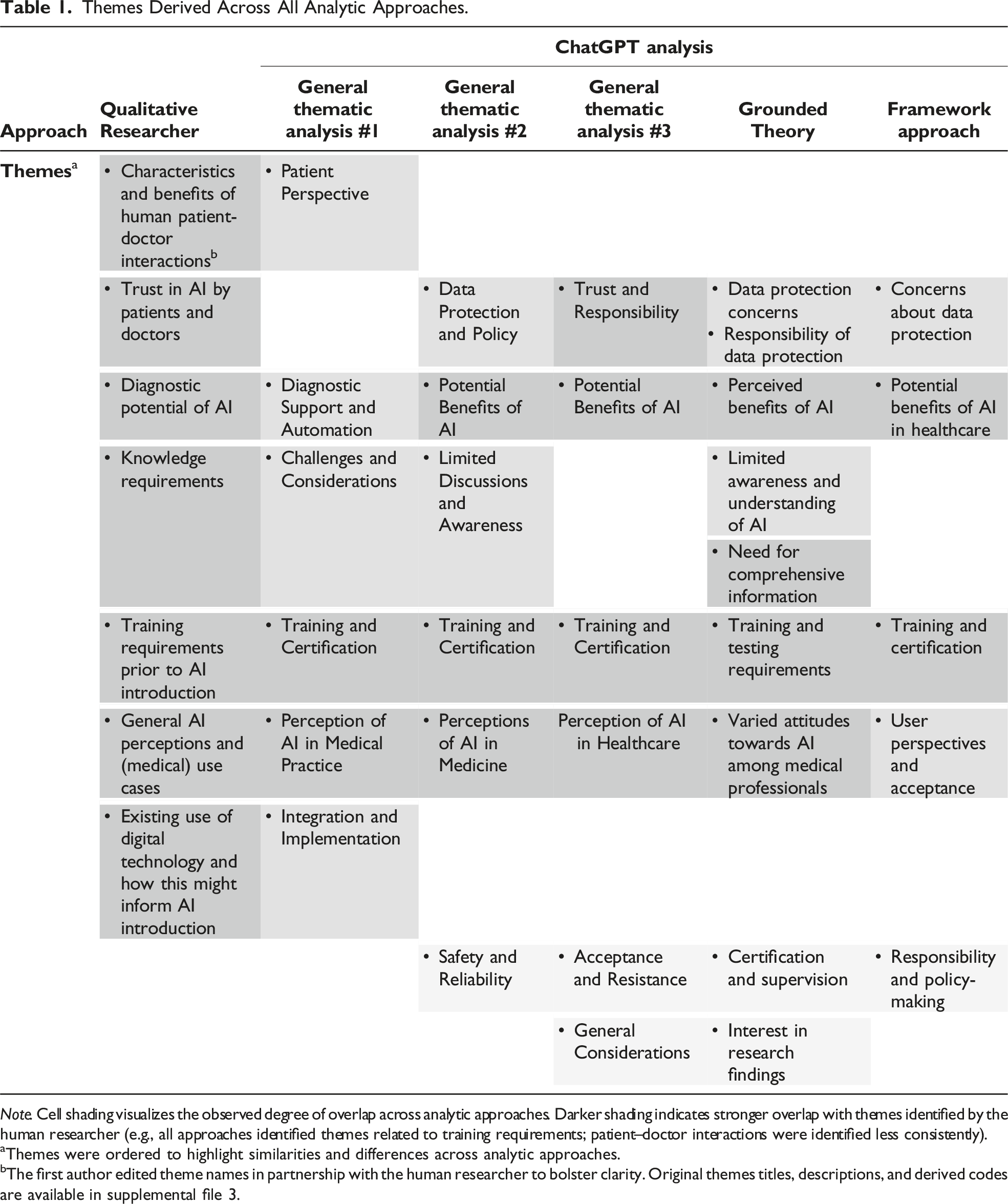
Note. Cell shading visualizes the observed degree of overlap across analytic approaches. Darker shading indicates stronger overlap with themes identified by the human researcher (e.g., all approaches identified themes related to training requirements; patient–doctor interactions were identified less consistently).
aThemes were ordered to highlight similarities and differences across analytic approaches.
bThe first author edited theme names in partnership with the human researcher to bolster clarity. Original themes titles, descriptions, and derived codes are available in supplemental file 3.
We also considered the similarity between the themes identified by ChatGPT across its three thematic analysis iterations compared to both the themes identified via the Grounded Theory or Framework Approach prompts and to those identified by the human. No clear pattern emerged: Each analysis performed by ChatGPT had some overlap with and some divergence from the other ChatGPT iterations and the human analysis. Additionally, when comparing similarities and differences between the three iterations of the same thematic analysis prompt and the other analytic approaches, we did not observe a systematically stronger overlap between themes identified via iterations of the same prompt. Neither the human researcher nor ChatGPT explicitly described integrating non-verbal cues included in the transcript (e.g., laughter and hesitation) into the identification of themes. However, both the human researcher and ChatGPT across analytic prompts highlighted their challenge to perform a comprehensive analysis based on one single transcript. ChatGPT additionally emphasized its own limitations as an AI language model that would not be able to perform analyses like an experienced human researcher. Across analytic prompts, ChatGPT predominantly identified rather descriptive themes (e.g., ‘potential benefits of AI in healthcare’ and ‘training and testing requirements’), supplemented by a few themes leaning toward more interpretative engagement with the data (e.g., ‘trust and responsibility’ and ‘acceptance and resistance’).
Qualitative Codebook Proposed by ChatGPT.

ChatGPT Explaining How It Undertook Discrete Steps of Framework Analysis.

Themes and Example Quotes.

Theoretical Engagement
ChatGPT Applying a Social Ecological Model to the Results.

ChatGPT Investigating the Data From a Marxist Perspective.

ChatGPT Applying the Vaccine-Specific 5C Model to Its Results.

Discussion
When asked to perform qualitative data analysis following various approaches, ChatGPT was able to produce thematic insights that to a considerable degree aligned with or resembled those produced by an experienced human researcher. In general, we ourselves were surprised by the extent to which utilizing ChatGPT for qualitative data analysis yielded data-driven results. A majority of identified themes remained on a descriptive level with few instances of more interpretative engagement with the data. This is in line with previous observations that ChatGPT performs better in recreating descriptive themes (Morgan, 2023) and that (non-literal) language interpretation or creativity poses a challenge for ChatGPT and similar applications (Ray, 2023).
Chances and Challenges of ChatGPT-Assisted Qualitative Research
ChatGPT in Qualitative Research—Observations and Future Opportunities.

Comparison Across Process Stages and Repeated Analyses
While in our work the human researcher provided insights across several analytic steps (i.e., sharing both codes and themes) without being explicitly asked to do so, ChatGPT only provided themes when prompted to perform the analysis. When specifically prompted to provide a codebook that could be used when thematically coding similar transcripts, ChatGPT was able to do so, but the resulting codebook did not go beyond the themes previously identified. Additionally, when prompted to provide verbatim quotes to support the identified themes, ChatGPT was able to suggest quotes that fit themes in their content but did not consistently highlight when and how it had edited original verbatim text. While these observations highlight areas that would require particular human supervision when using ChatGPT in qualitative analysis, they also link to ongoing discourses on the inherent opacity of generative AI regarding its content generation (Sallam, 2023): ChatGPT provides (often good quality) end results but no insights into the process of achieving these results (e.g., the codebook in qualitative analysis).
Our retrospective attempts to backtrack procedural components to understand ChatGPT’s analytic process (e.g., asking ChatGPT to provide a codebook or verbatim quotes after it had already presented themes) resulted in simulated intermediate steps, which left us with a sense that codes and quotes had been retrofitted onto themes.
Without being directly prompted to do so, ChatGPT presented guidance for conducting Grounded Theory–informed analysis. The output, which was described by ChatGPT as reflecting Charmaz’s approach, in our eyes aligned moreso with Strauss and Corbin (1998) than with the work of Charmaz (2014). Why ChatGPT enacts certain approaches based on prompts or the degree of ChatGPT’s fluency with various scholars are, to the best of our knowledge, not discernable to the user. One potential explanation in the context of our observation may be that ChatGPT is unable to interpret what Charmaz defines as the creation of both data and analysis based on shared experiences between the interviewer, interviewee, and other sources of data (Charmaz, 2014). Therefore, the more systematic approach defined by Straus and Corbin may offer a clearer process for ChatGPT to follow. However, this observation generally highlights how researchers utilizing ChatGPT have to be particularly cautious in contexts where differences within overarching methodologies have to be considered.
When we prompted ChatGPT to perform several analyses in succession within the same conversation, we commonly observed that identified themes overlapped to a much larger extent than when prompting analyses in separate conversations. This observation links to larger discourses on the learning capabilities of ChatGPT and comparable applications: Within one conversation, ChatGPT can ‘learn’ from interactions and adapt approaches according to user feedback and previous prompts; it therefore is plausible that subsequent analyses would be biased by previous results. In cases where several independent analyses are to be performed, we would therefore recommend using separate conversations. When using such separate conversations, there appears to be no indication that results would systematically differ between different researchers (if the exact same prompts are being used) beyond the general variation observed when repeatedly using the same prompt. However, it remains unclear how repeated interactions with many qualitative researchers on a global scale could contribute to further training of ChatGPT. We are not aware of any guidance on how substantive the interaction data needs to be to result in noticeable changes in general response patterns, but if the use of ChatGPT for qualitative research substantially increases, this might result in increased response quality, but also in increased bias if results are influenced by previous interactions. Future research could more systematically explore how ChatGPT’s theme generation might be shaped by previous interactions with researchers on the same or similar data and topics.
Theory and Rigor in ChatGPT-Assisted Qualitative Research
When prompted to link identified themes to larger theoretical constructs, ChatGPT was generally able to correctly identify framework components and move beyond a descriptive presentation of themes. However, the program also seemed inclined to ‘overfit’ the data to provided theories regardless of their apparent fit. ChatGPT’s precision in identifying themes in the qualitative data and some of its challenges when contextualizing themes within broader social theory (and other lenses through which we make sense of the world such as history and politics) merit discourse on depth and rigor of qualitative data analysis. On the one hand, observing similar themes being identified by both the human researcher and ChatGPT could be considered one marker of rigor in qualitative research, akin to analyst triangulation (Patton, 1999). We therefore encourage future research that explores ChatGPT’s potential as a complement to human analysis; beyond providing themes or codes, ChatGPT, for example, could serve as another resource in processes of triangulation (Patton, 1999) or thematic synthesis (Thomas & Harden, 2008), or in calculations of intercoder reliability (O’Connor & Joffe, 2020).
On the other hand, while acknowledging that the role of theory in qualitative inquiry varies between approaches and disciplinary traditions (Sandelowski, 1993), we follow arguments made by a number of scholars (Anfara & Mertz, 2014; Collins & Stockton, 2018; Emerson et al., 2011; Sandelowski, 1993) that qualitative research is not atheoretical in its nature but that engagement with theory commonly permeates various steps of good qualitative work, from literature searches to writing ethnographic field notes and result presentations. When we prompted ChatGPT to perform one such step, namely, to embed identified themes into broader theoretical discourses, ChatGPT to a limited degree seemed capable to link the identified themes to higher-level constructs if provided with specific instructions (and might perform even better with more data and more elaborate prompting). However, such engagement with theory also must be coined by a critical questioning of fit and appropriateness of the employed lenses, and while it is highly unlikely that any human researcher would have unquestioningly applied a vaccine-specific model to research on AI use in medical practice, ChatGPT did not comment on this apparent mismatch. ChatGPT’s application of the 5C model to the data was interesting in the sense that it sparked new ideas on potential lenses for further investigation (e.g., interpreting the lack of awareness for AI applications in medical practice under the frame of complacency). However, the program’s performance also emphasized the need for accompanying human reflection as a means to gauge framework fit.
Biases and Reflexivity When Employing ChatGPT
Across analytic approaches, ChatGPT emphasized its own limitations regarding qualitative data analysis. However, we did not see any indication regarding an acknowledgment of these limitations within the identified themes. As qualitative researchers, we would argue that reflexivity, including acknowledgment of and reflections on our own biases, theoretical lenses, and situated identities, should form a key part of our analysis: While we may not be able to identify all our biases—in fact, we certainly are blind to many of them—we are expected to be aware that biases exist and to try to reflect on how these biases affect what we see in the data. To the best of our knowledge, and in line with our interactive experiences with the program, ChatGPT cannot be expected to perform such reflexivity. It could be argued that the enormous breadth of data used for training ChatGPT might bestow it with something akin to history and perspective. However, reflecting on biases inherent to this training data (and the processes of its production) (Ray, 2023) and providing contextual information not inherent to the textual data (e.g., non-verbal cues and other observations during the data collection activity) remain the responsibility of the interacting human. In interrogating the biases presented in ChatGPT outputs, we see opportunity for a more vigorous conversation among thoughtful qualitative researchers about their own relationship to the data, the study processes, and the nature of knowledge co-production.
Ethical Considerations
Utilizing the full capabilities of ChatGPT in academic research raises ethical concerns (Parray et al., 2023; Sallam, 2023). For this work, we used an interview and transcript specifically created for this purpose, giving us full ownership of the data and exempting us from a need to acquire ethical and data protection approvals. Before we can recommend researchers to expand systematic exploration and utilization to real-world qualitative data, we urge in-depth considerations of data protection principles and ethical foundations. While first applications drawing on ChatGPT declare sufficient data protection, we note a need for institutional review boards and similar bodies to develop clear and comprehensive research guidelines that outline (in)acceptability of using ChatGPT or other platforms when engaging with specific types of data or for certain analytic purposes. In the meantime, we recommend researchers to employ a conservative approach, which would include refraining from loading sensitive datasets for analysis into ChatGPT. We also urge that researchers obtain ethical and legal assessments regarding data protection and confidentiality from institutional review boards and other bodies familiar with the specific context and data types.
Ongoing Developments Beyond ChatGPT
Generative AI applications, and LLMs in particular, are rapidly evolving, with various applications beyond ChatGPT being available as of this writing. For the purpose of this article, we focused on ChatGPT as the most well-known, freely available, and not qualitative research-specific application. However, certain observations might differ if utilizing a different application (especially applications powered by a different LLM not based on OpenAI technology, such as Google Bard). From a practical perspective, several applications [both freely accessible (e.g., perplexity.ai with a limit to the files per day in the free version) and paid (e.g., GPT-4)] at the time of writing allow for directly uploading files, which would overcome the challenge of splitting individual transcripts to align with prompt character limitations. While we do not expect there to be a systematic difference in the results obtained if the transcript is uploaded in several segments, as we did in our work, or as one single text file, we see this upload function to greatly facilitate the analysis of more than one transcript. Given the ethical challenges regarding data privacy highlighted above, some applications emphasize increased privacy (e.g., perplexity.ai); however, to the best of our knowledge, the question whether these privacy measures from an ethical perspective are sufficient for sensitive respondent data remains unanswered. Finally, a number of companies developing software specifically for qualitative research have started to include AI applications as paid add-ons (e.g., MaxQDA, NVivo, and ATLAS.ti), in many cases powered by OpenAI technology, which include specific functions (e.g., data summaries or AI coding). While the general aims of these functions overlap with what we explored in this article, we expect experiences to vary when utilizing paid, qualitative research-specific applications with pre-defined functions as compared to the less formalized utilization of LLMs directly. We call on researchers working with the various available tools to share their experiences and lessons learned.
Limitations
There are a number of ways in which gold-standard qualitative studies would go beyond the methodological approaches employed in this article. First, we only used one transcript for our presented assessment. While we acknowledge that obtaining in-depth thematic insights usually would require several transcripts (as also highlighted by ChatGPT in its outputs), using a single transcript allowed us to do side-by-side comparisons of human and ChatGPT engagement with the full dataset; we encourage further research that draws on larger datasets (provided data privacy and ethical regulations can be maintained). Similarly, our decisions regarding the interviewer, interviewee, and topic of the interview, as well as the fact that both the interviewer and the interviewee were aware of the interview objective to assess the analytic potential of ChatGPT, may have introduced biases. These decisions were made with the overarching goal to obtain a freely usable, in-depth transcript on a health- and technology-related topic in a timely manner, and while we therefore would not use the obtained insights to draw conclusions regarding the topic of the interview, we do believe that the transcript provides a useful starting point for exploring the general potential of AI-assisted analysis.
Additionally, while we asked ChatGPT to perform analysis using several approaches, the human researcher performed only one approach due to time and personnel constraints. Throughout our exploration, we aimed to strike a balance across two conflicting priorities: We wanted to minimize bias across the human analysis versus the ChatGPT analysis, yet we also wanted to involve multiple (human) analysts in each approach. The creation of two larger-but-completely-separated teams was not feasible due to time and resource constraints, but we aimed to facilitate analyst triangulation [or the process of bolstering result trustworthiness by involving multiple analysts to co-code data or review findings (Patton, 1999)] via the involvement of other team members (including the interviewee and senior researchers) in debriefings and discussions on codes and themes. The involvement of the interviewee-researcher formed a unique, and in real-life research unlikely, overlap between analyst triangulation (Patton, 1999) and member checking (Thomas, 2017), and while this process in our opinion helped to ensure trustworthiness of findings for the purpose of this article, we would encourage future research on the potential of AI-assisted qualitative analysis in larger projects and research teams.
Finally, we are not professional AI prompt designers and some of our instructions might seem clumsy at best. We note that this reality likely mirrors the use case of many qualitative researchers who lack familiarity with LLMs. Similarly, we used the freely available (and therefore for researchers flexibly accessible) ChatGPT (based on GPT-3.5) for our work. While not freely available, GPT-4 may perform considerably better on some tasks (Kocoń et al., 2023). Despite these limitations, we see our insights as contributing to an open debate on the potentials and drawbacks of LLMs as a qualitative analysis tool, and we encourage more systematic exploration of various tools and prompts.
Conclusion
When exploring the potential of ChatGPT in qualitative analysis, we were surprised by its apparent ability to provide useful insights across several steps of the analytic journey. While results were particularly convincing for the identification of descriptive themes in the provided data, ChatGPT could also provide more interpretative contributions, for example, when embedding themes into broader theories, as long as the researcher critically assessed applicability and usefulness of the specific theory to avoid overfitting.
Across potential use cases identified in our work, we echo scholars who argue that any use of ChatGPT in research and practice must be accompanied by careful (human) observation and reflection (Doshi et al., 2023; van Manen, 2023). However, given the rapid development of ChatGPT and similar applications, we expect the relevance of such tools to increase in a broad spectrum of fields, including in (qualitative) research. Based on our experiences, ChatGPT might not only be able to provide descriptive summaries of data or support with teaching and skill development as previously suggested, but might also hold potential for supporting or conducting specific analytic steps under human supervision.
Moving forward, we call for qualitative researchers to build on these first insights to further our understanding whether and under what conditions ChatGPT and similar applications can support qualitative work. We specifically suggest three directions for further exploration: First, we aimed to provide insights across several approaches to qualitative inquiry, but further research is needed that systematically assesses ChatGPT’s performance across specific approaches following gold-standards of qualitative research from a spectrum of epistemic communities. We particularly invite scholarship that explores the potential of ChatGPT within and across the four tiers of Crotty’s framework [epistemic, theoretical perspective, methodology, and methods (Crotty, 1998)] to facilitate informed decision-making on potential use cases and drawbacks for future research projects. Second, while ChatGPT in our eyes is the most prominent freely accessible LLM-based application, a number of comparable models exist or are in development, as well as several applications building on these LLMs that are specifically targeted at qualitative research. We would encourage researchers to share experiences across different models and applications to bolster our understanding of tool-specific benefits and drawbacks. Finally, moving from small amounts of data created explicitly for upload into ChatGPT to real-life research poses several ethical and data protection challenges. We therefore call for insights on the legal and ethical dimensions of various use cases of ChatGPT and other novel tools.
With this article, we hope to encourage an open discourse among qualitative scholars to ensure that, as a field, we leverage this new potential where possible without impeding the rigor of qualitative analysis—but that we also are aware of possible pitfalls, such as rapid but decontextualized analysis, that could hamper high-quality teaching and research.
Supplemental Material
Supplemental Material - Prompts, Pearls, Imperfections: Comparing ChatGPT and a Human Researcher in Qualitative Data Analysis
Supplemental Material for Prompts, Pearls, Imperfections: Comparing ChatGPT and a Human Researcher in Qualitative Data Analysis by Jonas Wachinger, Kate Bärnighausen, Louis N. Schäfer, Kerry Scott, and Shannon A. McMahon in Qualitative Health Research
Supplemental Material
Supplemental Material - Prompts, Pearls, Imperfections: Comparing ChatGPT and a Human Researcher in Qualitative Data Analysis
Supplemental Material for Prompts, Pearls, Imperfections: Comparing ChatGPT and a Human Researcher in Qualitative Data Analysis by Jonas Wachinger, Kate Bärnighausen, Louis N. Schäfer, Kerry Scott, and Shannon A. McMahon in Qualitative Health Research
Supplemental Material
Supplemental Material - Prompts, Pearls, Imperfections: Comparing ChatGPT and a Human Researcher in Qualitative Data Analysis
Supplemental Material for Prompts, Pearls, Imperfections: Comparing ChatGPT and a Human Researcher in Qualitative Data Analysis by Jonas Wachinger, Kate Bärnighausen, Louis N. Schäfer, Kerry Scott, and Shannon A. McMahon in Qualitative Health Research
Footnotes
Author Notes
Authors Contribution
JW, LNS, and SAM conceived of and conceptualized the study. JW, KB, and LNS conducted data collection and analysis. JW led manuscript writing and prepared the first draft. KS and SAM supported and supervised manuscript writing. KB, LNS, KS, and SAM critically revised the manuscript. All authors have read and approved the final version of the manuscript.
Acknowledgments
The authors would like to thank Agrin Zauyani Putri, Josephine Schwab, Katarzyna Skipiol, and the participants of the qualitative office hours at the Heidelberg Institute of Global Health for their insights and support.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Ethical Statement
The interview used for this study was conducted by two co-authors acting as the interviewer and interviewee and does not include any identifiable information of real individuals; ethical approval therefore was not required.
Supplemental Material
Supplemental material for this article isavailable online.
Note
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.